一种突变型Tn5转座酶及其制备方法和应用与流程
本发明属于生物技术领域,具体涉及一种突变型Tn5转座酶及其制备方法和应用。
背景技术:
转座酶是一大类细菌来源的蛋白,通过结合转座子序列末端并催化其移动到基因组上随机位置实现“剪切-粘贴”或“复制-粘贴”型的DNA插入的作用。转座酶的种类很多,最先被发现的是能使玉米随机改变颜色的Tn3转座子。天然的转座子在生物中活性很低,在进化过程中起到随机改变遗传物质并推动进化的重要作用。转座酶可以在基因组上引入随机突变的重要性质也被应用于最近迅速发展的二代测序技术中的建库过程,可以在基因组上随机加入已知序列接头用于测序分析。
Tn5转座酶是转座酶的一种,Tn5转座酶进行转座功能的实现需要三个部分共同作用:转座子序列、转座酶、靶DNA位置。野生型Tn5转座酶的活性也是很低的,以减少对宿主产生致命突变的风险。
Tn5转座酶活性很低的部分原因在于其蛋白的N端和C端在三维空间构象上相互接近,并发挥相互抑制的作用。对于N端或C端的突变可以得到高活性形式的突变形转座酶,如L372P,正常的372位亮氨酸处于一个α螺旋中,用丙氨酸取代后使α螺旋结构被破坏,从而产生了C端构象的改变,与N端在空间上发生分离,从而得到活性大大增加的突变蛋白。同时Tn5蛋白含有一个中心催化结构域DDE,即不同位置的D/D/E三个残基在三维构象上形成一个中心的酸性基团,构成能结合二价离子的环形位置,该结构域的已知功能为促进蛋白在DNA上的行进,对这三个酸性残基的分别交换突变可以得到催化性增加、行进性提升的突变蛋白。
目前主流技术为对转座酶表达序列进行定点突变,通过原核表达产生有活性的突变蛋白,对其功能进行体外验证。由此得到最知名的突变即为上文提到的,N端和C端空间距离得到高活性蛋白和改变催化基团DDE基团内残基得到的催化活性增加的突变蛋白。
虽然现在主流使用的突变型Tn5转座酶转座插入活性和对DNA的亲和性都得到了有效增强,但在目前酶的活性和稳定性提升的基础上还是存在靶DNA序列偏好性,偏好性是转座酶应用于建库的一个短板,在建库过程中加接头的偏好性会导致结果的不均一和缺失,导致结果的覆盖度有问题。
技术实现要素:
本发明的目的是在于提供一种突变型Tn5转座酶及其制备方法和应用,降低Tn5转座酶对DNA靶序列插入位点选择性,使测序DNA建库分布更均一,并具有更好的覆盖度,适应高通量测序建库的需求。
为达到上述目的,本发明的技术方案如下:
一种突变型Tn5转座酶,所述突变型Tn5转座酶的氨基酸序列为EK/LPTn5转座酶的氨基酸序列定点突变所得,所述定点突变是指D97E,D188E、E326D中的至少两个;其中,突变位点1:D97E,即EK/LP Tn5转座酶基酸序列中第97位的丙氨酸突变为谷氨酸;突变位点2:D188E,即EK/LP Tn5转座酶基酸序列中第188位的丙氨酸突变为谷氨酸;突变位点3:E326D,即EK/LP Tn5转座酶基酸序列中第326位的谷氨酸突变为丙氨酸。
优选的,一种突变型Tn5转座酶,包含3个定点突变:D97E,D188E、E326D,该突变型Tn5转座酶的氨基酸序列如SEQ NO.2所示。
本发明还提供编码氨基酸序列如SEQ NO.2所示的突变型Tn5转座酶的基因。
更优选的,还提供编码氨基酸序列如SEQ NO.2所示的突变型Tn5转座酶的如SEQ NO.3所示的核苷酸序列。需要说明的是,由于同一氨基酸可能有多种不同的密码子来决定,所以编码上述突变型Tn5转座酶的核苷酸序列并不局限于SEQ NO.3所示序列,也可以是由与SEQ NO.3所示核苷酸序列突变一个或几个核苷酸形成同义突变得到可编码相同氨基酸序列的核苷酸序列。
优选的,一种突变型Tn5转座酶,包含2个定点突变:D97E、D188E,编码该突变型Tn5转座酶的核苷酸序列如SEQ NO.4所示。
优选的,一种突变型Tn5转座酶,包含2个定点突变:D188E、E326D,编码该突变型Tn5转座酶的核苷酸序列如SEQ NO.5所示。
优选的,一种突变型Tn5转座酶,包含2个定点突变:D97E、E326D,编码该突变型Tn5转座酶的核苷酸序列如SEQ NO.6所示。
本发明所述突变型Tn5转座酶的制备方法,包括如下步骤:
1)构建含编码所述突变型Tn5转座酶的核苷酸序列的载体
利用含有突变位点信息的引物,对含有EK/LP Tn5转座酶基因的质粒进行PCR扩增;PCR扩增得到目的条带后切胶回收,利用Dpn1酶消化原始模板质粒;产物纯化后转化到感受态细胞中,涂板挑单克隆鉴定即可得到含突变型Tn5转座酶基因的载体;
2)得到重组细胞
将步骤1)得到的载体转化到B121宿主细胞中,利用抗生素筛选得到正确转化的重组细胞,并挑单克隆;
3)培养并收集重组细胞,提取纯化突变型Tn5转座酶。
进一步,步骤1)中所述含有突变位点信息的引物包含了需要突变的位点和替换过的碱基,具体序列如下:包含引入三个突变位点D97E,D188E、E326D的引物序列,包括:
A97-f:gccattgaggaaaccacct;
A97-r:aggtggtttcctcaatggc;
