一种基于多头注意力机制的深度学习语音情感识别方法
本发明涉及语音情感识别,具体为一种基于多头注意力机制的深度学习语音情感识别方法。
背景技术:
1、语音在传递语言信息之外,还是携带重要的情感信息,这些情感信息对于人类感知和决策具有重要的作用,因此该项技术也成为自然语言处理、人工智能、人机交互等领域的研究热点,也被广泛应用于刑侦、教育、医学、服务等行业。
2、早期的语音情感识别研究主要采用动态规划、线性预测分析等算法但是效果不理想。随着机器学习的不断发展,隐马尔可夫模型、支持向量机等新的算法应用到语音情感识别领域,进一步提升了识别效果,但由于语音情感和人为情感的复杂性,不同情感的区别性不够明显,语音情感识别鲁棒性还有待进一步提升。
3、目前,深度神经网络的出现大大推进了语音情感识别研究,如卷积神经网络、循环神经网络的广泛应用,大大推进了语音情感识别的研究,取得了很好的辨识效果。如zheng等提出的以语谱图为特征的深度卷积神经网络模型方法,进一步提高语音情感预测的准确性。lee等以语音信号时序为特征,提出一种循环神经网络的语音情感识别方法,进一步提升了识别精度。而zhao等提出一种改进的深度神经网络,应用循环神经网络和与lstm网络相结合的方法,在说话人相关和说话人无关的实验中取得很好的识别效果。近年来,注意力机制也被应用到语音情感识别领域,如mirsamadi等采用注意力机制,更加突出语音信号中情感特征,取得了很好的识别效果;
4、根据以上分析,注意力机制可以有效提升情感识别的性能,但是在语音信号中还往往存在非情感信息,如停顿、连读等,这些信息会在一定程度上影响情感识别效果。
技术实现思路
1、本部分的目的在于概述本发明的实施方式的一些方面以及简要介绍一些较佳实施方式。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
2、因此,本发明的目的是提供一种基于多头注意力机制的深度学习语音情感识别方法,将多头注意力机制方法应用于语音情感识别,从不同子空间全面地提取语音样本中所包含的情感特征信息,更加关注语音情感的细节。
3、为解决上述技术问题,根据本发明的一个方面,本发明提供了如下技术方案:
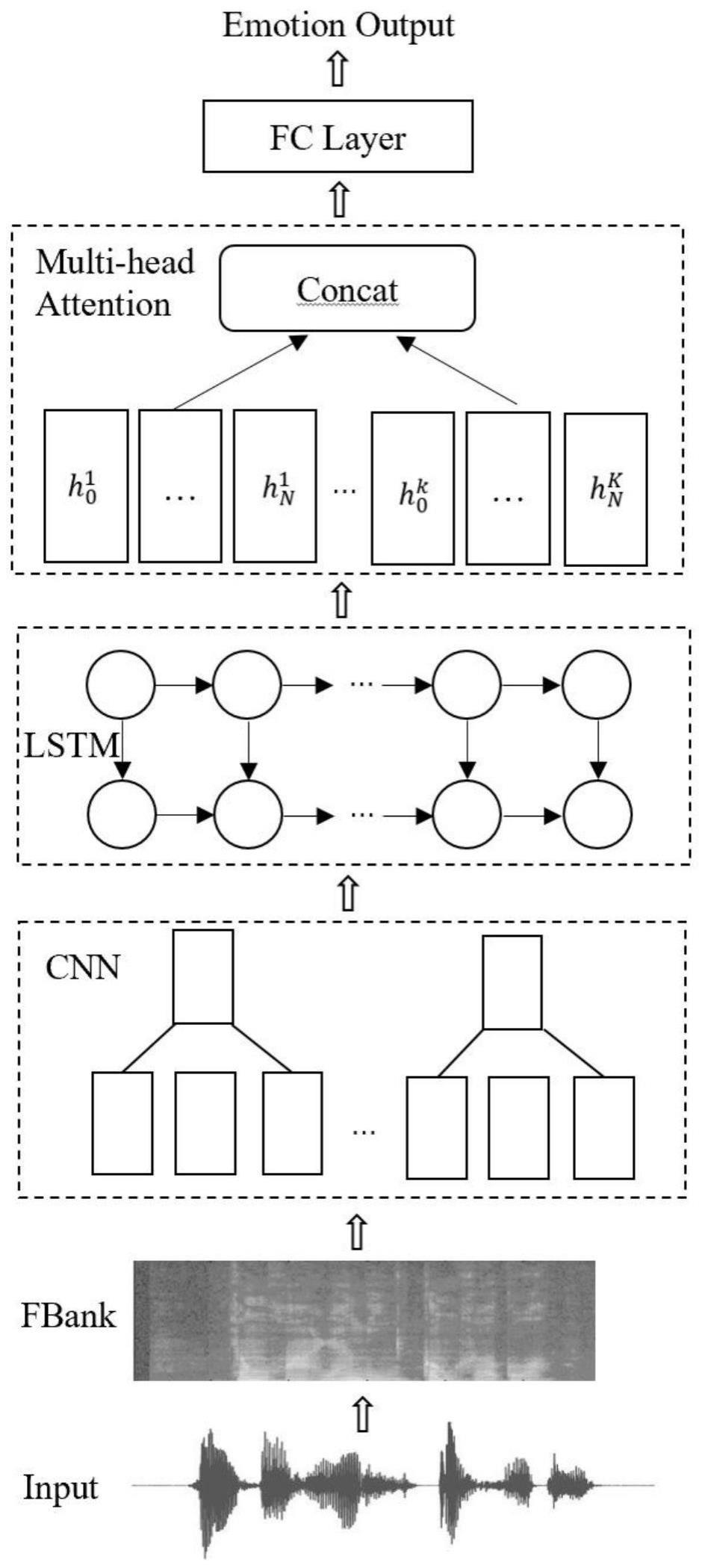
4、一种基于多头注意力机制的深度学习语音情感识别方法,其包括:
5、s1、提取语音信号的fbank特征向量作为模型输入;
6、s2、通过cnn提取局部情感特征;
7、s3、利用blstm层提取语音的序列信息;
8、s4、引入多头注意力机制对情感特征进行不同子空间的权重学习,然后通过全连接层做出情感类别的预测。
