二氯苯酚降解酶TcpA及其编码基因与生产菌的应用的制作方法
本发明属于应用环境微生物及生物工程技术领域,具体地说,涉及二氯苯酚降解酶tcpa及其编码基因与生产菌的应用。
背景技术:
氯代苯酚是环境中最常见的持久性有机污染物之一。由于卤代基的存在,氯代苯酚具有很高的毒性,且随着氯原子个数的增加,其毒性也逐渐增强。氯代苯酚被证明可以引起包括慢性毒性、诱变性和致癌性在内的多种有害生物效应。二氯苯酚是在环境水体中检出率最高的氯代苯酚,共含有2,3-二氯苯酚、2,4-二氯苯酚、2,5-二氯苯酚、2,6-二氯苯酚、3,4-二氯苯酚、3,5-二氯苯酚六种。二氯苯酚被广泛应用于农药、杀菌剂、阻燃剂、木材处理剂的加工和生产,同时经常作为造纸厂、化工厂和药厂的原料中间体被释放到环境中。因此,它们不仅出现在工业废水中,也经常出现在土壤和地下水中,危害人类健康。世界卫生组织规定饮用水中氯酚的限量浓度小于1mg/l。由于其溶解度高,流动性强,在水生环境中分布广泛,因此被美国epa列为优先控制污染物。
二氯苯酚的降解方式主要有物理、化学和生物降解。其中物理和化学方法存在降解成本高、反应过程复杂,处理不彻底,易产生二次污染物等问题。而生物降解因为具有代谢种类多、适应能力强、生长繁殖快、转化效率高等特点,成为最受关注的处理技术。要利用微生物降解技术解决氯代苯酚的环境污染问题,首先要获得优良的菌株和基因资源。虽然已经报道了多种氯代苯酚的降解菌株,但存在降解谱窄、降解基因少、表达效果不好等问题,极大地限制了这些降解菌株在实际处理氯代苯酚在工业废水和污染土壤中的应用。
技术实现要素:
本发明的目的是提供二氯苯酚降解酶tcpa及其编码基因与生产菌的应用。
本发明构思如下:发明人从一株二氯苯酚降解菌cupriavidustaiwanensisx1中克隆得到二氯苯酚降解酶基因tcpa(seqidn0:1),其编码的酶命名为tcpa。它与菌株ralstoniasp.t6注释的monooxygenase具有最高的相似性(98%),但不同于降解底物为2,4,6-三氯苯酚和3,5,6-三氯-2-吡啶醇,表明tcpa是一个新的二氯苯酚降解酶。
为了实现本发明目的,第一方面,本发明提供一株二氯苯酚降解菌--台湾嗜铜菌(cupriavidustaiwanensis)x1,该菌现已保藏于中国典型培养物保藏中心,地址:中国武汉,武汉大学,邮编430072,保藏编号cctccno:m2010233,保藏日期2010年9月15日。
第二方面,本发明提供来自于cupriavidustaiwanensisx1的二氯苯酚降解酶tcpa的以下任一应用:
a1)在降解二氯苯酚中的应用;
a2)在制备用于降解二氯苯酚的酶制剂中的应用。
其中,所述二氯苯酚降解酶tcpa为如下a)或b):
a)由seqidno:2所示的氨基酸序列组成的蛋白质;
b)seqidno:2所示序列经取代、缺失或添加一个或几个氨基酸且具有同等功能的由a)衍生的蛋白质。
第三方面,本发明提供二氯苯酚降解酶基因tcpa的以下任一应用:
b1)在构建降解二氯苯酚的基因工程菌中的应用;
b2)在构建降解二氯苯酚的转基因细胞系中的应用;
b3)在构建降解二氯苯酚的转基因植物中的应用。
第四方面,本发明提供含有二氯苯酚降解酶基因tcpa的生物材料在构建降解二氯苯酚的基因工程菌、转基因细胞系或转基因植物中的应用。其中,所述生物材料包括但不限于重组dna、表达盒、转座子、质粒载体、噬菌体载体或病毒载体。
第五方面,本发明提供携带二氯苯酚降解酶基因tcpa的工程菌的以下任一应用:
c1)在降解二氯苯酚中的应用;
c2)在制备用于降解二氯苯酚的菌剂中的应用;
c3)在发酵生产降解二氯苯酚的酶制剂中的应用。
第六方面,本发明提供携带二氯苯酚降解酶基因tcpa的转基因植物的以下任一应用:
d1)在降解二氯苯酚中的应用;
d2)在植物育种中的应用。
第七方面,本发明提供台湾嗜铜菌(cupriavidustaiwanensis)x1的以下任一应用:
e1)在降解二氯苯酚中的应用;
e2)在制备用于降解二氯苯酚的菌剂中的应用;
e3)在发酵生产降解二氯苯酚的酶制剂中的应用。
所述毒死蜱降解菌台湾噬铜菌(cupriavidustaiwanensis)x1现已保藏于中国典型培养物保藏中心,地址:中国武汉,武汉大学,邮编430072,保藏编号cctccno:m2010223,保藏时间2010年9月15日。
