合成乳酰N-新四糖的重组大肠杆菌及其构建方法与应用与流程
本发明涉及一种合成乳酰n-新四糖的重组大肠杆菌及其构建方法与应用,属于代谢工程技术领域。
背景技术:
母乳一直被视为婴幼儿最好的食物来源,除了为婴幼儿提供正常生长所需营养外,还具有众多牛乳不具有的健康促进效应。寡糖是母乳中仅次于乳糖和脂肪的第三大固体组分,母乳中的寡糖总含量为5~15g/l。
乳酰n-新四糖(lacto-n-neotetraose)是母乳中含量较高的母乳寡糖之一,对于调节肠道菌群、增强免疫力、促进细胞合成有着重要作用。作为一种重要的营养物质,乳酰n-新四糖已被美国fda和eu批准作为添加剂添加到婴幼儿奶粉中。
目前,乳酰n-新四糖可以通过化学合成法和酶合成法生产,但化学合成法存在反应步骤复杂、原材料价格昂贵等问题,造成生产成本较高不利于工业的大规模合成,且化学合成中使用的部分有毒试剂,使产品不宜用于食品添加剂,酶合成法存在底物价格昂贵等缺点。而生物法可以利用廉价碳氮源和底物,实现乳酰n-新四糖的合成,且对环境不造成影响。因此,通过生物法制备乳酰n-新四糖受到了越来越多的关注。
此前,已有研究通过对微生物进行改造以合成乳酰n-新四糖,包括在大肠杆菌属和枯草芽孢杆菌属中构建代谢途径,但之前的研究多采用质粒引入关键基因,质粒表达不够稳定,存在容易在发酵过程中丢失,或发酵产量不稳定等问题。部分研究尝试在基因组上表达关键基因,但没有对代谢途径进行进一步地调控,造成碳源多流向其他分支途径,代谢过程中底物利用率低,产物产量难以提高等问题。
技术实现要素:
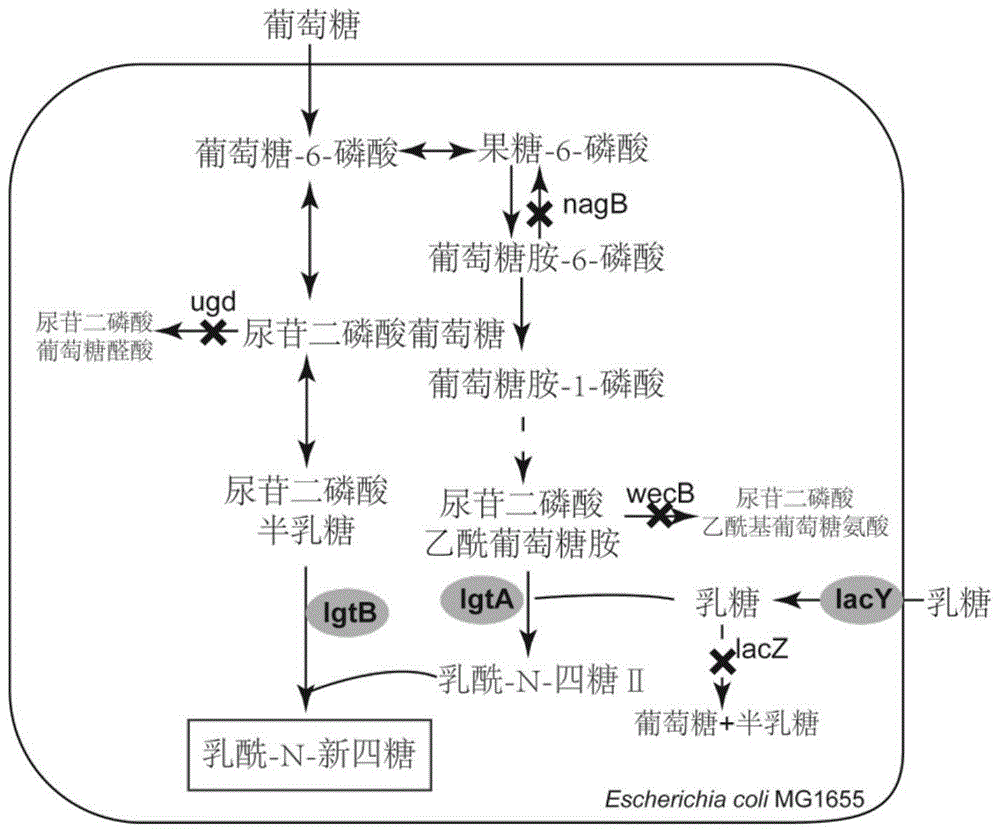
为解决上述技术问题,本发明构建了利用β-1,3-n-葡糖氨基酶lgta基因和β-1,4半乳糖转移酶lgtb基因在大肠杆菌中合成乳酰-n-新四糖的新途径,利用大肠杆菌自身代谢途径中的udp-半乳糖,udp-乙酰氨基葡萄糖作为前体物质,仅需要从外源添加乳糖并在乳糖运输酶的作用下转入细胞,合成乳酰-n-新四糖。
本发明的第一个目的是提供一种合成乳酰n-新四糖的重组大肠杆菌,所述的重组大肠杆菌是在大肠杆菌宿主基因组上敲除β-半乳糖苷酶lacz基因、葡萄糖胺-6-磷酸脱氨酶nagb基因、udp-乙酰氨基葡萄糖表异构酶wecb基因、udp-葡萄糖脱氢酶ugd基因,并在基因组上过表达乳糖运输酶lacy基因、β-1,3-n-葡糖氨基酶lgta基因和β-1,4半乳糖转移酶lgtb基因。
进一步地,所述的β-1,3-n-葡糖氨基酶的氨基酸序列如seqidno.1所示。
进一步地,所述的β-1,4半乳糖转移酶得氨基酸序列如seqidno.2所示。
进一步地,所述的β-半乳糖苷酶lacz基因的id为945006,葡萄糖胺-6-磷酸脱氨酶nagb基因的id为945290,udp-乙酰氨基葡萄糖表异构酶wecb基因的id为944789,udp-葡萄糖脱氢酶ugd基因的id为946571,乳糖运输酶lacy基因的id为949083。
进一步地,所述的大肠杆菌宿主为大肠杆菌mg1655。
进一步地,所述的重组大肠杆菌的β-1,3-n-葡糖氨基酶和β-1,4半乳糖转移酶的启动子是tac启动子。
本发明的第二个目的是提供所述的重组大肠杆菌的构建方法,包括如下步骤:
s1、构建包含β-1,3-n-葡糖氨基酶和β-1,4半乳糖转移酶的重组片段lgtab-tac;
s2、采用crispr/cas9系统进行基因编辑,依次敲除大肠杆菌mg1655中lacz、nagb、wecb、ugd基因,得到敲除lacz、nagb、wecb、ugd基因的重组菌;
s3、采用crispr/cas9系统进行基因编辑,在s2步骤得到的重组菌中过表达lacy基因,得到过表达lacy基因的重组菌;
s4、将重组片段lgtab-tac转入s3步骤得到的重组菌中,得到所述的重组大肠杆菌。
本发明的第三个目的是提供所述的重组大肠杆菌在发酵生产乳酰-n-新四糖的应用。
