一种恩拉霉素高产菌株及其构建方法与流程
本发明属于基因工程技术领域,具体涉及一种恩拉霉素高产菌株及其构建方法。
背景技术:
恩拉霉素(enramycin)又名持久霉素,是由土壤中的放线菌发酵产生的一种非核糖体多肽(nrp)类抗生素。该抗生素对革兰氏阳性菌特别是禽畜肠道内有害梭状芽孢杆菌具有较强的抑制作用;饲料中添加适量的恩拉霉素不仅可以预防常见的动物消化道疾病,还可改善动物肠道内的群落平衡,有利于饲料营养成份的消化吸收,促进动物增重。同时恩拉霉素具有广谱、低毒、无残留、不易产生耐药性和交叉抗性等优点,因此是目前少数几种可用于饲料添加剂的抗生素之一。
目前恩拉霉素的生产主要由杀真菌素链霉菌(streptomycesfungicidicus)发酵获得,由于该菌株在发酵过程中普遍存在发酵周期长、产素水平低、菌株退化严重等问题,限制了恩拉霉素的大规模生产和进一步的推广应用。因此采用遗传育种技术进一步提高恩拉霉素产生菌的产素水平及生产性能,对于降低恩拉霉素生产成本、提高市场竞争力具有重要的意义。
目前针对放线菌高产菌株的选育主要采用的是遗传育种的方法,遗传育种方法主要有两种:一种为传统(物理/化学)诱变育种技术,即利用紫外诱变、化学诱变、微波诱变、太空诱变以及离子束诱变等技术对生产菌株进行诱变处理,然后通过大量筛选,获得生产性能更为优良的变异菌株。该方法在抗生素高产菌株的选育方面贡献巨大,目前已成功选育出很多优良菌种。王世梅等利用紫外线诱变选育出数株阿扎霉素(azinomycin)b产量较出发菌株高3倍以上的高产菌株,且传代稳定;阎永贞等对一株纳他霉素产生菌(streptomycesnatalensis)sipi-nhf09进行了紫外和微波相结合的诱变处理,并获得了一株纳他霉素高产突变株,其纳他霉素产量是出发菌株的3.5倍,且遗传性状稳定,具有一定的产业化开发价值。但是传统的诱变育种技术也存在很大缺陷,优良突变菌株的筛选往往具有很大的盲目性,筛选工作量非常大。特别是对放线菌等生长周期较长的菌种而言,筛选工作更是费时费力,短时间内往往难以达到理想效果。另外一种针对放线菌的遗传育种方法为:现代分子生物学遗传育种技术,即通过对特定基因进行遗传改造来进一步提高菌株的生产性能。该方法可直接针对影响菌株产素水平的基因进行遗传改造,目的性更强,遗传操作也很简便。然而对于大部分抗生素产生菌而言,由于其抗生素的生物合成机制及代谢调控机制非常复杂,抗生素的产生往往受多重因素调控,因此很难通过简单的遗传操作而达到理想效果。
上述遗传育种方法虽然都存在各自的优势,但是它们都有以下几个共同的缺点:1)菌体突变方向不确定;2)选育时间较长;3)只能在宏观上去判断菌体抗性的变化,对于具体是由哪些基因的改变决定了产恩拉霉素菌体的抗性强弱这一问题并没有答案。
技术实现要素:
为了解决上述技术问题,本发明将传统高产菌的选育与转录组测序技术相结合,通过对比已知的两株抗性存在显著差异的菌株的基因组序列,进而找到两株菌的基因组序列之间的不同碱基并确定其所在基因组序列中的位置和它所决定的基因名称及作用,针对该基因对抗生素生产菌株进行遗传操作,从而筛选出高抗性工程菌株。
本发明所提供的技术方案之一,是一种恩拉霉素高产基因工程菌,所述基因工程菌是通过在杀真菌素链霉菌宿主中过表达以下基因中的至少一种获得:
(a)基因a(hypotheticalprotein;dehydratase;marrfamily),核苷酸序列如序列表seqidno.1所示;
(b)基因b(transcriptionalregulator),核苷酸序列如序列表seqidno.2所示;
(c)基因c(30sribosomalproteins12),核苷酸序列如序列表seqidno.3所示;
优选地,所述杀真菌素链霉菌宿主为敲除upp基因后的杀真菌素链霉菌(s.fungicidicus)f1,f1菌株已公开在(牟慧艳,刘扬,王应东,刘宝爱,魏建军,张会图.恩拉霉素生产菌株的遗传改造[j].《微生物学通报》,2017.06.20,44(1):126-132)上;