B188-f:gcggtctgtgaacgcgaagc;
B188-r:gcttcgcgttcacagaccgc;
C326-f:cggatcgacgagttccata;
C326-r:tatggaactcgtcgatccg;
或,引入二个突变位点D97E、D188E的引物序列,包括:
A97-f:gccattgaggaaaccacct;
A97-r:aggtggtttcctcaatggc;
B188-f:gcggtctgtgaacgcgaagc;
B188-r:gcttcgcgttcacagaccgc;
或,引入二个突变位点D188E、E326D的引物序列,包括:
B188-f:gcggtctgtgaacgcgaagc;
B188-r:gcttcgcgttcacagaccgc;
C326-f:cggatcgacgagttccata;
C326-r:tatggaactcgtcgatccg;
或,引入二个突变位点D97E、E326D的引物序列,包括:
C326-f:cggatcgacgagttccata;
C326-r:tatggaactcgtcgatccg;
A97-f:gccattgaggaaaccacct;
A97-r:aggtggtttcctcaatggc。
本发明上述的突变型Tn5转座酶可应用于DNA建库中。
本发明还提供一种利用所述突变型Tn5转座酶在DNA建库过程中进行基因组DNA片段化的反应体系:10~25mM HEPES缓冲液,pH 7.2~7.6;0.1~5mM beta-巯基乙醇;10~80μg/ml牛血清白蛋白;0.1~0.2M谷氨酸钾;0.2~0.5mM MnSO4;0.2~1mM KCl;100~500nM所述突变型Tn5转座酶;50~100ng基因组DNA;0.1~1ng含有19bp转座子序列的接头引物;反应程序:37℃,10min~1h。
进一步,所述含有19bp转座子序列的接头引物包括:转座酶识别序列:AGATGTGTATAAGAGACAG、第一接头序列:AATGATACGGCGACCACCGAGATCTACACTCGTCGGCAGCGTC;第二接头序列:CAAGCAGAAGACGGCATACGAGATGTCTCGTGGGCTCGG。
经测试,与EK/LP Tn5转座酶相比,使用本发明改造后的所述突变型Tn5转座酶进行加接头的测序文库均一性明显提高。
本发明的有益效果:
本发明对现有已改造的EK/LP Tn5转座酶进行降低DNA偏好性的定向改造,具体是改变其中心催化元件核心残基D97、D188、E326,从而通过定点突变改进了Tn5转座酶蛋白序列和构象,提高了Tn5转座酶对成对末端复合物的结合亲和性,基于提高的DNA结合亲和性和催化能力,从而消除了对DNA片段切断的碱基偏好性。本发明对EK/LP Tn5转座酶的中心催化元件残基的双突变,改变了对DNA碱基依赖性的结合而改良打断作用的碱基偏好性。
本发明所提供的突变型Tn5转座酶,改进了Tn5转座酶对DNA靶序列插入的偏好性,显著改善了DNA建库均一性,并使建库结果具有更好的覆盖度,显著改善的建库均一性,可以适当降低数值量,节约测序和分析成本。
本发明所设计的突变型Tn5转座酶的行进性增加,将其应用于DNA建库时设计了相对应的DNA片段化反应体系,对其中盐离子浓度和缓冲液都进行了调整,使反应更可控,更易于根据时间控制打断的片段大小。
附图说明
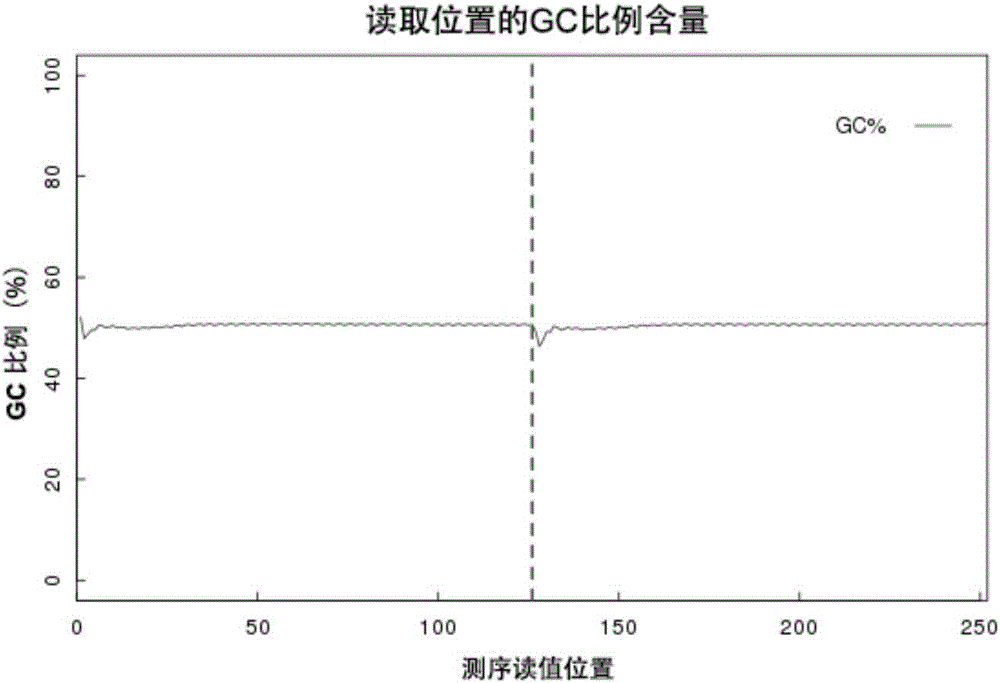
图1为现有EK/LP Tn5转座酶构建文库的GC偏好性分析结果图。
图2为本发明实施例4中突变型Tn5转座酶构建文库的GC偏好性分析结果图。
图3为本发明实施例7合成的突变型Tn5转座酶构建文库的GC偏好性分析结果图。
具体实施方式
以下结合具体实施例进一步详细描述本发明的技术方案。
实施例1氨基酸序列如SEQ ID NO.2所示的Tn5转座酶的制备方法,包括如下步骤:
1)构建含编码所述突变型Tn5转座酶的核苷酸序列的载体
利用基因合成的方法,合成包含了需要突变的位点和替换过的碱基的引物序列如下:
A97-f:gccattgaggaaaccacct;
A97-r:aggtggtttcctcaatggc;
B188-f:gcggtctgtgaacgcgaagc;
B188-r:gcttcgcgttcacagaccgc;
C326-f:cggatcgacgagttccata;
C326-r:tatggaactcgtcgatccg;
利用PCR对改造的EK/LP Tn5转座酶基因(其基因序列如SEQ ID NO.1所示)进行扩增,分别以引物A97-f和B188-r,B188-f和C326-r,C326-f和A97-r为引物,在50μl反应体系中,以含有EK/LP Tn5转座酶基因的质粒为模板,10μM的引物各加入2μl,以Phanta Max Super-Fidelity DNA Polymerase(由南京诺唯赞生物科技有限公司生产,Vazyme,货号P505)为DNA聚合酶。扩增条件为95℃ 30s;95℃ 15s;60℃ 15s;72℃ 30s-3min;72℃ 5min;共30个循环。
