用于声音信号的统一时域/频域编码的方法和装置与流程
本公开涉及使用混合时域和频域编码模式对输入声音信号进行编码的统一时域/频域编码设备和方法,以及相应的解码器设备和解码方法。在本公开和所附权利要求中:术语“声音”可以与语音、诸如音乐和混响语音的通用音频信号以及任何其他声音有关。
背景技术:
1、现有技术的会话编解码器可以以非常好的质量表示具有大约8kbps的比特率的干净语音信号,并且在16kbps的比特率下接近透明。然而,在低于16kbps的比特率下,低处理延迟会话编解码器(最经常在时域中编码输入语音信号)不适合于通用音频信号,如音乐和混响语音。为了克服这个缺点,已经引入了切换编解码器,基本上使用时域方法来对语音主导的输入声音信号进行编码,并且使用频域方法来对通用音频信号进行编码。然而,这种切换解决方案通常需要更长的处理延迟,这是语音-音乐分类和计算到频域的变换所需的。
2、为了克服与较长处理延迟相关的上述缺点,在美国专利no.9,015,038中已经提出了更统一的时域和频域编码模型(参见参考文献[1],其全部内容通过引用并入本文)。该统一的时域和频域编码模型是如参考文献[2]中所述的由3gpp(第三代合作伙伴计划)标准化的evs(增强型语音服务)声音编解码器的一部分,参考文件[2]的全部内容通过引用并入本文。近年来,3gpp开始致力于基于evs编解码器开发用于被称为ivas(沉浸式语音和音频服务)的沉浸式服务的3d(三维)声音编解码器(参见参考文献[3],其全部内容通过引用并入本文)。
3、为了使编码模型对于特定种类的信号甚至更有效,已经添加了编码模式以在时域和频域之间以及在低频和高频之间有效地分配可用比特。附加编码模式由新的语音/音乐分类器触发,该语音/音乐分类器的输出允许不能被清楚地分类为音乐或语音的信号的不清楚类别(参见参考文献[4],其全部内容通过引用并入本文)。
技术实现思路
1、本公开涉及一种用于对输入声音信号进行编码的统一时域/频域编码方法。该方法包括:将输入声音信号分类为多个声音信号类别中的一个,其中声音信号类别包括表示输入声音信号的性质不清楚的不清楚信号类型类别;选择用于在输入声音信号被分类为所述不清楚信号类型类别的情况下对所述输入声音信号进行编码的多个编码子模式中的一个;以及使用所选择的编码子模式对所述输入声音信号进行混合时域/频域编码。
2、本公开还涉及一种用于对输入声音信号进行编码的统一时域/频域编码方法,包括:将输入声音信号分类为多个声音信号类别中的一个,其中声音信号类别包括表示输入声音信号的性质不清楚的不清楚信号类型类别;以及响应于所述输入声音信号被分类为所述不清楚信号类型类别,对所述输入声音信号进行混合时域/频域编码。对输入声音信号进行混合时域/频域编码包括频带选择和比特分配,用于选择要量化的频带和用于在所选择的频带之间分配可用于量化的比特预算。
3、根据本公开,还提供了一种用于对输入声音信号进行编码的统一时域/频域编码设备,包括:将输入声音信号分类为多个声音信号类别中的一个的分类器,其中声音信号类别包括表示输入声音信号的性质不清楚的不清楚信号类型类别;用于在所述输入声音信号被分类为所述不清晰信号类型类别的情况下对所述输入声音信号进行编码的多个编码子模式中的一个的选择器;以及混合时域/频域编码器,用于使用所选择的编码子模式对输入声音信号进行编码。
4、本公开还涉及一种用于对输入声音信号进行编码的统一时域/频域编码设备,包括:将输入声音信号分类为多个声音信号类别中的一个的分类器,其中声音信号类别包括表示输入声音信号的性质不清楚的不清楚信号类型类别;以及混合时域/频域编码器,用于响应于输入声音信号被分类为不清楚信号类型类别而对输入声音信号进行编码。混合时域/频域编码器包括频带选择器和比特分配器,用于选择要量化的频带和用于在所选择的频带之间分配可用于量化的比特预算。
5、本发明提供了一种声音信号解码方法,包括:接收比特流,所述比特流传达可用于重构混合时域/频域激励的信息,所述混合时域/频域激励表示分类为不清楚信号类型类别的声音信号,所述不清楚信号类型类别示出所述声音信号的性质不清楚,其中,所述信息包括用于对分类为不清楚信号类型类别的声音信号进行编码的多个编码子模式中的一个;响应于在比特流中传送的包括用于对输入声音信号进行编码的编码子模式的信息,重构混合时域/频域激励;将所述混合时域/频域激励转换到时域;以及通过合成滤波器对转换到时域的混合时域/频域激励进行滤波,以产生声音信号的合成版本。
