声音信息保护方法及装置、存储介质、电子装置与流程
本技术涉及数据处理,具体而言,涉及一种声音信息保护方法及装置、存储介质、电子装置。
背景技术:
1、目前,相关技术中的声音转换的主要方式是先通过自动语音识别(automaticspeech recognition,简称为asr)技术对待转换的语音进行识别并提取巴科斯范式(backus-naur form,简称为bnf)特征,进一步通过从文本到语音(text to speech,简称为tts)技术对基于上述识别内容与bnf特征进行语音合成处理进而得到目标语音。上述过程受限于asr的识别准确度与效率,在实际处理过程中无论是声音转换的准确性亦或实时性均不理想。对此,相关技术进一步提出了端到端的声音转换方式,即不通过asr进行语音识别而直接对待转换语音实现音色转换进而得到目标语音,但通常而言,端到端的声音转换所依赖的网络模型体积较大,在实际进行声音转换过程中实时性欠佳。
2、当前,上述声音转换技术被某些不法分子用于电信诈骗的情形时有发生。不法分子在对某一受害人实施电信诈骗行为时,会通过各类渠道获取与该受害人存在关联的相关人员的语音样本,例如,获取受害人的亲属与第三方进行电话沟通的电话录音。不法分子获取上述语音样本后,即利用声音转换技术,以该相关人员的声音与受害人进行沟通,进而达成其不法目的。对此,虽然政策法规对个人信息的泄露进行了一定的规定,但是,个人的声音特征相较于传统的个人信息更为抽象,泄露行为也更为隐蔽,故而难以解决有关人员与第三方进行语音通信过程中可能的声音特征泄露发生。
3、相关技术中,对上述基于声音转换的电信诈骗进行防范的技术多侧重于对电信诈骗过程中是否采用声音转换技术进行检测,而对于上述如何避免用户声音特征的泄露的问题则尚未提出有效的解决方案。
技术实现思路
1、本技术实施例提供了一种声音信息保护方法及装置、存储介质、电子装置,以至少解决相关技术中如何避免用户声音特征的泄露的问题。
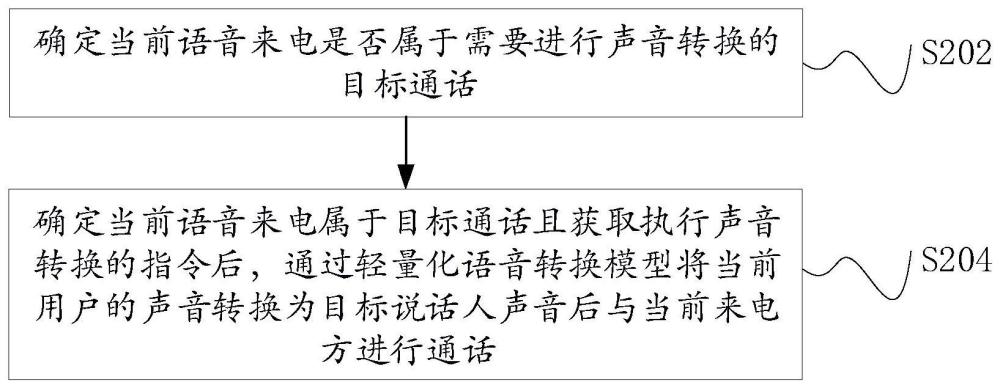
2、在本技术的一个实施例中,提供了一种声音信息保护方法,包括:确定当前语音来电是否属于需要进行声音转换的目标通话;其中,所述目标通话至少包括:被标注的骚扰电话、销售电话和客服电话,以及来电方未在当前终端的通讯录中进行记载的电话;确定当前语音来电属于所述目标通话且获取执行声音转换的指令后,通过轻量化语音转换模型将当前用户的声音转换为目标说话人声音后与当前来电方进行通话;其中,所述目标说话人为随机第三人或由所述当前用户进行指定,所述轻量化语音转换模型为使用包含所述目标说话人的语音的样本语音训练的模型,包括:后验编码器、先验编码器和解码器。
3、在一实施例中,在通过轻量化语音转换模型将当前用户的声音转换为目标说话人声音后与当前来电方进行通话之前,所述方法还包括:通过音频特征编码模块识别所述目标说话人语音样本的风格类别,并根据所述目标说话人语音样本的风格类别提取所述目标说话人语音样本的音频特征;其中,所述目标说话人语音样本的音频特征包含所述目标说话人语音样本的文本特征、韵律特征和音色特征;通过所述音频特征编码模块提取所述当前用户语音对应的音频特征,其中,所述当前用户语音对应的音频特征包含所述当前用户语音的文本特征、韵律特征和音色特征。
4、在一实施例中,所述通过轻量化语音转换模型将当前用户的声音转换为目标说话人声音后与当前来电方进行通话包括:通过所述后验编码器,将所述当前用户语音的音频特征与所述目标说话人语音样本的音频特征进行融合,得到联合编码特征,并根据所述目标说话人语音样本的音频特征提取第一隐式特征;通过所述先验编码器,根据所述目标说话人语音样本的后验概率图ppg特征,通过线性注意力机制从所述当前用户语音的音素中获取所述第一隐式特征的先验分布;其中,所述先验分布通过以所述ppg特征为约束条件求得的所述第一隐式特征对应的均值或方差进行表征;通过所述解码器根据所述先验编码器输出的先验分布,对所述联合编码特征进行标准流化操作后解码,并通过声码器输出转换后的语音;其中,所述解码器包括高频解码模块与低频解码模块,所述高频解码模块采用短时傅里叶逆变换的方式完成解码,所述低频解码模块采用声码器的方式完成解码。
5、在一实施例中,所述通过所述先验编码器,根据所述目标说话人语音样本的后验概率图ppg特征,通过线性注意力机制从所述当前用户语音的音素中获取所述第一隐式特征的先验分布,包括:预先训练独立于所述先验编码器的语音识别模型;其中,所述语音识别模型的训练样本数据不包含所述目标说话人的语音样本;通过训练后的所述语音识别模型提取所述目标说话人语音样本的ppg特征;通过独立于所述先验编码器设置的ppg特征预测单元,计算约束过程中的约束损失,并对提取的所述ppg特征进行补偿。
