1,3-丙二醇的制造方法与流程
本发明涉及一种1,3-丙二醇(1,3-propanediol)的制造方法。
背景技术:
现在,强烈希望将作为可再生资源的生物资源用作原料,代替被认为是全球变暖元凶的石油资源来生产化成品。因此,出于由糖类等来源于生物的原料生产化成品的目的,正在积极地进行研究,以便使用微生物及其转化体来生产用于工业原料、燃料、饲料、食品添加物等的化成品。例如,报告有使用酵母或大肠杆菌的转化体,由糖类来制造醇或氨基酸等有机化合物的情况(参照美国专利第9926577号、美国专利第8647847号)。
技术实现要素:
发明所要解决的问题
本发明的目的在于提供一种制造有机化合物的新颖方法。
使用微生物生产化成品时,作为其生产对象,通常限定于微生物代谢物。另外,即使是微生物代谢物,也存在很多因微生物代谢系统中的能量不足或氧化还原平衡的不均衡而难以生产的微生物代谢物。作为用以解决此种课题的一个有效方法(approach),可列举制作转化体。但本发明人等人认为,若仅通过该方法来解决课题,则能够生产对象化合物的菌体的开发有时会花费大量时间。另一方面,考虑今后会要求微生物代谢物以外的多种化合物也由来源于生物的原料来生产。因此,本发明人等人研究开发一种新颖的工艺,所述工艺对于有用物质的生产,并非仅依赖于制作微生物的转化体。
解决问题的技术手段
本发明人等人进行了努力研究,结果发现,通过在甲醛的存在下对具有特定基因的微生物进行培养来获得1,3-丙二醇的生产工艺,从而完成了本发明。
根据本发明,可提供一种1,3-丙二醇的制造方法,包括在糖类及甲醛的存在下,对包含以下基因的微生物进行培养以生产1,3-丙二醇:
(a)第一基因,对催化丙酮酸(pyruvicacid)与醛的羟醛反应(aldolreaction)的酶进行编码;
(b)第二基因,对催化α-酮酸的脱羧反应的酶进行编码;及
(c)第三基因,对催化醛的还原反应的酶进行编码。
根据本发明,可提供一种使用微生物来制造1,3-丙二醇的方法。
附图说明
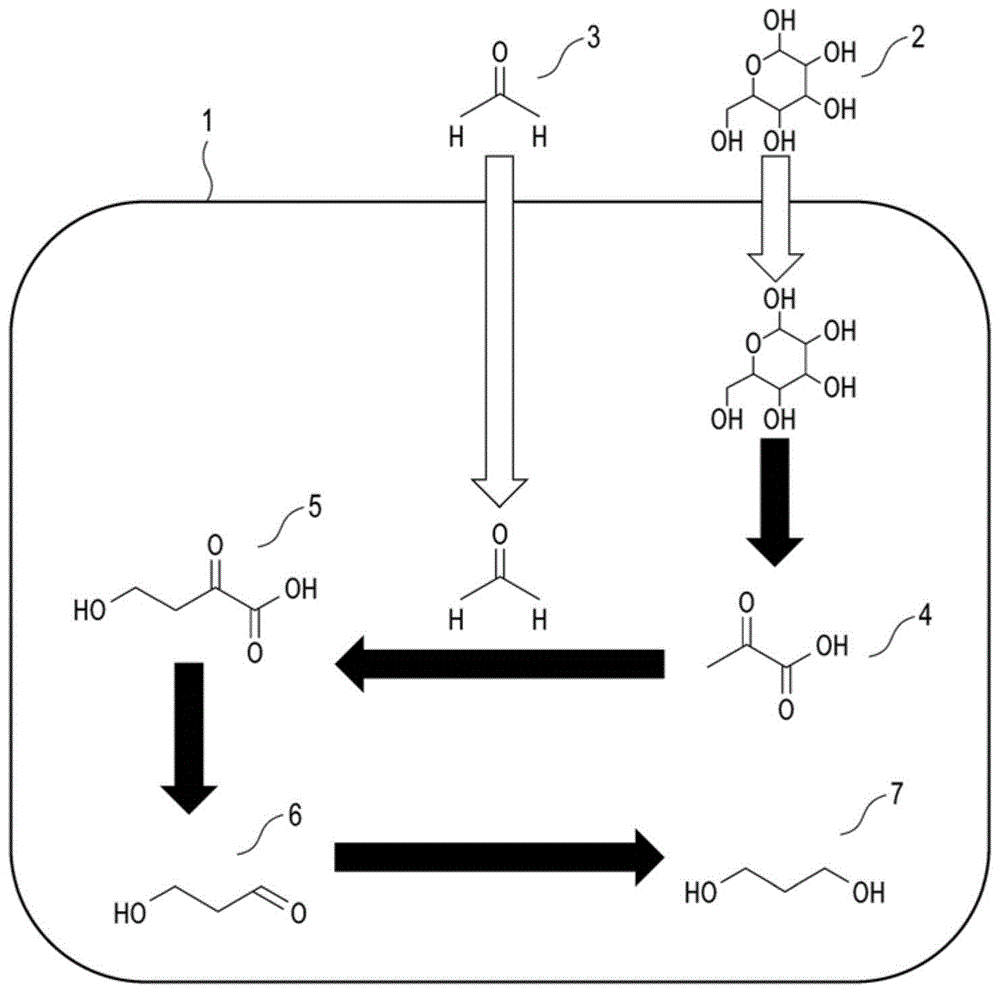
图1是表示微生物生产1,3-丙二醇的工艺的示意图。
具体实施方式
以下对本发明进行详细说明,但以下说明的目的在于对本发明进行详细说明,并未意图限定本发明。
1,3-丙二醇的制造方法包括在糖类及甲醛的存在下,对包含以下基因的微生物进行培养以生产1,3-丙二醇:
(a)第一基因,对催化丙酮酸与醛的羟醛反应的酶进行编码;
(b)第二基因,对催化α-酮酸的脱羧反应的酶进行编码;及
(c)第三基因,对催化醛的还原反应的酶进行编码。
在以下说明中,将包含第一基因、第二基因及第三基因的所述微生物也称为“1,3-丙二醇生产微生物”。1,3-丙二醇生产微生物可为原本便具有第一基因、第二基因及第三基因的微生物,也可为通过利用第一基因、第二基因及第三基因对宿主进行转化而获得的微生物。以下,以1,3-丙二醇生产微生物为转化体的情况为例进行说明。
(1.)转化体
(1.1)宿主
作为宿主,可使用任意的微生物。作为宿主,例如可使用酵母、细菌,更具体而言,可使用好氧性细菌,更具体而言,可使用棒状细菌(corynebacteria)、大肠杆菌或需钠弧菌(vibrionatriegens)。优选宿主为棒状细菌。
所谓棒状细菌,是伯杰氏细菌鉴定手册bargeysmanualofdeterminativebacteriology,第8卷(vol.8),599(1974)]中所定义的一群组微生物,只要是在通常的好氧条件下增殖的微生物,则并无特别限定。若列举具体例,则可列举:棒状杆菌属菌、短杆菌(brevibacterium)属菌、节杆菌(arthrobacter)属菌、分枝杆菌(mycobacterium)属菌、微球菌(micrococcus)属菌等。在棒状细菌中,优选为棒状杆菌属菌。
作为棒状杆菌属菌,可列举:谷氨酸棒状杆菌(corynebacteriumglutamicum)、有效棒状杆菌(corynebacteriumefficiens)、产氨棒状杆菌(corynebacteriumammoniagenes)、耐盐棒状杆菌(corynebacteriumhalotolerance)、解烷棒状杆菌(corynebacteriumalkanolyticum)等。其中,就1,3-丙二醇的生产性高的方面而言,优选为谷氨酸棒状杆菌。作为优选的菌株,可列举:美国菌种保藏中心(americantypeculturecollection,atcc)13032株、atcc13869株、atcc13058株、atcc13059株、atcc13060株、atcc13232株、atcc13286株、atcc13287株、atcc13655株、atcc13745株、atcc13746株、atcc13761株、atcc14020株、atcc31831株、mj-233(fermbp-1497)、mj-233ab-41(fermbp-1498)等。其中,优选为atcc13032株、atcc13869株。
此外,根据分子生物学的分类,黄色短杆菌(brevibacteriumflavum)、乳糖发酵短杆菌(brevibacteriumlactofermentum)、散枝短杆菌(brevibacteriumdivaricatum)、百合棒状杆菌(corynebacteriumlilium)等棒状细菌的菌名也统一于谷氨酸棒状杆菌(corynebacteriumglutamicum)中[利布尔等人(liebl,w.etal.,)散枝短杆菌dsm20297t、“黄色短杆菌”dsm20411、“乳糖发酵短杆菌”dsm20412和dsm1412、与谷氨酸棒状杆菌的转化及其利用rrna基因限制性图案的区分(transferofbrevibacteriumdivaricatumdsm20297t,“brevibacteriumflavum”dsm20411,“brevibacteriumlactofermentum”dsm20412anddsm1412,andcorynebacteriumglutamicumandtheirdistinctionbyrrnagenerestrictionpatterns.)国际系统菌学杂志(internationaljournalofsystematicbacteriology,intjsystbacteriol.)41:255-260.(1991),驹形和男等,棒状细菌的分类,发酵与工业,45:944-963(1987)]。
旧分类的乳糖发酵短杆菌atcc13869株、黄色短杆菌的mj-233株(fermbp-1497)、mj-233ab-41株(fermbp-1498)等也是优选的谷氨酸棒状杆菌。
作为短杆菌属菌,可列举产氨短杆菌(brevibacteriumammoniagenes)(例如atcc6872株)等。
作为节杆菌属菌,可列举球形节杆菌(arthrobacterglobiformis)(例如atcc8010株、atcc4336株、atcc21056株、atcc31250株、atcc31738株、atcc35698株)等。
作为分枝杆菌属菌,可列举牛分枝杆菌(mycobacteriumbovis)(例如atcc19210株、atcc27289株)等。
作为微球菌属菌,可列举弗氏微球菌(micrococcusfreudenreichii)(例如no.239株(fermp-13221))、藤黄微球菌(micrococcusleuteus)(例如no.240株(fermp-13222))、脲微球菌(micrococcusureae)(例如应用微生物研究所(instituteofappliedmicrobiology,iam)1010株)、玫瑰色微球菌(micrococcusroseus)(例如发酵研究所(ifo)3764株)等。
接着,对导入宿主中的第一基因、第二基因及第三基因进行说明。
(1.2)第一基因
第一基因对“催化丙酮酸与醛的羟醛反应的酶”进行编码。所谓“催化丙酮酸与醛的羟醛反应的酶”,是指依照后述的测定方法,且作为酶反应液而使用包含纯化蛋白质、丙酮酸(初始基质浓度1mm)及醛(初始基质浓度1mm)的酶反应液来进行测定时,具有10毫活性单位/毫克蛋白质(mu/mgprotein)以上的活性的酶。“催化丙酮酸与醛的羟醛反应的酶”中的醛例如为甲醛。“催化丙酮酸与醛的羟醛反应的酶”例如为醛缩酶(aldolase)。
第一基因可为对以下所例示的醛缩酶进行编码的基因。
(a1)2-脱氢-3-脱氧-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-phosphogluconatealdolase,酶学委员会(enzymecommission,ec)编号:4.1.2.14);
(a2)2-脱氢-3-脱氧-6-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-6-phosphogluconatealdolase,ec编号4.1.2.55);
(a3)4-羟基-2-氧代戊二酸醛缩酶(4-hydroxy-2-oxoglutaratealdolase,ec编号:4.1.3.16);
(a4)(4s)-4-羟基-2-氧代戊二酸醛缩酶((4s)-4-hydroxyl-2-oxoglutaratealdolase,ec编号4.1.3.42);
(a5)2-脱氢-3-脱氧-d-戊糖酸醛缩酶(2-dehydro-3-deoxy-d-pentonatealdolase,ec编号4.1.2.28);
(a6)2-脱氢-3-脱氧-d-葡萄糖酸醛缩酶(2-dehydro-3-deoxy-d-gluconatealdolase,ec编号4.1.2.51);
(a7)3-脱氧-d-甘露-辛酮糖酸醛缩酶(3-deoxy-d-manno-octulosonatealdolase,ec编号4.1.2.23);
(a8)4-羟基-2-氧代戊酸醛缩酶(4-hydroxyl-2-oxovaleratealdolase,ec编号4.1.3.39);
(a9)4-(2-羧基苯基)-2-氧代丁-3-烯酸醛缩酶(4-(2-carboxyphenyl)-2-oxobut-3-enoatealdolase,ec编号4.1.2.34);
(a10)4-羟基-2-氧代庚烷二酸醛缩酶(4-hydroxy-2-oxoheptanedioatealdolase,ec编号4.1.2.52);
(a11)2-脱氢-3-脱氧葡萄糖二酸醛缩酶(2-dehydro-3-deoxyglucaratealdolase,ec编号4.1.2.20);
(a12)2-酮-3-脱氧-l-鼠李糖酸醛缩酶(2-keto-3-deoxy-l-rhamnonatealdolase,ec编号4.1.2.53);
(a13)4-羟基-4-甲基-2-氧代戊二酸醛缩酶(4-hydroxyl-4-methyl-2-oxoglutaratealdolase,ec编号4.1.3.17);及
(a14)4-羟基-2-氧代己酸醛缩酶(4-hydroxy-2-oxohexanonatealdolase,ec编号4.1.3.43)。
作为(a1)、(a2)、(a3)及(a4)中包含的醛缩酶,例如可列举eda蛋白质。优选eda蛋白质来源于大肠杆菌。
作为(a2)中包含的醛缩酶,例如可列举dgoa蛋白质。优选dgoa蛋白质来源于大肠杆菌。
作为(a5)中包含的醛缩酶,例如可列举yjhh蛋白质。优选yjhh蛋白质来源于大肠杆菌。
作为(a6)中包含的醛缩酶,例如可列举yage蛋白质。优选yage蛋白质来源于大肠杆菌。
作为(a7)中包含的醛缩酶,例如可列举nana蛋白质。优选nana蛋白质来源于大肠杆菌。
作为(a8)中包含的醛缩酶,例如可列举mhpe蛋白质。优选mhpe蛋白质来源于大肠杆菌。此外,在第一基因为mhpe基因的情况下,mhpe基因可在与mhpf基因连结的状态下导入宿主中。
作为(a8)及(a10)中包含的醛缩酶,例如可列举hpai蛋白质。优选hpai蛋白质来源于大肠杆菌。
作为(a8)及(a14)中包含的醛缩酶,例如可列举bphi蛋白质。优选bphi蛋白质来源于食异源化合物伯克霍尔德氏菌(burkholderiaxenovorans)。此外,在第一基因为bphi基因的情况下,bphi基因可在与bphj基因连结的状态下导入宿主中。
作为(a9)中包含的醛缩酶,例如可列举phdj蛋白质。优选phdj蛋白质来源于类诺卡氏菌(nocardioidessp.)。
作为(a11)中包含的醛缩酶,例如可列举garl蛋白质。优选garl蛋白质来源于大肠杆菌。
作为(a12)中包含的醛缩酶,例如可列举rhma蛋白质。优选rhma蛋白质来源于大肠杆菌。
作为(a13)中包含的醛缩酶,例如可列举galc蛋白质。优选galc蛋白质来源于恶臭假单胞菌(pseudomonasputida)。
第一基因可对i类醛缩酶进行编码,也可对ii类醛缩酶进行编码。
作为i类醛缩酶,例如可列举:eda蛋白质、yjhh蛋白质、yage蛋白质、dgoa蛋白质、nana蛋白质、mphe蛋白质及phdj蛋白质。
作为ii类醛缩酶,例如可列举:hpai蛋白质、garl蛋白质、rhma蛋白质、galc蛋白质及bphi蛋白质。
优选第一基因选自由以下所组成的群组中:
(1-1)对作为包含序列号2中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的hpai蛋白质)的、且催化丙酮酸与醛的羟醛反应的蛋白质进行编码的基因,
(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因,
(1-3)对作为包含序列号4中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的rhma蛋白质)的、且催化丙酮酸与醛的羟醛反应的蛋白质进行编码的基因,
(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因,
(1-5)对作为包含序列号6中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的nana蛋白质)的、且催化丙酮酸与醛的羟醛反应的蛋白质进行编码的基因,及
(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因。
在本说明书中,“一个或多个氨基酸缺失、经取代或加成而成的”这一表述中的“一个或多个”根据氨基酸残基在蛋白质的立体结构中的位置或氨基酸残基的种类而不同,优选意指1个~60个,更优选意指1个~30个,进而优选意指1个~15个,进而优选意指1个~10个,进而优选意指1个~5个。
所述一个或多个氨基酸的缺失、取代或加成例如为正常维持蛋白质的功能下的保守性突变。作为保守性突变,有代表性的是保守性取代。所谓保守性取代,在取代部位为芳香族氨基酸的情况下,是在phe、trp、tyr间彼此进行取代的突变,在取代部位为疏水性氨基酸的情况下,是在leu、ile、val间彼此进行取代的突变,在取代部位为极性氨基酸的情况下,是在gln、asn间彼此进行取代的突变,在取代部位为碱性氨基酸的情况下,是在lys、arg、his间彼此进行取代的突变,在取代部位为酸性氨基酸的情况下,是在asp、glu间彼此进行取代的突变,在取代部位为具有羟基的氨基酸的情况下,是在ser、thr间彼此进行取代的突变。作为可视作保守性取代的取代,具体而言,可列举:ala取代为ser或thr;arg取代为gln、his或lys;asn取代为glu、gln、lys、his或asp;asp取代为asn、glu或gln;cys取代为ser或ala;gln取代为asn、glu、lys、his、asp或arg;glu取代为gly、asn、gln、lys或asp;gly取代为pro、his取代为asn、lys、gln、arg或tyr;ile取代为leu、met、val或phe;leu取代为ile、met、val或phe;lys取代为asn、glu、gln、his或arg;met取代为ile、leu、val或phe;phe取代为trp、tyr、met、ile或leu;ser取代为thr或ala;thr取代为ser或ala;trp取代为phe或tyr;tyr取代为his、phe或trp;及val取代为met、ile或leu。另外,氨基酸的缺失、取代或加成还包括基因在基于来源细菌的个体差异、种类不同的情况等下天然产生的突变(变异(mutant)或变型(variant))所产生的突变。
“对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号2中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因”。
“对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号4中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因”。
“对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号6中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因”。
来源于大肠杆菌的hpai蛋白质的通用蛋白质资源知识库(universalproteinresourceknowledgebase,uniprotkb)登录号(accessionnumber)例如为q47098,来源于大肠杆菌的rhma蛋白质的uniprotkb登录号例如为p76469,来源于大肠杆菌的nana蛋白质的uniprotkb登录号例如为p0a6l4。
更优选第一基因为:
包含序列号1中记载的碱基序列的来源于大肠杆菌的hpai基因、
包含序列号3中记载的碱基序列的来源于大肠杆菌的rhma基因、或
包含序列号5中记载的碱基序列的来源于大肠杆菌的nana基因。
序列号1中记载的碱基序列与序列号2中记载的氨基酸序列如下。
[表1]
[表2]
序列号3中记载的碱基序列与序列号4中记载的氨基酸序列如下。
[表3]
[表4]
序列号5中记载的碱基序列与序列号6中记载的氨基酸序列如下。
[表5]
[表6]
氨基酸序列的同一性可使用卡林及阿尔丘尔(karlinandaltschul)的算法即基本局部比对搜索工具(basiclocalalignmentsearchtool,blast)[美国科学院院报(proceedingsofthenationalacademyofsciencesoftheunitedstatesofamerica,pro.natl.acad.sci.usa),90,5873(1993)]或快速自适应收缩/阈值算法(fastadaptiveshrinkage/thresholdingalgorithm,fasta)[酶学方法(methodsinenzymology,methodsenzymol.),183,63(1990)]来决定。基于所述算法blast,开发了一种称为blastn或blastx的程序[分子生物学杂志(journalofmolecularbiology,j.mol.biol.),215,403(1990)]。另外,在基于blast而利用blastx对氨基酸序列进行分析的情况下,参数例如设为分值(score)=50、字长(wordlength)=3。为了获得空位比对(gappedalignment),如阿尔丘尔(altschul)等人(1997,核酸研究(nucleicacidsresearch,nucleicacidsres.)25:3389-3402)所记载,可利用空位blast(gappedblast)。或者可使用psi-blast或phi-blast来进行用以检测分子间的位置关系(id.)及共有共同图案的分子间的关系的重复检索。在利用blast、gappedblast、psi-blast及phi-blast程序的情况下,可使用各程序的默认参数(defaultparameter)。请参照http://www.ncbi.nlm.nih.gov.。