6、本公开提出了一种声音信号解码方法,包括:接收比特流,该比特流传达可用于重构混合时域/频域激励的信息,该混合时域/频域激励表示声音信号,该声音信号(a)被分类为不清楚信号类型类别,该不清楚信号类型类别表示声音信号的性质不清楚,并且(b)使用(i)被选择用于量化的频带和(ii)在频带之间分配的可用于量化的比特预算进行编码;响应于在所述比特流中传送的所述信息来重构所述混合时域/频域激励,其中重构所述混合时域/频域激励包括选择用于量化的所述频带以及可用于在所述频带之间进行量化的比特预算的分配;将所述混合时域/频域激励转换到时域;以及通过合成滤波器对转换到时域的混合时域/频域激励进行滤波,以产生声音信号的合成版本。
7、根据本公开,提供了一种声音信号解码器,包括:比特流的接收器,所述比特流传送可用于重构混合时域/频域激励的信息,所述混合时域/频域激励表示分类为不清楚信号类型类别的声音信号,所述不清楚信号类型类别表示声音信号的性质不清楚,其中,所述信息包括用于对分类为不清楚信号类型类别的声音信号进行编码的多个编码子模式中的一个;响应于在比特流中传送的包括用于对输入声音信号进行编码的编码子模式的信息的混合时域/频域激励的重构器;将所述混合时域/频域激励转换到时域的转换器;以及合成滤波器,用于对转换到时域的混合时域/频域激励进行滤波,以产生声音信号的合成版本。
8、本公开还涉及一种声音信号解码器,包括:比特流的接收器,所述比特流传送可用于重构混合时域/频域激励的信息,所述混合时域/频域激励表示声音信号,所述声音信号(a)被分类为不清楚信号类型类别,所述不清楚信号类型类别表示声音信号的性质不清楚,并且(b)使用(i)被选择用于量化的频带和(ii)在频带之间分配的可用于量化的比特预算进行编码;响应于在所述比特流中传送的所述信息的所述混合时域/频域激励的重构器,其中所述重构器选择用于量化的所述频带以及可用于在所述频带之间进行量化的比特预算的分配;将所述混合时域/频域激励转换到时域的转换器;以及合成滤波器,用于对转换到时域的混合时域/频域激励进行滤波,以产生声音信号的合成版本。
9、通过阅读以下对仅作为示例参考附图给出的统一时域/频域编码方法、统一时域/频域编码设备、解码方法和解码器设备的说明性实施例的非限制性描述,前述和其他特征将变得更加明显。
技术特征:
1.一种用于对输入声音信号进行编码的统一时域/频域编码设备,包括:
2.根据权利要求1所述的时域/频域统一编码设备,其中,所述声音信号类别包括语音、音乐和表示所述输入声音信号既不被分类为语音也不被分类为音乐的不清楚信号类型。
3.根据权利要求2所述的统一时域/频域编码设备,包括:频域编码器,用于在所述分类器将所述输入声音信号分类为音乐类别的情况下对所述输入声音信号进行编码。
4.根据权利要求2或3所述的统一时域/频域编码设备,包括:时域编码器,用于在所述分类器将所述输入声音信号分类为语音类别的情况下对所述输入声音信号进行编码。
5.根据权利要求1至4中任一项所述的统一时域/频域编码设备,其中,所述选择器响应于用于对所述输入声音信号进行编码的比特率和被分类为所述不清楚信号类型类别的所述输入声音信号的特性来选择所述编码子模式。
6.根据权利要求1到5中任一项所述的统一时域/频域编码设备,其中所述编码子模式由相应子模式标志标识。
7.根据权利要求5或6所述的统一时域/频域编码设备,其中,如果(a)可用于对所述输入声音信号进行编码的比特率不高于第一给定值并且(b)所述输入声音信号未被分类为语音也未被分类为音乐,则所述选择器选择使用传统统一时域和频域编码模型来对所述输入声音信号进行编码的后向编码子模式。
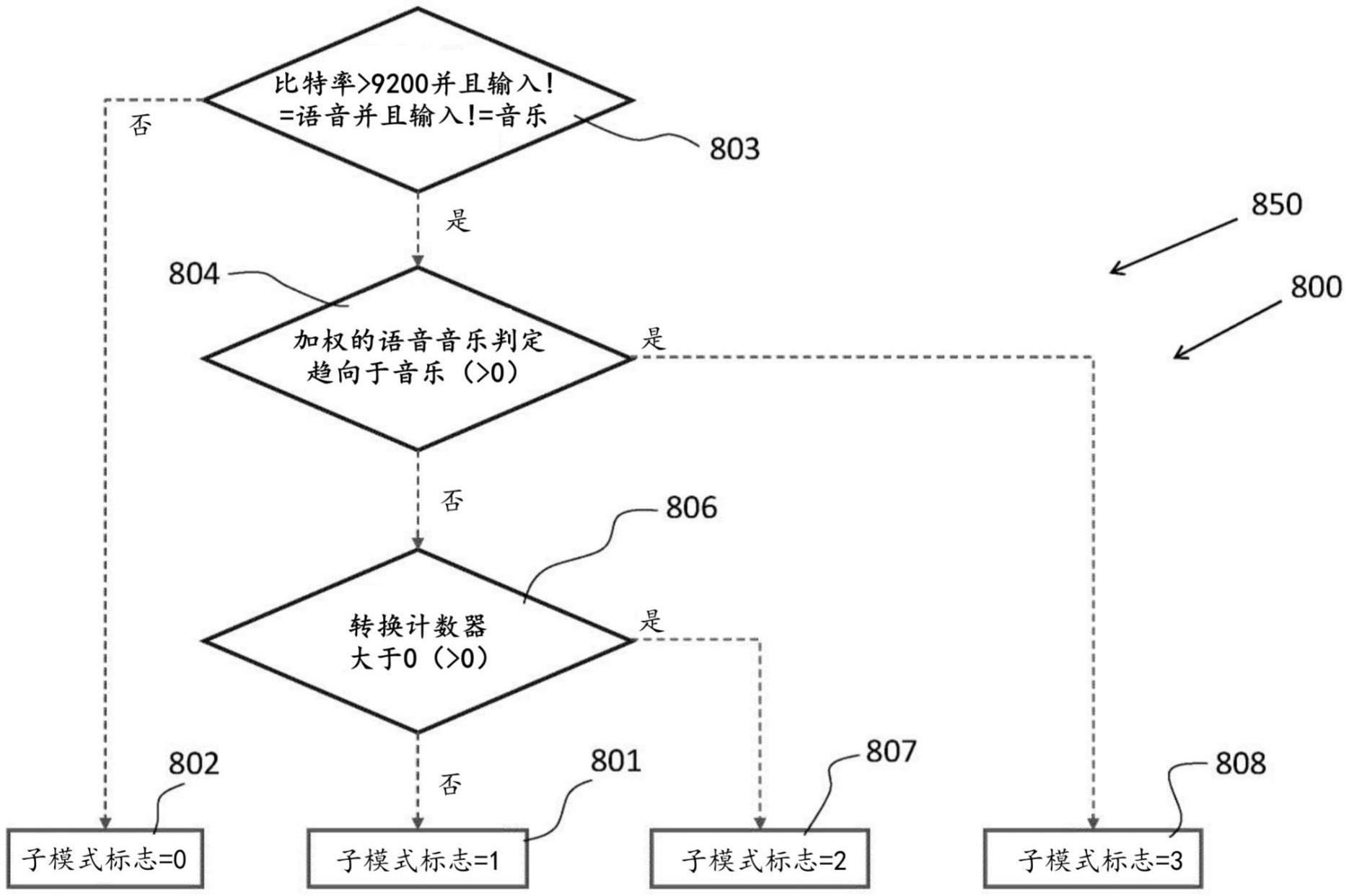
8.根据权利要求5至7中任一项所述的统一时域/频域编码设备,其中,如果类似“语音”的特性在所述输入声音信号中被检测到,则所述选择器选择第一编码子模式。
9.根据权利要求8所述的统一时域/频域编码设备,其中,如果(a)所述输入声音信号未被所述分类器分类为语音或音乐,并且可用于对所述输入声音信号进行编码的比特率高于第二给定值,(b)所述输入声音信号是音乐的概率不大于第三给定值,以及(c)在所述输入声音信号的当前帧中未检测到时间攻击,则所述选择器选择所述第一编码子模式。
10.根据权利要求5至9中任一项所述的统一时域/频域编码设备,其中,如果时间攻击在所述输入声音信号中被检测到,则所述选择器选择第二编码子模式。
11.根据权利要求10所述的统一时域/频域编码设备,其中,如果(a)所述输入声音信号未被所述分类器分类为语音或音乐,并且可用于对所述输入声音信号进行编码的比特率高于第四给定值,(b)所述输入声音信号是音乐的概率不大于第五给定值,以及(c)在所述输入声音信号的当前帧中检测到时间攻击,则所述选择器选择所述第二编码子模式。
12.根据权利要求5至11中任一项所述的统一时域/频域编码设备,其中,如果类似“音乐”的特性在所述输入声音信号中被检测到,则所述选择器选择第三编码子模式。