扩增结束后,在50μl反应体系中直接加入1μl DpnI,37℃恒温孵育2小时,消化原始质粒模板。以1%-1.5%(W/V)琼脂糖凝胶电泳,得到目的条带后切胶回收。将回收产物利用MutMultiS Fast Mutagenesis KitV2(由南京诺唯赞生物科技有限公司生产,Vazyme,货号C215)进行重组反应,37℃恒温孵育0.5小时。
取20μl冷却反应液,加入到100μl B121感受态细胞中,轻弹管壁数下混匀,在冰上放置30min。42℃热激90秒,冰水浴孵育2min。加入500μl LB培养基,37℃孵育10min充分复苏。37℃摇菌45min。取100μl菌液均匀涂布在含有氨苄青霉素的平板上。将平板倒置,于37℃过夜培养。第二天挑取单克隆,测序验证。测序结果表明:本发明合成的突变型Tn5转座酶的核苷酸序列如SEQ NO.3所示,氨基酸序列如SEQ NO.2所示。
实施例2将载体转化宿主细胞得到重组细胞:
将测序验证无误的载体,取10ng以同样转化方法转化到BL21感受态细胞中,涂布在含有氨苄青霉素的LB平板上,37℃过夜培养。第二天挑取单克隆。
实施例3培养并收集重组细胞,提取纯化突变型Tn5酶
具体步骤如下:
将单克隆重组细胞挑入3ml LB液体培养基中,摇培6-8h,然后转接扩大培养至300ml LB液体培养基中,摇培4-6h后,加入IPTG至终浓度为50mmol/L后继续摇培过夜,诱导目的蛋白表达。将300ml菌液分装至50ml离心管中,以5000rpm离心10min收集菌体。每100ml菌液离心后加入10ml洗脱缓冲液(50mmol/L Tris-HCl pH7.9;50mmol/L右旋糖;1mmol/L EDTA)重悬,冰上放置1h;3500rpm离心3min重新收集菌体,加入50ml预裂解缓冲液(洗脱缓冲液加4g/L溶菌酶),室温放置15min;加入50ml裂解缓冲液(10mmol/L Tris-HCl pH7.9;50mmol/L KCl;1mmol/L EDTA;1mmol/L PMSF;0.5%Tween-20(V/V);0.5%NP-40(V/V)),剧烈振荡混匀,75℃孵育1h,不时振荡,然后将裂解混合液转移至50ml离心管,4℃5000rpm离心15min,转移上清液至新的离心管中,加入30g硫酸铵,室温迅速混匀。15000rpm离心15min,将蛋白沉淀物重新悬浮至20ml洗脱缓冲液中,在储存缓冲液(50mmol/L Tris-HCl pH7.9;50mmol/L KCl;0.1mmol/L EDTA;0.5mmol/L PMSF;1mmol/L DTT;50%glycerol(V/V)中透析至少12h。透析后,用储存缓冲液1∶1稀释,储存于-80℃。
实施例4突变型Tn5转座酶和EK/LP Tn5转座酶的建库均一性比较
配制以基因组DNA为模板的处理体系,反应体系如下:25mM HEPES缓冲液,pH 7.4;1mM beta-巯基乙醇;50ug/ml牛血清白蛋白;0.1M谷氨酸钾;0.5mM MnSO4;0.5mM KCl;200nM实施例3所得的突变型Tn5转座酶;50ng基因组DNA;1ng含有19bp转座子序列的接头引物。反应程序:37℃30min。含有19bp转座子序列的接头引物包括:转座酶识别序列:AGATGTGTATAAGAGACAG、第一接头序列:AATGATACGGCGACCACCGAGATCTACACXXXXXXXXTCGTCGGCAGCGTC;第二接头序列:CAAGCAGAAGACGGCATACGAGATXXXXXXXXGTCTCGTGGGCTCGG;其中,XXXXXXXX为Index序列。
作为对比例的EK/LP Tn5转座酶进行DNA片段化的反应体系是常规反应体系为:100mM谷氨酸钾,25mM HEPES缓冲液(pH 7.4),50ug/ml牛血清白蛋白,1mM MgCl2,1mM beta-巯基乙醇,200nM Tn5转座酶,25nM DNA模板。
将2份100ng起始EK/LP Tn5转座酶及实施例1-3得到的突变转座酶打断处理过的DNA模板分别利用VAHTS Nano DNA Library Prep Kit for (Vazyme,ND601)进行末端修复和加接头连接,接着用试剂盒中的扩增模块进行文库扩增,得到文库。具体操作见试剂盒说明书。
使用荧光染料Qubit进行文库浓度测定,使用二代测序仪进行60M数据的读取,现有EK/LP Tn5转座酶、实施例1合成的突变型Tn5转座酶构建文库的GC偏好性分析结果分别参见图1、图2,分析数据在基因组上的均一性。
由图1可知,EK/LP Tn5转座酶构建的文库在数据前端均出现明显GC含量波动,表明EK/LP Tn5转座酶对片段化位点的某些碱基具有一定的偏好性。由图2可知,本发明实施例1所提供突变型Tn5转座酶构建的文库前端数据的GC含量波动甚微,说明本发明所述突变型Tn5转座酶片段化位点基本无偏好性。结果显示使用本发明设计的DNA片段化反应体系和实施例1-3所获得的突变型Tn5转座酶进行加接头的实验组文库均一性较使用EK/LP Tn5转座酶的明显提高。