催化丙酮酸与醛的羟醛反应的活性例如可通过以下方式来算出:在含有2mm氯化镁的100mm4-(2-羟乙基)-1-哌嗪乙烷磺酸(4-(2-hydroxyethyl)-1-piperazineethanesulfonicacid,hepes)-氢氧化钠(naoh)缓冲剂(buffer)(ph8.0)中在25℃下进行所述酶反应,测定由作为原料的丙酮酸与醛生成的羟醛化合物的初始生成速度。羟醛化合物的生成速度例如可根据羟醛化合物自身浓度的时间变化来算出。羟醛化合物的浓度的测定例如可通过以下方式来进行:通过将酶反应液与130mm的o-苄基羟基胺盐酸盐溶液(吡啶:甲醇:水=33:15:2)的溶液以1:5混合而使反应停止,使用高效液相色谱法来检测此时由羟醛化合物生成的o-苄基肟衍生物,并与浓度已知的样品进行比较。在此,将在25℃、1分钟内形成1μmol的羟醛化合物的活性设为1个单元。
“对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因(以下称为hpai基因突变体)”例如可通过聚合酶链式反应(polymerasechainreaction,pcr)或杂交(hybridization)而自其他生物种类的脱氧核糖核酸(deoxyribonucleicacid,dna)文库(library)中选择,所述pcr或杂交使用了依照基于序列号2的碱基序列的信息而设计的引物(primer)或探针(probe)。以所述方式选择的基因以高概率对具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行了编码。
“对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因(rhma基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种类的dna文库中选择。
“对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因(nana基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种类的dna文库中选择。
(1.3)第二基因
第二基因对“催化α-酮酸的脱羧反应的酶”进行编码。所谓“催化α-酮酸的脱羧反应的酶”,是指依照后述的测定方法,且作为酶反应液而使用包含纯化蛋白质及α-酮酸(初始基质浓度1mm)的酶反应液来进行测定时,具有1mu/mgprotein以上的活性的酶。第二基因对催化α-酮酸的脱羧反应的酶进行编码,所述α-酮酸例如是通过第一基因所编码的蛋白质催化的羟醛反应而获得。“催化α-酮酸的脱羧反应的酶”中的α-酮酸例如为4-羟基-2-氧代丁酸。“催化α-酮酸的脱羧反应的酶”例如为脱羧酶(decarboxylase)。
第二基因可为对以下所例示的脱羧酶进行编码的基因。
(b1)丙酮酸脱羧酶(pyruvatedecarboxylase,ec编号4.1.1.1);
(b2)苯甲酰甲酸脱羧酶(benzoylformatedecarboxylase,ec编号4.1.1.7);及
(b3)吲哚丙酮酸脱羧酶(indolepyruvatedecarboxylase,ec编号4.1.1.74)。
作为(b1)中包含的脱羧酶,例如可列举pdc蛋白质。优选pdc蛋白质来源于运动发酵单胞菌(zymomonasmobilis)。
作为(b2)中包含的脱羧酶,例如可列举mdlc蛋白质。优选mdlc蛋白质来源于恶臭假单胞菌(pseudomonasputida)。
作为(b3)中包含的脱羧酶,例如可列举kivd蛋白质。优选kivd蛋白质来源于乳酸乳球菌(lactococcuslactis)。
优选第二基因选自由以下所组成的群组中:
(2-1)对作为包含序列号8中记载的氨基酸序列的蛋白质(即,来源于恶臭假单胞菌的mdlc蛋白质)的、且催化α-酮酸的脱羧反应的蛋白质进行编码的基因,及
(2-2)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因。
“对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号8中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因”。
来源于恶臭假单胞菌的mdlc蛋白质的uniprotkb登录号例如为p20906。
更优选第二基因为包含序列号7中记载的碱基序列的来源于恶臭假单胞菌的mdlc基因。
序列号7中记载的碱基序列与序列号8中记载的氨基酸序列如下。
[表7]
[表8]
催化α-酮酸的脱羧反应的活性例如可通过以下方式来算出:在含有0.5mm硫胺素焦磷酸(thiaminepyrophosphate)、1mm氯化镁、10mm烟酰胺腺嘌呤二核苷酸的还原态(reducedformofnicotinamideadeninedinucleotide,nadh)、过量的醇脱氢酶的100mm磷酸钾缓冲剂(ph6.0)中在30℃下进行所述酶反应,测定由作为原料的α-酮酸生成的醛化合物被逐次还原而产生的醇化合物的初始生成速度。醇化合物的生成速度例如可根据醇化合物自身浓度的时间变化来算出。醇化合物的浓度的测定例如可通过以下方式来进行:使用高效液相色谱法对所述醇化合物进行检测,并将其与浓度已知的样品加以比较。在此,将在30℃、1分钟内可使1μmol的α-酮酸脱羧的活性设为1个单元。
“对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因(mdlc基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种类的dna文库中选择。
(1.4)第三基因
第三基因对“催化醛的还原反应的酶”进行编码。所谓“催化醛的还原反应的酶”,是指依照后述的测定方法,且作为酶反应液而使用包含纯化蛋白质及醛(初始基质浓度1mm)的酶反应液来进行测定时,具有10mu/mgprotein以上的活性的酶。此外,“催化醛的还原反应的酶”中的醛具体而言与作为第一基因所编码的酶催化的羟醛反应的基质的醛为不同种类。第三基因对催化醛的还原反应的酶进行编码,所述醛例如是通过第二基因所编码的蛋白质催化的脱羧反应而获得。“催化醛的还原反应的酶”中的醛例如为3-羟基丙醛。“催化醛的还原反应的酶”例如为醇脱氢酶。
第三基因例如可为对1,3-丙二醇脱氢酶(1,3-propanedioldehydrogenase,ec编号1.1.1.202)进行编码的基因。
作为1,3-丙二醇脱氢酶,例如可列举dhat蛋白质或lpo蛋白质。优选dhat蛋白质来源于肺炎克雷伯菌(klebsiellapneumoniae)。另外,优选lpo蛋白质来源于罗伊氏乳杆菌(lactobacillusreuteri)。
优选第三基因选自由以下所组成的群组中:
(3-1)对作为包含序列号10中记载的氨基酸序列的蛋白质(即,来源于肺炎克雷伯菌的dhat蛋白质)的、且催化醛的还原反应的蛋白质进行编码的基因;及
(3-2)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因。
“对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号10中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因”。
来源于肺炎克雷伯菌的dhat蛋白质的uniprotkb登录号例如为q59477。
更优选第三基因为包含序列号9中记载的碱基序列的来源于肺炎克雷伯菌的dhat基因。
序列号9中记载的碱基序列与序列号10中记载的氨基酸序列如下。
[表9]
[表10]
催化醛的还原反应的活性例如可通过以下方式来算出:在含有0.2mmnadh的50mm2-(n-吗啉代)乙磺酸(2-(n-morpholino)ethanesulfonicacid,mes)-naoh缓冲剂(ph6.5)中在30℃下进行所述酶反应,测定作为原料的醛被还原为醇化合物时所消耗的nadh的初始消耗速度。nadh的初始消耗速度例如可通过测定来源于酶反应液中的nadh的、340nm下的吸光度的减少速度来算出。在此,将在30℃、1分钟内可使1μmol的醛还原的活性设为1个单元。
“对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因(dhat基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种类的dna文库中选择。
(1.5)用于转化的重组载体的构建
第一基因、第二基因及第三基因可组入到适当的质粒载体(plasmidvector)中来进行转化。
作为质粒载体,可根据宿主而使用公知的质粒载体。作为质粒载体,可包含在宿主内掌控自主复制功能的基因,也可包含组入到宿主的染色体时所需的碱基序列。
第一基因、第二基因及第三基因分别可组入到各不相同的质粒载体中,或者也可组入到同一质粒载体中。可使用所获得的重组载体来制作转化体。
(1.6)转化
转化方法可无限制地使用公知的方法。作为此种公知的方法,例如可列举氯化钙/氯化铷法、磷酸钙法、二乙氨基乙基(diethylaminoethyl,deae)-葡聚糖(dextran)介导转染(transfection)、电脉冲法等。
所获得的转化体可在转化后,迅速使用通常用于转化体的培养的培养基进行培养。
培养温度只要是适于转化体增殖的温度,则可为任意温度。培养基的ph只要是适于转化体增殖的ph,则可为任意ph。培养基的ph调整可通过公知的方法进行。在培养过程中也可根据需要适宜调整培养基的ph。培养时间只要是对于转化体的增殖而言充分的时间,则可为任意时间。
此外,在如上所述使用重组载体制作转化体的情况下,第一基因、第二基因及第三基因可分别组入到宿主的染色体中,或者也可以重组载体的形态存在于宿主的细胞质内。
(1.7)宿主染色体基因的破坏或缺失
宿主不仅可为野生株,也可为其突变株或人工的基因重组体。在宿主为棒状细菌的情况下,宿主优选为通过使作为野生株的棒状细菌本来所具有的下述基因的至少一个破坏或缺失而获得的基因破坏株或基因缺失株:乳酸(lactate)脱氢酶(lactatedehydrogenase,例如ldha)基因、磷酸烯醇丙酮酸羧化酶(phosphoenolpyrvatecarboxylase,例如ppc)基因、丙酮酸羧化酶(pyruvatecarboxylase,例如pyc)基因、丙酮酸脱氢酶(pyruvatedehydrogenase,例如poxb)基因、谷氨酸-丙酮酸氨基转移酶(glutamate-pyruvateaminotransferase,例如alaa)基因、乙酰乳酸合酶(acetolactatesynthase,例如ilvb)基因、n-琥珀酰二氨基庚二酸(n-succinyldiaminopimelateaminotransferase,例如cg0931)基因、s-(羟甲基)分枝硫醇脱氢酶(s-(hydroxymethyl)mycothioldehydrogenase,例如adhe)基因、及乙醛脱氢酶(acetaldehydedehydrogenase,例如ald)基因。通过将此种基因破坏株或基因缺失株用作宿主,可提高1,3-丙二醇的生产性、或抑制副产物的生成。
基因破坏株或基因缺失株的构建可通过公知的方法进行。
(2.)培养工序
可在糖类及甲醛的存在下对1,3-丙二醇生产微生物(例如所述转化体)进行培养,以生产1,3-丙二醇。“在糖类及甲醛的存在下进行培养”可通过在包含糖类及甲醛的培养液中进行培养来进行。“在糖类及甲醛的存在下进行培养”优选可通过在添加了糖类及甲醛的培养液中进行培养来进行。
在糖类及甲醛的存在下进行培养之前,优选在好氧条件下对所述转化体进行培养以使其增殖。所述在好氧条件下进行的培养以下称为增殖培养,在糖类及甲醛的存在下进行的培养以下称为生产培养。具体而言,例如,所谓在好氧条件下进行的培养,是指在培养期间以对于转化体增殖而言充分的量向培养液供给氧的条件下进行培养。在好氧条件下进行的培养可通过公知的方法进行。在好氧条件下进行的培养例如可通过利用通气、搅拌、振荡或它们的组合而向培养液供给氧来实现。更具体而言,在好氧条件下进行的培养可通过振荡培养、深部通气搅拌培养来实现。
当在生产培养之前进行增殖培养时,增殖培养与其后的生产培养例如可以如下方式进行。在增殖培养后,首先,可将包含增殖培养中所使用的培养液(以下称为增殖用培养液)以及悬浮于增殖用培养液中的转化体的容器置于离心分离机中,使转化体沉淀。然后,可自容器中去除增殖用培养液,并将分离出的转化体悬浮于生产培养中使用的培养液(以下称为生产用培养液)中,以进行生产培养。
或者,增殖培养与其后的生产培养可通过在增殖培养后向含有转化体的增殖用培养液中添加糖类及甲醛,并将好氧条件变更为厌氧条件或微好氧条件,由此在不进行培养液的更换的条件下进行生产培养。如此,也可连续进行增殖培养与生产培养。
在本说明书中,“培养”这一用语是指在适于转化体生长的受到特定管理的条件下维持转化体。在培养期间,转化体可增殖,也可不增殖。因此,“培养”这一用语也可改称为“孵化(incubation)”。
(2.1)增殖用培养液
增殖用培养液可使用通常用于转化体的培养的培养基,例如含有碳源、氮源及无机盐类等的公知的培养基。
增殖培养的培养温度只要是适于转化体增殖的温度,则可为任意温度。增殖用培养液的ph只要是适于转化体增殖的ph,则可为任意ph。增殖用培养液的ph调整可通过公知的方法进行。增殖培养的培养时间只要是对于转化体的增殖而言充分的时间,则可为任意时间。
(2.2)生产用培养液
作为生产用培养液,可使用含有糖类、甲醛、及其他必要成分的培养液。作为其他必要成分,例如可使用无机盐类、糖类以外的碳源、或氮源。本说明书中记载的培养液中的各成分的浓度是指添加各成分的时间点下的培养液中的最终浓度。
作为糖类,只要是转化体可纳入生物体内且可转变为丙酮酸的糖类,则可使用任意的糖类。具体而言,作为糖类,可列举葡萄糖、果糖、甘露糖、木糖、阿拉伯糖、半乳糖之类的单糖;蔗糖、麦芽糖、乳糖、纤维二糖(cellobiose)、木二糖(xylobiose)、海藻糖之类的二糖;淀粉之类的多糖;糖蜜等。其中,优选为单糖,更优选为果糖及葡萄糖。另外,也优选为包含葡萄糖作为构成单糖的糖类,具体而言为蔗糖等二糖、包含葡萄糖作为构成单糖的寡糖、包含葡萄糖作为构成单糖的多糖。糖类可使用一种,也可混合使用两种以上。另外,糖类可以糖化液(其包含葡萄糖、木糖等多种糖类)的形式添加,所述糖化液是通过利用糖化酶等对稻草、蔗渣(bagasse)、玉米秸秆(cornstover)等非可食用农产废弃物、或柳枝稷(switchgrass)、象草、芒草等能源作物加以糖化而获得。
在不妨碍1,3-丙二醇的生产的范围内,生产用培养液中糖类的浓度可尽可能地提高。生产用培养液中糖类的浓度优选在0.1(w/v)%~40(w/v)%的范围内,更优选在1(w/v)%~20(w/v)%的范围内。另外,可与伴随1,3-丙二醇的生产的糖类的减少对应地进行糖类的追加添加。
生产用培养液中甲醛的浓度优选在0.001(w/v)%~10(w/v)%的范围内,更优选在0.01(w/v)%~1(w/v)%的范围内。另外,可与伴随1,3-丙二醇的生产的甲醛的减少对应地进行甲醛的追加添加。
进而,根据需要,还可添加无机盐类。作为无机盐类,可使用磷酸盐、硫酸盐、镁、钾、锰、铁、锌等金属盐。具体而言,可使用磷酸亚钾、磷酸钾、硫酸镁、氯化钠、硝酸亚铁、硫酸铁(ii)、硫酸锰、硫酸锌、硫酸钴、碳酸钙等。无机盐可使用一种,也可混合使用两种以上。生产用培养液中无机盐类的浓度根据所使用的无机盐而不同,但通常可设为约0.01(w/v)%~1(w/v)%。
进而,根据需要,还可添加糖类以外的碳源。作为糖类以外的碳源,可使用:甘露醇、山梨糖醇、木糖醇、丙三醇(glycerol)、甘油(glycerin)之类的糖醇;乙酸、柠檬酶、乳酸、富马酸、马来酸、葡萄糖酸之类的有机酸;正烷烃(normalparaffin)之类的烃等。
进而,根据需要,还可添加氮源。作为氮源,可使用:氯化铵、硫酸铵、硝酸铵、乙酸铵之类的无机或有机的铵盐;尿素;氨水;硝酸钠、硝酸钾等硝酸盐等。另外,也可使用:玉米浆(cornsteepliquor);肉提取物;酵母提取物;大豆水解物;蛋白胨、nz-胺或酪蛋白分解物等蛋白质水解物;氨基酸等含氮有机化合物等。氮源可使用一种,也可混合使用两种以上。生产用培养液中氮源的浓度根据使用的氮化合物而不同,但通常可设为约0.1(w/v)%~10(w/v)%。
进而,根据需要,还可添加维生素类。作为维生素类,可列举:生物素、硫胺素(维生素b1)、吡哆醇(维生素b6)、泛酸、肌醇、烟酸等。
作为具体的生产用培养液,可使用包含葡萄糖、甲醛、硫酸铵、磷酸二氢钾、磷酸氢二钾、硫酸镁、硫酸铁(ii)及硫酸锰(ii)且具有6.0的ph的培养基。
另外,作为生产用培养液,也可使用在与增殖培养中所使用的增殖用培养液相同组成的基础培养液中添加糖类与甲醛而获得的培养液。此外,在所述基础培养液中存在充分量的糖类的情况下,也可不添加糖类。
(2.3)生产培养的条件
生产培养的培养温度只要是适于生产1,3-丙二醇的温度,则可为任意温度。生产培养的培养温度优选为约20℃~50℃,更优选为约25℃~47℃。只要为所述温度范围,则可效率良好地制造1,3-丙二醇。生产用培养液的ph只要是适于生产1,3-丙二醇的ph,则可为任意ph。生产用培养液的ph优选维持于约6~8的范围内。生产用培养液的ph调整例如可使用氢氧化钾水溶液进行。在生产培养过程中也可根据需要适宜调整生产用培养液的ph。生产培养的培养时间只要是对于转化体生产1,3-丙二醇而言充分的时间,则可为任意时间。生产培养的培养时间优选为约3小时~7天,更优选为约1天~3天。
生产培养可在好氧条件下进行,也可在厌氧条件或微好氧条件下进行。其原因在于:所述转化体具有在好氧条件下及厌氧条件或微好氧条件下均起作用的生产1,3-丙二醇的途径。生产1,3-丙二醇的途径在后述的“(3.)作用及效果”一栏中叙述。
<厌氧条件或微好氧条件>
生产培养优选在厌氧条件或微好氧条件下进行。
若在厌氧条件下或微好氧条件下培养转化体,则转化体实质上不会增殖,可更有效率地生产1,3-丙二醇。
“厌氧条件或微好氧条件”例如是指生产用培养液中的溶解氧浓度在0ppm~2ppm范围内的条件。“厌氧条件或微好氧条件”优选是指生产用培养液中的溶解氧浓度在0ppm~1ppm范围内的条件,更优选是指生产用培养液中的溶解氧浓度在0ppm~0.5ppm范围内的条件。培养液中的溶解氧浓度例如可使用溶解氧计来测定。
严格来说,“厌氧条件”是指不存在溶解氧及硝酸等的氧化物之类的电子受体的条件的技术用语。另一方面,作为生产培养的优选条件,若为如下所述,则不需要采用所述严格的条件:所述电子受体并不充分,或者基于所述电子受体的性质,转化体不会增殖,相应地供给的碳源被用于1,3-丙二醇的生产,从而可提高其生产效率。即,作为生产培养的优选条件,只要可抑制转化体的增殖并提高1,3-丙二醇的生产效率,则生产用培养液中也可存在溶解氧及硝酸等氧化物之类的电子受体。因此,本说明书中使用的“厌氧条件或微好氧条件”这一表述也包括此种状态。
厌氧条件及微好氧条件例如可通过不通入包含氧的气体,使得自气液界面供给的氧对转化体的增殖而言变得不充分来实现。或者可通过在生产用培养液中通入惰性气体、具体而言为氮气来实现。或者还可通过将用于生产培养的容器加以密闭来实现。
<高密度条件>
生产培养优选在使转化体高密度地悬浮于生产用培养液中的状态下进行。若在此种状态下培养转化体,则可更有效率地生产1,3-丙二醇。
“使转化体高密度地悬浮于生产用培养液中的状态”例如是指以转化体的湿菌体重量%成为1(w/v)%~50(w/v)%的范围内的方式使转化体悬浮于生产用培养液中的状态。“使转化体高密度地悬浮于生产用培养液中的状态”优选是指以转化体的湿菌体重量%成为3(w/v)%~30(w/v)%的范围内的方式使转化体悬浮于生产用培养液中的状态。
生产培养更优选在厌氧条件或微好氧条件下,在使转化体高密度地悬浮于生产用培养液中的状态下进行。
(2.4)1,3-丙二醇的回收
如上所述,若在生产用培养液中对包含第一基因、第二基因及第三基因的转化体进行培养,则可在生产用培养液中生产1,3-丙二醇。可通过回收生产用培养液来回收1,3-丙二醇,但也可进一步通过公知的方法自生产用培养液中分离纯化1,3-丙二醇。作为此种公知的方法,可列举蒸馏法、浓缩法、离子交换树脂法、活性炭吸附洗脱法、溶媒萃取法、晶析法等。
此外,还可自生产用培养液中回收通过第一基因所编码的酶催化的羟醛反应而产生的4-羟基-2-氧代丁酸等物质。
(3.)作用及效果
将1,3-丙二醇生产微生物生产1,3-丙二醇的工艺示意性地示于图1。在图1所示的工艺中,以糖类为葡萄糖的情况为例进行说明。
