音频识别方法与多任务音频识别模型训练方法与流程
本技术涉及多媒体内容处理的,具体地涉及一种音频识别方法和一种多任务音频识别模型训练方法。另外,本技术还涉及相关的电子设备和存储介质。
背景技术:
1、随着互联网短视频、直播等行业快速发展,由此产生了海量音频内容或带有音频的视频内容。有些用户为了吸引流量或发泄情绪,在短视频或者直播中出现色情、低俗、涉嫌违反运营规则的音频内容,因此有必要对短视频、直播产生的音频进行违规内容检测。
2、然而,由于诸多原因,如音频中同时存在多种关联违规内容,违规内容有时比较晦涩或者因音频中正常播放声音、如背景音乐(bgm)的干扰,当前的音频违规内容检测效果不佳。
3、因此,在实现本发明过程中,发明人发现现有技术需要分别建立多个独立的算法模型,但是多个独立的算法模型消耗的计算资源是成倍的,且无法实现快速、准确识别音频违规内容。
4、本背景技术描述的内容仅为了便于了解本领域的相关技术,不视作对现有技术的承认。
技术实现思路
1、因此,本发明实施例意图提供一种音频识别方法、一种多任务音频识别模型训练方法以及相关电子设备和计算机存储介质。通过本发明实施例的音频识别方案,可以提高识别准确率,降低音频识别计算成本。
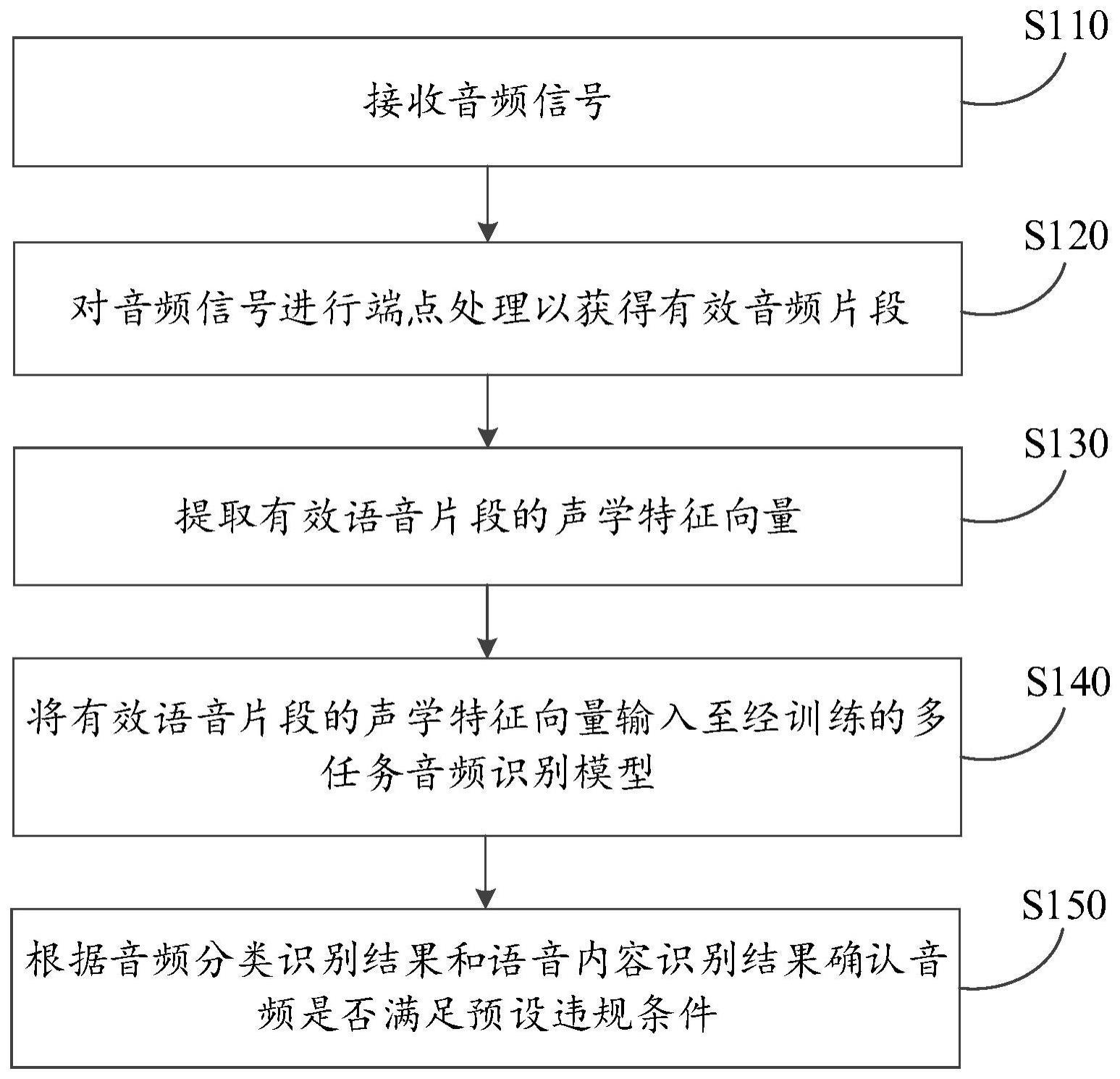
2、第一方面,本发明实施例提供了一种音频识别方法,包括:
3、接收音频信号;
4、对所述音频信号进行端点处理以获得有效音频片段;
5、提取所述有效语音片段的声学特征向量;
6、将所述有效语音片段的声学特征向量输入至经训练的多任务音频识别模型,其中,所述声学特征向量经所述多任务音频识别模型的共享编码器处理以获得编码特征向量,所述编码特征向量经所述多任务音频识别模型的第一分类子模型处理以获得音频分类识别结果,且所述编码特征向量经所述多任务音频识别模型的并行的第二解码器子模型处理以获得语音内容识别结果,以及,
7、根据所述音频分类识别结果和所述语音内容识别结果确认所述音频是否满足预设违规条件。
8、在本发明的一些实施例中,所述共享编码器包括支持输入具有相同维数的任意长度音频的瓶颈层,所述瓶颈层由多个神经网络层构成。
9、在本发明的一些实施例中,所述第一分类子模型包括对应音频分类数量的线性投射层和分类器。
10、在本发明的一些实施例中,所述第二解码器子模型包括用于获得多个候选语音内容识别结果的ctc解码器和用于对所述多个候选语音内容识别结果打分的注意力解码器。
