基于可控文本的语音合成方法、装置和系统
本技术涉及语音合成,尤其涉及一种基于可控文本的语音合成方法、装置和系统。
背景技术:
1、风格转换技术是一种将音频或文本的表达风格进行修改的技术,在语音合成中,风格转换通常包括调整音频的音调、语速、情感色彩等,以满足用户对语音输出更个性化的需求。当前,风格转换技术在将文本转化为特定风格的语音方面取得了显著进展,但目前仍存在一些挑战。
2、现有模型通常对大量训练数据和计算资源有高要求,限制了它们在实际场景中的广泛应用。此外,当前系统主要专注于处理单一说话人的语音,而在多说话人情境下存在一定的局限性。尽管近年来风格转换技术在性能上有所改善,但现有系统的风格控制往往依赖于基于具体离散风格类别的表达性语音录音构建的系统,即生成的语音风格和输入语音的风格基本一致,如果没有输入语音样本,无法生成对应风格的语音,风格可控的语音生成模型通常以音素作为输入,对于部分缺少高质量文字到音素转换的语音生成需求,难以按照需求生成高质量的语音。现有技术中的语音生成方法在实际应用中不够灵活,因为用户更愿意通过文本描述直接定义所需语音的风格,而无需参考特定风格的语音样本,难以满足用户使用的需求,且合成的语音受输入语音语言类型限定,即中文生成中文,对于切换语言类型的语音生成需求,难以满足。为此,研究人员致力于基于文本可控生成指定风格的语音技术的研究,提出了基于文本描述引导的跨说话人风格迁移方案promptstyle,然而上述方案直接将文本生成的风格提示与预先基于语音训练的风格提示对齐,以合成文本指定风格的语音,模型的训练依然要依赖于语音提示进行,对模型训练的样本要求较高,且训练的步骤较为繁琐,文本风格的对齐不能将风格的各类信息完全融入至最终合成的语音中,合成的语音较为生硬。
技术实现思路
1、有鉴于此,本技术提供一种基于可控文本的语音合成方法、装置和系统,用以提高生成语音的自然度和质量,同时减少模型训练对语音风格提示样本的依赖,扩宽了模型的应用场景。
2、具体地,本技术是通过如下技术方案实现的:
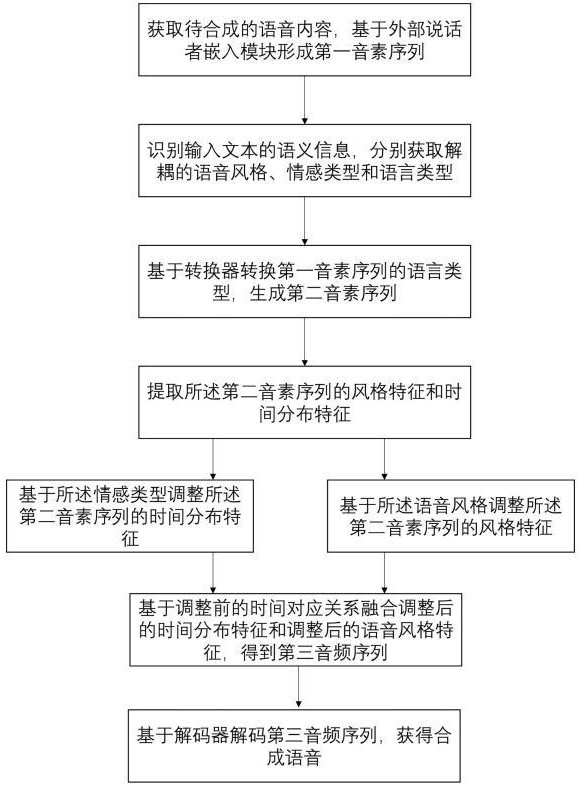
3、本技术第一方面提供一种基于可控文本的语音合成方法,其特征在于,所述基于可控文本的语音合成方法包括:
4、获取待合成的语音内容,基于外部说话者嵌入模块形成第一音素序列;
5、识别输入文本的语义信息,分别获取解耦的语音风格、情感类型和语言类型;
6、基于转换器转换第一音素序列的语言类型,生成第二音素序列;
7、提取所述第二音素序列的风格特征和时间分布特征,所述风格特征和所述时间分布特征具有时间对应关系;
8、基于所述情感类型调整所述第二音素序列的时间分布特征;
9、基于所述语音风格调整所述第二音素序列的风格特征;
10、基于调整前的时间对应关系融合调整后的时间分布特征和调整后的语音风格特征,得到第三音素序列;
11、基于解码器解码第三音素序列,获得合成语音,所述合成语音的语音内容与所述待合成的语音内容相同,所述合成语音的风格、情感与语言与输入文本相对应。
12、优选的,所述识别输入文本的语义信息,分别获取解耦的语音风格、情感类型和语言类型,包括:
13、获取输入文本;
14、将所述输入文本输入至语义理解模块,定位风格实体、情感实体和语言类型实体,所述风格实体、情感实体和语言类型实体不完全相同;
15、将所述风格实体、情感实体和语言类型实体分别输入至风格识别模块、情感分类模块和语言分类模块;
16、所述风格识别模块、情感分类模块和语言分类模块分别基于所述输入文本的全局语义输出识别结果,获取输入文本对应的解耦的语音风格、情感类型和语言类型。
17、优选的,所述风格实体包括多个,
18、所述风格识别模块、情感分类模块和语言分类模块分别基于所述输入文本的全局语义输出识别结果,具体包括:
19、所述风格识别模块根据所述输入文本的全局语义确定多个所述风格实体之间的关系;
20、所述风格识别模块获取多个所述风格实体的嵌入表示,基于嵌入表示和多个所述风格实体之间的关系输出识别到的语音风格。
21、优选的,所述风格识别模块、情感分类模块和语言分类模块分别基于所述输入文本的全局语义输出识别结果,具体包括:
22、所述情感分类模块识别所述输入文本的全局情感和所述情感实体的局部情感;
23、基于所述局部情感修正所述全局情感;
24、所述情感分类模块识别分类识别修正后的局部情感,获得情感类型。
