一种语音转换方法及相关设备与流程
本技术涉及终端,尤其涉及一种语音转换方法及相关设备。
背景技术:
1、语音转换算法,通过对源说话人的一段语音进行转换,在保留源说话人的语音的内容不变的情况下,得到目标说话人的一段语音,或者说,使转换后的语音听起来像目标说话人的声音。
2、目前,主要通过基于平行数据训练得到的神经网络进行语音转换,该神经网络能够将源说话人的语音映射到目标说话人的语音。该方式,若要获得一定量的平行数据,成本较高;且只能得到平行数据中提供的目标说话人的语音,有限的目标说话人限制了语音转换算法的趣味性。
3、因此,如何在提升语音转换效果的同时节省成本,成为亟待解决的问题。
技术实现思路
1、本技术提供了一种语音转换方法及相关设备,能够提升语音转换效果的同时节省成本。
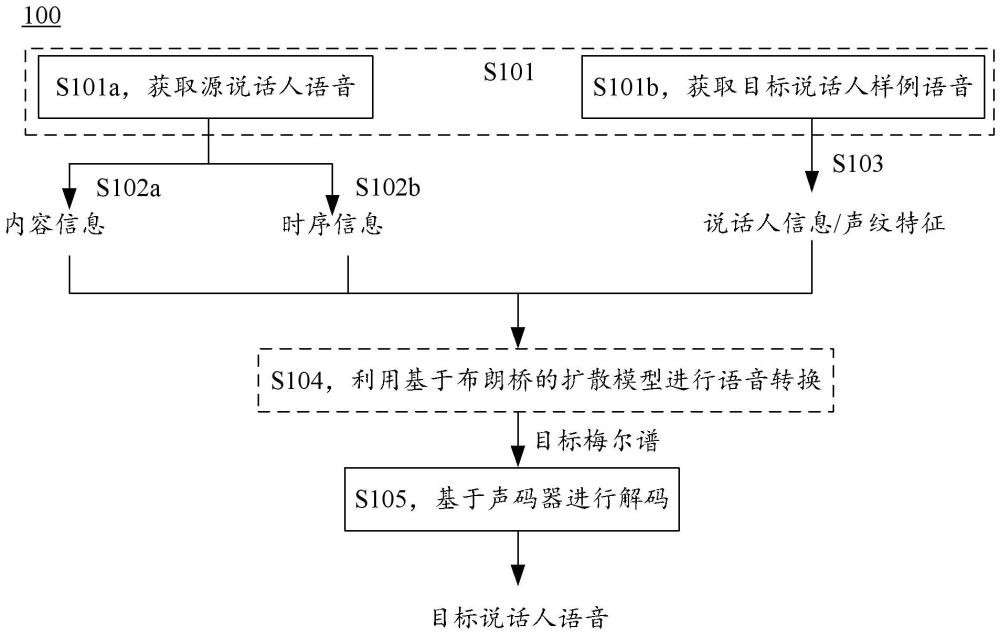
2、第一方面,提供一种语音转换方法,应用于电子设备,方法包括:获取待处理的源说话人语音和目标说话人样例语音;根据源说话人语音,得到内容信息,内容信息指示源说话人语音的内容;根据源说话人语音,得到时序信息,时序信息指示源说话人语音的节奏;根据目标说话人样例语音,得到目标说话人的声纹特征;根据内容信息、时序信息以及声纹特征,得到目标说话人语音特征,目标说话人语音特征为符合内容、节奏以及声纹特征的目标梅尔谱;基于声码器,对目标说话人语音特征进行解码处理,得到目标说话人语音。
3、可以理解,基于源说话语音的节奏生成目标说话人语音,能使得目标说话人语音和源说话人语音的节奏一致(或几乎一致)。
4、也就是说,本技术通过对齐目标说话人语音和源说话人语音的节奏,能够提升源说话人语音和目标说话人语音的相似性,相比于目前没有考虑到节奏的语音转换方法,能够提升语音转换的效果,使得转换后的语音在听感上更加自然,从而提升用户体验。
5、相比于基于平行数据训练的神经网络进行语音转换的方法,由于不需要基于平行数据进行训练,降低了成本;由于不限制目标说话人的类型,提升了语音转换的趣味性。
6、在一种可能的实施例中,节奏包括语速和重音,时序信息包括源说话人语音的音长特征和音强特征,音长特征指示语速,音强特征指示重音。
7、也就是说,基于音长和音强这两个语音要素,在语音转换时实现节奏的把控,提升语音转换的效果。
8、在一种可能的实施例中,根据源说话人语音,得到时序信息,包括:根据源说话人语音,得到源说话人语音的源梅尔谱;针对源梅尔谱的时间维度的每个时间帧,在梅尔谱的频率维度计算平均梅尔频率,并将平均梅尔频率作为每个时间帧对应的梅尔时频点的梅尔频率的值,得到时序信息谱,时序信息谱指示时序信息。
9、可理解,相比于通过梅尔谱生成梅尔倒谱系数,并由梅尔倒谱系数体现源说话人语音的音色和节奏的方案,上述方案通过一系列处理,主要保留了源说话人语音的节奏,以便于与目标说话人的声纹特征相结合,得到符合目标说话人的音色和音高,且符合源说话人语音节奏的目标说话人语音,能够提升语音转换的效果。
10、在一种可能的实施例中,时序信息谱中,相邻的两个时间帧的亮度的差值小于第一阈值的情况下,相邻的两个时间帧用于表征源说话人语音的同一个语音元素持续的时间长度;或者,时序信息谱中,相邻的两个时间帧的亮度的差值大于或等于第一阈值的情况下,两个时间帧中的每个时间帧用于表征源说话人语音的不同的语音元素持续的时间长度;其中,语音元素包括音节或字或词。