实施例5包含D97E、D188E突变的突变序列如SEQ NO.4所示的突变型Tn5转座酶的制备和性能测试
使用以下两对引物对EK/LP Tn5转座酶进行突变改造,具体实施方法同实施例1-3:
A97-f:gccattgaggaaaccacct;
A97-r:aggtggtttcctcaatggc;
B188-f:gcggtctgtgaacgcgaagc;
B188-r:gcttcgcgttcacagaccgc。
所得突变型Tn5转座酶的核苷酸序列如SEQ NO.4所示,该突变型Tn5转座酶与EK/LP Tn5转座酶同时进行DNA片段化处理并进行文库构建,具体同实施例4,其GC偏好性测试数据表明:实施例5所提供的突变型Tn5转座酶构建的文库前端数据的GC含量波动甚微,说明该突变型Tn5转座酶片段化位点基本无偏好性,进行加接头的实验组文库均一性较使用EK/LPTn5转座酶的明显提高。
实施例6包含D188E、E326D突变的突变序列如SEQ NO.5所示的突变型Tn5转座酶的制备和性能测试
使用以下两对引物对EK/LP Tn5转座酶进行突变改造,具体实施方法同实施例1-4。
B188-f:gcggtctgtgaacgcgaagc;
B188-r:gcttcgcgttcacagaccgc;
C326-f:cggatcgacgagttccata;
C326-r:tatggaactcgtcgatccg。
所得突变型Tn5转座酶的核苷酸序列如SEQ NO.5所示,该突变型Tn5转座酶与EK/LP Tn5转座酶同时进行DNA片段化处理并进行文库构建,具体同实施例4,其GC偏好性测试数据表明:实施例6所提供的突变型Tn5转座酶构建的文库前端数据的GC含量波动甚微,说明该突变型Tn5转座酶片段化位点基本无偏好性,进行加接头的实验组文库均一性较使用EK/LP Tn5转座酶的明显提高。
实施例7包含D97E、E326D突变的突变序列如SEQ NO.6所示的突变型Tn5转座酶的制备和性能测试
使用以下两对引物对EK/LP Tn5转座酶进行突变改造,具体实施方法同同实施例1-4。
A97-f:gccattgaggaaaccacct;
A97-r:aggtggtttcctcaatggc;
C326-f:cggatcgacgagttccata;
C326-r:tatggaactcgtcgatccg。
所得突变型Tn5转座酶的核苷酸序列如SEQ NO.6所示,该突变型Tn5转座酶与EK/LP Tn5转座酶同时进行DNA片段化处理并进行文库构建,具体同实施例4,其GC偏好性如图3所示。
由图1、图3可知,实施例7所提供的突变型Tn5转座酶构建的文库前端数据的GC含量波动甚微,说明该突变型Tn5转座酶片段化位点基本无偏好性,进行加接头的实验组文库均一性较使用EK/LP Tn5转座酶的明显提高。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围中。
序 列 表
<110>南京诺唯赞生物科技有限公司
<120>一种突变型Tn5转座酶及其制备方法和应用
<160> 6
<210>SEQ ID NO. 1
<211>1429
<212>DNA
<213>人工合成
atgataactt ctgctcttca tcgtgcggcc gactgggcta aatctgtgtt ctcttcggcg 60
gcgctgggtg atcctcgccg tactgcccgc ttggttaacg tcgccgccca attggcaaaa 120
tattctggta aatcaataac catctcatca gagggtagta aagccatgca ggaaggcgct 180
taccgatttt accgcaatcc caacgtttct gccgaggcga tcagaaaggc tggcgccatg 240
caaacagtca agttggctca ggagtttccc gaactgctgg ccattgagga caccacctct 300
ttgagttatc gccaccaggt cgccgaagag cttggcaagc tgggctctat tcaggataaa 360
tcccgcggat ggtgggttca ctccgttctc ttgctcgagg ccaccacatt ccgcaccgta 420
ggattactgc atcaggagtg gtggatgcgc ccggatgacc ctgccgatgc ggatgaaaag 480
gagagtggca aatggctggc agcggccgca actagccggt tacgcatggg cagcatgatg 540
agcaacgtga ttgcggtctg tgaccgcgaa gccgatattc atgcttatct gcaggacagg 600