如图1所示,首先,1,3-丙二醇生产微生物1纳入葡萄糖2及甲醛3。接着,葡萄糖2通过解糖体系转变为丙酮酸4。接着,丙酮酸4与甲醛3通过第一基因所编码的“催化丙酮酸与醛的羟醛反应的酶”而转变为4-羟基-2-氧代丁酸5。接着,4-羟基-2-氧代丁酸5通过第二基因所编码的“催化α-酮酸的脱羧反应的酶”而转变为3-羟基丙醛6。接着,3-羟基丙醛6通过第三基因所编码的“催化醛的还原反应的酶”而转变为1,3-丙二醇7。以如上方式生产1,3-丙二醇。
上述中所说明的方法发现了通过如上所述般在甲醛的存在下对具有特定的基因的微生物进行培养而获得1,3-丙二醇的生产工艺,从而完成了本发明。一般而言,甲醛对微生物的生长是有害的,因此在其存在下获得了有用的化合物令人惊讶。此外,1,3-丙二醇是可用作聚合物原料、化妆品材料、防冻液的化合物。
(4.)优选实施方式
以下,汇总示出本发明的优选实施方式。
[1]一种1,3-丙二醇的制造方法,包括在糖类及甲醛的存在下,对包含以下基因的微生物进行培养以生产1,3-丙二醇:
(a)第一基因,对催化丙酮酸与醛的羟醛反应的酶进行编码;
(b)第二基因,对催化α-酮酸的脱羧反应的酶进行编码;及
(c)第三基因,对催化醛的还原反应的酶进行编码。
[2]根据[1]所述的方法,其中,所述培养通过在包含所述糖类及甲醛的培养液中对所述微生物进行培养来进行。
[3]根据[2]所述的方法,其中,所述培养液为添加了所述糖类及甲醛的培养液。
[4]根据[3]所述的方法,其中,以在所述培养液中成为0.1(w/v)%~40(w/v)%、优选为1(w/v)%~20(w/v)%的浓度的方式添加所述糖类。
[5]根据[3]或[4]所述的方法,其中,以在所述培养液中成为0.001(w/v)%~10(w/v)%、优选为0.01(w/v)%~1(w/v)%的浓度的方式添加甲醛。
[6]根据[1]至[5]中任一项所述的方法,其中,所述糖类为:单糖,例如果糖或葡萄糖;二糖,例如蔗糖;多糖,例如包含葡萄糖作为构成单糖的多糖;或者利用糖化酶对植物(例如非可食用农产废弃物或能量作物)进行处理而获得的糖化液。
[7]根据[1]至[6]所述的方法,其中,所述糖类为葡萄糖。
[8]根据[1]至[7]中任一项所述的方法,其中,所述培养在厌氧条件或微好氧条件下进行。
[9]根据[8]所述的方法,其中,所述培养通过在包含所述糖类及甲醛的培养液中对所述微生物进行培养来进行。
[10]根据[9]所述的方法,其中,所述厌氧条件或所述微好氧条件是所述培养液中的溶解氧浓度在0ppm~2ppm的范围内、优选在0ppm~1ppm的范围内、更优选在0ppm~0.5ppm的范围内的条件。
[11]根据[1]至[10]中任一项所述的方法,其中,所述培养在使所述微生物高密度地悬浮于培养液中的状态下进行。
[12]根据[11]所述的方法,其中,所述培养通过在包含所述糖类及甲醛的培养液中对所述微生物进行培养来进行。
[13]如[12]所述的方法,其中,使所述微生物高密度地悬浮于所述培养液中的所述状态是以所述微生物的湿菌体重量%成为1(w/v)%~50(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态,优选是以所述微生物的湿菌体重量%成为3(w/v)%~30(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态。
[14]根据[1]至[13]中任一项所述的方法,其中,所述第一基因对醛缩酶进行编码。
[15]根据[1]至[14]中任一项所述的方法,其中,所述第一基因对i类醛缩酶进行编码。
[16]根据[1]至[14]中任一项所述的方法,其中,所述第一基因对ii类醛缩酶进行编码。
[17]根据[1]至[16]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:
(a1)2-脱氢-3-脱氧-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-phosphogluconatealdolase);
(a2)2-脱氢-3-脱氧-6-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-6-phosphogluconatealdolase);
(a3)4-羟基-2-氧代戊二酸醛缩酶(4-hydroxy-2-oxoglutaratealdolase);
(a4)(4s)-4-羟基-2-氧代戊二酸醛缩酶((4s)-4-hydroxyl-2-oxoglutaratealdolase);
(a5)2-脱氢-3-脱氧-d-戊糖酸醛缩酶(2-dehydro-3-deoxy-d-pentonatealdolase);
(a6)2-脱氢-3-脱氧-d-葡萄糖酸醛缩酶(2-dehydro-3-deoxy-d-gluconatealdolase);
(a7)3-脱氧-d-甘露-辛酮糖酸醛缩酶(3-deoxy-d-manno-octulosonatealdolase);
(a8)4-羟基-2-氧代戊酸醛缩酶(4-hydroxyl-2-oxovaleratealdolase);
(a9)4-(2-羧基苯基)-2-氧代丁-3-烯酸醛缩酶(4-(2-carboxyphenyl)-2-oxobut-3-enoatealdolase);
(a10)4-羟基-2-氧代庚烷二酸醛缩酶(4-hydroxy-2-oxoheptanedioatealdolase);
(a11)2-脱氢-3-脱氧葡萄糖二酸醛缩酶(2-dehydro-3-deoxyglucaratealdolase);
(a12)2-酮-3-脱氧-l-鼠李糖酸醛缩酶(2-keto-3-deoxy-l-rhamnonatealdolase);
(a13)4-羟基-4-甲基-2-氧代戊二酸醛缩酶(4-hydroxyl-4-methyl-2-oxoglutaratealdolase);及
(a14)4-羟基-2-氧代己酸醛缩酶(4-hydroxy-2-oxohexanonatealdolase)。
[18]根据[1]至[17]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:eda蛋白质,优选为来源于大肠杆菌的eda蛋白质;dgoa蛋白质,优选为来源于大肠杆菌的dgoa蛋白质;yjhh蛋白质,优选为来源于大肠杆菌的yjhh蛋白质;yage蛋白质,优选为来源于大肠杆菌的yage蛋白质;nana蛋白质,优选为来源于大肠杆菌的nana蛋白质;mhpe蛋白质,优选为来源于大肠杆菌的mhpe蛋白质;hpai蛋白质,优选为来源于大肠杆菌的hpai蛋白质;bphi蛋白质,优选为来源于食异源化合物伯克霍尔德氏菌的bphi蛋白质;phdj蛋白质,优选为来源于类诺卡氏菌属菌的phdj蛋白质;garl蛋白质,优选为来源于大肠杆菌的garl蛋白质;rhma蛋白质,优选为来源于大肠杆菌的rhma蛋白质;及galc蛋白质,优选为来源于恶臭假单胞菌的galc蛋白质。
[19]根据[1]至[18]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:nana蛋白质,优选为来源于大肠杆菌的nana蛋白质;hpai蛋白质,优选为来源于大肠杆菌的hpai蛋白质;及rhma蛋白质,优选为来源于大肠杆菌的rhma蛋白质。
[20]根据[1]至[19]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:
(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与醛的羟醛反应的蛋白质进行编码的基因,
(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因,
(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与醛的羟醛反应的蛋白质进行编码的基因,
(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因,
(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与醛的羟醛反应的蛋白质进行编码的基因,及
(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因。
[21]根据[1]至[20]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:
包含序列号1中记载的碱基序列的来源于大肠杆菌的hpai基因;
包含序列号3中记载的碱基序列的来源于大肠杆菌的rhma基因;及
包含序列号5中记载的碱基序列的来源于大肠杆菌的nana基因。
[22]根据[1]至[21]中任一项所述的方法,其中,所述第二基因对催化α-酮酸的脱羧反应的所述酶进行编码,所述α-酮酸是通过所述羟醛反应而获得。
[23]根据[1]至[22]中任一项所述的方法,其中,所述第二基因对脱羧酶进行编码。
[24]根据[1]至[23]中任一项所述的方法,其中,所述第二基因对选自由以下所组成的群组中的脱羧酶进行编码:
(b1)丙酮酸脱羧酶(pyruvatedecarboxylase);
(b2)苯甲酰甲酸脱羧酶(benzoylformatedecarboxylase);及
(b3)吲哚丙酮酸脱羧酶(indolepyruvatedecarboxylase)。
[25]根据[1]至[24]中任一项所述的方法,其中,所述第二基因对选自由以下所组成的群组中的脱羧酶进行编码:pdc蛋白质,优选为来源于运动发酵单胞菌的pdc蛋白质;mdlc蛋白质,优选为来源于恶臭假单胞菌的mdlc蛋白质;kivd蛋白质,优选为来源于乳酸乳球菌的kivd蛋白质。
[26]根据[1]至[25]中任一项所述的方法,其中,所述第二基因对mdlc蛋白质、优选为来源于恶臭假单胞菌的mdlc蛋白质进行编码。
[27]根据[1]至[26]中任一项所述的方法,其中,所述第二基因选自由以下所组成的群组中:
(2-1)对包含序列号8中记载的氨基酸序列、且催化α-酮酸的脱羧反应的蛋白质进行编码的基因,及
(2-2)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因。
[28]根据[1]至[27]任一项所述的方法,其中,所述第二基因为包含序列号7中记载的碱基序列的来源于恶臭假单胞菌的mdlc基因。
[29]根据[1]至[28]中任一项所述的方法,其中,所述第三基因对催化醛的还原反应的所述酶进行编码,所述醛与作为所述第一基因所编码的所述酶催化的所述羟醛反应的基质的醛为不同种类。
[30]根据[1]至[29]中任一项所述的方法,其中,所述第三基因对催化醛的还原反应的所述酶进行编码,所述醛是通过所述脱羧反应而获得。
[31]根据[1]至[30]中任一项所述的方法,其中,所述第三基因对醇脱氢酶进行编码。
[32]根据[1]至[31]中任一项所述的方法,其中,所述第三基因对1,3-丙二醇脱氢酶(1,3-propanedioldehydrogenase)进行编码。
[33]根据[1]至[32]中任一项所述的方法,其中,所述第三基因对选自由以下所组成的群组中的1,3-丙二醇脱氢酶进行编码:dhat蛋白质,优选为来源于肺炎克雷伯菌的dhat蛋白质;及lpo蛋白质,优选为来源于罗伊氏乳杆菌的lpo蛋白质。
[34]根据[1]至[33]中任一项所述的方法,其中,所述第三基因选自由以下所组成的群组中:
(3-1)对包含序列号10中记载的氨基酸序列、且催化醛的还原反应的蛋白质进行编码的基因,及
(3-2)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因。
[35]根据[1]至[34]中任一项所述的方法,其中,所述第三基因为包含序列号9中记载的碱基序列的来源于肺炎克雷伯菌的dhat基因。
[36]根据[1]至[35]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:
(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与醛的羟醛反应的蛋白质进行编码的基因,
(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因,
(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与醛的羟醛反应的蛋白质进行编码的基因,
(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因,
(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与醛的羟醛反应的蛋白质进行编码的基因,及
(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与醛的羟醛反应的活性的蛋白质进行编码的基因;
所述第二基因选自由以下所组成的群组中:
(2-1)对包含序列号8中记载的氨基酸序列、且催化α-酮酸的脱羧反应的蛋白质进行编码的基因,及
(2-2)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因;且
所述第三基因选自由以下组成的群组中:
(3-1)对包含序列号10中记载的氨基酸序列、且催化醛的还原反应的蛋白质进行编码的基因,及
(3-2)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因。
[37]根据[1]至[36]中任一项所述的方法,其中,所述微生物为好氧性细菌,优选为棒状细菌,更优选为棒状杆菌属(corynebacterium)菌,更优选为谷氨酸棒状杆菌(corynebacteriumglutamicum)。
[38]根据[1]至[37]中任一项所述的方法,其中,所述微生物是通过所述第一基因、所述第二基因及所述第三基因进行了转化的微生物。
[39]根据[1]至[38]中任一项所述的方法,其中,所述微生物是选自由以下所组成的群组中的至少一种基因的缺陷株:乳酸(lactate)脱氢酶(lactatedehydrogenase)基因、磷酸烯醇丙酮酸羧化酶(phosphoenolpyrvatecarboxylase)基因、丙酮酸羧化酶(pyruvatecarboxylase)基因、丙酮酸脱氢酶(pyruvatedehydrogenase)基因、谷氨酸-丙酮酸氨基转移酶(glutamate-pyruvateaminotransferase)基因、乙酰乳酸合酶(acetolactatesynthase)基因、n-琥珀酰二氨基庚二酸(n-succinyldiaminopimelateaminotransferase)基因、s-(羟甲基)分枝硫醇脱氢酶(s-(hydroxymethyl)mycothioldehydrogenase)基因、及乙醛脱氢酶(acetaldehydedehydrogenase)基因。
[40]根据[1]至[39]中任一项所述的方法,还包括:在所述培养之前,在好氧条件下对所述微生物进行培养。
[41]根据[1]至[40]中任一项所述的方法,还包括:对所生产的1,3-丙二醇进行回收。
实施例
1.材料及方法
(1-1)培养基
若未特别指明,则试剂是自富士胶片和光纯药股份有限公司购入。
(a培养基)
将尿素2.0g、硫酸铵7.0g、磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、酵母提取物(迪福科(difco)公司制造)2.0g、酪蛋白氨基酸(casaminoacid)维生素分析(vitaminassay)(迪福科(difco)公司制造)7.0g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg、d(+)-生物素0.20mg、盐酸硫胺素0.20mg溶解于0.92l的水中,使用5m氢氧化钾水溶液将ph调整为7.0。对其在121℃下进行20分钟高压釜灭菌,并在冷却至室温后,加入已完成高压釜灭菌的50%(w/v)葡萄糖水溶液80ml,由此制备的液体培养基。
(a琼脂培养基)
将尿素2.0g、硫酸铵7.0g、磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、酵母提取物(迪福科(difco)公司制造)2.0g、酪蛋白氨基酸维生素分析(vitaminassay)(迪福科(difco)公司制造)7.0g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg、d(+)-生物素0.20mg、盐酸硫胺素0.20mg、琼脂15g溶解、悬浮于0.92l的水中,使用5m氢氧化钾水溶液将ph调整为7.0。对其在121℃下进行20分钟高压釜灭菌,并在冷却至50℃后,加入已完成高压釜灭菌的50%(w/v)葡萄糖水溶液80ml,分注至培养皿后进行冷却固化,由此制备的固体培养基。
(ba培养基)
将尿素2.0g、硫酸铵7.0g、磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、酵母提取物(迪福科(difco)公司制造)2.0g、酪蛋白氨基酸维生素分析(vitaminassay)(迪福科(difco)公司制造)7.0g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg、d(+)-生物素0.20mg、盐酸硫胺素0.20mg、4-吗啉丙磺酸21g溶解于0.92l的水中,使用5m氢氧化钾水溶液将ph调整为7.0。对其在121℃下进行20分钟高压釜灭菌,冷却至室温后,加入已完成高压釜灭菌的50%(w/v)葡萄糖水溶液80ml,由此制备的液体培养基。
(lb培养基)
将细菌用胰胨(bacto-tryptone)(迪福科(difco)公司制造)10g、酵母提取物(迪福科(difco)公司制造)5.0g、氯化钠10g溶解于1l的水中,使用5m氢氧化钠水溶液将ph调整为7.0后,在121℃下进行20分钟高压釜灭菌,由此制备的液体培养基。
(lb琼脂培养基)
将细菌用胰胨(迪福科(difco)公司制造)10g、酵母提取物(迪福科(difco)公司制造)5.0g、氯化钠10g、琼脂15g溶解、悬浮于1l的水中,使用5m氢氧化钠水溶液将ph调整为7.0后,在121℃下进行20分钟高压釜灭菌,冷却至50℃后,分注至培养皿并进行冷却固化,由此制备的固体培养基。
(suc琼脂培养基)
将细菌用胰胨(迪福科(difco)公司制造)10g、酵母提取物(迪福科(difco)公司制造)5.0g、氯化钠10g、琼脂15g溶解、悬浮于0.5l的水中,使用5m氢氧化钠水溶液将ph调整为7.0。对其在121℃下进行20分钟高压釜灭菌,冷却至50℃后,加入已完成高压釜灭菌的20%(w/v)的蔗糖水溶液0.5l,分注至培养皿后进行冷却固化,由此制备的固体培养基。
(bhis培养基)
将脑心浸液(brainheartinfusion)(迪福科(difco)公司制造)36g、山梨糖醇91g溶解于1l的水中,使用5m氢氧化钠水溶液将ph调整为7.0后,在121℃下进行20分钟高压釜灭菌,由此制备的液体培养基。
(bhis-git培养基)
将脑心浸液(迪福科(difco)公司制造)36g、甘氨酸8.0g、异烟肼(isoniazide)1.3g、吐温(tween)803ml、山梨糖醇91g溶解于1l的水中,使用5m氢氧化钠水溶液将ph调整为7.0后,在121℃下进行20分钟高压釜灭菌,由此制备的液体培养基。
(1-2)缓冲剂及试剂
(te缓冲剂)
将三羟甲基氨基甲烷1.2g、乙二胺-n,n,n',n'-四乙酸二钠盐二水合物0.37g溶解于1l的水中,使用6m盐酸将ph调整为8.0后,在121℃下进行20分钟高压釜灭菌,由此制备的缓冲液。
(tg缓冲剂)
将三羟甲基氨基甲烷0.12g、丙三醇10g溶解于1l的水中,使用6m盐酸将ph调整为7.5后,在121℃下进行20分钟高压釜灭菌,由此制备的缓冲液。
(10%丙三醇水溶液)
将丙三醇100g溶解于1l的水中后,在121℃下进行20分钟高压釜灭菌,由此制备的水溶液。
(br缓冲剂)
将磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg溶解于1.0l的水中,使用5m氢氧化钾水溶液将ph调整为7.0,由此获得的缓冲液。
(1-3)分析条件的定义及实验方法
(琼脂糖凝胶电泳(agarosegelelectrophoresis)后的dna片段的提取、纯化)
