变态反应的抗原及其表位的制作方法
本发明涉及针对胶乳等的变态反应的新型抗原。本发明还涉及针对胶乳等的变态反应的诊断试剂盒、诊断用组合物和诊断方法。本发明还涉及包含该抗原的组合物和去除或降低了该抗原的加工品。本发明还涉及用于判断对象物中有无胶乳抗原的检测组合物。
本发明还涉及包含表位的多肽的抗原。本发明还涉及包含该多肽的变态反应的诊断试剂盒、诊断用组合物和诊断方法。本发明还涉及提供用于对对象的变态反应进行诊断的指标的方法。本发明还涉及包含该多肽的组合物和去除或降低了该多肽的加工品。本发明还涉及去除或降低了该多肽的加工品的制造方法。本发明进而还涉及用于判断对象物中有无包含该多肽的抗原的检测组合物。
背景技术:
变态反应患者的血清和组织中产生了针对特定抗原(以下,也称为变应原)特异的ige抗体。通过该ige抗体与特定抗原的相互作用产生的生理学结果,引起了变态反应。抗原广义上是指引起变态反应症状的物质/原材料等;狭义上是指特异的ige抗体所结合的、物质/原材料等所包含的蛋白质(以下,也称为变应原成分)。
现有的变态反应检测试剂中,大多是简单地将变应原候补物质/原材料等磨碎而制成抗原试剂(专利文献1)。因此,现有的抗原试剂中所包含的多个变应原成分中,对于与ige抗体的结合,只有在超过可判断阳性反应阈值含量时,才能在变态反应检查中检测出阳性反应,是诊断效率还不能说是充分高的状态。
变应原候补的物质/原材料中,启示了几种变应原成分,作为检测试剂盒而被商品化。然而,为了提高变态反应检查的可靠度,需要对变应原成分全面地进行鉴定,结果通过上述变应原成分测定的患者检测率还不是很充分。鉴定胶乳的新型变应原不仅需要提高诊断试剂的精度,作为低变应原材料、治疗药的靶标也是非常重要的。
另一方面,关于蛋白质的分离/纯化,近年来、作为从少量样品中对多种蛋白质进行分离纯化的方法,使用了第一维进行等电点电泳、第二维进行sds-page(十二烷基硫酸钠-聚丙烯酰胺凝胶电泳)的二维电泳法。申请人等到目前为止,开发出了分离能力高的二维电泳法(专利文献2~5)。
变应原特异性ige抗体识别作为变应原成分中的作为特定氨基酸序列的表位并结合。然而,现状是只有少量对于变应原成分解析至表位的例子(非专利文献1),解析是极少的。另外,在目前市场上也不存在利用包含表位的多肽的变态反应的诊断试剂盒。
现有技术文献
专利文献
专利文献1:日本特开2002-286716
专利文献2:日本特开2011-33544
专利文献3:日本特开2011-33546
专利文献4:日本特开2011-33547
专利文献5:日本特开2011-33548
非专利文献
非专利文献1:matsuo,h.,etal.,j.biol.chem.,(2004),vol.279,no.13,pp.12135-12140
技术实现要素:
发明要解决的问题
本发明提供作为蛋白质的变态反应的新型抗原。本发明还提供包含该抗原的变态反应的诊断方法和诊断试剂盒。本发明还提供包含该抗原的组合物和去除或降低了该抗原的加工品。本发明还提供用于判断对象物中有无抗原的检测组合物。
本发明还提供包含表位的多肽的抗原。本发明还提供包含该多肽的变态反应的诊断试剂盒、诊断用组合物和诊断方法。本发明还提供一种方法,所述方法提供用于对对象的变态反应进行诊断的指标。本发明还提供包含该多肽的组合物和去除或降低了包含该多肽的抗原的加工品。本发明还涉及去除或降低了该抗原的加工品的制造方法。本发明进而还提供用于判断对象物中有无包含该多肽的抗原的检测组合物。
用于解决问题的方案
本发明人等为了解决上述问题,对于胶乳变态反应的原因的抗原鉴定进行了深入研究。结果成功地鉴定出患有胶乳变态反应的患者血清中的ige抗体所特异性结合的蛋白质的新型的抗原。
另外,表位具有比较短的氨基酸序列,因此只要不同的变应原成分也存在有同一氨基酸序列,则该ige抗体能与多个变应原成分结合。不同的变应原成分中存在共通的表位,结果由于两者结合有变态反应患者的ige抗体,因此该抗原具有交叉性。因此,由本发明限定的表位能够使包含交叉性的变态反应的诊断、治疗、以及包含该表位的多个变应原成分的检测等变为可能。
本说明书中,“抗原”只要没有特别声明,则以包括作为蛋白质的狭义的抗原和源自蛋白质的“表位”这两者的含义使用。在明确说明的情况下,“抗原”以蛋白质或源自蛋白质的表位中的任意者的含义使用。
基于上述见解,完成了本发明。非限定性地,本发明包括以下的[1]~[9]的方式。
[1]一种多肽,其为与变态反应患者的ige抗体特异性结合的多肽,其选自由以下的(e1)-(e5)组成的组:
(e1)包含选自序列号5~24的氨基酸序列中的至少1个氨基酸序列的多肽;
(e2)包含选自序列号25~34的氨基酸序列中的至少1个氨基酸序列的多肽;
(e3)包含选自序列号35~67的氨基酸序列中的至少1个氨基酸序列的多肽;
(e4)包含选自序列号68~82的氨基酸序列中的至少1个氨基酸序列的多肽;和
(e5)包含选自序列号83~119的氨基酸序列中的至少1个氨基酸序列的多肽。
[2]根据上述[1]所述的多肽,其中,氨基酸残基数为500以下。
[3]一种变态反应的诊断试剂盒,其包含上述[1]或[2]所述的多肽的至少一种。
[4]一种变态反应的诊断用组合物,其包含上述[1]或[2]所述的多肽的至少一种作为抗原。
[5]一种提供用于对对象的变态反应进行诊断的指标的方法,所述方法包括以下的工序:
(i)使由对象得到的试样与抗原接触,此处,该试样是包含有ige抗体的溶液;
(ii)对由对象得到的试样中的ige抗体与该抗原的结合进行检测;
(iii)检测到对象的ige抗体与该抗原结合时,提供对象为变态反应的指标;
此处,该抗原为上述[1]或[2]所述的多肽的至少一种。
[6]一种用于判断对象物中有无抗原的检测组合物,其特征在于,其包含能与上述[1]或[2]所述的多肽的至少一种结合的抗体。
[7]一种加工品,其为特征在于去除或降低了抗原的加工品,该抗原为上述[1]或[2]所述的多肽的至少一种。
[8]一种去除或降低了抗原的加工品的制造方法,其具有在该加工品的制造过程中确认抗原已被去除或降低了的步骤,此处,该抗原为上述[1]或[2]所述的多肽的至少一种。
[9]一种用于判断对象物中有无成为变态反应的原因的抗原的检测组合物,其特征在于,其包含引物,所述引物含有编码上述[1]所述的多肽的核酸的碱基序列的一部分和/或其互补链的一部分。
发明的效果
通过本发明,能够提供变态反应(例如,胶乳变态反应)的新型抗原。本发明中,由于鉴定出了引起变态反应的新型变应原成分,因此能够提供变态反应的高灵敏度的诊断方法和诊断试剂盒、包含该抗原的组合物、该抗原被去除或降低的加工品、以及用于判断对象物中有无抗原的检测组合物。
另外,通过本发明,能够提供包含蛋白质抗原的表位的新型多肽的抗原。通过利用本发明的多肽,能够提供变态反应(例如,胶乳变态反应)的高灵敏度的诊断试剂盒、诊断用组合物和诊断方法、包含该多肽的组合物、用于判断对象物中有无包含该多肽的抗原的检测组合物、以及该多肽被去除或降低的加工品、及加工品的制造方法。
附图说明
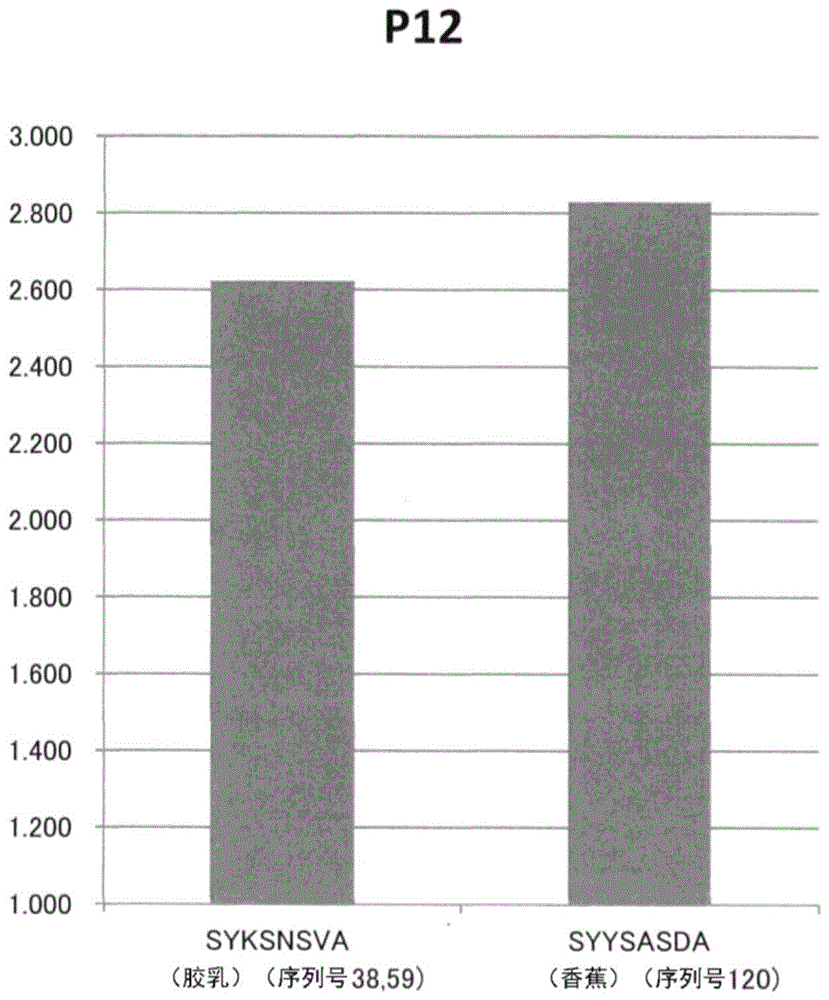
图1是对于具有各表位的氨基酸序列的肽,使用针对胶乳出现变态反应的患者的血清,利用elisa调查了交叉反应性的结果。表示变态反应患者编号p12的结果。纵轴表示变态反应患者的结果相对于非变态反应被检者的结果的比率。
具体实施方式
以下具体地对本发明进行说明,但本发明不限于这些内容。
本说明书中,只要没有特别的定义,与本发明相关联而使用的科学术语和技术术语为本领域技术人员通常理解的意思。
本说明书中变态反应是指:在对某抗原敏感的生物体中,该抗原再次进入时产生的、对生物体表现出不舒服的过敏反应的状态。与抗原接触时或者摄取该抗原时能够产生变态反应。此处,接触是指感觉到物体,特别是,对于人体,是指附着于皮肤、粘膜(眼、口唇等)等。另外,摄取是指被吸收进体内,是通过吸入、经口等手段被吸收。大多数变态反应疾病在血液和组织中产生对抗原特异的ige抗体。ige抗体与肥大细胞或嗜碱性粒细胞结合。对该ige抗体特异的抗原再次进入变态反应疾病患者的体内时,该抗原与结合有肥大细胞或嗜碱性粒细胞的ige抗体组合,产生ige抗体-抗原相互作用的生理学效果。作为它们的生理学的效果,可列举出组胺、5-羟色胺、肝素、嗜酸性细胞趋化因子或各种白细胞三烯等的释放。这些释放物质引起由ige抗体与特定抗原的组合产生的变态反应。详细而言,ige抗体识别作为特定抗原中的特定氨基酸序列的表位并结合,由该抗原产生的变态反应通过上述通路来实现。
本发明作为对象的变态反应只要是针对包含所使用的表位的变应原(抗原)的变态反应,就没有特别的限定。作为一个方式,变应原包含生物体(特别是人)所接触的物质、原材料等、生物体(特别是人)所摄取的谷物、海鲜类、水果、蔬菜、坚果类(种子果实类)、食用草、畜肉、乳汁、乳制品等,或者寄生于生物体(特别是人)的寄生虫等。在一个方式中,变应原源自胶乳。
本说明书中变态反应是指:具有将物质、原材料中包含的蛋白质等作为抗原而产生的变态反应的状态。变态反应是指:与物质、原材料(例如,胶乳或胶乳加工品))中包含的抗原接触时或摄取该抗原时能够产生变态反应。通常将与物质或原材料时产生的变态反应特别地称为变态反应性接触皮炎/变态反应性接触荨麻疹。胶乳变态反应也可以是变态反应性接触皮炎/变态反应性接触荨麻疹。
本说明书中,抗原是指引起变态反应的物质。抗原为原材料中所包含的蛋白质的情况下,也被称为变应原成分。抗原优选为蛋白质。
本说明书中,蛋白质是具有天然氨基酸通过肽键连接而成的结构的分子。对于蛋白质所包含的氨基酸的个数,没有特别的限定。本说明书中,“多肽”的术语还意味着:具有天然氨基酸通过肽键连接而成的结构的分子。对于多肽所包含的氨基酸的个数没有特别的限定。“多肽”是包含“蛋白质”的概念。另外,有时将2~50个左右的氨基酸通过肽键连接而成的多肽特别地称为肽。
关于氨基酸,在可能存在旋光异构体的情况下,只要没有特别明示则表示l体。本说明书中使用的蛋白质、多肽或肽的氨基酸序列的标记法如下:基于标准的用法和本领域中惯用的标记法,氨基酸用单字母标记表示,左方向是氨基末端方向并且右方向是羧基末端方向。需要说明的是,氨基酸的单字母标记中,x表示:只要是能与两端的氨基酸结合的具有氨基和羧基的物质则任意者即可,特别可以是20种天然氨基酸的任意者。
丙氨酸扫描法(或者“丙氨酸甘氨酸扫描”法)是指将蛋白质中的残基一个一个突变成丙氨酸(原来的氨基酸为丙氨酸时突变成甘氨酸)而制作突变体,对于蛋白质的结构、功能重要的残基部位特异地进行鉴定的方法。即便突变成丙氨酸(原来的氨基酸为丙氨酸时突变成甘氨酸),与患者的ige抗体的结合性残存的情况下,该残基与ige抗体的结合性不重要、即便变更为其他的氨基酸也残留有结合性。与ige抗体的结合性是指检测到对象的表位与ige抗体结合和反应。本发明的序列表中,x所表示的残基是通过实施例4所示的丙氨酸扫描,即便置换成丙氨酸(原来的氨基酸是丙氨酸时为甘氨酸)也残留有与变态反应患者的ige抗体的结合性的部位的氨基酸残基。本领域技术人员公知的是,对于这样的部位,即便在置换成其他任意的氨基酸的情况下,也能够残留有与该ige抗体结合性的盖然性高。即,并非仅仅是丙氨酸、甘氨酸,也可以为可置换成丙氨酸以外的任意氨基酸残基的残基。
ige与抗原(表位)的结合/维持对于之后的变态反应是重要的,该结合/维持承担着表位的电荷、疏水键、氢键、芳香族性相互作用。即便通过变成丙氨酸、甘氨酸而失去这些氨基酸也能结合/维持是指,这些氨基酸并不重要。
抗原的鉴定
橡胶树(heveabrasiliensis)所包含的蛋白质按照下述条件供于二维电泳,进行胶乳变态反应的抗原的鉴定。
第一维电泳作为等电点电泳用凝胶使用如下凝胶:凝胶长度5~10cm范围内并且凝胶的ph范围为3~10、相对于泳动方向的凝胶ph梯度在将凝胶的全长设为1、至ph5为止的凝胶长度设为a、ph5~7的凝胶长度设为b、ph7以上的凝胶长度设为c时,a为0.15~0.3的范围内、b为0.4~0.7的范围内、c为0.15~0.3范围内;具体而言,使用gehealthcarebioscience(以下,简称为ge公司)制的ipg凝胶immobilinedrystrip(ph3-10nl)进行等电点泳动。电泳仪使用ge公司制的ipgphor。将电泳仪电流值的上限设定为每1根凝胶75μa,将电压程序如下进行设置:(1)以300v恒定电压升压至750vhr为止,从而进行恒定电压工序(该工序结束前的泳动30分钟的电流変化幅度为5μa);(2)缓缓地使电压从300vhr升压至1000v为止;(3)进一步,缓缓地使电压从4500vhr升压至5000v为止;(4)之后,以5000v恒定电压直至总vhr成为12000,进行第一维的等电点电泳。
第二维电泳使用:泳动方向基端部的凝胶浓度被设定为3~6%且泳动方向前端侧部分的凝胶浓度被设定为高于泳动方向基端部凝胶浓度的聚丙烯酰胺凝胶,具体而言,使用lifetechnologies公司制的nupage4-12%bis-trisgelsipgwellmini1mm进行sds-page。电泳仪使用lifetechnologies公司制的xcellsurelockmini-cell。作为泳动缓冲液,使用50mmmops、50mmtris碱、0.1%(w/v)sds、1mmedta,在200v恒定电压下进行约45分钟泳动。
其结果表明,在对于胶乳的蛋白质按照上述的条件进行二维电泳时的凝胶中,后述的斑点1和2的抗原与胶乳变态反应患者的ige抗体特异性结合。
抗原(蛋白质)
对于各斑点利用质谱分析进行序列鉴定。将由质谱分析装置得到的质谱数据与uniprot的蛋白质数据行对照并解析。其结果,证明了斑点1和2的各斑点与公知的序列一致。
各斑点的信息汇总于以下的表1。在各表所示的氨基酸序列中,用下划线表示的部分以及用粗体和斜体表示的部分为表位序列。
[表1-1]
[表1-2]
非限定性地,本发明中斑点1的抗原可以是以下(1-a)~(1-f)中的任意者。
(1-a)包含序列号2的氨基酸序列的蛋白质;
(1-b)包含序列号2中缺失、置换、插入或附加有1个或多个氨基酸的氨基酸序列的蛋白质;
(1-c)包含与序列号2所示的氨基酸序列的同一性为70%以上的氨基酸序列的蛋白质;
(1-d)包含由序列号1中缺失、置换、插入或附加有1个或多个核苷酸的碱基序列编码的氨基酸序列的蛋白质;
(1-e)包含由与序列号1所示的碱基序列的同一性为70%以上的碱基序列编码的氨基酸序列的蛋白质;或
(1-f)包含由下述核酸编码的氨基酸序列的蛋白质,所述核酸和由与序列号1所示的碱基序列互补的碱基序列组成的核酸在严格的条件下杂交。
另外,非限定性地,本发明中斑点2的抗原可以是以下(2-a)~(2-f)中的任意者。
(2-a)包含序列号4的氨基酸序列的蛋白质;
(2-b)包含序列号4中缺失、置换、插入或附加有1个或多个氨基酸的氨基酸序列的蛋白质;
(2-c)包含与序列号4所示的氨基酸序列的同一性为70%以上的氨基酸序列的蛋白质;
(2-d)包含由序列号3中缺失、置换、插入或附加有1个或多个核苷酸的碱基序列编码的氨基酸序列的蛋白质;
(2-e)包含由与序列号3所示的碱基序列的同一性为70%以上的碱基序列编码的氨基酸序列的蛋白质;或
(2-f)包含由下述核酸编码的氨基酸序列的蛋白质,所述核酸和由与序列号3所示的碱基序列互补的碱基序列组成的核酸在严格的条件下杂交。
上述(1)~(2)的作为抗原的蛋白质和后述的(e1)-(e5)的多肽中还包含有:该蛋白质或多肽的氨基酸残基受到磷酸化、糖链修饰、氨基酰化、开环、脱氨基化等修饰的方案。
优选的是,上述(1)~(2)的作为抗原的蛋白质和后述的(e1)-(e5)的多肽是变态反应的抗原。
本说明书中,对于氨基酸序列,“缺失、置换、插入或附加有1个或多个氨基酸”这样的情况是指:在成为对象的氨基酸序列中,缺失有1个或多个氨基酸、或者置换为其他氨基酸、或者插入有其他氨基酸、和/或附加其他氨基酸而成的氨基酸序列。“多个氨基酸”是指:非限定地、200个以内、100个以内、50个以内、30个以内、20个以内、15个以内、12个以内、10个以内、8个以内、6个以内、4个以内、3个以内的氨基酸。或者,多个氨基酸是指:相对于氨基酸序列的全长为30%、优选为25%、20%、15%、10%、5%、3%、2%或1%的氨基酸。
上述中,置换优选为保守的置换。保守的置换是指将特定的氨基酸残基用具有类似的物理化学特征的残基进行置换;只要是不使原序列结构相关的特征实质上变化就可以为任意的置换,例如,置换氨基酸只要不破坏原序列中存在的螺旋、或者不破坏作为原序列特征的其他种类的二次结构就可以为任意的置换。以下,关于氨基酸残基的保守的置换,根据能够置换的残基分类而例示,但作为能够置换的氨基酸残基不限定于以下记载的物质。
