单基因遗传性肾脏病基因联合筛查方法、试剂盒及其制备方法与流程
本发明涉及一种基因筛查方法、试剂盒及其制备方法,尤其涉及一种筛查各类遗传性肾脏病的试剂盒及其制备和使用方法。
背景技术:
慢性肾脏病(ckd)为突出的全球健康问题,流行病学研究显示我国ckd的发病率为10.8%,美国为13.1%。ckd如得不到有效控制,会发展为终末期肾功能衰竭(esrd),为患者、家庭和社会带来沉重的负担。单基因遗传性肾脏病是ckd的重要病因,比如常染色体显性多囊肾病(adpkd)在成人尸体解剖中发病率为1:500,占esrd的10%左右,是我国esrd的第四位病因。薄基底膜病(tbmd)是另一种发病率很高的单基因遗传性肾脏病,由于该病的诊断依赖肾组织电子显微镜检查,所以大量病人被漏诊或误诊,有研究指出tbmd在普通人群中的发病率可以达到1%。单基因肾脏病的种类繁多,大多数缺乏特异性临床表现,诊断依赖基因检测、肾活检和特殊检查(比如tbmd需电子显微镜检查、fabry病需要进行α-gala酶活性检测、alport诊断亦依赖电子显微镜和iv型胶原不同a链在皮肤或肾组织染色等),临床诊断困难,漏误诊率极高。世界卫生组织(who)指出21世纪的医学将从疾病医学向健康医学发展,从群体治疗向个体治疗发展。个体化医学(individualizedmedicine)为运用个体的基因组信息对疾病进行预防、诊断以及治疗的科学。相信随着肾脏病遗传学研究的不断深入,个体化医学终将彻底改变现有的诊疗模式。个体化医学的发展将通过影响肾脏病诊断(包括产前诊断)、风险评估、治疗、预测预后以及肾移植等几个方面改变现有诊疗模式。个体化医学的重要组成部分之一是基因诊断,用基因检测来诊断疾病已经在全球范围内掀起了一股产业巨浪,著名企业google已经投资了几家基因测序的公司基金从事基因诊断的研究。基因检测也越来越被人民大众认知,越来越多的病人在了解自己的疾病的家族史时也会询问医生是否可以作基因检测。基因诊断对于符合孟德尔遗传规律的单基因肾脏病的诊断具有重要意义。特别当疾病临床表现不典型时,检测到致病突变可以帮助确诊。基因检测对于肾脏病诊断的重要性还在于可以应用于产前基因诊断。当了解妊娠女性所携带致病遗传变异后,可以通过对胎儿进行产前基因诊断,确定胎儿是否携带致病遗传变异,在分娩前评估其患病的可能性,使得早期干预成为可能。可见产前基因诊断对于优生优育具有重要作用。产前基因诊断需要获得胎儿的dna,目前可以通过母血胎儿细胞、羊水穿刺、绒毛活检以及胎儿脐带血穿刺等手段获得,在获取胎儿dna时要避免来自母体细胞的污染。产前基因诊断的关键在于正确定位该家系的致病基因突变,为达到此目的需要对临床表型、遗传方式进行准确的判断。目前能开展遗传性肾脏病产前诊断的单位还非常少,主要原因在于遗传检测的成本过高,且没有找到一个高效的模式,相信随着检测成本的降低以及对于遗传性肾脏病认识的提高,产前基因诊断总将成为可能。随着遗传学研究的不断开展和深入,近年来越来越多单基因遗传性肾脏病的致病基因被成功定位。
虽然基因检测的概念已经大众化,并且在国际著名影星安吉丽娜朱莉在乳腺癌易感基因brac检测发现突变后进行乳腺癌切除的事件报道后基因检测已经是广大病患常常咨询医生的问题,但是在国际上肾脏病的诊断仍然缺乏有效而经济的解决方案。下一代测序技术nextgenerationsequencing是对传统测序的一次革命性的改变,能一次并行地对几十万到几百万条dna分子进行序列测定。与传统测序技术相比较而言,下一代测序技术的显著优点是费用低,通量高,速度快,因此科学界开始越来越多地应用第二代测序技术来解决各种生物学问题和进行疾病治疗研究。其中一项重要的贡献是在于帮助和推进个性化医疗的发展。目前,二代测序的主要应用包括重头测序(denovosequencing),全基因组重测序(wholegenomeresequencing),外显子组捕获测序(exomecapturesequencing),转录组测序(transcriptomesequencing),小分子rna测序(smallrnasequencing),病毒基因组测序(viraldeepsequencing),染色质免疫共沉淀测序(chipsequencing)等等。