分子条码化的制作方法
相关申请
本申请要求2017年5月23日提交的美国临时申请62/510,095的权益,该申请通过引用整体并入本文。
关于通过efs-web以ascii文本文件形式提交的“序列表”
根据37c.f.r.§§1.821-1.825,在机型ibm-pc,ms-windows操作系统上,创建于2018年3月8日的2,423字节的文件seq_094868-1081968-113210pc_st25.txt的序列表通过引用全文纳入本文用于所有目的。
背景技术:
下一代测序技术可以从相对较小的样品(例如来自单细胞的核酸(例如,mrna)样品)提供大量的序列信息。然而,可能难以提取关于样品中核酸的绝对或相对丰度的定量信息。在一些情况下,将独特的分子标识符(umi)(例如独特的寡核苷酸条码(barcode)序列)连接到靶核酸,并在测序过程中检测此类umi,可以估计样品中靶核酸的绝对或相对丰度。
发明概述
在一个方面,本发明提供了一种用于产生包含带独特标签的靶核酸分子的反应混合物的方法,该方法包括:(a)将多个可变长度条码标签共价连接至多个靶核酸分子的第一端(所述可变长度条码标签由一个或多个核酸序列的0-10个核苷酸组成),从而所述多个中的个体靶核酸分子包含单个可变长度条码标签,并且所述多个包含至少5个不同的可变长度条码标签长度和/或序列;和(b)使靶核酸分子与多种转座酶接触,从而在所述多个中的个体靶核酸分子的第二端引入转座酶片段化位点和共价连接的转座子端,由此产生多个带独特标签的靶核酸分子,其中所述多个中的个体带独特标签的靶核酸分子包含:(i)位于第一端的可变长度条码标签;和(ii)位于第二端的转座酶片段化位点和转座子端,其中,所述多个中的带独特标签的个体靶核酸分子中的(i)与(ii)的组合一起包含独特分子条码,其相对于反应混合物中的所述多个中的、具有所述可变长度条码标签和所述转座酶片段化位点之间至少25个连续核苷酸的相同序列的所有其它带独特标签的个体靶核酸分子而言是独特的。在一些实施方式中,反应混合物包含具有不同序列的至少1,000个靶核酸分子。
在一些实施方式中,共价连接多个可变长度条码标签包括将包含可变长度条码标签的多个引物与包含至少部分靶核酸分子序列的多个核酸分子杂交,并用聚合酶延伸所述引物,由此产生多个双链可变长度条码标签化的靶核酸分子。在一些实施方式中,共价连接多个可变长度条码标签包括将可变长度条码标签连接至所述多个中的靶核酸分子。
在一些实施方式中,所述多个核酸分子包含mrna,并且所述聚合酶是rna依赖性dna聚合酶。在另一个实施方式中,所述多个核酸分子包含mrna,并且包含可变长度条码标签的所述多个引物包含3'寡-dt端。
在一些实施方式中,靶核酸分子的第一端包含多聚a区域。在另一个实施方式中,带独特标签的靶核酸分子的第一端包含多聚a区域和/或多聚t区域。在一些实施方式中,可变长度条码标签是多聚a区域的3'和/或多聚t区域的5'。
在一些实施方式中,该方法包括在步骤(a)之后和步骤(b)之前,形成带可变长度条码标签的双链靶核酸分子,其包含与反向互补第二dna链杂交的第一dna链。在另一个实施方式中,带可变长度条码标签的双链靶核酸分子包含双链靶cdna分子。
在一些实施方式中,带可变长度条码标签的双链靶核酸分子包含带可变长度条码标签的靶基因组dna分子。在一些实施方式中,该方法包括,通过以下方式产生带可变长度条码标签的靶基因组dna分子:使包含可变长度条码标签和基因组dna靶向区域的多个第一引物与包含至少部分靶核酸分子序列的多个基因组dna分子杂交,和,用dna依赖性dna聚合酶延伸所述引物,由此产生所述带可变长度条码标签的靶基因组dna分子。在一些实施方式中,该方法包括扩增带可变长度条码标签的靶基因组dna分子。
在一个方面,本发明提供了一种形成双链靶cdna分子的方法,该方法通过如下方式进行:(i)使多个个体引物与多个mrna分子杂交,其中所述个体引物包含可变长度条码标签,和,用rna依赖性dna聚合酶延伸所述引物,由此产生多个双链mrna:cdna杂合体,其包含与mrna分子杂交的第一链cdna分子;(ii)使所述mrna:cdna杂合体与含rna酶h活性的酶接触,由此产生与第一链cdna分子杂交的mrna片段;和(iii)使所述mrna片段与dna依赖性dna聚合酶接触,由此在模板导向的聚合酶反应中延伸所述mrna片段,其中所述模板是第一链cdna多核苷酸,和形成双链靶cdna分子。在一些实施方式中,该方法包括使双链靶cdna分子与连接酶接触。
在一些实施方式中,rna依赖性dna聚合酶包含rna酶h活性。在一些实施方式中,该方法包括使所述mrna:cdna杂合体与具有rna酶h活性的酶接触,并在rna依赖性dna聚合酶存在下孵育所述mrna:cdna杂合体,由此产生与第一链cdna分子杂交的mrna片段。在一些实施方式中,使mrna:cdna杂合体与包含rna酶h活性的酶接触包括使所述mrna:cdna杂合体与结构上不同于rna依赖性dna聚合酶的酶接触。
在一些实施方式中,包括步骤(i)和(ii)的、产生包含带独特标签的核酸分子的反应混合物的方法一起包含用于个体靶核酸分子序列的独特分子标识符,并且多个带独特标签的个体靶核酸分子不包含任何其它独特分子标识符。在一些实施方式中,多个带独特标签的个体靶核酸分子包含细胞条码。在一些实施方式中,多个带独特标签的个体靶核酸分子是cdna,并且细胞条码是多聚a区域的3'和/或多聚t区域的5'。
在一些实施方式中,步骤(a)在反应混合物中进行,其中靶核酸分子来自单细胞。在一些实施方式中,步骤(a)和(b)在反应混合物中进行,其中靶核酸分子来自单细胞。在一些实施方式中,步骤(b)在反应混合物中进行,其中靶核酸分子来自至少10个细胞。在另一个实施方式中,步骤(b)在反应混合物中进行,其中靶核酸分子来自约50至约500个细胞。在一个实施方式中,步骤(b)在反应混合物中进行,其中靶核酸分子来自约10至约5000个细胞。在另一个实施方式中,步骤(b)在反应混合物中进行,其中靶核酸分子来自约10至约10000个细胞。
在一些实施方式中,可变长度条码标签由单个核酸序列的0-10个核苷酸组成,其中可变长度条码标签的至少部分包含至少1个核苷酸。
在另一个实施方式中,可变长度条码标签由0-5个核苷酸组成,其中可变长度条码标签的至少部分包含至少1个核苷酸。
在一些实施方式中,进行方法步骤(a),然后对在方法步骤(a)中产生的多个双链带可变长度条码标签的靶核酸分子进行步骤(b),包括或不包括中间扩增步骤。
在一些实施方式中,转座子端包含:从5’至3’,gtctcgtgggctcgg(seqidno:2)或从5’至3’,tcgtcggcagcgtc(seqidno:3)。
在一些实施方式中,转座子端包含,从5’至3’,agatgtgtataagagacag(seqidno:4)。
在一些实施方式中,转座子端包含,从5’至3’,tcgtcggcagcgtcagatgtgtataagagacag(seqidno:5)。
在一些实施方式中,转座子端包含,从5’至3’,gtctcgtgggctcggagatgtgtataagagacag(seqidno:6)。
