利用肽标签的蛋白质可溶性表达的制作方法
本发明涉及重组蛋白质的生产技术,更具体地,涉及将重组蛋白质高效地表达在可溶性级分中的技术。
背景技术:
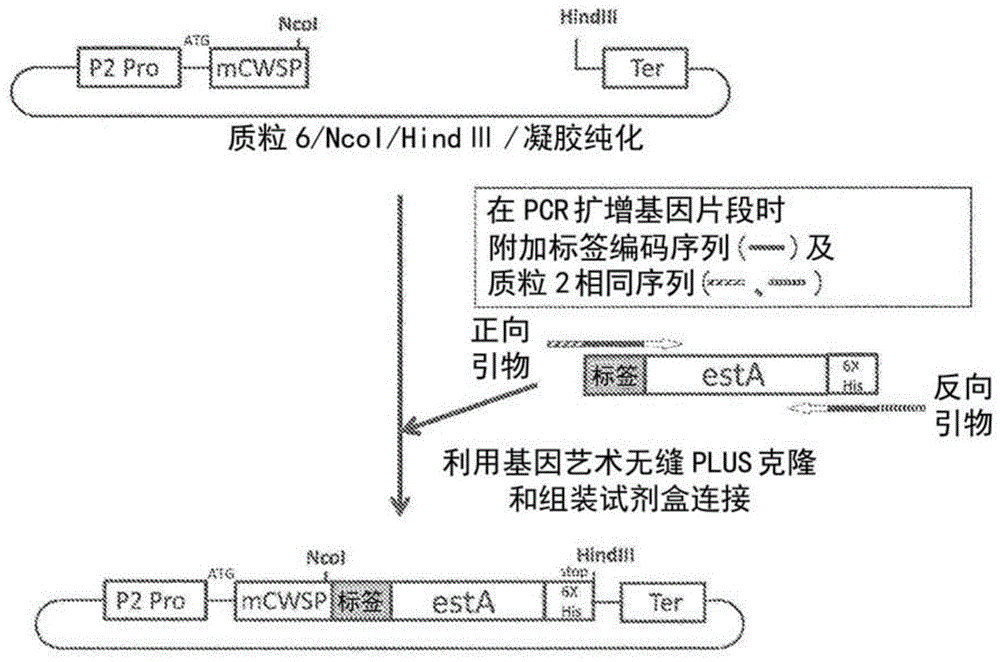
:随基因重组技术的发展,实现了将源自高等生物的有用蛋白质利用大肠杆菌、酵母等进行异种表达的可能。现在,异种表达的有用蛋白质的生产更已达到了广泛使用技术的地位。作为提高有用蛋白质的表达,蓄积量的对策,研究了启动子及终止子的选择,翻译增强子的利用,导入基因的密码子改变,蛋白质的细胞内输送及局域化等。另外,除此以外,还开发了多个通过使肽标签连接于有用蛋白质上而提高其表达的技术。例如,在专利文献1中,公开了通过使entropicbristledomain(ebd)肽连接于有用蛋白质上而表达,从而提高有用蛋白质在可溶性级分中的表达。然而,由于ebd肽中的脯氨酸和脯氨酸之间包含丝氨酸,因此,存在产生的蛋白质的总产量变低的担忧。现有技术文献专利文献专利文献1:美国专利公开20090137004号公报技术实现要素:发明所要解决的问题本发明的课题在于,在基因重组蛋白质生产技术中,在可溶性级分中高效产生目的蛋白。解决问题的手段本发明人为了解决上述课题进行了深入研究。结果发现,通过使用具有下述氨基酸序列的肽标签,目的蛋白在可溶性级分中的表达量显著提高。即,通过锐意改变被连接的肽标签的氨基酸组成及序列,在保持目的蛋白的表达量的同时,飞跃性地提高了在可溶性级分中的表达量,取得了成功。本发明是基于这样的见解而完成的。本发明的要点如下所述。[1]在导入有编码融合蛋白的多核苷酸的表达体系中,产生来自所述多核苷酸的所述融合蛋白并蓄积所述融合蛋白而成的可溶性级分,所述融合蛋白包含目的蛋白以及与该目的蛋白连接的含有下述氨基酸序列的肽标签,x(py)qpzp表示脯氨酸,x表示由0~5个氨基酸组成的氨基酸序列,所述氨基酸独立选自由精氨酸(r),甘氨酸(g),丝氨酸(s),赖氨酸(k),苏氨酸(t),亮氨酸(l),天冬酰胺(n),谷氨酰胺(q)及甲硫氨酸(m)组成的组,y表示由1~4个氨基酸组成的氨基酸序列,所述氨基酸独立选自由r,g,k,t,l,n,q及m组成的组,q表示1~10的整数,z表示由0~10个氨基酸组成的氨基酸序列,所述氨基酸独立选自由r,g,s,k,t,l,n,q及m组成的组,在所述肽标签的氨基酸序列中,q,m,l,n及t合计包含3个以上。[2]根据[1]所述的可溶性级分,其中,py为选自pgq,pgm,pgt,pgl,pqq,pgn,pgqg,pgmg,pgtg,pglg,pgng,pqqq中的1种以上。[3]根据[1]或[2]所述的可溶性级分,其中,所述肽标签的长度为10~30个氨基酸。[4]根据[1]~[3]中任一项所述的可溶性级分,其中,所述肽标签具有seqidno:7,10,12,15,17,19,21或23所示的氨基酸序列。[5]根据[1]~[4]中任一项所述的可溶性级分,其中,目的蛋白为酶。[6]根据[1]~[5]中任一项所述的可溶性级分,其中,所述融合蛋白包含分泌信号。[7]根据[1]~[6]中任一项所述的可溶性级分,其中,所述肽标签与所述目的蛋白的c末端侧连接。[8]融合蛋白的制备方法,其中回收[1]~[7]中任一项所述的可溶性级分,提取所述融合蛋白。[9]导入有编码融合蛋白的多核苷酸并产生未变性的所述融合蛋白的表达体系,其中,所述融合蛋白包含目的蛋白以及与该目的蛋白连接的含有下述氨基酸序列的肽标签,x(py)qpzp表示脯氨酸,x表示由0~5个氨基酸组成的氨基酸序列,所述氨基酸独立选自由精氨酸(r),甘氨酸(g),丝氨酸(s),赖氨酸(k),苏氨酸(t),亮氨酸(l),天冬酰胺(n),谷氨酰胺(q)及甲硫氨酸(m)组成的组,y表示由1~4个氨基酸组成的氨基酸序列,所述氨基酸独立选自由r,g,k,t,l,n,q及m组成的组,q表示1~10的整数,z表示由0~10个氨基酸组成的氨基酸序列,所述氨基酸独立选自由r,g,s,k,t,l,n,q及m组成的组,在所述肽标签的氨基酸序列中,q,m,l,n及t合计包含3个以上。[10]从[9]所述的表达体系产生并包含未变性的所述融合蛋白的溶液。[11]利用有酶参与的代谢体系以提高物质生产的效率的方法,其中,使用[9]所述的表达体系产生未变性蛋白形式的所述融合蛋白,所述融合蛋白的目的蛋白为酶,使用得到的未变性的酶融合蛋白进行底物转化反应。[12]融合蛋白,其包含目的蛋白以及与该目的蛋白连接的含有下述氨基酸序列的肽标签,x(py)qpzp表示脯氨酸,x表示由0~5个氨基酸组成的氨基酸序列,所述氨基酸独立选自由精氨酸(r),甘氨酸(g),丝氨酸(s),赖氨酸(k),苏氨酸(t),亮氨酸(l),天冬酰胺(n),谷氨酰胺(q)及甲硫氨酸(m)组成的组,y表示由1~4个氨基酸组成的氨基酸序列,所述氨基酸独立选自由r,g,k,t,l,n,q及m组成的组,q表示1~10的整数,z表示由0~10个氨基酸组成的氨基酸序列,所述氨基酸独立选自由r,g,s,k,t,l,n,q及m组成的组,在所述肽标签的氨基酸序列中,q,m,l,n及t合计包含3个以上,其中至少包含1个m。[13]根据[12]所述的融合蛋白,其中,py选自pgm和pgmg中的1种以上。[14]根据[12]或[13]所述的融合蛋白,其中,所述肽标签的长度为10~30个氨基酸。[15]根据[12]~[14]中任一项所述的融合蛋白,其中,所述肽标签具有seqidno:7,10,12,15,17,19,21或23所示的氨基酸序列。[16]根据[12]~[15]中任一项所述的融合蛋白,其中,目的蛋白为酶。[17]根据[12]~[15]中任一项所述的融合蛋白,其中,所述融合蛋白包含分泌信号。[18]根据[12]~[17]中任一项所述的融合蛋白,其中,所述肽标签与所述目的蛋白的c末端侧连接。[19]多核苷酸,其编码[12]~[18]中任一项所述的融合蛋白。[20]重组载体,其包含[19]所述的多核苷酸。发明的效果根据本发明,通过与包含特定的序列的肽标签连接,使目的蛋白的表达效率提高,并且能够使可溶性级分中的蓄积量提高,目的蛋白的分离、纯化变得容易。