单分子测序和唯一分子标识符以表征核酸序列的制作方法
相关申请的交叉引用
本申请要求2017年10月09日提交的美国临时申请系列号62/569,853的权益,其全部内容通过引用结合在本申请中。
本公开内容通常涉及基因组学和分子生物学。
背景技术:
在使用高通量测序技术来识别复杂混合物中的目标时依然待解决的一个关键挑战是,过度呈现的(overrepresented)核酸目标被数次测序,阻碍了在初始核酸库(nucleicacidpool)中低度呈现的(underrepresented)分子的检测。由于被测序数次,过度呈现的模板分子可能占据了测序运行的输出测序读取结果(reads)的大部分,这可能浪费了本可用于测序低度呈现的模板分子的循环。
单分子测序(singlemoleculesequencing,sms)(例如,与合成测序(sequencing-by-synthesis)策略相比较,等)可以包括不同的优势。sms可以容许dna分子的直接表征。sms当前应用的实例包括由太平洋生物科学(pacificbiosciences)和牛津纳米孔(oxfordnanopore)开发的技术。这些平台可以容许dna分子的实时测序,其与适当的计算机硬件和软件相关联,可以容许测序数据的实时处理。
附图说明
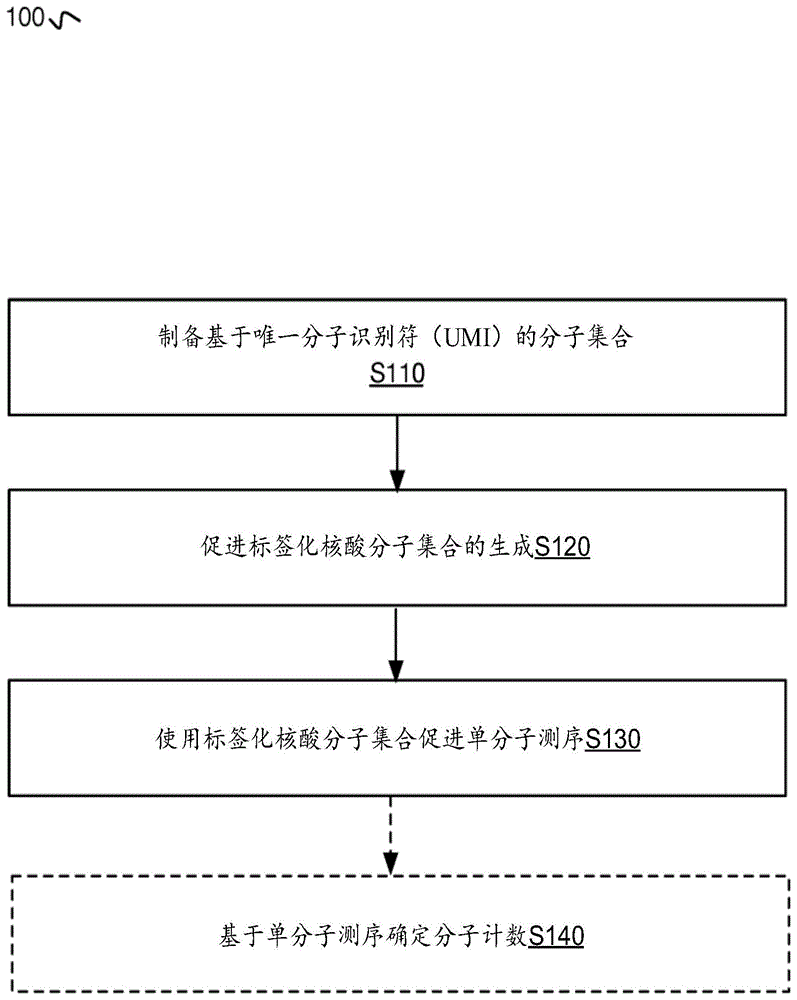
图1包括方法的实施方式的变型的流程图代表;
图2包括方法的实施方式的变型的流程图代表;
图3包括方法的实施方式的变型的流程图代表。
具体实施方式
以下的实施方式的说明并不旨在限制实施方式,而是在于使任何本领域的技术人员能够制造和使用。
1.概述
如图1-3所示,(例如,用于改进的单分子测序,等)方法100的实施方式可以包括制备与目标核酸序列集合相关联的基于唯一分子标识符(uniquemolecularidentifier,umi)的分子集合s110;基于所述基于umi的分子集合和相应于(例如,包括,等)所述目标核酸序列集合的核酸分子集合,促进标签化核酸分子集合的生成(generation)(例如,产生(generating),等)s120;和/或使用所述标签化核酸分子集合促进(例如,执行,等)单分子测序s130。额外地或替代地,方法100的实施方式可以包括基于所述单分子测序确定分子计数s140;和/或任何其他适合的过程。
在具体的实施例中,(例如,用于改进的单分子测序的)方法100可以包括:制备与目标核酸序列集合相关联的基于umi的分子集合(例如,包括目标相关联区域的基于umi的分子,所述目标相关联区域与目标核酸序列的目标序列区域互补;等);基于所述基于umi的分子集合和相应于(例如,包括,等)所述目标核酸序列集合的核酸分子集合,促进标签化核酸分子集合生成,其中所述标签化核酸分子集合的各标签化核酸分子包括:至少一个umi区域、其包括随机“n”碱基集合,其中各随机“n”碱基选自“a”碱基、“g”碱基、“t”碱基和“c”碱基的任一个,以及至少一个目标区域、其相应于所述目标核酸序列集合的目标核酸序列;和/或使用所述标签化核酸分子集合促进单分子测序,其中促进所述单分子测序包括:确定第一序列区域集合与第二序列区域集合之间的比较(例如,比较所述第一序列区域集合与所述第二序列区域集合之间的序列相似性;等),其中所述第一序列区域集合包括所述标签化核酸分子集合的已测序的标签化核酸分子(例如,在单分子测序的相同测序运行中先前测序的;等)的第一umi区域和第一目标区域,并且其中所述述第二序列区域集合包括所述标签化核酸分子集合的标签化核酸分子的第二umi区域和第二目标区域;以及基于所述第一序列区域集合与所述第二序列区域集合之间的所述比较,(例如,在测序运行期间,等)停止所述标签化核酸分子测序(例如,使得标签化核酸分子不会有助于相应的分子计数;使得相应于标签化核酸分子的核酸序列不被过度呈现;等)。
在具体的实施例中,(例如,用于改进的单分子测序的)方法100可以包括:以基于umi的分子集合和相应于目标核酸序列集合的核酸分子集合为基础,促进标签化核酸分子集合的生成;和/或使用所述标签化核酸分子集合促进单分子测序,其中促进所述单分子测序包括:确定第一umi区域与第二umi区域之间的比较,其中所述第一umi区域是所述标签化核酸分子集合的已测序标签化核酸分子的,并且其中所述第二umi区域是所述标签化核酸分子集合的标签化核酸分子的;序列区域集合与第二序列区域集合,其中所述第一序列区域集合包括所述标签化核酸分子集合的已测序标签化核酸分子的第一umi区域,并且其中所述第二序列区域集合包括所述标签化核酸分子集合的标签化核酸分子的第二umi区域和第二目标区域,以及基于所述第一umi区域与所述第二umi区域之间的比较停止所述标签化核酸分子的测序。
额外地或替代地,方法100和/或系统的实施方式可以包括处理(例如,收集;用于促进方法100实施方式的部分的样品制备;对其执行方法100实施方式的部分;等)诸如从一个或更多个收集位点收集的生物样品的来自一个或多个用户(例如,受试者;人类;动物;患者;植物;等)的一个或多个样品(例如,生物样品)和/或以其他方式与其相关联,该一个或多个收集位点可以包括肠位点(例如,如基于粪便样品分析的,等)、皮肤位点、鼻位点、口位点、生殖器位点、和/或其他适合的生理学位点;基于微生物序列数据集(例如,基于使用诸如与方法100实施方式的部分有关的标签化核酸分子的、单分子测序生成的微生物序列数据集;从生物信息学分析生成的微生物序列数据集,该生物信息学分析与诸如标签化核酸分子的umi区域的测序的umi区域相关联;包括对与目标核酸序列相关联的核酸分子的分子计数的微生物序列数据集;等)确定微生物组特性(例如,微生物组成特性;微生物功能特性;与诸如关于诊断和/或疗法的微生物相关状况相关联的特性,;等)。然而,方法100的实施方式可以额外地或替代地包括任何适合的过程。
通过使用umi分子、诸如通过改进样品的测序结果,方法100和/或系统的实施方式可以起到改进单分子测序(和/或其他测序技术)的作用,所述样品包括过度呈现的模板核酸分子和低度呈现的模板核酸分子;降低与扩增过程(例如,聚合酶链反应(polymerasechainreaction,pcr)过程)和/或富集过程相关联的偏差;降低与dna聚合酶相关联的误差(例如,在聚簇(cluster)生成过程期间;等);改进测序效率(例如,通过降低被用于过度呈现的模板核酸分子浪费的测序循环;等);使得核酸分子能够直接表征;和/或通过允许任何其他适合的改进。在具体的实施例中,方法100和/或系统可以利用测序技术(例如,基于读取待停(readuntil-based)的测序技术,诸如牛津纳米孔技术的纳米孔技术,诸如太平洋生物科学的单分子测序技术,等)和umi分子,来执行实时测序和/或处理(例如,将正在测序的当前标签化核酸分子与相同测序运行期间先前已测序的标签化核酸分子比较;等),同时克服测序过度呈现的模板核酸分子和低度呈现的模板核酸分子相关联的问题。