13.根据权利要求12所述的统一时域/频域编码设备,其中,如果(a)所述输入声音信号未被所述分类器分类为语音或音乐并且可用于对所述输入声音信号进行编码的比特率高于第六给定值,以及(b)所述输入声音信号是音乐的概率大于第七给定值,则所述选择器选择所述第三编码子模式。
14.根据权利要求1至13中任一项所述的统一时域/频域编码设备,其中:
15.根据权利要求14所述的统一时域/频域编码设备,其中,所述选择器(a)在所述第三编码子模式中逐帧选择给定数量的子帧以对所述输入声音信号进行编码,以及(b)在所述第一编码子模式和所述第二编码子模式中,选择小于所述给定数量的并且根据可用于对所述输入声音信号进行编码的比特率的数量的子帧。
16.一种用于对输入声音信号进行编码的统一时域/频域编码设备,包括:
17.根据权利要求16所述的统一时域/频域编码设备,其中,所述混合时域/频域编码器包括在所述输入声音信号的混合时域/频域编码期间产生的频域激励贡献与时域激励贡献的频率表示之间的差矢量的计算器,并且其中,所述频带是所述差矢量的频带。
18.根据权利要求16或17所述的统一时域/频域编码设备,其中,(a)所述混合时域/频域编码器包括截止频率的计算器,其中高于所述截止频率,时域激励贡献不用于所述输入声音信号的混合时域/频域编码,以及(b)所述统一时域/频域编码设备包括用于在所述输入声音信号被分类为所述不清楚信号类型类别的情况下对所述输入声音信号进行编码的多个编码子模式中的一个的选择器,,其中,所述频带选择器和比特分配器响应于所述截止频率和所选择的编码子模式来选择要量化的所述频带并且分配可用于量化的所述比特预算。
19.根据权利要求16所述的统一时域/频域编码设备,其中:
20.根据权利要求19所述的统一时域/频域编码设备,包括用于在所述输入声音信号被分类为所述不清楚信号类型类别的情况下对所述输入声音信号进行编码的多个编码子模式中的一个的选择器,其中,所述可用比特预算的一部分的所述估计器基于所选择的编码子模式来调整所述可用比特预算的所述一部分。
21.根据权利要求20所述的统一时域/频域编码设备,其中在所选择的编码子模式指示所述输入声音信号中存在时间攻击的情况下,所述可用比特预算的一部分的所述估计器将所述可用比特预算的所述一部分增大所述可用比特预算的第一给定百分比,并且在所选择的编码子模式指示所述输入声音信号中存在音乐特性的情况下,将所述可用比特预算的所述一部分减小所述可用比特预算的第二给定百分比。
22.根据权利要求17所述的统一时域/频域编码设备,包括用于在所述输入声音信号被分类为所述不清楚信号类型类别的情况下对所述输入声音信号进行编码的多个编码子模式中的一个的选择器,其中,所述频带选择器和所述比特分配器包括与所选择的编码子模式相关地要量化的所述差矢量的频带的最大数量的估计器。
23.根据权利要求22所述的统一时域/频域编码设备,其中,所述频带的最大数量的估计器(a)在响应于在所述输入声音信号中检测到类似“语音”的特性而选择第一编码子模式的情况下将要量化的所述差矢量的频带的最大数量设置为第一值,(b)在响应于在所述输入声音信号中检测到存在时间攻击而选择第二编码子模式的情况下将要量化的所述差矢量的频带的最大数量设置为第二值,以及(c)在响应于在所述输入声音信号中检测到类似“音乐”的特性而选择第三编码子模式的情况下将要量化的所述差矢量的频带的最大数量设置为第三值。
24.根据权利要求22或23所述的统一时域/频域编码设备,其中,所述频带的最大数量的估计器响应于可用于所述差矢量的频率量化的比特预算,重新调整要量化的所述差矢量的所述频带的最大数量。
25.根据权利要求22至24中任一项所述的统一时域/频域编码设备,其中,所述频带的最大数量的估计器与分配给所述差矢量的中频带和较高频带的频率量化的比特数相关地,进一步减小要量化的频带的最大数量。
26.根据权利要求19至21中任一项所述的统一时域/频域编码设备,其中,所述频带选择器和比特分配器包括比特计算器,所述比特计算器响应于(a)可用于对所述差矢量的较低频率进行频率量化的比特数以及(b)可用于对所述较低频率进行频率量化的比特预算的所述一部分,而被分配用于对所述差矢量的较低频带进行频率量化。
27.根据权利要求26所述的统一时域/频域编码设备,其中,分配用于对所述差矢量的较低频带进行频率量化的所述比特计算器还响应于:(a)分配用于对频带进行频率量化的最小比特数,(b)分配用于对所述较低频带之后的第一频带进行量化的比特数,以及(c)估计的要量化的频带的最大数量与校正的进一步减小的要量化的频带的最大数量之间的差。
28.根据权利要求16至27中任一项所述的统一时域/频域编码设备,其中,所述频带选择器和比特分配器包括频带表征器,所述频带表征器用于(a)找到与其相邻频带相比具有较低能量的频带,并标记较低能量频带,使得仅能够分配预定最小数量的比特用于对这些较低能量频带进行频率量化,以及(b)执行其他中能量频带和较高能量频带的位置排序。