a组:亮氨酸、异亮氨酸、缬氨酸、丙氨酸、蛋氨酸、甘氨酸、半胱氨酸、脯氨酸
b组:天冬氨酸、谷氨酸
c组:天冬酰胺、谷氨酰胺
d组:赖氨酸、精氨酸、
e组:丝氨酸、苏氨酸
f组:苯丙氨酸、酪氨酸、色氨酸、组氨酸
非保守的置换的情况下,也可以将上述种类中的、某一个成员替换为其他种类成员。例如,为了排除预料之外的糖链修饰,也可以将上述b、d、e组的氨基酸置换成除此以外组的氨基酸。或者,为了防止三维结构的蛋白质中被折叠,可以缺失半胱氨酸或者置换为其他氨基酸。或者,为了保持亲水性/疏水性平衡,或者为了容易地进行合成,为了提高亲水度而考虑与氨基酸相关的作为疏水性/亲水性指标的氨基酸的亲水指数(hydropathyindex)(j.kyte和r.doolittle,j.mol.biol.,vol.157,p.105-132,1982),也可以置换氨基酸。
作为另外的方式,可以为向比原来的氨基酸立体位阻少的氨基酸的置换,例如由f组向a、b、c、d、e组的置换;可以为由具有电荷的氨基酸向不具有电荷的氨基酸的置换、例如由b组向c组的置换。由此,与ige抗体的结合性得到改善。
本说明书中,2个氨基酸序列的同一性%可以通过视觉的检查和数学计算来确定。另外,也可以使用计算机程序确定同一性%。作为这样的计算机程序,可列举出例如:blast和clustalw等。特别是,利用blast程序进行的同一性检索的各种条件(参数)可以按照altschul等(nucl.acids.res.,25,p.3389-3402,1997)记载的、ncbi、dnadatabankofjapan(ddbj)网站等公开得到(blast手册、altschul等ncb/nlm/nihbethesda,md20894;altschul等)。另外,也可以使用遗传信息处理软件genetyxver.7(genetyx)、dinasispro(hitachisoft,ltd.)、vectornti(infomax)等程序来决定。
本说明书中,对于碱基序列,“缺失、置换、插入或附加有1个或多个核苷酸”这样的情况是指:在成为对象的碱基序列中,缺失有1个或多个核苷酸、或者置换为其他核苷酸、或者插入有其他核苷酸、和/或附加其他核苷酸而成的碱基序列。“多个核苷酸”是指:非限定地、600个以内、300个以内、150个以内、100个以内、50个以内、30个以内、20个以内、15个以内、12个以内、10个以内、8个以内、6个以内、4个以内、3个以内的核苷酸。或者,多个核苷酸是指:相对于碱基序列的全长为30%、优选为25%、20%、15%、10%、5%、3%、2%或1%的核苷酸。通过上述核苷酸的缺失、置换、插入或附加,优选在编码氨基酸的序列中不产生移码。
本说明书中,2个碱基序列的同一性%可以通过视觉的检查和数学计算来确定。另外,也可以使用计算机程序确定同一性%。作为这样的序列比较计算机程序,可列举出例如:从美国国立医学图书馆的网站https://blast.ncbi.nlm.nih.gov/blast.cgi能够利用的blastn程序(altschuletal.(1990)j.mol.biol.215:403-10):version2.2.7或者wu-blast2.0algorithm等。对于wu-blast2.0的标准的默认参数(defaultparameter)的设定可以使用以下互联网网站:http://blast.wustl.edu记载的。
本说明书中“严格条件下”是指中等程度或高度严格的条件下进行杂交。具体而言,作为中等程度严格的条件,例如可以由具有一般技术的本领域技术人员基于dna的长度容易地决定。基本的条件如sambrook等,molecularcloning:alaboratorymanual,第3版,第6-7章,coldspringharborlaboratorypress,2001所示。优选的是,中等程度严格的条件作为杂交条件可列举出:1×ssc~6×ssc、42℃~55℃的条件;更优选为1×ssc~3×ssc、45℃~50℃的条件;最优选为2×ssc、50℃的条件。杂交溶液中包含例如约50%甲酰胺的情况下,可以采用比上述温度低5~15℃的温度。洗涤条件可列举出:0.5×ssc~6×ssc、40℃~60℃。在杂交和洗涤时,通常加入0.05%~0.2%、优选约0.1%sds。作为高度严格的条件,还可以例如由本领域技术人员基于dna的长度容易地决定。通常,作为高度严格(highstringent)的条件,包括比中等程度严格的条件温度更高和/或盐浓度更低的杂交和/或洗涤。例如,作为杂交条件,可列举出:0.1×ssc~2×ssc、55℃~65℃的条件;更优选为0.1×ssc~1×ssc、60℃~65℃的条件;最优选为0.2×ssc、63℃的条件。作为洗涤条件,可列举出:0.2×ssc~2×ssc、50℃~68℃、更优选为0.2×ssc、60~65℃。
非限定性地,上述(1)-(2)的相当于(b)-(f)项目的突变体中,优选包含后述的表位(突变体)的氨基酸序列。所包含的表位的氨基酸序列不限定于1个,优选全部包含分别源自各蛋白质的表位序列。例如,源自蛋白质(1)的表位为(e1)、(e2)、(e3)和(e4)。(1-b)-(1-f)优选包含1个以上(e1)、(e2)、(e3)或(e4)表位的氨基酸序列(包括突变体)。
抗原也可以通过组合本领域技术人员公知的蛋白质纯化方法由胶乳进行分离/纯化来得到。或者,抗原也可以通过本领域技术人员公知的基因重组技术表达抗原作为重组蛋白质,然后通过本领域技术人员公知的蛋白质纯化方法进行分离/纯化来得到。
作为蛋白质的纯化方法,可列举出例如:盐析、溶剂沉淀法等利用溶解度的方法;透析、超滤、凝胶过滤、sds-page等利用分子量的差的方法;离子交换色谱、羟磷灰石色谱等利用荷电的方法;亲和色谱等利用特异的亲和性的方法;反相高效液相色谱等利用疏水性的差的方法;等电点电泳等利用等电点的差的方法等。
利用基因重组技术制备蛋白质可以如下进行:制备包含编码抗原的核酸的表达载体,将该表达载体通过基因导入或转化导入至适宜的宿主细胞中,在适合于重组蛋白质表达的条件下培养该宿主细胞,然后对该宿主细胞中表达的重组蛋白质进行回收。
“载体”是能够用于将与之连接的核酸导入宿主细胞内的核酸;“表达载体”是能够引导被载体导入的核酸所编码的蛋白质表达的载体。作为载体包括质粒载体、病毒载体等。本领域技术人员可以根据使用的宿主细胞的种类选择适合于重组蛋白质表达的表达载体。
“宿主细胞”是通过载体进行了基因导入或接受了转化的细胞。宿主细胞可以由本领域技术人员根据使用的载体适宜选择。宿主细胞可以来自例如大肠杆菌(e.coli)等原核生物。使用大肠杆菌这样的原核细胞作为宿主时,为了使原核细胞内的重组蛋白质的表达变得容易,本发明的抗原优选包含n末端蛋氨酸残基。该n末端蛋氨酸也可以在表达后从重组蛋白质切离。或者,可以是酵母等单细胞真核生物;植物细胞、动物细胞(例如,人细胞、猿猴细胞、仓鼠细胞、大鼠细胞、小鼠细胞或昆虫细胞)等来自真核生物的细胞、蚕。
表达载体向宿主细胞的基因导入或转化可以通过本领域技术人员公知的方法适宜进行。另外,本领域技术人员会根据宿主细胞的种类适宜选择适合于表达重组蛋白质的条件来培养宿主细胞,从而能够表达重组蛋白质。然后,对表达重组蛋白质的宿主细胞进行均质化处理,对由得到的均质混合物纯化成上述蛋白质的方法进行适宜组合,由此能够分离/纯化作为重组蛋白质表达的抗原。也可以将上述表达载体或合成的双链dna、或者由其转录的mrna导入至无细胞蛋白质合成系中进行表达,对所表达的蛋白质进行分离/纯化,由此来制备抗原。
本发明的抗原优选与变态反应患者的ige抗体特异性结合。
诊断试剂盒/诊断方法(1)
本发明是提供用于对对象的变态反应进行诊断的指标的方法,其包括以下的工序:
(i)使由对象得到的试样与抗原接触,此处,该试样是包含有ige抗体的溶液;
(ii)对由对象得到的试样中的ige抗体与该抗原的结合进行检测;
(iii)检测到对象的ige抗体与该抗原结合时,提供对象为变态反应的指标;
此处,该抗原为作为上述(1)~(2)的抗原限定的蛋白质的至少一种。
“变态反应”非限定性地在一个方式中为胶乳变态反应。
本说明书中“诊断”除了通常由医师(确定的)诊断以外、还包含含有可能性的单独的“检测”。本说明书中“诊断”“检测”在一个方式中是指体内、体外或离体的“诊断”“检测”。优选为体外的或离体的“诊断”“检测”。
由对象得到的试样是指包含有由对象采集的ige抗体的溶液。这样的溶液中包含有例如血液、唾液、痰、鼻涕、尿、汗、泪。在与抗原接触之前,也可以对由对象得到的试样实施用于提高试样中ige抗体浓度的前处理。作为试样的前处理,也可以包括例如由血液得到血清、血浆。另外,也可以进一步对作为与抗原结合部分的fab部分进行纯化。在特别优选的方式中,上述工序(i)通过使由对象得到的血清中的ige抗体与抗原接触来进行。
ige抗体可以是ige抗体自身,也可以是ige抗体所结合的肥大细胞等。
由对象得到的试样与抗原的接触以及它们的结合的检测可以通过已知的方法来进行。作为这样的方法,可以使用例如:利用elisa(酶联免疫吸附试验,enzyme-linkedimmunosorbentassay)、夹层免疫测定法(sandwichimmunoassays)、蛋白质免疫印迹法、免疫沉淀法、免疫层析法进行的检测。这些均是使抗原与对象ige抗体接触而结合,使之作用于对于与抗原特异地结合的ige抗体进行酶标记而成的二次抗体,加入酶的底物(通常为显色或发光试剂)而检测出酶反应的产物,由此能够检测抗原与对象ige抗体结合的方法。或者为检测被荧光标记的二次抗体的方法。或者,也可以使用表面等离子共振(spr)等能够评价抗原与ige抗体结合的测定方法进行检测。也可以混合多种抗原特异的ige抗体。
抗原也可以是分离的抗原被固定于载体的状态。该情况下,上述工序(i)和(ii)中可以利用elisa、夹层免疫测定法、免疫层析法、表面等离子共振等;另外,上述工序(i)中,由对象得到的试样与固定了抗原的面接触来进行。所分离的抗原可以通过组合本领域技术人员公知的蛋白质纯化方法由对象(原料、加工品等)分离/纯化来得到,或者也可以通过基因重组技术来制备。另外,载体也可以贴合有抗体。
抗原也可以是没有被固定于载体的状态。该情况下,在上述工序(i)和(ii)中,可以利用流式细胞仪等,可以通过激光确认结合有抗体的抗原的存在。可列举出例如嗜碱性粒细胞激活试验(bat)等。另外,也可列举出通过使抗原与试样中的血细胞进一步接触来确认是否使组胺游离的组胺游离试验(hrt)。
另外,抗原也可以由通过二维电泳分离的状态转印、通过蛋白质免疫印迹进行检测。二维电泳通过第一维进行等电点电泳、第二维进行sds-page,由此分离蛋白质试样的方法。该情况下,二维电泳的条件只要是能够分离本发明抗原的条件就没有特别的限定。例如,可以利用上述“抗原的鉴定”项目中记载的二维电泳的条件。或者,也可以参考上述专利文献1~4的记载设定电泳条件,例如,满足选自由以下组成的组中的至少一个条件下进行二维电泳:
(a)作为第一维等电点电泳凝胶,在凝胶长度为5~10cm的范围内且凝胶的ph范围为3~10、将相对于泳动方向的凝胶的ph梯度直至ph5为止的凝胶长度设为a、ph5~7的凝胶长度设为b、ph7以上的凝胶长度设为c的情况下,满足“a<b”和“b>c”的关系;
(b)在(a)的情况下,将凝胶的全长设为1时,a为0.15~0.3的范围内、b为0.4~0.7的范围内、c为0.15~0.3的范围内;
(c)在第一维的等电点电泳中,对于每1根包含被检体的凝胶施加100v~600v范围内值的恒定电压进行恒定电压工序,在每泳动30分钟的泳动变化幅度为5μa范围内之后,开始由前述恒定电压使电压上升的电压上升工序;
(d)在(c)的情况下,将电压上升工序的最终电压设为3000v~6000v的范围内;
(e)第一维等电点电泳凝胶的长边方向的凝胶长度设为5~10cm、第二维电泳凝胶的泳动方向基端部的凝胶浓度设为3~6%;以及
(f)在(e)的情况下,将第二维电泳凝胶的泳动方向前端侧部分的凝胶浓度设定为高于泳动方向基端部的凝胶浓度。
上述(1)~(2)的抗原为与变态反应的患者(例如,胶乳变态反应的患者)的ige抗体特异性结合的抗原。因此,检测到对象的ige抗体与该抗原结合时,提供对象具有变态反应的指标。
本发明还提供包含上述(1)~(2)抗原的至少一种的变态反应的诊断试剂盒。本发明的诊断试剂盒可以在上述提供用于诊断变态反应指标的方法或下述诊断方法中应用。本发明的诊断试剂盒除了包含上述(1)~(2)的抗原的至少一种之外,还可以包含被酶标记的抗ige抗体以及成为该酶底物的显色底物或发光底物。另外,也可以使用被荧光标记的抗ige抗体。本发明的诊断试剂盒中,也可以以抗原被固定化于载体的状态提供。本发明的诊断试剂盒还可以与关于用于诊断的步骤的说明书、包含该说明的方法包一起提供。
在另外的方式中,上述的诊断试剂盒包含变态反应的伴侣诊断药物。伴侣诊断药物是指用于以下用途的物质:期待医药品效果的患者的特定或医药品的具有重度副作用风险的患者的特定、或者为了最优化使用了医药品的治疗而研究该医药品的反应性。此处,治疗的最优化包括例如:用法容量的确定、给药中止的判断、使用何种变应原成分来确认是否获得免疫耐受。
本发明还提供包含上述(1)~(2)抗原的至少一种的变态反应的诊断用组合物。本发明的诊断用组合物可以用于下述的诊断方法中。本发明的诊断用组合物还可以根据需要包含通常与本发明的抗原一起使用的、药学上允许的载体、添加剂。
一个方式中,本发明为用于对对象的变态反应进行诊断的方法,其包括以下工序:
(i)使由对象得到的试样与抗原接触;
(ii)对由对象得到的试样中的ige抗体与该抗原的结合进行检测;
(iii)检测到对象的ige抗体与该抗原结合的情况下,判断对象为变态反应;
此处,该抗原为作为上述(1)~(2)的抗原限定的蛋白质的至少一种。其中,(i)和(ii)的各工序按照对于提供用于诊断变态反应指标的方法的各工序的说明来进行。
另一个方式中,本发明提供诊断对象的变态反应的方法,其包括对对象给予上述(1)~(2)的抗原的至少一种。该方法也可以以特征在于对皮肤施用抗原的皮肤测试的形式进行。皮肤测试中包含如下形式:对皮肤上施用诊断用组合物之后、以不出血程度地轻微抓伤,使皮肤浸透抗原再观察皮肤反应的点刺试验(pricktest);施用了诊断用组合物的基础上轻挠皮肤再观察反应的划痕试验(scratchtest);对皮肤施用霜、软膏等形式的诊断用组合物再观察反应的肤斑试验(patchtest);对皮内给予抗原再观察反应的皮内测试;等。在施用了抗原部分的皮肤出现肿胀等皮肤反应的情况下,诊断为该对象具有变态反应。此处,对皮肤施用的抗原的量也可以为例如每1次100μg以下的用量。
在变态反应的诊断中,经常进行的是以抗原的鉴定为目的的耐量试验。上述(1)~(2)的抗原的至少一种可以作为用于诊断变态反应的耐量试验的有效成分来使用。此处,作为耐量试验中使用的抗原蛋白质,可以为表达纯化的蛋白质,也可以为例如在稻子中转化杉木花粉抗原的基因,并且在米内使该抗原蛋白质表达的花粉米那样的、在原料/加工品中表达的蛋白质。
一个方式中,上述诊断用组合物、诊断试剂盒可以用于点刺试验、划痕试验、肤斑试验、皮内测试等。
另外,另一个方式中,本发明提供变态反应的诊断中使用的上述(1)~(2)的抗原的至少一种。此处,也包含将上述(1)~(2)抗原的至少一种与已知的抗原混合来提供。
进而在另一个实施方式中,本发明提供上述(1)~(2)的抗原的至少一种在制备变态反应的诊断用组合物中的应用。
组合物/治疗方法(1)
本发明提供包含上述(1)~(2)的抗原的至少一种的组合物。
一个方式中,本发明的组合物为药物组合物。一个方式中,本发明的组合物为准药物组合物、非药用组合物(例如化妆用组合物、食品组合物)。
一个方式中,上述的组合物用于治疗变态反应(例如,胶乳变态反应)。本说明书中,“变态反应的治疗”是为了增加即使摄入体内也不会发病的抗原极限量,最终旨在达到通常的抗原摄入量后不会发病的状态(缓解)。
本发明还提供治疗变态反应的方法,其包括:对于需要治疗变态反应的患者,给予上述(1)~(2)的抗原的至少一者。
另一个方式中,本发明提供变态反应的治疗中使用的上述(1)~(2)的抗原的至少一种。进而在另一个实施方式中,本发明提供上述(1)~(2)的抗原的至少一种在制备变态反应的治疗药物中的应用。
