人造血干细胞和祖细胞中α-珠蛋白基因座处的靶向整合
人造血干细胞和祖细胞中
α-珠蛋白基因座处的靶向整合
相关申请的交叉引用
1.本技术要求2019年11月15日提交的美国临时专利申请第62/936,248号的优先权,该申请通过引用以其整体并入本文。关于在联邦资助的研究和开发下作出的发明权利的声明
2.本发明是在美国国立卫生研究院(national institutes of health)给予的第hl135607号基金的政府支持下完成的。政府对本发明享有一定的权利。背景
3.β-地中海贫血是世界上最常见的遗传性血液病症之一,全球发病率为1/100,000(1)。患有这种疾病的患者遭受了严重的贫血,并且即使接受重症监护,中位预期寿命也只有30岁(2-4)。该疾病最严重形式—重型β地中海贫血—是由整个β-珠蛋白(hbb)基因的纯合(或复合杂合)功能丧失突变引起的。这会导致hbb蛋白损失,导致严重的贫血并降低红血细胞(rbc)向全身输送氧气的能力。未配对的α-珠蛋白(来自hba1和hba2基因)的积累会导致显著的红细胞毒性,导致患者中出现贫血。事实上,已知疾病严重程度与β-珠蛋白和α-珠蛋白链之间的不平衡程度直接相关(5)。目前对β-地中海贫血的护理标准包括频繁输血结合铁螯合疗法,使其成为年轻人中最昂贵的遗传病之一(6)。目前,这种疾病的唯一治愈策略是来自免疫匹配供体的同种异体造血干细胞移植(hsct)。然而,在大多数情况下,没有匹配的供体可用于同种异体hsct,并且即使确定了一名供体,来自这些供体的移植物也存在免疫排斥和移植物抗宿主病的风险(7)。
4.一种潜在的理想治疗包括分离患者来源的造血干细胞和祖细胞(hspc),引入hbb以恢复hbb蛋白水平,然后对患者自身校正的hspc进行自体hsct,这不会带来免疫排斥的风险。采用这种逻辑,已经开发了几种基因疗法作为β-地中海贫血的潜在治愈措施,主要是通过使用慢病毒载体递送hbb转基因进行(8,9)。虽然这些方法已经显示在β-地中海贫血的人类临床试验中将hbb恢复到治疗水平(10),但使用慢病毒和逆转录病毒载体进行递送导致半随机基因组整合,这能够使肿瘤抑制基因失活或激活癌基因。事实上,hspc中的半随机整合已经显示导致克隆扩增、骨髓发育不良和急性髓样白血病(11-14),其中一个实例被证明是致命的(15)。此外,慢病毒基因治疗方法虽然达到了对较轻形式的输血依赖性β-地中海贫血的注册状态(registration status),但并未导致严重形式的疾病的输血独立性。
5.由于这些剩余的安全性和功效问题,已经开发了替代策略,其采用基因组编辑(包括锌指核酸酶和crispr/cas9系统)来启动位点特异性dna双链断裂(dsb)以使胎儿血红蛋白的阻遏物失活,胎儿血红蛋白的上调可以弥补hbb的缺乏(16)。然而,有人担心由此产生的胎儿血红蛋白上调可能不足以挽救β-珠蛋白:α-珠蛋白失衡,以及在胎儿血红蛋白自然沉默的成年患者中,这种上调可能不会持续存在(17,18)。而且,这种方法没有解决β-地中海贫血的遗传原因—hbb失活—并且可能无法在体内充分挽救疾病表型。此外,所有这些疗法仅用于弥补hbb的缺乏,并不会降低α-珠蛋白的水平。
6.因此,需要新的、安全且有效的方法以在体内或离体将hbb或其他治疗性转基因引入自体hspc和红血细胞中。本公开内容满足了这种需要并且还提供了其他优势。
概述
7.在一方面,本公开内容提供了遗传修饰来自对象的造血干细胞和祖细胞(hspc)的方法,所述方法包括将包含与hba1基因序列或hba2基因序列杂交的序列的引导rna、rna引导的核酸酶和包含编码蛋白质的转基因的供体模板引入所述hspc中,其中所述rna引导的核酸酶在所述细胞中切割所述hba1基因序列或所述hba2基因序列,但不同时切割所述hba1基因序列和所述hba2基因序列;其中将所述转基因整合至所述切割的hba1基因序列或hba2基因序列中;从而生成遗传修饰的hspc,其中所述整合的转基因导致所述蛋白质在所述遗传修饰的hspc中表达。
8.在另一方面,本公开内容提供了遗传修饰来自对象的造血干细胞和祖细胞(hspc)的方法,所述方法包括将包含与hba1基因序列或hba2基因序列杂交的序列的引导rna、rna引导的核酸酶和包含编码蛋白质的转基因的供体模板引入所述hspc中,其中所述rna引导的核酸酶在所述细胞中切割所述hba1基因序列或所述hba2基因序列,但不同时切割所述hba1基因序列和所述hba2基因序列;其中将所述转基因整合至所述切割的hba1基因序列或hba2基因序列中;从而生成遗传修饰的hspc,其中所述引入导致与所述rna引导的核酸酶、所述供体模板以及与hba1基因序列和hba2基因序列杂交的引导rna的引入相比所述hspc的基因组中易位事件减少。
9.在另一方面,本公开内容提供了遗传修饰来自对象的造血干细胞和祖细胞(hspc)的方法,所述方法包括将包含与hba1基因序列或hba2基因序列杂交的序列的引导rna、rna引导的核酸酶和包含编码蛋白质的转基因的供体模板引入所述hspc中,其中所述rna引导的核酸酶在所述细胞中切割所述hba1基因序列或所述hba2基因序列,但不同时切割所述hba1基因序列和所述hba2基因序列;其中将所述转基因整合至所述切割的hba1基因序列或hba2基因序列中;从而生成遗传修饰的hspc,其中所述引入导致与所述rna引导的核酸酶、所述供体模板以及与hba1基因序列和hba2基因序列杂交的引导rna的引入相比所述hspc的基因组中供体模板的脱靶整合减少。
10.在本文公开的方法中的任一种的一些实施方案中,所述方法还包括在引入所述引导rna、所述rna引导的核酸酶和所述供体模板之前从所述对象分离所述hspc。在一些实施方案中,hba1基因序列或ba2基因序列包含3’utr区。在一些实施方案中,rna引导的核酸酶切割hba1基因序列但不切割hba2基因序列。在一些实施方案中,hba1基因序列包含seq id no:5的序列。在一些实施方案中,将转基因整合至hba1基因序列中。在一些实施方案中,rna引导的核酸酶切割hba2基因序列但不切割hba1基因序列。在一些实施方案中,hba2基因序列包含seq id no:2的序列。在一些实施方案中,将转基因整合至hba2基因序列中。
11.在本文公开的方法中的任一种的一些实施方案中,hspc包含与野生型hbb基因相比包含突变的hbb基因。在一些实施方案中,突变是疾病的病因。在一些实施方案中,疾病是β-地中海贫血。在一些实施方案中,转基因选自:hbb、pdgfb、idua、fix(如,padua变体)、ldlr和pah。在一些实施方案中,转基因是hbb。在一些实施方案中,hbb在hspc中表达并且与引入引导rna、rna引导的核酸酶和供体模板之前相比所述hbb提高了hspc中成人血红蛋白四聚体的水平。在一些实施方案中,转基因是hbb,其中引导rna与seq id no:5的序列杂交,并且其中hbb整合在hba1基因序列的位点处。
12.在一些实施方案中,对象患有β-地中海贫血,并且将表达hbb转基因的遗传修饰的
hspc重新引入对象中。在一些实施方案中,整合的转基因的表达由内源性hba1或hba2启动子驱动。在一些实施方案中,整合的转基因替换hspc基因组中的hba1或hba2编码序列。在一些实施方案中,整合的转基因替换hspc基因组中的hba1或hba2开放阅读框(orf)。在一些实施方案中,蛋白质是分泌蛋白。在一些实施方案中,蛋白质是治疗性蛋白。
13.在一些实施方案中,引导rna包含一个或多个2
’‑
o-甲基-3
’‑
硫代磷酸(ms)修饰。在一些此类实施方案中,一个或多个2
’‑
o-甲基-3
’‑
硫代磷酸(ms)修饰存在于引导rna的5’和3’端的三个末端核苷酸处。在一些实施方案中,rna引导的核酸酶是cas9。在一些实施方案中,将引导rna和rna引导的核酸酶作为核糖核蛋白(rnp)复合物通过电穿孔引入hspc中。在一些实施方案中,使用重组腺相关病毒(raav)载体将供体模板引入hspc中。在一些此类实施方案中,raav载体是aav6载体。
14.在一些实施方案中,离体进行引入。在一些实施方案中,所述方法还包括将遗传修饰的hspc引入对象中。在一些实施方案中,所述方法还包括诱导遗传修饰的hspc在体外或离体分化为红血细胞(rbc)。在一些实施方案中,对象是人。
15.在另一方面,本公开内容提供了引导rna,其包含与hba1基因序列或hba2基因序列杂交但不同时与两者杂交的序列。在一些实施方案中,引导rna与hba1基因序列或hba2基因序列的3’utr杂交。在一些实施方案中,引导rna与hba1基因序列杂交。在一些实施方案中,hba1基因序列包含seq id no:5的序列。在一些实施方案中,引导rna与hba2基因序列杂交。在一些实施方案中,hba2基因序列包含seq id no:2的序列。在一些实施方案中,引导rna包含一个或多个2
’‑
o-甲基-3
’‑
硫代磷酸(ms)修饰。在一些此类实施方案中,一个或多个2
’‑
o-甲基-3
’‑
硫代磷酸(ms)修饰存在于引导rna的5’和3’端的三个末端核苷酸处。
16.在另一方面,本公开内容提供了hspc,其包含本文公开的引导rna中的任一种。
17.在另一方面,本公开内容提供了遗传修饰的hspc,其包含整合在hba1或hba2基因序列中但不同时整合在两者中的转基因。在一些实施方案中,使用本文公开的方法中的任一种生成遗传修饰的hspc。在一些实施方案中,转基因选自:hbb、pdgfb、idua、fix(如,padua变体)、ldlr和pah。在一些实施方案中,转基因是hbb。在一些实施方案中,hbb整合在hba1基因序列处。在一些实施方案中,hbb转基因已经替换了遗传修饰的hspc的基因组中的内源性hba1编码序列。在一些实施方案中,hbb转基因已经替换了遗传修饰的hspc的基因组中的内源性hba1开放阅读框。
18.在另一方面,本公开内容提供了由诱导本文所述的遗传修饰的hspc中的任一种在体外或离体分化而产生的红血细胞。
19.在另一方面,本公开内容提供了用于治疗有需要的对象中的β-地中海贫血的方法,所述方法包括向所述对象施用本文公开的遗传修饰的hspc中的任一种,其中所述遗传修饰的hspc植入对象中并导致对象中成人血红蛋白四聚体水平与施用前相比提高,从而治疗对象中的β-地中海贫血。
20.在所述方法的一些实施方案中,遗传修饰的hspc来源于对象。
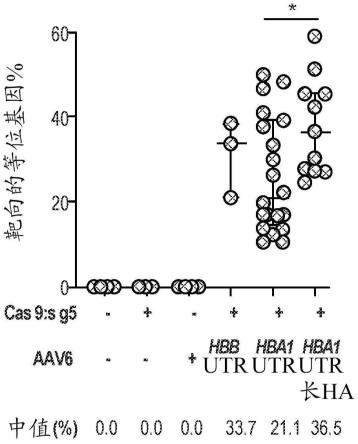
21.在另一方面,本公开内容提供了修饰细胞的方法,所述方法包括向所述细胞引入可编程核酸酶,其切割所述细胞中靶基因内的靶基因座;和核酸,其包含含有转基因的供体模板,其中所述转基因整合至所述靶基因座中,并且其中所述转基因替换由所述靶基因编码的蛋白质的整个或部分开放阅读框(orf)。
22.在一些实施方案中,所述转基因替换所述靶基因的选自以下的区域:5’utr、一个或多个外显子、一个或多个内显子、3’utr及以上的任何组合。在一些实施方案中,转基因替换靶基因的内含子和外显子。在一些实施方案中,细胞是原代细胞。在一些实施方案中,细胞是造血干细胞和祖细胞(hspc)。在一些实施方案中,转基因编码治疗性蛋白。在一些实施方案中,转基因选自:hbb、pdgfb、idua、fix(如,padua变体)、ldlr和pah。在一些实施方案中,转基因是hbb。在一些实施方案中,靶基因包含与疾病相关的突变。在一些实施方案中,靶基因包含与疾病相关的两个或更多个突变。在一些实施方案中,靶基因编码与疾病相关的蛋白并且其中转基因编码蛋白的野生型。在一些实施方案中,靶基因是安全港基因。在一些实施方案中,靶基因是hba1基因。在一些实施方案中,靶基因是hba2基因。
23.在本文公开的方法中的任一种的一些实施方案中,所述转基因侧接有第一同源臂和第二同源臂,其中所述第一同源臂包含与邻近所述靶基因座的第一序列的同源性并且所述第二同源臂包含与邻近所述靶基因座的第二序列的同源性。在一些实施方案中,所述第一同源臂包含与在所述靶基因的5’端处的序列的同源性并且所述第二同源臂包含与在所述靶基因的3’端处的序列的同源性。在一些实施方案中,所述第一同源臂或所述第二同源臂包含与所述靶基因的5’utr的一部分的同源性。在一些实施方案中,所述第一同源臂或所述第二同源臂包含与所述靶基因的3’utr的一部分的同源性。在一些实施方案中,所述第一同源臂或所述第二同源臂包含与作为所述靶基因的起始密码子的5’的一部分的同源性。在一些实施方案中,所述第一同源臂包含与所述靶基因的3’utr的一部分的同源性并且所述第二同源臂包含与作为所述靶基因的转录起始位点的5’的一部分的同源性。
24.在一些实施方案中,所述第一同源臂、所述第二同源臂或两者包含至少约200个碱基对。在一些实施方案中,所述第一同源臂、所述第二同源臂或两者包含至少约400个碱基对。在一些实施方案中,所述第一同源臂、所述第二同源臂或两者包含至少约500个碱基对。在一些实施方案中,所述第一同源臂、所述第二同源臂或两者包含至少约800个碱基对。在一些实施方案中,所述第一同源臂、所述第二同源臂或两者包含至少约850个碱基对。在一些实施方案中,所述第一同源臂、所述第二同源臂或两者包含至少约900个碱基对。
25.在一些实施方案中,供体模板包含与seq id no:6至少约85%的序列同一性。在一些实施方案中,供体模板包含seq id no:6的序列。在一些实施方案中,整合的转基因的表达由靶基因的启动子调控。在一些实施方案中,启动子是细胞基因组中的内源性启动子。在一些实施方案中,离体进行所述引入。在一些实施方案中,可编程核酸酶是crispr-cas蛋白。在一些实施方案中,可编程核酸酶是cas9蛋白。在一些实施方案中,可编程核酸酶是cpf1蛋白。在一些实施方案中,可编程核酸酶在靶基因座处产生双链断裂。在一些实施方案中,将供体模板在重组aav(raav)载体中引入细胞中。在一些此类实施方案中,raav载体是aav6载体。
26.在一些实施方案中,所述方法还包括将引导rna引入细胞中,其中引导rna指导可编程核酸酶切割靶基因中的靶基因座。在一些实施方案中,引导rna包含与靶基因中的靶序列杂交的序列。在一些实施方案中,引导rna是本文所述的引导rna中的任一种。附图简述
27.图1a-1f:用于crispr/aav6介导的靶向α-珠蛋白基因座的sgrna&aav6设计。图1a:hba2和hba1基因组dna的示意图。3’utr区中两个基因之间的序列差异被描绘为红星。指示
了五种预期sgrna的位置。图1b:人cd34
+
hspc中hba2和hba1处每种引导物的插入缺失(indel)频率分别以橙色和蓝色描绘。柱条代表中值
±
四分位数范围。*:p《0.05;**:p《0.005;***:p《0.0005,使用非配对t检验确定。图1c:在hba2和hba1基因座处描绘了用于引入sffv-gfp-bgh整合的aav6 dna修复供体设计示意图。图1d:如通过流式细胞术测定的使用hba2-和hba1-特异性引导物以及cs和wgr sffv-gfp aav6供体的gfp
+
细胞的百分比。柱条代表中值
±
四分位数范围。*:p《0.05,使用非配对t检验确定。图1e:如通过ddpcr测定的hba2和hba1处的靶向等位基因频率,以确定脱靶基因整合是否发生在非预期基因处。柱条代表中值
±
四分位数范围。*:p《0.05;***:p《0.0005,使用非配对t检验确定。图1f:如通过bd facsaria ii平台确定的每个靶向事件中gfp
+
细胞的mfi。柱条代表中值
±
四分位数范围。***:p《0.0005,使用非配对t检验确定。
28.图2a-2f:使用t2a方案进行的crispr/aav6介导的靶向α-基因座。图2a:在hba1基因座处描绘了用于引入hbb-t2a-yfp整合的aav6 dna修复供体设计示意图。图2b:如通过流式细胞术测定的获取rbc表面标志物gpa和cd71的cd34-/cd45-hspc的百分比。柱条代表中值
±
四分位数范围。图2c:如通过流式细胞术测定的使用hba2-和hba1-特异性引导物及hbb-t2a-yfp aav6供体的gfp
+
细胞的百分比。柱条代表中值
±
四分位数范围。**:p《0.005,使用非配对t检验确定。图2d:如通过ddpcr测定的hba2和hba1处的靶向等位基因频率。柱条代表中值
±
四分位数范围。***:p《0.0005,使用非配对t检验确定。图2e:如通过bd facsaria ii平台测定的每个靶向事件中gfp
+
细胞的mfi。柱条代表中值
±
四分位数范围。图2f:用hbb-t2a-yfp在hba1处(hba1 utr)靶向并在14天方案的时程内分化为rbc的人hspc的代表性流式细胞术染色和门控方案。这表明只有rbc(cd34-/cd45-/cd71
+
/gpa
+
)能够表达整合的t2a-yfp标志物。在bd facs aria ii平台上进行分析。
29.图3a-3f:在scd hspc中的α-珠蛋白基因座处crispr/aav6介导的靶向。图3a:用于在hba1基因座处引入全基因替换hbb转基因整合的aav6 dna修复供体设计示意图。图3b:如通过流式细胞术测定的获取rbc表面标志物gpa和cd71的cd34-/cd45-hspc的百分比。柱条代表中值
±
四分位数范围。图3c:如通过ddpcr测定的hba1处的靶向等位基因频率。柱条代表中值
±
四分位数范围。*:p《0.05,使用非配对t检验确定。图3d:人scd cd34
+
hspc的靶向和rbc分化后每种处理的代表性hplc图。hgba和hgbs四聚体峰的保留时间分别在~6.6和~9.8处指示。图3e:所有hplc结果的总结,显示hgba在总血红蛋白四聚体中的百分比。柱条代表中值
±
四分位数范围。*:p《0.05,使用非配对t检验确定。图3f:描绘了分化为rbc并通过hplc分析的hba1 utr-靶向样品中%hgba对比靶向等位基因%之间的相关性的图。各个载体的颜色如图所描绘。指示了r2值和趋势线公式。
30.图4a-4f:将α-珠蛋白靶向的人hspc植入nsg小鼠中。图4a:在将靶向的人cd34
+
hspc骨髓移植到nsg小鼠中后16周,收获骨髓并测定植入率。描绘了呈hhla
+
的mterr119-细胞(非rbc)占呈mcd45
+
或hhla
+
的总细胞数的百分比。用颜色编码指示了大、中和小剂量实验,其中最初分别移植了1.2m、750k或250k细胞。柱条代表中值
±
四分位数范围。图4b:在植入的人细胞中,指示了cd19
+
(b细胞)、cd33
+
(髓细胞)或其他(即hspc/rbc/t/nk/前b(pre-b))谱系之间的分布。柱条代表中值
±
四分位数范围。图4c:在体外(移植前)靶向的hspc和成批植入的hspc以及cd19
+
(b-细胞)、cd33
+
(髓细胞)和cd34
+
(hsc)谱系中如通过ddpcr测定的hba1处的靶向等位基因频率。柱条代表中值
±
四分位数范围。图4d:与移植前体外人hspc
群体的成批靶向率相比,植入的人细胞中hba1处的靶向等位基因频率。每只小鼠用不同的颜色表示。柱条代表中值
±
四分位数范围。图4e:在初始植入后,将植入的人细胞第二次移植到nsg小鼠的骨髓中。移植后16周,收获骨髓并测定植入率。描绘了呈hhla
+
的mterr119-细胞(非rbc)占呈mcd45
+
或hhla
+
的总细胞数的百分比。柱条代表中值
±
四分位数范围。图4f:在成批样品中植入的人细胞以及在cd19
+
(b细胞)和cd33
+
(髓细胞)谱系中(二次移植实验中)如通过ddpcr测定的hba1处的靶向等位基因频率。每只小鼠用不同的颜色表示。柱条代表中值
±
四分位数范围。
31.图5a-5e:靶向β-地中海贫血来源的hspc中的α-珠蛋白基因座。图5a:如通过ddpcr测定的β-地中海贫血来源的hspc中hba1处的靶向等位基因频率。柱条代表中值
±
四分位数范围。*:p《0.05,使用非配对t检验确定。图5b:在靶向的hspc分化成rbc后,收获mrna并转化为cdna。将hba(不区分hba1和hba2)和hbb转基因的表达归一化为gpa表达。图5c:在将靶向的β-地中海贫血来源的hspc骨髓移植到nsg小鼠中后16周,收获骨髓并测定植入率。描绘了呈hhla
+
的mterr119-细胞(非rbc)占呈mcd45+或hhla
+
的总细胞数的百分比。柱条代表中值
±
四分位数范围。图5d:在植入的人细胞中,指示了b细胞、髓细胞或其他(即hspc/rbc/t/nk/前b)谱系之间的分布。柱条代表中值
±
四分位数范围。图5e:在成批样品中植入的人细胞以及cd19
+
(b细胞)、cd33
+
(髓细胞)和其他(即hspc/rbc/t/nk/前b)谱系中(在二次移植实验中)如通过ddpcr测定的hba1处的靶向等位基因频率。每只小鼠用不同的颜色表示。柱条代表中值
±
四分位数范围。
32.图6a-6c:在内源性基因座处引入hbb转基因的预期结果。图6a:在源自β-地中海贫血患者的hspc的内源性基因座处整合未分散的全长hbb(含内含子)时的预期结果。图中注释了致病突变的种类。图6b:在源自β-地中海贫血患者的hspc的内源性基因座处整合分散的全长hbb(含内含子)时的预期结果。图6c:在源自β-地中海贫血患者的hspc的内源性基因座处整合分散的hbb cdna(不含内含子)时的预期结果。
33.图7a-7c:靶向α-珠蛋白基因座的cas9 sgrna的分析。图7a:含引导rna序列的表。pam以灰色显示,并且hba1和hba2之间的差异在每个引导物中以红色突出显示。图7b:通过cosmid对hba1 sg5在中靶和40个最高度预测的脱靶位点处的rhampseq靶向测序结果的概述。值是在减去每个实验重复的每个基因座处的模拟处理的插入缺失频率后,rnp处理的插入缺失频率。n=3,尽管没有显示所有值,因为在减去模拟插入缺失频率后,有些值《0.01%。柱条代表中值。图7c:通过cosmid对hba1 sg5的40个最高度预测的脱靶位点的基因组坐标列表。
34.图8a-8b:用gfp-hba整合载体靶向hspc。图8a:用gfp-hba整合载体靶向的hspc的编辑和分析的时间线。图8b:描绘了在编辑后14天已经通过crispr/aav6方法靶向的人hspc的代表性流式细胞术图像。这表明与hba1基因座处的切割位点(cs)整合相比,全基因置换(wgr)整合在每个gfp
+
细胞中产生更大的mfi。在bd accuri c6平台上进行分析。所有重复实验的中值mfi显示在每个流式细胞术图像下方,并且整合载体的示意图显示在上方。
35.图9:用hbb-t2a-yfp-hba整合载体靶向hspc的时间线。用hbb-t2a-yfp整合载体靶向hspc、分化为rbc和随后分析的时间线。
36.图10a-10b:用于分析rbc的靶向和分化率的代表性染色和门控方案。图10a:在hba1处用hbb-t2a-yfp靶向(hba1 utr)并在14天方案的时程内分化为rbc的人hspc的代表
性流式细胞术染色和门控方案。这表明只有rbc(cd34-/cd45-/cd71
+
/gpa
+
)能够表达整合的t2a-yfp标志物。在bd facs aria ii平台上进行分析。图10b:来源于用hba1 utr、hba2 utr和hbb utr载体靶向的hspc的rbc(cd34-/cd45-/cd71
+
/gpa
+
)的代表性yfp x fsc流式细胞术图像。每个载体仅使用aav对照来建立门控方案,导致图像之间的正/负截止值略有变化。
37.图11a-11e:接种到甲基纤维素中的hspc的集落形成单位的分析。图11a:图11b和11d中显示的甲基纤维素集落的基因型分布。每个类别对应的克隆数都包含在饼图中。图11b:将来自健康供体的体外(植入前)活cd34
+
hspc单细胞分选到含有半固体甲基纤维素培养基的96孔板中,用于集落形成测定。对分选后14天的细胞进行形态分析。描绘了每个谱系形成的集落数(cfu-e=红系谱系;cfu-gemm=多谱系;或cfu-gm=粒细胞/巨噬细胞谱系)除以可用于集落的总孔数。图11c:对于图11a的每种处理,每种谱系在所有集落中的百分比分布。图11d:将体外(移植前)活cd34