现有的测序平台主要包括roche/454flx、illumina/solexagenomeanalyzer,appliedbiosystemssolidsystem和最新推出的iontorrentilluminahiseq3000。本项目通过在测序平台illuminahiseq3000上实现不同的测序方式(外显子捕获测序),为肾脏疾病寻找致病的基因提供有力的支持。下一代技术在国内外已经被广泛用于临床(无创唐氏筛查)检测。该技术平台也以获美国的fda认证。但是国内目前还没有规范化经过临床验证的对肾脏病的基因检测的诊断试剂。综上所述,遗传性肾脏病是一类临床较为常见、诊断困难、漏误诊率很高的疾病。就此类疾病而言近几年,随着第二代测序平台(next-generationsequencing,ngs)的诞生和发展,可在10个小时内检测46亿个碱基序列。不仅极大地减少了测序时间,同时也极大地降低了成本。克服了sanger测序在应用范围和应用成本上的不足,基于ngs的靶向基因测序(targetgenesequencing,tgs)、全基因外显子组测序(wholeexomesequencing,wes)和全基因组测序(wholegenomesequencing,wgs),在肾脏单基因遗传病的基因诊断中已有应用。因此,设计一种涉及最多种类遗传性肾脏病、包含最全面的致病基因的检测试剂盒,并且能结合第二代测序技术,高效低成本地筛查遗传性肾脏疾病,实现对患者、致病基因携带者及高危产儿等对象的早期筛查,可在基因表达水平上确诊和预测疾病,对早期治疗、干预措施提供指导意见。
技术实现要素:
本发明所要解决的技术问题是提供一种单基因遗传性肾脏病基因联合筛查方法、试剂盒及其制备方法,能够快速、准确地找出与遗传性肾脏病相关基因的突变信息位点,以达到基因诊断的目的,且能够覆盖目前已知的所有遗传性肾脏病基因的外显子区域。
本发明为解决上述技术问题而采用的技术方案是提供一种单基因遗传性肾脏病基因筛查试剂盒,其中,包含多种遗传性肾脏病相关致病基因或疾病易感基因中全部外显子序列的特异性寡核苷酸捕获探针。
上述的单基因遗传性肾脏病基因筛查试剂盒,其中,所述探针长度为50~105bp。
上述的单基因遗传性肾脏病基因筛查试剂盒,其中,所述探针以生物素标记。
上述的单基因遗传性肾脏病基因筛查试剂盒,其中,所述多种遗传性肾脏病相关致病基因或疾病易感基因共有如下706种:
nphs1slc4a4kif7c3hps5wnt6anos1cpt1ampdu1mre11a
nphs2nek8cep41cfibloc1s6wnt10achd7cpt2dpm1stk11
lamb2glis2cspp1cd96bloc1s3wnt7aprokr2dmp1mpiepcam
lama2invscep104dhcr7hraswnt11fgfr1enpp1b4galt1mlh1
plce1nphp1kiaa0556dync2h1jag1lrp10kal1phexdolkchek2
ptpronphp4ofd1ift172notch2wnt4clcnkaslc34a3prps1msh6
arhgdiaanks6tctn3nek1kansl1lyzclcnkbfgf23sibard1
emp2nphp5evc2wdr60kat6bb2mkcnj1fhslc22a12axin2
adck4ttc21bexoc4wdr35kcnj10fgaslc12a1slc36a2slc22a5cdh1
itga3znf432kif14wdr34krasapoa1bsndslc6a19slc2a9msh2
dgkewdr19cc2d2acep120sos2abca1casrslc6a20slc37a4sdhc
wt1dcdc2cep290eif2ak3lztr1bmpercoq2slc3a1slc5a1gen1
actn4cep83tmem231hferit1col4a1coq6slc7a9slc5a2msh6
