无标签编码化合物文库的制作方法
本发明涉及编码化合物文库(chemicallibrary),特别地,涉及核酸编码文库,所述核酸编码文库包含空间上与编码标签相关联的无标签化合物结构。本发明还涉及核酸模板化(nucleicacid-templated)化合物文库生成方法、编码文库筛选方法以及用于制备和筛选编码文库的组合物。
背景技术:
药物发现通常包括:大型化合物文库的汇编,然后进行分析或筛选,其中将化合物单独地添加到包含目标物的微孔中以鉴定“命中物(hits)”,该“命中物”在目标物上显示所需活性(例如酶活性或标签位移)。这个过程被称为高通量筛选(hts)。尽管它可以通过使用机器人设备来自动化测试数百万种化学物质,但它既费力又昂贵。
因此存在根本性的问题,其源于增加的文库规模增加了筛选负担的事实:由于筛选分析具有离散性,筛选时间和成本规模与文库大小近似呈线性关系。这对可使用这种方法筛选的化合物文库大小施加了严重的实际限制:hts通常应用于包含103-106个成员的文库。
基于选择的筛选技术(例如淘选(panning)技术)的发展已经解决了这个问题。在此,文库中的所有化合物同时进行测试,以一锅(one-pot)式的方式测试它们与感兴趣的目标物进行相互作用的能力。在这类分析中,筛选步骤的时间和成本与文库的大小无关,因此该方法可以应用于相对较大的文库。含多达1012个成员的文库已经采用这类方法进行筛选。
基于微滴的文库的开发也已经解决了这个问题,其可以通过微流体技术进行处理,将通量提高几个数量级,并且与基于细胞表型的筛选兼容(参见,例如,clausell-tormos等人,(2008)chemistry&biology(《化学&生物学》)15:427-437)。
但是,基于选择的试验和基于微滴的筛选都需要能够容易地鉴定出所选择的化学化合物(即,“命中物”):可筛选的但不能解码的文库是无用的。
在1992年,brenner和lerner(brennerandlerner(1992)proc.natl.acad.sci.usa(《美国科学学院学报》)89:5381-5383)首次提出解决这个问题的方案,该方案基于dna编码化合物文库(decl)的生成。在decl中,每个化合物通过与对应于其结构或反应历史的dna序列连接(标记),由此作为该特定化合物的唯一标识符(即dna标签“编码”该化合物,由此用作分子的“条形码”)。
化合物可以采用多种不同的方式加标签(tagged),并且还可能的是,使用dna标签不仅可以编码特定的化合物结构(“dna记录”),还可以作为指导其合成的模板(“dna模板”)。近年来,mannocci等,(2011)chem.commun.(《化学通讯》)47:12747-12753、kleiner等,(2011)chemsocrev.(《化学学会评论》)40(12):5707-5717和mullard(2016)nature(《自然》)530:367-369对这类技术进行了回顾。
decl技术现在在制药行业已经很成熟:在2007年,gsk(葛兰素史克)以5500万美元收购了decl的先驱之一praecis制药(praecispharmaceuticals),而其他排名前十的制药公司也开始了他们自己内部的dna编码文库项目。包括x-chem、vipergen、ensembletherapeutics和philochem在内的其他生物技术公司也在积极开发和利用decl技术。
但是目前,当前decl的应用受到与标签存在相关问题的限制。例如,编码标签可能:(a)在化学上或空间上干扰被标记化合物接近感兴趣的目标物上的分子结合位点,从而限制回收的命中物的数量和/或类型;(b)限制细胞渗透性和/或扩散性,有效地防止细胞吸收,并排除依赖于接近细胞质的基于细胞表型的筛选的使用;(c)限制标记后化合物可以进行化学修饰的程度(某些反应在化学上与标签不相容);(d)限制结构-活性分析的有用性,因为这种分析会被标签本身对活性的潜在影响所混淆。还有,目前的方法得到的化合物混合池中含有多种低浓度的化合物,这一事实带来了进一步的限制。这导致需要从池中反褶积(deconvolution)活性,而低浓度严重限制了适用筛选的格式和性质:基于均质(homogeneous)细胞的表型筛选是不可能的。
因此存在对hts技术的需求,该技术允许筛选可解码的化合物文库并解决前述问题。
技术实现要素:
根据本发明的第一方面,本申请提供了一种筛选编码化合物文库的方法,该化合物文库包含多个不同的化合物结构(chemicalstructure),每个化合物结构都与编码标签可释放地连接,所述方法包括以下步骤:(a)提供加标签的化合物结构的所述文库;(b)将每个化合物结构从其标签中释放以产生多个游离的、无标签的化合物结构(tcs);(c)在保持每个tcs和其标签之间空间关联的条件下,通过将它们与分析系统接触来筛选tcs,以产生多个不同的筛选出的tcs,每个筛选出的tcs在空间上与其标签关联;(d)通过解码与其在空间上关联的标签来鉴定所筛选出的tcs。
对任何浓度的tcs都可以进行筛选。优选地,tcs的浓度便于基于片段的筛选,并且,例如,所述tcs的浓度可以在nm至mm的范围内。
因此,本发明的方法允许无标签的编码化合物结构文库的筛选,由此避免了与编码标签的存在相关的问题。
标签
根据本发明,可以使用任何编码标签,只要它包含唯一地鉴定其同源(cognate)化合物结构(或其反应历史)的信息(例如,以化学和/或光学性质/特性的形式),从而作为该特定化合物结构的唯一标识符。因此,该标签“编码”特定化合物结构并作为分子“条形码”。在优选的实施例中,所述标签是核酸(例如,dna)标签,其中所述信息被编码在核酸序列中。但是,也可以使用其它标签,其包括非dna标签、非rna标签、改性的核酸标签、肽标签、基于光的条形码(例如,量子点)和rfid标签。
正如上文所解释的,化合物结构可以采用各种不同的方式加标签,并且还可能不仅使用dna标签来编码特定的化合物结构(“dna记录”),而且还作为指导其合成的模板(“dna模板”——参见下文)。近年来,mannocci等(2011)chem.commun.(《化学通讯》)47:12747-12753,kleiner等(2011)chemsocrev.(《化学学会评论》)40(12):5707-5717以及mullard(2016)nature(《自然》)530:367-369对该技术进行了回顾。
在一些实施例中,使用了分开与合并(split-and-pool)标记技术(参见mannocci等(2011)chem.commun.(《化学通讯》),47:12747-12753,特别是其图3,该文件在此通过引用并入本文)。
鉴定步骤(d)包括解码所述编码标签的步骤,因此根据所述编码标签的性质选择该步骤。在核酸标签的情况下,所述鉴定步骤包括核酸(例如,dna)测序。
所述化合物结构可以是小分子(如本文所限定)。在一些实施例中,所述结构由许多相连接的结构组成。在其它实施例中,例如,在非药物应用筛选中,所述化合物结构可以是大分子(如本文所限定)。
连接子
所述化合物结构可以通过可裂解的连接子(linker)可释放地连接(直接地或间接地)至编码标签。在此类实施例中,所述可裂解的连接子可以包括选自以下连接子的连接子:酶解可裂解连接子;亲核试剂/碱敏感连接子;还原敏感连接子;光可裂解连接子;亲电试剂/酸敏感连接子;金属辅助型裂解敏感连接子;氧化敏感连接子;以及前述两种或两种以上的组合。
所述化合物结构可以通过核酸杂交与所述编码标签可释放地连接(直接地或间接地)。在此类实施例中,如上文所述,所述化合物结构还可以通过可裂解的连接子与所述编码标签可释放地连接(直接地或间接地)。
在优选的实施例中,所述可裂解的连接子可以包括rna,并且,在此类实施例中,步骤(b)可以包括用rna酶与加标签的化合物结构接触。
在其他实施例中,所述可裂解的连接子可以包括肽,并且,在此类实施例中,步骤(b)可以包括用肽酶与加标签的化合物结构接触。
在其他实施例中,所述可裂解的连接子可以包括dna,并且,在此类实施例中,步骤(b)可以包括用位点特异性核酸内切酶与加标签的化合物结构接触。
所述化合物结构可以通过核酸可释放地连接至所述编码标签,所述核酸:(a)与编码标签的核酸杂交;以及(b)与所述化合物结构偶联。在此类实施例中,通过如上文限定的可裂解的连接子,杂交核酸可以偶联到所述化合物结构上。在此,所述杂交核酸优选rna,在这种情况下,步骤(b)可以包括用rna酶与加标签的化合物结构接触。
在本发明的方法中,步骤(b)可以包括使核酸去杂交化,例如,融解(melting),所述核酸与所述化合物结构偶联并与编码标签的核酸杂交。
文库微区室(librarymicrocompartments)
步骤(a)编码的化合物文库可包含n个加标签的化合物结构克隆群,每个克隆群限定至(confinedto)n个离散(discrete)的文库微区室。在此类实施例中:(a)n>103;或者(b)n>104;或者(c)n>105;或者(d)n>106;或者(e)n>107;或者(f)n>108;或者(g)n>109;或者(h)n>1010;或者(i)n>1011;(j)n>1012;(k)n>1013;(i)n>1014;或者(m)n>1015。所述文库微区室可以选自微滴、微粒和微泡(microvesicle)。优选微颗粒文库微区室,例如,以珠粒的形式。
加标签的化合物结构可以以足够高的浓度存在于文库微区室中,以允许基于细胞或表型的筛选,尤其是基于均质细胞表型的分析。在某些实施例中,加标签的化合物结构可以以至少以下浓度存在于文库微区室中:0.1nm、0.5nm、1.0nm、5.0nm、10.0nm、15.0nm、20.0nm、30.0nm、50.0nm、75.0nm、0.1μm、0.5μm、1.0μm、5.0μm、10.0μm、15.0μm、20.0μm、30.0μm、50.0μm、75.0μm、100.0μm、200.0μm、300.0μm、500.0μm、1mm、2mm、5mm或者10mm。
在其它实施例中,加标签的化合物结构可以以至少以下浓度存在于文库微区室中:0.1pm、0.5pm、1.0pm、5.0pm、10.0pm、15.0pm、20.0pm、30.0pm、50.0pm、75.0pm、0.1nm、0.5nm、1.0nm、5.0nm、10.0nm、15.0nm、20.0nm、30.0nm、50.0nm、75.0nm、0.1μm、0.5μm、1.0μm、5.0μm、10.0μm、15.0μm、20.0μm、30.0μm、50.0μm、75.0μm、100.0μm、200.0μm、300.0μm、500.0μm、1mm、2mm、5mm或者10mm。
在其它实施例中,加标签的化合物结构可以以下浓度存在于文库微区室中:少于1μm;1-100μm;大于100μm;5-50μm或者10-20μm。
步骤(c)中的空间关联可以通过任意合适的手段保持,但是优选的是微区室化以使tcs和它的标签被限制在空间近距离内(spatialproximity)。物理限制能够通过采用各种微区室获得,包括微滴、微粒、微孔、微阵列和微泡(如下文更详细地描述)。
在优选的实施例中,步骤(c)的标签在功能上或物理上与所述分析系统划分开。这避免了标签对分析试剂的干扰。在此类实施例中,标签可以被划分、隔离、限制或定位在上文定义的文库微区室内或文库微区室上。
筛选微区室
在优选的实施例中,步骤(b)之前,每个文库微区室都可以置于离散的筛选微区室中,例如,通过微胶囊化、微喷注或微滴融合。所述筛选微区室可以采用任意形式,但是优选地,采用适合高通量筛选的形式。特别优选的是选自微液滴、微孔和/或微流体通道的筛选微区室。
筛选微区室优选地包括文库微区室,连同:(i)水性溶剂;和/或(iii)凝胶系统,例如,水凝胶;和/或(iii)分析系统。
筛选微区室可以方便地包括凝胶系统,该凝胶系统能够在鉴定步骤(d)之前凝胶化,使得文库微区室变得固定在胶凝化的筛选微区室内。在此类实施例中,凝胶化步骤之后鉴定步骤(d)之前可以是清洗步骤,由此去除潜在的干扰反应物/产物,否则,这些反应物或产物可能会降低解码步骤的可靠性。
本发明方法的步骤(b)中,tcs可以释放到筛选微区室内,同时,所述标签:(a)例如,通过共价键和/或氢键,保留在文库微区室内或所述文库微区室上;(b)由官能化的表面活性剂隔离在文库或筛选微滴的表面;或(c)由分析系统的元件隔离。
本发明的方法涉及从每个化合物结构的标签上释放每个化合物结构的步骤,以产生多个游离的、无标签的化合物结构(tcs)。所述tcs可以通过扩散便利地释放到筛选微区室内,例如,通过从文库微区室直接扩散。
筛选步骤(c)可以在筛选微滴内进行,所述筛选微滴包含分析系统、tcs的克隆群和含有标签的所述文库微区室。
模板化合成
在某些实施例中,编码的核酸标签用作化合物结构的模板。在此类实施例中,以核酸为模板(例如,以dna为模板)合成所述化合物结构以提供加标签的化合物结构的文库。可以使用任何合适的模板化技术,并例如mannocci等(2011)chem.commun.(《化学通讯》)47:12747-12753、kleiner等(2011)chemsocrev.(《化学学会评论》)40(12):5707-5717和mullard(2016)nature(《自然》)530:367-369描述了合适的技术。同样适用的是pehrharbury教授和他的同事们(stanforduniversity(斯坦福大学),usa)开发的dna路由方法(dna-routingapproach)。dna模板可以以任何方式绘制或构造:例如,yocto反应系统(yoctoreactorsystem)采用三向dna发卡环连接(three-waydna-hairpin-loopedjunction),通过将合适的供体化学部分(moiety)转移到核心受体位点来辅助文库合成(参见wo2006/048025,在此通过引用方式合并其公开内容)。
也可以使用可替代的结构几何图形,例如,lundberg等(2008)nucleicacidssymposium(《核酸研讨会》)(52):683-684中描述的四向dnaholliday连接(4-waydnahollidayjunctions)和六边形结构,以及由rothemund(2006)nature(《自然》)440:297-302综述的“dna支架折纸术(scaffoldeddnaorigami)”技术创建的复杂形状和图形。
反应器微区室
在编码核酸标签用作化合物结构的模板的实施例中,模板化合成之前可以是包括任选地通过pcr扩增编码核酸模板的步骤。这个扩增步骤可以在反应器微区室(reactormicrocompartment)内进行。
因此,本发明设想的文库合成包括以下步骤:(a')提供反应器微区室,该反应器微区室包含:(ⅰ)编码模板的克隆群;和(ii)多个化学子结构;和然后(b')在通过核酸模板化合成而使子结构反应形成化合物结构的克隆群的条件下,使模板与反应器微区室内的子结构接触,从而产生含有与编码模板杂交的化合物结构的克隆群的反应器微区室。
在此类实施例中所述反应器微区室可以选自微孔、微阵列、微流体通道、微颗粒、微泡和微滴。
优选的是微滴。微区室可以包括水凝胶,并且本文描述了这种含水凝胶的微区室的实例。
在本文中,所述方法可以进一步包括扩增化合物结构数量的步骤,这是通过:(i)从所述编码模板将所述化合物结构去杂交化,然后(ⅱ)在子结构通过核酸模板化合成而反应形成化合物结构的进一步的克隆群的条件下,使去杂交化的模板与反应器微区室内未反应的子结构接触;以及接下来(ⅲ)重复步骤(i)和(ii)。
在此类实施例中,步骤(i)和(ii)可以重复进行,直到在反应器微区室内所述化合物结构的浓度为至少0.1nm、0.5nm、1.0nm、5.0nm、10.0nm、15.0nm、20.0nm、30.0nm、50.0nm、75.0nm、0.1μm、0.5μm、1.0μm、5.0μm、10.0μm、15.0μm、20.0μm、30.0μm、50.0μm、75.0μm、100.0μm、200.0μm、300.0μm、500.0μm、1mm、2mm、5mm或10mm。因此,步骤(i)和(ii)可以重复进行,直到在反应器微区室内所述化合物结构浓度达到1-100μm、5-50μm或者10-20μm。
在本发明方法的上下文中,模板化合成可以包括偶联到化合物结构的核酸与编码标签模板的核酸之间的杂交。
现有的化合物文库的克隆标签
模板化合成不是用于本发明方法的一个必要要求,然而,可以通过任何合适的手段来提供加标签的化合物结构的文库。例如,根据本发明供使用的文库可以包含化合物结构的克隆群,而步骤(a)包括将编码标签可释放地连接到所述克隆群内每个化合物结构上。在此类实施例中,化合物结构的克隆群可以是商售化合物文库的一部分(element)。
在此类实施例中,编码标签可以包括核酸序列,例如,dna序列。所述标签在多个不同的交联位点可以可释放地连接到所述化合物结构,从而减轻在一个或多个特定位点的交联对化合物结构产生的任何有害影响。在此类实施例中,编码标签可以使用多个不同的交联基团进行官能化,使得能够在多个不同的交联位点加标签。
合适的基于核酸的标签是可商购的(例如来自twistbiosciencecorporation),但是可以如wo2015/021080中所描述的,合成这些标签。
靶细胞
本发明发现了在基于细胞、表型的分析法中的特定应用。
因此,分析系统可以是均相水相分析系统,以及筛选步骤(c)可以包括表型筛选。在此类实施例中,分析系统可以包括活的靶细胞。任何细胞都可以用于此类实施例,包括原核和真核细胞。合适的原核细胞包括古细菌细胞,例如选自以下门类的细胞:(a)泉古菌(crenarchaeota)、(b)广古菌(euryarchaeota)、(c)初古菌(korarchaeota)、(d)纳古菌(nanoarchaeota)和(e)奇古菌(thaumarchaeota),例如沃氏富盐菌(haloferaxvolcanii)和硫化叶菌(sulfolobusspp.)。