在一些实施方式中,该方法进一步包括在步骤(b)之后,扩增带独特标签的靶核酸分子,所述带独特标签的靶核酸分子在第一端具有可变长度条码标签并且在第二端具有转座酶片段化位点和转座子端。在一些实施方式中,扩增采用热启动dna依赖性dna聚合酶进行。在一些实施方式中,扩增在使聚合酶介导的核酸延伸基本上在初始变性步骤之后发生的条件下进行。
在一个方面,本发明提供了一种估计反应混合物中靶核酸分子数量的方法,该方法包括:(a)提供所述反应混合物,其中所述反应混合物包含多个带独特标签的靶核酸分子,所述带独特标签的靶核酸分子包含:(i)位于第一端的可变长度条码标签;和(ii)位于第二端的转座酶片段化位点和转座子端;和,其中(i)和(ii)的组合一起包含独特分子条码,在所述反应混合物中,所述独特分子条码相对于具有可变长度条码标签和转座酶片段化位点之间的至少25个连续核苷酸的相同序列的所有其它带独特标签的靶核酸分子而言是独特的;(b)获得多个序列读数,其中所述序列读数包含以下中的一种或多种:可变长度条码标签的序列,可变长度条码标签和转座酶片段化位点之间的靶核酸的部分的序列,和,片段化位点的序列;和(c)对具有所述可变长度条码标签和转座酶片段化位点之间的至少25个连续核苷酸的相同序列,但不同可变长度条码标签和/或转座酶片段化位点的靶核酸分子的数量进行计数,由此估计所述反应混合物中靶核酸分子的数量。
在一些实施方式中,根据本文公开的任何方法进行估计反应混合物中的靶核酸分子数量的方法。
在一些实施方式中,估计反应混合物中的靶核酸分子数量的方法还包括在步骤(a)之后和步骤(b)之前,扩增在第一端具有可变长度条码标签的靶核酸分子。
在一个方面,本发明提供了一种反应混合物,其包含多个带独特标签的靶核酸分子,其中所述多个带独特标签的靶核酸分子包含:(i)位于第一端的可变长度条码标签;和(ii)位于第二端的转座酶片段化位点和转座子端;和,其中(i)和(ii)的组合一起包含独特分子条码,在所述反应混合物中,所述独特分子条码相对于具有可变长度条码标签和转座酶片段化位点之间的相同序列的所有其它带独特标签的靶核酸分子而言是独特的。
在一些实施方式中,反应混合物包含至少10个不同的带独特标签的靶核酸分子。在一些实施方式中,反应混合物包含10至1000个不同的带独特标签的靶核酸分子,其中不同的带独特标签的靶核酸分子包含来自单细胞的mrna转录物。在一些实施方式中,反应混合物包含10至2000个不同的带独特标签的靶核酸分子,其中不同的带独特标签的靶核酸分子包含来自单细胞的mrna转录物。在一些实施方式中,反应混合物包含10至5000个不同的带独特标签的靶核酸分子,其中不同的带独特标签的靶核酸分子包含来自单细胞的mrna转录物。在一些实施方式中,反应混合物包含至少10个不同的带独特标签的靶核酸分子,其中不同的带独特标签的靶核酸分子包含来自单细胞的独特mrna转录物。在一些实施方式中,反应混合物包含10至5000个不同的带独特标签的靶核酸分子,其中不同的带独特标签的靶核酸分子包含来自多个细胞的独特mrna转录物。在一些实施方式中,反应混合物包含10至10000个不同的带独特标签的靶核酸分子,其中不同的带独特标签的靶核酸分子包含来自多个细胞的独特mrna转录物。在一些实施方式中,反应混合物包含流体分区(fluidpartition)。在一些实施方式中,反应混合物包含液滴。在一些实施方式中,反应混合物包含来自乳液的液滴,所述乳液例如但不限于油包水乳液。在另一个实施方式中,反应混合物包含多个液滴,任选地,其中每个液滴包含0至5000个不同的带独特标签的靶核酸分子。在另一个实施方式中,反应混合物包含多个流体分区,其中所述流体分区中的一个或多个包含10至1000个不同的带独特标签的靶核酸分子,其中不同的带独特标签的靶核酸分子包含来自单细胞的独特mrna转录物。在一些实施方式中,反应混合物还包含带独特标签的靶核酸分子的扩增产物。
在一个方面,本发明提供一种计算机程序产品,其包括存储程序代码的非暂时性机器可读介质,所述程序代码在由计算机系统的一个或多个处理器执行时使计算机系统实现一种用于估计反应混合物中靶核酸分子的数量的方法,采用:(a)靶核酸的序列;和(i)位于靶核酸的第一端的可变长度条码标签;和(ii)位于靶核酸的第二端的转座酶片段化位点和转座子端,以鉴定和估计反应混合物中靶核酸的个体分子的数量,所述程序代码包括:用于获得多个扩增的多核苷酸的读数的代码,其中所述多个扩增的多核苷酸是通过扩增反应混合物中这样的核酸片段而获得的,所述核酸片段包含位于第一端的可变长度条码标签;和(ii)位于第二端的转座酶片段化位点和转座子端;用于在可变长度条码标签和转座酶片段化位点的组合中识别多个物理独特分子标识符(umi)的代码;和用于对具有独特分子标识符的靶核酸分子的数量进行计数的代码。
附图简要说明
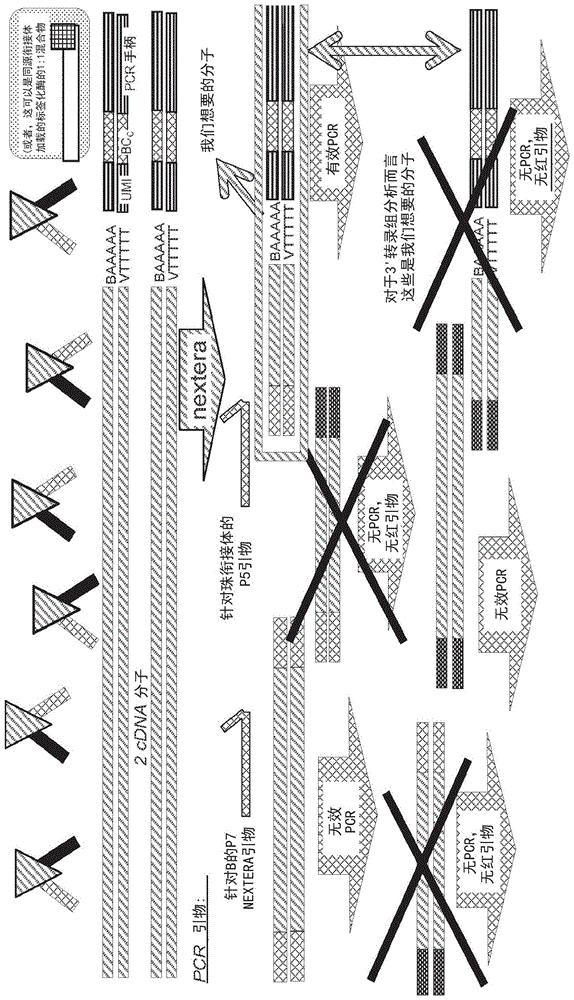
图1说明了产生cdna片段的方法和组合物,该cdna片段在一端具有由转座酶引入的转座子端,而在第二端具有独特分子标识符(umi)条码,其中第二端包含多聚a和多聚t区域。所示的cdna片段还包含位于第二端的细胞条码(bcc)和pcr“手柄”(pcr引物结合位点),以及位于第一端的由转座酶引入的相容的pcr引物结合位点。
图2显示了用于分析图1所示的cdna片段的文库的序列读数的方法。
图3显示在单个人细胞(左),小鼠细胞(右)和包含人和小鼠核酸的混合物的样品(中央)中发现的转录物拷贝数的直方图分析。
图4说明了本发明的一个实施方式,其中在通过多聚t引物延伸和转座酶介导的片段化产生的cdna片段中不存在umi条码。转座酶片段化位点的可变位置可提供条码多样性。
图5显示了用于分析图4所示的cdna片段的文库的序列读数的方法。
图6显示了使用具有0-5个核苷酸的可变长度条码标签(seqidno:1)来将由转座酶片段化提供的独特标识符的数目增加6倍。保守地估计,可变长度条码标签和转座酶片段化位点的可变位置的组合可提供至少1,000个独特分子标识符。
图7列出了图4-6中概述的方法的几个优点。
定义
除非另有说明,本文所用的所有科技术语具有本发明所属领域普通技术人员通常所理解的含义。通常,本文所用的命名和下述细胞培养、分子遗传学、有机化学和核酸化学以及杂交中的实验室步骤均为本领域熟知和常用的。使用标准技术进行核酸和肽合成。按照本领域和各种通用参考文献所述的常规方法进行这些技术和步骤(通常参见,sambrook等,《分子克隆:实验室手册》(molecularcloning:alaboratorymanual),第2版(1989)冷泉港实验室出版社(coldspringharborlaboratorypress),纽约冷泉港(coldspringharbor,n.y.),其通过引用纳入本文),全文中提供这些参考文献。本文所用的命名以及下述分析化学和有机合成中的实验室步骤均为本领域熟知且常用。
术语“扩增反应”指用于以线性或指数方式倍增核酸靶序列拷贝的各种体外方法。这类方法包括但不限于双引物方法,例如聚合酶链反应(pcr);连接酶方法,例如dna连接酶链式反应(参见美国专利号4,683,195和4,683,202,《pcr方案:方法和应用指南》(pcrprotocols:aguidetomethodsandapplications)(innis等编,1990))(lcr);基于qbetarna复制酶和基于rna转录的扩增反应(例如,涉及t7、t3或sp6引导的rna聚合),例如转录扩增系统(tas),基于核酸序列的扩增(nsaba),和自主维持序列复制(3sr);等温扩增反应(例如,单引物等温扩增(spia));以及本领域技术人员已知的其它方法。
