由多维测量分析聚合物的制作方法
本发明涉及由采集自聚合物的测量产生聚合物,例如,但不限于多核苷酸中的聚合物单元的靶序列的估计。
背景技术:
通过定义,一组k个聚合物单元以下称为k-链节(k-mer)。一般来说,k能够取值为一,在这种情况下k聚体是单个聚合物单元或能够是复整数(plural integer)。每个给定的聚合物单元可以是不同类型的,这取决于所述聚合物的性质。例如,在所述聚合物是多核苷酸的情况下,所述聚合物单元是核苷酸而所述不同类型是包括不同核碱基(如胞嘧啶,鸟嘌呤等)的核苷酸。每个给定的k-链节因此还可以是不同类型的,对应于所述k-链节的每个聚合物单元的不同类型的不同组合。
有许多类型的测量系统,为了确定所述序列的目的其提供聚合物单元的测量。例如但不限于,一种类型的测量系统使用了所述聚体通过其易位的纳米孔。所述系统的一些特性依赖于所述纳米孔中的所述聚合物单元,以及所采集的那种性质的测量。使用纳米孔的这种类型的测量系统,特别是在多核苷酸如DNA或RNA测序的领域中,具有相当大的前景,并已经成为最近很多开发的主题。
这种纳米孔测量系统能够提供数百至数万(并可能更多)核苷酸范围内的多核苷酸的较长连续的读取。按照这种方式收集的数据包括诸多测量,如离子电流的测量,其中所述序列通过所述纳米孔的所述敏感部分的每次易位在所测量的性质中导致微弱变化。
在所述测量系统的实际类型中,很难提供依赖于单个聚合物单元的测量,并且相反的是每个测量的值都依赖于k-链节,其中k是复整数。概念上,这可能认为是所述测量系统具有比所测量的聚合物单元更大的“钝读取头(blunt reader head)”。在这种情况下,要解析的不同k-链节的数目增加到k的幂。当测量取决于大量聚合物单元(大的k值)时,采集自不同类型的k-链节的测量可能难以解析,因为它们提供的信号分布发生了重叠,特别是在考虑所述测量系统中的噪声和/或伪影(artefact)时。这对于估计聚合物单元的基础序列(underlying sequence)是不利的。
在k是复整数的情况下,有可能合并来自重叠各自部分依赖于相同聚合物单元的k-链节的多个测量的信息以获得在聚合物单元水平下解析的单个值。举例而言,WO-2013/041878公开了一种利用关于每个系列测量将所述测量处理为不同可能类型的一系列k-链节状态的观察的模型由涉及聚合物的至少一个系列测量估计聚合物中聚合物单元的序列的方法。所述模型包括:关于在所述系列k-链节状态中的连续k聚体状态之间的每个转变,k-链节状态的所述可能类型之间的可能转变的转变权重;和关于每种类型的k-链节状态,表示观察到那个k-链节的给定测量的值的机会的发射权重。所述模型可以是例如隐马尔科夫模型。这样的模型能够通过将多个测量考虑到由通过聚合物单元的序列产生的系列测量的模型预测的所述可能性的考虑要素中而改进所述估计的精度。
为了改进超过由单系列测量能够达到的精度,就有可能通过包括所述靶序列或具有与所述靶序列的预定关系的序列,例如互补序列利用采集自对应于所述靶序列的相应序列的聚合物单元的多个系列测量。这些可以认为是多维测量,每个系列测量提供所述信息的维度。多维测量可以用于改进估计的精度。以及通过简单地增加所获得的测量的数目而降低错误,就可能具有附加受益,因为与每个系列测量相关的错误可能趋向于并非是系统性的,从而使不同的有用信息能够获自每个系列。
举例而言,WO-2013/041878公开了估计本文中公开的聚合物单元的序列的方法可以通过应用多维模型而应用于多维测量。虽然这种方法在WO-2013/041878中教导是可行的,但在所述不同序列的测量并未登记时,需要大量的处理能力,因为有必要执行考虑所述多个系列测量之间的所有可能的比对的分析。相比于大致与测量的数量相当(scale)的一维的单个系列测量进行的分析,所述处理需要考虑通过所述多维K-链节状态的所有可能的路径大致相当于测量数目与系列数的幂之比(the processing required to consider all possible all possible paths through the plural dimensional k-mer states approximately scales with the number of measurements to the power of the number of series)。
分析长系列测量,例如使用纳米孔测量系统可获得的系列测量所需的技术,在本质上是密集型的(intensive)而处理能力受限于实际考虑因素。关于处理的这些实际限制,特别随着系列和/或每个系列中的测量的数目增加,对有可能根据给定组的多个系列测量实现的所述估计的精度具有影响。
来自单个DNA分子的长读取具有优于当前“第二”代测序机产生的短读取的几个显著优点,三个实例包括:组装基因组,分配单核苷酸多态性(SNP)和母体或父系染色体的变体,和访问所述基因组的重复区。长读取可视为长度大于约2kB(2千个碱基)的DNA聚合物单元的未分段序列的测量。
基因组区域,尤其是基因的拷贝,已经是基因组中的新功能进化中的重要机制(例如,导致产生具有类似但专门功能的“共生同源(paralogous)”基因),并意味着存在非常相似的序列的区域(对于其而言,短读取是模糊的)。在极端的情况下,存在相同基因的拷贝数变体,例如涉及HIV抗性的CCL3L1基因。将短读取映射到这些区域中的对照基因组的模糊性(ambiguity)是指简单问题,如有多少重复发生,在哪里是困难的,而这些问题通过横跨整个区域的长读取琐碎地回答。重复序列也以其中重复序列简单模式的微卫星形式出现,并且重复数是遗传疾病如亨廷顿氏症的特性。
如上述的那些的序列的重复和其它相似性在试图由多个短读取组装基因组时会导致问题。组装的结果趋向于包括连续序列“重叠群(contig)”的许多片段,其顺序是模糊的,而不是单个完全解析的染色体—长读取能够轻松跨越重叠群,越过这种模糊序列,因此解吸所述顺序。
SNP可以出现在母系或父系染色体上,但两个SNP是否出现在相同染色体上在疾病中常常是关键的,例如,一个人会具有包含错误的基因的两个拷贝或一个好的和一个坏的拷贝吗?长读取(其可以覆盖整个基因)更加可能比短读取跨越多个SNP,因此证明了它们是在相同或不同的染色体(“分阶(phased)”)上;通过将多个这种读取链锁一起,即使远距离SNP都能够进行分阶。
因此,当应用这种多维技术时,非常希望能够确定长序列并能够如此完成而没有过度的处理负担。
技术实现要素:
根据本发明一个方面,提供了一种由采集自相同或不同聚合物中的聚合物单元的相应测量的序列的多个系列测量产生聚合物单元靶序列的估计的方法,其中所述相应测量的序列通过包括所述靶序列或具有与所述靶序列的预定关系的序列对应于所述靶序列,每个测量依赖于k-链节,是聚合物单元所述相应序列的k个聚合物单元,其中k是整数,
所述方法使用关于每个系列测量将所述测量处理为不同可能类型的一系列k-链节状态的观察的模型,并包括:
关于在所述系列k-链节状态中的连续k-链节状态之间的每个转变,所述k-链节状态的所述可能类型之间的可能转变的转变权重;和
关于每种类型的k-链节状态,所述k-链节状态属于那种类型时所观察的不同测量的发射权重,
所述方法包括:
推导所述多个系列测量之间的估计比对映射;和
由所述多个系列测量通过按照将每个模型的k-链节状态的这些类型处理为多维k-链节状态的维度并将每个序列的测量处理为这些多维k-链节状态的多维观察的方式,和使用所述多个系列测量之间的所述推导的比对映射约束通过所述多维k-链节状态的路径应用所述模型而产生聚合物单元的所述靶序列的估计。
因此,所述方法获得了使用采集自对应于所述靶序列的聚合物单元的相应序列的多个系列测量的能力。聚合物单元的这种序列可以包括所述靶序列或可以包括具有与所述靶序列的预定关系的序列,例如是互补序列。因此,每个系列的测量可以向所述靶序列的所述估计贡献信息。
另外,所述方法利用了关于每个系列测量将所述测量处理为不同可能类型的一系列k-链节状态的观察的模型,例如WO-2013/041878中公开的所述类型的模型,典型而言,隐马尔科夫模型。这容许这种模型的预测能力用于提供所述靶序列的所述估计。
然而,所述方法并不依赖于由所述系列测量的每个产生聚合物单元的所述靶序列的所述估计并随后寻求在所述聚合物单元空间中比对所述靶序列的这些估计。在下文中,这种技术将称为一维聚合物单元技术,因为所述聚合物单元的单独估计进行估计(调用(call)),每个都来自单个系列测量。所述方法,即使在用于采集所述测量的所述测量技术在单独测量中具有的错误水平比需要用于比对由所述不同系列的测量推导的聚合物单元的所述靶序列的所述估计的那些更糟时,能够提供优于一维聚合物单元技术的显著改进的估计精度。
相反,所述方法会推导出所述相应系列的测量之间的估计比对映射。相应系列的测量之间的所述估计比对映射随后用于产生聚合物单元的所述靶序列的估计。具体而言,所述模型按照将每个模型的k-链节状态的这些类型处理为多维k-链节状态的维度以及将每个系列的测量处理为这些多维k-链节状态的多维观察的方式进行应用。这种多维的方法通过合并所有来自同源特性的信息而提高精度,然而,所述估计比对映射用于约束所述通过多维k-链节状态的路径。这降低了所述分析的范围至小部分的所述总状态空间,大大降低了计算复杂性和存储要求,并因此降低了所需的处理能力的量。虽然所述处理能力当然增加超过一维中单个系列测量的处理能力,但它显著小于多维中未约束的分析。具体而言,所述所需的处理能力与测量数,而不是测量数与所述系列数的幂之比相当(the required processing power scales with the number of measurements,rather than the number of measurements to the power of the number of series)。因此,所述方法对于确定长读取,例如2000个聚合物单元或更多的序列,尤其有利。然而,所述方法同样适用于确定短于2000个聚合物单元的序列。
此外,在面对可以利用的处理能力的实际限制时,所需处理能力的降低足以改进采用可用的处理资源就可以获得的估计的精度。
有几种不同的技术用于推导所述相应系列的所述测量之间的估计比对映射。某些技术可以使用将所述测量处理为不同可能类型的一系列k-链节状态的观察的模型,包括:所述系列k-链节状态中的连续k-链节状态之间的转变的转变权重;和关于每个k-链节状态所观察的不同测量的发射权重。概括而言,这允许在所述k-链节状态的空间中,而不是在所述聚合物单元的空间中,推导所述比对映射。这容许所述比对映射的估计保留所述原始测量中所含的大量信息,而同时从所述测量空间向所述k-链节空间抽取允许数据直接对应的序列。由于所述k-链节状态能够通过多个系列中的每个测量获取信息,则它们能够具有关于所述靶序列中每个k链节的k-链节状态的类型比所述对应的原始测量多得多的信息。
现在将会描述用于将所述估计比对映射的推导建立在所述模型基础之上的技术的一些非限制性实例。
在第一种类型的技术中,所述估计比对映射由以下推导:
关于每个系列测量,通过将所述系列测量的所述模型应用于所述系列测量,产生k-链节状态的系列估计;和
通过对比所述的k链节状态的所述多个系列估计推导所述系列测量之间的所述估计比对映射。
这种技术在每个系列测量按照所述相同的方式进行处理而推导k-链节状态的系列估计的意义上是“对称的”。所述比对映射由k-链节状态的那些系列估计进行估计,并因而在所述k-链节状态的空间中进行推导。
生成和比较的k-链节状态的所述系列估计可以采取各种形式。
在第一种形式中,k-链节状态的每个估计可以包括k-链节状态的每个可能类型的权重。在这种情况下,k-链节状态的所述系列估计还可以包括关于每个测量k-链节状态的估计,即,具有k-链节状态的所述估计和所述测量之间的一对一的映射。因为k-链节状态的每个估计可以包括k-链节状态的每个可能类型的权重,每个估计包含对于给定测量的有关k-链节状态所有可能类型,而不仅仅是所述单个最有可能的k-链节状态的信息。这能够提供所述比对映射中的精度,尤其有助于与所述聚合物在所述测量系统中的迁移有关的错误。例如,在缺失事件的情况下,通过对比一维聚合物单元技术可能估计最可能的序列是具有聚合物单元丢失的序列,但本方法能够考虑对不同类型的k-链节状态的权重(其可能仍然具有与所述正确的k-链节状态相关的显著权重),容许所述比对能够正确地估计。
在第二种形式中,k-链节状态的每个估计可以包括所估计的k-链节状态。
对于这种形式的所述估计,所述k-链节状态的每个系列估计可以包括关于每个测量k-链节状态的估计。这可以当作关于每个测量调用所述k-链节状态。例如,如果多于一个测量依赖于所述相同k-链节(“停留”),或如果没有测量采集自给定的k-链节(“跳过”),这可能出现在与所述聚合物在所述测量系统中不适当的迁移相关的错误的情况下,这些估计不能够正确映射至聚合物单元的基础序列。然而,在这种情况下,在k-链节状态的估计和测量之间存在一对一的映射。
另外,对于作为估计k链节状态的这种形式的估计,所述k-链节状态的每个系列估计可以包括关于基础序列中的每个k-链节对应于聚合物单元的所测量序列的估计的估计k链节状态。在这种情况下,所述估计映射到聚合物单元基础序列的估计,因此这可以当作调用对应于所述测量的序列的所述k-链节状态,即来自每个系列测量的一维调用。为了推导来自所述估计的所述估计比对映射,则关于所述基础序列中的每个k-链节所述估计k-链节状态可以映射于所述测量。
关于基础序列中每个k-链节的这种估计k-链节状态可以通过关于每个测量将所述系列测量的所述模型应用于所述系列测量而产生k-链节状态的初始系列估计,并随后分析关于每个测量的k-链节状态的初始系列估计而推导关于所述基础序列中的每个k-链节的所述估计k-链节状态进行推导。
尽管以上所述形式之间具有相似性,但据发现,在某些情况下第二种形式比第一种形式能够在所述事件序列之间产生更精确的估计比对映射。
在第二种类型的技术中,所述估计比对映射由以下进行推导:
关于所述系列测量的第一种,实施以下步骤:
通过将所述第一系列测量的所述模型应用于所述第一系列测量产生关于每个测量k-链节状态的初始系列估计;和
分析关于每个测量k-链节状态的所述初始系列估计而推导关于基础序列中的每个k-链节(对应于聚合物单元所述测量的序列的估计)的估计k-链节状态,和
通过以对应于关于基础序列中的每个k-链节的所述推导的系列估计k-链节状态的所修改的转变权重应用所述其它测量系列的所述模型推导所述多个系列测量之间的估计比对映射。
这种技术在每个系列测量按照不同方式处理的意义上是“非对称的”。所述第一系列测量经过处理而推导映射于聚合物单元的基础序列的估计。这可以当作基于仅仅所述第一系列测量对应于所测量的序列的所述k-链节状态的调用,即,来自单个系列估计的一维调用。所述比对映射通过使用关于基础序列中的每个k-链节的所述估计k-链节状态,而为所述其它系列测量的所述模型提供修改的转变权重进行估计。以这种修改的转变权重应用所述其它系列测量的所述模型提供了所述多个系列测量之间的估计比对映射,因为它有效地将所述其它系列测量拟合于由所述第一系列测量估计的所述基础序列的所述估计k-链节状态。尽管所述技术具有不对称性质,但所述估计比对映射仍然在所述k-链节状态的空间中推导,因为它基于关于每个系列测量所述模型的应用。
基于对一些典型系列测量的应用,据发现,所述第二类型的技术,在某些情况下,能够以微小的额外计算付出为代价提供比所述第一类型技术的第一种形式更精确的比对映射。考虑到所述第二类型的技术的非对称性性质,这有些令人惊讶。
关于所有的技术,更精确的比对映射可以通过允许对通过所述多维k-链节状态的路径的约束更严格而降低由所述多个系列测量生成聚合物单元的所述靶序列的估计所需的所述处理要求。这在受限于关于处理能力的实际限制时进而可以提高聚合物单元的所述靶序列的估计的精度。
在提供最精确的估计比对映射的意义上的最适宜的技术可以不必是预先已知或估计的,并可以取决于各种实验因素,如环境温度和所述k-链节类型。然而,对于给定类型的测量系统和/或样品,所述各种技术可以相对于彼此,例如,通过在定义的实验条件下关于所述已知序列的所述测量应用所述技术而很容易评价。
根据本发明的其他方面,提供了执行类似于本发明的第一方面的方法的方法的分析系统。
附图说明
为了允许更好理解,本发明的实施方式现在将通过非限制性的实例参照附图进行描述,其中:
图1是由多个系列测量产生聚合物单元靶序列的估计的方法的流程图;
图2是包含纳米孔的测量系统的示意图;
图3是通过测量系统测量的事件信号随时间的曲线图;
图4是图1的状态检测步骤的流程图;
图5和6分别是经过所述状态检测步骤的一系列原始测量和所得的系列测量的曲线图;
图7是转变矩阵的图形表示;
图8是由单系列测量产生聚合物单元靶序列的估计的方法的流程图;
图9图示说明两个系列的测量之间的比对;
图10是实施图1的比对步骤的第一方法的流程图;
图11是实施图1的比对步骤的第二方法的流程图;
图12是k-链节状态的参考系列的实例的状态图;
图13是k-链节状态的参考系列的实例的状态图图示说明所述k-链节状态之间转变的可能类型;
图14是两个系列40测量之间可能比对的网格;
图15和16是一些模拟数据的基础调用质量的曲线图;
图17是一些模拟数据的比对错配的曲线图;和
图18是指示由图10和11的第一和第二方法对于100组模拟测量估计的两个比对映射的精度的分数的曲线图。
具体实施方式
许多核苷酸和氨基酸序列可以用于所描述的实施方式中。具体而言:
SEQ ID NO:1是编码所述孔MS-(B1)8(=MS-(D90N/D91N/D93N/D118R/D134R/E139K)8)的所述核苷酸序列。
SEQ ID NO:2是编码所述孔MS-(B1)8(=MS-(D90N/D91N/D93N/D118R/D134R/E139K)8)的所述氨基酸序列。
SEQ ID NO:3是编码所述孔MS-(B2)8(=MS-(L88N/D90N/D91N/D93N/D118R/D134R/E139K)8)的所述核苷酸序列。
SEQ ID NO:4是编码所述孔MS-(B2)8(=MS-(L88N/D90N/D91N/D93N/D118R/D134R/E139K)8)的所述氨基酸序列。B2的所述氨基酸序列除了所述突变L88N之外与B1是相同的。
SEQ ID NO:5是野生型大肠杆菌核酸外切酶I(WT EcoExo I),一种优选的多核苷酸处理酶的所述序列。
SEQ ID NO:6是大肠杆菌核酸外切酶III(一种优选的多核苷酸处理酶)的所述序列。
SEQ ID NO:7是嗜热栖热菌(T.thermophilus)RecJ(一种优选的多核苷酸处理酶)的所述序列。
SEQ ID NO:8是噬菌体λ核酸外切酶(一种优选的多核苷酸处理酶)的所述序列。
SEQ ID NO:9是Phi29DN聚合酶(一种优选的多核苷酸处理酶)的所述序列。
以下方法的多个方面使用了WO-2013/041878中公开的技术,但具有涉及相应系列的测量之间的估计比对映射的产生和使用的修改。因此,参考了WO-2013/041878,该专利结合于本文中作为参考。
图1显示了产生聚合物单元靶序列的估计的方法。
在步骤S1中,从聚合物单元的相应序列采集原始测量11的多个系列。通过配置成采集所述测量的测量系统8实施步骤S1。采集自步骤S1中的聚合物单元的所述序列的所述原始测量11作为输入信号供给于分析单元9进行分析。供给了来自聚合物单元的每个相应序列的原始测量11的系列。
由其推导所述测量的聚合物单元的单独序列的性质如下。以下描述的各种特性只是实施例而非限制性的。此外,所描述的特性不一定一起应用,并可以以任何组合进行应用。
根据所述聚体的性质,每种给定的聚合物单元可以是不同的类型(或特性(identity))。
所述聚体可以是多核苷酸(或核酸),多肽如蛋白,多糖,或任何其它聚合物。所述聚合物可以是天然的或合成的。所述聚合物单元可以是核苷酸。所述核苷酸可以是包括不同核碱基的不同类型。
