一种快速高效的构建二代测序文库的试剂盒的制作方法
mgcl
2
、1-10mm dtt、20-100μm dntp、0.2-1.0mm datp、20-80mm nacl、0.1-1mg/ml bsa、体积比0.1%-0.5%tritonx-100,体积比0.1%-1%enhance。
[0013]
上述任一方案中优选的是,所述enhance可以是twen20、np40其中的一种或两种的组合。
[0014]
上述任一方案中优选的是,所述dna片段化酶是非特异性核酸酶和t7 endonuclease i,所述非特异性核酸酶为嗜盐弧菌vvn(vibrio vulnificus)核酸酶。
[0015]
上述任一方案中优选的是,所述末端修复加尾酶为t4多聚核苷酸激酶、t4 dna聚合酶、taq dna聚合酶、klenow酶几种酶的组合。
[0016]
上述任一方案中优选的是,所述接头为u字形接头,且接头的序列如seq id no.1所示:
[0017]
seq id no.1:5
’-
gatcggaagagcacacgtctgaactccagtcuacactctttccctacacgacgctcttccgatct-3
’
;
[0018]
其中,第一位g碱基进行磷酸化修饰,3
′
端最后两个核苷酸之间的连接键进行硫代磷酸化修饰,u碱基为dutp。
[0019]
本发明的技术效果和优点:1、dna片段化酶使用了vvn核酸酶,这是一种序列非特异性的核酸酶,可以在dna上随机产生切口,不具有碱基偏好性;
[0020]
2、在dna片段化、末端修复和加a尾中,添加了enhance,可以促进taq酶的加尾活性,使得更多的末端修复片段加上a碱基,从而使更多的加a片段连上接头,提高了片段的利用率;
[0021]
3、接头使用u型接头,减少了接头二聚体的产生,使更多的接头用于连接dna片段,提高了文库的转化率。
附图说明
[0022]
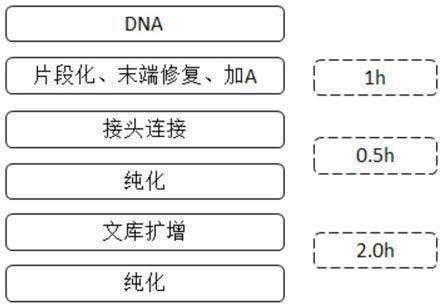
图1为本发明中的传统二代测序建库流程;
[0023]
图2为利用本发明的试剂盒采取的二代测序建库流程;
[0024]
图3为试验例1构建的文库2100图;
[0025]
图4为试验例2构建的文库2100图。
具体实施方式
[0026]
下面将结合本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0027]
下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的试验材料,如无特殊说明,均为自常规生化试剂商店购买得到的。以下实施例中的定量试验,均设置三次重复实验,结果取平均值。
[0028]
针对
背景技术:
提到的有些试剂盒的建库转化率低,尤其是对微量样本,这会造成样本很大的损失。针对微量样本,建议用酶切片段化的方法,以减少样本的损失。
[0029]
市面上报道可用于核酸打断的片段化酶有很多,应用于高通量测序的片段化酶有
dnase i、endonuclease v、tn5转座酶、限制性内切酶等。
[0030]
dnase-在不同的离子存在下可以片段化dsdna,如在镁离子存在条件下,dnase i随机剪切双链dna的任意位点;二价锰离子存在条件下,dnasei可在同一位点剪切dna双链,形成平末端,或1-2个核苷酸突出的粘末端。然而,实际操作中却易受到多种条件的影响,如酶的用量,反应温度,底物dna的纯度等。此外研究发现dnase-对嘧啶核苷酸旁边位点有偏好性,大大影响终文库的多样性。endonuclease v一般识别特定的位点,随机引入尿嘧啶可用于dna的随机片段化。由于碱基序列组成的差异,样本的gc含量对endonuclease v片段化效果有潜在影响,实际操作中尤其是ngs应用中也会受到诸多条件的限制。tn5转座酶也可以切割dna,但是由于其片段化的偏好性经常受到业界的诟病。据统计tn5在插入位点两侧9个碱基左右有明显的偏好性。还有些公司使用几种限制性内切酶的组合,虽然增加限制性内切酶的个数,可以在一定程度上缓解偏好性,但是限制性内切酶始终是存在对序列的偏好性。