trpc6cep164b9d2sod2sos1dkc1coq9abcd4slc7a7sdha
cd2apxpnpep3b9d1pon1raf1klcoq7acsf3xdhrad50
inf2pkd2inpp5eil1rnbrafgalnt3adck3cd320hprt1cdkn2a
apol1pkhd1exoc8vegfaptpn11gsncoq4mvkmaxnbn
myo1epkd1tctn2epolmx1bhsd17b4pdss1lmbrd1nf1bmpr1a
pax2renrpgrip1lerbb3lrp4ift122pdss2mmachcptensmad4
nxf5acebbs1adgrg6mafbift43cldn16mmadhcvhlcyp11b1
alg13bicc1bbs10cntnap1mbtps2ikbkapcldn19mthfrtp53cyp11b2
podxltbx18bbs12gle1mnx1rxfp2cnnm2mtrrgpc3hpse2
anlnagtbbs2adcy6myh9insl3egfmmaahnf1alrig2
col4a4agtr1bbs4mybpc1smc3irf4fxyd2mmabifngift80
fn1ift140bbs5zbtb42hdac8jam3trpm6mutmetpax6
umodnphp3bbs7pip5k1crad21lpin1kcna1sucla2ogg1slc1a1
robo2muc1bbs9dnm2nipblmefvslc12a3mtrpik3cabmp4
sox17crb2sdccag8esco2nlrp3odc1cfhr5galtakt1chd1l
tnxbupk3awdpcpeya1nsdhlplgacat1pcdis3l2chrm3
fan1col4a3ccdc28bsix5piglmgat2coa6pex5flcndstyk
aglcol4a5mkkssix1pignpmm2cox15zmpste24dirc2fgf20
eno3col4a5mks1fam20apigtporcnsco2pgk1nme1itga8
g6pccol4a6arl6fgf10pigaprocsurf1illuminahiseq30001prccsix2
gaapex1trim32fgfr2porscarb2fastkd2mogstfe3srgap1
gbe1abcd3ttc8fgfr3pqbp1serpinh1cox20tmem165pou6f2trap1
gyg1faap95lztfl1flnbrab40alsf3b4apopt1cadrnf139arhgap24
rbck1fanccift27foxc2rai1slc26a3cox8aalg6prcccubn
gys1brca2bbip1fras1myo15asmarcal1coa3cog8metfat1
gys2fancd2h19frem2rnu4atacnpc2cox10slc39a8sdhbitgb4
ldhafancecdkn1cgrip1dvl1npc1pet100alg6tsdhdkank1
pfkmfancfkcnq1ot1frem1dvl3smpd1sco1alg2abcc6kank2
pgam2xrcc9mrpl23g6pc3wnt5atrex1mt-ts1cog6xylt1kank4
phka2fancinsd1edn3twist1tsc1mt-co1alg11xylt2mttl1
phkbbrip1dhodhgdnfror2tsc2mt-co2alg1kif1bnup107
phkg2phf9fam20cednrbrrm2bcyp27b1mt-co3tmem199tmem127nup205
pyglfancmfam58asema3dsall1vdrmt-tealg12mlh3nup93
slc2a2palb2ercc6zhx2sall4cdc73mt-tnslc35a2pdgfrlwdr73
phka1rad51cercc8ahnaksema3emen1cox14ssr4pla2g2axpo5
