基于DDPG的线控转向系统转向补偿控制方法及装置
本发明涉及汽车转向系统技术领域,特别涉及一种基于ddpg的线控转向系统转向补偿控制方法及装置。
背景技术:
随着传统汽车理论的逐渐成熟以及电子科技工业水平和控制技术迅速发展,当今汽车工业的发展主题已经逐渐转变为智能化、电子化。汽车的转向系统作为汽车的五大系统之一,用来控制汽车行驶方向,是车辆稳定性控制的重要一环。线控转向利用执行电机来实现前轮转角对目标转角的跟随控制,为自动驾驶提供了良好的硬件基础。
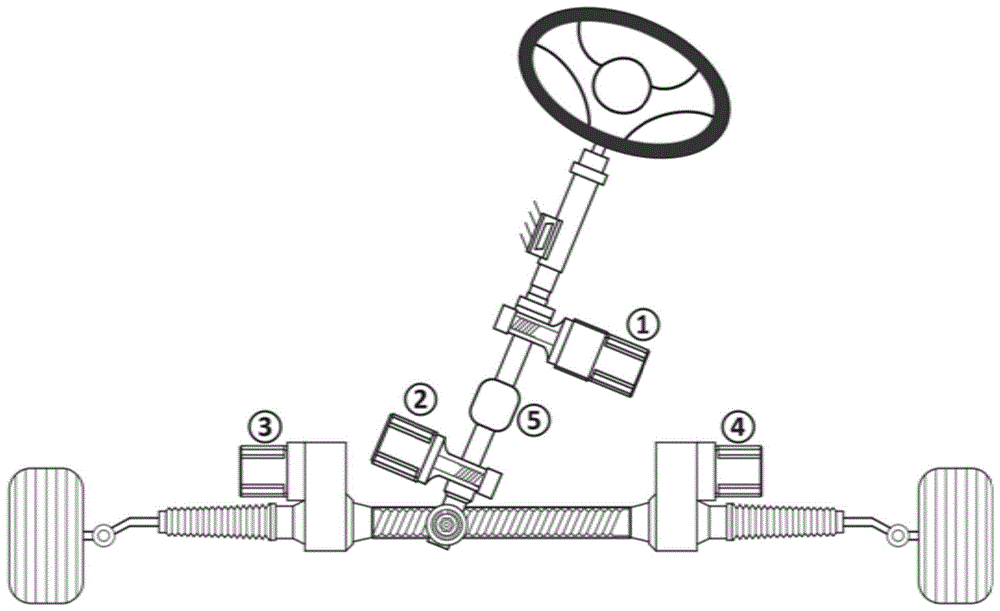
广义上来看,任何可以通过电信号控制而非通过驾驶员操纵的转向系统都可以看作sbw系统。如图1所示,转向系统中电机的可能安装位置有4个,即①转向管柱中间、②管柱末端、③和④转向齿条左右两端;管柱与齿条可以选择机械硬连接、离合软连接和完全分离,即⑤有三种形式。那么sbw的可能构型有3×24-1=47种。考虑到电机的类型可选无刷电机、永磁同步电机、双绕组电机等,传动机构可选蜗轮蜗杆、小齿轮、皮带轮、滚珠丝杠等之间的组合,sbw的最终方案有2000种以上。在实际控制过程中,线控转向系统的底层控制器的控制逻辑并不会开放给上层控制器,往往由车辆的上层控制器给出需要转向系统执行的目标前轮转角,通过控制器局域网(controllerareanetwork,can)通讯将目标前轮转角发送给线控转向的底层控制器,由底层控制器通过控制执行电机来实现这一目标转角,整体过程如图2所示。由于实际控制过程中,系统存在通讯延迟、转向系统迟滞等问题,线控转向系统实际的输出转角与上层控制器给出的目标值往往存在一定的误差以及响应延迟。此外,由于不同线控转向系统的控制策略并不相同,其控制效果往往也是千差万别。然而在实际车辆控制过程中,即便是很小的转向角的误差也会对控制效果产生很大的影响,尤其是在高速等极限工况下,前轮转角的误差极易引起车辆的失稳。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本发明的一个目的在于提出一种基于ddpg的线控转向系统转向补偿控制方法,该方法无需了解线控转向系统底层控制器的控制策略,可以广泛适配于任意结构形式的线控转向系统。
本发明的另一个目的在于提出一种基于ddpg的线控转向系统转向补偿控制装置。
为达到上述目的,本发明一方面实施例提出了一种基于ddpg的线控转向系统转向补偿控制方法,包括:
s1,建立线控转向系统的动作actor网络和动作价值critic网络,根据所述动作actor网络和所述动作价值critic网络构建深度确定性策略梯度学习算法框架;
s2,设计训练所需的奖励函数;
s3,根据所述奖励函数及所述深度确定性策略梯度学习算法框架建立深度确定性策略梯度算法;
s4,对所述深度确定性策略梯度算法进行硬件在环及实车训练,调整所述深度确定性策略梯度算法actor网络与critic网络的参数,以使所述深度确定性策略梯度算法得到目标转角补偿值。
另外,根据本发明上述实施例的基于ddpg的线控转向系统转向补偿控制方法还可以具有以下附加的技术特征:
进一步地,在本发明的一个实施例中,所述s1进一步包括:
s11,定义状态空间s={vx,wz,δ,δdes}和状态向量st=[vx_t,wz_t,δt,δt-1,δdes_t,δdes_t-1]t,st∈s,其中,vx为车辆纵向车速,wz为车辆横摆角速度,δ为实际转角,δdes为目标转角,t为当前时刻,t-1为上一时刻;
s12,建立所述动作actor网络a=μ(s|θμ),其中,μ表示actor网络,状态变量s为网络输入,θμ为网络参数,a为网络输出动作;
s13,建立所述动作价值critic网络q(s,a|θq),其中,q表示critic网络,状态变量s以及actor网络的输出动作a为输入,θq为网络参数。
进一步地,在本发明的一个实施例中,所述奖励函数为:
r=-w1|δdes-δa|-w2(δdes-δa)2-w3|δioutput|
其中,δdes为目标转角,δa为线控转向实际转角,δioutput为动作网络的当前输出和上一时刻的输出之间的距离,wi,i=1,2,3为各项的权重系数。