+
β-地中海贫血患者来源的hspc单细胞分选到含有半固体甲基纤维素培养基的96孔板中,用于集落形成测定。对分选后14天的细胞进行形态分析。描绘了每个谱系形成的集落数(b=bfu-e和c=cfu-e(红系谱系);ge=cfu-gemm(多谱系);或gm=cfu-gm(粒细胞/巨噬细胞谱系))除以可用于集落的总孔数。图11e:对于图11c的每种处理,每种谱系在所有集落中的百分比分布。
38.图12:筛选用于临床载体开发的整合盒。展示了载体s1-15的示意图和相应的设计原理以及最终结果。
39.图13:靶向hspc和移植到小鼠中的时间线。用hbb整合载体靶向hspc、移植到小鼠(1o和2o植入两者)中和随后分析的时间线。
40.图14:用于分析人hspc向nsg小鼠的植入和靶向率的代表性染色和门控方案。用于分析移植到nsg小鼠骨髓中的人hspc的靶向和植入率的代表性流式细胞术染色和门控方案。在hba1基因座处用ubc-gfp整合靶向该样品。这表明只有人细胞(hhla
+
)能够表达gfp。在bd facs aria ii平台上进行分析。
41.图15a-15g:在α-珠蛋白基因座处用gfp靶向的人hspc植入nsg小鼠中。图15a:用ubc-gfp整合载体靶向hspc,移植到小鼠中(1o和2o植入两者)和随后分析的时间线。图15b:在hba1基因座处描绘了用于引入ubc-gfp-bgh整合的aav6 dna修复供体设计示意图。图15c:在将靶向的人cd34
+
hspc骨髓移植到nsg小鼠中后16周,收获骨髓并测定植入率(1o)。描绘了呈hhla
+
的mterr119-细胞(非rbc)占呈mcd45
+
或hhla
+
的总细胞数的百分比。柱条代表中值
±
四分位数范围。图15d:在植入的人细胞中,指示了cd19+(b细胞)、cd33
+
(髓细胞)或其他(即hspc/rbc/t/nk/前b)谱系之间的分布。柱条代表中值
±
四分位数范围。图15e:移植前(体外,分选后)和成功植入的群体中,两个批次的hspc中及cd19
+
(b细胞)、cd33
+
(髓细胞)和其他谱系中的gfp
+
细胞的百分比。柱条代表中值
±
四分位数范围。图15f:在初始植入后,将植入的人细胞第二次移植到nsg小鼠的骨髓中。移植后16周,收获骨髓并测定植入率(2o)。描绘了呈hhla
+
的mterr119-细胞(非rbc)占呈mcd45
+
或hhla
+
的总细胞数的百分比。图15g:来自图15f中描绘的第二次移植的成功植入群体中gfp
+
细胞的百分比。
42.图16a-16g:β-地中海贫血患者来源的hspc中的靶向、β-珠蛋白产生和植入数据。图16a:如通过流式细胞术测定的获取rbc表面标志物gpa和cd71的cd34-/cd45-hspc的百分比。柱条代表中值
±
四分位数范围。对于每个处理组,n=4。图16b:如通过ddpcr测定的β-地中海贫血来源的hspc中hba1处的靶向等位基因频率。柱条代表中值
±
四分位数范围。对于
模拟,n=3;对于仅rnp和hba1utr,n=2;以及对于hba1 utr长ha处理,n=5。**:p《0.005,使用非配对t检验确定。图16c:在靶向的hspc分化成rbc后,收获mrna并转化为cdna。将hba(不区分hba1和hba2)和hbb转基因的表达归一化为hbg表达。柱条代表中值
±
四分位数范围。对于每个处理组,n=3,例外是hba1 utr,n=1。**:p《0.05,使用非配对t检验确定。图16d:显示归一化为hgbf的hgba的血红蛋白四聚体hplc结果的概述。柱条代表中值
±
四分位数范围。对于每个处理组,n≥3。***:p《0.0001,使用非配对t检验确定。图16e:hspc的靶向和rbc分化后每种处理的代表性血红蛋白四聚体hplc图。指示了hgbf和hgba四聚体峰的保留时间。图16f:反相珠蛋白链hplc结果的概述,显示了β-珠蛋白的曲线下面积(auc)/α-珠蛋白的auc。柱条代表中值
±
四分位数范围。对于每个处理组,n≥4。***:p《0.0001,使用非配对t检验确定。图16g:hspc的靶向和rbc分化后每种处理的代表性反相珠蛋白链hplc图。指示了hgbf和hgba四聚体峰的保留时间。
43.图17a-17c:β-地中海贫血患者来源的hspc中的靶向、β-珠蛋白产生和植入数据。图17a:在将靶向的β-地中海贫血来源的hspc移植到nsg小鼠中后16周,收获骨髓并测定植入率。描绘了呈hhla
+
的mterr119-细胞(非rbc)占呈mcd45
+
或hhla
+
的总细胞数的百分比。柱条代表中值
±
四分位数范围。n=10。图17b:在植入的人细胞中,指示了b细胞、髓细胞或其他(即hspc/rbc/t/nk/前b)谱系之间的分布。柱条代表中值
±
四分位数范围。n=9。图17c:在成批样品中植入的人细胞以及在cd19
+
(b细胞)、cd33
+
(髓细胞)和其他(即hspc/rbc/t/nk/前b)谱系中(在二次移植实验中)如通过ddpcr测定的hba1处的靶向等位基因频率。柱条代表中值
±
四分位数范围。对于模拟处理组,n=3;以及对于靶向处理组,n=10。
44.图18a-18b:靶向hba1的grna 5生成的插入缺失谱的另外信息。图18a:描绘了所有五条引导序列在基因组基因座处的位置的示意图。图18b:由tide软件生成的hba1特异性sg5的代表性插入缺失谱。
45.图19:hspc中靶向后的活力数据。通过流式细胞术在编辑后2-4天量化hspc活力。描绘了对ghostred活力染料染色呈阴性的细胞百分比。使用标准条件(即cas9 rnp+sg5的电穿孔,aav的5k moi和24小时无aav洗涤)使用我们优化的hbb基因替换载体编辑所有细胞。柱条代表中值
±
四分位数范围。wt:对于模拟,n=5,对于仅rnp,n=3,对于仅aav,n=1以及对于rnp+aav处理组,n=6;scd:对于每个处理组,n=2,例外是rnp+aav,n=4;β-thal:对于模拟,n=3,对于仅rnp,n=1以及对于rnp+aav处理组,n=7。
46.图20a-20c:由双色靶向载体生成的数据,以在靶向hba1时深入了解单等位基因和双等位基因的编辑频率。图20a:由hba1-wgr-gfp aav6(图16c中所示)和hba1-wgr-mplum aav6同时靶向的cd34
+
hspc的代表性facs图。图20b:显示了用仅gfp、仅mplum和两种颜色靶向的群体%的表。然后通过以下等式将编辑的细胞的百分比转换为编辑的等位基因的百分比:(总靶向细胞%+(双色%)*2)/2=总靶向等位基因%。图20c:对于图20b中所示的数据,将编辑的细胞百分比相对于编辑的等位基因百分比作图。多项式回归(r2=0.9981)用于确定将编辑的等位基因百分比转换为编辑的细胞百分比的等式,反之亦然。
47.图21a-21g.用于红血细胞递送的定制转基因整合在hba1处的更新数据。图21a:如通过流式细胞术测定的获取rbc表面标志物gpa和cd71的cd34-/cd45-hspc的百分比。柱条代表中值
±
四分位数范围。对于每个处理组,n=5。图21b:如通过ddpcr测定的原代hspc中hba1处的靶向等位基因频率。柱条代表中值
±
四分位数范围。对于每个处理组,n=3。图
21c:如通过fix elisa测定的,在原代hspc中靶向和红血细胞分化后细胞裂解物和上清液中的fix(因子ix)产生。图21d:在用表达转基因的质粒电穿孔的293t细胞的上清液中,酪氨酸的产量作为pah活性的代表。图21e:如通过流式细胞术测定的,在rbc分化过程中,用组成型gfp和无启动子yfp整合载体在hba1处靶向的原代hspc的%rbc。图21f:如通过流式细胞术测定的图21e中所示的靶向hspc的%gfp。图21g:如通过流式细胞术测定的图21f所示的相对于gfp
+
群体的d0测量的mfi倍数变化。详述1.引言
48.本公开内容提供了用于将例如用于治疗性基因诸如hbb、idua、pah、pdgfb、fix(如,因子ix padua变体)、ldlr等的转基因整合至造血干细胞和祖细胞(hspc)中的hba1或hba2基因座中的方法和组合物。
49.本方法可用于引入转基因,如具有任选元件(诸如启动子或其他调控元件(如增强子、阻遏物结构域)、内含子、wpre、poly a区、utr(如3’utr))的编码序列,特别是将转基因引入至hspc的hba1或hba2基因座中。特别地,本公开内容提供了特异性识别hba1但不识别hba2或识别hba2但不识别hba1的引导rna序列,从而能够通过rna指导的核酸酶诸如cas9选择性切割hba1或hba2。通过在包含转基因的供体模板的存在下切割hba1或hba2但不同时切割hba1和hba2,转基因可以通过同源定向重组(hdr)在切割位点处整合至基因组中,如替换内源性hba1或hba2基因。
50.在特别的实施方案中,本方法可用于将hbb转基因递送至hba1中,这可用作用于β-地中海贫血患者的通用治疗策略,而不管hbb中的哪些突变导致该疾病。特别地,在该基因座处的整合能够产生高水平的功能性转基因,能够形成成人血红蛋白四聚体。也可以在该基因座处使用位点特异性整合来进行rbc介导的其他治疗相关转基因的递送。2.总则
51.实施本公开内容利用分子生物学领域中的常规技术。在本公开内容中公开一般使用方法的基本教科书包括sambrook和russell,molecular cloning,a laboratory manual(第3版,2001);kriegler,gene transfer and expression:a laboratory manual(1990);和current protocols in molecular biology(ausubel等人编辑,1994))。
52.对于核酸,大小以千碱基(kb)、碱基对(bp)或核苷酸(nt)给出。单链dna和/或rna的大小可以以核苷酸给出。这些是来源于琼脂糖或丙烯酰胺凝胶电泳、来自测序的核酸或来自已公布的dna序列的估值。对于蛋白质,大小以千道尔顿(kda)或氨基酸残基数给出。蛋白质大小根据凝胶电泳、测序蛋白质、衍生的氨基酸序列或已公布的蛋白质序列来估计。
53.可以化学合成不可商购获得的寡核苷酸,如根据首次由beaucage和caruthers,tetrahedron lett.22:1859-1862(1981)描述的固相亚磷酰胺三酯法使用自动合成仪,如van devanter等人,nucleic acids res.12:6159-6168(1984)所述。使用任何本领域公认的策略,例如,如pearson和reanier,j.chrom.255:137-149(1983)中所述的天然丙烯酰胺凝胶电泳或阴离子交换高效液相色谱(hplc),进行寡核苷酸的纯化。3.定义
54.如本文所用,以下术语具有赋予它们的含义,除非另有说明。
55.如本文所用的术语“一个/一种(a)”、“一个/一种(a)”或“该”不仅包括具有一个成
员的方面,而且还包括具有多于一个成员的方面。例如,单数形式“一个/一种(a)”、“一个/一种(a)”或“该”包括复数指示物,除非上下文另有明确规定。因此,例如,对“一个/种细胞”的提及包括多个/种此类细胞等等。
56.如本文所用的术语“约”和“大约”一般应意指给定测量的性质或精度所测量的量的可接受的误差程度。通常,示例性误差程度在给定值或值范围的20百分比(%)以内,优选在10%以内,并且更优选在5%以内。对“约x”的任何提及具体表示至少值x、0.8x、0.81x、0.82x、0.83x、0.84x、0.85x、0.86x、0.87x、0.88x、0.89x、0.9x、0.91x、0.92x、0.93x、0.94x、0.95x、0.96x、0.97x、0.98x、0.99x、1.01x、1.02x、1.03x、1.04x、1.05x、1.06x、1.07x、1.08x、1.09x、1.1x、1.11x、1.12x、1.13x、1.14x、1.15x、1.16x、1.17x、1.18x、1.19x和1.2x。因此,“约x”旨在教导和提供如“0.98x”的权利要求限制的书面描述支持。
57.术语“核酸”或“多核苷酸”是指单链或双链形式的脱氧核糖核酸(dna)或核糖核酸(rna)及其聚合物。除非特别限定,否则该术语涵盖含有天然核苷酸的已知类似物的核酸,其具有与参考核酸相似的结合特性并且以与天然存在的核苷酸相似的方式代谢。除非另有说明,否则特定核酸序列还隐含地涵盖其保守修饰的变体(如简并密码子取代)、等位基因、直系同源物、snp和互补序列以及明确指出的序列。具体而言,简并密码子取代可通过产生其中一个或多个选定(或所有)密码子的第三个位置被混合碱基和/或脱氧肌苷残基取代的序列来实现(batzer等人,nucleic acid res.19:5081(1991);ohtsuka等人,biol.chem.260:2605-2608(1985);和rossolini等人,mol.cell.probes 8:91-98(1994))。
58.术语“基因”意指参与产生多肽链的dna区段。它可以包括编码区之前和之后的区域(前导和尾随)以及各个编码区段(外显子)之间的插入序列(内含子)。
[0059]“启动子”被定义为指导核酸转录的一系列核酸控制序列。如本文所用,启动子包括转录起始位点附近的必需核酸序列,诸如在聚合酶ii型启动子的情况下,tata元件。启动子还任选地包括远端增强子或阻遏物元件,它们可以位于距转录起始位点多达数千个碱基对的位置。启动子可以是异源启动子。
[0060]“表达盒”是重组或合成产生的核酸构建体,具有允许特定多核苷酸序列在宿主细胞中转录的一系列指定核酸元件。表达盒可以是质粒、病毒基因组或核酸片段的一部分。通常,表达盒包括可操作地连接至启动子的待转录的多核苷酸。启动子可以是异源启动子。在与多核苷酸可操作地连接的启动子的背景中,“异源启动子”是指不会如此可操作地连接到与在天然产物中(如,在野生型有机体中)中存在的相同多核苷酸的启动子。
[0061]
如本文所用,如果与有机体或第二多核苷酸或多肽相比,第一多核苷酸或多肽源自外来物种,或者如果来自相同物种,从其原始形式进行了修饰,则第一多核苷酸或多肽对于所述有机体或第二多核苷酸或多肽序列是“异源的”。例如,当启动子被称为与异源编码序列可操作地连接时,这意味着编码序列来源于一个物种,而启动子序列来源于另一个不同的物种;或者,如果两者都来源于同一物种,则编码序列不与启动子天然缔合(如,是基因工程化的编码序列)。
[0062]“多肽”、“肽”和“蛋白质”在本文中可互换使用以指代氨基酸残基的聚合物。所有三个术语都适用于其中一个或多个氨基酸残基是相应天然存在的氨基酸的人工化学模拟物的氨基酸聚合物,以及天然存在的氨基酸聚合物和非天然存在的氨基酸聚合物。如本文所用,该术语涵盖任何长度的氨基酸链,包括全长蛋白质,其中氨基酸残基通过共价肽键连
接。
[0063]
术语“表达”和“表达的”是指转录和/或翻译产物,如hbb cdna、转基因或编码的蛋白质的产生。在一些实施方案中,该术语是指由基因或其部分编码的转录和/或翻译产物的产生。细胞中dna分子的表达水平可以基于细胞内存在的相应mrna的量或由细胞产生的该dna编码的蛋白质的量来评估。
[0064]“保守修饰的变体”适用于氨基酸和核酸序列两者。对于特定的核酸序列,“保守修饰的变体”是指那些编码相同或基本相同的氨基酸序列的核酸,或在核酸不编码氨基酸序列的情况下,是指基本相同的序列。由于遗传密码的简并性,大量功能相同的核酸编码任何给定的蛋白质。例如,密码子gca、gcc、gcg和gcu都编码氨基酸丙氨酸。因此,在由密码子指定丙氨酸的每个位置,可以将密码子改变为所描述的任何相应密码子而不改变编码的多肽。这种核酸变异是“沉默变异”,其是一种保守修饰的变异。本文中编码多肽的每条核酸序列也描述了该核酸的每个可能的沉默变异。本领域技术人员将认识到,核酸中的每个密码子(除了通常是甲硫氨酸的唯一密码子的aug和通常是色氨酸的唯一密码子的tgg之外)可以被修饰以产生功能相同的分子。因此,编码多肽的核酸的每个沉默变异隐含在每条描述的序列中。
[0065]
至于氨基酸序列,本领域技术人员将认识到,对核酸、肽、多肽或蛋白序列的单独取代、缺失或添加(其改变、添加或缺失编码序列中的单个氨基酸或小百分比的氨基酸)是“保守修饰的变体”,其中改变导致氨基酸被化学上相似的氨基酸取代。提供功能相似氨基酸的保守置换表是本领域熟知的。此类保守修饰的变体是对多态性变体、种间同源物和等位基因的补充,但不排除这些。在一些情况下,蛋白质的保守修饰变体可以具有如本文所述的增加的稳定性、组装或活性。
[0066]
以下八组各自包含相互为保守取代的氨基酸:1)丙氨酸(a),甘氨酸(g);2)天冬氨酸(d),谷氨酸(e);3)天冬酰胺(n),谷氨酰胺(q);4)精氨酸(r),赖氨酸(k);5)异亮氨酸(i),亮氨酸(l),蛋氨酸(m),缬氨酸(v);6)苯丙氨酸(f),酪氨酸(y),色氨酸(w);7)丝氨酸(s),苏氨酸(t);和8)半胱氨酸(c),蛋氨酸(m)(参见,如creighton,proteins,w.h.freeman and co.,n.y.(1984))。
[0067]
氨基酸在本文中可以通过它们通常已知的三字母符号或通过iupac-iub生化命名委员会(iupac-iub biochemical nomenclature commission)推荐的单字母符号来指代。同样,核苷酸可以通过其普遍接受的单字母代码来指代。
[0068]
在本技术中,氨基酸残基根据它们在未修饰的野生型多肽序列中从最左边的残基(编号为1)的相对位置进行编号。
[0069]
如本文所用,在描述两条或更多条多核苷酸或氨基酸序列的上下文中,术语“相同的”或“同一性”百分比是指相同的两条或更多条序列或指定的子序列。当在比较窗口或指定区域上进行比较和比对以实现最大一致性时,如使用序列比较算法或通过手动比对和目
视检查(其中不指定特定区域)所测量的,“基本上相同”的两条序列具有至少60%的同一性,优选65%、70%、75%、80%、85%、90%、91%、92%、93、94%、95%、96%、97%、98%、99%或100%同一性。关于多核苷酸序列,该定义还指测试序列的互补物。关于氨基酸序列,在一些情况下,同一性存在于长度为至少约50个氨基酸或核苷酸的区域中,或更优选地存在于长度为75-100个氨基酸或核苷酸的区域中。
[0070]
对于序列比较,通常一条序列充当参考序列,测试序列与之进行比较。当使用序列比较算法时,将测试和参考序列输入计算机,如果需要,指定子序列坐标,并指定序列算法程序参数。可以使用默认程序参数,或可以指定替代参数。然后序列比较算法基于程序参数计算测试序列相对于参考序列的序列同一性百分比。对于核酸和蛋白质的序列比较,使用blast 2.0算法和下面讨论的默认参数。
[0071]
如本文所用,“比较窗口”包括提及选自20至600,通常约50至约200,更通常约100至约150的连续位置数中任一个的区段,其中在最佳比对两条序列后,可以将一条序列与相同数量的连续位置的参考序列进行比较。
[0072]
用于确定序列同一性和序列相似性百分比的算法是blast 2.0算法,其描述于altschul等人(1990)j.mol.biol.215:403-410中。进行blast分析的软件可在美国国家生物技术信息中心(national center for biotechnology information)网站ncbi.nlm.nih.gov上公开获得。该算法包括首先通过鉴定问询序列中长度w的短字符来鉴定高评分序列对(hsp),当与数据库序列中相同长度的字符比对时,所述问询序列中长度w的短字符匹配或满足某个正值阈值得分t。t被称为邻近字符得分阈值(altschul等人,同上)。这些初始邻近字符命中充当启动搜索以查找包含它们的更长hsp的种子。然后沿着每条序列在两个方向上延伸字符命中,直到可以增加累积比对得分。对于核苷酸序列,使用参数m(一对匹配残基的奖励得分;总是大于0)和n(错配残基的惩罚得分;总是小于0)计算累积得分。对于氨基酸序列,评分矩阵用于计算累积得分。当出现以下情形时,字符命中在每个方向上的延伸停止:累积比对得分从其最大实现值掉落x的量;由于一个或多个负评分残基比对的累积,累积得分变为零或更低;或到达任一序列的末端。blast算法参数w、t和x确定比对的灵敏度和速度。blastn程序(对于核苷酸序列)默认使用字长(w)为28、期望值(e)为10、m=1、n=-2,以及两条链的比较。对于氨基酸序列,blastp程序使用字长(w)为3、期望值(e)为10和blosum62评分矩阵作为默认值(参见henikoff&henikoff,proc.natl.acad.sci.usa 89:10915(1989))。
[0073]
blast算法还对两条序列之间的相似性进行统计分析(参见,如karlin&altschul,proc.nat’l.acad.sci.usa 90:5873-5787(1993))。由blast算法提供的一种相似性度量是最小和概率(p(n)),它提供了两条核苷酸或氨基酸序列之间偶然发生匹配的概率的指示。例如,如果测试核酸与参考核酸比较中的最小总概率小于约0.2,更优选小于约0.01并且最优选小于约0.001,则认为核酸与参考序列相似。
[0074]“crispr-cas”系统是指用于防御外来核酸的一类细菌系统。crispr-cas系统存在于各种细菌和古细菌有机体中。crispr-cas系统分为含i、ii、iii、iv、v和vi六种类型以及许多亚型的两类,其中1类包括i型和iii型crispr系统,并且2类包括ii型、ⅳ型、
ⅴ
型和ⅵ型;例如,1类亚型包括i-a至i-f亚型。参见,如fonfara等人,nature 532,7600(2016);zetsche等人,cell 163,759-771(2015);adli等人,(2018)。内源性crispr-cas系统包括
crispr基因座,其含有由对应于来自病毒和其他移动遗传元件的序列的非重复间隔序列分隔的重复簇;和cas蛋白,其执行多种功能,包括间隔子获取、来自crispr基因座的rna加工、靶标鉴定和切割。在1类系统中,这些活性受多种cas蛋白的影响,其中cas3提供核酸内切酶活性,而在2类系统中,它们都由单个cas即cas9进行。
[0075]“同源修复模板”是指可用于修复dna中的双链断裂(dsb),如使用本文所述的方法和组合物诱导的hba1或hba2基因座处的crispr/cas9介导的断裂的多核苷酸序列。同源修复模板包含与围绕dsb的基因组序列的同源性,即包含hba1或hba2同源臂。在一些实施方案中,模板上存在两个不同的同源区域,其中每个区域包含至少50、100、200、300、400、500、600、700、800、900或更多个核苷酸或与相应基因组序列更大同源性。在特定的实施方案中,模板包含两个同源臂,其包含从sgrna靶位点的任一位点延伸的约500个同源核苷酸。修复模板可以以任何形式存在,如,在引入细胞的质粒上,作为自由浮动的双链dna模板(如,从细胞中的质粒释放的模板),或作为单链dna。在特定的实施方案中,模板存在于病毒载体中,如腺相关病毒载体诸如aav6。本公开内容的模板还可以包含转基因,如hbb转基因。
[0076]
hba1和hba2(分别是血红蛋白亚基α1和2)密切相关,但不是编码作为血红蛋白组分的α-珠蛋白的相同基因。hba1和hba2位于人类染色体16上的α-珠蛋白基因座内。它们的编码序列是相同的,但基因不同,如在5’utr、内含子和特别是3’utr中。hba1的ncbi基因id是3039,并且hba2的ncbi基因id是3040,其全部公开内容通过引用并入本文。
[0077]
hbb(血红蛋白亚基β)是编码血红蛋白β亚基的基因,其在正常成人中包含两条α链和两条β链。hbb中的突变,如导致hbb表达或功能减少或不存在,可导致β-地中海贫血。人hbb的ncbi基因id no.是3043,并且uniprot id是p68871,其全部公开内容通过引用并入本文。