“扩增”指将溶液置于足以扩增多核苷酸的条件下的步骤(如果反应的所有组分是完整的)。扩增反应的组分包括,例如,引物、多核苷酸模板、聚合酶、核苷酸等。术语“扩增”通常指靶核酸的“指数型”增长。然而,本文所用的“扩增”也可指核酸的选择靶序列数量的线性增长,如由循环测序或线性扩增所得。在一个示例性实施方式中,扩增是指使用第一和第二扩增引物的pcr扩增。
术语“扩增反应混合物”指包含用于扩增靶核酸的各种试剂的水性溶液。这些试剂包括酶、水性缓冲剂、盐、扩增引物、靶核酸和三磷酸核苷。扩增反应混合物还可包含稳定剂和其它添加剂以优化效率和特异性。根据上下文,该混合物还可以是完整或不完整的扩增反应混合物。
“聚合酶链式反应”或“pcr”是指靶双链dna的特定区段或子序列得以几何级数式扩增的一种方法。pcr是本领域技术人员所熟知的;参见例如,美国专利号4,683,195和4,683,202;和《pcr方案:方法和应用指南》,innis等编,1990。示例性pcr反应条件一般包括两步或三步循环。两步循环具有变性步骤,之后是杂交/延伸步骤。三步循环包括变性步骤,之后是杂交步骤,之后是独立的延伸步骤。
“引物”指与靶核酸上的序列杂交并且用作核酸合成的起始点的多核苷酸序列。引物可以是各种长度的并且通常长度小于50个核苷酸,例如长度为12-30个核苷酸。可基于本领域技术人员已知的原理设计用于pcr的引物的长度和序列,参见例如innis等(同上)。引物可以是dna、rna或dna部分与rna部分的嵌合体。在一些情况中,引物可包括一个或多个带修饰或非天然的核苷碱基。在一些情况中,引物被标记。
核酸或其部分与另一核酸“杂交”的某些条件使得生理缓冲液(例如,ph6-9,25-150mm盐酸盐)中限定温度下的非特异性杂交最少。在一些情况中,核酸或其部分与一组靶核酸之间共有的保守序列杂交。在一些情况中,如果包括与超过一个核苷酸伴侣互补的“通用”核苷酸在内有至少约6、8、10、12、14、16或18个连续的互补核苷酸,引物或其部分能杂交至引物结合位点。或者,如果在至少约12、14、16、18或20个连续核苷酸上有0或少于2或3个互补错配,则引物或其部分能杂交至引物结合位点。在一些实施方式中,发生特异性杂交的限定温度是室温。在一些实施方式中,发生特异性杂交的限定温度高于室温。在一些实施方式中,发生特异性杂交的限定温度为至少约37、40、42、45、50、55、60、65、70、75或80℃。在一些实施方式中,发生特异性杂交的限定温度为37、40、42、45、50、55、60、65、70、75或80℃。
“模板”指包含待扩增、邻近引物杂交位点或侧接一对引物杂交位点的多核苷酸的多核苷酸序列。因此,“靶模板”包含毗邻引物的至少一个杂交位点的靶多核苷酸序列。在一些情况中,“靶模板”包含侧接有“正向”引物和“反向”引物的杂交位点的靶多核苷酸序列。
本文所用的“核酸”表示dna、rna、单链、双链、或更高度聚集的杂交基序及其任意化学修饰。修饰包括但不限于,提供引入其它电荷、极化性、氢键、静电相互作用、与核酸配体碱基或核酸配体整体的连接点和作用点的化学基团的那些修饰。这类修饰包括但不限于,肽核酸(pna)、磷酸二酯基团修饰(例如,硫代磷酸酯、甲基膦酸酯)、2'-位糖修饰、5-位嘧啶修饰、8-位嘌呤修饰、环外胺处的修饰、4-硫尿核苷的取代、5-溴或5-碘-尿嘧啶的取代、骨架修饰、甲基化、不常见的碱基配对组合如异碱基(isobases)、异胞苷和异胍(isoguanidine)等。核酸也可包含非天然碱基,如硝基吲哚。修饰还可包括3'和5'修饰,包括但不限于用荧光团(例如,量子点)或其它部分加帽。
“聚合酶”是指能进行模板引导的多核苷酸(例如,dna和/或rna)合成的酶。该术语同时包括全长多肽和具有聚合酶活性的结构域。dna聚合酶是本领域技术人员熟知的,包括但不限于分离或衍生自激烈火球菌(pyrococcusfuriosus)、滨海嗜热球菌(thermococcuslitoralis)和海栖热袍菌(thermotogamaritime)的dna聚合酶或其修饰版本。市售可得的聚合酶的其它示例包括但不限于:克列诺(klenow)片段(newengland
聚合酶包括dna依赖性聚合酶和rna依赖性聚合酶,如逆转录酶。已知至少5个dna依赖性dna聚合酶家族,虽然大多数落入a、b和c家族。其它类型dna聚合酶包括噬菌体聚合酶。相似地,rna聚合酶通常包括真核rna聚合酶i、ii和iii,和细菌rna聚合酶以及噬菌体和病毒聚合酶。rna聚合酶可以是dna依赖性和rna依赖性的。
本文所用术语“划分”或“经分区的”指将样品分为多个部分或多个“分区(partition)”。分区通常是实体意义上的,例如,一个分区中的样品不与或基本不与邻近分区中的样品混合。分区可以是固体或流体。在一些实施方式中,分区是固体分区,例如微通道或微孔。在一些实施方式中,分区是流体分区,例如液滴。在一些实施方式中,流体分区(如液滴)是不互溶的流体(如水和油)的混合物。在一些实施方式中,流体分区(如液滴)是水性液滴,其被不互溶的运载体流体(如油)包围。
一些情况下,分区是虚拟(virtual)的。在优选实施方式中,虚拟分区需要一种分子或一组分子的实体性改变,所述改变由此划定就该分子或该组分子而言独特的分区。适于确立或保持虚拟分区的典型实体性改变包括但不限于:核酸条码、可检测标记物等。例如,样品可被物理上划分,且各分区的组分带有分区特异性标识符(例如,核酸条码序列)的标签,从而所述标识符相对于其它分区而言是独特的,但在该分区的组分之间是共有的。然后,可利用分区特异性标识符在涉及物理上划分的物质的合并的下游应用中维持虚拟分区。因此,如果样品是被物理上划分为包含单个细胞的多个分区的细胞样品,那么标识符可在分区被重新合并之后鉴定衍生自单个细胞的不同核酸。
如本文所用,“标签”是指非靶核酸组分,通常是dna,其提供定位(address)与其连接的核酸片段的手段。例如,在优选的实施方式中,标签包含允许对标签所附连的dna进行鉴定,识别和/或分子或生物化学操作的核苷酸序列(例如,通过提供用于退火寡核苷酸的位点和/或独特或分区特异性序列,所述寡核苷酸例如用于通过dna聚合酶延伸的引物,或用于捕获或用于连接反应的寡核苷酸)。将标签连接到dna分子的过程在本文中有时称为“标签化”,并且经历标签化或含有标签的dna被称为“带标签的”(例如,“带标签的dna”)。标签可以是条码,衔接体序列,引物杂交位点或其组合。
