一种长效重组人生长激素融合蛋白及其工程细胞的制作方法
本发明涉及基因工程技术领域,特别是基因重组长效人生长激素技术领域,具体涉及一种长效重组人生长激素rhGH-Fc融合蛋白、其工程细胞及构建和筛选方法。
背景技术:
人生长激素(Human Growth Hormone,hGH)是人类出生后促生长最重要的一种蛋白质类激素,其具有种属特异性,由人脑垂体前叶的嗜酸性细胞分泌,人生长激素的蛋白受体遍及全身各个部位,而并不是通过靶腺作用来产生生理学效应。人生长激素含有191个氨基酸分子,其中大部分是以分子量22KDa形式存在,等电点为4.9,在第53位的半胱氨酸与 165位的半胱氨酸之间的以及第182位的半胱氨酸与189位半胱氨酸之间存在两个二硫键,少量生长激素以20KDa形式存在。生长激素最主要的生理作用是通过促进身体各组织、器官以及骨骼中受体细胞的蛋白质合成和脂肪的分解,进而促进人的代谢和生长发育。
若生长激素分泌不足会导致生长停滞及身体各功能紊乱,若分泌过多会引起不良反应,如出现“肢端肥大”、“巨人症”等。人生长激素最为明显的作用是增强蛋白质的合成、增强胶原蛋白的合成、促进骨组织的发育。虽然hGH对维持骨的生长十分重要,但是在骨生长中生长激素并非起直接作用,它是通过刺激血液中的硫化因子(SM)来实现的,SM可以促进身体内各种组织细胞及母细胞的分裂。人生长激素还可以促进氨基酸进入细胞中,减少氨类物质、含氮类物质的排出,保持机体的代谢状态平衡。人生长激素还能促使脂肪分解作用,抑制葡萄糖的氧化作用,减慢葡萄糖的消耗速度,还具有稳定糖原的作用。目前生长激素仍是一种非常复杂的激素,许多功能还有待研究。
人生长激素在临床上主要用于儿童生长激素缺乏症,Tuner综合症,促进大面积烧伤创面的愈合等。目前在中国,儿童生长发育迟缓发生率高达9.9%,居全球第二。根据中华医学会统计,目前全国4~15岁矮小患儿总数约有700万人,按其中的1/3为生长激素缺乏症推算,国内需要用生长激素治疗的儿童大概有200万,但能够接受合理治疗人数目前仍不到3 万人。对患者进行长期的随访时发现:约23%的儿童患者每个月会漏打三针以上;近13%的患者儿童会漏打处方剂量的一半以上;临床证据表明,没有严格遵守治疗方案患者可达50%以上。主要的原因是目前普通的重组人生长激素需要每日注射一次,以保持适当的血清生长激素水平。患者十分痛苦,治疗依从性差,并且价钱昂贵。对于那些需要长期接受生长激素治疗的病人,往往由于不能按时注射,造成治疗效果降低。目前在国内,重组人生长激素被批准的适应症主要有2种,其中大部分应用于治疗儿童“矮小症”,目前国内儿童矮小症患者治疗率很低,所以长效、高活性的重组人生长激素具有较大的未来市场潜力。
目前用于表达蛋白药物的表达系统分为两类,最早使用的是原核表达系统,主要为大肠杆菌。另一类为真核表达系统,昆虫、酵母、哺乳动物细胞均属此类表达系统。虽然大肠杆菌细胞具有良好的可操作性,成本相对较低,但是往往不能进行正确的糖基化修饰,在胞内容易形成包涵体。目前,国内的公司大多采用大肠杆菌分泌表达技术生产生长激素,其蛋白含有内毒素,需要繁琐的纯化步骤去除,致使最终产品收率较低,由于大肠杆菌是原核表达载体,所以目的蛋白的活性也较低。CHO细胞(仓鼠卵巢细胞,Chinese Hamster Ovary)属于真核细胞,具有转录修饰功能和蛋白质的翻译后修饰功能,表达的目的蛋白的构象、分子结构、理化特性、生物学功能都与天然的蛋白质十分接近。CHO细胞是成纤维细胞的一种,其自身的内源蛋白分泌量极少,对于后期重组蛋白的分离纯化十分有利;在培养方面,CHO细胞既具有贴壁生长的特性,若经驯化,也可进行悬浮培养,耐受较大剪切力和渗透压的能力较好;无血清培养可以提高产品的纯度,方便产物的分离纯化,同时可以减小由于血清带来的污染及过敏源,还可以延长细胞的G1期或G0期,从而提高目的蛋白表达量,也为后期大规模工业生产提供便利。
目前,国内商品化的长效生长激素均为PEG化生长激素,PEG化其能够增大蛋白分子量,不易通过肾小球,降低清除速率,防止蛋白酶的酶解作用,从而延长药物在体内的半衰期,但蛋白质聚乙二醇化过程会损失生物活性。
目前研究最热,发展最迅速的长效蛋白药物技术为Fc融合蛋白技术, Fc片段是IgG保持体内较长半衰期的主要因素,同时可以稳定蛋白,现已用于多种融合蛋白的开发。Fc片段通过两种机制发挥功能,第一种是与细胞表面的Fc受体结合,通过吞噬或裂解作用杀伤细胞并通过抗体依赖性细胞毒(ADCC)途径消化病原体。在四种人IgG亚型中IgG1与IgG3 能有效的结合细胞表面的Fc受体,而IgG2和IgG4与受体结合的亲和力较低。第二种是与第一补体成分C1的C1q结合,通过补体依赖的细胞毒 (CDC)途径裂解病原体。人IgG1和IgG3能有效的结合C1q从而介导补体级联反应,人IgG2与C1q的结合能力较弱,而人IgG4不与C1q结合。Fc融合蛋白主要是为了增加蛋白药物在体内的半衰期和简化生产工艺降低成本,Fc介导的IgG效应和裂解细胞的功能并不是必要的,甚至会产生副作用,基于以上原因选择IgG4亚型并进行相应的氨基酸突变以减弱其效应分子的功能。Fc融合蛋白技术不仅如PEG化般增大蛋白药物分子质量降低清除率,更加也能通过FcRn结合域,通过pH敏感性结合力以缓释的方式延长半衰期。目前的许多研究均表明,Fc融合蛋白具有比PEG化药物有更长的半衰期。