29.根据权利要求28所述的统一时域/频域编码设备,其中,所述频带表征器以能量递减顺序对所述中能量频带和较高能量频带进行位置排序。
30.根据权利要求28或29所述的统一时域/频域编码设备,其中,所述频带选择器和比特分配器包括要考虑到所述频带的频率和能量而量化的所述频带中的比特的最终分配器。
31.根据权利要求30所述的统一时域/频域编码设备,其中,为了对较低频带进行频率量化,所述比特的最终分配器线性地分配被分配用于对所述较低频带进行频率量化的比特,其中第一百分比的比特被分配给第一最低频带,并且第二百分比的比特被分配给最后一个较低频带。
32.根据权利要求30或31所述的统一时域/频域编码设备,其中,所述最终分配器按照线性函数将被分配用于对所述差矢量进行频率量化的剩余比特分配在其他中频带和较高频带上,但是考虑来自所述频带表征器的频带能量表征,使得更多比特被分配给较高能量频带,并且更少比特被分配给较低能量频带。
33.根据权利要求32所述的统一时域/频域编码设备,其中,所述最终分配器将任何未分配的比特分配给所述较低频带。
34.一种用于对输入声音信号进行编码的统一时域/频域编码方法,包括:
35.根据权利要求34所述的时域/频域统一编码方法,其中,所述声音信号类别包括语音、音乐和表示所述输入声音信号既不被分类为语音也不被分类为音乐的不清楚信号类型。
36.根据权利要求35所述的统一时域/频域编码方法,包括:在分类器将所述输入声音信号分类为音乐类别的情况下,对所述输入声音信号进行频域编码。
37.根据权利要求35或36所述的统一时域/频域编码方法,包括:在分类器将所述输入声音信号分类为语音类别的情况下,对所述输入声音信号进行时域编码。
38.根据权利要求34至37中任一项所述的统一时域/频域编码方法,其中,选择多个编码子模式中的一个包括:响应于用于对所述输入声音信号进行编码的比特率和被分类为所述不清楚信号类型类别的所述输入声音信号的特性来选择所述编码子模式。
39.根据权利要求34到38中任一项所述的统一时域/频域编码方法,包括通过相应子模式标志标识所述编码子模式。
40.根据权利要求38或39所述的统一时域/频域编码方法,其中,选择多个编码子模式中的一个包括:如果(a)可用于对所述输入声音信号进行编码的比特率不高于第一给定值并且(b)所述输入声音信号未被分类为语音也未被分类为音乐,则选择使用传统统一时域和频域编码模型来对所述输入声音信号进行编码的后向编码子模式。
41.根据权利要求38至40中任一项所述的统一时域/频域编码方法,其中,选择多个编码子模式中的一个包括:如果类似“语音”的特性在所述输入声音信号中被检测到,则选择第一编码子模式。
42.根据权利要求41所述的统一时域/频域编码方法,其中,如果(a)所述输入声音信号未被分类为语音或音乐,并且可用于对所述输入声音信号进行编码的比特率高于第二给定值,(b)所述输入声音信号是音乐的概率不大于第三给定值,以及(c)在所述输入声音信号的当前帧中未检测到时间攻击,则选择所述第一编码子模式。
43.根据权利要求38至42中任一项所述的统一时域/频域编码方法,其中,选择多个编码子模式中的一个包括:如果时间攻击在所述输入声音信号中被检测到,则选择第二编码子模式。
44.根据权利要求43所述的统一时域/频域编码方法,其中,如果(a)所述输入声音信号未被分类为语音或音乐,并且可用于对所述输入声音信号进行编码的比特率高于第四给定值,(b)所述输入声音信号是音乐的概率不大于第五给定值,以及(c)在所述输入声音信号的当前帧中检测到时间攻击,则选择所述第二编码子模式。
45.根据权利要求38至44中任一项所述的统一时域/频域编码方法,其中,选择多个编码子模式中的一个包括:如果类似“音乐”的特性在所述输入声音信号中被检测到,则选择第三编码子模式。
46.根据权利要求45所述的统一时域/频域编码方法,其中,如果(a)所述输入声音信号未被分类为语音或音乐并且可用于对所述输入声音信号进行编码的比特率高于第六给定值,以及(b)所述输入声音信号是音乐的概率大于第七给定值,则选择所述第三编码子模式。
47.根据权利要求34至46中任一项所述的统一时域/频域编码方法,其中:
48.根据权利要求47所述的统一时域/频域编码方法,其中,选择多个编码子模式中的一个包括:(a)在所述第三编码子模式中,逐帧选择给定数量的子帧来对所述输入声音信号进行编码,以及(b)在所述第一编码子模式和所述第二编码子模式中,选择小于所述给定数量的并且根据可用于对所述输入声音信号进行编码的比特率的数量的子帧。
49.一种用于对输入声音信号进行编码的统一时域/频域编码方法,包括:
50.根据权利要求49所述的统一时域/频域编码方法,其中,对所述输入声音信号进行混合时域/频域编码包括:计算在对所述输入声音信号进行混合时域/频域编码期间产生的频域激励贡献与时域激励贡献的频率表示之间的差矢量,并且其中,所述频带是所述差矢量的频带。
51.根据权利要求49或50所述的统一时域/频域编码方法,其中(a)对所述输入声音信号进行混合时域/频域编码包括计算截止频率,其中高于所述截止频率,时域激励贡献不用于所述输入声音信号的混合时域/频域编码,并且(b)所述统一时域/频域编码方法包括:选择用于在所述输入声音信号被分类为所述不清楚信号类型类别的情况下对所述输入声音信号进行编码的多个编码子模式中的一个,其中所述频带选择和比特分配响应于所述截止频率和所选择的编码子模式来选择要量化的所述频带并且分配可用于量化的所述比特预算。
52.根据权利要求49所述的统一时域/频域编码方法,其中:
53.根据权利要求52所述的统一时域/频域编码方法,包括:选择用于在所述输入声音信号被分类为所述不清楚信号类型类别的情况下对所述输入声音信号进行编码的多个编码子模式中的一个,其中,对所述可用比特预算的一部分进行估计包括基于所选择的编码子模式来调整所述可用比特预算的所述一部分。
54.根据权利要求53所述的统一时域/频域编码方法,其中对所述可用比特预算的一部分进行估计包括:在所选择的编码子模式指示所述输入声音信号中存在时间攻击的情况下,将所述可用比特预算的所述一部分分数增大所述可用比特预算的第一给定百分比,并且在所选择的编码子模式指示所述输入声音信号中存在音乐特性的情况下,将所述可用比特预算的所述一部分减小所述可用比特预算的第二给定百分比。
55.根据权利要求50所述的时域/频域统一编码方法,包括:选择用于在所述输入声音信号被分类为所述不清楚信号类型类别的情况下对所述输入声音信号进行编码的多个编码子模式中的一个,其中,所述频带选择和比特分配包括对与所选择的编码子模式相关地要量化的所述差矢量的频带的最大数量进行估计。
56.根据权利要求55所述的统一时域/频域编码方法,其中,对所述差矢量的频带的最大数量进行估计包括:(a)在响应于在所述输入声音信号中检测到类似“语音”的特性而选择第一编码子模式的情况下,将要量化的所述差矢量的频带的最大数量设置为第一值,(b)在响应于在所述输入声音信号中检测到存在时间攻击而选择第二编码子模式的情况下,将要量化的所述差矢量的频带的最大数量设置为第二值,以及(c)在响应于在所述输入声音信号中检测到类似“音乐”的特性而选择第三编码子模式的情况下,将要量化的所述差矢量的频带的最大数量设置为第三值。
57.根据权利要求55或56所述的统一时域/频域编码方法,其中,对所述差矢量的频带的最大数量进行估计包括:响应于可用于所述差矢量的频率量化的比特预算,重新调整要量化的所述差矢量的频带的最大数量。
58.根据权利要求55至57中任一项所述的统一时域/频域编码方法,其中,对所述差矢量的频带的最大数量进行估计包括:与分配给所述差矢量的中频带和较高频带的频率量化的比特数相关地,减小要量化的频带的最大数量。
59.根据权利要求52至54中任一项所述的统一时域/频域编码方法,其中,所述频带选择和比特分配包括:响应于(a)可用于对所述差矢量的较低频率进行频率量化的比特数,以及(b)可用于对所述较低频率进行频率量化的比特预算的所述一部分,计算被分配用于对所述差矢量的较低频带进行频率量化的比特。
60.根据权利要求59所述的统一时域/频域编码方法,其中,计算被分配用于对所述差矢量的较低频带进行频率量化的比特还响应于:(a)分配用于对频带进行频率量化的最小比特数,(b)分配用于对所述较低频带之后的第一频带进行量化的比特数,以及(c)估计的要量化的频带的最大数量与校正的进一步减小的要量化的频带的最大数量之间的差。
61.根据权利要求49至60中任一项所述的统一时域/频域编码方法,其中,所述频带选择和比特分配包括频带表征,用于(a)找到与其相邻频带相比具有较低能量的频带,并标记较低能量频带,使得仅能够分配预定最小数量的比特用于对这些较低能量频带进行频率量化,以及(b)执行其他中能量频带和较高能量频带的位置排序。
62.根据权利要求61所述的统一时域/频域编码方法,其中,所述频带表征包括以能量递减顺序对所述中能量频带和较高能量频带进行位置排序。
63.根据权利要求61或62所述的统一时域/频域编码方法,其中,所述频带选择和比特分配包括:要考虑到所述频带的频率和能量而量化的所述频带中的比特的最终分配。
64.根据权利要求63所述的统一时域/频域编码方法,其中,为了对较低频带进行频率量化,所述比特的最终分配线性地分配被分配用于对所述较低频率进行频率量化的比特,其中第一百分比的比特被分配给第一最低频带,并且第二百分比的比特被分配给最后一个较低频带。