如本文所用,“条码”是短核苷酸序列(例如,约1、2、3、4、5、6、7、8、9、10、11或12个核苷酸长),其鉴别与其偶联的分子。条码可用于例如识别反应混合物或分区中的分子。一般而言,相对于其它分区中存在的条码,这样的分区特异性条码应为该分区所独有。例如,含有来自单一细胞的靶rna的分区可以经受逆转录条件,各分区中采用的引物含有不同的分区特异性条码序列,从而将独特“细胞条码”的拷贝纳入各分区的逆转录所得核酸。由此,来自各细胞的核酸可因独特“细胞条码”的存在而与其它细胞的核酸相区分。在一些情况下,细胞条码以存在于与颗粒(例如磁珠)偶联的寡核苷酸上的“颗粒条码”的形式提供,其中颗粒条码由与该颗粒偶联的所有或基本上所有寡核苷酸共有(例如,在它们之间相同或基本相同)。因此,细胞和颗粒条码可存在于分区中、附着于颗粒或结合细胞核酸,以同一条码序列的多个拷贝。相同序列的细胞或颗粒条码可鉴定为衍生自相同细胞、分区或颗粒。此类分区特异性的细胞或颗粒条码可用各种方法产生,这些方法可导致条码偶联至或纳入固相或水凝胶支持物(例如,固体珠或颗粒或水凝胶珠或颗粒)。一些情况中,所述分区特异性的细胞或颗粒条码采用拆分与混合(也称拆分与合并(splitandpool))合成方案来生成。分区特异性条码可以是细胞条码和/或颗粒条码。类似地,细胞条码可以是分区特异性条码和/或颗粒条码。此外,颗粒条码可以是细胞条码和/或分区特异性条码。
其它情况中,条码专一性鉴别其偶联的分子。例如,通过使用各自含有“独特分子标识符”条码的引物进行逆转录。同样在另一些实施例中,可以利用包含各分区所独有的“分区特异性条码”、以及各分子独特的“分子条码”的引物。条码化之后,可以合并分区,并任选地扩增,而保持虚拟分区。因此,例如,可计算包括各条码的靶核酸(例如,逆转录所得的核酸)的存在与否(例如,通过测序),而无需维持实体分区。在一些情况下,独特分子标识符条码由在靶核酸一端带标签的核苷酸的连续序列编码。
在一些情况下,独特分子标识符条码由不连续的序列编码。不连续的umi可在靶核酸的第一端具有条码的部分,并且在靶核酸的第二端具有条码的部分。在一些情况下,umi是不连续的条码,其在靶核酸的第一端包含可变长度条码序列,在第二端包含第二标识符序列。在一些情况下,umi是不连续的条码,其在靶核酸的第一端具有可变长度条码序列,在第二端具有第二标识符序列,其中所述第二标识符序列由转座酶片段化事件的位置确定,例如,转座酶片段化位点和转座子端插入事件。
条码序列的长度可确定可对多少独特的样品进行区分。例如,1个核苷酸条码可以对不多于4个样品或分子进行分区;4个核苷酸条码可以对不多于44(即256)个样品进行分区;6个核苷酸条码可以对不多于4096个不同样品进行分区;而8个核苷酸的条码可以标引不多于65,536个不同样品。另外,条码可以通过针对第一和第二链合成的条码化的引物,通过连接,或在标签化(tagmentation)反应中连接至靶核酸分子(例如,gdna或cdna)的两条链。
在一些情况下,条码是“可变长度条码”。如本文所用,可变长度条码是在长度方面与群体中的其它可变长度条码寡核苷酸不同的寡核苷酸,这可以通过条码中连续核苷酸的数量来鉴别。在一些情况下,除了可变长度之外,还可通过使用可变核苷酸序列来提供可变长度条码的附加条码复杂性,如以上段落中所述。
在一个示例性的实施方式中,可变长度条码的长度可为0至不超过5个核苷酸。这样的可变长度条码可以用术语“[0-5]”表示。在这样的实施方式中,应理解,连接于这种可变长度条码的靶核酸的群体预期包括与具有至少1个核苷酸的可变长度条码相连的至少一个靶核酸(例如,连接于具有仅1个,仅2个,仅3个,仅4个或仅5个核苷酸的可变长度条码)。在这样的实施方式中,还应理解,连接于所述可变长度条码的靶核酸的群体可包括不包含可变长度条码(即,长度为0的可变长度条码)的至少一个靶核酸,和/或包含具有仅1个核苷酸的可变长度条码的至少一个靶核酸,和/或包含具有仅2个核苷酸的可变长度条码的至少一个靶核酸,和/或包含具有仅3个核苷酸的可变长度条码的至少一个靶核酸,和/或包含具有仅4个核苷酸的可变长度条码的至少一个靶核酸,和/或和包含具有仅5个核苷酸的可变长度条码的至少一个靶核酸。在这样的实施方式中,[0-5]可变长度条码可以通过其自身而独特地识别(区分)具有相同序列的5个不同靶核酸分子。此外,在这样的实施方式中,对于每个不同的靶核酸序列,[0-5]可变长度条码可独特地识别(区分)第一序列的5个不同的靶核酸分子,第二序列的5个不同的靶核酸分子等。
可变长度条码的群体通常具有相同数量或基本相同的数量的拥有各长度的寡核苷酸。例如,长度为0-5的可变长度条码的群体可以具有等同比例的拥有各长度的寡核苷酸。还应理解,跳过的(skipped)可变长度条码的群体可以跳过一个或多个长度。仅出于示例性目的,这种“跳过的可变长度条码”可以具有长度为0、1、2、4和5的寡核苷酸,而没有长度为3的寡核苷酸。
通常使用固有不精确的过程来合成和/或聚合(例如,扩增)条码。因此,旨在均一的条码(例如,单个分区、细胞或珠的全部条码化核酸所共有的细胞、颗粒或分区特异性条码)可以相对于范本条码序列包含不同的n-1缺失或其它突变。因此,被称作“相同的”或“基本相同的”的条码是指由于例如合成、聚合或纯化错误中一个或多个错误而导致条码相对范本条码序列含有不同的n-1缺失或其它突变的不同的条码。此外,在使用例如本文所述的拆分与汇集方法和/或核苷酸前体分子等同混合物的合成过程中,条码核苷酸的随机偶联可能导致低概率事件,其中条码并非绝对独特(例如,不同于群体的其它条码,或不同于不同分区、细胞或珠的条码)。但是,这类偏离理论上理想的条码的轻微偏差不会干扰本文所述的高通量测序分析方法、组合物和试剂盒。因此,如本文所用,术语“独特”在涉及颗粒、细胞、分区特异性或分子条码的内容中涵盖偏离理想条码序列的各种非有意的n-1缺失和突变。一些情况中,由于条码合成、聚合和/或扩增所致的不精确性质造成的问题通过对与待区分的条码序列的数量相比进行可能的条码序列的过量采样(oversampling)来克服(例如,至少约2、5、10倍或更多倍的可能的条码序列)。例如,可用具有9个条码核苷酸的细胞条码(代表262,144个可能的条码序列)来分析10,000个细胞。本领域熟知条码技术的应用,参见例如shiroguchi等,procnatlacadsciusa.,2012年1月24日;109(4):1347-52;和smith等,nucleicacidsresearch,2010年7月;38(13)11:e142。使用条码技术的其它方法和组合物包括u.s.2016/0060621中描述的那些。
“转座酶”或“标签化酶(tagmentase)”是指这样的酶,所述酶能够与含转座子端的组合物形成功能性复合物并催化含转座子端的组合物插入或转移到与该组合物在体外转座反应中孵育的双链靶dna中。通常,插入或转座导致靶dna的片段化。
术语“转座子端”是指双链dna,其包含与在体外转座反应中起作用的转座酶形成复合物所必需的核苷酸序列(“转座子端序列”)或由其组成。转座子端形成“复合物”或“突触复合物”或“转座体复合物”或具有转座酶或整合酶的“转座体组合物”,其识别并结合转座子端,并且该复合物能够将转座子端插入或转座到与该复合物在体外转座反应中孵育的靶dna中。转座子端显示两个互补序列,其由“转移的转座子端序列”或“转移的链”和“非转移的转座子端序列”或“非转移的链”组成。例如,一个转座子端与过度活跃的在体外转座反应中有活性的tn5转座酶(例如,ez-tn5tm转座酶,epicentre生物技术公司(epicentrebiotechnologies),美国威斯康星州麦迪逊)形成复合物,其包含显示如下“转移的转座子端序列”的转移的链:
5′agatgtgtataagagacag3′(seqidno:4),
以及显示如下“非转移的转座子端序列”的非转移的链:
5′ctgtctcttatacacatct3′(seqidno:7)。
转移的链的3'端在体外转座反应中接合或转移至靶dna。显示与转移的转座子端序列互补的转座子端序列的非转移的链在体外转座反应中不接合或转移至靶dna。
在另一个例子中,与在体外转座反应中有活性的转座酶形成复合物的转座子端包含显示如下“转移的转座子端序列”的转移的链:
5’-tcgtcggcagcgtcagatgtgtataagagacag–3’(seqidno:5);或
5’-gtctcgtgggctcggagatgtgtataagagacag-3(seqidno:6)。
以及显示如下“非转移的转座子端序列”的非转移的链:
5′ctgtctcttatacacatct3′(seqidno:7)。
在一些实施方式中,含转座子端的组合物包含形成双链核苷酸组合物的非转移的转座子端和转移的转座子端。在一些实施方式中,转座子端包含双链核苷酸组合物,该双链核苷酸组合物具有与转座酶形成功能复合物进而导致转座子端插入在体外转座反应中与之孵育的一个或多个靶核酸分子中所必需的核苷酸序列。在一些实施方式中,对应于转座子端的双链核苷酸组合物包含,从5’至3’,agatgtgtataagagacag(seqidno4)和从5’至3’,ctgtctcttatacacatct(seqidno:7)。在另一实施方式中,对应于转座子端的双链核苷酸组合物包含,从5’至3’,tcgtcggcagcgtcagatgtgtataagagacag(seqidno:5),和从5’至3’,ctgtctcttatacacatct(seqidno:7)。而在另一实施方式中,对应于转座子端的双链核苷酸组合物包含,从5’至3’,gtctcgtgggctcggagatgtgtataagagacag(seqidno:6),和从5’至3’,ctgtctcttatacacatct(seqidno:7)。
在一些实施方式中,转移的链和非转移的链共价连接。例如,在一些实施方式中,转移的和非转移的链序列在单个寡核苷酸上提供,例如以发夹构型提供。因此,尽管非转移的链的游离端不通过转座反应直接与靶dna连接,但非转移的链间接地附连至dna片段,因为非转移的链通过发夹结构的环与转移的链连接。
“转座子端组合体”是指包含转座子端(即,能够与转座酶作用以进行转座反应的最小双链dna区段),任选地加上转移的转座子端序列5′和/或非转移的转座子端序列3′的其它一个或多个序列的组合体。例如,连接于标签的转座子端是“转座子端组合体”。在一些实施方式中,转座子端组合体包含两个转座子端寡核苷酸或由两个转座子端寡核苷酸组成,所述两个转座子端寡核苷酸由“转移的转座子端寡核苷酸”或“转移的链”和“非转移的链端寡核苷酸”或“非转移的链”组成,它们组合显示转座子端的序列,并且其中一条或两条链包含其它序列。
术语“转移的转座子端寡核苷酸”和“转移的链”可互换使用,是指“转座子端”和“转座子端组合体”的转移部分,即无论转座子端是否连接于标签或其它部分。类似地,术语“非转移的转座子端寡核苷酸”和“非转移的链”可互换使用,并且指“转座子端”和“转座子端组合体”的非转移部分。在一些实施方式中,转座子端组合体是“发夹转座子端组合体”。如本文所用,“发夹转座子端组合体”是指由单个寡脱氧核糖核苷酸组成的转座子端组合体,所述寡脱氧核糖核苷酸在其5'端显示非转移的转座子端序列,在其3'端显示转移的转座子端序列,并且在非转移的转座子端序列和转移的转座子端序列之间显示足够长的间插任意序列以允许分子内茎环形成,使得转座子端部分可以在体外转座反应中起作用。在一些实施方式中,发夹转座子端组合体的5'-端在5'-核苷酸的5'-位置具有磷酸基团。在一些实施方式中,发夹转座子端组合体的非转移的转座子端序列和转移的转座子端序列之间的间插任意序列提供用于特定用途或应用的标签(例如,包括一个或多个标签结构域)。
如本文所用,术语“转座酶片段化位点”是指靶核酸中的转座子端与靶核酸的部分共价连接并且靶核酸被片段化的位置。转座酶片段化不是完全随机的,并且显示“对富含at的序列的轻微偏向”(参见goryshin等,proc.natl.acad.sci.usa.,(1998)95:10716-10721)。术语“转座酶片段化位点”不限于转座子端与靶核酸的部分共价连接处的靶核酸中的特定核苷酸位置(例如,自3’端起的第3远核苷酸)或单一类型的核苷酸(即,a或t),而是指对应于转座子端与靶核酸的部分共价连接处的靶核酸中的位置的核苷酸,因为标签化反应的位置是某种程度上随机的。带独特标签的个体靶核酸分子在可变长度条码标签和转座酶片段化位点之间包含至少25个连续核苷酸的相同序列。然而,转座酶片段化位点的选择是实质无偏见的,因此与可变长度条码标签联合使用时,至少50;100;200;300;400;500;1,000;1,500;2,000;2,500;3,000或更多不同具有给定序列的靶核酸分子或其部分(例如,具有给定靶核酸序列的至少25个连续核苷酸)可被独特鉴别。因此,例如,在含有靶核酸的样品中(所述靶核酸为单个人细胞的基因组的mrna转录物,或其衍生的cdna,其中99%的独特转录物序列或对应cdna存在于少于200或100个拷贝中,这取决于样品制备效率),转座酶片段化位点联合具有0-5或0-10个核苷酸长度的可变长度条码标签足以独特鉴别至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.5%、99.9%、99.95%或99.99%的靶核酸。
与个体靶核酸分子结合使用的术语“第二端”是指个体靶核酸分子中发生体外转座反应的位置。“第二端”不是指靶核酸分子的3'或5'端的实际的物理末端;而是将含转座子端的组合体插入双链靶核酸分子发生的位置。由于双链靶核酸分子的片段化,体外转座反应的完成产生了新端(即第二端)。这样,第二端是指朝向经历体外转座的个体靶核酸分子的3'或5'端的位置,而不是体外转座之前个体靶核酸分子的3'或5'端的实际物理末端。
发明详述
i.引言
发明人发现,对于不同的样品,(联合)使用转座酶片段化和可变长度条码标签能够提供足够数量的独特分子标识符(umi)条码,以通过高通量测序提供对于基本上全部(>90%、>93%、>95%或>99%)靶核酸的绝对或相对定量。在一些情况下,与转座酶片段化位置联合的可变长度条码的长度和/或序列可针对样品中的各靶核酸序列提供约50、100、200、300、400、500、1,000、1,500、2,000、2,500、3,000或更多不同条码。在一些情况下,与使用单独(separate)umi条码的方法相比,这消除了对单独umi条码序列的需要(例如,利用pcr引物纳入),由此允许对于靶核酸序列的更长读数。在另一方面,本文公开的方法在pcr引物序列中提供了更少的不同随机序列,由此在rt和/或pcr扩增的后续步骤过程中提高了特异性。
ii.标签化方法
因此,本文描述了产生包含靶核酸序列的反应混合物的方法,所述靶核酸序列已用可变长度条码标签和转座酶片段化位点标签化。通常,可变长度条码标签在靶核酸的第一端,而转座酶片段化位点在靶核酸的第二端,不过其顺序可以颠倒。或者,可变长度条码和转座酶片段化位点可在靶核酸的同一端。在一些情况下,可变长度条码标签在第一端,其中第一端包含或对应于mrna的3'端(例如3'多聚a区域)或cdna的多聚t区域。