pygmslx4ercc5ptch1nf2cdkn1bcox6b1dpm2ccnd1cyp24a1
ctnsercc4atrxcntn5smarcb1gata3coa5slc35c1bcl10sac
atp7bfancab3glctfat3srcapgnasagxtngly1ppargcfhr1
iqcb1hnf4accnd2irak3stra6gnas-as1grhpralg9bub1cfhr3
ocrltmem67pik3r2fbn1otx2hsd11b2hoga1stt3amutyhhmga2
clcn5znf423akt3crebbpsox2scnn1aaldoadpagt1kdrmll2
sars2ahi1alms1ntf3hccsscnn1baldobstt3bctnnb1apoa2
slc34a1tmem138bcs1lglararbscnn1galplrft1apcar
clcn5tmem216bub1bgli3lrba,mab21l2scnn2gaprtalg3flt4armc5
slc9a3r1tmem237cep57hnf1bvax1stx16aslsrd5a3ptpn12armc5
znf365b9d1fat4hoxa13hmgb3wnk1etfaccdc115mccatp6v0a4
avpr2pde6dccbe1hps1tfap2awnk4etfbalg8ptprjcdh5
aqp2arl13bcfbhps6tp63cul3etfdhcog7tlr2cdkn2a
atp6v0a4c5orf42baatap3b1vipas39klhl3gcdhcog4nrascdkn2b
atp6v1b1c2cd3c3ar1hps3vps33bnr3c2tatcog1sdhdclpb
ca2tctn1thbdhps4wnt3fgf8fahcog5retdach1
slc4a1kiaa0586cd46dtnbp1fzd5prok2cfhslc35a1xrcc2ednra
ehhadhhsd3b2kdm6armnd1mcm4drd1xrcc6pomcgata6il1a
gemin4igfbp1mitfslc16a12nr5a1mtormc2rankrd1tinagkcnip4
halirf6mrps7cyp21a2pde8bpebp1upf3bfmn1dirc3epha3
hif1akcnj5pax2tvclrp2cxcl8slc2a1arnt2foxi1fbxw7erbb2
ube2ql1ass1cdc5losr1rock2slc13a5erbb4foxc1oclntns3
dcnbmp7nat8pecam1pla2r1emx2。
本发明为解决上述技术问题还提供一种上述试剂盒的制备方法,其中,包括如下步骤:s1)根据人类基因组hg19序列,调取全部与遗传性肾脏病发生相关基因的外显子序列;s2)针对全部外显子序列非重复区域设计50~105bp长度的捕获探针,每个探针沿着基因位置挪动3~10bp,使得目标区域每个碱基被探针覆盖3~20次;s3)合成步骤s2)中的捕获探针,并以生物素标记。
本发明为解决上述技术问题还提供一种单基因遗传性肾脏病基因联合筛查方法,其中,包括以下步骤:s1)获取、检测受检者的全基因组dna样本;s2)构建受检者全基因组文库;s3)采用如权利要求1-4任一项所述试剂盒中的捕获探针与受检者dna文库混合,使得目标区域基因片段与探针杂交,探针通过标记的生物素与带有亲和素的磁珠结合;s4)洗脱未结合的非目标区域的dna片段;s5)利用高通量测序仪对目标区域基因组进行测序、分析,获取疾病相关基因的所有突变信息。
上述筛查方法,其中,所述高通量测序仪为illuminahiseq3000型。
上述筛查方法,其中,所述步骤s5)中的分析过程包含以下步骤:s51)从高通量测序仪获取原始数据;s52)利用trimgalore软件对测序数据从3’端动态去除接头序列片段和低质量片段;s53)用fastqc软件对预处理数据进行质量控制分析;s54)通过生物序列比对软件把有效测序数据比对到人类参考基因组中;s55)统计靶标区域信息,包括靶标区域平均覆盖度、插入片段平均分布图和目标区域测序深度;s56)采用gatk3.1.1进行变异检测,snp和indel变异识别、校正、过滤;s57)用annovar对变异位点进行注释,最后筛选出疾病相关的snp或indel变异。