额外地或替代地,方法100和/或系统的实施方式可以起到(例如,基于从标签化核酸分子的umi区域的测序和/或分析确定的分子计数;等)定量样品中存在的微生物的作用,诸如在确定微生物相关表征(例如,关于微生物组组成;微生物组功能;等)中使用。然而,微生物定量可以以任何适合的方式执行。
额外地或替代地,方法100和/或系统的实施方式可以起到促进微生物相关检测(例如,样品的生物体的分类学检测和/或定量,以及相同样品中呈现(present)或表达(express)的基因的检测;以直接的方式利用保守分类学基因的生物体检测和/或定量,和/或利用一个或多个生物样品中已表征的或未先前表征的dna对其他真核生物、原核生物、病毒生物体和/或其他适合的微生物的无偏检测和/或定量;新的、未知的、和/或未识别的潜在核酸目标的检测和/或定量;以无偏的方式、已知的或已识别的核酸目标的检测和/或定量,该核酸目标诸如与抗生素抗性、毒力因子、分子标志物、病毒衣壳基因(viralcapsidgene)、适合的兴趣的目标相关联;等)的作用。
方法100和/或系统的实施方式的任何适合的部分可以包括、用于、靶向、使用、处理、相应于、和/或以其他方式与以下一种或更多种相关联:抗生素抗性、毒力因子、分子标志物、病毒衣壳基因、感兴趣的适当目标。在具体的实施例中,方法100和/或系统的实施方式可以包括测序、确定分子计数(例如,基于标签化核酸分子的umi区域确定绝对分子计数,用于促进定量;等)、在不同的目标序列当中区分(例如,通过将umi区域的使用与读取待停技术(readuntil-technology)和/或适合的测序技术结合;等)、选择特定dna片段(例如,从两个以上不同的库(library)中,诸如16s与18s;16s与hpv(例如,hpv的e1基因);和/或分类学序列或分类学独立序列的其他适合的组合;用于将样品内dna分子的丰度标准化;等),和/或用于部分和/或全长分类学标记物基因(例如,16srrna、18srrna等)、部分和/或全长基因和/或标志物(例如,病毒衣壳基因;与抗生素抗性相关的基因和/或标志物;等)和/或任何适合的基因、标志物和/或目标的任何其他适合的过程。在具体的实施例中,所述目标核酸序列集合可以包括第一目标集合和第二目标集合的至少一个,其中所述第一目标集合包括16srrna目标和18srrna目标,并且其中所述第二目标集合包括16srrna目标和hpv相关联目标。在具体的实施例中,所述目标核酸序列集合可以包括与抗生素抗性和病毒衣壳基因的至少一种相关联的目标核酸序列。
然而,方法100和/或系统的实施方式可以包括任何适合的功能。
方法100(例如,促进单分子测序s130,等)和/或系统的实施方式的部分优选地包括、执行、关联于(例如,促进库制备,等)、和/或以其他方式促进单分子测序。单分子测序可以包括以下任一种或多种:单分子实时(singlemoleculerealtime,smrt)测序(例如,太平洋生物科学smrt测序,等)、纳米孔测序(例如,牛津纳米孔测序,等)、长读取(long-read)测序(例如,太平洋生物科学长读取测序;等)、海力斯科普(heliscope)单分子测序、与单分子测序相关联的任何代数的测序技术(例如,第二代测序技术、第三代测序技术、第四代测序技术等)和/或任何其他适合的单分子测序类型。
在变型中,单分子测序可以以独立于扩增的方式使用,其可以除去在pcr扩增和/或其他适合的扩增过程期间引入的偏差。在变型中,单分子测序可以独立于dna聚合酶而执行,从而避免在聚簇生成步骤期间由dna聚合酶引入的任何潜在的错误。
在具体的实施例中,可以使用牛津纳米孔测序技术和/或其他适合的基于读取待停的技术(例如,容许测序读取结果被读出直到满足条件;等),其使用膜上的纳米孔测序分子,容许停止特定孔的测序,并释放正在被分析的dna分子。在具体的实施例中,牛津纳米孔测序技术和/或其他适合的基于读取待停的技术可以至少能够选择特定的dna片段(例如,两种不同的库),其可以标准化和/或平衡样品中dna分子的丰度(例如,低度呈现的dna分子;过度呈现的dna分子;等);和/或能够将特定dna分子的测序限制到一定数量,诸如,其中代替生成特定dna分子的大量读取结果,而是可以诸如基于标签化核酸分子和/或其他适合的分子的umi区域、目标区域和/或其他适合的区域,限制给定分子将被测序的次数。
额外地或替代地,方法100和/或系统的实施方式优选地包括、执行、关联于(例如,促进库制备,等)和/或以其他方式促进任何适合的测序技术,包括以下任一种或多种:下一代测序(nextgenerationsequencing,ngs)技术、毛细管测序、桑格(sanger)测序(例如,微流sanger测序,等)、焦磷酸测序(pyrosequencing)和/或其他适合的测序技术。ngs技术可以包括以下一种或多种:高通量测序(例如,通过高通量测序技术促进的;大规模并行标志测序(massivelyparallelsignaturesequencing)、聚合酶克隆测序(polonysequencing)、454焦磷酸测序、依诺米那(illumina)测序、寡聚连接检测测序(sequencingbyoligoligationdetection,solid)测序、离子激流(iontorrent)半导体测序、dna纳米球测序、heliscope单分子测序,等)、任何代数的测序技术(例如,第二代测序技术、第三代测序技术、第四代测序技术,等)、扩增子相关联测序(例如,靶向扩增子测序)、宏基因组相关联测序(例如,宏转录组测序、宏基因组测序,等)、合成测序、隧道电流测序、杂交测序(sequencingbyhybridization)、质谱测序、基于显微术的技术和/或任何适合的ngs技术。