进一步地,所述的应用具体包括如下步骤:将重组大肠杆菌的种子液以od值0.1-0.2的接种量接入发酵培养基中培养至od达到1.8~2.2时,在28~32℃下,以0.15~0.25mm的iptg进行诱导45~50h。
进一步地,所述的发酵培养基的配方为:蛋白胨10~14g/l,酵母提取物22~26g/l,甘油3~5g/l,磷酸氢二钾2.2~2.5g/l,三水磷酸氢二钾16.2~16.5g/l,乳糖4~6g/l。
本发明的有益效果:
本发明构建了利用β-1,3-n-葡糖氨基酶lgta基因和β-1,4半乳糖转移酶lgtb基因在大肠杆菌中合成乳酰-n-新四糖的新途径,利用大肠杆菌自身代谢途径中的udp-半乳糖,udp-乙酰氨基葡萄糖作为前体物质,仅需要从外源添加乳糖并在乳糖运输酶的作用下转入细胞,合成乳酰-n-新四糖。本发明的重组大肠杆菌合成乳酰-n-新四糖的产量达到985mg/l,为进一步代谢工程改造大肠杆菌生产乳酰-n-新四糖奠定了基础。
附图说明
图1为本发明重组大肠杆菌合成乳酰-n-新四糖的代谢途径。
图2为本发明重组大肠杆菌合成的乳酰-n-新四糖的液质联用色谱图。
图3为本发明中m0ab、m04ab、m05ab的乳酰-n-新四糖产量比较。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
乳酰-n-新四糖利用液质联用色谱仪进行定性和定量检测。质谱离子方式:esi+,质量范围:20-2000m/z,检测器电压:1800volts,液相检测器:watersacquitypda,检测波长:200---400nm,分析柱:behc182.1x150mm1.7um,流动相:100%乙腈,柱温:45℃,流速:0.3ml/min,进样体积5μl。
实施例1:基因敲除同源臂片段的构建
根据e.colimg1655序列信息,设计如表1中所示引物,lacy基因的整合位点为flik,使用上述引物以e.colimg1655基因组为模板,pcr扩增出lacz、nagb、wecb、ugd、flik各基因的上下游同源臂片段,通过overlappingpcr分别融合各基因上下游同源臂,得到片段lacz12、nagb12、wecb12、ugd12、lacy12。
表1
实施例2:ptarget质粒的构建
分别在各待敲除基因上选取n20区(crispr/cas9系统中用于靶向待敲除基因的20bp的碱基序列),设计引物,以ptarget为模板,通过pcr取代模板的n20区。将pcr产物转入e.colijm109中,提取质粒,得到4个质粒,ptarget-lacz、ptarget-nagb、ptarget-wecb、ptarget-ugd、ptarget-lacy。
实施例3:基因敲除与整合
出发菌株e.colimg1655记为m0,将pcas9质粒转化m0,得到表达cas9蛋白的宿主m0(pcas9),随后将ptarget-lacz质粒和片段lacz12电转入m0(pcas9),得到敲除lacz基因的m01(pcas9),消除ptarget-lacz质粒,将ptarget-nagb质粒和片段nagb12电转入m01(cas9),敲除nagb基因,按此方法依次敲除各待敲除基因,最后消除ptarget和pcas9质粒,得到lacz、nagb、wecb、ugd基因敲除的m04。
在敲除lacz、nagb、wecb、ugd基因的m04菌株的基础上,将pcas9质粒转化m04,得到表达cas9蛋白的宿主m04(pcas9),再将ptarget-lacy质粒和带有lacy基因、tac启动子、上下同源臂的融合片段lacy12通过电转转入,使lacy基因整合至flik位点,最后消除ptarget和pcas9质粒,得到过表达lacy基因的m05。
实施例4:构建高效合成乳酰-n-新四糖的重组大肠杆菌
根据ncbi上公布的脑膜炎双球菌nesseriameningitides的β-1,3-n-葡糖氨基酶lgta基因和β-1,4半乳糖转移酶lgtb基因的氨基酸序列,如seqidno.1和seqidno.2所示。
