一种故障饱和下的高速列车群组分布式数据驱动控制方法
本发明属于高速列车群组分布式控制领域,尤其涉及一种故障饱和下的高速列车群组分布式数据驱动控制方法。
背景技术:
1、高速列车是高速铁路的核心装备,更是我国重要的基础设施和大众化交通工具。大力发展高速动车组系统技术是我国经济、社会乃至攸关国家安全的重大战略需求,是《中国制造2025》、《中长期铁路网规划(2016-2025)》、《交通强国建设纲要》、《“十四五”铁路科技创新规划》等行动纲领、路线规划的重要支撑。基于大数据、移动互联网、云计算等高新技术,国内外轨道交通装备正在经历智能化的高速发展阶段。目前,智能驾驶在国外已经成为了轨道交通行业发展的必然趋势。国外主要列车设计制造公司(西门子、阿尔斯通、ge等)都在加大力度研究辅助驾驶、自动驾驶和无人驾驶。因此,面向下一代高速列车,开展智能驾驶关键技术研究是我国轨道交通发展的必然趋势。
2、一方面,为了进一步提升客运铁路的旅客运载能力,欧盟明确将基于车车通信的多列车虚拟协同控制作为增强客运铁路弹性和互操作性的关键技术。基于车车直接通信的高铁协同控制框架下,列车能够直接与其通信范围内“拓扑-邻接”的列车直接进行通信。多列车协同控制技术能够统筹多辆列车运行状态,考虑相邻列车安全距离,将多辆列车动态运行过程作为整体,统一制定控制策略,从而实现路网列车对调度命令执行的快速性和对外界干扰的鲁棒性。基于车车通信信息交互结构的列车协同控制作为下一代列控系统的核心技术,是提升高铁系统乘客运载能力和突发事件下列车安全、快速、高效调整的有效手段,部分技术已在城市轨道交通得到成功应用,但在高速铁路系统中尚属空白。
3、另一方面,已有的高速列车控制方法大多依赖列车动力学模型或部分模型信息完成控制策略的设计,而实际中列车运行内部机理复杂,加之外部环境多变和不确定因素较多,难以建立其精确的动态模型。近年来,随着科学技术、特别是信息科学技术的快速发展,交通运输系统发生了重大变化,对高速列车运行质量的要求越来越高,使得基于受控对象精确数学模型的控制理论和方法在实际中的应用变得越来越困难。此外,高速列车运行过程中,始终在产生大量的过程数据,这些数据隐含着系统状态变化等信息。如何有效利用这些数据以及这些数据中蕴含的知识,在难以建立受控系统较准确模型的条件下,实现对系统和生产过程的优化控制已成为控制理论界迫切需要解决的问题。因此,研究和发展数据驱动控制理论与方法是新时期控制理论发展与应用的必然选择,具有重大的理论与现实意义。
4、无模型自适应控制是一种典型的数据驱动控制方法,仅利用受控系统的输入输出数据进行控制器的设计和分析,能实现未知非线性受控系统的参数自适应控制和结构自适应控制,摆脱了控制器设计对受控系统数学模型的依赖及上述各种模型驱动的仿生孪生的理论难题,为控制理论的研究和实际应用提供了一种全新的控制理论与方法。
技术实现思路
1、针对上述问题,本发明提供一种故障饱和下的高速列车群组分布式数据驱动控制方法。
2、本发明的一种故障饱和下的高速列车群组分布式数据驱动控制方法,包括以下步骤:
3、步骤1:建立高速列车群组动力学归一化离散模型。考虑一组高速列车运行在同一条铁路线上,根据牛顿定理建立第j列车的动力学模型:
4、v(k+1,j)=v(k,j)+t(u(k,j)-f(k,j))
5、s(k+1,j)=s(k,j)+tv(k,j)+0.5t2(u(k,j)-f(k,j))
6、其中,k为采样时刻,j为车次,t为采样周期;变量v(k,j),s(k,j),u(k,j)和f(k,j)分别表示列车j的速度、位置、控制输入和总阻力。