将牛克劳斯宾(nucleospin)(注册商标)凝胶与pcr清除(gelandpcrclean-up)(马歇雷纳高(macherey-nagel)公司制造)按照其使用说明书加以使用,来进行dna片段的提取、纯化。
(质粒提取)
将牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure)(马歇雷纳高(macherey-nagel)公司制造)按照其使用说明书加以使用,来进行质粒的提取、纯化。
(pcr法)
使用以下任一种dna聚合酶及其附属的试剂,依照其使用说明书进行pcr:原恒星(primestar)(注册商标)hsdna聚合酶(hsdnapolymerase)(宝生物(takarabio)公司制造)、原恒星(primestar)(注册商标)maxdna聚合酶(maxdnapolymerase)(宝生物(takarabio)公司制造)、tks吉福乐斯dna聚合酶(tksgflextmdnapolymerase)(宝生物(takarabio)公司制造)。
(有机酸分析用液相色谱法)
使用包括岛津制作所制造的以下设备的有机酸分析系统。系统控制器:cbm-20a、送液单元:lc-20ab、在线脱气单元:dgu-20a3r、自动注射器(autoinjector):sil-20ac、柱温箱(columnoven):cto-20ac、光电二极管阵列检测器:spd-m20a。
分析条件如下。
保护柱:tskgeloapak-p(东曹公司制造)
分析柱:tskgeloapak-a(东曹公司制造)
柱温箱温度:40℃
流动相:0.75mm硫酸
流速:1.0ml/min。
(糖分析用液相色谱法)
使用包括岛津制作所制造的以下设备的糖分析系统。系统控制器:cbm-20a、送液单元:lc-20ab、在线脱气单元:dgu-20a3r、自动注射器:sil-20ac、柱温箱:cto-20ac、折射率检测器:rid-10a。
分析条件如下。
预处理:脱盐筒(cartridge)(伯乐(bio-rad)公司制造)
分析柱:阿米内科斯(aminex)hpx-87p(伯乐(bio-rad)公司制造)
柱温箱温度:85℃
流动相:水
流速:0.6ml/min。
(基因组(genome)dna提取)
将按照提供方的使用说明书进行了液体培养的微生物通过离心分离予以回收,并在-80℃下冻结。将菌体颗粒在室温下解冻,加入10mg/ml溶菌酶水溶液537μl,在37℃下振荡1小时。接着加入0.5m乙二胺四乙酸(ethylenediaminetetraaceticacid,edta)水溶液30μl、10%十二烷基硫酸钠(sodiumdodecylsulfate,sds)水溶液30μl、20mg/ml蛋白酶(proteinase)k水溶液3μl,在37℃下振荡1小时。然后进一步加入5m氯化钠水溶液100μl与10%溴化十六烷基三甲基铵水溶液(0.7m氯化钠中)80μl,在65℃下加热10分钟。冷却至室温后,加入氯仿-异戊醇(24:1)780μl,并加以平稳混合。在15000xg、4℃下进行5分钟离心分离,回收水层600μl。向其中加入苯酚-氯仿-异戊醇(25:24:1)600μl,并加以平稳混合。在15000xg、4℃下进行5分钟离心分离,回收水层500μl。向其中加入异丙醇300μl,在15000xg、4℃下进行5分钟离心分离后,去除上清液。加入70%乙醇500μl来清洗作为沉淀物而获得的基因组dna,并在15000xg、4℃下进行5分钟离心分离。将所述清洗重复进行两次,在室温下加以干燥后,将所获得的基因组dna溶解于te缓冲剂100μl中。
(用于转化谷氨酸棒状杆菌atcc13032来源株的电穿孔法)
在无菌条件下,在a琼脂培养基中接种将要进行转化的谷氨酸棒状杆菌atcc13032来源株的丙三醇原种(glycerolstock),在33℃下进行培养。将琼脂培养基上生长出的菌体接种到10ml的a培养基中,在33℃下进行振荡培养,并作为种子培养液。将所述种子培养液以混浊度成为0.2的方式接种到500ml烧瓶中所准备的100ml的牛心浸液(beefheartinfusionsupplement,bhis)培养基中。在33℃下进行振荡,培养至混浊度成为0.5~0.7为止。对所述培养液在4℃、5500xg下进行20分钟离心分离,去除上清液。利用10ml的tg缓冲剂来清洗所回收的菌体,在4℃、5500xg下进行5分钟离心分离,去除上清液。进行两次所述清洗后,利用10ml的10%丙三醇水溶液进行清洗,在4℃、5500xg下进行5分钟离心分离,去除上清液。使所获得的菌体颗粒悬浮于1ml的10%丙三醇水溶液中,每150μl分注到已完成灭菌的1.5ml管中后,使用液氮进行冻结,并作为感受态细胞(competentcell)而保存于-80℃下。
基因组dna上的基因缺失及基因取代的情况:在冰上融解150μl的感受态细胞,并加入500ng的质粒。将其转移到已完成灭菌的0.2cm间距电穿孔杯(electroporationcuvettes)(伯乐(bio-rad)公司制造)中,使用基因脉冲器x单元tm(genepulserxcelltm)电穿孔系统(伯乐(bio-rad)公司制造),在25μf、200ω、2500v下进行电穿孔。利用1ml的bhis培养基来稀释菌体悬浮液,并在46℃下孵化6分钟后,在33℃下进行1小时孵化。将所述菌体悬浮液接种到包含适当的抗生素的a琼脂培养基中,并选择目标转化体。
导入基因超表达用质粒的情况:在冰上融解50μl的感受态细胞,并加入200ng的质粒。将其转移到已完成灭菌的0.2cm间距电穿孔杯(伯乐(bio-rad)公司制造)中,使用基因脉冲器x单元tm(genepulserxcelltm)电穿孔系统(伯乐(bio-rad)公司制造),在25μf、200ω、2500v下进行电穿孔。利用1ml的bhis培养基来稀释菌体悬浮液,并在46℃下孵化6分钟后,在33℃下进行1小时孵化。将所述菌体悬浮液接种到包含适当的抗生素的a琼脂培养基中,并选择目标转化体。
(菌落(colony)pcr)
使用可扩增目标dna序列的引物的组合,按照takaraextaq(注册商标)(宝生物(takarabio)公司制造)的使用说明书将模板dna以外的试剂混合。在其中少量悬浮琼脂培养基中所产生的菌株的菌落,将其固有的dna作为模板,按照使用说明书进行pcr。对pcr产物利用琼脂糖凝胶电泳进行分析,确认到保持了目标质粒、或基因组上相应的dna序列已缺失或经取代。
(混浊度测定)
大肠杆菌及谷氨酸棒状杆菌的培养液的混浊度是使用乌特罗斯派克(ultrospec)8000(ge保健(gehealthcare)公司制造)在610nm的波长下进行测定。
(1-4)引物dna、菌体及质粒的详情
引物dna、菌体及质粒的详情记载于以下的表11~表31中。
[表11]
[表12]
表12
[表13]
[表14]
[表15]
[表16]
[表17]
[表18]
[表19]
[表20]
[表21]
[表22]
[表23]
[表24]
[表25]
[表26]
[表27]
[表28]
[表29]
[表30]
[表31]
[表32]
[表33]
2.质粒构建
(2-1)基因缺失篇
2-1-(1)基因破坏用质粒的构建
以pnic28-bsa4(源生物科学(sourcebioscience)公司制造)为模板,使用由gep007(序列号11)与gep008(序列号12)所表示的碱基序列的dna,通过pcr法对包含来源于枯草芽孢杆菌(bacillussubtilis)的sacb基因的dna片段[分子微生物学(molecularmicrobiology,mol.microbiol.),6,1195(1992)]进行扩增。利用bamhi及psti对所述pcr产物进行处理,并在琼脂糖凝胶电泳后进行dna片段的提取、纯化。另外,利用bamhi及psti对具有赋予相对于卡那霉素(kanamycin)的抗性的基因的质粒phsg299(宝生物(takarabio)公司制造)进行处理,并在琼脂糖凝胶电泳后进行dna片段的提取、纯化。将dna连接试剂盒(dnaligationkit)<强混合(mightymix)>(宝生物(takarabio)公司制造)按照其使用说明书加以使用,来将所述两个dna片段连结,获得质粒pge015。
出于pge015将sacb上所具有的kpni识别部位删除的目的,以pge015为模型,使用由gep808(序列号13)及gep809(序列号14)所表示的碱基序列的dna,将原恒星(primestar)(注册商标)突变形成基底试剂盒(mutagenesisbasalkit)(宝生物(takarabio)公司制造)按照其使用说明书加以使用,来进行突变导入及质粒的扩增,获得pge209。
2-1-(2)ppc基因破坏株制作用质粒的构建
谷氨酸棒状杆菌atcc13032株是作为nbrc12168株而自独立行政法人制品评价技术基盘机构生物技术中心获取,并在按照随附的使用说明书进行培养后,进行了基因组dna提取。
以atcc13032株的基因组dna为模板,使用由gep132(序列号15)与gep133(序列号16)所表示的碱基序列的dna的组合、及由gep134(序列号17)与gep135(序列号18)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge020。
2-1-(3)ppc基因缺失株的制作
使用pge020,通过电穿孔法对谷氨酸棒状杆菌atcc13032株进行转化,在33℃下在包含25μg/ml的卡那霉素的a培养基上选择了卡那霉素抗性株。接着,将所获得的卡那霉素抗性株涂布于suc琼脂培养基上,在33℃下进行培养。对生长出的菌落进一步在a培养基中进行培养,并选择通过菌落pcr而ppc基因已缺失的株。将其命名为ges007。
2-1-(4)ldha基因破坏株制作用质粒的构建
以atcc13032株的基因组dna为模板,使用由gep169(序列号19)与gep170(序列号20)所表示的碱基序列的dna的组合、及由gep215(序列号21)与gep216(序列号22)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge033。
2-1-(5)ldha基因缺失株的制作
使用pge033,通过电穿孔法对ges007进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges048。
2-1-(6)pyc基因破坏株制作用质粒的构建
以atcc13032株的基因组dna为模板,使用由gep615(序列号23)与gep616(序列号24)所表示的碱基序列的dna的组合、及由gep617(序列号25)与gep618(序列号26)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge177。
2-1-(7)pyc基因缺失株的制作
使用pge177,通过电穿孔法对ges048进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges385。
2-1-(8)poxb基因破坏株制作用质粒的构建
以atcc13032株的基因组dna为模板,使用由gep406(序列号27)与gep407(序列号28)所表示的碱基序列的dna的组合、及由gep698(序列号29)与gep409(序列号30)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge191。
2-1-(9)poxb基因缺失株的制作
使用pge191,通过电穿孔法对ges385进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges388。
2-1-(10)alaa基因破坏株制作用质粒的构建
以atcc13032株的基因组dna为模板,使用由gep810(序列号31)与gep811(序列号32)所表示的碱基序列的dna的组合、及由gep812(序列号33)与gep813(序列号34)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge210。
2-1-(11)alaa基因缺失株的制作
使用pge210,通过电穿孔法对ges388进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges393。
2-1-(12)ilvb基因破坏株制作用质粒的构建
以atcc13032株的基因组dna为模板,使用由gep956(序列号35)与gep957(序列号36)所表示的碱基序列的dna的组合、及由gep958(序列号37)与gep959(序列号38)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge228。
2-1-(13)ilvb基因缺失株的制作
使用pge228,通过电穿孔法对ges393进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges405。
2-1-(14)cg0931基因破坏株制作用质粒的构建
以atcc13032株的基因组dna为模板,使用由gep1132(序列号39)与gep1133(序列号40)所表示的碱基序列的dna的组合、及由gep1134(序列号41)与gep1135(序列号42)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge253。
2-1-(15)cg0931基因缺失株的制作
使用pge253,通过电穿孔法对ges405进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges435。
2-1-(16)adhe基因破坏株制作用质粒的构建
以atcc13032株的基因组dna为模板,使用由gep2606(序列号43)与gep2607(序列号44)所表示的碱基序列的dna的组合、及由gep2608(序列号45)与gep2609(序列号46)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用kpni与bamhi对pge209进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge1171。
以atcc13032株的基因组dna为模板,使用由gep2688(序列号47)及gep2607(序列号44)所表示的碱基序列的dna的组合、及由gep2608(序列号45)与gep2689(序列号48)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用kpni与bamhi对pge209进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge1218。
2-1-(17)adhe基因缺失株的制作
使用pge1171,通过电穿孔法对ges048进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges1041。
2-1-(18)ald基因破坏株制作用质粒的构建
以atcc13032株的基因组dna为模板,使用由gep2610(序列号49)与gep2611(序列号50)所表示的碱基序列的dna的组合、及由gep2612(序列号51)与gep2613(序列号52)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用kpni与bamhi对pge209进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge1172。
以atcc13032株的基因组dna为模板,使用由gep2692(序列号53)与gep2611(序列号50)所表示的碱基序列的dna的组合、及由gep2612(序列号51)与gep2693(序列号54)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用kpni与bamhi对pge209进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge1221。
2-1-(19)ald基因缺失株的制作
使用pge1172,通过电穿孔法对ges1041进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges1070。
(2-2)基因取代篇
2-2-(1)pge409的构建
以phsg298(宝生物(takarabio)公司制造)为模板,使用由gep433(序列号55)与gep434(序列号56)所表示的碱基序列的dna的组合、及由gep437(序列号57)与gep438(序列号58)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含卡那霉素抗性基因及大肠杆菌用复制起点pucori的dna片段。
自独立行政法人制品评价技术基盘机构生物技术中心获取谷氨酸棒状杆菌nbrc12169株,按照随附的使用说明书进行培养,并通过离心分离回收菌体。利用1ml的10mm环己二胺四乙酸(cyclohexylenedinitrilotetraaceticacid)、25mmtris-hcl(ph8.0)缓冲液来清洗菌体颗粒,在6,000xg、4℃下进行5分钟离心分离,并再次进行回收。使菌体颗粒悬浮于包含15mg/ml溶菌酶的300μl的缓冲剂a1(buffera1)(附带于马歇雷纳高(macherey-nagel)公司制造的牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure))中,在37℃下振荡2小时。然后,依照牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure)的使用说明书,进行pcg1质粒的提取及纯化。以此为模板,使用由gep445(序列号59)与gep446(序列号60)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含棒状杆菌用复制起点pcg1ori的dna片段。
将以上三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge403。
以atcc13032株的基因组dna为模板,使用由gep472(序列号61)与gep478(序列号62)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。另外,以pflag-ctc(西格玛奥德里奇(sigmaaldrich)公司制造)为模板,使用由gep467(序列号63)与gep468(序列号64)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含atcc13032株的gapa启动子(promoter)(pgapa)及大肠杆菌核糖体核糖核酸(ribonucleicacid,rna)转录终止子(terminator)(trrnb)的dna片段。进而,利用bamhi与ecorv对pge403进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge409。
2-2-(2)pge1185(δadhe::hpai取代株制作用质粒)的构建
购买ecostm感受态大肠杆菌(competente.coli)bl21(de3)(日本基因(nippongene)公司制造),将其在无菌条件下接种到lb琼脂培养基中,并在37℃下进行培养。将琼脂培养基上生长出的菌体接种到10ml的lb培养基中,回收生长出的菌体,并进行基因组dna提取。以bl21(de3)株的基因组dna为模板,使用由gep2268(序列号65)与gep2269(序列号66)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含大肠杆菌bl21(de3)株hpai基因(ec_hpai)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含100μg/ml的氨苄青霉素(ampicillin)的lb琼脂培养基上进行培养来选择。在包含100μg/ml的氨苄青霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。如此般获得了ec_hpai被克隆到pet-15b的质粒pge1031。