本发明所提供的技术方案之二,是上述恩拉霉素高产基因工程菌的构建方法,包括如下步骤:
(1)构建含目的基因的接合转移质粒,所述接合转移质粒以upp基因作为标记;
优选地,所述接合转移质粒以pkc1139质粒为载体;
(2)将步骤(1)构建的质粒接合转移至恩拉霉素生产菌株;
(3)筛选:挑取转化子后传代,点板筛质粒丢失的菌株,并做菌落pcr验证,获取整合完成的菌株;
进一步地,上述恩拉霉素高产基因工程菌的构建方法,具体如下:
(1)构建含upp基因的整合型载体
以杀真菌素链霉菌的基因组为模板进行pcr,克隆出含upp基因的同源片段,将该片段与pkc1139载体连接后转化大肠杆菌jm109感受态细胞,即得含upp基因的整合型载体pkc1139-u;
(2)构建含目的基因的接合转移质粒
以杀真菌素链霉菌(s.fungicidicus)f1基因组为模板,设计引物,克隆出含目的基因的基因片段;将两段相同的目的基因片段酶切连接后,与t载体连接,将连接成功的载体转化至大肠杆菌jm109感受态细胞;提质粒酶切验证后,将正确的质粒与pkc1139-u载体进行连接,转化大肠杆菌jm109感受态细胞后,提质粒酶切验证,获得含目的基因的接合转移质粒;
(3)接合转移到链霉菌。
将含有目的基因的接合转移质粒化转到e.coliet12567感受态细胞中,菌落pcr验证后,挑取正确的大肠杆菌转化子与杀真菌素链霉菌做接合转移,通过接合转移的方法将质粒转移到杀真菌素链霉菌中,实现目的基因的过表达;
(4)筛选:挑取转化子在40℃条件下ms培养基上进行传代培养后,挑取在阿普拉抗性平板上不生长,在五氟尿嘧啶平板上生长的菌落进行菌落pcr验证,筛选获得成功表达目的基因的菌株。
本发明所提供的技术方案之三,是上述恩拉霉素高产基因工程菌的应用。
有益效果:
本发明通过对比已知的两株抗性存在显著差异的菌株的基因组序列,确定了3个影响恩拉霉素生产的基因-a、b、c,并针对上述基因对恩拉霉素生产菌株进行遗传操作,从而筛选出高抗性工程菌株。获得的基因工程菌较原始菌株的恩拉霉素产量分别提高了5%,18.3%和19.5%,本发明为恩拉霉素高产菌株的选育提供了一种新思路。
附图说明:
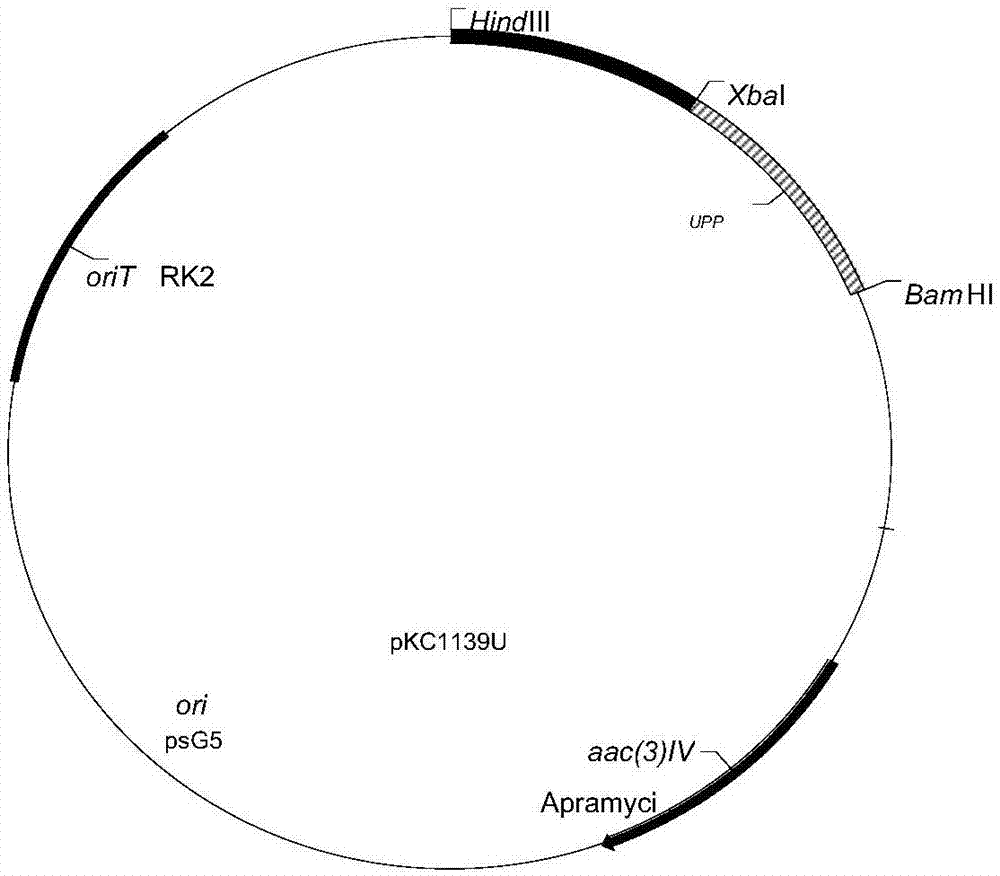
图1:重组载体pkc1139-u;
图2:重组质粒pkc1139-d;
图3:upp基因验证电泳图;
其中,泳道a为marker;泳道b为克隆片段;
图4:目的基因pcr验证电泳图;
其中,泳道a为marker;泳道b为尽量pcr样品;
图5:40℃下阿普拉抗性筛选结果;
图6:28℃下五氟尿嘧啶筛选结果。
具体实施方式:
下面将结合具体实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明将高产菌的选育与转录组测序技术相结合,通过对比已知的两株抗性存在显著差异的菌株的基因组序列,确定了3个影响杀真菌素链霉菌恩拉霉素产量的基因,并进一步将上述基因在杀真菌素链霉菌中进行过表达,从而筛选出3株恩拉霉素高产菌株。
表达质粒构建过程中采用upp基因作为筛选标记,upp基因是一种自杀性标记基因,含有该筛选标记基因的菌株不能在含有五氟尿嘧啶的抗性板上存活,然而不含有该筛选标记基因的菌株反而能在含有五氟尿嘧啶的抗性板上存活下来。这样一来,既不引入抗性基因,又能到达筛选的目的。
表达质粒构建完成后,首先化转到e.coliet12567感受态细胞中,进而通过接合转移的方法将质粒转移到杀真菌素链霉菌中,实现目的基因的过表达。接合转移的原理为:在质粒转移过程中,供体菌与受体菌细胞通过结合作用紧密接触,质粒从供体细胞向受体转移,同时进行质粒复制。质粒可以进行接合转移的前提是受体菌具备某些元件,比如orit,tra,mob等等。