9、作为本发明所述的一种基于多头注意力机制的深度学习语音情感识别方法的一种优选方案,其中,所述步骤s1中,提取语音信号的fbank特征向量作为模型输入的具体步骤如下:
10、将原始语音信号预加重、分帧、加窗,然后进行短时傅里叶变换,得到其频谱;
11、将频谱进行平方操作,得到能量谱,并将每个滤波器带内的能量进行叠加,第k个滤波器输出的功率谱为x[k];
12、
13、将每个滤波器的输出取对数,得到相应频带的对数功率谱yfbank[k]=logx[k]。
14、作为本发明所述的一种基于多头注意力机制的深度学习语音情感识别方法的一种优选方案,其中,所述步骤s2中,cnn具有四层,四层的卷积核数量分别对应为128、256、256和256,四层的卷积核大小均为5×3,步长均为2×1,且在第一层中使用池化操作,池化大小2×2,步长为1×1,每层卷积层的激活函数为leakyrelu,在每个卷积层中加入bn层和dropout层,其中dropout层概率设置为0.25。
15、作为本发明所述的一种基于多头注意力机制的深度学习语音情感识别方法的一种优选方案,其中,所述步骤s2中,cnn的最后还设置一个线性层。
16、作为本发明所述的一种基于多头注意力机制的深度学习语音情感识别方法的一种优选方案,其中,所述步骤s3中,blstm由两个lstm上下叠加在一起,第1层是从左边作为序列的起始输入,第2层是从右边作为序列的起始输入,输出由这两个lstm的状态共同决定;
17、设和分别表示前向lstm和后向lstm的状态向量,则t时刻blstm中前向lstm和后向lstm在时刻的状态向量ht计算如下列公式所示:
18、
19、
20、作为本发明所述的一种基于多头注意力机制的深度学习语音情感识别方法的一种优选方案,其中,所述步骤s4中,在多头注意力机制的计算过程中,首先将输入序列通过h个线性变换转换成相应的查询矩阵q、键矩阵k和值矩阵v;
21、然后进行缩放点积注意力计算,将某一位置的查询向量q和所有键向量k分别进行点积,计算出该位置的查询向量与各键向量的相似度,通过放缩因子调整后,经过softmax函数得到该位置的查询向量q对所有位置键向量的注意力权重向量,并将该权重向量与所有位置的值向量v进行加权求和得到该位置新的注意力值,即放缩点积注意力值,其中放缩因子的作用是保证点积结果在梯度范围内稳定收敛,公式如下:
22、
23、最后对查询矩阵q中其他位置的查询向量实施相同步骤,得到不同位置的放缩点积注意力值,再将这些注意力值通过线性变化后,并将h次放缩点积注意力的计算结果进行融合,从而得到多头注意力模型的最终结果;
24、headi=attention(qwiq,kwik,vwiv),i=1,2,...,h
25、multi head(q,k,v)=concat(head1,head2…headh)w0。
