一种服务器、显示设备及数字人生成方法与流程
本技术涉及数字人交互,尤其涉及一种服务器、显示设备及数字人生成方法。
背景技术:
1、随着元宇宙概念和数字人概念的火爆发展,3d数字人的应用越来越广,包括3d影视、3d游戏、ar(augmented reality,增强现实)/vr(virtual reality,虚拟现实)、虚拟办公、虚拟社交等场景。但目前3d数字人级别以普通播放为主,缺乏情绪化的分量,更缺乏情绪可控的方法,即使有的3d数字人带有一定的情绪,也是利用面捕设备捕获的,根本无法推广应用,严重影响3d数字人的应用范围。
技术实现思路
1、本技术一些实施例提供了一种服务器、显示设备及数字人生成方法,通过将通用口型驱动模型、风格口型驱动模型及风格情绪驱动模型分模型分阶段训练,可实现口型与情绪的驱动分离,在应用时可以实现不同风格口型和风格情绪的组合,使得数字人情绪表达及风格迁移更加自然。
2、第一方面,本技术一些实施例中提供一种服务器,被配置为:
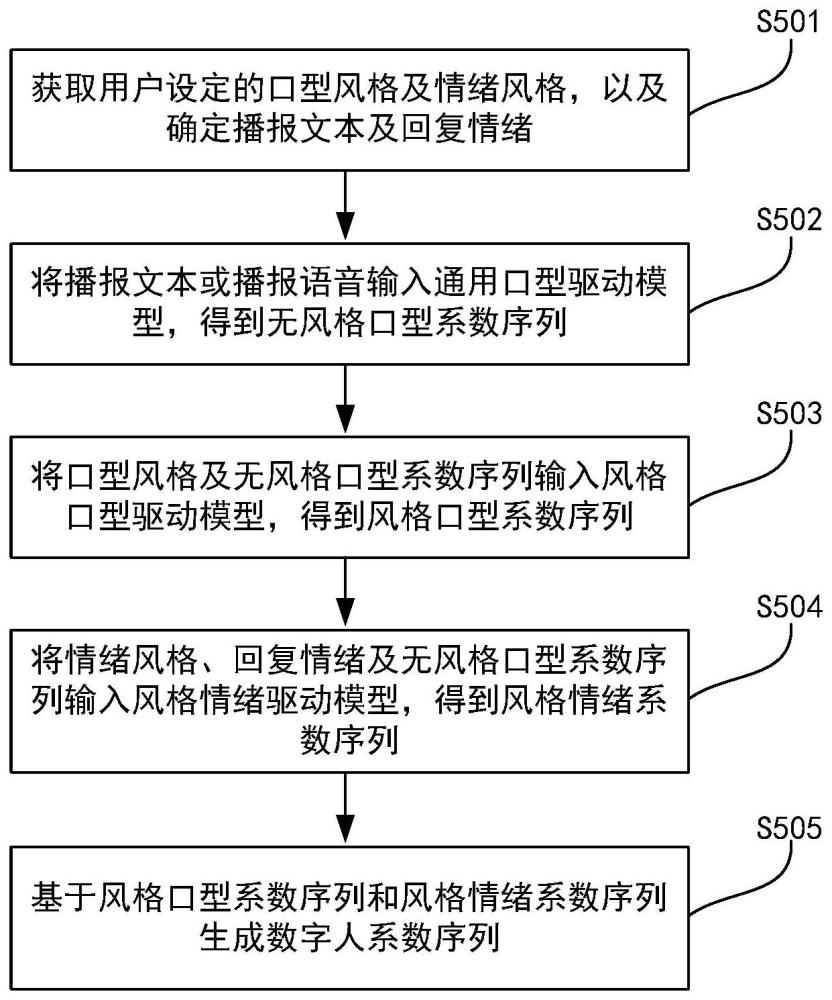
3、获取用户设定的口型风格及情绪风格,以及确定播报文本及回复情绪;
4、将播报文本或播报语音输入通用口型驱动模型,得到无风格口型系数序列,所述播报语音基于所述播报文本合成,所述通用口型驱动模型基于多人说话数据训练得到;
5、将所述口型风格及所述无风格口型系数序列输入风格口型驱动模型,得到风格口型系数序列,所述风格口型驱动模型融合所述通用口型驱动模型的输出结果与口型风格标签训练得到;
6、将所述情绪风格、所述回复情绪及所述无风格口型系数序列输入风格情绪驱动模型,得到风格情绪系数序列,所述风格情绪驱动模型融合所述通用口型驱动模型的输出结果、情绪风格标签及情绪标签训练得到;
7、基于所述风格口型系数序列和所述风格情绪系数序列生成数字人系数序列。
8、在一些实施例中,所述回复情绪包括情绪类型及情绪强度,所述情绪类型包括基本情绪和复合情绪,所述复合情绪为多种基本情绪复合后的情绪,所述服务器执行将所述情绪风格、所述回复情绪及所述无风格口型系数序列输入风格情绪驱动模型,得到风格情绪系数序列,被进一步配置为:
9、将所述情绪风格、所述情绪类型、所述情绪强度及所述口型系数序列输入风格情绪驱动模型,得到风格情绪系数序列。
10、在一些实施例中,所述风格情绪驱动模型基于情绪强度数据训练得到,所述服务器执行生成情绪强度数据,被进一步配置为:
11、根据多个语句的基本情绪目标强度系数序列与无情绪系数序列,得到基本情绪目标强度的残差情绪序列;
12、根据基本情绪目标强度的残差情绪序列确定基本情绪非目标强度的残差情绪序列;
13、根据基本情绪非目标强度的残差情绪序列和所述无情绪系数序列,确定基本情绪非目标强度系数序列;
14、根据至少两种基本情绪特定强度的残差情绪序列计算复合情绪的残差情绪序列;
15、根据复合情绪的残差情绪序列和所述无情绪系数序列,确定复合情绪系数序列。
16、在一些实施例中,所述服务器执行将所述情绪风格、所述回复情绪及所述无风格口型系数序列输入风格情绪驱动模型,得到风格情绪系数序列,被进一步配置为:
17、根据所述回复情绪及图像帧数量确定图像帧的情绪向量序列,所述情绪向量序列中的至少一组分量数值呈递增或递减趋势,所述情绪向量中的分量表征基本情绪,所述情绪向量中的分量数值表征所述分量对应基本情绪的情绪强度,所述图像帧数量基于所述播报文本或所述播报语音的长度确定;
18、将所述情绪风格、所述图像帧的情绪向量序列及所述口型系数序列输入风格情绪驱动模型,得到风格情绪系数序列。