以pge1031为模板,使用由gep2519(序列号67)与gep2518(序列号68)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ndei与bamhi对pge409进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。如此般获得了ec_hpai被亚克隆到pge409的质粒pge1143。
以pge1143为模板,使用由gep2637(序列号69)与gep2638(序列号70)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-hpai-trrnb的dna片段。进而,利用xhoi对pge1171进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge1185。
2-2-(3)pge1186(δald::hpai取代株制作用质粒)的构建
以pge1143为模板,使用由gep2639(序列号71)与gep2640(序列号72)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-hpai-trrnb的dna片段。进而,利用xhoi对pge1172进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1186。
2-2-(4)δadhe::hpaiδald::hpai取代株的制作
使用pge1186,通过电穿孔法对ges1041进行转化,在33℃下在包含25μg/ml的卡那霉素的a培养基上选择了卡那霉素抗性株。接着,将所获得的卡那霉素抗性株涂布于suc琼脂培养基上,在33℃下进行培养。对生长出的菌落进一步在a培养基中进行培养,并选择通过菌落pcr而ald基因在pgapa-hpai-trrnb中进行了取代的株。将其命名为ges1052。进而,使用pge1185,通过电穿孔法对ges1052进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-hpai-trrnb的株。将其命名为ges1063。
使用pge1171,通过电穿孔法对ges435进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges1042。进而,使用pge1186,通过电穿孔法对ges1042进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因在pgapa-hpai-trrnb中进行了取代的株。将其命名为ges1053。使用pge1185,通过电穿孔法对ges1053进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-hpai-trrnb的株。将其命名为ges1064。
2-2-(5)pge1304(δadhe::rhma取代株制作用质粒)的构建
购买大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造),将其在无菌条件下接种到lb琼脂培养基中,在37℃下进行培养。将琼脂培养基上生长出的菌体接种到10ml的lb培养基中,回收生长出的菌体,并进行基因组dna提取。以dh5α株的基因组dna为模板,使用由gep2765(序列号73)与gep2766(序列号74)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含大肠杆菌dh5α株rhma基因(ec_rhma)的dna片段。进而,利用ndei与bamhi对pge409进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1143时相同的操作,由此获得ec_rhma被克隆到pge409的质粒pge1258。
以pge1258为模板,使用由gep2637(序列号69)与gep2638(序列号70)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-rhma-trrnb的dna片段。进而,利用xhoi对pge1218进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1304。
2-2-(6)pge1302(δald::rhma取代株制作用质粒)的构建
以pge1258为模板,使用由gep2639(序列号71)与gep2640(序列号72)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用xhoi对pge1221进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-rhma-trrnb的dna片段。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1302。
2-2-(7)δadhe::rhmaδald::rhma取代株的制作
使用pge1302,通过电穿孔法对ges1041进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因在pgapa-rhma-trrnb中进行了取代的株。将其命名为ges1215。进而,使用pge1304,通过电穿孔法对ges1215进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-rhma-trrnb的株。将其命名为ges1242。
2-2-(8)pge1272(δadhe::nana取代株制作用质粒)的构建
购买大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造),将其在无菌条件下接种到lb琼脂培养基中,在37℃下进行培养。将琼脂培养基上生长出的菌体接种到10ml的lb培养基中,回收生长出的菌体,并进行基因组dna提取。以dh5α株的基因组dna为模板,使用由gep2722(序列号75)与gep2723(序列号76)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含大肠杆菌dh5α株nana基因(ec_nana)的dna片段。进而,利用ndei与bamhi对pge409进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1143时相同的操作,由此获得ec_nana被克隆到pge409的质粒pge1226。
以pge1226为模板,使用由gep2637(序列号69)与gep2638(序列号70)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-nana-trrnb的dna片段。进而,利用xhoi对pge1218进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1272。
2-2-(9)pge1273(δald::nana取代株制作用质粒)的构建
以pge1226为模板,使用由gep2639(序列号71)与gep2640(序列号72)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用xhoi对pge1221进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-nana-trrnb的dna片段。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1273。
2-2-(10)δadhe::nanaδald::nana取代株的制作
使用pge1273,通过电穿孔法对ges1041进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因在pgapa-nana-trrnb中进行了取代的株。将其命名为ges1188。进而,使用pge1272,通过电穿孔法对ges1188进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-nana-trrnb的株。将其命名为ges1223。
使用pge1273,通过电穿孔法对ges1042进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因在pgapa-nana-trrnb中进行了取代的株。将其命名为ges1189。进而,使用pge1272,通过电穿孔法对ges1189进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-nana-trrnb的株。将其命名为ges1233。
(2-3)超表达用质粒篇
2-3-(1)pge411的构建
以phsg298(宝生物(takarabio)公司制造)为模板,使用由gep433(序列号55)与gep434(序列号56)所表示的碱基序列的dna的组合、及由gep437(序列号57)与gep438(序列号58)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含卡那霉素抗性基因及大肠杆菌用复制起点pucori的dna片段。
自理化学研究所生物资源研究中心获取乳酪棒状杆菌(corynebacteriumcasei)jcm12072株,按照随附的使用说明书进行培养,并通过离心分离回收菌体。使菌体颗粒悬浮于1ml的10mm环己二胺四乙酸、25mmtris-hcl(ph8.0)缓冲液中,在6,000xg、4℃下进行5分钟离心分离,并再次进行回收。使菌体颗粒悬浮于包含15mg/ml溶菌酶的300μl的缓冲剂a1(buffera1)(附带于马歇雷纳高(macherey-nagel)公司制造的牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure))中,在37℃下振荡2小时。然后,依照牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure)的使用说明书,进行pcase1质粒的提取及纯化。以此为模板,使用由gep443(序列号77)与gep444(序列号78)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含棒状杆菌用复制起点pcase1ori的dna片段。
将以上三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge402。
以atcc13032株的基因组dna为模板,使用由gep474(序列号79)与gep477(序列号80)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。另外,以pflag-ctc(西格玛奥德里奇(sigmaaldrich)公司制造)为模板,使用由gep467(序列号63)与gep468(序列号64)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含atcc13032株的ldha启动子(pldha)及大肠杆菌核糖体rna转录终止子(trrnb)的dna片段。进而,利用bamhi与ecorv对pge402进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge411。
2-3-(2)pge945-2的构建
以pcr8/gw/topo(英杰(invitrogen)公司制造)为模板,使用由gep435(序列号81)与gep436(序列号82)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。另外,以phsg298(宝生物(takarabio)公司制造)为模板,使用由gep437(序列号57)与gep438(序列号58)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含壮观霉素(spectinomycin)抗性基因及大肠杆菌用复制起点pucori的dna片段。
将以上两个dna片段、及pge402的制作时所获得的包含pcase1ori的dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含100μg/ml的壮观霉素的lb琼脂培养基上进行培养来选择。在包含100μg/ml的壮观霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge619。
以atcc13032株的基因组dna为模板,使用由gep474(序列号79)与gep477(序列号80)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。另外,以pflag-ctc(西格玛奥德里奇(sigmaaldrich)公司制造)为模板,使用由gep467(序列号63)与gep2897(序列号83)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含atcc13032株的ldha启动子(pldha)及大肠杆菌核糖体rna转录终止子(trrnb)的dna片段。进而,利用bamhi及ecorv对pge619进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含100μg/ml的壮观霉素的lb琼脂培养基上进行培养来选择。在包含100μg/ml的壮观霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge945-2。
2-3-(3)pp_mdlc超表达用质粒的构建
自独立行政法人制品评价技术基盘机构生物技术中心获取恶臭假单胞菌nbrc14164株,按照随附的使用说明书进行培养后进行基因组dna提取。以nbrc14164株的基因组dna为模板,使用由gep2550(序列号84)与gep2551(序列号85)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含恶臭假单胞菌nbrc14164株mdlc基因(pp_mdlc)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1031时相同的操作,由此获得pp_mdlc被克隆到pet-15b的质粒pge1161。
以pge1161为模板,使用由gep2653(序列号86)与gep2654(序列号87)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ndei对pge409进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作ges1185时相同的操作,由此获得pp_mdlc被亚克隆到pge409的质粒pge1197。
2-3-(4)kp_dhat超表达用质粒的构建
由广岛大学田岛誉久博士提供了包含来源于肺炎克雷伯菌的基因(日本dna数据库(dnadatabankofjapan,ddbj)登录号:lc412902)的质粒pha12-dhabt。以其为模板,使用由gep2529(序列号88)与gep2530(序列号89)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在琼脂糖凝胶电泳后进行提取、纯化。其为包含肺炎克雷伯菌dhat基因(kp_dhat)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1161时相同的操作,由此获得kp_dhat被克隆到pet-15b的质粒pge1150。
利用ndei与bamhi对pge1150进行处理,并对1.2kb的dna片段在琼脂糖凝胶电泳后进行提取、纯化。进而,利用ndei与bamhi对pge945-2进行处理,并对其在琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将连接高版本2(ligationhighver.2)(东洋纺公司制造)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株通过在包含100μg/ml的壮观霉素的lb琼脂培养基上进行培养来选择。在包含100μg/ml的壮观霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。如此般获得kp_dhat被亚克隆到pge945-2的质粒pge1190。
3.菌体构建
(3-1)pp_mdlc及kp_dhat超表达质粒导入株的制作
使用pge1197与pge1190,通过电穿孔法对ges1070进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1206。
使用pge1197与pge1190,通过电穿孔法对ges1063进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1077。
使用pge1197与pge1190,通过电穿孔法对ges1064进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1068。
使用pge1197与pge1190,通过电穿孔法对ges1242进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1282。
谷氨酸棒状杆菌(corynebacteriumglutamicum)ges1068寄存在日本千叶县木更津市上总镰足2-5-8(邮政编码292-0818)的独立行政法人制品评价技术基盘机构专利微生物寄存中心(寄存日:2018年9月13日,受托编号:nitebp-02780)。
使用pge1197与pge1190,通过电穿孔法对ges1223进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1253。
使用pge1197与pge1190,通过电穿孔法对ges1233进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1254。
谷氨酸棒状杆菌(corynebacteriumglutamicum)ges1254寄存在日本千叶县木更津市上总镰足2-5-8(邮政编码292-0818)的独立行政法人制品评价技术基盘机构专利微生物寄存中心(寄存日:2018年9月13日,受托编号:nitebp-02781)。
4.物质生产实验
(4-1)4-羟基-2-氧代丁酸(hob)的生产
4-1-(1)ges1077的培养
将ges1077的丙三醇原种在无菌条件下接种到包含卡那霉素25μg/ml及壮观霉素100μg/ml的a琼脂培养基中,在33℃下进行培养。将琼脂培养基上生长出的菌体接种到包含卡那霉素25μg/ml及壮观霉素100μg/ml的10ml的ba培养基中,在33℃下进行振荡培养,作为种子培养液。将所述种子培养液以混浊度成为0.1的方式接种到2l烧瓶中所准备的、包含卡那霉素25μg/ml及壮观霉素100μg/ml的500ml的ba培养基中。在33℃下进行振荡,培养一整夜。对所述正式培养液在4℃、5500xg下进行15分钟离心分离,将上清液去除。将如此般获得的湿菌体用于以下反应。
4-1-(2)使用ges1077的hob的生产
将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲剂中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液及1.2m的甲醛水溶液,使它们分别成为50mm、40mm,一边使用1.0m氢氧化钾水溶液将ph维持于6.0,一边在33℃下进行培养。在培养过程中进行搅拌且不进行通气,以便有效率地混合氢氧化钾水溶液。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱法对反应液的上清液进行分析,结果生成了0.65mm的hob。
4-1-(3)比较例1
