一种基于博弈论的港口码头面自动驾驶换道决策方法与流程
1.本发明涉及无人驾驶技术领域,具体涉及一种基于博弈论的港口码头面自动驾驶换道决策方法。
背景技术:
2.近几年,随着人工智能的快速发展和传感器技术的突破,无人驾驶技术已经在一些特定场景中得到应用,比如:园区、矿山和港口等。对于港口码头来说,由于集卡司机的高昂成本及设施维护成本给港口运营带来的成本压力,无人驾驶集卡将会成为港口智能化改造的主要方向。港口集装箱的装卸过程通常会涉及三个作业环节,其中一个重要的环节是:货物通过岸桥设备,在码头面进行装卸箱。而在码头面上进行装卸箱时,常涉及到多车道规划和换道的情况,为了提高交通运输的效率和安全性,提高换道决策水平是必要的。
3.换道决策作为无人驾驶决策规划模块的子模块,以其过程的复杂性和决策的关键性一直备受广大学者的关注和研究。换道决策模块常采用的方法有间隙阈值接受模型和机器学习模型等。对于间隙阈值接受模型的方法来说,通过比较自车和前车、自车和目标车道的前后车距离进行换道判断,由于换道模型较为简单,故很难应对复杂的换道场景。对于机器学习方法来说,需要大量数据对模型进行训练,且在模型出现故障时,由于机器学习本身具有不可解释的性质,故很难对故障原因进行准确定位。
4.在换道过程中,由于目标车道的后方车辆可能选择减速让行或加速行驶等行为,所以任何换道行为的完成或放弃都是一方礼让或者妥协的产物,表现为两车的博弈平衡,否则两车之间的完全竞争将会导致交通事故的发生。
5.而博弈论为含有竞争倾向的问题提供了解决方法和分析手段,因此被广泛应用于各个领域中。每一个博弈的主要构成要素包括参与者、每个参与者所采取的策略以及参与者采取相应的策略所带来的收益函数。因此,可以应用博弈论研究换道过程中的多车动态交互作用。目前未见基于博弈论的港口码头面自动驾驶换道决策方法方面的报导。
技术实现要素:
6.为解决现有技术存在的问题,本发明提供一种基于博弈论的港口码头面自动驾驶换道决策方法,无需大量数据的处理和计算即能实现更合理的换道决策。
7.为此,本发明采用以下技术方案:
8.一种基于博弈论的港口码头面自动驾驶换道方法,包括以下步骤:
9.s1,通过换道车辆的车身传感器感知周围车辆信息;
10.s2,根据换道车辆和周围车辆的相对速度和距离,判断是否产生换道意图;
11.s3,若产生换道意图,则进入步骤s4;否则,返回到步骤s2;
12.s4,对于拟换道车辆,开始打转向灯并进行较小的横向移动以进行试探换道;
13.s5,考虑拟换道车辆和目标车道后方车辆之间的博弈:根据拟换道车辆的策略为换道或车道保持以及目标车道后方车辆的策略为避让或不避让构建换道博弈收益矩阵;
14.s6,根据拟换道车辆和目标车道后方车辆的总收益,进行换道博弈决策判断,其中:
15.总收益m计算公式为:
16.m=w1m
safety
+w2m
dist
+w3m
velocity
,
17.式中:
18.m
safety
为交互车辆在换道博弈中的安全收益;m
dist
为交互车辆在换道博弈中的距离收益;m
velocity
为交互车辆在换道博弈中的速度收益;w1、w2、w分别为m
safety
、m
dist
、m
velocity
的权重,且w1+w2+w3=1;
19.将所述安全收益、距离收益和速度收益进行归一化处理后引入到决策模型中,寻找最优策略,设cv为拟换道车辆,fv为前方车辆,lfv为目标车道的前方车辆,lrv为目标车道的后方车辆,在换道过程中,cv和lrv遵循两个参与者的stackelberg博弈,目标函数式为:
[0020][0021][0022]
约束条件定义如下:
[0023]vi
≥0,i=cv,lrv;
[0024]amin
≤ai≤a
max
,i=cv,lrv;
[0025]
sp
cv
》d
min
;
[0026]
式中:mi为i车的总收益;ai为i车的可能加速度,单位为m/s2;c
cv
为cv是否会换道;为cv的最佳加速度,单位为m/s2;为换道是否对cv有利;β2为lrv的最佳决策;λ
lrv
为已知cv的决策下,lrv的决策;a
min
为车辆最小加速度,单位为m/s2;a
ma
x为车辆最大加速度,单位为m/s2。
[0027]
其中,m
safety
计算公式如下:
[0028][0029]
式中,spt为换道t时刻的安全系数;sp0为换道开始时的安全系数,spt计算公式如下:
[0030][0031]
式中,th为换道t时刻的车头时距,单位为s;tb为期望车头时距,单位为s。
[0032]
其中,所述m
dist
以换道过程中车辆距离的变化表示,定义rp为两个交互车辆间的相对距离因子,则:
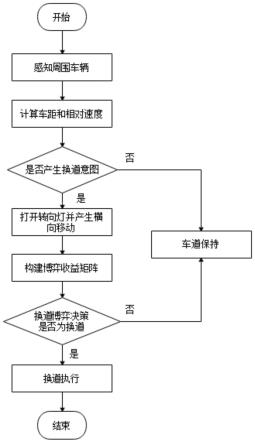
[0033][0034]
式中,rpt为换道t时刻的相对距离因子;rp0为换道开始时的相对距离因子。
[0035]
当cv与lrv在不同的车道上时,在t时刻相互作用的相对距离因子定义如下:
[0036][0037]
式中:rp
lrv-cv
(t)表示t时刻lrv的相对距离因子,lrv-cv表示lrv与cv交互;_lrv表示目标车道被lrv占用;
[0038]
其中,t
lrv-cv
表示lrv与cv的时间因子,表达式如下:
[0039][0040]
式中:d
lrv
为在道路坐标系上(沿道路方向)lrv的纵向距离;d
cv
为在道路坐标系上cv的纵向距离;v
lrv
为lrv的纵向速度;v
cv
为cv的纵向速度。
[0041]
其中,所述m
velocity
的计算公式如下:
[0042][0043]
式中:vpt为换道结束时的速度系数;vp0为换道开始时的速度系数;
[0044]
vp的计算方法如下:
[0045][0046][0047]
步骤s2中判断是否产生换道意图的方法如下:
[0048]
设v
cv
为本车实际车速,v
fv
为本车道内前车实际车速,v
lfv
为目标车道前车车速,v
lrv
为目标车道后车车速,c为速度优势因数,有:
[0049]
对于前车和左前车,速度因数c满足:
[0050]vcv
≤v
lfv
时,
[0051]vcv
》v
lfv
时,
[0052]
对于左后车,速度满足:
[0053]vcv
≥v
lrv
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0054]
当时认为前车行驶缓慢,进而产生换道意图,其中,为速度优势系数的阈值,通过在线标定获得。
[0055]
其中,最小跟车安全距离拟合公式如下:
[0056]
mfd=0.0029(v
cv
×
3.6)2+0.3049(v
cv
×
3.6)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0057]
当前车道前车与本车的间距产生换道意图的最大车间距s
max
:
[0058]smax
=(v
cv-v
fv
)
×
δt+mfd+d
safe
,v
cv
》v
fv
ꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0059]
目标车道前车与本车的间距产生换道意图的最小车间距s
min,lf
:
[0060]smin,lf
=(v
cv-v
lfv
)
×
δt+mfd+d
safe
,v
cv
》v
lfv
ꢀꢀꢀꢀꢀꢀꢀ
(6)
[0061]
或
[0062]smin,lfv
=mfd+d
safe
,v
cv
≤v
lfv
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0063]
目标车道后车与本车的间距产生换道意图的最小车间距s
min,lr
:
[0064]smin,lrv
=0.0029(v
lrv
×
3.6)2+0.3049(v
lrv
×
3.6)+d
safe
,v
cv
≥v
lrv
ꢀꢀꢀꢀꢀꢀꢀ
(8)
[0065]
式中,δt表示动态过程安全时间系数;d
safe
表示安全距离阈值。
[0066]
δt取值为0.5倍的换道时间;d
safe
为2~5m。
[0067]
所述周围车辆信息包括车辆的类别、位置、速度和朝向。
[0068]
与现有技术相比,本发明具有以下有益效果:
[0069]
本发明的基于博弈论的港口码头面自动驾驶换道决策方法综合考虑了动态场景下的最小安全间距、多车间的动态交互博弈的收益等因素,针对码头面经常需要换道的场景,通过博弈论的方式,在保证安全的前提下大大提高了决策模块对可换道时机的精准把控,进而提高了自动驾驶车辆在码头面的作业效率。同时,对安全的考量和效率的提高能够较好地处理不安全换道行为和长时间无法换道带来的排队时间浪费可能导致的安全员干预问题。
附图说明
[0070]