根据本发明,其它适于用作靶细胞的原核细胞包括细菌细胞。在此类实施例中,靶细胞可以是致病菌。其他细菌靶细胞包括选自革兰氏阳性细菌的细胞(例如,选自粪肠球菌(enterococcusfaecalis)、屎肠球菌(enterococcusfaecium)和金黄色葡萄球菌(staphylococcusaureus));革兰氏阴性细菌(例如,选自肺炎克雷伯氏菌(klebsiellapneumoniae)、鲍氏不动杆菌(acinetobacterbaumanii)、大肠埃希氏菌(escherichiacoli)、大肠杆菌st131菌株、铜绿假单胞菌(pseudomonasaeruginosa)、阴沟肠杆菌(enterobactercloacae)、产气肠杆菌(enterobacteraerogenes)和淋病奈瑟氏菌(neisseriagonorrhoeae))和表现出不确定的革兰氏反应的细菌。
根据本发明,适于用作靶细胞的真核细胞包括:(a)真菌细胞、(b)哺乳动物细胞、(c)高等植物细胞、(d)原生动物、(e)寄生虫(helminth)细胞;(f)藻类细胞;(g)来自临床组织样品的细胞(例如人类患者的样品)和(h)无脊椎动物细胞。
合适的哺乳动物细胞包括癌细胞,例如人癌细胞、肌肉细胞、人类神经元细胞和来自活人患者的显示疾病相关表型的其它细胞。
靶蛋白
分析系统可以包括分离的靶蛋白或分离的靶蛋白复合物。例如,所述靶蛋白/蛋白复合物可以是胞内靶蛋白/蛋白复合物。所述靶蛋白/蛋白复合物可以在溶液中,或者可以由膜蛋白/蛋白复合物或跨膜蛋白/蛋白复合物组成。在此类实施例中,可以筛选化合物结构配体,所述配体结合到靶蛋白/蛋白复合物。所述配体可以是所述靶蛋白/蛋白复合物的抑制剂。
所述分析系统可以包括或生成可检测标签。在此类实施例中,可检测标签可以连接到上文所述的靶细胞或分离的靶蛋白或分离的靶蛋白复合物。
所述筛选步骤可以包括fads和/或facs。所述筛选步骤还可以包括荧光分析,包括但不限于fret、flim、荧光团标记的抗体、荧光团标记的dna序列或荧光染料。
基于序列的结构-活性分析
本发明包括通过解码在空间上与其相关联的标签而鉴定筛选的tcs的步骤。在所述标签包括核酸序列的情况下,所述解码步骤可以包括对核酸测序。在此类实施例中,所述方法可以进一步包括比对多个不同的筛选的tcs的序列。这样的步骤之后,可以是对筛选出的tcs进行序列活性关系分析的步骤,其能够使被筛选出的文库成员分类成不同的化学类型。
文库
在另一个方面,本发明提供了用于本发明方法的编码化合物文库,所述文库包括n个化合物结构的克隆群,每个化合物结构都可释放地连接到编码标签上,每个克隆群被限定在n个离散的文库微区室。
在此,如上所述,化合物结构可以连接至编码标签,例如,通过可裂解的连接子和/或通过核酸杂交。
在另一个方面,本发明提供了用于本发明方法的编码化合物文库,所述文库包括游离化合物结构的n个克隆群,每个克隆群被限定到n个离散的文库微区室,其中所述化合物结构与编码标签一起被包含在所述微区室内,但是并不共价连接编码标签。
在另一个方面,本发明提供了用于本发明方法的分析组合物,包括本发明的文库,其中,在微区室内包含的化合物结构与分析系统接触。在此,编码标签可以在功能上或物理上与所述分析系统分离。例如,化合物结构可以被包含在文库微滴内,所述微滴包含分析系统,并且编码标签可以位于微滴、封装在所述文库微滴内的珠粒或微泡里或上面。
在另一个方面,本发明提供了用于本发明方法的核酸编码化合物文库反应器,其包含含有以下物质的微区室:(a)编码核酸模板分子的克隆群;和(b)多个化学子结构,其中,子结构适于核酸模板化组装以形成编码核酸加标签的化合物结构,其中编码标签可释放地连接到化合物结构。
在下文其它权利要求中限定并描述了本发明的其它方面和优选实施例。
具体实施方式
出于所有目的,本文提及的所有出版物、专利、专利申请和其它参考文献都通过整体引用的方式合并至本申请中,正如每个单独的出版物、专利或专利申请以其全部的内容被明确地和单独地注明通过引用合并至本申请中。
定义和一般性优选
除非明确地特别指出,该术语在本领域中可能具有的任何更宽(或更窄)的含义以外,本文所用的以下术语还旨在具有以下含义除了:
除非上下文另有要求,本文使用的单数将被理解为包括复数,反之亦然。术语“一(a)”或“一(an)”用于涉及的实体将被理解为指代一个或多个所述实体。这样,术语“一(a)”(或“一(an)”)、“一个或多个”和“至少一个”在本文中可互换使用。
如本文所使用的,术语“包括”或其变体例如“包含”或“含有”将被理解为表明包含任何所列举的整体(integer)(例如,特征、元素、特性、性质、方法/工艺步骤或限制)或整体(例如特征、元素、特性、性质、方法/工艺步骤或限制)组,但不排除包含其它任何整体或整体组。因此,如本文使用的术语“包括”是包括性的或开放式的,并且不排除额外的、未列举的整体或方法/工艺步骤。
术语革兰氏阳性细菌(gram-positivebacterium)是定义特定种类细菌的专业术语,其基于一定的细胞壁染色特征而分组在一起。
术语低g+c革兰氏阳性细菌(lowg+cgram-positivebacterium)是基于dna碱基组合物定义革兰氏阳性细菌内特定子类的进化相关的细菌的专业术语。该子类包括链球菌属(streptococcusspp.)、葡萄球菌(staphylococcusspp.)、李斯特氏菌(listeriaspp.)、芽孢杆菌属(bacillusspp.)、梭状芽孢杆菌属(clostridiumspp.)、肠球菌属(enterococcusspp.)和乳杆菌属(lactobacillusspp.))。
术语高g+c革兰氏阳性细菌(lowg+cgram-positivebacterium)是基于dna碱基组合物定义革兰氏阳性细菌内特定子类的进化相关的细菌的专业术语。该子类包括放线菌(放线细菌),包括放线菌属(actinomycesspp.)、节杆菌属(arthrobacterspp.)、棒状杆菌属(corynebacteriumspp.)、弗兰克氏菌属(frankiaspp.)、微球菌属(micrococcusspp.)、小单孢菌属(micromonosporaspp.)、分枝杆菌属(mycobacteriumspp.)、诺卡氏菌属(nocardiaspp.)、丙酸杆菌属(propionibacteriumspp.)和链霉菌属(streptomycesspp.)。
术语革兰氏阴性细菌(gram-negativebacterium)是定义特定种类细菌的专业术语,其基于一定的细胞壁染色特征而分组在一起。革兰氏阴性细菌属的实例包括克雷伯菌(klebsiella)、不动杆菌(acinetobacter)、埃希氏菌(escherichia)、假单胞菌(pseudomonas)、肠杆菌属(enterbacter)和奈瑟氏菌(neisseria)。
如本文中所用,术语“分析系统”定义用于检测所需活性的手段。当分析系统与存在于文库且具有所需活性的化合物结构接触或反应时,分析系统直接或间接地产生可检测的和/或可测量的信号。所需活性可以是靶蛋白结合、药物活性、细胞受体结合、抗生素、抗癌、抗病毒、抗真菌、抗寄生虫、农药、药物、免疫活性、产生任何所需的化合物、提高化合物产量、特定产品分解。所需活性可以是针对药理学靶细胞、细胞蛋白或代谢途径的活性。所需活性也可以是调节基因表达的能力,例如,通过降低或增强一个或多个基因的表达和/或它们的时间或空间(例如组织特异性)表达模式。所需活性可以是结合活性,例如作为靶蛋白的配体。所需活性也可以是在各种工业过程有用的性质,包括生物修复、微生物强化油采收、污水处理、食品生产、生物燃料生产、能量产生、生物生产、生物消化/降解、疫苗生产和益生菌生产。它也可以是化学试剂(如荧光团或颜料)、特定的化学反应或可以与颜色、基质结构或折射率变化相关的任何化学反应。
所述分析系统可以包含化学指示剂,该化学指示剂包括报告分子和可检测标签(如本文所限定的)。它可以是,例如,比色(即,导致在可见光范围内吸收光的有色反应产物)、荧光(例如,基于酶将底物转化成反应产物,当由特定波长的光激发时,该反应产物发出荧光)和/或发光(例如,基于生物发光、化学发光和/或光致发光)。
所述分析系统可以包括细胞,例如,如本文所述的靶细胞。所述分析系统还可以包括蛋白质,例如,如本文所述的靶蛋白。可替代地,或另外地,所述分析系统可以包括细胞碎片(cellfraction)、细胞组分、组织、组织提取物、多蛋白复合物、膜结合蛋白膜碎片和/或类器官。
如本文所使用的术语配体定义为用于在体内结合生物靶分子的结合伴侣(例如,酶或受体)。因此,这样的配体包括那些与体内的靶标结合(或直接物理相互作用)的结构,而不考虑该结合的生理后果。因此,本发明的配体可以结合作为细胞信号级联的一部分的靶标,其中所述靶标形成其一部分。或者,在细胞生理学一些其他方面的情况下,它们可结合靶标。在后一种情况下,配体可以例如在细胞表面结合靶标而不触发信号级联,在这种情况下,结合可能影响细胞功能的其它方面。因此,本发明的配体可以结合细胞表面和/或细胞内的靶标。
如本文中所使用的,术语小分子是指分子量为1000da或更小的任何分子,例如小于900da、小于800da、小于600da或小于500da。优选地,本发明的文库中存在的化合物结构可以是本文所限定的小分子,尤其是分子量小于600da的小分子。
如本文中所使用的,术语大分子指分子量大于1000da的任何分子。
如本文中所使用的,术语抗体限定为所有抗体(包括多克隆抗体和单克隆抗体(mabs))。该术语此处也用于指抗体片段,包括f(ab)、f(ab’)、f(ab’)2、fv、fc3和单链抗体(及它们的组合),这些抗体片段可以通过重组dna技术或通过酶解或化学裂解完整抗体生成。术语“抗体”此处也用于涵盖双特异性或双功能抗体,它们是合成的具有两个不同的重/轻链对和两个不同结合位点的杂合抗体。双特异性抗体可以通过多种方法产生,包括杂交瘤融合或fab'片段连接。术语“抗体”还包括嵌合抗体(合到一个或多个非人类可变抗体免疫球蛋白域的人类恒定抗体免疫球蛋白域的抗体,或其片段)。因此,这种嵌合抗体包括“人源化”抗体。术语“抗体”还涵盖微型抗体(参见wo94/09817)、单链fv-fc融合体和转基因动物产生的人抗体。术语“抗体”还包括多聚体抗体(multimericantibodies)和高阶蛋白质复合物(例如,异二聚体抗体)。
如本文所使用,术语肽、多肽和蛋白质可以互换使用,以限定包括通过肽键共价结合的两个或更多个氨基酸的有机化合物。相应的形容词“肽的”相应地解释。肽可以相对于组成氨基酸的数量而提及,即,二肽含有两个氨基酸残基,三肽含有三个氨基酸残基等等。含有十个或更少的氨基酸的肽可以称之为寡肽,而含有多于十个氨基酸残基的肽称之为多肽。这些肽也可以包括任何修饰的和附加的氨基和羧基。
如本文所使用的,术语点击化学(clickchemistry)是sharpless在2001年提出的术语,用于描述高产率的、宽范围的反应,所述反应仅生成不需采用色谱就能去除的副产物,所述反应具有立体特异性,易于进行,并能够在可容易去除的溶剂或良性溶剂中进行。它已经以许多不同的形式被实施,在化学和生物学上应用广泛。点击反应的一个亚类涉及到对周围生物环境呈惰性的反应物。这种点击反应被称为生物正交反应。适用于生物正交点击化学的生物正交反应物对是具有以下性质的分子群:(1)它们相互反应,但不与细胞内环境中的细胞生物化学系统发生显著的交叉反应或相互作用;(2)在生理环境中它们和它们的产物和副产物是稳定的和无毒的;(3)它们的反应是高度特异性和快速的。反应性基团(或点击反应物)可以参照所使用的具体点击化学来选择,因此,根据本发明,本领域技术人员已知的范围广泛的任何生物正交反应物的相容对都可以使用,包括反电子需求diels-alder环化加成反应(inverseelectrondemanddiels-aldercycloadditionreaction,iedda)、力引发叠氮炔环加成(strain-promotedalkyneazidecycloaddition,spaac)和施托丁格连接(staudingerligation)。
术语分离的在此用于指任何物质(例如,化合物、分析试剂、靶蛋白或靶细胞),以表明该物质存在的物理环境与其天然存在的环境不同。例如,分离的细胞可以指,相对于它们天然存在的复合组织环境,基本上被分离的(例如纯化的)分离的细胞。分离的细胞可以是,例如,纯化或分开的。在这种情况下,分离的细胞可以占存在的总的细胞类型的至少60%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%。分离的细胞可以通过本领域技术人员已知的常规技术获得,包括facs、密度梯度离心、富集培养、选择性培养、细胞分选和使用抗表面蛋白的固定化抗体的淘筛技术。
当分离的材料被纯化时,绝对纯度水平不是关键的,本领域技术人员可以根据材料的用途很容易地确定适当的纯度水平。然而,优选纯度水平为至少60%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或者100%w/w。在某些情况下,分离的材料形成组合物(例如,含有许多其他细胞组分的或多或少的粗细胞提取物)或缓冲系统的一部分,这可能包含其他组分。
此处使用的术语接触是用于指允许至少两个不同的部分(moiety)或系统(例如化合物结构和分析系统)变得足够近,足以发生反应、相互作用或物理接触的过程。
术语可检测的标签在本文中用于定义通过光谱、荧光、光化学、生物化学、免疫化学、化学、电化学、射频或通过任何其它物理手段可检测的部分。合适的标签包括荧光蛋白、荧光染料、电子致密试剂、酶(例如,在elisa中常用的)、生物素、地高辛或半抗原和蛋白质或其他可检测的实体,例如通过将放射性或荧光标签结合到肽或抗体(与靶肽特异性反应)来检测。
如本文所使用的,术语微滴限定为流体、液体或凝胶的小的、离散的体积,其直径为0.1μm至1000μm和/或体积在5x10-7pl至500nl之间。典型地,微滴的直径小于1000μm(例如小于500μm)、小于500μm、小于400μm、小于300μm、小于200μm、小于100μm、小于50μm、小于40μm、小于30μm、小于20μm、小于10μm、小于5μm或小于1μm。因此,微滴可以基本为球形,该球形直径为:(a)小于1μm;(b)小于10μm;(c)0.1-10μm;(d)10μm至500μm;(b)10μm至200μm;(c)10μm至150μm;(d)10μm至100μm;(e)10μm至50μm;或者(f)大约100μm。
本发明的微滴典型地由完全被第二流体、液体或凝胶(例如,不混溶的液体或气体)包围的第一流体、液体或凝胶的分离部分构成。在一些情况下,所述滴可以是球形或基本上为球形。然而,在一些情况下,微滴可以是非球形的,并且具有不规则的形状(例如,由于外部环境施加的力,或在本文所描述的分析和筛选过程的物理操作过程中)。因此,微滴可以是基本上圆柱形的、塞状的和或椭圆形的(例如,在它们符合周围微通道的几何形状的情况下)。
如本文所使用的,术语微粒定义为颗粒直径小于1000μm(例如小于500μm)、小于500μm、小于400μm、小于300μm、小于200μm、小于100μm、小于50μm、小于40μm、小于30μm、小于20μm、小于10μm、小于5μm或小于1μm。优选地,所述微粒是非平面的,并且具有:(a)10μm至500μm;(b)10μm至200μm;(c)10μm至150μm;(d)10μm至100μm;(e)10μm至50μm;或(f)约100μm的最大尺寸(或者基本上为球形,其直径如上所列举)。如本文所定义的,微粒可因此被封装在微滴内。微粒可以由刚性固体、柔性凝胶、多孔固体、多孔凝胶或网状物,或刚性或半刚性原纤维或小管基质形成。
如本文中所使用的,术语珠粒被用来定义固体微粒。优选的珠是由凝胶(包括水凝胶,诸如琼脂糖)形成的,例如,由胶凝的大块(bulk)组合物片段化或由预胶凝状态成型而形成。所述珠粒可以用反应性基团或部分(例如链霉素、胺或溴化氰)来官能化。或者,这些珠可以是固体支持物,例如由硅、聚苯乙烯(ps)、交联的聚(苯乙烯/二乙烯基苯)(p[s/dvb])以及聚(甲基丙烯酸甲酯)(pmma)制成。
术语微泡在本文中用于定义中空微粒,所述中空微粒包括封闭内部体积的外壁或膜,如脂质体。
本发明的微滴、微粒、微泡可以是单分散的。应用于根据本发明使用的微滴和微粒术语单分散限定具有液滴/粒径分散系数ε的微滴/微粒群,ε不大于1.0、不大于0.5,优选地,不大于0.3。所述分散系数ε通过下述公式计算:
ε=(90dp-10dp)/50dp(1)
其中,10dp、50dp和90dp是用乳液的相对累积粒度分布曲线估计累积频率分别为10%、50%和90%的颗粒尺寸。ε=0的情况是指乳液颗粒根本没有显示粒径分散的理想状态。
如本文中所使用的,术语编码标签与化合物结构相关,用于限定包含唯一地鉴定化合物结构或它的反应历史的信息的部分或试剂,从而用作那个特定的化合物结构的唯一的标识符(即,所述标签“编码”那个结构并用作分子“条形码”)。所述信息可以以任何形式被编码,但是在优选的实施例中,所述标签是核酸标签(例如,dna),其中所述信息被编码在核酸序列中。但是,也可以使用其它标签,包括非dna标签、非rna标签、改性的核酸标签、肽标签、基于光的条形码(例如,量子点)和rfid标签。
如本文所使用,与化合物结构相关的术语克隆定义为化合物结构群,其中每一个化合物结构都被共同的标签编码。所述化合物结构可以化学性质相同,或可以仅相对于可裂解连接子的性质或位置(或者在切割这种连接子后留下的瘢痕方面)不同,该可裂解连接子使所述化合物结构与其同源的编码标签结合。
如本文所使用的,应用于化合物结构的术语游离的用于定义不与固相结合的化合物结构。在一些实施例中,该术语定义了未共价结合到固相的化合物结构。游离的化合物结构可以因此进入液相和/或进入溶液中,并且在一些实施例中可以被存在于分析系统的细胞结合和/或摄取。
如本文中所使用的,术语微孔(在本文中与术语孔可互换使用)是指具有小于1毫升体积的腔室。尺寸在纳米范围内的微孔可以通过电子束光刻制造(参见例如odom等人,(2002)j.am.chem.soc.124:12112-12113)。微孔典型地设置在固体基材板或滴定板(也称为微孔板、微孔或多孔板)上,这通常采用具有用作小试管的多“孔”的平板形式。微孔板通常具有布置在2:3的矩形基质上的6、24、96、384或1536个样品微孔。