所述多核苷酸可以是脱氧核糖核酸(DNA),核糖核酸(RNA),cDNA或本领域中已知的合成核酸,如肽核酸(PNA),甘油核酸(GNA),苏糖核酸(TNA),锁核酸(locked nucleic acid)(LNA)或具有核苷酸侧链的其它合成聚合物。所述多核苷酸可以是单链的,是双链的或包含单链区和双链区。通常cDNA、RNA、GNA、TNA或LNA是单链的。
本文中所描述的方法可以用于识别任何核苷酸。所述核苷酸能够是天然存在的或人工的。核苷酸通常包含核碱基(其在本文中可以简称为“碱基(base)”),糖和至少一个磷酸酯基团。所述核碱基通常是杂环的。合适的核碱基包括嘌呤和嘧啶,以及更具体而言腺嘌呤,鸟嘌呤,胸腺嘧啶,尿嘧啶和胞嘧啶。所述糖通常是戊糖。合适的糖包括,但不限于,核糖和脱氧核糖。所述核苷酸通常是核糖核苷酸或脱氧核糖核苷酸。所述核苷酸通常包含单磷酸酯,二磷酸酯或三磷酸酯。
所述核苷酸能够包括损坏的或外遗传的碱基(epigenetic base)。所述核苷酸能够标记或修饰以充当具有独特信号的标记。这种技术能够用于识别所述多核苷酸中碱基的缺失,例如,无碱基单元(abasic unit)或间隔子(spacer)。
在考虑修饰或受损的DNA的测量(或类似系统)时尤其有用的是考虑互补数据的所述方法。所述提供的附加信息允许在更大量的基础状态(underlying state)之间的区分。
所述方法还可以应用于任何其它类型的聚合物,一些非限制性实例如下。
所述聚体可以是多肽,在这种情况下所述聚合物单元可以是天然存在的或合成的氨基酸。
所述聚合物可以是多糖,在这种情况下所述聚合物单元可以是单糖。
特别是在测量系统8包括纳米孔(nanopore)以及所述聚合物包括多核苷酸的情况下,所述多核苷酸可以是长的,例如,至少2kB(千碱基),即,至少2000个核苷酸,至少10kB,至少30kB,至少50kB。本文中,所述术语“k-链节(k-mer)”是指一组k-聚合物单元,其中k是正整数,包括k是1的这种情况,其中所述k-链节是单一聚合物单元。在一些情况下,提及其中k是复整数(plural integer)的k-链节,是一般不包括k是1的情况的k-链节的子集(subset)。
因此每个给定的k-链节也可以是不同类型的,对应于所述k-链节的每个聚合物单元的所述不同类型的不同组合。
所述测量的性质如下。
所述测量系统8可以是设备类型的范围的任一种。
所述测量系统8可以是包括纳米孔的纳米孔系统。在这种情况下,可以在所述聚合物易位(translocation)通过所述纳米孔期间取得所述测量。所述聚合物易位通过所述纳米孔,会在可以观察的所测量的特性中产生特性信号,并可以总称为“事件(event)”。
所述纳米孔是,通常具有纳米级的尺寸,允许聚合物从其中穿过的孔。可以测量依赖于易位通过所述孔的所述聚合物单元的属性。所述属性可以与所述聚合物和所述孔之间的相互作用有关。所述聚合物的相互作用可以发生于所述孔的收缩区(constricted region)。所述测量系统8测量所述属性,产生依赖于所述聚合物的所述聚合物单元的测量。
所述纳米孔可以是生物孔(biological pore)或固态孔(solid state pore)。
在所述纳米孔是生物孔的情况下,它可以具有以下属性。
所述生物孔可以是跨膜蛋白孔。用于本文所述方法的跨膜蛋白孔能够源自β-桶孔(β-barrel pore)或α-螺旋束孔(α-helix bundle pore)。β-桶孔包括由β-链形成的桶或通道。合适的β-桶孔包括,但不限于,β-毒素,如α-溶血素,炭疽毒素和杀白细胞素,以及细菌的外膜蛋白/孔蛋白,如包皮垢分支杆菌孔蛋白(Mycobacterium smegmatis porin)(Msp),例如MspA,外膜孔蛋白F(OmpF),外膜孔蛋白G(OmpG),外膜磷脂酶A和奈瑟自转运脂蛋白(Neisseria autotransporter lipoprotein)(NalP)。α-螺旋束孔包括由α-螺旋形成的桶或通道。合适的α-螺旋束孔包括,但不限于,内膜蛋白和α外膜蛋白,如WZA和ClyA毒素。所述跨膜孔可以源自Msp或α-溶血素(α-HL)。
合适的跨膜蛋白孔可以源自Msp,优选源自MspA。这种孔将是低聚的并通常包括源自Msp的7、8、9或10个单体。所述孔可以是源自包含相同单体的Msp的同源寡聚孔(homo-oligomeric pore)。另外,所述孔可以是源自包含不同于其他单体的至少一个单体的Msp的杂-寡聚孔(hetero-oligomeric pore)。所述孔还可以包括1个或多个包括源自Msp的两个或更多个共价连接的单体的构建体。合适的孔公开于WO-2012/107778中。所述孔可以源自MspA或其同源物或旁系同源物(paralog)。
所述生物孔可以是天然存在的孔或可以是突变体孔。典型的孔描述于WO-2010/109197,Stoddart D et al.,Proc Natl Acad Sci,12;106(19):7702-7,Stoddart D et al.,Angew Chem Int Ed Engl.2010;49(3):556-9,Stoddart D et al.,Nano Lett.2010Sep 8;10(9):3633-7,Butler TZ et al.,Proc Natl Acad Sci2008;105(52):20647-52和WO-2012/107778中。
所述生物孔可以是MS-(B1)8。编码B1的所述核苷酸序列和B1的氨基酸序列是Seq ID:1和Seq ID:2。
生物孔是更优选MS-(B2)8。B2的氨基酸序列是与B1相同的,除了突变L88N。编码B2的核苷酸序列和B2的氨基酸序列是SEQ ID:3和SEQ ID:4。
所述生物孔可以插入到膜,如两亲层,例如,脂双层中。两亲层是由具有亲水性和亲脂性的两亲分子,如磷脂,形成的层。所述两亲层可以是单层或双层。所述两亲层可以是如由(Gonzalez-Perez et al.,Langmuir,2009,25,10447-10450)公开的共嵌段聚合物。另外,生物孔可以插入到固态层中。
另外,所述纳米孔可以是包括在固态层中形成的孔(aperture)的固态孔。在这种情况下,它可以具有以下性质。
这种固态层通常不是生物源的。换句话说,固态层通常不是源自或分离自生物环境如生物体或细胞,或生物可用结构的合成生产版本。固态层能够由有机和无机材料形成,这些材料包括,但不限于,微电子材料,绝缘材料如Si3N4、A12O3和SiO,有机和无机聚合物如聚酰胺,塑料如或弹性体如双组分加成固化硅橡胶,和玻璃。所述固态层可以由石墨烯形成。合适的石墨烯层公开于WO-2009/035647和WO-2011/046706中。
当所述固态孔是固态层中的孔隙(aperture)时,所述孔隙可以进行化学上的或其它方式的修饰,以增强其作为纳米孔的性能。
固态孔可以与提供所述聚合物的替代的或其它测量的其它组件如隧道电极(tunnelling electrode)(Ivanov AP et al.,Nano Lett.2011Jan 12;11(1):279-85),或场效应晶体管(FET)器件(WO-2005/124888)组合使用。合适的固态孔可以通过已知的工艺方法,包括例如WO-00/79257中描述的那些形成。
在一种类型的测量系统8中,可以使用流动通过纳米孔的离子电流的电流测量。这些和其他的电测量可以使用如描述于Stoddart D et al.,Proc Natl Acad Sci,12;106(19):7702-7,Lieberman KR et al,J Am Chem Soc.2010;132(50):17961-72和WO-2000/28312中的标准单通道记录设备进行。另外,电测量可以使用多通道系统,例如WO-2009/077734和WO-2011/067559中所述的那些进行。
为了允许在所述聚合物易位通过纳米孔时取得测量,易位的速率能够通过聚合物结合部分控制。通常所述部分能够顺着或逆着所施加的场移动所述聚合物通过所述纳米孔。所述部分能够是使用例如,在所述部分是酶的情况下,酶活性的分子马达(molecular motor),或作为分子制动器(molecular brake)。在所述聚合物是多核苷酸的情况下,有许多提出的包括使用多核苷酸结合酶用于控制易位速率的方法。用于控制多核苷酸易位速率的合适酶包括,但不限于,聚合酶,解旋酶,核酸外切酶,单链和双链结合蛋白和拓扑异构酶,如促旋酶(gyrase)。对于其它聚合物类型,能够使用与所述聚合物类型相互作用的部分。所述聚合物相互作用的部分可以是公开于WO-2010/086603,WO-2012/107778和Lieberman KR et al,J Am Chem Soc.2010;132(50):17961-72中的,以及用于电压门控方案(Luan B et al.,Phys Rev Lett.2010;104(23):238103)的任何一种。
聚合物结合部分能够按照许多方式用于控制所述聚合物运动。所述部分能够将所述聚合物顺着或逆着所施加的场移动通过所述纳米孔。所述部分能够用作例如,所述部分是酶的情况下使用酶活性的分子马达,或作为分子制动器。所述聚合物的易位可以通过控制所述聚合物移动通过所述孔的分子棘轮(molecular ratchet)进行控制。所述分子棘轮可以是聚合物结合蛋白。
对于多核苷酸,所述多核苷酸结合蛋白优选是多核苷酸处理酶。多核苷酸处理酶是能够与多核苷酸相互作用和修改多核苷酸的至少一种性质的多肽。所述酶可以通过切割以形成单独核苷酸或多核苷酸,如二-或三核苷酸的短链来改性所述多核苷酸。所述酶可以通过将其定向或将其移动至特定位置而改性所述多核苷酸。所述多核苷酸处理酶只要它能够结合所述靶多核苷酸并控制其移动通过所述孔,不需要表现出酶活性。例如,所述酶可以经过改性而消除其酶活性或可以在防止它充当酶的条件下使用。这种条件在以下更详细地讨论。
所述多核苷酸处理酶可以源自溶核酶(nucleolytic enzyme)。在所述酶的构建体中使用的所述多核苷酸处理酶更优选源自任何所述酶分类(EC)组3.1.11、3.1.13、3.1.14、3.1.15、3.1.16、3.1.21、3.1.22、3.1.25、3.1.26、3.1.27、3.1.30和3.1.31中的成员。所述酶可以是WO-2010/086603中公开的任何一种。
优选的酶是聚合酶,核酸外切酶,解旋酶和拓扑异构酶,如促旋酶。合适的酶包括,但不限于,来自大肠杆菌的核酸外切酶I(SEQ ID:5),来自大肠杆菌酶的核酸外切酶III(SEQ ID:6),来自嗜热栖热菌的RecJ(Seq ID:7)和噬菌体λ外切核酸酶(SEQ ID:8)及它们的变体。包含Seq ID:8中所示的所述序列及其变体的三个亚基相互作用以形成三聚体外切核酸酶。所述酶优选源自Phi29DNA聚合酶。源自Phi29聚合酶的酶包括SEQ ID:9中所示的所述序列或其变体。
SEQ ID:5、6、7、8或9的变体是具有以下氨基酸序列的酶,其由SEQ ID:5、6、7、8或9的氨基酸序列变化而成并保留了多核苷酸结合能力。所述变体可以包括有利于在高盐浓度和/或室温下所述多核苷酸的结合和/或有利于其活性的改性。
在SEQ ID:5、6、7、8或9的所述氨基酸序列的整个长度内,基于氨基酸一致性变体将优选至少50%同源于那个序列。更优选基于氨基酸一致性所述变体多肽可以在所述整个序列中至少55%,至少60%,至少65%,至少70%,至少75%,至少80%,至少85%,至少90%并更优选至少95%,97%或99%同源于SEQ ID:5、6、7、8或9的所述氨基酸序列。在一段200或更长,例如230,250,270或280或更长的连续氨基酸内可以存在至少80%,例如至少85%,90%或95%的氨基酸一致性(“硬一致性(hard homology)”)。一致性如上所述进行确定。所述变体可以在任何以上参考Seq ID:2讨论的方式上不同于所述野生型序列。所述酶可以共价连接至如上所讨论的孔。
单链DNA测序的合适策略是所述DNA顺着或逆着所施加的电位通过纳米孔的易位,(顺(cis)至反(trans)和反至顺)。链测序的最有利机制是单链DNA在施加的电位下通过所述纳米孔的所述受控易位。逐步地(progressively)或持续地(processively)作用于双链DNA的核酸外切酶能够用于在施加的电位下将所述剩下的单链进料通过的所述孔的所述顺侧或在反向电位下的所述反侧。同样,退绕(unwind)所述双链DNA的解旋酶也能够以相似的方式使用。对于测序应用还有可能需要逆着所施加的电位的链易位,但所述DNA必须在反向或无电位下被所述酶首先“捕获”。随着结合之后随后切换回的所述电位,所述链将顺-反式通过所述孔并通过所述电流保持扩展构象。所述单链DNA核酸外切酶或单链DNA依赖的聚合酶能够充当分子马达而将所述最近易位的单链以控制的逐步方式,反-顺式逆着所述施加的电位拉拔(pull)返回通过所述孔。另外,所述单链DNA依赖性聚合酶能够充当分子制动器减慢多核苷酸通过所述孔的移动。WO-2012/107778或WO-2012/033524中所述的任何部分、技术或酶能够用于控制聚合物迁移。
一般情况下,当所述测量是通过纳米孔的离子电流流动的电流测量时,所述离子电流通常可以是所述直流离子电流,但是原理上一个替代方案是使用AC电流(即,所述交流电流在施加交流电压下流动的振幅)。
然而,所述测量系统8的替代类型和测量也是可能的。测量系统8的替代类型的一些非限制性实例如下。
所述测量系统8可以是扫描探针显微镜。所述扫描探针显微镜可以是原子力显微镜(AFM),扫描隧道显微镜(STM)或另一种形式的扫描显微镜。
在所述读取器是原子力显微镜的情况下,所述AFM尖端的分辨率可以不如单个聚合物单元的所述维度精细。同样所述测量可以是多个聚合物单元的函数。所述AFM尖端可以官能化以与所述聚合物单元按照如其未官能化的替代方式相互作用。所述AFM可以以接触模式,不接触方式,轻敲(tapping)模式或其他模式操作。
在所述读取器是STM的情况下,所述测量的分辨率可以不如各个聚合物单元的维度精细而使所述测量是多个聚合物单元的函数。所述STM可以以常规方式操作或进行分光测量(STS)或按照任何其它模式操作。
所述测量系统8可以采取光学测量。涉及荧光测量的合适光学方法由J.Am.Chem.Soc.2009,131 1652-1653公开。
所述测量系统8可以采取除了如上所述通过纳米孔的离子电流的电流测量之外的多种类型的电测量。可能的电测量包括:电流测量,阻抗测量,隧道(tunnelling)测量(例如正如Ivanov AP et al.,Nano Lett.2011Jan 12;11(1):279-85中所述)和场效应晶体管(FET)测量(例如,正如WO2005/124888中公开的)。
光学测量可以与电测量组合(Soni GV et al.,Rev Sci Instrum.2010Jan;81(1):014301)。
所述测量系统8可以采取不同性质的测量。所述测量可以是不同性质的,因为它们是不同物理性质的测量,其可以是上述那些的任一种。另外,所述测量可以是不同性质的,因为它们是所述相同物理性质但在不同条件下的测量,例如,电测量如在不同偏电压下的电流测量。
所述多个系列测量可以是对所述相同聚合物的相同区域同时作出的不同类型的,例如:在不同条件下作出的电测量;同时作出的跨膜电流测量和FET测量;或同时作出的光测量和电测量(Heron AJ et al.,J Am Chem Soc.2009;131(5):1652-3)。在这种情况下,所得到的系列的原始测量11可以包括一系列依赖于所述相同的k链节的不同性质的预定大量测量。
每个测量依赖于k-链节,k-链节是聚合物单元所述相应序列的k个聚合物单元,其中k是正整数。虽然理想的是所述测量将依赖于单个聚合物单元(即其中k为1),对于所述测量系统8的许多典型类型,每个测量依赖于多个k-聚合物单元的k-链节(即,k是复整数的情况)。也就是说,每个测量依赖于其中所述k是复整数的k-链节中每个所述聚合物单元的所述序列。
通常所述测量是与所述聚体和所述测量系统8之间的相互作用相关的属性的。本文中所描述的所述优点尤其是在应用于依赖其中所述k是复整数的k-链节的测量时获得。以下描述的所述分析方法是针对所述测量取决于其中所述k为2或更多的k-链节的情况,但相同的方法可以以简化的形式应用于依赖于其中k为1的k-链节的测量。
在某些情况下,优选使用依赖于小组的聚合物单元,例如双倍体或三倍体聚合物单元(即,其中k=2或k=3)的测量。在其他情况下,优选使用依赖于大组的聚合物单元,即具有“宽”分辨率的测量。这种宽分辨率可以特别适用于检查均聚物区域。
特别是在测量取决于其中k是复整数的k-链节的情况下,理想的是所述测量对于尽可能多的所述可能k-链节是可解析的(即,分开的)。通常情况下,如果由不同k-链节产生的所述测量在所述测量范围内良好地扩展和/或具有窄的分布时这就能够实现。这可以由测量系统8的不同类型实现到不同的程度。然而,特别有利的是,对于由不同k-链节产生的所述测量是可解析的并非很重要。
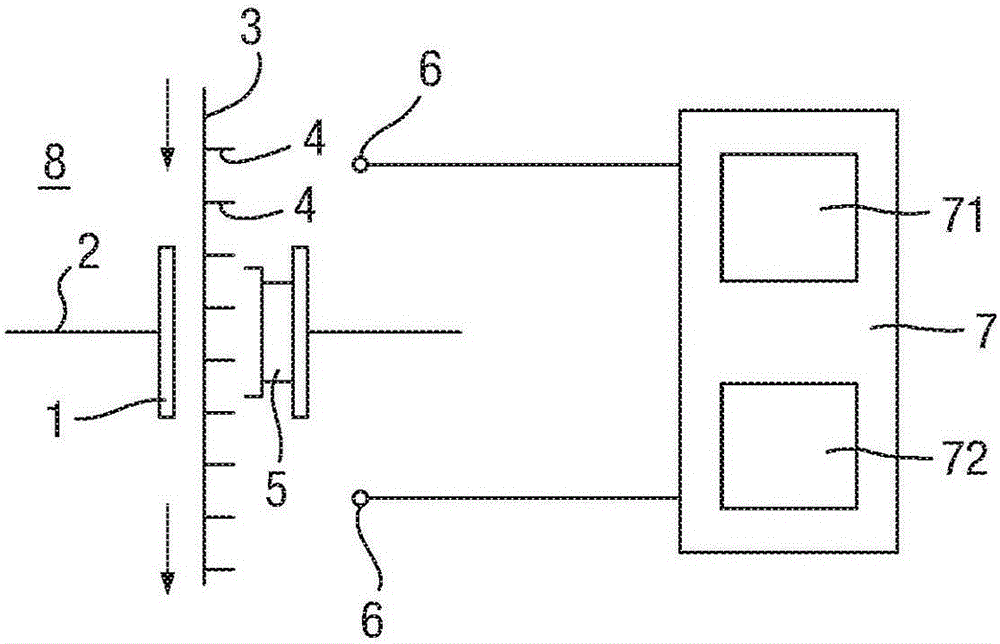
图2示意性地显示了包括纳米孔的测量系统8的实例,所述纳米孔是插入生物膜2如两亲层中属于生物孔1。包括一系列聚合物单元4的聚合物3易位通过由所述箭头所示的生物孔1。在本实例中,所述聚合物3可以是多核苷酸,其中所述聚合物单元4是核苷酸,如上所述。所述聚体3与所述生物孔1的活性部分5相互作用促使电性能如所述跨膜电流根据所述生物孔1内的k-链节而变化。在本实施例中,所述活性部分5显示为与三个聚合物单元4的k-链节相互作用,但这并非是限制性的。
排布于所述生物膜2每个侧面上的电极6连接至电路7,包括控制电路71和测量电路72。
控制电路71经过排布以对所述电极6施加电压以横跨所述生物孔1应用。
所述测量电路72经过排布以测量所述电性质。因此,所述测量取决于所述生物孔1内的所述k-链节。
所述多个系列测量每个可以通过所述相同技术作出或可以通过不同技术作出。所述多个系列测量可以使用相同或不同类型的所述测量系统8作出。多个测量能够通过使给定的具体或其区域多于一次易位通过所述孔而一个接着一个地作出。这些测量能够是相同的测量或不同测量并在相同的条件下,或在不同的条件下进行。
通过所述测量系统8的多种类型的典型形式的信号输出作为有待分析的所述系列的原始测量11,是“噪声型阶梯波(noisy step wave)”,但是不限于这种信号类型。具有这种形式的一系列原始测量11的实例如图3中对于使用包括纳米孔的一种类型的所述测量系统8获得的离子电流测量的情况所示。
这种类型包括输入系列的测量,其中连续组的多个测量取决于所述相同的k链节,每个组中的所述多个测量是恒定值的,经历了以下讨论的一些方差(variance),因此在所述系列的原始测量11中形成一个“水平(level)”。这样的水平通常可以通过依赖于所述相同k-链节(或相同类型的连续k-链节)的测量形成,因此对应于所述测量系统8的共同状态(common state)。
信号在一组水平之间移动,这组水平可以是较大组。考虑到所述仪器的采样速率和信号中的噪声,水平之间的转变能够认为是瞬时的,因此所述信号能够通过理想化的步迹线(step trace)进行近似。
所述对应于每个状态的测量在事件的时间尺度内是不变的,但对于大多数类型的测量系统8将会在短时间尺度内经受方差。方差可能是由测量噪声所致,例如由所述电路和信号处理产生,特别是由具体电生理学情况下的放大器产生。由于所测定的性质的幅度(magnitude)小,这种测量噪声是不可避免的。方差也可能由固有的变化产生或在所述测量系统8的基础物理或生物学系统中分散。大多数类型的所述测量系统8将会经历这种固有变化(更大或更小程度)。对于任何给定类型的所述测量系统8,变化的两个来源都可以贡献或这些噪声源中的一种可以是主要的。
此外,通常在所述组中还没有测量数目的现有知识,这会不可预测地变化。
方差和测量数知识缺乏这两个因素能够使其难以区分这些组中的一些,例如在所述组较短和/或两个连续组的测量水平彼此接近的情况下。