图1为多车道换道示意图;
[0071]
图2为本发明的基于博弈论的港口码头面自动驾驶换道决策方法的流程图。
具体实施方式
[0072]
下面结合附图对本发明的基于博弈论的港口码头面自动驾驶换道决策方法进行详细说明。
[0073]
如果相邻车道内的交通流速度整体较快、空间足够大,则拟换道车辆通过使用转向灯或发生较小的横向移动开始与周围车辆进行交互;然后,拟换道车辆通过车身传感器感知目标车道后方车辆的反应,根据后方交互车辆的反应是加速还是减速来确定是换道还是车道保持。
[0074]
换道过程一般分为三个阶段:换道意图产生,换道决策和换道执行。换道决策以及执行过程涉及多辆车的动态交互作用,是一个多车之间的博弈过程。而博弈论具有研究决策者之间交互作用的有利特点,因此,可以应用博弈论研究换道过程中的多车动态交互作用。
[0075]
根据博弈双方的期望收益,可以将博弈划分为合作博弈与非合作博弈:(1)在合作博弈的情况下,博弈双方组成联盟,在合作的基础上共享信息;(2)在非合作博弈下各参与者的策略从自身利益出发,博弈双方不存在交流。非合作博弈下根据参与者行动顺序的可见性和参与者信息的完整性可分为完全信息动态博弈、完全信息静态博弈、不完全信息动态博弈和不完全信息静态博弈四种类型。
[0076]
参见图2,本发明的基于博弈论的港口码头面自动驾驶换道决策方法包括以下步
骤:
[0077]
s1,通过换道车辆的车身传感器感知周围车辆信息,包括:类别、位置、速度和朝向等。
[0078]
s2,根据换道车辆和周围车辆的相对速度和距离,判断是否产生换道意图。
[0079]
参见图1,其中:cv为拟换道车辆,fv为前方车辆,lfv为目标车道(左车道)的前方车辆,lrv为目标车道的后方车辆。拟换道车辆cv做出从当前车道换道至目标车道的决策过程是与其他车辆交互博弈的过程。拟换道车辆cv为了规避一些潜在发生的风险或寻求更大速度空间、跟车距离等产生了换道意图,其他车辆要考虑自身所处的环境决定自己要不要为拟换道车辆cv让行,周围车辆采取的策略的不同将影响cv最终的决策结果。因此,车辆的换道决策过程可以视为一个博弈的过程,其包含博弈的所有基本要素,也能够达到博弈的均衡。
[0080]
本车道内前方车辆行驶缓慢,促使驾驶员产生换道意图的原因是目标车道上相对于本车道具有速度优势,因为前方缓慢行驶车辆使得本车在本车道内行驶的速度逐渐降低,而车辆为了获得更快的速度,进而产生了换道意图。因此目标车道具有速度优势的判断依据主要考虑本车道内前方车辆车速、本车期望车速、目标车道上最大限速等因素。设v
cv
为本车实际车速,v
fv
为本车道内前车实际车速,v
lfv
为目标车道前车车速,v
lrv
为目标车道后车车速,进而本发明定义了判断前方车辆行驶缓慢的方法。
[0081]
速度优势因数c反应的是目标车道相对于本车道的速度优势,进而可以得到公式(1)、(2)、(3)。在进行速度优势判断时,当时认为前车行驶缓慢,进而产生换道意图,其中,为速度优势系数的阈值,通过在线标定获得。
[0082]
对于前车和左前车,速度因数c满足:
[0083]vcv
≤v
lfv
时,
[0084]vcv
》v
lfv
时,
[0085]
对于左后车,速度满足:
[0086]vcv
≥v
lrv
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0087]
对于智能车的最小跟车安全距离,日本t.kuroda学者通过试验得到其拟合公式(kuroda t,wakitay,shimizu h,et al.simulation of generation and development of traffic jam in sag zone[j].transaction of the japan society for computational methods in engineering(in japanese),2008,8(11-081128).),最小跟车安全距离(mfd,minimum following distance)拟合公式如下:
[0088]
mfd=0.0029(v
cv
×
3.6)2+0.3049(v
cv
×
3.6)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0089]
