用于生产AAV颗粒的载体的制作方法
本发明涉及用于生产腺相关病毒(aav)颗粒的质粒的生产。特别地,本发明提供包含cap基因和rep基因的核酸分子,其中cap基因和rep基因都与相同的启动子可操作地相关联。本发明还提供包含本发明的核酸分子的宿主细胞及其使用方法。
背景技术:
aav载体是从属于细小病毒科的单链dna病毒开发而来的。该病毒能够感染广泛范围的宿主细胞,所述宿主细胞包括分裂细胞和非分裂细胞两者。另外,该病毒是在大多数患者中仅产生有限的免疫应答的非致病性病毒。
aav基因组包含两个基因,所述两个基因各自编码多个开放阅读框(orf):rep基因编码病毒基因组的aav生命周期和位点特异性整合所需的非结构蛋白;并且cap基因编码结构衣壳蛋白。另外,这两个基因的侧翼是由145个碱基组成的反向末端重复(itr)序列,该反向末端重复序列具有形成发夹结构的能力。这些发夹序列是第二dna链的非引发酶依赖性合成以及病毒dna整合到宿主细胞基因组中所需的。
为了消除病毒的任何整合能力,重组aav载体从病毒基因组的dna中去除了rep和cap。为了产生这种载体,将所需的转基因与用以驱动转基因转录的启动子一起插入反向末端重复(itr)之间;并且在第二质粒中反式提供rep基因和cap基因。也使用了提供辅助基因比如腺病毒e4、e2a和va基因的第三质粒。所有三种质粒随后被转染到培养的“包装”细胞(比如hek293)中。
在过去的几年中,aav载体已经作为一种非常有用和有希望的基因递送模式出现。这是由于这些载体具有以下特性:
-aav是小型无包膜病毒,并且aav仅具有两种天然基因(rep和cap)。因此,aav可以被容易地操纵以开发用于不同基因疗法的载体。
-aav颗粒不易被剪切力、酶或溶剂降解。这有利于这些病毒载体的容易纯化和最终配制。
-aav是非致病性的并且具有低免疫原性。这些载体的使用进一步降低了不良炎症反应的风险。与其他病毒载体(比如慢病毒、疱疹病毒和腺病毒)不同,aav是无害的并且不被认为是引起任何人类疾病的原因。
-可以使用aav载体将高达4000bp的遗传序列递送给患者。
-尽管野生型aav载体已显示有时会在人类19号染色体上插入遗传物质,但是通常通过将rep基因和cap基因从病毒基因组中去除来消除大多数aav载体的该特性。在这种情况下,病毒以附加形式保留在宿主细胞中。这些附加体在非分裂细胞中保持完整,而在分裂细胞中这些附加体在细胞分裂期间丢失。
技术实现要素:
然而,本发明的发明人已经认识到,可以通过优化在载体生产过程中存在的rep蛋白和cap蛋白的比例和量来改善用于生产aav载体的方法。
因此,本发明的目的是提供一种核酸分子,该核酸分子包含在单个启动子控制下的cap基因和rep基因;由此,cap多肽和rep多肽在同一mrna中编码。cap基因的翻译将通过在核糖体处将甲基鸟苷酸cap(m7g)对接在capmrna的5'末端处来启动。rep基因的翻译将通过将核糖体对接在位于rep基因上游的内部核糖体进入位点(ires)处来启动。
通过使用本发明的核酸分子,可以获得更高的病毒效价。
在本发明的一些实施方式中,所述ires替代野生型p5启动子。去除p5启动子的另一优势是,在野生型病毒中,p5启动子被e2adna结合蛋白(dbp)结合并激活。因此,去除p5启动子意味着不需要e2a基因(例如,在辅助质粒中)来产生病毒颗粒。
在一个实施方式中,本发明提供一种核酸分子,其包含:
(i)启动子,
(ii)cap基因,以及
(iii)rep基因,
按照以上5’-3’的顺序,其中,所述cap基因和所述rep基因都与所述启动子可操作地相关联,并且其中,所述rep基因也与ires可操作地相关联。
本发明还提供一种核酸分子,其包含:
(i)cap基因,以及
(ii)rep基因,
按照以上5’-3’的顺序,其中,所述rep基因与ires可操作地相关联。
所述核酸分子可以是dna或rna,优选是dna。所述核酸分子可以是单链或双链的,优选是双链的。
本发明的核酸分子包含rep基因。如本文中所使用的,术语“rep基因”是指编码一个或多个开放阅读框(orf)的基因,其中,所述orf中的每个orf均编码aavrep非结构蛋白或其变体或衍生物。这些aavrep非结构蛋白(或其变体或衍生物)参与aav基因组复制和/或aav基因组包装。
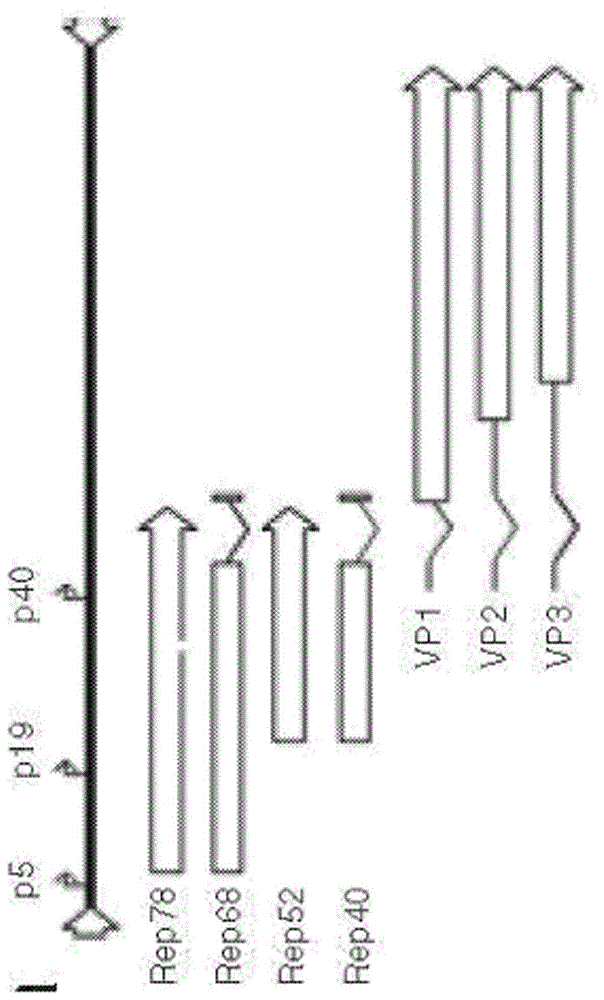
图1示出了野生型aav基因组的结构,其说明了野生型rep基因和cap基因的组织。
野生型rep基因包含三个启动子:p5、p19和p40。从p5和p19可以生产不同长度的两个重叠的信使核糖核酸(mrna)。这些mrna中的每个mrna均包含内含子,该内含子可以使用单个剪接供体位点和两个不同的剪接受体位点将其剪接掉或不剪接掉。因此可以形成六个不同的mrna,其中,只有四个是功能性的。未能去除内含子的两个mrna(一个从p5转录,而一个从p19转录)通读共享终止子序列并且分别编码rep78和rep52。去除内含子并使用最5’端剪接受体位点不会导致产生任何功能性rep蛋白-不能产生正确的rep68蛋白或rep40蛋白,这是因为序列的其余部分的框架发生了移位,也不会产生rep78或rep52的正确的c末端,这是因为它们的终止子被剪接掉。相反,去除内含子并使用3’剪接受体将会包括rep68和rep40的正确c末端,同时剪接掉rep78和rep52的终止子。因此,唯一的功能性剪接避免了将内含子完全剪接掉(产生rep78和rep52)或者使用3’剪接受体(以产生rep68和rep40)。因此,可以从这些启动子合成具有重叠序列的四个不同的功能性rep蛋白。
在野生型rep基因中,p40启动子位于3’端处。在野生型aav基因组中,cap蛋白(vp1、vp2和vp3)的转录从该启动子启动。
四种野生型rep蛋白是rep78、rep68、rep52和rep40。因此,野生型rep基因是一种编码四种rep蛋白rep78、rep68、rep52和rep40的基因。
rep78和rep68可以特异性结合由itr形成的发夹,并且可以在发夹内的特定区域(即,末端解离位点)处对发夹进行切割。在野生型病毒中,rep78和rep68也是aav基因组的aav特异性整合所必需的。rep78和rep68在野生型病毒中在p5启动子的控制下转录,并且rep78与rep68之间的差异反映了通过剪接而去除(或不去除)内含子,因此它们具有不同的c末端蛋白组成。
rep52和rep40参与基因组包装。rep52和rep40在野生型病毒中在p19启动子的控制下转录,并且rep52与rep40之间的差异反映了通过剪接而去除(或不去除)内含子,因此它们具有不同的c末端蛋白组成。
所有四种rep蛋白都结合atp并且具有解旋酶活性。它们上调p40启动子的转录,但下调p5启动子和p19启动子的转录。
如本文中所使用的,术语“rep基因”包含野生型rep基因及其衍生物以及具有等同功能的人工rep基因。
在一个实施方式中,所述rep基因编码功能性rep78蛋白、功能性rep68蛋白、功能性rep52蛋白和功能性rep40蛋白。
在该实施方式的一个优选实例中,rep78和rep68通过由5’与rep78和rep68atg起始密码子对接的核糖体翻译,从而允许产生这两种蛋白。在该实例中,rep78和rep68开放阅读框包含提供rep52和rep40两者的表达的活性p40启动子。
在本发明的一些实施方式中,p5启动子、p19启动子和p40启动子中的一个或多个的功能是去除的/有缺陷的,例如通过密码子改变和/或去除tata盒,以防止不希望的从该启动子的转录起始。
优选地,p5启动子是非功能性的(即,p5启动子不能用于启动转录)。更优选地,p5启动子被ires替代(因而去除了p5启动子的功能)。这允许rep78或rep68以与cap基因相同的mrna进行转录,但是rep78蛋白和rep68蛋白的翻译将在ires的控制之下。
去除p5启动子的另一优势是,在野生型病毒中,p5启动子被e2adna结合蛋白(dbp)结合并激活。因此,去除p5启动子意味着不需要e2a基因(例如,在辅助质粒中)来产生病毒颗粒。
在一个实施方式中,所述rep基因在上游不具有p5启动子。在另一实施方式中,p5启动子不在aav包装中使用。
优选地,所述rep基因内的p19启动子是功能性的。
在一些实施方式中,p40启动子的功能通过一个或多个密码子改变而在rep基因内被去除/缺陷。
cap基因优选地被重定位,并且其转录被置于替代性启动子(例如,cmv即刻早期启动子)的控制下。
在不同的rep蛋白的功能之间存在一定程度的冗余,并且因此,在本发明的一些实施方式中,并不是所有的rep蛋白都是必需的。
在一些实施方式中,所述rep基因仅编码rep78、rep68、rep52和rep40中的一者、两者、三者或四者,优选地编码rep78、rep68、rep52和rep40中的一者、两者或四者。
在一些实施方式中,所述rep基因不编码rep78、rep68、rep52和rep40中的一者或多者。
在一些实施方式中,所述rep基因编码rep78和rep52,但是不编码rep68或rep40。在该实施方式中,剪接供体位点保留在dna中,但是5’剪接受体位点和3’剪接受体位点都被去除。因此,内含子不可以通过剪接而被去除,并且转录继续直到rep78和rep52的终止子序列(该终止子序列是rep78和rep52这两者所共用的)。rep78蛋白在与cap基因相同的mrna中转录(因此由相同的启动子驱动),而rep78的翻译由ires驱动。rep52的转录由p19启动子驱动;因此,rep52的转录形成单独的mrna并且在核糖体上通过5’m7gcap依赖性对接来进行翻译。因此,在该实施方式中不能产生rep68和rep40。
在其他实施方式中,rep基因编码rep68和rep40,但是不编码rep78或rep52。在该实施方式中,在dna水平上去除剪接供体与3’剪接受体之间的内含子序列,将rep68和rep40的c末端与上游编码序列置于同一框架中。因此,生成了rep68和rep40(但不生成rep78和rep52)。为了清楚起见,rep68以与cap蛋白相同的mrna进行转录,并且rep68在ires的控制下进行翻译。相比之下,rep40通过p19启动子转录成单独的mrna,并且在核糖体上通过5’m7gcap对接而进行翻译。
在一些实施方式中,所述rep基因编码rep78和rep68,但是不编码rep52或rep40。这可以通过突变p19启动子(例如,在p19tata盒处插入突变)来实现。
在一些实施方式中,所述rep基因编码rep52和rep40,但是不编码rep78或rep68。这可以通过仅包含来自rep52/40的atg的编码序列来实现。
如上所使用的,术语“编码”是指rep基因编码该rep蛋白的功能形式。类似地,术语“不编码”是指rep基因不编码该rep蛋白的功能形式。
在没有足够的rep蛋白的情况下,由于待包装的itr质粒较少并且无法有效包装,因此观察到的效价(例如,基因组拷贝)较低(其可以通过qpcr来确定)。观察可能还包括夸大的空颗粒与全颗粒的比率;这可以通过elisa或光密度测量来确定。
seqidno:1给出了野生型aav(血清型2)rep基因核苷酸序列。seqidno:2、seqidno:3、seqidno:4和seqidno:5分别给出了野生型aav(血清型2)rep78氨基酸序列、野生型aav(血清型2)rep68氨基酸序列、野生型aav(血清型2)rep52氨基酸序列和野生型aav(血清型2)rep40氨基酸序列。编码rep78的野生型aav(血清型2)核苷酸序列在seqidno:6中给出。编码rep68的野生型aav(血清型2)核苷酸序列在seqidno:7中给出。编码rep52的野生型aav(血清型2)核苷酸序列在seqidno:8中给出。编码rep40的野生型aav(血清型2)核苷酸序列在seqidno:9中给出。
在一个实施方式中,术语“rep基因”是指与seqidno:1具有至少70%、80%、85%、90%、95%、99%或100%的序列同一性并且编码一个或多个rep78多肽、rep68多肽、rep52多肽和rep40多肽的核苷酸序列。
在另一个实施方式中,术语“rep基因”是指与seqidno:6具有至少70%、80%、85%、90%、95%、99%或100%的序列同一性并且编码功能性rep78多肽和/或rep52多肽(并且优选地不编码功能性rep68多肽或rep40多肽)的核苷酸序列。
在另一个实施方式中,术语“rep基因”是指与seqidno:7具有至少70%、80%、85%、90%、95%、99%或100%的序列同一性并且编码功能性rep68多肽和/或rep40多肽(并且优选地不编码功能性rep78多肽或rep52多肽)的核苷酸序列。
在另一个实施方式中,术语“rep基因”是指与seqidno:8具有至少70%、80%、85%、90%、95%、99%或100%的序列同一性并且编码功能性rep52多肽(并且优选地不编码功能性rep78多肽)的核苷酸序列。
在另一个实施方式中,术语“rep基因”是指与seqidno:9具有至少70%、80%、85%、90%、95%、99%或100%的序列同一性并且编码功能性rep40多肽(并且优选地不编码功能性rep68多肽)的核苷酸序列。
在另一个实施方式中,术语“rep基因”是指与编码seqidno:2的核苷酸序列具有至少90%、95%、99%或100%的序列同一性并且编码功能性rep78多肽和/或rep52多肽(并且优选地不编码功能性rep68多肽或rep40多肽)的核苷酸序列。
在另一个实施方式中,术语“rep基因”是指与编码seqidno:3的核苷酸序列具有至少90%、95%、99%或100%的序列同一性并且编码功能性rep68多肽和/或rep40多肽(并且优选地不编码功能性rep78多肽或rep52多肽)的核苷酸序列。
在另一个实施方式中,术语“rep基因”是指与编码seqidno:4的核苷酸序列具有至少90%、95%、99%或100%的序列同一性并且编码功能性rep52多肽(并且优选地不编码功能性rep78多肽)的核苷酸序列。
在另一个实施方式中,术语“rep基因”是指与编码seqidno:5的核苷酸序列具有至少90%、95%、99%或100%的序列同一性并且编码功能性rep40多肽(并且优选地不编码功能性rep68多肽)的核苷酸序列。
在一些实施方式中,本发明的核酸分子不编码功能性rep78多肽。在一些实施方式中,本发明的核酸分子不编码功能性rep68多肽。在一些实施方式中,本发明的核酸分子不编码功能性rep52多肽。在一些实施方式中,本发明的核酸分子不编码功能性rep40多肽。
所述核酸分子还包含cap基因。如本文中所使用的,术语“cap基因”是指编码一个或多个开放阅读框(orf)的基因,其中,所述orf中的每个orf均编码aavcap结构蛋白或其变体或衍生物。这些aavcap结构蛋白(或其变体或衍生物)形成aav衣壳。
这三种cap蛋白必须用于使得能够产生能够感染合适细胞的感染性aav病毒颗粒。所述三种cap蛋白分别是vp1、vp2和vp3,并且大小通常分别为87kda、72kda和62kda。因此,所述cap基因是一种编码三种cap蛋白vp1、vp2和vp3的基因。
在野生型aav中,这三种蛋白从p40启动子翻译以形成单个mrna。在合成该mrna之后,可以切除长或短的内含子,从而形成2.3kb或2.6kb的mrna。
通常,特别是在腺病毒的存在下,长内含子被切除。在这种形式中,切除了第一aug密码子(vp1蛋白的合成从该第一aug密码子开始),从而导致vp1蛋白合成的总体水平降低。保留的第一aug密码子是vp3蛋白的起始密码子。然而,同一开放阅读框中该密码子的上游是acg序列(编码苏氨酸),该acg序列被最优的kozak环境包围。这有助于vp2蛋白的低水平合成,而vp2蛋白实际上是具有额外n末端残基的vp3蛋白,vp1也是如此。
如果长内含子被剪接掉,并且由于在主要剪接中,acg密码子是弱得多的翻译起始信号,则体内合成aav结构蛋白的比例为约1:1:10,该比例与成熟的病毒颗粒中的比例相同。vp1蛋白n末端的独特片段已显示具有磷脂酶a2(pla2)活性,其可能是aav颗粒从晚期核内体释放所必需的。
aav衣壳由60个衣壳蛋白亚基(vp1、vp2和vp3)组成,所述衣壳蛋白亚基以1:1:10的比例以二十面体对称排列,估计的大小为3.9mda。
如本文中所使用的,术语“cap基因”包含野生型cap基因及其衍生物以及具有等同功能的人工cap基因。aav(血清型2)cap基因核苷酸序列和cap多肽序列分别在seqidno:10和seqidno:11中给出。
如本文中所使用的,术语“cap基因”优选地是指具有seqidno:10中给出的序列的核苷酸序列或编码seqidno:11的核苷酸序列;或者与seqidno:10具有至少70%、80%、85%、90%、95%或99%的序列同一性或与编码seqidno:11的核苷酸序列具有至少80%、90%、95%或99%的序列同一性并且编码vp1多肽、vp2多肽和vp3多肽的核苷酸序列。
rep基因和cap基因优选地是病毒基因或者衍生自病毒基因。更优选地,它们是aav基因或者衍生自aav基因。在一些实施方式中,aav是腺相关依赖性细小病毒a。在其他实施方式中,aav是腺相关依赖性细小病毒b。
已知11种不同的aav血清型。所有已知的血清型都可以感染来自多种不同组织类型的细胞。组织特异性由衣壳血清型确定。aav可以来自血清型1、血清型2、血清型3、血清型4、血清型5、血清型6、血清型7、血清型8、血清型9、血清型10或血清型11。优选地,aav是血清型1、血清型2、血清型5、血清型6、血清型7或血清型8。最优选地,aav血清型为2(即,aav2)。
rep基因和cap基因(以及其中的每个编码蛋白的orf)可以来自一种或多种不同的病毒(例如2种、3种或4种不同的病毒)。例如,rep基因可以来自aav2,而cap基因可以来自aav5。本领域人员认识到的是,aav的rep基因和cap基因随进化枝和分离株而变化。本文涵盖了来自所有这些进化枝和分离株的这些基因的序列及其衍生物。
cap基因和rep基因以5’→3’的顺序存在于核酸中。然而,由于rep52和/或rep40可以从它们自己的p19启动子转录,因此编码rep52和/或rep40的编码序列的位置可以改变。例如,编码rep52和/或rep40的编码序列可以置于编码rep78/68的cap基因和rep基因的上游或下游;或者实际上置于本发明的核酸的反向链上或置于不同的核酸上。
cap基因和rep基因都与同一启动子可操作地相关联。所述启动子优选地在cap基因和rep基因的5’(即,上游)。在一些实施方式中,所述启动子是组成型启动子。在其他实施方式中,所述启动子是诱导型的或阻遏型的。
组成型启动子的实例包括cmv、sv40、pgk(人或小鼠)、hsvtk、sffv、泛素、延伸因子α、chef-1、ferh、grp78、rsv、腺病毒e1a、cag或cmv-β-球蛋白启动子、或由此衍生的启动子。优选地,所述启动子是巨细胞病毒即刻早期(cmv)启动子、或由其衍生的启动子、或与人细胞和人细胞系(例如,hek-293细胞)中的cmv启动子相比强度相等或增加的启动子。
在一些实施方式中,所述启动子因包含诱导型或阻遏型调节(启动子)元件而是诱导型或阻遏型的。例如,所述启动子可以是用强力霉素、四环素、iptg或乳糖诱导的启动子。
优选地,诱导型启动子元件包含tet阻遏蛋白(tetr)所能够结合的多个tet操纵子序列。在结合状态下,获得了对转录的严格抑制。然而,在强力霉素(或不太优选地,四环素)的存在下,抑制被减轻,从而允许启动子获得完全的转录活性。这种诱导型启动子元件优选地置于另一启动子的下游,例如cmv启动子的下游。
tetr结合位点可以具有野生型序列,许多这些野生型序列是本领域已知的。优选地,所述tetr结合位点通过掺入微小的序列变化而进行了一种或多种改善。可以在本发明的实施方式中使用的优选形式具有序列tccctatcagtgatagaga(seqidno:12)。
结合tetr蛋白或tetr蛋白的衍生物的阻遏元件的替代形式也可以用于本发明的实施方式中,条件是tetr阻遏蛋白与所使用的tetr结合序列变体结合。一些阻遏/结合位点变体将具有比野生型更高的相互亲和性;这些在本发明的实施方式中是优选的。
tetr基因通常会整合到人类(宿主)细胞的染色体中。该基因可以或可以不邻近cap基因或rep基因整合或者结合cap基因或rep基因而整合。在一些实施方式中,tetr基因与cap基因或rep基因共表达。
在本发明的一个实施方式中,所述tetr蛋白的核苷酸序列如seqidno:13或者与seqidno:13具有至少80%、更优选至少85%、90%或95%序列同一性并且编码tetr蛋白的核苷酸序列中所给出的。
在本发明的另一个实施方式中,所述tetr蛋白的氨基酸序列如seqidno:14或者与seqidno:14具有至少80%、更优选至少85%、90%或95%序列同一性并且编码tetr蛋白的氨基酸序列中所给出的。
优选地,与cap基因和rep基因可操作地相关联的启动子是cmv即刻早期启动子或其衍生物。在一些特别优选的实施方式中,所述启动子是如wo2017/149292中所定义的启动子(更优选地,如其中定义为“p565”的启动子)。优选地,与cap基因和rep基因可操作地相关联的启动子不是aav启动子,例如其不是aavp5启动子、p19启动子或p40启动子。
cap基因的翻译优选地从mrna5’端处的标准5’m7g-cap启动。
rep基因还与内部核糖体进入位点(ires)可操作地相关联。
ires调节repmrna的翻译。ires是核酸分子的不同区域,其能够在称为非cap依赖性翻译的过程中将真核核糖体募集至mrna。ires通常位于rna病毒的5’-utr中。它们以非cap依赖的方式促进病毒rna的翻译。
病毒性ires的实例包括小核糖核酸病毒ires(脑心肌炎病毒,emcvires)、口疮病毒ires(口蹄疫病毒,fmdvires)、卡波西氏肉瘤相关疱疹病毒ires、甲型肝炎ires、丙型肝炎ires、瘟病毒ires、蟋蟀麻痹病毒内部核糖体进入位点(ires)、禾谷缢管蚜病毒内部核糖体进入位点(ires)和即刻早期转录本(ires)1的1.8-kb家族中的5’-前导ires和顺反子间ires。
本发明还包括上述ires的非天然衍生物,非天然衍生物保留了将真核核糖体募集至mrna的能力。在一些优选的实施方式中,ires是脑心肌炎病毒(emcv)ires。在本发明的一个实施方式中,emcvires的核苷酸序列如seqidno:15或者与seqidno:15具有至少80%、更优选至少85%、90%或95%的序列同一性并且编码ires的核苷酸序列中所给出的。