[0031]
本发明打断dna采用的是序列非特异性核酸酶——vvn核酸酶和t7 endonuclease i的组合。vvn核酸酶可以在dna上随机产生切刻,进而t7 endonuclease i识别这个缺刻并在互补链上切割,从而产生dna双链断裂。只需要改变酶切时间就可以将dna酶切至特定大小的dna片段,与初始的input dna量以及input dna长度无关。
[0032]
本发明所用的dna片段化酶所用的dna可以是各种原核真核微生物基因组、动植物基因组以及人和小鼠基因组等,也可以是cdna,但是需要保证dna是溶于无二价阳离子的溶剂中,不溶于二价阳离子的溶剂,如果溶于二价阳离子的溶剂中,需要事先对其进行纯化。因为二价阳离子会抑制片段化酶的活性。
[0033]
本发明为了进一步提高片段的利用率,在加尾时,添加了非离子型去污剂做为taq酶的增强剂,促进taq酶的活性,使得更多的末端修复片段加上a碱基,从而使更多的加a片段连上接头,促进了片段的利用率。
[0034]
为了进一步提高文库的转化率,本发明在接头连接步骤中,使用的是u字型的接头。这种类型的接头其一端是封闭的,可以减少接头间的反应,从而可以减少接头二聚体的产生,使更多的接头被有效的利用,进而使更多的连上接头的有效片段被测序。
[0035]
实施例一:
[0036]
一种快速高效的构建二代测序文库的试剂盒,包括r1、r2和r3;
[0037]
所述r1包括dna片段化末端修复加尾缓冲液、dna片段化酶和末端修复加尾酶;
[0038]
所述r2包括连接缓冲液、连接酶和接头;
[0039]
所述r3包括扩增酶、user酶、通用引物和index引物。
[0040]
dna片段化末端修复加尾缓冲液包括10mm tris-hcl、10mm mgcl
2
、1mm dtt、20μm dntp、0.2mm datp、20mm nacl、0.1mg/ml bsa、体积比0.1%tritonx-100,体积比0.1%twen20。
[0041]
所述dna片段化酶是非特异性核酸酶和t7 endonuclease i,其中非特异性核酸酶为vvn核酸酶。
[0042]
所述末端修复加尾酶为t4多聚核苷酸激酶、t4 dna聚合酶、taq dna聚合酶、klenow酶几种酶的组合。
[0043]
所述接头为u字形接头,且接头的序列如seq id no.1所示:
[0044]
5
’-
gatcggaagagcacacgtctgaactccagtcuacactctttccctacacgacgctcttccgatct-3
’
;
[0045]
其中,第一位g碱基进行磷酸化修饰,3
′
端最后两个核苷酸之间的连接键进行硫代磷酸化修饰,u碱基为dutp。
[0046]
实施例二:
[0047]
一种快速高效的构建二代测序文库的试剂盒,包括r1、r2和r3;
[0048]
所述r1包括dna片段化末端修复加尾缓冲液、dna片段化酶和末端修复加尾酶;
[0049]
所述r2包括连接缓冲液、连接酶和接头;
[0050]
所述r3包括扩增酶、user酶、通用引物和index引物。
[0051]
dna片段化末端修复加尾缓冲液包括30mm tris-hcl、30mm mgcl
2
、5mm dtt、130μm dntp、0.6mm datp、50mm nacl、0.5mg/ml bsa、体积比0.3%tritonx-100,体积比0.5%twen20。
[0052]
所述dna片段化酶是vvn核酸酶和t7 endonuclease i。
[0053]
所述末端修复加尾酶为t4多聚核苷酸激酶、t4 dna聚合酶、taq dna聚合酶、klenow酶几种酶的组合。
[0054]
所述接头为u字形接头,且接头的序列如seq id no.1所示:
[0055]
5
’-
gatcggaagagcacacgtctgaactccagtcuacactctttccctacacgacgctcttccgatct-3
’
;
[0056]
其中,第一位g碱基进行磷酸化修饰,3