如本文中所使用的,术语自脱落连接子(self-immolativelinker)定义为包括自脱落化学基团(在本文中可以称为自分解部分或“sim”)的连接子,该连接子能够直接或间接地(例如,通过肽部分)共价连接所述化合物结构和其编码标签以形成稳定的加标签的化合物结构,并且其通过涉及所述化合物结构的自发释放的机制能够从所述化合物结构上释放所述编码标签(例如,通过由酶裂解触发的电子级联反应,导致离去基团的排除和游离化合物结构的释放)。
微区室
本发明涉及维持游离的化合物结构和其编码标签之间的空间关联。这是通过微区室化便利地实现的,其是一种物理地限制所述化合物结构和其标签的过程,由此保持它们在物理上接近(即,每个化合物结构在其相应编码标签的1000μm以内(例如500μm、250μm、100μm、50μm、25μm、10μm或1μm以内)。正如下文所解释的,物理限制能够通过采用各种微区室来实现,包括微滴、微粒、微孔和微泡。物理限制允许通过解码空间关联的标签鉴定筛选命中物的化合物结构。
微滴
对于本领域技术人员来说,合适的材料以及根据本发明适于在微区室化中使用的制备和处理微滴的方法是公知常识的一部分,例如,在wo2010/009365、wo2006/040551、wo2006/040554、wo2004/002627、wo2004/091763、wo2005/021151、wo2006/096571、wo2007/089541、wo2007/081385和wo2008/063227中所描述的(在此通过引用合并其整体内容)。
微滴的大小将通过参照化合物结构的性质和将被封装的分析系统进行选择。微滴可以基本上为球形,其直径为:(a)小于1μm;(b)小于10μm;(c)0.1-10μm;(d)10μm至500μm;(b)10μm至200μm;(c)10μm至150μm;(d)10μm至100μm;(e)10μm至50μm;或(f)约100μm。
优选地,微滴是大小均匀的,由此相对于同一个文库中其他液滴的直径,所述文库内任何液滴的直径变化小于5%、4%、3%、2%、1%或0.5%。在一些实施例中,微滴是单分散的。然而,根据本发明也可以使用多分散微滴。
在单一w/o型乳液中,载液可以是任何与水不混溶的液体,例如油,任选地选自:(a)烃油;(b)氟碳油;(c)酯油;(d)硅油;(e)对水相生物组分溶解度低的油;(f)抑制微滴之间分子扩散的油;(g)疏水性和疏脂的油;(h)对于气体有良好溶解性的油;和/或(i)任何两种或更多种前述物质的组合。
因此,微滴可被包含在w/o乳液中,其中所述微滴构成水性分散相,以及载液构成连续的油相。
在其它实施例中,微滴被包含在w/o/w双乳液中,并且载液可以是含水液体。在此类实施例中,所述水性液体可以是磷酸盐缓冲液(pbs)。
微滴因此可以被包含在w/o/w双乳液中,其中所述微滴包括:(a)含水生长培养基(growthmedia)的内核,其被包封在作为分散相的外油壳中,以及(b)载液,所述载液作为连续水相。当然应该理解的是,o/w/o液滴对于筛选非生物实体特别有用。
表面活性剂
在微滴被包含在乳液中的实施例中,载液可以构成连续相,微滴构成分散相,并且在这种实施例中,乳液可进一步包含表面活性剂和任选的助表面活性剂。
表面活性剂和/或助表面活性剂可以位于分散相和连续相的界面处,并且当微滴被包括在w/o/w双乳液中时,表面活性剂和/或助表面活性剂可以位于水性核心和油壳的界面处及油壳和外连续相的界面处。
范围广泛的合适的表面活性剂是可用的,并且本领域技术人员根据所选择的筛选参数能够选择合适的表面活性剂(和助表面活性剂,如果需要的话)。例如,在bernath等(2004)analyticalbiochemistry(《分析生物化学》)325:151-157;holtzeandweitz(2008)labchip(《实验室芯片》)8(10):1632-1639;和holtze等(2008)labchip(《实验室芯片》)8(10):1632-1639中描述的合适的表面活性剂。在w02010/009365和w02008/021123(在此通过引用并入它们的内容)中描述了其它合适的表面活性剂,尤其包括含氟表面活性剂。
优选地,表面活性剂和/或助表面活性剂并入到w/o的界面中,因此,在采用单一w/o型乳液的实施例中,表面活性剂和或助表面活性剂可以存在于水性生长培养基微滴和连续(例如,油)相的界面处。类似地,根据本发明双w/o/w型乳液用于共封装时,表面活性剂和或和助表面活性剂可以存在于水性芯和不混溶的(例如油)壳的界面处以及油壳和连续水相之间的界面处这两种情况中的任一或两种界面处。
表面活性剂优选生物相容性的。例如,表面活性剂可以选择对筛选中使用的任何细胞都是无毒的。所选择的表面活性剂也可以对气体有良好的溶解性,这对任何被封装的细胞的生长和/或活力可能是必要的。
生物相容性可以通过任何合适的分析法测定,包括采用对照敏感性生化分析(例如,体外翻译)测试相容性的试验,该对照敏感性生化分析用作细胞水平生物相容性的替代。例如,使用荧光底物进行的编码酶β-半乳糖苷酶的质粒dna的体外翻译(ivt)(荧光素-二-β-d-吡喃半乳糖苷(fdg))可以作为生物相容性的指示剂,因为当被封装的dna、参与转录和翻译的分子和翻译的蛋白质没有吸附到液滴界面,并且蛋白质的高级结构保持完整时,形成荧光产物。
生物相容性的测定还可以通过:在存在表面活性剂的情况下,培养将用于分析的细胞,然后,用抗体或活细胞染料使细胞染色,以及相对于不存在表面活性剂的对照,测定细胞群的整体活力。
表面活性剂也可以防止生物分子吸附在微滴界面处。表面活性剂也可以起到分离单个微滴(和相应的微培养物)的作用。表面活性剂优选能稳定(即,防止合并)微滴。稳定性能可以通过例如相差显微术、光散射、聚焦光束反射测量、离心和/或流变学监控。
表面活性剂也可以形成分析系统的功能部分,并且可以例如用作区分或隔离分析法中存在的反应物和/或分析物和/或其它部分(例如,释放的标签)。例如,功能性表面活性剂亲水头部基团中的镍络合物能够将组氨酸标记的蛋白质集中在表面(参见,例如kreutz等人(2009)jamchemsoc.131(17):6042-6043)。这种官能化的表面活性剂也可以用作小分子合成的催化剂(参见,例如theberge等人(2009)chem.commun.:6225-6227)。它们也可用于使细胞溶解(参见,例如clausell-tormos等人(2008)chembiol.(《化学生物》)15(5):427-37)。因此,本发明涵盖了使用这类官能化表面活性剂。
用于乳液同封装的油
应当理解的是,与不连续相不混溶的任何液体都可以用于形成据本发明使用的微滴乳液,所述不混溶的流体典型地是油。
优选地,选择对水相生物组分溶解度低的油。其它优选的功能性质包括:对于气体的可调节(例如,高或低)溶解度、抑制微滴之间的分子扩散的能力,和/或组合的疏水性和疏油性。油可以是烃油,例如轻质矿物油、氟碳油、硅油或酯油。两种或更多种上述油的混合物也是优选的。
在wo2010/009365、wo2006/040551、wo2006/040554、wo2004/002627、w02004/091763、wo2005/021151、wo2006/096571、wo2007/089541、wo2007/081385和wo2008/063227中已描述了合适的油的实例(在此通过引用并入其内容)。
微滴乳化过程
范围广泛的不同的乳化方法是本领域技术人员所熟知的,其中的任何一个方法都可以用来产生本发明的微滴。
很多乳化技术包括大批量地混合两种液体,通常使用湍流以增强水滴破碎。这样的方法包括涡旋、超声处理、均质化或它们的组合。
在这些“自顶向下(top-down)”乳化的方法中,对单个液滴的形成几乎无法控制,并通常产生分布宽的微滴尺寸。可替代的“自底向上(bottomup)”的方法在单个微滴水平下操作,并且可能涉及使用微流体设备。例如,在微流体装置中,可以通过在t形连接处使油流和水流碰撞来形成乳液:产生的微滴大小取决于每个液流的流速而不同。
制备根据本发明使用的微滴的优选方法包括流动聚焦(如在例如anna等人(2003)appl.phys.lett.82(3):364-366中所描述的)。在此,连续相流体(聚焦或鞘流体)在分散相旁边或围绕分散相(被聚焦或核心流体),在两个流体都被挤出的孔附近产生液滴破裂。流动聚焦装置由使用连续聚焦液体供给进行加压的压力室组成。在内部,一个或多个聚焦流体通过毛细管进料管注入,其末端在连接压力室和外部环境的小孔前面打开。聚焦流体流将流体弯月面模压成尖头,通过孔产生流出腔室的稳定的微米或纳米射流;射流尺寸远小于出口孔。毛细不稳定性将稳定的射流打破为均匀的液滴或气泡。
进料管可以由两个或更多个同心针和注入的不同的导致复合液滴的不混溶液体或气体组成。流动聚焦确保了在射流破裂时极快地且可控地每秒产生数百万液滴。
其他微流体加工技术包括微注射(pico-injection),这是一种使用电场将试剂注入水滴中的技术(参见,例如eastburn等人(2013)picoinjectionenablesdigitaldetectionofrnawithdropletrt-pcr.plosone8(4):e62961.doi:10.1371/journal.pone.0062961)。微滴能够被融合以使两种试剂在一起,例如,主动地通过电熔(参见,例如tan和takeuchi(2006)labchip.6(6):757-63)或被动地(如由simonandlee(2012)“microdroplettechnology”,integratedanalyticalsystemspp23-50,10.1007/978-1-4614-3265-4_2所综述的)。
在所有的情况下,所选择的微滴形成过程的性能可以通过相差显微术、光散射、聚焦光束反射测量、离心和/或流变学监控。
荧光激活微滴分选
如本文所解释的,本发明的方法适合于高通量筛选,因为它们涉及在培养基微小体积中以分离的微滴的形式使筛选分析微区室化。这使得每个微滴都可以作为一个单独的培养容器来处理,允许使用已建立的微流体和/或细胞分选方法快速筛选大量单独的液体共培养物。
因此,在共封装步骤之后,通过调整成熟的荧光激活细胞分选(facs)设备和方案,可以对生成的微滴进行分选。这种技术已被称为荧光激活液滴分选(fads),并且,例如,在baret等人(2009)lapchip(《实验室芯片》)9:1850-1858中描述。可以通过使用荧光部分检测的任何变化都能够进行筛选。
靶细胞可以被荧光标记,以启用fads。多种荧光蛋白能够用作这个目的的标签,包括,例如,水晶果冻水母(aequoreavictoria)野生型绿色荧光蛋白(gfp)(chalfie等人1994,science(《科学》)263:802-805),以及修饰的gfp(heim等人1995,nature(《自然》)373:663-4;pct公布wo96/23810)。或者,dna2.0's
这种类型的报告基因的转录和翻译导致细胞中荧光蛋白的积累,因此使它们适合于fads。
可替代地,范围非常广泛的染料是可用的,所述染料在细胞内特定水平和条件下发出荧光。实例包括购自molecularprobes公司(thermoscientific)的那些。可替代地,可以用抗体检测细胞组分,这些组分可以用市售试剂盒用任意数量的荧光团染色。类似地,dna序列可以用荧光团标记引入细胞内,并通过在细胞内与互补的dna和rna序列杂交而附着,从而可以在称为荧光原位杂交(fish)的过程中直接检测基因表达。
任何可以应用于当前高通量筛选的标记过程都可以应用于fads,并检测为荧光信号相对于对照的变化。
标签模板化合成
编码标签可作为模板,利用dna模板技术指导编码的化合物结构的合成。对于本领域技术人员来说适合的技术是已知的,并且,例如,在mannocci等人(2011)chem.commun.,47:12747-12753;kleiner等人(2011)chemsocrev.40(12):5707-5717;和mullard(2016)nature530:367-369(在此通过引用合并其公开内容)中描述。因此,任何合适的模板技术都可以使用,包括正如davidliu教授和他的同事们(harvarduniversity,usa)描述的以及后来被ensemblediscovery(cambridge,ma,usa)商业化的基于dna模板化合成(dts)的那些技术。在此,通过watson-crick碱基配对使dna连接的试剂接近来促进化学反应。
同样适用的还有pehrharbury教授及其同事(stanforduniversity,usa)开发的dna-路由方法,以及vipergen公司(copenhagen,denmark)开发的yocto反应系统。在后一方法中,三向dna发卡环连接通过将合适的供体化学分子转移到核心受体位点上,协助文库合成(参见w02006/048025,在此通过引用合并其公开内容)。也可以使用可替代的结构几何图形,例如,lundberg等人(2008)nucleicacidssymposium(52):683-684描述的四向dnaholliday连接(4-waydnahollidayjunctions)和rothemund,(2006)nature440:297-302综述的“dna支架折纸”技术创建的复杂形状和图形。
例如,通过使用点击化学(如本文所定义的),可以促进近距离触发反应(proximity-triggeredreactions)。
标签测序
任何合适的测序技术都可以使用,包括sanger测序,但优选的是称为下一代测序(ngs)(也称为高通量测序)的测序方法和平台。存在许多商业上可获得的ngs测序平台适用于本发明的方法。基于边合成边测序(sbs)的测序平台尤其适用。特别优选的是illuminatm系统(其产生数百万个相对短的序列解读(54、75或100bp))。
其他合适的技术包括基于可逆染料终止剂(reversibledye-termintors)的方法,包括illuminatm销售的那些。在此,dna分子首先被附着在载玻片上的引物上并且扩增,从而形成局部克隆集落(桥式扩增)。加入四种类型的ddntp,并且洗去未掺入的核苷酸。与焦磷酸测序不同,dna一次只能延伸一个核苷酸。相机拍摄荧光标记的核苷酸图像,然后染料连同末端3'阻断剂被从dna中化学地去除,允许下一个循环。
其他能够读取短序列的系统包括solidtm和iontorrent技术(均由thermofisherscientificcorporation出售)。solidtm技术通过连接法测序。在此,所有可能的固定长度的寡核苷酸的库都根据测序位置进行标记。对寡核苷酸进行退火和连接;dna连接酶对匹配序列优先连接,产生该位置处核苷酸的信号信息。测序前,用乳液pcr法扩增dna。将获得的珠粒沉积在载玻片上,每个珠粒仅包含相同dna分子的拷贝。结果是相媲美于illumina测序的数量和长度的序列。
iontorrentsystems公司已经开发了基于使用标准测序化学的系统,但具有新颖的基于半导体的检测系统。此测序方法是基于检测在dna聚合过程中释放的氢离子,而不是其他测序系统中使用的光学方法。含有将被测序的模板dna链的微孔被单一类型的核苷酸浸没。如果引入的核苷酸与先导(leading)模板核苷酸互补,则其被合并到正在生长的互补链中。这导致氢离子的释放,从而触发超灵敏的离子传感器,这表明反应已经发生。如果模板序列中存在均聚物重复序列,则多个核苷酸将在单独的循环中合并。这将导致相应数量的氢被释放,并成比例地产生更高的电子信号。
例如或类似于oxfordnanoporetechnologies(牛津纳米孔技术)所使用的方法,其中核酸或其它大分子通过纳米尺度的孔,并且使用特定的离子电流变化或产生的电信号来鉴定它。例如,寡核苷酸的单个碱基可以在连续碱基通过离子孔时被鉴定为寡核苷酸的一部分,或者在连续的裂解步骤后被鉴定为单个核苷酸。
可裂解连接子
任何可裂解的连接子均可以用于连接化合物结构及其编码标签,条件是:(a)所述连接可以被断开,并保持标签的编码信息完整;和(b)编码化合物结构以完全或基本上不含连接子残基的形式被释放,使其活性在筛选中不受连接子裂解后残留的“疤痕(scars)”的影响。应当理解,一些连接子“疤痕”可被容忍,如-oh和/或-sh基团。裂解的方法优选与分析系统兼容。
范围宽阔的合适的可裂解连接子是本领域技术人员所熟知的,并且leriche等人(2012)bioorganic&medicinalchemistry(《生物有机化学与医药化学》)20(2):571-582中描述了合适的实施例。因此合适的连接子可以包括以下连接子:酶解可裂解连接子;亲核试剂/碱敏感连接子;还原敏感的连接子;光可裂解连接子;亲电试剂/酸敏感连接子;金属辅助型裂敏感连接子;氧化敏感的连接子;以及前述两种或两种以上的组合。
例如,在wo2017/089894;wo2016/146638;us2010273843;wo2005/112919;wo2017/089894;degroot等人(1999)j.med.chem.42:5277;degroot等(2000)jorg.chem.43:3093(2000);degroot等人,(2001)jmed.chem.66:8815;wo02/083180;carl等(1981)jmed.chem.lett.24:479;studer等人(1992)bioconjugatechem.(《生物共轭化学》)3(5):424-429;carl等人(1981)j.med.chem.24(5):479-480和dubowchik等人(1998)bioorg&med.chem.lett.(《生物有机化学与医药化学通讯》)8:3347中描述了酶可裂解连接子。它们包括选自以下酶的可裂解的连接子:β-葡萄糖醛酸酶、溶酶体酶、tev、胰蛋白酶、凝血酶、组织蛋白酶b、b和k、胱天蛋白酶、基质金属蛋白酶序列、磷酸二酯、磷脂、酯和β-半乳糖。亲核试剂/碱可裂解连接子包括:二烷基二烷氧基硅烷、氰乙基、砜、乙二醇二琥珀酸盐、2-n-丙烯基硝基苯磺酰胺、α-噻吩酯(α-thiophenylester)、不饱和乙烯基硫化物、磺胺、丙二醛吲哚衍生物、乙酰丙酸酯(levulinoylester)、肼、酰基腙、烷基硫酯。还原可裂解连接子包括二硫桥和偶氮化合物。辐射可裂解连接子包括:2-硝基苄基衍生物、苯酰基酯、8-喹啉基苯磺酸盐、香豆素、磷酸三酯、双芳酰腙、双胺双硫代丙酸(bimanebi-thiopropionicacid)衍生物。亲电试剂/酸敏感连接子包括:对甲氧苄基衍生物、叔丁基氨基甲酸酯类似物、二烷基或二芳基二烷氧基硅烷、原酸酯、缩醛、乌头酰基(aconityl)、肼、β-硫代丙酸盐、磷酸亚胺(phosphoramadite)、亚胺基、三苯甲基、乙烯基醚、聚酮基、烷基2-(二苯基膦基)苯甲酸酯衍生物。有机金属/金属可裂解连接子包括:烯丙基酯、8-羟基喹啉酯和吡啶甲酸酯。氧化可裂解连接子包括:邻二醇和硒化合物。
