基于场景自适应的婴儿哭声检测方法、系统、存储介质和设备
本发明涉及到语音识别和人工智能监护技术,尤其是涉及到一种基于场景自适应的婴儿哭声检测方法、系统、存储介质和设备,为新生儿婴儿哭声检测识别方法改进方面,属于计算机技术结合人工智能在医疗健康领域的应用。
背景技术:
1、作为一种生物标志物的婴儿哭声,能揭示婴儿的身体状况、需求、及情绪在内的多个抽象层次的信息。临床研究表明,婴儿哭声的声学分析可为医务人员提供有重要意义的医疗支持,如了解哭泣的原因、评估早产儿的发展情况、诊断特定疾病等。因此,开发一种能准确的婴儿哭声自动检测方法对于新生儿医疗保健至关重要。
2、近来,使用基于音频的机器学习方法进行自动的婴儿哭声检测已被广泛地研究,然而,新生儿的哭声检测依然存在局限性。具体来说,大部分方法在真实的临床环境中难以取得足够的检测性能,常表现出低精准度高召回率。这些方法在受控环境中进行性能评估,然而,受控环境不同于具有各种背景噪声的临床真实环境,如谈话、脚步声和警报声等。这些额外的背景噪声会导致大多数方法在真实环境中的性能恶化。另外,这些方法过度依赖于基于阈值的背景噪声滤除方法。在多数情况下,阈值的确定与采集设备的位置、房间大小以及不同声源变化相关,这意味着大多数方法必须手动调节阈值以适应新的环境。然而,采集并标注每个新环境的语音数据矫正阈值并不现实,尤其是在临床场景下的语音数据。这些现实因素阻碍了婴儿哭声检测在真实世界中的快速应用。
技术实现思路
1、综上所述,本发明的目的在于解决现有新生儿婴儿哭声检测识别方法在新环境下的性能恶化、泛化能力差、人工校准及训练数据不足,在真实的临床环境中难以取得足够的检测性能,常表现出低精准度高召回率的技术不足,而提出基于场景自适应的婴儿哭声检测方法、系统、存储介质和设备。
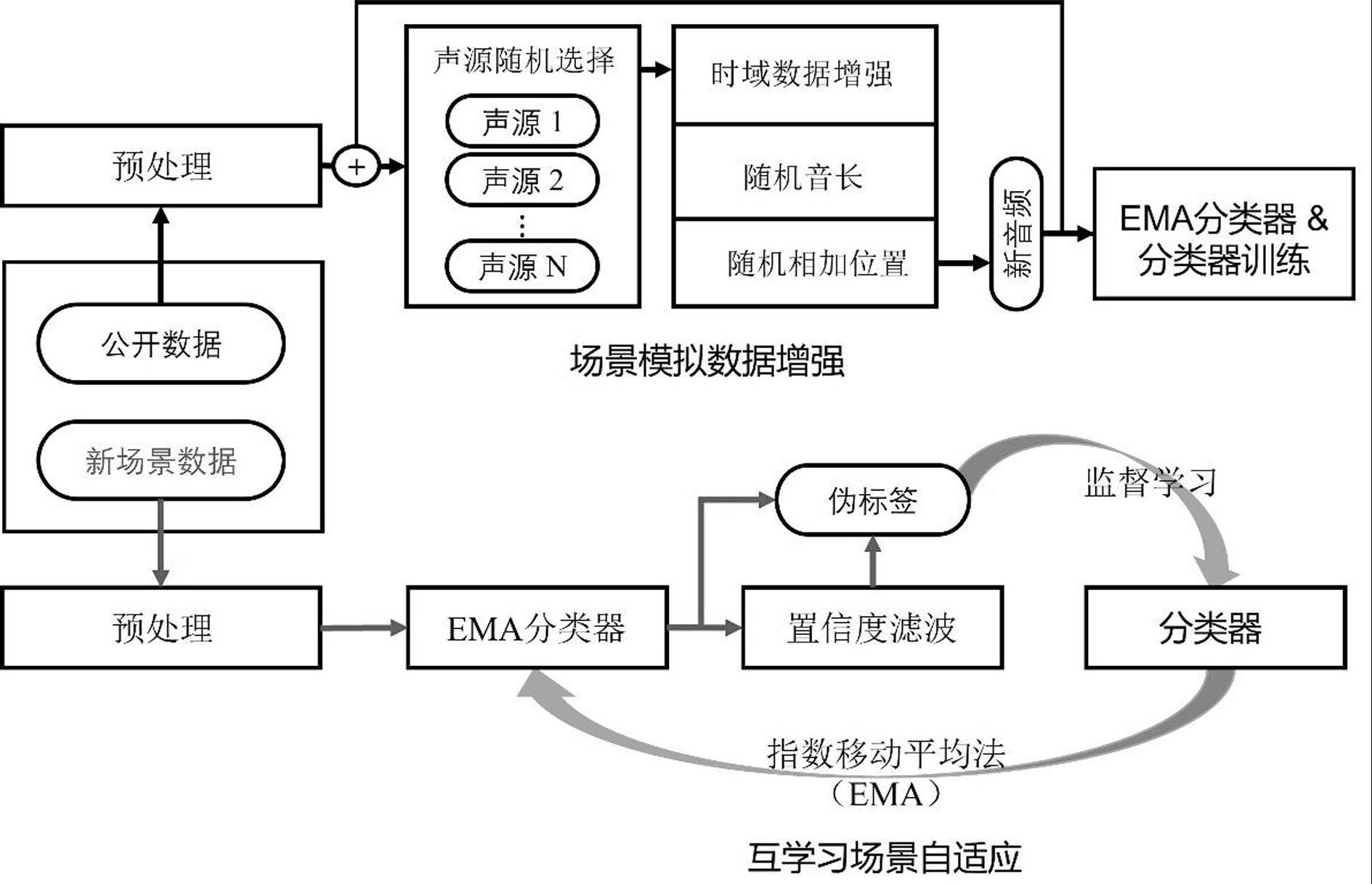
2、为解决本发明所提出的技术问题,采用的技术方案为:一种基于场景自适应的婴儿哭声检测方法,该方法包括有如下步骤:
3、步骤s1、基于语音线性相加特性的场景模拟数据增强:收集语音公开数据集和收集公开的婴儿哭声数据,利用公开标注数据进行数据增强,并利用场景模拟数据增强的样本对分类器进行训练,学习合成的混乱场景下的哭声特性;
4、步骤s2、场景自适应的互学习;采用了指数移动平均法和伪标签训练的方式,建立一个场景自适应的哭声检测学习闭环,不断推导新环境下的哭声数据分布,并修正步骤s1获得到的哭声特性,实现环境自适应的哭声检测。
5、一种基于场景自适应的婴儿哭声检测系统,该系统包括:
6、基于语音线性相加特性的场景模拟数据增强单元:用于收集语音公开数据集和收集公开的婴儿哭声数据,利用公开标注数据进行数据增强,并利用场景模拟数据增强的样本对分类器进行训练,学习合成的混乱场景下的哭声特性;
7、场景自适应的互学习单元;用于采用指数移动平均法和伪标签训练的方式,建立一个场景自适应的哭声检测学习闭环,不断推导新环境下的哭声数据分布,并修正基于语音线性相加特性的场景模拟数据增强单元中获得到的哭声特性,实现环境自适应的哭声检测。
8、一种存储介质,该存储介质存储有能实现如上述的基于场景自适应的婴儿哭声检测方法的程序。