方法100和/或系统的实施方式可以改进单分子测序和/或其他适合的方面(例如,本文描述的),用于(例如,基于衍生自使用标签化核酸分子的单分子测序的微生物序列数据集;等)促进一种或多种微生物相关状况的表征和/或疗法,其可以包括以下一种或多种:疾病、症状、病因(例如,触发物(trigger),等)、失调、相关联风险(例如,倾向性分值,等)、相关联严重度、行为(例如,咖啡因消耗、习惯、饮食,等)、和/或与微生物相关状况相关联的任何其他适合的方面。微生物相关状况可以包括一种或多种疾病相关状况,该一种或多种疾病相关状况可以包括以下任一种或更多种:胃肠相关状况(例如,肠易激综合征、炎症性肠病、溃疡性结肠炎、乳糜泻、克罗恩氏病(crohn’sdisease)、胀气、痔性疾病(hemorrhoidaldisease)、便秘、返流、血便、腹泻,等);过敏相关状况(例如,与小麦、麸质、乳品、大豆、花生、贝类、坚果、蛋等相关联的过敏和/或不耐受性,等);皮肤相关状况(例如,粉刺、皮肌炎、湿疹、红斑痤疮、干燥皮肤、银屑病、头皮屑、光敏感性,等);运动相关状况(例如,痛风、类风湿性关节炎、骨关节炎、反应性关节炎、多发性硬化、帕金森氏病(parkinson’sdisease),等);癌症相关状况(例如,淋巴瘤;白血病;胚细胞瘤;生殖细胞肿瘤;癌;肉瘤;乳腺癌;前列腺癌;基底细胞癌;皮肤癌;结肠;肺癌;与任何适合的生理区域相关的癌症状况;等)、心血管相关状况(例如,冠心病、炎症性心脏病、心脏瓣膜病、肥胖症、中风,等)、贫血状况(例如,地中海贫血;镰刀形红细胞;恶性贫血;范可尼(fanconi)贫血;溶血性贫血;再生障碍性贫血;铁缺乏;等)、神经学相关状况(例如,注意缺陷多动障碍(attentiondeficithyperactivitydisorder,adhd)、注意缺陷障碍(attentiondeficitdisorder,add)、焦虑、阿斯伯格综合症(asperger’ssyndrome)、孤独症、慢性疲劳综合症、抑郁症,等)、自体免疫相关状况(例如,口炎性腹泻(sprue)、获得性免疫缺乏综合征(acquiredimmunedeficiencysyndrome,aids)、肖格伦病(sjogren’s)、狼疮,等)、内分泌相关状况(例如,肥胖症、格雷夫斯氏病(graves’disease)、桥本氏甲状腺炎(hashimoto’sthyroiditis)、代谢疾病、i型糖尿病、ii型糖尿病,等)、莱姆病(lymedisease)状况、沟通相关状况、睡眠相关状况、代谢相关状况、体重相关状况、疼痛相关状况、遗传相关状况、慢性疾病、和/或任何其他适合的疾病相关状况类型。额外地或替代地,微生物相关状况可以包括一种或多种人行为状况,其可以包括以下任一种或多种:咖啡因消耗、酒精消耗、其他食物类消费、膳食补充剂消费、益生菌相关行为(例如,消费、规避(avoidance),等)、其他饮食行为、习惯性行为(例如,吸烟;运动状况,诸如低度、中度和/或极度运动状况;等)、绝经、其他生物学过程、社会行为、其他行为、和/或任何其他适合的人类行为状况。状况可以与任何适合的表型(例如,对人、动物、植物、真菌体等可测量的表型)相关联。
方法100和/或系统的实施方式可以针对来自单个用户的一个或多个生物样品实施,例如,关于执行方法100的实施方式的部分以促进来自单个用户的一个或多个生物样品测序库的制备,和/或促进使用该测序库(例如,包括标签化核酸分子的测序库;等)的单分子测序。额外地或替代地,实施方式可以针对来自用户集合(例如,包括用户、不包括用户的受试者的群体,等)的生物样品实施,其中用户集合可以包括类似于和/或不同于任何适合的特性类型(例如,关于微生物相关状况、人口统计学特征行为、微生物组组成和/或功能,等任何其他受试者的受试者;针对用户的子群体(例如,共享特性,诸如方法100的实施方式的部分的特性;等)实施;针对植物、动物、微生物(例如,来自环境微生物群落;等)和/或任何其他适合的实体实施。因而,衍生自用户集合(例如,受试者的群体、受试者的集合、用户的子群体,等)的信息可以用于对后续用户提供额外的洞察力(例如,关于执行方法100的实施方式的部分中使用的实验参数;关于停止某些标签化核酸分子测序中使用的序列区域指标(criteria);等)。在变型中,生物样品的聚集集合可以与各种各样的用户相关联并针对各种各样的用户而处理,诸如包括以下一种或多种的用户:不同的人口统计学(例如,性别、年龄、婚姻状况、种族、国籍、社会经济地位、性取向,等)、不同的微生物相关状况(例如,健康和疾病状态;不同的遗传学分布;等)、不同的生活情况(例如,独居、与宠物居住、与重要的他人举证、与儿童居住,等)、不同的饮食习惯(例如,杂食、素食、绝对素食(vegan)、糖类消耗、酸消耗、咖啡因消耗,等)、不同行为倾向(例如,身体活动水平、药物使用、酒精使用,等)、不同的活动性水平(例如,与给定时期的行进距离相关)、和/或任何其他适合的特性(例如,影响、相关于和/或以其他方式与微生物组组成和/或功能相关联的特性,等)。在实施例中,随着用户数量提高,方法100的实施方式的部分中实现的过程的预测能力可以提高,诸如关于基于各种各样的用户的微生物组来表征各种各样的用户(例如,关于用户样品的不同收集位点,等),诸如其中微生物组相关表征可以基于来自本文描述的单分子测序的测序输出来确定。然而,方法100和/或系统的实施方式的部分可以以任何适合的方式、针对任何适合的一个或多个实体执行和/或配置。
本文描述的数据(例如,诸如目标核酸序列的核酸序列;umi序列;诸如对于基于umi的分子的分子设计数据;诸如测序输入和/或输出的测序数据;诸如测序参数的测序数据,例如用于停止测序;与umi相关联标签相关联的数据;微生物序列数据集;微生物组特征;用户数据;补充数据;与微生物相关状况相关联的数据;微生物相关表征;等)可以与任何适合的时间指示物(例如,秒、分钟、小时、天、周,等)相关联,包括以下一种或多种:表明数据何时收集(例如,表明何时收集样品的时间指示物;等)、确定(例如,表明样品处理操作何时开始、完成的时间指示物;表明标签化目标分子何时测序、和/或何时保存相关联数据的时间指示物;等)、传输、接受、和/或以其他方式处理的时间指示物;将背景提供至数据描述的内容的时间指示物;时间指示物的改变;和/或与时间相关的任何其他适合的指示物。本文描述的分子和/或任何适合的生物学成分可以包括任何适合的大小(例如,序列长度,等)。序列区域和/或其他适合的成分之间的比较可以沿着任何适合的方面进行,包括以下任一种或多种:序列相似性(例如,按照百分比;按照碱基数量;关于任何适合的序列区域,该序列区域包括umi区域和/或目标区域;等)、完全序列匹配、序列相异性、序列位置、目标类型、序列区域类型、相关联微生物类型、微生物相关状况类型、和/或任何其他适合的方面。
额外地或替代地,参数、指标、输入、输出和/或其他适合的数据可以与数值类型相关联,该数值类型包括以下任一种或多种:分值、个体价值(individualvalue)、聚合值、二元值、相对值、分类、置信度水平、标识符、谱上值(valuesalongaspectrum)、和/或任何其他适合的值类型。本文描述的任何适合的数据类型、成分(例如,生物学成分)、(例如,样品处理操作的,等)产物,可以用作输入(例如,对于不同的样品处理操作;模型;混合物;测序技术;等)、生成为输出(例如,不同模型的;模块;样品处理操作的产物;等)、和/或对于与方法100和/或系统相关联的任何适合的成分以任何适合的方式操作。
本文描述的方法100和/或过程的实施方式的一个或多个实例和/或部分可以异步地(例如,顺序地)、同时地(例如,多重化;在方法100的实施方式的部分中处理多个样品;与测序分析和/或方法100的实施方式的部分相关联的并行数据处理;等)、与触发事件(例如,方法100的实施方式的部分的性能)的时间关系上(例如,基本上同时地、响应于、连续、之前、随后,等)、和/或在任何适合的时间和频率下以任何适合的顺序,通过和/或使用本文描述的系统、部件和/或实体的一个或多个实例来执行。