在某些实施例中,可裂解连接子包含共价和非共价键(例如,从核酸杂交产生的氢键)的组合。
可裂解的(例如酶可裂解的)肽连接子可以包含由单个氨基酸组成的肽部分,或氨基酸的二肽或三肽序列。所述氨基酸可以选自天然氨基酸和非天然的氨基酸,并且在每种情况下,侧链碳原子可以是d或l(r或s)构型。示例性氨基酸包括:丙氨酸、2-氨基-2-环己基乙酸、2-氨基-2-苯乙酸、精氨酸、天冬酰胺、天冬氨酸、半胱氨酸、谷氨酰胺、谷氨酸、甘氨酸、组氨酸、异亮氨酸、亮氨酸、赖氨酸、蛋氨酸、苯丙氨酸、脯氨酸、丝氨酸、苏氨酸、色氨酸、酪氨酸、缬氨酸、γ-氨基丁酸、β,β-二甲基γ-氨基丁酸、α,α-二甲基γ-氨基丁酸、鸟氨酸和瓜氨酸(cit)。合适的氨基酸还包括上述氨基酸的保护形式,其中侧链的反应性功能受到保护。这种被保护的氨基酸包括由乙酰基、甲酰基、三苯基甲基(三苯甲基)和单甲氧基三苯甲基(mmt)保护的赖氨酸。其它受保护的氨基酸单元包括甲苯磺酰基或硝基保护的精氨酸以及乙酰基或甲酰基基团保护的鸟氨酸。
自脱落连接子
特别适合作为可裂解连接子用于本发明的是自脱落连接子,其包括:(a)裂解部分;和(b)自脱落部分(“sim”)。
这样的连接子可以如图8所示使用,其表明sim在裂解后会自发消失,从而释放出游离的化合物结构。
特别适合的自脱落连接子包含:(a)酶解可裂解部分;(b)sim。在此类实施例中,酶解可裂解部分可以是肽序列(用蛋白酶裂解)或非肽酶解可裂解基团,例如,包含β-葡萄糖醛酸酶可裂解的亲水性糖基的葡萄糖苷醛酸部分(如在mccombsandowen(2015)antibodydrugconjugates:designandselectionoflinker,payloadandconjugationchemistrytheaapsjournal17(2):339-351所解释),其显示以下:
在wo2007/011968、us20170189542和wo2017/089894(它们的内容在此通过引用并入)中描述了合适的基于β-葡萄糖醛酸的连接子。因此这样的连接子可以具有下式:
其中,r3是氢或羧基保护基团,以及每个r4独立地是氢或羟基保护基。
对于本发明中使用的自脱落连接子的sim可以选自:取代的烷基、未取代的烷基、取代杂烷基、未取代的杂烷基、未取代的杂环烷基、取代的杂环烷基、取代和未取代的芳基,或取代和未取代的杂芳基。适合的sim因此包括对氨基苄醇(pab)单元和在电子方面与pab基团相似的芳香化合物(例如,hay等人(1999)bioorg.med.chem.lett.9:2237中描述的2-氨基咪唑-5-甲醇衍生物)以及邻位或对位氨基苄基乙缩醛(ortho-orpara-aminobenzylacetals)。
其他合适的sim是在酰胺键水解后发生环化的那些,例如,rodrigues等在(1995)chemistrybiology(《化学生物学》)2:223中描述的取代的和未取代的4-氨基丁酸酰胺。进一步的合适的sim包括适当被取代的双环[2.2.1]和双环[2.2.2]环系统(如storm等人(1972)jamer.chemsoc.94:5815中描述的)以及各种2-氨基苯丙酸酰胺(参见,例如,amsberry等人(1990)j.orgchem.55:5867)。
特别合适的是包含肽作为裂解部分的自脱落肽连接子。图9和图10显示了使用这种连接子构建和使用编码化合物文库。在此,可裂解肽为二肽缬氨酸-瓜氨酸,sim为对氨基苄醇(pab)。在此类实施例中,酰胺连接的pab的酶裂解触发1,6-去除二氧化碳以及伴随释放游离化合物结构。如图9也显示,编码标签和化合物结构可以通过珠粒连接,并且单个珠粒可以装载有多个(其中,n>1)化合物结构,例如,使编码标签与连接的化合物结构的比率为1:10至1:1000。在此类实施例中,肽连接子相对较小的尺寸使扩散速率提高和珠粒负载更高,而化合物结构只需要单一胺用于官能化。
根据本发明用作自脱落连接子的合适的裂解部分和sim的非限制性实施例,例如,在wo2017/089894;wo2016/146638;us2010273843;wo2005/112919;wo2017/089894;degroot等人(1999)j.med.chem.42:5277;degroot等人(2000)jorg.chem.43:3093(2000);degroot等人,(2001)jmed.chem.66:8815;wo02/083180;carl等人(1981)jmed.chem.lett.24:479;studer等人(1992)bioconjugatechem.3(5):424-429;carl等人(1981)j.med.chem.24(5):479-480和dubowchik等人(1998)bioorg&med.chem.lett.8:3347(在此通过引用合并其公开内容)中描述。
微粒
微粒可以由固体或凝胶形成。合适的凝胶包括聚合物凝胶,例如多糖或多肽凝胶,它们可以例如通过加热、冷却或ph调节而从液体凝固成凝胶。合适的凝胶包括水凝胶,包括海藻酸盐、明胶和琼脂糖凝胶。其他合适的微粒材料包括无机材料,如硅、玻璃、金属和陶瓷。其他合适的材料包括塑料(例如聚氯乙烯、环烯烃共聚物、聚丙烯酰胺、聚丙烯酸酯、聚乙烯、聚丙烯、聚(4-甲基丁烯)、聚苯乙烯、聚甲基丙烯酸酯、聚(对苯二甲酸乙二醇酯)、聚四氟乙烯(ptfe)、尼龙和聚乙烯基丁醛。
靶细胞
本发明的分析系统可以包括靶细胞。可以使用任何合适的靶细胞,包括原核细胞和真核细胞。
例如,靶细胞可以是古细菌,例如选自以下门类中的古细菌:(a)泉古菌(crenarchaeota)、(b)广古菌(euryarchaeota)、(c)初古菌(korarchaeota)、(d)纳古菌(nanoarchaeota)和(e)奇古菌(thaumarchaeota),例如沃氏富盐菌(haloferaxvolcanii)和硫化叶菌(sulfolobusspp)。
在其它实施例中,靶细胞可以是细菌,例如致病菌。在这种情况下,细菌可以是革兰氏阳性细菌(例如选自粪肠球菌、屎肠球菌和金黄色葡萄球菌)、革兰氏阴性细菌(例如选自肺炎克雷伯氏菌、鲍氏不动杆菌、大肠埃希氏杆菌、大肠杆菌st131菌株、铜绿假单胞菌、阴沟肠杆菌、产气肠杆菌和淋病奈瑟氏菌)或可以是表现出不确定革兰氏反应的细菌。
在其他实施例中,靶细胞可以是真核细胞,例如选自:(a)真菌、(b)哺乳动物、(c)高等植物细胞、(d)原生动物、(e)寄生虫细胞、(f)藻类和(h)无脊椎动物细胞。在此类实施例中,靶细胞可以是癌细胞例如人癌细胞、肌肉细胞、人类神经元细胞和来自活人患者的其它显示疾病相关表型的细胞。
在所述细胞为真核细胞的情况下(例如人类细胞),所述细胞可以选自:全能细胞、多能细胞、诱导多能细胞、专能细胞、寡能细胞、干细胞、胚胎干细胞(es)、体细胞、生殖系细胞、最终分化的细胞、不分裂的(有丝分裂后)细胞、有丝分裂细胞、原代细胞、细胞系来源的细胞和肿瘤细胞。
所述细胞优选地是分离的(即,不存在于它天然的细胞/组织环境中)和/或有代谢活性(例如,与维持细胞活力和/或活性和/或支持细胞生长或增殖的培养物或转运介质一起存在于分析系统中)。
合适的真核细胞可以从生物体分离,例如选自以下生物体:后生动物、真菌(如酵母)、哺乳动物、非哺乳动物、植物、原生动物、寄生虫、藻类、昆虫(如苍蝇)、鱼类(如斑马鱼)、两栖类(如青蛙)、鸟类、无脊椎动物及脊椎动物。
合适的真核细胞也可从下列非人类动物中分离:哺乳动物、啮齿动物、兔、猪、绵羊、山羊、牛、大鼠、小鼠、非人灵长类动物和仓鼠。在其他实施例中,所述细胞可以从表达异源基因的非人类疾病模型或转基因非人类动物中分离,所述异源基因例如编码治疗产品的异源基因。
细菌作为靶细胞
本发明使用的靶细胞可以是细菌细胞。在这些实施例中,细菌可以选自:(a)革兰氏阳性、革兰氏阴性和/或革兰氏染色不定(gran-variable)细菌;(b)孢子形成细菌;(c)非孢子形成细菌;(d)丝状细菌;(e)细胞内细菌;(f)专性需氧菌;(g)专性厌氧菌;(h)兼性厌氧菌;(i)微需氧细菌和/或(f)条件性细菌病原体。
在某些实施例中,根据本发明使用的靶细胞可以选自以下属的细菌:不动杆菌(acinetobacter)(例如鲍氏不动杆菌(a.baumannii));气单孢菌(aeromonas)(例如嗜水气单胞菌(a.hydrophila));芽孢杆菌(bacillus)(例如炭疽杆菌(b.anthracis));拟杆菌(bacteroides)脆弱拟杆菌(例如b.fragilis);博德特氏菌(bordetella)(例如百日咳杆菌(b.pertussis));疏螺旋体(borrelia)(例如伯氏疏螺旋体(b.burgdorferi));布鲁氏菌(brucella)(例如流产布鲁氏菌(b.abortus)、犬种布鲁氏菌(b.canis)、羊种布鲁氏菌(b.melitensis)和猪布鲁氏菌(b.suis));伯克氏菌(burkholderia)(例如洋葱伯克氏菌群(b.cepaciacomplex));弯曲杆菌(campylobacter)(例如空肠弯曲杆菌(c.jejuni));衣原体(chlamydia)(例如沙眼衣原体(c.trachomatis)、猪衣原体(c.suis)和鼠衣原体(c.muridarum));嗜性衣原体(chlamydophila)(例如(例如肺炎嗜性衣原体(c.pneumoniae)、反刍动物嗜性衣原体(c.pecorum)、鹦鹉热嗜性衣原体(c.psittaci)、流产嗜性衣原体(c.abortus)、猫嗜性衣原体(c.felis)和豚鼠嗜性衣原体(c.caviae));柠檬酸杆菌(citrobacter)(例如弗氏柠檬酸杆菌(c.freundii));梭菌(clostridium)(例如肉毒梭菌(c.botulinum)、艰难梭菌(c.difficile)、产气荚膜梭菌(c.perfringens)和破伤风梭菌(c.tetani));棒状杆菌(corynebacterium)(例如白喉棒状杆菌(c.diphteriae)和谷氨酸棒状杆菌(c.glutamicum));肠杆菌(enterobacter)(例如阴沟肠杆菌(e.cloacae)和产气肠杆菌(e.aerogenes));肠球菌(enterococcus)(例如粪肠球菌(e.faecalis)和屎肠球菌(e.faecium));埃希氏菌(escherichia)(例如大肠埃希氏杆菌(e.coli));黄杆菌(flavobacterium);弗朗西斯菌(francisella)(例如土拉热弗朗西丝菌(f.tularensis));梭杆菌(fusobacterium)(例如坏死梭杆菌(f.necrophorum));嗜血杆菌(haemophilus)(例如睡眠嗜血杆菌(h.somnus)、流感嗜血杆菌(h.influenzae)和副流感嗜血杆菌(h.parainfiuenzae));螺杆菌(helicobacter)(例如幽门螺杆菌(h.pylon));克雷伯氏菌(klebsiella)(例如产酸克雷伯氏菌(k.oxytoca)和肺炎克雷伯氏菌(k.pneumoniae));军团菌(legionella)(例如嗜肺军团菌(l.pneumophila));钩端螺旋体(leptospira)(例如问号钩端螺旋体(l.interrogans));李斯特菌(listeria)(例如单核细胞增生李斯特菌(l.monocytogenes));莫拉氏菌(moraxella)(例如卡他莫拉菌(m.catarrhalis));摩根氏菌(morganella)(例如摩氏摩根氏菌(m.morganii));分枝杆菌(mycobacterium)(例如麻风分枝杆菌(m.leprae)和结核分枝杆菌(m.tuberculosis));支原体(mycoplasma)(例如肺炎支原体(m.pneumoniae));奈瑟氏菌(neisseria)(例如淋病奈瑟氏菌(n.gonorrhoeae)和脑膜炎奈瑟球菌(n.meningitidis));巴氏杆菌(pasteurelia)(例如多杀性巴氏杆菌(p.multocida));消化链球菌(peptostreptococcus);普雷沃菌(prevotella);变形杆菌(proteus)(例如奇异变形杆菌(p.mirabilis)和普通变形杆菌(p.vulgaris));假单胞菌(pseudomonas)(例如铜绿假单胞菌(p.aeruginosa));立克次氏体(rickettsia)(例如立克次氏立克次氏体(r.rickettsii));沙门氏菌(salmonella)(例如伤寒(typhi)和鼠伤寒(typhimurium)血清型);沙雷氏菌(serratia)(例如粘质沙雷氏菌(s.marcesens));志贺氏菌(shigella)(例如福氏志贺氏菌(s.flexnaria)、痢疾志贺氏菌(sdysenteriae)和宋内氏志贺氏菌(s.sonnei));葡萄球菌(staphylococcus)(例如金黄色葡萄球菌(s.aureus)、溶血性葡萄球菌(shaemolyticus)、中间葡萄球菌(s.intermedius)、表皮葡萄球菌(s.epidermidis)和腐生葡萄球菌(s.saprophyticus);寡养单胞菌(stenotrophomonas)(例如嗜麦芽寡养单胞菌(s.maltophila));链球菌(streptococcus)(例如无乳链球菌(s.agalactiae)、变形链球菌(s.mutans)、肺炎链球菌(s.pneumoniae)和酿脓链球菌(s.pyogenes));密螺旋体(treponema)(例如苍白密螺旋体(t.pallidum));弧菌(vibrio)(例如霍乱弧菌(v.cholerae))和耶尔森氏菌(yersinia)(例如鼠疫耶尔森氏菌(y.pestis))。
根据本发明使用的靶细胞可选自高g+c革兰氏阳性细菌和低g+c革兰氏阳性细菌。
致病菌作为靶细胞
人类或动物细菌性病原体包括细菌例如:军团菌(legionellaspp.)、李斯特菌(listeriaspp.)、假单胞菌(pseudomonasspp.)、沙门氏菌(salmonellaspp.)、克雷伯氏菌(klebsiellaspp.)、哈夫尼菌(hafniaspp.)、嗜血杆菌(haemophilusspp.)、变形杆菌(proteusspp.)、沙雷氏菌(serratiaspp.)、志贺氏菌(shigellaspp.)、弧菌(vibriospp.)、芽孢杆菌(bacillusspp.)、弯曲杆菌(campylobacterspp.)、耶尔森氏菌(yersiniaspp.)、梭菌(clostridiumspp.)、肠球菌(enterococcusspp.)、奈瑟氏菌(neisseriaspp.)、链球菌(streptococcusspp.)、葡萄球菌(staphylococcusspp.)、分枝杆菌(mycobacteriumspp.)、肠杆菌(enterobacterspp.)。
真菌作为靶细胞
本发明使用的靶细胞可以是真菌细胞。它们包括酵母,例如念珠菌属,包括白色念珠菌(c.albicans)、克鲁斯念珠菌(ckrusei)和热带念珠菌(ctropicalis);以及丝状真菌,例如曲霉(aspergillusspp.)和青霉(penicilliumspp.),以及皮肤真菌,例如毛癣菌(trichophytonspp.)。
植物病原体作为靶细胞
根据本发明使用的靶细胞可以是植物病原体,例如假单胞菌(pseudomonasspp.)、木杆菌(xylellaspp.)、青枯菌(ralstoniaspp.)、黄单胞菌(xanthomonasspp.)、欧文氏菌(erwiniaspp.)、镰刀菌(fusariumspp.)、疫霉菌(phytophthoraspp.)、葡萄孢菌(botrytisspp.)、小球腔菌(leptosphaeriaspp.)、白粉菌(powderymildews)(子囊菌(ascomycota))和锈菌(rusts)(担子菌(basidiomycota))。
癌细胞作为靶标
癌细胞可以用作靶细胞。此类细胞可以源自细胞系或源自原发性肿瘤。癌细胞可以是哺乳动物细胞,且优选是人的癌细胞。在某些实施例中,所述癌细胞选自黑色素瘤、肺、肾、结肠、前列腺、卵巢、乳腺、中枢神经系统和白血病细胞系。
