一种基于深度强化学习的列车受电弓智能控制方法
1.本发明属于高速铁路受电弓的智能控制技术领域,尤其涉及一种基于深度强化学习的列车受电弓智能控制方法。
背景技术:
2.高速铁路的快速发展,对牵引供电系统的运行安全性提出了更高的要求。随着我国铁路往重载化和高速化方向发展,受电弓与接触网系统的耦合性能随着振动加剧现象日益恶化。受电弓-接触网系统是一个复杂的动力学系统。传统的优化方式主要从受电弓结构优化、接触网性能优化和弓网参数匹配等角度出发,但是花费的经济成本巨大难以推动。受电弓的主动控制是一项弓网性能优化技术。当受电弓与接触网接触力过大时,会导致接触线和受电弓碳滑板过度磨损,影响产品服务寿命。当受电弓与接触网接触力过小时,会导致受电弓与接触网脱离接触,造成离线电弧,灼伤受电弓碳滑板,并且产生谐波影响电流质量。
技术实现要素:
3.为实现对受电弓进行快速的智能控制,避免接触线和受电弓碳滑板过度磨损,提高列车受流质量,保障列车安全。本发明提供一种基于深度强化学习的列车受电弓智能控制方法。
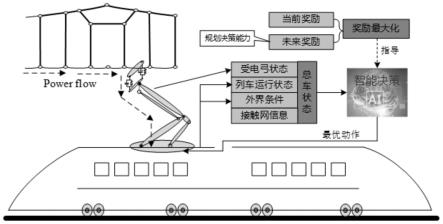
4.本发明的一种基于深度强化学习的列车受电弓智能控制方法,控制系统包括气囊、供气源、精密调压阀、控制器和信息采集单元;供气源连接气囊用于提供稳定气压,精密调压阀用于精确控制气囊压强,控制单元连接精密调压阀用于输出控制信号,信息采集单元用于采集控制器决策所用信息。控制方法具体包括以下步骤:
5.步骤1:信息采集单元获取受电弓状态信息、列车运行信息和接触网信息。
6.步骤2:建立控制器控制动作与接触网交互样本数据集。
7.步骤3:基于步骤2所建立的交互样本数据集,采用深度强化学习网络学习最优行为策略。
8.步骤4:根据步骤3的最优行为策略作为控制器,将控制器补偿动作输出受电弓气阀板上的精密调压阀从而控制气囊压强。
9.进一步的,步骤1中的受电弓状态信息包括受电弓升弓高度、弓头垂向速度、弓头垂向加速度和开闭口方向;列车运行信息包括列车运行速度和运行方向;接触网信息包括接触网的刚度、跨度和吊弦分布信息。
10.进一步的,步骤2具体为:
11.步骤21:定义深度强化学习马尔可夫决策环境关键要素:状态空间,动作空间和奖励函数:
12.1)状态空间:状态空间包含所有步骤1的状态信息,其表示为:
13.s={s|s
t
=(s
pantograph
,s
catenary
,s
train
)}
14.其中,s
pantograph
表示受电弓状态信息,s
catenary
表示接触网信息,s
train
表示列车运行信息。
15.2)动作空间:动作空间包含气囊气压变化的范围,其表示为:
16.a={a|a
min
≤a
t
≤a
max
}
17.其中,a
min
表示气囊最小设定气压,a
max
表示气囊最大设定气压。
18.3)奖励函数:奖励函数用于奖励策略网络向最优策略收敛;
19.r
t
=-|f
r-f
pc
(t)|
20.其中,fr表示最优弓网接触力,f
pc
(t)表示实际弓网接触力。
21.步骤22:以运行线路参数和受电弓参数建立虚拟仿真平台生成虚拟仿真样本库。
22.步骤23:步骤22样本获取过程如下:
23.深度强化学习网络获得当前时间步状态s
t
并生成动作a
t
给受电弓气阀板,气阀板执行控制后,深度强化学习网络获得奖励r
t
和下一时间步受电弓状态s
t+1
。这产生样本(s
t
,a
t
,r
t
,s
t+1
)并存储在数据库中,重复以上步骤直至训练结束。
24.步骤24:以运行线路参数和实际受电弓建立半实物半虚拟平台建立平台样本库,样本获取过程同步骤23。
25.步骤25:收集实际在线运营列车受电弓和实际铁路线路接触网交互数据建立实际样本库,样本获取过程同步骤23。
26.进一步的,步骤3具体为:
27.步骤31:利用步骤2产生的3个样本库,轮流训练深度强化学习网络。
28.步骤32:步骤31的深度强化学习网络具有1个策略网络和4个评估网络;策略网络用于输出最优动作,评估网络用于评估策略网络输出的策略是否优秀,并指导其生成最优策略。