然而,方法100和/或系统可以以任何适合的方式配置。
2.1制备基于umi的分子
方法100的实施方式可以包括制备(例如,确定、生成,等)与一个或多个目标(例如,目标核酸序列集合;与微生物相关联的目标;等)相关的基于umi的分子集合(例如,基于umi的引物,等)s110,其可以起到制备用于促进一个或多个目标的标签化(例如,使用基于umi的分子;umi区域;接头区域;等)、扩增、和/或其他适合的处理,诸如促进标签化核酸分子集合的生成。
目标(例如,感兴趣的目标;已知的或识别的目标;未知的或先前未识别的目标;等)可以包括以下任一种或多种:生物标志物;基因(例如,基因表达标志物,等);序列区域(例如,遗传序列;识别基因、染色体、微生物相关状况、保守序列、突变、多态性的序列;氨基酸序列;核苷酸序列;等);核酸(例如,基因组dna、染色体dna、染色体外dna、线粒体dna、质体dna、质粒dna、粘粒dna、噬菌粒dna、合成dna、获自rna的cdna、单链和双链dna,等)细胞;小分子;蛋白质;肽;与一种或多种微生物相关状况相关联的目标(例如,提供与一种或多种微生物相关状况相关联的诊断、预后、预测和/或疗法的有用信息的目标;等);与微生物组成(例如,指示样品中存在的微生物的系统分类(taxonomicclassification)的目标;指示任何适合的分类群的微生物的存在、丰度和/或缺乏的标志物;等)和/或微生物功能(例如,指示与微生物相关联的功能特征的目标)相关联的目标;脂质;总核酸;完整微生物;代谢物;碳水化合物;和/或任何适合的组合(例如,来自多个库;等)和/或目标类型。在具体的实施例中,目标可以包括部分和/或全长的分类学标志物基因(例如,16srrna、18srrna,等)、部分和/或全长的基因和/或标志物(例如,病毒衣壳基因;与抗生素抗性相关联的基因和/或标志物;等)和/或任何适合的基因和/或标志物。
基于umi的分子优选地与一个或多个目标(例如,微生物相关的核酸目标;等)相关联(例如,包括目标相关联区域,该目标相关联区域包括与一个或多个目标(例如,核酸目标,等)的一个或多个序列区域互补的一个或多个序列区域);靶向;可与其扩增;可与其处理;能够标记;等),但可以额外地或替代地与任何适合的成分相关联。
在变型中,基于umi的分子可以包括基于umi的引物(例如,以用于一个或多个扩增过程,诸如一个或多个pcr过程;包括一个或多个umi区域的引物;等),但可以额外地或替代地包括用于任何适合的目的的、任何适合类型的基于umi的分子。在实施例中,基于umi的引物可以省略简并引物(degenerateprimer)(例如,其中简并引物可能在pcr过程中、诸如通过偏向更紧密地匹配简并引物的序列的目标扩增而引入偏差,从而生成不同的pcr效率、并影响不同模板的检测极限;其中诸如minion的平台可以使得更长读取结果生成,诸如其中平台可以与具有靶向保守区域的限定序列的引物一起使用;等)。在具体的实施例中,所述基于umi的分子集合可以包括基于umi的引物,该基于umi的引物包括靶向与多个微生物分类群相关联的保守区域的限定序列区域(例如,其中使用这样的引物可以降低偏差和/或降低对目标序列的优先扩增;等)。在实施例中,基于umi的引物(例如,包括限定序列区域,所述限定序列区域靶向与多个微生物分类群相关联的保守区域;等)可以包括跨越不同的模板目标的相同或相似的亲和性,其可以降低生成标签化核酸分子中来自基于pcr的umi掺入的负面作用。在实施例中,基于umi的引物的使用可以用于控制不同目标的测序量,诸如其中可以容许测序进行,直到生成的数据量容许不同的微生物分类群和/或任何适合的目标(例如,其中需要识别目标的测序量、诸如测序的核酸分子的数量和/或测序读取深度,可以取决于具体目标而变化;等)的识别。
基于umi的分子(和/或其他适合的分子、诸如本文描述的引物和/或其他分子)优选地包括一个或多个umi区域(例如,其中基于umi的分子可以包括单个umi区域;其中基于umi的分子可以包括多个umi区域;等)。umi区域可以包括随机“n”碱基(base)集合(例如,n脱氧核苷酸碱基),其中各随机的“n”碱基选自“a”腺嘌呤碱基、“g”鸟嘌呤碱基、“t”胸腺嘧啶碱基和“c”胞嘧啶碱基。“n”碱基可以是连续的(例如,强烈的“n”碱基,等)、分开的(例如,通过限定的碱基;通过任何适合的序列区域;等)和/或位于所述基于umi的分子的任何适合的序列位置。umi区域可以包括任何适合的序列长度(例如,至少2个“n”碱基;少于21个“n”碱基;任何适合数量的“n”碱基;等)。在具体的实施例中,umi区域(例如,对于给定的反应;对于给定的标签化过程;等)可以各自包括固定的长度(例如,10个核苷酸长度;等)。在具体的实施例中,不同的反应可以基于不同长度的umi区域(例如,包括10个核苷酸长度的所有umi区域用于第一反应;包括15个核苷酸长度的所有umi区域用于第二反应;包括具有可变长度的umi区域的其他反应,诸如包括3到15个核苷酸范围内的长度的umi区域用于第三反应;等)。然而,任何数量和/或类型的具有任何适合长度(例如,固定长度;可变长度;等)的umi区域可以用于一个或多个反应。额外地或替代地,umi序列区可以包括单独的固定(例如,非随机的,等)核苷酸序列、固定核苷酸序列与随机核苷酸序列的组合(例如,“atcnnnnn”序列、“nnatcnnnn”序列、“nnnnatc”序列、“nnatcnngtnnn”序列,其中“n”碱基可以是随机的“n”碱基,等)和/或单独的随机核苷酸序列。
umi区域序列长度可以基于待处理的目标的数量和/或类型来确定(例如,定量、区分、起始核酸材料,等),诸如其中更长的umi区域可以促进更大数量的随机碱基组合和更大的唯一标识符集合(例如,用于分析更大数量的待区分的目标类型;用于分析包括大量模板、核酸材料和/或基因变体的样品;等)。在实施例中,不同长度和/或序列的umi区域可以取决于起始核酸材料的性质和数量(例如,从来自肠、口、皮肤、生殖器和/或鼻样品的微生物提取的核酸,等)来使用和/或掺入。在具体的实施例中,基于umi的分子集合(例如,基于umi的分子集合的umi区域;等)的长度和/或其他特性所允许的组合数量需要高于起始材料中存在的模板核酸分子至少单个分子、并至多任何给定的组合数量。
在实施例中,所述umi区域可以包括4numi区域(例如,包括4个“n”碱基的umi区域,等)。在具体的实施例中,umi区域可以包括诸如用于16s基因的扩增过程的8numi区域,诸如伴随一个或多个标签化促进分子、诸如mgcl2、二甲亚砜(dimethylsulfoxide,dmso)、热稳定的核酸结合蛋白(例如,极度热稳定的单链dna结合蛋白,等)和/或其他适合的成分的一种或多种。然而,umi区域可以以任何适合的方式配置。