在其他实施方式中,ires是口蹄疫病毒(fmdv)ires。在本发明的一个实施方式中,fmdvires的核苷酸序列如seqidno:16或者与seqidno:16具有至少80%、更优选至少85%、90%或95%的序列同一性并且编码ires的核苷酸序列中所给出的。
所述rep基因与ires可操作地相关联。优选地,ires位于cap基因的下游和rep78/68的翻译起始位点的上游。
哺乳动物培养物中稳定细胞系的产生通常需要选择方法以促进含有任何外源添加的dna的细胞的生长。
优选地,本发明的核酸分子另外包含选择基因或抗生素抗性基因。为此,已知当将编码它们的dna插入哺乳动物细胞基因组中时提供对特定化合物的抗性的一系列基因。
优选地,所述选择基因是嘌呤霉素n-乙酰基转移酶(puro)、潮霉素磷酸转移酶(hygro)、杀稻瘟菌素s脱氨酶(blast)、新霉素磷酸转移酶(neo)、谷胱甘肽s-转移酶(gs)、博来霉素抗性基因(shble)或二氢叶酸还原酶(dhfr)。这些基因中的每个基因均提供对已知对哺乳动物细胞有毒的小分子的抗性,或者在gs的情况下提供了在生长培养基中不存在谷胱甘肽的情况下用于细胞生成谷胱甘肽的方法。
在本发明的一个优选实施方式中,所述抗性基因是puro。该基因特别有效,这是因为在常用组织培养中使用的许多细胞系均对puro不具有抗性;这对于neo不是这样,许多特别是hek293衍生物因研究人员先前的基因操作而已经具有neo抗性(例如,hek293t细胞)。puro选择还具有在短时间窗(<72小时)内有毒的优势,并且因此puro选择允许快速测试变量并且允许将不携带待插入基因组中的外源dna的细胞从培养物系统中快速移除。这对于一些其他选择方法不是这样,比如hygro,其毒性起效要慢得多。
使用选择基因(例如puro)开发稳定细胞系需要在细胞中表达抗性基因。这可以通过多种方法来实现,包括但不限于内部核糖体进入位点(ires)、2a裂解系统、选择性剪接和专用启动子。
在本发明的一个优选实施方式中,所述选择基因将从专用启动子表达。该启动子将优选地在人细胞中以比驱动rep基因或cap基因的专用启动子更低的水平进行转录。
核酸分子中编码多肽或rna的基因中的每个将优选地与一个或多个调控元件可操作地相关联。这确保了多肽或rna以期望的水平和在期望的时间表达。在本文中,术语“调控元件”包括增强子、启动子、内含子、polya、绝缘子或终止子中的一者或多者。
在本文中公开的aav质粒或载体中使用的基因优选地被polya信号和/或绝缘子分开,为了使对其他基因的转录通读保持最小。
尽管通过使用具有多于一个的多肽或rna编码核苷酸序列(就其协同表达而言)的相同调控元件(例如,启动子序列)的拷贝可以获得一些优势,但在本发明的上下文中,非常期望使用具有每个多肽或rna编码核苷酸序列的不同的调控元件。
因此,优选地,rep基因和cap基因与不同的调控元件可操作地相关联,所述不同的调控元件例如为不同的启动子、不同的内含子、不同的polya、不同的绝缘子和/或不同的终止子序列。更优选地,rep启动子与cap启动子之间的核苷酸序列同一性程度小于95%或小于90%、更优选小于85%、80%、70%或60%。更优选地,rep终止子与cap终止子之间的核苷酸序列同一性程度小于95%或小于90%、更优选小于85%、80%、70%或60%。以这种方式,降低了这些调控元件之间同源重组的风险。
在大多数实施方式中,本发明的核酸分子将是用于生产aav的质粒或载体。因此,在大多数实施方式中,本发明的核酸分子(或包含其的载体或质粒)将不包含反向末端重复(itr)。
在一些实施方式中,本发明的核酸分子(或包含其的载体或质粒)将不包含选自腺病毒e1a、腺病毒e1b、腺病毒e4、腺病毒e2a或腺病毒va的一个或多个基因。在一些优选的实施方式中,本发明的核酸分子(或包含其的载体或质粒或质粒系统)不包含腺病毒e2a基因。如本文中所使用的,术语“e2a”或“e2a基因”是指病毒e2a基因或其变体或衍生物。优选地,e2a基因来自或衍生自人腺病毒例如ad5。在本发明的一个实施方式中,腺病毒e2a基因的核苷酸序列如在seqidno:17或者在与seqidno:17具有至少80%、更优选至少85%、90%或95%的序列同一性并且编码有助于病毒dna复制的延长的dna结合蛋白的核苷酸序列中给出的。
在另一个实施方式中,提供了一种包含本发明的核酸分子的质粒或载体。
本发明的优选实施方式的实例包括按以下顺序包含以下元件的核酸分子:
cmv启动子-aav2cap基因-fmdvires-rep基因
p565启动子-aav2cap基因-emcvires-rep基因
cmv启动子-aav2cap基因-emcvires-rep基因
在一些优选的实施方式中,所述“rep基因”是指编码rep78多肽、rep52多肽、rep68多肽和rep40多肽的基因。在其他优选的实施方式中,术语“rep基因”是指编码rep78多肽和rep52多肽(但是优选地不编码功能性rep68多肽或rep40多肽)的基因。
有许多已建立的算法可用于比对两个氨基酸或核酸序列。通常,一个序列用作参考序列,测试序列可以与该参考序列进行比较。序列比较算法基于指定的程序参数来计算测试序列相对于参考序列的百分比序列同一性。用于比较的氨基酸或核酸序列的比对可以例如通过计算机实现的算法(例如,gap、bestfit、fasta或tfasta)或者blast算法和blast2.0算法来进行。
氨基酸序列同一性和核苷酸序列同一性的百分比可以使用blast比对方法获得(altschul等(1997),“gappedblastandpsi-blast:anewgenerationofproteindatabasesearchprograms”,nucleicacidsres.25:3389-3402;以及http://www.ncbi.nlm.nih.gov/blast)。优选地,使用标准或默认比对参数。
标准蛋白-蛋白blast(blastp)可以用于在蛋白数据库中找到相似的序列。与其他blast程序一样,blastp设计成查找相似的局部区域。当序列相似性跨越整个序列时,blastp也将报告全局比对,这是出于蛋白鉴定目的的优选结果。优选地,使用标准或默认比对参数。在一些情况下,“低复杂度过滤器”可能会被取消。
blast蛋白搜索也可以使用blastx程序进行,得分=50,字长=3。为了获得用于比较目的的空位比对,如altschul等(1997)nucleicacidsres.25:3389中所描述的,可以利用空位blast(gappedblast)(blast2.0中)。或者,psi-blast(blast2.0中)可以用于执行迭代搜索,用以检测分子之间的远距离关系。(参见altschul等(1997),同上)。当使用blast、gappedblast、psi-blast时,可以使用相应程序的默认参数。
关于核苷酸序列比较,可以使用megablast、不连续megablast(discontiguous-megablast)和blastn来实现该目的。优选地,使用标准比对参数或默认比对参数。megablast经过特别设计以有效地发现非常相似的序列之间的长比对。不连续megablast可以用于发现与本发明的核酸相似但不相同的核苷酸序列。
blast核苷酸算法通过将查询分为称为字的短子序列来找到相似的序列。该程序首先识别与查询字的精确匹配(字命中)。然后,blast程序在多个步骤中扩展这些字命中,以生成最终的空位比对。在一些实施方式中,blast核苷酸搜索可以用blastn程序进行,得分=100,字长=12。
决定blast搜索的灵敏度的重要参数之一是字长(wordsize)。blastn比megablast更灵敏的最重要原因是blastn使用了较短的默认字长(11)。由于此原因,在寻找来自其他生物体的相关核苷酸序列的比对方面,blastn优于megablast。字长在blastn中是可调节的,并且可以从默认值减小至最小7以提高搜索灵敏度。
通过使用新引入的不连续megablast页面(www.ncbi.nlm.nih.gov/web/newsltr/fallwinter02/blastlab.html),可以实现更灵敏的搜索。该页面使用与ma等报道的算法相似的算法(bioinformatics.2002年3月;18(3):440-5)。不连续megablast在模板的较长窗口内使用非重叠字,而不是要求精确字匹配作为用于比对扩展的种子。在编码模式下,通过专注于在第一密码子位置和第二密码子位置找到匹配而忽略第三位置的不匹配来考虑第三碱基摆动。使用相同字长的不连续megablast来搜索比使用相同字长的标准blastn搜索更为灵敏和高效。不连续megablast的独特参数是:字长:11或12;模板:16、18或21;模板类型:编码(0)、非编码(1)、或两者(2)。
在一些实施方式中,可以使用默认参数来使用blastp2.5.0+算法(比如可从ncbi获得的)。在其他实施方式中,可以通过使用两个蛋白序列的needleman-wunsch比对来使用blast全局比对程序(比如可从ncbi获得的),其中,空位罚分:初始11和延伸1。
一种用于产生重组aav的方法是基于将aav产生所需的所有元件瞬时转染到宿主细胞(比如hek293细胞)中。这通常涉及用3个质粒共转染aav生产细胞:
(a)含有aavitr的质粒,其携带目的基因;
(b)携带aavrep-cap基因的质粒;以及
(c)提供从腺病毒分离的必需辅助基因的质粒。
在一些情况下,由于辅助基因被稳定地整合到宿主细胞基因组中(并且可从宿主细胞基因组表达),因此不需要质粒(c)。
因此,本发明提供了一种试剂盒,其包含:
(a)质粒或载体,其包含本发明的核酸分子,以及以下一种或多种-
(b)aav转移质粒,其包含侧翼为itr的转基因;
(c)辅助质粒,其包含一个或多个选自腺病毒e1a、腺病毒e1b、腺病毒e4和腺病毒va的基因。
在本发明的一些实施方式中,所述辅助质粒另外包含e2a基因。在其他实施方式中,所述辅助质粒不包含e2a基因。在后一种情况下,e2a基因的缺失显著减少辅助质粒中所需的dna的量。
本发明还提供了一种试剂盒,其包含:
(a)质粒或载体,其包含本发明的核酸分子,以及以下一种或多种-
(b)aav转移质粒,其包含侧翼为itr的转基因;
(c)哺乳动物宿主细胞(例如hek293),其包含一个或多个病毒基因,所述病毒基因选自能够从所述宿主细胞基因组表达的e1a、e1b、e4和va。
在本发明的一些实施方式中,哺乳动物宿主细胞另外包含能够从宿主细胞基因组表达的e2a基因。在其他实施方式中,哺乳动物宿主细胞不包含腺病毒e2a基因。
所述试剂盒还包含用于纯化aav颗粒的材料,比如与病毒颗粒的密度条带和纯化有关的那些材料,例如离心管、碘克沙醇、透析缓冲液和透析盒中的一种或多种。
本发明还提供一种包含本发明的核酸分子、质粒或载体的哺乳动物细胞。本发明的核酸分子可以稳定地整合到哺乳动物细胞的核基因组中或者可以存在于细胞内的载体或质粒(例如,附加体)内。
优选地,本发明的核酸分子被稳定整合到哺乳动物细胞的核基因组中(并且其中,rep基因和cap基因能够从中表达)。
所述细胞可以是分离的细胞,例如它们不位于活的动物或哺乳动物中。哺乳动物细胞的实例包括来自人、小鼠、大鼠、仓鼠、猴子、兔子、驴、马、绵羊、牛和猿的任何器官或组织的细胞。优选地,所述细胞是人细胞。所述细胞可以是原代细胞或永生化细胞。
优选的细胞包括hek-293、hek293t、hek-293e、hek-293ft、hek-293s、hek-293sg、hek-293ftm、hek-293sggd、hek-293a、mdck、c127、a549、hela、cho、小鼠骨髓瘤、perc6、911和vero细胞系。hek-293细胞已经被修饰为含有e1a蛋白和e1b蛋白,并且这消除了在辅助质粒上提供这些蛋白的需求。类似地,perc6细胞和911细胞包含相似的修饰,并且也可以被使用。最优选地,所述人细胞是hek293、hek293t、hek293a、perc6或911。其他优选的细胞包括cho细胞和vero细胞。
优选地,本发明的细胞能够诱导表达rep基因和cap基因。
本发明还提供一种aav包装细胞(优选哺乳动物细胞,更优选人细胞),其包含(a)本发明的核酸分子和任选地(b)包含侧翼为itr的转基因的aav转移质粒和(c)包含一个或多个选自e1a、e1b、e4和va的基因的辅助质粒中的一者或两者。在本发明的一些实施方式中,所述辅助质粒另外包含e2a基因。在其他实施方式中,所述辅助质粒不包含e2a基因。在后一种情况下,e2a基因的缺失显著减少辅助质粒中所需的dna的量。
本发明的核酸分子、质粒和载体可以通过任何合适的技术来制备。用于产生本发明的核酸分子和包装细胞的重组方法是本领域公知的(例如“分子克隆:实验室手册”(第四版),green,mr和sambrook,j.,(2014年更新))。
来自本发明的核酸分子的rep基因和cap基因的表达可以在任何合适的测定法中进行测定,例如通过qpcr来测定每毫升的基因组拷贝数(如本文的实施例所描述的)。
在另一个实施方式中,提供一种用于生产aav包装细胞的方法,该方法包括以下步骤:
(a)将本发明的核酸分子稳定整合到哺乳动物细胞中,从而产生表达病毒rep基因和cap基因的哺乳动物细胞。
本发明还提供一种本发明的aav包装细胞在生产aav颗粒中的用途。
本发明还提供一种用于生产aav的方法,该方法包括以下步骤:
(a)将包含侧翼为5’-aavitr和3’-aavitr的转基因的转移质粒引入aav包装细胞中,所述aav包装细胞包含本发明的核酸分子和用于包装所述转移质粒的足够的辅助基因(优选选自e1a、e1b、e4和va中的一种或多种),所述辅助基因存在于细胞内的附加型辅助质粒中或者整合到包装细胞基因组中;
(b)在使得aav由细胞组装和分泌的条件下培养所述细胞;以及
(c)从上清液中收获包装的aav。
在本发明的一些实施方式中,所述辅助基因另外包括e2a基因。在其他实施方式中,所述辅助基因不包括e2a基因。
优选地,随后对收获的aav进行纯化。
如本文中所使用的,术语“引入”一个或多个质粒或载体到细胞中包括转化、以及任何形式的电穿孔、接合、感染、转导或转染等。
在一些优选的实施方式中,所述转基因编码crispr酶(例如cas9、cpf1)或crisprsgrna。
用于这种引入的方法在本领域中是公知的(例如,proc.natl.acad.sci.美国.1995年8月1日;92(16):7297-301)。
本文中所阐述的每个参考文献的公开以其整体通过引用具体地并入本文中。
附图说明
图1示出了野生型aav基因组中rep蛋白基因和cap蛋白基因的组织。
图2a、图2b和图2c示出了本发明的核酸分子的三个实施方式。在图2b中,“oxgp3”是指具有两个tet操纵子位点的cmv启动子变体。
图3至图4示出了在用各种rep-cap质粒转染的细胞中产生的每毫升aav基因组拷贝数的测定结果。oxg=如在野生型病毒中发现的标准repcap构型,包括置于远端的p5启动子;cmv-cmv=其中以5’-3’顺序cmv-cap-cmv-rep将rep序列和cap序列都置于cmv启动子下的构型;cmv-pgk=其中以5’-3’顺序cmv-cap-pgk-rep将rep序列和cap序列分别置于pgk启动子和cmv启动子下的构型;cmv-emcv=其中以5’-3’顺序cmv-cap-emcv-rep将cap序列置于cmv启动子下且将rep序列置于iresemcv的控制下的构型。在图4中,将含有病毒的细胞裂解液稀释500倍并使用qpcr进行定量。这证明了物理效价。
图5示出了用aav颗粒感染72小时后的hek293t细胞的流式细胞术分析后的结果。数据以p1中gfp阳性细胞的百分比给出。p1对应于样品中的活细胞。
图6示出了每毫升感染的病毒样品的转导单位,如从图5的结果以及感染细胞的数量计算得出的。这证明了感染效价。
图7示出了在用各种rep-cap质粒转染的细胞中产生的每毫升aav基因组拷贝数的测定结果。有关质粒的细节,请参见上面图3至图4。clontech是指由clontech提供的3-质粒系统(paav-cmv-egfp;phelper;prepcap-mir342)。
图8示出了从以下产生的病毒获得的效价(gc,基因组拷贝):a)本发明的3-质粒aav系统;b)a)的系统,其中psf-helper质粒被仅包含cmv-e4orf6(编码序列)的质粒替代;c)a)的系统,其中psf-helper质粒被psf-e4orf6-vai替代;以及d)a)的系统,其中psf-helper质粒被去除并被填充物dna(对照)替代。
具体实施方式
实施例
通过以下实施例对本发明进行进一步说明,除非另有说明,否则在以下实施例中份数和百分数均以重量计,度为摄氏度。应当理解的是,这些实施例虽然表明了本发明的优选实施方式,但仅通过说明的方式给出。根据以上论述和这些实施例,本领域技术人员可以确定本发明的基本特征,并且在不脱离本发明的精神和范围的情况下,可以对本发明进行各种改变和修改以使其适应各种用途和条件。因此,除了本文中示出和描述的那些修改之外,根据前面的描述,本发明的各种修改对于本领域技术人员而言将是明显的。这样的修改也意图落入所附权利要求的范围内。
实施例1:aavcap-rep质粒的产生
产生了具有如图2a、图2b和图2c所示的遗传元件的以下质粒:
psf-cmv-aav2cap-fmdv-aav2rep
psf-cmv-aav2cap-emcv-aav2rep
psf-p565_2xteto-aav2cap-emcv-aav2rep
oxgp3启动子是如wo2017/149292中所定义的p565启动子。fmdv是口蹄疫病毒ires。cmv是巨细胞病毒启动子。aav2cap是腺相关病毒2cap基因。rep是仅编码rep78和rep52的腺相关病毒rep基因。
psf-aav-cmv-egfp
该质粒编码由cmv启动子驱动的egfp蛋白,其侧翼为两个aav2itr序列,以允许将itr-cmv-egfp-itr序列包装到aav衣壳中。
psf-helper
该质粒包含腺病毒5序列e2a、e4orf6和vairna,以提供hek293细胞中aav产生所需的辅助功能。
psf-repcap
该质粒包含野生型构型的repcap序列,其中,p5启动子被去除并置于远端以降低rep78/68的总体表达。
psf-cmv-cap-cmv-rep78/52
该质粒包含由cmv驱动的cap序列和由cmv启动子单独驱动的rep78/52序列。这产生了两个编码序列的同样强的表达。
psf-cmv-cap-pgk-rep78/52
该质粒包含由cmv驱动的cap序列和由pgk启动子单独驱动的rep78/52序列,其产生了比cmv启动子更低的表达。
psf-cmv-cap-emcv-rep78/52
该质粒包含由cmv启动子驱动的cap序列以及由iresemcv产生的rep78/52蛋白。emcv产生比cmv启动子低得多的表达水平。
实施例2:测定基因组拷贝(gc)
质粒载体psf-aav-cmv-egfp、psf-helper以及以下一种:psf-repcap、psf-cmv-cap-cmv-rep78/52、psf-cmv-cap-pgk-rep78/52或psf-cmv-cap-emcv-rep78/52以1:1:1的摩尔比转染到6孔板中>80%融合的hek293t细胞中,每个孔中总共2.5μgdna。转染试剂lipofectamine2000以总dna质量与lipofectamine为1:2.4的比例使用。在48小时收获全部孔内容物,以通过流式细胞术和qpcr进行分析。数据表示为每毫升裂解物的转导单位(tu)(图6)和每毫升裂解物的基因组拷贝(图3至图4)。
与oxg阳性对照中使用的野生型构型相比,通过使用质粒psf-cmv-cap-emcv-rep78/52使得感染和物理效价都得到改善。
图5示出了使用aav孵育72小时后gfp阳性的活细胞的百分比。病毒溶液稀释至1/500、1/2500和1/12500。使用给出5%至25%的gfp阳性细胞的稀释度来计算每毫升病毒溶液的转导单位。
实施例3:
质粒载体psf-aav-cmv-egfp、psf-helper以及以下一种:psf-repcap、psf-cmv-cap-emcv-rep78/52或psf-cmv-cap-fmdv-rep78/52以1:1:1的摩尔比转染到6孔板中的70%-80%融合的hek293t细胞中,每个孔中总共2.5μgdna。这与clontech3-质粒系统(www.clontech.com/gb/products/viral_transduction/aav_vector_systems/helper_free_expression_system?sitex=10030:22372:us)一起运行,也以1:1:1摩尔比进行转染达到总dna质量2.5μg。转染试剂lipofectamine2000以总dna质量与lipofectamine为1:2.4的比例使用。在48小时收获全部孔内容物用于qpcr分析。数据表示为每毫升裂解物的基因组拷贝(图7),其中,误差条代表平均值的标准误差。
该实验表明,psf-cmv-cap-emcv-rep78/52可靠地优于在psf-repcap和clontechprepcap-mir342这两者中使用的标准野生型构型。还表明的是,与野生型构型相比,使用替代的ires、fmdv使病毒效价增加。
实施例4:无需使用e2a获得提高的效价
使用含有/不含有ad5e2a基因的多组质粒对来自本发明的aav生产系统的e2a存在或不存在的影响进行评估。
所有实验均包含以下质粒:
(i)psf-aav-cmv-egfp,如实施例1中所定义的。
(ii)psf-cmv-cap-emcv-rep。该质粒包含由cmv启动子驱动的cap序列和由emcvires产生的rep蛋白。
除上述(i)和(ii)之外,以下实验还包含以下质粒:
a)psf-helper(其包含ad5区e2a、e4orf6和varnai);
b)psf-nano-cmv-e4orf6(其仅包含e4orf6蛋白的编码序列);
c)psf-e4orf6-vai(其包含完整的e4orf6区和完整的varnai序列);以及
d)og10(其是空的psf-cmv-kan)。
结果在图8中示出,其中,实验a)、b)、c)和d)的结果分别被示出(以基因组拷贝/ml的形式)并且被分别标记为“oxgpro”、“e4orf6/pro”、“无e2a”和“无ad5辅助”。
结果表明,通过在aav生产系统中使用本发明的cap/rep质粒而不使用e2a可以得到病毒的更高效价。
序列
seqidno:1-rep核苷酸序列(aav血清型2)
