一种抑制猪流行性腹泻病毒感染的多肽及应用的制作方法
本发明涉及病毒学、生物信息学和细胞生物学领域,特别是涉及一种抑制猪流行性腹泻病毒(porcineepidemicdiarrheavirus,pedv)感染的多肽及其应用。
背景技术:
猪流行性腹泻(porcineepidemicdiarrhea,ped)是一种高度接触性猪肠道传染病,以发病猪呕吐、水样腹泻、脱水为主要特征。ped对各年龄阶段的猪都会造成影响,尤其对7日龄以内的哺乳仔猪具有高致死性,病死率高达100%。ped已对我国养猪业造成巨大的经济损失,成为制约国内养猪业健康发展的传染病之一。ped病原猪流行性腹泻病毒(pedvirus,pedv)是一种具有囊膜的单股正链rna病毒,属于套式病毒目(nidovirales)冠状病毒科(coronaviridae)α-型冠状病毒属(alphacoronavirus),具有特征性的冠状病毒囊膜“纤突”结构。其中,pedv纤突糖蛋白(spikeglycoprotein,s)含有保守的七价重复1区(heptadrepeat1,hr1)和七价重复2区(heptadrepeat2,hr2)。hr1和hr2最终形成融合中心(fusioncore)完成病毒囊膜与宿主细胞靶膜融合这一关键过程,发挥着重要的致病和免疫学功能。虽然已有针对其他冠状病毒hr2的抗病毒学研究,但是基于pedvhr2抗病毒感染尚有待全面阐明。
技术实现要素:
针对现有研究的不足,本发明的目的是提供一种抑制猪流行性腹泻病毒感染的多肽及应用。
为了实现上述目的,本发明所采用的技术方案是:
一种抑制猪流行性腹泻病毒感染的多肽,其氨基酸序列为:natylnltgeiadleqrseslrntteelqsliyninntlvdl。
以所述多肽序列为核心,任何对所述多肽序列的优化、修饰,包括对多肽片段的截短。
一种多肽在制备猪流行性腹泻抗病毒疫苗和药物中的应用。
本发明根据生物信息学预测pedvhr2,通过氨基酸序列比对设计了基于hr2的衍生多肽并进行合成。本发明利用合成的hr2衍生多肽对pedv感染宿主小肠上皮细胞ipec-j2过程进行抑制;通过荧光定量pcr鉴定,合成多肽具有抑制病毒感染宿主细胞的作用,可应用于抗pedv感染。
本发明有益效果:
1、本发明综合利用病毒学、生物信息学和细胞生物学等技术,提供了一种抑制pedv感染的多肽,利用本发明所述的合成多肽可抑制pedv感染宿主细胞;
2、本发明提供的多肽信息丰富了pedvfusioncore功能,为后续研究pedv膜融合机制提供参考;
3、本发明提供的多肽可应用于制备pedv抗病毒疫苗和药物。
附图说明
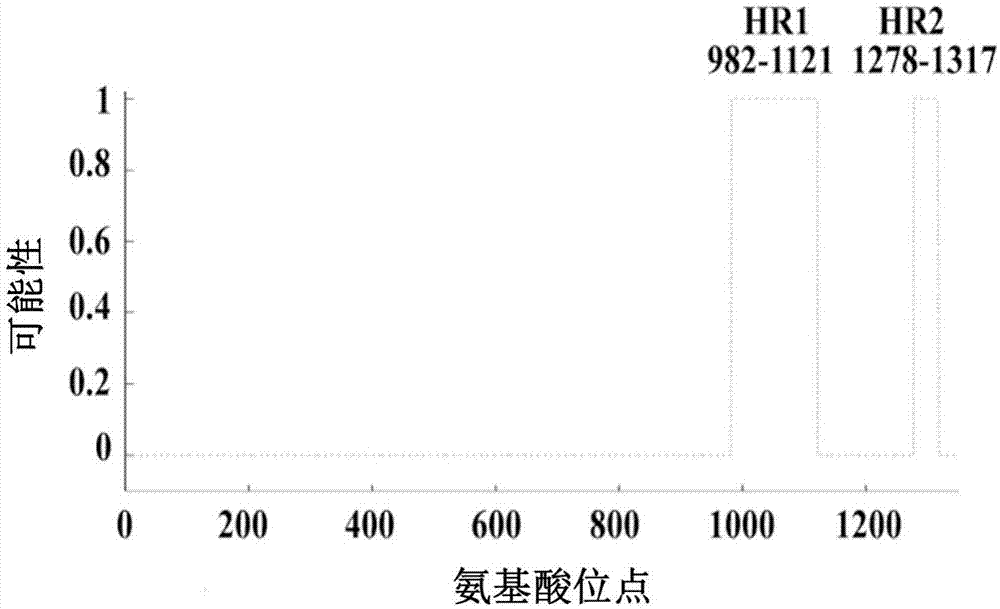
图1是pedvhr1和hr2预测情况。
图2是pedvhr1和hr2氨基酸序列示意图。
图中,pedv氨基酸序列在上,hcov-nl63氨基酸序列在下;氨基酸序列第982位至第1121位、第1278位至第1317位分别代表预测的hr1和hr2(窄框),第1005位至第1061位、第1273位至第1314位分别代表设计的hr1和hr2衍生多肽(宽框)。
图3是pedvhr1和hr2衍生多肽特征分析情况。
图中,七价重复氨基酸残基位置可用a、b、c、d、e、f和g表示,其中a和d位置的氨基酸残基为疏水性氨基酸或含有很大侧链的氨基酸。
图4是hr1和hr2合成衍生多肽抑制pedv感染宿主细胞情况。
图中,ns表示p>0.05,***表示p<0.001。
具体实施方式
以下结合实施例对本发明的具体实施方式作进一步详细说明。
实施例1.pedvhr2预测
通过在线软件learncoil-vmf(http://night-ingale.lcs.mit.edu/cgi-bin/vmf)对pedvch/hubei/2016毒株s蛋白的hr1和hr2进行预测。learncoil-vmf软件识别典型的hr特征,即在hr1和hr2中大约各自有3~4个七价重复,每个重复都从亮氨酸或异亮氨酸开始。结果如图1所示,pedvs蛋白预测的hr1和hr2分别位于第982-1121位氨基酸和第1278-1317位氨基酸。
实施例2.pedvhr2衍生多肽设计
参考fusioncore晶体结构已经解析的人冠状病毒nl63(hcov-nl63)hr1和hr2氨基酸序列(图2,宽框),对pedvhr1和hr2衍生多肽进行设计,最终分别选取第1005-1061位氨基酸和第1273-1314位氨基酸作为hr1和hr2衍生多肽序列,氨基酸序列分别为saignitsafesvkeaisqtskglntvahaltkvqevvnsqgaaltqltvqlqhnfq(seqidno.1)和natylnltgeiadleqrseslrntteelqsliyninntlvdl(seqidno.2)。经分析,其氨基酸组成符合冠状病毒七价重复特征,即一组整齐排列的七价重复氨基酸残基,其残基位置可用a、b、c、d、e、f和g表示,其中a和d位置的氨基酸残基为疏水性氨基酸或含有很大侧链的氨基酸(图3)。将hr1和hr2衍生多肽交由上海吉尔生化有限公司合成,纯度均大于95%。
