特异性识别N-cadherin的ssDNA适配体、其筛选方法及应用与流程
本发明涉及一种核酸适配体,具体涉及一种特异性识别n-cadherin的ssdna适配体、其筛选方法及应用,例如在n-cadherin蛋白的检测方法中的应用,属于检测技术领域。
背景技术:
核酸适配体,也被称为核酸适体、适配子等,是从人工合成的dna/rna文库中筛选得到的能够高亲合性和高特异性地与各种靶标结合的单链寡核苷酸。最早是由szostak和gold两个小组几乎同时提出。1990年,ellington和szostak报道了能结合小分子有机染料的rna片段,并将其命名为aptamer。适配体(aptamer)是指利用指数富集的配基系统进化(systematicevolutionofligandsbyexponentialenrichment,selex)技术,从人工合成的寡核苷酸文库中筛选得到的具有亲和性高、特异性强的能够与靶分子特异性结合的短的单链dna和rna分子。
钙粘附蛋白是由钙离子依赖的跨膜糖蛋白家族组成,是细胞黏附分子中的一个家族,主要包括上皮型、神经型和胎盘钙粘附蛋白,其功能是介导生物组织中的细胞-细胞选择性粘附。另外通过连环蛋白,可以将经典钙粘附蛋白的细胞膜内结构域与细胞骨架连接起来。
神经型钙粘附蛋白(n-cadherin,cd325,cdh2)最初发现存在于神经元组织中,其后在晶状体、骨骼、心肌细胞和成纤维细胞中也被发现,是一种细胞-细胞间粘附的重要分子。n-cadherin的瞬时表达与形态发生过程、细胞骨架的重排以及肿瘤侵袭有关。在前列腺癌、乳腺癌、头颈部鳞状细胞癌和黑色素瘤中,均发现n-cadherin表达量增加和功能性上皮型钙粘附蛋白/连环蛋白复合物的丧失。当钙粘附蛋白介导的细胞间连结作用紊乱时,会导致细胞间粘附作用大大减弱,细胞的移动性增加,细胞接触性抑制作用减弱及其细胞形态改变等现象,从而导致恶性肿瘤细胞的转移与扩散。针对疾病相关靶标的核酸适配体的筛选为肿瘤检测和靶向治疗提供了巨大的应用潜力。
因此获得蛋白n-cadherin的亲和分子非常重要,传统的检测分子为抗体。但使用抗体有一定的局限性,例如,抗体不能承受温度和环境变化,容易发生不可逆的变性;抗体的生产过程复杂,保质期短,价格昂贵;抗体的产生通常涉及动物批次间变化;抗体分子量高,且难以实现位点特异性标记;基于抗体的分析通常需要对抗体进行固定,并需要多次洗涤步骤,而难以进行均相分析。因此,非常需要将适配体引入发展生物医学诊断的新平台。适配体可用于药物开发、医疗诊断、食品安全检测等,尤其是在生物医学领域,具有非常好的应用前景。利用核酸探针检测靶标物质,将核酸探针和靶标物质之间的特异性识别结合性能转化为可检测的物理或化学信号,从而进行靶标物质检测。因此发展出一种能快速、可靠检测n-cadherin的方法极其重要。而新兴的以识别元件为核心的生物传感器法,如酶生物传感器法、免疫生物传感器法、分子印迹膜生物传感器法虽提高了其灵敏度,但识别分子稳定性差、制备困难、寻找合适的功能单体和模板分子洗脱溶剂的过程费时费力。本发明因此而来。
技术实现要素:
本发明提供一种核酸适配体,用于解决现有技术中n-cadherin蛋白的检测问题。
为了解决现有技术中的问题,本发明提供了一种特异性识别n-cadherin的ssdna适配体,其具有seqidno.1~8任意一项所示的核苷酸序列。
优选的,所述ssdna适配体的核苷酸序列如seqidno.6所示。
优选的技术方案中,所述ssdna适配体的两端之一为fam荧光分子修饰。
本发明的另一目的在于提供一种检测试剂,所述检测试剂包含所述ssdna适配体。优选的,所述检测试剂还可包括药学上可接受的载体等。
本发明的另一目的在于提供一种n-cadherin蛋白的检测方法,其包括:
使n-cadherin蛋白与所述的ssdna适配体接触,所述ssdna适配体与n-cadherin蛋白特异性结合,其中所述ssdna适配体的两端设置标识部分;
根据ssdna适配体与n-cadherin蛋白特异性结合的标识部分确定n-cadherin蛋白的含量。
本发明的另一目的在于提供一种所述的ssdna适配体在制备检测试剂中的用途。
优选的技术方案中,所述检测试剂用于分析定性或定量检测蛋白n-cadherin。
本发明实施例还提供了一种特异性识别n-cadherin的ssdna适配体的筛选方法,其包括:
(1)将n-cadherin蛋白固定在固相载体表面,并清洗去除游离的n-cadherin蛋白;
(2)将带有n-cadherin蛋白的固相载体与ssdna筛选文库于筛选缓冲液内进行孵育结合;
(3)利用筛选缓冲液清洗除未游离的ssdna序列,而保留与固相载体上的n-cadherin蛋白结合的ssdna;
(4)将载有与ssdna结合的n-cadherin蛋白的固相载体与n-cadherin蛋白溶液进行孵育结合,将ssdna从固相载体上的n-cadherin蛋白上竞争洗脱,获得包含ssdna与n-cadherin蛋白结合物的溶液;
(5)以所述包含ssdna与n-cadherin蛋白结合物的溶液为模板进行pcr扩增;
(6)以碱性试剂将pcr产物的双链dna碱处理为ssdna,以获得下一轮筛选的ssdna次级文库。
例如,在一较为具体的实施方式中,所述的筛选方法包括以下步骤:
s1、蛋白固定:将n-cadherin蛋白固定在镍珠表面,并将填充有镍珠的亲和柱用缓冲液进行清洗;
s2、孵育结合、洗涤分离:将s1清洗后带有靶标n-cadherin的镍珠与ssdna筛选文库于筛选缓冲液中进行孵育结合,并用筛选缓冲液去除未与n-cadherin结合的ssdna序列,保留亲和柱中与靶标结合的ssdna;
s3、竞争性洗脱:将s3中已处理的亲和柱与另一份n-cadherin溶液进行孵育结合,使得与靶标结合的ssdna从镍珠上解离至溶液中;
s4、pcr扩增:将s4中解离的ssdna-靶标溶液为模板进行pcr扩增;
s5、单链的制备与纯化:用氢氧化钠将pcr产物中的双链dna碱处理为ssdna,即获得下一轮筛选的ssdna次级文库;
s6、重复s1-s5筛选步骤,直至获得目标序列。
所述n-cadherin蛋白包括cd325、cdh2中的任意一种。所述ssdna适配体的5’端或3’端用fam标记。
本发明提供了一种特异性识别n-cadherin的ssdna适配体,所述适配体ncads1的核苷酸序列如seqidno.6所示。
本发明的又一目的在于提供一种特异性识别n-cadherin的ssdna适配体的应用,包括:将适配体的5’端或3’端标记fam,用于蛋白n-cadherin的分析检测。
本发明适配体可在体外筛选,筛选周期短,合成方便,易标记各种功能基团和报告分子,性质稳定,可长期保存使用。
针对现有技术存在的上述问题,本发明提供了一种特异性识别蛋白n-cadherin的寡核苷酸适配体。本发明适配体能特异性识别蛋白n-cadherin,具有稳定性高、合成方便、易标记功能基团等特点,可广泛应用于蛋白n-cadherin的快速检测。优选的,本发明提供了一种特异性识别蛋白n-cadherin的寡核苷酸适配体,所述ssdna适配体ncads1的核苷酸序列如seqidno.6所示。本发明特异性识别蛋白n-cadherin的寡核苷酸适配体的应用,将适配体的5’端标记fam荧光修饰,用于蛋白n-cadherin的分析检测。
本发明有益的技术效果在于:
本发明ssdna适配体来源于体外筛选,筛选周期短,合成方便,易标记各种功能基团,性质稳定,可长期保存使用。