接合转移完成后,本发明采用阿普拉抗性平板、五氟尿嘧啶平板以及菌落pcr联用的方法成功筛选出表达目的基因的菌株。因为pkc1139质粒本身含有阿普拉霉素抗性基因,将接合转移完成后得到的菌体转接于阿普拉抗性平板上,置于40℃的培养基中培养3-4天,筛选出发生了单交换的菌体;将上述菌体于无抗板上,28℃下培养6-7天,使其发生自然交换;将无抗板上的菌体转接到含有五氟尿嘧啶的平板上,28℃下培养6-7天,筛选出的菌体有两种可能:一种是发生了双交换的菌体,一种是又恢复成了原菌体;将这些菌体进行菌落pcr验证(如图4所示)之后,进行测序验证,找到发生双交换的菌体。
本发明所使用的杀真菌素链霉菌(s.fungicidicus)f1,已公开在(牟慧艳,刘扬,王应东,刘宝爱,魏建军,张会图.恩拉霉素生产菌株的遗传改造[j].《微生物学通报》,2017.06.20,44(1):126-132)上。公众可从天津科技大学生物工程学院获取该菌株。构建基因工程菌所使用的宿主是预先敲除upp基因的杀真菌素链霉菌(s.fungicidicus)f1。
本发明实验过程中所涉及的培养基组成如下:
lb培养基:蛋白胨10g,酵母粉5.0g,氯化钠10g,琼脂粉15g,加水至1000ml,121℃灭菌20min;
2×yt培养基:蛋白胨10g,酵母粉10g,氯化钠5.0g,加水至1000ml,121℃灭菌20min;
ms培养基:大豆粉20g,甘露醇20g,琼脂粉180g,加水1000ml,121℃灭菌20min。
种子培养基(50ml):玉米粉1.75g,碳酸钙0.25g,硫酸铵0.125g,玉米浆粉0.56g,棉籽饼粉0.25g,3.6%fe2(so4)3母液0.5ml,磷酸二氢钾0.065g,其余为水,调ph=7.0。
发酵培养基(50ml):玉米粉3g,黄豆粉1.2g,硫酸铵0.1g,葡萄糖0.25g,乳酸50μl,碳酸钙0.25g,淀粉酶35mg,玉米浆粉0.05g,其余为水,调ph=7.2左右。
本发明实验过程中所涉及的引物如下:
下文将结合具体实施例以基因b为例进一步详细阐述本发明的技术方案
实施例1:一种恩拉霉素高产菌株及其构建方法
(1)构建含upp基因的整合型载体
以杀真菌素链霉菌(s.fungicidicus)f1的基因组为模板进行pcr,设计引物upp-up、upp-down,克隆出含upp基因的同源片段(验证图如图3所示),长度为2500bp左右,酶切位点分别为bamhi、xbai,将该片段与pkc1139载体酶切、连接后转化大肠杆菌jm109感受态细胞,即得含upp基因的整合型载体pkc1139-u(如图1);
(2)构建含目的基因的接合转移质粒
以杀真菌素链霉菌(s.fungicidicus)f1基因组为模板,设计引物b-up、b-down,克隆出含目的基因b的基因片段(或者根据基因序列进行全基因合成获得目的基因b);单酶切后,将两段相同的目的基因b片段连接,连接片段与t载体连接命名为pmd19-t,将连接成功的载体转化至大肠杆菌jm109感受态细胞;提质粒酶切验证后,将正确的质粒命名为t-d,酶切t-d与pkc1139-u,回收目的片段及被切开的载体pkc1139-u,将目的片段及载体连接,将连接体系化转到大肠感受态jm109中,提质粒酶切验证,将正确的质粒命名为pkc1139d(如图2);
(3)接合转移到链霉菌
将质粒pkc1139d化转到e.coliet12567感受态细胞中,菌落pcr验证后,挑取正确的大肠杆菌转化子与杀真菌素链霉菌做接合转移,通过接合转移的方法将质粒转移到敲除upp基因后的杀真菌素链霉菌f1中,具体如下:
①e.coliet12567的化转
a.准备筛选平板:在预先制备好的100μg/ml氨苄霉素平板上加入浓度为100mmol/l的iptg溶液20μl和20mg/ml的x-gal40μl,均匀涂布于整个平板表面,室温放置2~3h备用;
b.向e.coliet12567感受态细胞中加入5μlpkc1139d质粒(25ng),轻轻混匀,冰浴30min;
c.42℃热击90s,立即冰浴2min;
d.每管加入800μl37℃预热的lb培养基(不含安普拉霉素),37℃,180r/min复苏培养1h;