具体到人生长激素,已有对其融合Fc片段的数项研究,以CN 102875683B为例,其公开了一种长效重组人生长激素Fc融合蛋白 hGH-L-vFc融合蛋白,含有人生长激素、约2-20个氨基酸的柔性肽接头、和人IgG Fc变体,所述人IgG Fc变体可以选自含有S228P和L235A突变的人IgG4铰链区、CH2和CH3区域。但上述数项研究中,对于人生长激素半衰期延长效果并不令人满意。
因此,仍进一步需要开发更加长效、高活性的人生长激素衍生物。
技术实现要素:
为解决现有技术的不足,本发明提供了一种长效重组人生长激素 rhGH-Fc融合蛋白,所述融合蛋白由人生长激素、连接肽和Fc片段组成;由N端至C端依次为:人生长激素、连接肽、Fc片段,其氨基酸序列共 431个氨基酸,其中前191个氨基酸序列为人生长激素序列,第192位至第206位为连接肽序列,第207位至第431位为人IgG的Fc片段。
进一步地,所述Fc片段选自人IgG的Fc片段,优选为人IgG4的 Fc片段。
进一步地,所述人IgG4的Fc片段包括四个氨基酸突变,所述氨基酸突变为:S228P、F234A、L235A和V308P,其中IgG Fc区中的残基的编号是依据Kabat Eu Index编号。其中,S228P位点突变是为了维持蛋白的稳定性;F234A及L235A位点突变是为了减低免疫融合蛋白与Fc 受体的亲和力从而达到降低免疫融合蛋白的ADCC活性的作用;而V308P 位点突变使融合蛋白与FcRn的结合呈pH依赖,故可通过提高蛋白分子量从而不被肾小球滤过和V308P位点的突变从而使蛋白呈pH依赖两个方面,使长效重组人生长激素rhGH-Fc免疫融合蛋白的半衰期高于普通 Fc融合蛋白药物。
进一步地,所述融合蛋白的氨基酸序列如SEQ ID NO:1所示,所述融合蛋白的编码核苷酸序列如SEQ ID NO:2所示。
本发明还提供一种工程细胞,所述工程细胞表达前述融合蛋白,更优选地,所述工程细胞为CHO-k1细胞,其能够稳定转染有前述融合蛋白的表达载体。
进一步地,所述工程细胞由如下步骤构建得到:
(1)首先将人抗体IgG4Fc序列(登录号:DI488112)经特异位点突变后与hGH基因(登录号:NM_000515)用柔性连接肽连接,并在hGH 序列前加入生长激素信号肽序列(登录号:CAI94177),全基因合成 rhGH-Fc序列;
(2)将双表达质粒p327.8GS经限制性内切酶HindⅢ、EcoRⅠ和 XbaⅠ、XhoⅠ两次双酶切,将回收的大片段与步骤(1)合成的rhGH-Fc 序列经T4DNA连接酶混匀,15~16℃连接过夜;
(3)采用CaCl2法制备感受态大肠杆菌DH5α,然后进行质粒转化,经含氨苄青霉素的LB平板培养筛选,挑取阳性菌落接种到LB液体培养基中,低速震荡培养14~16h后提取质粒;质粒经HindⅢ、EcoRⅠ和 XbaⅠ、XhoⅠ两次双酶切鉴定及测序,将基因序列鉴定正确的重组质粒命名为rhGH-Fc-1;
(4)将细胞接种于带血清的完全培养基的曲颈瓶中培养,当细胞密度达到90~95%时,采用脂质体转染法,在Lipofectamin 2000介导下,将步骤(3)制备的重组质粒rhGH-Fc-1稳定转染至CHO-k1细胞;
(5)将步骤(4)转染后的细胞转入96孔板中,加入SMM-CHO GSI 培养基(含10~12%FBS+25~30μmol MSX)混匀,在CO2培养箱35~37℃恒温培养箱10~12天后,在显微镜下,标记单克隆;
(6)逐渐提高MSX浓度采用ELISA法逐步筛选高表达株,从96 板(25~30μmol MSX)→24孔板(50~55μmol MSX)→6孔板(50~55 μmol MSX)→75cm2培养瓶(70~75μmol MSX)→125ml摇瓶(70~75 μmol MSX),选取表达量较高且增殖状态较好细胞株进行亚克隆筛选,将最终筛选细胞株命名为rhGH-Fc细胞株,表达的目的蛋白为rhGH-Fc 免疫融合蛋白。
本发明还提供一种表达载体,所述表达载体优选为双表达载体,更优选地,所述表达载体为以双表达质粒p327.8GS经限制性内切酶Hind III、EcoR I和XbaⅠ、XhoⅠ两次双酶切后,将回收的大片段与权利要求1 所述融合蛋白的编码核酸经T4DNA连接酶混匀,15~16℃连接过夜,使优化过的目的基因克隆至双表达载体上而获得。
本发明还提供一种融合蛋白的阳性克隆及亚克隆的筛选方法,所述方法为:通过逐渐提高蛋氨酸磺酰胺(MSX)浓度,从96板(25~30μmol MSX)→24孔板(50~55μmol MSX)→6孔板(50~55μmol MSX)→ 75cm2培养瓶(70~75μmol MSX)→125ml摇瓶(70~75μmol MSX),采用ELISA法逐步筛选出表达量较高且增殖状态较好的细胞株,将最终筛选细胞株命名为rhGH-Fc细胞株,表达的目的蛋白为rhGH-Fc免疫融合蛋白。
进一步地,所述融合蛋白所述融合蛋白可以延长血清半衰期,大大降低治疗时间内所需的注射给药频率,从而提高患者的依从性和医患双方的便利性;所述CHO细胞可用于制备重组人长效生长激素,其蛋白表达量高、生物活性好、降低蛋白的免疫原性,能够改善药效。
有益效果
本发明的rhGH-Fc融合蛋白通过将人生长激素与Fc片段构建融合蛋白来提高人生长激素的分子量从而不被肾小球滤过,并且通过Fc片段的氨基酸突变从而改善Fc片段的稳定性、降低融合蛋白的ADCC活性以及改善融合蛋白与FcRn结合的pH依赖性,综合上述效果,从而相对于普通的Fc融合蛋白药物而进一步提高了融合蛋白的半衰期。