第八方面,本发明提供用于降解二氯苯酚的制剂或组合物,其活性成分选自二氯苯酚降解酶tcpa、携带二氯苯酚降解酶基因tcpa的菌株、转基因细胞系或转基因植物中的至少一种。
第九方面,本发明提供所述用于降解二氯苯酚的制剂在去除工业废水、土壤和环境水体中二氯苯酚污染中的应用。
本发明中,二氯苯酚降解酶tcpa由tcpa基因编码,该基因在其全基因组中的标签为x1gm002595,基因tcpa的分子类型为双链dna,长度为1554bp,拓扑结构为线性,核苷酸序列如seqidno:1所示。降解酶tcpa的氮末端具有4-羟苯乙酸-3-单加氧酶(4-hydroxyphenylacetate3-monooxygenase,hpab)的结构域。
第十方面,本发明提供二氯苯酚降解酶tcpa的制备方法,包括以下步骤:
(1)以cupriavidustaiwanensisx1的基因组dna为模板,对tcpa基因进行pcr扩增;
(2)将tcpa基因插入到表达载体pmal-c5x,构建原核表达重组质粒pmal-mbp-tcpa;
(3)将重组质粒pmal-mbp-tcpa转化至e.colibl21(de3)细胞,获得重组表达菌株;
(4)对重组表达菌株进行诱导,表达mbp-tcpa蛋白;
(5)诱导表达后收集菌体并超声破碎细胞,获得重组蛋白粗酶液;
(6)过amylose树脂柱,进行亲和层析,用洗脱液洗脱后得到mbp-tcpa蛋白;
(7)利用超滤膜对洗脱后重组蛋白脱盐,离心后取超滤膜上层清液,即mbp-tcpa蛋白。
优选地,步骤(1)中用于pcr扩增tcpa基因的引物序列如下(seqidno:3-4):
tcpa-s:5’-cggaattcatgattcgcactggcaagcag
tcpa-a:5’-cccccaagctttacggtcatcgtgccgctca
其中,划线部分gaattc为限制性内切酶ecori的酶切位点,aagctt为限制性内切酶hindiii酶切位点。
优选地,步骤(1)中pcr扩增反应体系为50μl,其中包含35μl无菌水,5μl10×pcrbuffer,3μlmg2+,1μldntp,2μl引物tcpa-s,2μl引物tcpa-a,1μlcupriavidustaiwanensisx1基因组dna模板,1μltaqdna聚合酶。pcr扩增反应条件为:95℃5min,34个循环(95℃30s,63℃30s,72℃50s),72℃10min,4℃终止。
优选地,步骤(3)中,所述重组质粒pmal-mbp-tcpa在测序验证后转化至e.colibl21(de3),将阳性克隆接种于含有100mg/l氨苄青霉素的lb培养基中,37℃恒温震荡培养至od600nm=0.6时,加入异丙基硫代-β-d-半乳糖苷(iptg)使其终浓度为0.5mm,并将培养液转移至18℃恒温震荡诱导6h。
优选地,步骤(5)中,诱导后的菌液经过6000g离心5min,用50mmol/l磷酸盐缓冲液洗涤重悬后超声波破碎,细胞破碎条件为:200w工作3s,停止3s,共循环破碎100次。
优选地,步骤(6)中,洗脱液的成分为:20mmtris-hcl,ph7.4,0.2mnacl,1mmedta,1mmdtt,10mm麦芽糖。
借由上述技术方案,本发明至少具有下列优点及有益效果:
(一)本发明首次发现台湾嗜铜菌(cupriavidustaiwanensis)x1具有降解二氯苯酚的能力,108cfu能够将约4mg2,4-二氯苯酚在24h完全降解。可用于二氯苯酚污染环境的生态修复。
(二)本发明从cupriavidustaiwanensisx1中克隆得到基因tcpa,其编码二氯苯酚降解酶tcpa,降解酶tcpa或携带tcpa基因的工程菌能高效降解二氯苯酚。基因tcpa可用于构建降解二氯苯酚的转基因微生物和植物,亦可用于生产降解二氯苯酚的酶制剂,用于消除工业废水、土壤和环境水体中二氯苯酚污染。
(三)本发明中由携带tcpa基因的e.colibl21(de3)所表达的降解酶tcpa较降解菌cupriavidustaiwanensisx1具有更高的降解活性。1u降解酶tcpa对0.4mg2,3-二氯苯酚、2,4-二氯苯酚、2,5-二氯苯酚、2,6-二氯苯酚、3,4-二氯苯酚、3,5-二氯苯酚的降解半衰期分别为2.32h、1.84h、2.71h、5.63h、7.89h、3.57h。
附图说明