e.4000r/min离心5min,沉淀用200μllb培养基悬浮;取适量涂布于筛选平板上,待菌液充分吸收后,37℃倒置培养12~16h至出现单菌落;
f.将平板放置于4℃冰箱中数小时,使蓝色充分显现,以便于蓝白斑筛选;
g.挑取白色菌落,提取质粒dna,菌落pcr鉴定;
h.验证正确转化子命名为et-pkc1139d,-80℃保存备用
②e.coliet12567与杀真菌素链霉菌接合转移
a.取大肠杆菌et-pkc1139d于lb平板上划线,同时在含50μg/ml安普霉素、25μg/ml氯霉素、25μg/ml卡那霉素的lb平板上划线作对照(不应生长),37℃温箱培养过夜;
b.分别挑取大肠杆菌et-pkc1139d单菌落于5ml含有抗生素安普霉素(50μg/ml),氯霉素(25μg/ml)和卡那霉素(50μg/ml)的lb培养基中,37℃过夜培养。
c.取1ml(b)中大肠杆菌培养液于50ml新鲜含有抗生素安普霉素(50μg/ml),氯霉素(25μg/ml)和卡那霉素(50μg/ml)的lb培养基,37℃培养至od=0.4。
d.用20ml无抗lb培养基洗(c)中得到的菌体以防止残留的抗生素对链霉菌孢子抑制,最后用1mllb悬浮菌体。
e.取10μl(孢子悬液浓度为108个/ml)杀真菌素链霉菌孢子于500μl2×yt培养基中,50℃水浴锅热激10min,冷却至室温。
f.取500μl(d)大肠杆菌细胞悬浮液和500μl(e)中处理好的孢子,轻轻混匀。
g.取100μl(f)中混合悬浮液涂布与添加10mm氯化镁的ms培养基中,30℃培养18~20h。
h.在(g)中培养好的平板中覆盖1ml含有0.5mg奈丁酸(20μl的25mg/ml储存液)和1.25mg安普霉素(50mg/ml储存液)的灭菌水。用涂布器涂布均匀,30℃继续培养,观察结合转化子。
(4)筛选:pkc1139质粒本身含有阿普拉霉素抗性基因,将接合转移完成后得到的菌体转接于阿普拉抗性平板上,置于40℃的培养基中培养3-4天,筛选出发生了单交换的菌体(图5所示);将上述菌体于无抗板上,28℃下培养6-7天,使其发生自然交换;将无抗板上的菌体转接到含有五氟尿嘧啶的平板上,28℃下培养6-7天,筛选出的菌体(图6所示)有两种可能:一种是发生了双交换的菌体,一种是又恢复成了原菌体;将这些菌体进行菌落pcr验证(如图4所示)之后,进行测序验证,找到发生了双交换的基因工程菌,命名为基因工程菌2。
实施例2性能测定
本发明以实施例1相同的方法构建过表达基因a和基因c的恩拉霉素生产工程菌株1和3(与实施例1中的方法均相同,仅过表达基因不同,基因pcr引物分别为a-up/a-down、c-up/c-down),并测定菌株对枯草芽孢杆菌的抗性及恩拉霉素产量:
①检测菌株对枯草芽孢杆菌的抗性
将筛选获得的菌株和原始菌株(宿主菌)单菌落分别置于50ml种子培养基中28℃、220r/min培养2天后,分别取种子液5ml接种于50ml发酵培养基中,28℃、220r/min培养6天。发酵后取2ml发酵液,离心后,用丙酮浸提液浸提4h,离心取上清于1.5mlep管中备用。取6μl上清液于滤纸片上,吹干,将其贴于含有枯草芽孢杆菌的测定板上于4℃下渗透4h拿出,置于37℃培养12h后取出,测定工程菌1、2、3抗菌圈直径分别为:15.28mm,16.17mm,16.21mm;原始菌抗菌圈直径为:15.23mm。
②检测菌株的恩拉霉素产量
注:2000u相当于每0.0125g每ml标准品的活性,即称取0.05g标准品于10ml的离心管中,加入4ml的丙酮浸提液于振荡器上振荡4h,离心后的上清即为2000u的标准液。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
序列表
<110>天津科技大学
<120>一种恩拉霉素高产菌株及其构建方法
<130>1
<141>2018-09-25
<160>11
<170>siposequencelisting1.0
<210>1