合适的癌细胞系包括但不限于:卵巢癌细胞系(例如,caov-3、ovcar-3、es-2、sk-ov-3、sw626、tov-21g、tov-112d、ov-90、mda-h2774和pa-i);乳腺癌细胞系(例如,mcf7、mda-mb-231、mda-mb-468、mda-mb-361、mda-md-453、bt-474、hs578t、hcc1008、hcc1954、hcc38、hcci143、hcci187、hcc1395、hcc1599、hcc1937、hcc2218、hs574.t、hs742.t、hs605.t和hs606);肺癌细胞系(例如,nci-h2126、nci-h1395、nci-h1437、nci-h2009、nci-h1672、nci-h2171、nci-h2195、nci-hi184、nci-h209、nci-h2107和nci-h128);皮肤癌细胞系(例如colo829、te354.t、hs925.t、wm-115和hs688(a).t);骨癌细胞系(例如,hs919.t、hs821.t、hs820.t、hs704.t、hs707(a).t、hs735.t、hs860.t、hs888.t、hs889.t、hs890.t和hs709.t);结肠癌细胞系(例如,caco-2、dld-i、hct-116、ht-29和sw480);以及胃癌细胞系(例如,rf-i)。在本发明方法中有用的癌细胞系可以从任何方便的来源获得,包括美国典型培养物保藏中心(americantypeculturecollection,atcc)和国家癌症研究所(nationalcancerinstitute)。
其他癌症细胞系包括来自肿瘤细胞/受试者患有癌变的细胞系,包括增生性疾病、良性、癌前和恶性肿瘤、增生、化生和异型增生。增生性疾病包括但不限于癌症、癌症转移、平滑肌细胞增殖、系统性硬化、肝硬化、成人呼吸窘迫综合征、特发性心肌病、红斑狼疮、视网膜病变(例如糖尿病视网膜病变)、心脏增生、良性前列腺增生、卵巢囊肿、肺纤维化、子宫内膜异位症、纤维瘤病、错构瘤(harmatomas)、淋巴管瘤、结节病和硬纤维瘤。涉及平滑肌细胞增殖的肿瘤包括血管系统中细胞的过度增殖(例如,内膜平滑肌细胞增生、再狭窄和血管闭塞,特别是包括生物或机械介导的血管损伤后的狭窄,如血管成形术)。此外,内膜平滑肌细胞增生可以包括血管系统以外的平滑肌增生(例如,胆管、支气管气道阻塞和肾间质纤维化患者的肾脏阻塞)。非癌性增生性疾病还包括皮肤细胞的过度增殖,例如,银屑病及其各种临床表现形式,瑞特氏综合征、毛发红糠疹(pityriasisrubrapilaris)和角化病的过度增生性变异(包括光化性角化病、老年性角化病和硬皮病)。
细胞系作为靶标
从细胞系获得的其他细胞可以用作靶细胞。这些细胞包括患有罕见疾病患者的具有可检测的细胞表型的细胞,优选人类或哺乳动物细胞。所述细胞可以是任何类型的,包括但不限于血细胞、免疫细胞、骨髓细胞、皮肤细胞、神经组织和肌肉细胞。
在本发明方法中有用的细胞系可以从任何方便的来源获得,包括美国典型培养物保藏中心(americantypeculturecollection,atcc)和国家癌症研究所(nationalcancerinstitute)。
例如,所述细胞/细胞系可能来源于患有溶酶体贮积病、肌营养不良、囊性纤维化、马凡氏综合征、镰状细胞贫血、侏儒症、苯丙酮尿症、神经纤维瘤病、亨廷顿病、成骨不全症、地中海贫血和血色素沉着症的受试者(subject)。
例如,所述细胞/细胞系可以来源于患有其他疾病的受试者,包括:血液、凝血、细胞增殖和失调、肿瘤(包括癌症)、炎症过程、免疫系统(包括自身免疫性疾病)、代谢、肝、肾、肌肉骨骼、神经、神经元和眼部组织的疾病和紊乱。示例性的血液和凝血疾病和紊乱包括:贫血,裸淋巴细胞综合征,出血障碍,因子h、因子h样1、因子v、因子viii、因子vii、因子x、因子xi、因子xii、因子xiiia、因子xiiib缺陷,凡科尼贫血,噬血细胞性淋巴组织细胞增多症,血友病a,血友病b,出血性疾病,白细胞缺乏症,镰状细胞贫血和地中海贫血。
免疫相关疾病和紊乱的实例包括:aids;自身免疫性淋巴增生综合征;联合免疫缺陷;hiv-1;hiv易感性或感染;免疫缺陷和严重联合免疫缺陷(scid)。本发明可治疗的自身免疫性疾病包括格雷夫氏病、类风湿关节炎、桥本甲状腺炎、白癜风、i型(早发)糖尿病、恶性贫血、多发性硬化、肾小球肾炎、系统性红斑狼疮e(sle,狼疮)和干燥综合征。其他自身免疫性疾病包括硬皮病、银屑病、强直性脊柱炎、重症肌无力、天疱疮、多肌炎、皮肌炎、葡萄膜炎、格林-巴利综合征、克罗恩病和溃疡性结肠炎(通常统称炎症性肠病(ibd))。
其他典型疾病包括:淀粉样神经病变;淀粉样变性病;囊性纤维化;溶酶体贮积疾病;肝腺瘤;肝衰竭;神经系统疾病;肝脂酶缺乏症;肝母细胞瘤、癌症或癌;髓样囊性肾病;苯丙酮酸尿;多囊肾;或肝脏疾病。
典型的肌肉骨骼疾病和紊乱包括:肌营养不良(如duchenne和becker肌营养不良)、骨质疏松症和肌萎缩。
典型的神经和神经元疾病和紊乱包括:als,阿尔茨海默病;自闭症;脆性x综合征、亨廷顿病、帕金森病、精神分裂症、分泌酶相关疾病、三核苷酸重复疾病、肯尼迪病、弗里德里希共济失调、马沙多-约瑟夫病、脊髓小脑共济失调、强直性肌营养不良、齿状核红核苍白球路易体萎缩症(drpla)。
典型眼病包括:年龄相关性黄斑变性、角膜混浊和营养不良、先天性扁平角膜、青光眼、利伯尔先天性黑内障和黄斑营养不良。
所述细胞/细胞系可以,例如,来自患有至少部分由蛋白质稳态缺陷介导的疾病的受试者,包括聚集性和错误折叠性蛋白稳态(proteostatic)疾病,特别是包括神经退行性疾病(例如,帕金森氏症、阿尔茨海默病和亨廷顿氏病)、溶酶体贮积疾病、糖尿病、气肿、癌症和囊性纤维化。
古细菌作为靶细胞
靶细胞可以是古细菌,例如选自以下门类中的古菌:(a)泉古菌(crenarchaeota)、(b)广古菌(euryarchaeota)、(c)初古菌(korarchaeota)、(d)纳古菌(nanoarchaeota)和(e)奇古菌(thaumarchaeota),例如沃氏富盐菌(haloferaxvolcanii)和硫化叶菌(sulfolobusspp.)。
示例性的古细菌属包括喜酸菌属(acidianus)、酸叶菌属(acidilobus)、嗜酸球菌属(acidococcus)、aciduliprofundum、气火菌属(aeropyrum)、古丸菌属(archaeoglobus)、bacilloviridae、caldisphaera、暖枝菌属(caldivirga)、caldococus、餐古菌属(cenarchaeum)、除硫球菌属(desulfurococcus)、铁丸菌属(ferroglobus)、铁原体属(ferroplasma)、地球菌属(geogemma)、地丸菌属(geoglobus)、haladaptaus、盐碱球菌属(halalkalicoccus)、haloalcalophilium、盐盒菌属(haloarcula)、盐杆菌属(halobacterium)、盐棒菌属(halobaculum)、盐二型菌属(halobiforma)、盐球菌属(halococcus)、富盐菌属(haloferax)、盐几何菌属(halogeometricum)、盐微菌属(halomicrobium)、盐惰菌属(halopiger)、盐盘菌属(haloplanus)、盐方菌属(haloquadratum)、盐棍菌属(halorhabdus)、盐红菌属(halorubrum)、halosarcina、盐简菌属(halosimplex)、盐池栖菌属(halostagnicola)、盐陆生菌属(haloterrigena)、盐长命菌属(halovivax)、超热菌属(hyperthermus)、燃球菌属(ignicoccus)、燃球形菌属(ignisphaera)、生金球形菌属(metallosphaera)、甲烷微球菌属(methanimicrococcus)、甲烷杆菌属(methanobacterium)、甲烷短杆菌属(methanobrevibacter)、甲烷砾菌属(methanocalculus)、methantxaldococcus、甲烷胞菌属(methanocella)、甲烷类球菌属(methanococcoides)、甲烷球菌属(methanococcus)、甲烷粒菌属(methanocorpusculum)、甲烷囊菌属(methanoculleus)、甲烷泡菌属(methanofollis)、产甲烷菌属(methanogenium)、甲烷盐菌属(methanohalobium)、甲烷嗜盐菌属(methanohalophilus)、甲烷裂叶菌属(methanolacinia)、甲烷叶菌属(methanolobus)、甲烷食甲基菌属(methanomethylovorans)、甲烷微菌属(methanomicrobium)、甲烷盘菌属(methanoplanus)、甲烷火菌属(methanopyrus)、甲烷规则菌属(methanoregula)、甲烷鬃菌属(methanosaeta)、甲烷咸菌属(methanosalsum)、甲烷八叠球菌属(methanosarcina)、甲烷球形菌属(methanosphaera)、甲烷螺旋菌属(melthanospirillum)、甲烷热杆菌属(methanothermobacter)、甲烷热球菌属(methanothermococcus)、甲烷热菌属(methanothermus)、甲烷发菌属(methanothrix)、甲烷炎菌属(methanotorris)、纳古菌属(nanoarchaeum)、钠白菌属(natrialba)、钠线菌属(natrinema)、盐碱杆菌属(natronobacterium)、盐碱球菌属(natronococcus)、盐碱湖菌属(natronolimnobius)、盐碱单胞菌属(natronomonas)、盐碱红菌属(natronorubrum)、短小亚硝酸菌属(nitracopumilus)、古老球菌属(palaeococcus)、嗜苦菌属(picrophilus)、火棒菌属(pyrobaculum)、火球菌属(pyrococcus)、热网菌属(pyrodictium)、火叶菌属(pyrolobus)、葡萄热菌属(staphylothermus)、施铁特菌属(stetteria)、憎叶菌属(stygiolobus)、硫化叶菌属(sulfolobus)、厌硫球菌属(sulfophobococcus)、硫磺球形菌属(sulfurisphaera)、热分支菌属(thermocladium)、热球菌属(thermococcus)、热盘菌属(thermodiscus)、热丝菌属(thermofilum)、热原体属(thermoplasma)、热变形菌属(thermoproteus)、热球形菌属(thermosphaera)和火山鬃菌属(vulcanisaeta)。
示例性古细菌种类包括:敏捷气热菌(aeropyrumpernix)、闪烁古生球菌(archaeglobusfulgidus)、闪烁古生球菌(archaeoglobusfulgidus)、desulforcoccusspeciestok、嗜热自养甲烷杆菌(methanobacteriumthermoantorophicum)、詹氏甲烷球菌(methanococcusjannaschii)、需氧热棒菌(pyrobaculumaerophilum)、pyrobaculumcalidifontis、冰岛火棒菌(pyrobaculumislandicum)、深海热球菌(pyrococcusabyssi)、火球菌gb-d(pyrococcusgb-d)、pyrococcusglycovorans、掘越氏火球菌(pyrococcushorikoshii)、火球菌ge23(pyrococcusspp.ge23)、火球菌st700(pyrococcusspp.st700)、沃氏热球菌(pyrococcuswoesii)、隐蔽热网菌(pyrodictiumoccultum)、嗜酸热硫化叶菌(sulfolobusacidocaldarium)、sulfolobussolataricus、东工大硫化叶菌(sulfolobustokodalii)、thermococcusaggregans、thermococcusbarossii、速生热球菌(thermococcusceler)、thermococcusfumicolans、蛇发女怪热球菌(thermococcusgorgonarius)、热水高温球菌(thermococcushydrothermalis)、thermococcusonnurineusna1、太平洋热球菌(thermococcuspacificus)、thermococcusprofundus、thermococcussiculi、热球菌ge8(thermococcussppge8)、热球菌jdf-3(thermococcussppjdf-3)、热球菌ty(thermococcussppty)、thermococcusthioreducens、thermococcuszilligti、嗜酸热原体菌(thermoplasmaacidophilum)、火山嗜热支原体(thermoplasmavolcanium)、好客嗜酸两面菌(acidianushospitalis)、acidilobussacharovorans、aciduliprofundumboonei、敏捷气热菌(aeropyrumpernix)、闪烁古生球菌(archaeoglobusfulgidus)、archaeoglobusprofundus、嗜热硫酸盐还原菌(archaeoglobusveneficus)、caldivirgamaquilingensis、candidatuskorarchaeumcryptofilum、candidatusmethanoregulaboonei、candidatusnitrosoarchaeumlimnia、cenarchaeumsymbiosum、desulfurococcuskamchatkensis、ferroglobusplacidus、ferroplasmaacidarmanus、halalkalicoccusjeotgali、西班牙盐盒菌(haloarculahispanica)、holaoarculamarismortui、halobacteriumsalinarum、盐杆菌(halobacteriumspecies)、halobiformalucisalsi、沃氏嗜盐富饶菌(haloferaxvolvanii)、波多黎各盐几何形菌(halogeometricumborinquense)、向烟氏盐微菌(halomicrobiummukohataei)、halophilicarchaceonsp.dl31、halopigerxanaduensis、haloquadratumwalsbyi、halorhabdustiamatea、halorhabdusutahensis、湖渊盐红菌(halorubrumlacusprofundi)、haloterrigenaturkmenica、丁酸栖高温菌(hyperthermusbutylicus)、igniococcushospitalis、ignisphaeraaggregans、metallosphaeracuprina、勤奋生金球菌(metallosphaerasedula)、甲烷杆菌al-21(methanobacteriumsp.al-21)、甲烷杆菌swan-1(methanobacteriumsp.swan-1)、嗜热自养甲烷杆菌(methanobacteriumthermoautrophicum)、瘤胃甲烷短杆菌(methanobrevibacterruminantium)、史密斯甲烷杆菌(methanobrevibactersmithii)、methanocaldococcusfervens、methanocaldococcusinfernus、詹氏甲烷球菌(methanocaldococcusjannaschii)、甲烷暖球菌fs406-22(methanocaldococcussp.fs406-22)、methanocaldococcusvulcanius、methanocellaconradii、methanocellapaludicola、产甲烷胞菌水稻簇i(methanocellasp.riceclusteri(rc-i))、布氏拟甲烷球菌(methanococcoidesburtonii)、methanococcusaeolicus、海沼甲烷球菌(methanococcusmaripaludis)、万氏甲烷球菌(methanococcusvannielii)、沃氏甲烷球菌(methanococcusvoltae)、methanocorpusculumlabreantum、黑海甲烷袋状菌(methanoculleusmarisnigri)、methanohalobiumevestigatum、马氏甲烷嗜盐菌(methanohalophilusmahii)、methanoplanuspetrolearius、坎氏甲烷嗜高热菌(methanopyruskandleri)、联合甲烷鬃毛菌(methanosaetaconcilii)、竹节状甲烷鬃菌(methanosaetaharundinacea)、methanosaetathermophila、织里甲烷咸菌(methanosalsumzhilinae)、乙酸甲烷八叠球菌(methanosarcinaacetivorans)、巴氏甲烷八叠球菌(methanosarcinabarkeri)、马氏甲烷八叠球菌(methanosarcinamazei)、methanosphaerastadtmanae、methanosphaerulapalustris、亨氏甲烷螺菌(methanospiriullumhungatei)、mathanothermobactermarburgensis、冲绳甲烷球菌(methanothermococcusokinawensis)、炽热甲烷嗜热菌(methanothermusfervidus)、methanotorrisigneus、骑行纳古菌(nanoarchaeumequitans)、中亚无色需碱菌(natrialbaasiatica)、加蒂湖无色嗜盐菌(natrialbamagadii)、法老嗜盐碱单胞菌(natronomonaspharaonis)、海洋氨氧化古菌(nitrosopumilusmaritimus)、picrophilustorridus、需氧热棒菌(pyrobaculumaerophilum)、pyrobaculumarsenaticum、pyrobaculumcalidifontis、冰岛火棒菌(pyrobaculumislandicum)、热棒菌1860(pyrobaculumsp.1860)、深海热球菌(pyrococcusabyssi)、强烈炽热球菌(pyrococcusfuriosus)、pyrococcushorikoshii、火球菌na42(pyrococcussp.na42)、pyrococcusyayanosii、烟孔火叶菌(pyrolobusfumarii)、staphylothermushellenicus、staphylothermusmarinus、sulfolobusacidocaldirius、冰岛硫化叶菌(sulfolobusislandicus)、硫磺矿硫化叶菌(sulfolobussolfataricus)、sulfolobustokodaii、thermococcusbarophilus、thermococcusgammatolerans、thermococcuskodakaraensis、thermococcuslitoralis、thermococcusonnurineus、thermococcussibiricus、热球菌4557(thermococcussp.4557)、热球菌am4(thermococcussp.am4)、thermofilumpendens、嗜酸热原体菌(thermoplasmaacidophilum)、火山嗜热支原体(thermoplasmavolcanium)、thermoproteusneutrophilus、顽固热变形菌(thermoproteustenax)、thermoproteusuzoniensis、thermosphaeraaggregans、vulcanisaetadistributa和vulcanisaetamoutnovskia。