基于umi的分子(和/或本文描述的其他适合的分子、诸如引物和/或其他分子)优选地包括一个或多个目标相关联区域。目标相关联区域优选地包括序列区域(例如,遗传序列,等),但可以额外地或替代地包括任何适合的成分类型(例如,与目标相关联的任何适合的成分,诸如与其可结合、与其可偶联、与其可连接、对其影响、对其通知、对其修饰、和/或与目标的任何适合的关系;等)。目标相关联区域优选与一个或多个目标(例如,核酸目标的序列区域;核酸目标的其他适合的成分;等)相关联(例如,序列互补于;靶向;与其可扩增;与其可处理;等)。在实施例中,目标相关联区域可以包括与互补目标dna序列(例如,核酸目标的)可退火(annealable)的dna序列。在变型中,目标相关联区域可以与跨多个微生物分类群保守的序列相关联。在变型中,目标相关联区域使得聚合酶(例如,dna聚合酶)能够复制和扩增核酸目标和/或其他适合的成分,但是目标相关联区域可以包括任何适合的功能。目标相关联区域可以包括任何适合的长度(例如,至少15个碱基长度;任何适合数量的碱基;等)。替代地,基于umi的分子可以不包括目标相关联区域。然而,目标相关联区域(和/或其他适合的分子)可以以任何适合的方式配置。
基于umi的分子(和/或本文描述的其他适合的分子、诸如引物和/或其他分子)可以包括一个或多个接头区域(例如,其可以起到改进标签化核酸分子的生成的作用,诸如关于与核酸分子的目标序列结合的引物,等)。接头区域优选地不具有与一个或多个核酸目标(例如,与所述目标相关联区域相关联的核酸目标;等)的完全互补性(例如,无互补性、部分互补性,等)。接头区域可以包括任何适合的长度(例如,其中诸如对于基于umi的引物集合的各个基于umi的引物,接头区域包括少于21个碱基的长度;任何适合数量的碱基长度;等)。接头区域优选定位在umi区域与目标相关联区域之间(例如,分隔umi序列区域和目标相关序列区域;等),但可以位于任何适合的位置(例如,任何适合的序列位置;等),诸如其中,对于各基于umi的分子(例如,对于基于umi的引物集合的各基于umi的引物;等),接头区域位于基于umi的分子的umi区域和目标相关联区域之间。在具体的实施例中,接头区域可以包括限制pcr扩增中基于umi的分子任何潜在负面作用的长度的序列。替代地,基于umi的分子(和/或其他适合的分子)可以不包括接头区域。然而,接头区域可以以任何适合的方式配置。
基于umi的分子可以包括任何适合的大小(例如,任何适合的序列长度,等),且任何适合数量和/或类型的基于umi的分子可以在方法100的实施方式的部分中制备或使用。
在变型中,制备基于umi的分子可以包括基于计算方法和/或分析技术设计基于umi的分子,该计算的方法和/或分析技术包括标准版本或修改版本的距离指标(例如,海明(hamming)和/或莱文斯坦(levenshtein),等),并容许误差校正以及能够识别不同的模板分子。在具体的实施例中,基于umi的分子被设计为跨不同的模板分子是不同的。在具体的实施例中,距离指标的使用允许控制将umi区域转变成另一种umi区域所需的核苷酸数量的改变。在具体的实施例中,为了将第一umi区域(“aaa”)转变成第二umi区域(“ttt”),需要至少三个改变;其中对于具体的实施例,完成该转变的最简单的方法是在第一umi区域中用t(t’s)取代所有a(a’s)。在具体的实施例中,距离指标的使用容许控制可以用于计数不同分子的不同umi的数量,以及额外地或替代地,作为误差校正系统。额外地或替代地,任何适合的距离指标和/或分析技术可以在设计和/或确定基于umi的分子的数量中使用。在具体的实施例中,制备基于umi的分子集合包括基于目标核酸序列集合以及标签化核酸分子的测序的限定界限(例如,与目标核酸序列的期望测序量相关联的预定界限,等),来确定(例如,控制)不同umi区域的数量,以促进标签化核酸分子集合的生成。
可以在方法100的实施方式的任何适合的部分之前和/或之后(例如,标签化目标分子的生成之前或期间;标签化目标分子生成之后以重复生成标签化目标分子)、和/或以任何适合的时间和频率执行制备基于umi的分子。制备基于umi的分子可以包括将基于umi的分子集合提供给任何适合的实体(例如,第三方实体,以允许该第三方实体生成标签化目标分子集合,并使用所述标签化目标分子集合执行单分子测序;等)。
然而,制备基于umi的分子s110可以以任何适合的方式执行。
2.2促进标签化目标分子的生成
方法100的实施方式可以包括以基于umi的分子集合以及相应于(例如,包括,等)目标核酸序列集合的核酸分子集合为基础促进标签化核酸分子集合的生成(例如,产生,等)s120,其可以起到获取标签化目标分子,以促进下游测序(例如,单分子测序;等)和/或用于确定微生物相关表征(例如,一种或多种微生物相关状况的诊断和/或治疗确定;等)的生物信息学分析和/或适合的分析(例如,分子计数)。
(例如,待标签化的;等)核酸分子优选地来自一个或多个样品(例如,从肠位点、皮肤位点、生殖器位点、鼻位点、口位点和/或其他适合的身体位点的一个或多个收集的样品;生物样品;等)。
标签化目标分子(例如,标签化目标核酸分子)优选地包括以一个或多个基于umi的分子(例如,umi区域、接头区域和/或基于umi的分子的适合的区域;等)标签化(例如,附接、连接、偶联;等)的一个或多个目标(例如,包括目标的成分、诸如总核酸和/或包括目标序列区域的核酸片段,等),但可以额外地或替代地包括与一个或多个目标相关联的、且以任何适合的分子标签化的任何适合的成分。生成标签化目标分子集合优选地以基于umi的分子集合(例如,基于umi的引物,等)和一个或多个生物样品(例如,用所述基于umi的分子集合和/或所述基于umi的分子集合的成分标记所述一个或多个生物样品的成分;等)(例如,使用;以其处理;以其执行扩增过程;等)为基础,但可以额外地或替代地基于任何适合的成分。