<211>647
<212>dna
<213>抗真菌素链霉菌(streptomycesfungicidicus)
<400>1
ctgcgggacgcgctgcggcggatgctggctgggggctgacgggatcgctctgcggcgcgg60
cgccaggtggtgggtggggcggggccgggtcgggggtggacgtcctcggactggcgcgac120
tgccccggctggaatacgtcgggggcgcggacgcgccagccactgcgggcggccaccccc180
gccccgtcccctccacgccgtcggcggccacccgctgcacccgccgtctccacgggcagc240
cccacacccgccctccacaggcagccgcacctccgcgagccgccgcgcacctccgccctc300
cgcaggccgccgcacctccgcgagccgccgcgcacctccgccctccgcgggctcccgcgc360
ctccgccctccgcgggcccccgcgcctccgctctccgcgggcagtcgtgccgctggggcg420
gcacgggtgggcgcgacggcgccccgtgagcgccgggctgcgcgacaccccccggcacgc480
acccacgccgggttactgggggccgcggggggggggcggtcaggtgcaccaccacaggaa540
acggtcgcacgtctccgacggctcgggttcaggctcgggctcgggctcctgcgtggtcgg600
ctcgggcgtctccggctcaggaggaggctccgccggagccgaggacg647
<210>2
<211>1008
<212>dna
<213>抗真菌素链霉菌(streptomycesfungicidicus)
<400>2
ggaatgggatgacctgcgccagttgtcaggggtagacacggagcctcacagttccttggc60
cagtctgtggatgaggtcccgcgacttgccggggtcgagggacacgtccaccactctacg120
gaacaccgttcgaaagacgccgagttgtgcctcggagtcgatgaacccggtgccgtgggg180
tgcgtcgcgaacggctgtgtccagcttgggcaccgtcgcgcccgccagcatcatggggct240
ccaggcaccaccgaagccgtccaggtcgaacgggatgacactcacgctgatgtgatcggc300
ctcggagagttccaggacgcgagtgagctgcgcccgcgcggtggctcggtccccgaccct360
gatgcgcagcgctgcttcgtggatcacggcctggtacggggccagggattcgaggatcac420
ctttcgctgcatccggtggcgcactcgcaagtccaactccgctggaggaagctcgggcac480
ccgagaggagaaggcggcgcgggcgtagtcctccgtttgaagcaggccagggatgaacag540
gaactcgacgtcgcgccggtatgtggcgtggtactccaactcggcgagatccaggaacgc600
tgtaggcagtagaccccggtactcctcccaccacccacgagtccggtccgtcgccatgac660
gacgagggcgtcgatgaacgcctcgtccgtgcacgagtagtgcgcagcgagacggcgtag720
gcgttcctcactcacacctgcaagtccggactcgatgtggctgatctgaacgcggttcac780
tccaagcagtgccgccgcctcgatggcagagagtcctgccgcgtctcgcagcctgcgcaa840