7、步骤2:建立适用于控制器设计的等价线性化模型。
8、列车群组动力学模型满足:1.除有限采样时刻点外,函数f(·)对u(k,j)的偏导数是连续的;2.除有限采样时刻点外,函数f(·)满足广义lipschitz条件,即对于δu(k,j)≠0,对于任何k都有|δs(k+1,j)|≤b|δu(k,j)|,其中δu(k,j)=u(k,j)-u(k-1,j)、δs(k+1,j)=s(k+1,j)-s(k,j),且b>0表示一个常数。
9、构造非线性项:
10、f(s(k,j),s(k-1,j),v(k,j),v(k-1,j),u(k-1,j),u(k-1,j))
11、且令:
12、
13、然后,通过回顾δs(k,j)的定义、假设1和柯西中值定理,得到如下关系:
14、
15、其中表示f(·)在f(s(k,j),s(k-1,j),v(k,j),v(k-1,j),u(k-1,j),u(k-1,j))和f(s(k,j),s(k-1,j),v(k,j),v(k-1,j),u(k,j),u(k-1,j))之间的某一点上对u(k,j)的偏导数值。
16、对于每个采样时刻k,考虑以下带有变量的数据方程κ(k,j):
17、
18、由于δu(k,j)≠0,对于上述方程存在唯一的解κ*(k,j);定义后,非线性模型写成等价线性化模型δs(k+1,j)=φ(k,j)δu(k,j);根据假设2证明了φ(k,j)的有界性;因此,借助φ(k,j)将动力学未知的高速列车群组非线性模型转换为上述等价线性数据模型。
19、步骤3:设计高速列车群组数据驱动控制方案。
20、虑以下关于控制输入u(k,j)的准则函数:
21、j(u(k,j))=|sd(k+1)-s(k+1,j)|2+λ|u(k,j)-u(k-1,j)|2
22、其中λ是限制u(k,j)变化的正加权因子。
23、将得到的线性数据模型代入准则函数,并将其最小化,得到控制算法:
24、
25、设计以下准则函数来对φ(k,j)的值进行估计:
26、
27、其中μ>0为权重因子。
28、最小化上述准则函数得到:
29、
30、其中,为φ(k,j)的估计值,η∈(0,1]为步长因子。
31、步骤4:建立高速列车运行过程中间歇发生的执行器故障模型:
32、sfault(k,j)=α(k,j)s(k,j)
33、其中,sfault(k,j)代表执行器故障下实际可用的列车位置信息,α(k,j)={0,1}是一个随机伯努利变量,代表执行器的健康状态;若α(k,j)=1,代表当前时刻执行器健康状态良好,若α(k,j)=0则代表当前时刻的数据因故障而丢失;s(k,j)即为高速列车实际输出的位置信号。
34、高速列车的牵引动力由其上方的牵引网提供,该能量由于受到网压限制呈现出饱和特性;具体地,针对控制输入的饱和模型构建如下:
35、
36、其中,usat(k,j)为牵引网能够实际提供的控制输入信号,u(k,j)为控制器计算出的期望控制输入信号,umin为牵引网能够提供的最小能量,umax为牵引网能够提供的最大能量。
37、基于多智能体理论建立适用于高速列车群组的分布式数据驱动控制方法,利用图论对j个列车群组的通信拓扑进行建模,其中每列列车被视为一个独立的智能体,且只能与相邻的列车通信;将g=(v,e,a)定义为一个阶次为j的加权有向图,其中v={1,2,…j}表示j个顶点,e∈v×v是边的集合,a=[aij]j×j表示邻接矩阵,其中所有元素都是非负的;如果来自列车i的信息可以被列车j接收,则为aij=1,否则为aij=0;列车i的邻居表示为ni=(j∈v:((j,i)∈e));此外,期望轨迹由虚拟领导列车生成,其编号为0;因此,扩展后的有向图为阶次为j+1,其中和分别为对应的边矩阵和邻接矩阵。定义分布式误差如下:
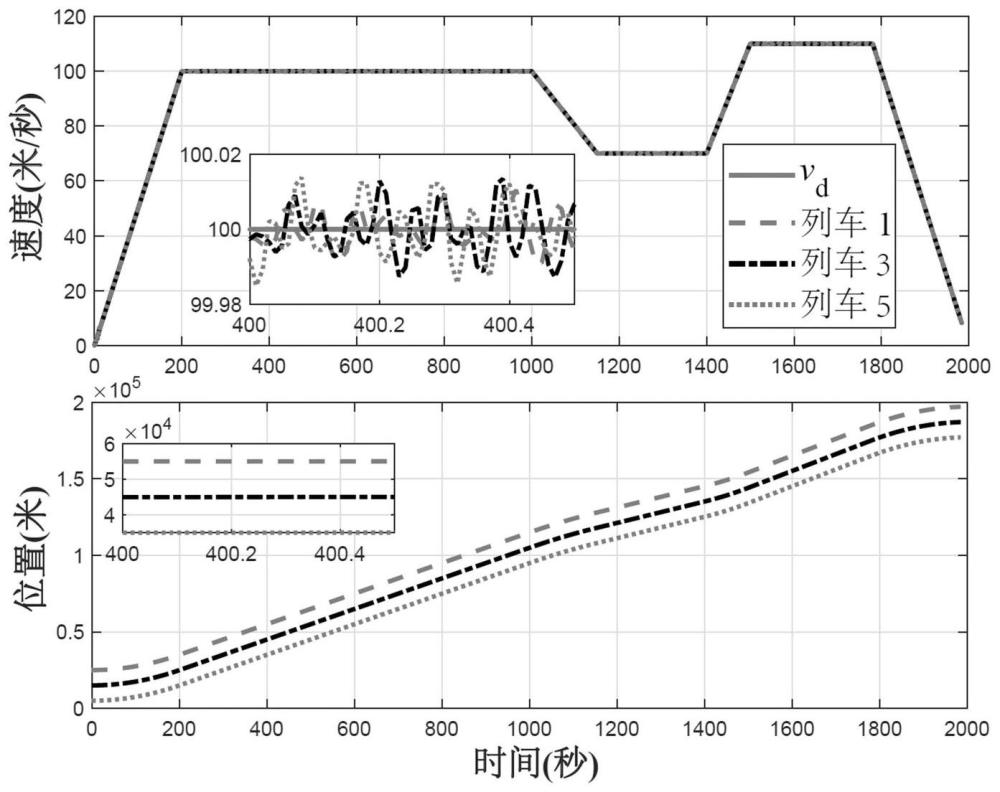
38、
39、其中jj表示列车j的邻域集,dj∈{0,1}中表示车头列车0与后面的列车j之间的通信关系;如果列车j可以从列车0访问所需的轨迹,则dj=1,否则dj=0;s表示两个相邻列车之间的最小安全距离,sd(k)-js表示列车j的期望轨迹。
40、考虑执行器间歇性故障和控制输入非线性饱和,适用于高速列车群组的分布式数据驱动抗饱和鲁棒控制方案设计如下:
41、
42、
43、
44、其中,δusat(k-1,j)=usat(k-1,j)-usat(k-2,j),δsfault(k,j)=sfault(k,j)-sfault(k-1,j);式中第二个方程为关于参数的重置算法,ε为一个小的正常数。
45、步骤5:在控制方案的基础上,将控制算法首先在数值仿真平台上进行验证,调整得到一套完整的、列车运行性能最优的控制器参数。进一步,将该方案移植到高速列车自动运行系统。
46、进一步的,步骤1中,根据戴维斯方程,f(k,j)被进一步描述为:f(k,j)=fb(k,j)+fa(k,j),其中,fb(k,j)代表基本运行阻力:
47、fb(k,j)=c0(k,j)+cv(k,j)v(k,j)+ct(k,j)v(k,j)2
48、其中,c0(k,j),cv(k,j)和ct(k,j)代表未知时变的阻力系数。
49、fa(k,j)代表附加阻力,满足:
50、fa(k,j)=m(j)g sin(θ(s(k,j)))+fc(s(k,j))+ft(s(k,j))
51、其中,m(j)、g和θ(s(k,j))分别为列车质量、重力加速度和线路坡道的坡度;未知非线性函数fc(·)和ft(·)与曲线和隧道有关。
52、列车模型和运行阻力仅与列车群组的历史速度和位置数据有关,且包含复杂的非线性和未知动力学;因此,上述动态模型可以改写为以下紧凑形式:
53、s(k+1,j)=f(s(k,j),s(k-1,j),v(k,j),v(k-1,j),u(k,j),u(k-1,j))
54、其中f(·)是一个未知的非线性函数。
55、进一步的,步骤5中控制器参数的选择需要满足以下条件:μ,λ>0、0<η≤1、0<ρ<0.5、ε设置为10-5或者10-6。
56、本发明的有益技术效果为:
57、一、本发明提出高速列车群组的数据驱动建模方法,得到了列车群的动态线性化数据模型。该建模方法与模型仅利用高速列车群组较易获得的位置信号和控制输入信息,摆脱了对系统模型先验信息的依赖,能够克服实际高速列车运行工况中列车动力学精准数学模型难以建立的难题,可同时为其他典型非线性系统的建模提供新的思路。
58、二、本发明在构造的等价线性化数据模型基础上,设计了由参数估计算法、参数重置算法以及控制输入算法组成的适用于高速列车群组的分布式数据驱动控制方案。这套方案不需要已知高速列车的精确非线性模型,且设计方法简单,易于在工程实际中得到应用。
59、三、本发明提出的适用于高速列车群组的分布式控制方案依托可靠的车车间直接通信网络。利用有向通信拓扑内的多车分布式跟踪误差信号代替了传统算法中用到的单列车跟踪误差信号,能够减少高速列车车间相对距离,提升列车群在区间内的运行密度,将进一步提升线路的运输效率和运载能力。
- 还没有人留言评论。精彩留言会获得点赞!