65.根据权利要求63或64所述的统一时域/频域编码方法,其中,所述比特的最终分配包括:按照线性函数将被分配用于对所述差矢量进行频率量化的剩余比特分配在其他中频带和较高频带上,但是考虑频带能量表征,使得更多的比特被分配给较高能量频带,并且更少的比特被分配给较低能量频带。
66.根据权利要求65所述的统一时域/频域编码方法,其中,所述比特的最终分配包括将任何未分配的比特分配给所述较低频带。
67.一种用于对输入声音信号进行编码的统一时域/频域编码设备,包括:
68.一种用于对输入声音信号进行编码的统一时域/频域编码设备,包括:
69.一种用于对输入声音信号进行编码的统一时域/频域编码设备,包括:
70.一种用于对输入声音信号进行编码的统一时域/频域编码设备,包括:
71.一种声音信号解码器,包括:
72.根据权利要求71所述的声音信号解码器,其中,所述编码子模式在所述比特流中由子模式标志标识。
73.根据权利要求71或72所述的声音信号解码器,其中,所述编码子模式包括:(a)在所述声音信号包含类似“语音”的特性的情况下的第一编码子模式,(b)在所述声音信号包含时间攻击的情况下的第二编码子模式,以及(c)在所述声音信号包含类似“音乐”的特性的情况下的第三编码子模式。
74.根据权利要求71至73中任一项所述的声音信号解码器,其中,所述重构器从所述比特流中传送的所述信息中恢复时域激励贡献的频率表示,重构频域激励贡献与所述时域激励贡献的所述频率表示之间的频率量化的差矢量,并将频率量化的差信号与所述时域激励贡献的所述频率表示相加,以产生所述混合时域/频域激励。
75.一种声音信号解码器,包括:
76.根据权利要求75所述的声音信号解码器,其中,(a)来自所述比特流的所述信息包括截止频率和用于对被分类为所述不清楚信号类型类别的所述声音信号进行编码的多个编码子模式中的一个,其中高于所述截止频率,时域激励贡献不用于所述声音信号的混合时域/频域编码,以及(b)所述重构器响应于所述截止频率和所使用的编码子模式,选择所述量化的频带并在所选择的频带之间分配可用于去量化的所述比特预算。
77.根据权利要求75所述的声音信号解码器,其中:
78.根据权利要求77所述的声音信号解码器,其中,来自所述比特流的所述信息包括用于对所述声音信号进行编码的多个编码子模式中的一个,并且其中,所述可用比特预算的一部分的估计器基于所使用的编码子模式来调整所述可用比特预算的所述一部分。
79.根据权利要求78所述的声音信号解码器,其中在所述编码子模式指示所述声音信号中存在时间攻击的情况下,所述可用比特预算的一部分的所述估计器将所述可用比特预算的所述一部分增大所述可用比特预算的第一给定百分比,并且在所述编码子模式指示所述输入声音信号中存在音乐特征的情况下,将所述可用比特预算的所述一部分减小所述可用比特预算的第二给定百分比。
80.根据权利要求75至79中任一项所述的声音信号解码器,其中,来自所述比特流的所述信息包括用于对被分类为所述不清楚信号类型类别的所述声音信号进行编码的多个编码子模式中的一个,并且其中,所述重构器包括与所使用的编码子模式相关地量化的差矢量的频带的最大数量的估计器,所述差矢量是在所述声音信号的混合时域/频域编码期间产生的频域激励贡献和时域激励贡献的频率表示之间确定的。
81.根据权利要求80所述的声音信号解码器,其中,所述频带的最大数量的估计器(a)在响应于在所述声音信号中检测到“语音”特性而使用第一编码子模式的情况下,将所述量化的差矢量的频带的最大数量设置为第一值,(b)在响应于在所述声音信号中检测到存在时间攻击而使用第二编码子模式的情况下,将所述量化的差矢量的频带的最大数量设置为第二值,以及(c)在响应于在所述声音信号中检测到“音乐”特性而选择第三编码子模式的情况下,将所述量化的差矢量的频带的最大数量设置为第三值。
82.根据权利要求80或81所述的声音信号解码器,其中,所述频带的最大数量的估计器响应于可用于所述差矢量的频率量化的比特预算,重新调整所述量化的差矢量的所述频带的最大数量。
83.根据权利要求80至82中任一项所述的声音信号解码器,其中,所述频带的最大数量的估计器与分配给所述差矢量的中频带和较高频带的频率量化的比特数相关地,进一步减小量化的频带的最大数量。
84.根据权利要求77至79中任一项所述的声音信号解码器,其中,所述重构器包括比特计算器,所述比特计算器响应于(a)可用于对所述差矢量的较低频率进行频率量化的比特数,以及(b)可用于对所述较低频率进行频率量化的比特预算的所述一部分,而被分配用于对所述差矢量的较低频带进行频率量化。