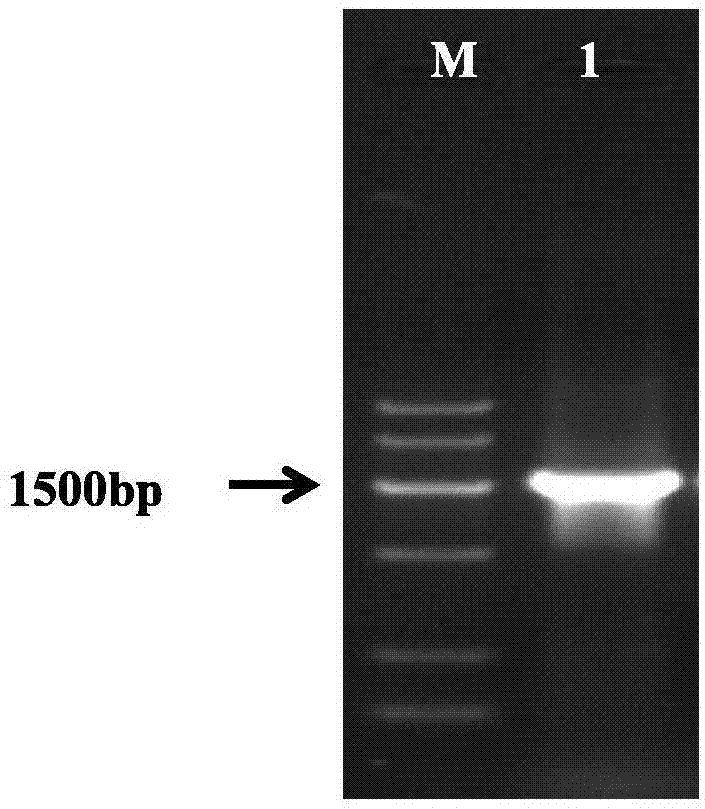
图1为本发明实施例1中二氯苯酚降解酶基因tcpa扩增产物的琼脂糖凝胶电泳图。其中,m为dnamarker,1为tcpa基因。
图2为本发明实施例1中二氯苯酚降解酶tcpa蛋白sds-page电泳图。其中,m为蛋白marker,1为e.colibl21(de3)中表达的降解酶tcpa,2为亲和层析纯化后的降解酶tcpa。
图3为本发明实施例2中二氯苯酚降解酶tcpa催化2,3-二氯苯酚降解动力学图谱。
图4为本发明实施例2中二氯苯酚降解酶tcpa催化2,4-二氯苯酚降解动力学图谱。
图5为本发明实施例2中二氯苯酚降解酶tcpa催化2,5-二氯苯酚降解动力学图谱。
图6为本发明实施例2中二氯苯酚降解酶tcpa催化2,6-二氯苯酚降解动力学图谱。
图7为本发明实施例2中二氯苯酚降解酶tcpa催化3,4-二氯苯酚降解动力学图谱。
图8为本发明实施例2中二氯苯酚降解酶tcpa催化3,5-二氯苯酚降解动力学图谱。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。若未特别指明,实施例均按照常规实验条件,如sambrook等分子克隆实验手册(sambrookj&russelldw,molecularcloning:alaboratorymanual,2001),或按照制造厂商说明书建议的条件。
以下实施例中e.colidh5α感受态细胞购自大连宝生物工程(takara)有限公司;表达宿主菌e.colibl21(de3)感受态细胞购自北京全式金生物技术有限公司。
实施例1tcpa基因的克隆与二氯苯酚降解酶tcpa的表达和纯化
1、选取cupriavidustaiwanensisx1基因组上tcpa基因序列,设计引物tcpa-s:cggaattcatgattcgcactggcaagcag,tcpa-a:cccccaagctttacggtcatcgtgccgctca(划线部分gaattc为限制性内切酶ecori的酶切位点,aagctt为限制性内切酶hindiii酶切位点)。以cupriavidustaiwanensisx1基因组dna为模板,pcr扩增tcpa基因。pcr扩增反应体系为50μl,其中包含35μl无菌水,5μl10×pcrbuffer,3μlmg2+,1μldntp,2μl引物tcpa-s,2μl引物tcpa-a,1μlcupriavidustaiwanensisx1基因组dna模板,1μltaqdna聚合酶,pcr扩增反应条件为95℃5min,34个循环(95℃30s,63℃30s,72℃50s),72℃10min,4℃终止。dna电泳结果如图1所示。利用ecori和hindiii限制性内切酶位点,将tcpa基因片段连接入表达载体pmal-c5x,得到重组质粒pmal-mbp-tcpa。该构建好的重组质粒将表达如seqidno:2所示的二氯苯酚降解酶tcpa完整蛋白。
2、重组二氯苯酚降解酶tcpa的表达
将重组质粒pmal-mbp-tcpa转化至e.colidh5α感受态细胞中,经过送检测序确定基因序列正确后,提取质粒,并将重组质粒pmal-mbp-tcpa转化至e.colibl21(de3)感受态细胞中,将阳性克隆接种于含有100mg/l氨苄青霉素的lb培养基中,37℃恒温震荡培养至od600nm=0.6时,加入异丙基硫代-β-d-半乳糖苷(iptg)使其终浓度为0.5mm,并将培养液转移至18℃恒温震荡诱导6h。离心弃培养基,sds-page电泳检测,结果如图2所示,表达蛋白在96kd位置。表明该菌株在iptg诱导下,准确表达了导入重组tcpa基因。
3、重组二氯苯酚降解酶tcpa的纯化
挑取冻存管中含有目的基因tcpa的表达菌株e.colibl21(de3)于含有100mg/l氨苄青霉素的100mllb培养基中,37℃恒温震荡培养至0d600nm=0.6时,加入iptg使其终浓度为0.5mmol/l,并将培养液转移至18℃恒温震荡诱导6h。诱导后的菌液经过6000g离心5min,用50mmol/l磷酸盐缓冲液洗涤重悬后超声波破碎,细胞破碎条件为:200w工作3s,停止3s,共循环破碎100次。将破碎后菌液于4℃,12000rpm离心10min,取上清,进行亲和层析,具体步骤如下:
(1)平衡:取10mlamylose树脂灌柱(柱直径1.6cm),并用5倍柱体积的结合缓冲液(20mmol/ltris-hcl缓冲液,ph7.4,0.2mol/lnacl,1mmol/ledta,1mmol/ldtt)平衡柱子。
(2)上样:取50ml二氯苯酚降解酶tcpa粗酶液,以0.8ml/min流速流经多糖树脂柱,并用10倍柱体积的缓冲液冲洗柱子。
(3)洗脱:用3倍柱体积的洗脱缓冲液(20mmol/ltris-hcl缓冲液,ph7.4,0.2mol/lnacl,1mmol/ledta,1mmol/ldtt,10mmol/l麦芽糖)洗脱目的蛋白,并收集流出液。
(4)再生:按如下顺序对柱子进行清洗与再生,先后加入3倍柱体积的去离子水,3倍柱体积的0.1%sds,1倍柱体积的去离子水,3倍柱体积的结合缓冲液,5倍柱体积的20%酒精,最后将填料保存于20%酒精中。
以上步骤均在4℃层析柜中进行。
(5)脱盐与浓缩:将含有目的蛋白的洗脱液加入至50kd超滤管,4℃5000g离心25min,弃下层废液;加入15ml20mmpbs缓冲液,4℃5000g离心25min,弃下层废液,并重复此步骤一次;将超滤管中纯化后的目的蛋白取出,利用sds-page测定,结果如图2所示。
实施例2重组二氯苯酚降解酶tcpa的活性检测
本发明中二氯苯酚降解酶tcpa酶活力定义与测定描述如下:
酶活力单位定义(u):在37℃下每分钟降解1um二氯苯酚所需要的酶量。将2,3-二氯苯酚、2,4-二氯苯酚、2,5-二氯苯酚、2,6-二氯苯酚、3,4-二氯苯酚、3,5-二氯苯酚分别配置成10mg/ml的母液,进行如下实验。一个标准1ml反应体系中包含:50mmol/lpbs缓冲液(ph7.0),25μmol/l黄素腺嘌呤二核苷酸(fad),10mmol/l还原型辅酶i(nadh),1mmol/l二氯苯酚,300ulnadh:fad黄素还原酶,600ul重组二氯苯酚降解酶tcpa。在37℃恒温反应8h,加入1ml乙腈终止反应。12000rpm离心2min,取上清液过0.22μm有机相滤膜,利用超高效液相色谱(uplc)测定上清液中二氯苯酚残留量。检测方法如下:色谱柱为acquityuplcbehc18柱(2.1×50mm,1.7μm),检测温度为40℃,进样体积为5μl,流速为0.5ml/min,紫外检测波长为300nm,流动相组成为0.1甲酸(a)和乙腈(b)组成。实验结果用一级动力学曲线拟合如图3-图8所示,结果表明,重组二氯苯酚降解酶tcpa可以高效降解全部的6种二氯苯酚。
实施例3cupriavidustaiwanensisx1对2,4-二氯苯酚降解能力测定
从冻存管中挑取1环cupriavidustaiwanensisx1菌液于lb固体培养基进行活化,待长出单菌落后,挑取单菌落接种于100mllb液体培养基,37℃恒温震荡培养12h。5000rpm室温离心10min收集菌体并用无机盐液体培养基(1.0g/l氯化钠,0.1g/l七水合硫酸镁,0.3g/l磷酸二氢钾,1g/l磷酸氢二钾,ph7.0)重悬洗涤2次后,用无机盐液体培养基定容至od600nm为0.8。1个标准20ml反应体系中包含:4mg2,4-二氯苯酚,1mlod600nm为0.8的x1菌液,其用无机盐液体培养基补齐至总体积20ml。在37℃恒温反应24h,加入1ml乙腈终止反应。12000rpm离心2min,取上清液过0.22μm有机相滤膜,利用超高效液相色谱测定上清液中2,4-二氯苯酚残留量。结果表明,108cfu能够将约4mg2,4-二氯苯酚在24h完全降解。
虽然,上文中已经用一般性说明及具体实施方案对本发明作了详尽的描述,但在本发明基础上,可以对之做一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
序列表
<110>安徽农业大学
<120>二氯苯酚降解酶tcpa及其编码基因与生产菌的应用
<130>pi201810531
<160>4
<170>siposequencelisting1.0
<210>1
<211>1554
<212>dna
<213>台湾嗜铜菌(cupriavidustaiwanensis)
<400>1
atgattcgcactggcaagcagtacctggaatcgctcaacgacggccgcaacgtatgggta60
ggcaacgagaagatcgacaacgtcgcaacgcaccccaagacacgggactacgcgcagcgc120