在一些实施方式中,该方法可包括将多个可变长度条码标签共价连接至多个靶核酸分子的第一端。通常,在共价连接可变长度条码标签之前,靶核酸没有与转座酶接触和/或被转座酶片段化。或者,可用转座酶使靶核酸片段化,例如,从而在一端产生带有转座子端组合体标签的片段,然后与可变长度条码标签共价连接。
可变长度条码标签的长度可以是(例如,由其组成)0-2、0-3、0-4、0-5、0-6、0-7、0-8、0-9、0-10、0-11、0-12、0-13、0-14或0-15个核苷酸。可变长度条码标签的长度可以是(例如,由其组成)1-2、1-3、1-4、1-5、1-6、1-7、1-8、1-9、1-10、1-11、1-12、1-13、1-14或1-15个核苷酸。在一些情况下,可变长度条码标签的长度为0-10或0-5个核苷酸。在一些情况下,可变长度条码标签的长度为1-10或1-5个核苷酸。
多个可变长度条码标签可通过用连接酶连接和/或聚合而共价连接至多个靶核酸分子。例如,可将多个可变长度条码标签与已经准备好通过5'端磷酸化,3'端去磷酸化,切割(例如核酸内切酶切割),加尾,末端修复等在一端或两端连接的靶核酸分子连接。作为另一个例子,可通过使含有可变长度条码标签的引物与靶核酸的部分杂交并用模板依赖性聚合酶延伸引物来将多个可变长度条码标签与靶核酸分子共价连接。
在一些实施方式中,未带标签的靶核酸分子是mrna,并且该方法包括使包含可变长度条码标签和任选的多聚t3'端的多个引物与包含靶核酸分子序列的至少部分的多个核酸分子杂交,并用rna依赖性dna聚合酶延伸引物,由此产生多个双链带可变长度条码标签的靶核酸分子。在一些情况下,可变长度条码标签是多聚a区域的3'和/或多聚t区域的5'。在一些情况下,该方法还包括产生多个双链带可变长度条码标签的靶cdna分子。例如,该方法可包括形成包含与反向互补第二dna链杂交的第一dna链的带可变长度条码标签的双链靶核酸分子。
在一些实施方式中,产生双链带可变长度条码标签的靶cdna分子包括(i)使多个个体引物与多个mrna分子杂交,其中所述个体引物包含可变长度条码标签,并用rna依赖性dna聚合酶延伸所述引物,由此产生多个双链mrna:cdna杂合体,其中第一链cdna分子与mrna分子杂交;(ii)使mrna:cdna杂合体与具有rna酶h活性的酶接触(例如,以诱导mrna的随机切口),从而产生与第一链cdna分子杂交的mrna片段;和(iii)使mrna片段与dna依赖性dna聚合酶接触,由此使mrna片段在模板导向的聚合酶反应中延伸,其中所述模板是第一链cdna多核苷酸,和形成双链cdna分子。
在一些情况下,rna依赖性dna聚合酶显示rna酶h活性,并且,使mrna:cdna杂合体与具有rna酶h活性的酶接触通过如下方式进行:在rna依赖性dna聚合酶存在下孵育mrna:cdna杂合体,由此产生与第一链cdna分子杂交的mrna片段。此外或或者,使mrna:cdna杂合体与包含rna酶h活性的酶接触可通过如下方式进行:使所述mrna:cdna杂合体与结构上不同于rna依赖性dna聚合酶的酶接触。
在一些实施方式中,带可变长度条码标签的双链靶核酸分子是基因组dna的带可变长度条码标签的片段,或其扩增子。例如,可提供基因组dna,与转座酶接触以片段化并引入转座子端组合体,然后可通过连接和/或聚合(例如,采用含随机引物3’区域和可变长度条码标签区域的引物的聚合)将片段共价连接至可变长度条码标签。在一些情况下,随后在与转座酶接触后(例如,在连接可变长度条码标签之前)和/或在共价连接可变长度条码标签之后,扩增片段。或者,基因组dna或其扩增子可以通过化学、物理或酶促手段片段化,通过连接和/或聚合共价连接至可变长度条码标签,然后与转座酶接触以进一步片段化并引入转座子端组合体。在一些情况下,随后在共价连接可变长度条码标签之前,共价连接可变长度条码标签之后(例如,在与转座酶接触之前)和/或在与转座酶接触之后,扩增基因组片段。
在其中与转座酶接触之后进行扩增的实施方式中,可在不进行预扩增“间隙填充”反应以填充转移的链与靶核酸分子之间的间隙的条件下进行扩增。在一些实施方式中,在含有扩增引物和标签酶产物的反应混合物中减少或消除一种或多种dna依赖性dna聚合酶的“间隙填充”可能是有利的。例如,在用扩增引物进行pcr扩增的第一个循环之前,通过减少或消除第一链cdna分子的3'末端的延伸可以实现增加的特异性(例如,通过附连至与第一链cdna分子杂交的第二链cdna分子的5'末端的转移的链而模板化)。当至少一些(例如一半)的靶核酸包括不与转座酶相关的衔接体(例如cdna衔接体)时,这是特别有利的。
因此,在一些实例中,将包含片段化酶产物的反应混合物保持在不允许聚合酶介导的延伸的温度(例如,0、4、8、10、15或25℃),直到将反应混合物转移至适于扩增(例如pcr)反应中的变性步骤的条件(例如,90℃或95℃)。或者或另外,反应混合物可含有热启动dna聚合酶,或含有热启动dna聚合酶而不含其它实质性dna聚合酶活性。因此,聚合酶介导的延伸基本上在pcr的初始变性步骤后发生。此外或可替代地,扩增反应的必要组分(例如聚合酶或dntp)可以在其平衡至变性温度后加入反应混合物中。
在一些实施方式中,通过以下方式产生带可变长度条码标签的靶基因组dna分子:使包含可变长度条码标签和基因组dna靶向区域的多个第一引物与包含至少部分靶核酸分子序列的多个基因组dna分子杂交,和,用dna依赖性dna聚合酶延伸所述引物,由此产生所述带可变长度条码标签的靶基因组dna分子。在一些情况下,基因组dna分子在产生带可变长度条码标签的靶基因组dna分子之前和/或在产生带可变长度条码标签的靶基因组dna分子之后被扩增。
在一些情况下,在足以产生具有至少5个不同可变长度条码标签长度或序列或其组合的带标签的靶核酸分子的条件下进行使多个可变长度条码标签与多个靶核酸分子共价连接的方法。例如,共价连接可在足以产生带可变长度条码标签的靶核酸的群体的条件下进行,其具有与具有仅1个核苷酸的长度的可变长度条码共价连接的群体的至少一个靶核酸分子,与具有仅2个核苷酸的长度的可变长度条码共价连接的群体的至少一个靶核酸分子,与具有仅3个核苷酸的长度的可变长度条码共价连接的群体的至少一个靶核酸分子,与具有仅4个核苷酸的长度的可变长度条码共价连接的群体的至少一个靶核酸分子,和与具有仅5个核苷酸的长度的可变长度条码共价连接的群体的至少一个靶核酸分子。
此外或替代性地,所述共价连接可在足以产生带可变长度条码标签的靶核酸的群体的条件下进行,其具有与具有第一序列的可变长度条码共价连接的群体的至少一个靶核酸分子,与具有第二不同序列的可变长度条码共价连接的群体的至少一个靶核酸分子,与具有不同于第一和第二序列的第三序列的可变长度条码共价连接的群体的至少一个靶核酸分子,与具有不同于第一、第二和第三序列的第四序列的可变长度条码共价连接的群体的至少一个靶核酸分子,和与具有不同于第一、第二、第三和第四序列的第五序列的可变长度条码共价连接的群体的至少一个靶核酸分子。可变长度条码序列可由核苷酸碱基的鉴定而有所不同(例如,各自共价连接至不同靶核酸分子的两个长度1的可变长度条码,其中第一可变长度条码是“a”且第二是“g”),和/或所述序列可由长度而有所不同(例如,长度1的可变长度条码和长度2的可变长度条码,其中长度1的可变长度条码是“a”且长度2的可变长度条码是“at”)。