11、可理解,基于时序信息谱的特征与音强和音长的对应关系,以便于根据源说话人语音的节奏生成目标说话人语音,使得转换后的语音在听感上更加自然,从而提升用户体验。
12、在一种可能的实施例中,声纹特征包括音高特征和/或音色特征。
13、还可以理解,本技术中,声纹特征优选包括音高和音色,或者,声纹特征优选不包括音强和音长。目标说话人的声纹特质,可以理解为目标说话人声音的特质。一段语言中的部分字词或部分音节的音长和音强,很容易受语种的习惯以及个人的习惯影响,而有所不同。也就是说,语音的节奏很容易受个人习惯或语种的习惯影响。
14、示例性的,在源说话人语音和目标说话人样例语音的语言种类不同的情况下,如果声纹特征包括音长和音强,很可能使得转换后的语音不够自然,甚至可能语义表达不够准确。比如,源说话人语音是汉语,目标说话人样例语音是英文,说汉语时的节奏与说英语时的节奏不同,若根据英文的节奏生成目标说话人语音,很容易让人觉得汉语说得不地道。再比如,源说话人语音是英文,目标说话人样例语音是汉语,若根据汉语的节奏生成目标说话人语音,很可能使得一些单词的音长或重音不符合内容信息指示的英文,从而,轻则语音不够自然,重则可能语义表达不够准确。
15、因此,在本技术中,声纹特征优选不包括音强和音长,以尽可能减少或避免目标说话人的音强和音长对源说话人语音的节奏的影响,提升目标说话人语音与源说话人语音的相似度,提升语音转换的效果。
16、在一种可能的实施例中,所述电子设备提供可供用户上传所述目标说话人样例语音的功能入口,所述电子设备基于所述功能入口检测到用户上传的所述目标说话人样例语音。也就是说,目标说话人样例语音不属于电子设备为用户提供的样例语音列表,样例语音列表预先设置在终端设备,样例语音列表包括一种或多种可供用户选择的目标说话人样例语音,目标说话人样例语音是用户提供的。
17、可理解,目标说话人样例语音可以是预配置在终端设备的,也可以是由用户提供的。例如,终端设备为用户提供可选择的样例语音列表,响应于用户在样例语音列表中选择感兴趣的目标说话人的操作,确定目标说话人样例语音。例如用户可以上传提前录制好的目标说话人样例语音(例如可以是用户录制的也可以是用户从网络下载的),或者,在语音转换之前由终端设备实时录制一段目标说话人样例语音。
18、也就是说,本技术可以由用户自由提供目标说话人样例语音,而不限制目标说话人的类型,从而相比于基于平行训练数据训练得到神经网络的方案,能够提升语音转换的趣味性和用户自由度,从而提升用户体验。
19、在一种可能的实施例中,根据内容信息、时序信息以及声纹特征,得到目标说话人语音特征,包括:利用基于布朗桥的扩散模型对内容信息、时序信息以及声纹特征进行处理,得到目标说话人语音特征,时序信息是基于源说话人语音的源梅尔谱得到的,源梅尔谱是基于源说话人语音得到的。
20、可理解,通过将时序信息等数据输入基于布朗桥的扩散模型得到目标说话人语音特征,而不是像一般的扩散模型的处理流程一样,将高斯噪声输入扩散模型得到目标说话人语音特征。由于时序信息已经包含最终要得到的目标说话人语音特征中的部分特征,相比于一般的扩散模型,能够节省推理步数从而节省算力和推理时间,并且能够体现出源说话人语音的节奏,因此能够进一步语音转换的效果,从而进一步提升用户体验。
21、并且,扩散模型的训练过程中不需要将平行数据作为训练数据集,相比于基于平行训练数据训练得到神经网络的方案,能够降低训练成本。