cacgccgatttctacgacctgcaccatcgccccgacctgcaggatgtgatgaccttcgtc180
gacaccgacggcgaacgccgcaccatgcaatggttcggccacttcgacaaggagcagctg240
cgccgcaagcgtaagtaccacgagaccatcatgcgcgagatggccggcgcttcgttcccg300
cgcacaccggacgtcaacaactacgtgctccagacctacatcgacgatccgtcgccgtgg360
gaaacgcagactatcggcgctgagggcaagatcaaggcaaagaacatcgtcgacttcgtc420
aacttcgccaagcagcatgacctgaactgtgcgccgcagttcgtcgacccgcagatggac480
cgctcgaaccccgatgcccagcagcgctcgcccgggctgcgcgtgatcgagaagaacgac540
aagggcatcgtcgtgtcaggtgtcaaggcggtcggcaccggcgtcgcctttgccgactgg600
atccacatcggggtgtttttccgccccggcctcccgggcgaccagatcatttttgccgcc660
accccggtcaacaccccgggcgtgaccatcgtctgccgcgagagcgtggtcaaggacgat720
cccatcgagcatccgctcgcctcacagggcgacgaactggacggcatgactgtattcgag780
aatgtcttcatcccctggtcgcacgtgttccacctaggcaaccccgaacacgccaagctc840
tacccgcagcgagtgttcgactgggtgcactatcacgccctcatccgccagtcggtgcgc900
gccgaactgatggccggcctggcgatcctgatcaccgagcatatcggcaccaacaagatt960
cccgcagtgcagactcgcgtggccaagctgatcggctttcaccaggccatgctggcgcac1020
atcgtcgccagcgaggaactgggcttccatacgcctgggggcgcctataagccgaacatc1080
ctcatctacgacttcggccgcgcgctatacctcgagaacttctcggagatgatctacgat1140
ctggtcgacctctccgggcgcagcgcactgatctttgccagcgaggaccagtggaacgac1200
aagaccctgcatggttggttcgagcgcatgaacaacggcccagtcggcaagccgcacgac1260
cgcgtgaagatcggtcgcgtgatccgcgacctgttcctgaccgactggggcaaccggctg1320
ttcgtcttcgagaacttcaatggcaccccgctgcagaccatccgcatgctgaccatgcag1380
cgcgccgagttctccgcagccggtccgtactgcaccctggcccgcaaggtctgcggcatc1440
gagctcaccgaggtccacgagagcgaatacaaggccaccgccggctacgcccaggcactg1500
gattcggcgcgacaccaggaaaagctcgcgctgagcggcacgatgaccgtatga1554
<210>2
<211>517
<212>prt
<213>台湾嗜铜菌(cupriavidustaiwanensis)
<400>2
metileargthrglylysglntyrleugluserleuasnaspglyarg
151015
asnvaltrpvalglyasnglulysileaspasnvalalathrhispro
202530
lysthrargasptyralaglnarghisalaaspphetyraspleuhis
354045
hisargproaspleuglnaspvalmetthrphevalaspthraspgly
505560
gluargargthrmetglntrppheglyhispheasplysgluglnleu