靶核酸分子可与多种转座酶接触,从而转座酶片段化位点和共价连接的转座子端被引入靶核酸分子的端部。在一些实施方式中,可以使用两种或更多种不同的转座酶(例如,每种转座酶具有不同转座子端序列,其能够形成功能复合物并将各转座酶的转座子端序列插入与其在体外转座反应中孵育的一个或多个靶核酸分子中)。在一些实施方式中,适用于本文概述的转座酶包括但不限于tn5转座酶。在一些情况下,使靶核酸分子与多种转座酶接触,由此引入转座子端组合体并使该靶核酸分子片段化以产生在第一端带标签的片段,然后这些片段被共价连接至多个可变长度条码标签(例如,在第二端)。在一些情况下,靶核酸分子共价连接至多个可变长度条码标签(例如,在第一端),然后与多种转座酶接触,由此引入转座子端组合体并将靶核酸分子片段化,以产生由可变长度条码标签和转座子端组合体标签化的片段。
在一些实施方式中,可变长度条码标签的共价连接和转座酶标签化产生多个带独特标签的靶核酸分子,其中,所述多个中的带独特标签的个体靶核酸分子包含:(i)位于第一端的可变长度条码标签;和(ii)位于第二端的转座酶片段化位点和转座子端,其中,所述多个中的带独特标签的个体靶核酸分子中的(i)和(ii)的组合一起包含独特分子条码,在反应混合物中,该独特分子条码相对于所述多个中的具有可变长度条码标签和转座酶片段化位点之间的至少25个连续核苷酸的相同序列的所有其它带独特标签的个体靶核酸分子而言是独特的。例如,前述(i)和(ii)一起可包含独特分子条码,在反应混合物中,所述独特分子条码相对于所述多个中的具有可变长度条码标签和转座酶片段化位点之间的至少25、50、75、100、120、150、175、200、250、300、350、400、450、500或750个连续核苷酸的相同序列的所有其它带独特标签的个体靶核酸分子而言是独特的。
通常,本文描述的方法适用于包含大量不同靶核酸分子序列的复杂样品。在一些实施方式中,本文所述的方法适用于鉴定和/或检测不同靶核酸分子中的低频(<1%、<0.5%或0.1%)突变。在另一个实施方式中,本文所述的方法适用于定量来自单细胞的低水平(例如,亚皮克)量的靶核酸分子。例如,所述方法可在含有、含有约、含有至少或含有至少约100、200、300、400、500、600、700、800、900、1,000、2,500、5,000、7,500、10,000、15,000、25,000或30,000个具有不同序列的靶核酸分子的反应混合物中进行。在一些实施方式中,反应混合物是来自单细胞的靶核酸分子的反应混合物。在另一个实施方式中,反应混合物是来自多个细胞的靶核酸分子的反应混合物。类似地,本文描述的方法适用于含有大量靶核酸分子的复杂样品。例如,该方法可以在含有、含有约、含有至少或含有至少约10,000、25,000、50,000、75,000、100,000、150,000、200,000、250,00或300,000个靶核酸分子的反应混合物中进行。在一些情况下,反应混合物是来自单细胞的靶核酸分子的反应混合物。在一些情况下,反应混合物是来自少量细胞(例如活检物)的靶核酸分子的反应混合物。例如,反应混合物可以是来自2、3、4、5、10、15、20、30、50、75、100、150、200、250、300、350、400、500或1,000个细胞或来自10-30、10-50、10-100、10-250、10-500、25-100、25-1,000、25-750、25-500、25-250、50-100、50-1,000、50-750、50-500或50-250个细胞的靶核酸的反应混合物。
在一些实施方式中,多个带独特标签的个体靶核酸分子(例如,由可变长度条码标签和转座酶片段化位点的组合而独特标签化的)还包含细胞条码。在一些情况下,多个带独特标签的个体靶核酸分子是cdna,并且细胞条码是多聚a区域的3'和/或多聚t区域的5'。在一些情况下,在可变长度条码标签的共价连接过程中,细胞条码与带独特标签的个体靶核酸分子共价连接。在一些情况下,细胞条码在与转座酶接触过程中共价连接至带独特标签的个体靶核酸分子。在一些情况下,在单独步骤中引入细胞条码,例如在共价连接可变长度条码标签之前,共价连接可变长度条码标签之后,与转座酶接触之前或与转座酶接触之后。
在前述实施方式、方面和实例中,靶核酸(例如,带可变长度条码标签的靶核酸或未带标签的靶核酸)可与转座酶接触,所述转座酶具有包含如下序列的转座子端:gtctcgtgggctcgg(seqidno:2),
tcgtcggcagcgtc(seqidno:3),
agatgtgtataagagacag(seqidno:4),
tcgtcggcagcgtcagatgtgtataagagacag(seqidno:5),
gtctcgtgggctcggagatgtgtataagagacag(seqidno:6),
ctgtctcttatacacatct(seqidno:7),或其任意二、三、四、五、六者或全部的组合。
iii.估计样品中靶核酸分子的数量的方法
本文描述了通过高通量测序来估计样品中靶核酸分子的绝对数量的方法。通常,该方法包括从多个带独特标签的靶核酸或其部分获得多个序列读数,通过转座酶片段化位点和可变长度条码标签的组合的存在来鉴定重复物(duplicate)(例如,扩增拷贝),和对不是重复物的序列读数进行计数。转座酶片段化位点和可变长度条码标签之间相同序列的存在,提供了一种鉴定重复物的方式,并因而从样品中靶核酸分子的绝对数量中排除了所述重复物。此外,带标签的靶核酸中细胞条码(bcc)的存在还提供了一种确定源自多个细胞的样品中靶核酸分子的绝对数量的方式。
在一些实施方式中,所述方法包括:(a)提供反应混合物,其中所述反应混合物包含多个带独特标签的靶核酸分子(例如,来自单细胞,或生物或环境样品),所述靶核酸分子包含:(i)位于第一端的可变长度条码标签;和(ii)位于第二端的转座酶片段化位点和转座子端;和,其中,(i)与(ii)的组合一起包含独特分子条码,在反应混合物中,所述独特分子条码相对于具有可变长度条码标签和转座酶片段化位点之间的相同序列的所有其它带独特标签的靶核酸分子而言是独特的。在一些实施方式中,反应混合物在(a)之后和测序之前被扩增。所述方法还可包括:(b)获得多个序列读数,其中所述序列读数包含以下中的一个或多个:可变长度条码标签的序列,在可变长度条码标签和转座酶片段化位点之间的靶核酸的部分的序列,和片段化位点的序列。该方法还可包括:(c)对在可变长度条码标签和转座酶片段化之间具有相同序列,但是具有不同可变长度条码标签和/或转座酶片段化位点的靶核酸分子的数量进行计数,由此估计反应混合物中靶核酸分子的绝对数量。
在另一实施方式中,所述方法包括:(a)提供反应混合物,其中所述反应混合物包含来自单细胞的多个带独特标签的靶核酸分子,所述靶核酸分子包含:(i)位于第一端的可变长度条码标签;和(ii)位于第二端的转座酶片段化位点和转座子端;和,其中,(i)与(ii)的组合一起包含独特分子条码,在反应混合物中,所述独特分子条码相对于具有可变长度条码标签和转座酶片段化位点之间的相同序列的所有其它带独特标签的靶核酸分子而言是独特的。在一些实施方式中,反应混合物在(a)之后和测序之前被扩增。所述方法还可包括:(b)获得多个序列读数,其中所述序列读数包含以下中的一个或多个:可变长度条码标签的序列,在可变长度条码标签和转座酶片段化位点之间的靶核酸的部分的序列,和片段化位点的序列。该方法还可包括:(c)对在可变长度条码标签和转座酶片段化之间具有相同序列,但是具有不同可变长度条码标签和/或转座酶片段化位点的靶核酸分子的数量进行计数,由此估计所述单细胞中靶核酸分子的绝对数量。