本发明对比现有技术有如下的有益效果:本发明提供的单基因遗传性肾脏病基因联合筛查方法、试剂盒及其制备方法,能够快速、准确地找出与遗传性肾脏病相关基因的突变信息位点,以达到基因诊断的目的,且能够覆盖目前已知的所有遗传性肾脏病基因的外显子区域。
附图说明
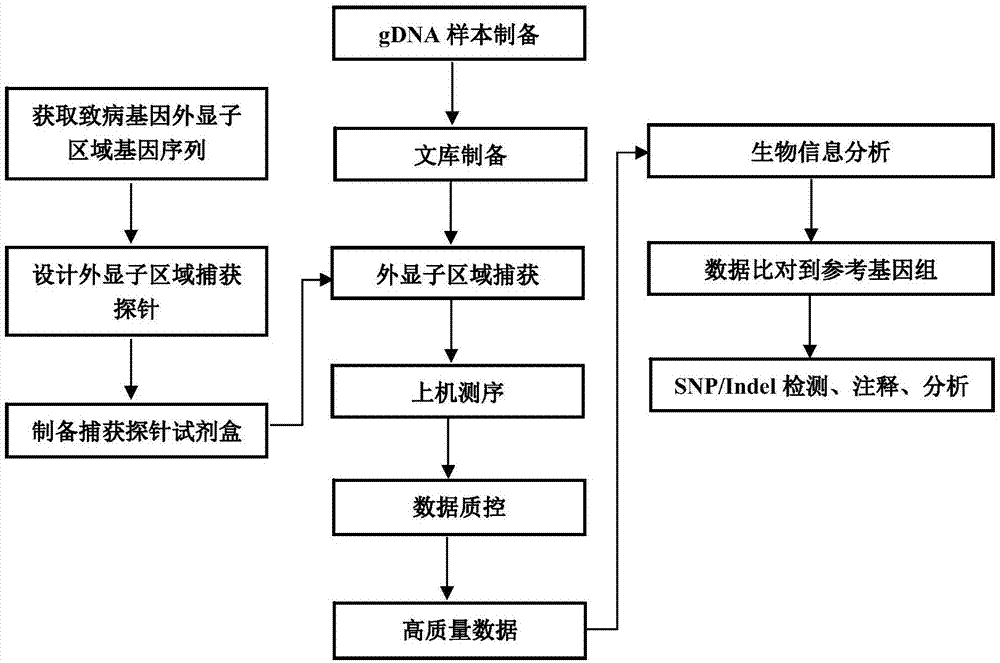
图1为本发明单基因遗传性肾脏病基因筛查示意图;
图2为本发明高通量测序示意图;
图3为本发明实施例alport综合征(xld)患者高通量测序对应位点reads支持图;
图4为本发明实施例alport综合征(xld)患者家系验证结果示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
缩写与定义:
snp单核苷酸多态性
indel插入缺失标记
gdna全基因组dna
本发明提供的单基因遗传性肾脏病基因筛查试剂盒,包含与表i中所示遗传性肾脏病相关的706个致病基因或疾病易感基因中全部外显子序列的特异性寡核苷酸捕获探针。
表i:单基因遗传性肾脏病基因筛查列表
遗传性肾病综合征
遗传性肾病综合征指由于肾小球滤过屏障组成蛋白的编码基因或其他相关基因突变所致的肾病综合征。此类疾病可累及肾单位的各部分而致肾小球疾病、肾小管功能不良、肾实质结构异常(如囊性疾病、先天畸形)等。据统计在全部肾脏疾病中约10-15%可能因遗传因素所致。遗传性肾病严重影响患者的生活质量,甚至威胁生命。目前在我国普遍存在认知率低、漏诊率高、误治率高等问题。基因检测从分子水平检测引起遗传性疾病的突变基因,利用基因检测技术对其诊断、治疗以及风险预测具有重大意义。
一旦被诊断出遗传性肾病,应在家族内积极进行筛查,以早期发现其他的患者进行早期干预。为预防或是避免该病的再发生,可进行产前诊断。
表ii.常见肾脏疾病的名称及分类
目标序列捕获探针
目标序列捕获是指通过某种方法有选择性的分离或者富集基因组的特定片段。目标序列捕获的一种重要的方法是根据核酸分子碱基互补杂交原理发展的。即根据目标基因组序列,设计与之完全互补的探针,将这些探针固定在某些支持物上(用于分离),然后打断基因组dna,加上接头(用于测序)后与探针杂交,洗脱未杂交上的dna,回收目标dna片段,可以直接建库进行dna测序。
根据杂交时状态不同,目标序列捕获可以分为固相杂交法和液相杂交法。固相杂交法所用的探针通常都是固定在固体支持物上,如玻璃片2,3、塑料球等,其中最典型的是基因芯片。固相捕获系统构建如下,首先选定目标dna区域,在修饰了的玻璃片基上原位合成一系列与目标区域互补的探针。通常,基因芯片是杂交后,洗脱未杂交上的dna片段,然后扫描成像获取每个探针的杂交信号,而固相杂交捕获则只有最后一步不同,即与探针杂交的dna被洗脱下来,用于后序的测序工作。
液相杂交与固相杂交最大的差异在于杂交反应的环境不同。液相杂交是通过在溶液中,目标dna片段和已带有生物素标记探针直接杂交,然后通过生物素-亲和素的反应使目标dna片段锚定在带有亲和素的微珠上。洗去非目标dna,洗脱后,富集的dna用于测序。液相杂交与固相杂交相比有两大优势:第一、杂交效率更高;第二、易于操作,时间短,便于自动化操作。
一般来说一个8碱基的探针就有了足够的杂交特异性,而探针越长,杂交的特异性就越差。目前商业试剂盒的探针长度都在60nt到200nt之间,这其中的一个重要考虑是,杂交的特异性限定(或杂交的错配容忍度)。本发明需要研究的是目标dna片段中发生的突变、插入/缺失等,如果探针特异性太高,在dna捕获时就会产生有利于参考序列(与探针完全互补的序列)的选择,这在后期数据统计上就会产生明显的偏差,而探针太长又会有太多的非特异杂交,非目标序列会急剧增加。
下面给出一个具体实施例。
一、使用试剂盒进行遗传性肾病基因检测