在目的蛋白包含分泌信号序列的情况下,也可以使目的蛋白向培养基中的分泌生产效率提高。另外,由于在目的蛋白为酶的情况下,容易利用培养基、细胞破碎液等制备含有未变性的酶融合蛋白的溶液,可以适用于基于有酶参与的代谢体系进行的酶反应,因此可以对利用了基质的高效的转换反应进行的物质生产作出贡献。另外,由于导入的酶在细胞内较少发生凝聚及不溶,因此也高效地促进细胞内的酶反应。本发明中使用的肽标签与在专利文献1中记载的肽标签不同,在脯氨酸之间不包含丝氨酸,因此,可以期待在可溶性级分中的蛋白质的产量提高。另外,即使在连接到目的蛋白的c末端侧的情况下,也能够提高融合蛋白在可溶性级分中的表达。附图说明[图1]是表示用于将酯酶的n末端连接了各种肽标签的融合蛋白在短小芽孢杆菌(brevibacillus)中表达的质粒的构建顺序的图。[图2]是表示用于将酯酶的c末端连接了各种肽标签的融合蛋白在短小芽孢杆菌中表达的质粒的构建顺序的图。[图3]是表示将各肽标签连接到n末端侧的酯酶在可溶性级分中的表达量的比较的图。[图4]是表示将各肽标签连接到c末端侧的酯酶在可溶性级分中的表达量的比较的图。[图5]是表示附加有标签(a:px12-32,b:px12-34)的酯酶的活性与没有标签的进行比较的结果的图。s表示分泌到培养基中的级分,p表示细胞内的可溶性级分。[图6]是表示将各肽标签连接到n末端侧的人生长激素在各级分中的表达量的比较的图(酵母)。具体实施方式可以在在导入有编码融合蛋白的多核苷酸的表达体系中,产生来自所述多核苷酸的所述融合蛋白并蓄积所述融合蛋白形成可溶性级分,回收所述可溶性级分,提取上述融合蛋白,其中,所述融合蛋白包含目的蛋白以及与该目的蛋白连接的含有下述氨基酸序列的肽标签。本发明使用的肽标签具有下述序列。x(py)qpzx表示由0~5个氨基酸成的氨基酸序列,所述氨基酸独立选自由精氨酸(r),甘氨酸(g),丝氨酸(s),赖氨酸(k),苏氨酸(t),亮氨酸(l),天冬酰胺(n),谷氨酰胺(q)及甲硫氨酸(m)组成的组。在x为0个氨基酸的情况下,肽标签的n末端的氨基酸为p。在x为1个氨基酸的情况下,肽标签的n末端为选自r,g,s,k,t,l,n,q及m的氨基酸。在x为1个氨基酸的情况下,优选为q,l,n,m或t,更优选为q,m或t。在x为2~5个氨基酸的情况下,2~5个x可以为选自r,g,s,k,t,l,n,q,m的相同的氨基酸残基,也可以为不同的氨基酸残基。x的个数优选为1~5个,更优选为2~5个,进一步优选为2~3个,特别优选为2个。在x为2~5个氨基酸的情况下,c末端侧的2氨基酸,即(py)q的前方紧邻2个氨基酸优选为rq,rl,rn,rm或rt,更优选为rq,rm或rt。(py)q中的y表示包含独立选自r,g,k,t,l,n,q及m中的1~4个氨基酸的氨基酸序列,q表示1~10的整数。即,(py)q是指将py,即,y为1个氨基酸(pya),2个氨基酸(pyayb),3个氨基酸(pyaybyc)或4个氨基酸(pyaybycyd),所以将pya,pyayb,pyaybyc,及pyaybycyd中的任一个以上进行连续,合计连续q次(p表示脯氨酸)。需要说明的是,py优选为2个氨基酸(pyayb)或3个氨基酸(pyaybyc)。q为1~10的整数,优选为2~10的整数,更优选为2~5的整数,进一步优选为2~3的整数,特别优选为2。各个y可以为选自r,g,k,t,l,n,q及m的相同的氨基酸残基,也可以为不同的氨基酸残基,然而优选地,连续q次的py中所含的全部的y(肽标签中包含的全部的y)中的至少1个为q,n,l,m或t,更优选2个以上为q,n,l,m或t。优选地,连续q次的py中包含的全部的y(肽标签中包含的全部的y)中的至少1个为q,m或t是优选的,更优选2个以上为q,m或t。另外,对连续q次的各个py(py1,py1y2,py1y2y3,及py1y2y3y4)而言,优选包含1个q,n,l,m或t,更优选包含1个q,m或t,在y中,优选除了q,n,l,m及t以外的氨基酸为g。例如,在y为2个氨基酸(py1y2)的情况下,py优选为pgq,pgn,pgl,pgm或pgt,更优选为pgq,pgm或pgt,在y为3个氨基酸(py1y2y3)的情况下,py优选为pgqg,pgng,pglg,pgmg或pgtg,更优选为pgqg,pgmg或pgtg,将这些中进行任意组合并连续q次的序列为优选的一种实施方式。z表示由0~10个氨基酸组成的氨基酸序列,所述氨基酸独立选自由r,g,s,k,t,l,n,q及m组成的组。在z为0个氨基酸的情况下,肽标签的c末端的氨基酸为p。在z为1个氨基酸的情况下,选自r,g,s,k,t,l,n,q及m的氨基酸形成肽标签的c末端。在z为2~10个氨基酸的情况下,2~10个z可以为选自r,g,s,k,t,l,n,q及m中的相同的氨基酸残基,也可以为不同的氨基酸残基。z的个数优选为1~10个,更优选为1~5个,更优选为2~5个,进一步优选为2~3个,特别优选为2个。在z为1个氨基酸的情况下,优选为r或s,更优选为r。在z为2~10个氨基酸的情况下,c末端侧的2氨基酸,即肽标签的最后2个氨基酸优选为rs。在肽标签中包含的氨基酸,即,在x中包含的氨基酸,y中包含的氨基酸,及z中包含的氨基酸中,优选q,n,l,m及t合计包含3个以上,更优选q,m或t合计包含3个以上。在肽标签中包含的氨基酸中,q,n,l,m及t的合计比例优选为20~50%,更优选为20~30%。需要说明的是,在肽标签中包含的氨基酸,即,x中包含的氨基酸,y中包含的氨基酸,及z中包含的氨基酸中,q,n,l,m及t合计包含3个以上,m包含至少1个的上述肽标签为新型肽标签,包含该新型肽标签的融合蛋白及编码其的多核苷酸,以及包含该多核苷酸的重组载体以它们本身包含在本发明的范围中。本发明使用的肽标签的长度优选为6~50个氨基酸,更优选为6~40个氨基酸,进一步优选为8~40个氨基酸,更进一步优选为10~30个氨基酸,更进一步优选为12~25个氨基酸,特别优选为12~20个氨基酸。