基于多域融合网络低成本自动搜索构建的语音增强方法
本发明涉及语音增强领域,尤其涉及的是一种基于多域融合网络低成本自动搜索构建的语音增强方法。
背景技术:
1、语音通信等任务广泛应用于日常生活中,但语音中的噪声会覆盖语音中的关键信息,降低语音感知质量和可理解性,对日常生活造成严重影响。因此,语音增强对语音的相关任务至关重要。
2、早期研究的语音增强方法主要是基于时频域的分析方法,更关注时频域中与振幅相关的训练目标,而忽略了相位即关注实部忽略虚部。最近一些研究开始重视虚部信息,在实值网络中进行训练,分别预测实部和虚部后进行叠加。如tan等人的卷积递归网络(convolutional recurrent neural network,crn)集成了卷积编解码器结构和长短期记忆网络(long short-term memory,lstm),已被证明有利于处理复杂的目标。这些方法虽利用了实部与虚部的信息,但实虚部也需分离计算且不受复乘规则的限制,没有充分利用实部与虚部的内在关联性。为将实部和虚部共同计算以充分利用其关联性,hu等人设计了dccrn网络,借鉴dcunet的复数思想并对crn进行大量修改,进一步更新了crn网络。此类基于复数的方法充分利用了实部和虚部,很大程度保留了有效的语音特征,提高了语音增强效果,但这些方法仍然只是基于语音信号的时频域进行分析,除此之外,这些深度模型所取得的卓越性能大部分是因为研究人员精心设计了较深的模型体系结构和层结构,这给模型自动化带来了巨大的挑战。
3、与人工设计的复杂网络相比,探索灵活可机动的模型体系结构更符合当前技术发展的需要。因此,近年来出现了大量的神经架构搜索方法(neural architecture search,nas)。早期专家尝试使用循环神经网络作为控制器并使用强化学习控制其参数来搜索-评估-更新模型,该方法需要超过60年的gpu计算日,因为其需要将所有搜索到的模型进行完全训练评估。为降低评估时间,beeche等人提出权重共享方法enas,使用经过策略梯度训练的控制器,并强制所有生成的体系结构共享参数来减少评估时间,在不到一个gpu计算日内完成有效评估,但造成性能下降等问题。上述提到的各类方法本质上均在离散空间中搜索及评估,它们将目标函数看作黑盒,但从已有研究可知,若搜索空间连续且目标函数可微,那么基于梯度信息的搜索评估策略则更加快速,因此huang等人提出基于梯度的darts方法,将目标函数看做可微函数,使用基于梯度的优化方法搜索评估最优模型;这类基于梯度的方法优点之一就是搜索评估效率高,结合一些像权重共享的加速手段,消耗可少于一个gpu计算日,但对语音增强应用来说评估时间仍然很长。虽然mellor等人提出了低成本评估策略,在不完全训练模型的情况下根据模型初始特征对模型性能进行评分,但上述方法的评分只是粗略评估,且该方向研究还相对较少,需进一步深入探索。