所述系列的原始测量11可以采取这种形式,因为所述物理或生物过程发生于所述测量系统8中。因此,在一些情况下,每个测量组可以称为“状态(state)”。
例如,在包括纳米孔的某些类型的测量系统8中,由所述聚合物易位通过所述纳米孔构成的所述事件可以按照棘轮方式发生。在所述棘轮移动的每个步骤中,在横跨所述纳米孔的给定电压下所述流动通过所述纳米孔的离子电流是恒定的,会经受上面讨论的方差。因此,每组测量与所述棘轮移动的步骤有关。每个步骤对应于其中所述聚体处于相对于所述纳米孔的相应位置的状态。虽然在一个状态的时间段期间所述精确位置会有一些变化,但在这些状态之间所述聚合物存在大尺度移动。根据所述测量系统8的性质,这些状态可能会由于在所述纳米孔中的结合事件而发生。
单独状态的持续时间可以取决于许多因素,如横跨所述孔施加的电位,用于棘轮驱动所述聚合物的酶的类型,所述酶是否推或拉所述聚合物通过所述孔,pH,盐浓度和存在的三磷酸核苷的类型。状态的持续时间可以通常在0.5ms~3s之间变化,这取决于所述测量系统8,而对于任何给定的纳米孔系统,在状态之间具有一些随机变化。对于任何给定的测量系统8,所述持续时间的预期分布可以通过实验确定。
正如下面进一步讨论,所述方法使用了多个输入系列的测量,它们的每个可以采取以上所述形式,在这种情况下每个系列中的连续组的多个测量依赖于所述相同的k-链节。虽然每个所述系列测量对应于所述靶序列,但本发明方法适用于未登记的多个系列使其不是现有技术已知的(其中来自相应系列的测量对应于并依赖于所述相同的k-链节)。例如,如果所述系列测量是通过不同测量系统8和/或在不同时间进行进行时,可能就是这种情况。
给定测量系统8提供依赖于k-链节和所述k-链节的大小的测量的程度可以通过实验测定。对此可能的方法公开于WO-2013/041878中。
现在将讨论由其取得不同系列的测量的聚合物单元的所述相应序列。
聚合物单元每个所述相应序列对应于有待估计的聚合物单元的所述靶序列。
聚合物单元的任何或所有所述相应序列可以通过实际包含所述靶序列而对应于所述靶序列。
类似地,它们中任何一种或全部可以通过具有与所述靶序列的预定关系而对应于所述靶序列。聚合物单元的所述相应序列可以以任何组合包括包含所述靶序列和/或具有与所述靶序列的预定关系的序列的序列。
由其取得测量的聚合物单元的所述相应序列可以处于相同或不同聚合物中,其是物理上相同或不同的聚合物。
在聚合物单元的所述相应序列处于相同聚合物中的情况下,它们可以是在相同或不同的条件下重复测量的相同序列。
在聚合物单元的所述相应序列处于相同聚合物中的情况下,它们可以是所述聚合物的不同部分,通常顺序地进行测定。在后一种情况下,所述序列每个可以是相同序列,通常是所述靶序列,或可以是所述靶序列和一个或多个与所述靶序列相关的序列。
在聚合物单元的所述相应序列处于不同聚合物中的情况下,它们可以是所述测量系统8的共同操作中测量的相同样品中的聚合物或可以处于通过相同或不同测量系统8测定的不同样品中。例如,在所述测量系统8使用了纳米孔的情况下,所述测量可以是使用不同纳米孔的相同序列的测量,例如提供有不同测量-序列特性。
在聚合物单元的所述相应序列处于不同聚合物中的情况下,它们可以是通过促使每个包括所述靶序列的工艺方法或通过促使不同聚合物包括所述靶序列和一个或多个与所述靶序列相关的序列的工艺方法制备的聚合物。
在所述相应序列包括具有与所述靶序列的预定关系的序列的情况下,这种关系可以是所述序列互补于所述靶序列。这可以称为“模板-互补”,模板是指所述靶序列和所述互补序列。例如,核碱基A与核碱基T配对而核碱基C和核碱基G配对。因此,具有序列AACTC的模板多核苷酸将具有TTGAG的互补序列。
作为使用互补序列的实例,可以使用对多核苷酸如DNA提出的技术,其中所述模板和所述互补序列提供于相同聚合物中,通过桥接部分,如发夹环连接。当所述模板和互补序列由发夹连接时,核苷酸的所述互补序列在所述纳米孔中按照相对于所述模板顺序的逆向顺序进行测量,但是这将直接在以下所述方法中,简单地通过逆转所述系列测量中一种的顺序而进行处理。
在这种情况下,所述模板和互补区域可以在所述样品中杂交,并可以在易位通过进行测量的纳米孔之前去杂交(dehybridize)。这种去杂交作用可以使用多核苷酸结合蛋白,例如解旋酶进行实施。测量可以按照WO2013/014451中公开的内容进行。
形成模板-互补核苷酸序列的方法可以也可以按照WO-2010/086622中公开的内容进行实施。
当存在时,所述发夹可以包括在互补链和模板之间进行区分的识别子(identifier)。所述识别子通常提供可以区分所述模板和互补区的易于识别和独特的信号。所述识别子可以包括例如天然或非天然多核苷酸的已知序列,1个或多个非碱基残基(abasic residue)或1个或多个改性的碱基。所述识别子可以包括1个或多个间隔子,其能够减缓(stall)DNA加工酶如解旋酶,其中所述DNA加工酶能够在施加横跨纳米孔的电位差之后移动经过所述一个或多个间隔子并移动所述模板和互补链通过所述纳米孔。所述1个或多个间隔子可以包括肽核酸(PNA),甘油核酸(GNA),苏糖核酸(TNA),锁核酸(LNA),或具有核苷酸侧链的合成聚合物。
尽管这个多维实例是对于模板-互补多核苷酸如DNA的情况,所述序列之间的其他关系也可以用于多维方法中。另一种类型的关系的一个例子是聚合物中的结构信息。这个信息可以存在于RNA中,其已知会形成功能性结构。这个信息也可以存在于多肽(蛋白质)中。在蛋白的情况下所述结构信息可以涉及疏水或亲水区域。所述信息也可以是关于α螺旋,β折叠或其他二级结构。所述信息可以是关于已知的功能基序如结合位点,催化位点和其他基序。
关系的另一个例子是所述序列中的一种是DNA而另一序列是cDNA。
现在将描述通过所述分析单元9分析所述系列的原始测量11。所述分析单元9自身或与其他单元一起构成分析系统。
所述分析在图1中图示说明的所述分析单元9中执行的步骤S2~S4中实施。所述分析单元9接收并分析通过所述测量系统8取得和由其供给的所述系列原始测量11。所述述分析单元9和所述测量系统8一起构成分析聚合物的装置。所述分析单元9也可以向控制电路7提供控制信号,例如,以选择横跨所述测量系统8中的生物孔1施加的电压。所述系列原始测量11可以在任何合适的连接上提供,例如在所述分析单元9和所述测量系统8物理上定位一起的情况下的直接连接,或在所述分析单元9和所述测量系统8物理上相互远离的情况下的任何类型的网络连接。
包括所述分析单元9和所述测量系统8的装置可以按照WO-2008/102210,WO-2009/07734,WO-2010/122293和/或WO-2011/067559任一种中公开的进行排布。
所述分析单元9可以通过执行计算机程序的计算机设备实施或可以通过专用硬件设备实施,或以其任何组合进行实施。在任一种情况下,通过所述方法使用的数据可以存储于所述分析单元9中的存储器10中,所述计算机装置,在使用的情况下,可以是任何类型的计算机系统,但通常具有常规构造。所述计算机程序以任何合适的编程语言编写。所述计算机程序可以存储于计算机可读的存储介质上,所述存储介质可以是任何类型的,例如:可插入到所述计算系统的驱动器中并可以磁、光或光-磁储存信息的记录介质;所述计算机系统的固定记录介质,如硬盘驱动器;或计算机存储器。
所述方法在所述系列原始测量11上实施,每个包括以上所述的含有依赖于所述相同k-链节而没有任何组中测量数的现有知识的连续组的多个测量的所述类型的系列测量。
在状态检测步骤S2中,每个系列的原始测量11经过处理以识别连续组的原始测量并相对于每个识别组推导由预定数目的测量构成的一系列测量12。因此,一系列测量12是对于测量的聚合物单元的每个序列推导的。在步骤S3~S5中对由此推导的系列测量12进行进一步的分析。
所述状态检测步骤S2的目的是为了将所述系列原始测量降低至与每个k-链节相关的预定数量的测量以简化所述后续分析。例如,噪声型阶梯波信号,如图3中所示,可以降低到其中与每个状态相关的单个测量可以是所述平均电流的状态。这种状态可以称为一个水平。
所述状态检测步骤S2可以使用图4中所示的如下寻找所述系列原始测量11的所述导数(derivative)的短期增长的所述方法对每个单独系列的原始测量11进行实施。
在步骤S2-1中,所述系列原始测量11求导(differentiate)以推导其导数。
在步骤S2-2中,来自步骤S2-1的导数经过低通过滤以抑制高频噪声,其中步骤S2-1的求导趋向于放大。
在步骤S2-3中,来自步骤S2-2的所述过滤的导数阈值化(threshold)以检测所述测量的组之间的转变点(transition point),并由此识别所述原始测量的组。
在步骤S2-4中,预定数量的测量由步骤S2-3中识别的每组原始测量推导。来自步骤S2-4的所述测量输出构成所述系列测量12。
测量的预定数量可以为1或更多。
在最简单的方法中,单一测量由每组原始测量推导,例如每个识别的组中原始测量的所述均值,中位数,标准偏差或数目。
在其它方法中,不同性质的预定大量测量由每个组推导,例如在每个识别的组中的原始测量的均值,中位数,标准差或数量中的任何两种或更多。在这种情况下,取得不同性质的预定大量测量以依赖于所述相同的k链节,因为它们是相同组的原始测量的不同测量(measure)。
所述状态检测步骤S2可以使用图4中所示的不同方法。例如,图4中所示的方法的共同简化(common simplification)是使用对比数据的两个相邻窗口的均值的滑动窗口分析。然后阈值能够直接置于平均差上,或能够基于两个窗口中所述数据点的方差(例如,通过计算学生t-统计(student’s t-statistic))设置。这些方法的具体优点是,它们能够应用而不会对所述数据施加许多假设。
与所述测得的水平相关的其它信息能够进行存储以供后续所述分析中使用。这样的信息可以包括,但不限于以下的任一种:所述信号的方差;非对称信息;所述观察的置信度;所述组的长度。
举例而言,图5图示说明了通过移动窗口t-检验而减少的实验测定的系列原始测量11。具体而言,图5显示了作为所述浅色线(light line)的系列原始测量11。状态检测之后的水平作为暗线(dark line)显示重叠。图6显示了对于所述整个迹线推导的所述系列测量12,由转变之间的平均值计算每个状态的水平。
然而,正如以下更详细的描述,所述状态检测步骤S2是可选的,并可以在以下进一步描述的替代方案中省略。在这种情况下,所述进一步的分析对相应系列的原始测量11本身而非所述系列测量12进行实施。尽管以下描述是指对所述系列测量12实施的方法,在所述状态检测步骤S2省略的这个替代方案中,则是指对所述系列测量12实施的所述步骤相反实施于所述系列原始测量11本身,而不是所述系列测量12。同样地,在这种情况下,所述系列原始测量11构成了本发明的定义中引述的所述“系列测量”。
所述方法使用了关于每个系列测量12的模型13,所述模型13存储于所述分析单元9的存储器10中。每个系列测量11的所述模型将所述测量处理为不同可能类型的系列k-链节状态的观察。所述模型13的所述k-链节状态可以模型化所述测量依赖的所述实际k-链节,尽管在数学上,这是没有必要的,因此所述k-链节状态可以是所述实际k-链节的抽象。因此,不同类型的k-链节状态可以对应于存在于聚合物单元的所述序列中的k-链节的不同类型。另外,k-链节状态数量比k-链节的类型更大。例如,当需要模型化由相同k-链节在进行测量的时间点所经历的不同物理条件时就是这种情况。
现在将考虑单系列测量的所述模型13的数学基础。
由其电流采样的随机变量的序列{T1,T2,...,Tn的}之间的关系可以通过简单模型A表示,其表示变量T1~Tn之间的所述条件独立关系。
每个电流测量依赖于所读取的k-链节,因此具有一个基础组的随机变量{S1,S2,…,Sn},以将每个随机变量S1~Sn关联于所述变量T1~Tn的对应的一个的对应模型B表示k-链节的所述基础序列(underlying sequence)。
适用于应用的当前区域的这些模型可以利用所述马尔科夫(Markov)特性。在模型A中,如果选取f(Ti)表示所述随机变量Ti的概率密度函数,则所述马尔科夫属性能够表示为:
f(Tm|Tm-1)=f(Tm|T1,T2,…,Tm-1)
在模型B中,所述马尔科夫属性能够表示为:
P(Sm|Sm-1)=P(Sm|S1,S2,…,Sm-1)
根据所述问题究竟如何编码,求解的自然方法可以包括贝叶斯(Bayesian)网络,马尔可夫随机场,隐马尔科夫(Hidden Markov)模型,并还包括这些模型的变种,例如,这类模型的条件或最大熵配制品(formulation)。在这些略显不同的框架内求解的方法往往是相似的。
一般而言,所述模型13关于对应于所述系列测量12的一系列k-链节状态包括转变权重(transition weighting)14和发射权重(emission weighting)15。
所述转变权重14关于在所述系列k-链节状态中的连续k-链节状态之间的每个转变提供。每个转变可以认为是从起点k-链节状态至终点k-链节状态。所述转变权重14表示所述k-链节状态的可能类型之间的可能转变,即从任何类型的起点(origin)k-链节状态至任何类型的终点(destination)k-链节状态的转变的相对权重。一般而言,这包括相同类型的两个k-链节状态之间转变的权重。
所述发射权重15关于每种类型的k-链节状态提供。所述发射权重15是所述k-链节状态具有那种类型时所观察的不同测量的权重。在概念上,发射权重15可以看作是表示观测到那种k-链节状态的测量的给定值的可能性,尽管它们并不需要是概率。
从概念上讲,所述转变权重14可以认为是表示了所述可能转变的可能性,尽管它们并不需要是概率。因此,所述转变权重14考虑的是所述测量依赖的所述k-链节状态在不同k-链节状态之间转变的可能性,这可能或多或少可能取决于所述起点的和终点的k-链节状态的类型。
具体而言,来自单独k-链节的测量并不需要是相互可解析的,并且也不要求存在从依赖于所述相同聚合物单元的k测量的组至关于所述转换的值的转换,即,所述观察的状态的组不需要是较少量的参数的函数(尽管这并不排除)。相反,所述模型13的使用通过考虑由聚合物单元的序列产生的所述系列测量的所述模型13预测的所述可能性将多个测量加以考虑而提供精确的估计。从概念上讲,所述转变权重14可以看作是在任何给定的聚合物单元的估计中允许所述模型13至少考虑部分依赖于所述聚合物单元而实际上还依赖于来自所述序列中较大距离的测量的所述k测量。所述模型13可以有效地考虑到任何给定聚合物单元的所述估计中的大量测量,以给出得到可以是更加精确的结果。
类似地,使用这种模型13可以允许所述分析技术考虑来自给定k-链节的丢失的(missing)测量和/或考虑由给定的k-链节产生的所述测量中的异常值(outlier)。这可以在转变权重14和/或发射权重15中加以考虑。例如,所述转变权重14可以代表至少一些所述非优选转变的非零可能性和/或所述发射权重可以表示观察所有可能测量的非零可能性。
通过示例说明而非限制,所述模型可以是隐马尔科夫模型,其中所述转变权重14和发射权重15是概率。现在将在该实例中进行解释。
所述隐马尔科夫模型(HMM)是本文中给出的设置中的自然表示。在HMM中,所述离散随机变量Sm和Sm+1之间的关系,其中m表示第m个k-链节状态,依据在这种情况下是表示每个随机变量能够选取的k-链节状态的所述可能类型之间,即从起点k-链节状态至终点k-链节状态的可能转变的可能性的概率的转变权重14的转变矩阵进行定义。例如,传统上,转变矩阵的第(i,j)项(entry),其中i和j代表k-链节状态的类型,是表示假定Sm=sm,i,Sm+1=Sm+1,j的概率的转变权重14,即,假设Sm取到其第i可能值时转变至Sm+1第j可能值的概率。
图7是关于连续k-链节状态之间一个转变,Sm至Sm+1,的所述转变矩阵的图示。本文中Sm和Sm+1出于举例说明之目的仅显示了4个值(k-链节状态的类型),但在现实中,将会具有与存在不同k-链节状态一样多的值。每个边表示k-链节状态的所述4个可能类型之间的可能转变,即总计16个可能转变。所述可能转变可以用所述转变矩阵(表示转变概率)的项进行标记。在图7中,将所述Sm层中的每个节点(k-链节状态的类型)连接至所述Sm+1层中的节点(k-链节状态的类型)的所述四个转变的概率将通常求和为1,尽管可以另外使用非概率权重。
一般而言,理想的是所述转变权重14包括非二进制变量的值(非二进制值)。这容许所述模型13表示所述k-链节状态之间转变的实际概率。
考虑到所述模型13代表所述k-链节状态,任何给定的k-链节状态都具有k个优选的转变,这是从起点k-链节状态向,具有其中所述终点k-链节状态的所述第一(k-1)聚合物单元是所述起点k-链节状态的所述最后(k-1)聚合物单元的序列的终点k-链节状态的转变。例如,在由所述4个核苷酸G、T、A和C构成的多核苷酸的情况下,所述起点3-链节TAC比所述3-链节ACA、ACC、ACT和ACG具有优选的转变。为了第一近似,在概念上人们可能会考虑所述四个优选的转变的转变概率是相等的为(0.25),而其他非优选转变的转变概率为零,所述非优选转变是从起点k-链节状态向具有不同于所述起点k-链节状态的序列并且其中所述第一(k-1)聚合物单元不是所述起点k-链节状态的所述最后(k-1)聚合物单元的终点k-链节状态的转变。然而,虽然这种近似对于理解是有用的,但转变的实际可能性一般而言可能会由任何给定的测量系统8中的这种近似而变化。这能够通过所述转变权重14取非二进制变量的值(非二进制值)进行反映。这种可以表示的变化的一些实例如下。
一个实例是所述优选转变的转变概率可能不相等。这容许所述模型13表示聚体序列中的聚合物之间存在相互关系的聚合物。
另一个例子是,至少一些非优选转变的转变概率可能是非零的。这容许所述模型13考虑丢失的测量,即,在这种情况下没有依赖于所述实际聚合物中一个(或多个)所述k-链节的测量。这种丢失的测量可能会由于所述测量系统8中的问题而发生以使所述测量并未物理采集,或由于所述后续数据分析中的问题,如所述状态检测步骤S2未识别所述测量组中的一组,例如,因为给定的组太短或两组没有充分分离水平。
尽管允许转变权重14具有任何值的通用性,通常这将是所述转变权重14表示从起点k-链节状态到具有其中所述终点k-链节状态的所述第一(k-1)聚合物单元是所述起点k-链节状态的所述最后(k-1)聚合物单元的序列的终点k-链节状态的所述优选转变的非零机会,并表示其它的,非优选转变的较低机会。即使所述机会可能接近于零,或对于绝对排除的一些所述转变可能是零,所述转变权重14通常还表示至少一些所述非优选转变的非零机会。
为了允许序列中单个丢失k-链节,所述转变权重14可以表示从起点k-链节状态至具有其中终点k-链节状态的所述第一(k-2)聚合物单元是起点k-链节状态的所述最后(k-2)聚合物单元的序列的终点k-链节状态非优选转变的非零机会。例如,在由4个核苷酸构成的多核苷酸的情况下,对于所述起点3-链节TAC,这些是以C起始的所有可能的3-链节的转变。对应于这些单个丢失的k-链节状态的转变可以称为“跳过”,因为中间k-链节状态(即,上述实例中以AC起始的状态)已经被跳过。
在关于每个k-链节状态分析包含单个测量的所述系列测量12的情况下,则所述转变权重14对于每个测量12将代表转变的高机会。根据所述测量的性质,从起点k-链节状态向与所述起点k-链节状态相同的终点k-链节状态转变的机会可以是零或接近于零,或可以类似于所述非优选转变的机会。
类似地,在关于每个k-链节状态(即,依赖所述相同k-链节)分析包含预定大量测量的系列测量12的情况下,则所述转变权重14可以表示关于所述相同k-链节状态所述测量12之间转变的低或零机会。这有可能改变转变权重14而允许起点k-链节状态和终点k-链节状态是相同的k-链节状态。这,例如,容许错误检测状态转变。我们可以将对应于所述重复的相同k-链节状态的转变定义为“停留(stay)”,因为所述的k-链节状态停留在相同类型上。在所述k-链节中的所有k-聚合物单元都是相同的,一种均聚物的情况下,优选的转变将是停留。在这些情况下,所述聚体已经移动了一个位置,但所述k-链节状态却保持相同。