作为本发明使用的肽标签的优选例,可以举出具有如下的序列的肽标签。[表1-1]rxpy1y2y3py4y5prsno.xy1y2y3y4y51-1(序列号33)qgqggq1-2(序列号34)ngnggn1-3(序列号35)mgmggm1-4(序列号36)tgtggt1-5(序列号37)lglggl1-6(序列号38)qgqggn1-7(序列号39)qgnggq1-8(序列号40)qgnggn1-9(序列号41)qgqggm1-10(序列号42)qgmggq1-11(序列号43)qgmggm1-12(序列号44)qgqggt1-13(序列号45)qgtggq1-14(序列号46)qgtggt1-15(序列号47)qgqggl1-16(序列号48)qglggq1-17(序列号49)qglggl1-18(序列号50)ngnggqt-19(序列号51)ngqggn1-20(序列号52)ngqggq1-21(序列号53)ngnggm1-22(序列号54)ngmggn1-23(序列号55)ngmggm1-24(序列号56)ngnggt1-25(序列号57)ngtggn1-26(序列号58)ngtggt1-27(序列号59)ngnggl1-28(序列号60)nglggn1-29(序列号61)nglggl1-30(序列号62)mgmggq1-31(序列号63)mgqggm1-32(序列号64)mgqggq1-33(序列号65)mgmggn1-34(序列号66)mgnggm1-35(序列号67)mgnggn1-36(序列号68)mgmggt1-37(序列号69)mgtggm1-38(序列号70)mgtggt1-39(序列号71)mgmggl1-40(序列号72)mglggm[表1-2]rxpy1y2y3py4y5prsno.xy1y2y3y4y51-41(序列号73)mglggl1-42(序列号74)tgtggq1-43(序列号75)tgqggt1-44(序列号76)tgqggq1-45(序列号77)tgtggn1-46(序列号78)tgnggt1-47(序列号79)tgnggn1-48(序列号80)tgtggm1-49(序列号81)tgmggt1-50(序列号82)tgmggm1-51(序列号83)tgtggl1-52(序列号84)tglggt1-53(序列号85)tglggl1-54(序列号86)lglggq1-55(序列号87)lgqggl1-56(序列号88)lgqggq1-57(序列号89)lglggn1-58(序列号90)lgnggl1-59(序列号91)lgnggn1-60(序列号92)lglggm1-61(序列号93)lgmggl1-62(序列号94)lgmggm1-63(序列号95)lglggt1-64(序列号96)lgtggl1-65(序列号97)lgtggt1-66(序列号98)qqqqqq1-67(序列号99)nnnnnn1-68(序列号100)mmmmmm1-69(序列号101)tttttt1-70(序列号102)llllll[表1-3]rxpy1y2y3py4y5grsno.xy1y2y3y4y52-1(序列号103)qgqggq2-2(序列号104)ngnggn2-3(序列号105)mgmggm2-4(序列号106)tgtggt2-5(序列号107)lglggl2-6(序列号108)qgqggn2-7(序列号109)qgnggq2-8(序列号110)qgnggn2-9(序列号111)qgqggm2-10(序列号112)qgmggq2-11(序列号113)qgmggm2-12(序列号114)qgqggt2-13(序列号115)qgtggq2-14(序列号116)qgtggt2-15(序列号117)qgqggl2-16(序列号118)qglggq2-17(序列号119)qglggl2-18(序列号120)ngnggq2-19(序列号121)ngqggn2-20(序列号122)ngqggq2-21(序列号123)ngnggm2-22(序列号124)ngmggn2-23(序列号125)ngmggm2-24(序列号126)ngnggt2-25(序列号127)ngtggn2-26(序列号128)ngtggt2-27(序列号129)ngnggl2-28(序列号130)nglggn2-29(序列号131)nglggl2-30(序列号132)mgmggq2-31(序列号133)mgqggm2-32(序列号134)mgqggq2-33(序列号135)mgmggn2-34(序列号136)mgnggm2-35(序列号137)mgnggn2-36(序列号138)mgmggt2-37(序列号39)mgtggm2-38(序列号140)mgtggt2-39(序列号141)mgmggl2-40(序列号142)mglggm[表1-4]rxpy1y2y3py4y5grsno.xy1y2y3y4y52-41(序列号143)mglggl2-42(序列号144)tgtggq2-43(序列号145)tgqggt2-44(序列号146)tgqggq2-45(序列号147)tgtggn2-46(序列号148)tgnggt2-47(序列号149)tgnggn2-48(序列号150)tgtggm2-49(序列号151)tgmggt2-50(序列号152)tgmggm2-51(序列号153)tgtggl2-52(序列号154)tglggt2-53(序列号155)tglggl2-54(序列号156)lglggq2-55(序列号157)lgqggl2-56(序列号158)lgqggq2-57(序列号159)lglggn2-58(序列号160)lgnggl2-59(序列号161)lgnggn2-60(序列号162)lglggm2-61(序列号163)lgmggl2-62(序列号164)lgmggm2-63(序列号165)lglggt2-64(序列号166)lgtggl2-65(序列号167)lgtggt2-66(序列号168)qqqqqq2-67(序列号169)nnnnnn2-68(序列号170)mmmmmm2-69(序列号171)tttttt2-70(序列号172)llllll[表1-5]rxpy1y2py3y4py5rsno.xy1y2y3y4y53-1(序列号173)qgqgqg3-2(序列号174)ngngng3-3(序列号175)mgmgmg3-4(序列号176)tgtgtg3-5(序列号177)lglglg3-6(序列号178)qgqgng3-7(序列号170)qgngqg3-8(序列号180)qgngng3-9(序列号181)qgqgmg3-10(序列号182)qgmgqg3-11(序列号183)qgmgmg3-12(序列号184)qgqgtg3-13(序列号185)qgtgqg3-14(序列号186)qgtgtg3-15(序列号187)qgqglg3-16(序列号188)qglgqg3-17(序列号189)qglglg3-18(序列号190)ngngqg3-19(序列号191)ngqgng3-20(序列号192)ngqgqg3-21(序列号193)ngngmg3-22(序列号194)ngmgng3-23(序列号195)ngmgmg3-24(序列号196)ngngtg3-25(序列号197)ngtgng3-26(序列号198)ngtgtg3-27(序列号199)ngnglg3-28(序列号200)nglgng3-29(序列号201)nglglg3-30(序列号202)mgmgqg3-31(序列号203)mgqgmg3-32(序列号204)mgqgqg3-33(序列号205)mgmgng3-34(序列号206)mgngmg3-35(序列号207)mgngng3-36(序列号208)mgmgtg3-37(序列号209)mgtgmg3-38(序列号210)mgtgtg3-39(序列号211)mgmglg3-40(序列号212)mglgmg[表1-6]rxpy1y2py3y4py5rsno.xy1y2y3y4y53-41(序列号213)mglglg3-42(序列号214)tgtgqg3-43(序列号215)tgqgtg3-44(序列号216)tgqgqg3-45(序列号217)tgtgng3-46(序列号218)tgngtg3-47(序列号219)tgngng3-48(序列号220)tgtgmg3-49(序列号221)tgmgtg3-50(序列号222)tgmgmg3-51(序列号223)tgtglg3-52(序列号224)tglgtg3-53(序列号225)tglglg3-54(序列号226)lglgqg3-55(序列号227)lgqglg3-56(序列号228)lgqgqg3-57(序列号229)lglgng3-58(序列号230)lgnglg3-59(序列号231)lgngng3-60(序列号232)lglgmg3-61(序列号233)lgmglg3-62(序列号234)lgmgmg3-63(序列号235)lglgtg3-64(序列号236)lgtglg3-65(序列号237)lgtgtg3-66(序列号238)qqqqqq3-67(序列号239)nnnnnn3-68(序列号240)mmmmmm3-69(序列号241)tttttt3-70(序列号242)llllll在本发明中,融合蛋白为在目的蛋白上连接有上述肽标签的蛋白。肽标签可以连接在目的蛋白的n末端上,肽标签也可以连接在目的蛋白的c末端上,也可以将肽标签连接在目的蛋白的n末端和c末端这两者上。肽标签可以直接连接在目的蛋白的n末端和/或c末端,也可以通过1~数个氨基酸(例如:1~5个氨基酸)的序列进行结合。1~数个氨基酸的序列只要是不会对目的蛋白的功能、表达量造成不良影响的序列,则可以为任意的序列,然而通过使其为蛋白酶识别序列,可以在表达,纯化后从目的蛋白中切掉肽标签。作为蛋白酶识别序列,可例示因子xa识别序列等。另外,融合蛋白也可以包含his标签,hn标签,flag标签等检测、纯化等所必需的其他标签序列。对融合蛋白中所含的目的蛋白的种类没有特别限制,优选为医疗用,诊断用,或物质生产用中使用的蛋白质,可以举出例如:生长因子,激素,细胞因子,血液蛋白质,酶,抗原,抗体,转录因子,受体,荧光蛋白质或它们的部分肽等。作为酶,可以举出例如脂酶,蛋白酶,类固醇合成酶,激酶,磷酸酶,木聚糖酶,酯酶,甲基化酶,去甲基化酶,氧化酶,还原酶,纤维素酶,芳香化酶,胶原蛋白酶,转谷氨酰胺酶,糖苷酶和几丁质酶。作为生长因子,可以举出例如表皮生长因子(egf),胰岛素样生长因子(igf),转化生长因子(tgf),神经生长因子(ngf),脑源性神经营养因子(bdnf),血管内皮细胞生长因子(vegf),粒细胞集落刺激因子(g-csf),粒细胞巨噬细胞集落刺激因子(gm-csf),血小板源性生长因子(pdgf),促红细胞生成素(epo),血小板生成素(tpo),成纤维细胞生长因子(fgf),肝细胞生长因子(hgf)。作为激素,可以举出例如胰岛素,胰高血糖素,生长激素释放抑制因子,生长激素,副甲状腺素,催乳素,瘦蛋白,降钙素。作为细胞因子,可以举出例如白介素,干扰素(ifnα,ifnβ,ifnγ),肿瘤坏死因子(tnf)。作为血液蛋白质,可以举出例如凝血酶,血清白蛋白,vii因子,viii因子,ix因子,x因子,组织纤溶酶原激活因子。作为抗体,可以举出例如完全抗体,fab,f(ab′),f(ab′)2,fc,fc融合蛋白,重链(h链),轻链(l链),单链fv(scfv),sc(fv)2,二硫键结合fv(sdfv),双抗体(diabody)。作为疫苗使用的抗原蛋白只要是可以引起免疫应答的蛋白,就没有特别限制,根据设想的免疫应答的对象适当地选择即可,可以举出例如来自于病原性细菌的蛋白质、来自于病原性病毒的蛋白质。融合蛋白可以附加有以分泌生产用途在宿主细胞中发挥作用的分泌信号肽。就分泌信号肽而言,在以酵母作为宿主的情况下,可以举出转化酶分泌信号,p3分泌信号,α因子分泌信号等,在以大肠杆菌作为宿主的情况下,可以举出pelb分泌信号,在以短小芽孢杆菌作为宿主的情况下,可以举出p2分泌信号,p22分泌信号等。