进一步地,在本发明的一个实施例中,所述动作actor网络和所述动作价值critic网络为隐层式神经网络。
进一步地,在本发明的一个实施例中,s3进一步包括:
s301,随机初始化在线critic网络q(s,a|θq)以及在线actor网络μ(s|θμ);
s302,初始化目标critic网络q(s,a|θq')以及目标actor网络μ(s|θμ'),θq'←θq,θμ'←θμ;
s303,初始化经验回放集r;
s304,在线actor网络基于状态s得到动作at=μ(st|θμ)+nt,其中,nt为随机过程噪声;
s305,执行动作at得到训练奖励rt和新状态st+1;
s306,将(st,at,rt,st+1)存入经验回放集r;
s307,从经验回放集r中采样n个随机样本(si,ai,ri,si+1),令yi=riγq'(si+1,μ'(si+1|θμ')|θq');γ为折扣因子,取值在(0,1);
s308,通过最小化损失函数
s309,根据采样梯度
s310,更新目标网络
θq'←ξθq+(1-ξ)θq'
θμ'←ξθμ+(1-ξ)θμ'
其中,ξ为更新参数,ξ=1;
s311,返回执行s304,进行多次迭代。
进一步地,在本发明的一个实施例中,对所述深度确定性策略梯度算法进行训练,进一步包括:
根据线控转向系统的不同工况下的转向场景,对深度确定性策略梯度算法进行硬件在环训练,硬件在环训练系统包括上位机pc、下位机pxi、线控转向系统ecu以及线控转向台架;训练过程中,ddpg的输出作为目标转角的补偿值,将补偿后的目标转角命令发送给线控转向系统底层控制器,此外,将线控转向台架底层执行的实际的转角发送给上位机,作为车辆运行仿真软件carsim的输入,ddpg的当前状态st=[vx_t,wz_t,δt,δt-1,δdes_t,δdes_t-1]t,st∈s通过carsim输出的车辆状态和系统最初输入的目标转角得到,利用学习算法调整actor和critic网络的参数。
进一步地,在本发明的一个实施例中,s4之后还包括:
s5,将硬件在环训练得到的算法先验网络参数作为算法网络参数的初始值应用到实车上,根据车辆运行过程中的即时数据,实时对算法的网络参数进行更新。
进一步地,在本发明的一个实施例中,将所述深度确定性策略梯度算法输出的目标转角补偿值与目标转角相加,得到补偿后的目标转角命令,将补偿后的目标转角命令作为实际发送给线控转向系统底层控制器的目标转角。
为达到上述目的,本发明另一方面实施例提出了一种基于ddpg的线控转向系统转向补偿控制装置,包括:
搭建模块,用于建立线控转向系统的动作actor网络和动作价值critic网络,根据所述动作actor网络和所述动作价值critic网络构建深度确定性策略梯度学习算法框架;
训练模块,用于设计训练所需的奖励函数;
建立模块,用于根据所述奖励函数及所述深度确定性策略梯度学习算法框架建立深度确定性策略梯度算法;
补偿模块,用于对所述深度确定性策略梯度算法进行硬件在环及实车训练,调整所述深度确定性策略梯度算法actor网络与critic网络的参数,以使所述深度确定性策略梯度算法得到目标转角补偿值。
另外,根据本发明上述实施例的基于ddpg的线控转向系统转向补偿控制装置还可以具有以下附加的技术特征:
进一步地,在本发明的一个实施例中,还包括:
调整模块,用于将硬件在环训练得到的算法先验网络参数作为算法网络参数的初始值应用到实车上,根据车辆运行过程中的即时数据,实时对算法的网络参数进行更新。
本发明实施例的基于ddpg的线控转向系统转向补偿控制方法及装置,无需了解线控转向系统底层控制器的控制策略,可以广泛适配于任意结构形式的线控转向系统,在车辆的上层控制器运行的转向补偿控制方法可以实现精确的转角控制,解决了相关技术中难以实现线控转向系统快速、准确、稳定的前轮转角响应的问题。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1为线控转向控制方法的流程图;
图2为线控转向控制方法的原理图;
图3为根据本发明一个实施例的基于ddpg的线控转向系统转向补偿控制方法流程图;
图4为根据本发明一个实施例的动作actor网络和动作价值critic网络的结构图;