类似地,在分析其中关于每个k-链节但具有未知量(其可以称为“粘附(sticking)”)通常有多个测量的一系列测量12的情况下,所述转变权重14可以代表所述起点k-链节状态和终点k-链节状态是相同k-链节状态的相对高概率,并且取决于不同的物理系统,在某些情况下可能会比如上所述是从起点k-链节状态向其中所述第一(k-1)聚合物单元与所述起点k-链节状态的所述最后(k-1)聚合物单元相同的终点k-链节状态转变的优选转变的概率更大。
在所述状态检测步骤S2被省略而所述进一步的分析实施于相应系列的原始测量11本身而不是所述系列测量12的替代方案中,则所述转变权重14是相似的但关于每个可能的转变进行改变(adapt)以表示所述起点k-链节状态和终点k-链节状态是相同类型的k-链节状态的相对高的概率。这从根本上允许相同地使用所述模型13,所述模型13的改变隐含地考虑了状态检测。
现在将考虑关于每种类型的K-链节状态的所述发射权重15。所述发射权重15是所述K-链节状态属于那种类型时针对所观察的不同测量。在隐马尔科夫模型的本实例中,所述发射权重15表示对于那种类型的k-链节状态观察到不同测量值的概率。因此,对于由图7中的所述节点Sm,i表示的类型i的所述k-链节状态m,所述发射权重15可以表示为概率密度函数g(Xm|Sm,i),其描述由其进行所述测量观察或采样的所述分布。合乎需要的是所述发射权重15包括非二进制变量的值。这容许所述模型13表示不同测量的概率,即一般而言并不具有简单的二进制形式。
一般而言,对于任何给定的k-链节状态的所述发射权重15可以采取任何反映测量的概率的形式。通过非限制性实例举例而言,所述发射权重可能具有是高斯、三角形或方形分布的所述模拟系数的分布,尽管任何任意分布(包括非参数分布)都可以进行定义。不同k-链节状态可以具有含所述相同发射分布形式的发射权重15或具有单个模型13中的参数化,但是这不非必需的而不同k-链节状态可以具有不同发射分布形式或参数化。
对于所述测量系统8的许多类型,k-链节的所述测量具有可以被所测量的物理或生物学属性的散布(spread)和/或被测量误差扩展(spread)的特定预期值。这能够在所述模型13中通过使用具有合适分布,例如是单峰的分布的发射权重15进行建模。
然而,对于某些类型的所述测量系统8,对于任何给定类型的K-链节状态所述发射权重15可以是多峰的,例如,物理上由所述测量系统8中两个不同类型的结合和/或由采取所述测量系统8中的多个构象的所述k-链节产生。
有利的是,所述发射权重15可以代表观察所有可能测量的非零机会。这容许所述模型13考虑由给定k-链节产生的意外测量,即异常值。例如所述发射权重15的概率密度函数可以在允许具有非零概率的异常值的宽泛支持(wide support)内进行选择。例如,在单峰分布的情况下,每种类型的k-链节状态的所述发射权重15可以具有对于所有实数具有非零权重的高斯或拉普拉斯分布。
可能有利的是,允许所述发射权重15是任意定义的分布,从而能够优雅处理异常测量并处理具有多值发射的单状态的情况。
例如,合乎需要的是可以在训练阶段期间凭经验确定所述发射权重15。
所述发射权重15的分布能够以在整个测量空间中的任何合适数量的数据包(bin)表示。例如,在以下描述的情况下,所述分布在所述数据范围内通过500个数据包定义。异常值测量能够通过所有数据包中具有非零概率(尽管所述边远数据包中较低)和如果所述数据不落在所述定义的数据包中之一内时的类似概率进行处理。足够数量的数据包能够经过定义而近似所需的分布。
因此,具体优点可以由表示至少一些非优选转变的非零机会的转变权重14的使用和/或表示观察到所有可能测量的非零机会的发射权重15的使用进行推导。
具体优点也可以由对应于观测到给定类型的k-链节状态的测量范围的相对机会的的发射权重15的使用进行推导。为了强调这些优点,推导序列的简单非概率方法被当作比较实施例。在该比较实施例中,产生在给定范围的所述观察值外面的测量的k-链节状态的类型不被允许以及对应于丢失测量(跳过)的转变不被允许,例如通过删除边缘和节点降低图7中的转变数。在所述比较实施例中,随后对所述唯一连接序列的k-链节状态的作出搜索,对于每个Si精确含有一个节点,并对应于聚合物单元的基础序列。然而,由于该比较实施例依赖于任意阈值以识别不被允许的节点和边缘,在跳过测量的情况下未能找到任何路径,因为所述适当的边缘并存在于所述图中。类似地,在边远测量(outlying measurement)的情况下,所述比较实施例将导致产生图7中要删除的对应节点,并再次不可能确定通过曲线图的正确路径。
相对地,使用模型13和以下描述的所述比对步骤S3中的分析技术,如概率或加权方法的具体优点,在于能够避免这种崩溃(breakdown)的情况。另一个优点是,在多个允许路径存在的情况下,能够确定所述最可能的路径,或可能路径的组。
该方法的另一个具体优点涉及检测均聚体,即相同聚合物单元的序列。所述基于模型的分析能够处理的均聚体区域最高达类似于贡献于所述信号的聚合物单元的数量的长度。例如,6-链节测量能够识别最高达6个聚合物单元长度的均聚体区域。
使用模型(其是用于模型化和分析来自钝读取头系统(blunt reader head system)的数据的HMM)的具体实例公开于WO-2013/041878中。
通常而言,所述发射权重15和转变权重14固定于恒定值,但这并不非必须的。作为一种替代方案,所述发射权重15和/或转变权重14对于要分析的所述测量系列的不同部分可以变化,或许通过关于所述过程的其他信息引导。作为一个实例,具有作为“停留”的注释(interpretation)的转变权重14的矩阵的元素能够依据特定事件()反映了所述聚合物的实际转变的置信度进行调整。作为进一步的实例,所述发射权重15能够经过调整以反映所述测量设备背景噪声的系统漂移和所述施加电压作出的变化。所述权重调节的范围并不限于这些实施例。
通常情况下,存在每个k-链节的单个表示(即,对于每个类型的k-链节的k-链节状态的单个类型),但这不是必须的。作为一种替代方案,所述模型13可以具有一些或所有k-链节的多个独特表示(即,对于某些或所有类型的k-链节多种类型的k-链节状态)。所述转变权重14在本文中能够处于独特起点和独特终点k-链节之间,因此每个起点和终点对可以根据每个k-链节独特表示的数目具有多个权重。这些独特表示的许多可能解释之一是,所述k-链节标有指示无法直接观察的所述系统的一些行为的标记,例如,在易位通过纳米孔期间聚合物可以采取的不同构象或易位行为的不同动态(dynamics)。
关于每个系列测量12的所述模型13考虑用于推导所述系列测量的所述测量系统8的属性。例如,在通过相同测量系统8采集的所述靶序列的测量的情况下,则每个系列测量的所述模型13可以是相同的。但在通过不同类型的测量系统8采集的所述靶序列的测量的情况下,则所述模型13可以考虑每个类型的测量系统13的所述不同信号响应,例如,测量对所述不同类型的k-链节的不同依赖性。
在所述测量是具有与所述靶序列的预定关系的序列的情况下,所述模型13还考虑到这种关系,从而将关于所述测量的序列中的聚合物的所述测量关联于所述靶序列中所述对应聚合物。例如,在通过互补于所述靶序列对应于所述靶序列的序列的测量的情况下,则,相比于所述靶序列的模型,所述模型13除了修改以应用于所述互补k-链节之外是相同的。例如,在所述模型13包括如上所述转变权重14和所述发射权重15的情况下,所述转变权重14表示不同类型的k-链节状态之间可能转变的相同机会,但应用于所述互补k-链节状态,而所述发射权重15代表观察给定测量值而应用于所述互补k-链节状态的相同机会。
对于测量系统8的任何给定类型的单独模型13训练,即在这些并未预定义的情况下所述发射权重15和转变权重14的求导,可以通过从已知聚合物进行测量和使用适合于模型13的类型的训练技术进行实施。举例而言,WO-2013/041878描述了模型13的训练方法的两个实例,其是关于包含用于测量多核苷酸的纳米孔的测量系统8的HMM,所述第一方法使用通过生物素/链霉素系统固定于所述纳米孔中特定位置的静态DNA链,而所述第二种方法使用来自易位通过所述纳米孔的DNA链的测量并通过利用对于k-链节估计描述的类似概率框架来估计所述发射权重。
在回转到使用多个系列测量12产生图1中所示的聚合物单元靶序列的估计的所述方法之前,现在将描述图8中所示的通过关于所述系列测量12应用所述模型13由单个系列测量12产生聚合物单元所述测量的序列的估计23的方法。这通过背景的方式是有用的,而这种方法的部分应用于以下进一步描述的图1的所述方法的某些替代方法中。
在估计步骤T1中,通过将所述系列测量12的所述模型13应用于所述系列测量12本身而产生关于每个测量的k-链节状态20的初始系列估计。对于每个测量,所述k-链节状态20的这个初始系列估计包括,关于每个测量,k-链节状态的每个可能类型的权重,其可以是所述测量由其观察的所述K-链节状态。因此,k-链节状态20的所述初始系列估计的每个估计会提供关于k-链节状态的所有可能类型的信息,包括除了所述最可能的之外的k-链节状态,而不是选择或调用单个k-链节状态。这个估计步骤T1可以使用适用于所述模型13的性质的技术进行实施。这可以基于由通过k-链节状态的不同序列产生的所述系列测量12的所述模型13预测的所述可能性。当使用为概率型的模型13时,所述权重可以类似地是概率,尽管这并非必须的。
应用于上述估计步骤T1中的分析技术可以采取多种适合于所述模型13的各种形式。例如,在所述模型13是HMM的情况下,所述分析技术可以是求解HMM的公知算法,例如正向-反向(Forwards-Backwards)算法,这是本领域中公知的。这种算法一般而言避免了通过所述状态的序列的所有可能路径的所述可能性的强力计算,并反而使用基于所述可能性的所述简化方法识别状态序列。
在k-链节调用步骤T2中,关于每个测量的k-链节状态20的所述初始系列估计经过分析以推导关于每个测量的一系列离散估计的K-链节状态21。这涉及选择或调用关于每个测量的单个k-链节状态。因此,离散估计的k-链节状态的所述系列可以视为k-链节状态关于每个测量的一系列估计,其每个包括认为是最可能k-链节状态的单个估计。所述k-链节调用步骤T2可以采取各种适合于所述模型13并与所述估计步骤T1中的所述方法一致的的形式。
作为所述估计步骤T1使用所述正向-反向算法的实例,k-链节状态20的所述初始系列的估计基于由从所述单独k-链节状态观察的所述系列测量的所述模型预测的所述可能性进行推导。所述正向-反向算法在本领域中是公知的。对于正向部分,给定k-链节状态中结束的所有序列的总可能性从所述第一个测量到所述最后的测量使用所述转变和发射权重正向递归计算。所述反向部分按照类似方式但从所述最后测量至所述第一测量进行工作。这些正向和反向概率合并,并连同所述数据的总可能性一起计算每个来自不同类型的k-链节状态的测量的概率,作为k聚体状态20的初始系列的估计。
在本实施例中,在所述k-链节调用步骤T2中,关于每个测量的所述系列离散估计K-链节状态21由正向-反向概率推导。这是基于与每个单独k-链节状态相关的所述可能性。一个简单的方法是关于每个测量采取最可能的k-链节状态,因为所述正向-反向概率指示每个测量下k-链节状态的相对可能性。
在另一个替代方案中,所述k-链节调用步骤T2可以关于每个测量通过估计所述整体序列,或多个整体序列,基于由通过k-链节状态的整体序列产生的所述系列测量的所述模型预测的所述可能性,推导出所述初始系列k-链节状态20的估计。
作为一种替代方案,所述估计步骤T1可以直接产生所述系列离散估计的k-链节状态21,在这种情况下所述k-链节调用步骤T2是不必要的,以及并未执行。在这个替代方案中,所述估计步骤T1中采用的所述分析技术可以采取适合于所述模型13的各种形式。
作为所述模型13是HMM的情况下的实例,所述分析技术可以是用于求解所述HMM的已知算法,例如,本领域中公知的维特比(Viterbi)算法。在这种情况下,所述系列离散估计的k-链节状态21基于由通过k-链节状态的整体序列产生的所述系列测量12的所述模型13预测的所述可能性进行推导。
作为在所述一般模型30是HMM的情况下的另一实例,所述分析技术可以是文献Fariselli et al.,“The posterior-Viterbi:a new decoding algorithm for hidden Markov models”,Department of Bilogy,University of Casadio,achived in Cornell University(2005年1月4日提交),中公开的所述类型。在所述方法中,后矩阵(posterior matrix)(表示所述测量由每个k-链节状态观察的概率),和获得一致路径,是邻近k-链节状态偏向重叠的路径,而不是每个事件简单选择所述最可能的k链节状态。在本质上,这允许回收直接从所述维特比算法的应用中获得的相同信息。
所述估计步骤T1和k-链节调用步骤T2中应用的上述技术并非限制性的。有许多方式可以利用使用概率或其他分析技术的所述模型13。产生k-链节状态20的所述初始系列估计和所述系列离散估计的k-链节状态21的过程能够经过剪裁而适于具体的应用。它可以是k-链节状态20初始系列估计和所述系列离散估计的k-链节状态21中的仅一个产生为一系列的估计。这没有必要推导所述系列的离散估计k-链节状态21为“硬(hard)”k-链节调用(call)。这能够考虑所有k-链节状态序列,或可能k-链节状态序列的子集。这能够考虑与k-链节状态序列相关或独立考虑具体k-链节状态序列的k-链节状态或k-链节状态集合,例如,所有k-链节状态序列内的加权和。
所述以上的描述依据是HMM的模型13给出,其中所述转变权重14和发射权重15都是概率而所述估计步骤T1和k-链节调用步骤T2使用称为所述模型13的概率技术。然而,另一方面,对于所述模型13有可能使用所述转变权重14和/或所述发射权重15不是概率但表示按照某些其它方式的转变或测量的机会的框架。在这种情况下,所述估计步骤T1和k-链节调用步骤T2可以使用分析技术而不是基于由通过聚合物单元的序列产生的所述系列测量的所述模型13预测的所述可能性的概率技术。所述分析技术可以明确使用似然函数(likelihood function),但一般而言,这并非是必需的。因此,在本公开的上下文中,所述术语“似然(likelihood)”按照考虑通过聚合物单元的序列产生的所述系列测量的机会的一般意义使用,而不需要计算或使用正式(formal)的似然函数。
例如,所述转变权重14和/或所述发射权重15可以由表示转变或发射的机会,但不是概率的并因此例如不受限求和为1的成本(或距离)表示。在这种情况下,所述估计步骤T1和k-链节调用步骤T2可以使用将所述分析处理为最小成本路径或最小路径问题的分析技术,例如,在运筹学研究(operation research)中通常所见的。标准方法如Dijkstra算法,或其他更有效的算法,都能够用于求解。
在所述状态检测步骤S2被省略的替代方案中,所述估计步骤T1直接应用于其中多个测量的组取决于所述相同k-链节(而没有先验知晓组中测量数量)的所述系列原始测量11。在这种情况下,非常类似的技术能够应用于所述估计步骤T1中,但对以上讨论的所述模型13具有调整,其中所述转变权重14从每个给定类型的所述起点k-链节状态降低至不同类型的终点k-链节状态而使远离从任何给定类型的所述起点k-状态至不同类型的终点k-链节状态的所述转变概率总和小于1,通常远小于1。这种降低考虑了关于每种类型的k-链节状态的更大量的测量存在所述系列原始测量11的事实。
例如,如果平均地所述系统在相同类型的k-链节状态下花费100个测量,则在所述转变矩阵对角线上的概率(表示未转变或所述起点k-链节状态和终点k-链节状态是相同k-链节状态的转变)将为0.99,而所有其他优选和非优选的转变之间的分开(split)0.01。所述优选的转变组可以类似于所述状态检测步骤S2进行实施的情况的那些。
在所述k为1的情况下,则关于每个测量的所述系列离散估计的k-链节状态21有效地是聚合物单元的所述测量的序列的最终估计,并因此以下描述的所述其它序列调用步骤T3并未实施。
然而,在k是复整数的情况下,则在序列调用步骤T3中,关于每个测量的所述系列离散估计的k-链节状态21,或替代地关于每个测量(包括k-链节状态的每个可能类型的权重)的所述初始系列估计20,经过分析而推导关于对应于聚合物单元23所述测量的序列的估计的基础序列中的每个k-链节的一系列估计k-链节状态22。这在k是复整数的情况下是可能的,因为连续离散估计的k-链节状态21对应于相互重叠的聚合物单元。在跳过或停留的情况下,关于每个测量的所述系列离散估计的k-链节状态21可以包括与聚合物单元的基础序列不一致的连续估计的k-链节状态。因此,所述系列的离散估计的k-链节状态21能够基于所述重叠进行分析而推导所述聚合物单元23的所述测量的序列的所述估计和所述对应系列的所估计的k-链节状态22。
所述序列调用步骤T3可以使用任何合适的技术进行实施。依据所述系列的离散估计的k-链节状态21,或可替代地所述初始系列的估计20,可以应用概率型方法推导聚合物单元的所述测量的序列的估计23。
对于所述序列调用步骤T3的一个直接方法是使用关于每个测量(其包括k-链节状态的每个可能类型的权重)的所述初始系列的估计20并将所述初始系列估计20的所述估计关联于所述聚合物单元的所述测量的序列的估计23中的聚合物单元。在这种情况下,聚合物单元的所述测量的序列的估计23的每个聚合物单元可以仅仅由所述对应k-链节状态的估计进行估计,推导这作为由此指示的最可能k-链节状态。所述相应系列的估计K-链节状态22可以通过括大所述聚合物单元的所述测量的序列的估计23进行推导。
对于所述序列调用步骤T3更复杂的方法是使用来自含有所述给定聚合物单元的所述估计的k-链节状态的组中的信息组合而估计每个聚合物单元。对于每个位置,使用了包含对应于所述位置的所述聚合物单元的所述k-链节状态的所有估计。因为这些估计是加权的或概率的,则它们可以经过组合而产生那个位置的最可能聚合物单元。
由于所述序列调用步骤T3使用权重或概率进行实施,所述序列调用步骤T3可以同样类似地对于所述估计23中的聚合物单元的不同可能类型进行加权或概率化。
在所述序列调用步骤T3中,保留了关于每个测量的所述系列的离散估计的k聚体状态21和关于基础序列中的每个k-链节的所述系列的估计k-链节状态22之间的所述映射,因此所述系列的估计k-链节状态22和所述聚合物单元的所述测量的序列的所述估计23每个都映射于所述系列的测量12本身,虽然不一定一对一映射。
本描述现在回到使用多个系列测量11产生图1中所示的聚合物单元靶序列的估计的方法。
在比对步骤S3中,推导了所述多个系列测量12之间的估计比对映射16。所述比对步骤S3,使用以下进一步描述的技术,基于将所述模型13关于每个系列测量12应用于那个系列的所述测量而推导出所述估计比对映射16。在所测量的序列具有相互的预定关系,而不是所述相同序列(例如,所测量的序列之一是所述靶序列而其他测量的序列具有与所述靶序列的预定关系,如互补关系,而不是所述序列二者都是所述靶序列)的情况下,则比对步骤S3考虑到了这种关系。即,所述测量关于关联的所述聚体进行映射,而不是关于所述相同聚合物的测量。
所述估计比对映射16将每个系列测量12的每个测量比对于其它系列中的测量或其它系列中的间隙。举例而言,图9图示说明了第一系列测量m1~m10和第二系列测量n1~n9之间的比对映射16的一个实例,其中所述垂直线指示两个测量之间的比对,或在一个系列的测量和所述其它系列中的间隙之间的比对之间的破折号(dash)的情况下。在这个实例中,所述第一系列测量中的测量m1~m3分别比对于(映射于)第二系列测量中的n1~n3,而所述第一系列测量中的测量m4~m5比对于(映射于)所述第二系列测量的间隙,等等。
