一种水声信号降噪识别联合训练方法、系统、设备及介质
本发明涉及水声信号降噪识别,尤其是涉及一种水声信号降噪识别联合训练方法、系统、设备及介质。
背景技术:
1、近年来,随着海洋信息技术的发展进步,基于数据驱动的水声信号智能识别方法,特别是基于深度神经网络(dnn)的方法表现出了显著的性能优势。然而,在低信噪比的复杂水下环境中,研究人员关注的目标信号(如舰船声信号、海洋生物声信号和海洋环境事件辐射声信号等)不可避免地会受到水下环境噪声和多径传播等因素的影响,甚至淹没在噪声环境中,造成基于dnn的模型无法有效提取目标信号特征,对水声信号识别系统的决策过程产生不利影响。
2、为了提升水声信号识别系统在复杂的低信噪比条件下的噪声鲁棒性,已有许多研究工作探究了此类问题的相关解决方案。考虑到音频降噪技术的发展进步,一类最直接的解决方案是在识别系统中集成声音信号降噪前端模块,利用该模块对低信噪比的音频信号进行噪声抑制,提升信号质量。经典的降噪模型,如谱减法、维纳滤波以及基于dnn的降噪方法都是通过优化模型来抑制噪声分量,通过提升带噪信号信噪比的方式对目标信号进行估计,这与信号识别系统的优化方向并不相同,后者是通过模型学习目标信号的可区分特征,提升分类精度。因此,由于训练目标的不匹配,使得声音信号降噪方法无法朝着最终的识别目标进行优化,进而导致降噪模型的结果并不是识别系统所需的最优解。已有研究表明,降噪模型对噪声信号的过度抑制以及去噪过程中可能引入的人为伪影干扰是引起音频信号失真的主要原因。通过舰船辐射声信号对应的带噪信号、干净信号和降噪后信号的幅度谱特征的实验证明,与原始信号相比,降噪后的音频信号表现出明显的信息损失,高频部分的线谱成分被当做噪声成分消除。由此可知,虽然降噪技术能够提升水声信号的信噪比,但过度的噪声抑制所造成的信息损失和失真并不会对识别系统产生正增益效果。另一类主流的解决方案是提升识别系统对噪声干扰信号的适应性,其中多条件训练(multi-conditiontraining,mct)方法是很多研究内容采用的方案,该方法使用不同类型的数据来训练识别模型,具体包括不同噪声级的干净目标信号和带噪音频信号。与mct方法不同,specaugment是另一种主流的数据增强方法,该方法应用于网络模型的输入特征上,仅在模型训练阶段使用,通过时域扭曲和频谱掩蔽来增加训练数据的数量和多样性,这些方法在一定程度上提升了识别系统的性能,但同时也增加了模型的计算成本,且此类方法仍需改进对低信噪比条件下的目标信号识别能力。此外,还可通过后端识别模型直接利用降噪后的数据进行训练的方式来提升识别模型对于失真干扰的容忍度。此类方法需要降噪模型首先对所需数据进行预处理,其在很大程度上依赖于降噪模型的去噪性能。
3、与独立应用降噪模型和识别模型相比,基于两种模型的联合训练方法被认为是提升识别系统噪声鲁棒性的另一种有效方案。然而已有的联合训练框架普遍采用级联方式进行训练,即后端识别模型的输入信息完全来自经过降噪模型处理后的特征,其无法利用到原始目标信号的特征,因此,这些方法依然会受到信号失真问题的影响。水声信号识别系统在处理水下环境中低信噪比的复杂数据时面临挑战,导致噪声鲁棒性有限,难以实现高准确性。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种水声信号降噪识别联合训练方法、系统、设备及介质,能够提高噪声鲁棒性,提高水声信号识别的准确性。
2、第一方面,本发明实施例提供了一种水声信号降噪识别联合训练方法,所述水声信号降噪识别联合训练方法包括:
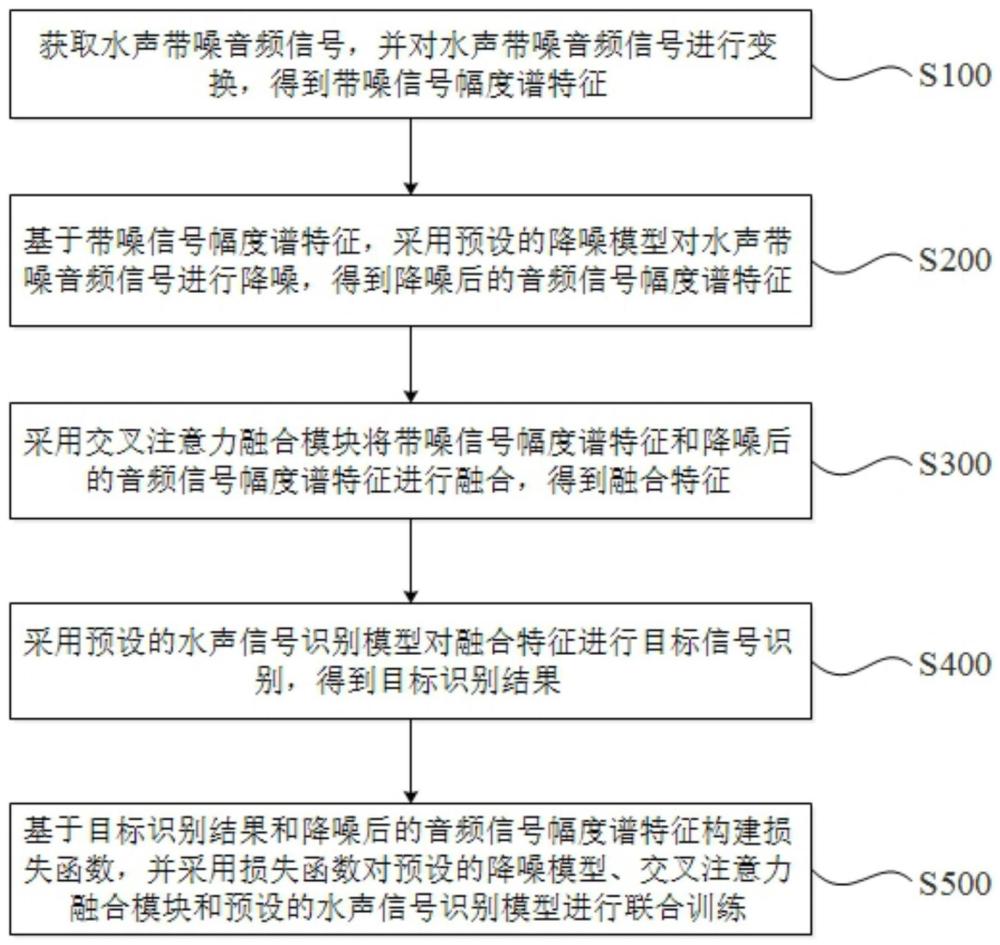
3、获取水声带噪音频信号,并对所述水声带噪音频信号进行变换,得到带噪信号幅度谱特征;
4、基于所述带噪信号幅度谱特征,采用预设的降噪模型对所述水声带噪音频信号进行降噪,得到降噪后的音频信号幅度谱特征;
5、采用交叉注意力融合模块将所述带噪信号幅度谱特征和所述降噪后的音频信号幅度谱特征进行融合,得到融合特征;
6、采用预设的水声信号识别模型对所述融合特征进行目标信号识别,得到目标识别结果;
7、基于所述目标识别结果和所述降噪后的音频信号幅度谱特征构建联合损失函数,并采用所述联合损失函数对所述预设的降噪模型、所述交叉注意力融合模块和所述预设的水声信号识别模型进行联合训练。
8、与现有技术相比,本发明第一方面具有以下有益效果:
9、本方法通过采用预设的降噪模型对水声带噪音频信号进行降噪,得到降噪后的音频信号幅度谱特征,采用交叉注意力融合模块将带噪信号幅度谱特征和降噪后的音频信号幅度谱特征进行融合,得到融合特征,通过同时将带噪信号幅度谱特征和降噪后的音频信号幅度谱特征应用于后端的水声信号识别模型,以此来改善信号的失真问题,并且通过融合特征,使得降噪后端不仅能够从前端获取高质量的目标音频特征,还能够从带噪音频中捕获相关的噪声细节,从而有效地解决噪声不匹配问题;采用预设的水声信号识别模型对融合特征进行目标信号识别,能够提高水声信号识别的准确性;基于目标识别结果和降噪后的音频信号幅度谱特征构建联合损失函数,并采用联合损失函数对预设的降噪模型、交叉注意力融合模块和预设的水声信号识别模型进行联合训练,通过联合损失函数联合优化去噪和识别目标,能够同时提高去噪性能和识别精度。
10、根据本发明的一些实施例,所述基于所述带噪信号幅度谱特征,采用预设的降噪模型对所述水声带噪音频信号进行降噪,得到降噪后的音频信号幅度谱特征,包括:
11、构建包含编码器、解码器和多个时频transformer块的预设的降噪模型;
12、将所述带噪信号幅度谱特征输入至所述编码器进行编码,得到编码后的带噪信号幅度谱特征,并采用多个所述时频transformer块对所述编码后的带噪信号幅度谱特征在时间维度和频率维度分别进行特征提取,得到提取特征;
13、采用所述解码器对所述提取特征进行解码,得到降噪后的音频信号幅度谱特征。
14、根据本发明的一些实施例,所述时频transformer块包括多头自注意力模块和前馈神经网络模块,所述时频transformer块通过如下方式实现:
15、sa=attention(d)
16、mid=layernorm(d+sa)
17、ffn=linear(relu(lstm(mid)))
18、output=layernorm(mid+ffn)
19、其中,attention表示多头自注意力模块,sa表示多头自注意力模块的输出,d表示输入特征,mid表示层归一化后的输出,layernorm表示层归一化,ffn表示前馈神经网络模块的输出,linear表示全连接层,relu表示激活函数,lstm表示长短期记忆网络层,output表示时频transformer块的输出。
20、根据本发明的一些实施例,所述采用交叉注意力融合模块将所述带噪信号幅度谱特征和所述降噪后的音频信号幅度谱特征进行融合,得到融合特征,包括:
21、将所述带噪信号幅度谱特征和所述降噪后的音频信号幅度谱特征分别转换为带噪信号的梅尔谱特征和降噪信号的梅尔谱特征;
22、采用多个所述交叉注意力融合模块分别对所述带噪信号的梅尔谱特征和所述降噪信号的梅尔谱特征进行特征融合,得到带噪信号的融合特征和降噪信号的融合特征;
