音频提取方法、装置、计算机设备和存储介质与流程
本技术涉及计算机,特别是涉及一种音频提取方法、装置、计算机设备和存储介质。
背景技术:
1、人类大脑在多个说话者和背景噪声存在时,可以通过屏蔽声学背景来集中听觉注意力于特定的声音,这种情况被称为鸡尾酒会效应。随着深度学习的发展,出现了越来越多解决鸡尾酒会效应问题的技术,比如通过预先录制参考者语音等类型的辅助线索,引导深度学习神经网络的注意力指向目标说话者。然而,现有技术并不能较好地解决说话者头部姿态变化对特定说话者声音提取的影响,从而导致对特定说话者声音提取的准确性较低。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够更准确地提取特定说话者的声音的音频提取方法、装置、计算机设备和存储介质,提高了提取特定说话者声音的准确性。
2、一种音频提取方法,所述方法包括:
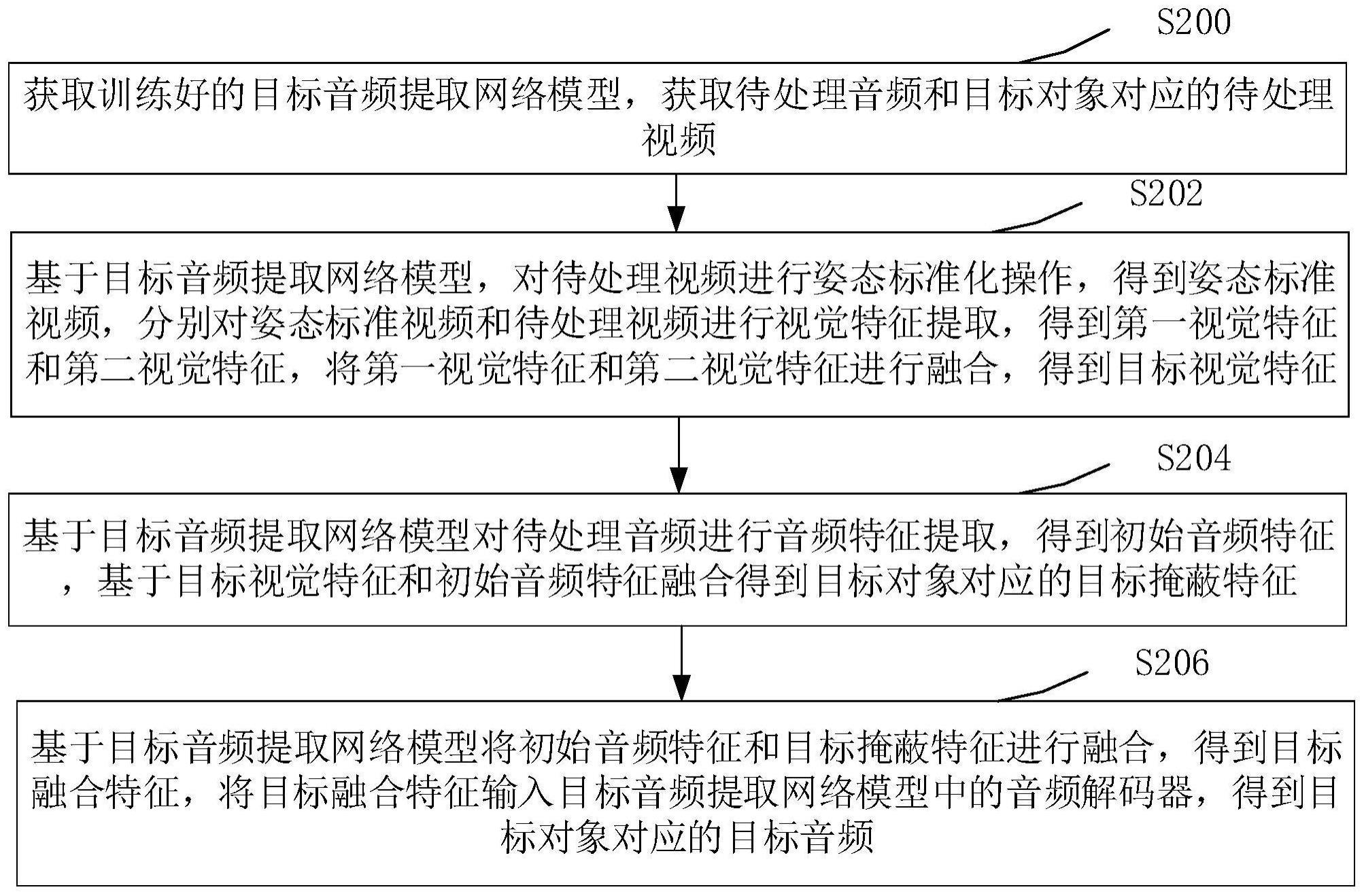
3、获取训练好的目标音频提取网络模型,获取待处理音频和目标对象对应的待处理视频;
4、基于所述目标音频提取网络模型,对所述待处理视频进行姿态标准化操作,得到姿态标准视频,分别对所述姿态标准视频和待处理视频进行视觉特征提取,得到第一视觉特征和第二视觉特征,将所述第一视觉特征和第二视觉特征进行融合,得到目标视觉特征;
5、基于所述目标音频提取网络模型对所述待处理音频进行音频特征提取,得到初始音频特征,基于所述目标视觉特征和初始音频特征融合得到所述目标对象对应的目标掩蔽特征;
6、基于所述目标音频提取网络模型将所述初始音频特征和所述目标掩蔽特征进行融合,得到目标融合特征,将所述目标融合特征输入所述目标音频提取网络模型中的音频解码器,得到所述目标对象对应的目标音频。
7、在其中一个实施例中,所述目标音频提取网络模型包括预设数量个视觉编码器和姿态标准化模型,所述基于所述目标音频提取网络模型,对所述待处理视频进行姿态标准化操作,得到姿态标准视频,分别对所述姿态标准视频和待处理视频进行视觉特征提取,得到第一视觉特征和第二视觉特征包括:
8、将所述待处理视频输入所述姿态标准化模型中,得到所述姿态标准视频,将所述姿态标准视频输入对应的视觉编码器中,得到所述第一视觉特征;
9、将所述待处理视频输入另一个视觉编码器中,得到所述第二视觉特征。
10、在其中一个实施例中,所述将所述待处理视频输入所述姿态标准化模型中,得到所述姿态标准视频包括:
11、基于所述姿态标准化模型中的面部几何编码器,对所述待处理视频中的每一帧图像进行面部形变操作,得到每一帧图像对应的面部形变图像;
