语音设备的测试方法、装置及设备与流程
本技术实施例涉及人工智能,尤其涉及一种语音设备的测试方法、装置及设备。
背景技术:
1、随着技术发展,越来越多的语音设备应用到人们生活中。用户可以通过语音方式与语音设备进行交互,提高了用户使用体验。
2、在语音设备出厂前,需要对语音设备进行稳定性测试。在对语音设备进行稳定性测试时,通常采用人工测试的方式。由测试人员向语音设备发出语音指令,并观察语音设备对语音指令的响应情况。测试人员重复执行上述测试过程,并根据多次测试的观察结果,确定稳定性测试是否通过。
3、然而,发明人在实现本技术的过程中发现,上述测试过程费时费力,测试效率较低。
技术实现思路
1、本技术实施例提供一种语音设备的测试方法、装置及设备,用以提高语音设备的测试效率。
2、第一方面,本技术实施例提供一种语音设备的测试方法,应用于测试设备,所述方法包括:
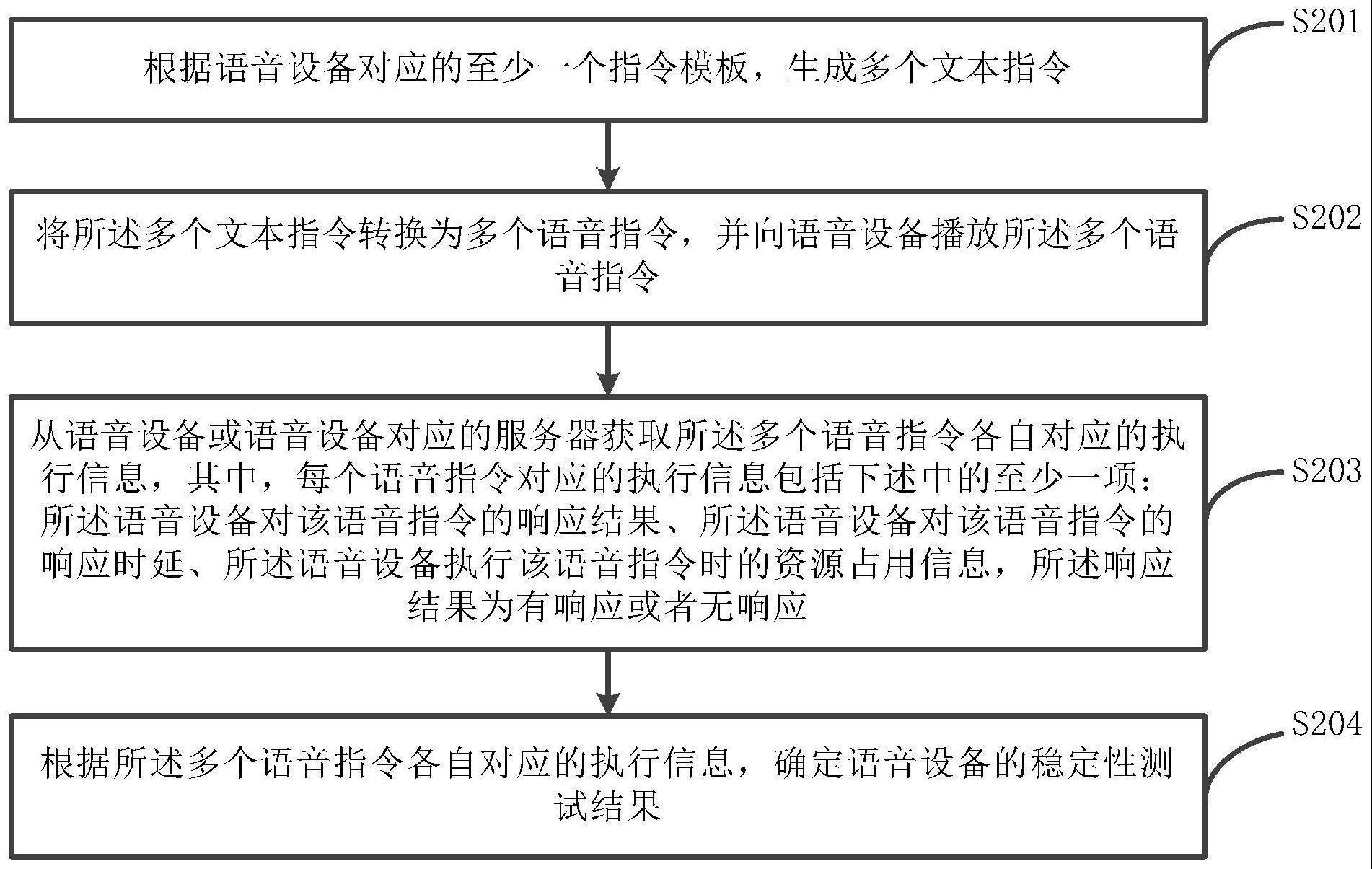
3、根据所述语音设备对应的至少一个指令模板,生成多个文本指令;
4、将所述多个文本指令转换为多个语音指令,并向所述语音设备播放所述多个语音指令;
5、从所述语音设备或所述语音设备对应的服务器获取所述多个语音指令各自对应的执行信息,其中,每个语音指令对应的执行信息包括下述中的至少一项:所述语音设备对该语音指令的响应结果、所述语音设备对该语音指令的响应时延、所述语音设备执行该语音指令时的资源占用信息,所述响应结果为有响应或者无响应;
6、根据所述多个语音指令各自对应的执行信息,确定所述语音设备的稳定性测试结果。
7、一种可能的实现方式中,每个语音指令对应的执行信息包括:所述语音设备对该语音指令的响应结果、所述语音设备对该语音指令的响应时延、以及所述语音设备执行该语音指令时的资源占用信息;
8、根据所述多个语音指令各自对应的执行信息,确定所述语音设备的稳定性测试结果,包括:
9、根据所述语音设备对各语音指令的响应结果,确定出所述响应结果为有响应的语音指令的第一数量;并根据所述第一数量以及所述多个语音指令的总数量,确定所述语音设备的响应率;
10、根据所述语音设备对各语音指令的响应时延,确定所述语音设备的平均响应时延;
11、根据所述语音设备执行各语音指令时的资源占用信息,确定所述语音设备的平均资源占用率;
12、根据所述响应率、所述平均响应时延、以及所述平均资源占用率,确定所述语音设备的稳定性测试结果。
13、一种可能的实现方式中,根据所述响应率、所述平均响应时延、以及所述平均资源占用率,确定所述语音设备的稳定性测试结果,包括:
14、若所述响应率大于或者等于预设响应率、所述平均响应时延小于或者等于预设响应时延、以及所述平均资源占用率小于或等于预设资源占用率,则确定所述语音设备的稳定性测试结果为测试通过;