22、在一种可能的实施例中,利用基于布朗桥的扩散模型对内容信息、时序信息以及声纹特征进行处理,得到目标说话人语音特征,包括:根据内容信息、时序信息以及声纹特征计算待采样梯度,待采样梯度用于表征目标梅尔谱的概率分布;根据待采样梯度以及第一高斯噪声,预测采样信号,第一高斯噪声是基于第一随机种子生成的;根据采样信号、内容信息、时序信息以及声纹特征计算待校正梯度,待校正梯度用于表征目标梅尔谱的概率分布;根据待校正梯度,对采样信号进行校正,得到校正信号;根据校正信号,得到目标说话人语音特征。
23、上述方案,通过对基于待采样梯度预测得到的采样信号继续计算待校正梯度,并基于该待校正梯度对采样信号进行校正,相比于只计算一次梯度的扩散模型,最终得到目标说话人语音特征准确度更高,相比于只预测不校正的扩散模型,预测准确度更高,从而提升最终得到的目标说话人语音与源说话人语音的节奏相似度。
24、示例性的,预测步骤采用祖先采样;校正步骤采用朗之万动力学采样或退火朗之万动力学采样,校正步骤用于校正预测步骤的预测结果。本技术中的预测和采样步骤均可以参照这里的示例,在此进行统一说明,下不赘述。
25、可理解,由于随机种子在不同的时间生成的随机数不同,因此本技术提供的语音转换方法在不同的时间针对同一段源说话人语音信号进行处理,分别输出的目标说话人语音特征不同或不完全相同。
26、在一种可能的实施例中,根据内容信息、时序信息以及声纹特征计算待采样梯度,包括:将内容信息、时序信息以及声纹特征,输入神经网络模型,得到待采样梯度,其中,神经网络模型是基于输入数据和目标数据训练得到的,输入数据包括样本内容信息、样本带噪时序信息、样本声纹特征,目标数据是根据第二高斯噪声值的方差生成的;其中,第二高斯噪声值是基于第二随机种子生成的,样本带噪时序信息是基于样本时序信息、基于第二高斯噪声值以及样本源梅尔谱生成的,样本时序信息、样本源梅尔谱、样本内容信息以及样本声纹特征是基于样本干净语音信号生成的。
27、可理解,在神经网络的训练过程中结合样本带噪时序信息和高斯噪声一起训练神经网络,由于样本带噪时序信息已经具备了目标梅尔谱的部分特征,相比于直接从高斯噪声开始训练,能够加快收敛速度。
28、在一种可能的实施例中,根据待采样梯度以及第一高斯噪声,预测采样信号,包括:根据时序信息计算漂移系数;根据漂移系数和待采样梯度计算逆漂移系数;根据逆漂移系数和第一高斯噪声,预测采样信号。
29、可理解,逆漂移系数可以用于描述采样过程中,带噪的语音信号趋向于干净语音信号的路径。即,减少不服从目标梅尔谱的概率分布的点,借助于第一高斯噪声生成服从目标梅尔谱的概率分布的点的过程。从而基于逆漂移系数进行采样,能够基于时序信息谱生成目标梅尔谱。
30、在一种可能的实施例中,根据采样信号、内容信息、时序信息以及声纹特征计算待校正梯度,包括:将采样信号、内容信息、时序信息以及声纹特征,输入神经网络模型,得到待校正梯度,其中,神经网络模型是基于输入数据和目标数据训练得到的,输入数据包括样本内容信息、样本带噪时序信息、样本声纹特征,目标数据是根据第二高斯噪声值的方差生成的;其中,第二高斯噪声值是基于第二随机种子生成的,样本带噪时序信息是基于样本时序信息、基于第二高斯噪声值以及样本源梅尔谱生成的,样本时序信息、样本源梅尔谱、样本内容信息以及样本声纹特征是基于样本干净语音信号生成的。
31、可理解,用样本源梅尔谱和样本时序信息生成样本带噪时序信息,能够使得样本序列生成得更加准确,以便于训练好的神经网络能够更准确地实现布朗桥,即时序信息的分布到目标说话人特征的映射,并且能够减少神经网络的训练步数,加速神经网络的收敛。