19、在一些实施例中,所述服务器,被配置为:
20、如果用户设定的口型风格及情绪风格为空,则获取随机情绪风格;
21、将所述随机情绪风格、所述回复情绪及所述无风格口型系数序列输入风格情绪驱动模型,得到风格情绪系数序列;
22、基于所述无风格口型系数序列和所述风格情绪系数序列生成数字人系数序列。
23、在一些实施例中,所述服务器执行确定播报文本,被进一步配置为:
24、接收显示设备发送用户输入的语音数据;
25、根据所述语音数据确定播报文本。
26、在一些实施例中,所述服务器执行确定回复情绪,被进一步配置为:
27、基于所述语音数据或所述语音数据对应的语音文本确定回复情绪;或者,
28、接收显示设备采集用户的人脸图像或生理信号;
29、将所述人脸图像或所述生理信号确定回复情绪。
30、在一些实施例中,所述服务器执行基于所述风格口型系数序列和所述风格情绪系数序列生成数字人系数序列,被进一步配置为:
31、获取预存储的用户图像数据;
32、将所述用户图像数据映射到三维空间,得到形象系数序列;
33、基于所述形象系数序列、所述风格口型系数序列和所述风格情绪系数序列生成数字人系数序列。
34、第二方面,本技术一些实施例中提供一种显示设备,包括:
35、显示器,被配置为显示用户界面;
36、通信器,被配置为与服务器进行数据通信;
37、控制器,被配置为:
38、接收用户输入的语音数据;
39、将所述语音数据通过所述通信器发送至服务器;
40、接收所述服务器基于所述语音数据下发的数字人图像数据及播报语音;
41、播放所述播报语音并基于所述数字人图像数据显示数字人图像。
42、第三方面,本技术一些实施例中提供一种数字人生成方法,包括:
43、获取用户设定的口型风格及情绪风格,以及确定播报文本及回复情绪;
44、将播报文本或播报语音输入通用口型驱动模型,得到无风格口型系数序列,所述播报语音基于所述播报文本合成,所述通用口型驱动模型基于多人说话数据训练得到;
45、将所述口型风格及所述无风格口型系数序列输入风格口型驱动模型,得到风格口型系数序列,所述风格口型驱动模型融合所述通用口型驱动模型的输出结果与口型风格标签训练得到;
46、将所述情绪风格、所述回复情绪及所述无风格口型系数序列输入风格情绪驱动模型,得到风格情绪系数序列,所述风格情绪驱动模型融合所述通用口型驱动模型的输出结果、情绪风格标签及情绪标签训练得到;
47、基于所述风格口型系数序列和所述风格情绪系数序列生成数字人系数序列。
48、本技术的一些实施例提供一种服务器、显示设备及数字人生成方法。获取用户设定的口型风格及情绪风格,以及确定播报文本及回复情绪;将播报文本或播报语音输入通用口型驱动模型,得到无风格口型系数序列,其中,所述播报语音基于所述播报文本合成,所述通用口型驱动模型基于多人说话数据训练得到;将所述口型风格及所述无风格口型系数序列输入风格口型驱动模型,得到风格口型系数序列,所述风格口型驱动模型融合所述通用口型驱动模型的输出结果与口型风格标签训练得到;将所述情绪风格、所述回复情绪及所述无风格口型系数序列输入风格情绪驱动模型,得到风格情绪系数序列。其中,所述风格情绪驱动模型融合所述通用口型驱动模型的输出结果、情绪风格标签及情绪标签训练得到。基于所述风格口型系数序列和所述风格情绪系数序列生成数字人系数序列。本技术实施例通过对通用口型驱动模型、风格口型驱动模型及风格情绪驱动模型进行分模型分阶段训练,可实现口型与情绪的驱动分离,在应用时可以实现不同风格口型和风格情绪的组合,使得数字人情绪表达及风格迁移更加自然。
- 还没有人留言评论。精彩留言会获得点赞!