根据本发明,用作生产细胞的古细菌细胞的具体实例包括沃氏富盐菌(haloferaxvolcanii)和硫化叶菌(sulfolobusspp.)。
靶蛋白
本发明的分析系统可以包括靶蛋白。
可以使用任何合适的靶蛋白,包括上面部分中讨论的任何靶细胞的蛋白。因此,适用于根据本发明分析系统的靶蛋白可以选自真核蛋白、原核蛋白、真菌蛋白和病毒蛋白。
因此合适的靶蛋白包括但不限于:癌蛋白、运输(核、载体、离子、通道、电子、蛋白质)、行为、受体、细胞死亡、细胞分化、细胞表面、结构蛋白、细胞粘附、细胞通讯、细胞运动、酶、细胞功能(解旋酶、生物合成、马达、抗氧化、催化、代谢、蛋白水解)、膜融合、发育、调节生物过程的蛋白质、具有信号转导活性的蛋白质、受体活性、异构酶活性、酶调节活性、伴侣调节、结合活性、转录调节活性、翻译调节活性、结构分子活性、连接酶活性、细胞外组织活性、激酶活性、生物发生活性、连接酶活性和核酸结合活性。
靶蛋白可以选自并且因此不限于:dna甲基转移酶、akt途径蛋白、mapk/erk途径蛋白质、酪氨酸激酶、上皮生长因子受体(egfr)、成纤维细胞生长因子受体(fgfr)、血管内皮生长因子受体(vegfr)、产生红细胞生成素的人肝细胞受体(eph)、原肌球蛋白受体激酶、肿瘤坏死因子、细胞凋亡调节bcl-2家族蛋白、极光激酶、染色质、g蛋白偶联受体(gpcr)、nf-κβ通路、hcv蛋白、hiv蛋白、天冬氨酰蛋白酶、组蛋白脱乙酰酶(hdac)、糖苷酶、脂肪酶、组蛋白乙酰转移酶(hat)、细胞因子和激素。
特定的靶蛋白质可选自:erk1/2、erk5、a-raf、b-raf、c-raf、c-mos、tpl2/cot、mek、mkk1、mkk2、mkk3、mkk4、mkk5、mkk6、mkk7、tyk2、jnk1、jnk2、jnk3、mekk1、mekk2、mekk3、mekk4、ask1、ask2、mlk1、mlk2、mlk3、p38α、p38β、p38γ、p38δ、brd2、brd3、brd4、磷脂酰肌醇-3激酶(pi3k)、akt、蛋白激酶a(pka)、蛋白激酶b(pkb)、蛋白激酶c(pkc)、pgc1α、sirt1、pd-l1、mtor、pdk-1、p70s6激酶、叉头易位因子、melk、elf4e、hsp90、hsp70、hsp60、i型拓扑异构酶、ii型拓扑异构酶、dnmt1、dnmt3a、dnmt3b、cdk11、cdk2、cdk3、cdk4、cdk5、cdk6、cdk7、α-微管蛋白、(β-微管蛋白、γ-微管蛋白、δ-微管蛋白、ε-微管蛋白、janus激酶(jak1、jak2、jak3)、abl1、abl2、egfr、epha1、epha2、epha3、epha4、epha5、epha6、epha7、epha8、epha10、ephb1、ephb2、ephb3、ephb4、ephb6、her2/neu、her3、her4、alk、fgfr1、fgfr2、fgfr3、fgfr4、igf1r、insr、insrr、vegfr-1、vegfr-2、vegfr-3、flt-3、flt4、pdgfra、pdgfrb、csf1r、axl、irak4、scfr、fyn、musk、btk、csk、plk4、fes、mer、c-met、lmtk2、frk、ilk、lck、tie1、fak、ptk6、tnni3、roscck4、zap-70、c-src、tec、lyn、trka、trkb、trkc、ret、ror1、ror2、ack1、syk、mdm2、hras、kras、nras、rock、pi3k、bace1、bace2、ctsd、ctse、napsa、pgc、肾素、mmset、极光激酶a、极光激酶b、极光激酶c、法尼基转移酶、端粒酶、腺苷酸环化酶、camp磷酸二酯酶、parp1、parp2、parp4、parp-5a、parp-5b、pkm2、keapl、nrf2、tnf、trail、ox40l淋巴毒素-α、ifnar1、ifnar2、ifn-α、ifn-β、ifn-γ、ifnlr1、ccl3、ccl4、ccl5、il1α、il1β、il-2、il-2、il-4、il-5、il-6、il-7、il-9、il-9、il-10、il-11、il-12、il-13、il-15、il-17、bcl-2、bcl-xl、bax、hcv解旋酶、e1、e2、p7、ns2、ns3、ns4a、ns4b、ns5a、ns5b、nf-kb1、nf-kb2、rela、relb、c-rel、rip1、ace、hiv蛋白酶、hiv整合酶、gag、pol、gp160、tat、rev、nef、vpr、vif、vpu、rna聚合酶、gaba转氨酶、逆转录酶、dna聚合酶、催乳素、acth、anp、胰岛素、pde、ampk、inos、hdac1、hdac2、hdac3、hdac4、hdac5、hdac6、hdac7、hdac8、hdac9、hdac10、hdac11、乳糖酶、淀粉酶溶菌酶、神经氨酸酶、转化酶(invertase)、几丁质酶、透明质酸酶、麦芽糖酶、蔗糖酶、磷酸酶、磷酸化酶、p、组氨酸脱羧酶、pten、组蛋白赖氨酸脱甲基酶(kdm)、gcn5、pcaf、hat1、atf-2、tip60、moz、morf、hbo1、p300、cbp、src-1、src-3、actr、tif-2、taf1、tfiiic、蛋白o甘露糖基转移酶1(pomt1)、淀粉样蛋白β和tau。
范例
本发明现将参照具体实例加以说明。这些仅仅是范例,并且仅仅供说明:它们并非以任何方式限制所要求的独占范围或所本发明描述的范围。
附图说明
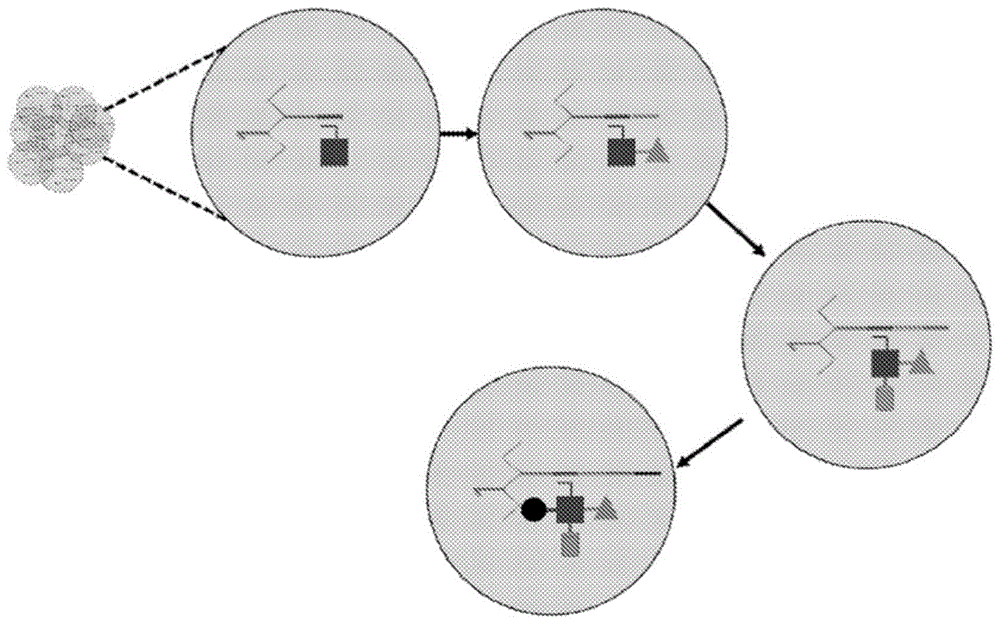
图1:分开与合并decl生成的示意图。通过对原药效团(primarypharmacore)具有特异性的互补寡核苷酸标记原药效团,并将其固定在珠粒上。从该珠粒内引导dna(guidedna)的μμ-mm浓度得到对应的在该珠内药效团的μμ-mm浓度。采用传统化学方法围绕原药效团进行组装——每个添加物都与连接到编码标签(作为条形码)末端的特定dna偶合。因此,该珠粒可用于固相合成,并且可添加大量的反应性二级药效团进行反应。额外寡核苷酸的连接可以同时进行(例如通过点击化学或类似化学)或通过合成后步骤进行。
图2:分开与合并decl的示意图。该合成步骤包括如图1所示的由dna序列(标签)添加而编码的药效团(子结构)组装。从珠粒内引导dna(guidedna)的μμ-mm浓度得到对应的合成的化合物结构的μμ-mm浓度。指示细胞用于表型筛选。滴(droplet)内标签的释放产生游离的、无标签的化合物结构,其浓度足以与表型筛选中的指示细胞相互作用。该滴内,dna标签在空间上与游离的化合物结构保持关联。用ngs测序法对阳性的facs命中物进行测序,以鉴定该化合物结构的结构。
图3:将编码的寡核苷酸连接到固定有捕获寡核苷酸的珠上。
图4:在凝胶上从可裂解连接子酶解释放有效载荷。
图5:在100μm的水性滴内从可裂解连接子上酶解释放有效载荷。
图6:采用huisgen1,3-偶极环加成反应,从珠粒结合的(bead-bound)寡核苷酸上释放用荧光染料官能化的化合物结构有效载荷。
图7:采用异硫氰酸加成,从珠粒结合的寡核苷酸上释放用荧光染料官能化的化合物结构有效载荷。
图8:使用自脱落连接子释放游离的化合物结构的示意图。
图9:使用自脱落二肽连接子的分开与合并decl的示意图。
图10:使用偶合到含编码标签的珠粒上的val-cit-pab自脱落肽连接子释放游离的化合物结构的示意图。
实施例1:采用水凝胶基质珠粒通过筛选在滴中生成无标签化合物文库
1:引导序列的组装
1)组装涉及5'标签寡核苷酸和3'标签寡核苷酸,其中,5'标签寡核苷酸包括12c连接子,组装至氨基用于交联,注意,引导序列是对应于用于文库的单体的寡核苷酸池,在这种情况下,200个寡核苷酸允许组装>1.6×109个独特(unique)序列。
2)添加1μm最终浓度的5'标签和3’标签。
3)250个条形码寡核苷酸被集中在池中,最终浓度1.25μm。
反应混合物:
10μlneb缓冲液1(newenglandbiolabs)
(1×反应混合物是10mmbis-tris-丙烷-hcl、10mmmgci2、1mmdtt、ph7@25℃)
5μl5’标签寡核苷酸@100μm
5μl3’标签寡核苷酸@100μm
6.25μl合并的寡核苷酸@100μm
2.5μl耐热型5’appdna/rna连接酶(newenglandbiolabs)
70.25μl无核酸酶的水
65℃下孵育(incubate)4h。
4)用1×10mmtris1mmedtaph7.0缓冲液加至300μl,并使用illustras-200microspinhr柱(gehealthcare)清理反应,以清除未连接的寡核苷酸和试剂。
5)加入40μl醋酸钠ph5.2和2.5体积(1ml)的100%乙醇。混合并置于-20℃至少1小时,然后在4℃,15,000rpm离心沉淀(pellet)dna15分钟。
6)移除上清液并用1ml70%乙醇清洗,然后旋转(spin)5分钟,重复冲洗,然后空气干燥沉淀。
7)将沉淀重悬于25μl无核酸酶的水中。
2:将5'标签寡核苷酸交联到琼脂糖上以允许pcr过程中的交联
1)制备交联用的琼脂糖:称取25g低熔点的琼脂糖,加入50ml18.2ωm的水中,并在4℃下混合30分钟成水合物。过滤干燥并用100ml水清洗,回收浆液,并测定其体积(通常为15-20ml)。
2)向浆状的琼脂糖中加入等体积的0.05mnaoh,确认ph值,如果需要,加入10mnaoh,调整到10.5到11之间。
3)将浆液放在磁力搅拌器上,边加入cnbr边搅拌。
4)加入100mg/ml浆液溴化氰活化的sepharose(cnbr)(sigma)(即,在40ml浆液中加4gcnbr),立即检查ph值并监视,直到cnbr完全溶解(可能需要加入1-2ml的10mnaoh以保持ph在10.5至11之间)。监测ph值,伴随反应进行15分钟。
5)15分钟后,或者一旦ph值稳定后,反应就完成了。通过加入等量体积ph8.5的200mmnahco3阻断任何剩余的活性cnbr。
6)利用布氏漏斗过滤浆液,并用100mm的nahco3500mmnaclph8.5以3×50ml洗涤。
7)在总体积为25ml的ph8.5的100mmnahco3和500mm氯化钠的缓冲液中重悬。
8)取250μl的100μm5'端上带有nh2-连接子的5'标签寡核苷酸,与浆状的琼脂糖混合,在室温下混合2小时。
9)加入等体积(25ml)的0.2m甘氨酸阻断任何剩余的活性cnbr结合位点。
10)将浆液过滤,用100ml的100mmnahco3500mmnacl的ph8.5缓冲液清洗,然后用100ml的水清洗,风干,收集凝胶并称重(注意:通过添加0.1%叠氮化钠可以保持存储此材料,或者,可以将其冷冻干燥并贮存在室温下供长期使用。如果添加叠氮化钠,那么,浆液必须进行过滤和洗涤,以在使用之前除去叠氮化物。
11)这是约40%琼脂糖,并且这个阶段中,其被通过胺连接子交联的5'标签寡核苷酸饱和,并且能够用来生产水凝胶基质。取小等份(100μl)并分析,以检查它仍然在大约75℃熔化,以及在20℃以下固化为固体,以确认交联没有对胶凝性质产生不利影响。
3:珠粒内pcr
这一步在单个滴内扩增单一特异性dna引导物,因此在每个珠粒内生成克隆的dna群。注意,交联的5’标签寡核苷酸在pcr中使用,但仍结合至琼脂糖作为共价连接。这不能从琼脂糖丢失。这得到了克隆珠粒,其具有在整个珠粒群上和珠粒内附着的μμ浓度的dna引导物。
1)溶解干燥的琼脂糖-cnbr-寡核苷酸或根据需要将浆液添加至0.5%的终浓度。
2)按如下指示制备含水反应混合物并保持温暖。降低3’反向(3’rev)标签有利于通过不对称pcr生成5’标签,因此与模板相比较产生了更多的交联的引导物。组装的引导dna为1拷贝/滴(有些滴是空的)。
反应组成1ml体积/封装
200μl5×phusionhf缓冲液
20μl10mmdntp混合物(等量混合)
2μl的3’反向-互补寡核苷酸(gggttaatggctaatatcgcg)
50μlphusionhsii聚合酶(newenglandbiolabs)
加至1000μl:用不含核酸酶的水,含0.015gcnbr-5'标签琼脂糖(因此1.5%琼脂糖珠粒)。
3)使用pico-surf1(2%表面活性剂,dolomite,uk)作为连续相(20μl/min水相,40μl/min油相),封装在14μm蚀刻的滴产生芯片(dolomite,uk)中。
4)批量pcr完整滴混合物——分在48个孔中(50μl//孔)。
5)98℃2分钟[98℃15秒,54℃15秒,72℃10秒]x30,72℃2分钟,然后至4℃20分钟以固化(保持4℃直至准备好用于下一步(readytoproceed))。
6)集中珠粒,并加入5体积(5ml)pbs+1%吐温80,然后倒置混合,在4℃下2500g离心15分钟至成沉淀物。
7)移除上清液,用5体积(5ml)pbs+1%吐温80再次清洗珠粒以去除所有的油,在4℃下2500g离心15分钟至成沉淀物。
8)现在珠粒上不含油,为去除任何杂交且未交联的dna(或与引导物反向互补的),用5ml0.1mnaoh清洗,rt混合5分钟,然后在4℃下2500g离心15分钟,成为沉淀物。
9)重复0.1mnaoh清洗。
10)向该珠粒加入5ml水,然后4℃下2500g离心15分钟至成为沉淀物。
11)重复水清洗,现在珠粒已经准备好可以引导化学反应。
4:化合物文库的引导组装
单体的dna引导组装——利用常规化学方法合成,rna标签由idt预先合成。最后3个核苷酸含有硫代磷酸酯键以防止核酸外切酶切割。然后利用针对引入到引导寡核苷酸中的独特序列的特异性rna的引导物来对各个试剂加标签(可以组装100个独特的单体,假设多达4个引导序列,可以合成多达100,000,000个独特的化合物)。引导物和标签介于18碱基和25碱基(mer)之间,dna的tm>60℃,但由于rna-dna相互作用更稳定,我们发现这些寡核苷酸的真实熔化温度为75-85℃。
1)将珠粒装入柱中(每个珠粒均克隆有独特dna序列以引导组装,但是每个珠粒上的克隆引导物为μm浓度)并且在20μm浓度下,每毫升珠粒体积可存在2亿个。
2)然后将一池单体和适当的试剂清洗到柱上,并使反应继续进行,柱子可以被清洗,并根据需要添加新的反应化学物质(注意,也可以添加新鲜的单体)。
3)化学合成随使用的单体不同而不同(见实施例2第4节)。
4)最后,用10柱体积的含100mmnacl的te洗涤珠粒,然后在表型筛选中使用2个柱体积的适合细胞生长的培养基(如rpmi)洗涤珠粒。
5)然后在生长培养基中收集珠粒,准备好用于与靶细胞封装。新合成的化合物通过dna引导物-rna标签相互作用保持结合(只要ph保持在5-9,温度低于75℃(因为新化合物通过2-4个引导物连接,其非常稳定)。
5:将化合物珠粒与指示细胞封装
珠粒上的化合物保持结合直到封装。将jurkat细胞稀释至2-8个/滴。
1)以100μl/min水性流速以及200μl/min的picosurf1(dolomite,uk),将琼脂糖珠粒、rpmi培养基中的2-8个jurkat细胞和0.4%w/vix-a型琼脂糖以及0.1μg/ml核糖核酸酶a(rnasea),包封在带有100μm连接点的滴生成芯片中。每滴包封<1个琼脂糖珠粒以维持克隆性。
2)杂交化合物的化学释放是由于在细胞混合物中掺入0.1μg/ml核糖核酸酶a。这并不影响细胞生长,至少48小时内测试在生长培养基中的细胞处于活性状态。在rpmi、lb、溶菌肉汤、胰蛋白酶大豆肉汤和dmem中,rna引导物在15-20分钟内发生裂解。核糖核酸酶a裂解rna标签(而不是dna),离去的和未加标签的化合物不再与引导物结合,并自由扩散出琼脂糖珠,进入指示剂滴中。这发生在0.5-100μm浓度条件下。
6:表型筛选
1)将指示细胞与化合物珠粒孵育24h后,使所述滴破碎。可以使细胞孵育更长的时间:例如,人细胞可以在化验中孵育10天,细菌细胞28天后被回收。然而,通常的孵育时间是24-144h。
2)将珠粒置于冰上进行固化,然后加入4体积的磷酸盐缓冲盐水(pbs)+1%吐温80,倒置混合,然后在4℃下以3500g离心15分钟,使其破碎。
3)除去上清液,再用4体积pbs+1%吐温80洗涤珠沉淀。
4)然后通过125μm到45μm颗粒过滤器过滤珠粒沉淀,这移除较大的滴和清洗通过小碎片和细胞。