atgccggggttttacgagattgtgattaaggtccccagcgaccttgacgagcatctgcccggcatttctgacagctttgtgaactgggtggccgagaaggaatgggagttgccgccagattctgacatggatctgaatctgattgagcaggcacccctgaccgtggccgagaagctgcagcgcgactttctgacggaatggcgccgtgtgagtaaggccccggaggcccttttctttgtgcaatttgagaagggagagagctacttccacatgcacgtgctcgtggaaaccaccggggtgaaatccatggttttgggacgtttcctgagtcagattcgcgaaaaactgattcagagaatttaccgcgggatcgagccgactttgccaaactggttcgcggtcacaaagaccagaaatggcgccggaggcgggaacaaggtggtggatgagtgctacatccccaattacttgctccccaaaacccagcctgagctccagtgggcgtggactaatatggaacagtatttaagcgcctgtttgaatctcacggagcgtaaacggttggtggcgcagcatctgacgcacgtgtcgcagacgcaggagcagaacaaagagaatcagaatcccaattctgatgcgccggtgatcagatcaaaaacttcagccaggtacatggagctggtcgggtggctcgtggacaaggggattacctcggagaagcagtggatccaggaggaccaggcctcatacatctccttcaatgcggcctccaactcgcggtcccaaatcaaggctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcccccgactacctggtgggccagcagcccgtggaggacatttccagcaatcggatttataaaattttggaactaaacgggtacgatccccaatatgcggcttccgtctttctgggatgggccacgaaaaagttcggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaagaccaacatcgcggaggccatagcccacactgtgcccttctacgggtgcgtaaactggaccaatgagaactttcccttcaacgactgtgtcgacaagatggtgatctggtgggaggaggggaagatgaccgccaaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgcgtggaccagaaatgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctccaacaccaacatgtgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccgttgcaagaccggatgttcaaatttgaactcacccgccgtctggatcatgactttgggaaggtcaccaagcaggaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtggagcatgaattctacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgcagatataagtgagcccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcggaagcttcgatcaactacgcagacaggtaccaaaacaaatgttctcgtcacgtgggcatgaatctgatgctgtttccctgcagacaatgcgagagaatgaatcagaattcaaatatctgcttcactcacggacagaaagactgtttagagtgctttcccgtgtcagaatctcaacccgtttctgtcgtcaaaaaggcgtatcagaaactgtgctacattcatcatatcatgggaaaggtgccagacgcttgcactgcctgcgatctggtcaatgtggatttggatgactgcatctttgaacaatag
seqidno:2-rep78氨基酸序列(aav血清型2)
mpgfyeivikvpsdldghlpgisdsfvnwvaekewelppdsdmdlnlieqapltvaeklqrdfltewrrvskapealffvqfekgesyfhmhvlvettgvksmvlgrflsqirekliqriyrgieptlpnwfavtktrngagggnkvvdecyipnyllpktqpelqwawtnmeqylsaclnlterkrlvaqhlthvsqtqeqnkenqnpnsdapvirsktsarymelvgwlvdkgitsekqwiqedqasyisfnaasnsrsqikaaldnagkimsltktapdylvgqqpvedissnriykilelngydpqyaasvflgwatkkfgkrntiwlfgpattgktniaeaiahtvpfygcvnwtnenfpfndcvdkmviwweegkmtakvvesakailggskvrvdqkckssaqidptpvivtsntnmcavidgnsttfehqqplqdrmfkfeltrrldhdfgkvtkqevkdffrwakdhvvevehefyvkkggakkrpapsdadisepkrvresvaqpstsdaeasinyadryqnkcsrhvgmnlmlfpcrqcermnqnsnicfthgqkdclecfpvsesqpvsvvkkayqklcyihhimgkvpdactacdlvnvdlddcifeq*
seqidno:3-rep68氨基酸序列(aav血清型2)
mpgfyeivikvpsdldehlpgisdsfvnwvaekewelppdsdmdlnlieqapltvaeklqrdfltewrrvskapealffvqfekgesyfhmhvlvettgvksmvlgrflsqirekliqriyrgieptlpnwfavtktrngagggnkvvdecyipnyllpktqpelqwawtnmeqylsaclnlterkrlvaqhlthvsqtqeqnkenqnpnsdapvirsktsarymelvgwlvdkgitsekqwiqedqasyisfnaasnsrsqikaaldnagkimsltktapdylvgqqpvedissnriykilelngydpqyaasvflgwatkkfgkrntiwlfgpattgktniaeaiahtvpfygcvnwtnenfpfndcvdkmviwweegkmtakvvesakailggskvrvdqkckssaqidptpvivtsntnmcavidgnsttfehqqplqdrmfkfeltrrldhdfgkvtkqevkdffrwakdhvvevehefyvkkggakkrpapsdadisepkrvresvaqpstsdaeasinyad*
seqidno:4-rep52氨基酸序列(aav血清型2)
melvgwlvdkgitsekqwiqedqasyisfnaasnsrsqikaaldnagkimsltktapdylvgqqpvedissnriykilelngydpqyaasvflgwatkkfgkrntiwlfgpattgktniaeaiahtvpfygcvnwtnenfpfndcvdkmviwweegkmtakvvesakailggskvrvdqkckssaqidptpvivtsntnmcavidgnsttfehqqplqdrmfkfeltrrldhdfgkvtkqevkdffrwakdhvvevehefyvkkggakkrpapsdadisepkrvresvaqpstsdaeasinyadryqnkcsrhvgmnlmlfpcrqcermnqnsnicfthgqkdclecfpvsesqpvsvvkkayqklcyihhimgkvpdactacdlvnvdlddcifeq*
seqidno:5-rep40氨基酸序列(aav血清型2)
melvgwlvdkgitsekqwiqedqasyisfnaasnsrsqikaaldnagkimsltktapdylvgqqpvedissnriykilelngydpqyaasvflgwatkkfgkrntiwlfgpattgktniaeaiahtvpfygcvnwtnenfpfndcvdkmviwweegkmtakvvesakailggskvrvdqkckssaqidptpvivtsntnmcavidgnsttfehqqplqdrmfkfeltrrldhdfgkvtkqevkdffrwakdhvvevehefyvkkggakkrpapsdadisepkrvresvaqpstsdaeasinyadrlarghsl*
seqidno:6-rep78核苷酸序列(aav血清型2)
atgccggggttttacgagattgtgattaaggtccccagcgaccttgacgggcatctgcccggcatttctgacagctttgtgaactgggtggccgagaaggaatgggagttgccgccagattctgacatggatctgaatctgattgagcaggcacccctgaccgtggccgagaagctgcagcgcgactttctgacggaatggcgccgtgtgagtaaggccccggaggcccttttctttgtgcaatttgagaagggagagagctacttccacatgcacgtgctcgtggaaaccaccggggtgaaatccatggttttgggacgtttcctgagtcagattcgcgaaaaactgattcagagaatttaccgcgggatcgagccgactttgccaaactggttcgcggtcacaaagaccagaaatggcgccggaggcgggaacaaggtggtggatgagtgctacatccccaattacttgctccccaaaacccagcctgagctccagtgggcgtggactaatatggaacagtacctcagcgcctgtttgaatctcacggagcgtaaacggttggtggcgcagcatctgacgcacgtgtcgcagacgcaggagcagaacaaagagaatcagaatcccaattctgatgcgccggtgatcagatcaaaaacttcagccaggtacatggagctggtcgggtggctcgtggacaaggggattacctcggagaagcagtggatccaggaggaccaggcctcatacatctccttcaatgcggcctccaactcgcggtcccaaatcaaggctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcccccgactacctggtgggccagcagcccgtggaggacatttccagcaatcggatttataaaattttggaactaaacgggtacgatccccaatatgcggcttccgtctttctgggatgggccacgaaaaagttcggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaagaccaacatcgcggaggccatagcccacactgtgcccttctacgggtgcgtaaactggaccaatgagaactttcccttcaacgactgtgtcgacaagatggtgatctggtgggaggaggggaagatgaccgccaaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgcgtggaccagaaatgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctccaacaccaacatgtgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccgttgcaagaccggatgttcaaatttgaactcacccgccgtctggatcatgactttgggaaggtcaccaagcaggaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtggagcatgaattctacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgcagatataagtgagcccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcggaagcttcgatcaactacgcagacaggtaccaaaacaaatgttctcgtcacgtgggcatgaatctgatgctgtttccctgcagacaatgcgagagaatgaatcagaattcaaatatctgcttcactcacggacagaaagactgtttagagtgctttcccgtgtcagaatctcaacccgtttctgtcgtcaaaaaggcgtatcagaaactgtgctacattcatcatatcatgggaaaggtgccagacgcttgcactgcctgcgatctggtcaatgtggatttggatgactgcatctttgaacaatag
seqidno:7-rep68核苷酸序列(aav血清型2)
atgccggggttttacgagattgtgattaaggtccccagcgaccttgacgagcatctgcccggcatttctgacagctttgtgaactgggtggccgagaaggaatgggagttgccgccagattctgacatggatctgaatctgattgagcaggcacccctgaccgtggccgagaagctgcagcgcgactttctgacggaatggcgccgtgtgagtaaggccccggaggcccttttctttgtgcaatttgagaagggagagagctacttccacatgcacgtgctcgtggaaaccaccggggtgaaatccatggttttgggacgtttcctgagtcagattcgcgaaaaactgattcagagaatttaccgcgggatcgagccgactttgccaaactggttcgcggtcacaaagaccagaaatggcgccggaggcgggaacaaggtggtggatgagtgctacatccccaattacttgctccccaaaacccagcctgagctccagtgggcgtggactaatatggaacagtacctcagcgcctgtttgaatctcacggagcgtaaacggttggtggcgcagcatctgacgcacgtgtcgcagacgcaggagcagaacaaagagaatcagaatcccaattctgatgcgccggtgatcagatcaaaaacttcagccaggtacatggagctggtcgggtggctcgtggacaaggggattacctcggagaagcagtggatccaggaggaccaggcctcatacatctccttcaatgcggcctccaactcgcggtcccaaatcaaggctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcccccgactacctggtgggccagcagcccgtggaggacatttccagcaatcggatttataaaattttggaactaaacgggtacgatccccaatatgcggcttccgtctttctgggatgggccacgaaaaagttcggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaagaccaacatcgcggaggccatagcccacactgtgcccttctacgggtgcgtaaactggaccaatgagaactttcccttcaacgactgtgtcgacaagatggtgatctggtgggaggaggggaagatgaccgccaaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgcgtggaccagaaatgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctccaacaccaacatgtgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccgttgcaagaccggatgttcaaatttgaactcacccgccgtctggatcatgactttgggaaggtcaccaagcaggaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtggagcatgaattctacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgcagatataagtgagcccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcggaagcttcgatcaactacgcagacagtag
seqidno:8-rep52核苷酸序列
catggagctggtcgggtggctcgtggacaaggggattacctcggagaagcagtggatccaggaggaccaggcctcatacatctccttcaatgcggcctccaactcgcggtcccaaatcaaggctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcccccgactacctggtgggccagcagcccgtggaggacatttccagcaatcggatttataaaattttggaactaaacgggtacgatccccaatatgcggcttccgtctttctgggatgggccacgaaaaagttcggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaagaccaacatcgcggaggccatagcccacactgtgcccttctacgggtgcgtaaactggaccaatgagaactttcccttcaacgactgtgtcgacaagatggtgatctggtgggaggaggggaagatgaccgccaaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgcgtggaccagaaatgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctccaacaccaacatgtgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccgttgcaagaccggatgttcaaatttgaactcacccgccgtctggatcatgactttgggaaggtcaccaagcaggaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtggagcatgaattctacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgcagatataagtgagcccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcggaagcttcgatcaactacgcagacaggtaccaaaacaaatgttctcgtcacgtgggcatgaatctgatgctgtttccctgcagacaatgcgagagaatgaatcagaattcaaatatctgcttcactcacggacagaaagactgtttagagtgctttcccgtgtcagaatctcaacccgtttctgtcgtcaaaaaggcgtatcagaaactgtgctacattcatcatatcatgggaaaggtgccagacgcttgcactgcctgcgatctggtcaatgtggatttggatgactgcatctttgaacaatag
seqidno:9-rep40核苷酸序列
atggagctggtcgggtggctcgtggacaaggggattacctcggagaagcagtggatccaggaggaccaggcctcatacatctccttcaatgcggcctccaactcgcggtcccaaatcaaggctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcccccgactacctggtgggccagcagcccgtggaggacatttccagcaatcggatttataaaattttggaactaaacgggtacgatccccaatatgcggcttccgtctttctgggatgggccacgaaaaagttcggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaagaccaacatcgcggaggccatagcccacactgtgcccttctacgggtgcgtaaactggaccaatgagaactttcccttcaacgactgtgtcgacaagatggtgatctggtgggaggaggggaagatgaccgccaaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgcgtggaccagaaatgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctccaacaccaacatgtgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccgttgcaagaccggatgttcaaatttgaactcacccgccgtctggatcatgactttgggaaggtcaccaagcaggaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtggagcatgaattctacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgcagatataagtgagcccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcggaagcttcgatcaactacgcagacagattggctcgaggacactctctctag