现在将描述一些推导可以应用于比对步骤S3中的所述多个系列测量12之间的所述估计比对映射16的不同技术。
实施所述比对步骤S3的第一方法如图10中所示并如下实施。这种方法在每个系列测量12按照相同方式处理的意义上是“对称的”。
在K-链节估计步骤S3-a1中,每个系列测量12按照相同的方式进行分析。具体而言,关于每个系列测量12,k-链节状态的一系列估计25是通过将那个系列的测量12的所述模型13应用于所述系列测量12本身进行推导。这可以通过按照各种替代方式应用图8中所示的所述方法而完成。
在第一替代方案中,k-链节状态的所述系列的估计25与k-链节状态20关于每个测量(包含如上所示对于k-链节状态的每个可能类型关于每个测量的权重)的k-链节状态20的所述初始系列估计相同。这可以通过包括图8的所述方法的所述估计步骤T1的所述k-链节估计步骤S3-a1而实现。
在第二替代方案中,k-链节状态的所述系列的估计25与如上所述关于每个测量的所述系列的离散估计k-链节状态21相同。这可以通过包括图8的所述方法的所述估计步骤T1和所述k-链节调用步骤T2(或仅仅以上描述的省略所述k-链节调用步骤的备选方案中的所述估计步骤T1)的所述k-链节估计步骤S3-a1实现。
在第三替代方案中,所述k-链节估计步骤S3-a1包括图8的所述完整方法,而使k-链节状态的所述系列估计25与如上所述的关于所述基础序列中每个k-链节(对应于聚合物单元23所述测量的序列的估计并映射到所述系列测量12本身)的所述系列的估计k-链节状态22相同。
关于所述第一类型的技术,在比对步骤S3-a2中,所述系列测量之间的所述估计比对映射16通过对比在所述k-链节估计步骤S3-a1推导的k-链节状态的所述多个系列的估计25进行推导。在所述测量的序列具有相互的预定关系,而非是所述相同序列的情况下,则比对步骤S3-a2考虑了这种关系。即,关于所关联的所述聚体映射测量,而不是关于所述相同聚体的测量。
所述比对步骤S3-a2可以使用替代评分函数18实施对比,并可以是用于逐对比对序列的已知比对技术的开发,如对于DNA序列比对已知的那些,例如,标准Needleman-Wunsch比对算法。
这些已知的DNA序列比对方法在单独核苷酸的估计本身是非常精确时对于将两个序列的核苷酸类型一起比对也相当不错。然而,在对此在所述碱基调用中的一种有错误存在而导致在所述结果比对中产生缺位一个误差(off-by-one error)的情况下仍然是在相当容易的。因此,尽管所述比对可能几乎是正确的,但这种方法并不适用于组合多维测量,因为所述比对将不足以纠正单独核苷酸的估计中产生的错误。这个问题通过在k-链节状态空间中的所述比对而降低。这是有用的,因为每个观察的测量并不依赖于单个碱基,而是依赖于可能当作某些长度的子序列的整个k-链节,所述k-链节的所有所述聚合物单元有助于对这个事件观察的所述电流水平。
所述替代评分函数18是关于所述相应系列测量12的所述测量之间的不同可能比对提供评分的函数。所述替代评分函数18可以包括,(a)替代评分和(b)所述可能比对的间隙罚分的组合,例如,求和。
关于所述可能比对一起比对的所述多个系列测量12中的测量产生所述替代评分。举例说明而言,关于图9的实施例中所示的所述可能比对,所述评分函数18提供关于在第一系列中的所述测量m1~m3,m6~m9和m10和其在第二系列中的比对测量n1~n3,n4~n7和n9的替代评分。
所述替代评分表示k-链节状态的所述系列估计25的单独估计关于所述系列测量12中的所述测量的所述可能性,可选地概率由由其推导所述系列测量12的所述相应序列中的对应聚合物单元推导,或换句话而言对应于产生所述系列中这些具体测量的任何基础聚合物单元的所述可能性。所述替代评分的目的是使一个序列的中符号比对于另一序列中的不同符号更加昂贵。
在以上提到的k-链节状态的所述系列估计25是k-链节状态20关于包括k-链节状态每个可能类型的权重的每个测量的所述初始系列估计的第一替代方案中,则所述替代评分可以由k-链节状态的每个可能类型的权重推导。这有效地使用了k-链节状态的不同可能类型关于每个测量的权重或概率分布,而不仅仅是单个结果。不是试图比对核苷酸的序列,而是比对权重或概率函数的序列。这使得所述替代评分考虑了对于不同类型的k-链节状态的可能性(即使是在不完善的测量的情况下仍然可以具有与k-链节状态的正确类型相关的显著权重并可以因此赋予有用信息)。
在一个简单的形式中,所述替代评分可以由每种类型的k-链节状态的概率乘积之和进行推导,例如等于那个和或那个和的自然对数。在所述两个权重或概率分布是相同的限制中,这将产生最大评分。在所述两个分布根本没有重叠的极端情况下,所述评分将是零。按照这种方式,与可以通过所述碱基调用器(base-caller)作出的所述类型的替代错误相关的相对可能性将自动作为因数进入所述评分函数中。各种标准化策略能够也能够使用。
在以上提及的k-链节状态的所述系列估计25是关于每个测量的所述系列离散估计的k-链节状态21的第二替代方案中,则所述替代评分可以以按照类似方式进行计算,但进行简化,因为代替了k-链节状态每种类型的权重,关于每个测量存在单个估计的k-链节状态。
数学上这能够如下表示。对于两个系列的测量12的实例在这种情况下k-链节状态每种类型的所述权重是概率。
首先,在N是k-链节状态所述可能类型的数目时,选取Xi=(X1,X2,...,XN)表示关于k-链节状态所述第n类型,所述第一系列测量12的所述第i测量的权重Xn集合,而选取Yj=(Y1,Y2,...,YN)表示关于k-链节状态所述第n类型,所述第二系列测量12的所述第j测量的权重Yn集合。
权重集合Xi和Yj的描述的水平可以变化。作为权重集合Xi和Yj是描述性的情况下的一个实例,在以上提及的k-链节状态的所述系列估计25是关于包括k-链节状态每个可能类型的权重的每个测量的k-链节状态20所述初始系列估计的所述第一替代方案中,则所述权重Xn和Yn是那些权重。
作为所述权重集合Xi和Yj不是描述性的情况下一个实例,在以上提及的k-链节状态的所述系列估计25是关于每个测量的所述系列离散估计的k-链节状态21的所述第二替代方案的情况中,则所述权重Xn和Yn对于已经估计的所述类型的k-链节状态具有的二进制值为1而对于其它类型的k-链节状态具有的二进制值为0。
其次,所使用的相对似然矩阵M包含的分量Mn,m,其表示实际k-链节状态(既估计为所述第一系列测量12的第n类型的k-链节状态又估计为所述第二系列的测量12的第m类型的k-链节状态)的相对可能性。换句话而言,所述相对似然矩阵M(其是表示关于单独k-链节状态能够相互比对如何容易的信息的转化)。这种相对似然矩阵(relative likelihood matrix)M提供了与符号每个可能匹配相关的评分。这种相对似然矩阵M的所述对角线(对应于符号本身的配对)将具有所述最高评分,而其它位置的评分则反映了这种配对预期的频繁程度。因此所述相对似然矩阵M储存的数据表示关于由所述第一系列测量估计的k-链节状态的类型和由所述第二系列测量估计的k-链节状态的类型的每种可能组合的这些相对似然性。
而且,所述相对似然矩阵M的描述的水平可以变化。
作为其不是描述性的情况下的一个实例,所述相对似然矩阵M可以简单地是一致性矩阵(identity matrix)。在这种情况下,所述错配评分将完全取决于权重集合Xi和Yj。这可以适用于那些权重集合Xi和Yj是描述性的情况,例如在以上提及的k-链节状态的所述系列估计25是关于包括k-链节状态每个可能类型的权重的每个测量的k-链节状态20的所述初始系列估计的第一个替代方案中。
作为在所述相对似然矩阵M是描述性的情况下的一个例子,所述相对似然矩阵M可以包括表示k-链节状态的所有可能类型的所述实际相对可能性的非零值。这可以适用于权重集合Xi和Yj不是描述性的情况,例如k-链节状态的所述系列估计25是关于每个测量的所述系列离散估计的k-链节状态21的情况,而使所述错配评分完全依赖于所述矩阵。
对于权重集合Xi和Yj和相对似然矩阵M的这种表示,对于所述第一序列的所述第i测量和所述第二系列的第j测量之间的比对所述替代评分Si,j可以通过以下两个方程(1)和(2)任一项给出:
应当注意的是,在相对似然矩阵M是所述一致性矩阵的情况下,则这些方程(1)和(2)会分别塌缩(collapse down)至以下方程(3)和(4):
同样,在k-链节状态的所述系列估计25是关于每个测量的所述系列离散估计的k-链节状态21的情况下,则由于权重集合Xi和Yj的二进制特性,方程(1)和(2)具有选择单一个所述分量Mn,m的结果,其是估计为实际由所述第一系列测量12估计的指数为n的所述离散估计(这通过所述具有二进制值1的第n类型的k-链节状态表示)和估计为由所述第二系列测量12估计的相同测量估计的指数为m的所述离散估计(这通过所述具有二进制值1的第m类型的k-链节状态表示)的所述实际k-链节状态的相对可能性。
所述相对似然矩阵M可以使用本领域已知的技术基于这种错配的物理来源的知识,例如,基于实际实验数据或基于由关于实验数据经过训练的模型模拟的数据进行推导。一般而言,这可以通过一组示例性比对中计数一种类型的k-链节状态比对于另一类型的k-链节状态的频次而实现。这种比对可以通过专家产生或自动生成。自动创建一组示例性比对的一种方法是从已知序列采集两个系列的测量并将每个系列测量比对于所述已知序列而获得所述测量和由此的k-链节之间的隐式比对(implicit alignment)。每个系列测量可以比对于已知序列的可能方法包括WO-13121224中公开的那些。所述相对似然M本身可以依赖于所述系统的状态,例如外部环境因素,如环境温度。
计算相对似然矩阵M的方法的一个实例如下。
使用一大组实验或模拟系列的测量为每种类型的k-链节状态提供许多环境(context)。对于每个系列测量,估计所述类型的k-链节状态。然后计数每个实际类型的k-链节状态估计为每个所述可能类型的k-链节状态的频次。这在所述估计中相对于实际可能类型的k-链节状态提供了可能类型的k-链节状态的计数的二维矩阵。一般而言,所述矩阵中的每个项能够具有一定值,尽管在实践中一些项,通常许多项,将为零,因为某些类型的k-链节绝不会简单地误调用为某些其它类型的k-链节状态。
接着,这个矩阵进行归一化,使得对于k-链节状态的每个实际类型(行),所述矩阵表示它调用为k-链节状态的每个可能类型(列)的时间分数。
这关于所述每系列测量的模型完成。在所述测量是具有与所述靶序列的预定关系的序列的情况下,所述矩阵还考虑了这种关系,从而将关于所测定的序列中的聚合物的所述测量关联于所述靶序列中的所述对应聚合物。例如,在通过互补于所述靶序列而对应于所述靶序列的序列的测量的情况下,则这通过所述矩阵经过组织而使每行不对应于所述互补序列中k-链节的实际类型,反而对应于所述靶序列中k-链节的对应类型而实现。
这意味着关于每个系列测量的所述矩阵的列表示已估计已经从不同实际类型的k-链节状态推导的k-链节状态的类型的相对可能性。因此,所述相对似然矩阵M中的每个项通过取得关于对应于k-链节状态的第一相应类型的一个系列测量的所述矩阵中的列和关于对应于k-链节状态的第二相应类型的其它系列测量的所述矩阵中的列的点积(dot product)而进行推导。为了举一个k为3的例子,对于由所述第一系列测量估计为k-链节状态“CTC”的所述类型的事件,和由所述第二系列测量估计为k-链节状态“GCG”的所述类型的事件,对应于“CTC”的所述第一矩阵的列,提供了与每个实际类型的k-链节状态相关的相对可能性,和对应于“GCG”的所述第二矩阵的列提供了与对于所述观察的每个实际k-链节状态相关的所述相对可能性。因此,这两列的点积为我们提供了任何实际k-链节状态将会产生所估计的状态对“CTC”和“GCG”的总可能性。当然,这种点积可以简单地通过一个矩阵乘以另一个矩阵的转置矩阵(transpose)而推导。所述获得的矩阵是所述相对似然矩阵M。
由于这些计算预先进行,所述替代评分Si,j的求导可以通过简单的查找(lookup)进行实施。类似地,在替代评分Si,j是根据方程(2)的自然对数的情况下,所述相对似然矩阵M中的这些项的自然对数可以预先计算。
用于所述比对的相对似然矩阵可以选自许多替代矩阵M1,M2,…,Mn,或许多这种矩阵M=faux(M1,M2,…,Mn)的算子(functor),所述选择或混合(blend)依赖于关于所述系统的辅助信息“aux”。例如,所述替代矩阵组中的每个成员可以适合于不同的已知温度,并且使用的所述实际替代矩阵可以是基于所述系统的所测量的温度的内插。作为简单内插的情况的一个实例,M=ai Mi+aj Mj,其中ai和aJ取决于所测量的温度t和对于Mi和Mj的所述已知温度,ti和tj分别是满足ti<=t<=tj的t的最接近的温度,并且其中ai=(tj-t)/(tj-ti)和aj=(t-ti)/(tj-ti)。
此外,人们可以发现它适用于通过将状态组合一起而形成更少的状态而降低所述k-链节状态空间。例如,所述方法采用5-聚体模型13进行实施,适用于所述功能比对分析步骤S4,所述概率型估计16可以在3-链节状态空间中的所述比对步骤S3中作出。5-链节降至3-链节,即1024个可能状态降至64个状态,大大降低了构成所述替代评分所需的计算量,而同时保留了有关所述比对的大部分信息。
从5-链节至3-链节的所述示例性变换是两个状态-空间之间的直接映射,其中每个5-链节对应于单个3-链节状态。降低的状态-空间不需要是所述k-链节空间的直接映射以及更一般而言,任何新的状态-空间能够定义,其中存在来自一个或多个k-链节状态的变换。所述变换不需要将k-链节状态唯一关联于所述新空间中的状态而每个新状态能够是表示k-链节状态的权重的抽象状态。例如,从5-链节降至3-链节能够通过关于具有来自含有所述特定3-链节的每个5-链节的单元贡献的所述k-链节概率的线性变换表示。其它类型的降低都能够应用。例如,更一般性的线性变换能够使用,其中每个抽象状态的评分是所述k-链节概率的线性权重。所用的变换不需要对所述两个系列的测量是相同的,但我们发现使用相同的变换也是令人满意的。一对从k-链节状态成为n个抽象状态的合适线性变换和适当降低的替代矩阵可以通过实施单值分解(Single Value Decomposition)和只保留这些具有所述n最大奇异值的分量而获得。所述剩余的奇异值构成所述抽象状态之间的对角替代矩阵。本领域已知用于构成矩阵的低维近似的其它方法也可以使用。
权重Xi和Yj可以用表示关于所述测量的其它信息的其它要素放大,这可以是非概率的,如表示所述测量被信任或是所述系统的一些状态的函数,例如外部环境因素如环境温度的评分。所述概率也可以用表示其他要素的非线性函数的其它要素放大。这容许进行一般性特征比对,其中所述“特征”能够是据发现最适用于决定测量是否应该相互比对的所述k-链节的任何特性组。
在上面提到的k-链节状态的所述系列估计25是关于所述基础序列中的每个k-链节(其对应于聚合物单元23所述测量的序列的估计)的所述系列的估计k-链节状态22的第三替代方案中,则所示替代评分可以以与所述第二替代方案(即,类似于所述第一替代方案,但简化之处在于代替每种类型的k-链节状态的权重,关于每个测量存在单个估计k-链节状态)相同的方式计算,但考虑了关于所述基础序列中的每个k-链节的所述系列估计k-链节状态22和所述系列测量12本身之间的映射。因此,对于所述第一系列测量12的所述第i测量和所述第二系列测量12的第j测量之间的比对的所述替代评分Si,j可以以以上所述的实例相同的方式进行计算,除了所述组Xi=(X1,X2,...,XN)和Yj=(Y1,Y2,...,YN)中的概率Xn和Yn对于k-链节状态的所述系列估计25中(其映射于所述第一和第二系列测量中的所述第i和第j测量)的所述估计类型的k-链节状态具有的值为1而对于所述其它类型的k-链节状态具有的值为0。
所述间隙罚分关于所述多个系列测量12中的测量产生(所述可能的比对比对其它系列中的间隙)。通过举例说明的方式,在图9的实例中,间隙罚分关于所述第一系列中的测量m4和m5和所述第二系列中的测量n8提供。
所述间隙罚分表示所述其它系列不包括对应测量的可能性。间隙罚分按照它们将是所述聚合物单元空间中传统比对的相同方式进行评价。
对于所述替代评分,合适间隙罚分的评价可以利用所述比对中这种间隙的物理来源是什么的信息。这意味着,所述间隙罚分可以反映间隙预期频繁度和所述间隙罚分大小应该如何与所述间隙的长度相称(scale)。在一个极端情况上,所述处罚能够与k-链节状态的数量成正比,这具有促使其同样有可能具有单一长间隙,或许多小间隙加起来等于所述相同长度的效果。这在所述比对中间隙是由于k链节状态的所述系列估计25求导中的误差,而不是由于采集所述测量的所述物理序列中的实际差异所致的情况下是有意义的。另一方面,在许多类型的测量系统8中,插入或缺失倾向于成组引入,在这种情况下对于打开间隙可以施加大罚分,随后对于继续所述间隙施加小得多的罚分。
所述间隙罚分可以与由关于所述其它系列不包括对应测量的所述系列测量12的模型13预测的所述可能性是一致的。例如,所述间隙罚分可以由通过测量比对于其它系列中的间隙的模型13预测的所述可能性或概率P间隙与通过测量未比对于其它系列中的测量的模型预测的概率P无间隙的所述可能性之比,例如等于那个比率(例如,在所述替代评分Si,j通过方程(1)或(3)提供的情况下)或等于那个比率的自然对数(例如,在所述替代评分Si,j由方程(2)或(4)给出的情况下)进行推导。数学上表达这一点,所述间隙罚分S间隙可以通过以下两个方程(5)和(6)中任一种给出:
所述间隙罚分也能够凭经验使用采集自已知序列的测量进行确定。在这样的情况下,由于所述正确的比对是已知的,直接估计一个系列的测量平均多久比对于另一系列中的间隙。
举例而言,以下考虑因素适用于基于来自所述相同多核苷酸的靶序列和互补于所述靶序列的序列的测量的模板-互补方法的评分函数。
在这个例子中,所述测量的模板和互补序列之间的任何差异,在考虑所述互补序列的所述反向互补性质之后,将是由于所述信号分析中产生的误差,而不是由于所述实际多核苷酸不同所致。这能够是由于许多因素,如所述信号中的假象(actefact),由于所述多核苷酸易位的速率所致碱基丢失,或所述模型13中的模糊性所致,这意味着多个多核苷酸序列能够导致相同或几乎相同的测量。
关于这个实例中的替代评分,不同核苷酸趋于误调用(miscall)为其它核苷酸的相对频率能够凭经验通过对大量的已知多核苷酸序列测序进行确定。一个最佳的替代矩阵M然后就能够由这些结果进行推导。
关于本实例中的间隙罚分,在大多数情况下使用同样适用于比对于间隙的每个核苷酸的固定间隙罚分是明智的。在某些情况下,如果观察到k-链节的丢失测量或由于伪影所致的过度测量倾向成簇出现,则反而能够使用作为长度的函数的间隙罚分,并且所述要使用的具体函数能够凭经验再次通过对已知核苷酸序列测序而确定。
所述比对步骤S3-a2通过推导所述估计比对映射16为最大化所述评分函数的所述可能比对而使用所述替代评分函数18。因此,在所述估计比对映射16是图9中所示的估计比对映射的实例中,这种比对映射具有比所述系列测量12之间的其他可能的比对映射更高的计分函数。
虽然所述比对分析原则上能够应用强力技术(brute force technique),这会考虑所述系列测量12之间的每个可能的比对映射,但计算量将是很大。因此,所述比对分析可以使用动态编程技术推导最大化所述评分函数的所述可能比对。一定范围的合适动态编程技术能够用于已知比对技术进行序列的逐对比对,如DNA序列比对并可以在本文中应用。合适的动态编程技术的非限制性实例将会使用标准的Needleman-Wunsch比对算法。
尽管上述方法参照使用两个系列的测量12的实例进行了描述,该实例可以简单地通过增加所述对比和考虑所述系列测量之间的可能比对的维度,具体而言增加所述评分函数18的维度而概括从而找到3个或更多系列的测量12之间的所述估计比对映射16。