另外,在以植物作为宿主的情况下,可以举出来自属于烟草属(nicotianatabacum),拟南芥属(arabidopsisthaliana),荷兰草莓属(fragaria×ananassa),莴苣属(lactucasativa)等的分泌信号。进一步,为了在特定的细胞分区中表达融合蛋白,也可以附加内质网滞留信号肽,液胞运输信号肽等运输信号肽。融合蛋白可以通过在表达体系中导入编码融合蛋白的多核苷酸而利用基因工程生产。在本发明中,多核苷酸是指具有承载编码融合蛋白的遗传信息的碱基序列的物质,在多核苷酸中包含dna,rna等。即,编码融合蛋白的多核苷酸包含编码目的蛋白的多核苷酸,及编码肽标签的多核苷酸。编码目的蛋白的多核苷酸,及编码肽标签的多核苷酸以将阅读框合并方式被连接。编码目的蛋白的多核苷酸例如可以基于公知的碱基序列利用一般的基因工程的手法获得。另外,编码融合蛋白的多核苷酸也优选根据生产该蛋白质的宿主细胞,以使融合蛋白的翻译量增大的方式适当地改变构成融合蛋白的氨基酸相对应的密码子。作为密码子改变的方法,例如可以以kangetal.(proteinexprpurif.2004nov;38(1):129-35.)的方法为参考。另外,可以举出选择宿主细胞中使用频率高的密码子,选择gc含量高的密码子,或选择宿主细胞的管家基因中使用频率高的密码子的方法。为了提高宿主细胞中的表达,编码融合蛋白的多核苷酸也可以包含在宿主细胞中发挥作用的增强子序列等。编码融合蛋白的多核苷酸可以利用一般的基因工程的手法制作,例如可以通过将编码上述肽标签的dna,及编码目的蛋白的dna等使用pcr、dna连接酶等连接来构建。编码融合蛋白的多核苷酸可以直接导入表达体系中,优选以包含该多核苷酸的重组载体的形式导入表达体系。重组载体只要是将编码上述融合蛋白的多核苷酸以能够在将载体导入的宿主细胞中表达的方式插入载体内的载体即可。载体只要能在宿主细胞中复制,就没有特别的限制,例如可以举出质粒dna,病毒dna等。另外,载体优选包含耐药性基因等选择标记。作为具体的质粒载体,例如可例示ptrchis2载体,puc119,pbr322,pbluescriptiiks+,pyes2,paur123,pqe-tri,pet,pgem-3z,pgex,pmal,pri909,pri910,pbi221,pbi121,pncmo2,pbi101,pig121hm,ptrc99a,pkk223,pa1-11,pxt1,prc/cmv,prc/rsv,pcdnai/neo,p3×flag-cmv-14,pcat3,pcdna3.1,pcmv等。载体内所用的启动子可以根据将载体导入的宿主细胞适当地选择。例如,在酵母中表达的情况下,可以使用gal1启动子,pgk1启动子,tef1启动子,adh1启动子,tpi1启动子,pyk1启动子等。在哺乳动物细胞中表达的情况下,可以使用cmv启动子,sv40启动子,ef1α启动子等。在植物中表达的情况下,可以使用花椰菜病毒35s启动子,水稻的肌动蛋白启动子,玉米的泛素启动子,莴苣的泛素启动子等。在大肠杆菌中表达的情况下,可以举出t7启动子等,在短小芽孢杆菌中表达的情况下,可以举出p2启动子、p22启动子等。也可以是能够诱导的启动子,例如可以使用作为能够利用iptg诱导的启动子的lac,tac,trc,此外还可以使用能够利用iaa诱导的trp,能够利用l-阿拉伯糖诱导的ara,能够利用四环素诱导的pzt-1,能够在高温(42℃)下诱导的pl启动子,作为冷休克基因的一种的cspa基因的启动子等。另外,根据需要,也可以根据宿主细胞包含终止子序列。重组载体例如可以通过将编码融合蛋白的dna用适当的限制性内切酶切割或利用pcr附加限制性内切酶位点,插入载体的限制性内切酶部位或多克隆位点而制作。在本发明中,通过将如上所述的编码融合蛋白的多核苷酸或包含其的重组载体导入表达体系中,在该表达体系中表达融合蛋白,可以使融合蛋白在可溶性级分中高效蓄积。在此,表达体系是指具备核糖体,trna及氨基酸等蛋白质表达所必需的翻译因子,可生产来自编码融合蛋白的多核苷酸或包含其的重组载体的融合蛋白的体系,可例示例如包括大肠杆菌,枯草杆菌(芽孢杆菌属细菌),短小芽孢杆菌属细菌,放线菌,棒状杆菌,蓝藻等细菌细胞的原核细胞,或面包酵母,毕赤酵母,裂殖酵母等酵母细胞,曲霉,昆虫细胞,哺乳动物细胞,植物细胞等真核细胞等。另外,也可例示来自大肠杆菌等原核细胞的无细胞蛋白质表达体系,及来自网织红细胞,小麦胚芽,昆虫细胞提取液等真核细胞的无细胞蛋白质表达体系等。表达体系优选为将编码融合蛋白的多核苷酸或包含其的重组载体利用表达体系进行了转化的转化细胞。转化细胞可以通过使用一般的基因工程的手法将编码融合蛋白的多核苷酸或重组载体导入宿主细胞而制作。例如,可以使用电穿孔法(tada,etal.,1990,theor.appl.genet,80:475),原生质体法(gene,39,281-286(1985)),聚乙二醇法(lazzeri,etal.,1991,theor.appl.genet.81:437),利用了农杆菌的导入方法(hood,etal.,1993,transgenic,res.2:218,hiei,etal.,1994plantj.6:271),基因枪法(sanford,etal.,1987,j.part.sci.tech.5:27),聚阳离子法(ohtsuki,etal.,febslett.1998may29;428(3):235-40.)等方法。需要说明的是,基因表达为可以是一过性地表达,也可以是编入染色体中的稳定的表达。在进行转化体的筛选时,也可以利用耐药性基因等选择标记。在上述的转化细胞、无细胞蛋白质表达体系等表达体系中,融合蛋白蓄积在可溶性级分中。用于蛋白质表达的培养基,温度,时间等条件可以根据表达体系的种类适当地选择。可溶性级分是指包括细胞外的培养基、细胞内的除了核、细胞器以外的液体级分等,能够将融合蛋白以溶液形式回收的级分。融合蛋白优选为以未变性蛋白质的形式产生。在此,未变性蛋白质是指保持有蛋白质的高级结构,不发生活性的消失、变得不溶等变化,或者这样的变化较小的蛋白质。