[0078]
如本文所用,“同源重组”或“hr”是指在经由同源定向修复机制修复dna中的双链断裂期间插入核苷酸序列。该过程使用与断裂区域中的核苷酸序列具有同源性的“供体模板”或“同源修复模板”作为修复双链断裂的模板。双链断裂的存在促进了供体序列的整合。供体序列可以物理整合或用作模板,用于经由同源重组修复断裂,导致引入全部或部分核苷酸序列。许多不同的基因编辑平台使用这个过程来产生双链断裂,诸如大范围核酸酶,诸如锌指核酸酶(zfn)、转录激活因子样效应物核酸酶(talen)和crispr-cas9基因编辑系统。在特定的实施方案中,hr涉及由crispr-cas9诱导的双链断裂。4.特异性靶向hba1或hba2基因座的crispr/cas系统
[0079]
本公开内容部分基于对crispr指导序列的鉴定,所述crispr指导序列特异性指导hba1或hba2被rna引导的核酸酶切割但不导致两种基因的切割。本公开内容提供了crispr/aav6介导的基因组编辑方法,其可以在两个基因座处实现高靶向整合率。整合的转基因表现出功能性转基因的rbc特异性表达,并且在该基因座处编辑的细胞能够长期植入和造血重建。
[0080]
由于hba1和hba2的冗余,在该基因座处的整合允许递送用于rbc特异性表达的转基因,而不会有导致有害细胞效应的双等位基因整合风险。此外,在β-地中海贫血的治疗中,由于病理是由缺乏hbb以及未配对的α-珠蛋白聚集引起的,将hbb敲入hba1解决了单个基因组编辑事件中的两个问题,从而允许同时提高hbb水平和降低α-珠蛋白水平。也有人尝试在α-珠蛋白基因座处引入b-样珠蛋白转基因,但这些方法在编辑后会产生大量潜在的遗
传事件,包括产生大的缺失、倒位或其他有害的重排。sgrna
[0081]
本公开内容的单引导rna(sgrna)靶向hba1或hba2基因座。sgrna与定点核酸酶诸如cas9相互作用并特异性结合细胞基因组内的靶核酸或与其杂交,使得sgrna和定点核酸酶共定位于细胞基因组中的靶核酸。如本文所用的sgrna包含与hba1或hba2基因座处的靶dna序列具有同源性(或互补性)的靶向序列,以及介导与cas9或另一种rna引导的核酸酶结合的恒定区。sgrna可以靶向与pam序列相邻的hba1或hba2内的任何序列。在特定的实施方案中,sgrna靶向hba1或hba2基因内而非两个基因内的序列,即sgrna靶向hba1或hba2内的序列,其在两个基因之间是不同的并且与pam序列相邻。在特定的实施方案中,sgrna靶向hba1但不靶向hba2(如,其特异性结合hba1和/或导致hba1的切割但不切割hba2,和/或其靶序列与hba1内的序列100%相同但与hba2内的序列并不100%相同)。在一些此类实施方案中,sgrna靶向seq id no:5的序列。在特定的实施方案中,sgrna靶向hba2但不靶向hba1(如,其特异性结合hba2和/或导致hba2的切割但不切割hba1,和/或其靶序列与hba2内的序列100%相同但与hba1内的序列并不100%相同)。在一些此类实施方案中,sgrna靶向seq id no:2的序列。在特定的实施方案中,使用单引导rna或sgrna。在一些实施方案中,靶序列在hba1或hba2的内含子2或3’utr内。在特定的实施方案中,靶序列在hba1或hba2的3’utr内。在特定的实施方案中,靶序列在hba1和hba2之间相差3个、4个、5个或更多个核苷酸。在一些实施方案中,靶序列包含如seq id no:1-5所示的序列之一,或包含与seq id no:1-5之一的1个、2个、3个或更多个错配的序列。在特定的实施方案中,靶序列包含sg2(seq id no:2)或sg5(seq id no:5)的靶序列。在一些实施方案中,sgrna靶向hba1或hba2基因内(即,编码序列、5’utr、内含子或3’utr内)的序列,但不靶向hba1和hba2基因之间的基因间区中的序列。在一些实施方案中,sgrna仅靶向基因组内的单个位点。
[0082]
在一些实施方案中,sgrna包含一个或多个修饰的核苷酸。例如,sgrna的多核苷酸序列还可以包含rna类似物、衍生物或其组合。例如,可以在碱基部分、糖部分或磷酸主链(如硫代磷酸酯)处修饰探针。在一些实施方案中,sgrna在一个或多个核苷酸处包含3’硫代磷酸酯核苷酸间键、2
’‑
o-甲基-3
’‑
磷酸乙酸酯修饰、2
’‑
氟-嘧啶、s-约束的乙基糖修饰或其他。在特定的实施方案中,sgrna在一个或多个核苷酸处包含2
’‑
o-甲基-3
’‑
硫代磷酸(ms)修饰(参见,如hendel等人(2015)nat.biotech.33(9):985-989,其全部公开内容通过引用并入本文)。在特定的实施方案中,2
’‑
o-甲基-3
’‑
硫代磷酸(ms)修饰在sgrna的5’和3’端的三个末端核苷酸处。
[0083]
可以通过多种方式中的任一种来获得sgrna。对于sgrna,可以在实验室中使用例如由applied biosystems、biolytic lab performance、sierra biosystems或其他公司出售的寡核苷酸合成仪合成引物。可替代地,具有任何所需序列和/或修饰的引物和探针可以很容易地从大量供应商,如thermofisher、biolytic、idt、sigma-aldritch、genescript等中的任一个订购。rna引导的核酸酶
[0084]
任何crispr-cas核酸酶,即能够与引导rna相互作用并在如由引导rna限定的靶位点处切割dna的crispr-cas核酸酶,可用于所述方法中。在一些实施方案中,核酸酶是cas9或cpf1。在特定的实施方案中,核酸酶是cas9。用于本方法中的cas9或其他核酸酶可以来自
任何来源,只要它能够结合如本文所述的sgrna,被引导至由sgrna的靶向序列靶向的特定hba1或hba2序列并对其进行切割。在特定的实施方案中,cas9来自酿脓链球菌(streptococcus pyogenes)。
[0085]
本文中还公开了靶向并切割hba1或hba2基因座处的dna的crispr/cas或crispr/cpf1系统。示例性crispr/cas系统包括(a)cas(如cas9)或cpf1多肽或编码所述多肽的核酸,和(b)与hba1或hba2特异性杂交的sgrna,或编码所述引导rna的核酸。在一些情况下,本文所述的核酸酶系统还包括如本文所述的供体模板。在特定的实施方案中,crispr/cas系统包括rnp,所述rnp包含靶向hba1或hba2的sgrna和cas蛋白(诸如cas9)。
[0086]
除了crispr/cas9平台(其是ii型crispr/cas系统)之外,还存在替代系统,包括i型crispr/cas系统、iii型crispr/cas系统和v型crispr/cas系统。已经公开了各种crispr/cas9系统,包括酿脓链球菌cas9(spcas9)、嗜热链球菌(streptococcus thermophilus)cas9(stcas9)、空肠弯曲杆菌(campylobacter jejuni)cas9(cjcas9)和灰色奈瑟球菌(neisseria cinerea)cas9(nccas9)等等。cas系统的替代物包括新凶手弗朗西丝氏菌(francisella novicida)cpf1(fncpf1)、氨基酸球菌(acidaminococcus sp.)cpf1(ascpf1)和毛螺菌科(lachnospiraceae)细菌nd2006 cpf1(lbcpf1)系统。任何上述crispr系统可用于在hba1或hba2基因座处诱导单链或双链断裂以实施本文公开的方法。将sgrna和cas蛋白引入细胞中
[0087]
可以使用任何适合的方法将引导rna和核酸酶引入细胞中,如通过将编码引导rna和核酸酶的一种或多种多核苷酸引入细胞中,如使用诸如病毒载体的载体或作为裸dna或rna递送,以使引导rna和核酸酶在细胞中表达。在特定的实施方案中,引导rna和核酸酶在递送至细胞之前组装成核糖核蛋白(rnp),并且通过如电穿孔将rnp引入细胞中。
[0088]
考虑了离体、体外或体内修饰的动物细胞、哺乳动物细胞,优选人细胞。还包括其他灵长类动物的细胞;哺乳动物,包括商业相关的哺乳动物,诸如牛、猪、马、绵羊、猫、狗、小鼠、大鼠的细胞;鸟类,包括商业相关的鸟类,诸如家禽、鸡、鸭、鹅和/或火鸡的细胞。
[0089]
在一些实施方案中,细胞是胚胎干细胞、干细胞、祖细胞、多能干细胞、诱导多能干(ips)细胞、体干细胞、分化细胞、间充质干细胞或间充质基质细胞、神经干细胞、造血干细胞或造血祖细胞、脂肪干细胞、角质细胞、骨骼干细胞、肌肉干细胞、成纤维细胞、nk细胞、b细胞、t细胞或外周血单核细胞(pbmc)。在特定的实施方案中,细胞是cd34
+
造血干细胞和祖细胞(hspc),如脐血来源(cb)的hspc、成人外周血来源(pb)的hspc或骨髓来源的hspc。
[0090]
hspc可以从对象中分离出来,如,通过收集动员的外周血,然后使用cd34标志物富集hspc。在一些实施方案中,细胞来自患有β-地中海贫血的对象。在此类实施方案中,整合至hspc的基因组中的转基因是hbb,如在hba1基因座处。在一个实施方案中,提供了治疗患有β-地中海贫血的对象的方法,其包括对从对象分离的多个hspc进行遗传修饰以便将hbb基因整合至hba1基因座处,以及将hspc重新引入对象。在一些此类实施方案中,hspc在体内分化为红血细胞(rbc),并且如与来自尚未进行本发明方法的对象中的rbc水平相比,rbc表达较高水平的β-珠蛋白和较低水平的α-珠蛋白。
[0091]
为避免向对象施用时修饰的细胞发生免疫排斥,待修饰细胞优选来源于对象自身的细胞。因此,优选哺乳动物细胞是来自待用修饰的细胞治疗的对象的自体细胞。
[0092]
在一些实施方案中,从对象收获细胞并根据本文公开的方法对所述细胞进行修
饰,其可以包括选择某些细胞类型、任选地扩增细胞和任选地培养细胞,并且还可以包括选择含有整合至hba1或hba2基因座中的转基因的细胞。在特定的实施方案中,然后将此类修饰的细胞重新引入对象。
[0093]
本文还公开了使用所述核酸酶系统产生本文所述的修饰的宿主细胞的方法,其包括将(a)靶向并切割hba1或hba2基因座处的dna的本公开内容的rnp,和(b)如本文所述的同源供体模板或载体引入细胞。每种组分可以直接引入细胞中,或者可以通过引入编码所述一种或多种核酸酶系统的组分的核酸而在细胞中表达。
[0094]
此类方法将靶向功能性转基因,如hbb转基因,在宿主细胞中的内源性hba1或hba2处的离体整合。此类方法还可以包括(a)将供体模板或载体引入细胞中,任选地在扩增所述细胞之后,或任选地在扩增所述细胞之前,和(b)任选地培养细胞。
[0095]
在一些实施方案中,本文的公开内容考虑了产生修饰的哺乳动物宿主细胞的方法,所述方法包括向哺乳动物细胞中引入:(a)rnp,其包含cas核酸酶(诸如cas9)和对hba1或hba2基因座有特异性的sgrna,和(b)如本文所述的同源供体模板或载体。
[0096]
在这些方法的任一种中,核酸酶可以在hba1或hba2基因座内产生一个或多个单链断裂,或者在hba1或hba2基因座内产生双链断裂。在这些方法中,hba1或hba2基因座通过与所述供体模板或载体的同源重组而被修饰,以导致转基因插入基因座中。所述方法还可以包括(c)选择含有整合至hba1或hba2基因座中的转基因的细胞。
[0097]
在一些实施方案中,将i53(canny等人(2018)nat biotechnol 36:95)引入细胞中,以便促进通过同源定向修复(hdr)进行的供体模板整合对比通过非同源末端连接(nhej)进行的整合。例如,可将编码i53的mrna例如通过电穿孔与sgrna-cas9 rnp同时引入细胞。i53的序列可特别见于www.addgene.org/92170/sequences/。
[0098]
用于插入能够表达功能性蛋白质(包括酶、细胞因子、抗体和细胞表面受体)的转基因(包括大转基因)的技术是本领域已知的(参见如bak和porteus,cell rep.2017年7月18日;20(3):750
–
756(egfr的整合);kanojia等人,stem cells.2015年10月;33(10):2985-94(抗her2抗体的表达);eyquem等人,nature.2017年3月2日;543(7643):113-117(car的位点特异性整合);o’connell等人,2010plos one 5(8):e12009(人il-7的表达);tuszynski等人,nat med.2005年5月;11(5):551-5(ngf于成纤维细胞中的表达);sessa等人,lancet.2016年7月30日;388(10043):476-87(在离体基因疗法中表达芳基硫酸酯酶a以治疗mld);rocca等人,science translational medicine,2017年10月25日:第9卷,第413期,eaaj2347(共济蛋白的表达);bak和porteus,cell reports,第20卷,第3期,2017年7月18日,第750-756页(将大转基因盒整合至单基因座中),dever等人,nature,2016年11月17日:539,384-389(将tngfr添加至造血干细胞(hsc)和hspc中以选择和富集修饰的细胞);其中的每一个都通过引用以其整体并入本文。具有降低的脱靶效应、倒位和/或易位的转基因整合
[0099]
在一方面,本文提供了用于减少供体模板的随机整合以将外源核酸引入靶基因组中的方法。当通过内源性或外源性dna切割机制(如核酸酶)产生双链断裂时,可能会发生供体模板的脱靶或随机整合,其中切割不在预期的基因组序列处。脱靶或随机整合可能导致靶基因组中基因表达的意外增加或减少,并可能产生有害影响。在一些实施方案中,本文所用的引导rna特异性结合靶基因组中的一条靶序列,从而减少靶基因组的脱靶结合和切割。
在一些实施方案中,可编程核酸酶,如由引导rna指导的cas核酸酶,或本文提供的锌指蛋白或talen蛋白,特异性结合靶基因组中的单个特定靶序列并导致其切割。在一些实施方案中,靶基因可以属于包含共有高度序列相似性的多个基因的基因家族或基因座。例如,本文所用的引导rna可靶向hba1或hba2基因。在一些实施方案中,本文所用的引导rna与hba1基因或hba2基因中的靶序列特异性杂交,但不同时特异性杂交两者。在一些实施方案中,引导rna与hba1基因的3’utr序列特异性杂交。在一些实施方案中,引导rna与hba2基因的3’utr序列特异性杂交。在一些实施方案中,引导rna与hba1基因的5’utr序列特异性杂交。在一些实施方案中,引导rna与hba2基因的5’utr序列特异性杂交。在一些实施方案中,与hba1或hba2基因中的靶序列特异性杂交的引导rna导致与同hba1和hba2基因两者中的靶序列杂交的引导rna相比宿主基因组中的脱靶切割减少。在一些实施方案中,与hba1或hba2基因中的靶序列特异性杂交的引导rna导致与同hba1和hba2基因两者中的靶序列杂交的引导rna相比宿主基因组中的dna供体模板的脱靶整合减少。在一些实施方案中,与hba1或hba2基因中的靶序列特异性杂交的引导rna不导致宿主基因组中的dna供体模板的脱靶整合。在一些实施方案中,与hba1或hba2基因中的靶序列特异性杂交的引导rna导致与同hba1和hba2基因两者中的靶序列杂交的引导rna相比,宿主基因组中的dna供体模板的脱靶整合减少至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、20%、25%、30%、35%、40%、50%、75%、90%、95或99%。
[0100]
染色体易位连接源自两个异源区域或染色体的基因组中的nda区段。易位事件可能因双链断裂(dsb)的不当修复而发生,包括由诸如cas9核酸酶的核酸酶产生的dsb。在一方面,本文提供了用于将一个或多个转基因整合至具有减少的易位事件的靶基因组中的方法和组合物。例如,本文提供的引导rna可以指导可编程核酸酶,如cas9,以在靶基因组的一个特定基因座处产生双链断裂。不希望受任何理论束缚,特异性靶向单条靶序列或单个靶基因座的引导rna或可编程核酸酶允许在靶序列处特异性切割。在一些实施方案中,靶基因属于包含共有高度序列相似性的多个基因的基因家族或基因座。例如,本文所用的引导rna可靶向hba1或hba2基因。在一些实施方案中,本文所用的引导rna与hba1基因或hba2基因中的靶序列特异性杂交,但不同时与两者特异性杂交。在一些实施方案中,引导rna与hba1基因的3’utr序列特异性杂交。在一些实施方案中,引导rna与hba2基因的3’utr序列特异性杂交。在一些实施方案中,引导rna与hba1基因的5’utr序列特异性杂交。在一些实施方案中,引导rna与hba2基因的5’utr序列特异性杂交。在一些实施方案中,与hba1或hba2基因中的靶序列特异性杂交的引导rna导致在靶基因组中的单个切割事件。在一些实施方案中,引导rna指导可编程核酸酶在hba1基因序列中并且不在hba2基因序列中产生切割。在一些实施方案中,引导rna指导可编程核酸酶在hba2基因序列中并且不在hba1基因序列中产生切割。在一些实施方案中,与hba1或hba2基因中的靶序列特异性杂交的引导rna导致与同hba1和hba2基因两者中的靶序列杂交的引导rna相比易位或倒位事件减少。在一些实施方案中,将与hba1并且不在hba2基因中的靶序列特异性杂交的引导rna、供体模板和rna引导的可编程核酸酶引入细胞群体中。在一些实施方案中,在引入后,细胞群体仅包含在hba1或hba2基因序列处的三个整合结果:1)无整合,2)在hba1序列中并且不在hba2序列中产生的插入缺失,和3)替换hba1序列的供体模板的整合。在一些实施方案中,在引入后,细胞群体不包含在hba1或hba2基因序列处的以下整合结果中的任一种:1)hba2序列中的插入缺失,2)hba1和
hba2序列中的插入缺失,3)hba1和hba2序列的缺失,4)替换hba2序列的供体模板的整合,5)hba2序列的缺失,6)hba1序列中的整合和hba2序列中的插入缺失,7)hba2序列中的整合和hba1序列中的插入缺失,8)含hba1和hba2基因序列的靶基因组区的倒位,或9)染色体易位。
[0101]
在一些实施方案中,将与hba2基因并且不是hba1基因中的靶序列特异性杂交的引导rna、供体模板和rna引导的可编程核酸酶引入细胞群体。在一些实施方案中,在引入后,细胞群体仅包含在hba1或hba2基因序列处的三个整合结果:1)无整合,2)在hba2序列中并且不在hba1序列中产生的插入缺失,和3)替换hba2序列的供体模板的整合。在一些实施方案中,在引入后,细胞群体不包含在hba1或hba2基因序列处的以下整合结果中的任一种:1)hba1序列中的插入缺失,2)hba1和hba2序列中的插入缺失,3)hba1和hba2序列中的缺失,4)替换hba1序列的供体模板的整合,5)hba1序列的缺失,6)hba1序列中的整合和hba2序列中的插入缺失,7)hba2序列中的整合和hba1序列中的插入缺失,8)含hba1和hba2基因序列的靶基因组区的倒位,或9)染色体易位。在一些实施方案中,特异性靶向靶基因组中的一条靶序列的可编程核酸酶(如由与靶基因组中的hba1序列或hba2序列特异性杂交但不同时与两者杂交的grna指导的cas9)导致与由与hba1序列和hba2序列杂交的grna指导的cas9相比易位事件减少。在一些实施方案中,易位事件的频率降低至少1.1倍、1.2倍、1.3倍、1.4倍、1.5倍、1.6倍、1.7倍、1.8倍、1.9倍、2倍、2.5倍、3倍、3.5倍、4倍、4.5倍、5倍、6倍、7倍、8倍、9倍、10倍或大于10倍。在一些实施方案中,将特异性靶向靶基因组中的一条序列的可编程核酸酶(如由与hba1序列或hba2序列特异性杂交但不同时与两者特异性杂交的grna指导的cas9)和供体模板引入细胞群体,如hspc细胞。在一些实施方案中,引入导致在小于10%的细胞群体中的易位事件。在一些实施方案中,引入导致在小于50%的细胞群体中的易位事件。在一些实施方案中,引入导致在小于5%的细胞群体中的易位事件。在一些实施方案中,引入导致在小于5%、小于10%、小于15%、小于20%、小于25%、小于30%、小于35%、小于40%、小于45%、小于50%、小于55%或小于60%的细胞群体中的易位事件。在一些实施方案中,引入导致在小于1%的细胞群体中的易位事件。在一些实施方案中,引入导致在小于0.5%的细胞群体中的易位事件。在一些实施方案中,引入导致在小于0.1%的细胞群体中的易位事件。在一些实施方案中,与参考或对照细胞群体相比,引入导致在细胞群中体不可检测的易位事件,其中向参考细胞群体引入,如可编程核酸酶并且不引入引导rna。
[0102]
易位事件可通过用于dna定量的标准taqman测定法检测,其中pcr与在与dna退火并随后被dna聚合酶降解后释放荧光团的探针结合进行。在完整的探针中,荧光团信号经由与共价附接的猝灭剂相互作用而被抑制。探针经设计用于在被pcr引物扩增的区域内退火。因此,检测到的荧光信号与样品中存在的扩增子的量成比例。如burman等人,genome biology 16,146(2015)中所述的用于检测易位的方法通过引用以其整体并入本文。
[0103]
在另一方面,本公开内容提供了使用本文公开的任何方法制备的在两种或更多种靶核酸处具有改变的细胞群体,其中细胞群体具有小于5%的易位频率。在一个实施方案中,易位频率小于4%。在一个实施方案中,易位频率小于3%。在一个实施方案中,易位频率小于2%。在一个实施方案中,易位频率小于1%。在一个实施方案中,易位频率小于0.5%。在一个实施方案中,易位频率小于0.25%。在一个实施方案中,易位频率小于0.1%。在一个实施方案中,细胞群体包含低于参考细胞群体的易位频率的易位频率,其中向参考细胞群体引入,如可编程核酸酶并且不引入引导rna。
同源修复模板
[0104]
由多核苷酸或供体构建体包含的待整合的转基因可以是任何转基因,其基因产物在红血细胞中是合乎需要的。例如,转基因可用于替换或补偿缺陷基因,如患有β-地中海贫血的对象中的缺陷hbb基因。在其他实施方案中,转基因可以表达在对象中提供潜在治疗益处的分泌蛋白,从而可以将遗传修饰的hspc引入对象中并分化成红血细胞,然后红血细胞在体内循环并分泌编码的蛋白质。适合的转基因的示例性非限制性列表包括pdfgb(血小板源性生长因子亚基b;参见如ncbi gene id no.5155)、idua(α-l-艾杜糖醛酸酶;参见如ncbi gene id no.3425)、pah(苯丙氨酸羟化酶;参见如ncbi gene id no.5053)、因子ix(或fix;参见如ncbi gene id no.2158),包括极度活跃的因子ix padua或padua变体(参见如simioni等人,(2009)nejm 361:1671-1675;cantore等人,(2012)blood 120:4517-4520;monahan等人,(2015)hum.gene.ther.26:69-81)、ldlr(低密度脂蛋白受体;参见如ncbi gene id no.3949)等等。
[0105]
转基因包含基因的功能编码序列,所述基因如对象中有缺陷的基因,具有任选元件,诸如启动子或其他调控元件(如增强子、阻遏物结构域)、内含子、wpre、poly a区、utr(如3’utr)。
[0106]
在一些实施方案中,同源修复模板中的转基因包含或来源于相应基因的cdna。在一些实施方案中,同源修复模板中的转基因包含来自相应基因的编码序列和一个或多个内含子。在一些实施方案中,同源修复模板中的转基因是密码子优化的,如包含与相应的野生型编码序列或cdna或其片段至少70%、75%、80%、85%、90%、95%或更高的同源性。
[0107]