ctggcgcata acgagcgctt cgtggtgcgc tccaagcacc cacgcaagga cgtagagtct 660
gggttgtatc tgatcgacca tctgaagaac caaccggagt tgggtggcta tcagatcagc 720
attccgcaaa agggcgtggt ggataaacgc ggtaaacgta aaaatcgacc agcccgcaag 780
gcgagcttga gcctgcgcag tgggcgcatc acgctaaaac aggggaatat cacgctcaac 840
gcggtgctgg ccgaggagat taacccgccc aagggtgaga ccccgttgaa atggttgttg 900
ctgaccggcg aaccggtcga gtcgctagcc caagccttgc gcgtcatcga catttatacc 960
catcgctggc ggatcgagga gttccataag gcatggaaaa ccggagcagg agccgagagg 1020
caacgcatgg aggagccgga taatctggag cggatggtct cgatcctctc gtttgttgcg 1080
gtcaggctgt tacagctcag agaaagcttc acgccgccgc aagcactcag ggcgcaaggg 1140
ctgctaaagg aagcggaaca cgtagaaagc cagtccgcag aaacggtgct gaccccggat 1200
gaatgtcagc tactgggcta tctggacaag ggaaaacgca agcgcaaaga gaaagcaggt 1260
agcttgcagt gggcttacat ggcgatagct agactgggcg gttttatgga cagcaagcga 1320
accggaattg ccagctgggg cgccctctgg taaggttggg aagccctgca aagtaaactg 1380
gatggctttc ttgccgccaa ggatctgatg gcgcagggga tcaagatct 1429
<210>SEQ ID NO. 2
<211>476
<212>PRT
<213>人工合成
10 20 30 40 50
MITSALHRAA DWAKSVFSSA ALGDPRRTAR LVNVAAQLAK YSGKSITISS
60 70 80 90 100
EGSKAMQEGA YRFIRNPNVS AEAIRKAGAM QTVKLAQDFP ELLAIEETTS
110 120 130 140 150
LSYRHQVAEE LGKLGSIQDK SRGWWVHSVL LLEATTFRTV GLLHQEWWMR
160 170 180 190 200
PDDPADADEK ESGKWLAAAA TSRLRMGSMM SNVIAVCERE ADIHAYLQDK
210 220 230 240 250
LAHNERFVVR SKHPRKDVES GLYLYDHLKN QPELGGYQIS IPQKGVVDKR
260 270 280 290 300
GKRKNRPARK ASLSLRSGRI TLKQGNITLN AVLAEEINPP KGETPLKWLL
310 320 330 340 350
LTSEPVESLA QALRVIDIYT HRWRIDEFHK AWKTGAGAER QRMEEPDNLE
360 370 380 390 400
RMVSILSFVA VRLLQLRESF TPPQALRAQG LLKEAEHVES QSAETVLTPD
410 420 430 440 450
ECQLLGYLDK GKRKRKEKAG SLQWAYMAIA RLGGFMDSKR TGIASWGALW
460 470
EGWEALQSKL DGFLAAKDLM AQGIKI
<210>SEQ ID NO. 3
<211>1429
<212>DNA
<213>人工合成
atgataactt ctgctcttca tcgtgcggcc gactgggcta aatctgtgtt ctcttcggcg 60
gcgctgggtg atcctcgccg tactgcccgc ttggttaacg tcgccgccca attggcaaaa 120
tattctggta aatcaataac catctcatca gagggtagtg aagccatgca ggaaggcgct 180
taccgatttt accgcaatcc caacgtttct gccgaggcga tcagaaaggc tggcgccatg 240
caaacagtca agttggctca ggagtttccc gaactgctgg ccattgagga aaccacctct 300
ttgagttatc gccaccaggt cgccgaagag cttggcaagc tgggctctat tcaggataaa 360