本发明的rhGH-Fc融合蛋白具有显著延长的血清半衰期,以及具有高生物活性,能够大大降低治疗时间内所需的注射给药频率,可提高患者的依从性和医患双方的便利性。
本发明的工程细胞选用CHO-k1细胞作为宿主细胞,通过采用GS双表达载体进行稳定转染,获得的工程细胞蛋白表达量高、生物活性好、降低蛋白的免疫原性,能够显著改善药效。
附图说明
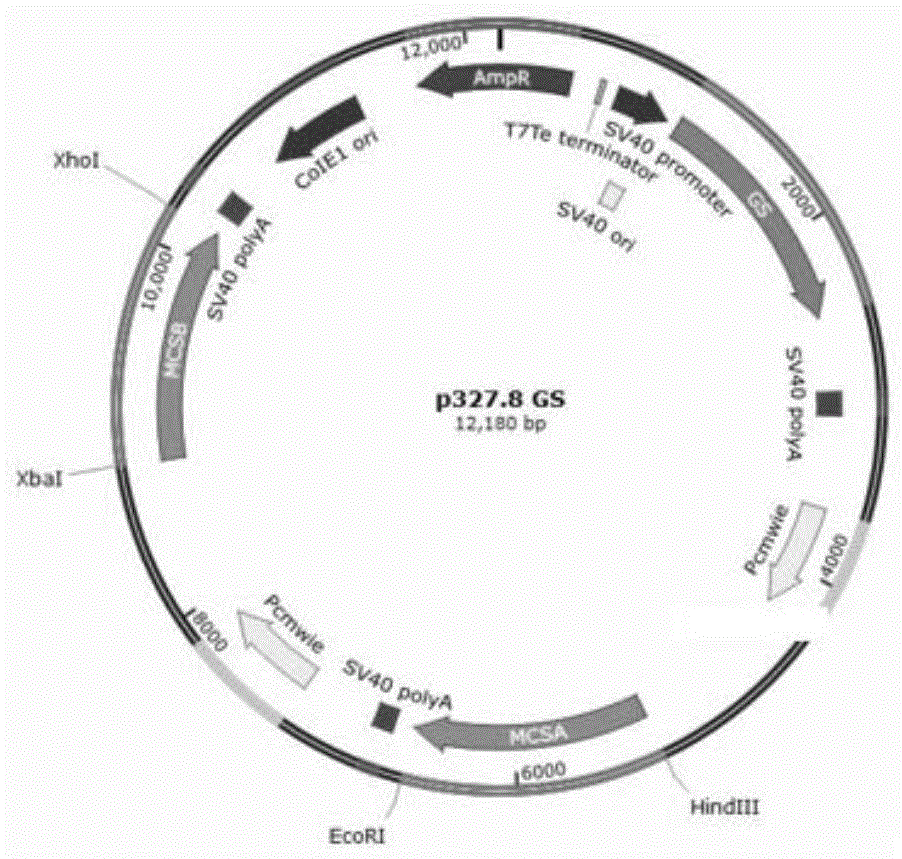
图1:p327.8GS双表达载体的质粒图谱。
图2:质粒的测序图谱。
图3:重组质粒rhGH-Fc-1双酶切鉴定,1:质粒rhGH-Fc-1的 HindIII、EcoRI双酶切产物;2:质粒rhGH-Fc-1的XhoI、XbaI双酶切产物;M:DNA marker DL 10000。
图4:125ml摇瓶中培养上清液ELISA结果。
图5:细胞株D 75cm2中培养上清ELISA结果。
图6:细胞株E 75cm2中培养上清ELISA结果。
图7:细胞株H 75cm2中培养上清ELISA结果。
图8:亚克隆125ml摇瓶中D1、E2、H2培养上清ELISA结果。
图9:亚克隆125ml摇瓶中D1、E2、H2细胞生长曲线。
图10:目的蛋白SDS-PAGE图谱,1:rhGH-Fc蛋白非还原型;2:蛋白质marker;M:rhGH-Fc蛋白还原型。
图11:目的蛋白等点聚焦电点电泳图,1:rhGH标准品;M1: HighpIKit,pH5~10.5;M2:BroadpIKit,pH3~10;2:rhGH-Fc蛋白。
图12:rhGH-Fc免疫融合蛋白的细胞培养液的上清液的HPLC图谱。
图13:rhGH-Fc免疫融合蛋白的HPLC图谱。
图14:各组大鼠给药后体重增长趋势图。
具体实施方式
在下文中更详细地描述了本发明以有助于对本发明的理解。
应当理解的是,在说明书和权利要求书中使用的术语或词语不应当理解为具有在字典中限定的含义,而应理解为在以下原则的基础上具有与其在本发明上下文中的含义一致的含义:术语的概念可以适当地由发明人为了对本发明的最佳说明而限定。
下列实施例中未注明具体条件的实验方法,通常按照常规条件如 Sambrook等人,分子克隆:实验室手册中所述的条件,或按照制造厂商所建议的条件。
实施例1:rhGH-Fc融合蛋白的设计与合成
将人抗体IgG4Fc序列(DI488112)经特异位点突变后与hGH基因 (NM_000515)用柔性Linker连接,获得成熟的rhGH-Fc,在hGH序列前加入生长激素信号肽序列(CAI94177),获得携带有信号肽的 rhGH-Fc。全基因合成成熟的rhGH-Fc以及携带信号肽的rhGH-Fc,其氨基酸序列如SEQ ID NO:1所示;全基因合成成熟的rhGH-Fc编码基因,其核苷酸序列如SEQ ID NO:2所示。
SEQ ID NO 1:
长效重组人生长激素rhGH-Fc免疫融合蛋白的氨基酸序列:
FPTIPLSRLFDNAMLRAHRLHQLAFDTYQEFEEAYIPKEQKYSFLQ NPQTSLCFSESIPTPSNREETQQKSNLELLRISLLLIQSWLEPVQFLR SVFANSLVYGASDSNVYDLLKDLEEGIQTLMGRLEDGSPRTGQIFK QTYSKFDTNSHNDDALLKNYGLLYCFRKDMDKVETFLRIVQCRSV EGSCGFSSASTKGPSVFPLAPGPPCPPCPAPEAAGGPSVFLFPPKPK DTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPRE EQFNSTYRVVSVLTPLHQDWLNGKEYKCKVSNKGLPSSIEKTISKA KGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNG QPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEA LHNHYTQKSLSLSLGK
SEQ ID NO 2:
长效重组人生长激素rhGH-Fc免疫融合蛋白的编码核苷酸序列:
TTCCCCACCATTCCTCTGTCCAGGCTGTTCGACAACGCCATGCT GAGGGCCCACAGGCTGCATCAACTGGCCTTCGACACCTACCAG GAGTTCGAGGAAGCCTACATCCCTAAGGAGCAGAAATACTCCTT CCTGCAGAACCCCCAGACTTCTCTGTGCTTCTCCGAGTCCATCC CAACCCCCTCCAACAGGGAGGAAACCCAACAGAAGTCCAACCT GGAACTGCTGAGGATCTCTCTGCTGCTGATTCAGTCCTGGCTGG AGCCCGTGCAATTCCTGAGGTCTGTGTTCGCAAACTCCCTGGTG TACGGCGCCTCCGACTCCAACGTGTACGATCTGCTGAAGGACCT GGAGGAGGGAATCCAGACACTGATGGGCAGGCTGGAAGACGG CTCCCCAAGGACCGGCCAAATCTTCAAGCAGACCTACTCCAAGT TTGACACCAACTCCCACAACGATGACGCCCTGCTGAAAAACTAC