在变态反应的治疗中,经常进行的是目的在于通过对患者给予抗原来诱导免疫耐受的、脱敏治疗法。上述(1)~(2)的抗原的至少一种可以作为用于治疗变态反应的脱敏治疗法的有效成分来使用。此处,作为脱敏治疗法中使用的抗原蛋白质,可以为表达纯化的蛋白质,也可以为例如在稻子中转化杉木花粉抗原的基因,并且在米内使该抗原蛋白质表达的花粉米那样的、在原料/加工品中表达的蛋白质。
本发明的组合物可以通过通常的给药途径进行给药。通常的给药途径包括例如:经口、舌下、经皮、皮内、皮下、血液内、鼻腔内、肌肉内、腹腔内、直肠内的给药。
本发明的组合物可以使用根据需要与本发明的抗原一起通过常规方法添加了通常使用的药学上允许的佐剂、赋形剂、或者各种添加剂(例如稳定剂、助溶剂、乳浊化剂、缓冲剂、储存剂、着色剂等)而成的组合物。组合物的剂型可以由本领域技术人员根据给药途径而适宜选择。也可以是例如:片剂、胶囊剂、糖浆剂、舌下片、注射剂、鼻腔内喷雾剂、贴膏剂、溶液剂、霜剂、露剂、栓剂等形式。本发明的组合物的给药量、给药次数和/或给药期间可以由医师根据给药途径、症状、年龄、体重等患者的特性等适宜选择。例如是成人的情况下,也可以以每1次100μg以下的用量给药。给药间隔可以是例如每天1次、每周1次、每月2次或者3个月1次左右。给药期间可以为例如数周~数年。在给药期间内,也可以是梯度地增加给药量的给药方法。
检测组合物(1)
本发明提供一种检测组合物,其包含针对上述(1)~(2)的抗原的至少一种的抗体。
该抗体可以通过常规方法来制作。例如,对兔子等哺乳动物用上述(1)~(2)的抗原进行免疫来制作。该抗体可以为ig抗体、多克隆抗体、单克隆抗体、或者它们的抗原结合片段(例如、fab、f(ab’)2、fab’)。
另外,上述检测组合物中,该抗体可以以与载体结合的形式提供。载体只要是在抗体与抗原结合的检测中能够利用的载体,就没有特别的限定。可以利用本领域技术人员公知的任意载体。
作为用于检查是否含有抗原的方法,可列举出例如以下的方法。
·使包含制作的ig抗体的检测组合物与由原料/加工品等得到的试样接触,例如使用elisa法等检测该ig抗体与试样中的抗原的结合,在检测到该ig抗体与抗原结合的情况下,判断为对象原料/加工品等中包含有该抗原的方法等。
·使滤纸等包裹原料/加工品,使之与抗体溶液反应来检测其中所包含的抗原的方法。
在本发明的另一个方式中,包含用于判断对象物中有无变态反应的抗原的检测组合物,其特征在于,其包含具有与序列号1或3所示的碱基序列的至少一部分互补的碱基序列的引物。非限定性地,上述引物具有例如:与序列号1或3所示的碱基序列的至少一个序列的一部分3’末端部分或中央部分的序列的、优选12个碱基、15个碱基、20个碱基、25个碱基互补的碱基序列。特别是在将mrna作为对象的情况下,具有poly(a)tail(尾)的互补引物。在优选的方式中,包含上述引物的检测组合物进一步包含含有序列号1或3所示的碱基序列的至少一个序列的5’末端部分的碱基序列、优选由12个碱基、15个碱基、20个碱基、25个碱基构成的碱基序列的引物。
例如,以由胶乳得到的dna或mrna作为模板、使用所述互补的引物,用包含rt-pcr(reversetranscription-polymerasechainreaction,逆转录-聚合酶链式反应)的pcr(聚合酶链式反应,polymerasechainreaction)对cdna进行扩增,将所扩增的cdna的序列与序列号1或3进行比较,从而判断抗原的有无。用pcr进行扩增的方法可例示出race法(rapidamplificationofcdnaend,cdna末端快速扩增技术)等。此时,在扩增的cdna与序列号1或3的比较中,编码相同氨基酸的点突变存在的情况下;或者、扩增的cdna的碱基序列中即便存在有对于序列号1或3的碱基序列的碱基插入、缺失、置换或附加时,该cdna所编码的氨基酸序列相对于序列号2或4的氨基酸序列的同一性为70%以上、优选为80、90、95、98、99%以上时,判定为抗原存在。
一个方式中,上述检测组合物可以用来检测例如在材料(胶乳)中或胶乳加工品生产线中等对象物中是否含有抗原。上述检测组合物可以由制造业者用在生产线和出厂前产品的质量检查;也可以由使用者自己用来检查对象原料/加工品是否含有抗原。另外也可以用来通过质谱分析装置由该蛋白质的峰的增减来检查有无含有抗原。
抗原有无的判定方法(1)
本发明包含抗原有无的判定方法,其中,使针对上述(1)~(2)的抗原的至少一种的抗体与原料/加工品(包含液体)接触,从而判定对象物质中有无上述(1)~(2)的抗原。
原料可以为胶乳,也可以为加工用原料、化妆品原料、医药品原料等。加工品可以为胶乳加工品,也可以为化妆品、医药品等。
对于该抗体、抗体的制作方法、使抗体与原料/加工品接触的方法、抗体与抗原的结合等,与“检测组合物(1)”中上述内容相同。
去除抗原的加工品(1)
本发明提供特征在于去除或降低了上述(1)~(2)的抗原的至少一种的加工品。一个方式中,“加工品”是指“胶乳加工品”
加工品中,去除或降低本发明的抗原的方法没有限定。抗原的去除或降低不限定于本发明抗原的去除或降低,可以使用任意的方法来进行。
本发明的去除或降低了抗原的加工品也可以是以本发明的去除或降低了抗原的原料作为材料的加工品。将以通常的原料作为材料的情况下,在加工品的制备前或制备后进行本发明的去除或降低抗原的处理。在以通常的原料作为材料的加工品中,作为本发明的去除或降低抗原的方法,可列举出:高压处理和利用中性盐溶液的洗脱、高温蒸汽等去除原料/加工品中的蛋白质成分的方法;通过热处理和酸处理进行水解、变性、氨基酸变性(侧链的化学修饰/脱离等)的方法。
去除或降低了抗原的加工品的制造方法(1)
本发明为去除或降低了抗原的加工品的制造方法,其具有如下步骤:在该加工品的制造过程中确认抗原被去除或降低,此处,该抗原是上述(1)~(2)的抗原的至少一种。
去除或降低了抗原的加工品的制造过程中,确认去除或降低了抗原的步骤可以通过上述“检测组合物(1)”的项目中记载的方法确认是否含有抗原来进行。
另外,去除或降低了抗原的胶乳加工品的制造可以通过上述“抗原去除加工品(1)”项目中记载的方法来进行。
表位
如实施例1-3所示对于特定的抗原,如实施例4所示,特定了表位以及该表位内对于与变态反应患者的ige抗体的结合性重要的氨基酸。
将结果汇总于表2。表2中、p1~p17是分别对17例变态反应患者赋予的患者编号。
[表2-1]
[表2-2]
[表2-3]
[表2-4]
[表2-5]
本发明作为包含与变态反应患者的ige抗体特异性结合的氨基酸序列的多肽,提供包含前述表2所述的序列号5-119的各氨基酸序列的多肽、或者包含由各氨基酸序列组成的(e1)~(e5)的氨基酸序列的多肽。(e1)~(e5)分别是与表2的“蛋白质名称”中记载的蛋白质来源的ige抗体结合的氨基酸序列(以下,有时称为“表位”)。
(1)柠檬酸结合蛋白(citrate-bindingprotein)(uniprot登录号:q39962)蛋白质来源:(e1)、(e2)、(e3)、(e4);
(2)几丁质酶-a(hevamine-a)(uniprot登录号:p23472)蛋白质来源:(e5);
非限定性地,本发明的表位抗原优选包含以下的多肽中的至少1种。
(e1)包含选自序列号5-24的氨基酸序列中的至少1个氨基酸序列的多肽;
(e2)包含选自序列号25-34的氨基酸序列中的至少1个氨基酸序列的多肽;
(e3)包含选自序列号35-67的氨基酸序列中的至少1个氨基酸序列的多肽;
(e4)包含选自序列号68-82的氨基酸序列中的至少1个氨基酸序列的多肽;或
(e5)包含选自序列号83-119的氨基酸序列中的至少1个氨基酸序列的多肽。
如表2所述,作为优选方式的上述的(e1)~(e5)的多肽是在本说明书的实施例中被鉴定为与ige抗体结合的表位的具体的序列。作为本发明的表位抗原,除了上述的优选的方式的(e1)~(e5)的多肽以外,还可包括下述说明的突变体等。以下对本发明的表位抗原中可包含的方式(突变体)进行说明。
表2的“共通15残基序列”中记载的、序列号5、25、35、68、83的5种的各序列是通过基于重叠的表位映射,在(e1)-(e5)的各表位中作为与ige抗体结合的表位而被鉴定出的共通15氨基酸残基序列。在本发明的一个方式中,是包含这些氨基酸序列的多肽、或者是由这些氨基酸序列组成的多肽。本发明的多肽中所包含的表位序列可以是该共通表位15个氨基酸残基整体、或者其一部分。表位序列为4个氨基酸残基以上、5个氨基酸残基以上、6个氨基酸残基以上、7个氨基酸残基以上、8个氨基酸残基以上、9个氨基酸残基以上、10个氨基酸残基以上、11个氨基酸残基以上、12个氨基酸残基以上、13个氨基酸残基以上、14个氨基酸残基以上。
本说明书的实施例中,例如,多个由4个氨基酸残基组成的多肽(例如,序列号6、11、13、19、24、30、32、78、79等)作为与ige抗体结合的表位而被鉴定出。进而,在5个氨基酸残基、5个氨基酸残基以上的情况下多数被确认与ige抗体结合性。由此,只要存在至少4个氨基酸残基,作为表位序列是有用的。
作为本发明的多肽的突变体的一个方式,包含含有上述(e1)~(e5)中具体记载的氨基酸序列的4个以上的氨基酸残基的多肽。例如,作为(e1)的突变体,可以包含“含有序列号5~24的氨基酸序列的至少1个氨基酸序列中的4个以上的氨基酸残基的多肽”。优选包含序列号5~24的氨基酸序列的至少1个氨基酸序列中的、4个氨基酸残基以上、5个氨基酸残基以上、6个氨基酸残基以上、7个氨基酸残基以上、8个氨基酸残基以上、9个氨基酸残基以上、10个氨基酸残基以上、11个氨基酸残基以上、12个氨基酸残基以上、13个氨基酸残基以上、14个氨基酸残基以上。(e2)~(e5)也是同样的。
表2中,“优选的”序列是“共通15残基序列”中的能作为表位起作用的更短的部分序列。“更优选的”序列是为了提高与ige抗体的结合性而与前述较短的部分片段相比更优选的序列。“关键”序列表示“共通15残基序列”或“关键”序列中的、被认为是特别重要的序列。“关键”序列中的、“x”所表示的氨基酸序列是通过丙氨酸甘氨酸扫描确认到即便变更为任意的丙氨酸(原来的氨基酸残基是丙氨酸的情况下为甘氨酸)也残留有与ige抗体的结合性的氨基酸残基。由此,x为任意的氨基酸残基,优选为丙氨酸(或甘氨酸)。需要说明的是,“关键”的序列中不包含“x”所表示的序列是指:没有发现用丙氨酸甘氨酸扫描能确认到与ige抗体的结合性残留的氨基酸残基的情况。
关于表2所述的各表位,表示为x的氨基酸残基是确认到即便变化与ige抗体的结合性也会残留的氨基酸残基。本发明优选的是,与各“优选的序列”对应的“关键序列”中表示为x的氨基酸残基的1个或多个氨基酸残基任选被置换成任意氨基酸残基。例如,一方式中,在作为优选的序列的序列号5中对应的关键序列存在多个序列号6、8等。以下,在(e1)及其他“优选的序列”、“关键序列”、(e2)-(e5)中是同样的。
任选被置换的氨基酸残基数没有限定,优选为6个以下、5个以下、4个以下、3个以下、2个以下、1个以下。以下,在(e2)-(e5)中是同样的。
本说明书中,“包含(e1)~(e5)的氨基酸序列的多肽”包含:作为优选方式的含有上述的(e1)~(e5)的多肽的各氨基酸序列、或由各氨基酸序列组成的多肽、以及如上所述置换了氨基酸残基的形式(突变体)的任意者。“包含序列号~~的各氨基酸序列”是指:在不对序列号~~的各氨基酸序列(也包含它们的进行了上述置换的方式)与ige抗体的结合(即,它们的作为表位的功能)带来影响的范围内,也可包含其他任意的氨基酸序列。
多肽中的、除了被具体限定的氨基酸序列以外的氨基酸残基可以从不对与ige抗体的结合(即,作为这些表位的功能)产生影响的范围内进行任意选择。非限定性地,优选的是,从成为各自对应的基础的表位的序列、成为基础的蛋白质的序列中适宜选择是理想的。例如,序列号6仅特定了“qkpy”,在添加了其它氨基酸残基的情况下,从适宜的成为基础的序列号5中选择是理想的。此外,对于作为(e1)记载于表2-1的序列,添加源自成为基础的蛋白质(1)(相当于斑点(1))的序列的氨基酸残基是理想的。
包含上述(e1)-(e5)的氨基酸序列的多肽也可以通过肽的固相合成等化学合成的方法来制备。或者,包含表位的多肽可以通过本领域技术人员公知的基因重组技术作为重组多肽表达,然后通过本领域技术人员公知的蛋白质生成方法进行分离/生成来得到。多肽可以组合两种以上而连接,也可以重复1种表位而连接。该情况下,通常与ig抗体的结合性得到改善。
包含上述(e1)-(e5)的氨基酸序列的多肽的长度没有特别限定。在优选的方式中,包含上述(e1)~(e5)的氨基酸序列的多肽的长度为500个氨基酸以下、300个氨基酸以下、200个氨基酸以下、100个氨基酸以下、50个氨基酸以下、30个氨基酸以下、20个氨基酸以下、15个氨基酸以下、10个氨基酸以下、或者5个氨基酸以下。多肽为将一种以上的上述(e1)~(e5)的氨基酸序列重复1次或2次以上而连接的多肽的情况下,在优选的实施方式中,该氨基酸序列部分的长度为1000个氨基酸以下、750个氨基酸以下、500个氨基酸以下、250个氨基酸以下、100个氨基酸以下、75个氨基酸以下、50个氨基酸以下、30个氨基酸以下、15个氨基酸以下、10个氨基酸以下、或者5个氨基酸以下。作为上述多肽的长度,在优选的方式中记载的氨基酸残基的个数是间隔子前后的(不包含间隔子)序列的长度的总计。
本发明的抗原优选的是与变态反应患者的ige抗体特异性结合。
诊断试剂盒/诊断方法(2)
本发明是提供用于对对象的变态反应进行诊断的指标的方法,其包括以下的工序:
(i)使由对象得到的试样与抗原接触,此处,该试样是包含有ige抗体的溶液;
(ii)对由对象得到的试样中的ige抗体与该抗原的结合进行检测;
(iii)检测到对象的ige抗体与该抗原结合时,提供对象为变态反应的指标;
此处,该抗原是包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种的多肽、或者是2种以上的包含上述(e1)~(e5)的氨基酸序列的多肽借由间隔子或不借由间隔子连接而成的多肽。
以下,本说明书中,有时将包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种的多肽、或者是2种以上的包含上述(e1)~(e5)的氨基酸序列的多肽借由间隔子或不借由间隔子连接而成的多肽记载为“包含上述(e1)~(e5)的抗原”。对于间隔子的种类没有特别的限定,为了连接多个肽,可以利用本领域技术人员通常使用的物质。间隔子也可以为例如acp(6)-oh等烃链、氨基酸链等的多肽。
包含上述(e1)~(e5)的氨基酸序列的多肽借由间隔子或不借由间隔子连接的情况下,对于所连接的多肽的个数没有特别的限定。一方式中,为2个以上、3个以上、4个以上、5个以上、6个以上、8个以上、10个以上、15个以上。一方式中,为30个以下、20个以下、15个以下、10个以下、8个以下、6个以下、5个以下、3个以下、2个以下。
包含上述(e1)~(e5)的氨基酸序列的多肽中,可以是相同多肽重复连接、也可以是不同多肽重复连接。这样,连接有多个包含上述(e1)-(e5)的氨基酸序列的多肽的情况下,作为本发明的多肽,可以适用本发明的方法、试剂盒、组合物。
由对象得到的试样如上述“诊断试剂盒/诊断方法(1)”的项目中记载。
由对象得到的试样与该多肽的接触以及它们的结合的检测可以通过上述“诊断试剂盒/诊断方法(1)”的项目中记载的已知的方法、例如:elisa(酶联免疫吸附试验,enzyme-linkedimmunosorbentassay)、夹层免疫测定法(sandwichimmunoassays)、蛋白质免疫印迹法、免疫沉淀法、免疫层析法等进行。
也可以是包含上述(e1)~(e5)的氨基酸序列的多肽被固定于载体的状态。该情况下,上述工序(i)和(ii)中可以利用elisa、夹层免疫测定法、免疫层析法、表面等离子共振等;上述工序(i)可以通过使由对象得到的试样与固定了包含上述(e1)~(e5)的氨基酸序列的多肽的面接触来进行。另外,也可以利用对象的ige抗体被固定于载体的状态的物质,通过上述的方法检测与包含上述(e1)~(e5)的氨基酸序列的多肽的结合。用于与载体的结合或者用于设置载体和间隔子,或者为了使多肽容易与抗体接触,也可以在多肽的n末端或c末端附加间隔子、生物素等标签。与生物素结合的情况下,载体中优选具有抗生物素蛋白。