促进标签化目标分子集合的生成可以基于(例如,包括;使用来自其输出;等)一个或多个扩增过程。(例如,与生成标签化目标分子集合相关联的;与方法100的实施方式的任何适合的部分相关联的;等)扩增过程可以包括一种或多种pcr过程(例如,固相pcr、反转录酶pcr(reversetranscriptionpcr,rt-pcr)、定量pcr(quantitativepcr,qpcr)、多重pcr、降落pcr、纳米pcr、嵌套pcr、热启pcr,等),但可以额外地或替代地包括解旋酶依赖性扩增(helicase-dependentamplification,hda)、环介导等温扩增(loopmediatedisothermalamplification,lamp)、自持的序列复制(self-sustainedsequencereplication,3sr)、基于核酸序列的扩增(nucleicacidsequencebasedamplification,nasba)、链交换扩增(stranddisplacementamplification,sda)、滚环扩增(rollingcircleamplification,rca)、连接酶链式反应(ligasechainreaction,lcr)和/或任何其他适合的扩增过程的一种或多种。在具体的实施例中,多步的pcr过程可以在促进标签化目标分子(例如,标签化核酸分子,等)的生成中使用,诸如以2018年6月20日提交的美国申请16/013,858号中描述的和/或类似的任何适合的方式,通过引用以其整体合并在本文中。额外地或替代地,方法100和/或系统的实施方式的任何适合的部分可以包括、应用、使用和/或与2018年6月20日提交的美国申请16/013,858号中描述的或类似的任何适合的方法,通过引用以其整体合并在本文中。
然而,执行任何适合的pcr过程和/或其他扩增过程(例如,关于生成标签化目标分子集合;关于方法100的实施方式的任何适合的部分;等)可以以任何适合的方式执行。额外地或替代地,独立于扩增的过程可以用于生成标签化核酸分子。在实施例中,可以生成标签化目标核酸分子的不同子集(例如,包括一个或多个pcr生成的标签化目标核酸分子子集和一个或多个独立于pcr的标签化目标核酸分子子集的标签化目标核酸分子集合;等)。在具体的实施例中,促进标签化核酸分子集合的生成包括:基于使用核酸分子集合的第一核酸分子子集执行pcr扩增过程,而生成pcr扩增的核酸分子子集;以及基于所述pcr扩增的核酸分子子集和核酸分子集合的独立于pcr的核酸分子子集,而生成标签化核酸分子集合。
生成标签化目标分子集合可以额外地或替代地基于一个或更多个标签化促进分子(例如,该标签化促进分子可以用于改进与标签化相关的效率和/或多功能性、诸如将基于umi的分子掺入核酸目标;该标签化促进分子可以用于改进扩增过程、诸如关于效率;等)(例如,使用;用其处理;用其执行扩增过程;等)。标签化促进分子可以包括mgcl2、二甲亚砜(dmso)、热稳定的核酸结合蛋白、甜菜碱、甲酰胺、吐温、曲通(triton)、np-40、氯化四甲基铵(tetramethylammoniumchloride,tmac)、牛血清白蛋白(bovineserumalbumin,bsa)、有机和/或无机增强子元件、化合物、盐、小分子、生物分子、和/或配置为促进标签化的任何其他适合的分子的任何一种或多种。
促进标签化目标分子的生成(和/或标签化任何适合的分子)可以以任何适合的时间和频率执行(例如,在生成测序准备(sequencing-ready)的标签化目标分子之前;在生成测序准备的标签化目标分子期间或之后,诸如在重复产物生成方法中,等)。促进标签化目标分子的生成可以基于向第三方实体和/或适合的实体(例如,该实体执行生成标签化目标分子所需的样品处理;等的基于umi的分子)的提供。
在变型中,生成标签化目标分子集合可以包括执行一个或多个碎片化过程、连接过程和/或其他适合的过程(例如,额外地或替代地基于pcr的过程,等)以用基于umi的分子标签化诸如核酸目标(和/或一个或多个生物样品的其他适合的成分,等)的一个或多个目标。在实施例中,生成标签化目标分子集合可以包括基于酶过程和机械过程(例如酶片段化和/或机械片段化)的至少一个使用一个或多个生物样品生成片段(例如,生成包括诸如响应于感兴趣目标的目标序列的一个或多个核酸目标的片段;从一个或多个生物样品生成片段;等);以及针对基于umi的分子和片段、诸如在扩增目标分子(例如,目标dna;用于测序库构建;等)之前,执行基于umi的分子与片段的连接过程(例如,使用连接酶的平端连接(blunt-endligation);等)(例如,将基于umi的分子连接到片段;等)。在实施例中,生成标签化目标分子集合可以包括从至少一种生物样品生成核酸片段;以及将基于umi的分子集合连接到该核酸片段。在实施例中,执行一个或多个片段化过程和/或连接过程可以引起不加区别地标签化所有可用的(例如,在溶液中的)分子,然而,在实施例中,使用pcr过程(例如,本文描述的,等)生成标签化目标分子集合可以促进umi标签化的特异性靶向(例如,目标dna序列的靶向)。用于umi标签化的连接过程可以使用与基于umi的分子类型相同的、相似的或不同的基于umi的分子(例如,来标签化生成的片段和/或其他分子;等),该基于umi的分子类型在用于生成执行片段化过程的标签化目标分子的pcr过程中使用。在具体的实施例中,核酸分子(例如,相应于目标核酸序列;等)可以在扩增标签化目标核酸分子(例如用于测序库的构建,等)之前,使用以连接酶平端连接的酶碎片化和/或机械碎片化之后,使用基于umi的分子来标签化。在基于pcr的标记(labeling)的变型中,在碎片化方法内生成突出(overhang)末端和/或粘性末端的酶,可以额外地或替代地与任何适合的连接过程组合使用,该连接过程包括平端和粘性末端碎片化和/或适当的连接过程的任何组合。在基于pcr的标记的变型中,在核酸分子中插入dna序列(例如,转座子)的酶可以用于标签化基于umi的分子,例如,与任何适合的连接过程(例如,本文描述的,等)组合。
然而,执行一个或多个碎片化过程和/或连接过程、和/或用于促进标签化目标核酸分子生成的任何适合的过程,可以以任何适合的方式执行。
额外地或替代地,促进标签化核酸分子的生成可以包括平衡(例如,标准化)不同扩增子的库,诸如以2018年9月7日提交的美国申请16/125,619号中描述的和/或与其类似的方式,通过引用以其整体合并在本文中。平衡不同扩增子的库、和/或执行方法100的实施方式的适合的部分可以防止过度呈现的分子阻碍较低丰度模板的测序,诸如其中在识别之前需要多个循环的测序的过度呈现的模板分子,可以防止低度呈现的分子的测序。在具体的实施例中,促进标签化核酸分子集合的生成可以包括基于所述基于umi的分子集合和核酸分子集合执行至少一种扩增过程,以平衡与核酸分子集合的低度呈现的核酸分子以及过度呈现的核酸分子相关联的扩增子集合。在变型中,额外的pcr过程(例如,在3-步pcr过程中;等)和/或适合的扩增过程可以允许不同扩增子的库平衡。然而,扩增子库和/或其他适合成分的平衡可以以任何适合的方式执行。
在变型中,生成标签化目标分子集合可以包括至少一种pcr过程与至少一种连接过程的组合(例如,串行组合(serialcombination);平行组合(parallelcombination);等)。例如,生成标签化目标分子集合可以包括使用引物集合(例如,包括一个或多个目标相关联区域、接头区域和/或任何其他适合的成分,等)执行pcr过程,诸如以提高pcr效率和目标扩增;以及使用一个或多个基于umi的分子(例如,包括一个或多个umi区域、衔接子区域和/或其他适合的成分,等)执行连接过程,诸如用于将基于umi的分子添加到pcr过程的产物(例如,扩增的核酸目标;等)上。在实施例中,生成标签化目标分子集合可以包括基于至少一个生物样品和引物集合执行pcr过程,该引物集合包括与目标集合的至少一个目标相关联的目标相关联区域;以及将基于umi的分子集合连接到pcr过程的产物上。然而,执行至少一个pcr过程和至少一个连接过程的组合可以以任何适合的方式执行。