GGACTGCTGTACTGCTTTAGGAAAGATATGGACAAAGTGGAGAC CTTTCTGAGGATTGTGCAGTGCAGGTCCGTGGAGGGCTCCTGC GGCTTCTCCTCCGCCTCCACCAAGGGCCCTTCCGTGTTCCCTCT GGCCCCTGGCCCTCCTTGCCCTCCTTGCCCTGCCCCTGAGgccgcc GGCGGCCCTTCCGTGTTCCTGTTCCCTCCTAAGCCTAAGGACAC CCTGATGATCTCCCGCACCCCTGAGGTGACCTGCGTGGTGGTG GACGTGTCCCAGGAGGACCCTGAGGTGCAGTTCAACTGGTACG TGGACGGCGTGGAGGTGCACAACGCCAAGACCAAGCCTCGCGA GGAGCAGTTCAACTCCACCTACCGCGTGGTGTCCGTGCTGACC CCCCTGCACCAGGACTGGCTGAACGGCAAGGAGTACAAGTGCA AGGTGTCCAACAAGGGCCTGCCTTCCTCCATCGAGAAGACCAT CTCCAAGGCCAAGGGCCAGCCTCGCGAGCCTCAGGTGTACACC CTGCCTCCTTCCCAGGAGGAGATGACCAAGAACCGGTGTCCCT GACCTGCCTGGTGAAGGGCTTCTACCCTTCCGACATCGCCGTG GAGTGGGAGTCCAACGGCCAGCCTGAGAACAACTACAAGACCA CCCCTCCTGTGCTGGACTCCGACGGCTCCTTCTTCCTGTACTCC CGCCTGACCGTGGACAAGTCCCGCTGGCAGGAGGGCAACGTGT TCTCCTGCTCCGTGATGCACGAGGCCCTGCACAACCACTACACC CAGAAGTCCCTGTCCCTGTCCCTGGGCAAGT
由SEQ ID NO:1所示的氨基酸序列可知,成熟的rhGH-Fc氨基酸序列共431个氨基酸,其中前191个氨基酸为人生长激素序列,“SSASTKGPSVFPLAP”为连接肽Linker,G207-K431为人IgG4的Fc 片段,并有S228P,F234A,L235A和V308P四个氨基酸的突变(根据 Kabat的Eu编码)。
S228P的突变是为了维持蛋白的稳定性,IgG4有时会发生铰链区域中重链间二硫键的解离从而形成半抗体分子,这种情况在其他三种IgG 同种型分子中通常不会发生。在IgG1和IgG2中的228位点为Pro,而在 IgG4中228位为Ser。将IgG4的Ser残基用Pro取代,可以使IgG4保持完整的抗体分子。F234A,L235A突变是为了减低免疫融合蛋白与Fc 受体的亲和力从而达到降低免疫融合蛋白的ADCC活性。Fc片段中 V308P突变,使融合蛋白与FcRn的结合呈pH依赖。在发生生物胞吞作用时,即pH为6左右时,此融合蛋白与FcRn亲和力较高,可以避免溶酶体的降解。在正常酸碱度pH7.4时与FcRn正常结合,从而使该长效生长激素的半衰期高于普通Fc融合蛋白药物。
实施例2:含rhGH-Fc融合蛋白编码基因的重组表达质粒的构建
(1)目的基因序列与GS双表达载体的连接
分别取8.0μl双表达质粒p327.8GS(其质粒图谱如图1所示)分别与0.5μl HindⅢ、0.5μl EcoRⅠ、2.0μl Cut Smart buffer、9.0μl ddH2O 和0.5μl XbaⅠ、0.5μl XhoⅠ、2.0μl Cut Smart buffer、9.0μl ddH2O 两次酶切体系在EP管中混匀,放入37℃恒温箱中反应2h进行双酶切。然后将5μl质粒GS、5μl携带信号肽的rhGH-Fc基因序列、2.0μl Buffer、 7.0μl ddH2O加入EP管中混匀,混合体系中加入1.0μl融化后的T4DNA 连接酶,混匀,16℃连接过夜。
(2)质粒的转化与提取
取大肠杆菌DH5α与LB培养基按体积比1:100比例接种于液体LB 培养基中(不含抗性),在37℃恒温状态下小幅度震荡,过夜培养。次日将震荡一夜后的菌液按体积比1:50比例接种于LB培养基中(不含抗性),继续培养至OD600在0.3~0.5。将培养好的大肠杆菌置于冰上10min,混匀后转移至1.5ml离心管中,在4℃下4000rpm低温离心5min,弃上清。用移液器枪准确吸取100μl预冷的0.1mol CaCl2溶液转移至离心管中,用手指轻轻弹均匀后置于冰上静置10min。4℃3000rpm低温离心5 min,弃上清。用移液器枪准确吸取50μl预冷的0.1mol CaCl2溶液加入离心管中混匀。
取100μl感受态大肠杆菌DH5α与1μl步骤(1)获得的质粒在EP 管内混匀,冰浴30min。剩余的感受态细胞要置于-80℃条件下保存。然后将EP管放入42℃温水浴90s,立即拿出,再冰浴2min。加入200μl 不含抗性的LB培养液,恒温37℃下低速震荡培养50min。2000rpm离心1min,弃去200μl上清,将余下溶液混合均匀。将液体在含氨苄西林抗性(Amp)的LB平板上涂布均匀,37℃恒温培养箱中培养16小时左右。用接种针挑取阳性菌落接种到5ml LB液体培养基中,200rpm低速震荡培养14h,准备提取质粒。