也可以是包含上述(e1)~(e5)的氨基酸序列的多肽没有被固定于载体的状态。该情况下,在上述工序(i)和(ii)中,可以利用流式细胞仪等,可以通过激光确认结合有ige抗体的包含上述(e1)~(e5)的氨基酸序列的多肽的存在。该方法可列举出例如:作为通过包含上述(e1)~(e5)的氨基酸序列的多肽的接触,对于嗜碱性粒细胞活化时出现的表面抗原cd203c进行检测的方法的、嗜碱性粒细胞活性化试验(bat)。另外,也可列举出通过使包含上述(e1)~(e5)的氨基酸序列的多肽与试样中的血细胞进一步接触来确认是否使组胺游离的组胺游离试验(hrt)。
包含上述(e1)~(e5)的氨基酸序列的多肽是与变态反应患者的ige抗体特异性结合的抗原。因此,检测到对象的ige抗体与该抗原结合的情况下,包含交叉性,提供对象为变态反应的指标。在包含上述(e1)~(e5)的氨基酸序列的多肽的合成中,例如为了容易进行使用大肠杆菌的合成,有时在表位前后附加序列、使序列长度变长。这种情况下,检测到对象的ige抗体与上述(e1)~(e5)的氨基酸序列结合的情况下,包含交叉性,提供对象为变态反应的指标。因此,在作为表位的上述(e1)-(e5)的氨基酸序列前后也可以附加任意的物质。
本发明还提供变态反应的诊断试剂盒,其含有至少一种多肽,所述多肽包含上述(e1)~(e5)的氨基酸序列。本发明的诊断试剂盒可以在上述提供用于诊断变态反应指标的方法或下述诊断方法中应用。本发明的诊断试剂盒除了包含至少一种含有上述(e1)~(e5)的氨基酸序列的多肽之外,还可以包含被酶标记的抗ige抗体以及成为该酶底物的显色底物或发光底物。另外,也可以使用被荧光标记的抗ige抗体。本发明的诊断试剂盒中,也可以以包含上述(e1)~(e5)的氨基酸序列的多肽被固定化于载体的状态提供。本发明的诊断试剂盒还可以与关于用于诊断的步骤的说明书、包含该说明的方法包一起提供。
在另外的方式中,上述的诊断试剂盒包含:针对变态反应的伴侣诊断药物。伴侣诊断药物是指用于以下用途的物质:期待医药品效果的患者的特定或医药品的具有重度副作用风险的患者的特定、或者为了最优化使用了医药品的治疗而研究该医药品的反应性。此处,治疗的最优化包括例如:用法容量的确定、给药中止的判断、使用何种变应原成分来确认是否获得免疫耐受。
本发明还提供包含至少一种含有上述(e1)~(e5)的氨基酸序列的多肽的变态反应的诊断用组合物。本发明的诊断用组合物可以用于下述的诊断方法中。本发明的诊断用组合物还可以根据需要包含通常与本发明的多肽一起使用的、药学上允许的载体、添加剂。
一方式中,本发明为对对象的变态反应进行诊断的方法,其包括以下工序:
(i)使由对象得到的试样与抗原接触;
(ii)对由对象得到的试样中的ige抗体与该抗原的结合进行检测;
(iii)检测到对象ige抗体与该抗原结合的情况下,判断对象为变态反应;
此处,该抗原为作为包含上述(e1)~(e5)的氨基酸序列的多肽而限定的多肽的至少一种。其中,(i)和(ii)的各工序按照对于提供用于诊断变态反应指标的方法的各工序的说明来进行。
另一个方式中,本发明提供诊断对象的变态反应的方法,其包括对对象给予包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种。该方法也可以以特征在于对皮肤施用包含上述(e1)~(e5)的氨基酸序列的多肽的皮肤测试的形式进行。皮肤测试中包含如下形式:对皮肤上施用诊断用组合物之后、以不出血程度地轻微抓伤,使皮肤浸透包含上述(e1)~(e5)的氨基酸序列的多肽再观察皮肤反应的点刺试验(pricktest);施用了诊断用组合物的基础上轻挠皮肤再观察反应的划痕试验(scratchtest);对皮肤施用霜、软膏等形式的诊断用组合物再观察反应的肤斑试验(patchtest);对皮内给予包含上述(e1)~(e5)的氨基酸序列的多肽再观察反应的皮内测试;等。在施用了包含上述(e1)~(e5)的氨基酸序列的多肽部分的皮肤出现肿胀等皮肤反应的情况下,诊断为该对象具有变态反应。此处,对皮肤施用的上述多肽的量也可以为例如每1次100μg以下的用量。
在变态反应的诊断中,经常进行的是以抗原的鉴定与抗原摄取和症状程度的验证为目的的经口耐量试验。包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种可以作为用于诊断变态反应的经口耐量试验的有效成分来使用。此处,作为经口耐量试验中使用的多肽,可以为表达纯化的多肽,也可以为例如在稻子中转化杉木花粉抗原的基因,并且在米内使该多肽表达的花粉米那样的、在原料/加工品中表达多肽。
一方式中,上述诊断用组合物、诊断试剂盒可以用于点刺试验、划痕试验、肤斑试验、皮内测试等。
另外,另一个方式中,本发明提供变态反应的诊断中使用的包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种。
进而在另一个实施方式中,本发明提供包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种在制备变态反应的诊断药物中的应用。
本项目中,成为诊断对象的变态反应为针对包含上述(e1)~(e5)的氨基酸序列的多肽的变态反应。即,包含提供变态反应的检测和诊断指标的变态反应的诊断不仅针对单一的包含上述(e1)~(e5)的氨基酸序列的多肽的变态反应,还可以诊断包含交叉性的变态反应。
组合物/治疗方法(2)
本发明提供含有至少一种包含上述(e1)-(e5)的氨基酸序列的多肽的组合物。
一个方式中,本发明的组合物为药物组合物。一个方式中,本发明的组合物为准药物组合物、非药用组合物(例如化妆用组合物、食品组合物)。
一个方式中,上述的组合物用于治疗变态反应。变态反应的治疗是为了增加即使摄入体内也不会发病的多肽极限量,最终旨在达到通常的多肽的摄取量后不会发病的状态(缓解)。
本发明还提供治疗变态反应的方法,其包括:对于需要治疗变态反应的患者,给予包含上述(e1)~(e5)的氨基酸序列的多肽的至少一者。
另一个方式中,本发明提供变态反应的治疗中使用的包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种。进而在另一个实施方式中,本发明提供包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种在制备变态反应的诊断药物中的应用。
在变态反应的治疗中,经常进行的是目的在于通过对患者给予抗原来诱导免疫耐受的、脱敏治疗法。包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种可以作为治疗变态反应的脱敏治疗法的有效成分来使用。此处,作为脱敏治疗法中使用的抗原,可以为表达纯化的多肽,也可以为例如花粉米那样的、在原料/加工品中表达的物质。
对于本发明的组合物的给药途径、给药量、给药次数和/或给药间隔、组合物中所包含的其他成分、以及剂型,可以设为上述“组合物/治疗方法(1)”项目中记载的内容。使用包含上述(e1)~(e5)的氨基酸序列的多肽的情况下的用量、例如是成人的情况下,也可以是每1次100μg以下的用量。
本项目中,成为治疗对象的变态反应为针对包含上述(e1)~(e5)的氨基酸序列的多肽的变态反应。即,变态反应的治疗不仅针对单一的包含上述(e1)~(e5)的氨基酸序列的多肽的变态反应,还可以治疗包含交叉性的变态反应。
检测组合物(2)
本发明提供检测组合物,其含有抗体,所述抗体针对包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种。
该抗体可以通过常规方法来制作。例如,对兔子等哺乳动物用包含上述(e1)~(e5)的氨基酸序列的多肽进行免疫来制作。该抗体可以为ig抗体、多克隆抗体、单克隆抗体、或者它们的抗原结合片段(例如、fab、f(ab’)2、fab’)。
另外,上述检测组合物中,该抗体可以以与载体结合的形式提供。载体只要是在抗体与包含上述(e1)~(e5)的氨基酸序列的多肽的结合的检测中能够利用的载体,就没有特别的限定。可以利用本领域技术人员公知的任意载体。另外,针对包含上述(e1)~(e5)的氨基酸序列的多肽的抗体优选为针对具有上述“抗原的表位”项目中记载的表位和重要的氨基酸相同的氨基酸序列的多肽的抗体。由此,可以制成能够包含交叉性而检测的检测组合物。
作为用于检查是否含有包含上述(e1)~(e5)的氨基酸序列的多肽的方法,可列举出例如以下的方法。
·使包含制作的抗体的检测组合物与由原料/加工品等得到的试样接触,例如使用elisa法等检测该抗体与试样中的包含上述(e1)~(e5)的氨基酸序列的多肽的结合,在检测到该抗体与包含上述(e1)~(e5)的氨基酸序列的多肽的结合的情况下,判断为对象原料/加工品等中含有包含该氨基酸序列的多肽的方法。(在“检测是否含有多肽的方法”中包含:在该抗体与包含上述(e1)~(e5)的氨基酸序列的多肽的结合降低的情况下,判断多肽被除去或降低了。)
·使滤纸等包裹原料/加工品等,使之与抗体溶液反应来检测其中所含有的包含上述(e1)~(e5)的氨基酸序列的多肽的方法。
本发明另外的实施方式中包含用于判断对象物中有无变态反应的包含上述(e1)~(e5)的氨基酸序列的多肽的检测组合物,其特征在于,其包含与如下多肽对应的引物,所述多肽具有表位和重要的氨基酸相同的氨基酸序列。非限定性地,上述引物被设计成例如包含编码上述(e1)~(e5)中限定的氨基酸序列的核酸的碱基序列的一部分或其互补链。或者,上述引物被设计成:在编码包含具有作为上述(e1)-(e5)中限定的氨基酸序列的表位和重要的氨基酸相同的氨基酸序列的多肽的蛋白质的核酸中,编码具有该表位和重要的氨基酸相同的氨基酸序列的多肽部分的上游侧区域的碱基序列、或者编码具有其表位和重要的氨基酸相同的氨基酸序列的多肽的部分的下游侧的区域的互补链的碱基序列。作为这样的引物,可列举出例如:作为序列号1或3的碱基序列的一部分的引物;和/或、作为与序列号1或3的碱基序列互补的序列的一部分的引物。此处,抗原的全长序列中的表位的位置基于实施例的结果如表1中所限定的那样。特别是在将mrna作为对象的情况下,也可以具有poly(a)tail的互补引物。
例如,以由试样得到的dna或mrna作为模板、使用所述引物,用包含rt-pcr的pcr(聚合酶链式反应,polymerasechainreaction)对dna进行扩增,在所扩增的dna序列中,对于是否含有编码上述(e1)-(e5)中所限定的氨基酸序列的核酸进行判定,从而判断含有上述(e1)-(e5)的抗原的有无。用pcr以mrna作为对象进行扩增的方法可例示出race法等。在扩增的dna中,可能的3种开放阅读框所编码的氨基酸序列之一包含上述(e1)-(e5)中限定的氨基酸序列的情况下,判断为具有抗原。在dna没有扩增的情况下,判断为不具有抗原。
一个方式中,上述检测组合物可以用来检测在加工品生产线中等的对象物中是否含有包含上述(e1)-(e5)的氨基酸序列的多肽。原料可以为食材,也可以为化妆品原料、医药品原料等。加工品可以为食用加工品,也可以为化妆品、医药品等。上述检测组合物可以用于探索可作为原料包含的生物种类,可以由制造业者用在生产线和出厂前产品的质量检查;也可以由品尝者或使用者自己用来检查对象原料/加工品是否含有抗原。
多肽有无的判定方法(2)
本发明包含一种方法,其用于判定在原料/加工品中是否有包含上述(e1)-(e5)的氨基酸序列的多肽。该方法包含在原料/加工品中检测具有包含上述(e1)-(e5)的氨基酸序列的多肽的氨基酸序列全体或部分的多肽。
一方式中,本发明的方法包含如下工序:使针对包含上述(e1)-(e5)的氨基酸序列的多肽的至少一种的抗体与原料/加工品(包含液体)接触的、判定对象物质中有无包含上述(e1)-(e5)的氨基酸序列的多肽。
对于该抗体、原料/加工品所定义抗体的制作方法、使抗体与原料/加工品接触的方法、抗体与抗原的结合等,与“检测组合物(2)”中上述内容相同。
或者,判定有无上述抗原的方法还包含如下方式:对于抗原中所含有的包含上述(e1)-(e5)的氨基酸序列的多肽的表位的部分进行检测。“表位的部分”优选为4个氨基酸残基以上、6个氨基酸残基以上、8个氨基酸残基以上。表位部分的检测可以通过用于检测多肽的一部分的特定的氨基酸序列的公知的方法来进行。可以考虑如下方法等,例如:将对象原料/加工品等(例如食材)的蛋白质通过用于抗原去除处理的消化酶切断,用hplc等进行分离,从而测定任意的表位肽的峰是否通过抗原去除处理而降低了。或者,也可以使用用于识别包含上述(e1)-(e5)的氨基酸序列的多肽部分的抗体,从而判定对象物质中有无包含上述(e1)-(e5)氨基酸序列的多肽的抗原。
抗原去除加工品(2)
本发明提供特征在于去除或降低了包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种的加工品。
对于在加工品中去除或降低本发明的抗原的方法没有限定。抗原的去除或降低不限定于去除或降低了包含上述(e1)~(e5)的氨基酸序列的多肽,可以使用任意的方法来进行,例如也可以使用上述“抗原去除加工品(1)”项目中记载的方法。
包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种被去除或降低可以是氨基酸序列全体被去除或降低而实现的;或者也可以是从抗原蛋白质中、上述(e1)~(e5)的氨基酸序列部分被切断或去除而实现的。“被去除”包含上述(e1)~(e5)所限定的序列部分的全部或一部分缺失和改变。
例如,包含上述(e1)-(e5)的氨基酸序列的多肽被去除或降低了的加工品如使用了蛋白质消化物作为原料的奶粉那样,可以是使用了包含上述(e1)-(e5)的氨基酸序列的多肽被去除或降低了的原料的加工品。使用通常的原料的情况下,在加工品的制备前、制备中或制备后进行去除或降低包含上述(e1)-(e5)的氨基酸序列的多肽的处理。“加工品的制备”是指:由例如胶乳原料制备胶乳加工品。
使用了通常原料的加工品中,作为去除或降低包含上述(e1)-(e5)的氨基酸序列的多肽的方法,也可以使用上述“抗原去除加工品(1)”的项目中记载的方法。作为切断包含上述(e1)-(e5)的氨基酸序列的多肽的方法,可列举出用特定的消化酶进行切断的处理的方法。
去除或降低了抗原的加工品的制造方法(2)
本发明为去除或降低了包含上述(e1)-(e5)的氨基酸序列的多肽的至少一种的加工品的制造方法,其具有如下步骤:在该加工品的制造过程中确认抗原被去除或降低了。
在该制造方法中,包含上述(e1)~(e5)的氨基酸序列的多肽被去除或降低是指:包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种被去除或降低;或者、从前述抗原中,上述(e1)~(e5)所限定的序列部分被切断或去除。
在加工品的制造过程中,对于确认多肽被去除或降低的方法没有特别的限定,可以使用能够检测包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种的任意手法。例如,通过包含在该加工品的制造过程中产生的材料的试样与针对包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种的抗体的结合性,也可以确认该加工品中的该多肽有无存在。这样的方法的详细内容如上述“诊断试剂盒/诊断方法(2)”项目中记载的那样。即,上述制造方法中,将上述“诊断试剂盒/诊断方法(2)”的项目中的“对象的ige抗体”置换为“针对包含上述(e1)~(e5)的氨基酸序列的多肽的至少一种的抗体”,将上述“诊断试剂盒/诊断方法(2)”的项目中的“抗原”“多肽”置换为“包含在加工品的制造过程中产生的材料的试样”,可以使用上述“诊断试剂盒/诊断方法(2)”的项目中记载的手法用于确认在加工品的制造过程中抗原被去除或降低了。另外,也可以使用上述“检测组合物(2)”的项目中记载的检测组合物。
本发明还涉及:试剂盒在诊断变态反应的方法中的应用、用于诊断变态反应的和/或用于提供用于诊断的指标的试剂盒的应用、用于诊断变态反应的方法的组合物、用于诊断变态反应的和/或用于提供用于诊断的指标的组合物的应用、用于诊断变态反应的和/或用于提供用于诊断的指标的方法、抗原在用于检测由对象(人等生物体)得到的试样中有无ige抗体的方法中的应用(蛋白质抗原或表位抗原)、将变态反应用于治疗的抗原(蛋白质抗原或表位抗原)、用于检测由对象(人等生物体)得到的试样中的ige抗体与抗原(蛋白质抗原或表位抗原)之间的结合的包含抗原(蛋白质抗原或表位抗原)的试剂盒或组合物、用于检测由对象(人等生物体)得到的试样中的ige抗体与抗原(蛋白质抗原或表位抗原)之间的结合的包含抗原(蛋白质抗原或表位抗原)的试剂盒或组合物的应用。“抗原”等各术语如上所述。
[实施例]
以下,对于本发明的实施例进行说明。本发明的技术范围不限定于这些实施例。