15、若满足下述中的至少一项:所述响应率小于预设响应率、所述平均响应时延大于预设响应时延、所述平均资源占用率大于预设占用率,则确定所述语音设备的稳定性测试结果为测试不通过。
16、一种可能的实现方式中,根据所述语音设备对应的至少一个指令模板,生成多个文本指令,包括:
17、对每个所述指令模板进行解析,得到多个指令单元的标识、所述多个指令单元的属性、以及所述多个指令单元之间的顺序;每个指令单元的属性包括可选或必选;
18、根据所述多个指令单元的标识,获取所述多个指令单元各自对应的至少一个候选关键词;
19、根据所述多个指令单元的属性、所述多个指令单元之间的顺序、以及所述多个指令单元各自对应的至少一个候选关键词,生成多个文本指令。
20、一种可能的实现方式中,根据所述多个指令单元的属性、所述多个指令单元之间的顺序、以及所述多个指令单元各自对应的至少一个候选关键词,生成多个文本指令,包括:
21、根据所述多个指令单元各自对应的至少一个候选关键词,生成多个不同的关键词组合;每个关键词组合中包括:所述多个指令单元各自对应的一个候选关键词;
22、针对每个关键词组合,根据所述多个指令单元的属性、以及所述多个指令单元之间的顺序,对所述关键词组合中的各候选关键词进行拼接处理,得到多个文本指令。
23、一种可能的实现方式中,向所述语音设备播放所述多个语音指令之前,还包括:
24、获取预设的环境噪声模型;
25、通过所述环境噪声模型对所述多个语音指令进行加噪处理,以得到含噪的多个语音指令。
26、一种可能的实现方式中,向所述语音设备播放所述多个语音指令,包括:
27、向所述语音设备播放第i个语音指令;
28、启动第一定时器,所述第一定时器的时长为第一预设时长,或者为随机时长;
29、在所述第一定时器结束后,返回执行所述向所述语音设备播放第i个语音指令;
30、所述i依次取1、2、3、……、n,所述n为所述多个语音指令的数量。
31、一种可能的实现方式中,每个语音指令包括:唤醒语句和命令语句;向所述语音设备播放第i个语音指令,包括:
32、向所述语音设备播放所述第i个语音指令中的唤醒语句;
33、启动第二定时器,所述第二定时器的时长为第二预设时长,或者为随机时长;
34、在所述第二定时器结束后,向所述语音设备播放所述第i个语音指令中的命令语句。
35、一种可能的实现方式中,向所述语音设备播放所述多个语音指令包括:
36、控制仿真嘴装置向所述语音设备播放所述多个语音指令。
37、一种可能的实现方式中,获取所述多个语音指令各自对应的执行信息,包括:
38、确定所述多个语音指令对应的起始播放时刻和结束播放时刻;