患者病征:男,17岁,血尿、蛋白尿、轻微系膜增生性肾小球肾炎。
诊断:遗传性肾炎亦称为alport综合征(xld)。
发病率:1/5000。
疾病特点:本病主要遗传方式是x-连锁显性遗传,致病基因定位在x染色体长臂中段,故遗传与性别有关,母病传子也传女,父病传女不传子。
检测病种:肾小球疾病、肾小管-间质疾病和相关的代谢性疾病、肾髓质囊性病、泌尿系统先天性畸形、肾相关肿瘤、与遗传性肾病相关的综合征及相关疾病等。
检测基因:col4a5等。
检测手段:用制备的肾脏遗传疾病基因筛查试剂盒捕获目的基因序列,再利用高通量测序平台(illuminahiseq3000)的双端150bp测序模式对样本进行检测,通过生物信息学分析数据结果,找出与肾脏遗传疾病相关基因的突变信息位点,以达到基因诊断的目的。
检测过程如图1所示。具体包括以下几个环节:
(一)遗传性肾脏病外显子区域捕获探针试剂盒制备
根据人类基因组hg19序列,调取表i中全部与遗传性肾脏病发生相关基因的外显子序列,基于罗氏液相杂交技术(seqcapez),采用rochenimblegen优化的迭代(repeatmask)算法,对每个外显子区域中非重复区域设计50-105bp的探针序列,每个探针沿着基因位置挪动设计,探针之间的挪动大小3-10bp,且目标区域每个碱基被探针至少覆盖3次,最多不超过20次。采用常规技术将探针以生物素标记。
(二)患者全基因组文库构建
从患者体内抽取3~5ml血液,从中抽提3-5μg基因组dna(gdna),片段化处理gdna,加接头、纯化、扩增以构建全基因组dna文库。具体过程如下:
1、dna样本制备(使用qigen公司qiaampdnabloodmaxikit提取):
(1)取200μlqigen蛋白酶加入到2ml全血中,混匀。
(2)加2.4mlal溶液,充分混匀,振荡1min,70℃孵育10min。
(3)加入2ml无水乙醇,充分振荡混匀后,转移至装在新离心管上的qiaampmidicolumn中,3000rpm离心3min。
(4)去离心后的废液,重复离心一次。
(5)在qiaampmidicolumn中加2mlaw1溶液,5000rpm离心15min。
(6)弃废液,向qiaampmidicolumn中加2mlaw2溶液,5000rpm离心15min。
(7)将qiaampmidicolumn转移至新的离心管上,在qiaampmidicolumn上加入300μlae,室温放15min,而后5000rpm离心2min。
(8)重复步骤7,最后得到600μlgdna溶液。
2、gdna质检:
取1μlgdna加入到nanodrop仪器(美国thermo公司)中检测dna溶液浓度,根据浓度取50ng用1%琼脂糖电泳检测。
3、dna文库构建
(1)dna片段化:取2μgdna,用rb溶液稀释至120μl,用超声破碎仪(biorupter公司)打断,7.5min/次,超声8次。
(2)dna末端补平:取60μl片段化的dna,加40μl末端补平缓冲液(illuminaendrepairbuffer),混匀,离心;pcr仪中30℃反应30min,再加入160μlampurebeads(美国beckman公司),充分混匀,室温放置15min;放磁力架,室温放置5min,去上清;加200μl80%乙醇,室温30s,去上清,重复1次;室温干燥15min;加20μlrb溶液,从磁力架上取下,充分混匀,室温放置5min,取上清17.5μl到一个新管中。
(3)加a:加12.5μla-tailingbuffer(瑞士roche公司)到17.5μldna中,充分混匀,pcr仪中37℃反应30min。
(4)加接头:依次加2.5μlrb,2.5μlligationmix2.5μl接头,混匀30℃反应10min;加5μlstopligationbuffer,混匀;再加42.5μlampurebeads(美国beckman公司),充分混匀,室温放置15min;放磁力架上,室温反应5min,去上清,勿动beads;加入200μl80%乙醇,室温30s,去上清,重复1次;室温干燥15min;加22μlrb,从磁力架上取下,充分混匀,室温放置5min;放置磁力架上,取上清20μl到一个新管中。