生成标签化目标分子集合(和/或方法100的实施方式的适合的部分)可以包括执行一个或多个纯化过程(例如,来纯化任何适合的成分;来除去任何适合的成分;等)。在实施例中,生成标签化目标分子集合可以包括使用第一扩增过程的产物执行纯化过程,来从该第一扩增过程的产物除去基于umi的引物集合的基于umi的引物(和/或除去其他适合的成分,等)。在实施例中,方法100可以包括针对从本文描述的扩增过程(例如,用于生成标签化目标分子产物的库(pool)的pcr过程)获得的产物执行纯化过程,诸如纯化从基于pcr的扩增过程获得的产物,该基于pcr的扩增过程使用第一基于umi的引物集合执行。纯化过程可以包括以下任一种或多种:基于二氧化硅的dna结合微型柱(mini-column)、固相可逆固定化(solidphasereversibleimmobilization,spri)磁性珠子(例如,用于扩大化和自动化,等)、从所述生物样品中沉淀核酸(例如,使用基于醇的沉淀方法)、基于液-液(liquid-liquid)的纯化技术(例如,苯酚-氯仿提取)、基于层析的纯化技术(例如,柱吸附(columnadsorption))、涉及使用结合部分结合的颗粒的纯化技术(例如,磁性珠子、浮力珠子、具有大小分布的珠子、超声响应性珠子,等),该部分结合的颗粒配置为结合核酸、且配置在存在洗脱环境(例如,具有洗脱溶液、提供ph改变、提供温度改变,等)的情况下释放核酸,和/或任何适合的纯化过程。在具体的实施例中,磁性珠子能够诸如通过dna与羧基包覆的珠子的静电相互作用,纯化pcr过程的少量产物。额外地或替代地,纯化过程可以以任何适合的方式执行(例如,关于所述方法100的实施方式的任何适合的部分,等)。
然而,生成标签化目标分子(例如,标签化核酸分子;等)s120可以以任何适合的方式执行。
2.3促进单分子测序
方法100的实施方式可以包括使用标签化核酸分子集合促进单分子测序s130,其可以起到利用以umi进行单分子测序(例如,基于读取待停的测序,等),来克服与关于低度呈现的模板分子、和/或特定目标模板分子(例如用于富集;等)的过度呈现的模板分子的测序相关联的问题的作用。在具体的实施例中,促进单分子测序s130可以起到诸如在测序运行期间实时地识别各被测序的核酸分子的作用。在具体的实施例中,使用标签化核酸分子集合促进单分子测序包括促进单分子测序,以改进检测、降低测序错误率、和/或改进来自核酸分子集合的低度呈现的核酸分子的绝对计数。在具体的实施例中,使用标签化核酸分子集合促进单分子测序包括使用基于读取待停的技术(和/或适合的测序技术;等)促进单分子测序。
在变型中,使用标签化核酸分子集合促进单分子测序s130可以包括确定已测序的标签化核酸分子的第一序列区域集合、与标签化核酸分子的第二序列区域集合之间的比较s132;停止标签化核酸分子的测序s134(例如,基于所述比较;通过释放标签化核酸分子,诸如从用于牛津纳米孔测序的膜上的纳米孔孔洞释放所述标签化核酸分子;等);限制针对特定目标核酸序列的测序s136(例如,针对与特定目标核酸序列相关联的标签化核酸分子;等);和/或其他适合的过程。
促进单分子测序s130可以包括诸如在测序运行期间基本上实时地和/或实时地执行促进单分子测序s130的任何适合的部分(例如,关于s132、s134、s136)。在具体的实施例中,实时地完成由测序仪(sequencer)生成的数据的生物信息学处理,以使得测序标签化核酸分子的数据能够与被测序的当前标签化核酸分子的数据比较,其可以使得针对特定标签化核酸分子的测序停止(例如,停止过度呈现的核酸分子,以允许低度呈现的核酸分子的测序;等)。
促进单分子测序s130可以额外地或替代地包括确定(例如,不同标签化核酸分子的序列区域的,序列区域之间的比较s132(例如,不同的标签化核酸分子的序列区域,诸如已经测序的标签化核酸分子和当前正在测序的标签化核酸分子的序列区域,等),其可以起到评估一种或多条件,该一种或多种条件用于确定是否停止对一个或多个核酸分子的测序和/或任何适合的过程。
比较序列区域优选地包括将已测序标签化核酸分子的第一umi区域和/或第一目标区域与(例如,当前正在测序的,等)标签化核酸分子的第二umi区域和/或第二目标区域执行比较。
在具体的实施例中,第一umi区域的序列可以与第二umi区域的序列比较,第一目标区域的序列可以与所述第二目标区域的序列比较。在具体的实施例中,确定比较可以包括确定第一序列区域集合与第二序列区域集合之间的比较,其中第一序列区域集合包括标签化核酸分子集合的已测序标签化核酸分子的第一umi区域和第一目标区域,并且其中第二序列区域集合包括标签化核酸分子集合的标签化核酸分子的第二umi区域和第二目标区域;诸如其中停止标签化核酸分子的测序可以基于所述第一序列区域集合与第二序列区域集合之间的比较。
在具体的实施例中,确定比较包括确定已测序标签化核酸分子的第一umi区域、第一目标区域、标签化核酸分子的第二umi区域和第二目标区域之间的比较,其中所述第一目标区域和第二目标区域与目标核酸序列集合的目标核酸序列(例如,相同的目标核酸序列,等)相关联,诸如其中停止标签化核酸分子的测序可以包括基于第一umi区域、第一目标区域、第二umi区域、和第二目标区域之间的比较(例如,基于第一umi区域与第二umi区域之间的匹配,和第一目标区域与第二目标区域之间的匹配,等)停止测序。
在具体的实施例中,促进单分子测序可以包括确定已测序标签化核酸分子的第一序列区域集合(例如,一个或多个umi区域和/或一个或多个目标区域,等);和储存第一序列区域集合(例如,在与测序系统相关联的计算系统中;在测序系统的计算子系统中;等),其中确定第一序列区域集合与第二序列区域集合之间的比较包括检索用于与第二序列区域集合(例如,当前正在测序的标签化核酸分子的一个或多个umi区域和/或一个或多个目标区域;等)比较第一序列区域集合。然而,确定序列区域之间的一个或多个比较s132可以以任何适合的方式执行。
促进单分子测序s130可以额外地或替代地包括确定一个或多个核酸分子(例如,标签化核酸分子;等)的停止测序s134,其可以起到停止一个或多个分子的测序的作用,诸如使得低度呈现的模板分子、特定目标分子和/或任何适合的分子类型能够充分测序。