将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲剂中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液而使所述葡萄糖水溶液成为50mm,一边使用1.0m氢氧化钾水溶液将ph维持于6.0,一边在33℃下进行培养。3小时后,通过有机酸分析用液相色谱法对反应悬浮液的上清液进行分析,结果未检测到hob。
4-1-(4)比较例2
对ges1206进行与所述4-1-(1)及4-1-(2)相同的实验。反应3小时后,通过有机酸分析用液相色谱法对反应悬浮液的上清液进行分析,结果未检测到hob。
根据4-1-(2)、4-1-(3)、4-1-(4)的结果可知,如ges1077般的具有对二类醛缩酶进行编码的基因的菌体通过在糖类及醛存在下进行培养,由糖类生成丙酮酸,且所述酶催化所述丙酮酸与醛之间的羟醛反应,由此生成如hob所代表的羟醛化合物。
4-1-(5)ges1282的培养
自ges1282的丙三醇原种,以与4-1-(1)相同的方式进行培养,将所获得的湿菌体用于以下反应。
4-1-(6)使用ges1282的hob的生产
以与4-1-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌且不进行通气,以便有效率地混合氢氧化钾水溶液。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱法对反应液的上清液进行分析,结果生成了0.36mm的hob。
4-1-(7)比较例1
以与4-1-(3)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌且不进行通气,以便有效率地混合氢氧化钾水溶液。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱法对反应悬浮液的上清液进行分析,结果未检测到hob。
根据4-1-(6)、4-1-(7)、4-1-(4)的结果可知,如ges1282般的具有对与ges1077不同的二类醛缩酶进行编码的基因的菌体也通过在糖类及醛存在下进行培养而由糖类生成丙酮酸,且所述酶催化所述丙酮酸与醛之间的羟醛反应,由此生成如hob所代表的羟醛化合物。
4-1-(8)ges1253的培养
自ges1253的丙三醇原种,以与4-1-(1)相同的方式进行培养,将所获得的湿菌体用于以下反应。
4-1-(9)使用ges1253的hob的生产
以与4-1-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌且不进行通气,以便有效率地混合氢氧化钾水溶液。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱法对反应液的上清液进行分析,结果生成了0.34mm的hob。
4-1-(10)比较例1
以与4-1-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌且不进行通气,以便有效率地混合氢氧化钾水溶液。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱法对反应悬浮液的上清液进行分析,结果未检测到hob。
根据4-1-(9)、4-1-(10)、4-1-(4)的结果可知,如ges1253般的具有对一类醛缩酶进行编码的基因的菌体通过在糖类及醛存在下进行培养,由糖类生成丙酮酸,且所述酶催化所述丙酮酸与醛之间的羟醛反应,由此生成如hob所代表的羟醛化合物。
4-1-(11)ges1068及ges1254的培养
自ges1068及ges1254的丙三醇原种,以与4-1-(1)相同的方式进行培养,将所获得的湿菌体用于以下反应。
4-1-(12)使用ges1068及ges1254的hob的生产
以与4-1-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌且不进行通气,以便有效率地混合氢氧化钾水溶液。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱法对反应液的上清液进行分析,结果在使用ges1068的反应中生成了1.2mm的hob,在使用ges1254的反应中生成了0.42mm的hob。
根据4-1-(12)的结果可知,即使是如ges1068及ges1254般的与ges1077及ges1253为不同基因型的微生物,但只要是具有对ii类醛缩酶进行编码的基因的菌体,则通过在糖类及醛存在下进行培养,也由糖类生成丙酮酸,且所述酶催化所述丙酮酸与醛之间的羟醛反应,由此也生成如hob所代表的羟醛化合物。
(4-2)1,3-丙二醇(pdo)的生产
4-2-(1)ges1077、ges1068的培养
将ges1077、ges1068的丙三醇原种在无菌条件下接种到包含卡那霉素25μg/ml及壮观霉素100μg/ml的a琼脂培养基中,在33℃下进行培养。将琼脂培养基上生长出的菌体接种到包含卡那霉素25μg/ml及壮观霉素100μg/ml的10ml的ba培养基中,在33℃下进行振荡培养,作为种子培养液。将所述种子培养液以混浊度成为0.1的方式接种到2l烧瓶中所准备的、包含卡那霉素25μg/ml及壮观霉素100μg/ml的500ml的ba培养基中。在33℃下进行振荡,培养一整夜。对所述正式培养液在4℃、5500xg下进行15分钟离心分离,将上清液去除。将如此般获得的湿菌体用于以下反应。
4-2-(2)使用ges1077、ges1068的pdo的生产
将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲剂中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液及1.2m的甲醛水溶液,使它们分别成为50mm、40mm,一边使用1.0m氢氧化钾水溶液将ph维持于6.0,一边在33℃下进行培养。在培养过程中进行搅拌且不进行通气,以便有效率地混合氢氧化钾水溶液。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过糖分析用液相色谱法对反应液的上清液进行分析,结果在使用ges1077的反应中生成了7.4mm的pdo,在使用ges1068的反应中生成了11.4mm的pdo。
根据以上结果可知,如ges1077及ges1068般的具有对二类醛缩酶进行编码的基因、且当在糖类及甲醛存在下进行培养时可生产hob的菌体在还具有对脱羧酶及醇脱氢酶进行编码的基因的情况下,hob进一步转变为pdo,从而可制造pdo。
4-2-(3)ges1282的培养
自ges1282的丙三醇原种,以与4-2-(1)相同的方式进行培养,将所获得的湿菌体用于以下反应。
4-2-(4)使用ges1282的pdo的生产
以与4-2-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌且不进行通气,以便有效率地混合氢氧化钾水溶液。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。6小时后,通过糖分析用液相色谱法对反应液的上清液进行分析,结果生成了1.4mm的pdo。
根据以上结果可知,如ges1282般的具有对与ges1077及ges1068不同的二类醛缩酶进行编码的基因、且当在糖类及甲醛存在下进行培养时可生产hob的菌体在还具有对脱羧酶及醇脱氢酶进行编码的基因的情况下,hob也进一步转变为pdo,从而也可制造pdo。
4-2-(5)ges1253、ges1254的培养
自ges1253、ges1254的丙三醇原种,以与4-2-(1)相同的方式进行培养,将所获得的湿菌体用于以下反应。
4-2-(6)使用ges1253、ges1254的pdo的生产
以与4-2-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌且不进行通气,以便有效率地混合氢氧化钾水溶液。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。6小时后,通过糖分析用液相色谱法对反应液的上清液进行分析,结果在使用ges1253的反应中生成了4.1mm的pdo,在使用ges1254的反应中生成了5.8mm的pdo。
根据以上结果可知,如ges1253及ges1254般的具有对一类醛缩酶进行编码的基因、且当在糖类及甲醛存在下进行培养时可生产hob的菌体在还具有对脱羧酶及醇脱氢酶进行编码的基因的情况下,hob进一步转变为pdo,从而可制造pdo。
参考资料
<110>绿色地球研究所株式会社
自然之美株式会社
<120>1,3-丙二醇的制造方法
<130>18f0401pct
<160>89
<170>patentinversion3.5
<210>1
<211>789
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>1
atggaaaacagttttaaagcggcgctgaaagcaggccgtccgcagattggattatggctg60
gggctgagcagcagctacagcgcggagttactggccggagcaggattcgactggttgttg120
atcgacggtgagcacgcaccgaacaacgtacaaaccgtgctcacccagctacaggcgatt180
gcgccctatcccagccagccggtagtacgtccgtcgtggaacgatccggtgcaaatcaaa240
caactgctggacgtcggcacacaaaccttactggtgccgatggtacaaaacgccgacgaa300
gcccgtgaagcggtacgcgccacccgttatccccccgccggtattcgcggtgtgggcagt360
gcgctggctcgcgcctcgcgctggaatcgcattcctgattacctgcaaaaagccaacgat420
caaatgtgcgtgctggtgcagatcgaaacgcgtgaggcaatgaagaacttaccgcagatt480
ctggacgtggaaggcgtcgacggcgtgtttatcggcccggcggatctgagcgccgatatg540
ggttatgccggtaatccgcagcacccggaagtacaggccgccattgagcaggcgatcgtg600
cagatccgcgaagcgggcaaagcgccggggatcctgatcgccaatgagctactggcaaaa660
cgctatctggaactgggcgcgctgtttgtcgccgtcggcgttgacaccaccctgctcgcc720
cgcgccgccgaagcgctggcagcacggtttggcgcgcaggctacagcgattaagcccggc780
gtgtattaa789
<210>2
<211>262
<212>prt
<213>大肠杆菌(escherichiacoli)
<400>2
metgluasnserphelysalaalaleulysalaglyargproglnile
151015
glyleutrpleuglyleusersersertyrseralagluleuleuala
202530
glyalaglypheasptrpleuleuileaspglygluhisalaproasn
354045
asnvalglnthrvalleuthrglnleuglnalailealaprotyrpro
505560
serglnprovalvalargprosertrpasnaspprovalglnilelys
65707580
glnleuleuaspvalglythrglnthrleuleuvalprometvalgln
859095
asnalaaspglualaargglualavalargalathrargtyrpropro
100105110
alaglyileargglyvalglyseralaleualaargalaserargtrp
115120125
asnargileproasptyrleuglnlysalaasnaspglnmetcysval
130135140
leuvalglnilegluthrargglualametlysasnleuproglnile
145150155160
leuaspvalgluglyvalaspglyvalpheileglyproalaaspleu
165170175
seralaaspmetglytyralaglyasnproglnhisprogluvalgln
180185190
alaalailegluglnalailevalglnileargglualaglylysala
195200205
proglyileleuilealaasngluleuleualalysargtyrleuglu
210215220
leuglyalaleuphevalalavalglyvalaspthrthrleuleuala
225230235240
argalaalaglualaleualaalaargpheglyalaglnalathrala
245250255
ilelysproglyvaltyr
260
<210>3
<211>804
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>3
atgaacgcattattaagcaatccctttaaagaacgtttacgcaagggcgaagtgcaaatt60
ggtctgtggttaagctcaacgactgcctatatggcagaaattgccgccacttctggttat120
gactggttgctgattgacggggagcacgcgccaaacaccattcaggatctttatcatcag180
ctacaggcggtagcgccctatgccagccaacccgtgatccgtccggtggaaggcagtaaa240
ccgctgattaaacaagtcctggatattggcgcgcaaactctactgatcccgatggtcgat300
actgccgaacaggcacgtcaggtggtgtctgccacgcgctatcctccctacggtgagcgt360
ggtgtcggggccagtgtggcacgggctgcgcgctggggacgcattgagaattacatggcg420
caagttaacgattcgctttgtctgttggtgcaggtggaaagtaaaacggcactggataac480
ctggacgaaatcctcgacgtcgaagggattgatggcgtgtttattggacctgcggatctt540
tctgcgtcgttgggctacccggataacgccgggcacccggaagtgcagcgaattattgaa600
accagtattcggcggatccgtgctgcgggtaaagcggctggttttctggctgtggctcct660
gatatggcgcagcaatgcctggcgtggggagcgaactttgtcgctgttggcgttgacacg720
atgctctacagcgatgccctggatcaacgactggcgatgtttaaatcaggcaaaaatggg780
ccacgcataaaaggtagttattaa804
<210>4
<211>267
<212>prt
<213>大肠杆菌(escherichiacoli)
<400>4
metasnalaleuleuserasnprophelysgluargleuarglysgly
151015
gluvalglnileglyleutrpleuserserthrthralatyrmetala
202530
gluilealaalathrserglytyrasptrpleuleuileaspglyglu
354045
hisalaproasnthrileglnaspleutyrhisglnleuglnalaval
505560
alaprotyralaserglnprovalileargprovalgluglyserlys
65707580
proleuilelysglnvalleuaspileglyalaglnthrleuleuile
859095
prometvalaspthralagluglnalaargglnvalvalseralathr
100105110
argtyrproprotyrglygluargglyvalglyalaservalalaarg
115120125
alaalaargtrpglyargilegluasntyrmetalaglnvalasnasp
130135140
serleucysleuleuvalglnvalgluserlysthralaleuaspasn
145150155160
leuaspgluileleuaspvalgluglyileaspglyvalpheilegly
165170175
proalaaspleuseralaserleuglytyrproaspasnalaglyhis
180185190
progluvalglnargileilegluthrserileargargileargala
195200205
alaglylysalaalaglypheleualavalalaproaspmetalagln
210215220
glncysleualatrpglyalaasnphevalalavalglyvalaspthr
225230235240
metleutyrseraspalaleuaspglnargleualametphelysser
245250255
glylysasnglyproargilelysglysertyr
260265
<210>5
<211>894
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>5
atggcaacgaatttacgtggcgtaatggctgcactcctgactccttttgaccaacaacaa60
gcactggataaagcgagtctgcgtcgcctggttcagttcaatattcagcagggcatcgac120
ggtttatacgtgggtggttcgaccggcgaggcctttgtacaaagcctttccgagcgtgaa180
caggtactggaaatcgtcgccgaagaggcgaaaggtaagattaaactcatcgcccacgtc240
ggttgcgtcagcaccgccgaaagccaacaacttgcggcatcggctaaacgttatggcttc300
gatgccgtctccgccgtcacgccgttctactatcctttcagctttgaagaacactgcgat360
cactatcgggcaattattgattcggcggatggtttgccgatggtggtgtacaacattcca420
gccctgagtggggtaaaactgaccctggatcagatcaacacacttgttacattgcctggc480
gtaggtgcgctgaaacagacctctggcgatctctatcagatggagcagatccgtcgtgaa540
catcctgatcttgtgctctataacggttacgacgaaatcttcgcctctggtctgctggcg600
ggcgctgatggtggtatcggcagtacctacaacatcatgggctggcgctatcaggggatc660
gttaaggcgctgaaagaaggcgatatccagaccgcgcagaaactgcaaactgaatgcaat720
aaagtcattgatttactgatcaaaacgggcgtattccgcggcctgaaaactgtcctccat780
tatatggatgtcgtttctgtgccgctgtgccgcaaaccgtttggaccggtagatgaaaaa840
tatctgccagaactgaaggcgctggcccagcagttgatgcaagagcgcgggtaa894
<210>6
<211>297
<212>prt
<213>大肠杆菌(escherichiacoli)
<400>6
metalathrasnleuargglyvalmetalaalaleuleuthrprophe