接着取5ml菌液至离心管中,7000rpm离心3min收集细菌,弃上清。向离心管中加入500μl含有RNaseA的Buffer P1,充分重悬。再向离心管中加入500μl Buffer P2,轻轻的上下颠倒5~6次,室温放置5min,至溶液变清亮粘稠。向离心管中加入500μl Buffer E3,立即颠倒6~8次,室温放置5min,1300rpm离心10min,将上清加到已加入Endo-Remover Column的收集管中,1300rpm离心1min,将收集管中的滤液转移到离心管中。将吸附柱装入收集管中加入200μl Buffer Ps,1300rpm离心2 min,平衡,弃掉滤液,重新将吸附柱放入收集管中。向离心管中加入450 μl异丙醇,上下颠倒混匀,将混合液转入平衡好的吸附柱中。1300rpm 离心1min,弃去废液,重新将吸附柱放回收集管中。加入750μl含无水乙醇的Buffer PW,1300rpm离心1min,弃去废液。1300rpm空离2min,弃去废液,置于室温干燥5min。把吸附柱放于新的离心管中。向吸附膜中间加入200μl Endo-Free Buffer EB,室温放置5min,300rpm离心2 min,提取出来的质粒要进行测序及鉴定,将基因序列鉴定正确的重组质粒命名为rhGH-Fc-1。图2显示的就是质粒的测序图谱。图3显示的是将重组质粒rhGH-Fc-1用HindⅢ、EcoRⅠ和XbaⅠ、XhoⅠ两次双酶切后的产物经1%琼脂糖凝胶电泳分析,图中均可见约为1300bp的目的条带,与预期1362bp一致。故测序及鉴定结果证实完全符合设计要求。
实施例3:CHO-k1细胞培养及转染
首先将培养CHO-k1细胞的细胞培养液(优选IMDM培养基)全部弃去,加入适量HYQtase(若为贴壁细胞),然后放入CO2培养箱中进行 37℃加速消化,消化完全后加入适量培养基稀释消化液终止消化。将细胞全部倒入离心管中,1500rpm离心5min,弃上清液。加入适量的冻存液 (培养基+10%DMSO),将离心管中细胞混匀,细胞计数,使其终浓度在3×106~1×107个/ml之间。将上述细胞转移至预冷的冷冻管中,放入带有异丙醇的冷冻盒中,置于-80℃过夜第二天再转入液氮中。
从液氮罐中取出冷冻塑料管。迅速将冷冻管放入38℃水浴,使其迅速融化。在75cm2曲颈瓶中加入适当的带血清的完全培养基,将细胞接种于曲颈瓶中培养。
当细胞密度达95%时开始进行转染。按照Lipofectamin 2000介导下,用250μl的IMDM培养基稀释6μg高纯度质粒DNA,室温放置5min。用250μl的IMDM培养基稀释20μl的Lipofectamin,室温放置5min。将二者混匀放置20min。用IMDM无血清培养基将细胞洗三次。将DNA- 脂质体混合物加入曲颈瓶中,加入14ml左右IMDM培养基,置于37℃、 5%CO2、饱和湿度下培养4~6h后,更换培养基,将原有培养基弃去,加入16ml IMDM+10%FBS培养基继续培养。
实施例4:稳定高效表达rhGH-Fc融合蛋白的工程细胞的筛选
(1)阳性克隆的筛选
将实施例3转染后的CHO-k1细胞的IMDM培养基弃去,加入2ml 左右HYQtase消化,放入恒温箱中加速消化。消化完全后,加入适量有血清培养基终止消化。将细胞及培养液倒入离心管中,1500rpm离心5 min,弃去上清。在离心管中加入30ml SMM-CHO GSI培养基(含10% FBS+25μmol MSX)混匀。将所需培养基与细胞混匀,用排枪移入96 孔板中,100μl/孔,96孔板中每孔细胞的计数应为5×103~8×103个。用保鲜膜封住,放入CO2培养箱中培养。一周后补加50μl SMM-CHO GSI培养基(含10%FBS+25μmol MSX)。转染后12天左右,在显微镜下,标记长有单克隆孔位。将标记孔位的细胞培养液吸干净,150μl/ 孔加入SMM-CHO GSI(25μmol MSX)无血清培养基。CO2培养箱中培养3~4天后,使用ELISA法检测培养上清液,进行第一次筛选。
将ELISA结果相对较好的单克隆刮下移入24孔板中,每孔加入1ml SMM-CHO GSI(25μmol MSX)培养基,置于CO2培养箱中培养3~4 天后,第一孔取150μl上清,其余三孔每孔加200μl PBS,从第一孔中取50μl到第二孔混匀依次稀释,取上清液4个梯度稀释,使用ELISA 法检测,进行第二次筛选。
将检测结果相对较好的孔位吹打均匀,移入6孔板中,每孔加入3ml SMM-CHO GSI(50μmol MSX),置于CO2培养箱中培养3~4天后,取上清液分4个梯度稀释,使用ELISA法检测培养上清液,进行第三次筛选。
选取检测结果相对较好的移入75cm2曲颈瓶中,每瓶再补加13ml SMM-CHO GSI(75μmol MSX),置于CO2培养箱中培养。继续培养一周左右,取75cm2曲颈瓶中的上清液4个梯度稀释,使用ELISA法检测,进行第四次筛选。
选取检测结果相对较好的进行细胞冻存,剩下一些继续培养。细胞生长至对数期时转移至125ml小摇瓶中,继续震荡培养。将125ml小摇瓶中的细胞及培养液1500rpm离心5min,加入10ml SMM-CHO GSI(75 μmol MSX)培养基吹打混匀进行细胞计数。在125ml摇瓶中加入30ml SMM-CHO GSI(75μmol MSX)新鲜培养基,移入适量细胞,使瓶内细胞总数均为1.2×107个,批次培养,每天计数观察。3~4天取125ml瓶中细胞培养上清,分别进行6个梯度稀释,使用ELISA法检测,进行第五次筛选。图4显示的是筛选结果,根据筛选125ml摇瓶中培养液上清 ELISA结果,选取表达量相对较高且细胞生长状态较好的D、E、H三株细胞冻存,准备进行第二轮亚克隆筛选。