tcccgcggat ggtgggttca ctccgttctc ttgctcgagg ccaccacatt ccgcaccgta 420
ggattactgc atcaggagtg gtggatgcgc ccggatgacc ctgccgatgc ggatgaaaag 480
gagagtggca aatggctggc agcggccgca actagccggt tacgcatggg cagcatgatg 540
agcaacgtga ttgcggtctg tgaacgcgaa gccgatattc atgcttatct gcaggacagg 600
ctggcgcata acgagcgctt cgtggtgcgc tccaagcacc cacgcaagga cgtagagtct 660
gggttgtatc tgatcgacca tctgaagaac caaccggagt tgggtggcta tcagatcagc 720
attccgcaaa agggcgtggt ggataaacgc ggtaaacgta aaaatcgacc agcccgcaag 780
gcgagcttga gcctgcgcag tgggcgcatc acgctaaaac aggggaatat cacgctcaac 840
gcggtgctgg ccgaggagat taacccgccc aagggtgaga ccccgttgaa atggttgttg 900
ctgaccggcg aaccggtcga gtcgctagcc caagccttgc gcgtcatcga catttatacc 960
catcgctggc ggatcgacga gttccataag gcatggaaaa ccggagcagg agccgagagg 1020
caacgcatgg aggagccgga taatctggag cggatggtct cgatcctctc gtttgttgcg 1080
gtcaggctgt tacagctcag agaaagcttc acgccgccgc aagcactcag ggcgcaaggg 1140
ctgctaaagg aagcggaaca cgtagaaagc cagtccgcag aaacggtgct gaccccggat 1200
gaatgtcagc tactgggcta tctggacaag ggaaaacgca agcgcaaaga gaaagcaggt 1260
agcttgcagt gggcttacat ggcgatagct agactgggcg gttttatgga cagcaagcga 1320
accggaattg ccagctgggg cgccctctgg taaggttggg aagccctgca aagtaaactg 1380
gatggctttc ttgccgccaa ggatctgatg gcgcagggga tcaagatct 1429
<210>SEQ ID NO. 4
<211>1249
<212>DNA
<213>人工合成
atgataactt ctgctcttca tcgtgcggcc gactgggcta aatctgtgtt ctcttcggcg 60
gcgctgggtg atcctcgccg tactgcccgc ttggttaacg tcgccgccca attggcaaaa 120
tattctggta aatcaataac catctcatca gagggtagtg aagccatgca ggaaggcgct 180
taccgatttt accgcaatcc caacgtttct gccgaggcga tcagaaaggc tggcgccatg 240
caaacagtca agttggctca ggagtttccc gaactgctgg ccattgagga aaccacctct 300
ttgagttatc gccaccaggt cgccgaagag cttggcaagc tgggctctat tcaggataaa 360
tcccgcggat ggtgggttca ctccgttctc ttgctcgagg ccaccacatt ccgcaccgta 420
ggattactgc atcaggagtg gtggatgcgc ccggatgacc ctgccgatgc ggatgaaaag 480
gagagtggca aatggctggc agcggccgca actagccggt tacgcatggg cagcatgatg 540
agcaacgtga ttgcggtctg tgaacgcgaa gccgatattc atgcttatct gcaggacagg 600
ctggcgcata acgagcgctt cgtggtgcgc tccaagcacc cacgcaagga cgtagagtct 660
gggttgtatc tgatcgacca tctgaagaac caaccggagt tgggtggcta tcagatcagc 720