seqidno:10-cap核苷酸序列(aav血清型2)
cagttgcgcagccatcgacgtcagacgcggaagcttcgatcaactacgcagacaggtaccaaaacaaatgttctcgtcacgtgggcatgaatctgatgctgtttccctgcagacaatgcgagagaatgaatcagaattcaaatatctgcttcactcacggacagaaagactgtttagagtgctttcccgtgtcagaatctcaacccgtttctgtcgtcaaaaaggcgtatcagaaactgtgctacattcatcatatcatgggaaaggtgccagacgcttgcactgcctgcgatctggtcaatgtggatttggatgactgcatctttgaacaataaatgatttaaatcaggtatggctgccgatggttatcttccagattggctcgaggacactctctctgaaggaataagacagtggtggaagctcaaacctggcccaccaccaccaaagcccgcagagcggcataaggacgacagcaggggtcttgtgcttcctgggtacaagtacctcggacccttcaacggactcgacaagggagagccggtcaacgaggcagacgccgcggccctcgagcacgacaaagcctacgaccggcagctcgacagcggagacaacccgtacctcaagtacaaccacgccgacgcggagtttcaggagcgccttaaagaagatacgtcttttgggggcaacctcggacgagcagtcttccaggcgaaaaagagggttcttgaacctctgggcctggttgaggaacctgttaagacggctccgggaaaaaagaggccggtagagcactctcctgtggagccagactcctcctcgggaaccggaaaggcgggccagcagcctgcaagaaaaagattgaattttggtcagactggagacgcagactcagtacctgacccccagcctctcggacagccaccagcagccccctctggtctgggaactaatacgatggctacaggcagtggcgcaccaatggcagacaataacgagggcgccgacggagtgggtaattcctcgggaaattggcattgcgattccacatggatgggcgacagagtcatcaccaccagcacccgaacctgggccctgcccacctacaacaaccacctctacaaacaaatttccagccaatcaggagcctcgaacgacaatcactactttggctacagcaccccttgggggtattttgacttcaacagattccactgccacttttcaccacgtgactggcaaagactcatcaacaacaactggggattccgacccaagagactcaacttcaagctctttaacattcaagtcaaagaggtcacgcagaatgacggtacgacgacgattgccaataaccttaccagcacggttcaggtgtttactgactcggagtaccagctcccgtacgtcctcggctcggcgcatcaaggatgcctcccgccgttcccagcagacgtcttcatggtgccacagtatggatacctcaccctgaacaacgggagtcaggcagtaggacgctcttcattttactgcctggagtactttccttctcagatgctgcgtaccggaaacaactttaccttcagctacacttttgaggacgttcctttccacagcagctacgctcacagccagagtctggaccgtctcatgaatcctctcatcgaccagtacctgtattacttgagcagaacaaacactccaagtggaaccaccacgcagtcaaggcttcagttttctcaggccggagcgagtgacattcgggaccagtctaggaactggcttcctggaccctgttaccgccagcagcgagtatcaaagacatctgcggataacaacaacagtgaatactcgtggactggagctaccaagtaccacctcaatggcagagactctctggtgaatccgggcccggccatggcaagccacaaggacgatgaagaaaagttttttcctcagagcggggttctcatctttgggaagcaaggctcagagaaaacaaatgtggacattgaaaaggtcatgattacagacgaagaggaaatcaggacaaccaatcccgtggctacggagcagtatggttctgtatctaccaacctccagagaggcaacagacaagcagctaccgcagatgtcaacacacaaggcgttcttccaggcatggtctggcaggacagagatgtgtaccttcaggggcccatctgggcaaagattccacacacggacggacattttcacccctctcccctcatgggtggattcggacttaaacaccctcctccacagattctcatcaagaacaccccggtacctgcgaatccttcgaccaccttcagtgcggcaaagtttgcttccttcatcacacagtactccacgggacaggtcagcgtggagatcgagtgggagctgcagaaggaaaacagcaaacgctggaatcccgaaattcagtacacttccaactacaacaagtctgttaatgtggactttactgtggacactaatggcgtgtattcagagcctcgccccattggcaccagatacctgactcgtaatctgtaa
seqidno:11-cap氨基酸序列(aav血清型2)
maadgylpdwledtlsegirqwwklkpgppppkpaerhkddsrglvlpgykylgpfngldkgepvneadaaalehdkaydrqldsgdnpylkynhadaefqerlkedtsfggnlgravfqakkrvleplglveepvktapgkkrpvehspvepdsssgtgkagqqparkrlnfgqtgdadsvpdpqplgqppaapsglgtntmatgsgapmadnnegadgvgnssgnwhcdstwmgdrvittstrtwalptynnhlykqissqsgasndnhyfgystpwgyfdfnrfhchfsprdwqrlinnnwgfrpkrlnfklfniqvkevtqndgtttiannltstvqvftdseyqlpyvlgsahqgclppfpadvfmvpqygyltlnngsqavgrssfycleyfpsqmlrtgnnftfsytfedvpfhssyahsqsldrlmnplidqylyylsrtntpsgtttqsrlqfsqagasdirdqsrnwlpgpcyrqqrvsktsadnnnseyswtgatkyhlngrdslvnpgpamashkddeekffpqsgvlifgkqgsektnvdiekvmitdeeeirttnpvateqygsvstnlqrgnrqaatadvntqgvlpgmvwqdrdvylqgpiwakiphtdghfhpsplmggfglkhpppqilikntpvpanpsttfsaakfasfitqystgqvsveiewelqkenskrwnpeiqytsnynksvnvdftvdtngvyseprpigtryltrnl*
seqidno:12-tetr结合位点
tccctatcagtgatagaga
seqidno:13-tetr蛋白的核苷酸序列
atgtcgcgcctggacaaaagcaaagtgattaactcagcgctggaactgttgaatgaggtgggaattgaaggactcactactcgcaagctggcacagaagctgggcgtcgagcagccaacgctgtactggcatgtgaagaataaacgggcgctcctagacgcgcttgccatcgaaatgctggaccgccatcacacccacttttgccccctggagggcgaatcctggcaagattttctgcggaacaatgcaaagtcgttccggtgcgctctgctgtcccaccgcgatggcgcaaaagtgcacctgggcactcggcccaccgagaaacaatacgaaaccctggaaaaccaactggctttcctttgccaacagggattttcactggagaatgccctgtacgcactatccgcggtcggccactttaccctgggatgcgtcctcgaagatcaggagcaccaagtcgccaaggaggaaagagaaactcctaccactgactcaatgcctccgctcctgagacaagccatcgagctgttcgaccaccagggtgctgaacctgcatttctgttcgggcttgaactgattatctgcggcctggagaaacagttgaagtgcgagtcgggatcctag
seqidno:14-tetr蛋白的氨基酸序列
msrldkskvinsalellnevgieglttrklaqklgveqptlywhvknkralldalaiemldrhhthfcplegeswqdflrnnaksfrcallshrdgakvhlgtrptekqyetlenqlaflcqqgfslenalyalsavghftlgcvledqehqvakeeretpttdsmppllrqaielfdhqgaepaflfgleliicglekqlkcesgs
seqidno:15-emcvires
cgttactggccgaagccgcttggaataaggccggtgtgcgtttgtctatatgttattttccaccatattgccgtcttttggcaatgtgagggcccggaaacctggccctgtcttcttgacgagcattcctaggggtctttcccctctcgccaaaggaatgcaaggtctgttgaatgtcgtgaaggaagcagttcctctggaagcttcttgaagacaaacaacgtctgtagcgaccctttgcaggcagcggaaccccccacctggcgacaggtgcctctgcggccaaaagccacgtgtataagatacacctgcaaaggcggcacaaccccagtgccacgttgtgagttggatagttgtggaaagagtcaaatggctcccctcaagcgtattcaacaaggggctgaaggatgcccagaaggtaccccattgtatgggatctgatctggggcctcggtgcacatgctttacatgtgtttagtcgaggttaaaaaacgtctaggccccccgaaccacggggac
seqidno:16-fmdvires
agcaggtttccccaactgacacaaaacgtgcaacttgaaactccgcctggtctttccaggtctagaggggtaacactttgtactgcgtttggctccacgctcgatccactggcgagtgttagtaacagcactgttgcttcgtagcggagcatgacggccgtgggaactcctccttggtaacaaggacccacggggccaaaagccacgcccacacgggcccgtcatgtgtgcaaccccagcacggcgactttactgcgaaacccactttaaagtgacattgaaactggtacccacacactggtgacaggctaaggatgcccttcaggtaccccgaggtaacacgcgacactcgggatctgagaaggggactggggcttctataaaagcgctcggtttaaaaagcttctatgcctgaataggtgaccggaggtcggcacctttcctttgcaattactgaccac
seqidno:17-ad5e2a
ggtacccaactccatgctcaacagtccccaggtacagcccaccctgcgtcgcaaccaggaacagctctacagcttcctggagcgccactcgccctacttccgcagccacagtgcgcagattaggagcgccacttctttttgtcacttgaaaaacatgtaaaaataatgtactagagacactttcaataaaggcaaatgcttttatttgtacactctcgggtgattatttacccccacccttgccgtctgcgccgtttaaaaatcaaaggggttctgccgcgcatcgctatgcgccactggcagggacacgttgcgatactggtgtttagtgctccacttaaactcaggcacaaccatccgcggcagctcggtgaagttttcactccacaggctgcgcaccatcaccaacgcgtttagcaggtcgggcgccgatatcttgaagtcgcagttggggcctccgccctgcgcgcgcgagttgcgatacacagggttgcagcactggaacactatcagcgccgggtggtgcacgctggccagcacgctcttgtcggagatcagatccgcgtccaggtcctccgcgttgctcagggcgaacggagtcaactttggtagctgccttcccaaaaagggcgcgtgcccaggctttgagttgcactcgcaccgtagtggcatcaaaaggtgaccgtgcccggtctgggcgttaggatacagcgcctgcataaaagccttgatctgcttaaaagccacctgagcctttgcgccttcagagaagaacatgccgcaagacttgccggaaaactgattggccggacaggccgcgtcgtgcacgcagcaccttgcgtcggtgttggagatctgcaccacatttcggccccaccggttcttcacgatcttggccttgctagactgctccttcagcgcgcgctgcccgttttcgctcgtcacatccatttcaatcacgtgctccttatttatcataatgcttccgtgtagacacttaagctcgccttcgatctcagcgcagcggtgcagccacaacgcgcagcccgtgggctcgtgatgcttgtaggtcacctctgcaaacgactgcaggtacgcctgcaggaatcgccccatcatcgtcacaaaggtcttgttgctggtgaaggtcagctgcaacccgcggtgctcctcgttcagccaggtcttgcatacggccgccagagcttccacttggtcaggcagtagtttgaagttcgcctttagatcgttatccacgtggtacttgtccatcagcgcgcgcgcagcctccatgcccttctcccacgcagacacgatcggcacactcagcgggttcatcaccgtaatttcactttccgcttcgctgggctcttcctcttcctcttgcgtccgcataccacgcgccactgggtcgtcttcattcagccgccgcactgtgcgcttacctcctttgccatgcttgattagcaccggtgggttgctgaaacccaccatttgtagcgccacatcttctctttcttcctcgctgtccacgattacctctggtgatggcgggcgctcgggcttgggagaagggcgcttctttttcttcttgggcgcaatggccaaatccgccgccgaggtcgatggccgcgggctgggtgtgcgcggcaccagcgcgtcttgtgatgagtcttcctcgtcctcggactcgatacgccgcctcatccgcttttttgggggcgcccggggaggcggcggcgacggggacggggacgacacgtcctccatggttgggggacgtcgcgccgcaccgcgtccgcgctcgggggtggtttcgcgctgctcctcttcccgactggccatttccttctcctataggcagaaaaagatcatggagtcagtcgagaagaaggacagcctaaccgccccctctgagttcgccaccaccgcctccaccgatgccgccaacgcgcctaccaccttccccgtcgaggcacccccgcttgaggaggaggaagtgattatcgagcaggacccaggttttgtaagcgaagacgacgaggaccgctcagtaccaacagaggataaaaagcaagaccaggacaacgcagaggcaaacgaggaacaagtcgggcggggggacgaaaggcatggcgactacctagatgtgggagacgacgtgctgttgaagcatctgcagcgccagtgcgccattatctgcgacgcgttgcaagagcgcagcgatgtgcccctcgccatagcggatgtcagccttgcctacgaacgccacctattctcaccgcgcgtaccccccaaacgccaagaaaacggcacatgcgagcccaacccgcgcctcaacttctaccccgtatttgccgtgccagaggtgcttgccacctatcacatctttttccaaaactgcaagatacccctatcctgccgtgccaaccgcagccgagcggacaagcagctggccttgcggcagggcgctgtcatacctgatatcgcctcgctcaacgaagtgccaaaaatctttgagggtcttggacgcgacgagaagcgcgcggcaaacgctctgcaacaggaaaacagcgaaaatgaaagtcactctggagtgttggtggaactcgagggtgacaacgcgcgcctagccgtactaaaacgcagcatcgaggtcacccactttgcctacccggcacttaacctaccccccaaggtcatgagcacagtcatgagtgagctgatcgtgcgccgtgcgcagcccctggagagggatgcaaatttgcaagaacaaacagaggagggcctacccgcagttggcgacgagcagctagcgcgctggcttcaaacgcgcgagcctgccgacttggaggagcgacgcaaactaatgatggccgcagtgctcgttaccgtggagcttgagtgcatgcagcggttctttgctgacccggagatgcagcgcaagctagaggaaacattgcactacacctttcgacagggctacgtacgccaggcctgcaagatctccaacgtggagctctgcaacctggtctcctaccttggaattttgcacgaaaaccgccttgggcaaaacgtgcttcattccacgctcaagggcgaggcgcgccgcgactacgtccgcgactgcgtttacttatttctatgctacacctggcagacggccatgggcgtttggcagcagtgcttggaggagtgcaacctcaaggagctgcagaaactgctaaagcaaaacttgaaggacctatggacggccttcaacgagcgctccgtggccgcgcacctggcggacatcattttccccgaacgcctgcttaaaaccctgcaacagggtctgccagacttcaccagtcaaagcatgttgcagaactttaggaactttatcctagagcgctcaggaatcttgcccgccacctgctgtgcacttcctagcgactttgtgcccattaagtaccgcgaatgccctccgccgctttggggccactgctaccttctgcagctagccaactaccttgcctaccactctgacataatggaagacgtgagcggtgacggtctactggagtgtcactgtcgctgcaacctatgcaccccgcaccgctccctggtttgcaattcgcagctgcttaacgaaagtcaaattatcggtacctttgagctgcagggtccctcgcctgacgaaaagtccgcggctccggggttgaaactcactccggggctgtggacgtcggcttaccttcgcaaatttgtacctgaggactaccacgcccacgagattaggttctacgaagaccaatcccgcccgcctaatgcggagcttaccgcctgcgtcattacccagggccacattcttggccaattgcaagccatcaacaaagcccgccaagagtttctgctacgaaagggacggggggtttacttggacccccagtccggcgaggagctcaacccaatccccccgccgccgcagccctatcagcagcagccgcgggcccttgcttcccaggatggcacccaaaaagaagctgcagctgccgccgccacccacggacgaggaggaatactgggacagtcaggcagaggaggttttggacgaggaggaggaggacatgatggaagactgggagagcctagacgaggaagcttccgaggtcgaagaggtgtcagacgaaacaccgtcaccctcggtcgcattcccctcgccggcgccccagaaatcggcaaccggttccagcatggctacaacctccgctcctcaggcgccgccggcactgcccgttcgccgacccaaccgtagatgggacaccactggaaccagggccggtaagtccaagcagccgccgccgttagcccaagagcaacaacagcgccaaggctaccgctcatggcgcgggcacaagaacgccatagttgcttgcttgcaagactgtgggggcaacatctccttcgcccgccgctttcttctctaccatcacggcgtggccttcccccgtaacatcctgcattactaccgtcatctctacagcccatactgcaccggcggcagcggcagcaacagcagcggccacacagaagcaaaggcgaccggatagcaagactctgacaaagcccaagaaatccacagcggcggcagcagcaggaggaggagcgctgcgtctggcgcccaacgaacccgtatcgacccgcgagcttagaaacaggatttttcccactctgtatgctatatttcaacagagcaggggccaagaacaagagctgaaaataaaaaacaggtctctgcgatccctcacccgcagctgcctgtatcacaaaagcgaagatcagcttcggcgcacgctggaagacgcggaggctctcttcagtaaatactgcgcgctgactcttaaggactagtttcgcgccctttctcaaatttaagcgcgaaaactacgtcatctccagcggccacacccggcgccagcacctgttgtcagcgccattatgagcaaggaaattcccacgccctacatgtggagttaccagccacaaatgggacttgcggctggagctgcccaagactactcaacccgaataaactacatgagcgcgggaccccacatgatatcccgggtcaacggaatacgcgcccaccgaaaccgaattcccttggaacaggcggctattaccaccacacctcgtaataaccttaatccccgtagttggcccgctgccctggtgtaccaggaaagtcccgctcccaccactgtggtacttcccagagacgcccaggccgaagttcagatgactaactcaggggcgcagcttgcgggcggctttcgtcacagggtgcggtcgcccgggc
