加条形码的XTEN多肽及其组合物以及其制备和使用方法与流程
加条形码的xten多肽及其组合物以及其制备和使用方法
1.序列表
2.本技术含有序列表,所述序列表已以ascii格式电子提交,并且在此以引用的方式全文并入。于2020年11月6日创建的所述ascii副本命名为20-1761-wo_sequence_listing_st25.txt,且大小为1494字节。
背景技术:
3.多肽可以以导致多肽混合物的方式产生。多肽混合物经常可以包括全长多肽,连同其大小变体(例如,截短)。与所需全长产物在大小方面不同的变体的存在可以影响多肽原料药(drug substance)的生物学行为,潜在地影响多肽原料药的安全性和/或功效。例如,用于癌症治疗的基于蛋白质的前药可以被改造为具有肿瘤靶向激活机制。更具体而言,全长治疗性蛋白质可以无活性的(非细胞毒性的)前药形式产生且施用,所述前药形式通过在预期生物侧(例如,肿瘤)处优先去除前药多肽的一部分而转换为活性药物。全长构建体的截短变体可以丧失保护序列并变得细胞毒性的(活性的),从而“污染”前药组合物并产生具有在预期生物学位点外非有意活性的组分的混合物。在一些情况下,此类较短长度的变体可以造成更大的免疫原性风险,对于肿瘤细胞具有更少的选择性毒性,或与全长蛋白质相比,显示更不期望的药代动力学概况(例如,导致治疗窗变窄),或在预期部位外(例如在健康组织中)在受体中有害地具有非预期效应。结果,蛋白质结构变化的检测和定量对于评价生物治疗剂的生物学性质(例如临床安全性和药理功效)和开发新的生物治疗剂(例如具有增加的功效和减少的副作用)可以是重要的。用于鉴定且定量“污染性”截短产物的量的现有技术和方法可以包括一个或多个缺点,例如具有有限的灵敏度、容易性、效率或有效性。
技术实现要素:
4.本文公开的是包含延伸重组多肽(xten)的多肽,所述延伸重组多肽包含多个非重叠序列基序。在本发明的xten多肽中,多个非重叠序列基序包含:一组非重叠序列基序,其中所述序列基序各自在xten多肽中重复至少两次;以及在xten多肽内仅出现一次的唯一的非重叠序列基序;其中所述多肽还包含在被蛋白酶消化后可从多肽中释放的第一条形码片段。在所述实施例中,第一条形码片段是xten的一部分,其包括在xten内仅出现一次的序列基序的至少一部分,并且在序列和分子量方面不同于多肽被蛋白酶完全消化后可从多肽中释放的所有其它肽片段。进一步地,在本文提供的本发明的xten实施例中,条形码片段不包括多肽的n末端氨基酸或c末端氨基酸。如本文进一步公开的,本发明的xten多肽的特征为包含长度为至少150个氨基酸,更具体而言长度为150-3000个氨基酸。构成本发明的xten多肽的氨基酸进行表征,其中这些残基的至少90%是甘氨酸(g)、丙氨酸(a)、丝氨酸(s)、苏氨酸(t)、谷氨酸盐(e)或脯氨酸(p),并且xten多肽包含这些氨基酸(g、a、s、t、e或p)中的至少四种。另外,如本文提供的xten多肽包含长度为9至14个氨基酸的序列的非重叠序列基序,并且在所述非重叠基序各自内,具有g、a、s、t、e或p氨基酸的序列关于构成xten多肽的任何
其它非重叠序列基序是基本上随机化的。
5.在一些实施例中,条形码片段不包括紧邻xten中的另一个谷氨酸的谷氨酸。在一些实施例中,条形码片段具有在其c末端处的谷氨酸。在一些实施例中,条形码片段具有之前紧为谷氨酸残基的n末端氨基酸。在一些实施例中,在n末端氨基酸之前的谷氨酸残基并不紧邻另一个谷氨酸残基。在一些实施例中,条形码片段不包括在除条形码片段的c末端外的位置处的谷氨酸残基,除非谷氨酸紧随其后为脯氨酸。在一些实施例中,条形码片段定位为距离多肽的n末端或多肽的c末端10个氨基酸至150个氨基酸。
6.在一些实施例中,该组非重叠序列基序的序列基序在本文中通过seq id no:182-203和1715-1722进行鉴定。在一些实施例中,该组非重叠序列基序的序列基序在本文中通过seq id no:186-189进行鉴定。在一些实施例中,该组非重叠序列基序包含序列基序seq id no:186-189中的至少两个、至少三个或所有四个。
7.在具体实施例中,本文提供的多肽包含如本文公开的xten多肽,其中所述条形码片段不包括多肽的n末端氨基酸或c末端氨基酸;不包括紧邻xten中的另一个谷氨酸的谷氨酸;具有在其c末端处的谷氨酸;具有之前紧为谷氨酸残基的n末端氨基酸;并且定位距离多肽的n末端或多肽的c末端10个氨基酸至125个氨基酸。
8.在这些具体实施例的一些中,在n末端氨基酸之前的谷氨酸残基并不紧邻另一个谷氨酸残基。在这些具体实施例的一些中,条形码片段不包括在除条形码片段的c末端外的位置处的谷氨酸残基,除非谷氨酸紧随其后为脯氨酸。
9.在一些实施例中,本文提供的xten多肽包含多个非重叠序列基序,其中每个所述序列基序在xten多肽中重复至少两次并且长度为9至14个氨基酸。在一些实施例中,该组非重叠序列基序的序列基序在本文中通过seq id no:182-203和1715-1722进行鉴定。在一些实施例中,该组非重叠序列基序的序列基序在本文中通过seq id no:186-189进行鉴定。在一些实施例中,该组非重叠序列基序包含序列基序seq id no:186-189中的至少两个、至少三个或所有四个。在一些实施例中,xten多肽的至少91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的氨基酸残基是甘氨酸(g)、丙氨酸(a)、丝氨酸(s)、苏氨酸(t)、谷氨酸盐(e)或脯氨酸(p)的组合,其中xten多肽包含这些氨基酸(g、a、s、t、e或p)中的至少四种。在一些实施例中,xten的长度为150至3000个氨基酸。在一些实施例中,xten的长度为150至1000个氨基酸。在一些实施例中,多肽可以被蛋白酶切割,所述蛋白酶在谷氨酸残基的c末端侧上切割,所述谷氨酸残基随后并非为脯氨酸。在某些实施例中,蛋白酶是glu-c蛋白酶。
10.在本文提供的xten多肽的一些实施例中,条形码片段定位于多肽的n末端的200、150、100或50个氨基酸内。在一些实施例中,条形码片段定位于距离蛋白质的n末端10至200、30至200、40至150、或50至100个氨基酸之间。在一些实施例中,条形码片段定位于多肽的c末端的200、150、100或50个氨基酸内。在一些实施例中,条形码片段定位于距离蛋白质的c末端10至200、30至200、40至150、或50至100个氨基酸之间。在一些实施例中,条形码片段的长度为至少4个氨基酸。在一些实施例中,条形码片段的长度为4至20、5至15、6至12、或7至10个氨基酸。在一些实施例中,条形码片段在本文中通过seq id no:8020-8030(bar001-bar011)进行鉴定。
11.在一些实施例中,多肽还包含第二条形码片段,其中所述第二条形码片段是xten
的一部分,并且在序列和分子量方面不同于多肽被蛋白酶完全消化后可从多肽中释放的所有其它肽片段。在一些实施例中,多肽还包含第三条形码片段,其中所述第三条形码片段是xten的一部分,并且在序列和分子量方面不同于多肽被蛋白酶完全消化后可从多肽中释放的所有其它肽片段。
12.在一些实施例中,xten与在本文中通过seq id no:8001-8019鉴定的序列具有至少90%、至少92%、至少95%、至少98%、至少99%或100%的序列同一性。在一些实施例中,xten的长度为至少200、至少250、至少300、至少350、至少400、至少450或至少500个氨基酸。
13.在一些实施例中,多肽还包含与xten多肽(bpxten)连接的生物活性多肽。在一些实施例中,xten多肽在xten的氨基或羧基末端处与生物活性多肽连接。在任一构型中,条形码片段定位于xten的区域内,如从与生物活性多肽连接的氨基或羧基末端测量的,所述区域延伸xten的长度的5%至50%、7%至40%、或10%至30%。
14.在一些实施例中,bpxten多肽还包含在被蛋白酶消化后可从多肽中释放的一个或多个参考片段,其中所述一个或多个参考片段各自包含生物活性多肽的一部分。在一些实施例中,一个或多个参考片段是在序列和分子量方面不同于多肽被蛋白酶消化后可从多肽中释放的所有其它肽片段的单个参考片段。在一些实施例中,所述参考片段包含肽,其在多肽混合物中的存在指示其存在或完整性(即,蛋白质尚未被降解或蛋白酶解切割)。
15.在一些实施例中,bpxten多肽还包含定位于xten和生物活性多肽之间的第一释放区段(rs1)。在一些实施例中,rs1包含与在本文中通过表4a-4h中的任何一种序列鉴定的序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。在一些实施例中,生物活性多肽在本文中通过表4a-4h和8a-8b中的任何一种序列或序列组合进行鉴定。
16.在一些实施例中,与未连接至任何xten的生物活性多肽相比,bpxten多肽有利地具有至少两倍的终末半衰期。
17.在一些实施例中,与未连接至任何xten的生物活性多肽相比,bpxten多肽有利地是更少免疫原性的,其中免疫原性可以通过在向人或动物施用可比较剂量后,测量与生物活性多肽选择性结合的igg抗体的产生来确定。
18.在一些实施例中,bpxten多肽在生理条件下显示出大于约6的表观分子量因子。
19.在一些实施例中,bpxten多肽还包含第二xten多肽,其中所述第二xten多肽包含具有与上文和本公开内容自始至终对于bpxten的这些实施例的第一xten组分阐述的相同特性的氨基酸序列,并且其中所述第一xten多肽定位于生物活性多肽的n末端,且所述第二xten多肽定位于生物活性多肽的c末端。在一些实施例中,第二xten多肽包含的氨基酸序列不同于构成bpxten的这些实施例的第一xten的氨基酸序列。在某些实施例中,第二xten多肽的氨基酸序列长于第一xten多肽的氨基酸序列。
20.在一些实施例中,bpxten多肽还包含定位于生物活性多肽和第二xten多肽之间的第二释放区段(rs2)。在一些实施例中,第一xten多肽的rs1和第二xten多肽的rs2序列相同。在一些实施例中,第一xten多肽的rs1和第二xten多肽的rs2各自是用于被多重蛋白酶在每个释放区段序列内的一个、或两个、或三个或更多个切割位点处切割的底物。
21.在这些实施例的一些中,bpxten多肽包含进一步的条形码片段,其是第二xten多肽的一部分,并且在序列和分子量方面不同于多肽被蛋白酶完全消化后可从多肽中释放的
所有其它肽片段。在这些实施例的一些中,进一步的条形码片段不包括多肽的c末端氨基酸。在这些实施例的一些中,进一步的条形码片段包含在其c末端处的谷氨酸残基。在这些实施例的一些中,第二xten多肽的进一步的条形码片段定位于bpxten多肽的第二xten组分的c末端的200、150、100或50个氨基酸内。在这些实施例的一些中,第二xten多肽的进一步的条形码片段定位于距离bpxten多肽的第二xten组分的c末端10至200、30至200、40至150、或50至100个氨基酸之间的位置处。在这些实施例的一些中,进一步的条形码片段的长度为4至20、5至15、6至12、或7至10个氨基酸。在这些实施例的一些中,进一步的条形码片段在本文中通过seq id no:8020-8030(bar001-bar011)进行鉴定。
22.在一些实施例中,第二xten多肽还包含一组条形码片段,其包括进一步的条形码片段和至少一个另外的条形码片段,其中该组条形码片段中的每个条形码片段在序列和分子量方面不同于多肽被蛋白酶完全消化后可从bpxten多肽中释放的所有其它肽片段。在一些实施例中,第二xten多肽通过seq id no:8001-8019进行鉴定。在一些实施例中,进一步的条形码片段不包括紧邻多肽中的另一个谷氨酸残基的谷氨酸残基。
23.在一些实施例中,第二xten多肽的至少91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的氨基酸残基是甘氨酸(g)、丙氨酸(a)、丝氨酸(s)、苏氨酸(t)、谷氨酸盐(e)和脯氨酸(p)的组合,其中xten多肽包含这些氨基酸(g、a、s、t、e或p)中的至少四种。在一些实施例中,第一xten多肽中的氨基酸总数和第二xten多肽中的氨基酸总数之和为至少300、至少350、至少400、至少500、至少600、至少700或至少800个氨基酸。在一些实施例中,第二xten多肽包含多个非重叠序列基序,其中所述序列基序各自在第二xten多肽序列中重复至少两次,并且长度为9至14个氨基酸。
24.在一些实施例中,对于第二xten多肽,多个非重叠序列基序的序列基序在本文中通过seq id no:182-203和1715-1722进行鉴定。在一些实施例中,多个非重叠序列基序的序列基序在本文中通过seq id no:186-189进行鉴定。在一些实施例中,对于第二xten多肽,多个非重叠序列基序包含下述基序中的至少两个、至少三个或所有四个:seq id no:186-189。在一些实施例中,第二xten多肽的长度为150至3000个氨基酸。在一些实施例中,第二xten多肽的长度为150至1000个氨基酸。在一些实施例中,第二xten多肽与在本文中通过seq id no:8001-8019鉴定的序列具有至少90%、至少92%、至少95%、至少98%、至少99%或100%的序列同一性。在一些实施例中,第二xten多肽的长度为至少200、至少250、至少300、至少350、至少400、至少450或至少500个氨基酸。
25.在特定实施例中,本文提供的bpxten多肽包括包含接近但不构成多肽的c末端的第一rs序列的第一xten多肽,所述第一xten多肽共价连接至串联共价连接的第一生物活性多肽和第二生物活性多肽,其中第二xten多肽共价连接至串联连接的生物活性多肽的c末端,其中所述第二xten多肽包含接近但不构成第二xten多肽的n末端的第二rs序列,其中所述第一rs序列和第二rs序列可以是相同或不同的。在特定实施例中,第二xten多肽包含比第一xten多肽的氨基酸序列更长的氨基酸序列。在某些实施例中,第一生物活性蛋白质或第二生物活性蛋白质或两者包含特异性结合蛋白,在某些实施例中,其中所述特异性结合蛋白与在所需生物学位点处表达的抗原或激动剂特异性结合。在特定实施例中,所需生物学位点是肿瘤,并且抗原是肿瘤特异性抗原。在特定实施例中,第一生物活性多肽和第二生物活性多肽是不同的,包括但不限于具有不同的特异性结合亲和力。
26.本文还公开的是核酸,其包含编码多肽例如本文公开的任何xten或bpxten多肽的多核苷酸或者所述多核苷酸的反向互补体。
27.本文还公开的是表达载体,其包含本文公开的任何多核苷酸序列和可操作地连接到多核苷酸序列的调控序列,所述调控序列调控所述多核苷酸序列的表达或其它生物活性。
28.本文公开的是包含如本文公开的表达载体的宿主细胞。在一些实施例中,宿主细胞是原核生物。在这些实施例的一些中,宿主细胞是大肠杆菌。在一些替代实施例中,宿主细胞是哺乳动物细胞。
29.本文另外公开的是药物组合物,其包含如本文公开的多肽和一种或多种药学上可接受的赋形剂。在一些实施例中,药物组合物配制用于施用于动物且特别是人,其中所述施用可以通过任何治疗有效的施用途径。如本文公开的药物组合物可以制备并用于任何制剂中,所述制剂是本领域已知的且特别适于对人或动物的施用途径、部位和预期效应。
30.本文公开的是如本文公开的多肽且特别是bpxten多肽在制备用于治疗人或动物中的疾病、病症或状况的药物中的用途。在一些实施例中,疾病、病症或状况可以是癌症。
31.本文公开的是如上文和本公开内容自始至终公开的治疗人或动物中的疾病的方法,该方法包括向有此需要的人或动物施用药物组合物的一个或多个治疗有效剂量。在一些实施例中,药物组合物作为一个或多个治疗有效剂量施用于人或动物,所述治疗有效剂量在临床上适当的时间表上每天一次、每周一次、每月一次或每年一次且以临床上适当的剂量施用。
32.本文公开的是包含各种长度的多种多肽特别是如本文公开的xten和bpxten多肽的混合物,该混合物包含:
33.第一组多肽,其中所述第一组多肽中的每种多肽包含条形码片段,所述条形码片段可通过用蛋白酶消化从所述多肽中释放,并且具有的序列和分子量不同于可从所述第一组多肽中释放的所有其它片段的序列和分子量;和
34.缺乏所述第一组多肽的条形码片段的第二组多肽;
35.其中所述第一组多肽和第二组多肽两者各自包含参考片段,所述参考片段是第一组多肽和第二组多肽共有的,并且通过用蛋白酶消化产生;和
36.其中所述第一组多肽/包含所述参考片段的多肽的比率大于0.7。
37.在一些实施例中,第一组多肽/包含参考片段的多肽的比率大于0.8、0.9、0.95或0.98。在一些实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现不多于一次。在一些实施例中,蛋白酶是在谷氨酸残基的c末端侧上切割的蛋白酶。在一些实施例中,来自包含第一组多肽的多肽的条形码释放通过胃蛋白酶、弹性蛋白酶、嗜热菌蛋白酶或glu-c蛋白酶得到促进。在一些实施例中,条形码释放通过glu-c蛋白酶得到促进。在一些实施例中,蛋白酶不是胰蛋白酶。在一些实施例中,各种长度的多肽包括包含如本文所述的至少一种xten多肽的多肽。
38.在一些实施例中,第一组多肽包含全长多肽,其中所述条形码片段是全长多肽的一部分。在一些实施例中,全长多肽是本文公开的任何多肽,且特别是xten和bpxten多肽。在一些实施例中,条形码片段不包含全长多肽的n末端氨基酸或c末端氨基酸。在一些实施例中,各种长度的多肽的混合物由于全长多肽的n末端截短、c末端截短或n末端和c末端截
短两者而彼此不同。
39.本文公开的是在包含各种长度的多肽且特别是如本文公开的xten和bpxten多肽的混合物中,用于评价混合物中的第一组多肽与混合物中的第二组多肽的相对量的方法,其中所述第一组多肽中的每种多肽共享在多肽中出现一次且仅一次的条形码片段,并且所述第二组多肽中的每种多肽缺乏由第一组多肽共享的条形码片段,其中所述第一组多肽和第二组多肽两者中的各个多肽各自包含参考片段,该方法包括:
40.使混合物与蛋白酶接触,以产生来源于第一组多肽和第二组多肽的切割的多个蛋白酶解片段,其中所述多个蛋白酶解片段包含多个参考片段和多个条形码片段;和
41.确定条形码片段的量/参考片段的量的比率,从而评价所述第一组多肽与所述第二组多肽的相对量。
42.在一些实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现不多于一次。
43.在一些实施例中,蛋白酶在谷氨酸残基的c末端侧上切割各种长度的多肽,所述谷氨酸残基随后并非脯氨酸残基。在一些实施例中,蛋白酶是glu-c蛋白酶。在一些实施例中,蛋白酶不是胰蛋白酶。在一些实施例中,确定条形码片段的量/参考片段的量的比率包括在多肽的混合物已与蛋白酶接触后,定量来自混合物的条形码片段和参考片段。在一些实施例中,条形码片段和参考片段基于其分别的质量进行鉴定。在一些实施例中,条形码片段和参考片段经由质谱法进行鉴定。在一些实施例中,条形码片段和参考片段经由液相色谱-质谱法(lc-ms)进行鉴定。在一些实施例中,确定条形码片段/参考片段的比率包括同量异序标记或稳定同位素标记。在一些实施例中,确定条形码片段/参考片段的比率包括用同位素标记的参考片段和同位素标记的条形码片段之一或两者掺料混合物。
44.在这些实施例的一些中,各种长度的多肽包含全长多肽及其截短片段。在这些实施例的一些中,各种长度的多肽的混合物由于全长多肽的n末端截短、c末端截短或n末端和c末端截短两者而彼此不同。在这些实施例的一些中,条形码片段/参考片段的量的比率大于0.5、0.6、0.7、0.8、0.9、0.95、0.98或0.99。
45.本文公开的是包含各种长度的多种多肽的混合物,该混合物包含第一组多肽,其中所述第一组多肽中的每种多肽包含条形码片段,所述条形码片段可通过用蛋白酶消化从多肽中释放,并且具有的序列和分子量不同于可从第一组多肽中释放的所有其它片段的序列和分子量。所述实施例还包括缺乏第一组多肽的条形码片段的第二组多肽,其中所述第一组多肽和第二组多肽两者各自包含参考片段,所述参考片段是第一组多肽和第二组多肽共有的,并且可通过用蛋白酶消化释放。在所述实施例中,在蛋白酶消化后多肽混合物中定量的参考片段的数目等于混合物中的第一组多肽和第二组多肽的数目之和,并且在蛋白酶消化后多肽混合物中定量的条形码片段的数目等于混合物中的第一组多肽的数目。在所述实施例中,第一组多肽包含一个参考片段,所述第一组多肽/混合物中包含参考片段的多肽的比率大于0.7。
46.在一些实施例中,混合物具有大于0.8、0.9或0.95的第一组多肽/包含参考片段的多肽的比率。
47.在一个特定实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现不多于一次。在替代实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现
两次。
48.在一些实施例中,第一组多肽包含全长多肽,其中所述条形码片段是全长多肽的一部分。
49.在一些实施例中,全长多肽包括本文公开的多肽。
50.在一个特定实施例中,混合物条形码片段不包含全长多肽的n末端氨基酸和c末端氨基酸。
51.在一些实施例中,混合物含有各种长度的多肽,其由于全长多肽的n末端截短、c末端截短或n末端和c末端截短两者而彼此不同。
52.在一些实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现不多于一次。在一个替代实施例中,第一组多肽中的参考片段数目可以不同于第二组多肽中的参考片段数目,但其在每组中的每种多肽中的数目必须是相同的。
53.在一个特定实施例中,混合物的多肽中的参考片段各自具有的序列和分子量不同于所有其它片段的序列和分子量。
54.本文公开的是包含各种长度的多种多肽的混合物,该混合物包含第一组多肽,其中所述第一组多肽中的每种多肽包含
55.条形码片段,所述条形码片段可通过用蛋白酶消化从多肽中释放,并且具有的序列和分子量不同于可从第一组多肽中释放的所有其它片段的序列和分子量。该混合物还包含缺乏第一组多肽的条形码片段的第二组多肽,其中所述第一组多肽和第二组多肽两者各自包含参考片段,所述参考片段是第一组多肽和第二组多肽共有的,并且可通过用蛋白酶消化释放。第一组多肽/混合物中的多肽的比率具有下式:
56.[含条形码的多肽]/[(含参考肽的多肽)x n]
[0057]
其中n是从混合物中的每种多肽中释放的参考肽的出现次数,并且其中当第一组多肽包含一个参考片段时,第一组多肽/混合物中包含参考片段的多肽的比率大于0.7。
[0058]
在一个特定实施例中,第一组多肽/包含参考片段的多肽的比率大于0.8、0.9或0.95。
[0059]
在一些实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现不多于一次。
[0060]
在一些实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现两次。
[0061]
在一个特定实施例中,第一组多肽包含全长多肽,其中所述条形码片段是全长多肽的一部分。
[0062]
在一些实施例中,全长多肽包括本文公开的多肽。在一个特定实施例中,条形码片段不包含全长多肽的n末端氨基酸和c末端氨基酸。
[0063]
在一些实施例中,各种长度的多肽的混合物由于全长多肽的n末端截短、c末端截短或n末端和c末端截短两者而彼此不同。
[0064]
在一些实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现不多于一次。在进一步的实施例中,第一组多肽中的参考片段数目可以不同于第二组多肽中的参考片段数目,但其在每组中的每种多肽中的数目必须是相同的。在一些实施例中,混合物的多肽中的参考片段具有的序列和分子量不同于所有其它片段的序列和分子量。
[0065]
本文公开的是在本文公开的混合物中检测包含第一组多肽的多肽的序列完整性的方法,该方法包括用蛋白酶消化多肽混合物的步骤,所述蛋白酶从第一组多肽中释放条形码片段和参考片段,且从第二组多肽中释放参考片段,并且确定来自第一组多肽的条形码片段/来自第一组多肽和第二组多肽的参考片段的比率。在一个特定实施例中,通过基于包含第一组多肽和第二组多肽的多肽中的条形码片段和参考片段数目,比较片段的比率与片段的预期比率来检测第一组多肽的多肽的序列完整性。
[0066]
本文考虑的方法容易地顺应例如通过使用lc/ms,含有条形码和/或参考片段的多肽的定性和定量分析。在一个特定实施例中,lc/ms是定量的,并且检测同位素可区分量的条形码片段、参考片段或两者。在示例性的此类方法中,多肽的混合物用已知量的“标准材料”进行掺料,以促进此类分析。例如,此类标准材料是包含待分析的所述各种长度的多种多肽的混合物的同位素标记形式的标准材料。这种同位素标记的标准可以在被所述蛋白酶消化之前作为完整序列加入混合物中。可替代地,各种长度的多肽的混合物的测试样品和同位素标记的标准材料在分开的反应中被蛋白酶消化,并且在通过lc/ms分析之前,将蛋白酶消化的同位素标记的标准材料加入测试样品中。本发明的方法还包括通过与检测到的同位素可区分量的条形码片段、参考片段或两者的定量的比较,定量来自测试样品的条形码片段、参考片段或两者的量。
[0067]
在审查本公开内容后,本领域技术人员将想到这些实施例的变化和修改。前述特征和方面可以用本文描述的一个或多个其它特征以任何组合和子组合(包括多重从属组合和子组合)来实现。上文描述或示出的各种特征,包括其任何组分,可以在其它实施例中组合或集成。此外,某些特征可以省略或不实现。
[0068]
以引用的方式并入
[0069]
本说明书中提到的所有出版物、专利和专利申请都以引用的方式并入本文,其程度与每个个别出版物、专利或专利申请特异性且个别地指示以引用的方式并入相同。
附图说明
[0070]
本公开内容的各种特征在所附权利要求中特别阐述。通过参考阐述其中利用本发明的原理的说明性实施例的下述详细描述以及附图,可以获得本公开内容的特征和优点的更好理解,在所述附图中:
[0071]
图1描绘了具有各种长度的xten多肽的xten化蛋白酶激活的t细胞接合剂(xtenylated protease-activated t cell engager)(“xpat”)多肽的混合物。全长xpat(顶部)包含在n末端处的长288个氨基酸的xten多肽和在c末端处的长864个氨基酸的xten多肽。例如,在发酵、纯化或产物制备中的其它步骤期间,可以在xpat中的n末端和c末端xten多肽之一或两者中出现各种截短。虽然具有有限截短(靠近距离与其连接的蛋白酶激活的t细胞接合剂远端的xten多肽一部分的截短)的产物可以以类似于全长构建体的方式发挥功能,但严重截短(更接近于距离与其连接的蛋白酶激活的t细胞接合剂近端的xten多肽一部分的截短)可以具有与其全长配对物显著不同的药理性质。截短的存在对于定量xpat产物中的药理学有效和无效变体提出了挑战。如图1中使用全长xpat示出的,每种xten多肽具有近端和远端,其中所述近端相对于远端定位更接近于生物活性多肽(例如,t细胞接合剂、细胞因子、单克隆抗体(mab)、抗体片段或xten化的其它蛋白质)。取决于键合取向,
xten多肽的近端或远端可以对应于xten多肽的n末端或c末端。
[0072]
图2描绘了具有各种长度的加条形码的xten多肽的xpat多肽的混合物。在全长xpat(顶部)中,长288个氨基酸的n末端xten多肽含有三个可切割地融合的条形码序列,“na”、“nb”和“nc”(从远端到近端),并且长864个氨基酸的c末端xten多肽含有三个可切割地融合的条形码序列,“cc”、“cb”和“ca”(从近端到远端)。每个条形码定位为指示相应xten多肽的药理学相关长度。例如,缺乏条形码“na”但具有更近端的条形码“nb”和“nc”的xpat的次要n末端截短产物,可以显示与全长构建体基本上相同的药理性质。相比之下,例如缺乏在n末端上的所有三个条形码的xpat的主要n末端截短产物,可以在药理活性方面可辨别地不同于全长构建体。从xpat的生物活性多肽(此处,包含t细胞接合剂的活性部分的串联scfv)中鉴定唯一的可蛋白酶解切割序列。由于其存在于xpat的所有长度变体(包括全长xpat、其次要截短和主要截短)中,唯一的可蛋白酶解切割序列可以用作用于相对于生物活性蛋白质的总量定量各种截短产物的量的参考。
[0073]
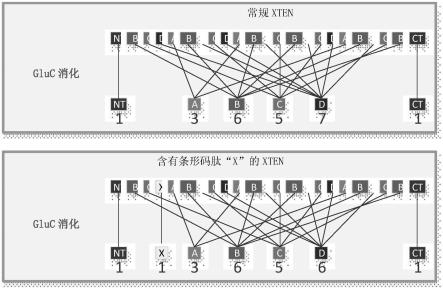
图3示出了通过将条形码生成序列插入通用(或常规)xten多肽内,关于加条形码的xten多肽的潜在设计。示例性通用(或常规)xten多肽(顶部)包含序列“bcdabdcdabdcbdcdabdcb”中的非重叠12聚体基序,其中序列基序“a”、“b”、“c”和“d”分别出现3、6、5和7次。示例性通用xten多肽(上图)的glu-c蛋白酶消化不产生除了两个末端(“nt”和“ct”)之外的唯一肽。将条形码生成序列“x”(例如,唯一的12聚体)插入xten多肽内,导致在xten多肽的其它任何地方都不出现的唯一的可蛋白酶解切割序列(或条形码序列)。条形码生成序列“x”可以这样定位,其中所得到的条形码标记xten多肽的药理学相关长度。例如,缺乏条形码的xten多肽可以在功能上不同于具有条形码的相应xten多肽。本领域普通技术人员将理解条形码生成序列(“x”)可以是条形码序列本身。可替代地,条形码生成序列(“x”)可以不同于所得到的条形码序列。例如,条形码序列可以与之前或之后的12聚体基序重叠并因此含有其部分。
[0074]
图4a-4b示出了关于n末端xten多肽的截短水平的定量。图4a证实了可以通过用条形码生成基序“x”替换通用xten多肽(上图)中的序列基序(例如,从n端开始的第三个序列基序,“d”),来构建加条形码的xten多肽(下图);并且,在这个例子中,条形码生成基序(“x”)本身是唯一的可蛋白酶解切割的条形码序列。如图4a中的下图中所示,条形码这样定位,其中xten多肽的所有严重截短形式都缺乏条形码,并且xten多肽的所有有限截短形式都含有条形码。图4b示出了xpat的两种不同混合物中的各种切割产物的相对丰度。在混合物之一中,条形码存在于99%的含有生物活性蛋白质的构建体中。在混合物的另一种中,13%的构建体缺乏条形码。图4a-4b示出了使用加条形码的xten多肽来区分具有基本上相似的平均分子量但具有可辨别地不同的药理活性的两种多肽混合物。
[0075]
图5a示出了xpat蛋白的分析尺寸排阻色谱法(sec)和全长蛋白质及其截短衍生物的检测。合成蛋白质+截短物级分包括与完整合成蛋白质一样大的片段。
[0076]
图5b示出了如通过质谱法检测到的,xpat制剂中的条形码肽的丰度。每个测量是针对其相应的重同位素标记的合成肽的400nm峰标准化的,n-条形码sgpgstpae(seq id no.8029)和c-条形码gsapgte(seq id no.8023)的xic面积。
[0077]
专利或申请文件含有至少一幅彩色绘图。本专利或专利申请公开的带彩色附图的副本将在请求和支付必要费用后由专利局提供。
[0078]
术语
[0079]
如本文使用的,除非另有说明,否则下述术语具有归于其的含义。
[0080]
如说明书和权利要求中使用的,单数形式“一个”、“一种”和“该/所述”包括复数所指物,除非上下文另有明确说明。例如,术语“细胞”包括多种细胞,包括其混合物。
[0081]
术语“多肽”、“肽”和“蛋白质”在本文中可互换使用,以指任何长度的氨基酸聚合物。聚合物可以是线性或分支的,它可以包含修饰的氨基酸,并且它可以被非氨基酸中断。该术语还涵盖氨基酸聚合物,其已例如通过二硫键形成、糖基化、脂化、乙酰化、磷酸化或任何其它操作例如与标记组分缀合进行修饰。