26、与现有技术相比,本发明具有的有益效果是:针对传统注意力机制对语音情感特征表达能力不足、区别性不够等问题,本文提出了一种基于多头注意力机制的情感识别方法。实验结果表明,随着注意力机制头数的增加,模型对语音情感的表达能力增强,能够进一步突出语音情感的细节性和隐含性信息,在不增加模型复杂度的情形下,本文提出的方法优于传统的方法。
技术特征:
1.一种基于多头注意力机制的深度学习语音情感识别方法,其特征在于,包括:
2.根据权利要求1所述的一种基于多头注意力机制的深度学习语音情感识别方法,其特征在于,所述步骤s1中,提取语音信号的fbank特征向量作为模型输入的具体步骤如下:
3.根据权利要求1所述的一种基于多头注意力机制的深度学习语音情感识别方法,其特征在于,所述步骤s2中,cnn具有四层,四层的卷积核数量分别对应为128、256、256和256,四层的卷积核大小均为5×3,步长均为2×1,且在第一层中使用池化操作,池化大小2×2,步长为1×1,每层卷积层的激活函数为leakyrelu,在每个卷积层中加入bn层和dropout层,其中dropout层概率设置为0.25。
4.根据权利要求1所述的一种基于多头注意力机制的深度学习语音情感识别方法,其特征在于,所述步骤s2中,cnn的最后还设置一个线性层。
5.根据权利要求1所述的一种基于多头注意力机制的深度学习语音情感识别方法,其特征在于,所述步骤s3中,blstm由两个lstm上下叠加在一起,第1层是从左边作为序列的起始输入,第2层是从右边作为序列的起始输入,输出由这两个lstm的状态共同决定;
6.根据权利要求1所述的一种基于多头注意力机制的深度学习语音情感识别方法,其特征在于,所述步骤s4中,在多头注意力机制的计算过程中,首先将输入序列通过h个线性变换转换成相应的查询矩阵q、键矩阵k和值矩阵v;
技术总结
本发明公开一种基于多头注意力机制的深度学习语音情感识别方法,包括提取语音信号的FBank特征向量作为模型输入、通过CNN提取局部情感特征、利用BLSTM层提取语音的序列信息以及引入多头注意力机制对情感特征进行不同子空间的权重学习,然后通过全连接层做出情感类别的预测,针对传统注意力机制对语音情感特征表达能力不足、区别性不够等问题,本文提出了一种基于多头注意力机制的情感识别方法。实验结果表明,随着注意力机制头数的增加,模型对语音情感的表达能力增强,能够进一步突出语音情感的细节性和隐含性信息,在不增加模型复杂度的情形下,本文提出的方法优于传统的方法。
技术研发人员:夏玉果
受保护的技术使用者:江苏信息职业技术学院
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!