ttcgaccgccagtcgcaactgacgtgcggtgcattcgcgcctcaagaccatgcagggctc900
cctccgttcaacgggccgatccgcgcgacccgttcggggtcagattaggggatcagcttg960
ccccgtatgacatgttagccctaccgtcagtgatgccgcgcacaccgt1008
<210>3
<211>779
<212>dna
<213>抗真菌素链霉菌(streptomycesfungicidicus)
<400>3
cgcatttgccgtgttccgcccgtcggcgcgggccgggcccatttgttttgaccgcagcga60
atgcggtaggtacgctcagaccttgtgcctggggtgtgccctggccttcgtgcgtgccat120
cagaccgcaccgggggctgttgaacggccaccgtaattcagcgcctctctgcctcgcggt180
aggagtccgcgggattcgacacacccgaccgcgtgggtcggagatgttccaggttagctg240
tacccatcggcacacagaaaccggagaagtagtgcctacgatccagcagctggtccgcaa300
gggccggcaggacaaggtcgagaagaacaagacgcccgcactcgagggttcccctcagcg360
tcgtggcgtctgcacgcgtgtgttcacgaccaccccgaagaagccgaactcggccctgcg420
taaggtcgcgcgtgtgcgtctgaccagcggcatcgaggtcacggcctacattccgggtga480
gggacacaacctgcaggagcactccatcgtgctcgtgcgcggcggccgtgtgaaggacct540
gccgggtgttcgctacaagatcatccgcggttccctcgacacccagggtgtcaagaaccg600
caagcaggctcgcagccgttacggcgccaagaaggagaagtaagaatgcctcgtaagggc660
cccgccccgaagcgcccggtcatcatcgacccggtctacggttctcctctggtgacctcc720
ctgatcaacaaggtgctgctcaacggcaagcgttccaccgccgagcgcatcgtctacgg779
<210>4
<211>26
<212>dna
<213>人工序列()
<400>4
tctagaggcacggagtcggcggaacc26
<210>5
<211>28
<212>dna
<213>人工序列()
<400>5
cggatccgcacgcccgcgtcctcgaact28
<210>6
<211>26
<212>dna
<213>人工序列()
<400>6
cggatccggcatttgccgtgttccgc26
<210>7
<211>27
<212>dna
<213>人工序列()
<400>7
cggatccgcttgtgcgtgtcctcgcgc27
<210>8
<211>23
<212>dna
<213>人工序列()
<400>8
ggaattccgtgtgcgcggcatca23
<210>9
<211>26
<212>dna
<213>人工序列()
<400>9
cggatccgacggtgtgcgcggcatca26
<210>10
<211>28
<212>dna
<213>人工序列()
<400>10
cggatccggcatttgccgtgccttccgc28
<210>11
<211>27
<212>dna
<213>人工序列()
<400>11
cggatccgcttgtgcgtgtcctcgcgc27
- 还没有人留言评论。精彩留言会获得点赞!