[0082]
如本文使用的,术语“氨基酸”指天然和/或非天然或合成氨基酸,包括但不限于甘氨酸和d或l光学异构体两者,以及氨基酸类似物和拟肽。标准的单字母代码或三字母代码用于指定氨基酸。
[0083]“宿主细胞”包括个别细胞或细胞培养物,其可以是或已经是人或动物载体的受体。宿主细胞包括单个宿主细胞的后代。由于天然存在或遗传改造的变异,后代不一定与原始亲本细胞完全等同(在形态学或总dna互补体的基因组方面)。
[0084]“嵌合”蛋白质含有至少一种多肽,其包含在序列中与自然界中存在的不同的位置中的区域。区域可以通常存在于分开的蛋白质中,并且在融合多肽中结合在一起;或者它们可以通常存在于相同的蛋白质中,但在融合多肽中以新的排列放置。所述蛋白质可以描述为“缀合的”、“连接的”、“融合的”或“融合”蛋白质;这些术语在本文中可互换使用,并且指通过包括化学缀合或重组手段的无论何种手段,将两种或更多种多肽序列连接在一起。例如,可以通过化学合成或通过产生且翻译其中肽区域以所需关系编码的多核苷酸来产生嵌合蛋白。
[0085]
术语“多核苷酸”、“核酸”、“核苷酸”和“寡核苷酸”可互换使用,并且指任何长度的核苷酸的聚合形式,所述核苷酸是脱氧核糖核苷酸或核糖核苷酸或其类似物。多核苷酸可以具有任何三维结构,并且可以执行已知或待发现或开发的任何功能。多核苷酸可以包含修饰的核苷酸,例如甲基化核苷酸和核苷酸类似物。如果存在的话,则可以在聚合物组装之前或之后赋予对核苷酸结构的修饰。核苷酸序列可以被非核苷酸组分中断。多核苷酸可以在聚合后例如通过与标记组分缀合进行进一步修饰。
[0086]
术语“多核苷酸的互补体”指示与参考序列相比,具有互补碱基序列和反向取向的多核苷酸分子,其中它可以完全保真地与参考序列杂交。
[0087]
如本文使用的,具有“同源性”或“同源”的多核苷酸是这样的多核苷酸,其在如本文定义的严格条件下与那些序列杂交,并且与那些序列具有至少70%、优选至少80%、更优选至少90%、更优选95%、更优选97%、更优选98%、且甚至更优选99%的序列同一性。
[0088]
当应用于多核苷酸序列时,术语“百分比同一性”和“%同一性”指使用标准化算法比对的至少两个多核苷酸序列之间的残基匹配的百分比。此类算法可以以标准化和可重现的方式在被比较的序列中插入空位,以便优化两个序列之间的比对,并且因此实现两个序列的更有意义的比较。百分比同一性可以在例如如由特定的seq id编号定义的整个限定多核苷酸序列的长度上进行测量,或者可以在较短的长度上,例如在取自较大的限定多核苷酸序列的片段的长度上进行测量,所述片段例如至少45、至少60、至少90、至少120、至少150、至少210或至少450个连续残基的片段。此类长度仅是示例性的,并且应理解,由本文在
表、附图或序列表中显示的序列支持的任何片段长度,都可以用于描述可以在其上测量百分比同一性的长度。
[0089]
关于本文鉴定的多肽序列的“百分比(%)氨基酸序列同一性”,定义为在比对序列和必要时引入空位以实现最大百分比序列同一性后,并且不考虑将任何保守取代作为序列同一性的部分,查询序列中与第二参考多肽序列或其一部分的氨基酸残基相同的氨基酸残基的百分比。用于确定百分比氨基酸序列同一性目的的比对可以以在本领域技术内的各种方式来实现,所述方式例如使用可公开可用的计算机软件如blast、blast-2、align或megalign(dnastar)软件。本领域技术人员可以确定用于测量比对的适当参数,包括在被比较的序列的全长上实现最大比对所需的任何算法。百分比同一性可以在例如如由特定的seq id编号定义的整个限定多肽序列的长度上进行测量,或者可以在较短的长度上,例如在取自较大的限定多肽序列的片段的长度上进行测量,所述片段例如至少15、至少20、至少30、至少40、至少50、至少70或至少150个连续残基的片段。此类长度仅是示例性的,并且应理解,由本文在表、附图或序列表中显示的序列支持的任何片段长度,都可以用于描述可以在其上测量百分比同一性的长度。
[0090]
如本文使用的,xten多肽氨基酸序列的“重复性”指3聚体重复性,并且可以通过计算机程序或算法或者通过本领域已知的其它手段进行测量。xten多肽氨基酸序列的3聚体重复性可以通过确定多肽内的重叠3聚体序列的出现次数进行评价。例如,具有200个氨基酸残基的多肽具有198个重叠的3氨基酸序列(3聚体),但唯一的3聚体序列的数目取决于序列内的重复性的量。可以生成反映整个多肽序列中的3聚体重复性程度的评分(在下文中“子序列评分”)。在本发明的上下文中,“子序列评分”意指跨越多肽的200个连续氨基酸的序列的每个唯一的3聚体构架的出现总和除以200个氨基酸的序列内唯一的3聚体子序列的绝对数目。源自重复多肽和非重复多肽的前200个氨基酸的此类子序列评分的例子呈现于国际专利申请公开号wo 2010/091122 a1的实例73中,所述国际专利申请以引用的方式全文并入。在一些实施例中,本发明提供了各自包含至少一种xten多肽的bpxten多肽,其中所述xten多肽氨基酸序列可以具有小于16、或小于14、或小于12、或更优选地小于10的子序列评分。
[0091]
如本文使用的,术语“基本上非重复的xten多肽氨基酸序列”指这样的xten多肽,其中存在很少或没有xten多肽氨基酸序列中的四个连续氨基酸是相同的氨基酸类型的情况,并且其中所述xten多肽氨基酸序列具有12、或10或更低的子序列评分(在本文的前一段中定义),或不存在构成多肽序列的序列基序从n末端到c末端的次序的模式。
[0092]
如本文所述,术语“非重叠的序列基序”包括完全非重叠的序列基序以及仅部分非重叠的序列基序,条件是所述部分非重叠的序列基序不是完全重叠的。
[0093]“载体”是优选在适当的宿主中自复制的核酸分子,其将插入的核酸分子转移到宿主细胞之内和/或之间。该术语包括主要发挥功能用于将dna或rna插入细胞内的载体,主要发挥功能用于dna或rna复制的复制载体,以及发挥功能用于dna或rna的转录和/或翻译的表达载体。还包括的是提供多于一种上述功能的载体。“表达载体”是这样的多核苷酸,当引入适当的宿主细胞内时,所述多核苷酸可以被转录且翻译成多肽。“表达系统”通常意味着包含表达载体的合适的宿主细胞,所述表达载体可以发挥功能以产生所需的表达产物。
[0094]
如本文使用的,术语“t
1/2”意指计算为ln(2)/k
el
的终末半衰期。k
el
是通过对数浓
度相对于时间曲线的末端线性部分的线性回归计算的终末消除速率常数。半衰期通常指沉积在活生物中的施用物质的一半数量被正常生物过程代谢或消除所需的时间。术语“t
1/2”、“终末半衰期”、“消除半衰期”和“循环半衰期”在本文中可互换使用。
[0095]
术语“抗原”、“靶抗原”或“免疫原”在本文中可互换使用,以指抗体片段或基于抗体片段的治疗剂与其结合或具有针对其的特异性的结构或结合决定簇。
[0096]
如本文使用的,术语“有效载荷”指具有生物活性或治疗活性的蛋白质或肽序列;小分子的药效团的配对物。有效载荷的例子包括但不限于细胞因子、酶、激素以及血液因子和生长因子。有效载荷还可以包含遗传融合或化学缀合的部分,例如化学治疗剂、抗病毒化合物、毒素或造影剂。这些缀合的部分可以经由接头与多肽的剩余部分连接,所述接头可以是可切割的或不可切割的。
[0097]
如本文使用的,“治疗(treatment)”或“治疗(treating)”、“缓解”和“改善”在本文中可互换使用,并且指用于获得有益结果或所需结果包括但不限于治疗益处和/或预防益处的方法。“治疗益处”意指正在治疗的潜在病症的根除或改善。另外,通过根除或改善与潜在疾病状况相关的一种或多种生理症状来实现治疗益处,其中在人或动物中观察到改善,尽管人或动物仍可以受到潜在病症的折磨。为了预防益处,可以将组合物施用于处于发展特定疾病状况的风险中的人或动物、或者报告疾病的一种或多种生理症状的人或动物,即使仍无法作出该疾病的诊断。
[0098]
如本文使用的,“治疗效应”指生理效应,包括但不限于由本发明的融合多肽引起的人或其它动物中的疾病状况的治愈、减轻、改善或预防,或者以其它方式增强人或动物的身体或精神健康,而不是诱导针对由生物活性蛋白质具有的抗原表位的抗体产生的能力。尤其是按照本文提供的详细公开内容,治疗有效量的确定完全在本领域技术人员的能力内。
[0099]
如本文使用的,术语“治疗有效量”和“治疗有效剂量”指单独或作为融合蛋白组合物一部分的生物活性蛋白质的量,当以一个剂量或重复剂量施用于人或动物时,所述量能够具有对疾病状态或状况的任何症状、方面、测量参数或特性的任何可检测的有益作用。此类效应无需是绝对有益的。疾病状况可以指病症或疾病。
[0100]
如本文使用的,术语“治疗有效剂量方案”指用于单独或作为融合蛋白组合物一部分的生物活性蛋白质的连续施用剂量的时间表,其中所述剂量以治疗有效量给予,以导致对疾病状态或状况的任何症状、方面、测量参数或特性的持续有益作用。
[0101]
融合多肽
[0102]
本文公开的是包含一种或多种延伸重组多肽(xten或xtens)(如下文更充分地描述的)的多肽,其可以融合或以其它方式缀合至另一种多肽,特别是生物活性多肽,其中所述实施例在本文中称为bpxten。
[0103]
在一些实施例中,多肽包含第一xten多肽(例如下文在“延伸重组多肽(xten)”节段中描述或在本文其它任何地方描述的那些多肽)。在一些实施例中,多肽还包含第二xten多肽(例如下文在“延伸重组多肽(xten)”节段中描述或在本文其它任何地方描述的那些多肽)。在一些实施例中,多肽包含在其n末端处或附近的xten多肽(“n末端xten”)。在一些实施例中,多肽包含在其c末端处或附近的xten多肽(“c末端xten”)。在一些实施例中,多肽包含n末端xten多肽和c末端xten多肽两者。在一些实施例中,第一xten多肽是n末端xten多
肽,并且第二xten多肽是c末端xten多肽。
[0104]
多肽还可以包含与xten多肽连接的生物活性多肽(“bp”),从而形成在本文中称为“bpxten”多肽的含有xten的融合多肽。
[0105]
xten多肽可以包含在融合多肽(或bpxten)被蛋白酶消化后,可从xten多肽中释放(配置为释放的)的一个或多个条形码片段(如下文更充分地描述的)。在一些实施例中,每个条形码片段在序列和分子量方面不同于多肽被蛋白酶完全消化后可从多肽中释放的所有其它肽片段(包括所有其它条形码片段,如果存在的话)。
[0106]
(融合)多肽可以包含例如在蛋白酶消化后,可从多肽中释放的一个或多个参考片段(如下文更充分地描述的),所述蛋白酶消化从多肽中释放条形码片段。在一些实施例中,每个参考片段可以是在序列和分子量方面不同于多肽被蛋白酶消化后可从多肽中释放的所有其它肽片段的单个参考片段。
[0107]
延伸重组多肽(xten)
[0108]
链长度和氨基酸组成
[0109]
在一些实施例中,xten多肽包含至少150个氨基酸。在一些实施例中,xten多肽的长度为150至3,000个氨基酸,或长度为150至1,000个氨基酸,或长度为至少200、至少250、至少300、至少350、至少400、至少450、或至少500个氨基酸。在一些实施例中,xten多肽的至少90%的氨基酸残基是甘氨酸(g)、丙氨酸(a)、丝氨酸(s)、苏氨酸(t)、谷氨酸盐(e)或脯氨酸(p)。在一些实施例中,xten多肽的至少91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的氨基酸残基选自g、a、s、t、e或p。在一些实施例中,xten多肽包含g、a、s、t、e或p氨基酸中的至少4种不同类型。在一些实施例中,xten多肽的特征在于它包含至少150个氨基酸;xten多肽的至少90%的氨基酸残基是g、a、s、t、e或p,并且它包含选自g、a、s、t、e和p的至少4种不同类型的氨基酸,其关于构成xten多肽的任何其它非重叠序列基序是基本上随机化的。在一些实施例中,含有xten的融合多肽(例如,包含与其缀合的生物活性多肽的融合多肽)包含第一xten多肽和第二xten多肽。在一些实施例中,第一xten中的氨基酸总数和第二xten多肽中的氨基酸总数之和为至少300、至少350、至少400、至少500、至少600、至少700、或至少800个氨基酸。
[0110]
非重叠序列基序
[0111]
在一些实施例中,本文提供的xten多肽包含多个非重叠序列基序或由多个非重叠序列基序形成。在一些实施例中,至少一个非重叠序列基序是重现的(或在xten中重复至少两次),并且其中至少另一个非重叠序列基序是非重现的(或在xten内仅发现一次)。在一些实施例中,多个非重叠序列基序包含一组(重现的)非重叠序列基序,其中所述序列基序各自在xten中重复至少两次;以及在xten内仅出现(或发现)一次的非重叠(非重现的)序列基序。在一些实施例中,每个非重叠序列基序的长度为9至14(或10至14、或11至13)个氨基酸。在一些实施例中,每个非重叠序列基序的长度为12个氨基酸。在一些实施例中,多个非重叠序列基序包含一组非重叠(重现的)序列基序,其中所述序列基序各自在xten中重复至少两次;并且长度为9至14个氨基酸。在一些实施例中,该组(重现的)非重叠序列基序包含在本文中通过表1中的seq id no:182-203和1715-1722鉴定的12聚体序列基序。在一些实施例中,该组(重现的)非重叠序列基序包含在本文中通过表1中的seq id no:186-189鉴定的12聚体序列基序。在一些实施例中,该组(重现的)非重叠序列基序包含表1中的seq id no:
186-189的12聚体序列基序中的至少两个、至少三个或所有四个。
[0112]
表1.用于构建xten的示例性12聚体序列基序
[0113]
[0114][0115]
*表示个别基序序列,当以各种排列一起使用时,所述个别基序序列导致“家族序列”[0116]
条形码片段
[0117]
在一些实施例中,本文提供的多肽包含在被蛋白酶消化后可从多肽中释放的条形码片段(例如,xten多肽的第一条形码片段、第二条形码片段或第三条形码片段)。在一些实施例中,条形码片段是xten的一部分,其包括在xten内仅出现(或发现)一次的(非重现的、非重叠的)序列基序的至少一部分;并且在序列和分子量方面不同于多肽被蛋白酶完全消化后可从多肽中释放的所有其它肽片段。本领域普通技术人员将理解,术语“条形码片段”(或“条形码”或“条形码序列”)可以指通过在多肽内可切割地融合的本文鉴定的xten的一部分、或从多肽中释放的所得到的肽片段。
[0118]
在一些实施例中,条形码片段不包括xten多肽的n末端氨基酸或c末端氨基酸。如下文更充分地描述或本文任何地方描述的,在一些实施例中,条形码片段在融合多肽的
glu-c消化后是可释放的(配置为释放的)。在一些实施例中,条形码片段不包括紧邻xten多肽中的另一个谷氨酸的谷氨酸。在一些实施例中,条形码片段具有在其c末端处的谷氨酸。本领域普通技术人员将理解,当在xten多肽内可切割地融合的时,条形码片段的c末端可以指条形码片段内的“最后一个”(或最c末端)氨基酸残基,即使其它“非条形码”氨基酸残基定位于同一xten多肽内的条形码片段的c末端。在一些实施例中,条形码片段具有之前紧为谷氨酸残基的n末端氨基酸。在一些实施例中,在n末端氨基酸之前的谷氨酸残基并不紧邻另一个谷氨酸残基。在一些实施例中,条形码片段不包括在除条形码片段的c末端外的位置处的谷氨酸残基,除非谷氨酸紧随其后为脯氨酸。在一些实施例中,条形码片段定位为距离多肽的n末端或多肽的c末端10至150、或10至125个氨基酸。在一些实施例中,条形码片段定位于距离多肽的n末端300、280、260、250、240、220、200、190、180、170、160、150、140、130、120、110、100、90、80、70、60、50、48、40、36、30、24、20、12或10个氨基酸内或在其位置处,或在前述的任一个之间的范围内的位置处。在一些实施例中,条形码片段定位于多肽的n末端200、150、100或50个氨基酸内。在一些实施例中,条形码片段定位距离多肽的n末端10至200、30至200、40至150、或50至100个氨基酸之间。在一些实施例中,条形码片段定位距离多肽的c末端300、280、260、250、240、220、200、190、180、170、160、150、140、130、120、110、100、90、80、70、60、50、48、40、36、30、24、20、12或10个氨基酸内,或在前述的任一个之间的范围内。在一些实施例中,条形码片段定位于多肽的c末端的200、150、100或50个氨基酸内。在一些实施例中,条形码片段定位距离多肽的c末端10至200、30至200、40至150、或50至100个氨基酸之间。在一些实施例中,条形码片段不包括多肽的n末端氨基酸或c末端氨基酸;不包括紧邻xten中的另一个谷氨酸的谷氨酸;具有在其c末端处的谷氨酸;具有之前紧为谷氨酸残基的n末端氨基酸;并且(v)定位为距离多肽的n末端或多肽的c末端10至150、或10至125个氨基酸。在一些实施例中,在n末端氨基酸之前的谷氨酸残基并不紧邻另一个谷氨酸残基。在一些实施例中,条形码片段不包括在除条形码片段的c末端外的位置处的谷氨酸残基,除非谷氨酸紧随其后为脯氨酸。在一些实施例中,对于与生物活性多肽融合的加条形码的xten多肽,加条形码的xten中含有的至少一个条形码片段(或至少两个条形码片段、或三个条形码片段)定位距离生物活性多肽至少50、75、100、125、150、175、200、225、250、275、300个氨基酸。在一些实施例中,条形码片段的长度为至少4、至少5、至少6、至少7或至少8个氨基酸。在一些实施例中,条形码片段的长度为至少4个氨基酸。在一些实施例中,条形码片段的长度为4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25个氨基酸,或在前述值的任一个之间的范围内。在一些实施例中,条形码片段的长度为4至20、5至15、6至12、或7至10个氨基酸。在一些实施例中,条形码片段选自表2中的seq id no:8020-8030(bar001-bar011)。
[0119]
表2.在glu-c消化后可释放的示例性条形码片段
[0120]
氨基酸序列 seq id no:spatsgstpebar0018020gsapatsebar0028021gsapgtatebar0038022gsapgtebar0048023patsgptebar0058024
saspebar0068025patsgstebar0078026gsapgtsaebar0088027satsgsebar0098028sgpgstpaebar0108029sgsebar0118030
[0121]
在一些实施例中,加条形码的xten多肽仅包含一个条形码片段。在一些实施例中,加条形码的xten多肽包含一组条形码片段,其包含第一条形码片段,例如上文或本文其它任何地方描述的那些第一条形码片段。在这些实施例中,可以基于氨基酸序列或分子量,将该组条形码序列的每个成员与所有其它条形码序列区别开(其中用于区别不同条形码序列的这些方法将是相关的)。在一些实施例中,该组条形码片段包含第二条形码片段(或进一步的条形码片段),例如上文或本文其它任何地方描述的那些第二条形码片段。在一些实施例中,该组条形码片段包含第三条形码片段,例如上文或本文其它任何地方描述的那些第三条形码片段。在n末端xten多肽内融合的该组条形码片段可以被称为n末端组条形码(“n末端组”)。在c末端xten多肽内融合的该组条形码片段可以被称为c末端组条形码(“c末端组”)。在一些实施例中,n末端组包含第一条形码片段和第二条形码片段。在一些实施例中,n末端组还包含第三条形码片段。在一些实施例中,c末端组包含第一条形码片段和第二条形码片段。在一些实施例中,c末端组还包含第三条形码片段。在一些实施例中,第二条形码片段定位于同一组的第一条形码片段的n末端。在一些实施例中,第二条形码片段定位于同一组的第一条形码片段的c末端。在一些实施例中,第三条形码片段定位于第一条形码片段和第二条形码片段两者的n末端。在一些实施例中,第三条形码片段定位于第一条形码片段和第二条形码片段两者的c末端。在一些实施例中,第三条形码片段定位于第一条形码片段和第二条形码片段之间。在一些实施例中,多肽包含一组条形码片段,其包括第一条形码片段、进一步的(第二)条形码片段和至少一个另外的条形码片段,其中该组条形码片段中的每个条形码片段是第二xten多肽的一部分,并且在序列和分子量方面不同于多肽被蛋白酶完全消化后可从多肽中释放的所有其它肽片段。
[0122]
示例性加条形码的xten
[0123]
表3a中示出了13种示例性加条形码的xten的氨基酸序列,其含有一个条形码(例如,seq id no:8002-8003、8005-8009和8013)、或两个条形码(例如,seq id no:8001、8004、8010和8012)、或三个条形码(例如,seq id no:8011)。在这13种示例性加条形码的xten多肽中,六种(seq id no:8001-8003、8008-8009和8011)可以在生物活性蛋白质的c末端处与生物活性蛋白质融合,且七种(seq id no:8004-8007、8010和8012-8013)可以在生物活性蛋白质的n末端处融合。在一些实施例中,xten多肽与选自表3a中的seq id no:8001-8019的序列具有至少90%、至少92%、至少95%、至少98%、至少99%或100%的序列同一性。
[0124]
表3a.示例性加条形码的xten
[0125]
[0126]
[0127]
[0128]
[0129]
[0130]
[0131]
[0132]
[0133]
[0134]
[0135]
[0136]
[0137]
[0138]
[0139][0140]
在一些实施例中,可以通过根据下述标准中的一种或多种,对通用xten多肽例如表3b中列出的任何多肽制备一种或多种突变来获得加条形码的xten多肽:使xten多肽中的序列变化降到最低、使xten多肽中的氨基酸组成变化降到最低、基本上维持xten多肽的净电荷、基本上维持(或改善)xten多肽的低免疫原性、以及基本上维持(或改善)xten多肽的药代动力学性质。在一些实施例中,xten多肽氨基酸序列与表3b中列出的seq id no:676-734中的任何一个具有至少90%、至少92%、至少95%、至少98%、至少99%或100%的序列同一性。在一些实施例中,通过来自表3b的相应序列的一种或多种突变(例如,少于10种、少于8种、少于6种、少于5种、少于4种、少于3种、少于2种突变),来获得与表3b中列出的seq id no:676-734中的任一个具有至少90%(例如,至少92%、至少95%、至少98%或至少99%)但小于100%的序列同一性的xten序列。在一些实施例中,一种或多种突变包含谷氨酸残基的缺失、谷氨酸残基的插入、谷氨酸残基的取代、或取代谷氨酸残基、或其任何组合。在一些实施例中,其中xten多肽氨基酸序列不同于表3b中列出的seq id no:676-734中的任何一个,但与之具有至少90%(例如,至少92%、至少95%、至少98%或至少99%)的序列同一性,xten多肽氨基酸序列和表3b的相应序列之间的至少80%、至少90%、至少95%、至少97%或约100%的差异涉及谷氨酸残基的缺失、谷氨酸残基的插入、谷氨酸残基的取代、或取代谷氨酸残基、或其任何组合。在一些此类实施例中,xten多肽氨基酸序列和表3b的相应序列之间的至少80%、至少90%、至少95%、至少97%或约100%的差异涉及谷氨酸残基的取代、或取代谷氨酸残基或两者。如本文使用的,术语“第一氨基酸的取代”指用第一氨基酸残基替换第二氨基酸残基,导致第二氨基酸残基在获得的序列中的取代位置处出现。例如,“谷氨酸的取代”指用谷氨酸(e)残基替换非谷氨酸残基(例如,丝氨酸(s))。如本文使用的,术语“取代第一氨基酸”指用第二氨基酸残基替换第一氨基酸残基,导致第一氨基酸残基在获得的序列中的取代位置处出现。例如,“取代谷氨酸”指用非谷氨酸残基(例如,丝氨酸(s))替换谷氨酸残基。
[0141]
表3b.用于改造成加条形码的xten的示例性通用xten
[0142]
[0143]
[0144]
[0145]
[0146]
[0147]
[0148]
[0149]
[0150]
[0151]
[0152]
[0153]
[0154]
[0155]
[0156]
[0157]
[0158]
[0159]
[0160]
[0161]
[0162]
[0163]
[0164][0165]
在一些实施例中,为了构建加条形码的xten多肽的序列,对表3b的那些xten多肽中具有中等长度的xten多肽以及比表3b的那些xten多肽更长长度的xten多肽,例如其中将表1的一个或多个12聚体基序加入表3b的通用xten的n末端或c末端的那些xten多肽执行氨基酸突变。
[0166]
可以根据本公开内容使用的通用xten多肽氨基酸序列的另外例子公开于美国专利公开号2010/0239554 a1、2010/0323956 a1、2011/0046060 a1、2011/0046061 a1、2011/0077199 a1或2011/0172146 a1,或者国际专利公开号wo 2010091122 a1、wo 2010144502 a2、wo 2010144508 a1、wo 2011028228 a1、wo 2011028229 a1、wo 2011028344 a2、wo 2014/011819 a2或wo 2015/023891中,所述专利的公开内容各自以引用的方式明确并入本文。
[0167]
在一些实施例中,在与多肽链的n末端相邻的多肽链内融合的加条形码的xten多肽(“n末端xten”)可以附着到包含多个聚(his)残基,包括在n末端处的六至八个his残基的his标签,以促进融合多肽的纯化。在一些实施例中,在多肽链的c末端处在多肽链内融合的加条形码的xten多肽(“c末端xten多肽”)可以包含或附着到在c末端处的序列epea,以促进融合多肽的纯化。在一些实施例中,融合多肽包含n末端加条形码的xten多肽和c末端加条形码的xten多肽两者,其中所述n末端加条形码的xten附着到包含多个聚(his)残基,包括在n末端处的六至八个his残基的his标签;并且其中所述c末端加条形码的xten多肽附着到在c末端处的序列epea,从而促进通过本领域已知的色谱方法将融合多肽纯化例如到至少90%、91%、92%、93%、94%、95%、96%、97%、98%或至少99%纯度,所述色谱法包括但不限于imac色谱法、c-tagxl亲和基质和其它此类方法,包括但不限于下文实例节段中描述的那些方法。
[0168]
蛋白酶消化
[0169]
如上文或本文其它任何地方描述的条形码片段可以可切割地融合在xten多肽内,并且在多肽被蛋白酶消化后可从xten多肽中释放(配置为释放的)。在一些实施例中,蛋白酶是glu-c蛋白酶。在一些实施例中,蛋白酶在谷氨酸残基的c末端侧上切割,所述谷氨酸残基随后并非脯氨酸。本领域普通技术人员将理解,加条形码的xten多肽(在其内含有条形码片段的xten多肽)被设计为实现蛋白酶消化的高效率、精确度和准确度。例如,本领域普通技术人员将理解xten序列中的相邻glu-glu(ee)残基可以在glu-c消化后导致各种切割模式。相应地,当glu-c蛋白酶用于条形码释放时,加条形码的xten多肽或条形码片段可以不含任何glu-glu(ee)序列。本领域普通技术人员还将理解如果存在于融合多肽中,则二肽glu-pro(ep)序列可以在条形码释放过程期间无法被glu-c蛋白酶切割。
[0170]
bpxten的结构构型
[0171]
在一些实施例中,bpxten融合蛋白包含单个bp多肽和单个xten多肽。此类bpxten蛋白可以具有至少下述构型排列,其各自以n末端至c末端取向列出:bp-xten;xten-bp;bp-s-xten;和xten-s-bp,其中“s”是如下文阐述的间隔区序列。
[0172]
在一些实施例中,bpxten蛋白包含c末端xten多肽以及任选地在xten多肽和bp多肽之间的间隔区序列(s)。此类bpxten蛋白可以由式i表示(描绘为n末端至c末端):
[0173]
(bp)-(s)
x-(xten)
ꢀꢀꢀ
(i),
[0174]
其中bp是如下文所述的生物活性蛋白质;s是具有1至约50个氨基酸残基的间隔区序列,其可以任选地包括bp释放区段(如下文更充分地描述的);x为0或1;并且xten可以是本文所述的任何xten多肽。
[0175]
在一些实施例中,bpxten蛋白包含n末端xten多肽以及任选地在xten多肽和bp蛋白之间的间隔区序列(s)。此类bpxten蛋白可以由式ii表示(描绘为n末端至c末端):
[0176]
(xten)-(s)
x-(bp)
ꢀꢀꢀ
(ii),
[0177]
其中bp是如下文所述的生物活性蛋白质;s是具有1至约50个氨基酸残基的间隔区序列,其可以任选地包括bp释放区段(如下文更充分地描述的);x为0或1;并且xten可以是如本文所述的任何xten多肽。
[0178]
在一些实施例中,bpxten蛋白包含n末端xten多肽和c末端xten多肽两者。此类bpxten蛋白(例如,图1-2中的xpat)可以由式iii表示:
[0179]
(xten)-(s)
y-(bp)-(s)
z-(xten)
ꢀꢀꢀ
(iii)
[0180]
其中bp是如下文所述的生物活性蛋白质;s是具有1至约50个氨基酸残基的间隔区序列,其可以任选地包括bp释放区段(如下文更充分地描述的);y为0或1;z为0或1;并且xten可以是如本文所述的任何xten多肽。
[0181]
生物活性多肽
[0182]
可以融合至一种或多种xten多肽(如本文所述)的生物活性蛋白质(bp),特别是下文公开的那些生物活性蛋白质,包含在本文中通过表4a-4h和表6a-6f鉴定的序列,连同其对应的核酸序列和氨基酸序列是本领域众所周知的。这些bp的描述和序列可在公共数据库中获得,所述数据库例如chemical abstracts services databases(例如,cas registry)、genbank、the universal protein resource(uniprot)和订阅提供的数据库例如genseq(例如,derwent)。编码bp的多核苷酸序列可以是编码天然bp(例如,全长或成熟)的野生型多核苷酸序列,或者在一些情况下,该序列可以是野生型多核苷酸序列(例如,编码野生型、生物活性蛋白质的多核苷酸)的变体,其中所述多核苷酸的核苷酸序列已例如对于在特定物种中的表达进行优化;或编码野生型蛋白质的变体的多核苷酸,例如定点突变体或等位基因变体。使用本领域已知的方法和/或与本文提供的指导和方法结合,使用野生型或共有cdna序列或bp的密码子优化变体来产生由本发明考虑的bpxten构建体,完全在技术人员的能力内。
[0183]
用于包括在本文公开的bpxten蛋白(例如,包含至少一种bp和至少一种xten多肽的融合多肽)中的bp可以包括任何蛋白质,其具有生物学、治疗、预防或诊断目的或功能,或者当施用于人或动物时,可用于介导生物活性或者预防或改善疾病、病症或状况。特别有利的是对于其寻求药代动力学参数增加、增加的溶解度、增加的稳定性、活性掩蔽或一些其它
增强的药学性质的bp,或者对于其增加终末半衰期将改善功效、安全性或导致减少给药频率和/或改善患者依从性的那些bp。因此,可以记住各种目标来制备bpxten融合蛋白组合物,所述目标包括与未连接至xten多肽的bp相比,通过例如增加当施用于人或动物时的体内暴露或bpxten保留在治疗窗内的时间长度,改善生物活性化合物的治疗功效。