图5为根据本发明一个实施例的深度确定性策略度算法的流程图;
图6为根据本发明一个实施例的线控转向硬件在环系统原理图;
图7为根据本发明一个实施例的线控转向补偿算法训练流程;
图8为根据本发明一个实施例的基于ddpg的线控转向系统转向补偿控制装置结构示意图。
附图标记:1-执行电机;2-路感电机。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面参照附图描述根据本发明实施例提出的基于ddpg的线控转向系统转向补偿控制方法及装置。
首先将参照附图描述根据本发明实施例提出的基于ddpg的线控转向系统转向补偿控制方法。
图3为根据本发明一个实施例的基于ddpg的线控转向系统转向补偿控制方法流程图。
如图3所示,该基于深度确定性策略梯度(deepdeterministicpolicygradient,ddpg)的线控转向系统转向补偿控制方法包括以下步骤:
步骤s1,建立线控转向系统的动作actor网络和动作价值critic网络,根据动作actor网络和动作价值critic网络构建深度确定性策略梯度学习算法框架。
进一步地,s1进一步包括:
s11,定义状态空间s={vx,wz,δ,δdes}和状态向量st=[vx_t,wz_t,δt,δt-1,δdes_t,δdes_t-1]t,st∈s,其中,vx为车辆纵向车速,wz为车辆横摆角速度,δ为实际转角,δdes为目标转角,t为当前时刻,t-1为上一时刻;
s12,建立动作actor网络a=μ(s|θμ),其中,μ表示actor网络,状态变量s为网络输入,θμ为网络参数,a为网络输出动作(action);
s13,建立动作价值critic网络q(s,a|θq),其中,q表示critic网络,状态变量s以及actor网络的输出动作a为输入,θq为网络参数。
动作actor网络和动作价值critic网络的结构和相互关系如图4所示,二者均为隐层式神经网络。
步骤s2,设计训练所需的奖励函数。
训练奖励r设计如下所示:
r=-w1|δdes-δa|-w2(δdes-δa)2-w3|δioutput|
其中,δdes为目标转角,δa为线控转向实际转角,δioutput为动作网络的当前输出和上一时刻的输出之间的距离,wi,i=1,2,3为各项的权重系数。
训练奖励分为两部分,第一部分为上式中的前两项,目的是评价实际转角与目标转角之间的跟踪误差,第二部分为上式中最后一项,目的是减少抖动。
步骤s3,根据奖励函数及深度确定性策略梯度学习算法框架建立深度确定性策略梯度算法。
建立深度确定性策略梯度算法流程如图5所示。
s301,随机初始化在线critic网络q(s,a|θq)以及在线actor网络μ(s|θμ);
s302,初始化目标critic网络q(s,a|θq')以及目标actor网络μ(s|θμ'),θq'←θq,θμ'←θμ;
s303,初始化经验回放集r;
s304,在线actor网络基于状态s得到动作at=μ(st|θμ)+nt,其中,nt为随机过程噪声;
s305,执行动作at得到训练奖励rt和新状态st+1;
s306,将(st,at,rt,st+1)存入经验回放集r;
s307,从经验回放集r中采样n个随机样本(si,ai,ri,si+1),令yi=riγq'(si+1,μ'(si+1|θμ')|θq');γ为折扣因子,取值在(0,1);
s308,通过最小化损失函数
s309,根据采样梯度
s310,更新目标网络
θq'←ξθq+(1-ξ)θq'
θμ'←ξθμ+(1-ξ)θμ'
其中,ξ为更新参数,ξ=1;
s311,返回执行s304,进行多次迭代。
可以理解的是,i=1…t,通过多次迭代直至满足迭代终止条件或满足迭代次数结束迭代。
步骤s4,对深度确定性策略梯度算法进行硬件在环及实车训练,调整深度确定性策略梯度算法actor网络与critic网络的参数,以使深度确定性策略梯度算法得到目标转角补偿值。
进一步地,对深度确定性策略梯度算法进行训练进一步包括:
根据线控转向系统的不同工况下的转向场景,对深度确定性策略梯度算法进行硬件在环训练。