实施例3.pedvhr2衍生多肽抑制pedv感染宿主细胞
3.1pedvhr2衍生多肽抑制pedv增殖
将pedv宿主小肠上皮细胞ipec-j2按2×105个/ml,500μl/孔铺设24孔板,于37℃co2培养箱中培养24h。使用无血清dmem培养基(美国gibco公司)分别稀释pedvch/hubei/2016毒株和hr1、hr2合成衍生多肽,病毒感染复数(moi)为1,合成衍生多肽终浓度为0.1-1000nm,以只含病毒和二甲基亚砜(dmso)的dmem培养基为对照。将moi=1的病毒和终浓度为0.1-1000nm的合成衍生多肽混匀后,37℃放置1h。使用pbs洗板3遍,每孔加入500μl混合液,每组处理细胞设置三个重复孔。37℃孵育1h后,pbs洗板3遍,洗去没有与ipec-j2细胞结合的病毒和合成衍生多肽,加入500μl细胞维持液(含100u/ml青霉素,100μg/ml链霉素,质量分数0.3%胰蛋白胨磷酸盐肉汤和质量分数0.03%酵母浸出粉的dmem培养基),37℃培养12h。弃去上清,收集细胞,通过荧光定量pcr方法检测细胞内感染病毒的含量。该实验独立重复三次。
3.2荧光定量pcr检测pedvhr2衍生多肽抑制pedv感染宿主细胞
使用rna提取试剂trizol(美国invitrogen公司)提取pedv感染细胞的总rna,使用primescripttm反转录试剂盒(takara公司)生成互补dna(cdna)作为荧光定量pcr模板。采用相对荧光定量pcr对感染细胞内的病毒含量进行测定,以pedv核衣壳蛋白(n)mrna含量表示病毒的含量,以3-磷酸甘油醛脱氢酶(gapdh)为内参,采用2-δδct法对数据进行分析。引物和反应体系见表1和表2,反应程序使用abi荧光定量pcr仪自带fast测序(美国appliedbiosystems公司)。
表1相对荧光定量pcr引物序列
表2相对荧光定量pcr反应体系
实验数据以组平均值和均值标准误差(sem)表示,统计学分析利用origin软件非配对双尾studentt检验进行。p>0.05为无统计学差异,p<0.05为有统计学差异,p<0.01为有显著统计学差异,p<0.001为有极其显著的统计学差异。
结果如图4显示,0.1-1000nmhr1合成衍生多肽均没有明显抑制作用,而hr2合成衍生多肽即使在0.1nm低浓度下也能够显著降低细胞内病毒的含量,表明hr2合成衍生多肽具有抑制病毒感染宿主细胞的作用。
以上所述仅为本发明较佳的实施例,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
序列表
<110>河南省农业科学院
<120>一种抑制猪流行性腹泻病毒感染的多肽及应用
<160>6
<170>siposequencelisting1.0
<210>1
<211>57
<212>prt
<213>猪流行性腹泻(porcineepidemicdiarrheavirus)
<400>1
seralaileglyasnilethrseralaphegluservallysgluala
151015
ileserglnthrserlysglyleuasnthrvalalahisalaleuthr
202530
lysvalglngluvalvalasnserglnglyalaalaleuthrglnleu
354045
thrvalglnleuglnhisasnphegln
5055
<210>2
<211>42
<212>prt
<213>猪流行性腹泻(porcineepidemicdiarrheavirus)
<400>2
asnalathrtyrleuasnleuthrglygluilealaaspleuglugln
151015
argsergluserleuargasnthrthrglugluleuglnserleuile
202530
tyrasnileasnasnthrleuvalaspleu
3540
<210>3
<211>22
<212>dna
<213>人工序列()
<400>3
cgcaaagactgaacccactaac22
<210>4
<211>24
<212>dna
<213>人工序列()
<400>4
ttgcctctgttgttacttggagat24
<210>5
<211>23
<212>dna
<213>人工序列()
<400>5
ccttccgtgtccctactgccaac23
<210>6
<211>22
<212>dna
<213>人工序列()
<400>6
gacgcctgcttcaccaccttct22
- 还没有人留言评论。精彩留言会获得点赞!