9、一种电子设备,包括:语音采集模块、处理器和存储有程序的存储介质,语音采集模块实时采集环境音频并提供给处理器,存储介质存储有能实现如上述的基于场景自适应的婴儿哭声检测方法的程序,处理器根据存储介质存储的计算机程序执行对语音采集模块实时采集环境音频进行信号处理。
10、作为对本发明作进一步限定的技术方案的特征包括有:
11、所述的步骤s1中,数据增强时采用多个随机因子模拟场景中可能出现的音频片段,多个随机因子包括:
12、(i)声源随机因子:采用声源随机因子对公开数据集样本进行随机抽选,以模拟场景同步发声的声源数量;
13、(ii)声长随机因子:利用声长随机因子对(i)所选的样本进行裁剪,以模拟不同时长的音频片段;
14、(iii)起始随机因子:采用起始随机因子确定样本之间的相加位置,实现不同语音样本之间的相加组合,从而模拟真实环境中的语音发声时间不同的特性。
15、所述的步骤s2中,建立场景自适应的哭声检测学习闭环包括如下子步骤:
16、步骤2-1:利用步骤s1中训练获得的分类器结构和模型参数新建一个分类器,定义为ema分类器;
17、步骤s2-2:冻结ema分类器参数,对新场景下的数据进行预测,生成伪标签;
18、步骤s2-3:解冻ema分类器参数,并使用ema分类器的参数更新方式,将分类器中的权重过渡到ema分类器中,改善ema分类器生成的伪标签质量;
19、步骤s2-4:通过不断迭代步骤s2-2和步骤s2-3,分类器不断推导新环境下的哭声数据分布,并修正步骤s1中获得到的哭声特性,实现环境自适应的哭声检测。
20、步骤s1中,收集语音公开数据集时,利用音频下载工具从公开的音频下载网站进行语音公开数据集的收集,收集时下载原始的含有环境音的音频数据集片段;收集公开的婴儿哭声数据时,从包含婴儿哭声数据的网站上下载婴儿哭声数据。
21、所述的语音公开数据集利用设定时长标签截取相关语音片段。
22、所述的标签采用秒级标签。
23、所述的语音公开数据集和婴儿哭声数据进行预处理,以获得统一的数据范式。
24、所述的预处理为按照设定的采样频率以及设定的时长对收集到的音频数据进行分割处理,以获得数据样本。
25、所述的采样频率设定为下采样至8khz。
26、所述的分割处理时采用无重叠的滑动窗口进行分割。
27、所述的设定的时长为2.5s。
28、所述的步骤s2-2中,通过置信度阈值法选择具有高置信度的样本和对应的伪标签对分类器进行训练。
29、所述的步骤s2-2中,对分类器进行训练时,采用公开数据初步训练分类器,采用多个随机因子协作的方式模拟在临床场景下的语音数据,然后新建一个分类器进行训练,分类器的结构采用深度学习模型。
30、所述的深度学习模型为全连接神经网络、卷积神经网络或循环神经网络。
31、所述的步骤s2-2中,对分类器进行训练时,采用的数据还包括采集临床数据。
32、所述的采集临床数据时,采用单通道麦克风采集临床环境下的实时音频,并进行相同的预处理。
33、所述的基于语音线性相加特性的场景模拟数据增强单元中,数据增强时采用多个随机因子模拟场景中可能出现的音频片段,多个随机因子包括:
34、(i)声源随机因子:采用声源随机因子对公开数据集样本进行随机抽选,以模拟场景同步发声的声源数量;
35、(ii)声长随机因子:利用声长随机因子对(i)所选的样本进行裁剪,以模拟不同时长的音频片段;