11、在本发明的一些实施例中,所述解码器包括多层transformer解码层,每层维度与所述共享编码器的维数相同。
12、在本发明的一些实施例中,所述编码特征向量经所述多任务音频识别模型的并行的第二解码器子模型处理以获得语音内容识别结果,包括:
13、所述ctc解码器计算语音内容识别的候选结果及得分,并按照得分从高至低次序输出所述候选结果;
14、利用所述注意力解码器对所述候选结果进行重打分;以及,
15、输出得分最高的所述候选结果作为语音内容识别结果。
16、在本发明的一些实施例中,提取所述有效语音片段的声学特征向量,包括:
17、提取经过短时傅里叶变换的所述有效语音片段的一种或多种指定维数的声学特征;以及,
18、依据所述一种或多种所述声学特征组成所述声学特征向量。
19、在本发明的一些实施例中,所述接收音频信号包括:
20、从音视频源中音频通道接收所述音频信号,所述音视频源包括音视频文件和/或直播流链接;和/或,
21、对所述音频信号进行预处理;对所述音频信号进行预处理包括对所述音频信号进行包括指定编码格式转化、归一化和预加重中一种或多种预处理。
22、在本发明的一些实施例中,对获取的音频信号进行端点处理以获得所述有效音频片段,包括:
23、确定所述音频信号的一个或多个表征信息;
24、根据所述一个或多个表征信息在所述音频信号中截取出所述有效音频片段,其中,所述有效片段包括静音段和/或噪音段,所述表征信息包括幅度、能量、过零率和基频中的一种或多种。
25、在本发明的一些实施例中,经共享编码器处理之前,可对所述声学特征向量进行下采样。
26、在本发明的一些实施例中,所述多任务音频识别模型还包括:用于识别音频语种的语种检测解码器;和/或,用于识别所述音频所在环境的情景识别器。
27、第二方面,提出一种多任务音频识别模型训练方法,包括:
28、提取训练音频的声学特征向量;
29、将所述训练音频的所述声学特征向量输入至待训练多任务音频识别模型,其中,所述多任务音频识别模型包括共享编码器、第一分类子模型和第二编码器子模型,其中所述第一分类子模型包括分类器,所述第二编码器子模型包括一个或多个解码器,其中所述第一分类子模型与所述第二编码器子模型并行设置;
30、由所述多任务音频识别模型的第一分类子模型和第二编码器子模型分别输出音频分类识别训练结果和语音内容识别训练结果;
31、依据所述音频分类识别训练结果和所述语音内容识别训练结果迭代更新所述多任务音频识别模型的参数,直至达到预设的迭代终止条件,以获得经训练的多任务音频识别模型。