32、在一种可能的实施例中,扩散模型的处理包括:预测n次采样信号以及进行n次校正处理,1≤n≤n,n和n均为正整数。
33、在n=1的情况下,根据内容信息、时序信息以及声纹特征计算待采样梯度,包括:根据内容信息、时序信息以及声纹特征计算第1个第一梯度;根据待采样梯度以及第一高斯噪声,预测采样信号,包括:根据第1个待采样梯度以及第1个第一高斯噪声,预测第1个采样信号;根据采样信号、内容信息、时序信息以及声纹特征计算待校正梯度,包括:根据第1个采样信号、内容信息、时序信息以及声纹特征计算第1个待校正梯度;根据待校正梯度,对采样信号进行校正,得到校正信号,包括:根据第1个待校正梯度,对第1个采样信号进行校正,得到第1个校正信号;根据校正信号,得到目标说话人语音特征,包括:根据第1个校正信号,得到第1个目标说话人语音特征。
34、或者,在2≤n≤n的情况下,根据内容信息、时序信息以及声纹特征计算待采样梯度,包括:根据第n-1个校正信号、内容信息、时序信息以及声纹特征计算第n个待采样梯度;根据待采样梯度以及第一高斯噪声,预测采样信号,包括:根据第n个待采样梯度以及第n个第一高斯噪声,预测第n个采样信号;根据采样信号、内容信息、时序信息以及声纹特征计算待校正梯度,包括:根据第n个采样信号、内容信息、时序信息以及声纹特征计算第n个待校正梯度;根据待校正梯度,对采样信号进行校正,得到校正信号,包括:根据第n个待校正梯度,对第n个采样信号进行校正,得到第n个校正信号;根据校正信号,得到目标说话人语音特征,包括:根据第n个校正信号,得到第n个目标说话人语音特征。
35、在一种可能的实施例中,n=n的情况下,根据第n个校正信号,得到第n个目标说话人语音特征,包括:根据第n个校正信号,得到第n个目标说话人语音特征,输出第n个目标说话人语音特征。
36、也就是说,上述计算梯度和预测的步骤需要迭代n次,以便于得到更准确的效果。
37、第二方面,本技术提供了一种电子设备,该电子设备包括一个或多个处理器和一个或多个存储器;其中,一个或多个存储器与一个或多个处理器耦合,一个或多个存储器用于存储计算机程序代码,计算机程序代码包括计算机指令,当一个或多个处理器执行计算机指令时,使得电子设备执行如第一方面以及第一方面中任一可能的实现方式描述的方法。
38、第三方面,本技术实施例提供了一种芯片系统,该芯片系统应用于电子设备,该芯片系统包括一个或多个处理器,该处理器用于调用计算机指令以使得该电子设备执行如第一方面以及第一方面中任一可能的实现方式描述的方法。
39、第四方面,本技术提供一种计算机可读存储介质,包括指令,当上述指令在电子设备上运行时,使得上述电子设备执行如第一方面以及第一方面中任一可能的实现方式描述的方法。
40、第五方面,本技术提供一种包含指令的计算机程序产品,当上述计算机程序产品在电子设备上运行时,使得上述电子设备执行如第一方面以及第一方面中任一可能的实现方式描述的方法。
41、可以理解地,上述第二方面提供的电子设备、第三方面提供的芯片系统、第四方面提供的计算机存储介质、第五方面提供的计算机程序产品均用于执行本技术所提供的方法。因此,其所能达到的有益效果可参考对应方法中的有益效果,此处不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!