实施例1:蛋白质图谱的确认
使用下述二维电泳方法,检测橡胶树(heveabrasiliensis)中包含的蛋白质。
蛋白质的提取
胶乳中包含的蛋白质的提取和纯化如下进行。在由天然橡胶的树液得到的蛋白质中加入哺乳动物细胞裂解试剂盒;mcl1(sigma-aldrich公司制)来提取蛋白质。
哺乳动物细胞裂解试剂盒;mcl1的组成如下所述。
50mmtris-hclph7.5
1mmedta
250mmnacl
0.1%(w/v)sds
0.5%(w/v)脱氧胆酸钠
1%(v/v)igepalca-630(sigma-aldrich公司制的表面活性剂(辛基苯氧基)聚乙氧基乙醇)
适量的蛋白酶抑制剂,之后,使用2d-cleanup试剂盒(ge公司制)进行2次沉淀操作。第1次的沉淀操作向回收的上述蛋白质提取液中加入tca(三氯乙酸)进行沉淀,对该操作所产生的沉淀(tca沉淀)进行回收。第2次沉淀操作通过向回收的前述tca沉淀中加入丙酮进行沉淀,对该操作得到的沉淀(被检体)进行回收。
检体溶液的制备
将得到的被检体的一部分(以蛋白质重量计50μg)溶解于第一维等电点电泳用凝胶的溶胀用缓冲液destreakrehydrationsolution(ge公司制)150μl中,作为第一维等电点电泳用的被检体溶液(溶胀用被检体溶液)。destreakrehydrationsolution的组成如下。
7m硫脲
2m尿素
4%(w/v)chaps
0.5%(v/v)ipg缓冲液;ge公司制
适量的bpb(溴酚蓝)
被检体向第一维等电点电泳用凝胶的浸透
将第一维等电点电泳用凝胶(ge公司制:ipg凝胶immobilinedrystrip(ph3-10nl))浸渍于前述的第一维等电点电泳用的被检体溶液(溶胀用被检体溶液)140μl中,在室温下使之浸透一晚。
本实施例中,作为电泳仪使用ge公司制的ipgphor。
泳道中填满了硅油。在浸透了被检体的凝胶两端设置被水润湿的滤纸,以凝胶被硅油覆盖的方式设置泳道,在与凝胶之间以夹着该滤纸的状态设置电极。
将等电点电泳仪电流值的上限设定为每1根凝胶75μa,将电压程序如下进行设置:(1)以300v恒定电压升压至750vhr为止,从而进行恒定电压工序(该工序结束前的泳动30分钟的电流变化幅度为5μa);(2)缓缓地使电压从300vhr升压至1000v为止;(3)进一步,缓缓地使电压从4500vhr升压至5000v为止;(4)之后,以5000v恒定电压直至总vhr成为12000,进行第一维的等电点电泳。
等电点电泳凝胶的sds平衡化
进行了上述第一维等电点电泳之后,从等电点电泳仪将凝胶卸下,在包含还原剂的平衡化缓冲液中浸渍该凝胶,在室温下振荡15分钟。上述包含还原剂的平衡化缓冲液的组成如下。
100mmtris-hcl(ph8.0)
6m尿素
30%(v/v)甘油
2%(w/v)sds
1%(w/v)dtt
接着,去除上述包含还原剂的平衡化缓冲液,使凝胶浸渍于包含烷基化剂的平衡化缓冲液中,在室温下振荡15分钟,得到进行了sds平衡化的凝胶。上述包含烷基化剂的平衡化缓冲液的组成如下。
100mmtris-hcl(ph8.0)
6m尿素
30%(v/v)甘油
2%(w/v)sds
2.5%(w/v)碘乙酰胺
第二维的sds-page
本实施例中,作为电泳仪使用lifetechnologies公司制的xcellsurelockmini-cell。第二维泳动用凝胶使用lifetechnologies公司制nupage4-12%bis-trisgels。另外,制备以下的组成的泳动用缓冲液并使用。
50mmmops
50mmtris碱
0.1%(w/v)sds
1mmedta
另外,本实施例中,使用在泳动用缓冲液中溶解0.5%(w/v)的琼脂糖s(nippongeneco.,ltd.制)和适量的bpb(溴酚蓝)而成的粘接用琼脂糖溶液。
将sds-page的孔中充分地用上述泳动用缓冲液进行洗涤之后,去除该洗涤中使用的缓冲液。接着,向孔中添加充分溶解的粘接用琼脂糖溶液。接着,使进行了sds平衡化的凝胶浸渍于琼脂糖中,用镊子使进行了sds平衡化的凝胶与第二维泳动用凝胶密合。在该两凝胶密合的状态下确认到琼脂糖充分地凝固,以200v恒定电压进行约45分钟泳动。
凝胶的荧光染色
使用syproruby(lifetechnologies公司制)进行凝胶的荧光染色。
首先,将所使用的密闭容器事先用98%(v/v)的乙醇充分地进行洗涤。进行2次如下处理:从sds-page仪器将泳动后的第二维泳动用凝胶卸下,放置于洗净的密闭容器中,在含有50%(v/v)甲醇和7%(v/v)乙酸的水溶液中浸渍30分钟的处理。之后,将该水溶液置换为水,浸渍10分钟。接着,将第二维泳动用凝胶浸渍于40ml的syproruby中,在室温下振荡一晩。接着,去除syproruby,将第二维泳动用凝胶用水洗涤之后,用含有10%(v/v)甲醇和7%(v/v)乙酸的水溶液振荡30分钟。进一步,将该水溶液置换为水,振荡30分钟以上。
解析
将实施了上述一系列处理的第二维泳动用凝胶供于使用了typhoon9500(ge公司制)的荧光图像的扫描中。
实施例2:用免疫印迹的抗原确认
用免疫印迹确认抗原是如下进行的:将实施例1中记载的步骤进行至“第二维的sds-page”为止,之后进行以下的“向膜的转印”、“免疫印迹”、“解析”的操作。
向膜的转印
向膜的转印使用以下的转印装置和转印用缓冲液进行。
转印装置:xcellsurelockmini-cell和xcelliiblotmodule(lifetechnologies公司制)
转印用缓冲液:将nupagetransfer缓冲液(×20)(lifetechnologies公司制)用milliq水稀释200倍然后使用。
具体而言,按照以下的步骤,将二维电泳凝胶中的蛋白质转印到膜(pvdf膜)。
(1)将pvdf膜浸渍于100%甲醇中,然后浸渍于milliq水中,然后转移至转印用缓冲液中,进行pvdf膜的亲水化处理。
(2)按照海绵、滤纸、第二维sds-page结束后的凝胶、亲水化处理后的pvdf膜、滤纸、海绵的顺序进行设置,在转印装置中、30v恒定电压下通电1小时。
免疫印迹
作为第一抗体使用具有胶乳变态反应的患者的血清或者非胶乳变态反应被检者的血清进行膜的免疫印迹。
膜的免疫印迹按照以下的步骤进行。
(1)将转印的膜在5%脱脂奶/pbst溶液(包含0.1%非离子表面活性剂tween20的pbs缓冲液)中、室温下振荡1小时。
(2)作为第一抗体,在4%血清/3%脱脂奶/pbst溶液中、室温下静置1小时。
(3)用pbst溶液进行洗涤(5分钟×3次)。
(4)作为第二抗体将抗人ige-hrp(西洋山葵过氧化酶)在用3%脱脂奶/pbst溶液稀释了1000倍的溶液中、室温下静置1小时。
(5)用pbst溶液进行洗涤(5分钟×3次)。
(6)在piercewesternblottingsubstrateplus(thermo公司制)中静置5分钟。
解析
将实施了上述一系列处理的膜供于使用了typhoon9500(ge公司制)的荧光图像的扫描中。
将使用了胶乳变态反应患者血清的免疫印迹与作为对照的使用了非胶乳变态反应被检者血清的免疫印迹进行比较。对于胶乳所包含的蛋白质使用了胶乳变态反应患者血清的免疫印迹中,与使用了非胶乳变态反应被检者的血清的情况不同,并且检测到与公知的胶乳变应原蛋白质不同的2个斑点。将各斑点的等电点记载于表1。
实施例3:质谱分析和抗原的鉴定
对于上述产生各斑点的抗原,利用质谱分析进行氨基酸序列的鉴定。
具体而言,按照以下的步骤进行蛋白质的提取和质谱分析。
(1)对于胶乳,按照实施例1和2的步骤进行蛋白质提取、二维电泳和膜转印,用0.008%直接蓝(directblue)/40%乙醇·10%乙酸进行振荡而染色。
(2)之后,用40%乙醇·10%乙酸进行5分钟的处理3次进行脱色,用水洗涤5分钟之后进行风干。
(3)将目标的斑点用干净的裁刀切取,加入至离心试管中。用50μl的甲醇进行膜亲水处理之后,用100μl的水洗涤2次之后离心除去,加入20μl的20mmnh4hco3·50%乙腈。
(4)加入1pmol/μl赖氨酸-肽链内切酶(wako)1μl,在37℃下静置60分钟之后,将溶液回收至新的离心试管中。对膜加入20μl的20mmnh4hco3·70%乙腈,在室温下浸渍10分钟,进一步进行回收。用0.1%甲酸、4%乙腈10μl溶解,转移至试管中。
(5)对回收的溶液进行减压干燥之后,用a液(0.1%甲酸、4%乙腈溶液)15μl进行溶解,进行质谱分析(esi-tof6600,absciex公司制)。
(6)基于由质谱仪得到的质谱数据的蛋白质鉴定通过搜索ncbi来进行。
结果
对于各斑点检测了以下的氨基酸序列,进一步,对于各斑点,将由质谱仪得到的质谱数据用uniprot进行解析的结果,鉴定出各斑点为表1所示的蛋白质。
实施例4:表位的鉴定
胶乳的变应原成分的表位
对于胶乳的变应原成分的表位,按照以下的步骤进行表位的鉴定。
(a)胶乳表位映射(1)
通过重叠肽(长度:15个氨基酸)的文库进行表位映射,所述重叠肽对应于作为胶乳的变态反应成分鉴定的氨基酸序列。具体而言,基于序列号2和4的氨基酸序列,制备重叠肽的文库。
使合成的各肽各迁移10个氨基酸。即,各肽具有与前肽和后肽各5个氨基酸的重复。
为了制备肽阵列,使用了intaviscelluspots(商标)技术。即,按照以下步骤进行:(1)在氨基修饰纤维素盘上使用自动化合成装置(intavismultipeprs)合成目标的肽;(2)使前述氨基修饰纤维素盘溶解而得到纤维素结合肽溶液;(3)在实施了涂布的载玻片上点前述纤维素结合肽的斑点,制备肽阵列。各步骤的详细内容如下。
(1)肽的合成
在384孔合成板中的氨基修饰纤维素盘上,利用9-芴甲氧羰酰基(fmoc)化学反应,阶段地进行肽合成。即,将氨基结合有fmoc基的氨基酸在二甲基甲酰胺(dmf)中的n,n’-二异丙基碳二亚胺(dic)和1-羟基苯并三唑(hobt)的溶液中活性化,向前述纤维素盘滴加而使纤维素盘上的氨基与前述fmoc基结合氨基酸结合(偶联),对未反应的氨基用无水乙酸进行封闭反应(capping),并用dmf进行洗涤,进而用哌啶进行处理、利用dmf进行洗涤,从纤维素盘上的氨基所结合的氨基酸的氨基去除fmoc基。对于前述纤维素盘上的氨基所结合的氨基酸,反复进行上述偶联、进行封闭反应和fmoc基的去除,使氨基末端伸长而进行肽合成。
(2)氨基修饰纤维素盘的溶解
将上述“(1)肽的合成”中得到的目标的肽所结合的纤维素盘转移至96孔板,为了进行氨基酸侧链的脱保护,用三氟乙酸(tfa)、二氯甲烷、三异丙基硅烷(tips)和水的侧链脱保护混合液进行处理。之后,将脱保护得到的纤维素结合肽用tfa、三氟甲烷磺酸(tfmsa)、tips和水的混合液进行溶解,用四丁基甲基醚(tbme)使之沉淀,再悬浮于二甲基亚砜(dmso)中,与nacl、柠檬酸钠和水的混合液进行混合,得到载玻片斑点用肽溶液。
(3)纤维素结合肽溶液的斑点
对于上述“(2)氨基修饰纤维素盘的溶解”中得到的载玻片斑点用肽溶液,使用intavis载玻片点样机器人,在intaviscelluspots(商标)载玻片上点斑点,使其干燥而制备肽阵列。
使用所述肽片段,对于各肽片段测定是否通过抗原抗体反应结合有胶乳变态反应患者的血清中的ige抗体。测定按以下步骤进行。
(1)将肽在pierceprotein-free(pbs)blockingbuffer(thermo公司制)中、室温下振荡1小时。
(2)在2%血清/pierceprotein-free(pbs)blockingbuffer(thermo公司制)中、4℃下振荡一晩。
(3)用pbst(包含3%非离子性表面活性剂tween20的pbs缓冲液)进行5分钟洗涤(×3次)。
(4)添加抗人ige抗体-hrp(1:20000、pierceprotein-free(pbs)blockingbuffer(thermo公司制)),在室温下振荡1小时。
(5)用pbst进行5分钟洗涤(×3次)。
(6)添加pierceeclpluswesternblottingsubstrate(thermo公司制),在室温下进行5分钟振荡。
(7)使用amershamimager600,测定实施了上述(1)~(6)处理的肽的化学发光。
对于上述(7)中测定而得到的图像,使用imagequanttl(gehealthcare公司)将化学发光量数值化。由使用4名非胶乳变态反应被检者的血清的结果得到的图像,分别数值化的值中,将第2高的值作为n2nd值,取由使用了17名患者(胶乳变态反应患者17例:分别赋予了患者编号p1~p17)的血清的结果得到的图像数值化得到的值分别减去肽的n2nd值的差而得到的值中,将具有35000以上值的肽判断为特异地与患者ige抗体结合的肽。
其结果,确认了:不包含已知表位的、源自斑点1或斑点2的肽(序列号5、25、35、68、83)与患者ige抗体特异性结合。
(b)胶乳表位映射(2):重叠
以通过上述(a)特异地与患者血清中ige抗体结合的肽的序列(序列号5、25、35、68、83)为基础,在该肽的序列以及包含该肽的序列的变应原成分的氨基酸序列中附加了该肽的前后序列而得到的序列中,制作重叠肽片段(长度:10个氨基酸)的文库、进行了表位映射。
使合成的各肽各迁移1个氨基酸。即,各肽具有与前肽和后肽各9个氨基酸的重复。
文库用与上述(a)同样的步骤制备,用与上述同样的方法针对各肽片段测定是否结合有患者的血清中的ige抗体。将由前述(3)纤维素结合肽溶液的斑点的栏中记载的仅进行了(1)、(4)~(6)时的结果而得到的图像分别数值化的值作为对照值、由使用了患者的血清的结果得到的图像数值化的值减去各肽的对照值的差而得到的值中,与由作为重叠基础的肽而得到的值进行比较,将通过各迁移1个氨基酸的肽而与患者的ige抗体的结合性丧失或显著降低了的肽,判定为没有ige抗体的结合性的肽。
与上述(a)同样地,对于测定而得到的图像,将化学发光量数值化。在将由前述(3)纤维素结合肽溶液的斑点的栏中记载的仅进行了(1)、(4)~(6)时的结果(第二抗体测定值)而得到的图像分别数值化的值作为对照值、由使用了患者的血清的结果得到的图像数值化的值减去各肽的对照值的差而得到的值中,将由作为重叠的基础的序列(序列号5、25、35、68、83)得到的值设为100%时,小于30%判定为没有与ige抗体的结合性;30%以上且小于50%判定为与ige抗体的结合性差但有与ige抗体的结合性;50%以上且小于70%判定为与ige抗体的结合性稍差、但有与ige抗体的结合性;70%以上判定为与ige抗体的结合性没有差别或者与ige抗体的结合性好,是残留有与ige抗体的结合性的肽。
通过该解析,在作为重叠基础的序列中,发现了对于与患者的ige抗体的结合重要的区域。
(c)胶乳表位映射(3):丙氨酸甘氨酸扫描
对于上述(a)中确定的氨基酸序列,通过被称为丙氨酸甘氨酸扫描的方法(非专利文献5),与上述同样的方法制备由氨基酸末端侧起将各1个氨基酸置换为丙氨酸(原来的氨基酸为丙氨酸时置换为甘氨酸)而得到的肽片段的文库,用与上述同样的手法,对于各肽片段测定是否结合有患者血清中的ige抗体。对于通过丙氨酸甘氨酸置换而与患者的ige抗体的结合性丧失或者显著降低了的位置的氨基酸,判断为对于用来表达本来的抗原性重要的氨基酸、或者对于本来的抗原性的表达带来影响的氨基酸;对于与患者的ige抗体的结合性没有丧失或者显著降低了的氨基酸,判断为对于用来表达本来的抗原性并不重要且能够进行置换的氨基酸。
与上述(a)同样地,对于测定而得到的图像,将化学发光量数值化。在将由第二抗体测定值而得到的图像数值化的值作为对照值、由使用了17名患者(患者编号p1~p17)的血清的结果得到的图像数值化的值减去各肽的对照值的差而得到的值中,将由作为丙氨酸甘氨酸扫描的基础的序列(序列号5、25、35、68、83)得到的值设为100%时,小于30%判定为没有与ige抗体的结合性;30%以上且小于50%判定为与ige抗体的结合性差但有与ige抗体的结合性;50%以上且小于70%判定为与ige抗体的结合性稍差、但有与ige抗体的结合性;70%以上判定为与ige抗体的结合性没有差别或者与ige抗体的结合性好,是残留有与ige抗体的结合性的肽。
对于(a)~(c)的结果进行了解析的结果,在以丙氨酸甘氨酸扫描作为基础的序列中的对于与患者的ige抗体的结合重要的区域中,发现了对于用来表达本来的抗原性重要的共通序列。对于5种全部表位限定序列,将结果总结而示于以下的表2。
实施例5:表位的交叉性的确认