65707580
argarglysarglystyrhisgluthrilemetargglumetalagly
859095
alaserpheproargthrproaspvalasnasntyrvalleuglnthr
100105110
tyrileaspaspproserprotrpgluthrglnthrileglyalaglu
115120125
glylysilelysalalysasnilevalaspphevalasnphealalys
130135140
glnhisaspleuasncysalaproglnphevalaspproglnmetasp
145150155160
argserasnproaspalaglnglnargserproglyleuargvalile
165170175
glulysasnasplysglyilevalvalserglyvallysalavalgly
180185190
thrglyvalalaphealaasptrpilehisileglyvalphephearg
195200205
proglyleuproglyaspglnileilephealaalathrprovalasn
210215220
thrproglyvalthrilevalcysarggluservalvallysaspasp
225230235240
proilegluhisproleualaserglnglyaspgluleuaspglymet
245250255
thrvalphegluasnvalpheileprotrpserhisvalphehisleu
260265270
glyasnprogluhisalalysleutyrproglnargvalpheasptrp
275280285
valhistyrhisalaleuileargglnservalargalagluleumet
290295300
alaglyleualaileleuilethrgluhisileglythrasnlysile
305310315320
proalavalglnthrargvalalalysleuileglyphehisglnala
325330335
metleualahisilevalalaserglugluleuglyphehisthrpro
340345350
glyglyalatyrlysproasnileleuiletyrasppheglyargala
355360365
leutyrleugluasnpheserglumetiletyraspleuvalaspleu
370375380
serglyargseralaleuilephealasergluaspglntrpasnasp
385390395400
lysthrleuhisglytrpphegluargmetasnasnglyprovalgly
405410415
lysprohisaspargvallysileglyargvalileargaspleuphe
420425430
leuthrasptrpglyasnargleuphevalphegluasnpheasngly
435440445
thrproleuglnthrileargmetleuthrmetglnargalagluphe
450455460
seralaalaglyprotyrcysthrleualaarglysvalcysglyile
465470475480
gluleuthrgluvalhisgluserglutyrlysalathralaglytyr
485490495
alaglnalaleuaspseralaarghisglnglulysleualaleuser
500505510
glythrmetthrval
515
<210>3
<211>29
<212>dna
<213>人工序列(artificialsequence)
<400>3
cggaattcatgattcgcactggcaagcag29
<210>4
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>4
cccccaagctttacggtcatcgtgccgctca31
- 还没有人留言评论。精彩留言会获得点赞!