在特定的实施方案中,模板还包含在cdna的3’末端处的polya序列或信号,如牛生长激素polya序列或兔β-珠蛋白polya序列。在特定的实施方案中,土拨鼠肝炎病毒转录后调控元件(wpre)包含在模板的3’utr(如在编码序列的3’端和polya序列的5’端之间)中,以增加转基因的表达。可使用任何适合的wpre序列;参见,如zufferey等人(1999)j.virol.73(4):2886-2892;donello等人(1998).j virol72:5085-5092;loeb等人(1999).hum gene ther 10:2295-2305;其全部公开内容通过引用并入本文)。
[0108]
为了促进同源重组,转基因在多核苷酸或供体构建体中侧接有与靶基因组序列同源的序列。例如,转基因可侧接有由引导rna定义的切割位点周围的序列。在特定的实施方案中,转基因侧接有与hba1或hba2基因或编码序列的3’端和5’端同源的序列,使得hba1或hba2基因在hdr介导的转基因整合后被替换。在一个此类的实施方案中,转基因在一侧侧接有与hba1或hba2基因的3’utr对应的序列,并且在另一侧侧接有与hba1或hba2的转录起始位点(如正好起始位点的5’)区域对应的序列。同源区可以是任何尺寸,如100-1000bp、300-800bp、400-600bp或约100、200、300、400、500、600、700、800、900、1000或更多bp。在一些实施方案中,转基因包含启动子,如组成型或诱导型启动子,使得启动子驱动转基因在体内表达。在特定的实施方案中,转基因替换hba1或hba2的编码序列,使得其表达由内源性hba1或hba2启动子驱动。在特定的实施方案中,供体模板包含与seq id no:6至少约70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或更高同一性的序列或其片段。在特定的实施方案中,供体模板包含如seq id no:6所示的序列或其片段。
[0109]
如本文所述,用于引入靶基因组中的靶序列的转基因可以是编码蛋白质或其部分或片段的多核苷酸、包含基因的调控序列的多核苷酸、基因的非翻译区、启动子、增强子、内
含子、外显子、表达盒、表达标签或其任何组合。在一些实施方案中,转基因(或用于插入的多核苷酸,如编码序列或其片段、调控序列、内含子、外显子、表达盒或标签,例如荧光标签)侧接有与靶基因组中的核酸序列具有序列同源性或同一性的一个或多个同源臂。例如,转基因可在转基因的5’端或3’端上侧接有第一同源臂和/或第二同源臂。在一些实施方案中,第一同源臂和/或第二同源臂包含与靶基因的3’端和/或5’端同源的序列。例如,转基因可侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的5’侧接序列同源,或其中3’同源臂与靶基因的3’侧接序列同源。在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的5’侧接序列同源,并且3’同源臂与靶基因的3’侧接序列同源。在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的5’utr序列同源,和/或其中3’同源臂与靶基因的3’utr序列同源。在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的5’utr序列的5’序列同源,和/或其中3’同源臂与靶基因的3’utr序列的3’序列同源。在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的5’utr序列的5’紧接的序列同源,和/或其中3’同源臂与靶基因的3’utr序列的3’紧接的序列同源。在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的编码区的5’末端的5’序列同源,和/或其中3’同源臂与靶基因的编码区的3’末端的3’序列同源。在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的编码区的5’末端的5’紧接序列同源,和/或其中3’同源臂与靶基因的编码区的3’末端的3’紧接序列同源。在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的开放阅读框的5’末端的5’序列同源,和/或其中3’同源臂与靶基因的开放阅读框的3’末端的3’序列同源。在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的开放阅读框的5’末端的5’紧接序列同源,和/或其中3’同源臂与靶基因的开放阅读框的3’末端的3’紧接序列同源。如本文所用,开放阅读框是指具有被转录成前体mrna和/或蛋白质能力的基因的阅读框。orf可以以起始密码子(如atg)起始并以终止密码子(如uaa)结束。在一些实施方案中,该蛋白质从orf翻译为全长和/或功能性蛋白质。
[0110]
在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的全部编码序列的5’末端的5’序列同源,和/或其中3’同源臂与靶基因的全部编码序列的3’末端的3’序列同源。在一些实施方案中,转基因侧接有5’同源臂和3’同源臂,其中5’同源臂与靶基因的全部编码序列的5’末端的5’紧接序列同源,和/或其中3’同源臂与靶基因的全部编码序列的3’末端的3’紧接序列同源。在一些实施方案中,转基因侧接有5’同源臂,其中5’同源臂与靶基因的转录起始开始位点的5’序列同源。在一些实施方案中,转基因侧接有5’同源臂,其中5’同源臂与靶基因的转录起始开始位点的5’紧接序列同源。在一些实施方案中,转基因侧接有5’同源臂,其中5’同源臂与靶基因的第一外显子的5’序列同源。在一些实施方案中,转基因侧接有5’同源臂,其中5’同源臂与靶基因的第一外显子的5’紧接序列同源。在一些实施方案中,转基因侧接有5’同源臂,其中5’同源臂与靶基因的第一内含子的5’序列同源。在一些实施方案中,转基因侧接有5’同源臂,其中5’同源臂与靶基因的第一内含子的5’紧接序列同源。在一些实施方案中,转基因侧接有5’同源臂,其中5’同源臂与靶基因的最后一个内含子的5’序列同源。在一些实施方案中,转基因侧接有5’同源臂,其中5’同源臂与靶基因的最后一个内含子的5’紧接序列同源。在一些实施方案中,转基因侧接有
700bp、700-750bp、700-800bp、700-850bp、700-900bp、700-950bp、700-1000bp、700-1100bp、700-1200bp、700-1300bp、700-1500bp、750-800bp、750-850bp、750-900bp、750-950bp、750-1000bp、750-1100bp、750-1200bp、750-1300bp、750-1500bp、800-850bp、800-900bp、800-950bp、800-1000bp、800-1100bp、800-1200bp、800-1300bp、800-1500bp、850-900bp、850-950bp、850-1000bp、850-1100bp、850-1200bp、850-1300bp、850-1500bp、900-950bp、900-1000bp、900-1100bp、900-1200bp、900-1300bp、900-1500bp、1000-1100bp、1100-1200bp、1200-1300bp、1300-1400bp或1400-1500bp。
[0115]
在一些实施方案中,3’同源臂的长度是至少100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1000bp或更多。在一些实施方案中,3’同源臂的长度是100bp、150bp、200bp、250bp、275bp、300bp、325bp、350bp、375bp、400bp、450bp或大于500bp。在一些实施方案中,3’同源臂的长度是至少400bp。在一些实施方案中,3’同源臂的长度是至少500bp、600bp、700bo、800bp、900bp或1000bp。在一些实施方案中,3’同源臂的长度是至少850bp。在一些实施方案中,3’同源臂是400
–
500bp。在一些实施方案中,3’同源臂的长度是400-500bp、400-550bp、400-600bp、400-650bp、400-700bp、400-750bp、400-800bp、400-850bp、400-900bp、400-950bp、400-1000bp、400-1100bp、400-1200bp、400-1300bp、400-1400bp、450-500bp、450-550bp、450-600bp、450-650bp、450-700bp、450-750bp、450-800bp、450-850bp、450-900bp、450-950bp、450-1000bp、450-1100bp、450-1200bp、450-1300bp、450-1450bp、500-600bp、500-650bp、500-700bp、500-750bp、500-800bp、500-850bp、500-900bp、500-950bp、500-1000bp、500-1100bp、500-1200bp、500-1300bp、500-1500bp、550-600bp、550-650bp、550-700bp、550-750bp、550-800bp、550-850bp、550-900bp、550-950bp、550-1000bp、550-1100bp、550-1200bp、550-1300bp、550-1500bp、600-650bp、600-700bp、600-750bp、600-800bp、600-850bp、600-900bp、600-950bp、600-1000bp、600-1100bp、600-1200bp、600-1300bp、600-1600bp、650-700bp、650-750bp、650-800bp、650-850bp、650-900bp、650-950bp、650-1000bp、650-1100bp、650-1200bp、650-1300bp、650-1500bp、700-700bp、700-750bp、700-800bp、700-850bp、700-900bp、700-950bp、700-1000bp、700-1100bp、700-1200bp、700-1300bp、700-1500bp、750-800bp、750-850bp、750-900bp、750-950bp、750-1000bp、750-1100bp、750-1200bp、750-1300bp、750-1500bp、800-850bp、800-900bp、800-950bp、800-1000bp、800-1100bp、800-1200bp、800-1300bp、800-1500bp、850-900bp、850-950bp、850-1000bp、850-1100bp、850-1200bp、850-1300bp、850-1500bp、900-950bp、900-1000bp、900-1100bp、900-1200bp、900-1300bp、900-1500bp、1000-1100bp、1100-1200bp、1200-1300bp、1300-1400bp或1400-1500bp。
[0116]
可以使用任何适合的方法将多核苷酸或供体构建体引入细胞中。在一些情况下,供体模板是单链、双链、质粒或dna片段。在一些情况下,质粒包含复制所必需的元件,包括启动子和任选的3’utr。载体可以是病毒载体,诸如逆转录病毒、慢病毒(能够整合的慢病毒载体和有整合缺陷的慢病毒载体)、腺病毒、腺相关病毒或单纯疱疹病毒载体。病毒载体还可以包含病毒载体复制所必需的基因。在特定的实施方案中,使用重组腺相关病毒载体(如raav6)引入多核苷酸。
[0117]
在一些实施方案中,靶向构建体包含:(1)病毒载体骨架,如aav骨架,用于生成病毒;(2)与每侧至少200bp但理想情况下至少400bp的靶位点同源的臂,以确保高水平的可重
复靶向位点(参见,porteus,annual review of pharmacology and toxicology,第56卷:163-190(2016);其在此通过引用以其整体并入);(3)编码功能性蛋白并且能够表达功能性蛋白的转基因、polya序列和任选的wpre元件;和任选的(4)允许富集和/或监测修饰的宿主细胞的另外标志物基因。可以使用本领域已知的任何aav。在一些实施方案中,原代aav血清型是aav6。在一些实施方案中,包含供体模板的载体,如raav6载体,是约1-2kb、2-3kb、3-4kb、4-5kb、5-6kb、6-7kb、7-8kb或更大。
[0118]
在一些实施方案中,以如每细胞约1x103、5x103、1x104、5x104、1x105、2x104至1x105个病毒、或小于1x105的感染复数(moi)转导病毒载体,如aav6载体。
[0119]
适合的标志物基因是本领域中已知的并且包括myc、ha、flag、gfp、截短的ngfr、截短的egfr、截短的cd20、截短的cd19以及抗生素抗性基因。在一些实施方案中,同源修复模板和/或载体(如aav6)包含表达盒,其包含可操作地连接至启动子(诸如泛素c启动子)的截短的神经生长因子受体(tngfr)的编码序列。
[0120]
在一些实施方案中,供体模板或载体包含与hba1或hba2基因座的片段同源的核苷酸序列,或核苷酸序列与hba1或hba2基因座的至少200、250、300、350、400、450、500或更多个连续核苷酸至少85%、88%、90%、92%、95%、98%或99%相同。
[0121]
在由于急性毒性可能需要快速去除细胞的情况下,插入的构建体还可包含其他安全开关,诸如进入基因座的标准自杀基因(如icasp9)。本公开内容提供了稳健的安全开关,从而可以如通过去除营养缺陷因子而消除移植到体内的任何工程化细胞。如果工程化细胞已转化为癌性细胞,则这一点尤其重要。
[0122]
本发明的方法允许供体模板有效整合在内源性hba1或hba2基因座处。在一些实施方案中,本发明的方法允许供体模板插入20%、25%、30%、35%、40%或更多个细胞,如来自患有β-地中海贫血的个体的细胞。所述方法还允许编码的蛋白在具有整合的转基因的细胞(如来自患有β-地中海贫血的个体的细胞)中高水平表达,如相对于健康对照细胞中的表达是至少约70%、75%、80%、85%、90%、95%或更高的表达水平。
[0123]
在一些实施方案中,如本文所述的crispr介导的系统(如,包含引导rna、rna引导的核酸酶和同源修复模板)在如来源于动员的外周血或脐带血的原代hspc中进行评估。在此类实施方案中,hspc可以是wt原代hspc(如,用于系统的初始测试)或来自患者来源的hspc(如,用于临床前体外测试)。5.治疗方法
[0124]
在将转基因整合至hspc的基因组中并确认所编码的治疗性蛋白的表达之后,可以将多个修饰的hspc重新引入对象中。在一个实施方案中,hspc通过股内注射引入,使得它们可以填充骨髓并分化成如红血细胞。在一些实施方案中,hspc在体外被诱导分化为红血细胞,然后将修饰的红血细胞重新引入对象中。
[0125]
在一些实施方案中,本文公开了治疗有需要的个体中的遗传病症,如β-地中海贫血的方法,所述方法包括使用本文公开的基因组修饰方法向个体提供蛋白替换疗法。在一些情况下,所述方法包括离体修饰的宿主细胞,其包含整合在hba1或hba2基因座处的功能性转基因,如hbb转基因,其中修饰的宿主细胞表达个体中缺乏的编码的蛋白,从而治疗个体中的遗传病症。药物组合物
[0126]
在一些实施方案中,本文公开了用于修饰的细胞的方法、组合物和试剂盒,其包括药物组合物、治疗方法和施用方法。尽管本文所提供的药物组合物的描述主要针对适合施用至人的药物组合物,但本领域技术人员将理解此类组合物通常适合施用给任何动物。
[0127]
在一些实施方案中,提供了包含如本文所述的修饰的自体宿主细胞的药物组合物。修饰的自体宿主细胞经遗传工程化以在hba1或hba2基因座处包含整合的转基因。本文公开内容的修饰的宿主细胞可使用一种或多种赋形剂配制,以例如:(1)增加稳定性;(2)改变生物分布(如,使细胞系靶向特定组织或细胞类型);(3)改变编码的治疗因子的释放曲线。
[0128]
本公开内容的制剂可以包括但不限于盐水、脂质体、脂质纳米颗粒、聚合物、肽、蛋白质及其组合。本文所述的药物组合物的制剂可通过药理学领域中已知的或以后开发的任何方法制备。如本文所用,术语“药物组合物”是指包含至少一种活性成分(如,修饰的宿主细胞)和任选的一种或多种药学上可接受的赋形剂的组合物。本公开内容的药物组合物可以是无菌的。
[0129]
根据本公开内容的药物组合物中的活性成分(如,修饰的宿主细胞)、药学上可接受的赋形剂和/或任何另外成分的相对量可以根据被治疗的对象的身份、大小和/或条件以及进一步根据施用组合物的途径而变化。例如,该组合物可包含0.1%至99%(w/w)的活性成分。举例来说,该组合物可包含0.1%至100%,如0.5至50%、1-30%、5-80%或至少80%(w/w)的活性成分。
[0130]
如本文所用的赋形剂包括但不限于适合于所需的特定剂型的任何和所有溶剂、分散介质、稀释剂或其他液体媒介物、分散或悬浮助剂、表面活性剂、等渗剂、增稠剂或乳化剂、防腐剂等。用于配制药物组合物的各种赋形剂和用于制备组合物的技术是本领域中已知的(参见remington:the science and practice of pharmacy,第21版,a.r.gennaro,lippincott,williams&wilkins,baltimore,md,2006;将其通过引用以其整体并入本文)。在本公开内容的范围内可以考虑使用常规的赋形剂介质,除非任何常规的赋形剂介质可能与物质或其衍生物不相容,诸如通过产生任何不希望的生物效应或在其他方面以有害方式与药物组合物的任何其他组分相互作用。
[0131]
示例性稀释剂包括但不限于碳酸钙、碳酸钠、磷酸钙、磷酸二钙、硫酸钙、磷酸氢钙、磷酸钠、乳糖、蔗糖、纤维素、微晶纤维素、高岭土、甘露糖醇、山梨糖醇、肌醇、氯化钠、干淀粉、玉米淀粉、糖粉等,和/或其组合。
[0132]
可注射制剂可以,例如,通过细菌截留过滤器过滤,和/或通过掺入无菌固体组合物形式的灭菌剂(其在使用前可溶解或分散在无菌水或其他无菌可注射介质中)进行灭菌。给药和施用
[0133]
包含在上文所述的药物组合物中的本公开内容的修饰的宿主细胞可以通过任何递送途径、全身递送或局部递送来施用,这导致治疗有效的结果。这些包括但不限于肠内、胃肠道、硬膜外、口服、透皮、脑内、脑室内、经表皮、皮内、皮下、经鼻、静脉内、动脉内、肌内、心内、骨内、鞘内、实质内、腹膜内、膀胱内、玻璃体内、海绵窦内、间质、腹腔内、淋巴内、髓内、肺内、脊柱内、滑膜内、鞘内、管内、肠胃外、经皮、关节周围、硬膜外、神经周、牙周、直肠、软组织和局部。在特定的实施方案中,静脉内施用细胞。
[0134]
在一些实施方案中,对象将在细胞移植前经历调理方案。例如,在造血干细胞移植
之前,对象可以经历清髓疗法、非清髓疗法或降低强度调理以防止干细胞移植排斥,即使干细胞来自同一对象亦如此。调理方案可涉及施用细胞毒性剂。调理方案还可以包括免疫抑制、抗体和辐射。其他可能的调理方案包括抗体介导的调理(参见,如czechowicz等人,318(5854)science 1296-9(2007);palchaudari等人,34(7)nature biotechnology 738-745(2016);chhabra等人,10:8(351)science translational medicine 351ra105(2016))和car t介导的调理(参见,如arai等人,26(5)molecular therapy 1181-1197(2018);其中的每一个在此通过引用以其整体并入)。例如,需要使用调理以在脑中产生空间,用于使源自工程化造血干细胞(hsc)的小胶质细胞迁移到其中以递送目的蛋白(如在针对ald和mld的最近基因疗法试验中)。调理方案还经设计以产生小生境“空间”,以允许移植的细胞在体内有一个位置进行移植和增殖。例如,在hsc移植中,调理方案在骨髓中产生用于移植的hsc植入的小生境空间。在没有调理方案的情况下,移植的hsc无法植入。
[0135]
本公开内容的某些方面涉及向哺乳动物对象的靶组织提供包含本公开内容的修饰的宿主细胞的药物组合物的方法,其通过使靶组织与包含修饰的宿主细胞的药物组合物在使得它们基本上被保留在这样的靶组织中的条件下接触进行。在一些实施方案中,包含修饰的宿主细胞的药物组合物包含一种或多种细胞渗透剂,尽管也考虑了含有或不含药学上可接受的赋形剂的“裸”制剂(诸如没有细胞渗透剂或其他试剂)。
[0136]
本公开内容另外提供了将根据本公开内容的修饰的宿主细胞施用至有需要的对象的方法。包含修饰的宿主细胞的药物组合物和本公开内容的组合物可使用有效预防、治疗或控制病症如β-地中海贫血的任何量和任何施用途径施用至对象。所需的精确量将因对象而异,这取决于对象的种类、年龄和一般状况,疾病的严重程度,特定的组合物,其施用模式,其活性模式等。对象可以是人、哺乳动物或动物。任何特定个体的具体治疗或预防有效剂量水平将取决于多种因素,包括所治疗的病症和病症的严重程度;采用的具体有效载荷的活性;采用的具体组合物;患者的年龄、体重、一般健康状况、性别和饮食;施用时间、施用途径;治疗的持续时间;与所采用的特定修饰的宿主细胞组合或同时使用的药物;以及医学领域中众所周知的类似因素。
[0137]
在某些实施方案中,根据本公开内容的修饰的宿主细胞药物组合物可以以足以将如约1x104至1x105、1x105至1x106、1x106至1x107或更多个修饰的细胞递送至对象的剂量水平或足以获得所需治疗或预防作用的任何量施用。本公开内容的修饰的宿主细胞的所需剂量可施用一次或多次。在一些实施方案中,将修饰的宿主细胞递送至对象提供了持续至少1个月、2个月、3个月、4个月、5个月、6个月、7个月、8个月、9个月、10个月、11个月、1年、13个月、14个月、15个月、16个月、17个月、18个月、19个月、20个月、20个月、21个月、22个月、23个月、2年、3年、4年、5年、6年、7年、8年、9年、10年或大于10年的治疗作用。
[0138]
修饰的宿主细胞可以与一种或多种其他治疗剂、预防剂、研究剂或诊断剂或医学程序依序或同时组合使用。通常,每种药剂将以针对该药剂确定的剂量和/或时间表施用。
[0139]
本公开内容还包括根据本公开内容的修饰的哺乳动物宿主细胞用于治疗β-地中海贫血或其他遗传病症的用途。
[0140]
本公开内容还考虑了试剂盒,其包含本公开内容的组合物或组分,如sgrna、cas9、rnp、i53和/或同源模板,以及任选的用于如将组分引入细胞中的试剂。试剂盒还可以包含一个或多个容器或小瓶,以及使用组合物以根据本文所述方法修饰细胞和治疗对象的说明
书。
实施例
[0141]
将通过具体实施例更详细地描述本公开内容。提供以下实施例仅用于说明目的,并不旨在以任何方式限制本公开内容。本领域技术人员将容易地认识到可以改变或修改的各种非关键参数以产生基本相同的结果。实施例1:用β-珠蛋白基因替换α-珠蛋白恢复了β-地中海贫血来源的造血干细胞和祖细胞中的血红蛋白平衡。引言
[0142]
在这项研究中,我们利用组合的cas9/aav6基因组编辑方法来介导全长hbb转基因到hba1基因座中的位点特异性整合,同时保持几乎相同的hba2基因不受干扰。我们发现这个过程允许我们用hbb转基因高频替换hba1的整个编码区,这既使β-地中海贫血来源的hspc中的β-珠蛋白:α-珠蛋白失衡正常化,又挽救了rbc中的功能性成人血红蛋白四聚体。在对免疫缺陷nsg(非肥胖糖尿病scidγ)小鼠进行移植实验后,我们发现编辑的hsc能够在体内再填充造血系统,并可以加强长期植入,表明编辑过程不会破坏正常的造血干细胞功能。
[0143]