实施图10中所示关于所述系列测量12是对称的所述比对步骤S3的这个第一方法,通过使用每个系列测量12的所述模型13将所述每个系列测量12转化成k-链节状态的一系列估计25而在所述k-链节状态的空间内推导所述估计比对映射16。这允许所述比对映射16的所述估计以保留大部分包含于所述原始测量中的信息,而同时从所述测量空间向允许数据直接对应的所述k-链节空间进行抽象。由于所述k-链节状态能够通过所述多个系列中的每个测量提供信息,则它们能够比所述对应原始测量对所述靶序列中的每个k-链节的所述类型的k-链节状态具有更多的信息。
实施适合当k是复整数的所述比对步骤S3的第二方法如图11中所示并如下实施。这种方法在所述每个系列测量12以不同的方式处理的意义上是“不对称的”。为了在以下讨论中区分所述系列测量12,标记12a和12b提供于第一系列测量12a和所述其它系列测量12b。在这个例子中,只有一个其它系列测量12b,但所述方法可以以类似的方式应用于多个其他系列测量。
所述第一系列测量12a如下进行分析。
在k-链节估计步骤S3-b1中,所述第一系列测量12a的所述模型13适用于所述系列测量12本身以推导一系列估计k-链节状态26。这一步骤可能使用图8所示的所述方法。
所述系列估计k-链节状态26可以是关于每个测量的估计k-链节状态。在这种情况下,所述k-链节估计步骤S3-b1可以包括所述估计步骤T1和图8的所述方法的所述k-链节调用步骤T2,以使估计k-链节状态26的所述系列估计与关于每个测量的所述系列离散估计k-链节状态21相同,如上所述。
可替代地,所述系列估计k-链节状态26可以是关于对应于聚合物单元23的所述测量的序列的估计的基础序列中的每个K-链节状态的估计k-链节状态。在这种情况下,所述k-链节估计步骤S3-b1可以包括所述估计步骤T1,所述k-链节调用步骤T2和图8的所述方法的序列调用步骤T3,以使所述系列估计k-链节状态26与系列估计k-链节状态22相同,如上所述。在这种情况下,所述系列估计k-链节状态26的所述估计k-链节状态,尽管不一定是一对一映射,但每一个都映射于所述第一系列测量12的所述测量。
在所测量的序列具有相互的预定关系,而不是所述相同序列的情况下,则在k-链节估计步骤S3-b1中,通过应用所述模型13推导的所述系列估计k-链节状态考虑那种关系进行变换以推导所述估计k-链节状态26。即,通过应用所述模型13推导的每个估计k-链节状态变换成所述其它系列测量12b的所述相关的k-链节状态。例如,在所述预定关系是所述第一系列测量12a和所述其它系列测量12b互补的情况下,则由应用所述模型13推导的每个估计k-链节状态变换成将其作为所述估计k-链节状态26的所述互补状态。按照这种方式,所述多个系列测量12之间的估计比对映射16的以下描述的所述比对步骤S3-b3的推导考虑了所述预定关系。
在模型生成步骤S3-b2中,对照模型30由所述系列估计k-链节状态26推导。
所述对照模型30是所述测量系统8中的所述系列估计k-链节状态26的所述测量的模型。所述对照模型30可以当作改编以上所述的模型13以模型化尤其是在测量所述系列估计k-链节状态26时获得的所述测量。因此,所述对照模型30将所述测量处理为所述系列估计k-链节状态26的所述观察。因此,所述对照模型30具有以上描述的所述模型13的相同形式,具体而言,包含如现在将要描述的转变权重31和发射权重32。
所述转变权重31代表所述模型30的所述k-链节状态26之间的转变。同样地,每个k-链节状态26是k-链节状态的所述可能类型中的一种。因此,所述对照模型30的所述系列k-链节状态26可以当作通过所述模型13的所述k-链节状态的一条特定路径。
这是参照图12的状态图进行的图示说明,其显示了在所述系列估计k-链节状态26中三个连续k-链节状态26的一个实例。在本例中,k是3以及聚合物单元的所述参照序列包括标记A、A、C、G、T的连续聚合物单元。(当然尽管这些特定类型的所述k-链节状态26并非限制性的)。因此,对应于那些聚合物单元的所述模型30的所述连续k-链节状态26是类型AAC、ACG、CGT,它们对应于聚合物单元AACGT的测量的序列。
图13的状态图图示说明了所述模型30的所述k-链节状态26之间的转变,这通过所述转变权重31表示。在这个例子中,通过所述模型30的所述k-链节状态26的仅正向进展是允许的(虽然一般而言反向进展可能另外允许)。三种不同类型的转变34、35和36如下图示说明。
从所述系列k-链节状态26中的每个给定k-链节状态26,容许转变34至所述下一k-链节状态26。这模型化了采集自所述系列k-链节状态26连续k-链节的所述系列测量12中的连续测量的所述可能性。由于所述分析是经过处理以识别连续组的原始测量并推导由关于每个识别组的预定数量的测量构成的一系列测量12的所述系列测量12,则所述转变权重31表示这种转变34具有相对高可能性。
从所述系列k-链节状态26中的每个给定k-链节状态26,容许转变35至所述相同k-链节状态26。这模型化了采集自所述系列k-链节状态26的相同k-链节26的所述系列测量12中的连续测量的所述可能性。这可以称之为“停留(stay)”。由于所述分析是经过处理以识别连续组原始测量并推导由关于每个识别组的预定数量的测量构成的一系列测量12的所述系列测量12,则所述转变权重31表示这种转变35具有相比于所述转变34相对低可能性。
从所述系列k-链节状态26中的每个给定k-链节状态26,容许转变36至所述后续k-链节状态26越过所述下一k-链节状态26。这模型化了没有采集自所述下一k-链节状态的测量的所述可能性,以使所述系列测量12中的连续测量采集自分隔开的聚合物单元的所述参照序列的k-链节。这可以称之为“跳过(skip)”。因为所述分析是经过处理以识别连续组原始测量并推导由关于每个识别组的预定数量的测量构成的一系列测量12的所述系列测量12,则所述转变权重31表示这种转变36具有相比于所述转变34相对低可能性。
表示跳过和停留的所述转变35和36的所述转变权重31的水平,相对于表示所述转变34的所述转变权重31的水平,可以按照所述转变权重31的相同方式对于所述模型13中的跳过和停留进行推导,如上所述。
在省略了所述状态检测步骤S2以使所述进一步的分析实施于所述系列原始测量11本身,而不是所述系列测量12的替代方案中,则所述转变权重31是相似的,但经过改编以增加了表示跳过的所述转变35的所述可能性以表示采集自所述相同k-链节的连续测量的所述可能性。对于转变35的所述转变权重31的水平取决于预期采集自任何给定k-链节的测量数量并可以通过实验对于要使用的具体测量系统8进行确定。
发射权重32关于每个k-链节状态26提供。所述发射权重32是对于在观察所述k-链节状态26时采集的不同测量的权重。因此,所述发射权重32依赖于所述k-链节状态26所讨论的所述类型。具体而言,对于任何给定类型的k-链节状态26的所述发射权重32,是与如上所述的对于所述模型13中那种类型的k-链节状态的发射权重32相同。
在所述模型生成步骤S3-b2中,对照模型30如下由所述系列估计k-链节状态26推导。
所述转变权重31对于在所述k-链节估计步骤S3-b1中推导的所述系列估计k-链节状态26之间的转变进行推导。所述转变权重21采取以上所述的形式,关于所述系列估计k-链节状态26进行定义。
所述发射权重32对于在所述k-链节估计步骤S3-b1中推导的所述系列估计k-链节状态26的每个k-链节状态26,通过根据所述k-链节状态26的所述类型从所述其它系列测量12b的所述模型13的所述权重中选择所述发射权重32而进行推导。因此,对于所述对照模型30中的每种类型的k-链节状态26的所述发射权重32是与如上所述对于所述模型13中那种类型的k-链节状态13的所述发射权重相同。
在一个比对步骤S3-b3中,所述多个系列测量12之间的所述估计比对映射16通过将对照模型30应用于所述其它测量系列12b而进行推导。
由于所述对照模型30的形式,具体而言是所述对照系列的k-链节状态26之间的转变的表示,应用所述对照模型30本质上推导出所述多个系列测量12之间的所述估计比对映射16。这可以如下理解。由于如上所述的模型13表示所述可能类型的k聚体状态之间的转变,则应用所述模型13提供了由其观察每个测量的所述类型k-链节状态的估计,即,k-链节状态20和所述离散估计k-链节状态21的所述初始系列的估计,这每个是由其观察每个测量的所述类型的所述k-链节状态的估计的形式。由于所述对照模型30表示所述参照系列的k-链节状态26之间的转变,应用所述对照模型30反而估计了由其观察每个测量的所述对照系列的k-链节状态26的所述k-链节状态26,这是所述多个系列测量12之间的比对映射。
在所述测量的序列具有相互的预定关系,而不是所述相同序列的情况下,则所述预定关系由通过应用如上所述的k-链节估计步骤S3-b1中实施的所述模型13而推导的所述系列估计k-链节状态的变换进行考虑。
根据所应用的所述方法,估计比对映射16的所述形式可以进行变化,如下所示。
如上所述,在所述比对步骤S3-b3中应用的所述分析技术可以采取多种适合于所述对照模型20的所述形式的形式。例如,在所述对照模型20是HMM的情况下,所述分析技术可以是求解HMM的已知算法,例如,所述正向-反向(Forwards-Backwards)算法或维特比(Viterbi)算法,这在本领域内是公知的。这种算法一般而言避免了所有通过状态的所述序列的可能路径的所述可能性的强力计算,并反而使用基于所述可能性的简化方法识别了状态序列。
采用所述比对步骤S3-b3中应用的一些技术,所述估计比对映射16包括,对于所述系列中的每个测量12b,关于所述估计系列的k-链节状态26中的不同k-链节状态26的权重。例如,这种比对映射可以通过Mi,j表示,其中所述指数i标记其它系列测量12b的所述测量而指数j标记所述估计系列的k-链节状态26中的k链节状态,因此在具有K个k-链节状态的情况下,值Mi,1~Mi,K,表示对于关于每个K-链节状态26的第i测量的所述权重。在这种情况下,所述估计比对映射16不表示映射于每个测量的单个k-链节状态26,但反而提供了对于如此映射于每个测量的不同可能k-链节状态26的权重。
作为在所述对照模型30是HMM的情况下的例子,所述推导的估计可以是在所述应用的分析技术是如上所述的所述正向-反向算法时的这种类型。在正向-反向算法中,终止于给定k-链节状态中的所有序列的所述总可能性在正向和反向方向上使用所述转变和发射权重进行递归计算。这些正向和反向概率连同所述数据的所述总可能性一起进行合并以计算来自给定k-链节状态的每个测量的概率。称作后矩阵(posterior matrix)的这个概率矩阵是所述比对映射的所述估计13。
采用应用于所述比对步骤S3-b3中的其他技术,所述估计比对映射16包括,对于所述其它系列测量中的每个测量,所述系列估计k-链节状态26中的k-链节状态26的离散估计。例如,这种比对映射可以通过Mi表示,其中所述指数i标记所述测量而Mi能够取值1至指示所述K个k-链节状态的K。在这种情况下,所述估计13表示映射于每个测量的单个k-链节状态23。
作为在所述对照模型30是HMM的情况下的例子,所述推导的估计可以是在所述应用的分析技术是如上所述的维特比算法时这种类型,其中所述其他系列的测量12b是基于由通过系列K-链节状态26生产的所述对照模型30预测的所述可能性进行分析。
作为在所述对照模型30是HMM的情况下的另一个例子,所述分析技术可以是2005年1月4日提交康奈尔大学存档的的文献Fariselli et al.,“The posterior-Viterbi:a new decoding algorithm for hidden Markov model”,Department of Bilogy,University of Casadio中公开的所述类型(如上所述)。
执行所述比对步骤S3的所述第二方法在所述系列测量按照不同方式处理的意义上包含非对称性。所述第一系列测量用于生成用于产生对照模型的k-链节状态初始系列估计,而所述对照模型应用于所述第二系列的测量。一般而言,所述方法不管哪一系列的测量用作所述第一系列测量都能生效而推导出k-链节状态的初始系列估计。然而,可以存在通过选择所述系列测量的特定一种作为所述第一系列而实现优点的情况。
在某些情况下,这可以是系列测量在按照系统方式估计所述靶聚合物序列的估计中按照本身不同的精度提供的意义上已知是不同的品质的这种情况。例如,这可能是由用于生成所述系列测量的所述测量系统8的性质所致。这可能发生的情形的一个例子是,使用包含生物孔1的所述相同测量系统8顺序地推导两个系列的测量的情况,例如,在所述两个序列通过桥接部分连接时,在这种情况下所述生物孔内的条件可以在所述易位过程期间发生变化。在这个例子中,它可以是所述系列测量之一是更高的数据质量的。例如,在某些情况下,按照系统的方式,据观察在所述纳米孔中测量的所述第一系列聚合物单元具有的数据质量比所述第二系列更高。这可能是由于所述第二系列部分地与所述纳米孔的所述反侧上的所述第一系列杂交所致。所述系列测量中的一种是更高质量的事实可以通过实验使用已知序列确定。在其他情况下,数据的质量可以从测量的分析来确定。
在系列测量是不同质量的情况下,无论预先确定或是基于所述测量的分析,则所述估计比对映射在选择质量更好的所述系列测量作为所述第一系列测量时是更精确的。所述估计比对通过利用在推导k-链节状态的所述初始系列估计中提供了最好的精度的所述系列测量而具有最好的信息,因为这是最接近对应于所述靶聚合物序列的所述k-链节状态。
本描述现在回归到图1中所示的产生聚合物单元靶序列的估计的方法。具体而言,在聚合物单元估计步骤S4中,聚合物单元的所述靶序列的估计17由所述多个系列测量12通过应用每个系列测量12的所述模型13而产生。具体而言,这涉及实施类似于关于图8中所示并如上所述的单系列测量12的所述方法的分析,但连同在考虑了所述估计比对映射16的多维模型中一起使用了所有所述系列测量12。因此,所述聚合物单元估计步骤S4将每个模型的k-链节状态的这些类型13处理为多维k-链节状态的维度并将每个系列测量12的所述测量处理为这些多维k-链节状态的多维观察。所述聚合物单元估计步骤S4包括与以上所述的步骤T1~T3相同的步骤,但扩展至这种多维的情况。
从数学上而言,图8的所述方法直接拓展至将所述系列测量12和模型13按照多维中的排布进行处理。所述发射权重15按照多维出现,对于每个系列测量12的一个维度。考虑上述模型B,概念上所述模型是相同的,不同的是Ti现在表示这些值的多维向量,而不是单个值。在HMM而不是一维概率密度函数g()的状态发射值的情况下,这些值由多维密度函数发射,例如在两个序列的测量的情况下,Ti发射测量对(tis,tia),其中tis是一个序列的所述测量而tia是另一序列的所述测量。这个发射的测量对可以包含未观测到的跳过状态以及真实电流测量。正如在所述基本一维的情况下,异常值和丢失数据,或跳过状态,能够进行模型化。一维模型13的所有优点转移至多维应用的所述模型13中。
相比于所述测量分析步骤S2,使用多维方式的所述模型需要考虑增加可能多维k-链节状态的数目,这在采用WO-2013/041878中所公开的多维方法会发生。在不知晓所述测量之间的所述比对时,所述维数将大大增加所述计算要求,会不利于在实际可用的计算资源范围内迅速和/或精确地执行所述计算。
然而,与WO-2013/041878中公开的所述多维方法相反,聚合物单元估计步骤S4使用所述系列测量12之间的所述估计比对映射16,具体而言通过使用所述推导的比对映射16约束通过要考虑的所述多维k-链节状态的路径而进行实施。例如,所述通过所述多维K-链节状态的路径可以经过约束而处于距离所述多个系列测量之间的所述推导的比对映射16的预定距离内。
正如上所述,对于图8的所述方法的所述一维的情况,所应用的所述分析技术可以采取适合于所述模型13的各种形式。例如,在所述模型13是HMM的情况下,所述聚合物单元估计步骤S4可以使用任何求解所述HMM的已知算法,例如,所述正向-反向算法或维特比算法。这种算法一般而言避免了通过这些状态的所述序列的所有可能路径的所述可能性的强力计算,并反而使用基于所述可能性的简化方法识别状态序列。使用所述估计比对映射16作为约束,降低了需要进行搜索的所述搜索空间,从而降低了所述计算要求。
仅仅举例而言,将要讨论所述维特比算法对多维排布的系列测量12的应用。所述维特比算法在本领域内是公知的。对于一维HMM,终结于每个可能k-链节状态K的所述最可能路径的所述可能性Li(k)对于向前移动从所述第一状态至最后状态(i=1…n)通过所述状态序列的每个状态i进行计算。不是考虑所有这样的路径,所述估计比对映射16用作降低要考虑的状态的数目的约束。所述值Li(k)能够仅仅使用来自所述立即在前的状态的所述值Li-1(.)连同所述转变和发射概率一起,形成递归而进行计算。在多维HMM中,可以使用类似的方案。
举例而言,图14显示了两个系列的测量12之间的可能比对的网格(grid),在这个实施例中每个由40个测量构成,尽管通常测量的数量将高得多。在所述网格中的每个节点(node)表示一对测量,一个来自每个系列。对于无约束的2D方法,必须处理所有1600个节点。
在图14中,所述交叉阴影线节点(cross-hatched node)20表示来自所述相应系列的所述测量之间的所述估计比对映射16的实施例中具体路径上两个系列的测量12的测量对。所述阴影线节点21表示来自处于距离所述多个系列测量12之间的所述推导的比对映射16的预定距离之内的所述两个系列的测量12的测量对,在本实施例中的所述预定距离为五。所述空节点(empty node)22表示来自处于距离所述比对映射16的所述预定距离之外的所述两个系列测量12的所述其余测量对。在这个实施例中,步骤S5-3中的所述测量分析通过仅仅考虑横跨所述交叉阴影线节点20和所述阴影线节点(hatched node)21的路径,即考虑来自距离所述推导的比对映射16预定距离之内的每个系列测量12的测量对而进行约束。
只要通过所述未约束的测量分析将产生的路径并不超出所述交叉阴影线节点20和所述阴影线节点21之外,所述受约束分析将会产生相同的比对碱基调用(base-call)。
所述约束的程度也依赖于所述估计比对映射16的精度进行选择。即,随着所述精度增加,所述约束的程度可以降低。正如以下进一步讨论,所述精度可以取决于所述用于推导所述估计比对映射16的所述方法并可以从实验上对于任何给定的方法和测量系统8基于用于训练所述模型的所述测量进行测定。所述约束的程度是潜在错配数目之间的折中(trade-off),其随着所述约束的程度和数据处理的量而降低,其随着所述约束的程度而增加。
在所述估计步骤S5中,使用在产生聚合物单元的所述靶序列的所述估计17中推导的所述估计比对映射16,允许来自所述多个系列测量12的所述信息按照校正许多将会在由单系列测量12推导的所述靶序列的估计中产生的所述误差的方式进行组合。
在最简单的情况下,聚合物单元的所述靶序列的所述估计17可以是为每个聚合物单元提供单个估计类型(一致性(identity))的表示。更一般而言,聚合物单元的所述靶序列的所述估计17可以是所述靶序列根据一些最优准则的任何表示。例如,聚合物单元的所述靶序列的所述估计17可以,关于每个聚合物单元,表示最可能聚合物单元的所述类型的权重或概率,并也可以表示对于聚合物单元的不同类型,可选地对于聚合物单元的所有可能类型的权重或概率。可替代地,聚合物单元的所述靶序列的所述估计17可以包括多个序列,例如每个包括部分或所有所述聚体的一个或多个聚合物单元的多个估计类型。
应用在k-链节状态的估计25的所述系列是关于包括k-链节状态的每个可能类型的权重的每个测量的k-链节状态20的估计的所述初始系列的替代方案中实施所述比对步骤S3的第一方法的实例,已经利用使用由实验数据推导的5-链节模型的模拟测序数据进行实施,如下所述。
选择了所述λ基因组的2000个碱基对的块(chunk),以及事件数据通过基于所述模型采集所述预期的电流水平,加上具有1pA标准偏差的高斯噪声进行模拟。所述模拟的链是“发夹”,是指在每个情况下,我们具有紧接所述互补序列的所述模板序列。
