语种识别方法、系统、设备及存储介质与流程
本发明涉及语种识别,特别涉及一种语种识别方法、系统、设备及存储介质。
背景技术:
1、语种识别是指计算机自动判定一段语音信号的语言类别的技术。该技术主要用在多语言语音处理系统的前端,先进行语种分类,再调用对应语言的asr(自动语音识别)模型。机器学习的语种识别系统主要有gmm-ubm(gaussian mixture model-universalbackground model)(声纹识别)、i-vector(线性降维模型)。深度学习时代,各种深度学习架构虽然在不断提升语种识别的性能,但是大大增加了系统复杂度,增加了资源消耗。同时对于语种识别的两个问题,短时语音的语种识别和易混淆的语种识别,仍然不能进行一劳永逸的解决。这主要是由于语言信息属于语音信号中的弱信息,隐藏在语音信号中,需要通过对语音中的信息进行提取和分析才能进行判定。判决结果的好坏强烈地依赖于语音信息段中的相关统计信息,而在短时语音段和高混淆语言任务中,现有方法对这些统计信息的估计缺乏鲁棒性。
2、在现实研究中,大都只使用音频信息进行语种模型的训练,直接进行语种分类,但不能较好解决音频过短、不同语种发音相同和语种混淆问题,因此在使用场景中识别效果较差。
3、而对于一个拥有多语言技能组的呼叫中心来说,虽然可以通过规则的方式使用户进入对应的技能组,但仍有例外。比如,用户进入外语技能组后,如果客服是拥有外语技能组的中国人,此时客人仍然会使用普通话和客服交流。对于客服来说,这并不会造成任何困扰。但如果希望接入语音识别,就需要一个前置的语种识别模型来决定到底调用哪一种语种的asr模型进行转写。同时根据使用场景,需要解决另外一个主要问题是非母语人士(non-native speakers)的语种识别。由于发音的不标准或者发音时间较短,如果从音素和语调的角度来判断语种,容易产生误判,给现在语种识别带来巨大的困难。同时,对于不同语种发音相似时,单纯通过语音是无法辨别出语种的类别的,对于该类发音是无法判断是哪种语言。
技术实现思路
1、本发明要解决的技术问题是为了克服现有技术中对于音频过短、不同语种发音相同和语种混淆的识别方式,存在识别效果差的缺陷,提供一种语种识别方法、系统、设备及存储介质。
2、本发明是通过下述技术方案来解决上述技术问题:
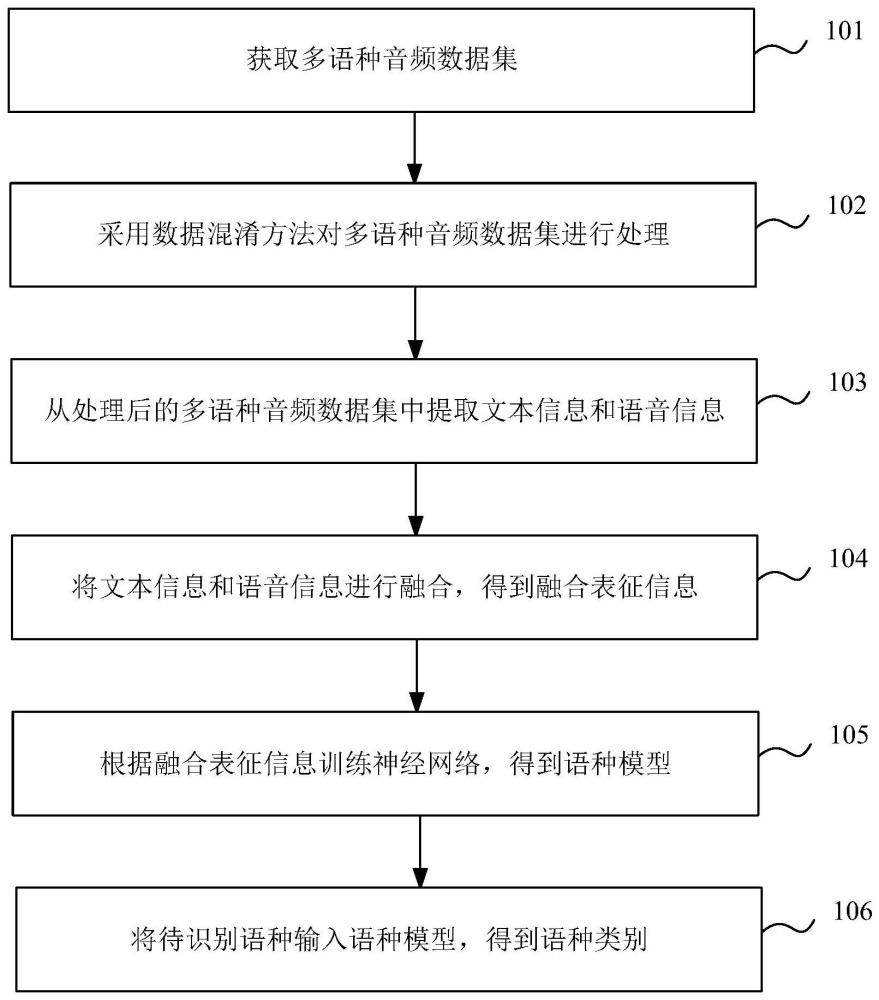
3、本发明第一方面提供了一种语种识别方法,所述语种识别方法包括:
4、获取多语种音频数据集,所述多语种音频数据集包括短时音频数据和场景音频数据,所述短时音频数据为音频时长小于预设音频时长的不同语种的音频数据;所述场景音频数据为在场景内分布的不同语种的长短时音频数据;
5、采用数据混淆方法对所述多语种音频数据集进行处理;
6、从处理后的多语种音频数据集中提取文本信息和语音信息;
7、将所述文本信息和所述语音信息进行融合,得到融合表征信息;
8、根据融合表征信息训练神经网络,得到语种模型;
9、将待识别语种输入所述语种模型,得到语种类别。
10、优选地,所述采用数据混淆方法对所述多语种音频数据集进行处理的步骤包括:
11、采用数据混淆方法对所述多语种音频数据集进行剪切和拼接处理;
12、所述从处理后的多语种音频数据集中提取文本信息和语音信息的步骤包括:
13、从剪切和拼接处理后的多语种音频数据集中提取文本信息和语音信息。
14、优选地,所述从处理后的多语种音频数据集中提取文本信息和语音信息的步骤包括:
15、从所述处理后的多语种音频数据集中提取声学特征;
16、将所述声学特征分别输入时延神经网络以及自动语音识别网络,分别得到所述语音信息和所述文本信息。
17、优选地,所述将所述文本信息和所述语音信息进行融合,得到融合表征信息的步骤包括:
18、通过所述自动语音识别网络和注意力机制网络从所述文本信息中提取词向量;
19、将所述声学特征和所述词向量进行融合,得到所述融合表征信息;
20、和/或,
21、所述语种识别方法还包括:
22、获取所述待识别语种的语种类别概率值;
23、选择所述语种类别概率值最高的类别作为所述待识别语种的语种类别。
24、本发明第二方面提供了一种语种识别系统,所述语种识别系统包括:
25、第一获取模块,用于获取多语种音频数据集,所述多语种音频数据集包括短时音频数据和场景音频数据,所述短时音频数据为音频时长小于预设音频时长的不同语种的音频数据;所述场景音频数据为在场景内分布的不同语种的长短时音频数据;
26、处理模块,用于采用数据混淆方法对所述多语种音频数据集进行处理;
27、提取模块,用于从处理后的多语种音频数据集中提取文本信息和语音信息;
28、融合模块,用于将所述文本信息和所述语音信息进行融合,得到融合表征信息;
29、训练模块,用于根据融合表征信息训练神经网络,得到语种模型;
30、识别模块,用于将待识别语种输入所述语种模型,得到语种类别。
31、优选地,所述处理模块,具体用于采用数据混淆方法对所述多语种音频数据集进行剪切和拼接处理;
32、所述提取模块,具体用于从剪切和拼接处理后的多语种音频数据集中提取文本信息和语音信息。
33、优选地,所述提取模块包括:
34、第一提取单元,用于从所述处理后的多语种音频数据集中提取声学特征;
35、输入单元,用于将所述声学特征分别输入时延神经网络以及自动语音识别网络,分别得到所述语音信息和所述文本信息。
36、优选地,所述融合模块包括:
37、第二提取单元,用于通过所述自动语音识别网络和注意力机制网络从所述文本信息中提取词向量;
38、融合单元,用于将所述声学特征和所述词向量进行融合,得到所述融合表征信息;
39、和/或,
40、所述语种识别系统还包括:
41、第二获取模块,用于获取所述待识别语种的语种类别概率值;
42、选择模块,用于选择所述语种类别概率值最高的类别作为所述待识别语种的语种类别。
43、本发明第三方面提供了一种电子设备,包括存储器、处理器及存储在存储器上并用于在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如第一方面所述的语种识别方法。
44、本发明第四方面提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的语种识别方法。
45、在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
46、本发明的积极进步效果在于:
47、本发明获取包括短时音频数据和场景音频数据的多语种音频数据集,采用数据混淆方法对多语种音频数据集进行处理;并将从处理后的多语种音频数据集中提取文本信息和语音信息进行融合,将待识别语种输入根据融合表征信息训练得到的语种模型,得到语种类别,提升了语种模型的识别效果和识别准确率,改善了短时音频识别效果差以及语种混淆的问题。
- 还没有人留言评论。精彩留言会获得点赞!