关于上述表2中针对胶乳的各蛋白质所发现的各表位序列中的对于维持与ige抗体结合重要的氨基酸除外的氨基酸设为任意的氨基酸(x)的关键序列,针对各患者同时具有的变应原食材用ncbi对具有相同序列的蛋白质进行检索。此时,胶乳变态反应患者被观察到对于香蕉、牛油果、猕猴桃、栗子等显示出交叉性的现象,因此作为一个例子检索了源自香蕉的共通的序列。其结果,作为有关斑点1的蛋白质的表位(e3)的一个例子,命中了源自香蕉的氨基酸序列(syysasda:序列号120)。
对于作为表位(e3)的序列的一个例子具有序列号38、59的氨基酸序列的多肽和具有源自香蕉的序列号120的氨基酸序列的多肽,通过elisa法确认与具有变态反应的患者(患者编号:p12)的ige抗体的结合性。肽以通过fmoc法在n末端侧生物素化的方式合成。
elisa具体而言按照以下的步骤进行。
(1)以生物素化肽的浓度成为10μg/ml的方式用pbst(0.1%tween20)进行制备。
(2)向覆盖了链霉抗生物素蛋白的384孔板的各孔中添加20μl各肽溶液,在室温下振荡1小时。回收溶液之后,用pbst洗涤5次。
(3)添加40μl的pierceprotein-free(pbs)blockingbuffer(thermo公司制),在室温下振荡1小时。去除溶液之后,用pbst洗涤5次。
(4)添加20μl的2%血清/cangetsignalsolutioni(toyobo公司制),在室温下振荡1小时。去除溶液之后,用pbst洗涤5次。
(5)添加20μl的第二抗体稀释液(1:10000、cangetsignalsolutionii(toyobo公司制),在室温下振荡1小时。去除溶液之后,用pbst洗涤5次。
(6)添加20μl的1-stepultratmb-elisa(thermofisherscientifick.k.),室温下振荡15分钟。
(7)添加了20μl的2mh2so4。测定了450nm的吸光度。
用与实施例4的(a)同样的步骤制备具有这些氨基酸序列的肽,对于是否结合有变态反应患者的血清以及非变态反应被检者血清中的ige抗体进行测定。对于非变态反应被检者的血清,使用测定3名并用其平均值作除法而得到的值。
将结果示于图1。图1的柱状图纵轴是“变态反应患者的吸光度/非变态反应被检者的吸光度”。
由图1可知,在具有图中记载的氨基酸序列的每个多肽中,相比于非变态反应被检者的血清中的ige抗体,对于变态反应患者的ige抗体表示出更高的结合性(大于“1”),确认了这些多肽的交叉性。这表示,这些表位能够用于检测与胶乳以外的抗原的交叉性。进而,证明了“x”部分可以取任意的氨基酸残基。
序列表
<110>学校法人藤田学园(fujitaacademy)
朋友股份有限公司(hoyuco.,ltd.)
<120>变态反应的抗原及其表位
<130>fa1621-20044
<160>120
<170>patentinversion3.5
<210>1
<211>714
<212>dna
<213>橡胶树(heveabrasiliensis)
<220>
<221>cds
<222>(1)..(714)
<400>1
atgaaaatgaaacgctctccctactgcttctgctgcagttttgccctt48
metlysmetlysargserprotyrcysphecyscysserphealaleu
151015
ttgcttcttgtgagcttcttgaaggacagacatttttgctctgctgat96
leuleuleuvalserpheleulysasparghisphecysseralaasp
202530
ccaactgatgggttcactgaggtgccattaacagaggacaactttgtc144
prothraspglyphethrgluvalproleuthrgluaspasnpheval
354045
atacagaaaccttatgacaaacccttgaacgatcgttactcttacaaa192
ileglnlysprotyrasplysproleuasnaspargtyrsertyrlys
505560
aatggaattcgacgtttatgggtttatgaaaatgataagcccttcaaa240
asnglyileargargleutrpvaltyrgluasnasplysprophelys
65707580
gttggcagccccaccaggccccgaaccgaaattcgcatcaagggacat288
valglyserprothrargproargthrgluileargilelysglyhis
859095
gactactcatctggagtttggcaattcgaaggccaagtgcatgttcca336
asptyrserserglyvaltrpglnphegluglyglnvalhisvalpro
100105110
gaagggacttctggcgttacagtaatgcaggtatttggcgcagttaac384
gluglythrserglyvalthrvalmetglnvalpheglyalavalasn
115120125
aaagccacggctctgcaacttagggtttacaatggggacttgaagtcc432
lysalathralaleuglnleuargvaltyrasnglyaspleulysser
130135140
tacaagtccaactctgttgccacagacatctacaataagtggttaagg480
tyrlysserasnservalalathraspiletyrasnlystrpleuarg
145150155160
gttaatgtgatccataaagtaggaaaaggagaaataacagttttcatc528
valasnvalilehislysvalglylysglygluilethrvalpheile
165170175
aacggtcaacagaaactggtggtcaatgatgacggaccggcggagcat576
asnglyglnglnlysleuvalvalasnaspaspglyproalagluhis
180185190
tatttcaagtgcggggtgtatgcagcgcctgatggttcaagcaactac624
tyrphelyscysglyvaltyralaalaproaspglyserserasntyr
195200205
atggaatcaaggtggaaaaacatcaagctttacaaaagtgacaataaa672
metgluserargtrplysasnilelysleutyrlysseraspasnlys
210215220
cttgaaggctgtaataataatcatggaacttggctagttcaa714
leugluglycysasnasnasnhisglythrtrpleuvalgln
225230235
<210>2
<211>238
<212>prt
<213>橡胶树(heveabrasiliensis)
<400>2
metlysmetlysargserprotyrcysphecyscysserphealaleu
151015
leuleuleuvalserpheleulysasparghisphecysseralaasp
202530
prothraspglyphethrgluvalproleuthrgluaspasnpheval
354045
ileglnlysprotyrasplysproleuasnaspargtyrsertyrlys
505560
asnglyileargargleutrpvaltyrgluasnasplysprophelys
65707580
valglyserprothrargproargthrgluileargilelysglyhis
859095
asptyrserserglyvaltrpglnphegluglyglnvalhisvalpro
100105110
gluglythrserglyvalthrvalmetglnvalpheglyalavalasn
115120125
lysalathralaleuglnleuargvaltyrasnglyaspleulysser
130135140
tyrlysserasnservalalathraspiletyrasnlystrpleuarg
145150155160
valasnvalilehislysvalglylysglygluilethrvalpheile
165170175
asnglyglnglnlysleuvalvalasnaspaspglyproalagluhis
180185190
tyrphelyscysglyvaltyralaalaproaspglyserserasntyr
195200205
metgluserargtrplysasnilelysleutyrlysseraspasnlys
210215220
leugluglycysasnasnasnhisglythrtrpleuvalgln
225230235
<210>3
<211>933
<212>dna
<213>橡胶树(heveabrasiliensis)
<220>
<221>cds
<222>(1)..(933)
<400>3
atggccaaaagaacccaagccatccttcttcttctcctagcaatctca48
metalalysargthrglnalaileleuleuleuleuleualaileser
151015
ctgattatgtccagctctcatgttgatggtggtggcattgccatttac96
leuilemetserserserhisvalaspglyglyglyilealailetyr
202530
tggggtcaaaatggcaacgaaggaactctaacacaaacatgctccaca144
trpglyglnasnglyasngluglythrleuthrglnthrcysserthr
354045
cgcaaatattcttacgtgaatatagcctttctcaataaatttggcaat192
arglystyrsertyrvalasnilealapheleuasnlyspheglyasn
505560
ggtcaaaccccacaaatcaaccttgccggccattgtaacccggctgct240
glyglnthrproglnileasnleualaglyhiscysasnproalaala
65707580
ggaggttgcaccattgtcagcaatggcatcaggagttgccaaatccaa288
glyglycysthrilevalserasnglyileargsercysglnilegln
859095
ggaattaaggtgatgctttctcttggcggtgggattggaagctacacc336
glyilelysvalmetleuserleuglyglyglyileglysertyrthr
100105110
ctggcctctcaagctgatgcaaaaaacgttgcagactatttgtggaat384
leualaserglnalaaspalalysasnvalalaasptyrleutrpasn
115120125
aatttcttgggtgggaaatcttcttcccgtcccttaggtgatgctgta432
asnpheleuglyglylysserserserargproleuglyaspalaval
130135140
ttggatggtattgattttgacatagagcatggttcaaccctgtactgg480
leuaspglyileasppheaspilegluhisglyserthrleutyrtrp
145150155160
gacgatcttgcacgttacttatctgcatatagcaagcaaggcaagaag528
aspaspleualaargtyrleuseralatyrserlysglnglylyslys
165170175
gtgtatttaactgcagctcctcaatgtccattccctgatagatattta576
valtyrleuthralaalaproglncyspropheproaspargtyrleu
180185190
gggactgcccttaatactggtctttttgactatgtatgggttcaattc624
glythralaleuasnthrglyleupheasptyrvaltrpvalglnphe
195200205
tataacaatcctccatgccagtatagctcaggtaacattaacaacatc672
tyrasnasnproprocysglntyrserserglyasnileasnasnile
210215220
attaactcgtggaatcgatggaccacatctataaatgcagggaaaata720
ileasnsertrpasnargtrpthrthrserileasnalaglylysile
225230235240
tttttggggttgccggcagctcctgaggcagccggaagcggatatgtt768
pheleuglyleuproalaalaproglualaalaglyserglytyrval
245250255
ccaccggatgtgctgatttctcggattcttcctgaaataaagaaatca816
proproaspvalleuileserargileleuprogluilelyslysser
260265270
cctaagtacggaggtgttatgctttggtcaaagttctacgatgataag864
prolystyrglyglyvalmetleutrpserlysphetyraspasplys
275280285
aatggctatagttcctccattctggatagtgtattgttcctccattct912
asnglytyrserserserileleuaspservalleupheleuhisser
290295300
gaagagtgtatgacagtactt933
gluglucysmetthrvalleu
305310
<210>4
<211>311
<212>prt
<213>橡胶树(heveabrasiliensis)
<400>4
metalalysargthrglnalaileleuleuleuleuleualaileser
151015
leuilemetserserserhisvalaspglyglyglyilealailetyr
202530
trpglyglnasnglyasngluglythrleuthrglnthrcysserthr
354045
arglystyrsertyrvalasnilealapheleuasnlyspheglyasn
505560
glyglnthrproglnileasnleualaglyhiscysasnproalaala
65707580
glyglycysthrilevalserasnglyileargsercysglnilegln
859095
glyilelysvalmetleuserleuglyglyglyileglysertyrthr
100105110
leualaserglnalaaspalalysasnvalalaasptyrleutrpasn
115120125
asnpheleuglyglylysserserserargproleuglyaspalaval
130135140
leuaspglyileasppheaspilegluhisglyserthrleutyrtrp
145150155160
aspaspleualaargtyrleuseralatyrserlysglnglylyslys
165170175
valtyrleuthralaalaproglncyspropheproaspargtyrleu
180185190
glythralaleuasnthrglyleupheasptyrvaltrpvalglnphe
195200205
tyrasnasnproprocysglntyrserserglyasnileasnasnile
210215220
ileasnsertrpasnargtrpthrthrserileasnalaglylysile
225230235240
pheleuglyleuproalaalaproglualaalaglyserglytyrval