基因替换策略的高效率表明所述方法可广泛适用于由散布在整个特定基因中的功能丧失突变引起的多种单基因疾病,从而通过使用同源重组的新方法扩展基因组编辑工具箱以精确地工程化治疗相关的人类原代细胞的基因组。结果
[0144]
cas9/aav6介导的基因组编辑是一种稳健系统,其能够在包括hspc在内的多种细胞类型中的许多基因座处以高频率引入大型基因组整合(19-22)。事实上,该系统已成功用于纠正导致hspc中hbb基因座处高频率镰状细胞病(scd)的致病突变(23)。然而,β-地中海贫血由分散在整个hbb中的功能丧失突变导致,而不是由导致scd的单一多态性引起。因此,用于所有患者的通用校正方案需要递送hbb的全长拷贝。最简单的如此做的方法是在内源性基因座处敲入功能性hbb转基因。然而,这种方法存在许多技术问题:1)hbb中的cas9介导的dsb可以破坏β-地中海贫血轻度和中度患者体内的部分功能等位基因;2)需要密码子发散以在内源性基因座处整合全长β-珠蛋白cdna以便预防cas9 dsb位点周围的部分重组,这会对转基因表达水平产生负面影响(24);3)必须去除内含子,因为它们不能被合理地发散,这可能会破坏已知hbb内含子在基因调控中发挥的重要功能作用(25,26);4)在发散的cdna整合后,周围调控区域中的致病突变可能会持续存在;以及5)这种策略对许多患有由β-珠蛋白基因座大量缺失引起的疾病的患者无效(图6)(27)。
[0145]
先前的工作已经表明,α-珠蛋白水平降低的β-地中海贫血患者表现出较不严重的疾病表型(5,28)。因此,在α-珠蛋白基因座处敲入全长hbb可以最有效地允许我们改善单个基因组编辑事件中的β-珠蛋白:α-珠蛋白失衡,同时克服将hbb引入内源性基因座所固有的问题。α-珠蛋白基因中的有效且特异性插入缺失形成
[0146]
因为当hspc分化为rbc时α-珠蛋白从两种基因(hba1和hba2)表达,我们假设hbb到单个α-珠蛋白基因中的位点特异性整合可以允许我们在不消除关键α-珠蛋白产生的情况
下实现rbc特异性hbb表达。虽然hba1和hba2基因几乎无法区分(5’utr、所有三个外显子和内含子1是100%相同的;内含子是94.0%相同的;3’utr是83.8%相同的),我们能够鉴定有限数量的crispr/cas9单引导rna(sgrna)位点(称为sg1-5;参见,如seq id no:1-5),预计其会促进切割一种α-珠蛋白基因而不促进切割另一种(图1a)。筛选区分这两种基因的引导物至关重要,因为cas9/sgrna核糖核蛋白递送系统在cd34
+
hspc(》90%插入/缺失(插入缺失))中变得如此有效,以至于我们不想通过具有在两种α-珠蛋白基因处都有活性的sgrna来创建四基因敲除α-地中海贫血。因此,我们选择测试利用位于3’utr内的两种基因之间的序列差异的引导物。为此,我们通过电穿孔将与cas9核糖核蛋白(rnp)预复合的每种化学修饰的sgrna(29)递送到人cd34
+
hspc,以确定五种3’utr引导物中的哪一种可以最有效和特异性地诱导预期的基因处的插入缺失(插入/缺失)。然后,我们pcr扩增了hba2和hba1的3’utr区,并使用tide分析分析了相应sanger序列的插入缺失频率(30)。我们发现五种引导物中有四种有助于高频插入缺失的形成,其中两种允许区分hba1和hba2(sg2切割hba2并且sg5切割hba1),并且其中两种没有(sg1和sg4切割hba2和hba1两者)(图1b)。sg1和sg4所针对的hba1和hba2靶序列在来自pam的位置19处仅相差一个碱基对(图7a),这可能是缺乏特异性的原因。另一方面,高度特异性的sg2和sg5所针对的靶序列相差五个碱基对。此外,为了确定这些sgrna中的一种的脱靶活性,我们用与sg5复合的高保真cas9(31)对细胞进行电穿孔,然后对通过cosmid(32)预测的40个最可能的脱靶位点进行靶向测序。这确定了hba1特异性sg5具有极高的特异性,平均中靶活性为66.6%并且在40个预测位点中只有两个显示出高于检测阈值的活性(脱靶位点1和12处的活性中值分别为0.31%和0.14%)(图7b)。这些脱靶位点分别位于基因ptgfrn和rapgef1的3’utr中,并且由于这些区域是非编码的,因此预计小插入缺失的产生不会有功能影响(图7c)。上游同源臂策略允许用定制整合替换α-珠蛋白
[0147]
在鉴定hba1-和hba2-特异性引导物后,我们测试了这些基因座处aav6介导的同源重组(hr)的频率。我们设计了aav6供体模板载体,其将gfp表达盒直接整合至cas9 rnp诱导的断裂位点中。这通过紧接每个sgrna的切割位点(下文称为“cs”)的400bp同源臂来促进(图1c)。我们通过电穿孔向人cd34
+
hspc中递送与cas9rnp复合的最有特异性的引导物(sg2,以靶向hba2和sg5,以靶向hba1)。由于之前曾报道过电穿孔可以帮助aav转导(33),我们在cas9rnp电穿孔后立即添加了每个aav6载体,以最大化aav递送。几天后,在“仅aav”对照中的附加体(episomal)表达减少后,我们通过流式细胞术分析了整合频率(图8a)。如所预期的,我们发现具有侧接切割位点的同源臂的载体有效地整合在cd34
+
hspc中的hba2和hba1处(中值分别为16.5%和28.2%的细胞是gfp
+
),如通过如流式细胞术测定的(图1d)。然而,由于切割位点位于每个基因的3’utr中,这种方法不能确保在hr后敲除任一α-珠蛋白基因。因此,我们还克隆了修复模板载体,其左同源臂位于切割位点上游,跨越每个基因起始密码子的5’紧接的400bp。这种方法利用了hr修复过程,并且可以促进每种α-珠蛋白基因的编码区的完全替换,不仅减少了α-珠蛋白产生,而且还允许整合转基因的表达由内源性α-珠蛋白启动子驱动(以下称为“wgr”,表示“全基因替换”)(图1c)。发现全基因替换过程在t细胞中以低但可测量的频率发生,用于由talen工程化cd40l(34)。我们发现,在wgr策略中,具有切割位点上游的左同源臂显著降低了hba2处的编辑频率(16.5%对比13.2%;p《0.05)(图1d)。令人惊讶的是,这种作用似乎是基因依赖性的,因为hba1处的wgr策略没有产
生编辑频率的协调降低(28.2%对比37.8%)(图1d)。因为每种wgr载体中的左同源臂是相同的,我们使用液滴数字pcr(ddpcr)来确认我们的整合仅对目标基因具有特异性,并且与我们的靶向频率很好地相关,如由gfp表达确定的(图1e)。值得注意的是,当对这些细胞进行流式细胞术时,我们发现与cs载体相比,对于wgr载体,gfp
+
细胞的平均荧光强度(mfi)显著更高(p《0.0005)(图1f;图8b)。在α-珠蛋白处的全基因替换产生rbc特异性转基因表达
[0148]
由于事实上hba1处的wgr修复模板设计:1)导致与cs设计相比等效的整合频率,2)产生高于cs设计的gfp表达水平,以及3)确保敲除α-珠蛋白的一个基因拷贝,我们接下来调整该方案以在hba1基因座处整合全长hbb转基因。为了便于追踪hbb转基因表达,我们将其与t2a-yfp序列融合,这使得荧光读出编辑频率作为hbb蛋白水平的替代物(图2a)。为了确定侧接hbb-t2a-yfp盒(hbb utr或内源性hba1/2utr)的非翻译区(utr)的重要性,以及去除最大hbb内含子(内含子2,850bp)的影响,我们设计了多个不同的aav6修复模板载体并分析了整合频率和转基因表达。我们如前所述靶向hspc,然后使用建立的方案(35,36)将细胞分化成红细胞,并通过流式细胞术测定整合频率和表达水平(图9)。我们发现,与“模拟”(即仅电穿孔)、“仅rnp”和“仅aav”对照相比,在hba1和hba2处靶向hspc对它们分化成rbc的能力没有明显影响(图2b)。通过流式细胞术和ddpcr证实了靶向频率,允许我们得出以下结论:具有hba1 utr整合的载体最有效(平均55.4%的细胞是yfp+,并且平均24.4%的总等位基因被靶向)(图2c-2d)。此外,我们发现,与具有hbb utr的任一载体相比,对于hba1 utr载体,yfp+细胞的mfi显著更高(p《0.05)(图2e;图10),这可能表明在hba1调控区的背景下hbb表达水平更高。因为hbb-t2a-yfp整合由内源性启动子驱动,我们能够确定yfp仅在gpa+/cd71+rbc中表达(图2f),使我们得出以下结论:hba1是用于实现rbc特异性表达的有效安全港位点,同时使来自hba2的α-珠蛋白产生不受干扰。hbb转基因在hba1基因座处的整合产生成人血红蛋白四聚体
[0149]
为了确认hbb靶向整合至hba1后β-珠蛋白的产生,我们筛选了仅整合了hbb转基因而没有t2a-yfp的许多aav6载体。这些载体使用调控元件,诸如hbb和hba1 3’utr、wpre和bgh polya区的各种组合,以及各种表达tngfr的载体,这将使我们能够鉴定和富集高度编辑的细胞群体(图3a;图11)。我们还创建了具有加长左和右同源臂的整合载体,假设这样做可以帮助细胞鉴定同源区—特别是在切割位点上游的左臂内—从而增加我们hbb转基因的整合频率。为了筛选这些载体,我们靶向scd来源的cd34
+
hspc,因为它们专门表达镰状血红蛋白(hgbs),使我们能够确定由我们的编辑方案产生的成人血红蛋白(hgba)拯救程度。如前,靶向的hspc被编辑然后分化为rbc,这表明hba1基因座处的编辑对细胞分化为rbc的能力几乎没有影响(图3b)。我们发现通过加长同源臂显著提高了整合频率,将靶向的等位基因从平均21.1%增加到36.5%(p《0.05)(图3c)。根据接种到96孔板中的单细胞的基因分型,预计36.5%的等位基因的靶向率对应于59.5%的细胞已经经历了至少一个编辑事件(图11a)。当通过hplc分析rbc的人血红蛋白时,我们发现所有三种载体都能够表达和形成hgba四聚体(图3d)。如hbb-t2a-yfp载体所预测的那样,使局部hba1 utr完整的整合产生了更多的hgba四聚体,表明t2a-yfp系统对转基因表达具有高度预测性。有趣的是,当通过hplc分析hbb-t2a-yfp-编辑的rbc的血红蛋白四聚体形成时,我们发现没有高于背景的hgba四聚体形成(图12)。我们认为这可能是由于据报道会破坏蛋白质功能的残留的t2a切
割尾(37)。尽管如此,我们发现具有延长同源臂的载体不仅比具有400bp同源臂的载体产生显著更高的整合频率,而且产生的hgba四聚体百分比也显著增加(p《0.05)(图3e)。重要的是,由于具有延长同源臂的载体将相同的基因组编辑事件引入具有较短400bp同源臂的hba1 utr载体,我们预计hgba产量的这种增加仅仅是由于长同源臂载体能够整合的频率更高。与这一假设一致,我们发现靶向频率与hgba四聚体产生之间存在很强的相关性(r2=0.8695)(图3f),表明每个hbb靶向的hba1等位基因都有助于内源性蛋白质水平。在hba1处以hbb靶向的hspc能够在nsg小鼠中长期植入和造血重建
[0150]
为了确定编辑过程是否会影响hspc在体内植入和重建髓细胞和淋巴谱系的能力,我们进行在hba1基因座处靶向的人类hspc到免疫受损的nsg小鼠中的移植实验。为了尽可能接近地复制临床hsct过程,使用g-csf和plerixafor动员来自健康供体的hspc(38)。收集动员的外周血,然后使用cd34标志物富集hspc并如上在hba1处靶向。靶向后两天,将活cd34+hspc单细胞分选到含有甲基纤维素培养基的96孔板中,并在孵育14天后对集落形成能力进行评分。这表明编辑的hspc能够产生所有谱系的细胞(图11b-11c)。尽管编辑过程似乎减少了集落总数,但减少主要是由于能够在粒细胞/巨噬细胞谱系中形成集落,而不影响多谱系和红系谱系集落的形成及其相对分布。
[0151]
将未用于集落形成测定的全部成批编辑的细胞群体经股骨内注射到免疫缺陷的nsg小鼠中,这些小鼠已进行了亚致死辐射以便清除骨髓中的造血干细胞小生境(图13)。该实验是在三个单独的健康hspc供体上进行的,并且由于这些供体之间的扩增率不同,用于移植的细胞总数因复制而异。因此,我们将这些指定为大剂量、中剂量和小剂量,分别对应于每只小鼠注射120万、750,000和250,000个细胞。注射后16周,收获来自这些小鼠的骨髓,并使用人hla-a/b/c作为标志物确定人细胞的植入(图14)。我们发现所有治疗组中的所有三种剂量都能够成功植入骨髓中(图4a)。我们发现,在中剂量和小剂量中,与模拟电穿孔和仅rnp对照相比,仅aav和rnp+aav处理中细胞的植入能力受到负面影响,如前所述(22,23)。然而,当移植更大数目的细胞时,我们不再观察到治疗组之间植入的任何显著差异。我们还发现,编辑过程不会影响人hspc在体内重建髓细胞和淋巴谱系的能力,并且对植入的人类细胞中在这些谱系的分布没有明显影响(图4b)。接下来,我们使用ddpcr来确定植入细胞群体中所需靶向事件的频率。我们发现,在我们成功植入的hspc的成批群体中,中值为11.0%的总等位基因被适当靶向(图4c),预计这对应于17.9%的细胞已经经历了至少一次编辑事件。我们还将植入的细胞谱系-分选为cd19
+
(b细胞)、cd33
+
(髓细胞)和lin-/cd10-/cd34
+
(hspc)群体,并确定这些亚群中的等位基因靶向频率,其中值分别为7.8%、14.9%和17.2%。我们观察到从体外、移植前群体到成功植入的细胞群体的靶向等位基因频率适度降低(图4d),这与之前的报告中观察到的一致(23,39),并且严重程度比pattabhi等人最近报道的下降要低得多(40)。除了使用临床相关的hbb整合载体进行编辑外,我们还使用wgr修复模板载体靶向细胞,以用强ubc启动子表达的gfp替换hba1基因(图15a-15e)。我们发现中值为8.7%的人类细胞的植入率,表明hba1基因的替换对hspc植入能力影响不大。我们还使用流式细胞术确定成功植入细胞的编辑频率的中值为25.6%,而在b细胞、髓细胞和hspc谱系中的中值分别为1.0%、15.9%和0.9%,表明编辑的细胞能够植入和重建各种谱系。
[0152]
在收获在初始移植实验中成功植入的细胞后,我们将这些细胞静脉内注射到新小鼠中作为二次移植,以确定编辑过程是否会影响细胞在二级小鼠(secondary mouse)中长
期植入和再填充造血系统的能力。事实上,对照模拟电穿孔处理以及用rnp/aav6靶向的细胞都能够以》20%植入(图4e)。然后,我们像以前一样使用ddpcr来确定能够在第二轮移植中成功植入的人类细胞群体内的整合频率。在这样做的过程中,我们观察到成批样品和谱系中的整合率与在初始移植实验中植入的细胞中观察到的整合率一致(图4f)。通过用我们的wgr gfp载体靶向进一步证实了这些结果,这也证明了当从二级小鼠中收获骨髓时,编辑的(gfp
+
)细胞能够长期植入(图15f-15g)。在β-地中海贫血来源的hspc中递送hbb转基因校正了α-珠蛋白:β-珠蛋白失衡
[0153]
在证明源自wt供体的长期再填充hsc中hba1基因座处的稳定整合频率后,我们将该策略应用于β-地中海贫血来源的hspc。cd34
+
细胞从β-地中海贫血患者保存的备用g-csf和plerixafor-动员外周血中分离。如前,我们使用hba1 utr载体扩增和靶向这些hspc(图3a),并将单个活cd34
+
hspc分选到96孔板的每个孔中以进行集落形成测定。我们发现编辑的hspc能够产生所有谱系的细胞(图11d-11e)。尽管没有明显的谱系偏斜,但编辑的β-地中海贫血来源的hspc形成集落的总体能力似乎略有降低,这与cas9/aav6介导的基因组编辑后的先前报道一致(41)。
[0154]
除了集落形成测定外,靶向的hspc的亚组在编辑后2天进行rbc分化。我们发现两种载体都能够成功靶向这些β-地中海贫血来源的hspc,并且如前所示,加长同源臂显著提高了这些细胞中的编辑频率,如通过ddpcr所确定的(13.8%对比48.5%;p《0.05)(图5a)。为了深入了解我们的编辑方案如何影响α-珠蛋白和β-珠蛋白的表达,我们设计了ddpcr引物/探针,其允许我们评估α-珠蛋白的mrna表达(不区分hba1和hba2)以及来自整合的hbb转基因的mrna表达。如所预期的,当将表达标准化为rbc标志物gpa时,我们发现用400bp同源臂hba1 utr载体编辑的细胞显示出α-珠蛋白表达适度下降以及转基因表达水平适度(图5b)。可能由于使用延长的同源臂载体实现了更高的编辑频率,我们观察到α-珠蛋白表达甚至更大的减少以及β-珠蛋白转基因表达的增加。事实上,我们发现延长同源臂载体能够近乎实现1:1比率的α-珠蛋白:β-珠蛋白mrna表达。靶向的β-地中海贫血来源的hspc能够在nsg小鼠中长期植入和造血重建
[0155]
除了rbc分化和分析,我们还通过将靶向的β-地中海贫血来源的hspc注射到亚致死辐照的nsg小鼠中进行了植入实验。移植后16周,我们从小鼠收获骨髓,并分别通过流式细胞术和ddpcr确定植入和靶向频率。我们发现在hba1基因座处以我们的转基因靶向的患者来源的hspc确实能够成功移植,其中骨髓中人类细胞的中值为19.8%(图5c)。我们还观察到我们的编辑方案对成功植入的细胞的谱系分布几乎没有影响(图5d)。使用ddpcr,我们还确定成功植入的细胞以5.5%的中值频率在成批群体中编辑以及分别以1.5%、17.1%和1.7%的中值频率在b细胞、髓细胞和hspc谱系中编辑(图5e)。讨论
[0156]
总之,我们已经开发了一种用于潜在地治疗β-地中海贫血的新型基因组编辑方案,该方案解决了在单个基因组编辑事件中导致疾病的两个分子因素—β-珠蛋白的损失和过量α-珠蛋白的累积。先前的数据表明,骨髓中大约25%的编辑的细胞嵌合体似乎是在地中海贫血患者中实现输血独立性的阈值(42)。我们在β-地中海贫血来源的hspc中实现的编辑频率是体外靶向的等位基因的48.5%,预计这对应于具有至少一个编辑的等位基因的细胞的79.0%。因为我们的方法是位点特异性的并且使用患者自己的细胞,所以它会:1)克服
免疫匹配供体短缺;2)消除持续输血和/或铁螯合疗法的需要;3)消除伴随同种异体hsct的免疫排斥的可能性;和4)避免病毒载体在基因组中半随机整合的风险。由于这些原因,我们描述的技术有助于克服当前治疗策略的缺陷。
[0157]
除了对β-地中海贫血治疗的直接影响之外,我们还认为我们的结果与整个基因组编辑领域具有更广泛的相关性。先前的工作已经证明全基因替换可能在t细胞中以低频率发生(34),但我们的工作表明全基因替换的频率可以显著增加并在hspc中得到利用。由于大多数隐性遗传疾病是由整个特定基因的功能丧失突变引起的,因此我们开发的方案可以适应各种遗传病症的一刀切(one-size-fits-all)治疗策略,从而有效地扩展了基因组编辑工具箱。
[0158]
我们的研究还表明,与荧光报告子偶联的t2a切割肽系统高度预测转基因表达。这证明了该系统在快速鉴定成功编辑的细胞和比较各种整合载体(即具有不同调控区、有或没有特定内含子等的那些)方面的实用性。由于患者来源的hspc很难获得,尤其是从多个供体中获得,因此该t2a筛选系统还允许在健康hspc中鉴定最佳翻译载体,所述载体可以在患者来源的hspc中进行验证。最后,因为我们优化了α-珠蛋白基因座(一种仅在rbc中表达的基因)处的盒整合,所以这项工作已经表征了安全港基因座用于通过rbc递送有效载荷,诸如治疗性酶和单克隆抗体。这将允许未来的工作在hba1基因座处以高频率整合定制载体,从而实现rbc特异性表达,而不会有敲除对rbc发育至关重要的基因(因为hba2保持完整)。出于这些原因,我们希望这项研究的发现能够指导未来的基因组编辑工作,既可以作为纠正各种遗传病症的策略,也可以作为各种细胞工程化应用的策略。方法aav6载体设计、产生和纯化
[0159]
将所有aav6载体克隆至含有源自aav2的倒置末端重复(itr)的paav-mcs质粒(agilent technologies,santa clara,ca,usa)中。gibson assembly mastermix(new england biolabs,ipswich,ma,usa)用于根据制造商的说明书产生每种载体。切割位点(cs)载体被设计为使得左同源臂和右同源臂(分别是“lha”和“rha”)紧密侧接hba2或hba1基因处的切割位点。全基因替换(wgr)载体具有侧接hba2或hba1基因的5’utr的lha,而rha紧密侧接在其相应切割位点的下游。除非另有说明,否则每个载体的lha和rha均为400bp,载体名称(hba2/hba1和cs/wgr)分别指代使用的靶整合位点和同源臂。在图1中,cs和wgr载体由sffv-gfp-bgh表达盒组成。可替代的启动子ubc也用于产生针对hba1的wgr载体(图15)。在图2中,wgr-t2a-yfp载体由全长hbb基因(除非另有说明)与紧邻hbb基因的外显子3之后的t2a-yfp表达盒(使用之前针对wgr所述的lha和rha)组成。这些全长hbb-t2a-yfp载体侧接有hbb、hba2或hba1的5’和3’utr,如在图2a中所示。在随后的实验中,为了靶向scd或β-地中海贫血患者来源的cd34+hspc,wgr载体被设计为靶向hba1位点,并含有侧接有hba1 utr或hbb utr的全长hbb基因。虽然“hbb utr”和“hba1 utr”载体共享400bp ha,但“hba1 utr长ha”载体被修饰为具有880bp ha。如所述,对产生aav6载体进行了一些修改(43)。将293t细胞(life technologies,carlsbad,ca,usa)以每板13-15
×
106个细胞接种在十个15cm2盘中。24小时后,每个盘用标准聚乙烯亚胺(pei)转染6μg含itr的质粒和22μg含有aav6帽基因、aav2 rep基因和ad5辅助基因的pdgm6来转染。48-72小时孵育后,将细胞通过3次冻融循环裂解,用250u/ml的benzonase(thermo fisher scientific,waltham,ma,usa)
处理,然后通过在18℃下以48,000rpm进行碘克沙醇梯度离心纯化载体2.25小时。之后,在40-58%碘克沙醇界面分离完整衣壳,然后在80℃下储存直至进一步使用。作为替代方法,aavpro纯化试剂盒(所有血清型)(takara bio usa,mountain view,ca,usa)也在48-72小时孵育期后用于按照制造商的说明书提取完整的aav6衣壳。如前所述,使用ddpcr对aav6载体进行滴定以测量载体基因组的数量(44)。cd34
+
hspc的培养
[0160]
如前所述培养人cd34
+
hspc(19,23,33,41,45,46)。cd34+hspc来源于新鲜脐带血、冷冻脐带血和plerixafor-和/或g-csf-动员的外周血(allcells,alameda,ca,usa和stemcell technologies,vancouver,canada),scd患者的冷冻的plerixafor-和/或g-csf-动员外周血以及β-地中海贫血患者的冷冻g-csf和plerixafor-动员外周血。将cd34
+
hspc在补充有干细胞因子(scf)(100ng/ml)、血小板生成素(tpo)(100ng/ml)、flt3-配体(100ng/ml)、il-6(100ng/ml)、um171(35nm)、20mg/ml链霉素和20u/ml青霉素的stemspan sfem ii(stemcell technologies,vancouver,canada)基础培养基中以2.5
×
10
5-5
×
105个细胞/ml培养。细胞孵育器条件是37℃,5%co2和5%o2。cd34
+
hspc的基因组编辑
[0161]
用于在hba2或hba1处编辑cd34
+
hspc的化学修饰的sgrna购自synthego(menlo park,ca,usa)和trilinkbiotechnologies(san diego,ca,usa),并通过高效液相色谱法(hplc)纯化。添加的sgrna修饰是在前述的5’和3’端的三个末端核苷酸处的2
’‑
o-甲基-3
’‑
硫代磷酸(29)。sgrna的靶序列如下:sg1:5