为了训练线控转向补偿算法,在仿真环境中搭建不同工况下的转向场景,对线控转向系统进行硬件在环预训练,硬件在环系统控制原理图见图6,硬件在环系统包括上位机pc、下位机pxi、线控转向系统ecu以及线控转向台架组成,在控制过程中,上位机为硬件在环系统提供车辆运行仿真环境carsim,同时将上层控制程序下载到下位机pxi,下位机将上层控制程序所得的目标转角发送给线控转向系统ecu,由ecu控制线控转向系统执行器实现线控转向台架的转角控制,同时台架的传感器也会将采集到的线控转向系统转角等信号发送给ecu、下位机以及上位机。算法的训练流程见图7,算法的目标是保证线控转向系统可以快速精确地实现目标转角,在训练过程中,ddpg的输出作为目标转角的补偿值,与目标转角相加,得到补偿后的目标转角命令,将补偿后的目标转角命令发送给线控转向系统底层控制器,此外,将线控转向系统底层执行的实际的转角发送给上位机,作为仿真软件carsim的输入,ddpg的当前状态st=[vx_t,wz_t,δt,δt-1,δdes_t,δdes_t-1]t,st∈s通过carsim输出的车辆状态和系统最初输入的目标转角得到,利用学习算法调整actor和critic网络的参数。
为了保证本发明提出的补偿算法的性能,算法的训练过程应尽可能包含尽量多的场景。训练时应采用时变的目标转角以及时变的纵向车速。之后,基于前述数据进行批量预训练,获得算法先验网络参数。
进一步地,在本发明的实施例中,还包括:
s5,将硬件在环训练得到的算法先验网络参数作为算法网络参数的初始值应用到实车上,根据车辆运行过程中的即时数据,实时对算法的网络参数进行更新。
可以理解的是,将硬件在环训练得到的算法先验网络参数作为算法网络参数的初始值应用到实车上,在车辆运行过程中,基于即时数据,实时对算法的网络参数进行更新。为提升算法的泛化迁移能力,保障其在新环境中的表现,建立终身学习机制,维护回放缓存,并采用批训练方法避免长时遗忘问题。
根据本发明实施例提出的基于ddpg的线控转向系统转向补偿控制方法,无需了解线控转向系统底层控制器的控制策略,可以广泛适配于任意结构形式的线控转向系统,在车辆的上层控制器运行的转向补偿控制方法可以实现精确的转角控制,解决了相关技术中难以实现线控转向系统快速、准确、稳定的前轮转角响应的问题。
其次参照附图描述根据本发明实施例提出的基于ddpg的线控转向系统转向补偿控制装置。
图8为本发明一个实施例的基于ddpg的线控转向系统转向补偿控制装置结构示意图。
如图8所示,该基于ddpg的线控转向系统转向补偿控制装置包括:搭建模块801、训练模块802、建立模块803和补偿模块804。
搭建模块801,用于建立线控转向系统的动作actor网络和动作价值critic网络,根据动作actor网络和动作价值critic网络构建深度确定性策略梯度学习算法框架。
训练模块802,用于设计训练所需的奖励函数。
建立模块803,用于根据奖励函数及深度确定性策略梯度学习算法框架建立深度确定性策略梯度算法。
补偿模块804,用于对深度确定性策略梯度算法进行硬件在环及实车训练,调整深度确定性策略梯度算法actor网络与critic网络的参数,以使深度确定性策略梯度算法得到目标转角补偿值。
进一步地,在本发明的实施例中,还包括:
调整模块,用于将硬件在环训练得到的算法先验网络参数作为算法网络参数的初始值应用到实车上,根据车辆运行过程中的即时数据,实时对算法的网络参数进行更新。
进一步地,在本发明的实施例中,将深度确定性策略梯度算法输出的目标转角补偿值与目标转角相加,得到补偿后的目标转角命令,将补偿后的目标转角命令作为实际发送给线控转向系统底层控制器的目标转角。
需要说明的是,前述对方法实施例的解释说明也适用于该实施例的装置,此处不再赘述。
根据本发明实施例提出的基于ddpg的线控转向系统转向补偿控制装置,无需了解线控转向系统底层控制器的控制策略,可以广泛适配于任意结构形式的线控转向系统,在车辆的上层控制器运行的转向补偿控制方法可以实现精确的转角控制,解决了相关技术中难以实现线控转向系统快速、准确、稳定的前轮转角响应的问题。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!