245250255
proproaspvalleuileserargileleuprogluilelyslysser
260265270
prolystyrglyglyvalmetleutrpserlysphetyraspasplys
275280285
asnglytyrserserserileleuaspservalleupheleuhisser
290295300
gluglucysmetthrvalleu
305310
<210>5
<211>15
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>5
proleuthrgluaspasnphevalileglnlysprotyrasplys
151015
<210>6
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>6
glnlysprotyr
1
<210>7
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>7
aspasnphevalileglnlysprotyrasp
1510
<210>8
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(2)..(2)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(4)..(4)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(8)..(8)
<223>xaa可以为任意天然存在的氨基酸
<400>8
aspxaaphexaaileglnlysxaatyrasp
1510
<210>9
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>9
gluaspasnphevalileglnlysprotyr
1510
<210>10
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>10
glnlysprotyrasplys
15
<210>11
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>11
glnlysprotyr
1
<210>12
<211>5
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>12
glnlysprotyrasp
15
<210>13
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>13
glnlysprotyr
1
<210>14
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>14
glnlysprotyrasplys
15
<210>15
<211>5
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>15
glnlysprotyrasp
15
<210>16
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>16
glnlysprotyrasplys
15
<210>17
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>17
gluaspasnphevalileglnlysprotyr
1510
<210>18
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>18
glnlysprotyrasplys
15
<210>19
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>19
glnlysprotyr
1
<210>20
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>20
glnlysprotyrasplys
15
<210>21
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>21
phevalileglnlysprotyrasp
15
<210>22
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>22
glnlysprotyrasplysproleuasn
15
<210>23
<211>5
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>23
glnlysprotyrasp
15
<210>24
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>24
glnlysprotyr
1
<210>25
<211>15
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>25
lysprotyrasplysproleuasnaspargtyrsertyrlysasn
151015
<210>26
<211>5
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>26
asplysproleuasn
15
<210>27
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>27
lysprotyrasplyspro
15
<210>28
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>28
lysproleuasnaspargtyrser
15
<210>29
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>29
asplysproleuasnasparg
15
<210>30
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>30
lysproleuasn
1
<210>31
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>31
asplysproleuasnasp
15
<210>32
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>32
lysproleuasn
1
<210>33
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>33
lysprotyrasplysproleuasnasparg
1510
<210>34
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>34
asplysproleuasnaspargtyrser
15
<210>35
<211>15
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>35
aspleulyssertyrlysserasnservalalathraspiletyr
151015
<210>36
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>36
leulyssertyrlysserasnservalala
1510
<210>37
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>37
sertyrlysserasnservalalathrasp
1510
<210>38
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>38
sertyrlysserasnservalala
15
<210>39
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>39
sertyrlysserasnserval
15
<210>40
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(1)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(4)..(4)
<223>xaa可以为任意天然存在的氨基酸
<400>40
xaatyrlysxaaasnserval
15
<210>41
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>41
sertyrlysserasnserval
15
<210>42
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(2)..(2)
<223>xaa可以为任意天然存在的氨基酸
<400>42
serxaalysserasnserval
15
<210>43
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(2)
<223>xaa可以为任意天然存在的氨基酸
<400>43
xaaxaalysserasnserval
15
<210>44
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>44
sertyrlysserasnser
15
<210>45
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(1)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(3)..(3)
<223>xaa可以为任意天然存在的氨基酸
<400>45
xaatyrxaaserasnser
15
<210>46
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>46
leulyssertyrlysserasnservalala
1510
<210>47
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>47
leulyssertyrlysserasnserval
15
<210>48
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>48
lysserasnservalalathraspile
15
<210>49
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>49
lysserasnservalalathrasp
15
<210>50
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(2)..(2)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<400>50
lysxaaasnserxaaalathrasp
15
<210>51
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(2)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(7)..(7)
<223>xaa可以为任意天然存在的氨基酸
<400>51
lysxaaxaaserxaaalaxaaasp
15
<210>52
<211>5
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>52
leulyssertyrlys
15
<210>53
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>53
lysserasnservalalathraspiletyr
1510
<210>54
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(3)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(10)..(10)
<223>xaa可以为任意天然存在的氨基酸
<400>54
lysserxaaservalalathraspilexaa
1510
<210>55
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(3)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(7)..(7)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(10)..(10)
<223>xaa可以为任意天然存在的氨基酸
<400>55
lysserxaaserxaaalaxaaaspilexaa
1510
<210>56
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(3)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(7)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(10)..(10)
<223>xaa可以为任意天然存在的氨基酸
<400>56
lysserxaaserxaaxaaxaaaspilexaa
1510
<210>57
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>57
leulyssertyrlysserasnservalala
1510
<210>58
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>58
sertyrlysserasnservalalathrasp
1510
<210>59
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>59
sertyrlysserasnservalala
15
<210>60
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<400>60
sertyrlysserxaaservalala
15
<210>61
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(7)..(7)
<223>xaa可以为任意天然存在的氨基酸
<400>61
sertyrlysserxaaserxaaala
15
<210>62
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(1)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(3)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(7)..(7)
<223>xaa可以为任意天然存在的氨基酸
<400>62
xaatyrxaaserxaaserxaaala
15
<210>63
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>63
valalathraspiletyr
15
<210>64
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(6)..(6)
<223>xaa可以为任意天然存在的氨基酸
<400>64
valalathraspilexaa
15
<210>65
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(1)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(6)..(6)