4、综上所述,目前语音增强方法仍存在一些挑战:
5、(1)特征提取上的挑战:目前鲜有nas发明为语音增强设计专用的复数搜索空间,搜索空间中也同样缺乏高性能复数特征提取模块,造成模型计算时间过长,效率过低。除此之外,现有语音增强方法更侧重于时频域中语音信号的振幅和相位信息,忽视了语音信号其他空间域的信息表达,导致收集的数据样本单一,特征间相关性表达不充分,将会限制后续语音增强模型效果,进而阻碍语音增强技术的进一步发展。
6、(2)搜索性能上的挑战:目前nas中大多数搜索策略对搜索目标函数的设计具有较高要求,常用的基于梯度下降的搜索策略需对目标函数进行复杂的设计,常常面临内存短缺且搜索性能较为低下。
7、(3)评估效率上的挑战:目前主流模型性能评估方法需对候选模型进行完全训练,计算成本高,低成本评估策略也存在评估性能弱等问题,在算力薄弱或时间不足时将难以保证语音增强效果。
技术实现思路
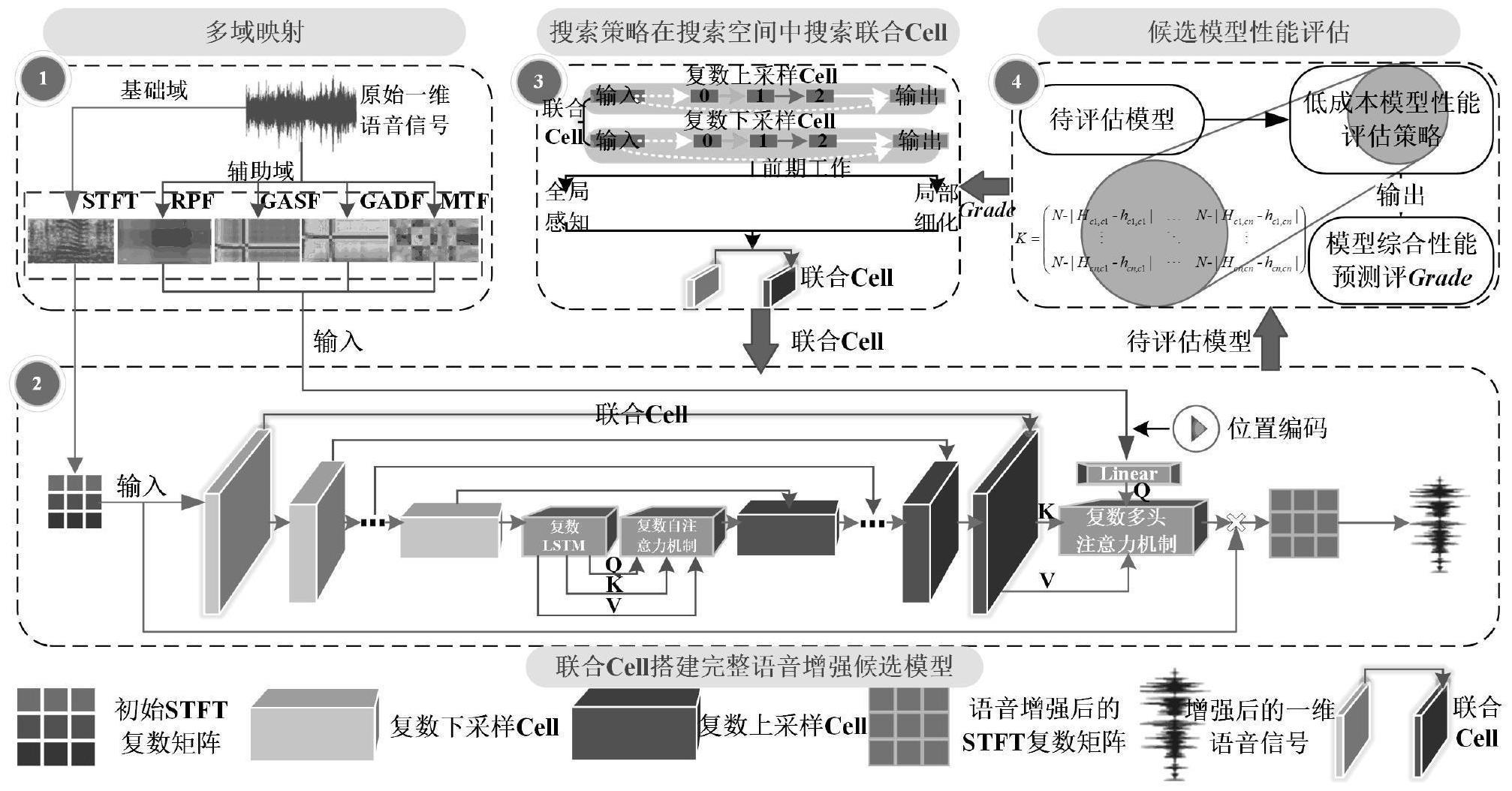
1、针对现有技术中存在的问题和不足,本发明提供一种基于多域融合网络低成本自动搜索构建的语音增强方法,将一维语音信号映射至多个空间域中生成基础域和辅助域提高语音信号的特征丰富度,通过为语音增强设计的轻量化基于联合cell的可分离复数搜索空间,利用高性能自适应全局/局部协同特征感知的搜索策略得到候选模型,使用低成本模型性能评估策略对候选模型进行自适应评估,以此近似预测模型的最终性能,提高对候选模型的评估效率。
2、为实现上述目的,本发明采用如下技术方案:
3、一种基于多域融合网络低成本自动搜索构建的语音增强方法,将一维语音信号映射至多个空间域中生成基础域和辅助域提高语音信号的特征丰富度,利用轻量化复数特征融合模块将基础域和辅助域的多域信息进行融合,构建轻量化基于联合cell的可分离复数搜索空间,将搜索空间分为复数卷积子空间及复数池化子空间,利用自适应全局/局部协同特征感知的搜索策略寻找性能满足要求的语音增强模型,并对语音增强模型进行自适应评估,具体包括以下步骤:
4、步骤1.将一维语音信号映射至多个空间域中生成基础域和辅助域提高语音信号的特征丰富度,通过短时傅里叶变换stft得到语音信号的时频特性,利用格拉姆角场域gaf将试件序列在极坐标系统内进行编码同时保持语音信号的视角相关性,衍生出格拉姆角和场域gasf和格拉姆角差场域gadf,通过马尔科夫转移场域mtf得到序列样本的时间和位置信息,通过递归图域rpf分离出数据样本的内部结构、相似性以及预测性;利用轻量化复数特征融合模块将基础域与辅助域相结合,从语音信号中提取语音特征,实现不同类型信息融合;