(5)pcr富集:取20μldna,5μlppc,25μlpcrmix;98℃反应30s,10个循环(98℃10s,60℃30s,72℃30s),72℃5min,10℃保存;再加入50μlampurebeads(美国beckman公司),充分混匀,室温放置15min;放磁力架,室温放置5min,去上清,勿动beads;加200μl80%乙醇,室温30s,去上清,重复1次,室温干燥15min;加32μlrb,从磁力架上取下,充分混匀,室温放置5min;放置磁力架上,取上清30μl到一个新管中。
(6)定量:qubit(美国invitrogen公司)定量dna文库。
(三)采用试剂盒捕获目的基因序列并进行高通量测序、分析
用步骤(一)制备的单基因遗传性肾脏病基因筛查试剂盒捕获靶基因序列并进行高通量测序、分析过程如图2所示,具体步骤如下:
1、靶序列捕获
(1)第一次杂交:每个文库取500ng,6个不同接头的文库等量混合,真空浓缩至40μl;加50μlcapturetargetbuffer1;加10μlexomeenrichmentusecapturetargetoligos(瑞士roche公司),充分混匀,离心;pcr,95℃10min,18个循环(93℃1min,每个循环降低2℃),58℃18h。
(2)第一次wash:加250μl充分混匀的链霉亲和素磁珠(streptavidinmagneticbeads),充分混匀,室温静置30min;磁力架放置2min,去上清;加200μlwashsolution1(瑞士roche公司),充分混匀;磁力架放置2min,去上清;加200μlwashsolution2(瑞士roche公司),充分混匀;磁力架放置2min,去上清。
(3)dna洗脱:加混合好的naoh,30μl到管中,混匀,室温放置5min;磁力架放置2min,取上清28.5μl至一新离心管中;加5μlelutetargetbuffer2(瑞士roche公司),混匀。
(4)第二次杂交:取30μldna,加10μlddh2o,至40μl;加50μlcapturetargetbuffer1(瑞士roche公司);加10μlexomeenrichmentusecapturetargetoligos(瑞士roche公司);充分混匀,离心;pcr,95℃10min,18个循环(93℃1min,每个循环降低2℃),58℃18h。
(5)第二次wash:加250μl充分混匀的链霉亲和素磁珠(streptavidinmagneticbeads),充分混匀,室温静置30min;磁力架放置2min,去上清;加200μlwashsolution1(瑞士roche公司),充分混匀;磁力架放置2min,去上清;加200μlwashsolution2(瑞士roche公司),充分混匀;磁力架放置2min,去上清。
(6)dna洗脱:加混合好的naoh,30μl到管中,混匀,室温放置5min;磁力架放置2min,取上清28.5μl至一新离心管中;加5μlelutetargetbuffer2(瑞士roche公司),混匀。
(7)pcr:20μldna,5μlppc,25μlpcrmix;98℃30s,10个循环(98℃10s,60℃30s,72℃30s),72℃5min,10℃保存;加50μlampurebeads(美国beckman公司),充分混匀,室温放置15min;放磁力架,室温放置5min,去上清,勿动beads;加200μl80%乙醇,室温30s,去上清,重复1次;室温干燥15min;加32μlrb,从磁力架上取下,充分混匀,室温放置5min;放置磁力架上,取上清30μl到一个新管中,得到靶序列文库。
2、簇生成
(1)用qubit仪器(美国invitrogen公司)定量文库;
(2)将文库稀释至10nm;
(3)取4μl10nm文库,加1μl2nnaoh,加15μltriscl,混匀,室温放置5min;
(4)取6μl步骤3溶液,加994μl冷的杂交buffer;