如图3中所示,停止一个或多个核酸分子的测序优选地基于序列区域之间的一个或多个比较(例如,如s132中确定的比较,等)。在具体的实施例中,如果umi区域和目标区域(和/或适合的非umi区)的给定组合已经测序,并且匹配正在测序的umi区域和目标区域的当前组合,则可以向测序仪提供信号(例如,数字信号,等)并且反应停止(例如,其从而可以使得测序系统本身的功能化能够改进;等)。在具体的实施例中,停止标签化核酸分子的测序可以基于比较,该比较包括响应于匹配第二umi区域和第二目标区域的第一umi区域和第一目标区域来停止标签化核酸分子的测序。在具体的实施例中,基于读取待停的技术可以用于扫描特定的umi区域、目标区域和/或标签化核酸分子的适合的区域,并停止针对不具有特定区域或成分(例如,不具有umi区域;等)的核酸分子的测序(例如,拒绝测序读取结果和/或其他适合的输出)。在具体的实施例中,任何适合的区域之间(例如,已测序标签化核酸分子的第一umi区域与标签化核酸分子的第二umi区域之间;核酸分子的其他适合类型的区域之间;等)的任何适合的匹配可以用作停止测序的条件。在具体的实施例中,停止标签化核酸分子的测序可以基于比较,该比较包括基于匹配第二umi区域的第一umi区域停止标签化核酸分子的测序。
在具体的实施例中,促进单分子测序可以包括使用处理软件来(例如,实时地;等)读取通过测序系统(例如,单分子测序系统;等)生成的数据流,随后,该数据流可以分析以确定序列区域之间的比较(例如,如s132中的)、和/或停止一个或多个核酸分子的测序(例如,如s134中的,诸如基于比较;等)、和/或继续读取核酸分子。在具体的实施例中,确定(例如,已测序的标签化核酸分子的;等)第一序列区域集合、储存该第一序列区域集合、确定该第一序列区域集合与第二序列区域集合(例如,诸如当前正在测序的标签化核酸分子的标签化核酸分子的第二序列区域集合;等)之间的比较、和/或停止标签化核酸分子的测序,可以在单分子测序的单个测序运行期间、至少基本上实时地执行。
额外地或替代地,停止测序可以基于任何适合的条件(例如,测序相关条件),诸如基于序列读取结果、测序的区域、限定的界限、和/或任何适合的条件。然而,停止测序s134可以以任何适合的方式执行。
促进单分子测序可以额外地或替代地包括限制核酸分子的测序,该限定核酸分子的测序可以起到诸如基于特定核酸分子的umi区域、目标区域和/或适合的区域的识别,将特定核酸分子(例如,特定的标签化核酸分子)的测序限制到一定量(例如,数量,等)的作用。限制核酸分子的测序可以基于与核酸分子相对应的目标核酸序列的限定界限,诸如其中不同的限定界限可以针对给定的目标核酸序列,设置关于待测序的核酸分子的量的限制。在具体的实施例中,停止标签化核酸分子的测序包括基于所述比较和对于与第一序列区域集合相关联的(例如,对于包括序列区域的标签化核酸分子,该序列区域相应于第一序列区域集合的序列;等)标签化核酸分子的测序的限定界限(例如,其中限定界限已经达到与标签化核酸分子相对应的目标核酸分子序列;其中限定界限已经达到标签化核酸分子的类型;等),来停止测序,其中标签化核酸分子集合包括与第一序列区域集合相关联的标签化核酸分子。然而,限制核酸分子的测序s136可以以任何适合的方式执行。
促进单分子测序s130可以以任何适合的时间和频率执行。促进单分子测序可以基于针对第三方实体和/或适合的实体(例如,该实体执行生成标签化目标分子所需的样品处理;执行单分子测序的部分,诸如与样品加载相关联的部分;其中第一方可以执行与比较的确定、停止测序、和/或限制测序相关联的过程;等)提供基于umi的分子和/或促进标签化核酸分子的生成。
然而,促进单分子测序s130可以以任何适合的方式执行。
2.4确定分子计数
额外地或替代地,方法100的实施方式可以包括基于单分子测序确定分子计数s140,其可以起到针对一个或多个目标(例如,目标核酸序列;与标签化核酸分子相关联的目标;等),确定分子计数相关联指标的作用。分子计数可以包括以下任一种或多种:绝对分子计数、与测序读取量相关联的计数、和/或任何适合的分子计数相关联指标。确定分子计数优选地基于标签化核酸分子的umi区域的识别和/或分析,诸如其中umi区域的umi序列可以在一个或多个样品中存在的一个或多个目标的识别和/或定量中使用。
在具体的实施例中,方法100可以包括基于标签化核酸分子集合的umi区域的单分子测序确定与微生物相关联的绝对分子计数,该微生物来自包括核酸分子集合的样品。在具体的实施例中,方法100基于针对与目标核酸序列相关联的标签化核酸分子的测序的限定界限,来确定与目标核酸序列相关联的绝对分子计数,诸如其中限定界限(例如,在核酸分子的停止测序和/或限制测序中额外地或替代地使用;等)可以是提供确定一个或多个分子计数相关联指标的有用信息的、和/或在确定一个或多个分子计数相关联指标(例如,其中限定界限可以指示该分子计数将不会大于由该限定界限指示的计数;等)中使用。
确定分子计数可以以任何适合的时间和频率执行(例如,在测序运行期间实时地执行;基本上实时地执行,诸如在测序运行之后立即地执行;在umi区域的测序和/或分析之后的任何时间执行;等)。
然而,确定分子计数s140可以以任何适合的方式执行。
3.其他
然而,方法100的实施方式可以包括任何其他适合的块(block)或步骤,该块或步骤配置为促进接收来自受试者的生物样品、处理来自受试者的生物样品、分析衍生自生物样品的数据、以及根据受试者的具体微生物组组成和/或功能特征生成可以用于提供定制诊断和/或基于益生菌的疗法的模型。
方法100和/或系统的实施方式可以包括各种系统部件和各种方法过程的每一种组合和排列,包括任何变型(例如,实施方式、变型、实施例、具体实施例、附图,等),其中本文描述的方法100和/或过程的实施方式的部分可以异步地(例如,顺序地)、同时地(例如,并行地)、或以任何其他适合的顺序,通过和/或利用本文描述的系统和/或其他实体的一个或多个实例、元素、成分和/或其他方面来执行。
本文描述的任何变型(例如,实施方式、变型、实施例、具体实施例、附图,等)和/或本文描述的变型的任何部分可以额外地或替代地组合、聚合、排除、使用、连续进行、并行执行、和/或以其他方式应用。
方法100和/或系统的实施方式的部分可以至少部分地作为机器来呈现和/或实施,所述机器配置为接收储存计算机可读指令的计算机可读介质。该指令可以由可与系统整合的计算机可执行部件执行。计算机可读介质可以储存在任何适合的计算机可读介质上,诸如ram、rom、闪速存储器、eeprom、光学设备(cd或dvd)、硬盘、软盘驱动器、或任何适合的设备。计算机可执行部件可以是通用的或应用专用的处理器,但是任何适合的专用硬件或硬件/固件组合设备可以替代地或额外地执行指令。
如本领域的技术人员将从先前的详细说明并且从附图和权利要求中认识到的,可以在不背离权利要求中限定的范围的情况下,对所述方法100、系统和/或变型的实施方式进行修改和改变。
- 还没有人留言评论。精彩留言会获得点赞!