<223>xaa可以为任意天然存在的氨基酸
<400>65
xaaalathraspilexaa
15
<210>66
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>66
sertyrlysserasnser
15
<210>67
<211>5
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>67
lysserasnserval
15
<210>68
<211>15
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>68
valasnvalilehislysvalglylysglygluilethrvalphe
151015
<210>69
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>69
hislysvalglylysglygluile
15
<210>70
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>70
hislysvalglylysgly
15
<210>71
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>71
valasnvalilehislysvalglylysgly
1510
<210>72
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(3)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(8)..(8)
<223>xaa可以为任意天然存在的氨基酸
<400>72
valasnxaailexaalysvalxaalysgly
1510
<210>73
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(2)..(5)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(7)..(8)
<223>xaa可以为任意天然存在的氨基酸
<400>73
valxaaxaaxaaxaalysxaaxaalysgly
1510
<210>74
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>74
valilehislysvalglylysglygluile
1510
<210>75
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>75
hislysvalglylysglygluile
15
<210>76
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(1)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(4)..(4)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(8)..(8)
<223>xaa可以为任意天然存在的氨基酸
<400>76
xaalysvalxaalysglygluxaa
15
<210>77
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(1)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(4)..(4)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(7)..(8)
<223>xaa可以为任意天然存在的氨基酸
<400>77
xaalysvalxaalysglyxaaxaa
15
<210>78
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>78
lysvalglylys
1
<210>79
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>79
lysvalglylys
1
<210>80
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>80
lysvalglylysglygluilethrvalphe
1510
<210>81
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(6)
<223>xaa可以为任意天然存在的氨基酸
<400>81
xaaxaaxaalysxaaxaailethrvalphe
1510
<210>82
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(6)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(9)..(9)
<223>xaa可以为任意天然存在的氨基酸
<400>82
xaaxaaxaalysxaaxaailethrxaaphe
1510
<210>83
<211>15
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>83
trpserlysphetyraspasplysasnglytyrserserserile
151015
<210>84
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>84
serlysphetyraspasplysasngly
15
<210>85
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>85
serlysphetyraspasplysasn
15
<210>86
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(3)
<223>xaa可以为任意天然存在的氨基酸
<400>86
xaaxaaxaatyraspasplysasn
15
<210>87
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>87
tyraspasplysasnglytyrserserser
1510
<210>88
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>88
aspasplysasnglytyrserserser
15
<210>89
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(8)..(9)
<223>xaa可以为任意天然存在的氨基酸
<400>89
aspasplysasnxaatyrserxaaxaa
15
<210>90
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(2)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(8)..(9)
<223>xaa可以为任意天然存在的氨基酸
<400>90
aspxaaxaaasnxaatyrserxaaxaa
15
<210>91
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>91
trpserlysphetyraspasplys
15
<210>92
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>92
lysphetyraspasplysasnglytyrser
1510
<210>93
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>93
lysphetyraspasplys
15
<210>94
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(1)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(4)..(4)
<223>xaa可以为任意天然存在的氨基酸
<400>94
xaaphetyrxaaasplys
15
<210>95
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>95
aspasplysasnglytyrserserser
15
<210>96
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(1)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<400>96
xaaasplysasnxaatyrserserser
15
<210>97
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(1)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(5)..(5)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(8)..(9)
<223>xaa可以为任意天然存在的氨基酸
<400>97
xaaasplysasnxaatyrserxaaxaa
15
<210>98
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>98
trpserlysphetyraspasplys
15
<210>99
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>99
lysphetyraspasplysasnglytyrser
1510
<210>100
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>100
lysphetyraspasplys
15
<210>101
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>101
asplysasnglytyrserserser
15
<210>102
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(2)..(2)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(6)..(6)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(8)..(8)
<223>xaa可以为任意天然存在的氨基酸
<400>102
aspxaaasnglytyrxaaserxaa
15
<210>103
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(2)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(6)..(6)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(8)..(8)
<223>xaa可以为任意天然存在的氨基酸
<400>103
xaaxaaasnglytyrxaaserxaa
15
<210>104
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>104
trpserlysphetyraspasplys
15
<210>105
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>105
serlysphetyraspasplys
15
<210>106
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>106
lysphetyraspasplys
15
<210>107
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>107
tyraspasplysasnglytyrserserser
1510
<210>108
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(1)..(2)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(6)..(6)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(8)..(10)
<223>xaa可以为任意天然存在的氨基酸
<400>108
xaaxaaasplysasnxaatyrxaaxaaxaa
1510
<210>109
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>109
trpserlysphetyraspasplys
15
<210>110
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>110
tyraspasplysasnglytyrserserser
1510
<210>111
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<220>
<221>misc_feature
<222>(2)..(3)
<223>xaa可以为任意天然存在的氨基酸
<220>
<221>misc_feature
<222>(10)..(10)
<223>xaa可以为任意天然存在的氨基酸
<400>111
tyrxaaxaalysasnglytyrserserxaa
1510
<210>112
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>112
trpserlysphetyraspasplysasngly
1510
<210>113
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>113
trpserlysphetyraspasplysasn
15
<210>114
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>114
lysphetyraspasplys
15
<210>115
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>115
trpserlysphetyraspasplysasn
15
<210>116
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>116
trpserlysphetyrasp
15
<210>117
<211>5
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>117
serlysphetyrasp
15
<210>118
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>118
tyraspasplysasnglytyrserserser
1510
<210>119
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>119
asplysasnglytyrserserser
15
<210>120
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>表位(epitope)
<400>120
sertyrtyrseralaseraspala
15
- 还没有人留言评论。精彩留言会获得点赞!