[0184]
bp可以是天然的全长蛋白质,或者可以是保留天然蛋白质的至少一部分生物活性的生物活性蛋白质的片段或序列变体。
[0185]
在一个实施例中,掺入人或动物组合物内的bp可以是重组多肽,其具有对应于自然界中发现的蛋白质的序列。在另一个实施例中,bp可以是天然序列的序列变体、片段、同源物和模拟物,其保留天然bp的至少一部分生物活性。在非限制性例子中,bp可以是与选自表4a-4h的蛋白质序列显示出至少约80%的序列同一性,或者可替代地81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性的序列。在进一步的非限制性例子中,bp可以是包含第一结合结构域和第二结合结构域的双特异性序列,其中对肿瘤特异性标记物或靶细胞的抗原具有特异性结合亲和力的第一结合结构域,与表6f中鉴定的抗cd3抗体的配对vl和vh序列显示出至少约80%的序列同一性,或者可替代地81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性;并且其中对效应细胞具有特异性结合亲和力的第二结合结构域,与表6a中鉴定的抗靶细胞抗体的配对vl和vh序列显示出至少约80%的序列同一性,或者可替代地81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性。在一个实施例中,bpxten融合蛋白可以包含与xten多肽连接的单个bp蛋白。在另一个实施例中,bpxten蛋白可以包含第一bp和相同bp的第二分子,导致包含与一种或多种xten多肽连接的两个bp(例如,两个胰高血糖素分子、或两个hgh分子)的融合蛋白。
[0186]
一般而言,当在体内使用或在体外测定中利用时,bp显示出对给定靶(或给定数目的靶)或另一种所需生物学特性的结合特异性。例如,bp可以是激动剂、受体、配体、拮抗剂、酶、抗体(例如,单特异性或双特异性)或激素。特别感兴趣的是用于或已知可用于疾病或病症的bp,其中所述天然bp具有相对较短的终末半衰期,并且对于其药代动力学参数的增强(其任选地可以通过间隔区序列的切割从融合蛋白中释放)将允许更不频繁的给药或增强的药理效应。还感兴趣的是具有在最小有效剂量或血液浓度(cmin)与最大耐受剂量或血液浓度(cmax)之间的窄治疗窗的bp。在这种情况下,与未连接至一种或多种xten多肽的bp相比,bp与包含选择的xten多肽序列的融合蛋白的连接可以导致这些性质的改善,使得其更可用作治疗剂或预防剂。
[0187]
葡萄糖调节肽
[0188]
内分泌和肥胖相关疾病或病症已在大多数发达国家达到流行病的比例,并且在大多数发达国家代表巨大且不断增加的医疗保健负担,其包括影响身体器官、组织和循环系统的大量各种状况。特别值得关注的是内分泌和肥胖相关疾病和病症,其中主要是糖尿病,美国的主要死因之一。
[0189]
葡萄糖稳态和胰岛素应答中的大多数代谢过程由多重肽和激素调控,并且许多此类肽和激素以及其类似物已在代谢疾病和病症的治疗中发现效用。这些肽中的许多趋于彼
此高度同源,即使当它们具有相反的生物学功能时。增加葡萄糖的肽以肽激素胰高血糖素为例,而降低葡萄糖的肽包括exendin-4、胰高血糖素样肽1和胰淀素。然而,即使当通过使用小分子药物进行加强时,治疗性肽和/或激素的使用在此类疾病和病症的管理中也取得了有限的成功。特别地,剂量优化对于用于治疗代谢疾病的药物和生物制剂,尤其是具有窄治疗窗的那些药物和生物制剂是重要的。一般而言的激素和涉及于葡萄糖稳态的肽经常具有窄治疗窗。窄治疗窗加上此类激素和肽通常具有短半衰期(其需要频繁给药以便实现临床益处)的事实,导致此类患者的管理中的困难。虽然对治疗性蛋白质的化学修饰例如聚乙二醇化可以修饰其体内清除率和后续血清半衰期,但它需要另外的制造步骤并导致异质的最终产物。另外,已报道了来自长期施用的无法接受的副作用。可替代地,通过fc结构域与治疗性蛋白质或肽的融合的遗传修饰增加治疗性蛋白质的大小,减少通过肾脏的清除率,并且促进通过fcrn受体的来自溶酶体的再循环。不幸的是,fc结构域在重组表达期间无法有效折叠,并且趋于形成称为包涵体的不溶性沉淀物。这些包涵体必须溶解,并且功能性蛋白质必须复活;这是耗时、低效且昂贵的过程。
[0190]
因此,本发明的一个方面是将涉及于葡萄糖稳态、胰岛素抗性和肥胖的肽(统称为“葡萄糖调节肽”)掺入bpxten融合蛋白中,以产生在葡萄糖、胰岛素和肥胖病症、疾病和相关状况的治疗中具有效用的组合物。可以与本文公开的xten多肽连接以产生bpxten蛋白(其尤其包括所有生物活性多肽)的合适的葡萄糖调节肽,增加通过胰腺β细胞的葡萄糖依赖性胰岛素分泌或加强胰岛素的作用。葡萄糖调节肽还可以包括在胰腺β细胞中刺激胰岛素原基因转录的生物活性多肽。此外,葡萄糖调节肽还可以包括减缓胃排空时间和减少食物摄入的生物活性多肽。葡萄糖调节肽还可以包括抑制来自朗格罕氏岛的α细胞的胰高血糖素释放的生物活性多肽。表4a提供了可以由本发明的bpxten融合蛋白涵盖的葡萄糖调节肽序列的非限制性列表。本文公开的本发明的bpxten组合物的葡萄糖调节肽可以是与选自表4a的氨基酸序列显示出至少约80%的序列同一性(例如,81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性)的肽。
[0191]
表4a:葡萄糖调节肽
[0192]
[0193]
[0194]
[0195][0196]“肾上腺髓质素”或“adm”意指人肾上腺髓质素肽激素及其具有成熟adm的至少一部分生物活性的物种和序列变体。adm由185个氨基酸的前激素原通过连续的酶促切割和酰胺化生成,导致52个氨基酸的生物活性肽,具有22分钟的测量的血浆半衰期。本发明的含有adm的融合蛋白可以特别用于糖尿病中,用于对来自胰岛细胞的胰岛素分泌的刺激作用以用于葡萄糖调控,或者用于具有持续性低血压的人或动物中。关于人am的完整基因组基础结构已得到报道(ishimitsu等人,1994,biochem.biophys.res.commun 203:631-639),并且adm肽的类似物已得到克隆,如美国专利号6,320,022中所述。
[0197]“胰淀素”意指被称为胰淀素的人肽激素、普兰林肽及其具有成熟胰淀素的至少一部分生物活性的物种变化,如美国专利号5,234,906中所述。胰淀素是响应营养素摄入,通过胰腺β细胞与胰岛素共分泌的37个氨基酸的多肽激素(koda等人,1992,lancet 339:1179-1180),并且已报道为调节碳水化合物代谢的几个关键途径,包括将葡萄糖掺入糖原内。本发明的含有胰淀素的融合蛋白可以补充胰岛素的作用,所述胰岛素调控葡萄糖从循环中的消失速率及其被外周组织的摄取。胰淀素类似物已得到克隆,如美国专利号5,686,411和7,271,238中所述。
[0198]
可以产生保留生物活性的胰淀素模拟物。例如,普兰林肽具有序列kcntatcatnrlanflvhssnnfgpilpptnvgsnty(seq id no:43),其中来自大鼠胰淀素序列的氨基酸取代人胰淀素序列中的氨基酸。在一个实施例中,本发明考虑了包含序列kcntatcatx1rlanflvhssnnfgx2ilx2x2tnvgsnty(seq id no:44)的胰淀素模拟物的融合蛋白,其中x1独立地是n或q并且x2独立地是s、p或g。在一个实施例中,掺入bpxten内的胰淀素模拟物可以具有序列kcntatcatnrlanflvhssnnfggilggtnvgsnty(seq id no:45)。在另一个实施例中,其中所述胰淀素模拟物用于bpxten的c末端处,所述模拟物可以具有序列kcntatcatnrlanflvhssnnfggilggtnvgsnty(nh2)(seq id no:46)。
[0199]“降钙素”(ct)意指人降钙素蛋白及其具有成熟ct的至少一部分生物活性的物种和序列变体,包括鲑鱼降钙素(“sct”)。ct是从较大的甲状腺激素原中切割的32个氨基酸的肽,其似乎在神经系统和血管系统中发挥功能,但也已报道为饱腹感反射的有力激素介质。(在becker,jcem,89(4):1512-1525(2004)以及sexton,current medicinal chemistry 6:1067-1093(1999)中综述)。本发明的含有降钙素的融合蛋白可以特别用于治疗骨质疏松症和用作佩吉特骨病的疗法。合成的降钙素肽已得到产生,如美国专利号5,175,146和5,364,840中所述。
[0200]“降钙素基因相关肽”或“cgrp”意指人cgrp肽及其具有成熟cgrp的至少一部分生
物活性的物种和序列变体,所述cgrp是肽的降钙素家族的成员,其在人中以两种形式存在:α-cgrp(37个氨基酸的肽)和β-cgrp。cgrp与人胰淀素具有43-46%的序列同一性。本发明的含有cgrp的融合蛋白可以特别用于降低与糖尿病相关的发病率,改善高血糖和胰岛素缺乏,抑制淋巴细胞浸润到胰岛内和保护β细胞免受自身免疫破坏。用于制备合成和重组cgrp的方法在美国专利号5,374,618中进行描述。
[0201]“胆囊收缩素”或“cck”意指人cck肽及其具有成熟cck的至少一部分生物活性的物种和序列变体。cck-58是成熟序列,而首先在人中鉴定的cck-33氨基酸序列是该肽的主要循环形式。cck家族还包括8个氨基酸的体内c末端片段(“cck-8”),c末端肽cck(29-33)的五肽胃泌素或cck-5,以及c末端四肽cck(30-33)的cck-4。cck是胃肠系统的肽激素,其负责刺激脂肪和蛋白质的消化。本发明的含有cck-33和cck-8的融合蛋白可以特别用于减少在膳食摄入后的循环葡萄糖增加且加强循环胰岛素的增加。cck-8的类似物已得到制备,如美国专利号5,631,230中所述。
[0202]“exendin-3”意指从珠毒蜥(heloderma horridum)中分离的葡萄糖调节肽及其具有成熟exendin-3的至少一部分生物活性的序列变体。exendin-3酰胺是特异性exendin受体拮抗剂,其介导胰腺camp的增加以及胰岛素和淀粉酶的释放。本发明的含有exendin-3的融合蛋白可以特别用于治疗糖尿病和胰岛素抗性病症。序列和用于其测定的方法在美国专利5,4242,86中进行描述。
[0203]
exendin-4”意指在钝尾毒蜥美国毒蜥(heloderma suspectum)的唾液中发现的葡萄糖调节肽及其物种和序列变体,并且包括天然的39个氨基酸的序列hgegtftsdlskqmeeeavrlfieylknggpssgappps(seq id no:47)以及同源序列和肽模拟物及其变体;例如来自灵长类动物的天然序列和具有成熟exendin-4的至少一部分生物活性的非天然序列。exendin-4是肠促胰岛素多肽激素,其降低血糖、促进胰岛素分泌、减缓胃排空并改善饱腹感,提供餐后高血糖的显著改善。表4b显示了来自广泛各种物种的序列,而表4c显示了合成glp-1类似物的列表;所有这些都考虑用于本文所述的bpxten蛋白中。
[0204]
成纤维细胞生长因子21或“fgf-21”意指由fgf-21基因编码的人蛋白质,或其具有成熟fgf-21的至少一部分生物活性的物种和序列变体。fgf-21刺激脂肪细胞中的葡萄糖摄取,但在其它细胞类型中则不是;该效应对于胰岛素活性是累加的。本发明的含有fgf-21的融合蛋白可以特别用于治疗糖尿病,包括引起增加的能量消耗、脂肪利用和脂质排泄。fgf-21已得到克隆,如美国专利号6,716,626中公开的。
[0205]“成纤维细胞生长因子19”或“fgf-19”意指由fgf-19基因编码的人蛋白质,或其具有成熟fgf-19的至少一部分生物活性的物种和序列变体。fgf-19是成纤维细胞生长因子(fgf)家族的蛋白质成员。fgf-19增加瘦素受体的肝脏表达、代谢率,刺激脂肪细胞中的葡萄糖摄取,并且导致肥胖小鼠模型中的重量减轻(fu等人,2004,endocrinology 145:2504-2603)。本发明的含有fgf-19的融合蛋白可以特别用于增加代谢率以及逆转饮食和瘦素缺乏型糖尿病。fgf-19已得到克隆且表达,如美国专利申请号20020042367中所述。
[0206]“胃泌素”意指人胃泌素肽、截短形式、以及其具有成熟胃泌素的至少一部分生物活性的物种和序列变体。胃泌素主要以三种形式发现:胃泌素-34(“大胃泌素”);胃泌素-17(“小胃泌素”);和胃泌素-14(“小促胃液素”),并且与cck共享序列同源性。本发明的含有胃泌素的融合蛋白可以特别用于治疗肥胖和糖尿病,以用于葡萄糖调控。胃泌素已得到合成,
如美国专利号5,843,446中所述。
[0207]“饥饿素”意指诱导饱足感的人激素,或其物种和序列变体,包括天然的、加工的27或28个氨基酸的序列和同源序列。饥饿素水平在餐前增加且在餐后降低,并且可以通过在下丘脑水平上发挥的作用导致食物摄入增加且增加脂肪量。本发明的含有饥饿素的融合蛋白可以特别用作激动剂;例如,在胃肠动力病症中选择性地刺激gi道的动力,加速胃排空,或刺激生长激素的释放。例如美国专利号7,385,026中所述的具有序列取代或截短变体的饥饿素类似物,可以特别用作具有xten多肽的融合配偶体,以用作改善葡萄糖稳态的拮抗剂、治疗胰岛素抗性和治疗肥胖。饥饿素的分离和表征已得到报道(kojima等人,1999,nature.402:656-660),并且合成的类似物已通过肽合成进行制备,如美国专利号6,967,237中所述。
[0208]“胰高血糖素”意指人胰高血糖素葡萄糖调节肽,或其物种和序列变体,包括天然的29个氨基酸的序列和同源序列;例如来自灵长类动物的天然序列变体,以及具有成熟胰高血糖素的至少一部分生物活性的非天然序列变体。如本文使用的,术语“胰高血糖素”还包括胰高血糖素的肽模拟物。本发明的含有胰高血糖素的融合蛋白可以特别用于增加具有现存肝糖原储备的个体中的血糖水平且维持糖尿病患者中的葡萄糖稳态。胰高血糖素已得到克隆,如美国专利号4,826,763中公开的。
[0209]“glp-1”意指人胰高血糖素样肽-1及其具有成熟glp-1的至少一部分生物活性的序列变体。术语“glp-1”包括人glp-1(1-37)、glp-1(7-37)和glp-1(7-36)酰胺。glp-1刺激胰岛素分泌,但仅在高血糖时期期间。与胰岛素相比,glp-1的安全性因这一性质和分泌的胰岛素量与高血糖的量级成比例的观察而得到增强。glp-1(7-37)oh的生物半衰期仅为3至5分钟(美国专利号5,118,666)。本发明的含有glp-1的融合蛋白可以特别用于治疗糖尿病和胰岛素抗性病症,以用于葡萄糖调控。glp-1已得到克隆并制备了衍生物,如美国专利号5,118,666中所述。来自广泛各种物种的glp-1序列的非限制性例子显示于表4b中,而表4c显示了许多合成glp-1类似物的序列;所有这些都考虑用于本文所述的bpxten组合物中。
[0210]
表4b:作为bp候选者的代表性天然存在的glp-1同源物
[0211]
[0212]
[0213][0214][0215]
表4c:代表性glp-1合成类似物
[0216]
[0217]
[0218]
[0219][0220]
glp天然序列可以通过下文呈现的几个序列基序进行描述。括号中的字母代表在每个序列位置处可接受的氨基酸:{hvy}{agistv}{dehq}{ag}{ilmpstv}{fly}{dinst}{adeknst}{adenstv}{lmvy}{anrsty}{ehiknqrst}{ahilmqvy}{lmrt}{adegkqs}{adegknqsy}{aeiklmqr}{akqrsvy}{{ailmqstv}{gkqr}{deklqr}{fhlvwy}{ilv}{adeghiknqrst}{adegnrstw}{gilvw}{aiklmqsv}{adgiknqrst}{gkrsy}(seq id no:9399)。另外,glp-1的合成类似物可以用作xten多肽的融合配偶体,以产生具有可用于治疗葡萄糖相关病症的生物活性的bpxten蛋白。
[0221]“glp-2”意指人胰高血糖素样肽-2及其具有成熟glp-2的至少一部分生物活性的序列变体。更特别地,glp-2是连同glp-1一起由小肠和大肠中的肠内分泌细胞共分泌的33个氨基酸的肽。
[0222]“胰岛素样生长因子1”或“igf-1”意指人igf-1蛋白及其具有成熟igf-1的至少一部分生物活性的物种和序列变体。igf-1由70个氨基酸组成,并且主要通过肝脏作为内分泌激素产生,以及以旁分泌/自分泌方式在靶组织中产生。本发明的含有igf-1的融合蛋白可以特别用于治疗糖尿病和胰岛素抗性病症,以用于葡萄糖调控。igf-1已在大肠杆菌和酵母中得到克隆且表达,如美国专利号5,324,639中所述。
[0223]“胰岛素样生长因子2”或“igf-2”意指人igf-2蛋白及其具有成熟igf-2的至少一部分生物活性的物种和序列变体。igf-2已得到克隆,如bell等人,1985,proc natl acad sci u s a.82:6450-4中所述。
[0224]“胰岛新生相关蛋白”(ingap)或“胰腺β细胞生长因子”意指人ingap肽及其具有成熟ingap的至少一部分生物活性的物种和序列变体。本发明的含有ingap的融合蛋白可以特别用于治疗或预防糖尿病和胰岛素抗性病症。ingap已得到克隆且表达,如r rafaeloff等人,1997,j clin invest.99(9):2100
–
2109中所述。
[0225]“垂体中叶素”或“afp-6”意指人垂体中叶素肽及其具有成熟垂体中叶素的至少一部分生物活性的物种和序列变体。垂体中叶素治疗导致正常和高血压的人或动物中的血压降低,以及胃排空活性的抑制,并且牵涉葡萄糖稳态。本发明的含有垂体中叶素的融合蛋白可以特别用于治疗糖尿病、胰岛素抗性病症和肥胖。垂体中叶素肽和变体已得到克隆,如美国专利号6,965,013中所述。
[0226]“瘦素”意指来自任何物种的天然存在的瘦素,以及生物活性的d-同种型、或其片
段和序列变体。本发明的含有瘦素的融合蛋白可以特别用于治疗糖尿病,以用于葡萄糖调控、胰岛素抗性病症和肥胖。瘦素已得到克隆,如美国专利号7,112,659中所述,并且瘦素类似物和片段已得到克隆,如美国专利号5,521,283、美国专利号5,532,336、pct/us96/22308和pct/us96/01471中所述。
[0227]“神经介素”意指肽的神经介素家族,包括神经介素u和s肽,及其序列变体。神经介素u家族中包括的是各种截短或剪接变体,例如flfhysktqklgksnvveelqspfasqsrgyflfrprn(seq id no:180)。神经介素s家族的示例是具有序列ilqrgsgtaavdftkkdhtatwgrpfflfrprn(seq id no:181)的人神经介素s,特别是其酰胺形式。本发明的神经介素融合蛋白可以特别用于治疗肥胖、糖尿病、减少食物摄入以及如本文所述的其它相关状况和病症。
[0228]“胃泌酸调节素”或“oxm”意指人胃泌酸调节素及其具有成熟oxm的至少一部分生物活性的物种和序列变体。oxm是在结肠中产生的37个氨基酸的肽,其含有胰高血糖素的29个氨基酸的序列,随后是8个氨基酸的羧基末端延伸。本发明的含有oxm的融合蛋白可以特别用于治疗糖尿病以用于葡萄糖调控、胰岛素抗性病症、肥胖,并且可以用作重量减轻治疗。
[0229]“pyy”意指人肽yy多肽及其具有成熟pyy的至少一部分生物活性的物种和序列变体。本发明的含有ppy的融合蛋白可以特别用于治疗糖尿病,以用于葡萄糖调控、胰岛素抗性病症和肥胖。pyy的类似物已得到制备,如美国专利号5,604,203、5,574,010和7,166,575中所述。
[0230]“尿皮质素”意指人尿皮质素肽激素及其具有成熟尿皮质素的至少一部分生物活性的序列变体。存在三种人尿皮质素:ucn-1、ucn-2和ucn-3。进一步的尿皮质素和类似物已在美国专利号6,214,797中进行描述。本发明的包含尿皮质素的bpxten蛋白还可以特别用于治疗或预防与刺激acth释放相关的状况、由于血管舒张效应的高血压、经由除acth升高外介导的炎症、高热、食欲障碍、充血性心力衰竭、压力、焦虑和牛皮癣。含有尿皮质素的融合蛋白也可以与利钠肽模块、胰淀素家族和exendin家族或glp1家族模块组合,以提供增强的心血管益处,例如如通过提供有益的血管舒张效应来治疗chf。
[0231]
代谢疾病和心血管蛋白
[0232]
代谢疾病和心血管疾病在大多数发达国家代表巨大的医疗保健负担,其中心血管疾病仍然是美国和大多数欧洲国家的第一大死亡和残疾原因。代谢疾病和病症包括影响身体器官、组织和循环系统的大量多种状况。
[0233]
血脂异常在糖尿病患者和患有心血管疾病的人或动物中频繁出现;通常特征在于参数例如升高的血浆甘油三酯、低hdl(高密度脂蛋白)胆固醇、正常至升高水平的ldl(低密度脂蛋白)胆固醇和血液中增加水平的小而致密的ldl颗粒。血脂异常和高血压是患有代谢疾病如糖尿病和心血管疾病的人或动物中的冠状动脉事件、肾脏疾病和死亡的发病率增加的主要贡献者。
[0234]
心血管疾病可以表现为涉及心脏、遍及全身的血管和器官系统的许多病症、症状和临床参数变化,尤其包括动脉瘤、心绞痛、动脉粥样硬化、脑血管意外(中风)、脑血管疾病、充血性心力衰竭、冠状动脉疾病、心肌梗塞、心输出量减少和外周血管疾病、高血压、低血压、血液标记物(例如c反应蛋白、bnp和酶如cpk、ldh、sgpt、sgot)。
[0235]
大多数代谢过程和许多心血管参数由多重肽和激素(“代谢蛋白质”)调控,并且许
多此类肽和激素以及其类似物已在此类疾病和病症的治疗中发现效用。然而,即使当通过使用小分子药物进行加强时,治疗性肽和/或激素的使用在此类疾病和病症的管理中也取得了有限的成功。特别地,剂量优化对于用于治疗代谢疾病的药物和生物制剂,尤其是具有窄治疗窗的那些药物和生物制剂是重要的。一般而言的激素和涉及于葡萄糖稳态的肽经常具有窄治疗窗。窄治疗窗加上此类激素和肽通常具有短半衰期(其需要频繁给药以便实现临床益处)的事实,导致此类患者的管理中的困难。因此,仍然需要在代谢疾病的治疗中具有增加的功效和安全性的治疗剂。
[0236]
因此,本发明的一个方面是将涉及于或用于治疗代谢和心血管疾病和病症的生物活性代谢蛋白质掺入bpxten融合蛋白内,以产生在此类病症、疾病和相关状况的治疗中具有效用的组合物。代谢蛋白质可以包括具有生物学、治疗或预防目的或功能的任何蛋白质,其可用于预防、治疗、介导或改善代谢或心血管疾病、病症或状况。表4d提供了由本发明的bpxten融合蛋白涵盖的代谢bp的此类序列的非限制性列表。本发明的bpxten组合物的代谢蛋白质可以是这样的蛋白质,其与选自表4d的蛋白质序列显示出至少约80%的序列同一性,或者可替代地81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性。
[0237]
表4d:用于代谢病症和心脏病学的生物活性蛋白质
[0238]
[0239][0240][0241]“抗cd3”意指针对t细胞表面蛋白cd3的单克隆抗体、物种和序列变体及其片段,包
括okt3(也称为莫罗单抗)和人源化抗cd3单克隆抗体(hokt31(ala-ala))(herold等人,2002,new england journal of medicine 346:1692-1698)。本发明的含有抗cd3的融合蛋白可以特别用于减缓新发作的1型糖尿病,包括使用抗cd3作为bpxten组合物中的第二治疗性bp的治疗效应物和靶向部分。关于可变区的序列和抗cd3的产生已在美国专利号5,885,573和6,491,916中进行描述。
[0242]“il-1ra”意指人il-1受体拮抗剂蛋白及其具有成熟il-1ra的至少一部分生物活性的物种和序列变体,包括序列变体阿那白滞素阿那白滞素是非糖基化的重组人il-1ra,并且通过n末端甲硫氨酸的添加而不同于内源性人il-1ra。阿那白滞素的商业化版本作为上市。它以与天然il-1ra和il-1b相同的亲合力与il-1受体结合,但并不导致受体激活(信号转导),所述效应归于il-1ra上仅存在一个受体结合基序相对于il-1α和il-1β上的两个此类基序。阿那白滞素具有153个氨基酸和17.3kd的大小,并且具有大约4-6小时的报道半衰期。
[0243]
增加的il-1产生已在患有各种微生物传染病和各种其它疾病的患者中报道。本发明的含有il-1ra的融合蛋白可以特别用于治疗前述疾病和病症中的任一种。il-1ra已得到克隆,如美国专利号5,075,222和6,858,409中所述。
[0244]“利钠肽”意指心房钠尿肽(anp)、脑利钠肽(bnp或b型利钠肽)和c型利钠肽(cnp);其具有成熟配对物利钠肽的至少一部分生物活性的人和非人物种和序列变体两者。有用形式的利钠肽的序列公开于美国专利公开20010027181中。anp的例子包括人anp(kangawa等人,1984,bbrc 118:131)或来自各个物种的anp,包括猪和大鼠anp(kangawa等人,1984,bbrc 121:585)。序列分析揭示了bnp前体原由134个残基组成,并且切割成108个氨基酸的bnp前体。从bnp前体的c末端中切割32个氨基酸的序列导致人bnp(77-108),其是循环的生理活性形式。32个氨基酸的人bnp涉及二硫键的形成(sudoh等人,1989,bbrc 159:1420)以及美国专利号5,114,923、5,674,710、5,674,710和5,948,761。含有一种或多种利钠功能的bpxten可以用于治疗高血压,利尿诱导,利钠诱导,血管传导扩张或松弛,利钠肽受体(例如npr-a)结合,来自肾上腺的醛固酮分泌抑制,治疗心血管疾病和病症,减少、停止或逆转心脏事件后或由于充血性心力衰竭导致的心脏重塑,治疗肾脏疾病和病症;治疗或预防缺血性中风,以及治疗哮喘。
[0245]“肝素结合生长因子2”或“fgf-2”意指人fgf-2蛋白及其具有成熟配对物的至少一部分生物活性的物种和序列变体。fgf-2已得到克隆,如burgess,w.h.和maciag,t.,ann.rev.biochem.,58:575-606(1989);coulier,f.等人,1994,prog.growth factor res.5:1;以及pct公开wo 87/01728中所述。
[0246]“tnf受体”意指关于tnf的人受体及其具有成熟tnfr的至少一部分生物受体活性的物种和序列变体。由人p55 tnf受体的细胞外结构域和tnfβ形成的复合物的x射线晶体结构已得到确定(banner等人,1993 cell 73:431,以引用的方式并入本文)。
[0247]
凝血因子
[0248]
在血友病中,血液凝固因缺乏某些血浆凝血因子而受到干扰。人因子ix(fix)是丝氨酸蛋白酶的酶原,所述丝氨酸蛋白酶是凝血级联的内源性途径的重要组分。因子viia(fviia)蛋白已发现可用于治疗具有针对fviii或fix的抑制剂的血友病a或b患者和患有获得性血友病的患者中的出血发作,以及预防具有针对fviii或fix的抑制剂的血友病a或b患
者中的手术干预或侵入性程序中的出血。因此,仍然需要当作为用于血友病b的预防和/或治疗方案的一部分施用时,具有延长的半衰期和活性保留的因子ix和因子viia组合物,以及减少副作用并且可以通过静脉内和皮下途径两者施用的制剂。
[0249]
用于包括在本发明的bpxten中的凝血因子可以包括具有生物学、治疗或预防目的或功能的蛋白质,其可用于预防、治疗、介导或改善血液凝固病症、疾病或缺陷。合适的凝血蛋白包括作为底物、酶或辅因子涉及于凝血级联的生物活性多肽。
[0250]
表4e提供了由本发明的bpxten融合蛋白涵盖的凝血因子序列的非限制性列表。用于包括在本发明的bpxten中的凝血因子可以是这样的蛋白质,其与选自表4e的蛋白质序列显示出至少约80%的序列同一性,或者可替代地81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性。
[0251]
表4e:凝血因子多肽序列
[0252]
[0253]
[0254]
[0255]
[0256][0257]
[0258]“因子ix”(“fix”)包括人因子ix蛋白及其具有成熟因子ix的至少一部分生物受体活性的物种和序列变体。在一些实施例中,fix肽是本文描述的任何fix肽的结构类似物或肽模拟物,包括表4e的序列。在一些实施例中,fix肽是本文描述的任何fix肽的结构类似物或肽模拟物,包括表4e的序列。在本发明的一个具体例子中,fix是人fix。在另一个实施例中,fix是来自表4e的多肽序列。成熟因子ix是415个氨基酸残基的单链蛋白质,其含有按重量计大约17%的碳水化合物(schmidt 2003,trends cardiovasc med,13:39)。
[0259]
在一些情况下,凝血因子是因子ix、因子ix的序列变体或因子ix部分,例如表4e的示例性序列,以及与其基本上同源的任何蛋白质或多肽,其生物学性质导致因子ix的活性。
[0260]“因子vii”(fvii)意指人蛋白质及其具有活化因子vii的至少一部分生物活性的物种和序列变体。因子vii和重组人fviia已引入用于血友病患者(具有因子viii或ix缺陷)中的无法控制的出血,所述血友病患者已发展针对替代凝血因子的抑制剂。重组人因子viia具有在治疗血友病患者(具有因子viii或ix缺陷)中的无法控制的出血中的效用,所述血友病患者包括已发展针对替代凝血因子的抑制剂的那些血友病患者。在一些实施例中,fvii肽是活化形式(fviia)、本文描述的任何fvii肽的结构类似物或肽模拟物,包括表4e的序列。因子vii和viia已得到克隆,如美国专利号6,806,063和美国专利申请号20080261886中所述。
[0261]
生长激素蛋白质
[0262]“生长激素”或“gh”意指人生长激素蛋白质及其物种和序列变体,并且包括但不限于gh的191个氨基酸的单链人序列。本发明考虑在bpxten中包括任何gh同源序列,例如来自灵长类动物、哺乳动物(包括驯养动物)的天然的序列片段,以及非天然序列变体,其保留gh的至少一部分生物活性或生物学功能和/或可用于预防、治疗、调解或改善gh相关疾病、缺陷、病症或状况。非哺乳动物gh序列在文献中充分描述。例如,鱼gh的序列比对可以在genetics and molecular biology 2003 26第295-300页中找到。另外,与人gh同源的天然序列可以通过标准同源性搜索技术如ncbi blast找到。
[0263]
在一个实施例中,掺入人或动物组合物内的gh可以是重组多肽,其具有对应于自然界中发现的蛋白质的序列。在另一个实施例中,gh可以是天然序列的序列变体、片段、同源物或模拟物,其保留天然gh的至少一部分生物活性。表4f提供了由本发明的bpxten融合蛋白涵盖的来自广泛各种哺乳动物物种的gh序列的非限制性列表。通过在种类或家族之间改组各个突变而构建的这些gh序列或同源衍生物中的任一种都可以用于本发明的融合蛋白。可以掺入bpxten融合蛋白内的gh可以包括这样的蛋白质,其与选自表4f的蛋白质显示出至少约80%的序列同一性,或者可替代地81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性。
[0264]
表4f:来自动物物种的生长激素氨基酸序列
[0265]
[0266]
[0267]
[0268]
[0269]
[0270][0271]
细胞因子
[0272]