12、获取面部模板,基于所述姿态标准化模型中的面部关联特征融合器,将每一帧图像对应的面部形变图像分别与所述面部模板进行融合,得到所述姿态标准视频。
13、在其中一个实施例中,所述目标音频提取网络模型包括视觉特征适配器,所述视觉特征适配器用于调整视觉特征之间的时间依赖关系,所述对所述第一视觉特征和第二视觉特征进行融合,得到目标视觉特征包括:
14、将所述第一视觉特征和所述第二视觉特征进行融合,得到初始融合视觉特征,将所述初始融合视觉特征输入所述视觉特征适配器,得到适配融合视觉特征;
15、基于预设插值算法,对所述适配融合视觉特征对应的特征维度进行上采样操作,得到所述目标视觉特征。
16、在其中一个实施例中,所述目标音频提取网络模型包括音频编码器和特征融合器;所述基于所述目标音频提取网络模型对所述待处理音频进行音频特征提取,得到初始音频特征,基于所述目标视觉特征和初始音频特征进行融合得到所述目标对象对应的目标掩蔽特征包括:
17、将所述待处理音频输入所述音频编码器,得到所述初始音频特征;
18、基于所述特征融合器中的音频处理网络层对所述初始音频特征进行特征优化,得到待融合音频特征;
19、基于所述特征融合器中的特征融合网络层,将所述待融合音频特征和目标视觉特征进行融合,得到所述目标对象对应的目标掩蔽特征。
20、在其中一个实施例中,所述获取训练好的目标音频提取网络模型之前,还包括:
21、获取待训练的图像重构模型,获取待训练图像集和面部模板;
22、将所述待训练图像集和所述面部模板输入所述图像重构模型中,基于所述图像重构模型中的面部几何编码器,对所述待训练图像进行形变操作,得到姿态形变图像和面部形变图像;
23、基于所述图像重构模型中的面部关联特征融合器,将所述面部形变图像和面部模板进行融合,得到姿态标准化图像;
24、将所述姿态形变图像和姿态标准化图像输入所述图像重构模型的图像重构器中,得到重构图像和更新的图像重构模型,重复将所述待训练图像集和所述面部模板输入所述图像重构模型中的操作,直至所述更新的图像重构模型满足训练终止条件;
25、将满足所述训练终止条件的图像重构模型中的面部几何编码器和面部关联特征融合器构成初始姿态标准化模型。
26、在其中一个实施例中,所述获取训练好的目标音频提取网络模型之前,还包括:
27、获取待训练音频提取网络模型,所述待训练音频提取网络模型中包括所述初始姿态标准化模型;
28、获取待训练音频集和所述待训练音频集中对应的音频对象对应的待训练视频集;
29、基于所述待训练音频集和待训练视频集对所述待训练音频提取网络模型进行训练,得到所述目标音频提取网络模型。
30、一种音频提取装置,所述装置包括:
31、获取模块,用于获取训练好的目标音频提取网络模型,获取待处理音频和目标对象对应的待处理视频;