′
端最后两个核苷酸之间的连接键进行硫代磷酸化修饰,u碱基为dutp。
[0057]
实施例三:
[0058]
一种快速高效的构建二代测序文库的试剂盒,包括r1、r2和r3;
[0059]
所述r1包括dna片段化末端修复加尾缓冲液、dna片段化酶和末端修复加尾酶;
[0060]
所述r2包括连接缓冲液、连接酶和接头;
[0061]
所述r3包括扩增酶、user酶、通用引物和index引物。
[0062]
dna片段化末端修复加尾缓冲液包括50mm tris-hcl、50mm mgcl
2
、10mm dtt、100μm dntp、1.0mm datp、80mm nacl、1mg/ml bsa、体积比0.5%tritonx-100,体积比1%twen20。
[0063]
所述dna片段化酶是vvn核酸酶和t7 endonuclease i。
[0064]
所述末端修复加尾酶为t4多聚核苷酸激酶、t4 dna聚合酶、taq dna聚合酶、klenow酶几种酶的组合。
[0065]
所述接头为u字形接头,且接头的序列如seq id no.1所示:
[0066]
5
’-
gatcggaagagcacacgtctgaactccagtcuacactctttccctacacgacgctcttccgatct-3
’
;
[0067]
其中,第一位g碱基进行磷酸化修饰,3
′
端最后两个核苷酸之间的连接键进行硫代磷酸化修饰,u碱基为dutp。
[0068]
实施例四:
[0069]
一种快速高效的构建二代测序文库的试剂盒,包括r1、r2和r3;
[0070]
所述r1包括dna片段化末端修复加尾缓冲液、dna片段化酶和末端修复加尾酶;
[0071]
所述r2包括连接缓冲液、连接酶和接头;
[0072]
所述r3包括扩增酶、user酶、通用引物和index引物。
[0073]
dna片段化末端修复加尾缓冲液包括30mm tris-hcl、30mm mgcl
2
、5mm dtt、130μm dntp、0.6mm datp、50mm nacl、0.5mg/ml bsa、体积比0.3%tritonx-100,体积比0.5%twen20、体积比0.5%np40。
[0074]
所述dna片段化酶是vvn核酸酶和t7 endonuclease i。
[0075]
所述末端修复加尾酶为t4多聚核苷酸激酶、t4 dna聚合酶、taq dna聚合酶、klenow酶几种酶的组合。
[0076]
所述接头为u字形接头,且接头的序列如seq id no.1所示:
[0077]
5
’-
gatcggaagagcacacgtctgaactccagtcuacactctttccctacacgacgctcttccgatct-3
’
;
[0078]
其中,第一位g碱基进行磷酸化修饰,3
′
端最后两个核苷酸之间的连接键进行硫代磷酸化修饰,u碱基为dutp。
[0079]
一种快速高效的构建二代测序文库的方法,按照先后顺序包括以下步骤:
[0080]
s1,向含有dna的试管中加入dna片段化末端修复加尾缓冲液、dna片段化酶和末端修复加尾酶,充分混合后,于4℃孵育1分钟,32℃孵育5-35分钟,65℃-75℃孵育15-30分钟,得到末端修复、加a尾的dna片段;
[0081]
s2,然后向上述dna片段中加入接头、连接缓冲液和连接酶充分混合,于20℃-37℃孵育15-30分钟,得到带接头的片段,对带接头的片段进行pcr富集,接着通过磁珠纯化步骤进行纯化;
[0082]
s3,然后向上述带接头的片段中加入高保真扩增酶、通用引物和index引物,对带接头的片段进行扩增,得到dna文库。
[0083]
为了更好的理解本发明的用法,下面将展示两个具体的试验例。
[0084]
试验例1:以人基因组dna为实验材料,构建快速高效的可测序文库。
[0085]
建库流程如图2所示,具体实验步骤如下:
[0086]
(1)样本准备:用qubit精确测定基因组dna的浓度,按测定的浓度计算10ng所需要添加的片段体积,剩下用水(nfw)补足至27.6μl;
[0087]