attccgcaaa agggcgtggt ggataaacgc ggtaaacgta aaaatcgacc agcccgcaag 780
gcgagcttga gcctgcgcag tgggcgcatc acgctaaaac aggggaatat cacgctcaac 840
gcggtgctgg ccgaggagat taacccgccc aagggtgaga ccccgttgaa atggttgttg 900
ctgaccggcg aaccggtcga gtcgctagcc caagccttgc gcgtcatcga catttatacc 960
catcgctggc ggatcgagga gttccataag gcatggaaaa ccggagcagg agccgagagg 1020
caacgcatgg aggagccgga taatctggag cggatggtct cgatcctctc gtttgttgcg 1080
gtcaggctgt tacagctcag agaaagcttc acgccgccgc aagcactcag ggcgcaaggg 1140
ctgctaaagg aagcggaaca cgtagaaagc cagtccgcag aaacggtgct gaccccggat 1200
gaatgtcagc tactgggcta tctggacaag ggaaaacgca agcgcaaaga gaaagcaggt 1260
agcttgcagt gggcttacat ggcgatagct agactgggcg gttttatgga cagcaagcga 1320
accggaattg ccagctgggg cgccctctgg taaggttggg aagccctgca aagtaaactg 1380
gatggctttc ttgccgccaa ggatctgatg gcgcagggga tcaagatct 1429
<210>SEQ ID NO. 5
<211>1249
<212>DNA
<213>人工合成
atgataactt ctgctcttca tcgtgcggcc gactgggcta aatctgtgtt ctcttcggcg 60
gcgctgggtg atcctcgccg tactgcccgc ttggttaacg tcgccgccca attggcaaaa 120
tattctggta aatcaataac catctcatca gagggtagtg aagccatgca ggaaggcgct 180
taccgatttt accgcaatcc caacgtttct gccgaggcga tcagaaaggc tggcgccatg 240
caaacagtca agttggctca ggagtttccc gaactgctgg ccattgagga caccacctct 300
ttgagttatc gccaccaggt cgccgaagag cttggcaagc tgggctctat tcaggataaa 360
tcccgcggat ggtgggttca ctccgttctc ttgctcgagg ccaccacatt ccgcaccgta 420
ggattactgc atcaggagtg gtggatgcgc ccggatgacc ctgccgatgc ggatgaaaag 480
gagagtggca aatggctggc agcggccgca actagccggt tacgcatggg cagcatgatg 540
agcaacgtga ttgcggtctg tgaacgcgaa gccgatattc atgcttatct gcaggacagg 600
ctggcgcata acgagcgctt cgtggtgcgc tccaagcacc cacgcaagga cgtagagtct 660
gggttgtatc tgatcgacca tctgaagaac caaccggagt tgggtggcta tcagatcagc 720
attccgcaaa agggcgtggt ggataaacgc ggtaaacgta aaaatcgacc agcccgcaag 780
gcgagcttga gcctgcgcag tgggcgcatc acgctaaaac aggggaatat cacgctcaac 840
gcggtgctgg ccgaggagat taacccgccc aagggtgaga ccccgttgaa atggttgttg 900
ctgaccggcg aaccggtcga gtcgctagcc caagccttgc gcgtcatcga catttatacc 960
catcgctggc ggatcgacga gttccataag gcatggaaaa ccggagcagg agccgagagg 1020
caacgcatgg aggagccgga taatctggag cggatggtct cgatcctctc gtttgttgcg 1080