seqidno:18-cmv启动子wt
agtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatgctgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctggtttagtgaaccgtc
seqidno:19-诱导型cmv启动子(p565-2xteto)
cgtgaggctccggtgcccgtcagtgggcagagcgcacatcgcccacagtccccgagaagttggggggaggggtcggcaattgaaccggtgcctagagaaggtggcgcggggtaaactgggaaagtgatgtcgtgtactggctccgcctttttcccgagggtgggggagaaccgtatataagtgcactagtcgccgtgaacgtcaatggaaagtccctattggcgttactatgggaacatacgtcattattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatgctgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctgtccctatcagtgatagagatgtccctatcagtgatagagatcgtcgagcagctcgtttagtgaaccgtcagatc
seqidno:20-5’utr序列:cap序列
cagttgcgcagccatcgacgtcagacgcggaagcttcgatcaactacgcagacaggtaccaaaacaaatgttctcgtcacgtgggcatgaatctgatgctgtttccctgcagacaatgcgagagaatgaatcagaattcaaatatctgcttcactcacggacagaaagactgtttagagtgctttcccgtgtcagaatctcaacccgtttctgtcgtcaaaaaggcgtatcagaaactgtgctacattcatcatatcatgggaaaggtgccagacgcttgcactgcctgcgatctggtcaatgtggatttggatgactgcatctttgaacaataaatgatttaaatcaggtatggctgccgatggttatcttccagattggctcgaggacactctctctgaaggaataagacagtggtggaagctcaaacctggcccaccaccaccaaagcccgcagagcggcataaggacgacagcaggggtcttgtgcttcctgggtacaagtacctcggacccttcaacggactcgacaagggagagccggtcaacgaggcagacgccgcggccctcgagcacgacaaagcctacgaccggcagctcgacagcggagacaacccgtacctcaagtacaaccacgccgacgcggagtttcaggagcgccttaaagaagatacgtcttttgggggcaacctcggacgagcagtcttccaggcgaaaaagagggttcttgaacctctgggcctggttgaggaacctgttaagacggctccgggaaaaaagaggccggtagagcactctcctgtggagccagactcctcctcgggaaccggaaaggcgggccagcagcctgcaagaaaaagattgaattttggtcagactggagacgcagactcagtacctgacccccagcctctcggacagccaccagcagccccctctggtctgggaactaatacgatggctacaggcagtggcgcaccaatggcagacaataacgagggcgccgacggagtgggtaattcctcgggaaattggcattgcgattccacatggatgggcgacagagtcatcaccaccagcacccgaacctgggccctgcccacctacaacaaccacctctacaaacaaatttccagccaatcaggagcctcgaacgacaatcactactttggctacagcaccccttgggggtattttgacttcaacagattccactgccacttttcaccacgtgactggcaaagactcatcaacaacaactggggattccgacccaagagactcaacttcaagctctttaacattcaagtcaaagaggtcacgcagaatgacggtacgacgacgattgccaataaccttaccagcacggttcaggtgtttactgactcggagtaccagctcccgtacgtcctcggctcggcgcatcaaggatgcctcccgccgttcccagcagacgtcttcatggtgccacagtatggatacctcaccctgaacaacgggagtcaggcagtaggacgctcttcattttactgcctggagtactttccttctcagatgctgcgtaccggaaacaactttaccttcagctacacttttgaggacgttcctttccacagcagctacgctcacagccagagtctggaccgtctcatgaatcctctcatcgaccagtacctgtattacttgagcagaacaaacactccaagtggaaccaccacgcagtcaaggcttcagttttctcaggccggagcgagtgacattcgggaccagtctaggaactggcttcctggaccctgttaccgccagcagcgagtatcaaagacatctgcggataacaacaacagtgaatactcgtggactggagctaccaagtaccacctcaatggcagagactctctggtgaatccgggcccggccatggcaagccacaaggacgatgaagaaaagttttttcctcagagcggggttctcatctttgggaagcaaggctcagagaaaacaaatgtggacattgaaaaggtcatgattacagacgaagaggaaatcaggacaaccaatcccgtggctacggagcagtatggttctgtatctaccaacctccagagaggcaacagacaagcagctaccgcagatgtcaacacacaaggcgttcttccaggcatggtctggcaggacagagatgtgtaccttcaggggcccatctgggcaaagattccacacacggacggacattttcacccctctcccctcatgggtggattcggacttaaacaccctcctccacagattctcatcaagaacaccccggtacctgcgaatccttcgaccaccttcagtgcggcaaagtttgcttccttcatcacacagtactccacgggacaggtcagcgtggagatcgagtgggagctgcagaaggaaaacagcaaacgctggaatcccgaaattcagtacacttccaactacaacaagtctgttaatgtggactttactgtggacactaatggcgtgtattcagagcctcgccccattggcaccagatacctgactcgtaatctgtaa
seqidno:21–3’utr:聚腺苷酸化序列(sv40)
cagacatgataagatacattgatgagtttggacaaaccacaactagaatgcagtgaaaaaaatgctttatttgtgaaatttgtgatgctattgctttatttgtaaccattataagctgcaataaacaagttaacaacaacaattgcattcattttatgtttcaggttcagggggaggtgtgggaggtttttt
序列表
<110>牛津遗传学有限公司
<120>用于生产aav颗粒的载体
<130>fsp1v201226zx
<160>21
<170>patentinversion3.5
<210>1
<211>1866
<212>dna
<213>腺相关病毒2
<400>1
atgccggggttttacgagattgtgattaaggtccccagcgaccttgacgagcatctgccc60
ggcatttctgacagctttgtgaactgggtggccgagaaggaatgggagttgccgccagat120
tctgacatggatctgaatctgattgagcaggcacccctgaccgtggccgagaagctgcag180
cgcgactttctgacggaatggcgccgtgtgagtaaggccccggaggcccttttctttgtg240
caatttgagaagggagagagctacttccacatgcacgtgctcgtggaaaccaccggggtg300
aaatccatggttttgggacgtttcctgagtcagattcgcgaaaaactgattcagagaatt360
taccgcgggatcgagccgactttgccaaactggttcgcggtcacaaagaccagaaatggc420
gccggaggcgggaacaaggtggtggatgagtgctacatccccaattacttgctccccaaa480
acccagcctgagctccagtgggcgtggactaatatggaacagtatttaagcgcctgtttg540
aatctcacggagcgtaaacggttggtggcgcagcatctgacgcacgtgtcgcagacgcag600
gagcagaacaaagagaatcagaatcccaattctgatgcgccggtgatcagatcaaaaact660
tcagccaggtacatggagctggtcgggtggctcgtggacaaggggattacctcggagaag720
cagtggatccaggaggaccaggcctcatacatctccttcaatgcggcctccaactcgcgg780
tcccaaatcaaggctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcc840
cccgactacctggtgggccagcagcccgtggaggacatttccagcaatcggatttataaa900
attttggaactaaacgggtacgatccccaatatgcggcttccgtctttctgggatgggcc960
acgaaaaagttcggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaag1020
accaacatcgcggaggccatagcccacactgtgcccttctacgggtgcgtaaactggacc1080
aatgagaactttcccttcaacgactgtgtcgacaagatggtgatctggtgggaggagggg1140
aagatgaccgccaaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgc1200
gtggaccagaaatgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctcc1260
aacaccaacatgtgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccg1320
ttgcaagaccggatgttcaaatttgaactcacccgccgtctggatcatgactttgggaag1380
gtcaccaagcaggaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtg1440
gagcatgaattctacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgca1500
gatataagtgagcccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcg1560
gaagcttcgatcaactacgcagacaggtaccaaaacaaatgttctcgtcacgtgggcatg1620
aatctgatgctgtttccctgcagacaatgcgagagaatgaatcagaattcaaatatctgc1680
ttcactcacggacagaaagactgtttagagtgctttcccgtgtcagaatctcaacccgtt1740
tctgtcgtcaaaaaggcgtatcagaaactgtgctacattcatcatatcatgggaaaggtg1800
ccagacgcttgcactgcctgcgatctggtcaatgtggatttggatgactgcatctttgaa1860
caatag1866
<210>2
<211>621
<212>prt
<213>腺相关病毒2
<400>2
metproglyphetyrgluilevalilelysvalproseraspleuasp
151015
glyhisleuproglyileseraspserphevalasntrpvalalaglu
202530
lysglutrpgluleuproproaspseraspmetaspleuasnleuile
354045
gluglnalaproleuthrvalalaglulysleuglnargasppheleu
505560
thrglutrpargargvalserlysalaproglualaleuphepheval
65707580
glnpheglulysglyglusertyrphehismethisvalleuvalglu
859095
thrthrglyvallyssermetvalleuglyargpheleuserglnile
100105110
argglulysleuileglnargiletyrargglyilegluprothrleu
115120125
proasntrpphealavalthrlysthrargasnglyalaglyglygly
130135140
asnlysvalvalaspglucystyrileproasntyrleuleuprolys
145150155160
thrglnprogluleuglntrpalatrpthrasnmetgluglntyrleu
165170175
seralacysleuasnleuthrgluarglysargleuvalalaglnhis
180185190
leuthrhisvalserglnthrglngluglnasnlysgluasnglnasn
195200205
proasnseraspalaprovalileargserlysthrseralaargtyr
210215220
metgluleuvalglytrpleuvalasplysglyilethrserglulys
225230235240
glntrpileglngluaspglnalasertyrileserpheasnalaala
245250255
serasnserargserglnilelysalaalaleuaspasnalaglylys
260265270
ilemetserleuthrlysthralaproasptyrleuvalglyglngln
275280285
provalgluaspileserserasnargiletyrlysileleugluleu
290295300
asnglytyraspproglntyralaalaservalpheleuglytrpala
305310315320
thrlyslyspheglylysargasnthriletrpleupheglyproala
325330335
thrthrglylysthrasnilealaglualailealahisthrvalpro
340345350
phetyrglycysvalasntrpthrasngluasnphepropheasnasp
355360365
cysvalasplysmetvaliletrptrpglugluglylysmetthrala
370375380
lysvalvalgluseralalysalaileleuglyglyserlysvalarg
385390395400
valaspglnlyscyslysserseralaglnileaspprothrproval
405410415
ilevalthrserasnthrasnmetcysalavalileaspglyasnser
420425430
thrthrphegluhisglnglnproleuglnaspargmetphelysphe
435440445
gluleuthrargargleuasphisasppheglylysvalthrlysgln
450455460
gluvallysaspphepheargtrpalalysasphisvalvalgluval
465470475480
gluhisgluphetyrvallyslysglyglyalalyslysargproala
485490495
proseraspalaaspilesergluprolysargvalarggluserval
500505510
alaglnproserthrseraspalaglualaserileasntyralaasp
515520525
argtyrglnasnlyscysserarghisvalglymetasnleumetleu
530535540
pheprocysargglncysgluargmetasnglnasnserasnilecys
545550555560
phethrhisglyglnlysaspcysleuglucyspheprovalserglu
565570575
serglnprovalservalvallyslysalatyrglnlysleucystyr
580585590
ilehishisilemetglylysvalproaspalacysthralacysasp
595600605
leuvalasnvalaspleuaspaspcysilepheglugln
610615620
<210>3
<211>528
<212>prt
<213>腺相关病毒2
<400>3
metproglyphetyrgluilevalilelysvalproseraspleuasp
151015
gluhisleuproglyileseraspserphevalasntrpvalalaglu
202530
lysglutrpgluleuproproaspseraspmetaspleuasnleuile
354045
gluglnalaproleuthrvalalaglulysleuglnargasppheleu
505560
thrglutrpargargvalserlysalaproglualaleuphepheval
65707580
glnpheglulysglyglusertyrphehismethisvalleuvalglu
859095
thrthrglyvallyssermetvalleuglyargpheleuserglnile
100105110
argglulysleuileglnargiletyrargglyilegluprothrleu
115120125
proasntrpphealavalthrlysthrargasnglyalaglyglygly
130135140