(2)亚克隆筛选
选取步骤(1)获得的表达量较高且增殖状态较好的D、E、H三株细胞株进行亚克隆筛选。
首先进行细胞计数。然后稀释细胞,培养基为SMM-CHO GSI+10% FBS(25μmol MSX),使5ml中共含有500个细胞左右,每个细胞株铺 5块96孔板,100μl/孔,铺好的96孔板用保鲜膜封好,放入37℃,CO2培养箱中培养。后续筛选方法与阳性克隆的筛选实验方法相同,从96板 (25μmol MSX)→24孔板(50μmol MSX)→6孔板(50μmol MSX) →75cm2培养瓶(75μmol MSX)→125ml摇瓶(75μmol MSX)。
图5显示的是细胞株D在75cm2中培养上清ELISA结果,由图所示,选取D1继续培养;图6显示的是细胞株E在75cm2中培养上清ELISA 结果,由图所示,选取E2继续培养;图7显示的是细胞株H在75cm2培养瓶中培养上清ELISA结果,由图所示,选取H2继续培养;将在亚克隆筛选中的125ml摇瓶中相同培养状态下的D1、E2、H2培养上清用 ELISA法检测,根据图8显示的ELISA结果,图9显示的亚克隆125ml 摇瓶中D1、E2、H2细胞生长曲线,选择细胞生长状态及检测结果都较好的H2为最终筛选细胞株,并命名为rhGH-Fc细胞株,表达的目的蛋白为rhGH-Fc免疫融合蛋白。
实施例5:rhGH-Fc免疫融合蛋白的初步纯化
培养rhGH-Fc细胞株以生产rhGH-Fc免疫融合蛋白,培养约10~15 天,待细胞接近于全部死亡时,收集上清,4000rpm离心20min,将上清收集准备纯化rhGH-Fc免疫融合蛋白。将蛋白培养液离心的上清与硅藻土按3g/100ml比例混合过滤后开始进行亲和层析纯化目的蛋白。首先将细胞培养上清液经0.22μm孔径的滤膜过滤。将蛋白纯化柱(预装柱 Hitrap Mabselect Sure 5*1ml)连在蛋白纯化仪上。用50mM Tris+150 mM NaCl(HCl调pH 7.3~7.5)的平衡液以5ml/min流速平衡柱子3~5 个体积,紫外检测仪上显示0左右数值即可。以5ml/min流速上样,紫外检测仪上可能显示百级数值。上样结束后用平衡液清洗柱子3~5个体积,紫外检测仪上再次显示0左右数值即可。用0.1M甘氨酸(HCl调pH 3.5~3.8)的洗脱液以2~3ml/min流速冲洗,收集洗脱峰。用0.1M NaOH 清洗液清洗纯化柱3~5个柱体积,20%乙醇保存。
实施例6:rhGH-Fc免疫融合蛋白的鉴定
将初步纯化后的rhGH-Fc免疫融合蛋白经非还原及还原型10% SDS-PAGE分析相对分子质量,经等电点聚焦电泳测定等电点。图10显示的是rhGH-Fc免疫融合蛋白的SDS-PAGE鉴定图谱,由图可见,非还原型电泳显示在相对分子量约95kDa处可见特异蛋白条带,与理论值 97.3kDa相符,还原型电泳显示在相对分子量约为42kDa处可见特异蛋白条带,与理论值43.7kDa相符。
图11显示的是rhGH-Fc免疫融合蛋白的等电点聚焦电泳图,结果显示rhGH-Fc免疫融合蛋白的等电点在5.2~5.85之间,与理论预测值5.35 一致。
实施例7:rhGH-Fc免疫融合蛋白的表达水平
培养实施例4所获得的rhGH-Fc细胞株以生产rhGH-Fc免疫融合蛋白,培养条件为:SMM-CHO GSI培养基(含75μmol MSX),37℃, CO2培养箱中振荡培养,培养约12天后测定其rhGH-Fc免疫融合蛋白表达水平。
使用高效液相色谱法(HPLC)来检测rhGH-Fc免疫融合蛋白的细胞培养液的上清液及经过亲和层析初步纯化后的rhGH-Fc免疫融合蛋白。色谱柱采用G3000WS,检测波长设为280nm,流速为1ml/min,上样量为20μl。通过纯化后的已知浓度蛋白的HPLC检测结果确定目的蛋白保留时间,通过峰面积对比确定细胞培养上清中目的蛋白表达量。
图12显示的是rhGH-Fc免疫融合蛋白的细胞培养液的上清液的 HPLC图谱,图13显示的是rhGH-Fc免疫融合蛋白的HPLC图谱。由 HPLC检测结果可看出,rhGH-Fc免疫融合蛋白的主峰保留时间约为10.6 min,细胞培养液的上清液中目的蛋白的峰面积为17804703,纯化后的 rhGH-Fc免疫融合蛋白的峰面积为21131703,纯度为95.21%。估算细胞上清表达量为1.4g/L以上。
实施例8:rhGH-Fc免疫融合蛋白的生物活性测定
rhGH-Fc免疫融合蛋白活性的测定按《中国药典》2015年版四部通则1219大鼠去垂体生长激素生物测定法进行活性测定。