’‑
ctaccgaggctccagcttaa-3’;sg2:5
’‑
ggcaggaggaacggctaccg-3’;sg3:5
’‑
ggggaggagggcccgttggg-3’;sg4:5
’‑
ccaccgaggctccagcttaa-3’以及sg5:5
’‑
ggcaagaagcatggccaccg-3’。使用的所有cas9蛋白(alt-rs.p.cas9 nuclease v3)购自integrated dna technologies(coralville,iowa,usa)。在电穿孔之前,将rnp在25℃下以1:2.5的cas9:sgrna摩尔比复合10min。将cd34
+
细胞重悬于含复合rnp的p3缓冲液(lonza,basel,switzerland)中,并使用lonza 4d nucleofector(programdz-100)进行电穿孔。在先前描述的补充细胞因子的培养基中电穿孔后,将细胞以2.5
×
105个细胞/ml涂铺。电穿孔后立即基于由ddpcr测定的滴度以5
×
10
3-1
×
104个载体基因组/细胞向细胞提供aav6。通过tide进行的插入缺失频率分析
[0162]
靶向后2-4天,收获hspc,并使用quickextract dna提取溶液(epicentre,madison,wi,usa)收集gdna。然后根据制造商的说明书,使用以下引物与cleanamp pcr 2x主混合物(trilink,sandiego,ca,usa)一起扩增hba2和hba1处的相应切割位点:hba2(sg1-3):正向:5
’‑
cccgaaaggaaagggtggcg-3’反向:5
’‑
tggcacctgcacttgcactg-3’;hba1(sg4-5):正向:5
’‑
tccggggtgcacgagccgac-3’,反向:5
’‑
gcggtggctccactttccct-3’。然后在1%琼脂糖凝胶上进行pcr反应,并根据制造商的说明书使用genejet凝胶提取试剂盒(thermo fisher scientific,waltham,ma,usa)切割适当的条带并进行凝胶提取。然后用以下引物对凝胶提取的扩增子进行sanger序列:hba2(sg1-3):正向:5
’‑
ggggtgcgggctgactttct-3’反向:5
’‑
ctgagacaggtaaacacctccat-3’;hba1(sg4-5):正向:5
’‑
tggagacgtcctggcccc-3’,反向:5
’‑
cctggcacgtttgctgagg-3’。所得的sanger色谱图用作通过tide进行的插入缺失频率分析的输入,如前所述(30)。
通过流式细胞术进行的基因靶向分析
[0163]
用荧光整合载体靶向后4-8天,收获cd34
+
hspc,并通过流式细胞术测定编辑的细胞的百分比。使用ghost dye red 780(tonbo biosciences,san diego,ca,usa)分析细胞的活力,并使用accuri c6流式细胞仪(bd biosciences,san jose,ca,usa)或facs aria ii(bd biosciences,san jose,ca,usa)评估报告子表达。随后使用flowjo(flowjo llc,ashland,or,usa)分析数据。通过ddpcr进行的等位基因靶向分析
[0164]
靶向后2-4天,收获hspc,并使用quickextract dna提取溶液(epicentre,madison,wi,usa)收集gdna。然后按照制造商的说明书(new england biolabs,ipswich,ma,usa)使用bamh1-hf消化gdna。使用以下反应混合物通过ddpcr测量细胞群体内靶向的等位基因的百分比:1-4μl消化的gdna输入,10μl ddpcr supermix for probes(无dutp)(bio-rad,hercules,ca,usa),引物/探针(比例为1:3.6;integrated dna technologies,coralville,iowa,usa),体积高达20μl,含h2o。然后按照制造商的说明书(bio-rad,hercules,ca,usa)生成ddpcr液滴:20μl ddpcr反应物,70μl液滴生成油和40μl液滴样品。热循环仪(bio-rad,hercules,ca,usa)设置如下:1.98℃(10分钟),2.94℃(30秒),3.57.3℃(30秒),4.72℃(1.75分钟)(返回至步骤2
×
40
–
50个循环),5.98℃(10分钟)。使用qx200液滴数字pcr系统(bio-rad,hercules,ca,usa)对液滴样品进行分析。为了确定靶向的等位基因的百分比,泊松校正的整合体拷贝数/ml除以泊松校正的参考dna拷贝数/ml。以下引物和6-fam/zen/ibfq-标记的水解探针作为定制设计的primetime qpcr assays购自integrated dna technologies(coralvilla,ia,usa):所有hba2-整合gfp载体(跨越bgh至外部400bp hba2 rha):正向:5
’‑
tagttgccagccatctgttg-3’,反向:5
’‑
ggggacagcctattttgcta-3’,探针:5
’‑
aaatgaggaaattgcatcgc-3’;所有hba1-整合gfp载体(跨越bgh至外部400bp hba1 rha):正向:5
’‑
tagttgccagccatctgttg-3’,反向:5
’‑
tagtgggaacgatgggggat-3’,探针:5
’‑
aaatgaggaaattgcatcgc-3’;hba2-整合hbb-t2a-yfp载体(跨越yfp至外部400bp hba2 rha):正向:5
’‑
agtccaagctgagcaaaga-3’,反向:5
’‑
ggggacagcctattttgcta-3’,探针:5
’‑
cgagaagcgcgatcacatggtcctgc-3’;所有hba1-整合hbb-t2a-yfp载体(跨越yfp至外部400bp hba1 rha):正向:5
’‑
agtccaagctgagcaaaga-3’,反向:5
’‑
tagtgggaacgatgggggat-3’,探针:5
’‑
cgagaagcgcgatcacatggtcctgc-3’;hba1-整合hbb载体(含400bp ha,不含t2a-yfp)(跨越hbb外显子3至外部400bp hba1rha):正向:5
’‑
gctgcctatcagaaagtggt-3’,反向:5
’‑
tagtgggaacgatgggggat-3’,探针:5
’‑
ctggtgtggctaatgccctggccc-3’;hba1-整合hbb载体(含880bp ha,不含t2a-yfp)(跨越hbb外显子3至外部880bp hba1 rha):正向:5
’‑
gctgcctatcagaaagtggt-3’,反向:5
’‑
atcacaaacgcaggcagag-3’,探针:5
’‑
ctggtgtggctaatgccctggccc-3’。作为定制设计的primetime qpcr assays从integrated dna technologies(coralvilla,ia,usa)购买的引物和hex/zen/ibfq-标记的水解探针用于扩增ccrl2参考基因:正向:5
’‑
gctgtatgaatccaggtcc-3’,反向:5
’‑
cctcctggctgagaaaaag-3’,探针:5
’‑
tgtttcctccaggataaggcagctgt-3’。由于“hba1 utr长ha”载体的长度并确保未检测到附加型aav,ddpcr扩增子超过了ddpcr制造商推荐的模板大小。在分析数据后,该载体的靶向等位基因的百分比被低估了。因此,在这些情况下,通过用两套ddpcr引物和探针(针对含
400bp和880bp ha的载体的那些)以及ccrl2参考探针扩增从用含400bp ha的hba1 utr载体靶向的hspc收获的gdna确定了解释这种低估的校正因子。然后将得到的校正因子应用于来自用针对880bp ha的引物和探针靶向和扩增的样品的靶向等位基因百分比。通过rhampseq进行的脱靶活性分析
[0165]
使用在19个pam近端碱基和pam序列ngg中允许最多三个错配的cosmid鉴定针对hba1 sg5的预测脱靶位点。使用rhampseq技术(integrated dna technologies)进行多重pcr扩增子测序,以计算40个最高度预测的脱靶位点的总编辑频率。使用定制的管道分析ngs数据。pcr扩增子在illumina miseq(v2化学;2x 150)上进行测序,并使用picard工具v2.9(https://github.com/broadinstitute/picard)对数据进行多路分配(demultiplex)。将正向和反向读段合并为扩增的扩增子(flash v1.2.11)(47)中,之后与grch38基因组参考(minimap2 v2.12)(48)比对。将读段分配到多重引物池(bedtools标签v2.25)(49)中的靶标,并与靶标重新比对,从而有利于在预测的cas9切割位点附近使用插入缺失进行对齐选择。在每个靶标处,编辑被计算为在切割位点的4bp窗口内包含插入缺失的总读段的百分比。cd34
+
hspc在体外分化为红细胞
[0166]
靶向后,将源自健康、scd或β-地中海贫血患者的hspc在sfem ii培养基(stemcell technologies,vancouver,canada)中于37℃和5%co2下培养14-16天,如前所述(35,36)。sfemii基础培养基补充有100u/ml青霉素-链霉素、10ng/ml scf、1ng/ml il-3(peprotech,rocky hill,nj,usa)、3u/ml促红细胞生成素(ebiosciences,san diego,ca,usa)、200μg/ml转铁蛋白(sigma-aldrich,st.louis,mo,usa)、3%抗体血清(热灭活的,来自atlanta biologicals,flowery branch,ga,usa)、2%人血浆(脐带血)、10μg/ml胰岛素(sigma-aldrich,st.louis,mo,usa)和3u/ml肝素(sigma-aldrich,st.louis,mo,usa)。在第一阶段,第0-7天(第0天为靶向后2天)分化期间,将细胞以1
×
105个细胞/ml培养。在第二阶段,第7-10天,将细胞维持在1
×
105个细胞/ml,并从培养物中去除il-3。在第三阶段,第11-16天,将细胞以1
×
106个细胞/ml培养,并且将培养基中的转铁蛋白增加到1mg/ml。mrna分析
[0167]
在hspc分化成红细胞后,收获细胞并使用rneasy plus mini kit(qiagen,hilden,germany)提取rna。随后,使用iscript reverse transcription supermix for rt-qpcr(bio-rad,hercules,ca,usa)从大约100ng rna制备cdna。使用作为定制设计的primetime qpcr assays购自integrated dna technologies(coralvilla,ia,usa)的以下引物和6-fam/zen/ibfq-标记的水解探针通过ddpcr定量β-珠蛋白转基因和α-珠蛋白mrna的表达水平:hbb:正向:5
′‑
gagaacttcaggctcctg-3
′
,反向:5
’‑
cgggggtacgggtgcaggaa-3’,探针:5
’‑
tggccatgcttcttgcccct-3’;hba(不区分hba2和hba1):正向:5
’‑
gacctgcacgcgcacaagctt-3’,反向:5
’‑
gctcacagaagccaggaacttg-3’,探针:5
’‑
caacttcaagctcctaagcca-3’。为了标准化rna输入,使用作为定制设计的primetime qpcr assays购买购自integrated dnatechnologies(coralvilla,ia,usa)的以下引物和hex/zen/ibfq-标记的水解探针在每个样品中测定rbc特异性参考基因gpa的水平:正向:5
′‑
atatgcagccactcctagagctc-3
′
,反向:5
’‑
ctggttcagagaaatgatgggca-3’,探针:5
’‑
aggaaaccggagaaagggta-3’。使用相应的引物和探针产生ddpcr反应物,并且如上所述生成
液滴。thermocycler(bio-rad,hercules,ca,usa)设置如下:1.98℃(10分钟),2.94℃(30秒),3.59.4℃(30秒),4.72℃(30秒)(返回至步骤2
×
40
–
50个循环),5.98℃(10分钟)。使用qx200液滴数字pcr系统(bio-rad,hercules,ca,usa)对液滴样品进行分析。为了确定相对表达水平,将泊松校正的hba或hbb转基因拷贝数/ml除以泊松校正的gpa拷贝数/ml。分化红细胞的免疫表型
[0168]
使用facs aria ii(bd biosciences,san jose,ca,usa)在第14-16天分析经历上述红细胞分化的hspc的红细胞谱系特异性标志物。使用以下抗体通过流式细胞术分析编辑和未编辑的细胞:hcd45v450(hi30;bd biosciences,san jose,ca,usa)、hcd34 apc(561;biolegend,san diego,ca,usa)、hcd71 pe-cy7(okt9;affymetrix,santa clara,ca,usa)和hcd235a pe(gpa)(ga-r2;bd biosciences,san jose,ca,usa)。稳态血红蛋白四聚体分析
[0169]
使用相当于三体积沉淀细胞的水来裂解经历上述红细胞分化的hspc。将混合物在室温下孵育15分钟,然后进行30秒的超声处理。为了从红细胞影中分离裂解物,以13,000rpm进行离心5分钟。在弱阳离子交换polycat a柱(100
×
4.6-mm,3μm,)(polylc inc.,columbia,md,usa)上使用shimadzu uflc系统在室温下对呈天然形式的血红蛋白进行hplc分析。流动相a(mpa)由20mm bis-tris+2mm kcn(ph 6.96)组成。流动相b(mpb)由20mm bis-tris+2mm kcn+200mm nacl(ph 6.55)组成。将透明溶血产物在mpa中稀释四倍,然后将20μl上样到柱上。1.5ml/min的流速和以下梯度以时间(min)/%b有机溶剂计使用:(0/10%;8/40%;17/90%;20/10%;30/停止)。甲基纤维素cfu评估
[0170]
靶向后2天,使用cd34 apc(561;biolegend,san diego,ca,usa)、ghost dye red 780viability dye(tonbo biosciences,san diego,ca,usa)对hspc进行染色,并将活cd34
+
细胞分选于含methocult optimum(stemcell technologies,vancouver,canada)的96孔板中。12-16天后,根据外观以盲法对集落进行适当评分。cd34
+
hspc移植到免疫缺陷nsg小鼠中
[0171]
6至8周龄的全雌性nsg小鼠(jackson laboratory,bar harbor,me,usa)在用靶向的hspc(靶向后2天)经由股骨内或尾静脉注射进行移植前12-24小时使用200rads照射进行辐照。使用带有27g,0.5英寸(12.7mm)针的胰岛素注射器注射大约2.5
×
10
5-1.3
×
106个电穿孔的hspc(图中注明的确切数量)。该实验方案得到了斯坦福大学实验动物护理管理小组(stanford university’s administrative panel on laboratory animal care)的批准。在数据收集或分析期间,无需对组别分配、治疗随机化或排除标准设盲,以解释原稿中报告的任何实验中的意外偏倚。所有报告的实验均按照斯坦福大学的政策,由实验动物护理行政小组(administrative panel on laboratory animal care,aplac;协议号25065)在斯坦福管理的机构动物护理和使用委员会(institutional animal care and use committee,iacuc;协议号d16-00134)完成。本研究中使用的样本量在先前cas9/aav6介导的基因组编辑研究中报告的范围内(21-23)。人类植入的评估
[0172]
移植cd34
+-编辑的hspc后15-17周,对小鼠实施安乐死,并使用研杵和研钵从胫骨、股骨、骨盆、胸骨和脊柱收获骨髓。单核细胞使用在室温下2,000g的ficoll梯度离心
(ficoll-paque plus,ge healthcare,chicago,il)持续25分钟进行富集。然后将样品在4℃下用以下抗体染色30分钟:单克隆hcd33 v450(wm53;bd biosciences,san jose,ca,usa);hhla-a/b/c fitc(w6/32;biolegend,san diego,ca,usa);cd19 percp-cy5.5(hib19;bd biosciences);mter119 pe-cy5(ter-119;ebiosciences,san diego,ca,usa);mcd45.1 pe-cy7(a20;ebiosciences,san diego,ca,usa);hgpa pe(hir2;ebiosciences,san diego,ca,usa);hcd34 apc(581;biolegend,san diego,ca,usa);和hcd10 apc-cy7(hi10a;biolegend,san diego,ca,usa)。通过植入的人细胞(cd45
+
;hla-a/b/c
+
细胞)的髓系细胞(cd33
+
)和b细胞(cd19
+
)的存在来建立多谱系移植。对于表达gfp的细胞,使用hhla-a/b/c-apc-cy7(w6/32;biolegend,san diego,ca,usa)而非hhla-fitc。对于二次移植,只有一部分原代小鼠单核细胞群体被染色,并且其余的细胞(2.5x105个细胞-1.3x106个细胞)在辐照调理后移植到6至8周龄的nsg小鼠中。在移植到二级小鼠后16周,以与上述相同的方式评估细胞。统计分析
[0173]
图中呈现的所有数据点均取自不同的治疗组,而不是对相同治疗的重复测量。本研究中使用的样本量在先前cas9/aav6介导的基因组编辑研究中报告的范围内(21-23)。在执行本文报告的任何实验之前,没有建立数据排除标准,并且在实验结束后也没有排除数据。在可能的情况下,所有实验都在至少三个或更多个cd34
+
hspc供体中重复。对此的一个例外是来源于单个hspc供体的图5中报告的数据,这是由于我们对β-地中海贫血患者的访问有限。对实验组进行的所有统计测试均使用prism7 graphpad软件完成。双尾非配对t检验用于确定治疗组之间的统计学差异。确定了所有治疗组的样品方差,并且在发现不相等的情况下,韦尔奇t检验(welch’s t test)也证实了统计显著性。实施例2:另外的实验和数据
[0174]
我们检查了β-地中海贫血患者来源的hspc中的靶向、β-珠蛋白产生和植入数据。图16a显示了如通过流式细胞术测定的获取rbc表面标志物gpa和cd71的cd34-/cd45-hspc的百分比,以及图16b显示了如通过ddpcr测定的β-地中海贫血来源的hspc中hba1处的靶向等位基因频率。在靶向的hspc分化为rbc后,收获mrna,将其转化为cdna,并将hba(不区分hba1和hba2)和hbb转基因的表达归一化为hbg表达(图16c)。显示hgba归一化为hgbf的血红蛋白四聚体hplc结果显示于图16d中,并且hspc的靶向和rbc分化之后的每个处理的代表性血红蛋白四聚体hplc图显示于图16e中。指示了hgbf和hgba四聚体峰的保留时间。图16f提供了显示β-珠蛋白的曲线下面积(auc)/α-珠蛋白的auc的反相珠蛋白链hplc结果的总结,以及图16g呈现了hspc的靶向和rbc分化后每种处理的代表性反相珠蛋白链hplc图。
[0175]
在将靶向的β-地中海贫血来源的hspc移植到nsg小鼠中后16周,收获骨髓并测定植入率(图17a)。在植入的人细胞中,在b细胞、髓细胞或其他(即hspc/rbc/t/nk/前b)谱系之间的分布显示于图17b中。hba1处的靶向等位基因频率显示于图17c中,如在成批样品中植入的人细胞以及cd19
+
(b细胞)、cd33
+
(髓细胞)和其他(即hspc/rbc/t/nk/前b)谱系中(二次移植实验中)通过ddpcr测定的。
[0176]
我们还检查了由hba1靶向grna 5生成的插入缺失谱的另外方面。图18a提供了描绘所有五条引导序列在基因组基因座处的位置的示意图,以及图18b呈现了由tide软件生成的hba1特异性sg5的代表性插入缺失谱。
[0177]
我们还检查了hspc中靶向后的活力数据。通过流式细胞术在编辑后2-4天量化hspc活力,并测定对ghostred活力染料呈染色阴性的细胞百分比(图19)。使用标准条件(即cas9 rnp+sg5的电穿孔,aav的5k moi和24小时无aav洗涤)使用我们优化的hbb基因替换载体编辑所有细胞。
[0178]
我们由双色靶向载体生成了数据,以在靶向hba1时深入了解单等位基因和双等位基因的编辑频率。图20a显示了由hba1-wgr-gfp aav6和hba1-wgr-mplum aav6同时靶向的cd34
+
hspc的代表性facs图。测定了用仅gfp、仅mplum和两种颜色靶向的群体百分比(图20b)。对于图20b中所示的数据,还将编辑的细胞百分比相对于编辑的等位基因百分比作图(图20c)。
[0179]
我们还获得了用于红血细胞递送的在hba1处的定制转基因整合(使用如pah或fxi作为转基因)的更新数据。获取rbc表面标志物gpa和cd71的cd34-/cd45-hspc的百分比通过流式细胞术测定(图21a)。我们还测定了如通过ddpcr测定的原代hspc中hba1处的靶向的等位基因频率(图21b)。图21c显示了如通过fix elisa测定的,在原代hspc中靶向和红血细胞分化后细胞裂解物和上清液中的fix产生,以及图21d显示了在用表达转基因的质粒电穿孔的293t细胞的上清液中,酪氨酸的产量作为pah活性的代表。在rbc分化过程期间在hba1处用组成型gfp和无启动子yfp整合载体靶向的原代hspc的rbc百分比通过流式细胞术测定(图21e),并且也测定了图21e中所示的靶向的hspc的gfp百分比。图21g显示了相对于图21f中所示的gfp
+
群体的d0测量的mfi倍数变化。实施例3:用于挽救疾病特异性治疗性蛋白的示例性dna供体。
[0180]
该实施例提供了可用于在hba1或hba2基因座处敲入基因的供体模板的几个非限制性实例。
[0181]