151015
aspglnglnglnalaleuasplysalaserleuargargleuvalgln
202530
pheasnileglnglnglyileaspglyleutyrvalglyglyserthr
354045
glyglualaphevalglnserleusergluarggluglnvalleuglu
505560
ilevalalagluglualalysglylysilelysleuilealahisval
65707580
glycysvalserthralagluserglnglnleualaalaseralalys
859095
argtyrglypheaspalavalseralavalthrprophetyrtyrpro
100105110
pheserpheglugluhiscysasphistyrargalaileileaspser
115120125
alaaspglyleuprometvalvaltyrasnileproalaleusergly
130135140
vallysleuthrleuaspglnileasnthrleuvalthrleuprogly
145150155160
valglyalaleulysglnthrserglyaspleutyrglnmetglugln
165170175
ileargarggluhisproaspleuvalleutyrasnglytyraspglu
180185190
ilephealaserglyleuleualaglyalaaspglyglyileglyser
195200205
thrtyrasnilemetglytrpargtyrglnglyilevallysalaleu
210215220
lysgluglyaspileglnthralaglnlysleuglnthrglucysasn
225230235240
lysvalileaspleuleuilelysthrglyvalpheargglyleulys
245250255
thrvalleuhistyrmetaspvalvalservalproleucysarglys
260265270
propheglyprovalaspglulystyrleuprogluleulysalaleu
275280285
alaglnglnleumetglngluarggly
290295
<210>7
<211>1587
<212>dna
<213>恶臭假单胞菌(pseudomonasputida)
<400>7
atggcttcggtacacggcaccacatacgaactcttgcgacgtcaaggcatcgatacggtc60
ttcggcaatcctggctcgaacgagctcccgtttttgaaggactttccagaggactttcga120
tacatcctggctttgcaggaagcgtgtgtggtgggcattgcagacggctatgcgcaagcc180
agtcggaagccggctttcattaacctgcattctgctgctggtaccggcaatgctatgggt240
gcactcagtaacgcctggaactcacattccccgctgatcgtcactgccggccagcagacc300
agggcgatgattggcgttgaagctctgctgaccaacgtcgatgccgccaacctgccacga360
ccacttgtcaaatggagctacgagcccgcaagcgcagcagaagtccctcatgcgatgagc420
agggctatccatatggcaagcatggcgccacaaggccctgtctatctttcggtgccatat480
gacgattgggataaggatgctgatcctcagtcccaccacctttttgatcgccatgtcagt540
tcatcagtacgcctgaacgaccaggatctcgatattctggtgaaagctctcaacagcgca600
tccaacccggcgatcgtcctgggcccggacgtcgacgcagcaaatgcgaacgcagactgc660
gtcatgttggccgaacgcctcaaagctccggtttgggttgcgccatccgctccacgctgc720
ccattccctacccgtcatccttgcttccgtggattgatgccagctggcatcgcagcgatt780
tctcagctgctcgaaggtcacgatgtggttttggtaatcggcgctccagtgttccgttac840
caccaatacgacccaggtcaatatctcaaacctggcacgcgattgatttcggtgacctgc900
gacccgctcgaagctgcacgcgcgccaatgggcgatgcgatcgtggcagacattggtgcg960
atggctagcgctcttgccaacttggttgaagagagcagccgccagctcccaactgcagct1020
ccggaacccgcgaaggttgaccaagacgctggccgacttcacccagagacagtgttcgac1080
acactgaacgacatggccccggagaatgcgatttacctgaacgagtcgacttcaacgacc1140
gcccaaatgtggcagcgcctgaacatgcgcaaccctggtagctactacttctgtgcagct1200
ggcggactgggcttcgccctgcctgcagcaattggcgttcaactcgcagaacccgagcga1260
caagtcatcgccgtcattggcgacggatcggcgaactacagcattagtgcgttgtggact1320
gcagctcagtacaacatccccactatcttcgtgatcatgaacaacggcacctacggtgcg1380
ttgcgatggtttgccggcgttctcgaagcagaaaacgttcctgggctggatgtgccaggg1440
atcgacttccgcgcactcgccaagggctatggtgtccaagcgctgaaagccgacaacctt1500
gagcagctcaagggttcgctacaagaagcgctttctgccaaaggcccggtacttatcgaa1560
gtaagcaccgtaagcccggtgaagtga1587
<210>8
<211>528
<212>prt
<213>恶臭假单胞菌(pseudomonasputida)
<400>8
metalaservalhisglythrthrtyrgluleuleuargargglngly
151015
ileaspthrvalpheglyasnproglyserasngluleupropheleu
202530
lysasppheprogluasppheargtyrileleualaleuglngluala
354045
cysvalvalglyilealaaspglytyralaglnalaserarglyspro
505560
alapheileasnleuhisseralaalaglythrglyasnalametgly
65707580
alaleuserasnalatrpasnserhisserproleuilevalthrala
859095
glyglnglnthrargalametileglyvalglualaleuleuthrasn
100105110
valaspalaalaasnleuproargproleuvallystrpsertyrglu
115120125
proalaseralaalagluvalprohisalametserargalailehis
130135140
metalasermetalaproglnglyprovaltyrleuservalprotyr
145150155160
aspasptrpasplysaspalaaspproglnserhishisleupheasp
165170175
arghisvalserserservalargleuasnaspglnaspleuaspile
180185190
leuvallysalaleuasnseralaserasnproalailevalleugly
195200205
proaspvalaspalaalaasnalaasnalaaspcysvalmetleuala
210215220
gluargleulysalaprovaltrpvalalaproseralaproargcys
225230235240
propheprothrarghisprocyspheargglyleumetproalagly
245250255
ilealaalaileserglnleuleugluglyhisaspvalvalleuval
260265270
ileglyalaprovalpheargtyrhisglntyraspproglyglntyr
275280285
leulysproglythrargleuileservalthrcysaspproleuglu
290295300
alaalaargalaprometglyaspalailevalalaaspileglyala
305310315320
metalaseralaleualaasnleuvalglugluserserargglnleu
325330335
prothralaalaprogluproalalysvalaspglnaspalaglyarg
340345350
leuhisprogluthrvalpheaspthrleuasnaspmetalaproglu
355360365
asnalailetyrleuasngluserthrserthrthralaglnmettrp
370375380
glnargleuasnmetargasnproglysertyrtyrphecysalaala
385390395400
glyglyleuglyphealaleuproalaalaileglyvalglnleuala
405410415
gluprogluargglnvalilealavalileglyaspglyseralaasn
420425430
tyrserileseralaleutrpthralaalaglntyrasnileprothr
435440445
ilephevalilemetasnasnglythrtyrglyalaleuargtrpphe
450455460
alaglyvalleuglualagluasnvalproglyleuaspvalprogly
465470475480
ileasppheargalaleualalysglytyrglyvalglnalaleulys
485490495
alaaspasnleugluglnleulysglyserleuglnglualaleuser
500505510
alalysglyprovalleuilegluvalserthrvalserprovallys
515520525
<210>9
<211>1164
<212>dna
<213>肺炎克雷伯菌(klebsiellapneumoniae)
<400>9
atgagctatcgtatgttcgattatctggtgccaaacgttaacttttttggccccaacgcc60
atttccgtagtcggcgaacgctgccagctgctgggggggaaaaaagccctgctggtcacc120
gacaaaggcctgcgggcaattaaagatggcgcggtggacaaaaccctgcattatctgcgg180
gaggccgggatcgaggtggcgatctttgacggcgtcgagccgaacccgaaagacaccaac240
gtgcgcgacggcctcgctgtgtttcgccgcgaacagtgcgacatcatcgtcaccgtgggc300
ggcggcagcccgcacgattgcggcaaaggcatcggcatcgccgccacccatgagggcgat360
ctgtaccagtatgccggaatcgagaccctgaccaacccgctgccgcctatcgtcgcggtc420
aataccaccgccggcaccgccagcgaggtcacccgccactgcgtcctgaccaacaccgaa480
accaaagtgaagtttgtgatcgtcagctggcgcaacctgccgtcggtctctatcaacgat540
ccactgctgatgatcggtaaaccggccgccctgaccgcggcgaccgggatggatgccctg600
acccacgccgtagaggcctatatctccaaagacgctaacccggtgacggacgccgccgcc660
atgcaggcgatccgcctcatcgcccgcaacctgcgccaggccgtggccctcggcagcaat720
ctgcaggcgcgggaaaacatggcctatgcctctctgctggccgggatggctttcaataac780
gccaacctcggctacgtgcacgccatggcacaccagctgggcggcctgtacgacatgccg840
cacggcgtggccaacgctgtcctgctgccgcatgtggcgcgctacaacctgatcgccaac900
ccggagaaattcgccgatattgctgaactgatgggcgaaaatatcaccggactgtccact960
ctcgacgcggcggaaaaagccatcgccgctatcacgcgtctgtcgatggatatcggtatt1020
ccgcagcatctgcgcgatctgggagtaaaagaggccgacttcccctacatggcggagatg1080
gctctgaaagacggcaatgcgttctcgaacccgcgtaaaggcaacgagcaggagattgcc1140
gcgattttccgccaggcattctaa1164
<210>10
<211>387
<212>prt
<213>肺炎克雷伯菌(klebsiellapneumoniae)
<400>10
metsertyrargmetpheasptyrleuvalproasnvalasnphephe
151015
glyproasnalaileservalvalglygluargcysglnleuleugly
202530
glylyslysalaleuleuvalthrasplysglyleuargalailelys
354045
aspglyalavalasplysthrleuhistyrleuargglualaglyile
505560
gluvalalailepheaspglyvalgluproasnprolysaspthrasn
65707580
valargaspglyleualavalpheargarggluglncysaspileile
859095
valthrvalglyglyglyserprohisaspcysglylysglyilegly
100105110
ilealaalathrhisgluglyaspleutyrglntyralaglyileglu
115120125
thrleuthrasnproleuproproilevalalavalasnthrthrala
130135140
glythralasergluvalthrarghiscysvalleuthrasnthrglu
145150155160
thrlysvallysphevalilevalsertrpargasnleuproserval
165170175
serileasnaspproleuleumetileglylysproalaalaleuthr
180185190
alaalathrglymetaspalaleuthrhisalavalglualatyrile
195200205
serlysaspalaasnprovalthraspalaalaalametglnalaile
210215220
argleuilealaargasnleuargglnalavalalaleuglyserasn
225230235240
leuglnalaarggluasnmetalatyralaserleuleualaglymet
245250255
alapheasnasnalaasnleuglytyrvalhisalametalahisgln
260265270
leuglyglyleutyraspmetprohisglyvalalaasnalavalleu
275280285
leuprohisvalalaargtyrasnleuilealaasnproglulysphe
290295300
alaaspilealagluleumetglygluasnilethrglyleuserthr
305310315320
leuaspalaalaglulysalailealaalailethrargleusermet
325330335
aspileglyileproglnhisleuargaspleuglyvallysgluala
340345350
asppheprotyrmetalaglumetalaleulysaspglyasnalaphe
355360365
serasnproarglysglyasngluglngluilealaalailephearg
370375380
glnalaphe
385
<210>11
<211>30
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>sacb基因的顺向引物
<400>11
ggggaagcttgacgtccacatatacctgcc30
<210>12
<211>24
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>sacb基因的反向引物
<400>12
attcggatccgtatccacctttac24
<210>13
<211>26
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>用于将sacb基因上所具有的kpni识别部位删除的顺向引物
<400>13
tgaacagataccatttgccgttcatt26
<210>14
<211>26
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>用于将sacb基因上所具有的kpni识别部位删除的反向引物
<400>14
aatggtatctgttcactgactcccgc26
<210>15
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ppc基因缺失的上-顺向引物
<400>15
ccatgattacgaattcgggaaacttttttaagaaa35
<210>16
<211>20
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ppc基因缺失的上-反向引物
<400>16
taactactttaaacactctt20
<210>17
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ppc基因缺失的下-顺向引物
<400>17
tgtttaaagtagttatccagccggctgggtagtac35
<210>18
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ppc基因缺失的下-反向引物
<400>18
taccgagctcgaattgaagtattcaaggggatttc35
<210>19
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ldha基因缺失的上-顺向引物
<400>19
gacggccagtgaatttttcatacgaccacgggcta35
<210>20
<211>20
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ldha基因缺失的上-反向引物
