在用于端到端语音识别的神经换能器模型中分离声学和语言信息的制作方法
背景技术:
1、本发明总体上涉及语音识别,并且更具体地,涉及在用于端到端语音识别的神经换能器模型中分离声学和语言信息。
2、利用神经换能器的端到端语音识别在训练和推断方面均具有各种优点,在神经换能器中,仅一个神经网络对每件事物建模以用于语音识别。仅仅从转录和音频纯粹地端到端训练是可能的。推断仅需要在一个神经网络上进行束搜索,从而导致较小的计算成本、较小的存储器占用面积和较简单的推断引擎。
3、神经换能器模型的训练是简单的,但是具有一些缺点。例如,端到端训练易于过度拟合,因为一个话语可仅充当一个样本。虽然神经换能器模型包括用作声学模型的编码器网络、用作语言模型的预测网络、以及将来自编码器和预测网络的声学和语言嵌入进行组合的联合网络,但是端到端训练没有考虑这样的模块化。因此,神经换能器的定制比其中声学和语言模型被分开训练并且可被独立地定制的常规混合模型更困难。提高的准确性和更具反应性的定制对于提供来自云的竞争性服务都是至关重要的。所以,需要(1)通过减轻过度拟合来改进语音识别准确度,以及(2)建立对定制更具反应性的模型。
技术实现思路
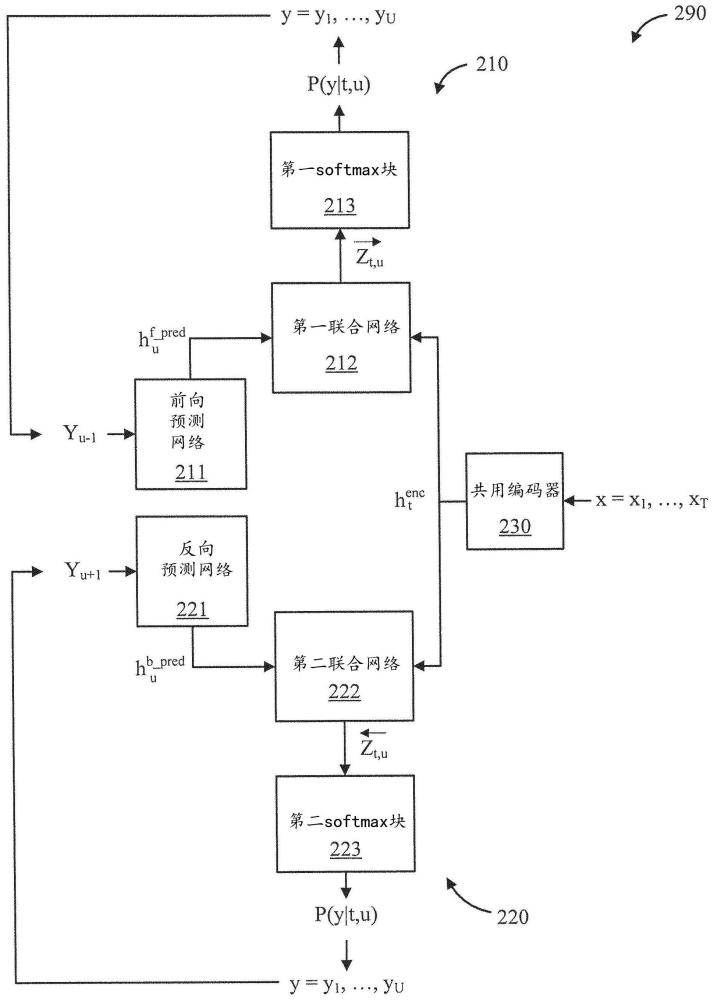
1、根据本发明的方面,提供了一种用于训练递归神经网络换能器(rnn-t)的计算机实现的方法。该方法包括通过输入音频数据集合来训练第一rnn-t,该第一rnn-t包括共用编码器、前向预测网络以及组合共用编码器和前向预测网络两者的输出的第一联合网络。前向预测网络前向预测标签序列。该方法还包括通过输入音频数据集合来训练第二rnn-t,该第二rnn-t包括共用编码器、反向预测网络以及组合共用编码器和反向预测网络两者的输出的第二联合网络。反向预测网络反向预测标签序列。经训练的第一rnn-t用于推断。
2、根据本发明的其他方面,提供了一种用于训练递归神经网络换能器(rnn-t)的计算机程序产品。该计算机程序产品包括非瞬态计算机可读存储介质,该非瞬态计算机可读存储介质具有随其体现的程序指令。程序指令可由计算机执行以使计算机执行方法。该方法包括由处理器设备输入音频数据集合来训练第一rnn-t,该第一rnn-t包括共用编码器、前向预测网络、以及组合共用编码器和前向预测网络两者的输出的第一联合网络。前向预测网络前向预测标签序列。该方法还包括由处理器设备训练第二rnn-t,该第二rnn-t包括共用编码器、反向预测网络以及组合共用编码器和反向预测网络两者的输出的第二联合网络。反向预测网络反向预测标签序列。经训练的第一rnn-t用于推断。
3、根据本发明的又另外的方面,提供了一种用于训练递归神经网络换能器(rnn-t)的计算机处理系统。该系统包括用于存储程序代码的存储器设备。该系统还包括可操作地耦合至存储器设备的处理器设备,该处理器设备用于运行程序代码以通过输入音频数据集合来训练第一rnn-t,该第一rnn-t包括共用编码器、前向预测网络、以及组合共用编码器和前向预测网络两者的输出的第一联合网络。前向预测网络前向预测标签序列。处理器设备还可操作来运行程序代码以通过输入音频数据集合来训练第二rnn-t,该第二rnn-t包括共用编码器、反向预测网络、以及组合共用编码器和反向预测网络两者的输出的第二联合网络。反向预测网络反向预测标签序列。经训练的第一rnn-t用于推断。
4、从以下将结合附图阅读的对其说明性实施例的详细描述,这些和其他特征和优点将变得显而易见。
技术特征:
1.一种用于训练递归神经网络换能器(rnn-t)的计算机实现的方法,所述方法包括:
2.根据权利要求1所述的计算机实现的方法,其中,所述训练的步骤联合地训练所述前向预测网络和所述反向预测网络,同时忽略和不捕获语言信息。
3.根据权利要求1所述的计算机实现的方法,其中,来自所述共用编码器的同一编码被用于联合地训练所述第一rnn-t和所述第二rnn-t。
4.根据权利要求1所述的计算机实现的方法,其中,所述第一rnn-t包括softmax层,并且所述方法还包括将softmax操作应用于所述第一联合网络的输出。
5.根据权利要求1所述的计算机实现的方法,其中,所述第二rnn-t包括softmax层,并且所述方法还包括将softmax操作应用于所述第二联合网络的输出。