36、(iii)起始随机因子:采用起始随机因子确定样本之间的相加位置,实现不同语音样本之间的相加组合,从而模拟真实环境中的语音发声时间不同的特性。
37、所述的场景自适应的互学习单元中,建立场景自适应的哭声检测学习闭环包括:
38、分类器新建单元:用于利用基于语音线性相加特性进行场景模拟数据增强单元中训练获得的分类器结构和模型参数新建一个分类器,定义为ema分类器;
39、ema分类器参数冻结单元:用于冻结ema分类器参数,对新场景下的数据进行预测,生成伪标签;
40、ema分类器参数解单元:用于解冻ema分类器参数,并使用ema分类器的参数更新方式,将分类器中的权重过渡到ema分类器中,改善ema分类器生成的伪标签质量;
41、迭代单元:用于通过不断迭代基于语音线性相加特性进行场景模拟数据增强单元和ema分类器参数解单元,使分类器不断推导新环境下的哭声数据分布,并修正基于语音线性相加特性进行场景模拟数据增强单元中获得到的哭声特性,实现环境自适应的哭声检测,通过互学习方法的不断迭代,提升分类器在新环境下的性能,从而实现场景自适应的即插即用哭声检测。
42、所述的基于语音线性相加特性进行场景模拟数据增强单元中,收集语音公开数据集时,利用音频下载工具从公开的音频下载网站进行语音公开数据集的收集,收集时下载原始的含有环境音的音频数据集片段;收集公开的婴儿哭声数据时,从包含婴儿哭声数据的网站上下载婴儿哭声数据。
43、所述的语音公开数据集利用设定时长标签截取相关语音片段。
44、所述的标签采用秒级标签。
45、所述的语音公开数据集和婴儿哭声数据进行预处理,以获得统一的数据范式。
46、所述的预处理为按照设定的采样频率以及设定的时长对收集到的音频数据进行分割处理,以获得数据样本。
47、所述的采样频率设定为下采样至8khz。
48、所述的分割处理时采用无重叠的滑动窗口进行分割。
49、所述的设定的时长为2.5s。
50、所述的ema分类器参数冻结单元中,通过置信度阈值法选择具有高置信度的样本和对应的伪标签对分类器进行训练。
51、所述的ema分类器参数冻结单元中,对分类器进行训练时,采用公开数据初步训练分类器,采用多个随机因子协作的方式模拟在临床场景下的语音数据,然后新建一个分类器进行训练,分类器的结构采用深度学习模型。
52、所述的深度学习模型为全连接神经网络、卷积神经网络或循环神经网络。
53、所述的ema分类器参数冻结单元中,对分类器进行训练时,采用的数据还包括采集临床数据。
54、所述的采集临床数据时,采用单通道麦克风采集临床环境下的实时音频,并进行相同的预处理。
55、本发明的有益效果为:本发明基于语音线性相加的特性,对现有数据进行场景模拟的数据增强,以获取类似临床场景的语音数据,强迫分类器在合成的混乱场景中学习婴儿哭声特性;再利用无监督的互学习方法不断推导新临床场景下的哭声数据分布,并修正合成的混乱场景中学习到的婴儿哭声特性,以实现场景自适应的哭声检测,提升哭声检测模型的鲁棒性和泛化能力。本发明充分利用现有公开数据集,提升婴儿哭声检测性能,对临床环境下的哭声检测具有较好的鲁棒性,维持召回率,同时提升精准度,该算法对任意深度分类器均有效,可实现临床场景的自适应过程。
- 还没有人留言评论。精彩留言会获得点赞!