本发明ssdna适配体是亲和力、特异性均相对较强的适配体序列,能够特异识别蛋白n-cadherin。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
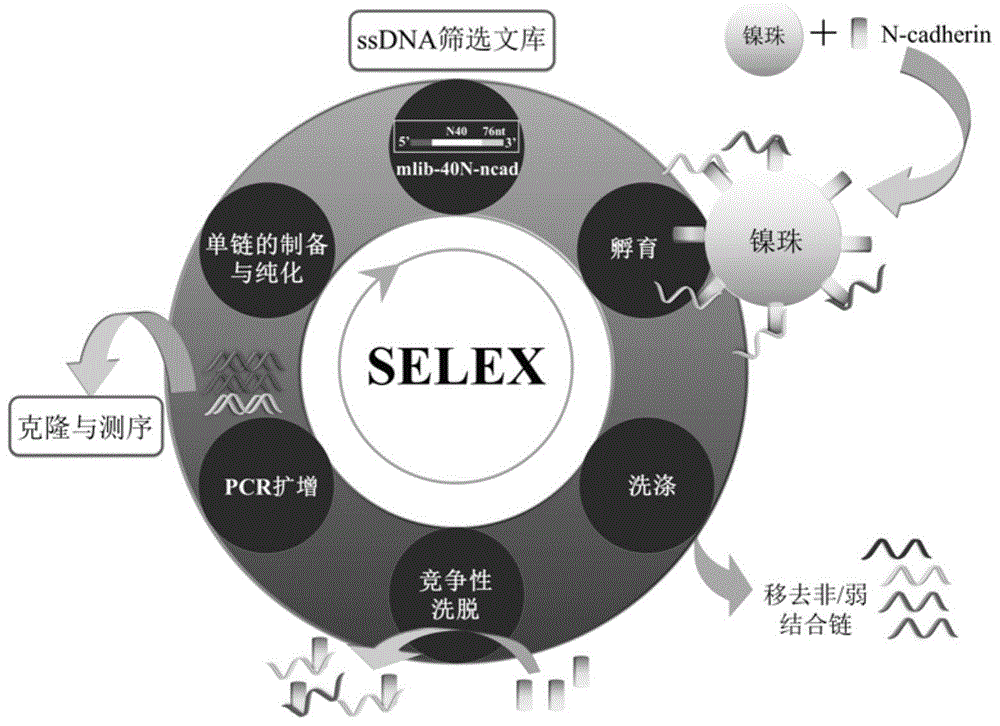
图1为基于亲和柱selex技术筛选出蛋白ssdna适配体的示意图;
图2为琼脂糖凝胶电泳监测第一轮筛选文库的富集程度;其中s条带为筛选缓冲液(selexbuffer)清洗镍柱的收集液;cd条带为另一份n-cadherin溶液与已处理的镍柱进行竞争洗脱的收集液。可观察到,第一轮中,cd条带亮度较低,收集液中的ssdna量较少,未出现富集效果;
图3为琼脂糖凝胶电泳监测第十轮筛选文库的富集程度;第十轮中,cd条带亮度明显增加,收集液中的ssdna明显增加,出现富集效果;
图4为荧光定量pcr实验通过相对荧光强度监测筛选文库的富集程度;
图5为荧光定量pcr实验通过相对荧光强度的一阶导数监测筛选文库的富集程度;
图6为elisa法监测筛选文库的富集程度;
图7为寡核苷酸预选序列的荧光强度柱状图;
图8为核酸适配体ncads1的亲和力拟合曲线;
图9为核酸适配体ncad2的亲和力拟合曲线;
图10为mfold软件预测ncads1的二级结构图谱;
图11为mfold软件预测ncad2的二级结构图谱;
图12为基于核酸适配体ncads1检测蛋白n-cadherin浓度梯度的曲线;
图13为基于核酸适配体ncad2检测蛋白n-cadherin浓度梯度的曲线;
具体实施方式
通过应连同所附图式一起阅读的以下具体实施方式将更完整地理解本发明。本文中揭示本发明的详细实施例;然而,应理解,所揭示的实施例仅具本发明的示范性,本发明可以各种形式来体现。因此,本文中所揭示的特定功能细节不应解释为具有限制性,而是仅解释为权利要求书的基础且解释为用于教示所属领域的技术人员在事实上任何适当详细实施例中以不同方式采用本发明的代表性基础。
本发明提供了一种特异性识别n-cadherin的ssdna适配体,所述适配体的核苷酸序列为seqidno.1~8任意一种所示的核苷酸序列;将适配体的5’端荧光标记fam,用于蛋白n-cadherin的分析检测。
本发明涉及肿瘤生物标志物的分子识别领域,尤其是涉及一种利用生物技术中的selex技术,筛选出一种能特异性识别蛋白n-cadherin的ssdna适配体,为该ssdna适配体在检测n-cadherin蛋白的应用提供科学依据和理论基础。
本发明人经长期研究,针对n-钙粘附蛋白的ssdna适配体的筛选,n-cadherin是i型钙粘附蛋白亚家族的135kda成员,它的膜外域部分与细胞间识别与结合有关,拟采用78.5kda膜外片段来筛选n-cadherin的ssdna适配体。
本发明研究人员发现,与n-cadherin蛋白特异性结合的ssdna适配体,一级结构为seqidno:1~3任意一项的核苷酸序列为其核心序列,该核心序列是保证所述ssdna适配体分子与n-cadherin蛋白特异性结合的关键。在该核心序列的基础上,可以进行不同的变化,衍生得到不同的能与n-cadherin蛋白特异性结合的ssdna适配体分子,这种衍生的方式,可以是在seqidno:1的核苷酸序列的基础上,进行插入或者延长的方式。
在ssdna适配体的两端,可以进行基团修饰,所述修饰的基团可以是选自氨基、羧基、巯基、荧光分子、生物素、胆固醇或聚乙二醇基团修饰。本发明的一个实施例中,提供了在所述的核心的ssdna适配体的两端分别进行生物素、荧光素修饰后得到的经修饰的ssdna适配体分子,经修饰后的ssdna适配体分子,能够与n-cadherin蛋白特异性结合。