gtcaggctgt tacagctcag agaaagcttc acgccgccgc aagcactcag ggcgcaaggg 1140
ctgctaaagg aagcggaaca cgtagaaagc cagtccgcag aaacggtgct gaccccggat 1200
gaatgtcagc tactgggcta tctggacaag ggaaaacgca agcgcaaaga gaaagcaggt 1260
agcttgcagt gggcttacat ggcgatagct agactgggcg gttttatgga cagcaagcga 1320
accggaattg ccagctgggg cgccctctgg taaggttggg aagccctgca aagtaaactg 1380
gatggctttc ttgccgccaa ggatctgatg gcgcagggga tcaagatct 1429
<210>SEQ ID NO. 6
<211>1249
<212>DNA
<213>人工合成
atgataactt ctgctcttca tcgtgcggcc gactgggcta aatctgtgtt ctcttcggcg 60
gcgctgggtg atcctcgccg tactgcccgc ttggttaacg tcgccgccca attggcaaaa 120
tattctggta aatcaataac catctcatca gagggtagtg aagccatgca ggaaggcgct 180
taccgatttt accgcaatcc caacgtttct gccgaggcga tcagaaaggc tggcgccatg 240
caaacagtca agttggctca ggagtttccc gaactgctgg ccattgagga aaccacctct 300
ttgagttatc gccaccaggt cgccgaagag cttggcaagc tgggctctat tcaggataaa 360
tcccgcggat ggtgggttca ctccgttctc ttgctcgagg ccaccacatt ccgcaccgta 420
ggattactgc atcaggagtg gtggatgcgc ccggatgacc ctgccgatgc ggatgaaaag 480
gagagtggca aatggctggc agcggccgca actagccggt tacgcatggg cagcatgatg 540
agcaacgtga ttgcggtctg tgaccgcgaa gccgatattc atgcttatct gcaggacagg 600
ctggcgcata acgagcgctt cgtggtgcgc tccaagcacc cacgcaagga cgtagagtct 660
gggttgtatc tgatcgacca tctgaagaac caaccggagt tgggtggcta tcagatcagc 720
attccgcaaa agggcgtggt ggataaacgc ggtaaacgta aaaatcgacc agcccgcaag 780
gcgagcttga gcctgcgcag tgggcgcatc acgctaaaac aggggaatat cacgctcaac 840
gcggtgctgg ccgaggagat taacccgccc aagggtgaga ccccgttgaa atggttgttg 900
ctgaccggcg aaccggtcga gtcgctagcc caagccttgc gcgtcatcga catttatacc 960
catcgctggc ggatcgacga gttccataag gcatggaaaa ccggagcagg agccgagagg 1020
caacgcatgg aggagccgga taatctggag cggatggtct cgatcctctc gtttgttgcg 1080
gtcaggctgt tacagctcag agaaagcttc acgccgccgc aagcactcag ggcgcaaggg 1140
ctgctaaagg aagcggaaca cgtagaaagc cagtccgcag aaacggtgct gaccccggat 1200
gaatgtcagc tactgggcta tctggacaag ggaaaacgca agcgcaaaga gaaagcaggt 1260
agcttgcagt gggcttacat ggcgatagct agactgggcg gttttatgga cagcaagcga 1320
accggaattg ccagctgggg cgccctctgg taaggttggg aagccctgca aagtaaactg 1380
gatggctttc ttgccgccaa ggatctgatg gcgcagggga tcaagatct 1429
- 还没有人留言评论。精彩留言会获得点赞!