5)过滤器上的珠粒用5体积的pbs冲洗,然后在离心管中收集。
6)用pbs配制混合物至100ml。
7)添加tmrm和hoescht33342(thermofisherscientific)染料,终浓度分别为200μm和1μg/ml。室温孵育30分钟。
8)在4℃以3500g离心15分钟,使珠粒沉淀。
9)重悬于50mlpbs,重复洗涤步骤以去除染料。
10)使用荧光激活细胞分选仪(facs)利用405nm激光激发hoescht,利用488nm激光激发tmrm,与已知对照进行比对来检测这些通道的输出。
11)任何显示tmrm/hoescht染色比升高的滴都被分选进管中。
7:测序靶标以鉴定命中化合物
1)沉淀“命中物”珠粒并重悬在25μl水中。
2)设置第一轮pcr,以增加每一个命中物的拷贝数——注意,通过长连接子,每滴数百万个结合到琼脂糖上。
10μl的hf缓冲液(thermofisherscientific)
1μl的10μm5’标签(无连接子版本attatgaccgtaggccttggc)
1μl的10μm3’反向-互补寡核苷酸(gggttaatggctaatatcgcg)
0.25μlphusiondna聚合酶(thermofishersceintific)
25μl的水中的珠粒
用12.75μl不含核酸酶的水加到50μl
pcr98℃2分钟[98℃15秒,54℃15秒,72℃10秒]×1572℃2分钟。
3)用ampurexp珠粒(beckmancoulter)清理
·添加1.8体积(90μlampurexp珠粒),通过移液混合均匀
·等待2分钟后放在磁铁上,一旦珠粒收集了2-5分钟,移除上清液
·用200μl的80%乙醇清洗,在室温下孵育2分钟
·放回磁铁上2-5分钟,并除去乙醇
·重复乙醇清洗,这一次,空气干燥5分钟,直到珠粒变干
·用20μl的10mmtris-hclph7.0重悬,洗脱dna,并放回到磁体上
·收集和保存上清。
4)第二轮pcr以添加引物。
5)使用5'和3'标签及illumina的改性rc_index和ps_i2索引引物来编码(12×ec和8×ps_i2),标签序列在引物3’端,这些标签是恒定的,但索引改变以在以下条件下编码96孔板pcr:
·10μl2×nebnextpcr预混液(mastermix)(newenglandbiolabs)
·2.5μlrc_索引(rc_index)3.3μm(1:30稀释贮液)
·2.5μlps_i2引物3.3μm(1:30稀释贮液)
·5μl从pcr一(步骤3)洗脱的dna
·pcr98℃2分钟[98℃10秒,54℃60秒,72℃30秒]×3072℃2分钟。
6)采用ampurexp珠粒(beckmancoulter)选择250-350bppcr产物选择素(selectin)的大小。
为去除较大片段:
·添加15μl的水以增加体积到65μl。
·添加49μl(0.75×体积)的ampure珠粒,混匀,孵育5分钟。
·置磁体上2分钟,转移上清至干净的孔中。
·为收集(bin)期望的片段
·添加10μl(0.15×体积)ampure珠粒,混匀,孵育5分钟。
·置磁体上,这一次,弃上清。
·用200μl80%乙醇清洗,在室温下孵育2分钟。
·放回磁体上2-5分钟,并除去乙醇。
·重复乙醇清洗,这一次,空气干燥5分钟,直到珠粒变干。
·重悬于35μl的10mmtris-hclph7.0,洗脱dna,并放回到磁体上。
·收集和保存25μl上清。
7)设置稀释1:100、1:10000和1:200000。采用kapa快速qpcr(kapabiosytems)用于illumina定量试剂盒,在12μl反应中,通过qpcr测定dna浓度。
8)使用qpcr结果创建所有样本的2nm文库混合物,并按照lllumina方案加载到测序器上,所述lllumina方案用于nextseq500系统指引(guide)(15046563)和nextseq变性和稀释文库指引(15048776)。
9)被两个标签标记的引导核酸的返回序列很容易鉴定,并用于确定化合物组装的顺序和其结构——引导物(少于200个核苷酸)如果有必要可以使用ultramers从idt合成,以用这种方式从单体快速地生成更多的化合物,并确认其活性。或者,该化合物根据从dna测序数据解码的结构直接合成。
实施例2-使用固体珠上固定的dna引导物生成无标签的化合物文库
1:引导序列的组装
除了5’标签将被生物素化而不是胺,其它正如实施例1第1节所描述的。
2:将单个引导物连接到链霉亲合素包被的珠粒上
将单个dna分子附着在包被有链霉亲和素的活化珠粒上,使其附着。珠粒从bangs实验室购买,其目录号:cp01n,平均直径为4.95μm。珠粒是包被有链霉亲和素的聚合物。
1)取1000μl(5mg珠粒),并通过室温5000g离心5’形成沉淀。
2)移除上层清液,并用1000μl的100mmtris-hclph8,0.1%吐温20清洗珠粒。
3)重复清洗2次或更多次以除去任何残留的缓冲液。
4)在100μl最终体积的100mmtris-hclph8、0.1%吐温20里重悬该珠粒。
5)珠粒为6×107个珠粒/mg,因此在1000μl中,我们获得6×108个珠粒,意味着我们需要相同数量的引导物以获得平均每个珠粒一个。为此,我们需要大约3飞摩尔(femtomoles)的dna,因为平均引导物长度为123bp,这意味着我们需要0.25ng的寡核苷酸dna,根据经验,我们发现我们需要大约它的两倍才能获得最佳结果,因此使用0.4ngdna引导物构建体——将其稀释成100μl的100mmtris-hclph8,0.1%吐温20并与珠粒混合。
6)在室温下混合该珠粒1小时。
7)正如步骤1和2所描述,通过离心沉淀该珠粒,并用5×500μl的100mmtris-hclph8、0.5%吐温20冲洗该珠粒以除去未结合的dna。
8)在500μl的10mmtris-hclph8,1mmedta缓冲液中最后重悬,并可以在4℃下保存数周,取10μl跑0.5%琼脂糖凝胶,用1×sypro-ruby染色,以染色珠粒上的蛋白,用1×sybr金(sybrgold)对dna进行染色,两者的定位都应当看到,虽然sybr金在凝胶上很弱,并且作为较大片段的主要跑胶,多达4个不同的条带(在引导物内有1-4可变区)。因为附着到珠粒上,因此在所有情况下,片段似乎都>10kb。如果可以看到更多的条带,该批次就是不均匀的,并因此必须重做。
9)随着滴被制成一个珠粒每滴,样品被稀释。
3:扩增官能化珠上的引导寡核苷酸
1)将寡核苷酸官能化的珠粒在以下混合物中稀释至70,000个珠粒/ul:
反应组成1ml体积/封装:
200μl5×phusionhf缓冲液(thermofisherscientific)
20μl10mmdntp混合物(等量混合)
2μl的3’反向互补寡核苷酸(gggttaatggctaatatcgcg)(idt)
50μlphusionhsii聚合酶(thermofishersceintific)。
2)使用pico-surf1(2%表面活性剂,dolomite,uk)作为连续相(20μl/min水相,40μl/min油相),封装在14μm蚀刻的滴产生芯片(dolomite,uk)中。珠粒的稀释确保每10滴有一个粒珠,保证克隆性,并且大约需要1小时来封装整个混合物)。
3)在eppendorf管里收集所得到的14μm的滴(18pl)。
4)批量pcr完整的滴混合物——分在60个孔中(50μl//孔)。
5)98℃2分钟[98℃15秒,54℃15秒,72℃10秒]x30,72℃2分钟,然后,至4℃20分钟以固化(保持在4℃直到直至准备好用于下一步)。
6)遵照制造商的方案,用pico-break1(dolomite,uk)将珠粒合并,并打碎液滴。
7)回收珠粒并用5体积(5ml)pbs+1%吐温80清洗珠粒,以去除所有的油,在4℃下2500g离心15分钟至成沉淀物。
8)现在珠粒上不含油,为去除任何杂交的且未交联的dna(或与引导物反向互补的),用5ml0.1mnaoh清洗,rt混合5分钟,在4℃下2500g离心15分钟至成沉淀物。
9)重复0.1mnaoh清洗。
10)向珠粒加入5ml水,然后4℃下2500g离心15分钟至成沉淀物。
11)重复水清洗,现在珠粒已经准备好待用。
4:在珠粒上的dna模板化辅助合成
利用常规化学方法合成了用于dna指导组装的加标签单体的组装。通过idt预先合成rna标签,并且最后三个核苷酸含有硫代磷酸酯键,以防止外切酶的裂解。然后单独的试剂用针对独特引导物序列的特异性rna的引导物标记,其中该独特序列被掺入到引导寡核苷酸上(100个独特单体可以被组装,假设多达4个引导序列,可以合成超过100,000,000个独特化合物)。引导物和标签设计成18个碱基(mer)至25个碱基之间,tm>60℃,但是,由于rna-dna相互作用更稳定,我们已经看到这些寡核苷酸在75-85℃的稳定性。单体浓度保持低于0.5μm以最小化交叉反应性。试剂被连接到序列的5'末端,所述序列对应于引导寡核苷酸池。在这个说明性实施例中,使用包含(a)醛或(b)胺的构建区块(buildingblocks)将单体连接在一起,从而在还原胺化之后形成次级胺键。
1)将官能化引导珠粒(来自实施例2第x部分)稀释至20,000个珠粒/μl,稀释在50mmtaps缓冲液ph8.0中,其具有250mmnacl,10mm硼氢化钠和0.5μm反应性寡核苷酸连接单体。
2)使用具有20μm蚀刻深度的微流体芯片(dolomite,uk),以50μl/min的水性流速和100μl/min的pico-surf1(2%表面活性剂,dolomite,uk)封装此混合物,得到20μm直径的滴(42pl)。
3)将滴收集到50mlfalcon管中,并且使其在25℃下反应24小时。
5:组装化合物、引导珠粒和指示细胞的滴融合
这一步涉及到定制的微流体芯片,其包括小滴生成位点、用于制造直径100μm的滴的单独的较大滴生成位点、用于滴同步的y型通道和用于滴聚并的一对可寻址电极。这些设备可以很容易地从公司购置,例如dolomite,uk或micronit,nl。
1)制备含有以下物质的混合物,用于指示滴(indicatordroplet):
jurkat细胞(21,000个细胞/ul,用于5个细胞/滴)
核糖核酸酶a(rnasea),0.1μg/ml
0.5%wtix-a型琼脂糖(sigma)
rpmi培养基。
2)在定制芯片中,开始回注来自实施例2步骤4的20μm的滴。
3)开始制备100μm的滴,使用流速100μl/ml、pico-surf1流速200μl/min。
4)使用高速照相机(pixellink,canada),使20μm的滴的回注速度匹配100μm的滴的生成速率,以确保y通道处1:1同步。较小的滴在通道内经历较低的流体动力学阻力,并且移动速度较快,赶上100μm的滴并且自同步成对。
5)从脉冲发生器(aim-tti,rscomponents,uk)以及高压放大器(trek2220,trek,usa)在1khz产生方波脉冲,施加4kv/cm电场,在电极处通过电熔合将相邻的滴对融合。
6)从芯片上收集融合后的滴,在37℃、5%co2的组织培养瓶(fisher,uk)中培养。
6:表型筛选
如实施例1第6部分所描述。
7:测序靶标以鉴定命中化合物
如实施例1第7部分所描述。
实施例3-可逆地给现有的化合物文库加标签
1:生成随机寡核苷酸标签用于添加到化合物文库
1)随机标签购自twistbioscience,其包含100,000-1,000,000独特序列,18-25碱基,tm>55℃,向每个都添加5'rna_衔接子1(5'rna_adaptor1)寡核苷酸和3'dna_衔接子1寡核苷酸,每一个都被修饰以确保添加到特定的末端。
2)用于200μl反应的反应混合物:
20μl10×缓冲液(1×反应缓冲液(50mmtris-hcl,ph7.5,10mmmgcl2,1mmdtt)
100μl50%peg8000(w/v)(1×25%(w/v)peg8000)
20μl10mm氯化六氨合钴(1×1mm氯化六氨合钴)
20μl(100单位)t4rna连接酶
20μl10mmatp(1×1mmatp)
20μl寡核苷酸混合物(随机的条形码寡核苷酸及rna和dna衔接子的等量混合,每种30μμ,在水中)。在25℃下孵育16小时。通过添加40μl10mmtris-hclph8.0,2.5mmedta终止反应。
3)用10mmtris,1mmedta缓冲液ph7制成300μl,并使用illustras-200microspinhr柱(gehealthcare)清理反应,以清除未被连接的寡核苷酸和试剂。
4)加入40μl醋酸钠ph5.2和2.5倍体积(1ml)的100%乙醇。混合并置-20℃至少1小时,然后在4℃,15,000rpm离心15分钟,使dna沉淀。
5)移除上清液并用1ml70%乙醇清洗,然后旋转(spin)5分钟,重复冲洗,然后空气干燥沉淀。
6)将沉淀重悬于25μl无核酸酶的水中。
2:将5'标签寡核苷酸交联到琼脂糖上以允许pcr过程中的交联
1)称25g低熔点琼脂糖(sigma),加入到50ml18.2ωm的水中,在4℃混合30分钟以水合,由此制备用于交联的琼脂糖。通过过滤干燥,用100ml水冲洗,回收浆液并测量其体积(通常为15-20ml)。
2)向浆状的琼脂糖中加入等体积的0.05mnaoh,确认ph值,如果需要,根据需要加入10mnaoh,调整到10.5到11之间。
3)将浆液放在磁力搅拌器上,边加入cnbr(sigma)边搅拌。
4)加入100mg/ml的浆液cnbr,即,在40ml浆液中加4gcnbr,立即检查ph值并监视,直到cnbr已经完全溶解(可能需要加入1-2ml的10mnaoh以保持ph在10.5和11单位之间)。监测ph值,伴随反应进行15分钟。
5)15分钟后,或者一旦ph值稳定后,反应就完成了。通过加入等体积的ph8.5200mmnahco3阻断任何剩余的活性cnbr。
6)利用布氏漏斗过滤浆液,并用100mmnahco3500mmnaclph8.5以3×50ml的方式洗涤。
7)在总体积为25ml的100mmnahco3500mmnaclph8.5缓冲液中重悬。
8)取250μl的100μm5'标签寡核苷酸(带有5'末端的nh2-连接子),与浆状的琼脂糖混合,在室温下混合2小时。
9)加入等体积(25ml)的0.2m甘氨酸阻断任何剩余的活性cnbr结合位点。
10)将浆液过滤,用100ml的100mmnahco3500mmnacl在ph8.5缓冲液中清洗,然后用100ml的水清洗,风干,收集凝胶并称重(注意:通过添加0.1%叠氮化钠可以保持存储,或者,它可以冷冻干燥并贮存在室温下供长期使用。如果添加叠氮化物,那么,浆液必须进行过滤和洗涤,以在使用之前以除去叠氮化物。
11)这是约40%琼脂糖,并且这个阶段中,其被通过胺连接子交联的5'标签寡核苷酸饱和,并且能够在以后用来生产水凝胶基质。取小等份(100μl)并分析,以检查它仍然在大约75℃熔化,并在20℃以下固化成为固体,以确认交联没有对胶凝性质产生不利影响。
3)给化合物文库加标签(化学方法)
这个反应的确切性质将取决于所讨论的文库和其中包含的官能团,但在这个例子中,文库被大量的氨基官能团官能化。然后,将条形码寡核苷酸在末端用琥珀酰亚胺酯进行官能化。条形码寡核苷酸用可裂解的基团官能化,以便在滴内释放化合物。
(1)将单独的文库成员溶解在0.1m碳酸氢钠缓冲液中,ph8.3,至最终浓度1mm。
(2)在单独的孔中加入琥珀酰亚胺酯官能化引导寡核苷酸,使其摩尔比达到1:1。确保每个单独的孔只添加一个特定的序列。
(3)室温孵育1小时。
(4)加热溶液至40℃。
(5)将步骤3的珠粒储液稀释并加到孔里。目标是加载至少100个珠粒/孔,以确保在筛选过程中过采样。
(6)在40℃孵育,以将加标签的化合物杂交到珠上。
(7)旋转(spindown)下来,从每个孔中去除上清液。用1×pbs缓冲液清洗三次。
(8)用1×pbs缓冲液将珠粒清洗出孔。合并在一起,然后在新鲜1×pbs缓冲液中重新悬浮。
4)给化合物加标签(酶解方法)
再次,这个反应和官能团的确切性质,基本上任何合适的酶都可以使用,包括糖基化酶、非核糖体肽合成酶、泛素酶、磷酸化酶(举几个例子)。在本说明中,我们使用磷酸化酶。
将化合物溶解于水或dmso中至0.5mm(如果在dmso中,不多于2.5μl):
(1)5μl的10×反应缓冲液(最终是70mmtris-hcl、10mmmgcl2、5mmdttph7.6@25℃
(2)10μl50%(w/v)peg-4000(终浓度10%)
(3)2.5μl10mmatp(终浓度500μm)
(4)5μt4pnk(newenglandbiolabs)
(5)用水加至50μl
在37℃下孵育4小时。
随机标签购自twistbioscience,其包含100,000-1,000,000独特序列,18-25碱基(mer),tm>55℃,向每个中都添加5'dna_衔接子1寡核苷酸和3'rna_衔接子1寡核苷酸,每一个都被修饰,以确保添加到特定的末端。这个反应将条形码连接在一起。
准备下列混合物至200μl:
(1)20μl10×缓冲液(1×反应缓冲液(50mmtris-hcl,ph7.5,10mmmgci2,1mmdtt)
(2)100μl50%peg8000(w/v)(1×25%(w/v)peg8000)
(3)20μl10mm氯化六氨合钴(1×1mm氯化六氨合钴)
(4)20μl(100单位)t4rna连接酶(newenglandbiolabs)
(5)20μl10mmatp(1×1mmatp)(sigma)
(6)20μl寡核苷酸混合物(随机的条形码寡核苷酸与rna和dna衔接子以每个30μμ在水中的等量混合物)。
在25℃下孵育16小时。
通过添加40μl10mmtris-hclph8.0,2.5mmedta终止反应。
1)用10mmtris、1mmedtaph7缓冲液制成300μl,并用illustras-200microspinhr柱(gehealthcare)清理反应,以清除未被连接的寡核苷酸和试剂。