29.步骤33:步骤32的策略网络输入状态信息,输出最优动作;使用π表示策略网络,φ表示策略网络的参数。从数据库中采样一批样本(s
t
,a
t
,r
t
,s
t+1
)训练策略网络,其损失函数写为:
[0030][0031]
其中m表示采样样本的数量,qi(s
t
,a
t
)
i=1,2
表示两个评估网络,s
t
,a
t
表示样本中状态和动作值。
[0032]
步骤34:步骤33的评估网络输入状态信息和动作,输出状态动作价值,有两种策略网络,使用q表示当前策略网络,使用θ表示其参数;使用q
target
目标策略网络,使用表示其参数;每种网络训练两个网络用于减少方差和稳定训练,使用θ1和θ2表示。
[0033]
当前评估网络参数的损失函数写为:
[0034][0035]
q(s
t+1
,a
t+1
)=min(q1(s
t+1
,a
t+1
),q2(s
t+1
,a
t+1
))
[0036]qtarget
(s
t+1
,a
t+1
)=min(q
1target
(s
t+1
,a
t+1
),q
2target
(s
t+1
,a
t+1
))
[0037]
目标策略网络通过当前评估网络参数定期软更新:
[0038][0039]
其中τ表示软更新的速度。
[0040]
进一步的,步骤4具体为:接受控制器输出的设定气囊气压,并将设定气囊气压设定于受电弓气阀板上的精密调压阀从而控制气囊压强。
[0041]
本发明的有益技术效果为:
[0042]
1.本发明通过深度强化学习方法对高铁受电弓的精准、提前控制,保证受电弓和接触网的良好接触,提升列车的受流质量,降低接触部件的磨损、提升服役寿命。
[0043]
2.本发明受电弓与接触网的长期运行特征,利用深度强化学习方法智能化地学习最优控制策略。
[0044]
3.本发明方法能够有效利用的具体线路在线运行的数据样本,持续性地优化具体线路的控制策略,优化列车受流条件。
附图说明
[0045]
图1为本发明方法处理过程框图。
[0046]
图2为本发明马尔可夫决策过程环境定义。
[0047]
图3为本发明马尔可夫决策过程。
[0048]
图4为本发明的深度强化学习网络结构。
[0049]
图5为本发明在建立虚拟仿真平台时所使用的受电弓模型。
[0050]
图6为本发明在建立虚拟仿真平台时所使用的接触网模型。
[0051]
图7为本发明建立平台样本库所建立的半实物半虚拟平台。
[0052]
图8为本发明持续性地在线优化具体线路的控制方法,优化列车受流条件的流程图。
[0053]
图9为本发明控制策略在所建立虚拟仿真平台时验证的控制效果。
[0054]
图10为控制器输出的控制力时域和频域波形。
[0055]
图11为本发明控制策略在所建立半实物半虚拟平台验证的控制效果。
[0056]
图12为本发明控制策略在所建立半实物半虚拟平台验证的控制效果统计。
具体实施方式
[0057]
下面结合附图和具体实施例对本发明做进一步详细说明。
[0058]
本发明的一种基于深度强化学习的列车受电弓智能控制方法,控制系统包括气囊、供气源、精密调压阀、控制器和信息采集单元;供气源连接气囊用于提供稳定气压,精密调压阀用于精确控制气囊压强,控制单元连接精密调压阀用于输出控制信号,信息采集单元用于采集控制器决策所用信息。控制方法流程如图1所示,具体包括以下步骤:
[0059]
步骤1:信息采集单元获取受电弓状态信息、列车运行信息和接触网信息。
[0060]
受电弓状态信息包括受电弓升弓高度、弓头垂向速度、弓头垂向加速度和开闭口方向;列车运行信息包括列车运行速度和运行方向;接触网信息包括接触网的刚度、跨度和吊弦分布信息。
[0061]
步骤2:建立控制器控制动作与接触网交互样本数据集。
[0062]
步骤21:定义深度强化学习马尔可夫决策环境关键要素:状态空间,动作空间和奖
励函数。
[0063]
1)状态空间:状态空间包含所有步骤1的状态信息,其表示为:
[0064]
s={s|s
t
=(s
pantograph
,s
catenary
,s
train
)}
[0065]
其中,s
pantograph
表示受电弓状态信息,s
catenary
表示接触网信息,s
train
表示列车运行信息。