通过回收上述可溶性级分,能够得到包含未变性的蛋白质的溶液。在此,包含未变性的蛋白质的溶液是指在细胞内及细胞外,未变性状态的蛋白质为在水中处于溶解的状态。在细胞内,表达的该蛋白质为不凝聚地位于胞液或细胞内的合适的位置,容易发挥原本的功能、活性的状态,在细胞外,目的蛋白为不凝聚地在以水为主体的溶剂中处于溶解的状态,处于溶解的该蛋白质为具有原本的功能、活性的状态。蓄积于可溶性级分中的融合蛋白可以直接用于酶反应等,也可以按照本领域技术人员熟知的方法进行分离纯化。例如,可以利用盐析,乙醇沉淀,超滤,凝胶过滤色谱,离子交换柱层析,亲和色谱,中高压液相色谱,反相色谱,疏水色谱等已知的合适的方法,或将这些方法组合而进行分离纯化。实施例以下,对本发明的实施例进行说明,然而本发明并不限于该实施例。(1)编码用于短小芽孢杆菌的带有肽标签的酯酶的基因表达用质粒的构建及转化将编码来自枯草芽孢杆菌(bacillussubtilis)的酯酶(esta,序列号25)的人工合成dna(序列号26),插入puc19修饰质粒pucfa(fasmac)的ecorv识别部位,得到质粒1。作为短小芽孢杆菌表达用质粒使用了pncmo2(takarabio)(质粒2)。按照下述步骤,分别构建出用于在短小芽孢杆菌中表达在酯酶的n末端附加了各种肽标签,在c末端附加了检测用及纯化用的6xhis标签的融合蛋白,或在酯酶的n末端附加了检测用及纯化用的6xhis标签,在c末端附加了各种肽标签的融合蛋白的质粒(图1,2)。表2.各肽标签的氨基酸序列no.标签附加位置氨基酸序列比较例1-标签(-)-n--比较例2-pg12-nn末端rspgsgpgsprs(序列号1)比较例3-px12-20-nn末端rkpgkgpgkprs(序列号4)实施例11-1px12-32-nn末端rqpgqgpgqprs(序列号7)实施例21-2px12-33-nn末端rnpgngpgnprs(序列号10)实施例31-3px12-34-nn末端rmpgmgpgmprs(序列号12)实施例41-4px12-35-nn末端rtpgtgpgtprs(序列号15)实施例51-5px12-36-nn末端rlpglgpglprs(序列号17)实旌例61-66px1290-nn末端rqpqqqpqqprs(序列号23)实施例72-1px12-89-nn末端rqpgqgpgqgrs(序列号21)实施例83-3px12-83-nn末端rmpgmpgmpgrs(序列号19)比较例4-标签(-)-c--比较例5-pg12-cc末端rspgsgpgsprs(序列号1)比较例6-px12-20-cc末端rkpgkgpgkprs(序列号4)实施例91-1px12-32-cc末端rqpgqgpgqprs(序列号7)实施例101-3px12-34-cc末端rmpgmgpgmprs(序列号10)首先,为了在酯酶的n或c末端附加各种肽标签,实施了利用表3所示的模板质粒,正向引物,反向引物的组合的pcr。在各引物的5’末端附加了与质粒2相同的序列。另外,接在信号肽后附加2个氨基酸残基ad的方式设计了正向引物。pcr使用kod-plus-ver.2(东洋纺),以达到2pg/μl模板质粒,0.3μm正向引物,0.3μm反向引物,0.2mmdntps,用于kod-plus-ver.2的1×缓冲液,1.5mmmgso4,0.02u/μlkod-plus-ver.2的方式制备50μl反应液,在94℃加热5分钟之后,进行30个循环的在98℃加热10秒,在60℃加热30秒,在68℃加热40秒的加热处理,最后在68℃加热5分钟。将所得的扩增片段用qiaquickpcr纯化试剂盒(qiagen)进行了纯化。将质粒2用ncoi,hindiii消化后,利用使用了0.8%seakemgtg琼脂糖的电泳进行分离,使用qiaquick凝胶回收试剂盒(qiagen)从凝胶中提取。将约50ng分量的所提取的质粒2与纯化pcr产物2μl混合,将液量调整为5μl后,与基因艺术无缝plus克隆和组装试剂盒(geneartseamlesspluscloningandassemblykit,thermofisherscientific)所附的2×酶混合物(enzymemix)5μl混合,在室温下静置30分钟,其后在冰上静置5分钟。将反应液5μl与感受态细胞dh5-α混合,在冰上静置30分钟后,在42℃加热45秒并在冰上静置2分钟后,添加250μl的soc,在37℃,以200rpm振荡1小时。其后,将振荡物的50μl涂布于包含100mg/l氨苄西林的2×yt琼脂培养基上后,在37℃静置培养一夜,得到转化集落。将集落移植到包含100mg/l氨苄西林的2×yt液体培养基中,在37℃以200rpm振荡培养一夜后,提取基因表达用质粒,确认碱基序列后,用于短小芽孢杆菌的转化。将桥石短小芽孢杆菌(brevibacilluschoshinensis)sp3株的感受态细胞在37℃在加热块中静置30秒而急速解冻,离心分离(12,000rpm,室温,1分钟)后除去上清液,然后添加将上述基因表达用质粒溶液1μl与50μl溶液a混合而得的全部溶液,利用涡旋使感受态细胞的颗粒完全悬浮,静置5分钟。加入150μl的溶液b,利用涡旋混合10秒,离心(5,000rpm,室温,5分钟)后除去上清液,再次离心分离(5,000rpm,室温,30秒)完全地除去上清液。向其中加入1mlmt培养基,使用微量移液器完全地悬浮后,在37℃以200rpm振荡培养1小时。将培养液铺板于mtnm平板中,在37℃静置培养1夜,得到转化短小芽孢杆菌。(2)短小芽孢杆菌的蛋白质表达培养将转化短小芽孢杆菌的单集落涂布于mtnm平板上,在30℃,静置一夜而进行了培养。从培养后的平板培养基中用1μl灭菌一次性接种环刮取菌体,植入到预先移液到灭菌聚苯乙烯制50ml管中的5mltmnm培养基中,在30℃以120rpm振荡培养48小时。培养结束后,对包含菌体的培养液进行取样。将包含菌体的培养液每份100μl地分到1.5mleppendorf管中,利用离心分离(8,000×g,4℃,10分钟)分为培养上清液和菌体,将培养上清液50μl和菌体全量以-80℃保存。