(2)片段化、末端修复及加a:具体反应体系如表1所示:
[0088]
表1
[0089]
组分体积(μl)dna27.6dna片段化末端修复加尾缓冲液10dna片段化酶10末端修复加尾酶2.4总计50
[0090]
其中,末端修复加尾酶组分为:t4多聚核苷酸激酶0.2u/μl,t4 dna聚合酶0.02u/μl,klenow片段0.02u/μl,taq酶0.02u/μl;
[0091]
dna片段化末端修复加尾缓冲液组分为:tris-hcl 50mm,mgcl
2 10mm,dtt 1mm,dntp 20μm,datp 0.2mm,nacl 20mm,bsa 0.1mg/ml,tritonx-100体积比0.1%,twen20体积
比0.5%;
[0092]
体系配制完成后将反应管置于pcr仪或其它热孵育反应仪器中,设置32℃孵育22分钟;65℃孵育30分钟,取出反应管进行下一步反应;
[0093]
(3)接头连接:向经步骤(2)处理过的修复片段及所在反应液中加入连接试剂,将接头与dna片段连接起来,反应体系如下表2所示:
[0094]
表2
[0095]
组分体积(μl)上一步产物50接头8连接缓冲液16连接酶6总计80
[0096]
体系配制完成后将反应管置于pcr仪或其它热孵育反应仪器中,设置25℃15min,反应结束后取出反应管进行下一步纯化过程;
[0097]
该步骤中使用的接头的序列如seq id no.1所示,由seq id no.1自身退火环化而成;
[0098]
(4)带接头片段纯化:连接完成后的反应体系使用0.8x磁珠进行纯化;然后分别经过80%乙醇漂洗、nfw洗脱得到纯化后的带接头片段;
[0099]
(5)pcr扩增:利用扩增酶、user酶、通用引物、index引物对纯化后的带接头片段进行pcr富集,得到dna文库,具体见表3:
[0100]
表3
[0101]
组分体积(μl)上一步产物17高保真扩增酶混液25user酶3通用引物(10μm)2.5index引物(10μm)2.5总计50
[0102]
接着,按照表4的pcr程序进行pcr扩增;
[0103]
表4
[0104][0105]
(6)pcr后纯化:反应完成后,将pcr管拿出,瞬时离心,将所有液体收集到管底,用等体积的磁珠进行纯化,纯化完毕后用20μl无核酸酶水进行洗脱即可出库;
[0106]
(7)文库质检:使用dsdna hs assay kit检测文库的浓度,使用2100生物分析仪分析文库片段大小,均按照说明书要求进行操作,经质检,如表5和图3可以看出,本发明的方法快速,构建的文库总量高。
[0107]
表5
[0108]
起始量ng浓度ng/μl体积μl总量ng1020.220404
[0109]
试验例2:
[0110]
与实施例一不同的是,dna片段化末端修复加尾缓冲液组分为:tris-hcl 40mm,mgcl
2 5mm,dtt 3mm,dntp 30μm,datp 0.3mm,nacl 30mm,bsa 0.2mg/ml,tritonx-100体积比0.15%,twen20体积比0.75%;
[0111]
末端修复加尾酶组分为:t4多聚核苷酸激酶0.1/μl,t4 dna聚合酶0.02u/μl,klenow片段0.01/μl,taq酶0.02u/μl;
[0112]
其余均与实施例一相同,建库效果同实施例1基本一致,结果如下表6和图4。
[0113]
表6
[0114]
起始量ng浓度ng/μl体积μl总量ng1019.820396
[0115]
可见,本发明通过改进缓冲液体系和酶体系,改变接头的形状,使得微量起始建库快速且高效,该方法有效解决了部分珍贵的、难获得的样本总量过低无法建库测序,或者建库转化率低,文库质量较差的问题,提高了二代测序的适用范围,使得其应用范围更广。
[0116]
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的方法及技术内容作出些许的更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1