32、提取模块,用于基于所述目标音频提取网络模型,对所述待处理视频进行姿态标准化操作,得到姿态标准视频,分别对所述姿态标准视频和待处理视频进行视觉特征提取,得到第一视觉特征和第二视觉特征,将所述第一视觉特征和第二视觉特征进行融合,得到目标视觉特征;
33、融合模块,用于基于所述目标音频提取网络模型对所述待处理音频进行音频特征提取,得到初始音频特征,基于所述目标视觉特征和初始音频特征融合得到所述目标对象对应的目标掩蔽特征;
34、解码模块,用于基于所述目标音频提取网络模型将所述初始音频特征和所述目标掩蔽特征进行融合,得到目标融合特征,将所述目标融合特征输入所述目标音频提取网络模型中的音频解码器,得到所述目标对象对应的目标音频。
35、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述音频提取方法中的步骤。
36、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述音频提取方法中的步骤。
37、上述音频提取方法、装置、计算机设备和存储介质,通过获取训练好的目标音频提取网络模型,获取待处理音频和目标对象对应的待处理视频;基于目标音频提取网络模型,对待处理视频进行姿态标准化操作,得到姿态标准视频,分别对姿态标准视频和待处理视频进行视觉特征提取,得到第一视觉特征和第二视觉特征,将第一视觉特征和第二视觉特征进行融合,得到目标视觉特征;基于目标音频提取网络模型对待处理音频进行音频特征提取,得到初始音频特征,基于目标视觉特征和初始音频特征融合得到目标对象对应的目标掩蔽特征;基于目标音频提取网络模型将初始音频特征和目标掩蔽特征进行融合,得到目标融合特征,将目标融合特征输入目标音频提取网络模型中的音频解码器,得到目标对象对应的目标音频。将目标对象在说话时对应的待处理视频中的头部姿势进行标准化,使得目标对象在说话时不管头部姿势位置如何,都可以获得一致的正面图像,完成从原始姿态视角到姿态不变视角的转变,从而能够更加有效的提取出目标对象在头部姿态变化时的视觉特征,又将标准化后的头部姿势与原始姿势时对应的特征进行融合,以得到对目标对象对应的音频提取更为有效的信息;将视觉特征和音频特征进行融合得到的特征中非目标对象对应的干扰特征进行掩蔽,考虑了目标对象说话时头部姿态对说话信息有效提取的影响,得到更能表征目标对象对应的音频信息的融合特征,再进一步将掩蔽了干扰噪声特征的融合特征与原始的音频特征进行融合,以获取有效性更高更能表征目标对象对应的语音信息的特征,从而使得最终提取得到的目标对象对应的目标音频准确性更高,提高了在混合音频中提取特定说话者声音的准确性。
- 还没有人留言评论。精彩留言会获得点赞!