bp可以是细胞因子或者一种或多种细胞因子。细胞因子指由细胞释放的蛋白质(如趋化因子、干扰素、淋巴因子、白细胞介素和肿瘤坏死因子),其可以影响细胞行为。细胞因子可以由广泛范围的细胞产生,所述细胞包括免疫细胞如巨噬细胞、b淋巴细胞、t淋巴细胞和肥大细胞,以及内皮细胞、成纤维细胞和各种基质细胞。给定的细胞因子可以由多于一种类型的细胞产生。细胞因子可以涉及产生全身或局部免疫调节效应。
[0273]
某些细胞因子可以充当促炎细胞因子。促炎细胞因子指涉及于诱导或放大炎症反应的细胞因子。促炎细胞因子可以与免疫系统的各种细胞如嗜中性粒细胞和白细胞一起工作,以生成免疫应答。某些细胞因子可以充当抗炎细胞因子。抗炎细胞因子指涉及于减少炎症反应的细胞因子。在一些情况下,抗炎细胞因子可以调控促炎细胞因子应答。一些细胞因子可以充当促炎细胞因子和抗炎细胞因子两者。
[0274]
由本发明的组合物涵盖的细胞因子可以具有在治疗各种治疗或疾病范畴中的效用,包括但不限于癌症、类风湿性关节炎、多发性硬化、重症肌无力、系统性红斑狼疮、阿尔茨海默氏病、精神分裂症、病毒感染(例如慢性丙型肝炎、aids)、过敏性哮喘、视网膜神经退行性过程、代谢病症、胰岛素抗性和糖尿病性心肌病。细胞因子在治疗炎症状况和自身免疫状况方面可以是尤其有用的。
[0275]
可由本公开内容的系统和组合物调控的细胞因子的例子包括但不限于淋巴因子、单核因子以及除了人生长激素之外的传统多肽激素。细胞因子中包括的是甲状旁腺激素;甲状腺素;胰岛素;胰岛素原;松弛素;松弛素原;糖蛋白激素,例如促卵泡激素(fsh)、促甲状腺激素(tsh)和促黄体激素(lh);肝生长因子;成纤维细胞生长因子;催乳素;胎盘催乳素;肿瘤坏死因子-α;苗勒管抑制物质;小鼠促性腺素关连肽;抑制素;激活素;血管内皮生长因子;整联蛋白;促血小板生成素(tpo);神经生长因子,例如ngf-α;血小板生长因子;转化生长因子(tgf),例如tgf-α、tgf-β、tgf-β1、tgf-β2和tgf-β3;胰岛素样生长因子-i和-ii;促红细胞生成素(epo);flt-3l;干细胞因子(scf);骨诱导因子;干扰素(ifn),例如ifn-α、ifn-β、ifn-γ;集落刺激因子(csf),例如巨噬细胞-csf(m-csf);粒细胞-巨噬细胞-csf(gm-csf);粒细胞-csf(g-csf);巨噬细胞刺激因子(msp);白细胞介素(il),例如il-1、il-1a、il-1b、il-1ra、il-18、il-2、il-3、il-4、il-5、il-6、il-7、il-8、il-9、il-10、il-11、il-12、il-12b、il-13、il-14、il-15、il-16、il-17、il-20;肿瘤坏死因子,例如cd154、lt-β、tnf-α、tnf-β、4-1bbl、april、cd70、cd153、cd178、gitrl、light、ox40l、tall-1、trail、tweak、trance;以及其它多肽因子,包括lif、制瘤素m(osm)和kit配体(kl)。细胞因子受体指结合细胞因子的受体蛋白。细胞因子受体既可以是膜结合的,也可以是可溶性的。
[0276]
靶多核苷酸可以编码细胞因子。细胞因子的非限制性例子包括4-1bbl、激活素βa、激活素βb、激活素βc、激活素βe、神经鞘胚素(artemin)(artn)、baff/blys/tnfsf138、bmp10、bmp15、bmp2、bmp3、bmp4、bmp5、bmp6、bmp7、bmp8a、bmp8b、骨形态发生蛋白1(bmp1)、ccl1/tca3、ccl11、ccl12/mcp-5、ccl13/mcp-4、ccl14、ccl15、ccl16、ccl17/tarc、ccl18、ccl19、ccl2/mcp-1、ccl20、ccl21、ccl22/mdc、ccl23、ccl24、ccl25、ccl26、ccl27、ccl28、ccl3、ccl3l3、ccl4、ccl4l1/lag-1、ccl5、ccl6、ccl7、ccl8、ccl9、cd153/cd30l/tnfsf8、cd40l/cd154/tnfsf5、cd40lg、cd70、cd70/cd27l/tnfsf7、clcf1、c-mpl/cd110/tpor、cntf、cx3cl1、cxcl1、cxcl10、cxcl11、cxcl12、cxcl13、cxcl14、cxcl15、cxcl16、cxcl17、cxcl2/mip-2、cxcl3、cxcl4、cxcl5、cxcl6、cxcl7/ppbp、cxcl9、eda-a1、fam19a1、fam19a2、fam19a3、fam19a4、fam19a5、fas配体/faslg/cd95l/cd178、gdf10、gdf11、gdf15、gdf2、gdf3、gdf4、gdf5、gdf6、gdf7、gdf8、gdf9、神经胶质细胞系源性神经营养因子(gdnf)、生长分化因子1(gdf1)、ifna1、ifna10、ifna13、ifna14、ifna2、ifna4、ifna5/ifnag、ifna7、ifna8、ifnb1、ifne、ifng、ifnz、ifnω/ifnw1、il11、il18、il18bp、il1a、il1b、il1f10、il1f3/il1ra、il1f5、il1f6、il1f7、il1f8、il1f9、il1rl2、il31、il33、il6、il8/cxcl8、抑制素-a、抑制素-b、瘦素、lif、lta/tnfb/tnfsf1、ltb/tnfc、神经秩蛋白(nrtn)、osm、ox-40l/tnfsf4/cd252、persephin(pspn)、rankl/opgl/tnfsf11(cd254)、tl1a/tnfsf15、tnfa、tnf-α/tnfa、tnfsf10/trail/apo-2l(cd253)、tnfsf12、tnfsf13、tnfsf14/light/cd258、xcl1和xcl2。在一些实施例中,靶基因编码免疫检查点抑制剂。此类免疫检查点抑制剂的非限制性例子包括pd-1、ctla-4、lag3、tim-3、a2ar、b7-h3、b7-h4、btla、ido、kir和vista。在一些实
施例中,靶基因编码t细胞受体(tcr)α、β、γ和/或δ链。
[0277]
在一些情况下,细胞因子可以是趋化因子。趋化因子可以选自包括但不限于以下的组:armcx2、bca-1/cxcl13、ccl11、ccl12/mcp-5、ccl13/mcp-4、ccl15/mip-5/mip-1δ、ccl16/hcc-4/ncc4、ccl17/tarc、ccl18/parc/mip-4、ccl19/mip-3b、ccl2/mcp-1、ccl20/mip-3α/mip3a、ccl21/6ckine、ccl22/mdc、ccl23/mip 3、ccl24/eotaxin-2/mpif-2、ccl25/teck、ccl26/eotaxin-3、ccl27/ctack、ccl28、ccl3/mip1a、ccl4/mip1b、ccl4l1/lag-1、ccl5/rantes、ccl6/c10、ccl8/mcp-2、ccl9、cml5、cxcl1、cxcl10/crg-2、cxcl12/sdf-1β、cxcl14/brak、cxcl15/lungkine、cxcl16/sr-psox、cxcl17、cxcl2/mip-2、cxcl3/groγ、cxcl4/pf4、cxcl5、cxcl6/gcp-2、cxcl9/mig、fam19a1、fam19a2、fam19a3、fam19a4/tafa4、fam19a5、fractalkine/cx3cl1、i-309/ccl1/tca-3、il-8/cxcl8、mcp-3/ccl7、nap-2/ppbp/cxcl7、xcl2和armo il10。
[0278]
表4g提供了由本发明的bpxten融合蛋白涵盖的bp的此类序列的非限制性列表。本发明的bpxten组合物的代谢蛋白质可以是这样的蛋白质,其与选自表4g的蛋白质序列显示出至少约80%的序列同一性,或者可替代地81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性。
[0279]
表4g:用于缀合的细胞因子
[0280]
[0281][0282]“il-1ra”意指人il-1受体拮抗剂蛋白及其具有成熟il-1ra的至少一部分生物活性的物种和序列变体,包括序列变体阿那白滞素人il-1ra是152个氨基酸残基的成熟糖蛋白。本发明的含有il-1ra的融合蛋白可以特别用于治疗前述疾病和病症中的任一种。il-1ra已得到克隆,如美国专利号5,075,222和6,858,409中所述。
[0283]
在一些情况下,bp可以是il-10。il-10可以是有效的抗炎细胞因子,其阻遏促炎细胞因子和趋化因子的产生。il-10可以用于治疗自身免疫性疾病和炎性疾病,例如类风湿性关节炎、多发性硬化、重症肌无力、系统性红斑狼疮、阿尔茨海默氏病、精神分裂症、过敏性哮喘、视网膜神经退行性过程和糖尿病。
[0284]
在一些情况下,可以修饰il-10以改善稳定性并降低蛋白酶解降解(prolytic degradation)。修饰可以是一个或多个酰胺键取代。在一些情况下,il-10主链内的一个或多个酰胺键可以被取代以实现上述效应。il-10中的一个或多个酰胺键(-conh-)可以替换为其是酰胺键合的电子等排体的键合,例如-ch2nh-、-ch2s-、-ch2ch
2-、-ch=ch-(顺式和反式)、-coch
2-、-ch(oh)ch
2-或-ch2so-。此外,il-10中的酰胺键合也可以由还原的电子等排体假肽键替换。参见couder等人(1993)int.j.peptide protein res.41:181-184,其在此以引用的方式全文并入。
[0285]
一种或多种酸性氨基酸,包括天冬氨酸,谷氨酸,高谷氨酸,酪氨酸,2,4-二氨基丙酸的烷基、芳基、芳基烷基和杂芳基磺酰胺,鸟氨酸或赖氨酸和四唑取代的烷基氨基酸;以及侧链酰胺残基,例如天冬酰胺,谷氨酰胺,以及天冬酰胺或谷氨酰胺的烷基或芳香族取代
衍生物;以及含羟基的氨基酸,包括丝氨酸、苏氨酸、高丝氨酸、2,3-二氨基丙酸、以及丝氨酸或苏氨酸的烷基或芳香族取代衍生物,可以是取代的。
[0286]
il-10中的一种或多种疏水性氨基酸,例如丙氨酸、亮氨酸、异亮氨酸、缬氨酸、正亮氨酸、(s)-2-氨基丁酸、(s)-环己基丙氨酸或其它简单的α-氨基酸可以由氨基酸取代,所述氨基酸包括但不限于来自c1-c10碳的脂肪族侧链,包括支链、环状和直链烷基、烯基或炔基取代。
[0287]
在一些情况下,il-10中的一种或多种疏水性氨基酸例如可以由芳香族取代的疏水性氨基酸取代,所述氨基酸包括苯丙氨酸、色氨酸、酪氨酸、磺基酪氨酸、联苯丙氨酸、1-萘基丙氨酸、2-萘基丙氨酸、2-苯并噻吩基丙氨酸、3-苯并噻吩基丙氨酸、组氨酸,包括上文列出的芳香族氨基酸的氨基、烷基氨基、二烷基氨基、氮杂、卤代(氟、氯、溴或碘)或烷氧基(c
1-c4)取代形式,其说明性例子是:2-、3-或4-氨基苯丙氨酸,2-、3-或4-氯苯丙氨酸,2-、3-或4-甲基苯丙氨酸,2-、3-或4-甲氧基苯丙氨酸,5-氨基-、5-氯-、5-甲基-或5-甲氧基色氨酸,2'-、3'-或4'-氨基-,2'-、3'-或4'-氯-,2、3或4-联苯丙氨酸,2'-、3'-或4'-甲基-,2-、3-或4-联苯丙氨酸和2-或3-吡啶基丙氨酸;
[0288]
il-10中的一种或多种疏水性氨基酸,例如苯丙氨酸、色氨酸、酪氨酸、磺基酪氨酸、联苯丙氨酸、1-萘基丙氨酸、2-萘基丙氨酸、2-苯并噻吩基丙氨酸、3-苯并噻吩基丙氨酸、组氨酸,包括氨基、烷基氨基、二烷基氨基、氮杂、卤代(氟、氯、溴或碘)或烷氧基可以由芳香族氨基酸取代,所述芳香族氨基酸包括:2-、3-或4-氨基苯丙氨酸,2-、3-或4-氯苯丙氨酸,2-、3-或4-甲基苯丙氨酸,2-、3-或4-甲氧基苯丙氨酸,5-氨基-、5-氯-、5-甲基-或5-甲氧基色氨酸,2'-、3'-或4'-氨基-,2'-、3'-或4'-氯-,2、3或4-联苯丙氨酸,2'-、3'-或4'-甲基-,2-、3-或4-联苯丙氨酸和2-或3-吡啶基丙氨酸。
[0289]
包含碱性侧链的氨基酸,包括精氨酸、赖氨酸、组氨酸、鸟氨酸、2,3-二氨基丙酸、高精氨酸,包括前述氨基酸的烷基、烯基或芳基取代的衍生物可以是取代的。例子是n-ε-异丙基-赖氨酸、3-(4-四氢吡啶基)-甘氨酸、3-(4-四氢吡啶基)-丙氨酸、n,n-γ,γ'-二乙基-高精氨酸、α-甲基-精氨酸、α-甲基-2,3-二氨基丙酸、α-甲基-组氨酸和α-甲基-鸟氨酸,其中烷基占据α-碳的前-r位置。修饰的il-10可以包含由以下的任何组合形成的酰胺:烷基、芳香族、杂芳香族、鸟氨酸或2,3-二氨基丙酸、羧酸或许多众所周知的活化衍生物中的任一种,例如酰氯、活性酯、活性azolide和相关衍生物、赖氨酸和鸟氨酸。
[0290]
在一些情况下,il-10可以包含一种或多种天然存在的l-氨基酸、合成的l-氨基酸和/或氨基酸的d-对映异构体。il-10多肽可以包含下述氨基酸中的一种或多种:ω-氨基癸酸、ω-氨基十四烷酸、环己基丙氨酸、α,γ-二氨基丁酸、α,β-二氨基丙酸、δ-氨基戊酸、叔丁基丙氨酸、叔丁基甘氨酸、n-甲基异亮氨酸、苯基甘氨酸、环己基丙氨酸、正亮氨酸、萘基丙氨酸、鸟氨酸、瓜氨酸、4-氯苯丙氨酸、2-氟苯丙氨酸、吡啶基丙氨酸、3-苯并噻吩基丙氨酸、羟脯氨酸、β-丙氨酸、邻氨基苯甲酸、间氨基苯甲酸、对氨基苯甲酸、间氨基甲基苯甲酸、2,3-二氨基丙酸、α-氨基异丁酸、n-甲基甘氨酸(肌氨酸)、3-氟苯丙氨酸、4-氟苯丙氨酸、青霉胺、1,2,3,4-四氢异喹啉-3-羧酸、β-2-噻吩丙氨酸、甲硫氨酸亚砜、高精氨酸、n-乙酰赖氨酸、2,4-二氨基丁酸、ρ-氨基苯丙氨酸、n-甲基缬氨酸、高半胱氨酸、高丝氨酸、ε-氨基己酸、ω-氨基己酸、ω-氨基庚酸、ω-氨基辛酸和2,3-二氨基丁酸。
[0291]
il-10可以包含半胱氨酸残基或半胱氨酸,其可以充当经由二硫键合与另一种肽
的接头或提供用于il-10多肽的环化。引入半胱氨酸或半胱氨酸类似物的方法是本领域已知的;参见例如,美国专利号8,067,532。il-10多肽可以是环化的。其它环化手段包括引入肟接头或羊毛硫氨酸接头;参见例如,美国专利号8,044,175。可以使用和/或引入可以形成环化键的氨基酸(或非氨基酸部分)的任何组合。环化键可以由具有官能团的氨基酸的任何组合(或氨基酸和-(ch2)nco-或-(ch2)nc6h
4-co-)生成,所述官能团允许引入桥。一些例子是二硫化物、二硫化物模拟物例如-(ch2)
n-碳桥(carba bridge)、硫缩醛、硫醚桥(胱硫醚或羊毛硫氨酸)以及含有酯和醚的桥。
[0292]
il-10可以由n-烷基、芳基或主链交联取代,以构建内酰胺和其它环状结构、c末端羟甲基衍生物、o-修饰的衍生物、n末端修饰的衍生物,包括取代的酰胺例如烷基酰胺和酰肼。在一些情况下,il-10多肽是逆反类似物。
[0293]
il-10可以是天然蛋白质,具有天然il-10的至少一部分生物活性的il-10的肽片段或修饰的肽。可以修饰il-10以改善细胞内摄取。一种此类修饰可以是蛋白质转导结构域的附着。蛋白质转导结构域可以附着到il-10的c末端。可替代地,蛋白质转导结构域可以附着到il-10的n末端。蛋白质转导结构域可以经由共价键附着到il-10。蛋白质转导结构域可以选自表4h中列出的任何序列。
[0294]
表4h.示例性蛋白质转导结构域
[0295]
seq id no氨基酸序列277ygrkkrrqrrr;278rrqrrtsklmkr279gwtlnsagyllgkinlkalaalakkil280kalaweaklakalakalakhlakalakalkcea281rqikiwfqnrrmkwkk282ygrkkrrqrrr283rkkrrqrrr284ygrkkrrqrrr285rkkrrqrr286yaraaarqara287thrlprrrrrr288ggrrarrrrrr
[0296]
人或动物组合物的bp并不限于天然的全长多肽,还包括重组形式以及其生物和/或药理活性变体或片段。例如,技术人员将了解可以在bp中制备各种氨基酸取代以产生变体,而不背离本发明关于bp的生物活性或药理性质的精神。关于多肽序列中的氨基酸的保守取代的例子显示于表5中。然而,在其中与本文公开的特定序列相比,bp的序列同一性小于100%的bpxten的实施例中,本发明考虑了关于给定bp的给定氨基酸残基的其它19种天然l-氨基酸中任一种的取代,所述氨基酸残基可以位于bp序列内的任何位置处,包括相邻的氨基酸残基。如果任何特定取代导致生物活性中不希望有的变化,则可以采用替代氨基酸,并且通过本文所述的方法,或使用例如在其内容以引用的方式全文并入的美国专利号5,364,934中阐述的关于保守和非保守突变的任何技术和指南,或使用本领域技术人员一般已知的方法来评估构建体。另外,变体还可以包括例如其中一个或多个氨基酸残基在bp
的全长天然氨基酸序列的n末端或c末端处添加或缺失的多肽,其保留了天然肽的至少一部分生物活性。
[0297]
表5:示例性保守氨基酸取代
[0298]
原始残基示例性取代ala(a)val;leu;ilearg(r)lys;gin;asnasn(n)gin;his;iys;argasp(d)glucys(c)sergln(q)asnglu(e)aspgly(g)prohis(h)asn:gin:iys:argxile(i)leu;val;met;ala;phe:正亮氨酸leu(l)正亮氨酸:ile:val;met;ala:phelys(k)arg:gin:asnmet(m)leu;phe;ilephe(f)leu:val:ile;alapro(p)glyser(s)thrthr(t)sertrp(w)tyrtyr(y)trp:phe:thr:serval(v)ile;leu;met;phe;ala;正亮氨酸
[0299]
在一些实施例中,掺入bpxten多肽内的bp可以具有这样的序列,其与来自表4a-4h的序列显示出至少约80%的序列同一性,可替代地与来自表4a-4h的序列相比,至少约81%、或约82%、或约83%、或约84%、或约85%、或约86%、或约87%、或约88%、或约89%、或约90%、或约91%、或约92%、或约93%、或约94%、或约95%、或约96%、或约97%、或约98%、或约99%或100%的序列同一性。在一些实施例中,掺入bpxten内的bp可以是包含第一结合结构域和第二结合结构域的双特异性序列,其中对肿瘤特异性标记物或靶细胞的抗原具有特异性结合亲和力的第一结合结构域,与选自表6f的抗cd3抗体的配对vl和vh序列显示出至少约80%的序列同一性,或者可替代地81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性;并且其中对效应细胞具有特异性结合亲和力的第二结合结构域,与选自表6a的抗靶细胞抗体的配对vl和vh序列显示出至少约80%的序列同一性,或者可替代地81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性。可以使用如本文所述的测定或者测量或确定的参数评估前述实施例的bp的活性,并且与相应的天然bp序列相比,保留至少约40%、或约50%、或约55%、或约60%、或约70%、或约80%、或约90%、或约95%或更多活性的那些序列被视为适
合于包括在人或动物bpxten中。发现保留合适活性水平的bp可以连接到上文或本文其它任何地方描述的一种或多种xten多肽。在一个实施例中,发现保留合适活性水平的bp可以连接到一种或多种xten多肽,其与来自表3a-3b的序列具有至少约80%的序列同一性(例如,至少约81%、至少约82%、至少约83%、至少约84%、至少约85%、至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%的序列同一性),导致嵌合融合蛋白。
[0300]
t细胞接合剂
[0301]
bpxten的另外结构构型式涉及xten化蛋白酶激活的t细胞接合剂(“xpat”或“xpats”),其中bp是双特异性抗体(例如,双特异性t细胞接合剂)。在一些实施例中,xpat组合物包括包含第一结合结构域和第二结合结构域的第一部分、包含释放区段的第二部分和包含xten填充部分的第三部分。在一些实施例中,xpat组合物具有式ia的构型(描绘为n末端至c末端):
[0302]
(第一部分)-(第二部分)-(第三部分)(ia)
[0303]
其中第一部分是包含两个scfv的双特异性,其中第一结合结构域对肿瘤特异性标记物或靶细胞的抗原具有特异性结合亲和力,并且第二结合结构域对效应细胞具有特异性结合亲和力;第二部分包含能够被哺乳动物蛋白酶(如下文更充分地描述的,蛋白酶可以是肿瘤特异性或抗原特异性的,从而活化)切割的释放区段(rs);并且第三部分是填充部分。在前述实施例中,第一部分结合结构域可以按以下次序:(vl-vh)1-(vl-vh)2,其中“1”和“2”分别代表第一结合结构域和第二结合结构域,或(vl-vh)1-(vh-vl)2,或(vh-vl)1-(vl-vh)2,或(vh-vl)1-(vh-vl)2,其中配对的结合结构域通过多肽接头(如下文更充分地描述的)进行连接。在一个实施例中,关于第一部分vl和vh的替代物在表6a-6f中进行鉴定;关于rs的替代物在表8a-8b(如下文更充分地描述的)中所示的序列中进行鉴定;并且关于填充部分的替代物在本文中通过以下进行鉴定:xten;白蛋白结合结构域;白蛋白;igg结合结构域;由脯氨酸、丝氨酸和丙氨酸组成的多肽;脂肪酸;fc结构域;聚乙二醇(peg),plga;以及羟乙基淀粉。需要时,填充部分是xten,其与由表3a-3b中所示的序列鉴定的序列具有至少约90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性。在前述实施例中,组合物是重组融合蛋白。在另一个实施例中,部分通过化学缀合进行连接。
[0304]
在另一个实施例中,xpat组合物具有式iia的构型(描绘为n末端至c末端):
[0305]
(第三部分)-(第二部分)-(第一部分)(iia)
[0306]
其中第一部分是包含两个scfv的双特异性,其中第一结合结构域对肿瘤特异性标记物或靶细胞的抗原具有特异性结合亲和力,并且第二结合结构域对效应细胞具有特异性结合亲和力;第二部分包含能够被哺乳动物蛋白酶切割的释放区段(rs);并且第三部分是填充部分。在前述实施例中,第一部分结合结构域可以按次序(vl-vh)1-(vl-vh)2,其中“1”和“2”分别代表第一结合结构域和第二结合结构域,或(vl-vh)1-(vh-vl)2,或(vh-vl)1-(vl-vh)2,或(vh-vl)1-(vh-vl)2,其中配对的结合结构域通过本文下文描述的多肽接头进行连接。在一个实施例中,关于第一部分vl和vh的替代物在表6a-6f中进行鉴定;关于rs的替代物在表8a-8b中所示的序列中进行鉴定;并且关于填充部分的替代物在本文中通过以下进行鉴定:xten;白蛋白结合结构域;白蛋白;igg结合结构域;由脯氨酸、丝氨酸和丙氨酸
组成的多肽;脂肪酸;以及fc结构域。需要时,填充部分是xten,其与选自表3a-3b中所示的序列的序列具有至少约90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性。在前述实施例中,组合物是重组融合蛋白。在另一个实施例中,部分通过化学缀合进行连接。
[0307]
在另一个实施例中,xpat组合物具有式iiia的构型(描绘为n末端至c末端):
[0308]
(第五部分)-(第四部分)-(第一部分)-(第二部分)-(第三部分)
[0309]
(iiia)
[0310]
其中第一部分是包含两个scfv的双特异性,其中第一结合结构域对肿瘤特异性标记物或靶细胞的抗原具有特异性结合亲和力,并且第二结合结构域对效应细胞具有特异性结合亲和力;第二部分包含能够被哺乳动物蛋白酶切割的释放区段(rs);第三部分是填充部分;第四部分包含能够被哺乳动物蛋白酶切割的释放区段(rs),其可以与第二部分是相同的或不同的;并且第五部分是填充部分,其可以与第三部分是相同的或可以是不同的。在前述实施例中,第一部分结合结构域可以按次序(vl-vh)1-(vl-vh)2,其中“1”和“2”分别代表第一结合结构域和第二结合结构域,或(vl-vh)1-(vh-vl)2,或(vh-vl)1-(vl-vh)2,或(vh-vl)1-(vh-vl)2,其中配对的结合结构域通过本文下文描述的多肽接头进行连接。在前述实施例中,关于rs的替代物在表8a-8b中阐述的序列中进行鉴定。在前述实施例中,关于填充部分的替代物在本文中通过以下进行鉴定:xten;白蛋白结合结构域;白蛋白;igg结合结构域;由脯氨酸、丝氨酸和丙氨酸组成的多肽;脂肪酸;以及fc结构域。需要时,填充部分是xten,其与选自表3a-3b中所示的序列的序列具有至少约90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性。在前述实施例中,组合物是重组融合蛋白。在另一个实施例中,部分通过化学缀合进行连接。
[0311]
基于其设计和特异性组分,人或动物组合物有利地提供双特异性治疗剂,一旦所述双特异性治疗剂被与靶组织或因疾病而致使不健康的组织相关发现的蛋白酶切割,它们就具有更高的选择性,更长的半衰期,并导致更小的毒性和更少的副作用,其中所述人或动物组合物与本领域已知的双特异性抗体组合物相比具有改善的治疗指数。此类组合物可用于治疗某些疾病,包括但不限于如本文所述的癌症。不限于任何机制理论,技术人员将了解本发明的组合物通过机制的组合以非特异性相互作用来实现这种减少,所述机制包括通过将结合结构域定位到庞大的xten分子的空间位阻,其中通过栓系到组合物,xten多肽的柔性、非结构化特性能够在结合结构域周围振荡且移动,提供在组合物和组织或细胞之间的阻断,以及由于与个别结合结构域的大小相比的大分子质量(由xten多肽的实际分子量、以及由于非结构化xten多肽的大流体动力学半径两者贡献的),提供完整组合物穿透细胞或组织的能力的减少。然而,这样设计组合物,其中当接近携带或分泌能够切割rs的蛋白酶的靶组织或细胞时,或当结合结构域已结合配体时内化到靶细胞或组织内时,双特异性结合结构域通过蛋白酶的作用从xten的大部分中释放,去除空间位阻屏障,并且更自由地发挥其药理效应。人或动物组合物可用于治疗其中需要将治疗性双特异性抗体组合物选择性递送至细胞、组织或器官的各种状况。在一个实施例中,靶组织是癌症,其可以是白血病、淋巴瘤或者器官或系统的肿瘤。
[0312]
结合结构域
[0313]
本公开内容考虑了使用单链结合结构域,例如但不限于fv、fab、fab’、fab
’‑
sh、f
(ab’)2、线性抗体、单结构域抗体、单结构域骆驼科抗体、单链抗体分子(scfv)、以及能够结合与效应细胞以及患病组织或细胞的抗原相关的配体或受体的双抗体,所述患病组织或细胞是癌症、肿瘤或其它恶性组织。在一些实施例中,双特异性抗体包含对靶细胞标记物具有结合特异性的第一结合结构域、以及对效应细胞抗原具有结合特异性的第二结合结构域。在一些实施例中,第一结合结构域和第二结合结构域可以是非抗体支架,例如anticalin、adnectin、fynomer、affilin、亲和体、centyrins、darpin。在其它实施例中,关于肿瘤细胞靶的结合结构域是t细胞受体的可变结构域,其已改造为结合装载有蛋白质的肽片段的mhc,所述蛋白质由肿瘤细胞过表达。在一些实施例中,伴随以下考虑设计xpat组合物:靶组织蛋白酶的定位以及相同蛋白酶在不预期靶向的健康组织中的存在,以及靶配体在健康组织中的存在,但在不健康的靶组织中的更大存在,以便提供宽治疗窗。“治疗窗”指关于给定治疗组合物的最小有效剂量和最大耐受剂量之间的最大差异。为了帮助实现宽治疗窗,组合物的第一部分的结合结构域通过填充部分(例如,xten多肽)的接近进行屏蔽,其中与已被哺乳动物蛋白酶切割的组合物相比,完整组合物对于配体之一或两者的结合亲和力是减少的,从而将第一部分从填充部分的屏蔽效应中释放。
[0314]
关于单链结合结构域,如本领域充分确立的,fv是含有完整抗原识别和结合位点的最小抗体片段,由以非共价结合的一个重链可变结构域(vh)和一个轻链可变结构域(vl)的二聚体组成。在每条vh和vl链内的是三个互补决定区(cdr),其相互作用以限定vh-vl二聚体的表面上的抗原结合位点;结合结构域的六个cdr对抗体或单链结合结构域赋予抗原结合特异性。在一些情况下,产生这样的scfv,其中在每个结合结构域内各自具有3、4或5个chr。侧接cdr的构架序列具有跨越物种在天然免疫球蛋白中基本上保守的三级结构,并且构架残基(fr)作用于将cdr保持在其适当的取向上。恒定结构域不是结合功能所需的,但可以帮助稳定vh-vl相互作用。在一些实施例中,多肽结合位点的结构域可以是相同或不同免疫球蛋白的一对vh-vl、vh-vh或vl-vl结构域,然而一般优选使用来自亲本抗体的分别vh和vl链来制备单链结合结构域。多肽链内的vh和vl结构域的次序对于本发明并非限制性的;所给出的结构域的次序通常可以颠倒,而不丧失任何功能,但应理解vh和vl结构域这样排列,使得抗原结合位点可以正确地折叠。因此,人或动物组合物的双特异性scfv实施例的单链结合结构域可以按以下次序:(vl-vh)
1-(vl-vh)2,其中“1”和“2”分别代表第一结合结构域和第二结合结构域,或(vl-vh)
1-(vh-vl)2,或(vh-vl)
1-(vl-vh)2,或(vh-vl)
1-(vh-vl)2,其中配对的结合结构域通过如本文下文所述的多肽接头进行连接。
[0315]
因此,本文公开的示例性双特异性单链抗体中的结合结构域的排列可以是其中第一结合结构域定位于第二结合结构域的c末端的排列。v链的排列可以是vh(靶细胞表面抗原)-vl(靶细胞表面抗原)-vl(效应细胞抗原)-vh(效应细胞抗原)、vh(靶细胞表面抗原)-vl(靶细胞表面抗原)-vh(效应细胞抗原)-vl(效应细胞抗原)、vl(靶细胞表面抗原)-vh(靶细胞表面抗原)-vl(效应细胞抗原)-vh(效应细胞抗原)或vl(靶细胞表面抗原)-vh(靶细胞表面抗原)-vh(效应细胞抗原)-vl(效应细胞抗原)。对于其中第二结合结构域定位于第一结合结构域的n末端的排列,下述次序是可能的:vh(效应细胞抗原)-vl(效应细胞抗原)-vl(靶细胞表面抗原)-vh(靶细胞表面抗原)、vh(效应细胞抗原)-vl(效应细胞抗原)-vh(靶细胞表面抗原)-vl(靶细胞表面抗原)、vl(效应细胞抗原)-vh(效应细胞抗原)-vl(靶细胞表面抗原)-vh(靶细胞表面抗原)或vl(效应细胞抗原)-vh(效应细胞抗原)-vh(靶细胞表面抗
原)-vl(靶细胞表面抗原)。如本文使用的,“其n末端”或“其c末端”及其语法变体表示在一级氨基酸序列内的相对定位,而不是置于双特异性单链抗体的绝对n末端或c末端处。因此,作为非限制性例子,“定位于第二结合结构域的c末端”的第一结合结构域表示第一结合定位于双特异性单链抗体内的第二结合结构域的羧基侧上,并不排除另外的序列例如his-标签或另一种化合物例如放射性同位素定位于双特异性单链抗体的c末端处的可能性。
[0316]