将基因lgta、lgtb和tac启动子通过融合pcr进行连接,构建出重组片段lgtab-tac,将片段分别整合到菌株m0、m04和m05上,获得重组菌株m0ab、m04ab和m05ab。
实施例5:发酵合成乳酰-n-新四糖
将重组菌株m0ab、m04ab和m05ab的种子液以od值0.1-0.2的接种量接入发酵培养基中37℃,200rpm培养,发酵培养基的配方为:蛋白胨12g/l,酵母提取物24g/l,甘油4g/l,磷酸氢二钾2.31g/l,三水磷酸氢二钾16.42g/l,乳糖5g/l。当od值达到2时,在30℃下,以0.2mm的iptg进行诱导48h。
发酵结束后,使用液质联用色谱仪对发酵液中的乳酰-n-新四糖进行定性和定量分析,乳酰-n-新四糖的液质联用色谱图如图2所示。乳酰-n-新四糖产量结果如图3所示,m0ab的乳酰-n-新四糖产量仅为23mg/l,经改造后的工程菌株,乳酰-n-新四糖产量得到提升,m04ab的产量为569mg/l,m05ab的产量达到985mg/l,比m04产量提高了73%。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
序列表
<110>江南大学
<120>合成乳酰n-新四糖的重组大肠杆菌及其构建方法与应用
<160>34
<170>patentinversion3.3
<210>1
<211>221
<212>prt
<213>(人工序列)
<400>1
metglulysaspargserileilealametglyalatrpleugluval
151015
leusergluglulysaspglyasnargleualaarghishisarghis
202530
glylysiletrplyslysprothrarghisgluaspilealaaspphe
354045
phepropheglyasnproilehisasnasnthrmetilemetargarg
505560
servalileaspglyglyleuargtyrasnthrgluargasptrpala
65707580
gluasptyrglnphetrptyraspvalserlysleuglyargleuala
859095
tyrtyrproglualaleuvallystyrargleuhisalaasnglnval
100105110
serserlystyrservalargglnhisgluilealaglnglyilegln
115120125
lysthralaargasnasppheleuglnsermetglyphelysthrarg
130135140
pheaspserleuglutyrargglnilelysalavalalatyrgluleu
145150155160
leuglulyshisleuproglugluaspphegluargalaargargphe
165170175
leutyrglncysphelysargthraspthrleuproalaglyalatrp
180185190
leuaspphealaalaaspglyargmetargargleuphethrleuarg
195200205
glntyrpheglyileleuhisargleuleulysasnarg
210215220
<210>2
<211>275
<212>prt
<213>(人工序列)
<400>2
metglnasnhisvalileserleualaseralaalagluargargala
151015
hisilethraspthrpheglyvalargglyilepropheglnphephe
202530
aspalaleumetprosergluargleugluglnvalmetalagluleu
354045
valproglyleuseralahisprotyrleuserglyvalglulysala
505560
cysphemetserhisalavalleutrplysglnalaleuaspglugly