32、在本发明的一些实施例中,所述多任务音频识别模型的目标损失函数可包括加权的第一分类子损失函数和一个或多个第二解码器子损失函数。
33、在本发明的一些实施例中,所述第二解码子损失函数可包括ctc解码子损失函数和注意力解码子损失函数,其中所述第一分类子损失函数、ctc解码子损失函数和注意力解码子损失函数的权重值之和为1。
34、在本发明的一些实施例中,还包括:在被输入待训练多任务音频识别模型前,对所述训练音频信号的声学特征向量进行数据增强处理,所述数据增强处理包括对训练音频信号的时域信号和/或频域信号进行加噪和/或加混响。
35、在本发明的一些实施例中,所述第二编码器子模型包括ctc解码器和注意力解码器。
36、在本发明的一些实施例中,所述ctc解码器和所述注意力解码器的输出均连接线性层。
37、第三方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,其中,所述程序被处理器执行时,实现任一本发明实施例的音频识别方法,任一本发明实施例的多任务音频识别模型训练方法。
38、第四方面,本发明实施例提供一种电子设备,包括:处理器和存储有计算机程序的存储器,所述处理器被配置为在运行计算机程序时执行任一本发明实施例的音频识别方法,任一本发明实施例的多任务音频识别模型训练方法。
39、本技术方案提供了音频识别的方法,构建多任务音频识别模型,多任务音频识别模型具有共享编码器,通过上下文关系和音频特点等关联信息,形成音频编码特征向量,并行经过分类子模型和编码子模型,同时得到分类识别结果和语音内容识结果,进而基于音频类别与语音内容的识别结果识别音频中的低俗、色情等违规内容。本发明方案可有效提高音频识别准确率,节省音频识别计算资源成本和人工审核成本;音频识别结果可进一步作为对用户或黑产恶意上传的违规音频作出警告或封号处理的依据,为音频内容安全检测提供技术保障。
40、相比之下,在本发明人已知的某些方案中,对音频检测需要分别建立多个独立的算法模型,如针对娇喘的算法模型、针对区别歌曲和说话的音频类型算法模型等;虽然多个独立任务及其模型能满足音频检测需求,但是多个独立的算法模型消耗的计算资源是成倍的,且其未曾考虑音频任务的关联性,其无法实现快速、准确识别音频违规内容。
41、本发明实施例的其他可选特征和技术效果一部分在下文描述,一部分可通过阅读本文而明白。
- 还没有人留言评论。精彩留言会获得点赞!