6、在一实施例中,通过所述先验编码器,根据所述目标说话人语音样本的后验概率图ppg特征,通过线性注意力机制从所述当前用户语音的音素中获取所述第一隐式特征的先验分布之后,所述方法还包括:通过所述先验编码器中的归一化层,将所述第一隐式特征的先验分布进行复杂化处理,并输出对应的频谱信息;其中,所述归一化层由多个耦合层构成,每一所述耦合层由多个残差块构成,多个所述耦合层之间共享参数。
7、在一实施例中,所述轻量化语音转换模型在训练过程中,包括以下步骤:获取所述目标说话人语音样本的音频特征及其对应的第二隐式特征;根据所述目标说话人语音样本的音频特征与所述第二隐式特征生成所述目标说话人语音样本的预估值;根据所述目标说话人语音样本的预估值与所述目标说话人语音样本的真实值训练第一损失函数;其中,所述第一损失函数用于指示所述目标说话人语音样本的预估值相对于真实值的损失;通过对齐预估单元将所述目标说话人语音样本的音频特征与所述第二隐式特征进行对齐处理以计算对齐矩阵,并根据对齐矩阵训练第二损失函数,所述第二损失函数用于指示所述目标说话人语音样本的音频特征与所述第二隐式特征之间的离散度;根据所述目标语音样本的预估值与所述真实值的差异确定鉴别结果,并根据所述鉴别结果训练第三损失函数;根据所述第一损失函数、所述第二损失函数和所述第三损失函数得到训练后的所述轻量化语音转换模型。
8、在一实施例中,在通过所述音频特征编码模块提取所述当前用户语音对应的音频特征之前,所述方法还包括:使用第一训练样本训练第一聚类模型,其中,所述第一训练样本包括多个说话人的语音样本,且多个说话人的语音样本对应不同的风格类型;所述第一聚类模型用于对所述第一训练样本进行聚类,并根据聚类结果确定所述第一训练样本对应的类别标签;使用第二训练样本训练第二聚类模型,其中,所述第二训练样本包括多个说话人的语音样本,且多个说话人的语音样本对应不同的风格类型;所述第二聚类模型用于对所述第二训练样本进行聚类,并根据聚类结果确定所述第二训练样本对应的类别标签;所述第一聚类模型和所述第二聚类模型采用不同结构的特征提取器,以从不同的维度进行聚类;将第三训练样本同时输入训练后的所述第一聚类模型、训练后的所述第二聚类模型以及初始音频特征编码模块,其中,所述第三训练样本包含多个说话人的语音样本;根据所述初始音频特征编码模块的损失函数训练所述初始音频特征编码模块,同时根据所述第一聚类模型和所述第二聚类模型输出的真实类别标签和所述初始音频特征编码模块输出的预测类别标签,训练所述初始音频特征编码模块至收敛,得到所述音频特征编码模块,其中,所述音频特征编码模块用于根据语音的风格类型进行音频特征的提取。
9、根据本技术的另一个实施例,还提供了一种声音信息保护装置,包括:确定模块,配置为确定当前语音来电是否属于需要进行声音转换的目标通话;其中,所述目标通话至少包括:被标注的骚扰电话、销售电话和客服电话,以及来电方未在当前终端的通讯录中进行记载的电话;转换模块,配置为确定当前语音来电属于所述目标通话且获取执行声音转换的指令后,通过轻量化语音转换模型将当前用户的声音转换为目标说话人声音后与当前来电方进行通话;其中,所述目标说话人为随机第三人或由所述当前用户进行指定,所述轻量化语音转换模型为使用包含所述目标说话人的语音的样本语音训练的模型,包括:后验编码器、先验编码器和解码器。
10、在本技术的一个实施例中,还提出了一种计算机可读的存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
11、在本技术的一个实施例中,还提出了一种电子装置,包括存储器和处理器,其特征在于,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。
12、通过本技术实施例提供的声音信息保护方法,确定当前语音来电属于所述目标通话且获取执行声音转换的指令后,通过轻量化语音转换模型将当前用户的声音转换为目标说话人声音后与当前来电方进行通话;所述轻量化语音转换模型为使用包含所述目标说话人的语音的样本语音训练的模型,包括:后验编码器、先验编码器和解码器。解决了相关技术中如何避免用户声音特征的泄露的问题,通过音频特征编码模块识别目标语音样本的风格类别,不是从电信诈骗过程中是否采用声音转换技术进行检测,而是从根源上避免用户的声音泄露,防止诈骗分子获取相关用户的声音信息。
- 还没有人留言评论。精彩留言会获得点赞!