在一个实施例中,嵌合多肽组装组合物包括包含第一结合结构域和第二结合结构域的第一部分,其中所述结合结构域各自是scfv,并且其中每个scfv包含一个vl和一个vh。在另一个实施例中,嵌合多肽组装组合物包括包含第一结合结构域和第二结合结构域的第一部分,其中所述结合结构域为双抗体构型,并且其中每个结构域包含一个vl结构域和一个vh。在前述实施例中,第一结构域对肿瘤特异性标记物或靶细胞的抗原具有结合特异性,并且第二结合结构域对效应细胞抗原具有结合特异性。在前述的一个实施例中,效应细胞抗原在效应细胞之上或之内表达。在一个实施例中,效应细胞抗原在t细胞例如cd4+、cd8+或天然杀伤(nk)细胞上表达。在另一个实施例中,效应细胞抗原在b细胞、肥大细胞、树突状细胞或髓样细胞上表达。在一个实施例中,效应细胞抗原是cd3,细胞毒性t细胞的分化簇3抗原。在前述的一些实施例中,第一结合结构域显示出对与肿瘤细胞相关的肿瘤特异性标记物的结合特异性。在一个实施例中,结合结构域对肿瘤特异性标记物具有结合亲和力,其中所述肿瘤细胞可以包括但不限于来自以下的细胞:基质细胞肿瘤、成纤维细胞肿瘤、肌成纤维细胞肿瘤、神经胶质细胞肿瘤、上皮细胞肿瘤、脂肪细胞肿瘤、免疫细胞肿瘤、血管细胞肿瘤和平滑肌细胞肿瘤。在一个实施例中,肿瘤特异性标记物或靶细胞的抗原可以是α4整联蛋白、ang2、b7-h3、b7-h6、ceacam5、cmet、ctla4、folr1、epcam、ccr5、cd19、her2、her2 neu、her3、her4、her1(egfr)、pd-l1、psma、cea、trop-2、muc1(粘蛋白)、muc-2、muc3、muc4、muc5ac、muc5b、muc7、muc16βhcg、lewis-y、cd20、cd33、cd38、cd30、cd56(ncam)、cd133、神经节苷脂gd3;9-o-乙酰基-gd3、gm2、globo h、岩藻糖基gm1、gd2、碳酸酐酶ix、cd44v6、nectin-4、sonic hedgehog(shh)、wue-1、浆细胞抗原1、黑色素瘤硫酸软骨素蛋白聚糖(mcsp)、ccr8、前列腺6-跨膜上皮抗原(steap)、间皮素、a33抗原、前列腺干细胞抗原(psca)、ly-6、桥粒芯蛋白4、胎儿乙酰胆碱受体(fnachr)、cd25、癌抗原19-9(ca19-9)、癌抗原125(ca-125)、苗勒管抑制物质受体ii型(misiir)、唾液酸化tn抗原(s tn)、成纤维细胞活化抗原(fap)、内皮唾液酸蛋白(cd248)、表皮生长因子受体变体iii(egfrviii))、肿瘤相关抗原l6(tal6)、sas、cd63、tag72、汤姆森-弗里登赖希抗原(thomsen-friedenreich antigen)(tf抗原)、胰岛素样生长因子i受体(igf-ir)、cora抗原、cd7、cd22、cd70、cd79a、cd79b、g250、mt-mmp、f19抗原、ca19-9、ca-125、甲胎蛋白(afp)、vegfr1、vegfr2、dlk1、sp17、ror1和epha2。在一个实施例中,显示出对cd70的结合亲和力的第一结合结构域是其天然配体cd27,而不是抗体片段。在另一个实施例中,显示出对b7-h6的结合亲和力的第一结合结构域是其天然配体nkp30,而不是抗体片段。
[0317]
本发明的xpat组合物的scfv实施例包含第一结合结构域和第二结合结构域,其中vl和vh结构域分别源自对肿瘤特异性标记物或靶细胞的抗原和效应细胞抗原具有结合特异性的单克隆抗体。在其它情况下,第一结合结构域和第二结合结构域各自分别包含源自单克隆抗体的六个cdr,所述单克隆抗体对靶细胞标记物例如肿瘤特异性标记物和效应细胞抗原具有结合特异性。在其它实施例中,人或动物组合物的第一部分的第一结合结构域
和第二结合结构域可以具有在每个结合结构域内的3、4或5个chr。在其它实施例中,本发明的实施例包含第一结合结构域和第二结合结构域,其中每种包含cdr-h1区、cdr-h2区、cdr-h3区、cdr-l1区、cdr-l2区和cdr-h3区,其中所述区域各自分别源自能够结合肿瘤特异性标记物或靶细胞的抗原和效应细胞抗原的单克隆抗体。在一个实施例中,本发明提供了嵌合多肽组装组合物,其中第二结合结构域包含源自能够结合人cd3的单克隆抗体的vh和vl区。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其中scfv第二结合结构域包含vh和vl区,其中每个vh和vl区与表6a中所示的抗cd3抗体的配对vl和vh序列显示出至少约90%、或91%、或92%、或93%、或94%、或95%、或96%、或97%、或98%、或99%的同一性或者与之相同。在另一个方面,本发明的第二结构域实施例包含cdr-h1区、cdr-h2区、cdr-h3区、cdr-l1区、cdr-l2区和cdr-h3区,其中所述区域各自源自如表6a中所示的单克隆抗体。在前述实施例中,vh和/或vl结构域可以配置为scfv、双抗体、单结构域抗体或单结构域骆驼科抗体。
[0318]
在其它实施例中,人或动物组合物的第二结构域源自如表6a中所示的抗cd3抗体。在前述的一个实施例中,人或动物组合物的第二结构域包含如表6a中所示的抗cd3抗体的配对vl和vh区序列。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其中第二结合结构域包含vh和vl区,其中每个vh和vl区与表6a的huucht1抗cd3抗体的配对vl和vh序列显示出至少约90%、或91%、或92%、或93%、或94%、或95%、或96%、或97%、或98%、或99%的同一性或者与之相同。在前述实施例中,vh和/或vl结构域可以配置为scfv、双抗体的一部分、单结构域抗体或单结构域骆驼科抗体。
[0319]
在其它实施例中,组合物的第一结构域的scfv源自如表6f中所示的抗肿瘤细胞抗体。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其中第一结合结构域包含vh和vl区,其中每个vh和vl区与表6f中所示的抗肿瘤细胞抗体的配对vl和vh序列显示出至少约90%、或91%、或92%、或93%、或94%、或95%、或96%、或97%、或98%、或99%的同一性或者与之相同。在前述的一个实施例中,所述组合物的第一结构域包含本文公开的抗肿瘤细胞抗体的配对vl和vh区序列。在前述实施例中,vh和/或vl结构域可以配置为scfv、双抗体的一部分、单结构域抗体或单结构域骆驼科抗体。
[0320]
在另一个实施例中,嵌合多肽组装组合物包括包含第一结合结构域和第二结合结构域的第一部分,其中所述结合结构域为双抗体构型,并且所述结合结构域各自包含一个vl结构域和一个vh结构域。在一个实施例中,本发明的双抗体实施例包含第一结合结构域和第二结合结构域,其中vl和vh结构域分别源自对肿瘤特异性标记物或靶细胞的抗原和效应细胞抗原具有结合特异性的单克隆抗体。在另一个实施例中,本发明的双抗体实施例包含第一结合结构域和第二结合结构域,其中每种包含cdr-h1区、cdr-h2区、cdr-h3区、cdr-l1区、cdr-l2区和cdr-h3区,其中所述区域各自分别源自能够结合肿瘤特异性标记物或靶细胞抗原和效应细胞抗原的单克隆抗体。设想本发明的双抗体实施例包含第一结合结构域和第二结合结构域,其中vl和vh结构域分别源自对肿瘤特异性标记物或靶细胞抗原和效应细胞抗原具有结合特异性的单克隆抗体。在另一个方面,本发明的双抗体实施例包含第一结合结构域和第二结合结构域,其中每种包含cdr-h1区、cdr-h2区、cdr-h3区、cdr-l1区、cdr-l2区和cdr-h3区,其中所述区域各自分别源自能够结合肿瘤特异性标记物或靶细胞抗原和效应细胞抗原的单克隆抗体。在一个实施例中,本发明提供了嵌合多肽组装组合物,其
中双抗体第二结合结构域包含源自能够结合人cd3的单克隆抗体的配对vh和vl区。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其中双抗体第二结合结构域包含vh和vl区,其中每个vh和vl区与如表6a中所示的抗cd3抗体的配对vl和vh序列显示出至少约90%、或91%、或92%、或93%、或94%、或95%、或96%、或97%、或98%、或99%的同一性或者与之相同。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其中双抗体第二结合结构域包含vh和vl区,其中每个vh和vl区与如表6a中所示的huucht1抗体的vl和vh序列显示出至少约90%、或91%、或92%、或93%、或94%、或95%、或96%、或97%、或98%、或99%的同一性或者与之相同。在其它实施例中,组合物的双抗体第二结构域源自本文所述的抗cd3抗体。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其中双抗体第一结合结构域包含vh和vl区,其中每个vh和vl区与如表6f中所示的抗肿瘤细胞抗体的vl和vh序列显示出至少约90%、或91%、或92%、或93%、或94%、或95%、或96%、或97%、或98%、或99%的同一性或者与之相同。在其它实施例中,组合物的双抗体第一结构域源自本文所述的抗肿瘤细胞抗体。
[0321]
用于人或动物组合物的vl和vh和cdr结构域可以源自其的治疗性单克隆抗体是本领域已知的。关于上文抗体的序列可以得自可公开获得的数据库、专利或参考文献。另外,单克隆抗体以及来自抗cd3抗体的vh和vl序列的非限制性例子在表6a中阐述,并且针对癌症、肿瘤或靶细胞标记物的单克隆抗体以及vh和vl序列的非限制性例子在表6f中阐述。
[0322]
抗cd3结合结构域
[0323]
在一些实施例中,本发明提供了嵌合多肽组装组合物,其包含对t细胞具有结合亲和力的第一部分的结合结构域。在一个实施例中,第二部分的结合结构域包含源自针对cd3抗原的单克隆抗体的vl和vh。在另一个实施例中,结合结构域包含源自针对cd3ε和cd3δ的单克隆抗体的vl和vh。针对cd3 neu的单克隆抗体是本领域已知的。针对cd3的单克隆抗体的vl和vh序列的示例性非限制性例子在表6a中阐述。在一个实施例中,本发明提供了嵌合多肽组装,其包含对cd3具有结合亲和力的结合结构域,所述结合结构域包含表6a中所示的抗cd3 vl和vh序列。在另一个实施例中,本发明提供了嵌合多肽组装,其包含对cd3ε具有结合亲和力的第一部分的结合结构域,所述结合结构域包含表6a中所示的抗cd3εvl和vh序列。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其中第一部分的scfv第二结合结构域包含vh和vl区,其中每个vh和vl区与表6a的huucht1抗cd3抗体的配对vl和vh序列显示出至少约90%、或91%、或92%、或93%、或94%、或95%、或96%、或97%、或98%、或99%的同一性或者与之相同。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其包含对cd3具有结合亲和力的结合结构域,所述结合结构域包含cdr-l1区、cdr-l2区、cdr-l3区、cdr-h1区、cdr-h2区和cdr-h3区,其中每种源自表6a中所示的分别的抗cd3 vl和vh序列。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其包含对cd3具有结合亲和力的结合结构域,所述结合结构域包含cdr-l1区、cdr-l2区、cdr-l3区、cdr-h1区、cdr-h2区和cdr-h3区,其中所述cdr序列是rasqdirnyln(seq id no:8034)、ytsrles(seq id no:8035)、qqgntlpwt(seq id no:8036)、gysftgytmn(seq id no:8037)、linpykgvst(seq id no:8038)、和sgyygdsdwyfdv(seq id no:8039)。
[0324]
cd3复合物是一组细胞表面分子,其与t细胞抗原受体(tcr)结合,并且在tcr的细胞表面表达和信号传导转导级联中发挥功能,当肽:mhc配体与tcr结合时,所述信号传导转
导级联起始。通常,当抗原与t细胞受体结合时,cd3通过细胞膜向t细胞内的细胞质发送信号。这导致t细胞的活化,所述t细胞快速分裂以产生致敏的新的t细胞,以攻击tcr暴露于其的特定抗原。cd3复合物包含cd3ε分子,连同四种其它膜结合多肽(cd3-γ、-δ、-ζ和-β)。在人中,cd3-ε由染色体11上的cd3e基因编码。每条cd3链的细胞内结构域含有基于免疫受体酪氨酸的激活基序(itam),其充当在t细胞受体接合后的细胞内信号转导机制的成核点。
[0325]
许多治疗策略通过靶向tcr信号传导来调节t细胞免疫,特别是临床上广泛用于免疫抑制方案中的抗人cd3单克隆抗体(mab)。cd3特异性小鼠mab okt3是批准用于人中的首个mab(sgro,c.side-effects of a monoclonal antibody,muromonab cd3/orthoclone okt3:bibliographic review.toxicology 105:23-29,1995),并且在临床上广泛用作移植(chatenoud,clin.transplant 7:422-430,(1993);chatenoud,nat.rev.immunol.3:123-132(2003);kumar,transplant.proc.30:1351-1352(1998))、1型糖尿病和牛皮癣中的免疫抑制剂。重要的是,抗cd3 mab可以诱导部分t细胞信号传导和克隆无能(smith,ja,nonmitogenic anti-cd3 monoclonal antibodies deliver a partial t cell receptor signal and induce clonal anergy j.exp.med.185:1413-1422(1997))。okt3在文献中已描述为t细胞有丝分裂原以及有力的t细胞杀伤剂(wong,jt.the mechanism of anti-cd3 monoclonal antibodies.mediation of cytolysis by inter-t cell bridging.transplantation 50:683-689(1990))。特别地,wong的研究证实了,通过桥接cd3 t细胞和靶细胞,可以实现靶的杀伤,并且对于二价抗cd3mab,既不需要fcr介导的adcc也不需要补体固定来裂解靶细胞。
[0326]
okt3显示出以时间依赖性方式的促有丝分裂和t细胞杀伤活性;在导致细胞因子释放的t细胞的早期激活之后,在进一步施用后,okt3随后阻断了所有已知的t细胞功能。正是由于t细胞功能的这种以后阻断,已发现okt3在用于减少或甚至消除同种异体移植组织排斥的治疗方案中作为免疫抑制剂的此类广泛应用。对于cd3分子特异性的其它抗体公开于tunnacliffe,int.immunol.1(1989),546-50中,wo2005/118635和wo2007/033230描述了抗人单克隆cd3ε抗体,美国专利5,821,337描述了鼠抗cd3单克隆ab ucht1(muxcd3,shalaby等人,j.exp.med.175,217-225(1992)的vl和vh序列以及这种抗体的人源化变体(hu ucht1),并且美国专利申请20120034228公开了能够结合人和非黑猩猩灵长类动物cd3ε链的表位的结合结构域。
[0327]
表6a:抗cd3单克隆抗体和序列
[0328]
[0329]
[0330]
[0331]
[0332]
[0333][0334]
*加下划线的序列(如果存在的话)是在vl和vh内的cdr
[0335]
cd3细胞抗原结合片段
[0336]
在另一个方面,本公开内容涉及对于效应细胞抗原具有特异性结合亲和力的抗原结合片段(af2),其可以掺入本文所述的任何人或动物组合物实施例内。在一些情况下,效应细胞抗原在效应细胞的表面上表达,所述效应细胞选自浆细胞、t细胞、b细胞、细胞因子诱导的杀伤细胞(cik细胞)、肥大细胞、树突状细胞、调节性t细胞(regt细胞)、辅助性t细胞、髓样细胞和nk细胞。
[0337]
结合效应细胞抗原的各种af2具有用于以组合物形式与抗原结合片段配对的特定效用,所述抗原结合片段对与患病细胞或组织相关的egfr抗原具有结合亲和力,以便实现患病细胞或组织的细胞杀伤。结合特异性可以通过互补决定区或cdr,例如轻链cdr或重链cdr来确定。在许多情况下,结合特异性由轻链cdr和重链cdr确定。重链cdr和轻链cdr的给定组合提供了给定的结合口袋,与其它参考抗原相比,所述结合口袋针对效应细胞抗原赋予更大亲和力和/或特异性。具有通过短的柔性肽接头连接到对效应细胞抗原具有结合特异性的第二抗原结合片段(af2)的针对egfr的第一抗原结合片段(af1)的所得到的双特异
性组合物是双特异性的,其中每个抗原结合片段对其分别的配体具有特异性结合亲和力。技术人员将理解,在此类组合物中,针对疾病组织的egfr的af1与针对效应细胞标记物的af2组合使用,以便使效应细胞紧密接近疾病组织的细胞,以便实现患病组织的细胞的细胞裂解。进一步地,将af1和af2掺入包含可切割释放区段和xten的特别设计的多肽内,以便对组合物赋予前药特性,当接近具有能够在释放区段序列中的一个或多个位置中切割释放区段的蛋白酶的疾病组织时,所述组合物在释放区段的切割后,通过释放融合的af1和af2而变得激活。
[0338]
在一个实施例中,人或动物组合物的af2对于t细胞的表面上表达的效应细胞抗原具有结合亲和力。在另一个实施例中,人或动物组合物的af2对于cd3具有结合亲和力。在另一个实施例中,人或动物组合物的af2对于cd3复合物的成员具有结合亲和力,所述成员包括以个别形式或独立组合形式的cd3复合物的所有已知cd3亚基;例如,cd3ε、cd3δ、cd3γ、cd3ζ、cd3α和cd3β。在另一个实施例中,af2对于cd3ε、cd3δ、cd3γ、cd3ζ、cd3α或cd3β具有结合亲和力。
[0339]
由本公开内容考虑的抗原结合片段的起源可以源自天然存在的抗体或其片段、非天然存在的抗体或其片段、人源化抗体或其片段、合成抗体或其片段、杂合抗体或其片段、或者改造抗体或其片段。用于生成关于给定靶标记物的抗体的方法是本领域众所周知的。例如,单克隆抗体可以使用首先由kohler等人,nature,256:495(1975)描述的杂交瘤方法进行制备,或者可以通过重组dna方法(美国专利号4,816,567)进行制备。抗体及其片段、抗体重链和轻链的可变区(vh和vl)、单链可变区(scfv)、互补决定区(cdr)和结构域抗体(dab)的结构是充分理解的。用于生成具有对给定抗原具有结合亲和力的所需抗原结合片段的多肽的方法是本领域已知的。
[0340]
技术人员将理解,对于本文公开的组合物实施例使用术语“抗原结合片段”预期包括保留结合抗原的能力的抗体的一部分或片段,所述抗原是相应完整抗体的配体。在此类实施例中,抗原结合片段可以是但不限于cdr和插入构架区、抗体轻链和/或重链(vl、vh)的可变区或高变区、可变片段(fv)、fab'片段、f(ab')2片段、fab片段、单链抗体(scab)、vhh骆驼科抗体、单链可变片段(scfv)、线性抗体、单结构域抗体、互补决定区(cdr)、结构域抗体(dab)、bhh或bnar类型的单结构域重链免疫球蛋白、单结构域轻链免疫球蛋白、或本领域已知的含有能够结合抗原的抗体片段的其它多肽。具有cdr-h和cdr-l的抗原结合片段可以从n末端到c末端以(cdr-h)-(cdr-l)或(cdr-h)-(cdr-l)取向进行配置。两个抗原结合片段的vl和vh也可以以单链双抗体构型进行配置;即,af1和af2的vl和vh配置有适当长度的接头,以允许作为双抗体排列。
[0341]
本公开内容的各种结合cd3的af2已进行特异性修饰,以增强其在本文所述的多肽实施例中的稳定性。抗体的蛋白质聚集在其可开发性方面继续是重大问题,并且仍然是抗体生产的主要焦点领域。抗体聚集可以通过其结构域的部分解折叠来触发,导致单体-单体结合,随后为成核和聚集体生长。尽管抗体和基于抗体的蛋白质的聚集倾向可以受到外部实验条件的影响,但它们强烈依赖于如通过其序列和结构决定的固有抗体性质。尽管众所周知的是蛋白质在其折叠状态下仅略微稳定,但经常不太了解的是大多数蛋白质在其解折叠或部分解折叠状态下固有地易于聚集,并且所得到的聚集体可以是非常稳定且长寿的。聚集倾向的减少也已显示伴随着表达滴度的增加,显示了减少蛋白质聚集在开发过程自始
至终都是有益的,并且可以导致更有效的临床研究路径。对于治疗性蛋白质,聚集体是患者中的有害免疫应答的显著风险因素,并且可以经由各种机制形成。控制聚集可以改善蛋白质稳定性、可制造性、损耗率、安全性、制剂、滴度、免疫原性和溶解度。蛋白质的固有性质如大小、疏水性、静电和电荷分布在蛋白质溶解度中起重要作用。由于表面疏水性的治疗性蛋白质的低溶解度已显示致使制剂开发更加困难,并且可以导致在体内的弱生物分布、不期望有的药代动力学行为和免疫原性。降低候选单克隆抗体的整体表面疏水性还可以提供与纯化和给药方案有关的益处和成本节约。个别氨基酸可以通过结构分析鉴定为有助于抗体中的聚集潜力,并且可以定位于cdr以及构架区中。特别地,残基可以预测为在给定抗体中处于引起疏水性问题的高风险中。在一个实施例中,本公开内容提供了具有特异性结合cd3的能力的af2,其中相对于亲本抗体或抗体片段,所述af2具有在构架区中的疏水性氨基酸的至少一个氨基酸取代,其中所述疏水性氨基酸选自异亮氨酸、亮氨酸或甲硫氨酸。在另一个实施例中,cd3 af2具有在一个或多个构架区中的疏水性氨基酸的至少两个氨基酸取代,其中所述疏水性氨基酸选自异亮氨酸、亮氨酸或甲硫氨酸。
[0342]
在设计本文所述实施例的af2的序列时,考虑了关于多肽的净电荷的变化,特别是关于构成本文阐述的本发明的特定实施例的抗体或抗体片段的变化,其中相对于用作起点的亲本抗体制备个别氨基酸取代。与这些设计考虑有关的是多肽的等电点(pi),其为在其下抗体或抗体片段没有净电荷的ph。抗体或抗体片段通常具有净正电荷,其趋于与增加的血液清除率和组织保留相关联,具有一般较短的半衰期,而净负电荷导致降低的组织摄取和更长的半衰期。能够通过对构架残基的突变来操纵这种电荷。多肽的等电点可以通过体外测定在算术上(例如,计算上)或实验上进行确定。在一些实施例中,af1和af2的等电点设计在彼此的特定范围内,从而促进稳定性。
[0343]
在一个实施例中,本公开内容提供了用于本文所述的任何多肽实施例中的af2,其包含cdr-l和cdr-h,其中所述af2(a)特异性结合t细胞受体的分化簇3(cd3);并且(b)包含分别具有seq id no:742、743和744的氨基酸序列的cdr-h1、cdr-h2和cdr-h3。在另一个实施例中,本公开内容提供了用于本文所述的任何多肽实施例中的af2,其包含cdr-l和cdr-h,其中所述af2(a)特异性结合t细胞受体的分化簇3(cd3);(b)包含分别具有seq id no:742、743和744的氨基酸序列的cdr-h1、cdr-h2和cdr-h3;并且(c)包含cdr-l,其中所述cdr-l包含具有seq id no:735或736的氨基酸序列的cdr-l1、具有seq id no:738或739的氨基酸序列的cdr-l2、以及具有seq id no:740的氨基酸序列的cdr-l3。在另一个实施例中,该段落的前述af2实施例还包含轻链构架区(fr-l)和重链构架区(fr-h),其中af2包含与seq id no:746的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l1,与seq id no:747的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l2,与seq id no:748-751中任何一个的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l3,与seq id no:754的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l4,与seq id no:755或seq id no:756的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同
一性或与之相同的fr-h1,与seq id no:759的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h2,与seq id no:760的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h3;以及与seq id no:764的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h4。在另一个实施例中,用于本文所述的任何多肽实施例中的af2包含轻链构架区(fr-l)和重链构架区(fr-h),其中af2包含与seq id no:746的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l1,与seq id no:747的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之等同的fr-l2,与seq id no:748的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之等同的fr-l3,与seq id no:754的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l4,与seq id no:755的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之等同的fr-h1,与seq id no:759的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之等同的fr-h2,与seq id no:760的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h3;以及与seq id no:764的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h4。在另一个实施例中,用于本文所述的任何多肽实施例中的af2包含轻链构架区(fr-l)和重链构架区(fr-h),其中af2包含与seq id no:746的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之等同的fr-l1,与seq id no:747的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之等同的fr-l2,与seq id no:749的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l3,与seq id no:754的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l4,与seq id no:755的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h1,与seq id no:759的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h2,与seq id no:760的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h3;以及与seq id no:764的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h4。在另一个实施例中,本文所述的人或动物多肽实施例的af2包含轻链构架区(fr-l)和重链构架区(fr-h),其中af2包含与seq id no:746的氨基酸序列
显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l1,与seq id no:747的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l2,与seq id no:750的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l3,与seq id no:754的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l4,与seq id no:755的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之等同的fr-h1,与seq id no:759的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h2,与seq id no:760的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h3;以及与seq id no:764的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h4。在另一个实施例中,本文所述的人或动物多肽实施例的af2包含轻链构架区(fr-l)和重链构架区(fr-h),其中af2包含与seq id no:746的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l1,与seq id no:747的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l2,与seq id no:751的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l3,与seq id no:754的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-l4,与seq id no:756的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h1,与seq id no:759的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h2,与seq id no:760的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h3;以及与seq id no:764的氨基酸序列显示出至少86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的fr-h4。
[0344]
在另一个实施例中,本公开内容提供了用于本文所述的任何多肽实施例中的af2,其中所述af2包含与seq id no:766或seq id no:769的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的可变重(vh)氨基酸序列。在另一个实施例中,本公开内容提供了用于本文所述的任何多肽实施例中的af2,其中所述af2包含与seq id no:765、767、768、770或771中任何一个的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的可变轻(vl)氨基酸序列。在另一个实施例中,本公开内容提供了用于本文所述的任何多肽实施例中的af2,其中所述af2包含与seq id no:766或seq id no:769的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的可变