6.根据权利要求1所述的计算机实现的方法,其中,训练所述第一rnn-t包括:从所述音频数据集合和所述第一rnn-t的输出形成第一输出概率栅格,其中所述音频数据集合沿着x轴且所述第一rnn-t的输出沿着y轴,其中,所述方法还包括在右上方向上计算关于第一输出概率矩阵的rnn-t损失。
7.根据权利要求1所述的计算机实现的方法,其中,所述第一输出概率栅格的每个节点表示对应于前向方向的所述第一联合网络的输出的softmax。
8.根据权利要求1所述的计算机实现的方法,其中,训练所述第二rnn-t包括:从所述音频数据集合和所述第二rnn-t的输出形成第二输出概率栅格,其中所述音频数据集合沿着x轴且所述第二rnn-t的输出沿着y轴,其中,所述方法还包括在左下方向上计算关于第二概率矩阵的rnn-t损失。
9.根据权利要求1所述的计算机实现的方法,其中,所述第二输出概率栅格的每个节点表示对应于反向方向的所述第二联合网络的输出的softmax。
10.一种用于训练递归神经网络换能器(rnn-t)的计算机程序产品,所述计算机程序产品包括非瞬态计算机可读存储介质,所述非瞬态计算机可读存储介质具有随其体现的程序指令,所述程序指令可由计算机执行以使所述计算机执行方法,所述方法包括:
11.根据权利要求10所述的计算机程序产品,其中,所述训练的步骤联合地训练所述前向预测网络和所述反向预测网络,同时忽略和不捕获语言信息。
12.根据权利要求10所述的计算机程序产品,其中,来自所述共用编码器的同一编码被用于联合地训练所述第一rnn-t和所述第二rnn-t。
13.根据权利要求10所述的计算机程序产品,其中,所述第一rnn-t包括softmax层,并且所述方法还包括将softmax操作应用于所述第一联合网络的输出。
14.根据权利要求10所述的计算机程序产品,其中,所述第二rnn-t包括softmax层,并且所述方法还包括将softmax操作应用于所述第二联合网络的输出。
15.根据权利要求10所述的计算机程序产品,其中,训练所述第一rnn-t包括:从所述音频数据集合和所述第一rnn-t的输出形成第一输出概率栅格,其中所述音频数据集合沿着x轴且所述第一rnn-t的输出沿着y轴,其中,所述方法还包括在右上方向上计算关于第一输出概率矩阵的rnn-t损失。
16.根据权利要求10所述的计算机程序产品,其中,所述第一输出概率栅格的每个节点表示对应于前向方向的所述第一联合网络的输出的softmax。
17.根据权利要求10所述的计算机程序产品,其中,训练所述第二rnn-t包括:从所述音频数据集合和所述第二rnn-t的输出形成第二输出概率栅格,其中所述音频数据集合沿着x轴且所述第二rnn-t的输出沿着y轴,其中,所述方法还包括在左下方向上计算关于第二概率矩阵的rnn-t损失。
18.根据权利要求10所述的计算机程序产品,其中,所述第二输出概率栅格的每个节点表示对应于反向方向的所述第二联合网络的输出的softmax。
19.一种用于训练递归神经网络换能器(rnn-t)的计算机处理系统,所述系统包括:
20.根据权利要求19所述的计算机处理系统,其中,来自所述共用编码器的同一编码被用于联合地训练所述第一rnn-t和所述第二rnn-t。
21.一种计算机程序,包括程序代码部件,当所述程序在计算机上运行时,所述程序代码部件适于执行根据权利要求1至9中任一项所述的方法。
技术总结
提供了一种用于训练递归神经网络换能器(RNN‑T)的计算机实现的方法。该方法包括通过输入音频数据集合训练第一RNN‑T,该第一RNN‑T包括共用编码器、前向预测网络、以及组合共用编码器和前向预测网络两者的输出的第一联合网络。前向预测网络前向预测标签序列。所述方法还包括通过输入音频数据集合训练第二RNN‑T,该第二RNN‑T包括共用编码器、反向预测网络及组合共用编码器及反向预测网络两者的输出的第二联合网络。反向预测网络反向预测标签序列。经训练的第一RNN‑T用于推断。
技术研发人员:仓田岳人
受保护的技术使用者:国际商业机器公司
技术研发日:
技术公布日:2024/5/9
- 还没有人留言评论。精彩留言会获得点赞!