25、优选的,所述风格识别模块、情感分类模块和语言分类模块分别基于所述输入文本的全局语义输出识别结果,具体包括:
26、所述语言分类模块获取所述语言类型实体的嵌入表示;
27、识别所述语言类型实体的嵌入表示获得语言类型的分类结果。
28、优选的,提取所述第二音素序列的风格特征和时间分布特征,包括:
29、在所述第二音素序列的时间段内,根据各个时间点是否存在音素,生成时间分布特征,所述时间分布特征用于表征各个时间点是否存在音素;
30、在所述第二音素序列的时间段内,提取各个时间点下所述第二音素序列的风格特征,所述各个时间点下的风格特征至少包括音调、音色和响度。
31、优选的,所述基于调整前的时间对应关系融合调整后的时间分布特征和调整后的语音风格特征,得到第三音素序列,具体包括:
32、以调整后的时间分布特征为基准,确定所述第三音素序列的音素时间分布,所述音素时间分布用于表示第三音素序列中各个时间点是否存在音素;
33、根据所述第三音素序列的音素时间分布和调整前的时间对应关系在调整后的语音风格特征中匹配各个时间点的风格特征,生成第三音素序列中各个时间点的音素。
34、优选的,所述第二音素序列的语言类型与所述输入文本限定的语言类型相同,所述第二音素序列表征的语音内容与所述待合成的语音内容相同;
35、所述第三音素序列的语言、情感、语音风格与所述输入文本对应的语言类型、情感类型、语音风格相同,所述第三音素序列表征的语音内容与所述待合成的语音内容相同。
36、本发明第二方面提供一种基于可控文本的语音合成装置,所述基于可控文本的语音合成装置包括:
37、语音获取模块,用于获取待合成的语音内容,基于外部说话者嵌入模块形成第一音素序列;
38、解耦模块,用于识别输入文本的语义信息,分别获取解耦的语音风格、情感类型和语言类型;
39、语言转换模块,用于基于转换器转换第一音素序列的语言类型,生成第二音素序列;
40、提取模块,用于提取所述第二音素序列的风格特征和时间分布特征,所述风格特征和所述时间分布特征具有时间对应关系;
41、调整模块,用于基于所述情感类型调整所述第二音素序列的时间分布特征;所述调整模块还用于基于所述语音风格调整所述第二音素序列的风格特征;
42、融合模块,用于基于调整前的时间对应关系融合调整后的时间分布特征和调整后的语音风格特征,得到第三音素序列;
43、解码模块,用于基于解码器解码第三音素序列,获得合成语音,所述合成语音的语音内容与所述待合成的语音内容相同,所述合成语音的风格、情感与语言与输入文本相对应。
44、本发明第三方面提供一种基于可控文本的语音合成系统,所述基于可控文本的语音合成系统至少包括:
45、提示层,包括外部说话者嵌入层和解耦层,所述提示层用于接收输入语音和输入文本,其中所述外部说话者嵌入层用于接收输入语音以获取待合成的语音内容,利用所述待合成的语音内容形成第一音素序列;解耦层用于分别于识别输入文本的语义信息,分别获取解耦的语音风格、情感类型和语言类型;
46、风格调整层,与所述提示层连接,接收所述外部说话者嵌入层和所述解耦层的输出信号,实现输入语音的语音风格、情感和语言调整,所述风格调整层输出信号为音素序列,其中,输出的音素序列风格、情感、语言与输入文本相匹配;
47、解码层,与所述风格调整层连接,解码所述风格调整层输出的音素序列,获得合成语音,所述合成语音的语音内容与所述待合成的语音内容相同,所述合成语音的风格、情感与语言与输入文本相对应;
48、所述提示层、风格调整层和所述解码层独立训练。
49、本发明提供的基于可控文本的语音合成方法、装置和系统,通过改进语音风格调整模块,通过从输入文本中解耦地提取出风格、语言和情感等多种类型地特征,实现了没有样本训练地情况下,直接生成指定语言的语音,即零样本生成语音。其次,从听觉上来看,语音的风格由语音风格和情绪共同决定,本发明通过解耦地理解输入文本中限定的上述信息,独立修改音素序列,最后融合修改后的音素序列,实现了调整过程的解耦调整和效果的融合,避免了整体调整情况下调整效果控制不佳,音效变化联动性强等现象,提高了最终合成的语音的质量。此外,模型无需语音-语音的样本集进行训练,直接通过文本-语音、序列-语音的方式,降低了对适用方法的依赖,提高了方法的适用性。本发明生成与所述输入文本指定的风格一致的语音,有助于更全面地捕捉目标语音的不同属性,提高了语音合成的多样性和灵活性,且应用范围更广,提高了目标语音的可控性和风格、语言类型切换的灵活性。
- 还没有人留言评论。精彩留言会获得点赞!