粘多糖贮积症1型:敲入idua cdna以过表达idua酶。序列元件:左同源臂:1-500bppgk启动子:501-1001bpidua cdna:1002-2960bpt2a-tngfr:2961-3848bpbgh polya:3849-4099bp右同源臂:4100-4599bp序列:tttcatgaattcccccaacagagccaagctctccatctagtggacagggaagctagcagcaaaccttcccttcactacaaaacttcattgcttggccaaaaagagagttaattcaatgtagacatctatgtaggcaattaaaaacctattgatgtataaaacagtttgcattcatggagggcaactaaatacattctaggactttataaaagatcactttttatttatgcacagggtggaacaagatggattatcaagtgtcaagtccaatctatgacatcaattattatacatcggagccctgccaaaaaatcaatgtgaagcaaatcgcagcccgcctcctgcctccgctctactcactggtgttcatctttggttttgtgggcaacatgctggtcatcctcatcctgataaactgcaaaaggctgaagagcatgactgacatctacctgctcaacctggccatctctgacctgtttttccttcttactgtccccttctctagataccgggtaggggaggcgcttttcccaaggcagtctggagcatgcgctttagcagccccgctgggcacttggcgctacacaagtggcctctggcctcgcacacattccacatccaccggtaggcgccaaccggctccgttctttggtggccccttcgcgccaccttctac
tcctcccctagtcaggaagttcccccccgccccgcagctcgcgtcgtgcaggacgtgacaaatggaagtagcacgtctcactagtctcgtgcagatggacagcaccgctgagcaatggaagcgggtaggcctttggggcagcggccaatagcagctttgctccttcgctttctgggctcagaggctgggaaggggtgggtccgggggcgggctcaggggcgggctcaggggcggggcgggcgcccgaaggtcctccggaggcccggcattctgcacgcttcaaaagcgcacgtctgccgcgctgttctcctcttcctcaggatccatgcgtcccctgcgcccccgcgccgcgctgctggcgctcctggcctcgctcctggccgcgcccccggtggccccggccgaggccccgcacctggtgcatgtggacgcggcccgcgcgctgtggcccctgcggcgcttctggaggagcacaggcttctgccccccgctgccacacagccaggctgaccagtacgtcctcagctgggaccagcagctcaacctcgcctatgtgggcgccgtccctcaccgcggcatcaagcaggtccggacccactggctgctggagcttgtcaccaccagggggtccactggacggggcctgagctacaacttcacccacctggacgggtacctggaccttctcagggagaaccagctcctcccagggtttgagctgatgggcagcgcctcgggccacttcactgactttgaggacaagcagcaggtgtttgagtggaaggacttggtctccagcctggccaggagatacatcggtaggtacggactggcgcatgtttccaagtggaacttcgagacgtggaatgagccagaccaccacgactttgacaacgtctccatgaccatgcaaggcttcctgaactactacgatgcctgctcggagggtctgcgcgccgccagccccgccctgcggctgggaggccccggcgactccttccacaccccaccgcgatccccgctgagctggggcctcctgcgccactgccacgacggtaccaacttcttcactggggaggcgggcgtgcggctggactacatctccctccacaggaagggtgcgcgcagctccatctccatcctggagcaggagaaggtcgtcgcgcagcagatccggcagctcttccccaagttcgcggacacccccatttacaacgacgaggcggacccgctggtgggctggtccctgccacagccgtggagggcggacgtgacctacgcggccatggtggtgaaggtcatcgcgcagcatcagaacctgctactggccaacaccacctccgccttcccctacgcgctcctgagcaacgacaatgccttcctgagctaccacccgcaccccttcgcgcagcgcacgctcaccgcgcgcttccaggtcaacaacacccgcccgccgcacgtgcagctgttgcgcaagccggtgctcacggccatggggctgctggcgctgctggatgaggagcagctctgggccgaagtgtcgcaggccgggaccgtcctggacagcaaccacacggtgggcgtcctggccagcgcccaccgcccccagggcccggccgacgcctggcgcgccgcggtgctgatctacgcgagcgacgacacccgcgcccaccccaaccgcagcgtcgcggtgaccctgcggctgcgcggggtgccccccggcccgggcctggtctacgtcacgcgctacctggacaacgggctctgcagccccgacggcgagtggcggcgcctgggccggcccgtcttccccacggcagagcagttccggcgcatgcgcgcggctgaggacccggtggccgcggcgccccgccccttacccgccggcggccgcctgaccctcagacctgcacttagattgccttcccttttgttggtccacgtttgcgctaggcccgagaaaccgccaggacaagtaacacggcttcgggcgctgccacttactcaggggcagctggtgctggtttggtcagacgagcatgtcggaagcaaatgcctttggacctacgagatacaattttcacaggatggtaaggcttacactccggtctcaagaaagcccagtacctttaacctttttgtgttcagtccagatactggagcagtaagcggttcatatagagtcagagcgctggattactgggccaggcccggacctttctcagatccggtcccctacctggaagttcccgtgccgcggggtcctccatcaccaggcaacccaggaagcggagctactaacttcagcctgctgaagcaggctggagacgtggaggagaaccctggacctggggcaggtgccaccggccgcgccatggacgggccgcgcctgctgctgttgctgcttctgggggtgtcccttggaggtgccaaggaggcatgccccacaggcctgtacacacacagcggtgagtgctgcaaagcctgcaacctgggcgagggtgtggcccagccttgtggagccaaccagaccgtgtgtgagccctgcctggacagcgtgacgttctccgacgtggtgagcgcgaccgagccgtgcaagccgtgcaccgagtgcgtggggctccagagcatgtcggcgccatgcgtggaggccgacgacgccgtgtgccgctgcgcctacggctactaccaggatgagacgactgggcgctgcgaggcgtgccgcgtgtgcgaggcgggctcgggcctcgtgttctcctgccaggacaagcagaacaccgtgtgcgaggagtgccccgacggcacgtattccgacgaggccaaccacgtggacccgtgcctgccctgcaccgtgtgcgaggacaccgagcgccagctccgcgagtgcacacgctgggccgacgccgagtgcgaggagatccctggccgttggattacacggtccacacccccagagggctcgga
cagcacagcccccagcacccaggagcctgaggcacctccagaacaagacctcatagccagcacggtggcgggtgtggtgaccacagtgatgggcagctcccagcccgtggtgacccgaggcaccaccgacaacctcatccctgtctattgctccatcctggctgctgtggttgtgggtcttgtggcctacatagccttcaagaggtaataactcgagccgctgatcagcctcgactgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctactagttgggctcactatgctgccgcccagtgggactttggaaatacaatgtgtcaactcttgacagggctctattttataggcttcttctctggaatcttcttcatcatcctcctgacaatcgataggtacctggctgtcgtccatgctgtgtttgctttaaaagccaggacggtcacctttggggtggtgacaagtgtgatcacttgggtggtggctgtgtttgcgtctctcccaggaatcatctttaccagatctcaaaaagaaggtcttcattacacctgcagctctcattttccatacagtcagtatcaattctggaagaatttccagacattaaagatagtcatcttggggctggtcctgccgctgcttgtcatggtcatctgctactcgggaatcctaaaaactctgcttcggtgtcgaaatgagaagaagaggcacagggctgtgaggcttatcttcaccatcatgattgtttattttctcttctgggctccctacaa
[0182]
伤口愈合因子:敲入pgdfb中以过表达蛋白质。序列元件:左同源臂:1-538bpsffv启动子:539-1083bppdgf-b cdna:1084-1806bpt2a-gfp:1807-2550bpbgh polya:2551-2835bp右同源臂:2836-3255bp序列:gtcctgtaagtattttgcatattctggagacgcaggaagagatccatctacatatcccaaagctgaattatggtagacaaaactcttccacttttagtgcatcaacttcttatttgtgtaataagaaaattgggaaaacgatcttcaatatgcttaccaagctgtgattccaaatattacgtaaatacacttgcaaaggaggatgtttttagtagcaatttgtactgatggtatggggccaagagatatatcttagagggagggctgagggtttgaagtccaactcctaagccagtgccagaagagccaaggacaggtacggctgtcatcacttagacctcaccctgtggagccacaccctagggttggccaatctactcccaggagcagggagggcaggagccagggctgggcataaaagtcagggcagagccatctattgcttacatttgcttctgacacaactgtgttcactagcaacctcaaacagacaccatggtgcacctgactcctgaggagaagtctgccgttactgcccattaccctgttatccctaccgataaaataaaagattttatttagtctccagaaaaaggggggaatgaaagaccccacctgtaggtttggcaagctagctgcagtaacgccattttgcaaggcatggaaaaataccaaaccaagaatagagaagttcagatcaagggcgggtacatgaaaatagctaacgttgggccaaacaggatatctgcggtgagcagtttcggccccggcccggggccaagaacagatggtcaccgcagtttcggccccggcccgaggccaagaacagatggtccccagatatggcccaaccctcagcagtttcttaagacccatcagatgtttccaggctcccccaaggacctgaaatgaccctgcgccttatttgaattaaccaatcagcctgcttctcgcttctgttcgcgcgcttctgcttcccgagctctataaaagagctcacaacccctcactcggcgcgccagtcctccgacagactgagtcgcccgggggggtaccgagctcttcgaaggatccatcgccaccatgaatcgctgctgggcgctcttcctgtctctctgctgctacctgcgtctggtcagcgccgagggggaccccattcccgaggagctttatgagatgctgagtgaccactcgatccgctcctttgatgatctccaacgcctgctgcacggagaccccggagaggaagatggggccgagttggacctgaacatgacccgctcc
cactctggaggcgagctggagagcttggctcgtggaagaaggagcctgggttccctgaccattgctgagccggccatgatcgccgagtgcaagacgcgcaccgaggtgttcgagatctcccggcgcctcatagaccgcaccaacgccaacttcctggtgtggccgccctgtgtggaggtgcagcgctgctccggctgctgcaacaaccgcaacgtgcagtgccgccccacccaggtgcagctgcgacctgtccaggtgagaaagatcgagattgtgcggaagaagccaatctttaagaaggccacggtgacgctggaagaccacctggcatgcaagtgtgagacagtggcagctgcacggcctgtgacccgaagcccggggggttcccaggagcagcgagccaaaacgccccaaactcgggtgaccattcggacggtgcgagtccgccggccccccaagggcaagcaccggaaattcaagcacacgcatgacaagacggcactgaaggagacccttggagccggcagcggcgagggccgcggcagcctgctgacctgcggcgacgtggaggagaaccccggccccatgcccgccatgaagatcgagtgccgcatcaccggcaccctgaacggcgtggagttcgagctggtgggcggcggagagggcacccccgagcagggccgcatgaccaacaagatgaagagcaccaaaggcgccctgaccttcagcccctacctgctgagccacgtgatgggctacggcttctaccacttcggcacctaccccagcggctacgagaaccccttcctgcacgccatcaacaacggcggctacaccaacacccgcatcgagaagtacgaggacggcggcgtgctgcacgtgagcttcagctaccgctacgaggccggccgcgtgatcggcgacttcaaggtggtgggcaccggcttccccgaggacagcgtgatcttcaccgacaagatcatccgcagcaacgccaccgtggagcacctgcaccccatgggcgataacgtgctggtgggcagcttcgcccgcaccttcagcctgcgcgacggcggctactacagcttcgtggtggacagccacatgcacttcaagagcgccatccaccccagcatcctgcagaacgggggccccatgttcgccttccgccgcgtggaggagctgcacagcaacaccgagctgggcatcgtggagtaccagcacgccttcaagacccccatcgccttcgccagatctcgagtctagctcgagggcgcgcccgctgatcagcctcgacctgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggcttctgaggcggaaagaacgtttcgcgcctgtggggcaaggtgaacgtggatgaagttggtggtgaggccctgggcaggttggtatcaaggttacaagacaggtttaaggagaccaatagaaactgggcatgtggagacagagaagactcttgggtttctgataggcactgactctctctgcctattggtctattttcccacccttaggctgctggtggtctacccttggacccagaggttctttgagtcctttggggatctgtccactcctgatgctgttatgggcaaccctaaggtgaaggctcatggcaagaaagtgctcggtgcctttagtgatggcctggctcacctggacaacctcaagggcacctttgccacactgagtgagctgcactgtgacaagctgcacgtggatcctgagaacttcagggtgagtctatgggacgct
[0183]
β地中海贫血:将hbb基因(包括内含子)敲入hba1基因的外显子1中,其用hbb基因替换hba1基因。序列元件:左同源臂:1-880bphbb基因:881-2370bp右同源臂:2371-3249bp序列:gctccagccggttccagctattgctttgtttacctgtttaaccagtatttacctagcaagtcttccatcagatagcatttggagagctgggggtgtcacagtgaaccacgacctctaggccagtgggagagtcagtcacacaaactgtgagtccatgacttggggcttagccagcacccaccaccccacgcgccaccccacaaccccgggtagaggagtctgaatctggagccgcccccagcccagccccgtgctttttgcgtcctggtgtttattccttcccggtgcctgtcactcaagcacactagtgactatcgccagagggaaagggagctgcaggaagcgaggctggagagcaggaggggctctgcgcagaaattcttttgagttcctatgggccagggcgtccgggtgcgcgcattcctctccgccccaggattgggcgaag
cctcccggctcgcactcgctcgcccgtgtgttccccgatcccgctggagtcgatgcgcgtccagcgcgtgccaggccggggcgggggtgcgggctgactttctccctcgctagggacgctccggcgcccgaaaggaaagggtggcgctgcgctccggggtgcacgagccgacagcgcccgaccccaacgggccggccccgccagcgccgctaccgccctgcccccgggcgagcgggatgggcgggagtggagtggcgggtggagggtggagacgtcctggcccccgccccgcgtgcacccccaggggaggccgagcccgccgcccggccccgcgcaggccccgcccgggactcccctgcggtccaggccgcgccccgggctccgcgccagccaatgagcgccgcccggccgggcgtgcccccgcgccccaagcataaaccctggcgcgctcgcggcccggcactcttctggtccccacagactcagagagaacccaccatggtgcatctgactcctgaggagaagtctgccgttactgccctgtggggcaaggtgaacgtggatgaagttggtggtgaggccctgggcaggttggtatcaaggttacaagacaggtttaaggagaccaatagaaactgggcatgtggagacagagaagactcttgggtttctgataggcactgactctctctgcctattggtctattttcccacccttaggctgctggtggtctacccttggacccagaggttctttgagtcctttggggatctgtccactcctgatgctgttatgggcaaccctaaggtgaaggctcatggcaagaaagtgctcggtgcctttagtgatggcctggctcacctggacaacctcaagggcacctttgccacactgagtgagctgcactgtgacaagctgcacgtggatcctgagaacttcagggtgagtctatgggacgcttgatgttttctttccccttcttttctatggttaagttcatgtcataggaaggggataagtaacagggtacagtttagaatgggaaacagacgaatgattgcatcagtgtggaagtctcaggatcgttttagtttcttttatttgctgttcataacaattgttttcttttgtttaattcttgctttctttttttttcttctccgcaatttttactattatacttaatgccttaacattgtgtataacaaaaggaaatatctctgagatacattaagtaacttaaaaaaaaactttacacagtctgcctagtacattactatttggaatatatgtgtgcttatttgcatattcataatctccctactttattttcttttatttttaattgatacataatcattatacatatttatgggttaaagtgtaatgttttaatatgtgtacacatattgaccaaatcagggtaattttgcatttgtaattttaaaaaatgctttcttcttttaatatacttttttgtttatcttatttctaatactttccctaatctctttctttcagggcaataatgatacaatgtatcatgcctctttgcaccattctaaagaataacagtgataatttctgggttaaggcaatagcaatatctctgcatataaatatttctgcatataaattgtaactgatgtaagaggtttcatattgctaatagcagctacaatccagctaccattctgcttttattttatggttgggataaggctggattattctgagtccaagctaggcccttttgctaatcatgttcatacctcttatcttcctcccacagctcctgggcaacgtgctggtctgtgtgctggcccatcactttggcaaagaattcaccccaccagtgcaggctgcctatcagaaagtggtggctggtgtggctaatgccctggcccacaagtatcactaatggccatgcttcttgccccttgggcctccccccagcccctcctccccttcctgcacccgtacccccgtggtctttgaataaagtctgagtgggcggcagcctgtgtgtgcctgagttttttccctcagcaaacgtgccaggcatgggcgtggacagcagctgggacacacatggctagaacctctctgcagctggatagggtaggaaaaggcaggggcgggaggaggggatggaggagggaaagtggagccaccgcgaagtccagctggaaaaacgctggaccctagagtgctttgaggatgcatttgctctttcccgagttttattcccagacttttcagattcaatgcaggtttgctgaaataatgaatttatccatctttacgtttctgggcactctgtgccaagaactggctggctttctgcctgggacgtcactggtttcccagaggtcctcccacatatgggtggtgggtaggtcagagaagtcccactccagcatggctgcattgatcccccatcgttcccactagtctccgtaaaacctcccagatacaggcacagtctagatgaaatcaggggtgcggggtgcaactgcaggccccaggcaattcaataggggctctactttcacccccaggtcaccccagaatgctcacacaccagacactgacgccctggggctgtcaagatcaggcgtttgtctctgggcccagctcagggcccagctcagcacccactcagctcccctgaggctggggagcctgtcccattgcgactggagaggagagcggggccacagaggcctggctagaaggtcccttctccctggtgtgtgttttctctctgctgagcaggcttgcagtgcctggggtatca参考文献1.galanello,r.&origa,r.beta-thalassemia.orphanet j rare dis 5,11