而在另一实施方式中,所述方法包括:(a)提供反应混合物,其中所述反应混合物包含在多个流体分区中的多个带独特标签的靶核酸分子,所述靶核酸分子包含:(i)位于第一端的可变长度条码标签;和(ii)位于第二端的转座酶片段化位点和转座子端;和,其中,(i)与(ii)的组合一起包含独特分子条码,在反应混合物中,所述独特分子条码相对于具有可变长度条码标签和转座酶片段化位点之间的相同序列的所有其它带独特标签的靶核酸分子而言是独特的。在一些实施方式中,在(a)之后和测序之前扩增包含多个流体分区的反应混合物。所述方法还可包括:(b)获得多个序列读数,其中所述序列读数包含以下中的一个或多个:可变长度条码标签的序列,在可变长度条码标签和转座酶片段化位点之间的靶核酸的部分的序列,和片段化位点的序列。该方法还可包括:(c)对在可变长度条码标签和转座酶片段化之间具有相同序列,但是具有不同可变长度条码标签和/或转座酶片段化位点的靶核酸分子的数量进行计数,由此估计反应混合物中靶核酸分子的绝对数量。
在一些实施方式中,具有可变长度条码标签和转座酶片段化位点的前述带独特标签的靶核酸分子通过进行上述第ii节中描述的一种或多种方法来提供。例如,可变长度条码标签可通过聚合酶介导的引物延伸而连接,然后可将带标签的靶核酸与转座酶接触。
在一些实施例中,该方法包括执行计算机实现的方法,其中由计算机系统执行包含非暂时性机器可读代码的计算机程序产品,以分析包含(b)中产生的多个序列读数的数据,由此估计样品中靶核酸分子的绝对数量。在一些情况下,存储程序代码的非暂时性机器可读介质使计算机系统实施一种估计反应混合物中的靶核酸分子的数量的方法,其使用:(a)靶核酸的序列;和(i)位于靶核酸的第一端的可变长度条码标签;和(ii)位于靶核酸的第二端的转座酶片段化位点和转座子端,以鉴定和估计反应混合物中靶核酸的个体分子的绝对数量。
在一些情况下,程序代码包含:用于获得多个,例如扩增的,具有可变长度条码标签和转座酶片段化位点的靶核酸的测序读数的代码。在一些情况下,程序代码包含:用于由可变长度条码标签和转座酶片段化位点的组合鉴别多个独特分子标识符(umi)的代码;和,用于对具有这种独特分子标识符的靶核酸分子的数量进行计数的代码。
iv.组合物
本文描述了由一种或多种前述方法产生的或适合于进行一种或多种前述方法的各种反应混合物。这样的反应混合物可以包括但不限于测序文库,可变长度条码标签(例如,作为引物或衔接体的组分)和/或带可变长度条码标签的靶核酸。
在一些实施方式中,反应混合物可包含多个带独特标签的靶核酸分子,其中所述多个带独特标签的靶核酸分子包含:(i)位于第一端的可变长度条码标签;和(ii)位于第二端的转座酶片段化位点和转座子端;和,其中(i)和(ii)的组合一起包含独特分子条码,在所述反应混合物中,所述独特分子条码相对于具有可变长度条码标签和转座酶片段化位点之间的相同序列的所有其它带独特标签的靶核酸分子而言是独特的。在一些实施方式中,反应混合物可包含至少1000个不同的带独特标签的靶核酸分子。在一些实施方式中,反应混合物可包含或包含至少500、5,000、7,500、10,000、15,000、25,000、30,000、50,000、75,000、100,000、150,000、200,000、250,00或300,000个带独特标签的靶核酸分子。在一些实施方式中,反应混合物还包含带独特标签的靶核酸分子的扩增产物。
虽然通过阐述和举例的方式详细描述了上述发明以清晰理解,但本发明技术人员应理解可在所附权利要求书范围内实施某些改变和修改。通过引用将本文引用的所有专利、专利申请和其它公开文献包括genbank登录号,entrez基因id和由pubmedid(pmid)引用的公开文献全文纳入本文用于所有目的。
序列表
<110>生物辐射实验室股份有限公司(bio-radlaboratories、inc.)
<120>分子条码化
<130>1081968
<140>pct/us18/33653
<141>2018-05-21
<150>us62/510,095
<151>2017-05-23
<160>7
<170>patentinversion3.5
<210>1
<211>150
<212>dna
<213>人工序列
<220>
<223>合成条码标签序列
<220>
<221>misc_feature
<222>(1)..(1)
<223>t在n末端连接至珠
<220>
<221>misc_feature
<222>(24)..(53)
<223>测序引物寡核苷酸
<220>
<221>misc_feature
<222>(54)..(58)
<223>n=a、c、g或t;n可存在或不存在
<220>
<221>misc_feature
<222>(59)..(64)
<223>n=a、c、g、t或u
<220>
<221>misc_feature
<222>(80)..(85)
<223>n=a、c、g、t或u
<220>
<221>misc_feature
<222>(101)..(106)
<223>n=a、c、g、t或u
<220>
<221>misc_feature
<222>(110)..(117)
<223>n=a、c、g或t
<400>1
tttttttuuuctacacgcctgtccgcggaagcagtggtatcaacgcagagtacnnnnnnn60
nnnntagccatcgcattgcnnnnnntaccactgagctgaannnnnnacgnnnnnnnngac120
tttttttttttttttttttttttttttttt150
<210>2
<211>15
<212>dna
<213>人工序列
<220>
<223>合成寡核苷酸序列
<400>2
gtctcgtgggctcgg15
<210>3
<211>14
<212>dna
<213>人工序列
<220>
<223>合成寡核苷酸序列
<400>3
tcgtcggcagcgtc14
<210>4
<211>19
<212>dna
<213>人工序列
<220>
<223>合成寡核苷酸序列
<400>4
agatgtgtataagagacag19
<210>5
<211>33
<212>dna
<213>人工序列
<220>
<223>合成寡核苷酸序列
<400>5
tcgtcggcagcgtcagatgtgtataagagacag33
<210>6
<211>34
<212>dna
<213>人工序列
<220>
<223>合成寡核苷酸序列
<400>6
gtctcgtgggctcggagatgtgtataagagacag34
<210>7
<211>19
<212>dna
<213>人工序列
<220>
<223>合成寡核苷酸序列
<400>7
ctgtctcttatacacatct19
- 还没有人留言评论。精彩留言会获得点赞!