(3)从短小芽孢杆菌中提取蛋白质相对于冻存过的培养上清液50μl,加入2×样品缓冲液(ezapply,atto制)50μl,利用涡旋混合器搅拌后,在沸水中加热10分钟而进行了sds化。另一方面,对于菌体,利用包含0.01%的sem-核酸酶(wako)的xtractor缓冲液(takarabio)100μl而将细胞破碎之后,以10,000xg,10分钟,在4℃进行离心分离。之后,向上清级分(细胞内的可溶性级分)50μl中加入2×样品缓冲液50μl,利用同样的工序进行了sds化。(4)western分析作为蛋白质定量时的标准物质使用了酯酶(esta)标品。通过将其用样品缓冲液反复进行2倍稀释而制成稀释系列,使用它们作为标准品。蛋白质的电泳(sds-page)使用了电泳槽(criterioncell,biorad)及criteriontgx-凝胶(biorad)。向电泳槽中加入泳动缓冲液(tris/glycine/sds缓冲液,biorad)放入,向孔中点入sds化了的样品4μl,以200v定电压进行40分钟泳动。电泳后的凝胶使用trans-blot转印系统(biorad),利用trans-blotturbo(biorad)进行了印迹。将印迹后的膜浸渍于封闭溶液(tbs系,ph7.2,nacalaitesque)中,在室温下振荡1小时或在4℃静置16小时后,在tbs-t(137mm氯化钠,2.68mm氯化钾,1%聚氧乙烯失水山梨糖醇单月桂酸酯,25mmtris-hcl,ph7.4)中在室温下进行3次5分钟的振荡而清洗。在酯酶的检测时,将抗血清小鼠单克隆抗6xhis抗体(abcam)用tbs-t稀释6,000倍后使用。通过将膜浸渍于稀释液中,并在室温振荡2小时而进行了抗原抗体反应,在tbs-t中在室温进行3次5分钟的振荡而进行清洗。作为二次抗体,使用tbs-t稀释3,000倍的抗小鼠igg,ap-连接抗体(cellsignalingtechnology)。通过将膜浸渍于本稀释液中,并在室温振荡1小时而进行了抗原抗体反应,在tbs-t中在室温进行3次5分钟的振荡而进行清洗。利用碱性磷酸酶的显色反应是通过将膜浸渍于显色液(0.1m氯化钠,5mm氯化镁,0.33mg/ml硝基四唑氮蓝,0.33mg/ml5-溴-4-氯-3-吲哚基-磷酸,0.1mtris-hcl,ph9.5)中,在室温下振荡15分钟而进行,将膜用蒸馏水清洗后,在常温下干燥。将显色了的膜利用扫描仪(pm-a900,epson)以解析度600dpi进行图像化,使用图像分析软件(csanalyzerver.3.0,atto),进行培养上清液中和菌体可溶化级分中的酯酶的定量,并将培养上清液中和菌体可溶化级分中的该酶量的合计作为可溶化总酯酶量进行了比较。(5)酶纯化用的培养样品的准备将在-80℃保存的用于酯酶表达而构建的短小芽孢杆菌株用灭菌环涂布于mtnm平板上,在37℃下培养16~20小时。接着,向50ml的聚丙烯制锥形管中移液5ml的tmnm之后,用灭菌环接种了上述平板样品。在30℃下以120rpm振荡培养16~20小时后,将上述的培养物的全量加入至移液了150mltmnm培养基的500ml带挡板的锥形瓶中,以120rpm在30℃下振荡48小时进行培养。将培养物50ml分取到50ml聚丙烯制锥形管中,以8,000×g在4℃下离心分离10分钟,将菌体沉淀后,将40ml的上清液移至另外的管中,其余的上清液用移液器完全吸出后,将分别放入有上清液及菌体(沉淀)的管利用液氮进行冷冻,于-80℃保存。(6)从上清级分中纯化his标签融合酶蛋白质将在-80℃中冻存的40ml的上清级分解冻后,加入含有1.2mnacl及0.04m咪唑的13.3ml的ph7.4,0.4m磷酸钠缓冲液并混合。向econo-pac柱(biorad)中填充talonhis标签融合蛋白纯化树脂(clontech)5ml,用25ml的平衡缓冲液(含有0.3mnacl及0.01m咪唑的ph7.4,0.1m磷酸钠缓冲液)进行平衡后,将用磷酸缓冲液制备完毕的上述上清样品的10ml左右装料于柱,使树脂悬浮,使用其余的样品对树脂的全量进行洗涤并转移至100ml的聚丙烯制离心管(iwaki制)中。将加入有样品的离心管设置于转子中,在低温库内(4℃)使his标签融合酶蛋白质与树脂吸附2小时。接着,将悬浮有吸附了样品的树脂的样品缓冲液转移到空的柱中,仅将缓冲液洗脱。进一步,将平衡缓冲液50ml流过柱,进行了树脂的清洗。清洗结束后,用洗脱用缓冲液(含有0.3mnacl及0.15m咪唑的ph7.4,0.1m磷酸钠缓冲液)20ml将吸附于树脂的his标签融合酶蛋白质进行洗脱。洗脱采用了将每份2ml级分分取至用铝块进行了冰冷却的2mleppendorf管中,将本操作重复10次而将级分分到10只管中的方法。将20μl的各级分分取到1.5mleppendorf管中,加入20μl的2×样品缓冲液(ezapply,atto制),利用涡旋混合器搅拌后,在沸水中加热10分钟而进行了样品的sds化。(7)从菌体级分中纯化his标签融合酶蛋白质将在-80℃中冻存的菌体级分解冻后,加入含有sem核酸酶(wako制)5μl的xtractor缓冲液(clonthech)50ml,于室温振荡约20分钟,使菌体溶解。向econo-pac柱(biorad)填充talonhis标签融合蛋白纯化树脂(clontech)5ml,将上清液样品同样地利用以下同样的方法进行了his标签融合酶蛋白质的纯化,将20μl的各级分分取到1.5mleppendorf管中,加入20μl的2×样品缓冲液(ezapply,atto制),利用涡旋混合器搅拌后,在沸水中加热10分钟而进行了样品的sds化。(8)纯化级分的western分析对于蛋白质定量时的标准物质,与粗提取级分的定量同样地,将纯化酯酶用作标品。通过将其用样品缓冲液反复进行2倍稀释而制成稀释系列,使用它们作为标准品。蛋白质的电泳(sds-page)使用了电泳槽(criterioncell,biorad)及criteriontgx-凝胶(biorad)。