asnlysvalvalaspglucystyrileproasntyrleuleuprolys
145150155160
thrglnprogluleuglntrpalatrpthrasnmetgluglntyrleu
165170175
seralacysleuasnleuthrgluarglysargleuvalalaglnhis
180185190
leuthrhisvalserglnthrglngluglnasnlysgluasnglnasn
195200205
proasnseraspalaprovalileargserlysthrseralaargtyr
210215220
metgluleuvalglytrpleuvalasplysglyilethrserglulys
225230235240
glntrpileglngluaspglnalasertyrileserpheasnalaala
245250255
serasnserargserglnilelysalaalaleuaspasnalaglylys
260265270
ilemetserleuthrlysthralaproasptyrleuvalglyglngln
275280285
provalgluaspileserserasnargiletyrlysileleugluleu
290295300
asnglytyraspproglntyralaalaservalpheleuglytrpala
305310315320
thrlyslyspheglylysargasnthriletrpleupheglyproala
325330335
thrthrglylysthrasnilealaglualailealahisthrvalpro
340345350
phetyrglycysvalasntrpthrasngluasnphepropheasnasp
355360365
cysvalasplysmetvaliletrptrpglugluglylysmetthrala
370375380
lysvalvalgluseralalysalaileleuglyglyserlysvalarg
385390395400
valaspglnlyscyslysserseralaglnileaspprothrproval
405410415
ilevalthrserasnthrasnmetcysalavalileaspglyasnser
420425430
thrthrphegluhisglnglnproleuglnaspargmetphelysphe
435440445
gluleuthrargargleuasphisasppheglylysvalthrlysgln
450455460
gluvallysaspphepheargtrpalalysasphisvalvalgluval
465470475480
gluhisgluphetyrvallyslysglyglyalalyslysargproala
485490495
proseraspalaaspilesergluprolysargvalarggluserval
500505510
alaglnproserthrseraspalaglualaserileasntyralaasp
515520525
<210>4
<211>397
<212>prt
<213>腺相关病毒2
<400>4
metgluleuvalglytrpleuvalasplysglyilethrserglulys
151015
glntrpileglngluaspglnalasertyrileserpheasnalaala
202530
serasnserargserglnilelysalaalaleuaspasnalaglylys
354045
ilemetserleuthrlysthralaproasptyrleuvalglyglngln
505560
provalgluaspileserserasnargiletyrlysileleugluleu
65707580
asnglytyraspproglntyralaalaservalpheleuglytrpala
859095
thrlyslyspheglylysargasnthriletrpleupheglyproala
100105110
thrthrglylysthrasnilealaglualailealahisthrvalpro
115120125
phetyrglycysvalasntrpthrasngluasnphepropheasnasp
130135140
cysvalasplysmetvaliletrptrpglugluglylysmetthrala
145150155160
lysvalvalgluseralalysalaileleuglyglyserlysvalarg
165170175
valaspglnlyscyslysserseralaglnileaspprothrproval
180185190
ilevalthrserasnthrasnmetcysalavalileaspglyasnser
195200205
thrthrphegluhisglnglnproleuglnaspargmetphelysphe
210215220
gluleuthrargargleuasphisasppheglylysvalthrlysgln
225230235240
gluvallysaspphepheargtrpalalysasphisvalvalgluval
245250255
gluhisgluphetyrvallyslysglyglyalalyslysargproala
260265270
proseraspalaaspilesergluprolysargvalarggluserval
275280285
alaglnproserthrseraspalaglualaserileasntyralaasp
290295300
argtyrglnasnlyscysserarghisvalglymetasnleumetleu
305310315320
pheprocysargglncysgluargmetasnglnasnserasnilecys
325330335
phethrhisglyglnlysaspcysleuglucyspheprovalserglu
340345350
serglnprovalservalvallyslysalatyrglnlysleucystyr
355360365
ilehishisilemetglylysvalproaspalacysthralacysasp
370375380
leuvalasnvalaspleuaspaspcysilepheglugln
385390395
<210>5
<211>312
<212>prt
<213>腺相关病毒2
<400>5
metgluleuvalglytrpleuvalasplysglyilethrserglulys
151015
glntrpileglngluaspglnalasertyrileserpheasnalaala
202530
serasnserargserglnilelysalaalaleuaspasnalaglylys
354045
ilemetserleuthrlysthralaproasptyrleuvalglyglngln
505560
provalgluaspileserserasnargiletyrlysileleugluleu
65707580
asnglytyraspproglntyralaalaservalpheleuglytrpala
859095
thrlyslyspheglylysargasnthriletrpleupheglyproala
100105110
thrthrglylysthrasnilealaglualailealahisthrvalpro
115120125
phetyrglycysvalasntrpthrasngluasnphepropheasnasp
130135140
cysvalasplysmetvaliletrptrpglugluglylysmetthrala
145150155160
lysvalvalgluseralalysalaileleuglyglyserlysvalarg
165170175
valaspglnlyscyslysserseralaglnileaspprothrproval
180185190
ilevalthrserasnthrasnmetcysalavalileaspglyasnser
195200205
thrthrphegluhisglnglnproleuglnaspargmetphelysphe
210215220
gluleuthrargargleuasphisasppheglylysvalthrlysgln
225230235240
gluvallysaspphepheargtrpalalysasphisvalvalgluval
245250255
gluhisgluphetyrvallyslysglyglyalalyslysargproala
260265270
proseraspalaaspilesergluprolysargvalarggluserval
275280285
alaglnproserthrseraspalaglualaserileasntyralaasp
290295300
argleualaargglyhisserleu
305310
<210>6
<211>1866
<212>dna
<213>腺相关病毒2
<400>6
atgccggggttttacgagattgtgattaaggtccccagcgaccttgacgggcatctgccc60
ggcatttctgacagctttgtgaactgggtggccgagaaggaatgggagttgccgccagat120
tctgacatggatctgaatctgattgagcaggcacccctgaccgtggccgagaagctgcag180
cgcgactttctgacggaatggcgccgtgtgagtaaggccccggaggcccttttctttgtg240
caatttgagaagggagagagctacttccacatgcacgtgctcgtggaaaccaccggggtg300
aaatccatggttttgggacgtttcctgagtcagattcgcgaaaaactgattcagagaatt360
taccgcgggatcgagccgactttgccaaactggttcgcggtcacaaagaccagaaatggc420
gccggaggcgggaacaaggtggtggatgagtgctacatccccaattacttgctccccaaa480
acccagcctgagctccagtgggcgtggactaatatggaacagtacctcagcgcctgtttg540
aatctcacggagcgtaaacggttggtggcgcagcatctgacgcacgtgtcgcagacgcag600
gagcagaacaaagagaatcagaatcccaattctgatgcgccggtgatcagatcaaaaact660
tcagccaggtacatggagctggtcgggtggctcgtggacaaggggattacctcggagaag720
cagtggatccaggaggaccaggcctcatacatctccttcaatgcggcctccaactcgcgg780
tcccaaatcaaggctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcc840
cccgactacctggtgggccagcagcccgtggaggacatttccagcaatcggatttataaa900
attttggaactaaacgggtacgatccccaatatgcggcttccgtctttctgggatgggcc960
acgaaaaagttcggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaag1020
accaacatcgcggaggccatagcccacactgtgcccttctacgggtgcgtaaactggacc1080
aatgagaactttcccttcaacgactgtgtcgacaagatggtgatctggtgggaggagggg1140
aagatgaccgccaaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgc1200
gtggaccagaaatgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctcc1260
aacaccaacatgtgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccg1320
ttgcaagaccggatgttcaaatttgaactcacccgccgtctggatcatgactttgggaag1380
gtcaccaagcaggaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtg1440
gagcatgaattctacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgca1500
gatataagtgagcccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcg1560
gaagcttcgatcaactacgcagacaggtaccaaaacaaatgttctcgtcacgtgggcatg1620
aatctgatgctgtttccctgcagacaatgcgagagaatgaatcagaattcaaatatctgc1680
ttcactcacggacagaaagactgtttagagtgctttcccgtgtcagaatctcaacccgtt1740
tctgtcgtcaaaaaggcgtatcagaaactgtgctacattcatcatatcatgggaaaggtg1800
ccagacgcttgcactgcctgcgatctggtcaatgtggatttggatgactgcatctttgaa1860
caatag1866
<210>7
<211>1589
<212>dna
<213>腺相关病毒2
<400>7
atgccggggttttacgagattgtgattaaggtccccagcgaccttgacgagcatctgccc60
ggcatttctgacagctttgtgaactgggtggccgagaaggaatgggagttgccgccagat120
tctgacatggatctgaatctgattgagcaggcacccctgaccgtggccgagaagctgcag180
cgcgactttctgacggaatggcgccgtgtgagtaaggccccggaggcccttttctttgtg240
caatttgagaagggagagagctacttccacatgcacgtgctcgtggaaaccaccggggtg300
aaatccatggttttgggacgtttcctgagtcagattcgcgaaaaactgattcagagaatt360
taccgcgggatcgagccgactttgccaaactggttcgcggtcacaaagaccagaaatggc420
gccggaggcgggaacaaggtggtggatgagtgctacatccccaattacttgctccccaaa480
acccagcctgagctccagtgggcgtggactaatatggaacagtacctcagcgcctgtttg540
aatctcacggagcgtaaacggttggtggcgcagcatctgacgcacgtgtcgcagacgcag600
gagcagaacaaagagaatcagaatcccaattctgatgcgccggtgatcagatcaaaaact660
tcagccaggtacatggagctggtcgggtggctcgtggacaaggggattacctcggagaag720
cagtggatccaggaggaccaggcctcatacatctccttcaatgcggcctccaactcgcgg780
tcccaaatcaaggctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcc840
cccgactacctggtgggccagcagcccgtggaggacatttccagcaatcggatttataaa900
attttggaactaaacgggtacgatccccaatatgcggcttccgtctttctgggatgggcc960
acgaaaaagttcggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaag1020
accaacatcgcggaggccatagcccacactgtgcccttctacgggtgcgtaaactggacc1080
aatgagaactttcccttcaacgactgtgtcgacaagatggtgatctggtgggaggagggg1140
aagatgaccgccaaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgc1200
gtggaccagaaatgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctcc1260
aacaccaacatgtgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccg1320
ttgcaagaccggatgttcaaatttgaactcacccgccgtctggatcatgactttgggaag1380
gtcaccaagcaggaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtg1440
gagcatgaattctacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgca1500
gatataagtgagcccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcg1560
gaagcttcgatcaactacgcagacagtag1589
<210>8
<211>1195
<212>dna
<213>腺相关病毒2
<400>8
catggagctggtcgggtggctcgtggacaaggggattacctcggagaagcagtggatcca60
ggaggaccaggcctcatacatctccttcaatgcggcctccaactcgcggtcccaaatcaa120
ggctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcccccgactacct180
ggtgggccagcagcccgtggaggacatttccagcaatcggatttataaaattttggaact240
aaacgggtacgatccccaatatgcggcttccgtctttctgggatgggccacgaaaaagtt300
cggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaagaccaacatcgc360
ggaggccatagcccacactgtgcccttctacgggtgcgtaaactggaccaatgagaactt420
tcccttcaacgactgtgtcgacaagatggtgatctggtgggaggaggggaagatgaccgc480
caaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgcgtggaccagaa540
atgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctccaacaccaacat600
gtgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccgttgcaagaccg660
gatgttcaaatttgaactcacccgccgtctggatcatgactttgggaaggtcaccaagca720
ggaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtggagcatgaatt780
ctacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgcagatataagtga840
gcccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcggaagcttcgat900
caactacgcagacaggtaccaaaacaaatgttctcgtcacgtgggcatgaatctgatgct960
gtttccctgcagacaatgcgagagaatgaatcagaattcaaatatctgcttcactcacgg1020
acagaaagactgtttagagtgctttcccgtgtcagaatctcaacccgtttctgtcgtcaa1080
aaaggcgtatcagaaactgtgctacattcatcatatcatgggaaaggtgccagacgcttg1140
cactgcctgcgatctggtcaatgtggatttggatgactgcatctttgaacaatag1195
<210>9
<211>939
<212>dna
<213>腺相关病毒2
<400>9
atggagctggtcgggtggctcgtggacaaggggattacctcggagaagcagtggatccag60
gaggaccaggcctcatacatctccttcaatgcggcctccaactcgcggtcccaaatcaag120
gctgccttggacaatgcgggaaagattatgagcctgactaaaaccgcccccgactacctg180