可以对所述的ssdna适配体的碱基进行修饰,如硫代、氨代、氟代、甲氧基修饰,得到碱基修饰后的ssdna适配体分子,优选地,对所述碱基进行硫代修饰,硫代修饰的方式为将碱基磷酸基团中的氧原子用硫原子替代。本发明的一优选实施例中,将所述ssdna适配体中所有的碱基a进行硫代,例如将核心序列的a经硫代,得到所述的硫代修饰的核心适配体序列;又如,将优选的ssdna适配体序列碱基a经硫代,得到优所述的硫代修饰的优选ssdna适配体序列,经硫代修饰后,其具有较未经修饰的ssdna适配体更为优异的稳定性,可抗核酸酶。
本发明所述的载体也可以是造影剂粒子(如纳米铁、包裹了造影剂的纳米粒等),将所述适配体偶联到造影剂粒子上,作为n-cadherin蛋白靶向分子,用于n-cadherin蛋白的靶向显影,将适配体偶联到造影粒子上的方法,本发明技术人员可以根据现已有的制剂技术进行。或者,本发明所述的载体还可以是染色分子(如辣根过氧化物酶),作为n-cadherin蛋白靶向分子,用于n-cadherin蛋白的组化染色等等。
本发明的各方面、实施例、特征及实例应视为在所有方面为说明性的且不打算限制本发明,本发明的范围仅由权利要求书界定。在不背离所主张的本发明的精神及范围的情况下,所属领域的技术人员将明了其它实施例、修改及使用。
在本发明案中标题及章节的使用不意味着限制本发明;每一章节可应用于本发明的任何方面、实施例或特征。
在本发明案通篇中,在将组合物描述为具有、包含或包括特定组份之处或者在将过程描述为具有、包含或包括特定过程步骤之处,预期本发明教示的组合物也基本上由所叙述组份组成或由所叙述组份组成,且本发明教示的过程也基本上由所叙述过程步骤组成或由所叙述过程步骤组组成。
除非另外具体陈述,否则术语“包含(include、includes、including)”、“具有(have、has或having)”的使用通常应理解为开放式的且不具限制性。
除非另外具体陈述,否则本文中单数的使用包含复数(且反之亦然)。此外,除非上下文另外清楚地规定,否则单数形式“一(a、an)”及“所述(the)”包含复数形式。另外,在术语“约”的使用在量值之前之处,除非另外具体陈述,否则本发明教示还包括特定量值本身。
应理解,各步骤的次序或执行特定动作的次序并非十分重要,只要本发明教示保持可操作即可。此外,可同时进行两个或两个以上步骤或动作。
实施例1:适配体的筛选
图1为利用selex筛选能特异性识别n-cadherin的适配体的流程图,具体包括如下步骤:
(1)蛋白固定:利用n-cadherin蛋白上标记的his标签和琼脂糖微珠上的镍离子之间的特异性结合将n-cadherin蛋白固定在镍珠表面,并将填充有镍珠的亲和柱进行三次清洗,去除未结合的n-cadherin蛋白,反应在tris缓冲液(20mmtris-hcl,ph7.4)进行;
(2)孵育结合:将清洗后的带有靶标n-cadherin的镍珠与ssdna筛选文库于筛选缓冲液(20mmtris-hcl,ph7.4,150mmnacl,5mmkcl,2mmmgcl2)进行孵育结合;孵育过程中ssdna与靶标结合时会由原先的单链状态折叠成三维空间结构,导致ssdna结合在镍珠上;
(3)洗涤分离:在筛选缓冲液的作用下去除未与n-cadherin结合的ssdna序列,保留亲和柱中与靶标结合的ssdna;
(4)竞争性洗脱:将已处理的亲和柱与另一份n-cadherin溶液进行孵育结合;孵育过程中n-cadherin将结合的ssdna从镍珠的蛋白上竞争洗脱下来,导致与靶标结合的ssdna从镍珠上解离至溶液中;
(5)pcr扩增:以上一步骤中解离的ssdna-靶标溶液为模板进行pcr扩增;
(6)单链的制备与纯化:利用0.1mnaoh将pcr产物的双链dna(dsdna)碱处理为ssdna,以获得下一轮筛选的ssdna次级文库。