2)加入40μl醋酸钠ph5.2和2.5倍体积(1ml)的100%乙醇。混合并置-20℃至少1小时,然后在4℃,15,000rpm离心dna15分钟。
3)移除上清液并用1ml70%乙醇清洗,然后旋转5分钟,重复冲洗,然后空气干燥沉淀。
4)将沉淀重悬于25μl无核酸酶的水中。
5)将化合物附着到珠粒上
1)向上述化合物添加50μl通用附着珠粒,所述珠粒具有nh-c12-gggttaatggctaatatcgcg寡核苷酸(如实施例3第2部分所描述的)。
6)表型筛选
如实施例1第6部分所描述。
7)测序靶标以确定命中化合物
如实施例1第7部分所描述。
实施例4——用于无标签decl合成的分开-合并(split-pool)方法
广泛使用的分开与合并策略(参见,例如mannocci等(2011)chem.commun.,47:12747-12753;mannocci等人(2008)proc.natl.acad.sci.105:17670-17675)可用来产生根据本发明使用的单药效团decl,其基于多组化学子结构和相应的dna编码片段的逐步分开与合并组合组装,其涉及迭代化学合成和dna编码步骤,如下文所述。
1)概述
现在参考图1,引导寡核苷酸首先附着到官能化的琼脂糖珠粒上,每个珠粒至少含有1011个用于寡核苷酸附着的官能团。加标签的子结构(在这里可之称为“药效团”)通过可裂解连接子连接到与引导寡核苷酸互补的寡核苷酸上,然后通过连接附着到该引导寡核苷酸上。这用作初级的药效团,其然后用进一步的药效团(二级、三级等药效团)“装饰(decorate)”,正如下文所解释的)。
然后进行连续的几轮合成,通过与进一步的子结构/药效团发生反应来装饰初级药效团结构。将用于每个反应的编码寡核苷酸和构建区块通过连接也添加到引导寡核苷酸上。该文库是使用分开与合并技术,用化学合成和编码连接交替的多轮构建的。在文库生成之后,每个珠粒都装饰有单个化合物的多个拷贝。
现在参考图2,然后,文库珠粒被封装在带有指示细胞(也可以使用蛋白质靶标)的微滴内。在微滴中通过添加酶来释放化合物,该酶剪切可裂解连接子,将化合物释放到水性内部。然后将微滴孵育预定的时间段,并使用facs测定化合物的表型效应。表现出期望表型的细胞的微滴被分类和收集。因此,编码文库成员合成的寡核苷酸在空间上但不是在物理上与它引起的表型效应关联。
化合物鉴定是通过限制性消化将引导寡核苷酸从珠粒上裂解,然后测序来进行的。寡核苷酸的编码序列描述了药效团所暴露的合成步骤,以及造成由facs观察到的表型效应的化合物的结构。尽管如有需要可用pcr扩增,但是由于存在>1010的寡核苷酸分子,所以,pcr扩增引导寡核苷酸并不是必须的。
这种加标签的文库合成保留了dna编码(条形码化)和规模合成的关键优势,但也允许使用少量相对昂贵的加标签的化学子结构合成分子文库。它也减少从单独的裂解事件产生的任何疤痕。因此,该分开与合并方法允许使用已知的化学方法添加不同的药效团,因为没有必要对所有的药效团子结构单元进行加标签。
2)琼脂糖胺珠粒的官能化
将2ml等分的50%胺官能化琼脂糖珠粒的悬浮液(cubebioscience)在500xg下旋转10分钟旋转下来,并且用ro水清洗3次,然后悬浮在5mlph5.5的100mmmes+150mmnacl偶联缓冲液中。在不同的试管中,制备叠氮化物官能化混合物。将都在偶联缓冲液中的2.5ml20mmn-羟琥珀酰亚胺溶液(nhs,sigmaaldrich)和2.5ml20mmn-(3-二甲基氨基丙基)-n'-乙基碳二亚胺盐酸盐溶液(edc,sigmaaldrich)溶液混合。加入2-叠氮乙酸(5μl,carbosynth),并让此混合物在室温下反应20分钟。20分钟后,将胺珠粒旋转下来并重新悬浮在5ml的叠氮化物官能化混合物中。室温下将该试管置于旋转器1小时,然后旋转下来,并在5ml新鲜叠氮化物官能化混合物中重新悬浮。将其置于旋转器中,并允许反应过夜。然后,用5ml的1×pbs,ph7.4清洗珠粒3次,再在5ml100mm碳酸氢钠ph7.5中重新悬浮,4℃下保存至需要时。
3)将捕获寡核苷酸附着至官能化叠氮化物-琼脂糖珠粒
将1ml叠氮化物珠粒储备液旋转下来,并用1ml的100mmmopsph7.0清洗3次。然后在785μlmops缓冲液中悬浮珠粒。添加100ul捕获寡核苷酸(5'-gaagggtcgactaagattatactgcatagctaggggaatggatcccgccttttttt(lnt5-octadiynyldu)tttttttttggcgggatcc-3',adtbio,48.92μm),然后加入10μl50mm三(3-羟基丙基三唑基甲基)胺(thpta,sigmaaldrich)、5μl20mm硫酸铜(ii)溶液(sigmaaldrich)以及100μl10mm抗坏血酸钠溶液(sigmaaldrich)。将珠粒放置在旋转器中并让其反应过夜,然后将混合物旋转下来,用1×ml100mmmops缓冲液清洗,然后重悬浮在758μlmops缓冲液,100μl10mm炔丙醇(sigmaaldrich),然后是10μl的50mmthpta,5μl20mm硫酸铜(ii)以及100μl10mm抗坏血酸钠溶液。1小时后,将珠粒用3×1mlmops缓冲液清洗,然后重悬浮于100mm碳酸氢钠缓冲液,ph7.5中。
4)可裂解寡核苷酸与初级药效团连接
将1ml叠氮化物琼脂糖珠粒+捕获寡核苷酸旋转下来,并用500μl无核酸酶的水(nfw)清洗3次,之后重新悬浮在475μlnfw和500ul2x快速连接酶(quickligase)缓冲液(neb)中。加入15μl有效载荷寡核苷酸(5'attcccctagctatgcaagtrgrargrrarargrux3',其中x=己炔基氢过氧脯氨酸(hexynylhydrodroxyprolinol),adtbio,81.53μm)和10μl快速连接酶(quickligase)。将珠在37℃下旋转孵育,然后用100mm碳酸氢钠缓冲液ph7.5清洗3次,在4℃下储存直到需要时。
5)加标签
将编码寡核苷酸与珠粒上的捕获寡核苷酸连接进行加标签,这是通过将珠粒清洗到水中实现的(将珠粒以5000g离心5分钟,用5×珠体积的不含核酸酶的水(nfw)重新悬浮,重复清洗总共2次。然后用5×珠粒体积的连接混合物重新悬浮该珠粒,该连接混合物的终浓度为:1×快速连接酶(quickligase)缓冲液(newenglandbiolabs),250nm夹板(splint)寡核苷酸,250nm编码寡核苷酸,20u/μlt4dna连接酶(newenglandbiolabs)和接着是无核酸酶的水,至5×珠体积)。
为了测试连接效率和使连接效率最大化,将样品分成两个。一个样品在热循环仪中被加热至95℃2分钟,然后冷却至4℃,0.2℃/秒。另一个样品不进行热处理,并放置于室温下。加热步骤之后加入t4dna连接酶(20u/μl)。
两个反应都在37℃下孵育1h,以进行连接。一旦孵育好,经加热至95℃20分钟,热灭活连接酶,然后使用20u/μlbamhi(neb)将寡核苷酸从珠粒切割掉,在37℃下再孵育1个小时。通过离心(5000g,5分钟)使珠粒沉淀,然后取下(takeoff)上清液。通过加入0.1×体积的3m乙酸钠ph5.2和2.5×体积的100%乙醇,将从珠粒切下的dna沉淀,用于检测。然后将此在冰上孵育1h,经过17,000g离心20分钟,使沉积(precipitated)材料沉淀(pelleted),倾倒上清液,并用500μl70%乙醇清洗2次。然后风干沉淀,并用100μl无核酸酶的水重新悬浮。然后将这种悬浮液25μl与变性加载染料(95%甲酰胺,0.1%二甲苯蓝,0.1%溴酚蓝,20mmtris-hclph7.5)1:1混合,将样品煮沸95℃2分钟,然后以4℃/s冷却速率降至4℃。然后将沉淀的样品加载到变性tbe凝胶(12.5%聚丙烯酰胺,7m尿素)上。在150v,室温下跑胶45分钟。一旦跑胶结束,在milliq等级水中清洗凝胶2x以去除尿素,然后用1×sybr金(thermoscientific)染色,在1×tbe中染色dna20分钟,之后再次用水清洗2x以去除染色溶液。
然后使用syngenelngenius3geldoc系统对凝胶进行成像(图3)。可以看出,当所有试剂都存在时,连接发生,但当使用加热步骤时更高效——尽管这对于连接在合理水平进行并不是必须的,因为在合成泡内每个dna我们都有多个拷贝。
6)从编码标签上释放化合物结构
通过从寡核苷酸中剪切有效载荷来去除编码寡核苷酸标签。
现在参考图4,为了显示连接子的裂解和药效团的释放,将寡核苷酸制成在可裂解寡核苷酸序列内将荧光团(fitc,如图4所示的f)掺入可裂解连接子5’侧。然后,将猝灭分子bhq-1连接到可裂解连接子上。这可以通过裂解被释放,其方式与文库产生中使用的任何化合物结构相同。当猝灭剂从可裂解连接子去除时,看到寡核苷酸发出光。
已经鉴定出三种不同的酶,它们以无疤痕的方式裂解它们相关的连接子(核糖核酸酶a、核糖核酸酶t1a和核糖核酸酶1a;在图4中分别标记为酶a、b和c)。所有的3种酶都用他们自己(compatriot)的连接子测试。在每种情况下,设置10μl反应;10mmtris-hcl,1mmedta,150nm可裂解寡核苷酸,0.1μl储存酶(核糖核酸酶a=10mg/ml,核糖核酸酶t1=10mg/ml,核糖核酸酶1=1.5mg/ml),然后用无核酸酶的水加至10μl。样品在37℃孵育15分钟,然后加入10μl变性加载染料(95%甲酰胺,0.1%二甲苯蓝,0.1%溴酚蓝,20mmtris-hclph7.5)。样品在95℃下煮沸2分钟,然后以4℃/s快速冷却至4℃。然后将这些样品加载到变性tbe凝胶(12.5%聚丙烯酰胺,7m尿素)上。在150v跑胶75分钟,使用syngeneingenius3系统激发fitc成像。猝灭剂的释放意味着荧光团是可见的并成像为“发光”。这可以看出,在酶的存在下出现黄色dna条带。通过用sybr金(thermo)染色可以看到dna,并且当猝灭剂存在时,这再次淬灭,但是可以看到对应于质量变化的尺寸位移(sizeshift)以及增强的信号(荧光团下面的灰度图,图4)。在两种情况下,我们都可以看到,仅在存在酶的情况下发生释放,并且释放是快速的(<15分钟)。另外,酶非常活跃,在10mmtris-hclph7.5,1mmedta中进行酶的10倍系列稀释,并以相同的方式设置反应。酶从10-2稀释至10-5时,我们能够看到,核糖核酸酶a在10-4有活性,核糖核酸酶t1和核糖核酸酶1在10-3有活性。这意味着存在大的酶活性窗口,以及对于多种酶,在10-4稀释水平,该过程能够在少于30分钟内发生。
我们也证实了在滴的环境下酶的功能(见图5)。显示了核糖核酸酶a的结果。使用10mmtris-hcl,1mmedta,150nm可裂解寡核苷酸,10μl储存核糖核酸a(10mg/ml),然后用不含核酸酶的水加至1ml,设立1ml水相。使用100μm蚀刻深度芯片制备100μm平均直径的滴,该芯片具有水相(如上文所描述)和油相,油相包含psf-2cst油(clearcoproductsinc.)及2%w/vgransurfg67(grantindustriesinc.)。滴在存在或不存在酶的情况下37℃孵育15分钟,使用荧光显微镜在482/18nm发光和532/59nm发射滤光片下成像。可以看出,在酶的存在下,液滴内会发光,以及反应不受滴环境的影响。
7)使用huisgen1,3-偶极环加成和硫代氨基甲酸乙酯形成来使可裂解化合物结构有效载荷官能化
用可裂解连接子使两份100μl的珠粒官能化,用100mmmopsph7.0清洗核心有效载荷(己炔基氢过氧脯氨酸)三次,并在100μl该溶液中重新悬浮。向两份都加入2ul10mm5-fam-叠氮化物(jenabioscience)在dmso中的储存液。一份保持为未反应的阴性对照,向另一份中加入5μl50mm三(3-羟基丙基三唑基甲基)胺(thpta,sigmaaldrich),2.5μl20mm硫酸铜(ii)溶液(sigmaaldrich)和100μl10mm抗坏血酸钠溶液(sigmaaldrich)。还以同样的方式处理包含仅用捕获寡核苷酸(无可裂解连接子或官能化核心)官能化珠粒的另一样品。
将珠粒放置在旋转器中并让其反应过夜,然后将混合物旋转下来,用1×ml100mmmops缓冲液ph7.0清洗。
为了确认官能化,通过悬浮在30μlneb缓冲液3.1、10μlbamh1和260μl无核酸酶的水,将官能化有效载荷从珠粒样品中分裂下来。在37℃孵育1小时后,将样品分成2×150μl份量。加入5μl核糖核酸酶a,并且在37℃再孵育样品1小时,然后使珠粒沉淀下来。将上清液转移到干净的管中并且加入15μl3m乙酸钠ph5.2和375μl100%乙醇。让样品在-20℃下沉积过夜,然后使其沉淀,用500ul70%乙醇清洗,风干20分钟。将沉淀物在20ul的无核酸酶的水中重新悬浮,加入20μl变性加载染料(95%甲酰胺,0.1%二甲苯蓝,0.1%溴酚蓝,20mmtris-hclph7.5)。将样品在95℃下加热5分钟,然后冷却至4℃。将样品加载到tbe尿素凝胶并在100v下跑胶75分钟。
如图6所示,在用被连接的可裂解连接子、官能化核心和染料两者处理的样品中,可以看到游离的染色组分,这表明官能化和释放的核心,而不是游离的5-fam叠氮化物的存在,其存在于未连接的样品中。
分别地,用干乙腈(mecn,sigmaaldrich)清洗另外两份100μl官能化珠粒。一份悬浮在1mm荧光素异硫氰酸酯异构体1(sigmaaldrich)的mecn溶液中,连同0.6μl10mg/ml三乙烯二胺的mecn溶液。在37℃旋转过夜后,将珠粒用mecn清洗3×,然后用100mm碳酸氢钠缓冲液ph7.5清洗3×。为了确认官能化,如上面所描述地对样品进行酶裂解,并在tbe凝胶上跑胶。然后使用syngenelngenius3geldoc系统对凝胶进行成像,以观察荧光团,然后在tbe中用50μl的1×sybr金染色。然后记录第二次成像。
如图7所示,与无染色对照相比较,经过核糖核酸酶a处理的消化样品中可以看到强烈的信号,这表明了经裂解化合物的官能化。
8)使用分开与合并方法在珠粒上加标签构建具有100个成员的功能文库
正如在实施例4第3节所描述的,用捕获寡核苷酸对叠氮化物官能化珠粒储液(stock)进行功能化。然后将珠粒储液与可裂解寡核苷酸相连接,该可裂解寡核苷酸含有可裂解的有效载荷(5'attcccctagctatgcaagtrgrargrrarargrux3’,其中x=3'-(o-炔丙基)-腺苷)(adtbio),使用与实施例4(第4节)所描述的相同技术。使用血球计数仪测定珠粒的数量为5.6x106个珠粒/ml。将200μl这种储液加入到深的96孔板(fisher)的十个独立的孔中。在下面的描述中,除非另有说明,所有的储液溶液都是在100mmmopsph7.0中制成的。将该板离心,并且向每个被占据的孔中加入140μl的100mmmopsph7.0,100mm,然后是20μl的50mm三(3-羟基丙基三唑基甲基)胺(sigma-aldrich)储液和10μl20mm的20mm硫酸铜(ii)(sigma-aldrich)储液。
向每个单独的被占据的孔中加入十种单独选择的叠氮化物(10μl50mmdmso,enamine)之一。加入20μl100mm抗坏血酸钠(sigma-aldrich)储液,并使用平的(peaceable)密封盖(fisher)将该板密封。将板在室温下振荡孵育18小时。然后将该板离心并且每个被占据的孔都用1ml不含核酸酶的水(nfw,fisher)清洗3×,然后在250μl快速连接酶缓冲液2x(neb)中重新悬浮。
将200μl50mm编码寡核苷酸的储液加入每个孔中,所述编码寡核苷酸包含序列gaagggtcgactccgxxxxxxxxxxgatgggcatcatcct,其中xxxxxxxxx=表示选自选择的20种独特编码寡核苷酸的核苷酸(a、c、g或t)的随机序列,每一个都来自于integrateddnatechnologies(idt)。加入50μl100um夹板寡核苷酸(cttagtcgacccggcaggatgatgcccat/3ddc/,/3ddc=双脱氧胞苷,idt)和2.5μl快速连接酶(neb)。将板密封,并在37℃震荡孵育。
在10个孔中每个单独的珠群现在都用与特定叠氮化物连接的独特dna序列编码,使得使用的构建区块在筛选后能被追踪,以确定任何化合物的结构。两小时孵育之后,每个孔用1ml的nfw清洗3×,并重新悬浮在200μl的200mm醋酸钠ph5.5中。然后在15ml离心管中将每个孔中内容物合并在一起组成2ml混合池,通过涡旋彻底混合,之后分在新的深96孔板的10个独立的孔中,200μl一份。将该板离心,并且在190μl200mm醋酸钠ph5.5中重新悬浮珠粒。向单独的孔中加入十种单独选择的醛中的其中一种的储液(83μl50mmdmso储液,enamine)。然后向每个被占据的孔中加入26μl10mg/ml氰基硼氢化钠在200mm醋酸钠ph5.5中的储液。将板密封,并在室温下震荡孵育18小时。所有的孔都用1ml无核酸酶的水清洗3×,然后重新悬浮在250μl的快速连接酶缓冲液中,使用与前文描述的叠氮化物区块相同的方法,将每个孔都与独特的编码寡核苷酸连接。然后用1mlnfw清洗每个孔3×,并重新悬浮在200μl无核酸酶的水中,之后在15ml的离心管中合并成为2ml储液。使珠粒沉淀,然后重悬浮在200μl2×快速连接酶缓冲液中。加入200μl的100um寡核苷酸储液,其序列为cgggtcgacttcggttagactttcggacctgatgggcatcatcct,以及10ul的快速连接酶(newenglandbiolabs)。然后将该珠粒在37℃下旋转孵育2小时,然后用1ml的10mmtrishcl+1mmedtaph7.5洗涤3次。将珠粒在1mltris缓冲液中重悬,然后在4℃下存储直到需要用时。
等同
上文的描述给出了本发明优选的实施例的细节。可以预期的是,本领域技术人员在考虑这些描述时可以进行许多修改和变化。那些修改和变化应理解为包括在本文所附的权利要求中。
- 还没有人留言评论。精彩留言会获得点赞!