65707580
leuprotyrilethrvalphegluaspaspvalleuleuglyglugly
859095
alaglulyspheleualagluaspalatrpleuglngluargpheasp
100105110
proaspseralapheilevalargleugluthrmetphemethisval
115120125
leuthrserproserglyvalalaasptyrglyglyargalaphepro
130135140
leuleuglusergluhistrpglythralaglytyrileileserlys
145150155160
lysalaileargphepheleuaspargphealaalaleuproproglu
165170175
glyleuhisprovalaspleumetmetpheseraspphepheasparg
180185190
gluglyvalprovalcysglnleuasnproalaleucysalaglnglu
195200205
leuhistyralalysphehisaspglnasnseralaleuglyserleu
210215220
ilegluhisaspargleuleuasnarglysglnglntrpargaspser
225230235240
proalaasnthrphelysargargleuileargalaleuthrlysile
245250255
serarggluargglulysargargglnargarggluglnpheileval
260265270
prophegln
275
<210>3
<211>45
<212>dna
<213>(人工序列)
<400>3
ttctccgtgggaacaaacgggttttagagctagaaatagcaagtt45
<210>4
<211>45
<212>dna
<213>(人工序列)
<400>4
ccgtttgttcccacggagaaactagtattatacctaggactgagc45
<210>5
<211>21
<212>dna
<213>(人工序列)
<400>5
ccaacacagccaaacatccgc21
<210>6
<211>41
<212>dna
<213>(人工序列)
<400>6
atttcacacaggaaacagcttaataaccgggcaggccatgt41
<210>7
<211>48
<212>dna
<213>(人工序列)
<400>7
catggcctgcccggttattaagctgtttcctgtgtgaaattgttatcc48
<210>8
<211>19
<212>dna
<213>(人工序列)
<400>8
ggcatcgttcccactgcga19
<210>9
<211>45
<212>dna
<213>(人工序列)
<400>9
gttcacgcaaccttcaacgggttttagagctagaaatagcaagtt45
<210>10
<211>45
<212>dna
<213>(人工序列)
<400>10
ccgttgaaggttgcgtgaacactagtattatacctaggactgagc45
<210>11
<211>18
<212>dna
<213>(人工序列)
<400>11
agcgcggcatcaggctta18
<210>12
<211>35
<212>dna
<213>(人工序列)
<400>12
caacggcttacatttttgttatccctgccctggct35
<210>13
<211>38
<212>dna
<213>(人工序列)
<400>13
ccagggcagggataacaaaaatgtaagccgttggcgga38
<210>14
<211>28
<212>dna
<213>(人工序列)
<400>14