gtgggccagcagcccgtggaggacatttccagcaatcggatttataaaattttggaacta240
aacgggtacgatccccaatatgcggcttccgtctttctgggatgggccacgaaaaagttc300
ggcaagaggaacaccatctggctgtttgggcctgcaactaccgggaagaccaacatcgcg360
gaggccatagcccacactgtgcccttctacgggtgcgtaaactggaccaatgagaacttt420
cccttcaacgactgtgtcgacaagatggtgatctggtgggaggaggggaagatgaccgcc480
aaggtcgtggagtcggccaaagccattctcggaggaagcaaggtgcgcgtggaccagaaa540
tgcaagtcctcggcccagatagacccgactcccgtgatcgtcacctccaacaccaacatg600
tgcgccgtgattgacgggaactcaacgaccttcgaacaccagcagccgttgcaagaccgg660
atgttcaaatttgaactcacccgccgtctggatcatgactttgggaaggtcaccaagcag720
gaagtcaaagactttttccggtgggcaaaggatcacgtggttgaggtggagcatgaattc780
tacgtcaaaaagggtggagccaagaaaagacccgcccccagtgacgcagatataagtgag840
cccaaacgggtgcgcgagtcagttgcgcagccatcgacgtcagacgcggaagcttcgatc900
aactacgcagacagattggctcgaggacactctctctag939
<210>10
<211>2559
<212>dna
<213>腺相关病毒2
<400>10
cagttgcgcagccatcgacgtcagacgcggaagcttcgatcaactacgcagacaggtacc60
aaaacaaatgttctcgtcacgtgggcatgaatctgatgctgtttccctgcagacaatgcg120
agagaatgaatcagaattcaaatatctgcttcactcacggacagaaagactgtttagagt180
gctttcccgtgtcagaatctcaacccgtttctgtcgtcaaaaaggcgtatcagaaactgt240
gctacattcatcatatcatgggaaaggtgccagacgcttgcactgcctgcgatctggtca300
atgtggatttggatgactgcatctttgaacaataaatgatttaaatcaggtatggctgcc360
gatggttatcttccagattggctcgaggacactctctctgaaggaataagacagtggtgg420
aagctcaaacctggcccaccaccaccaaagcccgcagagcggcataaggacgacagcagg480
ggtcttgtgcttcctgggtacaagtacctcggacccttcaacggactcgacaagggagag540
ccggtcaacgaggcagacgccgcggccctcgagcacgacaaagcctacgaccggcagctc600
gacagcggagacaacccgtacctcaagtacaaccacgccgacgcggagtttcaggagcgc660
cttaaagaagatacgtcttttgggggcaacctcggacgagcagtcttccaggcgaaaaag720
agggttcttgaacctctgggcctggttgaggaacctgttaagacggctccgggaaaaaag780
aggccggtagagcactctcctgtggagccagactcctcctcgggaaccggaaaggcgggc840
cagcagcctgcaagaaaaagattgaattttggtcagactggagacgcagactcagtacct900
gacccccagcctctcggacagccaccagcagccccctctggtctgggaactaatacgatg960
gctacaggcagtggcgcaccaatggcagacaataacgagggcgccgacggagtgggtaat1020
tcctcgggaaattggcattgcgattccacatggatgggcgacagagtcatcaccaccagc1080
acccgaacctgggccctgcccacctacaacaaccacctctacaaacaaatttccagccaa1140
tcaggagcctcgaacgacaatcactactttggctacagcaccccttgggggtattttgac1200
ttcaacagattccactgccacttttcaccacgtgactggcaaagactcatcaacaacaac1260
tggggattccgacccaagagactcaacttcaagctctttaacattcaagtcaaagaggtc1320
acgcagaatgacggtacgacgacgattgccaataaccttaccagcacggttcaggtgttt1380
actgactcggagtaccagctcccgtacgtcctcggctcggcgcatcaaggatgcctcccg1440
ccgttcccagcagacgtcttcatggtgccacagtatggatacctcaccctgaacaacggg1500
agtcaggcagtaggacgctcttcattttactgcctggagtactttccttctcagatgctg1560
cgtaccggaaacaactttaccttcagctacacttttgaggacgttcctttccacagcagc1620
tacgctcacagccagagtctggaccgtctcatgaatcctctcatcgaccagtacctgtat1680
tacttgagcagaacaaacactccaagtggaaccaccacgcagtcaaggcttcagttttct1740
caggccggagcgagtgacattcgggaccagtctaggaactggcttcctggaccctgttac1800
cgccagcagcgagtatcaaagacatctgcggataacaacaacagtgaatactcgtggact1860
ggagctaccaagtaccacctcaatggcagagactctctggtgaatccgggcccggccatg1920
gcaagccacaaggacgatgaagaaaagttttttcctcagagcggggttctcatctttggg1980
aagcaaggctcagagaaaacaaatgtggacattgaaaaggtcatgattacagacgaagag2040
gaaatcaggacaaccaatcccgtggctacggagcagtatggttctgtatctaccaacctc2100
cagagaggcaacagacaagcagctaccgcagatgtcaacacacaaggcgttcttccaggc2160
atggtctggcaggacagagatgtgtaccttcaggggcccatctgggcaaagattccacac2220
acggacggacattttcacccctctcccctcatgggtggattcggacttaaacaccctcct2280
ccacagattctcatcaagaacaccccggtacctgcgaatccttcgaccaccttcagtgcg2340
gcaaagtttgcttccttcatcacacagtactccacgggacaggtcagcgtggagatcgag2400
tgggagctgcagaaggaaaacagcaaacgctggaatcccgaaattcagtacacttccaac2460
tacaacaagtctgttaatgtggactttactgtggacactaatggcgtgtattcagagcct2520
cgccccattggcaccagatacctgactcgtaatctgtaa2559
<210>11
<211>735
<212>prt
<213>腺相关病毒2
<400>11
metalaalaaspglytyrleuproasptrpleugluaspthrleuser
151015
gluglyileargglntrptrplysleulysproglypropropropro
202530
lysproalagluarghislysaspaspserargglyleuvalleupro
354045
glytyrlystyrleuglypropheasnglyleuasplysglyglupro
505560
valasnglualaaspalaalaalaleugluhisasplysalatyrasp
65707580
argglnleuaspserglyaspasnprotyrleulystyrasnhisala
859095
aspalaglupheglngluargleulysgluaspthrserpheglygly
100105110
asnleuglyargalavalpheglnalalyslysargvalleuglupro
115120125
leuglyleuvalglugluprovallysthralaproglylyslysarg
130135140
provalgluhisserprovalgluproaspserserserglythrgly
145150155160
lysalaglyglnglnproalaarglysargleuasnpheglyglnthr
165170175
glyaspalaaspservalproaspproglnproleuglyglnpropro
180185190
alaalaproserglyleuglythrasnthrmetalathrglysergly
195200205
alaprometalaaspasnasngluglyalaaspglyvalglyasnser
210215220
serglyasntrphiscysaspserthrtrpmetglyaspargvalile
225230235240
thrthrserthrargthrtrpalaleuprothrtyrasnasnhisleu
245250255
tyrlysglnileserserglnserglyalaserasnaspasnhistyr
260265270
pheglytyrserthrprotrpglytyrpheasppheasnargphehis
275280285
cyshispheserproargasptrpglnargleuileasnasnasntrp
290295300
glypheargprolysargleuasnphelysleupheasnileglnval
305310315320
lysgluvalthrglnasnaspglythrthrthrilealaasnasnleu
325330335
thrserthrvalglnvalphethraspserglutyrglnleuprotyr
340345350
valleuglyseralahisglnglycysleupropropheproalaasp
355360365
valphemetvalproglntyrglytyrleuthrleuasnasnglyser
370375380
glnalavalglyargserserphetyrcysleuglutyrpheproser
385390395400
glnmetleuargthrglyasnasnphethrphesertyrthrpheglu
405410415
aspvalprophehissersertyralahisserglnserleuasparg
420425430
leumetasnproleuileaspglntyrleutyrtyrleuserargthr
435440445
asnthrproserglythrthrthrglnserargleuglnphesergln
450455460
alaglyalaseraspileargaspglnserargasntrpleuprogly
465470475480
procystyrargglnglnargvalserlysthrseralaaspasnasn
485490495
asnserglutyrsertrpthrglyalathrlystyrhisleuasngly
500505510
argaspserleuvalasnproglyproalametalaserhislysasp
515520525
aspgluglulysphepheproglnserglyvalleuilepheglylys
530535540
glnglyserglulysthrasnvalaspileglulysvalmetilethr
545550555560
aspgluglugluileargthrthrasnprovalalathrgluglntyr
565570575
glyservalserthrasnleuglnargglyasnargglnalaalathr
580585590
alaaspvalasnthrglnglyvalleuproglymetvaltrpglnasp
595600605
argaspvaltyrleuglnglyproiletrpalalysileprohisthr
610615620
aspglyhisphehisproserproleumetglyglypheglyleulys
625630635640
hisproproproglnileleuilelysasnthrprovalproalaasn
645650655
proserthrthrpheseralaalalysphealaserpheilethrgln
660665670
tyrserthrglyglnvalservalgluileglutrpgluleuglnlys
675680685
gluasnserlysargtrpasnprogluileglntyrthrserasntyr
690695700
asnlysservalasnvalaspphethrvalaspthrasnglyvaltyr
705710715720
sergluproargproileglythrargtyrleuthrargasnleu
725730735
<210>12
<211>19
<212>dna
<213>人工序列
<220>
<223>tetr结合位点
<400>12
tccctatcagtgatagaga19
<210>13
<211>624
<212>dna
<213>人工序列
<220>
<223>tetr蛋白的核苷酸序列
<400>13
atgtcgcgcctggacaaaagcaaagtgattaactcagcgctggaactgttgaatgaggtg60
ggaattgaaggactcactactcgcaagctggcacagaagctgggcgtcgagcagccaacg120
ctgtactggcatgtgaagaataaacgggcgctcctagacgcgcttgccatcgaaatgctg180
gaccgccatcacacccacttttgccccctggagggcgaatcctggcaagattttctgcgg240
aacaatgcaaagtcgttccggtgcgctctgctgtcccaccgcgatggcgcaaaagtgcac300
ctgggcactcggcccaccgagaaacaatacgaaaccctggaaaaccaactggctttcctt360
tgccaacagggattttcactggagaatgccctgtacgcactatccgcggtcggccacttt420
accctgggatgcgtcctcgaagatcaggagcaccaagtcgccaaggaggaaagagaaact480
cctaccactgactcaatgcctccgctcctgagacaagccatcgagctgttcgaccaccag540
ggtgctgaacctgcatttctgttcgggcttgaactgattatctgcggcctggagaaacag600
ttgaagtgcgagtcgggatcctag624
<210>14
<211>207
<212>prt
<213>人工序列
<220>
<223>tetr蛋白的氨基酸序列
<400>14
metserargleuasplysserlysvalileasnseralaleugluleu
151015
leuasngluvalglyilegluglyleuthrthrarglysleualagln
202530
lysleuglyvalgluglnprothrleutyrtrphisvallysasnlys
354045
argalaleuleuaspalaleualaileglumetleuasparghishis
505560
thrhisphecysproleugluglyglusertrpglnasppheleuarg
65707580
asnasnalalysserpheargcysalaleuleuserhisargaspgly
859095
alalysvalhisleuglythrargprothrglulysglntyrgluthr
100105110
leugluasnglnleualapheleucysglnglnglypheserleuglu
115120125
asnalaleutyralaleuseralavalglyhisphethrleuglycys
130135140
valleugluaspglngluhisglnvalalalysglugluarggluthr
145150155160
prothrthraspsermetproproleuleuargglnalailegluleu
165170175
pheasphisglnglyalagluproalapheleupheglyleugluleu
180185190
ileilecysglyleuglulysglnleulyscysgluserglyser
195200205
<210>15
<211>519
<212>dna
<213>脑心肌炎病毒
<400>15
cgttactggccgaagccgcttggaataaggccggtgtgcgtttgtctatatgttattttc60
caccatattgccgtcttttggcaatgtgagggcccggaaacctggccctgtcttcttgac120
gagcattcctaggggtctttcccctctcgccaaaggaatgcaaggtctgttgaatgtcgt180
gaaggaagcagttcctctggaagcttcttgaagacaaacaacgtctgtagcgaccctttg240
caggcagcggaaccccccacctggcgacaggtgcctctgcggccaaaagccacgtgtata300
agatacacctgcaaaggcggcacaaccccagtgccacgttgtgagttggatagttgtgga360
aagagtcaaatggctcccctcaagcgtattcaacaaggggctgaaggatgcccagaaggt420
accccattgtatgggatctgatctggggcctcggtgcacatgctttacatgtgtttagtc480
gaggttaaaaaacgtctaggccccccgaaccacggggac519
<210>16
<211>461
<212>dna
<213>口蹄疫病毒
<400>16
agcaggtttccccaactgacacaaaacgtgcaacttgaaactccgcctggtctttccagg60
tctagaggggtaacactttgtactgcgtttggctccacgctcgatccactggcgagtgtt120
agtaacagcactgttgcttcgtagcggagcatgacggccgtgggaactcctccttggtaa180
caaggacccacggggccaaaagccacgcccacacgggcccgtcatgtgtgcaaccccagc240
acggcgactttactgcgaaacccactttaaagtgacattgaaactggtacccacacactg300
gtgacaggctaaggatgcccttcaggtaccccgaggtaacacgcgacactcgggatctga360
gaaggggactggggcttctataaaagcgctcggtttaaaaagcttctatgcctgaatagg420
tgaccggaggtcggcacctttcctttgcaattactgaccac461
<210>17
<211>5341
<212>dna
<213>人腺病毒5型
<400>17
ggtacccaactccatgctcaacagtccccaggtacagcccaccctgcgtcgcaaccagga60
acagctctacagcttcctggagcgccactcgccctacttccgcagccacagtgcgcagat120
taggagcgccacttctttttgtcacttgaaaaacatgtaaaaataatgtactagagacac180
tttcaataaaggcaaatgcttttatttgtacactctcgggtgattatttacccccaccct240
tgccgtctgcgccgtttaaaaatcaaaggggttctgccgcgcatcgctatgcgccactgg300
cagggacacgttgcgatactggtgtttagtgctccacttaaactcaggcacaaccatccg360
cggcagctcggtgaagttttcactccacaggctgcgcaccatcaccaacgcgtttagcag420
gtcgggcgccgatatcttgaagtcgcagttggggcctccgccctgcgcgcgcgagttgcg480
