一种多源语音识别方法及系统与流程
本发明属于语音识别,尤其涉及一种多源语音识别方法。
背景技术:
1、为了提升语音识别系统的语音识别结果的可靠性和鲁棒性,现有技术方案中通过利用多个麦克风或多个声源进行语音信号采集和处理,并根据采集得到的语音信号进行对齐处理后进行语音识别结果的输出,因此实现对不同的声源的协调管理进行语音识别结果的输出成为亟待解决的技术问题。
2、为了解决上述技术问题,现有技术方案中cn201810673599.3《基于多源识别的语音识别方法、系统、音箱及存储介质》中通过在智能音箱内设置至少两个语音识别平台对用户语音时行识别,在识别结果相同时进行输出,在识别结果不同时,进行同一化后得到最终识别结果再进行输出,极大的提高了智能音箱语音识别精度,但是与此同时,却存在以下技术问题:
3、在某些场景下用户的位置并不是固定不变的,例如在某些会议中用户的位置有可能会发生变动,因此若不能对用户的位置变动情况的识别,则无法实现对不同的声源的解析可靠性的确定,从而无法实现对语音识别结果的准确输出。
4、针对上述技术问题,本发明提供了一种多源语音识别方法及系统。
技术实现思路
1、本发明的目的是提供一种多源语音识别方法。
2、为了解决上述技术问题,本发明提供了一种多源语音识别方法,具体包括:
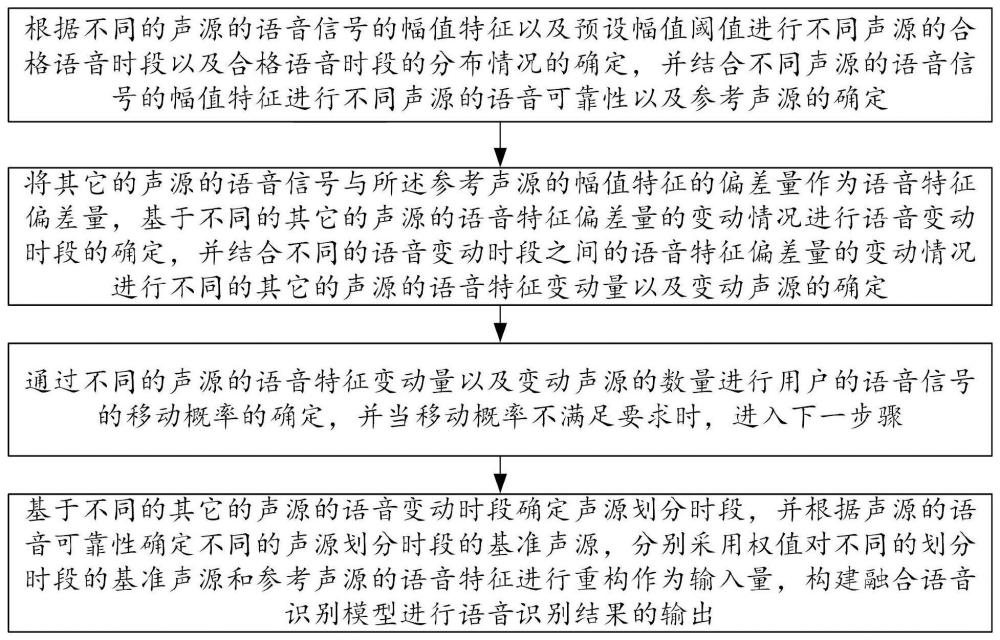
3、s1根据不同的声源的语音信号的幅值特征以及预设幅值阈值进行不同声源的合格语音时段以及合格语音时段的分布情况的确定,并结合不同声源的语音信号的幅值特征进行不同声源的语音可靠性以及参考声源的确定;
4、s2将其它的声源的语音信号与所述参考声源的幅值特征的偏差量作为语音特征偏差量,基于不同的其它的声源的语音特征偏差量的变动情况进行语音变动时段的确定,并结合不同的语音变动时段之间的语音特征偏差量的变动情况进行不同的其它的声源的语音特征变动量以及变动声源的确定;
5、s3通过不同的声源的语音特征变动量以及变动声源的数量进行用户的语音信号的移动概率的确定,并当移动概率不满足要求时,进入下一步骤;
6、s4基于不同的其它的声源的语音变动时段确定声源划分时段,并根据声源的语音可靠性确定不同的声源划分时段的基准声源,分别采用权值对不同的划分时段的基准声源和参考声源的语音特征进行重构作为输入量,构建融合语音识别模型进行语音识别结果的输出。
7、本发明的有益效果在于:
8、1、通过根据合格语音时段以及语音信号的幅值特征进行不同声源的语音可靠性以及参考声源的确定,从而既考虑到不同的声源的合格语音时段的时长和分布连续性,同时还考虑到幅值特征的差异导致不同的声源的识别准确率的差异,实现了对参考声源的可靠筛选,也为进一步实现语音变动情况的确定奠定了基础。
9、2、通过不同的声源的语音特征变动量以及变动声源的数量进行用户的语音信号的移动概率的确定,从而实现了从多个角度对语音信号的移动情况的准确评估,充分考虑到不同的声源的语音特征的变动情况以及变动声源的数量,避免了由于语音信号移动导致的语音识别结果不够准确的技术问题。
10、3、通过分别采用权值对不同的划分时段的基准声源和参考声源的语音特征进行重构作为输入量,构建融合语音识别模型进行语音识别结果的输出,在减少融合语音识别模型的输入量的基础上,提升了语音识别处理的效率,同时通过对基准声源和参考声源的语音特征进行重构,充分考虑到由于语音特征的变动情况导致的不同的声源的参考意义的差异,提升了语音识别处理的准确性。
11、进一步的技术方案在于,所述预设幅值阈值根据在不同的语音信号的幅值特征下的语音识别结果进行确定,具体的通过语音识别结果的准确率大于预设准确率阈值所对应的幅值特征进行确定。
12、进一步的技术方案在于,基于不同的其它的声源的语音特征偏差量的变动情况进行语音变动时段的确定,具体包括:
13、根据不同时刻的语音特征偏差量的相似度将所述其它的声源划分为多个时段,并根据不同时段之间的语音特征偏差量的偏差量进行语音变动时段的确定。
14、另一方面,本申请实施例中提供一种多源语音识别系统,采用上述的一种多源语音识别方法,具体包括:参考声源确定模块,变动声源筛选模块,移动概率评估模块,语音识别模块;