具体如下:SD大鼠,雌雄各半,3~4周龄,戊巴比妥钠(浓度15mg/ml) 45mg/kg腹腔注射麻醉(给药容积3ml/kg),麻醉后固定于立体定向垂体切除仪(Stoelting,USA),进行垂体去除手术,手术后记录每只动物的体重和尾长(从尾末端到肛门的距离)。手术完毕,术后3天内,每日单次皮下注射青霉素(40×104IU/ml)0.1ml/只,并让动物自由饮用5%葡萄糖水(装入给水瓶中);自由饮水和进食。术后3周,测量每只存活动物的体重,取术后2~3周体重变化小于手术前±10%去垂体大鼠为合格模型动物,并按体重随机均衡分为模型对照组(生理盐水),人生长激素国际活性标准品低剂量组(0.4IU/kg)、高剂量组(1.6IU/kg),rhGH-Fc免疫融合蛋白的低剂量组(0.4IU/kg)、高剂量组(1.6IU/kg),每组10只;给药方法:皮下注射;给药体积:2.5ml/kg/d;给药频率及期限:依分组给药,标准品组每日一次,连续6日;模型对照组、供试品组间隔3天注射1次,共注射2次;注射剂量及分组设置详细见表1。
表1注射剂量及分组设置
每日称重记录(实验分组给药当天记为D1)。图14显示的是各组大鼠给药后体重增长趋势图。体重测定结果显示,供试品组rhGH-Fc免疫融合蛋白注射后3天内都在生长,而标准品组不给药后,立即停止生长,可以初步判断rhGH-Fc免疫融合蛋白的半衰期长于生长激素标准品。第 10天处死动物并刨取后两腿胫骨,按药典附录方法测量胫骨骨骺板宽度 (每鼠两腿胫骨测量10个数值,去掉最高值和最低值,取其平均值)。将反应值实验结果按《中国药典》2015年版四部通则1431生物检定统计法中的量反应平行线测定随机设计法列表的格式整理,按量反应平行线测定法随机设计处理结果,表2显示的就是各组大鼠胫骨骨骺板宽度测量结果。将数据进行统计学处理,表3显示的是低剂量组大鼠骨骺板宽度测量数据统计学分析,表4显示的是高剂量组大鼠骨骺板宽度测量数据统计学分析。从表中可以看出,低剂量和高剂量组中供试品与标准品的数据证明本发明研制的免疫融合蛋白半衰期显著长于标准品。供试品按剂量折算后理论估计效价为:1.24IU/mg,按药典规定的生物检定统计法计算的效价结果为1.1IU/mg。
表2各组大鼠胫骨骨骺板宽度测量结果
表3低剂量组大鼠骨骺板宽度测量数据统计学分析
表4高剂量组大鼠骨骺板宽度测量数据统计学分析
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
序列表
<110> 长春生物制品研究所有限责任公司
<120> 一种长效重组人生长激素融合蛋白及其工程细胞
<141> 2019-05-16
<160> 2
<170> SIPOSequenceListing 1.0
<210> 1
<211> 431
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 1
Phe Pro Thr Ile Pro Leu Ser Arg Leu Phe Asp Asn Ala Met Leu Arg
1 5 10 15
Ala His Arg Leu His Gln Leu Ala Phe Asp Thr Tyr Gln Glu Phe Glu
20 25 30
Glu Ala Tyr Ile Pro Lys Glu Gln Lys Tyr Ser Phe Leu Gln Asn Pro
35 40 45
Gln Thr Ser Leu Cys Phe Ser Glu Ser Ile Pro Thr Pro Ser Asn Arg
50 55 60
Glu Glu Thr Gln Gln Lys Ser Asn Leu Glu Leu Leu Arg Ile Ser Leu
65 70 75 80
Leu Leu Ile Gln Ser Trp Leu Glu Pro Val Gln Phe Leu Arg Ser Val
85 90 95
Phe Ala Asn Ser Leu Val Tyr Gly Ala Ser Asp Ser Asn Val Tyr Asp
100 105 110
Leu Leu Lys Asp Leu Glu Glu Gly Ile Gln Thr Leu Met Gly Arg Leu
115 120 125
Glu Asp Gly Ser Pro Arg Thr Gly Gln Ile Phe Lys Gln Thr Tyr Ser
130 135 140
Lys Phe Asp Thr Asn Ser His Asn Asp Asp Ala Leu Leu Lys Asn Tyr
145 150 155 160
Gly Leu Leu Tyr Cys Phe Arg Lys Asp Met Asp Lys Val Glu Thr Phe
165 170 175
Leu Arg Ile Val Gln Cys Arg Ser Val Glu Gly Ser Cys Gly Phe Ser
180 185 190
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Gly Pro
195 200 205
Pro Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val
210 215 220
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
225 230 235 240
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
245 250 255
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
260 265 270