另外,在筛选过程中,为提高适配体的亲和性、特异性,可以通过改变一些实验条件来增加筛选压力。如随着筛选轮数的增加,降低n-cadherin的浓度;筛选孵育时间从30min降低到10min等。重复循环以上筛选步骤,利用每一轮的洗脱液为样品监控筛选进程。
根据实验监测筛选结果将第10轮筛选得到的产物进行pcr扩增,用于克隆测序。
实施例2:克隆测序
克隆测序共得到30条适配体序列。采用dnaman,clustal,mega,mfold等软件分析,根据其一级结构,二级结构等将其分为5个家族,从这些家族中挑选出具有代表性的序列,共挑出5条候选适配体用于特性分析,并根据elisa结果将荧光增强较强的3条序列进行截短优化。5条全长序列分别命名为ncad1、ncad2、ncad3、ncad4、ncad5,其中,3条裁短序列分别命名为ncads1、ncads2、ncads3,详细序列信息见表1。
表1
实施例3:结合能力分析
合成上述8条候选适配体,其5’端进行荧光素fam标记,用灭菌水稀释配制成2μm溶液,贮存在-20℃下备用。dna溶液使用前先在95℃变性5min,立即0℃冷却10min。结合能力测定步骤如下;
首先将100μl30nmn-cadherin溶液包被于nunc96孔酶联板上,4℃包被过夜,包被液为碳酸盐缓冲液(0.05mol/lna2co3/nahco3,ph9.6),同时设置空白对照孔;清洗板子,加入3%bsa溶液在25℃条件下封闭2h;清洗板子,30μl2μm的荧光素fam标记的dna序列在25℃条件下结合90min,空白组用结合缓冲液(50mmtris-hcl,5mmkcl,100mmnacl,1mmmgcl2,ph7.4)代替适配体并在25℃条件下结合孵育90min。清洗板子,每孔加入100μltris缓冲液,测荧光强度(激发波长485nm,发射波长585nm)。测试数据如图7所示。
实施例4:亲和性分析
使用带有5’端进行荧光素标记的适配体ncads1和ncad2,用灭菌水稀释配制成2μm溶液,贮存在-20℃下备用。亲和性测定步骤如下:
首先将100μl30nmn-cadherin溶液包被于nunc96孔酶联板上,4℃包被过夜,包被液为碳酸盐缓冲液(0.05mol/lna2co3/nahco3,ph9.6),同时设置空白对照孔;清洗板子,加入3%bsa溶液在25℃条件下封闭2h;清洗板子,适宜浓度的荧光素fam标记的dna序列在25℃条件下结合90min,空白组用结合缓冲液(50mmtris-hcl,5mmkcl,100mmnacl,1mmmgcl2,ph7.4)代替适配体并在25℃条件下结合孵育90min。清洗板子,每孔加入100μltris缓冲液,测荧光强度(激发波长485nm,发射波长585nm)。
亲和力测定中选取适配体终浓度分别为5,10,50,80,100,125nmol/l。梯度浓度的适配体先在95℃变性5min,立即0℃冷却10min,做三次平行实验。利用origin9.0软件根据公式f-f0=fmax*c/(kd+c)进行非线性拟合得到各个适配体的解离常数kd值,并绘制其结合曲线,如图8和9所示。其kd值越低,亲和力越强,适配体与靶标的结合能力就越强,其中两条亲和力较好的测试数据,如图8和9图中所示。
实施例5:适配体检测蛋白n-cadherin
使用带有5’端进行荧光素标记的适配体ncads1和ncad2,用灭菌水稀释配制成2μm溶液,贮存在-20℃下备用。dna溶液使用前先在95℃变性5min,立即0℃冷却10min。检测步骤如下:
首先将适宜浓度的n-cadherin溶液包被于nunc96孔酶联板上,4℃包被过夜,包被液为碳酸盐缓冲液(0.05mol/lna2co3/nahco3,ph9.6),同时设置空白对照孔;清洗板子,加入3%bsa溶液在25℃条件下封闭2h;清洗板子,100μl2μm的荧光素fam标记的dna序列在25℃条件下结合90min,空白组用结合缓冲液(50mmtris-hcl,5mmkcl,100mmnacl,1mmmgcl2,ph7.4)代替适配体并在25℃条件下结合孵育90min。清洗板子,每孔加入100μltris缓冲液,测荧光强度(激发波长485nm,发射波长585nm)。测试数据如图12和13所示。
综述之,本发明得到了一种能特异性识别蛋白n-cadherin的ssdna适配体,为该适配体在检测n-cadherin蛋白的应用提供科学依据和理论基础。
尽管已参考说明性实施例描述了本发明,但所属领域的技术人员将理解,在不背离本发明的精神及范围的情况下可做出各种其它改变、省略及/或添加且可用实质等效物替代所述实施例的元件。另外,可在不背离本发明的范围的情况下做出许多修改以使特定情形或材料适应本发明的教示。因此,本文并不打算将本发明限制于用于执行本发明的所揭示特定实施例,而是打算使本发明将包含归属于所附权利要求书的范围内的所有实施例。此外,除非具体陈述,否则术语第一、第二等的任何使用不表示任何次序或重要性,而是使用术语第一、第二等来区分一个元素与另一元素。
序列表
<110>中国科学院苏州纳米技术与纳米仿生研究所
<120>特异性识别n-cadherin的ssdna适配体、其筛选方法及应用
<160>8
<170>siposequencelisting1.0
<210>1
<211>76
<212>dna
<213>人工序列(人工序列)
<400>1
ataccagcttattcaattccgatcgtcgaacttgctctgatgcgacaaccttttgcccag60
atagtaagtgcaatct76
<210>2
<211>76
<212>dna
<213>人工序列(人工序列)
<400>2
ataccagcttattcaattagacgagttttattcattttccatgtcgtagcttaccgtgag60
atagtaagtgcaatct76
<210>3
<211>76
<212>dna
<213>人工序列(人工序列)
<400>3
ataccagcttattcaattggccgttgtttatgtttccgtcagctcttgtttggccgctag60
atagtaagtgcaatct76
<210>4
<211>76
<212>dna
<213>人工序列(人工序列)
<400>4
ataccagcttattcaattccggtgttcgagaggcgcaaatagtggactggcgatatgtag60
atagtaagtgcaatct76
<210>5
<211>76
<212>dna
<213>人工序列(人工序列)
<400>5
ataccagcttattcaattacgagatgatggttgtcgctacgataagatctgagctgcaag60
atagtaagtgcaatct76
<210>6
<211>40
<212>dna
<213>人工序列(人工序列)
<400>6
acttgctctgatgcgacaaccttttgcccagatagtaagt40
<210>7
<211>40
<212>dna
<213>人工序列(人工序列)
<400>7
agacgagttttattcattttccatgtcgtagcttaccgtg40
<210>8
<211>40
<212>dna
<213>人工序列(人工序列)
<400>8
ggccgttgtttatgtttccgtcagctcttgtttggccgct40
- 还没有人留言评论。精彩留言会获得点赞!