a.当前车道前车与本车的间距产生换道意图的最大车间距s
max
:
[0090]smax
=(v
cv-v
fv
)
×
δt+mfd+d
safe
,v
cv
》v
fv
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0091]
b.目标车道前车与本车的间距产生换道意图的最小车间距s
min,lf
:
[0092]smin,lf
=(v
cv-v
lfv
)
×
δt+mfd+d
safe
,v
cv
》v
lfv
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0093]
或
[0094]smin,lfv
=mfd+d
safe
,v
cv
≤v
lfv
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0095]
c.目标车道后车与本车的间距产生换道意图的最小车间距s
min,lr
:
[0096]smin,lrv
=0.0029(v
lrv
×
3.6)2+0.3049(v
lrv
×
3.6)+d
safe
,v
cv
≥v
lrv
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0097]
式中:v
cv
表示本车车速;v
fv
表示前车车速;v
lfv
表示左前车车速;v
lrv
表示左后车车速;δt表示动态过程安全时间系数,一般取值为0.5倍的换道时长;d
safe
表示安全距离阈值,一般取2~5m。
[0098]
s3,若产生换道意图,则进入步骤s4,否则,返回到步骤s2,具体如下:
[0099]
第1步,判断目标车道相对于本车道是否有速度优势,若不具有速度优势,则输出不产生换道意图;若具有速度优势,则执行第2步,继续进行判断:
[0100]
第2步,判断当前车间距是否小于等于产生换道意图的最大车间距s
max
,若条件成立,则执行第3步,继续进行判断;若条件不成立,则输出不产生换道意图;
[0101]
第3步,判断目标车道左前车与本车的间距是否大于最小车间距s
min,lf
和s
min,lr
,若条件成立,则输出产生换道意图;若条件不成立,则输出不产生换道意图。
[0102]
s4,对于拟换道车辆,开始打转向灯并进行较小的横向移动以进行试探换道。
[0103]
s5,考虑拟换道车辆和目标车道后方车辆之间的博弈。根据拟换道车辆的策略为换道或车道保持以及目标车道后方车辆的策略为避让或不避让构建换道博弈收益矩阵。
[0104]
车辆换道过程在多数情况下是一个多辆车之间的博弈过程,即多车之间相互作用的过程。假设前车fv和左前车lfv对博弈过程影响较小,即只考虑拟换道车辆cv和目标车道后方车辆lrv之间的博弈。所以cv的决策为{换道、车道保持},lrv的决策为{避让、不避让}。则车辆换道博弈决策与结果如表1所示。
[0105]
两车博弈过程中知晓对方的坐标、车速、所处车道等信息,为完全信息博弈;两车同时采取换道、加减速等策略,为静态博弈;在博弈过程中,两车均为独立的个体,决策均从自身效益出发,为非合作博弈。综上所述,cv与lrv的博弈为完全信息下的非合作静态博弈,基本要素如下:
[0106]
1)参与者:这场博弈的参与者为换道车辆与其周围的车辆,本发明主要研究cv与lrv之间的博弈现象,故主要参与者为cv与lrv;
[0107]
2)策略:cv可以选择换道或者在原车道内继续行驶;lrv可以选择减速避让为cv提供换道空间,也可以选择加速阻止cv的换道行为;
[0108]
3)收益函数:拟换道车辆采取换道和车道保持策略都会带来一定的收益;目标车道后车亦然。
[0109]
在换道过程中,博弈各参与者的收益对应各车辆的驾驶收益,而在换道过程中,收益函数在决策过程中起着重要的作用。为了产生合理的决策逻辑,本发明设计并考虑三个收益函数的组合。第一个函数m
safety
量化交互车辆在换道博弈中的安全收益;第二个函数m
dist
量化交互车辆在换道博弈中的距离收益;第三个函数m
velocity
量化交互车辆在换道博弈中的速度收益。具体如下:
[0110]
(1)安全收益:
[0111]
安全收益以换道过程中的车辆运行安全系数表示,安全收益如下:
[0112]
[0113]
式中,spt为换道t时刻的安全系数;sp0为换道开始时的安全系数。