85.根据权利要求84所述的声音信号解码器,其中,分配用于对所述差矢量的较低频带进行频率量化的所述比特计算器还响应于(a)分配给所述量化的频带的最小比特数,(b)分配用于对所述较低频带之后的第一频带进行量化的比特数,以及(c)估计的量化的频带的最大数量与校正的进一步减小的量化的频带的最大数量之间的差。
86.根据权利要求75至85中任一项所述的声音信号解码器,其中,所述重构器包括频带表征器,所述频带表征器用于(a)找到与其相邻频带相比具有较低能量的频带,并标记较低能量频带,使得仅能够分配预定最小数量的比特用于对这些较低能量频带进行频率量化,以及(b)执行其他中能量频带和较高能量频带的位置排序。
87.根据权利要求86所述的声音信号解码器,其中,所述频带表征器以能量递减顺序对所述中能量频带和较高能量频带进行位置排序。
88.根据权利要求86或87所述的声音信号解码器,其中,所述重构器包括考虑到所述频带的频率和能量的量化的频带中的比特的最终分配器。
89.根据权利要求88所述的声音信号解码器,其中,为了对较低频带进行频率去解量,所述比特的最终分配器线性地分配被分配给所述较低频率的比特,其中第一百分比的比特分配给第一最低频带,并且第二百分比的比特分配给最后一个较低频带。
90.根据权利要求88或89所述的声音信号解码器,其中,所述最终分配器按照线性函数将被分配用于对所述差矢量进行频率去量化的剩余比特分配在其它中频带和较高频带上,但是考虑来自所述频带表征器的频带能量表征,使得更多的比特被分配给较高能量频带,并且更少的比特被分配给较低能量频带。
91.根据权利要求90所述的声音信号解码器,其中,所述最终分配器将任何未分配的比特分配给所述较低频带。
92.根据权利要求75至91中任一项所述的声音信号解码器,其中,所述重构器从所述比特流中传送的所述信息中恢复时域激励贡献的频率表示,从所述比特流中传送的所述信息中重构频域激励贡献与所述时域激励贡献的所述频率表示之间的频率量化的差矢量,并且将频率量化的差信号与所述时域激励贡献的所述频率表示相加,以产生所述混合时域/频域激励。
93.根据权利要求92所述的声音信号解码器,其中,所述重构器使用所述频带选择和在所述频带之间的比特预算的分配来重构所述频率量化的差矢量。
94.一种声音信号解码方法,包括:
95.根据权利要求94所述的声音信号解码方法,其中,所述编码子模式在所述比特流中由子模式标志标识。
96.根据权利要求94或95所述的声音信号解码方法,其中,所述编码子模式包括:(a)在所述声音信号包含类似“语音”的特性的情况下的第一编码子模式,(b)在所述声音信号包含时间攻击的情况下的第二编码子模式,以及(c)在所述声音信号包含类似“音乐”的特性的情况下的第三编码子模式。
97.根据权利要求94至96中任一项所述的声音信号解码方法,其中,重构所述混合时域/频域激励包括:从所述比特流中传送的所述信息中恢复时域激励贡献的频率表示,从所述比特流中传送的所述信息重构频域激励贡献与时域激励贡献的频率表示之间的频率量化的差矢量,以及将频率量化的差信号与所述时域激励贡献的频率表示相加,以产生所述混合时域/频域激励。
98.一种声音信号解码方法,包括:
99.根据权利要求98所述的声音信号解码方法,其中,(a)来自所述比特流的所述信息包括截止频率和用于对被分类为所述不清楚信号类型类别的所述声音信号进行编码的多个编码子模式中的一个,其中高于所述截止频率,时域激励贡献不用于所述声音信号的混合时域/频域编码,并且(b)重构所述混合时域/频域激励包括:响应于所述截止频率和所使用的编码子模式,选择量化的频带,并且在所选择的频带之间分配可用于去量化的所述比特预算。
100.根据权利要求98所述的声音信号解码方法,其中:
101.根据权利要求100所述的声音信号解码方法,其中,来自所述比特流的所述信息包括用于对所述声音信号进行编码的多个编码子模式中的一个,并且其中,对所述可用比特预算的一部分进行估计包括基于所使用的编码子模式来调整所述可用比特预算的所述一部分。
102.根据权利要求101所述的声音信号解码方法,其中对所述可用比特预算的一部分进行估计包括:在所述编码子模式指示所述声音信号中存在时间攻击的情况下,将所述可用比特预算的所述一部分增大所述可用比特预算的第一给定百分比,并且在所述编码子模式指示所述输入声音信号中存在音乐特征的情况下,将所述可用比特预算的所述一部分减小所述可用比特预算的第二给定百分比。
103.根据权利要求98至102中任一项所述的声音信号解码方法,其中,来自所述比特流的所述信息包括用于对被分类为所述不清楚信号类型类别的所述声音信号进行编码的多个编码子模式中的一个,并且其中,重构所述混合时域/频域激励包括:对与所使用的编码子模式相关地量化的差矢量的频带的最大数量进行估计,所述差矢量是在所述声音信号的混合时域/频域编码期间产生的频域激励贡献和时域激励贡献的频率表示之间确定的。