<400>20
gacaatcttgttaccgacgg20
<210>21
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ldha基因缺失的下-顺向引物
<400>21
ggtaacaagattgtccattccgcaaataccctgcg35
<210>22
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>dha基因缺失的下-反向引物
<400>22
taccgagctcgaattgggacgttgatgacgctgcc35
<210>23
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pyc基因缺失的上-顺向引物
<400>23
gacggccagtgaattgttgatgactgttggttcca35
<210>24
<211>26
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pyc基因缺失的上-反向引物
<400>24
ctcgagtagagtaattattcctttca26
<210>25
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pyc基因缺失的下-顺向引物
<400>25
attactctactcgagacctttctgtaaaaagcccc35
<210>26
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pyc基因缺失的下-反向引物
<400>26
taccgagctcgaattcacgatccgccgggcagcct35
<210>27
<211>33
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>poxb基因缺失的上-顺向引物
<400>27
gacggccagtgaaaacgttaatgaggaaaaccg33
<210>28
<211>20
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>poxb基因缺失的上-反向引物
<400>28
aattaattgttctgcgtagc20
<210>29
<211>41
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>poxb基因缺失的下-顺向引物
<400>29
gcagaacaattaattctcgagtcgaacataaggaatattcc41
<210>30
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>poxb基因缺失的下-反向引物
<400>30
taccgagctcgaattttccaggtacggaaagtgcc35
<210>31
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>alaa基因缺失的上-顺向引物
<400>31
gacggccagtgaatttttcaccgaagtgacaccta35
<210>32
<211>26
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>alaa基因缺失的上-反向引物
<400>32
ctcgagccgctcaatgttgccacttt26
<210>33
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>alaa基因缺失的下-顺向引物
<400>33
attgagcggctcgagtagttgttaggattcaccac35
<210>34
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>alaa基因缺失的下-反向引物
<400>34
taccgagctcgaattgttccctggaaattgtttgc35
<210>35
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ilvb基因缺失的上-顺向引物
<400>35
gacggccagtgaattaccgcacgcgaccagttatt35
<210>36
<211>26
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ilvb基因缺失的上-反向引物
<400>36
gctagcgactttctggctcctttact26
<210>37
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ilvb基因缺失的下-顺向引物
<400>37
cagaaagtcgctagcggagagacccaagatggcta35
<210>38
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ilvb基因缺失的下-反向引物
<400>38
taccgagctcgaattctcgatgtcgttggtgaaga35
<210>39
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>cg0931基因缺失的上-顺向引物
<400>39
gacggccagtgaattagcagggacgaaagtcggga35
<210>40
<211>26
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>cg0931基因缺失的上-反向引物
<400>40
ctcgaggcagctactatatttgatcc26
<210>41
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>cg0931基因缺失的下-顺向引物
<400>41
agtagctgcctcgagtttgaacaggttgttggggg35
<210>42
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>cg0931基因缺失的下-反向引物
<400>42
taccgagctcgaattatcgacggcaaaacgcccaa35
<210>43
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>adhe基因缺失的上-顺向引物
<400>43
gtgaattcgagctcgcagaagcagatcttgcaatc35
<210>44
<211>32
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>adhe基因缺失的上-反向引物
<400>44
cttcctcgagaattccaggcactacagtgctc32
<210>45
<211>32
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>adhe基因缺失的下-顺向引物
<400>45
gaattctcgaggaagaggctttcaacaccatg32
<210>46
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>adhe基因缺失的下-反向引物
<400>46
aggtggatacggatcggaacaaagtgtctccagag35
<210>47
<211>37
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>adhe基因缺失的上-顺向引物
<400>47
gtgaattcgagctcgattcaggatttgcttcgcgacg37
<210>48
<211>37
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>adhe基因缺失的下-反向引物
<400>48
aggtggatacggatcacagtgtccggatcatctgctg37
<210>49
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ald基因缺失的上-顺向引物
<400>49
gtgaattcgagctcgccgaaacctcaaagaatccc35
<210>50
<211>32
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ald基因缺失的上-反向引物
<400>50
ggtactcgagtcctggatttgcgtagacagtc32
<210>51
<211>32
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ald基因缺失的下-顺向引物
<400>51
caggactcgagtaccagcagaccaagaacctg32
<210>52
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ald基因缺失的下-反向引物
<400>52
aggtggatacggatcgatctccagaggtttcaagc35
<210>53
<211>38
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ald基因缺失的上-顺向引物
<400>53
gtgaattcgagctcgaacgccagatggtcgtactttgc38
<210>54
<211>38
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ald基因缺失的下-反向引物
<400>54
aggtggatacggatcttcaacaccgctgatttcctacg38
<210>55
<211>39
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>knr基因的顺向引物
<400>55
cggtaccgtcgacgatatcgaggtctgcctcgtgaagaa39
<210>56
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>knr基因的反向引物
<400>56
gcctttttacggttcgatttattcaacaaagccgc35
<210>57
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pucori的顺向引物
<400>57
gaaccgtaaaaaggccgcgttgctggcgtttttcc35
<210>58
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pucori的反向引物
<400>58
gcggccgcgtagaaaagatcaaaggatcttcttga35
<210>59
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pcg1ori的顺向引物
<400>59
tttctacgcggccgcccatggtcgtcacagagctg35
<210>60
<211>40
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pcg1ori的反向引物
<400>60
tcgtcgacggtaccggatccttgggagcagtccttgtgcg40
<210>61
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pgapa的顺向引物
<400>61
ctgctcccaaggatcgaagaaatttagatgattga35
<210>62
<211>39
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pgapa的反向引物
<400>62
ccgtcgacgatatcatatggtgtctcctctaaagattgt39
<210>63
<211>39
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>trrnb的顺向引物
<400>63
tgatatcgtcgacggatcctgcctggcggcagtagcgcg39
<210>64
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>trrnb的反向引物
<400>64
gaggcagacctcgataaaaaggccatccgtcagga35
<210>65
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ec_hpai的顺向引物
<400>65
cgcgcggcagccatatggaaaacagttttaaagcg35
<210>66
<211>37
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ec_hpai的反向引物
<400>66
ggatcctcgagcatattaatacacgccgggcttaatc37
<210>67
<211>36
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ec_hpai的顺向引物
<400>67
agaggagacaccatatgggcagcagccatcatcatc36
<210>68
<211>38
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ec_hpai的反向引物
<400>68
ccgccaggcaggatccttaatacacgccgggcttaatc38
<210>69
<211>37
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pgapa-hpai-trrnb的顺向引物
<400>69
gcctggaattctcgagaaggactgctcccaaggatcg37
<210>70
<211>34
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pgapa-hpai-trrnb的反向引物
<400>70
aagcctcttcctcgatcttcacgaggcagacctc34
<210>71
<211>37
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pgapa-hpai-trrnb的顺向引物
<400>71
aaatccaggactcgagaaggactgctcccaaggatcg37
<210>72
<211>34
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pgapa-hpai-trrnb的反向引物
<400>72
tctgctggtactcgatcttcacgaggcagacctc34
<210>73
<211>34
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ec_rhma的顺向引物
<400>73
agaggagacaccatatgaacgcattattaagcaa34
<210>74
<211>41
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ec_rhma的反向引物
<400>74
ccgccaggcaggatcagatcttaataactaccttttatgcg41
<210>75
<211>34
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ec_nana的顺向引物
<400>75
agaggagacaccatatggcaacgaatttacgtgg34
<210>76
<211>38
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>ec_nana的反向引物
<400>76
ccgccaggcaggatccttacccgcgctcttgcatcaac38
<210>77
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pcase1ori的顺向引物
<400>77
tttctacgcggccgccactggaagggttcttcagg35
<210>78
<211>40
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pcase1ori的反向引物
<400>78
tcgtcgacggtaccggatccctgacttggttacgatggac40
<210>79
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pldha的顺向引物
<400>79
accaagtcagggatcgcggaactagctctgcaatg35
<210>80
<211>39
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pldha的反向引物
<400>80
ccgtcgacgatatcatatgcgatcccacttcctgatttc39
<210>81
<211>39
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>spr的顺向引物
<400>81
cggtaccgtcgacgatatctctagaccagccaggacaga39
<210>82
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>spr的反向引物
<400>82
gcctttttacggttcctcgagggttatttgccgac35
<210>83
<211>35
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>trrnb的反向引物
<400>83
ggctggtctagagataaaaaggccatccgtcagga35
<210>84
<211>34
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pp_mdlc的顺向引物
<400>84
cgcgcggcagccatatggcttcggtacacggcac34
<210>85
<211>37
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pp_mdlc的反向引物
<400>85
ggatcctcgagcatatcacttcaccgggcttacggtg37
<210>86
<211>34
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pp_mdlc的顺向引物
<400>86
agaggagacaccatatggcttcggtacacggcac34
<210>87
<211>36
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>pp_mdlc的反向引物
<400>87
gtcgacgatatcatatcacttcaccgggcttacggt36
<210>88
<211>39
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>kp_dhat的顺向引物
<400>88
cgcgcggcagccatatgagctatcgtatgttcgattatc39
<210>89
<211>38
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>kp_dhat的反向引物
<400>89
ggatcctcgagcatattagaatgcctggcggaaaatcg38
pct/ro/134表
- 还没有人留言评论。精彩留言会获得点赞!