(5)取140μl步骤4溶液,放在8连管中,置于cbot的template栏中;
3、通过illuminahiseq3000测序,得到测序数据。测序参数如下:
4、生物信息分析流程:
(1)利用trimgalore软件对测序数据从3’端动态去除接头序列片段和低质量片段。
(2)用fastqc软件对预处理数据进行质量控制分析;fastqc是一款基于java的软件,一般都是在linux环境下使用命令行运行,它可以快速多线程地对测序数据进行质量评估。
(3)通过生物序列比对软件(bwa软件)把有效测序数据比对到人类参考基因组中(最多的错误匹配数目为3个,seed长度为32,seed中错误匹配的个数不得超过2个)。
(4)统计靶标区域信息:靶标区域平均覆盖度、插入片段的大小、reads落于目的区域、目的区域附近、非目的区域的分布比例、目的区域内不同覆盖深度的碱基分布比例等。
(5)采用gatk3.1.1(gatk全称是thegenomeanalysistoolkit,是broadinstitute开发的用于二代重测序数据分析的一款软件)进行变异检测,snp和indel变异识别、校正、过滤。采用picard-tools软件去除由于在建库过程中pcr产生的重复序列;采用smith-waterman序列比对算法(smith-watermanalignmentalgorithm)针对已知indels(来自dbsnp138数据库,1kgindels)附近区域进行局部重新比对,去除在比对中的错误;针对来自测序仪产生的碱基质量分数qualityscore进行校正;通过gatk的unifiedgenotyper程序对以上一系列操作后的比对bam文件进行snp和indel的变异检测;针对上一步call出来的变异位点进行过滤,去掉不可信的位点。
(6)用annovar(annovar是一个perl编写的命令行工具,能在安装了perl解释器的多种操作系统上执行;annovar能快速注释遗传变异并预测其功能)对变异位点进行注释,利用千人基因组、dbsnp信息、esp、clinvar、cadd、cosmic、nci60等数据库对变异注释。确定变异发生的基因、位置、碱基改变、杂合或纯合变异、变异发生的频率等信息。判别snp变异为同义或非同义变异、预测氨基酸的改变对蛋白质功能的影响,注释indel变异为译码框缺失或是插入突变等信息。
(7)对候选snp和indel位点筛选,对变异质量分数、基因组区域特征等信息过滤变异位点,snp变异位于编码区且影响氨基酸变化的错义突变或终止子突变为筛选条件,indel变异是否为译码框突变为筛选条件。其他辅助筛选条件包括测序深度、千人基因组中突变频率、物种间的保守性、是否为有害突变(siftscore)等,最后筛选出疾病相关的snp或indel变异。
(8)检测结果及分析
检测发现受检者col4a5基因在chrx:107865121位置发生碱基a>g的半合子变异,理论上该位点的为同义变异。由于col4a5基因c.a2766g位点位于第32号外显子的倒数第二个碱基,可能会对剪接有一定的影响。家系共分离结果显示,受检者该位点的变异来源于其母亲基因组,其母亲有相关的临床症状,符合x连锁显性遗传规律,且家族中患有相似症状的受检者姨、受检者舅舅、受检者表弟在该位点均发生变异,而无相似症状的受检者表姐在该位点未发生变异。上述结果表明col4a5基因c.a2766g位点的变异可能是受检者疾病的致病位点。家系验证结果如表iv所示,sanger测序对应位点reads支持图如图3所示,sanger测序结果如图4所示。
表iii.1例alport综合征(xld)患者发生col4a5基因nm_000495:exon32:c.a2766g:p.k922k突变位点信息
注:“hem”表示半合子变异;“vus”表示临床意义不明确变异(根据美国医学遗传学和基因组学学会acmg标准判断);“xld”表示x连锁显性遗传。
表iv家系验证结果
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!