向电泳槽中加入泳动缓冲液(tris/glycine/sds缓冲液,biorad),向孔中点入sds化的级分样品4μl,以200v定电压进行40分钟泳动。电泳后的凝胶使用trans-blot转印系统(biorad),利用trans-blotturbo(biorad)进行了印迹。以下,通过与上述粗提取样品的western分析同样的方法实施了印迹后的操作。(9)纯化his标签融合酶蛋白质的超滤和浓缩将利用上述western分析确认了目的酶蛋白质的存在的级分合在一起,移至离心过滤单元(amiconultra-10k,merck)中,以5,000×g,在4℃超滤30分钟。接着,弃去滤液,加入10ml的1×pbs缓冲液ph7.4,通过与上述相同的方法进行了超滤。进一步将同样的操作重复3次,将样品浓缩到约1.0ml,将样品中的咪唑除去。浓缩物的酶蛋白质浓度以bsa作为标准物质,根据bradford法确定。(10)酯酶活性的测定酯酶活性测定使用了dspharmabiomedical的lipasekits通过以下方法进行。首先,将附带的缓冲液2.4ml加入显色剂容器中,使其完全溶解,加入蒸馏水22ml制成了显色原液。将制备的显色原液每份1.1ml移液至1.5mleppendorf管中,在-20℃冻存。接着,将附带的反应停止原液在30℃中孵育5~10分钟溶解后,将全量用蒸馏水进行稀释并定容至500ml后,在4℃冰箱中保存。在即将活性测定之前将上述显色原液1.1ml进行溶解,加入附带的缓冲液1.1ml和蒸馏水8.8ml而制备了显色液。接着,相对于显色液100μl,将5μl的测定用酯酶样品移液至96孔微量滴定板中,利用涡旋混合器混合后,将10μl的附带的底物溶液(balb)加入各孔中,进一步进行混合。接着,将板用铝箔覆盖,在暗处条件下在30℃进行酶反应30分钟。在反应后,加入预先在30℃下孵育了的反应停止液150μl,使反应停止。作为空白,也准备了在反应后加入底物的样品系列,用酶标仪测定两者的吸光度(412nm),将减去空白值后的值乘以1,000而得到balb单位值,将该值作为酶活性的指标。(11)在酿酒酵母s.cerevisiae中的评价利用在wo2017/115853的图2中记载的方法,将导入了编码在人生长激素蛋白质(hgh)的n末端附加了肽标签的融合蛋白的质粒的各转化酵母进行培养,将200μl的培养物分取到1.5ml的eppendorf管中后,以2,000xg在4℃离心分离5分钟,弃去上清液,将沉淀(菌体)用液氮冷冻,然后在-80℃保存。接着,在冰上将沉淀解冻后,通过涡旋将细胞团块散开。进一步添加包含completeultra鸡尾酒(merck公司制)及0.1μg/ml的sem核酸酶(富士胶片和光纯药制造)的0.5ml的yeastprelysis缓冲液(atto公司制造),在室温静置10分钟。接着,将上述细胞裂解液以10,000xg在4℃下离心10分钟,将离心上清液和沉淀分别作为可溶性级分和不溶性级分,利用给定的方法进行了sds化后,进行利用sds-page的泳动,通过western分析测定了各个级分的hgh量。<结果>(1)由各种肽标签的n末端附加带来的在短小芽孢杆菌中可溶性级分中的蛋白质的表达量提高将所制成的基因重组短小芽孢杆菌在给定的条件下培养,在给定的条件下提取酯酶,利用western分析测定出在可溶性级分中该酶的表达量。其结果是,根据图3,在作为比较例2的向n末端附加了pg12(序列号1)时,与没有附加标签相比,没有确认到在可溶性级分中的酯酶的表达提高。另外,在作为比较例3的向n末端附加了px12-20时,与没有标签附加相比,表达量为3.6倍。与此相对,在向酯酶的n末端附加了px12-32,px12-33,px12-34,px12-35,px12-36,px12-90,px12-89及px12-83时,这些可得到与没有标签相比6倍以上的表达量,与比较例相比显然更优秀。特别是,在向n末端附加了px12-32时,得到了高生产率。(2)由各种肽标签的c末端附加带来的在短小芽孢杆菌中可溶性级分中的蛋白质的表达量提高将所制成的基因重组短小芽孢杆菌在给定的条件下培养,在给定的条件下提取酯酶,利用western分析测定出在可溶性级分中该酶的表达量。其结果是,根据图4,在作为比较例5的向c末端附加了pg12(序列号1)情况下,与没有附加标签相比,没有确认到在可溶性级分中的酯酶的表达提高。另外,在作为比较例6的向c末端附加了px12-20时,与没有标签相比,表达量为4倍左右。与此相对,在向酯酶的c末端附加了px12-32及px12-32时,可得到与没有标签相比8倍以上的高表达量,相对于比较例6(附加px12-20),在可溶性级分中的酯酶的产量也显然更优秀。(3)各种肽标签附加对酯酶活性的影响将所制成的基因重组短小芽孢杆菌在给定的条件下培养,对于分泌到培养基中的酯酶和在细菌体内可溶性级分中的酯酶利用给定的条件进行了纯化,确认了标签附加对酶活性的影响。其结果是,如图5所示,确认了分泌到培养基中的n末端附加了标签的酯酶(px12-32-s,px12-34-s)与没有标签的(标签(-))酯酶具有同等活性。另外,对将菌体破碎所得到的n末端附加了标签的酯酶(pxl2-32-p,px12-34-p)而言,也确认了与没有标签的(标签(-))酯酶具有同等活性。(4)由各种肽标签的n末端附加带来的在酵母中可溶性级分中的蛋白质的表达量提高将所制成的基因重组酵母进行培养,利用western分析测定出在各级分中的hgh的表达量。其结果是,根据图6,在向n末端附加了px12-20-n时,可溶性级分中hgh的量少于不溶性级分,在向hgh的n末端附加了px12-32及pxl2-34时,可溶性级分中hgh的表达量显著增加。由此可知,即使在真核细胞中,也发现了在可溶性级分中蛋白质的表达量提高的效果。可以期待在真核生物中通过连接包含特定的序列的肽标签抑制融合蛋白分解的效果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1