5、步骤2.构建轻量化基于联合cell的可分离复数搜索空间,将搜索空间中的联合cell分为复数卷积子空间及复数池化子空间,上述两个空间中分别包含不同卷积核的复数卷积候选操作及不同滑动窗口的复数池化候选操作,将每个联合cell中待搜索节点分离为卷积节点及池化节点,利用了卷积及池化的特性,降低搜索空间复杂度和体积,可分离复数搜索空间能够自适应的对非平稳语音信号进行深层特征提取或特征降维;
6、步骤3.利用具有全局感知和局部细化特性的高性能自适应全局/局部协同特征感知的搜索策略,对步骤2中获取的联合cell的复数卷积节点及复数池化节点分别进行全局感知及局部细化搜索,并依据搜索到的最优联合cell搭建语音增强候选模型;
7、步骤4.对步骤3所得的语音增强候选模型进行低成本自适应评估,通过观测不同性能模型下输入的原图及对应特征图间的差异性与模型真实准确率的隐含关系,当评估候选模型时,在相同位置为每张输入图片提取一张特征图,并构建k差异矩阵将原图及对应特征图的数据对两两进行相似性对比,计算模型grade分值,实现无需对候选模型完全训练即可对候选模型性能进行精细化快速近似评估,减少评估候选模型的计算开销。
8、进一步,步骤1中,轻量化复数特征融合模块采用复数多头注意力机制,将复数多头注意力机制中的q、k参数运算得到的w的实部矩阵wr和虚部矩阵wi分别进行softmax计算后转换为概率值,再将实部矩阵wr和虚部矩阵wi转换后的概率值分别与vr和vi对应相乘,得到的实部矩阵和虚部矩阵叠加得到输出output,并通过维度重构将output的维度重构到与输入input相同,即:
9、w=q×kt=(qr×krt-qi×kit)+j(qr×kit+qi×krt)
10、output=softmax(w)×v。
11、进一步,步骤2中,为确保语音增强模型编解码时特征映射维度相同,以及语音信号在降噪后的维度恢复,将非平稳语音信号编码到高维潜在空间去除噪音信息后,再将去噪后的语音信号转换回原始的输入大小,将一个复数上采样cell与一个复数下采样cell结合共同作为一个联合cell,对联合cell进行搜索,再将搜索到的最优联合cell由外向内搭建5次,结合轻量化复数特征融合模块构建语音增强模型。
12、进一步,联合cell拓扑进行编码,使用字符串和“0”字符分别描述运算符信息和分离点,其中“0”字符代表复数上采样cell与复数下采样cell信息流的分离。
13、进一步,步骤3中利用自适应全局/局部协同特征感知的搜索策略,根据种群子代与父代间的个体性能优劣对联合cell中的复数卷积节点及复数池化节点分别进行全局感知及局部细化搜索。