[0114]
车辆在换道t时刻的安全系数由车头时距表示,公式如下:
[0115][0116]
式中,th为换道t时刻的车头时距(s);tb为期望车头时距(s)。
[0117]
(2)距离收益:
[0118]
距离收益以换道过程中车辆距离的变化表示,rp定义为两个交互车辆间的相对距离因子。距离收益计算公式如下:
[0119][0120]
式中,rpt为换道t时刻的相对距离因子;rp0为换道开始时的相对距离因子。
[0121]
一辆车的相对距离因子rp值表明了它在博弈中的竞争优势,可以防止保证安全的3秒车头时距被与其交互的另一辆车侵入,其值为(-1,1)。当cv与lrv在不同的车道上时,在t时刻相互作用的相对距离因子如下所示:
[0122][0123]
式中:rp
lrv-cv
(t)表示t时刻lrv的相对距离因子,lrv-cv表示lrv与cv交互;_lrv表示目标车道被lrv占用;
[0124]
其中,t
lrv-cv
表示lrv与cv交互的时间因子,表达式如下:
[0125][0126]
式中:d
lrv
为在道路坐标系上(沿道路方向)lrv的纵向距离;d
cv
为在道路坐标系上cv的纵向距离;v
lrv
为lrv的纵向速度;v
cv
为cv的纵向速度。
[0127]
由以上公式可知,相距很远和并行行驶的空间因子分别为-1和1。如果两车相距不远,距离系数会随着相对距离的增加而逐渐增大。
[0128]
(3)速度收益:
[0129]
收益函数mvelocity由换道过程中的速度因子变化表示,vp定义为两个交互车辆间相对速度函数。收益函数公式如下:
[0130][0131]
式中:vpt为换道结束时的速度系数;vp0为换道开始时的速度系数。
[0132]
vp的计算方法如下:
[0133]
[0134][0135]
(4)总收益:
[0136]
总收益函数是三个收益的线性组合,如下:
[0137]
m=w1m
safety
+w2m
dist
+w3m
velocity
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0138]
式中:wi为各收益的权重,w1+w2+w3=1。
[0139]
在确定多车动态交互博弈的换道收益函数后,动态交互博弈的车辆需要,根据自身的驾驶收益来做出决策,为了便于决策,对于车辆cv和车辆lrv的收益矩阵如表1所示:
[0140]
表1 cv与lrv博弈收益矩阵
[0141][0142]mcv
、m
lrv
分别为cv与lrv的收益。
[0143]
s6,根据拟换道车辆和目标车道后方车辆的总收益,进行换道博弈决策判断。
[0144]
将安全收益、距离收益和速度收益进行归一化处理后引入到决策模型中,寻找最优策略。换道过程多车动态交互博弈的解决方案:从cv的角度出发,在考虑lrv的反应策略的同时,使驾驶收益的下限最大化。换言之,该解决方案是在满足约束条件的情况下,在最坏情况下使交互博弈双方的收益最大化的一组策略。在换道过程中,cv和lrv遵循2个参与者的stackelberg博弈。是一个双层优化问题,目标函数如式:
[0145][0146][0147]
由于博弈者对另一方运行状态的预测及反映无法做到十分准确和及时,因此,应在约束条件中增加车辆之间的最小安全距离d
min
,因此,约束条件定义如下:
[0148]vi
≥0,i=cv,lrv
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20)
[0149]amin
≤ai≤a
max
,i=cv,lrv
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(21)
[0150]
sp
cv
》d
min
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0151]
式中:mi为i车的总收益;ai为i车的可能加速度(m/s2);c
cv
为cv是否会换道;为cv的最佳加速度(m/s2);为换道是否对cv有利;β2为lrv的最佳决策;λ
lrv
为已知cv的决策下,lrv的决策;a
min
为车辆最小加速度(m/s2);a
ma
x为车辆最大加速度(m/s2)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1