为了正确模拟所述类型的误差和在实验测序数据中常见的人为因素(artefact),“跳过(skip)”和“停留(stay)”插入到所述模拟的事件数据中,“跳过”是省略事件而“停留”是先前事件的重复(但具有所述噪声的新实现(new realization))。
为了获取一定范围的碱基调用质量,对于1%,2%,5%,10%,20%,30%和40%的跳过和停留百分数生成模拟的事件数据。在每种情况下,所述跳过和停留百分比是相等的。每种条件的十个实现生成,以允许在各试验上进行平均。
首先,对每个事件序列计算出所述1D碱基调用精度。这提供的碱基调用精度范围为对于具有40%的跳过-停留百分比的数据低至48%,至对于具有1%的跳过-停留百分比的数据的78%。然后,实施所述模板和互补碱基调用的标准碱基空间比对,以及所得的比对用于实施所述合并的模板-互补数据的新碱基调用。使用本文中描述的所述类型的一种方法,也实施所述1D碱基调用后验概率(posterior probability)的k-链节状态比对,而所述合并的模板-互补数据的新碱基调用使用所述比对进行实施。最后,所述k聚体状态比对用作所述2D维特比(Viterbi)碱基调用方法的约束。
所述结果如图14和15中所示,其中水平轴是所述1D碱基调用质量,而所述垂直轴是2D碱基调用质量,图15绘制了所述绝对值,而图16绘制了1D碱基调用上的改进。
下部迹线显示了使用标准碱基空间比对的结果。对于低于70%的1D调用质量,所述结果比1D碱基调用更差,这表明所述比对基本上已经失败。对于更高的1D调用值观察到指示更好比对的改进。所述中间迹线显示了根据本文中所描述的所述方法使用比对方法的结果,适用于k-链节状态。本文中,所述1D碱基调用上的改进能够在约55%的1D质量周围观察到。对于更高的质量,所述改进是相当大的。在所示的所有情况下,所述特征比对导致比所述碱基空间比对更高的精度。最后,所述上部迹线显示了使用所述k-链节状态比对作为约束完成2D维特比碱基调用的所述结果。在本文中,能够观察到所述1D碱基调用结果上额外的改进。
原则上,所述模板和互补数据之间的任何比对能够用于约束所述2D维特比方法,只要所述比对足够好而使所述估计比对和所述真实比对之间的差异受约束(即,所述估计比对不会以无约束的方式在某些类型的随机游走(random-walk)中迷失方向(wander off))。在这种情况下,所述更精确的特征比对的优点是在所述2D调用上更严格的约束,导致存储和计算要求降低。对于所述2D不受约束方法的所述存储和计算要求对于长度大于5kB和更长的多核苷酸序列的比对变得特别苛刻。对于40kB或更长的序列的所述比对,对于所述无约束2D方法的所述存储和计算要求是如此之大而使之不实际。
图17显示了相对于所述1D碱基调用质量绘制的比对错配,图示说明了对于所述碱基空间和所述模拟数据的所述k-链节状态比对二者的所述最大错配(即,所述2D碱基调用中所需的计算复杂性)。所述上部迹线表示碱基空间比对。对于低于60%的1D碱基调用所述比对基本失败。不仅这会妨碍所述2D碱基调用进行改进(如图12和图13中所示),而且这也意味着所述比对不能用于约束所述2D维特比方法。所述下部迹线显示了所述k-链节状态比对。这显示了超过50%的1D碱基调用的合理比对。此外,对于较高1D碱基调用,在所述碱基空间比对进行工作的情况下,所述k-链节状态比对的所述比对错配小得多。这容许所述2D维特比方法受到更加严格的约束,这显著地降低了存储和计算要求。
精确的估计比对是合乎需要的,因为它允许对所述靶序列的所述估计使用所述多维模型进行更严格的约束。这进而可以增加降低生产所述靶序列的所述估计所需的处理要求,这在受到处理能力的实际限制时可以改进估计的精确度。
所述提供最精确的估计比对映射的方法可以取决于各种实验因素,如测量系统、样品、环境温度和所述k-链节类型。然而,所述各种比对方法可以很容易对于给定类型的系统和实验条件相对于彼此进行评价而确定最精确的事物。
所述以下结果证明了其中实施所述比对步骤S3的所述第二方法提供优于实施所述比对步骤S3的第一方法的优点的情况。
对于已知的800个碱基的DNA序列和其反向互补物的一对测量系列,基于通过在图2中所示和以上描述的所述类型的测量系统8的已知类型上的实验推导的特性进行模拟。由于所述两个碱基序列具有预定的关系以及控制了所述测量序列如何构造,则所述两个测量序列之间的所述真实比对映射是已知的。许多这种模拟进行实施,以上描述的所述第一和第二类型的方法估计所述比对映射。
这些估计比对映射然后通过计算表示使用以下步骤计算的所述估计比对映射的精度的评分对比于所述真实比对映射。
所述真实比对映射和估计比对映射以明显的表示法表示为笛卡尔坐标的列表:[(x1,y1),(x2,y2),(x2,y2),…,(xN,yN)],其中N是所述比对映射的长度,每个xi是指所述第一序列中的测量,而每个yi是指在第二序列中的测量。在形成所述比对映射的这种表达中,所述序列中的任何间隙(间隙)具有重复的值。
所述评分如下进行推导。对于真实比对映射的所述列表中的每个条目,识别出具有相同xi值的所述估计比对映射的列表中的所有条目。然后,所述真实比对映射的所述列表的所述yi值与所述估计比对映射的列表的所述一个或多个yi值进行对比。选取所述真实列表的所述yi和所述估计列表的所述yi之间的最大绝对差。找出所述真实列表中的所有条目中所有这种值的所述最大值。这提供了所述两个比对映射的最大垂直偏移。用所述前者描述中相互变化的xi和yi重复所述过程会产生最大水平差异。给予估计比对映射的所述评分随后是所述最大水平和最大垂直差异的最大值。因此,较低评分指示更精确的估计比对。
关于100对系列测量的评分绘制于图18中,其中对于所述第一和第二方法的所述评分都分别沿着所述垂直和水平轴绘制。在任何情况下所述评分都不等于零,但在明显大多数情况下,所述第二方法会产生比所述第一方法更精确的估计比对(即,较低分数)。
序列表
<110> 牛津楠路珀尔科技有限公司
<120> 由多维测量分析聚合物
<130> N401218WO
<150> GB 1405090.0
<151> 2014-03-21
<150> GB 1418373.5
<151> 2014-10-16
<160> 9
<170> PatentIn version 3.5
<210> 1
<211> 558
<212> DNA
<213> 人工序列
<220>
<223> MS-(B1)8 = MS-(D90N/D91N/D93N/D118R/D134R/E139K)8
<400> 1
atgggtctgg ataatgaact gagcctggtg gacggtcaag atcgtaccct gacggtgcaa 60
caatgggata cctttctgaa tggcgttttt ccgctggatc gtaatcgcct gacccgtgaa 120
tggtttcatt ccggtcgcgc aaaatatatc gtcgcaggcc cgggtgctga cgaattcgaa 180
ggcacgctgg aactgggtta tcagattggc tttccgtggt cactgggcgt tggtatcaac 240
ttctcgtaca ccacgccgaa tattctgatc aacaatggta acattaccgc accgccgttt 300
ggcctgaaca gcgtgattac gccgaacctg tttccgggtg ttagcatctc tgcccgtctg 360
ggcaatggtc cgggcattca agaagtggca acctttagtg tgcgcgtttc cggcgctaaa 420
ggcggtgtcg cggtgtctaa cgcccacggt accgttacgg gcgcggccgg cggtgtcctg 480
ctgcgtccgt tcgcgcgcct gattgcctct accggcgaca gcgttacgac ctatggcgaa 540
ccgtggaata tgaactaa 558
<210> 2
<211> 184
<212> PRT
<213> 人工序列
<220>
<223> MS-(B1)8 = MS-(D90N/D91N/D93N/D118R/D134R/E139K)8
<400> 2
Gly Leu Asp Asn Glu Leu Ser Leu Val Asp Gly Gln Asp Arg Thr Leu
1 5 10 15
Thr Val Gln Gln Trp Asp Thr Phe Leu Asn Gly Val Phe Pro Leu Asp
20 25 30
Arg Asn Arg Leu Thr Arg Glu Trp Phe His Ser Gly Arg Ala Lys Tyr
35 40 45
Ile Val Ala Gly Pro Gly Ala Asp Glu Phe Glu Gly Thr Leu Glu Leu
50 55 60
Gly Tyr Gln Ile Gly Phe Pro Trp Ser Leu Gly Val Gly Ile Asn Phe
65 70 75 80
Ser Tyr Thr Thr Pro Asn Ile Leu Ile Asn Asn Gly Asn Ile Thr Ala
85 90 95
Pro Pro Phe Gly Leu Asn Ser Val Ile Thr Pro Asn Leu Phe Pro Gly
100 105 110
Val Ser Ile Ser Ala Arg Leu Gly Asn Gly Pro Gly Ile Gln Glu Val
115 120 125
Ala Thr Phe Ser Val Arg Val Ser Gly Ala Lys Gly Gly Val Ala Val
130 135 140
Ser Asn Ala His Gly Thr Val Thr Gly Ala Ala Gly Gly Val Leu Leu
145 150 155 160
Arg Pro Phe Ala Arg Leu Ile Ala Ser Thr Gly Asp Ser Val Thr Thr
165 170 175
Tyr Gly Glu Pro Trp Asn Met Asn
180
<210> 3
<211> 558
<212> DNA
<213> 人工序列
<220>
<223> MS-(B2)8 = MS-(L88N/D90N/D91N/D93N/D118R/D134R/E139K)8
<400> 3
atgggtctgg ataatgaact gagcctggtg gacggtcaag atcgtaccct gacggtgcaa 60
caatgggata cctttctgaa tggcgttttt ccgctggatc gtaatcgcct gacccgtgaa 120
tggtttcatt ccggtcgcgc aaaatatatc gtcgcaggcc cgggtgctga cgaattcgaa 180
ggcacgctgg aactgggtta tcagattggc tttccgtggt cactgggcgt tggtatcaac 240
ttctcgtaca ccacgccgaa tattaacatc aacaatggta acattaccgc accgccgttt 300
ggcctgaaca gcgtgattac gccgaacctg tttccgggtg ttagcatctc tgcccgtctg 360
ggcaatggtc cgggcattca agaagtggca acctttagtg tgcgcgtttc cggcgctaaa 420
ggcggtgtcg cggtgtctaa cgcccacggt accgttacgg gcgcggccgg cggtgtcctg 480
ctgcgtccgt tcgcgcgcct gattgcctct accggcgaca gcgttacgac ctatggcgaa 540
ccgtggaata tgaactaa 558
<210> 4
<211> 184
<212> PRT
<213> 人工序列
<220>
<223> MS-(B2)8 = MS-(L88N/D90N/D91N/D93N/D118R/D134R/E139K)8
<400> 4
Gly Leu Asp Asn Glu Leu Ser Leu Val Asp Gly Gln Asp Arg Thr Leu
1 5 10 15
Thr Val Gln Gln Trp Asp Thr Phe Leu Asn Gly Val Phe Pro Leu Asp
20 25 30
Arg Asn Arg Leu Thr Arg Glu Trp Phe His Ser Gly Arg Ala Lys Tyr
35 40 45
Ile Val Ala Gly Pro Gly Ala Asp Glu Phe Glu Gly Thr Leu Glu Leu
50 55 60
Gly Tyr Gln Ile Gly Phe Pro Trp Ser Leu Gly Val Gly Ile Asn Phe
65 70 75 80
Ser Tyr Thr Thr Pro Asn Ile Asn Ile Asn Asn Gly Asn Ile Thr Ala
85 90 95
Pro Pro Phe Gly Leu Asn Ser Val Ile Thr Pro Asn Leu Phe Pro Gly
100 105 110
Val Ser Ile Ser Ala Arg Leu Gly Asn Gly Pro Gly Ile Gln Glu Val
115 120 125
Ala Thr Phe Ser Val Arg Val Ser Gly Ala Lys Gly Gly Val Ala Val
130 135 140
Ser Asn Ala His Gly Thr Val Thr Gly Ala Ala Gly Gly Val Leu Leu
145 150 155 160
Arg Pro Phe Ala Arg Leu Ile Ala Ser Thr Gly Asp Ser Val Thr Thr
165 170 175
Tyr Gly Glu Pro Trp Asn Met Asn
180
<210> 5
<211> 485
<212> PRT
<213> 大肠杆菌
<400> 5
Met Met Asn Asp Gly Lys Gln Gln Ser Thr Phe Leu Phe His Asp Tyr
1 5 10 15
Glu Thr Phe Gly Thr His Pro Ala Leu Asp Arg Pro Ala Gln Phe Ala
20 25 30
Ala Ile Arg Thr Asp Ser Glu Phe Asn Val Ile Gly Glu Pro Glu Val
35 40 45
Phe Tyr Cys Lys Pro Ala Asp Asp Tyr Leu Pro Gln Pro Gly Ala Val
50 55 60
Leu Ile Thr Gly Ile Thr Pro Gln Glu Ala Arg Ala Lys Gly Glu Asn
65 70 75 80
Glu Ala Ala Phe Ala Ala Arg Ile His Ser Leu Phe Thr Val Pro Lys
85 90 95
Thr Cys Ile Leu Gly Tyr Asn Asn Val Arg Phe Asp Asp Glu Val Thr
100 105 110
Arg Asn Ile Phe Tyr Arg Asn Phe Tyr Asp Pro Tyr Ala Trp Ser Trp
115 120 125
Gln His Asp Asn Ser Arg Trp Asp Leu Leu Asp Val Met Arg Ala Cys
130 135 140
Tyr Ala Leu Arg Pro Glu Gly Ile Asn Trp Pro Glu Asn Asp Asp Gly
145 150 155 160
Leu Pro Ser Phe Arg Leu Glu His Leu Thr Lys Ala Asn Gly Ile Glu
165 170 175
His Ser Asn Ala His Asp Ala Met Ala Asp Val Tyr Ala Thr Ile Ala
180 185 190
Met Ala Lys Leu Val Lys Thr Arg Gln Pro Arg Leu Phe Asp Tyr Leu
195 200 205
Phe Thr His Arg Asn Lys His Lys Leu Met Ala Leu Ile Asp Val Pro
210 215 220
Gln Met Lys Pro Leu Val His Val Ser Gly Met Phe Gly Ala Trp Arg
225 230 235 240
Gly Asn Thr Ser Trp Val Ala Pro Leu Ala Trp His Pro Glu Asn Arg
245 250 255
Asn Ala Val Ile Met Val Asp Leu Ala Gly Asp Ile Ser Pro Leu Leu
260 265 270
Glu Leu Asp Ser Asp Thr Leu Arg Glu Arg Leu Tyr Thr Ala Lys Thr
275 280 285
Asp Leu Gly Asp Asn Ala Ala Val Pro Val Lys Leu Val His Ile Asn
290 295 300
Lys Cys Pro Val Leu Ala Gln Ala Asn Thr Leu Arg Pro Glu Asp Ala
305 310 315 320
Asp Arg Leu Gly Ile Asn Arg Gln His Cys Leu Asp Asn Leu Lys Ile
325 330 335
Leu Arg Glu Asn Pro Gln Val Arg Glu Lys Val Val Ala Ile Phe Ala
340 345 350
Glu Ala Glu Pro Phe Thr Pro Ser Asp Asn Val Asp Ala Gln Leu Tyr
355 360 365
Asn Gly Phe Phe Ser Asp Ala Asp Arg Ala Ala Met Lys Ile Val Leu
370 375 380
Glu Thr Glu Pro Arg Asn Leu Pro Ala Leu Asp Ile Thr Phe Val Asp
385 390 395 400
Lys Arg Ile Glu Lys Leu Leu Phe Asn Tyr Arg Ala Arg Asn Phe Pro
405 410 415
Gly Thr Leu Asp Tyr Ala Glu Gln Gln Arg Trp Leu Glu His Arg Arg
420 425 430
Gln Val Phe Thr Pro Glu Phe Leu Gln Gly Tyr Ala Asp Glu Leu Gln
435 440 445
Met Leu Val Gln Gln Tyr Ala Asp Asp Lys Glu Lys Val Ala Leu Leu
450 455 460
Lys Ala Leu Trp Gln Tyr Ala Glu Glu Ile Val Ser Gly Ser Gly His
465 470 475 480
His His His His His
485
<210> 6
<211> 268
<212> PRT
<213> 大肠杆菌
<400> 6