104.根据权利要求103所述的声音信号解码方法,其中对频带的最大数量进行估计包括:(a)在响应于在所述声音信号中检测到“语音”特性而使用第一编码子模式的情况下,将所述量化的差矢量的频带的最大数量设置为第一值,(b)在响应于在所述声音信号中检测到存在时间攻击而使用第二编码子模式的情况下,将所述量化的差矢量的频带的最大数量设置为第二值,以及(c)在响应于在所述声音信号中检测到“音乐”特性而选择第三编码子模式的情况下,将所述量化的差矢量的频带的最大数量设置为第三值。
105.根据权利要求103或104所述的声音信号解码方法,其中,对所述差矢量的频带的最大数量进行估计包括:响应于可用于所述差矢量的频率量化的比特预算,重新调整所述差矢量的量化的频带的最大数量。
106.根据权利要求103至105中任一项所述的声音信号解码方法,其中,对所述差矢量的频带的最大数量进行估计包括:与分配给所述差矢量的中频带和较高频带的频率量化的比特数相关地,减小量化的频带的最大数量。
107.根据权利要求100至102中任一项所述的声音信号解码方法,其中,重构所述混合时域/频域激励包括:响应于(a)可用于对所述差矢量的较低频率进行频率量化的比特数,以及(b)可用于对所述较低频率进行频率量化的比特预算的所述一部分,计算被分配用于对所述差矢量的较低频带进行频率量化的比特数。
108.根据权利要求107所述的声音信号解码方法,其中,计算被分配用于对所述差矢量的较低频带进行频率量化的比特数还响应于:(a)分配给所述量化的频带的最小比特数,(b)分配用于对所述较低频带之后的第一频带进行量化的比特数,以及(c)估计的量化的频带的最大数量与校正的进一步减小的量化的频带的最大数量之间的差。
109.根据权利要求98至108中任一项所述的声音信号解码方法,其中,重构所述混合时域/频域激励包括表征所述频带,用于(a)找到与其相邻频带相比具有较低能量的频带,并标记较低能量频带,使得仅能够分配预定最小数量的比特用于对这些较低能量频带进行频率量化,以及(b)执行其他中能量频带和较高能量频带的位置排序。
110.根据权利要求109所述的声音信号解码方法,其中,表征所述频带包括以能量递减顺序对所述中能量频带和较高能量频带进行位置排序。
111.根据权利要求109或110所述的声音信号解码方法,其中,重构所述混合时域/频域激励包括:考虑到所述频带的频率和能量的所述量化的频带中的比特的最终分配。
112.根据权利要求111所述的声音信号解码方法,其中,所述比特的最终分配包括:为了对较低频带进行频率去量化,线性分配被分配给所述较低频率的比特,其中第一百分比的比特分配给第一最低频带,并且第二百分比的比特分配给最后一个较低频带。
113.根据权利要求111或112所述的声音信号解码方法,其中,所述比特的最终分配包括:按照线性函数将分配用于对所述差矢量进行频率去量化的剩余比特分配在其他中频带和较高频带上,但是考虑所述频带能量特征,使得更多的比特被分配给较高能量频带,并且更少的比特被分配给较低能量频带。
114.根据权利要求113所述的声音信号解码方法,其中,所述最终分配包括将任何未分配的比特分配给所述较低频带。
115.根据权利要求98至114中任一项所述的声音信号解码方法,其中重构混合时域/频域激励包括:从所述比特流中传送的所述信息中恢复时域激励贡献的频率表示,从所述比特流中传送的所述信息重构频域激励贡献与时域激励贡献的频率表示之间的频率量化的差矢量,以及将频率量化的差信号与所述时域激励贡献的频率表示相加,以产生所述混合时域/频域激励。
116.根据权利要求115所述的声音信号解码方法,其中,重构所述混合时域/频域激励包括:使用所述频带选择和在所述频带之间的比特预算的分配来重构所述频率量化的差矢量。
117.一种声音信号解码器,包括:
118.一种声音信号解码器,包括:
119.一种声音信号解码器,包括:
120.一种声音信号解码器,包括:
技术总结
一种用于对输入声音信号进行编码的统一时域/频域编码方法和设备,包括将输入声音信号分类为多个声音信号类别中的一个的分类器,所述多个声音信号类别包括表示输入声音信号的性质不清楚的不清楚信号类型类别。用于在输入声音信号被分类为不清楚信号类型类别的情况下对输入声音信号进行编码的多个编码子模式中的一个被选择。混合时域/频域编码器使用所选择的编码子模式对输入声音信号进行编码。混合时域/频域编码器包括频带选择器和比特分配器,用于选择要量化的频带和用于在所选择的频带之间分配可用于量化的比特预算。还提供了对应的声音信号解码器和解码方法。
技术研发人员:T·瓦尔兰科特,V·马列诺夫斯基
受保护的技术使用者:沃伊斯亚吉公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!