[0066]
2)动作空间:动作空间包含气囊气压变化的范围,其表示为:
[0067]
a={a|a
min
≤a
t
≤a
max
}
[0068]
其中,a
min
表示气囊最小设定气压,a
max
表示气囊最大设定气压。
[0069]
3)奖励函数:奖励函数用于奖励策略网络向最优策略收敛;
[0070]rt
=-|f
r-f
pc
(t)|
[0071]
其中,fr表示最优弓网接触力,f
pc
(t)表示实际弓网接触力。
[0072]
图2为本发明所述的马尔可夫决策过程环境定义,图3本发明所述的马尔可夫决策过程。
[0073]
步骤22:以运行线路参数和受电弓参数建立虚拟仿真平台生成虚拟仿真样本库。
[0074]
步骤23:以运行线路参数和实际受电弓建立半实物半虚拟平台建立平台样本库。
[0075]
步骤24:收集实际在线运营列车受电弓和实际铁路线路接触网交互数据建立实际样本库。
[0076]
步骤3:基于步骤2所建立的交互样本数据集,采用深度强化学习网络学习最优行为策略。
[0077]
步骤31:利用步骤2产生的3个样本库,轮流训练深度强化学习网络。
[0078]
步骤32:如图4所示,步骤31的深度强化学习网络具有1个策略网络和4个评估网络;策略网络用于输出最优动作,评估网络用于评估策略网络输出的策略是否优秀,并指导其生成最优策略。
[0079]
步骤33:步骤32的策略网络输入状态信息,输出最优动作;使用π表示策略网络,φ表示策略网络的参数。从数据库中采样一批样本(s
t
,a
t
,r
t
,s
t+1
)训练策略网络,其损失函数写为:
[0080][0081]
其中,m表示采样样本的数量,qi(s
t
,a
t
)
i=1,2
表示两个评估网络,s
t
,a
t
表示样本中状态和动作值。
[0082]
步骤34:步骤33的评估网络输入状态信息和动作,输出状态动作价值,有两种策略网络,使用q表示当前策略网络,使用θ表示其参数;使用q
target
目标策略网络,使用表示其参数;每种网络训练两个网络用于减少方差和稳定训练,使用θ1和θ2表示;
[0083]
当前评估网络参数的损失函数写为:
[0084][0085]
q(s
t+1
,a
t+1
)=min(q1(s
t+1
,a
t+1
),q2(s
t+1
,a
t+1
))
[0086]qtarget
(s
t+1
,a
t+1
)=min(q
1target
(s
t+1
,a
t+1
),q
2target
(s
t+1
,a
t+1
))
[0087]
目标策略网络通过当前评估网络参数定期软更新:
[0088][0089]
其中τ表示软更新的速度。
[0090]
步骤4:根据步骤3的最优行为策略作为控制器,将控制器补偿动作输出受电弓气阀板上的精密调压阀从而控制气囊压强。
[0091]
接受控制器输出的设定气囊气压,并将设定气囊气压设定于受电弓气阀板上的精密调压阀从而控制气囊压强。
[0092]
实施案例:
[0093]
1、数据样本集建立。如图5、6所示,利用模型建立虚拟仿真平台,收集虚拟仿真样本库。如图7所示,以运行线路参数和实际受电弓建立半实物半虚拟平台,收集平台样本库。收集实际在线运营列车受电弓和实际铁路线路接触网交互数据建立实际样本库。
[0094]
2、虚拟仿真平台控制策略训练。根据如上建立的数据样本,利用深度强化学习方法训练最优控制策略。
[0095]
3、半实物半虚拟平台控制策略优化。将步骤2所训练的控制策略部署至半实物半虚拟平台,并利用半实物半虚拟平台所产生的平台样本库继续训练最优控制策略。
[0096]
4、控制策略在线运行微调。控制策略部署至实际线路后,根据运行数据建立实际样本库。控制策略从实际样本库中学习经验,并逐步微调控制策略,直至生成最优控制策略。整个控制策略训练流程图如图8所示。本发明控制策略在所建立虚拟仿真平台时验证的控制效果如图9所示,控制器输出的控制力时域和频域波形如图10所示。本发明控制策略在所建立半实物半虚拟平台验证的控制效果如图11所示,控制效果统计如图12所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1