15、其中所述参考声源确定模块负责根据不同的声源的语音信号的幅值特征以及预设幅值阈值进行不同声源的合格语音时段以及合格语音时段的分布情况的确定,并结合不同声源的语音信号的幅值特征进行不同声源的语音可靠性以及参考声源的确定;
16、所述变动声源筛选模块负责将其它的声源的语音信号与所述参考声源的幅值特征的偏差量作为语音特征偏差量,基于不同的其它的声源的语音特征偏差量的变动情况进行语音变动时段的确定,并结合不同的语音变动时段之间的语音特征偏差量的变动情况进行不同的其它的声源的语音特征变动量以及变动声源的确定;
17、所述移动概率评估模块负责通过不同的声源的语音特征变动量以及变动声源的数量进行用户的语音信号的移动概率的确定;
18、所述语音识别模块负责基于不同的其它的声源的语音变动时段确定声源划分时段,并根据声源的语音可靠性确定不同的声源划分时段的基准声源,分别采用权值对不同的划分时段的基准声源和参考声源的语音特征进行重构作为输入量,构建融合语音识别模型进行语音识别结果的输出。
19、另一方面,本发明提供了一种计算机存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行上述的一种多源语音识别方法。
20、其他特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点在说明书以及附图中所特别指出的结构来实现和获得。
21、为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
技术特征:
1.一种多源语音识别方法,其特征在于,具体包括:
2.如权利要求1所述的多源语音识别方法,其特征在于,所述预设幅值阈值根据在不同的语音信号的幅值特征下的语音识别结果进行确定,具体的通过语音识别结果的准确率大于预设准确率阈值所对应的幅值特征进行确定。
3.如权利要求1所述的多源语音识别方法,其特征在于,所述参考声源的确定的方法为:
4.如权利要求3所述的多源语音识别方法,其特征在于,通过所述语音可靠性确定所述声源是否属于参考声源,具体包括:
5.如权利要求1所述的多源语音识别方法,其特征在于,基于不同的其它的声源的语音特征偏差量的变动情况进行语音变动时段的确定,具体包括:
6.如权利要求1所述的多源语音识别方法,其特征在于,所述声源的语音特征变动量的确定的方法为:
7.如权利要求1所述的多源语音识别方法,其特征在于,当所述声源的语音特征变动量不满足要求是,则确定所述声源为变动声源,具体的当所述声源的语音特征变动量大于预设变动量阈值时,则确定所述声源为变动声源。
8.如权利要求1所述的多源语音识别方法,其特征在于,构建融合语音识别模型进行语音识别结果的输出,具体包括:
9.一种多源语音识别系统,采用权利要求1-8任一项所述的多源语音识别方法,具体包括:参考声源确定模块,变动声源筛选模块,移动概率评估模块,语音识别模块;
10.一种计算机存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行权利要求1-8任一项所述的多源语音识别方法。
技术总结
本发明提供一种多源语音识别方法及系统,属于语音识别技术领域,具体包括:根据不同的声源的语音信号的幅值特征以及预设幅值阈值进行不同声源的合格语音时段以及合格语音时段的分布情况的确定,并结合不同声源的语音信号的幅值特征进行不同声源的语音可靠性以及参考声源的确定,基于不同的其它的声源的语音变动时段确定声源划分时段,并根据声源的语音可靠性确定不同的声源划分时段的基准声源,分别采用权值对不同的划分时段的基准声源和参考声源的语音特征进行重构作为输入量,构建融合语音识别模型进行语音识别结果的输出,从而提升了语音识别的可靠性。
技术研发人员:吕召彪,赵文博,许程冲,黄莉梅,肖清
受保护的技术使用者:联通(广东)产业互联网有限公司
技术研发日:
技术公布日:2024/5/9
- 还没有人留言评论。精彩留言会获得点赞!