23、将所述带噪信号的融合特征和所述降噪信号的融合特征进行拼接,得到融合特征。
24、根据本发明的一些实施例,所述采用多个所述交叉注意力融合模块分别对所述带噪信号的梅尔谱特征和所述降噪信号的梅尔谱特征进行特征融合,得到带噪信号的融合特征和降噪信号的融合特征,包括:
25、采用多个所述交叉注意力融合模块对所述带噪信号的梅尔谱特征进行特征融合,得到带噪信号的融合特征:
26、
27、采用多个所述交叉注意力融合模块对所述降噪信号的梅尔谱特征进行特征融合,得到降噪信号的融合特征:
28、
29、其中,表示第i个交叉注意力融合模块输出的降噪信号的融合特征,表示第i-1个交叉注意力融合模块输出的降噪信号的融合特征,cafi表示第i个交叉注意力融合模块,表示第i-1个交叉注意力融合模块输出的带噪信号的融合特征,表示第i个交叉注意力融合模块输出的带噪信号的融合特征。
30、根据本发明的一些实施例,所述采用预设的水声信号识别模型对所述融合特征进行目标信号识别,得到目标识别结果,包括:
31、构建包含多个卷积层、多个时频transformer块和分类层的预设的水声信号识别模型;
32、采用多个所述卷积层对所述融合特征提取抽象特征;
33、采用多个所述时频transformer块对所述抽象特征提取高级特征;
34、采用所述分类层对所述高级特征进行目标信号识别,得到目标识别结果。
35、根据本发明的一些实施例,通过如下方式构建所述联合损失函数:
36、l=αldenoising+(1-α)lrecognition
37、其中,α表示权重因子,ldenoising表示所述降噪后的音频信号幅度谱特征,lrecognition表示所述目标识别结果。
38、第二方面,本发明实施例还提供了一种水声信号降噪识别联合训练系统,所述水声信号降噪识别联合训练系统包括:
39、数据变换单元,用于获取水声带噪音频信号,并对所述水声带噪音频信号进行变换,得到带噪信号幅度谱特征;
40、信号降噪单元,用于基于所述带噪信号幅度谱特征,采用预设的降噪模型对所述水声带噪音频信号进行降噪,得到降噪后的音频信号幅度谱特征;
41、特征融合单元,用于采用交叉注意力融合模块将所述带噪信号幅度谱特征和所述降噪后的音频信号幅度谱特征进行融合,得到融合特征;
42、目标识别单元,用于采用预设的水声信号识别模型对所述融合特征进行目标信号识别,得到目标识别结果;
43、联合训练单元,用于基于所述目标识别结果和所述降噪后的音频信号幅度谱特征构建联合损失函数,并采用所述联合损失函数对所述预设的降噪模型、所述交叉注意力融合模块和所述预设的水声信号识别模型进行联合训练。
44、第三方面,本发明实施例还提供了一种水声信号降噪识别联合训练设备,包括至少一个控制处理器和用于与所述至少一个控制处理器通信连接的存储器;所述存储器存储有可被所述至少一个控制处理器执行的指令,所述指令被所述至少一个控制处理器执行,以使所述至少一个控制处理器能够执行如上所述的一种水声信号降噪识别联合训练方法。
45、第四方面,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行如上所述的一种水声信号降噪识别联合训练方法。
46、可以理解的是,上述第二方面至第四方面与相关技术相比存在的有益效果与上述第一方面与相关技术相比存在的有益效果相同,可以参见上述第一方面中的相关描述,在此不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!