重(vh)氨基酸序列,以及与seq id no:765、767、768、770或771中任何一个的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性或与之相同的可变轻(vl)氨基酸序列。
[0345]
在另一个实施例中,本公开内容提供了用于本文所述的任何多肽实施例中的af2,其中所述af2包含与seq id no:776-780中任何一个的氨基酸序列具有至少95%、96%、97%、98%、99%的序列同一性或与之相同的氨基酸序列。
[0346]
在另一个方面,本公开内容提供了与cd3蛋白复合物结合的af2抗原结合片段,与本领域已知的cd3结合抗体或抗原结合片段相比,其具有增强的稳定性。另外,本公开内容的cd3抗原结合片段被设计为对它们整合到其内的嵌合双特异性抗原结合片段组合物赋予更高程度的稳定性,导致融合蛋白的改善表达和回收、增加的贮存期限和当施用于人或动物时增强的稳定性。在一种方法中,本公开内容的cd3 af2被设计为与本领域已知的某些cd3结合抗体和抗原结合片段相比具有更高程度的热稳定性。结果,用作它们整合到其内的嵌合双特异性抗原结合片段组合物的组分的cd3af2显示出有利的药学性质,包括高热稳定性和低聚集倾向,导致在制造和贮存过程中改善的表达和回收,以及促进长血清半衰期。生物物理性质例如热稳定性经常受到抗体可变结构域的限制,所述抗体可变结构域在其固有性质方面极大地不同。高热稳定性经常与高表达水平和其它所需性质相关,包括较不易受聚集影响(buchanan a等人engineering a therapeutic igg molecule to address cysteinylation,aggregation and enhance thermal stability and expression.mabs 2013;5:255)。热稳定性通过测量“解链温度”(tm)来确定,所述解链温度定义为在其下一半分子变性的温度。每个异二聚体的解链温度是其热稳定性的指标。确定tm的体外测定是本领域已知的,包括下文实例中描述的方法。可以使用技术例如差示扫描量热法(chen等人(2003)pharm res 20:1952-60;ghirlando等人(1999)immunol lett 68:47-52)来测量异二聚体的熔点。可替代地,可以使用圆二色性(murray等人(2002)j.chromatogr sci 40:343-9)或如下文实例中所述的测量异二聚体的热稳定性。
[0347]
cd3结合片段和包含所述抗cd3结合片段的抗cd3双特异性抗体的热变性曲线和本公开内容的参考结合显示了,与由seq id no:781中所示的序列组成的抗原结合片段或对照双特异性抗体(其中所述对照双特异性抗原结合片段包含seq id no:781)和结合本文所述的egfr实施例的参考抗原结合片段相比,本公开内容的构建体对热变性更具抗性。在一个实施例中,本文所述的任何人或动物组合物实施例的多肽包含本文所述的实施例的抗cd3 af2,其中如通过体外测定中的解链温度增加所确定的,与由seq id no:781的序列组成的抗原结合片段的tm相比,所述af2的tm高至少2℃、或高至少3℃、或高至少4℃、或高至少5℃、或高至少6℃、或高至少7℃、或高至少8℃、或高至少9℃、或高至少10℃。
[0348]
在另一个实施例中,本文所述的任何人或动物组合物实施例的多肽包含特异性结合人或食蟹猴cd3的af2,其解离常数(kd)为约10nm至约400nm、或约50nm至约350nm、或约100nm至300nm,如在包含人或食蟹猴cd3抗原的体外抗原结合测定中确定的。在另一个实施例中,本文所述的任何人或动物组合物实施例的多肽包含特异性结合人或食蟹猴cd3的af2,其解离常数(kd)弱于约10nm、或约50nm、或约100nm、或约150nm、或约200nm、或约250nm、或约300nm、或约350nm,或者弱于约400nm,如在体外抗原结合测定中确定的。为清楚起见,kd为400的抗原结合片段与其配体的结合弱于kd为10nm的抗原结合片段。在另一个实
施例中,本文所述的任何人或动物组合物实施例的多肽包含特异性结合人或食蟹猴cd3的af2,其结合亲和力是由seq id no:781的氨基酸序列组成的抗原结合片段的至多1/2、1/3、1/4、1/5、1/6、1/7、1/8、1/9或至多1/10,如通过在体外抗原结合测定中的分别解离常数(kd)确定的。在另一个实施例中,本公开内容提供了包含af2的双特异性多肽,相对于掺入人或动物多肽内的本文所述的af1 egfr实施例,其对cd3显示出的结合亲和力是至多1/2、1/3、1/4、1/5、1/6、1/7、1/8、1/9、1/10、1/20、1/50、1/100或至多1/1000,如通过在体外抗原结合测定中的分别解离常数(kd)确定的。人或动物组合物对于靶配体的结合亲和力可以使用以下进行测定:结合或竞争性结合测定,例如如美国专利5,534,617中所述的具有芯片结合受体或结合蛋白的biacore测定或者elisa测定,本文实例中所述的测定,放射受体测定或本领域已知的其它测定。然后可以使用标准方法,例如如通过van zoelen等人,trends pharmacol sciences(1998)19)12):487描述的scatchard分析,或本领域已知的其它方法,来确定结合亲和力常数。
[0349]
在相关方面,本公开内容提供了af2,其与cd3结合并且掺入嵌合双特异性多肽组合物内,所述组合物被设计为具有这样的等电点(pi),与本领域已知的包含cd3结合抗体或抗原结合片段的相应组合物相比,所述等电点对本公开内容的组合物赋予增强的稳定性。在一个实施例中,本文所述的任何人或动物组合物实施例的多肽包含与cd3结合的af2,其中所述af2显示出在6.0和6.6之间的pi,包含端点在内。在另一个实施例中,本文所述的任何人或动物组合物实施例的多肽包含与cd3结合的af2,其中与由seq id no:781中所示的序列组成的参考抗原结合片段的pi相比,所述af2显示出低至少0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9或1.0ph单位的pi。在另一个实施例中,本文所述的任何人或动物组合物实施例的多肽包含与结合egfr抗原的af1融合的结合cd3的af2,其中所述af2显示出的pi在结合egfr抗原或其表位的af1的pi的至少0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0、1.1、1.2、1.3、1.4或1.5ph单位内。在另一个实施例中,本文所述的任何人或动物组合物实施例的多肽包含与结合egfr抗原的af1融合的结合cd3的af2,其中所述af2显示出的pi在af1的pi的至少约0.1至约1.5、或至少约0.3至约1.2、或至少约0.5至约1.0、或至少约0.7至约0.9ph单位内。特别预期通过其中两个抗原结合片段的pi在此类范围内的此类设计,所得到的融合抗原结合片段对它们整合到其内的嵌合双特异性抗原结合片段组合物赋予更高程度的稳定性,导致以可溶性、非聚集形式的融合蛋白的改善表达和增强回收,配制的嵌合双特异性多肽组合物的贮存期限增加,以及当将组合物施用于人或动物时增强的稳定性。换句话说,使af2和af1在相对窄的pi范围内可以允许选择其中af2和af1两者均是稳定的缓冲液或其它溶液,从而促进组合物的整体稳定性。
[0350]
在某些实施例中,抗原结合片段的vl和vh通过相对长的接头进行融合,所述接头包含25、26、27、28、29、30、31、32、33、34或35个亲水性氨基酸,当连接在一起时,所述亲水性氨基酸具有柔性性质。在一个实施例中,本文所述的任何scfv实施例的vl和vh通过亲水性氨基酸的相对长的接头进行连接,所述接头为gsgegsegegggegsegegsgeggegegsg(seq id no:8058)、
[0351]
tgsgegsegegggegsegegsgeggegegsgt(seq id no:8059)、
[0352]
gatppetgaetespgettggsaeseppgeg(seq id no:8060、或
[0353]
gsaaptagttpsaspapptggssaagspst(seq id no:8061)。在另一个实施例中,af1和
af2通过具有3、4、5、6或7个氨基酸的亲水性氨基酸的短接头连接在一起。在一个实施例中,短接头序列是sggggs(seq id no:8062)、ggggs(seq id no:8063)、ggsggs(seq id no:8064)、ggs或gsp。在另一个实施例中,本公开内容提供了包含单链双抗体的组合物,其中在折叠后,第一结构域(vl或vh)与最后一个结构域(vh或vl)配对以形成一个scfv,并且中间的两个结构域配对形成另一个scfv,其中第一结构域和第二结构域以及第三结构域和最后一个结构域通过前述短接头之一融合在一起,并且第二可变结构域和第三可变结构域通过前述相对长的接头之一进行融合。如本领域技术人员将了解的,短接头和相对长的接头的选择是为了防止相邻可变结构域的不正确配对,从而促进包含第一抗原结合片段和第二抗原结合片段的vl和vh的单链双抗体构型的形成。
[0354]
表6b.示例性cd3 cdr序列
[0355][0356]
表6c.示例性cd3 fr序列
[0357]
[0358]
[0359][0360]
表6d:示例性vl和vh序列
[0361]
[0362][0363]
表6e:示例性scfv序列
[0364]
[0365]
[0366]
[0367]
[0368][0369]
抗epcam结合结构域
[0370]
在一些实施例中,本发明提供了嵌合多肽组装组合物,其包含对肿瘤特异性标记物epcam具有结合亲和力的结合结构域。在一个实施例中,结合结构域包含源自针对epcam的单克隆抗体的vl和vh。针对epcam的单克隆抗体是本领域已知的。epcam单克隆抗体及其vl和vh序列的示例性非限制性例子在表6f中阐述。在一个实施例中,本发明提供了嵌合多肽组装组合物,其包含对肿瘤特异性标记物epcam具有结合亲和力的结合结构域,所述结合结构域包含表6f中所示的抗epcam vl和vh序列。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其中第一部分第一结合结构域包含vh和vl区,其中每个vh和vl区与表6f中所示的4d5mucb抗-epcam抗体的配对vl和vh序列显示出至少约90%、或91%、或92%、或93%、或94%、或95%、或96%、或97%、或98%、或99%的同一性或者与之相同。在另一个实施例中,本发明提供了嵌合多肽组装组合物,其包含对肿瘤特异性标记物具有结合亲和力的结合结构域,所述结合结构域包含cdr-l1区、cdr-l2区、cdr-l3区、cdr-h1区、cdr-h2区和cdr-h3区,其中每种源自表6f中所示的分别的vl和vh序列。
[0371]
表6f.抗靶细胞单克隆抗体和序列
[0372]
[0373]
[0374]
[0375]
[0376]
[0377]
[0378]
[0379]
[0380]
[0381]
[0382]
[0383]
[0384]
[0385]
[0386]
[0387]
[0388]
[0389]
[0390]
[0391]
[0392]
[0393]
[0394]
[0395]
[0396]
[0397]
[0398]
[0399]
[0400]
[0401]
[0402]
[0403]
[0404]
[0405]
[0406]
[0407]
[0408]
[0409]
[0410]
[0411]
[0412]
[0413]
[0414]
[0415]
[0416]
[0417]
[0418]
[0419]
[0420][0421]
*加下划线且粗体的序列(如果存在的话)是vl和vh内的cdr
[0422]
上皮细胞粘附分子(epcam,也称为17-1a抗原)是在某些上皮和许多人癌中表达的由314个氨基酸组成的40-kda膜整合糖蛋白(参见balzar,the biology of the 17-1a antigen(ep-cam),j.mol.med.1999,77:699-712)。由于其上皮细胞起源,来自大多数癌的肿瘤细胞在其表面上表达epcam(比正常、健康的细胞更多),包括大多数原发性、转移性和播散性非小细胞肺癌细胞(passlick,b.等人the 17-1a antigen is expressed on primary,metastatic and disseminated non-small cell lung carcinoma cells.int.j.cancer 87(4):548
–
552,2000)、胃和胃食管结合部腺癌(martin,i.g.,expression of the 17-1a antigen in gastric and gastro-oesophageal junction adenocarcinomas:a potential immunotherapeutic target?j clin pathol 1999;52:701
–
704)、以及乳腺癌和结肠直肠癌(packeisen j等人detection of surface antigen 17-1a in breast and colorectal cancer.hybridoma.1999 18(1):37-40),在乳腺癌中,epcam在肿瘤细胞上的过表达是存活的预测因子(gastl,lancet.2000,356,1981-1982)。由于其上皮细胞起源,来自大多数癌的肿瘤细胞在其表面上表达epcam。
[0423]
在一个实施例中,本文提供的是具有第一部分的双特异性嵌合多肽组装组合物,所述第一部分具有对于epcam特异性的结合结构域和对于cd3特异性的结合结构域。待解决的技术问题是提供用于生成改善组合物的手段和方法,所述改善组合物显示出良好耐受和更方便用药(较不频繁的给药)的性质,用于肿瘤疾病的有效治疗和或改善。所述技术问题的解决方案通过本文公开且在权利要求中表征的实施例来实现。
[0424]
相应地,在一些实施例中,本发明涉及嵌合多肽组装组合物,由此所述组合物包括包含双特异性单链抗体组合物的第一部分,所述双特异性单链抗体组合物包含至少两个结
合结构域,由此所述结构域之一结合效应细胞抗原例如cd3抗原,且第二结构域结合epcam抗原,其中所述结合结构域包含对于epcam特异性的vl和vh以及对于人cd3抗原特异性的vl和vh。优选地,在实施例中,对于epcam特异性的所述结合结构域具有大于10-7
至10-10
m的kd值,如在体外结合测定中确定的。在前述的一个实施例中,结合结构域是scfv形式。在前述的另一个实施例中,结合结构域是单链双抗体形式。
[0425]
在一些实施例中,本发明提供了嵌合多肽组装组合物,其包含对肿瘤特异性标记物具有结合亲和力的第一部分结合结构域、以及与效应细胞抗原例如cd3抗原结合的第二结合结构域。构成本发明的这些实施例的肿瘤特异性标记物包括但不限于ccr5、cd19、her-2、her-3、her-4、egfr、psma、cea、muc1、muc2、muc3、muc4、muc5ac、muc5b、muc7、βhcg、lewis-y、cd-20、cd33、cd30、神经节苷脂gd3、9-o-乙酰基-gd3、globo h、岩藻糖基gm1、gd-2、碳酸酐酶ix、cd44v6、sonic hedgehog、wue-1、浆细胞抗原1、黑色素瘤硫酸软骨素蛋白聚糖、ccr8、前列腺6-跨膜上皮抗原(steap)、间皮素、a33抗原、前列腺干细胞抗原(psca)、ly-6、sas、桥粒芯蛋白4、胎儿乙酰胆碱受体、cd-25、癌抗原19-9(ca19-9)、癌抗原125(ca-125)、苗勒管抑制物质ii型受体(misiir)、唾液酸化tn抗原、成纤维细胞活化抗原(fap)、内皮唾液酸蛋白(cd248)、表皮生长因子受体变体iii(egfrviii)、肿瘤相关抗原l6(tal6)、cd-63、tag-72、汤姆森-弗里登赖希抗原(tf抗原)、胰岛素样生长因子i受体(igf-ir)、cora抗原、cd7、cd22、cd79a、cd79b、g250、f19、epha2和mt-mm。在某些实施例中,本发明提供了嵌合多肽组装组合物,其包含对肿瘤特异性标记物具有结合亲和力的第一部分结合结构域,所述第一部分结合结构域包含抗标记物vl和vh序列。对于这些肿瘤标记物中的某些特异性的vl和vh序列的示例性、非限制性例子在表6f中阐述。在其它实施例中,本发明提供了嵌合多肽组装组合物,其包含对肿瘤特异性标记物具有结合亲和力的第一部分结合结构域,所述第一部分结合结构域包含cdr-l1区、cdr-l2区、cdr-l3区、cdr-h1区、cdr-h2区和cdr-h3区,其中每种源自分别的vl和vh序列。优选地,在实施例中,所述结合具有大于10-7
至10-10
m的kd值,如在体外结合测定中确定的。
[0426]
特别考虑嵌合多肽组装组合物可以包含前述结合结构域或其序列变体中的任何一种,只要变体显示出对于所述抗原的结合特异性。在一个实施例中,序列变体将通过用不同氨基酸取代vl或vh序列中的氨基酸而产生。在缺失变体中,去除如本文所述的vl或vh序列中的一个或多个氨基酸残基。因此,缺失变体包括结合结构域多肽序列的所有片段。在取代变体中,vl或vh(或cdr)多肽的一个或多个氨基酸残基被去除并且替换为替代残基。在一个方面,取代在性质中是保守的,并且这种类型的保守取代是本领域众所周知的。另外,特别考虑本文公开的包含第一结合结构域和第二结合结构域的组合物可以用于本文公开的任何方法中。
[0427]
非结构化构象
[0428]
通常,尽管聚合物的延伸长度,但本文公开的融合蛋白的xten多肽组分被设计为在生理条件下表现得如同变性肽序列。“变性的”描述了肽在溶液中的状态,其特征在于肽主链的大构象自由度。大多数肽和蛋白质在高浓度变性剂的存在下或在高温下采用变性构象。处于变性构象的肽具有例如特征性圆二色性(cd)光谱,并且特征在于如通过nmr确定的长距离相互作用的缺乏。“变性构象”和“非结构化构象”在本文中同义使用。在一些情况下,本发明提供了xten多肽,其在生理条件下可以类似于在很大程度上缺乏二级结构的变性序
列。在其它情况下,xten多肽在生理条件下可以基本上缺乏二级结构。如在此上下文中使用的,“在很大程度上缺乏”意指每种xten多肽的少于50%的xten氨基酸残基促成二级结构,如通过本文描述的手段测量或确定的。如在此上下文中使用的,“基本上缺乏”意指xten序列的至少约60%、或约70%、或约80%、或约90%、或约95%、或至少约99%的xten氨基酸残基并不促成二级结构,如通过本文描述的手段测量或确定的。
[0429]
本领域已建立了各种方法来辨别给定多肽中的二级结构和三级结构的存在或不存在。特别地,xten二级结构可以例如通过“远uv”光谱区域(190-250nm)中的圆二色光谱,用分光光度法进行测量。二级结构元件例如α-螺旋和β-折叠,各自产生cd光谱的特征性形状和量级。还可以经由某些计算机程序或算法预测多肽序列的二级结构,例如众所周知的chou-fasman算法(chou,p.y.等人(1974)biochemistry,13:222-45)和garnier-osguthorpe-robson(“gor”)算法(garnier j,gibrat jf,robson b.(1996),gor method for predicting protein secondary structure from amino acid sequence.methods enzymol 266:540-553),如美国专利申请公开号20030228309a1中所述。对于给定序列,算法可以预测是存在一些二级结构还是根本不存在二级结构,表示为形成例如α-螺旋或β-折叠的序列残基总数和/或百分比或预测为导致无规卷曲形成(其缺乏二级结构)的序列残基百分比。
[0430]
在一些情况下,本发明的融合蛋白组合物中使用的xten多肽可以具有范围为0%至小于约5%的α-螺旋百分比,如通过chou-fasman算法确定的。在其它情况下,构成融合蛋白组合物的xten多肽可以具有范围为0%至小于约5%的β-折叠百分比,如通过chou-fasman算法确定的。在一些情况下,融合蛋白组合物的xten序列可以具有范围为0%至小于约5%的α-螺旋百分比以及范围为0%至小于约5%的β-折叠百分比,如通过chou-fasman算法确定的。在优选的实施例中,构成融合蛋白组合物的xten多肽可以具有小于约2%的α-螺旋百分比和小于约2%的β-折叠百分比。在其它情况下,融合蛋白组合物的xten序列可以具有高度的无规卷曲百分比,如通过gor算法确定的。在一些实施例中,xten多肽可以具有至少约80%、更优选至少约90%、更优选至少约91%、更优选至少约92%、更优选至少约93%、更优选至少约94%、更优选至少约95%、更优选至少约96%、更优选至少约97%、更优选至少约98%、且最优选至少约99%的无规卷曲,如通过gor算法确定的。
[0431]
净电荷
[0432]
在其它情况下,xten多肽可以具有通过掺入具有净电荷的氨基酸残基和/或减少xten多肽中的疏水性氨基酸比例而赋予的非结构化特性。可以通过修改xten多肽中的荷电氨基酸含量来控制总体净电荷和净电荷密度。在一些情况下,组合物的xten的净电荷密度可以高于+0.1或低于-0.1电荷/残基。在其它情况下,xten多肽的净电荷可以是约0%、约1%、约2%、约3%、约4%、约5%、约6%、约7%、约8%、约9%、约10%约11%、约12%、约13%、约14%、约15%、约16%、约17%、约18%、约19%、或约20%或更多。
[0433]
因为人或动物中的大多数组织和表面具有净负电荷,所以xten多肽可以设计为具有净负电荷,以使含xten多肽的组合物和各种表面例如血管、健康组织或各种受体之间的非特异性相互作用降到最低。不受特定理论的束缚,由于xten多肽的各个氨基酸之间的静电排斥,xten多肽可以采取开放构象,所述氨基酸个别地携带高净负电荷并且跨越xten多肽的序列分布。xten多肽的延伸序列长度中的此类净负电荷分布可以导致非结构化构象,
其依次又可以导致流体动力学半径的有效增加。相应地,在一个实施例中,本发明提供了xten多肽,其中所述xten多肽含有约8、10、15、20、25或甚至约30%的谷氨酸。本发明的组合物的xten多肽一般不具有或具有低含量的带正电荷的氨基酸。在一些情况下,xten多肽可以具有小于约10%的带正电荷的氨基酸残基,或小于约7%、或小于约5%、或小于约2%的带正电荷的氨基酸残基。然而,本发明考虑了这样的构建体,其中有限数目的带正电荷的氨基酸例如赖氨酸可以掺入xten多肽内,以允许赖氨酸的ε胺与肽上的反应基团、接头桥、或者待缀合至xten多肽主链的药物或小分子上的反应基团之间的缀合。在前文中,可以构建融合蛋白,其包含一种或多种xten多肽、生物活性蛋白质、加上可用于治疗代谢疾病或病症的化学治疗剂,其中掺入xten多肽组分内的试剂的分子最大数目由掺入xten内的赖氨酸或具有反应性侧链的其它氨基酸(例如,半胱氨酸)的数目决定。
[0434]
在一些情况下,xten多肽可以包含通过其它残基例如丝氨酸或甘氨酸分开的荷电残基,其可以导致更好的表达或纯化行为。基于净电荷,人或动物组合物的xten多肽可以具有1.0、1.5、2.0、2.5、3.0、3.5、4.0、4.5、5.0、5.5、6.0或甚至6.5的等电点(pi)。在优选的实施例中,xten多肽具有1.5至4.5的等电点。在这些实施例中,掺入本发明的bpxten融合蛋白组合物内的xten在生理条件下将携带净负电荷,其可以促成xten多肽组分的非结构化构象以及与哺乳动物蛋白质和组织的减少结合。
[0435]
由于疏水性氨基酸可以赋予多肽结构,本发明提供了xten多肽中的疏水性氨基酸含量通常小于5%、或小于2%、或小于1%的疏水性氨基酸含量。在一个实施例中,bpxten融合蛋白的xten组分中的甲硫氨酸和色氨酸的氨基酸含量通常小于5%、或小于2%、且最优选小于1%。在另一个实施例中,xten多肽具有这样的序列,其具有小于10%的带正电荷的氨基酸残基,或小于约7%、或小于约5%、或小于约2%的带正电荷的氨基酸残基,甲硫氨酸和色氨酸残基之和小于2%,并且天冬酰胺和谷氨酰胺残基之和是总xten多肽的小于10%。
[0436]
增加的流体动力学半径
[0437]
在一些实施例中,xten多肽可以具有高流体动力学半径,赋予掺入xten多肽的bpxten融合蛋白相应的增加的表观分子量。xten多肽与bp序列的连接可以导致这样的bpxten组合物,与未连接至xten多肽的bp相比,所述bpxten组合物可以具有增加的流体动力学半径、增加的表观分子量和增加的表观分子量因子。例如,在其中需要延长半衰期的治疗应用中,其中将具有高流体动力学半径的xten多肽掺入包含一种或多种bp的融合蛋白内的组合物,可以将组合物的流体动力学半径有效地扩大到超过大约3-5nm的肾小球孔径(对应于约70kda的表观分子量)(caliceti.2003.pharmacokinetic and biodistribution properties of poly(ethylene glycol)-protein conjugates.adv.drug deliv.rev.55:1261-1277),导致循环蛋白质的肾脏清除率减少。不受特定理论的束缚,由于肽的各个电荷之间的静电排斥或通过序列中缺乏赋予二级结构的潜力的特定氨基酸赋予的固有柔性,xten多肽可以采取开放构象。与具有可比较的序列长度和/或分子量的具有二级结构和/或三级结构的多肽,例如典型的球状蛋白质相比,xten多肽的开放、延伸和非结构化构象可以具有更大比例的流体动力学半径。用于确定流体动力学半径的方法是本领域众所周知的,例如通过使用尺寸排阻色谱法(sec),如美国专利号6,406,632和7,294,513中所述。增加长度的xten多肽的添加导致流体动力学半径、表观分子量和表观分子量因子的参数的成比例增加,允许对所需的特征性截断表观分子量或流体动力学半径定制bpxten。相应地,在某些
实施例中,bpxten融合蛋白可以配置有xten多肽,其中所述融合蛋白可以具有至少约5nm、或至少约8nm、或至少约10nm、或12nm、或至少约15nm的流体动力学半径。在前述实施例中,由bpxten融合蛋白中的xten多肽赋予的大流体动力学半径可以导致所得到的融合蛋白的肾脏清除率减少,导致终末半衰期的相应增加、平均停留时间的增加和/或肾脏清除率的降低。
[0438]
在另一个实施例中,选定长度和序列的xten多肽可以选择性地掺入bpxten内,以产生在生理条件下具有以下表观分子量的融合蛋白:至少约150kda、或至少约300kda、或至少约400kda、或至少约500kda、或至少约600kda、或至少约700kda、或至少约800kda、或至少约900kda、或至少约1000kda、或至少约1200kda、或至少约1500kda、或至少约1800kda、或至少约2000kda、或至少约2300kda或更多。在另一个实施例中,选定长度和序列的xten多肽可以选择性地连接至bp,以导致这样的bpxten融合蛋白,其在生理条件下具有至少三、可替代地至少四、可替代地至少五、可替代地至少六、可替代地至少八、可替代地至少10、可替代地至少15的表观分子量因子,或者至少20或更大的表观分子量因子。在另一个实施例中,bpxten融合蛋白在生理条件下具有相对于融合蛋白的实际分子量,约4至约20、或约6至约15、或约8至约12、或约9至约10的表观分子量因子。在一些实施例中,(融合)多肽在生理条件下显示出大于约6的表观分子量因子。
[0439]
增加的终末半衰期
[0440]
在一些实施例中,与未连接至xten多肽的生物活性多肽相比,(融合)多肽具有至少两倍、或至少三倍、或至少四倍、或至少五倍的终末半衰期。在一些实施例中,与未连接至xten多肽的生物活性多肽相比,(融合)多肽具有至少两倍的终末半衰期。
[0441]
将治疗有效剂量的本文所述的bpxten融合蛋白的任何实施例施用于有此需要的人或动物,可以导致与未连接至xten多肽并以可比较的剂量施用于人或动物的相应bp相比,在关于融合蛋白的治疗窗内花费时间的至少两倍、或至少三倍、或至少四倍、或至少五倍或更多增加。
[0442]
低免疫原性
[0443]
在另一个方面,本发明提供了组合物,其中xten多肽具有低程度的免疫原性或是基本上无免疫原性的。几种因素可以促成xten多肽的低免疫原性,例如,基本上非重复的序列、其非结构化构象、高溶解度、低程度的自聚集或缺乏自聚集、序列内低程度的蛋白酶解位点或缺乏蛋白酶解位点、以及xten多肽中低程度的表位或缺乏表位。
[0444]
本领域普通技术人员将理解,一般而言,具有高度重复的短氨基酸序列(例如,其中长200个氨基酸的序列平均含有有限组的3-或4聚体的20个或更多个重复)和/或具有连续重复的氨基酸残基(例如,其中5或6聚体序列具有相同的氨基酸残基)的多肽具有聚集或形成更高级结构或形成接触的趋势,导致晶体或假晶体结构。
[0445]
在一些实施例中,xten多肽是基本上非重复的,其中所述xten氨基酸序列不具有为相同氨基酸类型的三个连续氨基酸,除非该氨基酸是丝氨酸,在这种情况下不多于三个连续氨基酸可以是丝氨酸残基;并且其中所述xten氨基酸序列不含有在xten多肽的长200个氨基酸的序列内出现多于16、多于14、多于12或多于10次的3氨基酸序列(3聚体)。本领域普通技术人员将理解,此类基本上非重复的序列具有较小的聚集倾向,并且因此,使得能够设计具有相对低频率的荷电氨基酸的长序列xten,如果序列或氨基酸残基在其它方面更具
重复性,则所述长序列xten很可能聚集。
[0446]
构象表位由蛋白质表面的区域形成,所述区域由蛋白质抗原的多重不连续的氨基酸序列组成。蛋白质的精确折叠使这些序列达到定义明确的、稳定的空间构型或表位,其可以被宿主体液免疫系统识别为“外源的”,导致产生针对蛋白质的抗体或触发细胞介导的免疫应答。在后一种情况下,个体中针对蛋白质的免疫应答受到t细胞表位识别的严重影响,所述t细胞表位识别是个体的hla-dr同种异型的肽结合特异性的功能。mhc ii类肽复合物通过t细胞的表面上的同源t细胞受体的接合,连同某些其它共受体例如cd4分子的交叉结合,可以在t细胞内诱导激活状态。激活导致细胞因子的释放,进一步激活其它淋巴细胞如b细胞以产生抗体,或激活t杀伤细胞作为完全的细胞免疫应答。
[0447]
肽结合给定mhc ii类分子用于在apc(抗原呈递细胞)的表面上呈递的能力取决于许多因素;最值得一提的是其一级序列。在一个实施例中,可以通过设计抵抗抗原呈递细胞中的抗原加工的xten多肽和/或选择不能良好地结合mhc受体的序列,来实现较低程度的免疫原性。本发明提供了具有基本上非重复的xten多肽的bpxten融合蛋白,所述xten多肽设计为减少与mhc ii受体的结合,以及避免形成关于t细胞受体或抗体结合的表位,导致低程度的免疫原性。免疫原性的避免部分是xten多肽的构象柔性的直接结果;即,由于氨基酸残基的选择和次序的二级结构缺乏。例如,特别感兴趣的是在水溶液中或在可以导致构象表位的生理条件下,具有适应紧密折叠构象的低倾向的序列。使用常规治疗实践和给药,包含xten多肽的融合蛋白的施用一般并不导致针对xten多肽的中和抗体的形成,并且还可以减少bpxten组合物中的bp融合配偶体的免疫原性。
[0448]