Met Lys Phe Val Ser Phe Asn Ile Asn Gly Leu Arg Ala Arg Pro His
1 5 10 15
Gln Leu Glu Ala Ile Val Glu Lys His Gln Pro Asp Val Ile Gly Leu
20 25 30
Gln Glu Thr Lys Val His Asp Asp Met Phe Pro Leu Glu Glu Val Ala
35 40 45
Lys Leu Gly Tyr Asn Val Phe Tyr His Gly Gln Lys Gly His Tyr Gly
50 55 60
Val Ala Leu Leu Thr Lys Glu Thr Pro Ile Ala Val Arg Arg Gly Phe
65 70 75 80
Pro Gly Asp Asp Glu Glu Ala Gln Arg Arg Ile Ile Met Ala Glu Ile
85 90 95
Pro Ser Leu Leu Gly Asn Val Thr Val Ile Asn Gly Tyr Phe Pro Gln
100 105 110
Gly Glu Ser Arg Asp His Pro Ile Lys Phe Pro Ala Lys Ala Gln Phe
115 120 125
Tyr Gln Asn Leu Gln Asn Tyr Leu Glu Thr Glu Leu Lys Arg Asp Asn
130 135 140
Pro Val Leu Ile Met Gly Asp Met Asn Ile Ser Pro Thr Asp Leu Asp
145 150 155 160
Ile Gly Ile Gly Glu Glu Asn Arg Lys Arg Trp Leu Arg Thr Gly Lys
165 170 175
Cys Ser Phe Leu Pro Glu Glu Arg Glu Trp Met Asp Arg Leu Met Ser
180 185 190
Trp Gly Leu Val Asp Thr Phe Arg His Ala Asn Pro Gln Thr Ala Asp
195 200 205
Arg Phe Ser Trp Phe Asp Tyr Arg Ser Lys Gly Phe Asp Asp Asn Arg
210 215 220
Gly Leu Arg Ile Asp Leu Leu Leu Ala Ser Gln Pro Leu Ala Glu Cys
225 230 235 240
Cys Val Glu Thr Gly Ile Asp Tyr Glu Ile Arg Ser Met Glu Lys Pro
245 250 255
Ser Asp His Ala Pro Val Trp Ala Thr Phe Arg Arg
260 265
<210> 7
<211> 666
<212> PRT
<213> 嗜热栖热菌
<400> 7
Met Arg Asp Arg Val Arg Trp Arg Val Leu Ser Leu Pro Pro Leu Ala
1 5 10 15
Gln Trp Arg Glu Val Met Ala Ala Leu Glu Val Gly Pro Glu Ala Ala
20 25 30
Leu Ala Tyr Trp His Arg Gly Phe Arg Arg Lys Glu Asp Leu Asp Pro
35 40 45
Pro Leu Ala Leu Leu Pro Leu Lys Gly Leu Arg Glu Ala Ala Ala Leu
50 55 60
Leu Glu Glu Ala Leu Arg Gln Gly Lys Arg Ile Arg Val His Gly Asp
65 70 75 80
Tyr Asp Ala Asp Gly Leu Thr Gly Thr Ala Ile Leu Val Arg Gly Leu
85 90 95
Ala Ala Leu Gly Ala Asp Val His Pro Phe Ile Pro His Arg Leu Glu
100 105 110
Glu Gly Tyr Gly Val Leu Met Glu Arg Val Pro Glu His Leu Glu Ala
115 120 125
Ser Asp Leu Phe Leu Thr Val Asp Cys Gly Ile Thr Asn His Ala Glu
130 135 140
Leu Arg Glu Leu Leu Glu Asn Gly Val Glu Val Ile Val Thr Asp His
145 150 155 160
His Thr Pro Gly Lys Thr Pro Ser Pro Gly Leu Val Val His Pro Ala
165 170 175
Leu Thr Pro Asp Leu Lys Glu Lys Pro Thr Gly Ala Gly Val Val Phe
180 185 190
Leu Leu Leu Trp Ala Leu His Glu Arg Leu Gly Leu Pro Pro Pro Leu
195 200 205
Glu Tyr Ala Asp Leu Ala Ala Val Gly Thr Ile Ala Asp Val Ala Pro
210 215 220
Leu Trp Gly Trp Asn Arg Ala Leu Val Lys Glu Gly Leu Ala Arg Ile
225 230 235 240
Pro Ala Ser Ser Trp Val Gly Leu Arg Leu Leu Ala Glu Ala Val Gly
245 250 255
Tyr Thr Gly Lys Ala Val Glu Val Ala Phe Arg Ile Ala Pro Arg Ile
260 265 270
Asn Ala Ala Ser Arg Leu Gly Glu Ala Glu Lys Ala Leu Arg Leu Leu
275 280 285
Leu Thr Asp Asp Ala Ala Glu Ala Gln Ala Leu Val Gly Glu Leu His
290 295 300
Arg Leu Asn Ala Arg Arg Gln Thr Leu Glu Glu Ala Met Leu Arg Lys
305 310 315 320
Leu Leu Pro Gln Ala Asp Pro Glu Ala Lys Ala Ile Val Leu Leu Asp
325 330 335
Pro Glu Gly His Pro Gly Val Met Gly Ile Val Ala Ser Arg Ile Leu
340 345 350
Glu Ala Thr Leu Arg Pro Val Phe Leu Val Ala Gln Gly Lys Gly Thr
355 360 365
Val Arg Ser Leu Ala Pro Ile Ser Ala Val Glu Ala Leu Arg Ser Ala
370 375 380
Glu Asp Leu Leu Leu Arg Tyr Gly Gly His Lys Glu Ala Ala Gly Phe
385 390 395 400
Ala Met Asp Glu Ala Leu Phe Pro Ala Phe Lys Ala Arg Val Glu Ala
405 410 415
Tyr Ala Ala Arg Phe Pro Asp Pro Val Arg Glu Val Ala Leu Leu Asp
420 425 430
Leu Leu Pro Glu Pro Gly Leu Leu Pro Gln Val Phe Arg Glu Leu Ala
435 440 445
Leu Leu Glu Pro Tyr Gly Glu Gly Asn Pro Glu Pro Leu Phe Leu Leu
450 455 460
Phe Gly Ala Pro Glu Glu Ala Arg Arg Leu Gly Glu Gly Arg His Leu
465 470 475 480
Ala Phe Arg Leu Lys Gly Val Arg Val Leu Ala Trp Lys Gln Gly Asp
485 490 495
Leu Ala Leu Pro Pro Glu Val Glu Val Ala Gly Leu Leu Ser Glu Asn
500 505 510
Ala Trp Asn Gly His Leu Ala Tyr Glu Val Gln Ala Val Asp Leu Arg
515 520 525
Lys Pro Glu Ala Leu Glu Gly Gly Ile Ala Pro Phe Ala Tyr Pro Leu
530 535 540
Pro Leu Leu Glu Ala Leu Ala Arg Ala Arg Leu Gly Glu Gly Val Tyr
545 550 555 560
Val Pro Glu Asp Asn Pro Glu Gly Leu Asp Tyr Ala Arg Lys Ala Gly
565 570 575
Phe Arg Leu Leu Pro Pro Glu Glu Ala Gly Leu Trp Leu Gly Leu Pro
580 585 590
Pro Arg Pro Val Leu Gly Arg Arg Val Glu Val Ala Leu Gly Arg Glu
595 600 605
Ala Arg Ala Arg Leu Ser Ala Pro Pro Val Leu His Thr Pro Glu Ala
610 615 620
Arg Leu Lys Ala Leu Val His Arg Arg Leu Leu Phe Ala Tyr Glu Arg
625 630 635 640
Arg His Pro Gly Leu Phe Ser Glu Ala Leu Leu Ala Tyr Trp Glu Val
645 650 655
Asn Arg Val Gln Glu Pro Ala Gly Ser Pro
660 665
<210> 8
<211> 226
<212> PRT
<213> 噬菌体λ
<400> 8
Met Thr Pro Asp Ile Ile Leu Gln Arg Thr Gly Ile Asp Val Arg Ala
1 5 10 15
Val Glu Gln Gly Asp Asp Ala Trp His Lys Leu Arg Leu Gly Val Ile
20 25 30
Thr Ala Ser Glu Val His Asn Val Ile Ala Lys Pro Arg Ser Gly Lys
35 40 45
Lys Trp Pro Asp Met Lys Met Ser Tyr Phe His Thr Leu Leu Ala Glu
50 55 60
Val Cys Thr Gly Val Ala Pro Glu Val Asn Ala Lys Ala Leu Ala Trp
65 70 75 80
Gly Lys Gln Tyr Glu Asn Asp Ala Arg Thr Leu Phe Glu Phe Thr Ser
85 90 95
Gly Val Asn Val Thr Glu Ser Pro Ile Ile Tyr Arg Asp Glu Ser Met
100 105 110
Arg Thr Ala Cys Ser Pro Asp Gly Leu Cys Ser Asp Gly Asn Gly Leu
115 120 125
Glu Leu Lys Cys Pro Phe Thr Ser Arg Asp Phe Met Lys Phe Arg Leu
130 135 140
Gly Gly Phe Glu Ala Ile Lys Ser Ala Tyr Met Ala Gln Val Gln Tyr
145 150 155 160
Ser Met Trp Val Thr Arg Lys Asn Ala Trp Tyr Phe Ala Asn Tyr Asp
165 170 175
Pro Arg Met Lys Arg Glu Gly Leu His Tyr Val Val Ile Glu Arg Asp
180 185 190
Glu Lys Tyr Met Ala Ser Phe Asp Glu Ile Val Pro Glu Phe Ile Glu
195 200 205
Lys Met Asp Glu Ala Leu Ala Glu Ile Gly Phe Val Phe Gly Glu Gln
210 215 220
Trp Arg
225
<210> 9
<211> 608
<212> PRT
<213> 噬菌体phi-29
<400> 9
Met Lys His Met Pro Arg Lys Met Tyr Ser Cys Ala Phe Glu Thr Thr
1 5 10 15
Thr Lys Val Glu Asp Cys Arg Val Trp Ala Tyr Gly Tyr Met Asn Ile
20 25 30
Glu Asp His Ser Glu Tyr Lys Ile Gly Asn Ser Leu Asp Glu Phe Met
35 40 45
Ala Trp Val Leu Lys Val Gln Ala Asp Leu Tyr Phe His Asn Leu Lys
50 55 60
Phe Asp Gly Ala Phe Ile Ile Asn Trp Leu Glu Arg Asn Gly Phe Lys
65 70 75 80
Trp Ser Ala Asp Gly Leu Pro Asn Thr Tyr Asn Thr Ile Ile Ser Arg
85 90 95
Met Gly Gln Trp Tyr Met Ile Asp Ile Cys Leu Gly Tyr Lys Gly Lys
100 105 110
Arg Lys Ile His Thr Val Ile Tyr Asp Ser Leu Lys Lys Leu Pro Phe
115 120 125
Pro Val Lys Lys Ile Ala Lys Asp Phe Lys Leu Thr Val Leu Lys Gly
130 135 140
Asp Ile Asp Tyr His Lys Glu Arg Pro Val Gly Tyr Lys Ile Thr Pro
145 150 155 160
Glu Glu Tyr Ala Tyr Ile Lys Asn Asp Ile Gln Ile Ile Ala Glu Ala
165 170 175
Leu Leu Ile Gln Phe Lys Gln Gly Leu Asp Arg Met Thr Ala Gly Ser
180 185 190
Asp Ser Leu Lys Gly Phe Lys Asp Ile Ile Thr Thr Lys Lys Phe Lys
195 200 205
Lys Val Phe Pro Thr Leu Ser Leu Gly Leu Asp Lys Glu Val Arg Tyr
210 215 220
Ala Tyr Arg Gly Gly Phe Thr Trp Leu Asn Asp Arg Phe Lys Glu Lys
225 230 235 240
Glu Ile Gly Glu Gly Met Val Phe Asp Val Asn Ser Leu Tyr Pro Ala
245 250 255
Gln Met Tyr Ser Arg Leu Leu Pro Tyr Gly Glu Pro Ile Val Phe Glu
260 265 270
Gly Lys Tyr Val Trp Asp Glu Asp Tyr Pro Leu His Ile Gln His Ile
275 280 285
Arg Cys Glu Phe Glu Leu Lys Glu Gly Tyr Ile Pro Thr Ile Gln Ile
290 295 300
Lys Arg Ser Arg Phe Tyr Lys Gly Asn Glu Tyr Leu Lys Ser Ser Gly
305 310 315 320
Gly Glu Ile Ala Asp Leu Trp Leu Ser Asn Val Asp Leu Glu Leu Met
325 330 335
Lys Glu His Tyr Asp Leu Tyr Asn Val Glu Tyr Ile Ser Gly Leu Lys
340 345 350
Phe Lys Ala Thr Thr Gly Leu Phe Lys Asp Phe Ile Asp Lys Trp Thr
355 360 365
Tyr Ile Lys Thr Thr Ser Glu Gly Ala Ile Lys Gln Leu Ala Lys Leu
370 375 380
Met Leu Asn Ser Leu Tyr Gly Lys Phe Ala Ser Asn Pro Asp Val Thr
385 390 395 400
Gly Lys Val Pro Tyr Leu Lys Glu Asn Gly Ala Leu Gly Phe Arg Leu
405 410 415
Gly Glu Glu Glu Thr Lys Asp Pro Val Tyr Thr Pro Met Gly Val Phe
420 425 430
Ile Thr Ala Trp Ala Arg Tyr Thr Thr Ile Thr Ala Ala Gln Ala Cys
435 440 445
Tyr Asp Arg Ile Ile Tyr Cys Asp Thr Asp Ser Ile His Leu Thr Gly
450 455 460
Thr Glu Ile Pro Asp Val Ile Lys Asp Ile Val Asp Pro Lys Lys Leu
465 470 475 480
Gly Tyr Trp Ala His Glu Ser Thr Phe Lys Arg Ala Lys Tyr Leu Arg
485 490 495
Gln Lys Thr Tyr Ile Gln Asp Ile Tyr Met Lys Glu Val Asp Gly Lys
500 505 510
Leu Val Glu Gly Ser Pro Asp Asp Tyr Thr Asp Ile Lys Phe Ser Val
515 520 525
Lys Cys Ala Gly Met Thr Asp Lys Ile Lys Lys Glu Val Thr Phe Glu
530 535 540
Asn Phe Lys Val Gly Phe Ser Arg Lys Met Lys Pro Lys Pro Val Gln
545 550 555 560
Val Pro Gly Gly Val Val Leu Val Asp Asp Thr Phe Thr Ile Lys Ser
565 570 575
Gly Gly Ser Ala Trp Ser His Pro Gln Phe Glu Lys Gly Gly Gly Ser
580 585 590
Gly Gly Gly Ser Gly Gly Ser Ala Trp Ser His Pro Gln Phe Glu Lys
595 600 605
- 还没有人留言评论。精彩留言会获得点赞!