ggcgaagattaatgcgaggttatcaaaa28
<210>15
<211>45
<212>dna
<213>(人工序列)
<400>15
acaaacggtaaatactcctggttttagagctagaaatagcaagtt45
<210>16
<211>45
<212>dna
<213>(人工序列)
<400>16
caggagtatttaccgtttgtactagtattatacctaggactgagc45
<210>17
<211>19
<212>dna
<213>(人工序列)
<400>17
ttttgccagccagcgtgca19
<210>18
<211>37
<212>dna
<213>(人工序列)
<400>18
agaaatggtcgcaaaacctatttcgagcaacggcggg37
<210>19
<211>43
<212>dna
<213>(人工序列)
<400>19
ccgttgctcgaaataggttttgcgaccatttctgttatcggac43
<210>20
<211>25
<212>dna
<213>(人工序列)
<400>20
gaccattacctgtcctggtaacacg25
<210>21
<211>45
<212>dna
<213>(人工序列)
<400>21
taaccaccataaccaaacgagttttagagctagaaatagcaagtt45
<210>22
<211>45
<212>dna
<213>(人工序列)
<400>22
tcgtttggttatggtggttaactagtattatacctaggactgagc45
<210>23
<211>29
<212>dna
<213>(人工序列)
<400>23
gtttttctcgttcttcctgattatccagc29
<210>24
<211>44
<212>dna
<213>(人工序列)
<400>24
ccgaatggctggattaacatcttgttatcagggctatttacgcc44
<210>25
<211>45
<212>dna
<213>(人工序列)
<400>25
agccctgataacaagatgttaatccagccattcggtatggaacac45
<210>26
<211>20
<212>dna
<213>(人工序列)
<400>26
tctctggtccgcaagcacag20
<210>27
<211>43
<212>dna
<213>(人工序列)
<400>27
caacgccatcgtctgagcgggttttagagctagaaatagcaag43
<210>28
<211>45
<212>dna
<213>(人工序列)
<400>28
ccgctcagacgatggcgttgactagtattatacctaggactgagc45
<210>29
<211>18
<212>dna
<213>(人工序列)
<400>29
cccttgattaccgccgac18
<210>30
<211>22
<212>dna
<213>(人工序列)
<400>30
ggtgaagggcaatcagctgttg22
<210>31
<211>47
<212>dna
<213>(人工序列)
<400>31
gtgtaaggagatataccatgtactatttaaaaaacacaaacttttgg47
<210>32
<211>38
<212>dna
<213>(人工序列)
<400>32
tgcacttcacctaaatttaagcgacttcattcacctga38
<210>33
<211>36
<212>dna
<213>(人工序列)
<400>33
tgaagtcgcttaaatttaggtgaagtgcaaatctcc36
<210>34
<211>21
<212>dna
<213>(人工序列)
<400>34
ttaggcgaaaatatcaacgcc21
- 还没有人留言评论。精彩留言会获得点赞!