在一个实施例中,用于人或动物融合蛋白中的xten多肽可以基本上不含由人t细胞识别的表位。为了生成较低免疫原性蛋白质的目的而消除此类表位先前已得到公开;参见例如,以引用的方式并入本文的wo 98/52976、wo 02/079232和wo 00/3317。用于人t细胞表位的测定已得到描述(stickler,m.等人(2003)j immunol methods,281:95-108)。特别感兴趣的是可以寡聚化而不生成t细胞表位或非人序列的肽序列。这可以通过以下来实现:就t细胞表位的存在以及非人的6至15聚体且特别是9聚体序列的出现,测试这些序列的直接重复,然后改变xten多肽的设计以消除或破坏表位序列。在一些情况下,xten多肽通过限制预测为结合mhc受体的xten多肽的表位数目而是基本上无免疫原性的。随着能够结合mhc受体的表位数目的减少,存在关于t细胞活化的潜力以及t细胞辅助功能的伴随减少、减少的b细胞活化或上调以及减少的抗体产生。预测的t细胞表位的低程度可以通过表位预测算法来确定,所述算法例如tepitope(sturniolo,t.等人(1999)nat biotechnol,17:555-61),如以引用方式全文并入的国际专利申请公开号wo 2010/144502 a2的实例74中所示。如sturniolo,t.等人(1999)nature biotechnology 17:555)中公开的,在蛋白质内的给定肽构架的tepitope评分是该肽构架与多重最常见的人mhc等位基因结合的kd(解离常数、亲和力、解离速率)的对数。评分范围超过至少20个对数,约10至约-10(对应于10e
10 kd至10e-10
kd的结合约束),并且可以通过避免疏水性氨基酸而得到减少,所述疏水性氨基酸在mhc上的肽展示过程中可以充当锚定残基,例如m、i、l、v、f。在一些实施例中,掺入bpxten内的xten多肽不具有tepitope评分为约-5或更大、或-6或更大、或-7或更大、或-8或更大,或tepitope评分为-9或更大的预测t细胞表位。如本文使用的,
“‑
9或更大”的评分将涵盖10至-9的tepitope评分,包含端点在内,但不涵盖-10的评分,因为-10小于-9。
[0449]
在另一个实施例中,本发明的xten多肽,包括掺入人或动物bpxten融合蛋白内的那些xten多肽,可以通过限制来自xten多肽序列的已知蛋白酶解位点,减少xten多肽加工成可以与mhc ii受体结合的小肽,而致使基本上无免疫原性。在另一个实施例中,xten多肽可以通过使用基本上缺乏二级结构的序列,由于结构的高熵而赋予对许多蛋白酶的抗性,而致使基本上无免疫原性。相应地,减少的tepitope评分和从xten多肽中消除已知蛋白酶解位点可以致使xten-多肽组合物,包括bpxten融合蛋白组合物的xten多肽,基本上不能被哺乳动物受体,包括免疫系统的受体结合。在一个实施例中,bpxten融合蛋白的xten多肽可以具有针对哺乳动物细胞表面或循环多肽受体,与哺乳动物受体的》100nm kd、或大于500nm kd、或大于1μm kd的结合。
[0450]
另外,xten多肽的此类实施例的基本上非重复的序列和表位的相应缺乏,可以限制b细胞结合xten多肽或被xten多肽激活的能力。虽然xten多肽可以在其延伸序列上与许多不同的b细胞接触,但每个个别b细胞只能与个别xten多肽进行一次或少量接触。结果,xten多肽通常可以具有低得多的刺激b细胞增殖并因此刺激免疫应答的倾向。在一个实施例中,与未融合的相应bp相比,bpxten可以具有减少的免疫原性。在一个实施例中,向哺乳动物施用至多三个肠胃外剂量的bpxten可以导致在1:100的血清稀释度下,而不是在1:1000的稀释度下可检测到的抗bpxten igg。在另一个实施例中,向哺乳动物施用至多三个肠胃外剂量的bpxten可以导致在1:100的血清稀释度下,而不是在1:1000的稀释度下可检测到的抗bp igg。在另一个实施例中,向哺乳动物施用至多三个肠胃外剂量的bpxten可以导致在1:100的血清稀释度下,而不是在1:1000的稀释度下可检测到的抗xten igg。在前述实施例中,哺乳动物可以是小鼠、大鼠、兔或食蟹猴。
[0451]
相对于那些较少非重复的序列(例如具有相同的三个连续氨基酸的序列),具有基本上非重复序列的xten多肽的某些实施例的另外特征可以是非重复的xten多肽与抗体形成更弱的接触(例如单价相互作用),从而导致免疫清除的可能性较小,其中所述bpxten组合物可以在循环中保留增加的时间段。
[0452]
在一些实施例中,与未连接至xten多肽的生物活性多肽相比,(融合)多肽是较少免疫原性的,其中免疫原性通过在向人或动物施用可比较的剂量后,测量选择性地结合生物活性多肽的igg抗体的产生来确定。
[0453]
间隔区和bp释放区段
[0454]
在一些实施例中,分别bp的至少一部分生物活性由完整的bpxten保留。在一些实施例中,在其通过掺入bpxten内的间隔区序列内的任选切割序列的切割而从xten多肽中释放后,bp组分变得具有生物活性或具有增加的生物活性,如下文更充分地描述的。
[0455]
任何间隔区序列组在由本发明涵盖的融合蛋白中是任选的。可以提供间隔区,以增强来自宿主细胞的融合蛋白的表达或降低空间位阻,其中bp组分可以采取其所需的三级结构和/或与其靶分子适当地相互作用。对于间隔区和鉴定期望间隔区的方法,参见例如,以引用的方式具体并入本文的george等人(2003)protein engineering 15:871-879。在一个实施例中,间隔区包含长度为1至50个氨基酸残基、或约1至25个残基、或长度为约1至10个残基的一种或多种肽序列。排除切割位点,间隔区序列可以包含20种天然l氨基酸中的任一种,并且优选包含空间上不受阻碍的亲水性氨基酸,其可以包括但不限于甘氨酸(g)、丙氨酸(a)、丝氨酸(s)、苏氨酸(t)、谷氨酸盐(e)和脯氨酸(p)。在一些实施例中,间隔区可以
是聚甘氨酸或聚丙氨酸,或占优势地甘氨酸和丙氨酸残基的组合的混合物。排除切割序列的间隔区多肽在很大程度上基本上缺乏二级结构。在一个实施例中,bpxten融合蛋白组合物中的一个或两个间隔区序列还可以各自含有切割序列,其可以是相同的或可以是不同的,其中所述切割序列可以被蛋白酶作用,以从融合蛋白中释放bp。
[0456]
在一些情况下,将切割序列掺入bpxten被设计为允许bp的释放,所述bp在其从xten多肽中释放后变得活性或更具活性。切割序列与bp序列定位足够接近,一般在bp序列末端的18个、或12个、或6个或2个氨基酸内,其中在切割后与bp附着的任何剩余残基并不明显干扰bp的活性(例如,与受体的结合),而是提供与能够实现切割序列的切割的蛋白酶的足够接近。在一些实施例中,切割位点是可以通过对于哺乳动物人或动物内源性的蛋白酶切割的序列,其中bpxten可以在施用于人或动物后被切割。在这种情况下,bpxten可以充当bp的前药或循环贮库。由本发明考虑的切割位点的例子包括但不限于可被以下切割的多肽序列:选自fxia、fxiia、激肽释放酶、fviia、fixa、fxa、fiia(凝血酶)、弹性蛋白酶-2、颗粒酶b、mmp-12、mmp-13、mmp-17或mmp-20的哺乳动物内源性蛋白酶,或者非哺乳动物蛋白酶如tev、肠激酶、prescission
tm
蛋白酶(鼻病毒3c蛋白酶)和分选酶a。已知被前述蛋白酶切割的序列是本领域已知的。示例性切割序列和序列内的切割位点以及序列变体在表7a中阐述。例如,凝血酶(活化凝血因子ii)作用于序列ltprsllv(seq id no:222){rawlings n.d.等人(2008)nucleic acids res.,36:d320},其将在序列中的位置4处的精氨酸后被切割。活性fiia通过在磷脂和钙的存在下通过fxa切割fii而产生,并且位于凝血途径中的因子ix的下游。一旦激活,它在凝血中的天然作用就是切割纤维蛋白原,所述纤维蛋白原然后依次又起始血块形成。fiia活性受到严格控制,并且仅在凝血对于适当止血是必需时才发生。然而,由于凝血是哺乳动物中的持续过程,因此通过将ltprsllv(seq id no:223)序列掺入bp和xten多肽之间的bpxten内,当生理上需要凝血时,xten多肽将在外源性或内源性凝血途径激活的同时从相邻的bp中去除,从而随着时间过去释放bp。类似地,将受内源性蛋白酶作用的其它序列掺入bpxten内,将提供bp的持续释放,在某些情况下,这可以对于来自bpxten的“前药”形式的bp提供更高程度的活性。
[0457]
在一些情况下,仅侧接切割位点两侧的两个或三个氨基酸(总共四至六个氨基酸)将掺入切割序列内。在其它情况下,已知的切割序列可以对于已知序列中的任何一个或两个或三个氨基酸具有一个或多个缺失或插入、或者一个或两个或三个氨基酸取代,其中所述缺失、插入或取代导致对蛋白酶的敏感性减少或增强,而不是敏感性的缺乏,导致定制bp从xten中的释放速率的能力。示例性取代显示于表7a中。
[0458]
表7a:用于bp释放的蛋白酶切割序列
[0459][0460][0461]
↓
指示切割位点;
[0462]
na:不适用;
[0463]
*在斜线之前、之间或之后的多重氨基酸列表指示可以在该位置处取代的替代氨基酸;
[0464]
“‑”
指示任何氨基酸都可以取代中间一列中指示的相应氨基酸
[0465]
在一些实施例中,bpxten融合蛋白可以包含间隔区序列,其还可以包含一种或多种切割序列,所述切割序列被配置为当被蛋白酶作用时从融合蛋白中释放bp。在一些实施例中,一种或多种切割序列可以是与表7a中所示的序列具有至少约80%(例如,至少约85%、至少约90%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%)的序列同一性的序列。
[0466]
在一些实施例中,本公开内容提供了bp释放区段肽(或释放区段(rs)),其是一种或多种哺乳动物蛋白酶的底物,所述哺乳动物蛋白酶与疾病组织或在疾病组织附近发现的细胞相关或者由其产生。此类蛋白酶可以包括但不限于例如金属蛋白酶、半胱氨酸蛋白酶、天冬氨酸蛋白酶和丝氨酸蛋白酶的蛋白酶类别,包括但不限于表7b中所示的蛋白酶。rs尤其可用于掺入人或动物重组多肽内,赋予可以通过rs被哺乳动物蛋白酶切割而激活的前药形式。如本文所述,将rs掺入人或动物重组多肽组合物内,将掺入的结合部分连接至xten(其构型在下文更充分地描述),其中在rs通过rs是其底物的一种或多种蛋白酶的作用切割后,结合部分和xten从组合物中释放,并且不再被xten屏蔽的结合部分重新获得其结合其配体的全部潜力。在包含第一抗体片段和第二抗体片段的那些重组多肽组合物中,组合物在本文中也被称为可激活抗体组合物(aac)。
[0467]
表7b:靶组织的蛋白酶
[0468]
[0469]
[0470][0471]
在一个实施例中,本公开内容提供了包含第一释放区段(rs1)序列的可激活重组多肽,当最佳比对时,所述第一释放区段序列与选自表8a中所示的序列的序列具有至少88%、或至少94%、或100%的序列同一性,其中所述rs1是一种或多种哺乳动物蛋白酶的底物。在其它实施例中,本公开内容提供了包含rs1和第二释放区段(rs2)序列的可激活重组多肽,当最佳比对时,所述释放区段序列各自与选自表8a中所示的序列的序列具有至少88%、或至少94%、或100%的序列同一性,其中所述rs1和rs2各自是一种或多种哺乳动物蛋白酶的底物。在另一个实施例中,公开内容提供了包含第一rs(rs1)序列的可激活重组多肽,当最佳比对时,所述第一rs序列与选自表8a中所示的序列的序列具有至少90%、至少93%、至少97%、或100%的同一性,其中所述rs是一种或多种哺乳动物蛋白酶的底物。在其它实施例中,本公开内容提供了包含rs1和第二释放区段(rs2)序列的可激活重组多肽,当最佳比对时,所述释放区段序列各自与选自表8b中所示的序列的序列具有至少88%、或至少94%、或100%的序列同一性,其中所述rs1和rs2各自是一种或多种哺乳动物蛋白酶的底物。在包含rs1和rs2的可激活重组多肽的实施例中,两个释放区段可以是相同的或序列可以是不同的。
[0472]
本公开内容考虑了其为一种、两种或三种不同蛋白酶类别的底物的释放区段,所述蛋白酶类别选自金属蛋白酶、半胱氨酸蛋白酶、天冬氨酸蛋白酶和丝氨酸蛋白酶,包括表7b中所示的蛋白酶。在一个特定特征中,rs充当与疾病组织或细胞密切相关发现或共定位的蛋白酶的底物,所述疾病组织或细胞例如但不限于肿瘤、癌细胞和炎症组织,并且在rs切割后,否则被人或动物重组多肽组合物的xten屏蔽(并且因此对于其分别的配体具有较低
的结合亲和力)的结合部分从组合物中释放,并且重新获得其结合靶和/或效应细胞配体的全部潜力。在另一个实施例中,人或动物重组多肽组合物的rs包含其为定位于靶向细胞内的细胞蛋白酶的底物的氨基酸序列,所述细胞蛋白酶包括但不限于表7b中所示的蛋白酶。在人或动物重组多肽组合物的另一个特定特征中,其为两种或三种蛋白酶类别的底物的rs被设计为具有能够在rs序列的不同位置被不同蛋白酶切割的序列。因此,其为两种、三种或更多种蛋白酶类别的底物的rs具有在rs序列中的两个、三个或多个不同的切割位点,但通过单一蛋白酶的切割仍导致结合部分和xten从包含rs的重组多肽组合物中的释放。
[0473]
在一个实施例中,用于掺入人或动物重组多肽组合物内的本公开内容的rs是一种或多种蛋白酶的底物,所述蛋白酶包括穿膜肽酶、脑啡肽酶(cd10)、psma、bmp-1、去整合素和金属蛋白酶(adam)、adam8、adam9、adam10、adam12、adam15、adam17(tace)、adam19、adam28(mdc-l)、具有血小板反应蛋白基序的adam(adamts)、adamts1、adamts4、adamts5、mmp-1(胶原酶1)、基质金属蛋白酶-1(mmp-1)、基质金属蛋白酶-2(mmp-2、明胶酶a)、基质金属蛋白酶-3(mmp-3、基质分解素1)、基质金属蛋白酶-7(mmp-7、基质溶素1)、基质金属蛋白酶-8(mmp-8、胶原酶2)、基质金属蛋白酶-9(mmp-9、明胶酶b)、基质金属蛋白酶-10(mmp-10、基质分解素2)、基质金属蛋白酶-11(mmp-11、基质分解素3)、基质金属蛋白酶-12(mmp-12、巨噬细胞弹性蛋白酶)、基质金属蛋白酶-13(mmp-13、胶原酶3)、基质金属蛋白酶-14(mmp-14、mt1-mmp)、基质金属蛋白酶-15(mmp-15、mt2-mmp)、基质金属蛋白酶-19(mmp-19)、基质金属蛋白酶-23(mmp-23、ca-mmp)、基质金属蛋白酶-24(mmp-24、mt5-mmp)、基质金属蛋白酶-26(mmp-26、基质溶素2)、基质金属蛋白酶-27(mmp-27、cmmp)、legumain、组织蛋白酶b、组织蛋白酶c、组织蛋白酶k、组织蛋白酶l、组织蛋白酶s、组织蛋白酶x、组织蛋白酶d、组织蛋白酶e、分泌酶、尿激酶(upa)、组织型纤溶酶原激活物(tpa)、纤溶酶、凝血酶、前列腺特异性抗原(psa、klk3)、人嗜中性粒细胞弹性蛋白酶(hne)、弹性蛋白酶、类胰蛋白酶、ii型跨膜丝氨酸蛋白酶(ttsp)、desc1、hepsin(hpn)、蛋白裂解酶、蛋白裂解酶-2、tmprss2、tmprss3、tmprss4(cap2)、成纤维细胞活化蛋白(fap)、激肽释放酶相关肽酶(klk家族)、klk4、klk5、klk6、klk7、klk8、klk10、klk11、klk13和klk14。在一个实施例中,rs是adam17的底物。在一个实施例中,rs是bmp-1的底物。在一个实施例中,rs是组织蛋白酶的底物。在一个实施例中,rs是htra1的底物。在一个实施例中,rs是legumain的底物。在一个实施例中,rs是mmp-1的底物。在一个实施例中,rs是mmp-2的底物。在一个实施例中,rs是mmp-7的底物。在一个实施例中,rs是mmp-9的底物。在一个实施例中,rs是mmp-11的底物。在一个实施例中,rs是mmp-14的底物。在一个实施例中,rs是upa的底物。在一个实施例中,rs是蛋白裂解酶的底物。在一个实施例中,rs是mt-sp1的底物。在一个实施例中,rs是嗜中性粒细胞弹性蛋白酶的底物。在一个实施例中,rs是凝血酶的底物。在一个实施例中,rs是tmprss3的底物。在一个实施例中,rs是tmprss4的底物。在一个实施例中,人或动物重组多肽组合物的rs是至少两种蛋白酶的底物,所述两种蛋白酶是legumain、mmp-1、mmp-2、mmp-7、mmp-9、mmp-11、mmp-14、upa和蛋白裂解酶。在另一个实施例中,人或动物重组多肽组合物的rs是legumain、mmp-1、mmp-2、mmp-7、mmp-9、mmp-11、mmp-14、upa和蛋白裂解酶的底物。
[0474]
表8a:bp释放区段序列。
[0475]
[0476]
[0477]
[0478]
[0479][0480]
表8b:释放区段序列
[0481]
[0482]
[0483]
[0484]
[0485]
[0486]
[0487]
[0488]
[0489]
[0490]
[0491]
[0492]
[0493]
[0494]
[0495]
[0496]
[0497]
[0498]
[0499]
[0500]
[0501]
[0502]
[0503]
[0504]
id no:8261)的对照rs序列ac1611(rsr-1517)被确定为具有通过蛋白酶legumain、mmp-2、mmp-7、mmp-9、mmp-14、upa和蛋白裂解酶的适当的基线切割效率。通过选择性取代rs肽中的各个位置处的氨基酸,创建了rs文库,并且针对7种蛋白酶的实验对象组进行评估(在实例中更充分地详述),导致用于建立关于适当氨基酸取代的指南的概况,以便实现具有所需切割效率的rs。在制备具有所需切割效率的rs时,使用亲水性氨基酸a、e、g、p、s和t的取代是优选的,然而,其它l-氨基酸可以在给定位置处进行取代,以便调整切割效率,只要rs保留被蛋白酶切割的至少一些敏感性。肽中的氨基酸的保守取代以保留或影响活性完全在本领域技术人员的知识和能力内。在一个实施例中,本公开内容提供了rs,其中rs被选自legumain、mmp-1、mmp-2、mmp-7、mmp-9、mmp-11、mmp-14、upa或蛋白裂解酶的蛋白酶切割,与具有序列eagrsanheplglvat(seq id no:8261)的对照序列rsr-1517被相同蛋白酶的切割相比,在体外生物化学竞争测定中,具有高至少0.2log2、或0.4log2、或0.8log2、或1.0log2的切割效率。在另一个实施例中,本公开内容提供了rs,其中rs被选自legumain、mmp-1、mmp-2、mmp-7、mmp-9、mmp-11、mmp-14、upa或蛋白裂解酶的蛋白酶切割,与具有序列eagrsanheplglvat(seq id no:8261)的对照序列rsr-1517被相同蛋白酶的切割相比,在体外生物化学竞争测定中,具有低至少0.2log2、或0.4log2、或0.8log2、或1.0log2的切割效率。在一个实施例中,本公开内容提供了rs,其中与具有序列eagrsanheplglvat(seq id no:8261)的对照序列rsr-1517相比,rs被选自legumain、mmp-1、mmp-2、mmp-7、mmp-9、mmp-11、mmp-14、upa或蛋白裂解酶的蛋白酶的切割速率是至少2倍、或至少4倍、或至少8倍、或至少16倍。在另一个实施例中,本公开内容提供了rs,其中与具有序列eagrsanheplglvat(seq id no:8261)的对照序列rsr-1517相比,rs被选自legumain、mmp-1、mmp-2、mmp-7、mmp-9、mmp-11、mmp-14、upa或蛋白裂解酶的蛋白酶的切割速率是至多1/2、或至多1/4、或至多1/8、或至多1/16。
[0508]
在另一个方面,本公开内容提供了包含多重rs的aac,其中每个rs序列选自表8a中所示的序列组,并且rs通过选自甘氨酸、丝氨酸、丙氨酸和苏氨酸的1至6个氨基酸彼此连接。在一个实施例中,aac包含第一rs和不同于第一rs的第二rs,其中每个rs序列选自表8a中所示的序列组,并且rs通过选自甘氨酸、丝氨酸、丙氨酸和苏氨酸的1至6个氨基酸彼此连接。在另一个实施例中,aac包含第一rs、不同于第一rs的第二rs、以及不同于第一rs和第二rs的第三rs,其中每个序列选自表8a中所示的序列组,并且第一rs和第二rs和第三rs通过选自甘氨酸、丝氨酸、丙氨酸和苏氨酸的1至6个氨基酸彼此连接。特别预期aac的多重rs可以串联以形成序列,其可以被多重蛋白酶以不同的切割速率或切割效率切割。在另一个实施例中,本公开内容提供了aac,其包含选自表8a-8b中所示的序列组的rs1和rs2、以及xten 1和xten 2,例如上文描述或本文其它地方描述的那些,其中rs1在xten1和结合部分之间融合,并且rs2在xten2和结合部分之间融合。与健康组织或在正常循环中时相比,考虑此类组合物将更容易被表达多重蛋白酶的患病靶组织切割,结果是所得到的带有结合部分的片段将更容易穿透靶组织;例如肿瘤,并且具有增强的结合靶细胞和效应细胞(或在设计为具有单个结合部分的aac的情况下,仅靶细胞)并且将二者连接的能力。
[0509]
本公开内容的rs可作为治疗剂用于包括在重组多肽中,用于治疗癌症、自身免疫性疾病、炎性疾病和其中重组多肽的局限性活化是期望的其它状况。人或动物组合物解决了未满足的需求,并且与在注射后具有活性的常规抗体治疗剂或双特异性抗体治疗剂相
比,在一个或多个方面是优越的,所述方面包括增强的终末半衰期、靶向递送和改善的治疗比率,伴随对健康组织的减少毒性。
[0510]
在一些实施例中,(融合)多肽包含定位于(第一)xten和生物活性多肽之间的第一释放区段(rs1)。在一些实施例中,多肽还包含定位于生物活性多肽和第二xten之间的第二释放区段(rs2)。在一些实施例中,rs1和rs2序列相同。在一些实施例中,rs1和rs2序列不同。在一些实施例中,rs1包含与表8a-8b中所示的序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性的氨基酸序列。在一些实施例中,rs2包含与表8a-8b中所示的序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的序列同一性的氨基酸序列。在一些实施例中,rs1和rs2各自是用于被多重蛋白酶在每个释放区段序列内的一个、两个或三个切割位点处切割的底物。
[0511]
参考片段
[0512]
在一些实施例中,(融合)多肽还包含在被蛋白酶消化后可从多肽中释放的一个或多个参考片段。在一些实施例中,一个或多个参考片段各自包含生物活性多肽的一部分。在一些实施例中,一个或多个参考片段是在序列和分子量方面不同于多肽被蛋白酶消化后可从多肽中释放的所有其它肽片段的单个参考片段。
[0513]
多肽混合物
[0514]
本文公开的包括包含各种长度的多种多肽的混合物;该混合物包含第一组多肽和第二组多肽。在一些实施例中,第一组多肽中的每种多肽包含条形码片段,其(a)可通过用蛋白酶消化从多肽中释放,并且(b)具有的序列和分子量不同于可从第一组多肽中释放的所有其它片段的序列和分子量。在一些实施例中,第二组多肽缺少第一组多肽的条形码片段。在一些实施例中,第一组多肽和第二组多肽两者各自包含参考片段,其(a)是第一组多肽和第二组多肽共有的,并且(b)可通过用蛋白酶消化释放。在一些实施例中,第一组多肽/包含参考片段的多肽的比率大于0.70。在一些实施例中,第一组多肽/包含参考片段的多肽的比率大于0.8、0.9、0.95或0.98。在一些实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现不多于一次。在一些实施例中,蛋白酶是在谷氨酸残基的c末端侧上切割的蛋白酶。在一些实施例中,蛋白酶是glu-c蛋白酶。在一些实施例中,蛋白酶不是胰蛋白酶。在一些实施例中,各种长度的多肽包括包含至少一种延伸重组多肽(xten)的多肽,例如上文描述或本文其它任何地方描述的任何多肽。在一些实施例中,第一组多肽包含全长多肽,其中所述条形码片段是全长多肽的一部分。在一些实施例中,全长多肽是(融合)多肽,例如上文描述或本文其它任何地方描述的任何多肽。在一些实施例中,条形码片段缺少(不包含)全长多肽的n末端氨基酸和c末端氨基酸两者。在一些实施例中,各种长度的多肽的混合物由于全长多肽的n末端截短、c末端截短或n末端和c末端截短两者而彼此不同。在一些实施例中,第一组多肽和第二组多肽可以在一种或多种药理性质方面不同。非限制性的示例性性质包括。
[0515]
多肽表征方法
[0516]
本文公开的包括在包含各种长度的多肽的混合物中,用于评价混合物中的第一组多肽与混合物中的第二组多肽的相对量的方法,其中(1)第一组多肽中的每种多肽共享在多肽中出现一次且仅一次的条形码片段,并且(2)第二组多肽中的每种多肽缺乏由第一组多肽共享的条形码片段,其中所述第一多肽和第二组多肽两者中的各个多肽各自包含参考
片段。该方法可以包括使混合物与蛋白酶接触,以产生来源于第一组多肽和第二组多肽的切割的多个蛋白酶解片段,其中所述多个蛋白酶解片段包含多个参考片段和多个条形码片段。该方法还可以包括确定条形码片段的量/参考片段的量的比率,从而评价第一组多肽与第二组多肽的相对量。在一些实施例中,条形码片段在第一组多肽中的每种多肽中出现不多于一次。在一些实施例中,参考片段在第一组多肽和第二组多肽中的每种多肽中出现不多于一次。在一些实施例中,多个蛋白酶解片段包含多个参考片段和多个条形码片段。在一些实施例中,蛋白酶在谷氨酸残基的c末端侧上切割第一组多肽和第二组多肽(或各种长度的多肽),所述谷氨酸残基随后并非脯氨酸残基。在一些实施例中,蛋白酶是glu-c蛋白酶。在一些实施例中,蛋白酶不是胰蛋白酶。在一些实施例中,确定条形码片段的量/参考片段的量的比率的步骤包括在混合物已与蛋白酶接触后,定量来自混合物的条形码片段和参考片段。在一些实施例中,条形码片段和参考片段基于其分别的质量进行鉴定。在一些实施例中,条形码片段和参考片段经由质谱法进行鉴定。在一些实施例中,条形码片段和参考片段经由液相色谱-质谱法(lc-ms)进行鉴定。在一些实施例中,确定条形码片段/参考片段的比率的步骤包括同量异序标记。在一些实施例中,确定条形码片段/参考片段的比率的步骤包括用同位素标记的参考片段和同位素标记的条形码片段之一或两者掺料混合物。在一些实施例中,各种长度的多肽包括包含至少一种延伸重组多肽(xten)的多肽,如上文描述或本文其它任何地方描述的。在一些实施例中,xten的特征在于(i)它包含至少150个氨基酸;(ii)xten的至少90%的氨基酸残基选自甘氨酸(g)、丙氨酸(a)、丝氨酸(s)、苏氨酸(t)、谷氨酸盐(e)和脯氨酸(p);并且(iii)它包含选自g、a、s、t、e和p的至少4种不同类型的氨基酸。在一些实施例中,当存在时,条形码片段是xten的一部分。在一些实施例中,各种长度的多肽的混合物包含如上文描述或本文其它任何地方描述的任何多肽。在一些实施例中,各种长度的多肽包含全长多肽及其截短片段。在一些实施例中,各种长度的多肽基本上由全长多肽及其截短片段组成。在一些实施例中,各种长度的多肽的混合物由于全长多肽的n末端截短、c末端截短或n末端和c末端截短两者而彼此不同。在一些实施例中,全长多肽是如上文描述或本文其它任何地方描述的多肽。在一些实施例中,条形码片段/参考片段的量的比率大于0.5、0.6、0.7、0.8、0.9、0.95、0.98或0.99。
[0517]
基于同量异序标记的肽定量
[0518]
在一些实施例中,同量异序标记可以用于确定条形码片段/参考片段的比率。普通技术人员将理解,同量异序标记是定量蛋白质组学中使用的质谱法策略,其中肽或蛋白质(或其一部分)用各种化学基团进行标记,所述化学基团是同量异序的(质量相同),但在其结构周围的重同位素分布方面不同。通常被称为串联质量标签的这些标签这样进行设计,使得在串联质谱法期间,在高能碰撞诱导解离(cid)后,质量标签在特异性接头区域处被切割,从而产生不同质量的报告离子。普通技术人员将理解最常见的同量异序标签之一是胺反应性标签。
[0519]
检测和定量截短产物(例如,经由同量异位标记)的增强能力可以生成可以帮助设计包括纯化步骤的制造工艺的知识,以使纯化的原料药/产物中不需要的变体的存在降到最低。
[0520]
重组生产
[0521]
本文的公开内容包括核酸。核酸可以包含编码(融合)多肽的多核苷酸(或多核苷
酸序列),例如上文描述或本文其它任何地方描述的任何多肽;或者核酸可以包含此类多核苷酸(或多核苷酸序列)的反向互补体。
[0522]
本文的公开内容包括表达载体,其包含多核苷酸序列例如在前一段中描述的任何多核苷酸序列,以及可操作地连接到多核苷酸序列的调控序列。
[0523]
本文的公开内容包括包含例如在前一段中描述的表达载体的宿主细胞。在一些实施例中,宿主细胞是原核生物。在一些实施例中,宿主细胞是大肠杆菌。在一些实施例中,宿主细胞是哺乳动物细胞。
[0524]
在另一个方面,本公开内容提供了制造人或动物组合物的方法。在一个实施例中,该方法包括在促进多肽或bpxten融合多肽表达的条件下,培养包含核酸构建体的宿主细胞,所述核酸构建体编码本文所述的任何实施例的多肽或含xten的组合物,随后使用其中回收组合物的标准纯化方法(例如,柱色谱法、hplc等等)回收多肽或bpxten融合多肽,其中所表达多肽或bpxten融合多肽的至少70%、或至少80%、或至少90%、或至少95%、或至少97%、或至少99%的结合片段是正确折叠的。在制备方法的另一个实施例中,回收所表达的多肽或bpxten融合多肽,其中至少或至少90%、或至少95%、或至少97%、或至少99%的多肽或bpxten融合多肽以单体、可溶形式回收。
[0525]
在另一个方面,本公开内容涉及使用大肠杆菌或哺乳动物宿主细胞,在功能性蛋白质的高发酵表达水平下,制备多肽和bpxten融合多肽,以及提供编码可用于方法中的构建体的表达载体,以产生以高表达水平的细胞毒性活性多肽构建体组合物的方法。在一个实施例中,该方法包括以下步骤:1)制备编码本文公开的任何实施例的多肽的多核苷酸,2)将多核苷酸克隆到表达载体内,所述表达载体可以是在适当的转录和翻译序列的控制下以用于在生物系统中的高水平蛋白质表达的质粒或其它载体,3)用表达载体转化适当的宿主细胞,并且4)在适合多肽组合物表达的条件下,在常规营养培养基中培养宿主细胞。需要时,宿主细胞是大肠杆菌。通过该方法,多肽的表达导致至少0.05g/l、或至少0.1g/l、或至少0.2g/l、或至少0.3g/l、或至少0.5g/l、或至少0.6g/l、或至少0.7g/l、或至少0.8g/l、或至少0.9g/l、或至少1g/l、或至少2g/l、或至少3g/l、或至少4g/l、或至少5g/l的宿主细胞的表达产物的发酵滴度,并且其中至少70%、或至少80%、或至少90%、或至少95%、或至少97%、或至少99%的表达蛋白质是正确折叠的。如本文使用的,术语“正确折叠的”意指组合物的抗原结合片段组分具有特异性结合其靶配体的能力。在另一个实施例中,本公开内容提供了用于产生多肽或bpxten融合多肽的方法,该方法包括在有效表达多肽产物的条件下,在发酵反应中培养宿主细胞,所述宿主细胞包含编码包含多肽或bpxten融合多肽的多肽的载体,当发酵反应在600nm的波长处达到至少130的光密度时,所述多肽产物的浓度大于约10毫克/克干重宿主细胞(mg/g)、或至少约250mg/g、或约300mg/g、或约350mg/g、或约400mg/g、或约450mg/g、或约500mg/g的所述多肽,并且其中所表达蛋白质的抗原结合片段是正确折叠的。在另一个实施例中,本公开内容提供了用于产生多肽或bpxten融合多肽的方法,该方法包括在有效表达多肽产物的条件下,在发酵反应中培养宿主细胞,所述宿主细胞包含编码组合物的载体,当发酵反应在600nm的波长处达到至少130的光密度时,所述多肽产物的浓度大于约10毫克/克干重宿主细胞(mg/g)、或至少约250mg/g、或约300mg/g、或约350mg/g、或约400mg/g、或约450mg/g、或约500mg/g的所述多肽,并且其中所表达的多肽产物是可溶性的。