14、进一步,搜索策略首先进行全局感知搜索,通过轮盘赌从种群中选择两个父代个体并编码,即p1和p2,p1和p2将进行交叉、变异生成子代k1和k2,将子代k1和k2的编码分离为三种字符串,即复数卷积操作字符串、复数池化操作字符串及其他操作字符串,利用子代的复数卷积字符串,进行m次全局感知搜索,生成m个新的复数卷积字符串;全局感知搜索结束后,将上述三种字符串进行融合生成代表新个体的字符串,并判断生成新个体的语音增强性能,当新个体中存在个体的性能优于父代,则证明当前种群所处搜索范围可能存在最优解,对新个体的池化空间进行局部细化搜索更新所有新个体信息,通过局部细化扩大种群在可能存在最优解空间的搜索范围,在局部细化过程中发现的最佳个体被用于取代种群中的父代个体p1和p2。
15、进一步,步骤4中使用平均哈希值计算图片的差异性,对每个模型评分时将n张同分类小批次数据输入待评测模型中,在相同位置为每张输入图片提取一张特征图,并构建k差异矩阵将原图及对应特征图的数据对两两进行相似性对比,计算模型grade分值,公式如下:
16、
17、grade=ln|k|
18、其中,n为图片像素值,hcm,ck-hcm,ck=0(m=k)且hcm,ck-hcm,ck≤n(m≠k),性能优异的模型可使k差异矩阵主对角线元素均为n,非主对角线元素均为0,即grade达到最大值,实际计算获取的grade越接近最大值,说明训练后最终准确率越高,利用grade与最大值比较,近似预测未经完全训练模型的最终性能,而不必将整个模型训练完成,降低了模型评估成本。
19、综上所述,发明具有以下有益效果:
20、本发明将一维语音信号映射至多个高维空间域中生成基础域和辅助域,通过高维空间域的形式,研究语音信号在不同信息粒度、内部结构、位置关系、非线性信息差异及变化率、相邻关联等方面的特点,增强一维信号特征表达,得到更丰富的语音特征,并在此基础上为模型设计了轻量化复数特征融合模块将多域信息进行高性能融合,从语音信号中提取更有效的语音特征,充分利用不同域的特点实现深层浅层不同类型信息的融合。轻量化基于联合cell的可分离复数搜索空间考虑到卷积的全局感知与池化的局部细化特点,将cell分离为复数卷积子空间及复数池化子空间,,并为本发明的可分离复数搜索空间匹配设计了一种高性能自适应全局/局部协同特征感知的搜索策略,在上述搜索空间中,根据种群状态权衡开发和勘探以进行全局感知或局部细化搜索最优联合cell,并以此搭建最优语音增强模型,由于卷积和池化搜索算子的分离,与现有的联合搜索cell对比,本发明提出的分离cell搜索方法更加灵活,可以快速有效地发现性能良好的语音增强模型;低成本模型性能评估策略对候选模型进行自适应评估,通过观测不同性能模型下输入的原图及对应特征图间的差异性与模型真实准确率的隐含关系,设计搭建性能评估矩阵,在预设搜索空间及搜索策略下,实现无需对候选模型完全训练即可对其性能进行精细化快速近似评估,大大减少评估候选模型的计算开销。
- 还没有人留言评论。精彩留言会获得点赞!