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
275 280 285
Val Leu Thr Pro Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
290 295 300
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
305 310 315 320
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
325 330 335
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
340 345 350
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
355 360 365
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
370 375 380
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
385 390 395 400
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
405 410 415
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
420 425 430
<210> 2
<211> 1293
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 2
ttccccacca ttcctctgtc caggctgttc gacaacgcca tgctgagggc ccacaggctg 60
catcaactgg ccttcgacac ctaccaggag ttcgaggaag cctacatccc taaggagcag 120
aaatactcct tcctgcagaa cccccagact tctctgtgct tctccgagtc catcccaacc 180
ccctccaaca gggaggaaac ccaacagaag tccaacctgg aactgctgag gatctctctg 240
ctgctgattc agtcctggct ggagcccgtg caattcctga ggtctgtgtt cgcaaactcc 300
ctggtgtacg gcgcctccga ctccaacgtg tacgatctgc tgaaggacct ggaggaggga 360
atccagacac tgatgggcag gctggaagac ggctccccaa ggaccggcca aatcttcaag 420
cagacctact ccaagtttga caccaactcc cacaacgatg acgccctgct gaaaaactac 480
ggactgctgt actgctttag gaaagatatg gacaaagtgg agacctttct gaggattgtg 540
cagtgcaggt ccgtggaggg ctcctgcggc ttctcctccg cctccaccaa gggcccttcc 600
gtgttccctc tggcccctgg ccctccttgc cctccttgcc ctgcccctga ggccgccggc 660
ggcccttccg tgttcctgtt ccctcctaag cctaaggaca ccctgatgat ctcccgcacc 720
cctgaggtga cctgcgtggt ggtggacgtg tcccaggagg accctgaggt gcagttcaac 780
tggtacgtgg acggcgtgga ggtgcacaac gccaagacca agcctcgcga ggagcagttc 840
aactccacct accgcgtggt gtccgtgctg acccccctgc accaggactg gctgaacggc 900
aaggagtaca agtgcaaggt gtccaacaag ggcctgcctt cctccatcga gaagaccatc 960
tccaaggcca agggccagcc tcgcgagcct caggtgtaca ccctgcctcc ttcccaggag 1020
gagatgacca agaaccggtg tccctgacct gcctggtgaa gggcttctac ccttccgaca 1080
tcgccgtgga gtgggagtcc aacggccagc ctgagaacaa ctacaagacc acccctcctg 1140
tgctggactc cgacggctcc ttcttcctgt actcccgcct gaccgtggac aagtcccgct 1200
ggcaggaggg caacgtgttc tcctgctccg tgatgcacga ggccctgcac aaccactaca 1260
cccagaagtc cctgtccctg tccctgggca agt 1293
- 还没有人留言评论。精彩留言会获得点赞!