[0526]
药物组合物
[0527]
本文公开的包括药物组合物,其包含bpxten多肽,例如上文描述或本文其它任何地方描述的任何多肽,以及一种或多种药学上可接受的赋形剂。在一些实施例中,药物组合物被配制用于皮内、皮下、静脉内、动脉内、腹内、腹膜内、玻璃体内、鞘内或肌内施用。在一些实施例中,药物组合物是液体形式。在一些实施例中,药物组合物在植入眼或另一个身体部位内的装置中。在一些实施例中,药物组合物在用于单次注射的预填充注射器中。在一些实施例中,药物组合物配制为冻干粉末以在施用之前重构。
[0528]
在一些实施例中,皮内、皮下、静脉内、玻璃体内(或以其它方式注射到眼内)、动脉内、腹内、腹膜内、鞘内或肌内施用剂量。在一些实施例中,使用植入眼或其它身体部位内的装置施用药物组合物。在一些实施例中,人或动物是小鼠、大鼠、猴或人。
[0529]
可以通过任何合适的途径施用药物组合物用于治疗。另外,药物组合物还可以含有其它药物活性化合物或多种本发明的化合物。
[0530]
在一些实施例中,可以以治疗有效剂量施用药物组合物。在前述的一些情况下,治疗有效剂量导致与未连接至融合蛋白并以可比较的剂量施用于人或动物的融合蛋白的相应bp相比,在关于融合蛋白的治疗窗内花费时间的增加。
[0531]
在另一个实施例中,本发明提供了治疗疾病、病症或状况的方法,其包括使用药物组合物的多重连续剂量,将上述药物组合物施用于人或动物,所述多重连续剂量使用治疗有效剂量方案进行施用。
[0532]
本发明的bpxten多肽可以根据已知方法进行配制,以制备药学上有用的组合物,由此多肽与药学上可接受的载体媒介物,例如水溶液或缓冲液、药学上可接受的悬浮液和乳状液组合。通过将具有所需程度的纯度的活性成分与任选的生理学上可接受的载体、赋形剂或稳定剂混合,来制备用于贮存的治疗制剂,如remington’s pharmaceutical sciences第16版,osol,a.编辑(1980)中所述。
[0533]
药物试剂盒
[0534]
在另一个方面,本发明提供了促进bpxten多肽的使用的试剂盒。在一个实施例中,试剂盒在至少第一容器中包含:(a)在向有此需要的人或动物施用后,足以治疗疾病、状况或病症的一定量的bpxten融合蛋白组合物;以及(b)一定量的药学上可接受的载体;一起在准备用于注射或者用无菌水、缓冲液或右旋糖重构的制剂中;连同标识bpxten药物以及贮存和处理条件的标签,以及以下的传单:关于药物的批准适应症,用于重构和/或施用bpxten药物以用于预防和/或治疗批准适应症、适当剂量和安全信息的说明书,以及标识药物批次和有效期的信息。在前述的另一个实施例中,试剂盒可以包含第二容器,所述第二容器可以携带用于bpxten组合物的合适稀释剂,其为使用者提供适当浓度的bpxten以递送至人或动物。
[0535]
治疗方法
[0536]
本文公开的包括多肽,例如上文描述或本文其它任何地方描述的任何多肽,在制备用于治疗人或动物中的疾病的药物中的用途。在一些实施例中,待治疗的特定疾病取决于生物活性蛋白质的选择。在一些实施例中,疾病是癌症。
[0537]
本文公开的包括治疗人或动物中的疾病的方法,该方法包括向有此需要的人或动物施用一个或多个治疗有效剂量的药物组合物,例如上文描述或本文其它任何地方描述的
任何药物组合物。在一些实施例中,疾病是癌症。在一些实施例中,药物组合物作为一个或多个治疗有效剂量施用于人或动物,所述治疗有效剂量根据剂量方案施用。在一些实施例中,人或动物是小鼠、大鼠、猴或人。
[0538]
下述是本公开内容的组合物和组合物评估的实例。应理解,鉴于上文提供的一般描述,可以实践各种其它实施例。
[0539]
实例
[0540]
实例1.通过来自通用xten的最小突变设计加条形码的xten
[0541]
该实例示出了通过制备通用xten多肽(例如上文表3b之一)的氨基酸序列的最小突变,加条形码的xten多肽的示例性设计方法。用于执行最小突变的有关标准包括下述中的一种或多种:(a)使相应xten多肽的序列变化降到最低;(b)使相应xten多肽中的氨基酸组成变化降到最低;(c)基本上维持相应xten多肽的净电荷;(d)基本上维持相应xten多肽的低免疫原性;并且(e)基本上维持由xten多肽提供的药代动力学性质。
[0542]
例如,加条形码的xten通过对表9中的通用xten执行一种或多种突变进行构建,所述突变包含谷氨酸残基的缺失、谷氨酸残基的插入、谷氨酸残基的取代、或取代谷氨酸残基或其任何组合。
[0543]
表9.用于加条形码的xten多肽的改造的四种通用xten
[0544]
[0545]
[0546][0547]
实例2.用于与生物活性多肽(“bp”)融合的加条形码的xten多肽的序列分析及其选择
[0548]
该实例示出了用于与生物活性多肽融合的加条形码的xten多肽(以及多于一种加条形码的xten组装成一组)的设计和选择。取决于条形码片段在xten内的位置,以及其中xten多肽与生物活性蛋白质融合以形成含有xten多肽的构建体(例如,xten化蛋白酶激活的t细胞接合剂(xpat))的方式,所述条形码片段可以指示xten多肽的截短。
[0549]
对两种示例性xten多肽(xten864和xten288_1)执行在计算机中(in silico)的gluc消化分析,以定量在xten多肽的完全gluc消化后可释放的肽片段。在计算机中的分析考虑到,对于具有连续谷氨酸残基(例如,“ee”)的xten多肽,gluc可以在任一个谷氨酸残基后切割。如下表10中概括的结果所示,10聚体肽序列“tpgtstepse(seq id no:8880)”和14聚体肽序列“gsapgsepatsgse(seq id no:8881)”各自在较长的xten864中出现一次且仅一次,而所有其它肽序列在xten864中出现两次或更多次。并且14聚体肽序列“gsapgsepatsgse(seq id no:8881)”也在较短的xten288_1中出现一次且仅一次。
[0550]
相对于可从含有xten多肽的构建体中释放的所有其它肽片段评价候选条形码的唯一性。相应地,一种xten多肽中的条形码序列不能出现在含有xten多肽的构建体中的其它任何地方(包括其中包含的任何其它xten多肽、其中包含的任何生物活性蛋白质或其中相邻组分之间的任何连接)。例如,表11显示了一个有两种xten多肽的组的肽“唯一性”表。由于其存在于xten864和xten288两者中,14聚体肽序列“gsapgsepatsgse(seq id no:8881)不是包含xten864和xten288两者的xten多肽组中唯一的,并且因此不能用作检测含有这两种xten多肽的多肽产品中的截短的条形码。
[0551]
条形码(或一组条形码)的选择还可以涉及鉴定且确定候选条形码在xten多肽内的适当定位或位置。候选条形码的定位或位置可以与xten多肽(以及作为整体的含有xten多肽的构建体)的药理学有关信息相关,例如xten多肽的截短超出临界长度和/或xten多肽中的缺失。如果将xten864置于含有xten多肽的产物的n末端处,并且如果从产物的n末端238个氨基酸的截短并不显著影响产物的药理性质,则10聚体肽“tpgtstepse(seq id no:8880)”可以充当合适的条形码片段。
[0552]
表10.用于gluc消化分析的代表性xten序列
[0553][0554][0555]
表11.肽“唯一性”分析
[0556][0557]
所有加下划线的序列都产生唯一的gluc肽
[0558]
非xten核心是加下划线且斜体的
[0559]
条形码肽是粗体的
[0560]
示例性条形码肽序列在下表12中示出。这些条形码序列应该根据结构式(i)进行侧接:
[0561]
aaa-glu-条形码肽-bbb,
[0562]
其中“aaa”代表gly、ala、ser、thr或pro,并且“bbb”代表gly、ala、ser或thr,其被配置为通过gluc消化促进条形码肽的有效释放。值得注意的是,在xten中插入每个条形码肽可以得到紧邻插入的条形码肽之前或之后的额外的唯一序列。
[0563]
表12.合适条形码肽的列表
[0564][0565]
实例3:完全序列xten化多肽构建体中xten的设计和选择
[0566]
该实例示出了完全序列多肽构建体的设计,所述完全序列多肽构建体含有一个在n末端处且另一个在c末端处的两个xten多肽。
[0567]
下表13示出了用于代表性的加条形码的bpxten(在n末端和c末端两者处均含有加条形码的xten多肽)和参考bpxten(在n末端和c末端两者处均含有通用xten)中的xten多肽。在代表性的加条形码的bpxten中,加条形码的xten多肽(seq id no.8014)在bp的n末端处融合,并且另一个加条形码的xten多肽(seq id no.8015)在bp的c末端处融合。在参考bpxten中,“ref-n”xten多肽(seq id no.8896)在bp的n末端处融合,并且“ref-c”xten多肽(seq id no.8897)在bp的c末端处融合。“ref-n”xten多肽(seq id no.8896)在长度上与加条形码的xten多肽seq id no.8014可比较;并且“ref-c”xten多肽(seq id no.8897)在长度上与加条形码的xten多肽seq id no.8015可比较。加条形码的bpxten和参考bpxten各自含有在bp组分中的参考序列。参考序列是唯一的,并且在分子量方面不同于在被gluc蛋白酶完全消化(例如,根据实例5)后可从相应bpxten中释放的所有其它肽片段。相对于可从bpxten构建体中释放的所有其它肽片段评价参考序列的唯一性。
[0568]
表13.全长bpxten构建体中使用的代表性n末端和c末端xten组
[0569]
[0570][0571]
实例4:加条形码的xten化融合多肽的重组构建和生产
[0572]
实例4a-4b示出了使用本文公开的方法重组构建、生产和纯化含有加条形码的xten多肽的全长多肽。
[0573]
实例4a.在c末端处含有加条形码的xten的xten化融合多肽
[0574]
表达:编码含有抗epcam单链可变片段(scfv)和在c末端处的长864个氨基酸的加条形码的xten序列(seq id no:8008)的xten化融合多肽的构建体,在有专利权的大肠杆菌ame098菌株中表达,并且经由n末端分泌前导序列(mkkniafllasmfvfsiatnaya-)(seq id no:8898)分配到周质内,所述n末端分泌前导序列在易位过程中被切割。发酵培养物在37℃下用无动物成分复合培养基生长;并且在磷酸盐耗尽之前将温度转变为26℃。在收获期间,将发酵全肉汤离心,以使细胞形成团块。在收获时,记录总体积和湿细胞重量(wcw;团块/上清液的比率),并且收集形成团块的细胞并在-80℃下冷冻。
[0575]
回收:将冷冻的细胞团块重悬浮于靶向30%湿细胞重量的裂解缓冲液(17.7mm柠檬酸、22.3mm na2hpo4、75mm nacl、2mm edta,ph 4.0)中。允许重悬浮液在ph 4下平衡,然后经由在800
±
50巴下的两次通过进行匀浆化,同时监测输出温度并将其维持在15
±
5℃下。确认匀浆的ph在指定范围内(ph 4.0
±
0.2)。
[0576]
澄清:为了减少内毒素和宿主细胞杂质,允许匀浆经历低温(10
±
5℃)、酸性(ph 4.0
±
0.2)絮凝过夜(15-20小时)。为了去除不溶性级分,将絮凝的匀浆在2-8℃下以16,900rcf离心40分钟,并且保留上清液。上清液用milli-q水(mq)稀释大约3倍,然后用5m nacl调整至7
±
1ms/cm。为了去除核酸、脂质和内毒素并充当助滤剂,将上清液调整为0.1%(m/m)硅藻土。为了保持助滤剂悬浮,上清液经由叶轮进行混合,并且允许平衡30分钟。组装由深度过滤器随后为0.22μm过滤器组成的过滤器串,然后用mq冲洗。将上清液泵送通过过滤器串,同时调节流量以维持25
±
5psig的压降。为了将复合缓冲系统(基于柠檬酸和na2hpo4的比率)调整到关于捕获色谱法的所需范围,用500mm na2hpo4调整滤液,其中na2hpo4/柠檬酸的最终比率为9.33:1,并且缓冲滤液的ph确认在指定范围(ph7.0
±
0.2)内。
[0577]
纯化
[0578]
aex捕获:为了将二聚体、聚集体和大的截短物与单体产物分开,并且去除内毒素和核酸,利用阴离子交换(aex)色谱法来捕获带负电的c末端xten结构域。在本文中使用aex1固定相(ge q sepharose ff)、aex1流动相a(12.2mm na2hpo4,7.8mm nah2po4,40mm nacl)和aex1流动相b(12.2mm na2hpo4、7.8mm nah2po4、500mm nacl)。用aex1流动相a平衡柱。基于通过二辛可宁酸(bca)测定所测量的总蛋白浓度,将滤液装载到靶向28
±
4g/l-树脂的柱上,用aex1流动相a逐出,然后用一步洗涤至30%b。结合的材料经过20cv用30%b至60%b的梯度进行洗脱。当a220高于(局部)基线≥100mau时,在1cv等分试样中收集级分。在sds-page和se-hplc的基础上分析且合并洗脱级分。
[0579]
imac中间纯化:为了确保c末端完整性,使用固定化金属亲和色谱法(imac)来捕获c末端多组氨酸标签(his(6)(seq id no:8031))。在本文中使用imac固定相(ge imac sepharose ff)、imac流动相a(18.3mm na2hpo4、1.7mm nah2po4、500mm nacl、1mm咪唑)和imac流动相b(18.3mm na2hpo4、1.7mm nah2po4、500mm nacl、500mm咪唑)。用锌溶液填充柱,并且用imac流动相a平衡。将aex1池调整至ph 7.8
±
0.1、50
±
5ms/cm(用5m nacl)和1mm咪唑,装载到靶向2g/l-树脂的imac柱,并且用imac流动相a逐出,直到在280nm处的吸光度(a280)恢复到(局部)基线。结合的材料用一步洗脱至25%imac流动相b。当a280高于(局部)基线≥10mau时,起始imac洗脱收集,引导至用足以使2cv达到2mm edta的edta预掺料的容器内,并且一旦收集到2cv就终止。通过sds-page分析洗脱物。
[0580]
蛋白l中间纯化:为了确保n末端完整性,蛋白l用于捕获接近于bpxten分子的n末端(特别是aepcam scfv)存在的κ结构域。在本文中使用蛋白l固定相(ge capto l)、蛋白l流动相a(16.0mm柠檬酸、20.0mm na2hpo4,ph 4.0
±
0.1)、蛋白l流动相b(29.0mm柠檬酸、7.0mm na2hpo4,ph 2.60
±
0.02)和蛋白l流动相c(3.5mm柠檬酸、32.5mm na2hpo4、250mm nacl,ph 7.0
±
0.1)。柱用蛋白l流动相c进行平衡。将imac洗脱物调整至ph 7.0
±
0.1和30
±
3ms/cm(用5m nacl和mq),并且装载到靶向2g/l-树脂的蛋白l柱上,然后用蛋白l流动相c逐出,直到在280nm处的吸光度(a280)恢复到(局部)基线。用蛋白l流动相a洗涤柱,并且蛋白l流动相a和b用于实现低ph洗脱。在大约ph 3.0下洗脱结合的材料,并且收集到对于每10
份收集的体积用一份0.5m na2hpo4预掺料的容器内。通过sds-page分析级分。
[0581]
hic精化:为了分离n末端变体(在绝对n末端处的4个残基对于蛋白l结合不是必需的)和整体构象变体,使用疏水作用色谱法(hic)。在本文中使用hic固定相(ge capto phenyl impres)、hic流动相a(20mm组氨酸、0.02%(w/v)聚山梨醇酯80,ph 6.5
±
0.1)和hic流动相b(1m硫酸铵、20mm组氨酸、0.02%(w/v)聚山梨醇酯80,ph 6.5
±
0.1)。柱用hic流动相b进行平衡。将调整的蛋白l洗脱物装载到靶向2g/l-树脂的hic柱上,并且用hic流动相b逐出,直到在280nm处的吸光度(a280)恢复到(局部)基线。柱用50%b进行洗涤。结合的材料经过75cv用50%b至0%b的梯度进行洗脱。当a280高于(局部)基线≥3mau时,在1cv等分试样中收集级分。在se-hplc和hi-hplc的基础上分析且合并洗脱级分。
[0582]
配制:为了将产物交换到配制缓冲液内,并且使产物达到靶浓度(0.5g/l),再次使用阴离子交换来捕获c末端xten。在本文中使用aex2固定相(ge q sepharose ff)、aex2流动相a(20mm组氨酸、40mm nacl、0.02%(w/v)聚山梨醇酯80,ph 6.5
±
0.2)、aex2流动相b(20mm组氨酸、1m nacl、0.02%(w/v)聚山梨醇酯80,ph 6.5
±
0.2)和aex2流动相c(12.2mm na2hpo4、7.8mm nah2po4、40mm nacl、0.02%(w/v)聚山梨醇酯80,ph 7.0
±
0.2)。柱使用aex2流动相c进行平衡。将hic池调整至ph 7.0
±
0.1和7
±
1ms/cm(用mq),并且装载到靶向2g/l-树脂的aex2柱上,然后用aex2流动相c逐出,直到a280恢复到(局部)基线。用aex2流动相a(20mm组氨酸、40mm nacl、0.02%(w/v)聚山梨醇酯80,ph 6.5
±
0.2)洗涤柱。aex2流动相a和b用于生成{nacl}步骤并实现洗脱。结合的材料用一步洗脱至38%aex2流动相b。当a280高于(局部)基线≥5mau时起始aex2洗脱收集,并且一旦收集2个柱体积就终止。aex2洗脱物在bsc内进行0.22μm过滤,等分,标记并在80℃下作为散装原料药(bds)贮存。散装原料药(bds)通过各种分析方法确认为符合所有批次放行标准。通过sds-page分析整体质量,通过se-hplc分析单体/二聚体和聚集体的比率,并且通过hi-hplc分析n末端质量和产物同质性。
[0583]
实例4b.含有在c末端处的加条形码的xten和在n末端处的另一个加条形码的xten的xten化融合多肽
[0584]
表达:编码含有抗egfr单链可变片段(scfv)、在c末端处的长864个氨基酸的加条形码的xten(seq id no:8008)、以及在n末端处的长288个氨基酸的条形码xten(seq id no:8007)的xten化融合多肽的构建体,在有专利权的大肠杆菌ame098菌株中表达,并且经由n末端分泌前导序列(mkkniafllasmfvfsiatnaya-)(seq id no:8898)分配到周质内,所述n末端分泌前导序列在易位过程中被切割。发酵培养物在37℃下用无动物成分复合培养基生长;并且在磷酸盐耗尽之前将温度转变为26℃。在收获期间,将发酵全肉汤离心,以使细胞形成团块。在收获时,记录总体积和湿细胞重量(wcw;团块/上清液的比率),并且收集形成团块的细胞并在-80℃下冷冻。
[0585]
回收:将冷冻的细胞团块重悬浮于靶向30%湿细胞重量的裂解缓冲液(100mm柠檬酸)中。允许重悬浮液在ph 4.4下平衡,然后在17,000
±
200巴下进行匀浆化,同时监测输出温度并将其维持在15
±
5℃下。确认匀浆的ph在指定范围(ph 4.4
±
0.1)内。
[0586]
澄清:为了减少内毒素和宿主细胞杂质,允许匀浆经历低温(10
±
5℃)、酸性(ph 4.4
±
0.1)絮凝过夜(15-20小时)。为了去除不溶性级分,将絮凝的匀浆在8,000rcf和2-8℃下离心40分钟,并且保留上清液。为了去除核酸、脂质和内毒素并充当助滤剂,将上清液调
整为0.1%(m/m)硅藻土。为了保持助滤剂悬浮,上清液经由叶轮进行混合,并且允许平衡30分钟。组装由深度过滤器随后为0.22μm过滤器组成的过滤器串,然后用mq冲洗。将上清液泵送通过过滤器串,同时调节流量以维持25
±
5psig的压降。
[0587]
纯化
[0588]
蛋白l捕获:为了去除宿主细胞蛋白质、内毒素和核酸,蛋白l用于捕获存在于bpxten分子的aegfr scfv内的κ结构域。在本文中使用蛋白l固定相(tosoh tp af-rprotein l-650f)、蛋白l流动相a(11.5mm柠檬酸、24.5mm na2hpo4、125mm nacl、0.005%聚山梨醇酯80,ph 5.0)和蛋白l流动相b(11mm磷酸、0.005%聚山梨醇酯80,ph 2.0)。柱用蛋白l流动相a进行平衡。将滤液调整至ph 5.5
±
0.2,并且装载到靶向2-4g/l-树脂的蛋白l柱上,然后用蛋白l流动相a逐出,直到在280nm处的吸光度(a280)恢复到(局部)基线。结合的材料用流动相b进行洗脱,并且作为用0.4cv 0.5m na2hpo4预掺料的2cv级分进行收集,并且通过sds-page进行分析。
[0589]
imac中间纯化:为了确保n末端完整性,使用固定化金属亲和色谱法(imac)来捕获融合多肽分子的n末端多组氨酸标签(his(6);(seq id no:8031))。在本文中使用imac固定相(ge imac sepharose ff)、imac流动相a(12.2mm na2hpo4、7.8mm nah2po4、500mm nacl、0.005%聚山梨醇酯80,ph 7.0)和imac流动相b(50mm组氨酸、200mm nacl、0.005%聚山梨醇酯80,ph 6.5)。柱用imac流动相a进行平衡。将蛋白l洗脱物调整到ph 7.8
±
0.1和50
±
5ms/cm(用5m nacl)。将调整的蛋白l池装载到靶向2g/l-树脂的imac柱上,并且用imac流动相a逐出,直到在280nm处的吸光度(a280)恢复到(局部)基线。结合的材料用imac流动相b进行洗脱。imac洗脱物作为用0.02cv 200mm edta预掺料的2cv级分进行收集,并且通过sds-page进行分析。
[0590]
c-标签中间纯化:为了确保c末端完整性,使用c-标签亲和色谱法来捕获c末端-epea标签(seq id no:8033)。在本文中使用c-标签固定相(thermo c-tagxl)、c-标签流动相a(50mm组氨酸、200mm nacl、0.005%聚山梨醇酯80,ph 6.5)和c-标签流动相b(20mm tris、0.6m mgcl2、0.005%聚山梨醇酯80,ph 7.0)。柱用c-标签流动相a进行平衡。将imac洗脱物装载到靶向2g/l-树脂的c-标签柱上,并且用c-标签流动相a逐出,直到在280nm处的吸光度(a280)恢复到(局部)基线。结合的材料用c-标签流动相b进行洗脱。c-标签洗脱物作为2cv级分进行收集,并且通过sds-page进行分析。
[0591]
aex精化:为了将二聚体和聚集体与单体产物分开,利用阴离子交换(aex)色谱法来捕获带负电的n末端和c末端xten结构域。在本文中使用aex1固定相(bia qa-80)、aex1流动相a(50mm组氨酸、200mm nacl、0.005%聚山梨醇酯80,ph 6.5)和aex1流动相b(50mm组氨酸、500mm nacl、0.005%聚山梨醇酯80,ph 6.5)。柱用aex流动相a进行平衡。用mq将c-标签洗脱物稀释至10ms/cm,装载靶向2g/l-树脂,然后用aex流动相a逐出,直到在280nm处的吸光度恢复到(局部)基线。结合的材料经过60cv用0%b至100%b的梯度进行洗脱。当a280高于(局部)基线≥2mau时,在1cv等分试样中收集级分。洗脱级分通过sds-page和se-hplc进行分析,并且将发现为≥98%单体的级分合并(aex池)用于进一步处理。
[0592]
配制:为了将产物交换到配制缓冲液内,并且使产物达到靶浓度(0.5g/l),使用超滤/渗滤(uf/df)。使用面积为0.1m2和tmp靶为15psi的10kda膜,将aex池浓缩至0.5g/l,然后用配制缓冲液(50mm组氨酸、200mm nacl、0.005%聚山梨醇酯80,ph 6.5)稀释10倍。将
aex池浓缩10倍,并且再10倍稀释两次。回收的配制产物在bsc内进行0.22μm过滤,等分,标记并在80℃下作为散装原料药(bds)贮存。bds已通过各种分析方法确认为符合所有批次放行标准。通过sds-page分析整体质量,通过se-hplc分析单体/二聚体和聚集体的比率,并且通过hi-hplc分析n末端质量和产物同质性。身份通过esi-ms进行确认。
[0593]
实例5.通过蛋白酶消化释放条形码肽
[0594]
该实例示出了使用本文公开的方法,从含有各种长度或截短形式的含xten构建体的多肽混合物中释放条形码片段和参考片段。
[0595]
含有xten的构建体的样品经由序贯地在dtt中,然后在碘乙酰胺中温育进行还原且烷基化。然后使用尺寸排阻旋转药液筒,对样品进行缓冲液交换且脱盐。将glu-c蛋白酶以1:5的酶/底物比率加入样品中,并且使样品在37℃下温育用于消化。然后将样品移动至4℃以停止蛋白酶解反应,并且置于自动进样器小瓶中用于分析。
[0596]
实例6.条形码肽和参考肽的检测和定量
[0597]
该实例示出了用于生成个别条形码肽的定量测量的质谱法方法。将lc-平行反应监测(prm)方法编程到高分辨率精确质量(hram)质谱仪内。与传统的数据依赖性采集(dda)质谱法方法不同,prm方法集中于在一次运行中的特定一组15-30种肽,每个工作周期通过一次ms-ms对每种肽进行测序。因此,这种方法对于完整肽的非碎片化的前体离子以及肽的每种碎片离子生成萃取离子色谱图(xic),以确认其序列。碎片离子xic经常比亲本离子碎片更灵敏且是选择性定量的。使用的lc-prm方法包括七种条形码肽的轻和重形式。采集后测量这14种肽的所有碎片离子的色谱峰面积,并且使用最强的碎片离子用于定量测量。然后计算xten条形码肽/pat条形码肽的峰面积比,得到在跨越xten分子的各个点处的相对xten:pat丰度。
[0598]
实例7.稳定同位素标记以通过质谱法(ms)来定量肽
[0599]
该实例示出了稳定同位素标记方案,以允许来自含xten多肽的条形码肽的绝对(而不是相对)定量。采用标准的重标记氨基酸定量方案,其中条形码肽的合成类似物从专门的供应商处获得,在所述合成类似物中,c末端谷氨酸替换为(
13
c)5h7(
15
n)o3重标记类似物。制备校准曲线,其中将已知量的含有xten条形码的多肽连续稀释到基质内,其中重标记的合成肽保持在恒定浓度下。可以通过针对含有相同掺料水平的重标记肽的研究样品校准来自曲线的色谱峰面积重:轻比率,来执行准确的定量。
[0600]
实例8.含xten多肽的截短的定量
[0601]
该实例示出了在含xten多肽的混合物中的长度变体或截短变体的定量。
[0602]
例如,条形码肽“sgpgstpaesgse”(seq id no:8899)定位于实例3中描述且由其获得的代表性加条形码的bpxten序列的76个氨基酸内,以指示在bpxten的n末端端部处xten的严重截短。还考虑了潜在的条形码片段“spagsptstesgtse”(seq id no:8260)定位于n末端处。遵循实例6的程序,每种条形码肽相对于来自生物活性蛋白质(例如,scfv片段)序列的独特参考肽序列的丰度测量比率,指示可以影响样品混合物中的药理功效的全长多肽和具有截短的变体的总量。至少一个参考片段的丰度测量用于指示样品混合物中的所有多肽变体的总量。相应地,参考片段和条形码片段之间的差异丰度告知截短多肽变体的量。分析lc-ms数据,以确定条形码片段/参考片段的量的比率,指示了多肽混合物中的药理学有效变体的相对量。
[0603]
一组两个(或三个)条形码用于指示多肽的不同截短水平。lc-ms数据用于确定每个条形码片段的量/参考片段的量的比率,从而定量多肽混合物中的截短变体的分布。
[0604]
实例9.含xten多肽的截短的定量
[0605]
ac2329的纯化中的一个步骤是qir阴离子交换色谱法。来自该柱的主洗脱峰的后一半含有全长蛋白质,而该峰的前一半含有全长蛋白质以及许多截短形式的混合物。为了条形码肽评估的目的,获取两个级分。一个级分仅包括峰的后半部分,此前被称为“全长”级分。第二级分包括峰的前半部分,此前被称为本文所述的“合成蛋白质和截短物”级分:
[0606]
分析尺寸排阻色谱法(sec)覆盖全长(蓝色)级分和全长+截短物级分(黑色)。显而易见的是,合成蛋白质+截短物级分包括与完整合成蛋白质一样大的片段,但还有许多较小的组分,如通过在峰的右侧上的大斜肩指示的。
[0607]
全长合成蛋白质以及全长合成蛋白质和截短物以稀释矩阵中所述的比率进行混合。
[0608]
稀释矩阵
[0609]
稀释123456789化合物1(nm)400350300250200150100500化合物1截短(nm)050100150200250300350400总nm400400400400400400400400400总体积606060606060606060
[0610]
然后在含有50mm tris-hcl ph 7.5+0.1%rapigest(waters 186001861)的反应缓冲液中,用1mg/ml gluc(roche 10791156001)消化各400nm样品。gluc消化在37℃下在振荡培养箱中执行过夜。在消化之后,将甲酸加入至10%的最终浓度,并且在37℃下温育45分钟。通过以16,000x g离心10分钟去除rapigest沉淀物,并且将重肽标准混合物加入至400nm的最终浓度。如所述的执行每种消化物的lc-ms分析。每个样品一式两份进行测量。
[0611]
通过lc-ms的分析
[0612]
使用连接到q-exactive plus质谱仪(thermo)的vanquish(thermo)uhplc系统,在waters hss-t3柱(176003994)上使用30分钟梯度法分析消化物。ms方法由前十位dda方法组成,其中前十种肽在每次ms扫描后通过msms分析进行测序。使用skyline software(maccoss lab,uw)软件处理所得的数据文件,其中可以计算且测量每种条形码肽的重肽标准化浓度。
[0613]
如图5b中所示,每个测量是针对其相应重同位素标记的合成肽的400nm波峰标准化的n-条形码sgpgstpae(seq id no.8029)和c-条形码gsapgte(seq id no.8023)的xic面积。稀释1具有最低量的截短物,而稀释9具有最高的量。这些数据指示了,n-条形码肽跨越含有截短物和非截短物的样品以相对相似的丰度进行测量。然而,在含有截短物的级分中可见c-条形码肽的丰度降低。这提示了翻译终止是截短种类的最强贡献因素,因为原核生物中的翻译在n末端处起始。
[0614]
已通过参考本发明的具体方面和/或实施例详细描述了本发明,显而易见的是修改和变化是可能的,而不脱离所附权利要求中限定的本发明的范围。更具体而言,尽管本发明的一些方面可以在本文中鉴定为特别有利的,但考虑本发明并不限于本发明的这些特定方面。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1