atacacagggttgcagcactggaacactatcagcgccgggtggtgcacgctggccagcac540
gctcttgtcggagatcagatccgcgtccaggtcctccgcgttgctcagggcgaacggagt600
caactttggtagctgccttcccaaaaagggcgcgtgcccaggctttgagttgcactcgca660
ccgtagtggcatcaaaaggtgaccgtgcccggtctgggcgttaggatacagcgcctgcat720
aaaagccttgatctgcttaaaagccacctgagcctttgcgccttcagagaagaacatgcc780
gcaagacttgccggaaaactgattggccggacaggccgcgtcgtgcacgcagcaccttgc840
gtcggtgttggagatctgcaccacatttcggccccaccggttcttcacgatcttggcctt900
gctagactgctccttcagcgcgcgctgcccgttttcgctcgtcacatccatttcaatcac960
gtgctccttatttatcataatgcttccgtgtagacacttaagctcgccttcgatctcagc1020
gcagcggtgcagccacaacgcgcagcccgtgggctcgtgatgcttgtaggtcacctctgc1080
aaacgactgcaggtacgcctgcaggaatcgccccatcatcgtcacaaaggtcttgttgct1140
ggtgaaggtcagctgcaacccgcggtgctcctcgttcagccaggtcttgcatacggccgc1200
cagagcttccacttggtcaggcagtagtttgaagttcgcctttagatcgttatccacgtg1260
gtacttgtccatcagcgcgcgcgcagcctccatgcccttctcccacgcagacacgatcgg1320
cacactcagcgggttcatcaccgtaatttcactttccgcttcgctgggctcttcctcttc1380
ctcttgcgtccgcataccacgcgccactgggtcgtcttcattcagccgccgcactgtgcg1440
cttacctcctttgccatgcttgattagcaccggtgggttgctgaaacccaccatttgtag1500
cgccacatcttctctttcttcctcgctgtccacgattacctctggtgatggcgggcgctc1560
gggcttgggagaagggcgcttctttttcttcttgggcgcaatggccaaatccgccgccga1620
ggtcgatggccgcgggctgggtgtgcgcggcaccagcgcgtcttgtgatgagtcttcctc1680
gtcctcggactcgatacgccgcctcatccgcttttttgggggcgcccggggaggcggcgg1740
cgacggggacggggacgacacgtcctccatggttgggggacgtcgcgccgcaccgcgtcc1800
gcgctcgggggtggtttcgcgctgctcctcttcccgactggccatttccttctcctatag1860
gcagaaaaagatcatggagtcagtcgagaagaaggacagcctaaccgccccctctgagtt1920
cgccaccaccgcctccaccgatgccgccaacgcgcctaccaccttccccgtcgaggcacc1980
cccgcttgaggaggaggaagtgattatcgagcaggacccaggttttgtaagcgaagacga2040
cgaggaccgctcagtaccaacagaggataaaaagcaagaccaggacaacgcagaggcaaa2100
cgaggaacaagtcgggcggggggacgaaaggcatggcgactacctagatgtgggagacga2160
cgtgctgttgaagcatctgcagcgccagtgcgccattatctgcgacgcgttgcaagagcg2220
cagcgatgtgcccctcgccatagcggatgtcagccttgcctacgaacgccacctattctc2280
accgcgcgtaccccccaaacgccaagaaaacggcacatgcgagcccaacccgcgcctcaa2340
cttctaccccgtatttgccgtgccagaggtgcttgccacctatcacatctttttccaaaa2400
ctgcaagatacccctatcctgccgtgccaaccgcagccgagcggacaagcagctggcctt2460
gcggcagggcgctgtcatacctgatatcgcctcgctcaacgaagtgccaaaaatctttga2520
gggtcttggacgcgacgagaagcgcgcggcaaacgctctgcaacaggaaaacagcgaaaa2580
tgaaagtcactctggagtgttggtggaactcgagggtgacaacgcgcgcctagccgtact2640
aaaacgcagcatcgaggtcacccactttgcctacccggcacttaacctaccccccaaggt2700
catgagcacagtcatgagtgagctgatcgtgcgccgtgcgcagcccctggagagggatgc2760
aaatttgcaagaacaaacagaggagggcctacccgcagttggcgacgagcagctagcgcg2820
ctggcttcaaacgcgcgagcctgccgacttggaggagcgacgcaaactaatgatggccgc2880
agtgctcgttaccgtggagcttgagtgcatgcagcggttctttgctgacccggagatgca2940
gcgcaagctagaggaaacattgcactacacctttcgacagggctacgtacgccaggcctg3000
caagatctccaacgtggagctctgcaacctggtctcctaccttggaattttgcacgaaaa3060
ccgccttgggcaaaacgtgcttcattccacgctcaagggcgaggcgcgccgcgactacgt3120
ccgcgactgcgtttacttatttctatgctacacctggcagacggccatgggcgtttggca3180
gcagtgcttggaggagtgcaacctcaaggagctgcagaaactgctaaagcaaaacttgaa3240
ggacctatggacggccttcaacgagcgctccgtggccgcgcacctggcggacatcatttt3300
ccccgaacgcctgcttaaaaccctgcaacagggtctgccagacttcaccagtcaaagcat3360
gttgcagaactttaggaactttatcctagagcgctcaggaatcttgcccgccacctgctg3420
tgcacttcctagcgactttgtgcccattaagtaccgcgaatgccctccgccgctttgggg3480
ccactgctaccttctgcagctagccaactaccttgcctaccactctgacataatggaaga3540
cgtgagcggtgacggtctactggagtgtcactgtcgctgcaacctatgcaccccgcaccg3600
ctccctggtttgcaattcgcagctgcttaacgaaagtcaaattatcggtacctttgagct3660
gcagggtccctcgcctgacgaaaagtccgcggctccggggttgaaactcactccggggct3720
gtggacgtcggcttaccttcgcaaatttgtacctgaggactaccacgcccacgagattag3780
gttctacgaagaccaatcccgcccgcctaatgcggagcttaccgcctgcgtcattaccca3840
gggccacattcttggccaattgcaagccatcaacaaagcccgccaagagtttctgctacg3900
aaagggacggggggtttacttggacccccagtccggcgaggagctcaacccaatcccccc3960
gccgccgcagccctatcagcagcagccgcgggcccttgcttcccaggatggcacccaaaa4020
agaagctgcagctgccgccgccacccacggacgaggaggaatactgggacagtcaggcag4080
aggaggttttggacgaggaggaggaggacatgatggaagactgggagagcctagacgagg4140
aagcttccgaggtcgaagaggtgtcagacgaaacaccgtcaccctcggtcgcattcccct4200
cgccggcgccccagaaatcggcaaccggttccagcatggctacaacctccgctcctcagg4260
cgccgccggcactgcccgttcgccgacccaaccgtagatgggacaccactggaaccaggg4320
ccggtaagtccaagcagccgccgccgttagcccaagagcaacaacagcgccaaggctacc4380
gctcatggcgcgggcacaagaacgccatagttgcttgcttgcaagactgtgggggcaaca4440
tctccttcgcccgccgctttcttctctaccatcacggcgtggccttcccccgtaacatcc4500
tgcattactaccgtcatctctacagcccatactgcaccggcggcagcggcagcaacagca4560
gcggccacacagaagcaaaggcgaccggatagcaagactctgacaaagcccaagaaatcc4620
acagcggcggcagcagcaggaggaggagcgctgcgtctggcgcccaacgaacccgtatcg4680
acccgcgagcttagaaacaggatttttcccactctgtatgctatatttcaacagagcagg4740
ggccaagaacaagagctgaaaataaaaaacaggtctctgcgatccctcacccgcagctgc4800
ctgtatcacaaaagcgaagatcagcttcggcgcacgctggaagacgcggaggctctcttc4860
agtaaatactgcgcgctgactcttaaggactagtttcgcgccctttctcaaatttaagcg4920
cgaaaactacgtcatctccagcggccacacccggcgccagcacctgttgtcagcgccatt4980
atgagcaaggaaattcccacgccctacatgtggagttaccagccacaaatgggacttgcg5040
gctggagctgcccaagactactcaacccgaataaactacatgagcgcgggaccccacatg5100
atatcccgggtcaacggaatacgcgcccaccgaaaccgaattcccttggaacaggcggct5160
attaccaccacacctcgtaataaccttaatccccgtagttggcccgctgccctggtgtac5220
caggaaagtcccgctcccaccactgtggtacttcccagagacgcccaggccgaagttcag5280
atgactaactcaggggcgcagcttgcgggcggctttcgtcacagggtgcggtcgcccggg5340
c5341
<210>18
<211>573
<212>dna
<213>巨细胞病毒属
<400>18
agtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataac60
ttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataa120
tgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagt180
atttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgcccc240
ctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttat300
gggactttcctacttggcagtacatctacgtattagtcatcgctattaccatgctgatgc360
ggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtc420
tccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaa480
aatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggagg540
tctatataagcagagctggtttagtgaaccgtc573
<210>19
<211>637
<212>dna
<213>人工序列
<220>
<223>诱导型cmv启动子(p565-2xteto)
<400>19
cgtgaggctccggtgcccgtcagtgggcagagcgcacatcgcccacagtccccgagaagt60
tggggggaggggtcggcaattgaaccggtgcctagagaaggtggcgcggggtaaactggg120
aaagtgatgtcgtgtactggctccgcctttttcccgagggtgggggagaaccgtatataa180
gtgcactagtcgccgtgaacgtcaatggaaagtccctattggcgttactatgggaacata240
cgtcattattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgac300
cttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatgct360
gatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttcc420
aagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactt480
tccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtg540
ggaggtctatataagcagagctgtccctatcagtgatagagatgtccctatcagtgatag600
agatcgtcgagcagctcgtttagtgaaccgtcagatc637
<210>20
<211>2559
<212>dna
<213>腺相关病毒2
<400>20
cagttgcgcagccatcgacgtcagacgcggaagcttcgatcaactacgcagacaggtacc60
aaaacaaatgttctcgtcacgtgggcatgaatctgatgctgtttccctgcagacaatgcg120
agagaatgaatcagaattcaaatatctgcttcactcacggacagaaagactgtttagagt180
gctttcccgtgtcagaatctcaacccgtttctgtcgtcaaaaaggcgtatcagaaactgt240
gctacattcatcatatcatgggaaaggtgccagacgcttgcactgcctgcgatctggtca300
atgtggatttggatgactgcatctttgaacaataaatgatttaaatcaggtatggctgcc360
gatggttatcttccagattggctcgaggacactctctctgaaggaataagacagtggtgg420
aagctcaaacctggcccaccaccaccaaagcccgcagagcggcataaggacgacagcagg480
ggtcttgtgcttcctgggtacaagtacctcggacccttcaacggactcgacaagggagag540
ccggtcaacgaggcagacgccgcggccctcgagcacgacaaagcctacgaccggcagctc600
gacagcggagacaacccgtacctcaagtacaaccacgccgacgcggagtttcaggagcgc660
cttaaagaagatacgtcttttgggggcaacctcggacgagcagtcttccaggcgaaaaag720
agggttcttgaacctctgggcctggttgaggaacctgttaagacggctccgggaaaaaag780
aggccggtagagcactctcctgtggagccagactcctcctcgggaaccggaaaggcgggc840
cagcagcctgcaagaaaaagattgaattttggtcagactggagacgcagactcagtacct900
gacccccagcctctcggacagccaccagcagccccctctggtctgggaactaatacgatg960
gctacaggcagtggcgcaccaatggcagacaataacgagggcgccgacggagtgggtaat1020
tcctcgggaaattggcattgcgattccacatggatgggcgacagagtcatcaccaccagc1080
acccgaacctgggccctgcccacctacaacaaccacctctacaaacaaatttccagccaa1140
tcaggagcctcgaacgacaatcactactttggctacagcaccccttgggggtattttgac1200
ttcaacagattccactgccacttttcaccacgtgactggcaaagactcatcaacaacaac1260
tggggattccgacccaagagactcaacttcaagctctttaacattcaagtcaaagaggtc1320
acgcagaatgacggtacgacgacgattgccaataaccttaccagcacggttcaggtgttt1380
actgactcggagtaccagctcccgtacgtcctcggctcggcgcatcaaggatgcctcccg1440
ccgttcccagcagacgtcttcatggtgccacagtatggatacctcaccctgaacaacggg1500
agtcaggcagtaggacgctcttcattttactgcctggagtactttccttctcagatgctg1560
cgtaccggaaacaactttaccttcagctacacttttgaggacgttcctttccacagcagc1620
tacgctcacagccagagtctggaccgtctcatgaatcctctcatcgaccagtacctgtat1680
tacttgagcagaacaaacactccaagtggaaccaccacgcagtcaaggcttcagttttct1740
caggccggagcgagtgacattcgggaccagtctaggaactggcttcctggaccctgttac1800
cgccagcagcgagtatcaaagacatctgcggataacaacaacagtgaatactcgtggact1860
ggagctaccaagtaccacctcaatggcagagactctctggtgaatccgggcccggccatg1920
gcaagccacaaggacgatgaagaaaagttttttcctcagagcggggttctcatctttggg1980
aagcaaggctcagagaaaacaaatgtggacattgaaaaggtcatgattacagacgaagag2040
gaaatcaggacaaccaatcccgtggctacggagcagtatggttctgtatctaccaacctc2100
cagagaggcaacagacaagcagctaccgcagatgtcaacacacaaggcgttcttccaggc2160
atggtctggcaggacagagatgtgtaccttcaggggcccatctgggcaaagattccacac2220
acggacggacattttcacccctctcccctcatgggtggattcggacttaaacaccctcct2280
ccacagattctcatcaagaacaccccggtacctgcgaatccttcgaccaccttcagtgcg2340
gcaaagtttgcttccttcatcacacagtactccacgggacaggtcagcgtggagatcgag2400
tgggagctgcagaaggaaaacagcaaacgctggaatcccgaaattcagtacacttccaac2460
tacaacaagtctgttaatgtggactttactgtggacactaatggcgtgtattcagagcct2520
cgccccattggcaccagatacctgactcgtaatctgtaa2559
<210>21
<211>192
<212>dna
<213>猴病毒40
<400>21
cagacatgataagatacattgatgagtttggacaaaccacaactagaatgcagtgaaaaa60
aatgctttatttgtgaaatttgtgatgctattgctttatttgtaaccattataagctgca120
ataaacaagttaacaacaacaattgcattcattttatgtttcaggttcagggggaggtgt180
gggaggtttttt192
- 还没有人留言评论。精彩留言会获得点赞!