cells.mol ther 26,2431-2442(2018).46.bak,r.o.&porteus,m.h.crispr-mediated integration of large gene cassettes using aav donor vectors.cell rep 20,750-756(2017).47.magoc,t.&salzberg,s.l.flash:fast length adjustment of short reads to improve genome assemblies.bioinformatics 27,2957-2963(2011).48.li,h.minimap2:pairwise alignment for nucleotide sequences.bioinformatics 34,3094-3100(2018).49.quinlan,a.r.&hall,i.m.bedtools:a flexible suite of utilities for comparing genomic features.bioinformatics 26,841-842(2010).50.pct publication no.wo2020208223.
[0184]
尽管为了清楚理解的目的已经通过说明和实例的方式对前述公开内容进行了一些详细的描述,但是本领域技术人员将理解在所附权利要求的范围内可以实施某些改变和修改。此外,本文提供的每篇参考文献均通过引用以其整体并入,其程度与每篇参考文献单独通过引用并入一样。非正式(部分)序列表seq id no:1sg1靶序列:5’ctaccgaggctccagcttaa-3
′
seq id no:2sg2靶序列:5
′‑
ggcaggaggaacggctaccg-3
′
;seq id no:3sg3靶序列:5
′‑
ggggaggagggcccgttggg-3
′
seq id no:4sg4靶序列:5
′‑
ccaccgaggctccagcttaa-3
′
;seq id no:5sg5靶序列:5
′‑
ggcaagaagcatggccaccg-3’seq id no:6将hbb基因(包括内含子)敲入hba1基因的外显子1的供体模板,用hbb基因替换hba1基因序列元件:左同源臂:1-880bphbb基因:881-2370bp右同源臂:2371-3249bpgctccagccggttccagctattgctttgtttacctgtttaaccagtatttacctagcaagtcttccatcagatagcatttggagagctgggggtgtcacagtgaaccacgacctctaggccagtgggagagtcagtcacacaaa
ctgtgagtccatgacttggggcttagccagcacccaccaccccacgcgccaccccacaaccccgggtagaggagtctgaatctggagccgcccccagcccagccccgtgctttttgcgtcctggtgtttattccttcccggtgcctgtcactcaagcacactagtgactatcgccagagggaaagggagctgcaggaagcgaggctggagagcaggaggggctctgcgcagaaattcttttgagttcctatgggccagggcgtccgggtgcgcgcattcctctccgccccaggattgggcgaagcctcccggctcgcactcgctcgcccgtgtgttccccgatcccgctggagtcgatgcgcgtccagcgcgtgccaggccggggcgggggtgcgggctgactttctccctcgctagggacgctccggcgcccgaaaggaaagggtggcgctgcgctccggggtgcacgagccgacagcgcccgaccccaacgggccggccccgccagcgccgctaccgccctgcccccgggcgagcgggatgggcgggagtggagtggcgggtggagggtggagacgtcctggcccccgccccgcgtgcacccccaggggaggccgagcccgccgcccggccccgcgcaggccccgcccgggactcccctgcggtccaggccgcgccccgggctccgcgccagccaatgagcgccgcccggccgggcgtgcccccgcgccccaagcataaaccctggcgcgctcgcggcccggcactcttctggtccccacagactcagagagaacccaccatggtgcatctgactcctgaggagaagtctgccgttactgccctgtggggcaaggtgaacgtggatgaagttggtggtgaggccctgggcaggttggtatcaaggttacaagacaggtttaaggagaccaatagaaactgggcatgtggagacagagaagactcttgggtttctgataggcactgactctctctgcctattggtctattttcccacccttaggctgctggtggtctacccttggacccagaggttctttgagtcctttggggatctgtccactcctgatgctgttatgggcaaccctaaggtgaaggctcatggcaagaaagtgctcggtgcctttagtgatggcctggctcacctggacaacctcaagggcacctttgccacactgagtgagctgcactgtgacaagctgcacgtggatcctgagaacttcagggtgagtctatgggacgcttgatgttttctttccccttcttttctatggttaagttcatgtcataggaaggggataagtaacagggtacagtttagaatgggaaacagacgaatgattgcatcagtgtggaagtctcaggatcgttttagtttcttttatttgctgttcataacaattgttttcttttgtttaattcttgctttctttttttttcttctccgcaatttttactattatacttaatgccttaacattgtgtataacaaaaggaaatatctctgagatacattaagtaacttaaaaaaaaactttacacagtctgcctagtacattactatttggaatatatgtgtgcttatttgcatattcataatctccctactttattttcttttatttttaattgatacataatcattatacatatttatgggttaaagtgtaatgttttaatatgtgtacacatattgaccaaatcagggtaattttgcatttgtaattttaaaaaatgctttcttcttttaatatacttttttgtttatcttatttctaatactttccctaatctctttctttcagggcaataatgatacaatgtatcatgcctctttgcaccattctaaagaataacagtgataatttctgggttaaggcaatagcaatatctctgcatataaatatttctgcatataaattgtaactgatgtaagaggtttcatattgctaatagcagctacaatccagctaccattctgcttttattttatggttgggataaggctggattattctgagtccaagctaggcccttttgctaatcatgttcatacctcttatcttcctcccacagctcctgggcaacgtgctggtctgtgtgctggcccatcactttggcaaagaattcaccccaccagtgcaggctgcctatcagaaagtggtggctggtgtggctaatgccctggcccacaagtatcactaatggccatgcttcttgccccttgggcctccccccagcccctcctccccttcctgcacccgtacccccgtggtctttgaataaagtctgagtgggcggcagcctgtgtgtgcctgagttttttccctcagcaaacgtgccaggcatgggcgtggacagcagctgggacacacatggctagaacctctctgcagctggatagggtaggaaaaggcaggggcgggaggaggggatggaggagggaaagtggagccaccgcgaagtccagctggaaaaacgctggaccctagagtgctttgaggatgcatttgctctttcccgagttttattcccagacttttcagattcaatgcaggtttgctgaaataatgaatttatccatctttacgtttctgggcactctgtgccaagaactggctggctttctgcctgggacgtcactggtttcccagaggtcctcccacatatgggtggtgggtaggtcagagaagtcccactccagcatggctgcattgatcccccatcgttcccactagtctccgtaaaacctcccagatacaggcacagtctagatgaaatcaggggtgcggggtgcaactgcaggccccaggcaattcaataggggctctactttcacccccaggtcaccccagaatgctcacacaccagacactgacgccctggggctgtcaagatcaggcgtttgtctctgggcccagctcagggcccagctcagcaccc
actcagctcccctgaggctggggagcctgtcccattgcgactggagaggagagcggggccacagaggcctggctagaaggtcccttctccctggtgtgtgttttctctctgctgagcaggcttgcagtgcctggggtatcaseq id no:7fix(padua变体)基因长度(具有内含子):2824bp序列:atgcagagggtgaacatgatcatggctgagagccctggcctgatcaccatctgcctgctgggctacctgctgtctgctgaatgtacaggtttgtttccttttttataatacattgagtatgcttgccttttagatatagaaatatctgattctgtcttcttcactaaattttgattacatgatttgacagcaatattgaagagtctaacagccagcacccaggttggtaagtactggttctttgttagctaggttttcttcttcttcacttttaaaactaaatagatggacaatgcttatgatgcaataaggtttaataaacactgttcagttcagtatttggtcatgtaattcctgttaaaaaacagtcatctccttggtttaaaaaaattaaaagtgggaaaacaaagaaatagcagaatatagtgaaaaaaaataaccacagtatttttgtttggacttaccactttgaaatcaaattgggaaacaaaagcacaaacagtggccttatttacacaaaaagtctgattttaagatatgtgacaattcaaggtttcagaagtatgtaaggaggtgtgtctctaattttttaaattatatatcttcaatttaaagttttagttaaaacataaagattaacctttcattagcaagctgttagttatcaccaaagcttttcatggattaggaaaaaatcattttgtctctatctcaaacatcttggagttgatatttggggaaacacaatactcagttgagttccctaggggagaaaagcaagcttaagaattgacacaaagagtaggaagttagctattgcaacatatatcactttgttttttcacaactacagtgactttatttatttcccagaggaaggcatacagggaagaaattatcccatttggacaaacagcatgttctcacagtaagcacttatcacacttacttgtcaactttctagaatcaaatctagtagctgacagtaccaggatcaggggtgccaaccctaagcacccccagaaagctgactggccctgtggttcccactccagacatgatgtcagctgtgaaatccacctccctggaccataattaggcttctgttcttcaggagacatttgttcaaagtcatttgggcaaccatattctgaaaacagcccagccagggtgatggatcactttgcaaagatcctcaatgagctattttcaagtgatgacaaagtgtgaagttaagggctcatttgagaactttctttttcatccaaagtaaattcaaatatgattagaaatctgaccttttattactggaattctcttgactaaaagtaaaattgaattttaattcctaaatctccatgtgtatacagtactgtgggaacatcacagattttggctccatgccctaaagagaaattggctttcagattatttggattaaaaacaaagactttcttaagagatgtaaaattttcatgatgttttcttttttgctaaaactaaagaattattcttttacatttcagtttttcttgatcatgaaaatgccaacaaaattctgaatagaccaaagaggtataactctggcaagcttgaagagtttgtacaggggaatctggagagagagtgtatggaagagaagtgcagctttgaggaagccagagaagtgtttgaaaatacagagagaacaactgaattttggaagcagtatgtggatggtgatcaatgtgagagcaatccctgcttgaatggggggagctgtaaagatgatatcaacagctatgaatgttggtgtccctttggatttgaggggaaaaactgtgagcttgatgtgacctgtaatatcaagaatggcaggtgtgagcaattttgcaagaattctgctgataacaaagtggtctgtagctgcactgagggatataggctggctgaaaaccagaagagctgtgaacctgcagtgccttttccctgtgggagagtgtctgtgagccaaaccagcaagctgactagggctgaagcagtctttcctgatgtagattatgtgaatagcactgaggctgagacaatccttgacaatatcactcagagcacacagagcttcaatgacttcaccagggtggtaggaggggaggatgccaagcctgggcagttcccctggcaggtagtgctcaatggaaaagtggatgccttttgtggaggttcaattgtaaatgagaagtggattgtgactgcagcccactgtgtggaaactggagtcaagattactgtggtggctggagagcacaatattgaggaaactgagcacactgagcagaagaggaatgtgatcaggattatcccccaccacaactacaatgctgctatcaacaagtacaaccatgacattgccctcctggaactggatgaacccctggtcttgaacagctatgtgacacccatctgtattgctgataaagagtacaccaacatcttcttgaaatttgggtctggatatgtgtctggctggggcagggtgttccataaaggcaggtct
gccctggtattgcagtatttgagggtgcctctggtggatagagcaacctgcttgctgagcaccaagtttacaatctacaacaatatgttctgtgcagggttccatgaaggtggtagagacagctgccagggagattctgggggtccccatgtgactgaggtggagggaaccagcttcctgactgggattatcagctggggtgaggagtgtgctatgaagggaaagtatgggatctacacaaaagtatccagatatgtgaactggattaaggagaaaaccaagctgacttgaseq id no:8ldlrcdna长度(无内含子):2460bp序列:atggggccctggggctggaaattgcgctggaccgtcgccttgctcctcgccgcggcggggactgcagtgggcgacagatgcgaaagaaacgagttccagtgccaagacgggaaatgcatctcctacaagtgggtctgcgatggcagcgctgagtgccaggatggctctgatgagtcccaggagacgtgctcccccaagacgtgctcccaggacgagtttcgctgccacgatgggaagtgcatctctcggcagttcgtctgtgactcagaccgggactgcttggacggctcagacgaggcctcctgcccggtgctcacctgtggtcccgccagcttccagtgcaacagctccacctgcatcccccagctgtgggcctgcgacaacgaccccgactgcgaagatggctcggatgagtggccgcagcgctgtaggggtctttacgtgttccaaggggacagtagcccctgctcggccttcgagttccactgcctaagtggcgagtgcatccactccagctggcgctgtgatggtggccccgactgcaaggacaaatctgacgaggaaaactgcgctgtggccacctgtcgccctgacgaattccagtgctctgatggaaactgcatccatggcagccggcagtgtgaccgggaatatgactgcaaggacatgagcgatgaagttggctgcgttaatgtgacactctgcgagggacccaacaagttcaagtgtcacagcggcgaatgcatcaccctggacaaagtctgcaacatggctagagactgccgggactggtcagatgaacccatcaaagagtgcgggaccaacgaatgcttggacaacaacggcggctgttcccacgtctgcaatgaccttaagatcggctacgagtgcctgtgccccgacggcttccagctggtggcccagcgaagatgcgaagatatcgatgagtgtcaggatcccgacacctgcagccagctctgcgtgaacctggagggtggctacaagtgccagtgtgaggaaggcttccagctggacccccacacgaaggcctgcaaggctgtgggctccatcgcctacctcttcttcaccaaccggcacgaggtcaggaagatgacgctggaccggagcgagtacaccagcctcatccccaacctgaggaacgtggtcgctctggacacggaggtggccagcaatagaatctactggtctgacctgtcccagagaatgatctgcagcacccagcttgacagagcccacggcgtctcttcctatgacaccgtcatcagcagagacatccaggcccccgacgggctggctgtggactggatccacagcaacatctactggaccgactctgtcctgggcactgtctctgttgcggataccaagggcgtgaagaggaaaacgttattcagggagaacggctccaagccaagggccatcgtggtggatcctgttcatggcttcatgtactggactgactggggaactcccgccaagatcaagaaagggggcctgaatggtgtggacatctactcgctggtgactgaaaacattcagtggcccaatggcatcaccctagatctcctcagtggccgcctctactgggttgactccaaacttcactccatctcaagcatcgatgtcaacgggggcaaccggaagaccatcttggaggatgaaaagaggctggcccaccccttctccttggccgtctttgaggacaaagtattttggacagatatcatcaacgaagccattttcagtgccaaccgcctcacaggttccgatgtcaacttgttggctgaaaacctactgtccccagaggatatggttctcttccacaacctcacccagccaagaggagtgaactggtgtgagaggaccaccctgagcaatggcggctgccagtatctgtgcctccctgccccgcagatcaacccccactcgcccaagtttacctgcgcctgcccggacggcatgctgctggccagggacatgaggagctgcctcacagaggctgaggctgcagtggccacccaggagacatccaccgtcaggctaaaggtcagctccacagccgtaaggacacagcacacaaccacccgacctgttcccgacacctcccggctgcctggggccacccctgggctcaccacggtggagatagtgacaatgtctcaccaagctctgggcgacgttgctggcagaggaaatgagaagaagcccagtagcgtgagggctctgtccattgtcctccccatcgtgctcctcgtcttcctttgcctgggggtcttccttctatggaagaactggcggcttaagaacatcaacagcatcaactttgacaaccccgtctatcagaagaccacagaggat
gaggtccacatttgccacaaccaggacggctacagctacccctcgagacagatggtcagtctggaggatgacgtggcgtga
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1