39、向服务器发送请求信息,所述请求信息包括:所述起始播放时刻、所述结束播放时刻、以及所述语音设备的标识;
40、从所述服务器接收所述多个语音指令各自对应的执行信息。
41、一种可能的实现方式中,根据所述多个语音指令各自对应的执行信息,确定所述语音设备的稳定性测试结果之后,还包括:
42、显示所述稳定性测试结果;或者,
43、向预设设备发送所述稳定性测试结果。
44、第二方面,本技术实施例提供一种语音设备的测试装置,部署于测试设备中,所述装置包括:
45、生成模块,用于根据所述语音设备对应的至少一个指令模板,生成多个文本指令;
46、处理模块,用于将所述多个文本指令转换为多个语音指令;
47、播放模块,用于向所述语音设备播放所述多个语音指令;
48、获取模块,用于从所述语音设备或所述语音设备对应的服务器获取所述多个语音指令各自对应的执行信息,其中,每个语音指令对应的执行信息包括下述中的至少一项:所述语音设备对该语音指令的响应结果、所述语音设备对该语音指令的响应时延、所述语音设备执行该语音指令时的资源占用信息,所述响应结果为有响应或者无响应;
49、确定模块,用于根据所述多个语音指令各自对应的执行信息,确定所述语音设备的稳定性测试结果。
50、第三方面,本技术实施例提供一种电子设备,包括:
51、至少一个处理器;以及
52、与所述至少一个处理器通信连接的存储器;其中,
53、所述存储器存储有计算机程序,所述计算机程序被所述至少一个处理器执行,以实现如第一方面任一项所述的方法。
54、第四方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序被所述至少一个处理器执行,以实现如第一方面任一项所述的方法。
55、第五方面,本技术实施例提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如第一方面任一项所述方法。
56、本技术实施例提供一种语音设备的测试方法、装置及设备,测试设备根据语音设备对应的至少一个指令模板,生成多个文本指令,将多个文本指令转换为多个语音指令,并向语音设备播放该多个语音指令,从语音设备或语音设备对应的服务器获取各语音指令的执行信息,每个语音指令对应的执行信息包括下述中的至少一项:语音设备对该语音指令的响应结果、语音设备对该语音指令的响应时延、语音设备执行该语音指令时的资源占用信息,响应结果为有响应或者无响应,进而,根据多个语音指令对应的执行信息,确定语音设备的稳定性测试结果。通过上述过程,实现了测试设备自动化地对语音设备进行稳定性测试,提高了测试效率。
- 还没有人留言评论。精彩留言会获得点赞!