一种自平衡高空作业台及其控制方法
本发明涉及一种自平衡高空作业台及其控制方法,属于高空作业平台技术领域。
背景技术:
随着我国城市化进程的推进,高层建筑、高架桥等高度较高的设施、设备的数量日益增加。因此,为方便对上述设施进行维护,则需要利用带平台的作业车将维修人员升至相应位置。但就目前来说,在将维护人员从地面升至高空的过程中,作业平台的姿态需要人员手动调整,导致了繁琐的操作以及云台中人员的不适。在这种背景下,采用自平衡的作业平台可减少作业过程中的繁琐操作,并大大提高作业人员的舒适感。因此,该平台具有良好的应用前景。
技术实现要素:
本发明设计开发了一种自平衡高空作业台,能够在作业过程中调整作业平台的姿态,提高作业效率,减轻操作人员的负担。
本发明还设计开发了一种自平衡高空作业台的控制方法,通过ddpg网络对驱动电机的输出力矩进行控制,实现在作业过程中自动控制作业平台姿态,适应性强。
本发明提供的技术方案为:
一种自平衡高空作业台,包括:
小臂;
伺服电机,其设置在所述小臂一端,位于所述小臂的内部;
行星减速机构,其一端连接所述伺服电机的输出端;
制动机构,其设置在所述伺服电机和所述行星减速机构之间;
作业平台,其与所述行星减速机构的另一端固定连接。
优选的是,所述行星减速机构包括:
太阳轮,其与所述伺服电机的输出端固定连接;
至少两个行星轮,其与所述太阳轮啮合;
行星架,其固定连接所述行星轮;
齿圈,其与所述作业平台固定连接,所述齿圈具有内齿,并与所述行星轮相啮合。
优选的是,所述行星减速机构为2k-h轮系。
优选的是,所述减速机构的减速比为13。
优选的是,所述制动机构包括:
制动器,其设置在所述小臂的内壁上;
制动盘,其固定设置在在所述伺服电机输出轴上。
优选的是,还包括:
运算与控制单元,其与所述驱动电机、所述制动机构以及所述作业平台电连接。
一种自平衡高空作业台的控制方法,其特征在于,通过ddpg网络根据作业平台的位置信息控制驱动电机,使驱动电机带动作业平台进行相应运动,具体包括:
建立并训练ddpg网络,保存训练所得权重参数;
将训练好的ddpg网络移植到运算与控制单元中,对作业平台的位置进行控制。
优选的是,还包括:
在训练过程中,ddpg网络根据通过传感器获取作业平台与水平面的夹角信息、作业平台角速度、作业平台载荷,决策出当前动作并执行;
奖励函数针对当前状态给出奖励标量,并通过ddpg网络采集下一时刻的状态信息,得出最优的神经网络权重后进行复制;
优选的是,所述ddpg网络的状态空间st包括:
其中,θ表征作业平台与水平面归一化的夹角关系,θ∈(-1,1];
当θ=0度时,作业平台呈水平姿态;
优选的是,本发明的奖励函数为:
reward=reward1+reward2
其中,
式中,m0,m1为阈值常数,m0=1,m1=1,reward1为第一奖励分量,reward2为第二奖励分量,done为训练结束标志;
当done=1,θ=m0、
或当前回合步长超过1000时,本回合训练终止,reward2=-100。
本发明所述的有益效果:本发明提供的自平衡高空作业台能够减少作业过程中的繁琐操作,并大大提高作业人员的舒适感,减轻操作人员的操作负担。本发明提供的自平衡高空作业台的控制方法通过ddpg网络根据作业平台反馈的平台状态信息给驱动机构发出相应的控制信号,驱动机构对控制信号进行处理后驱动作业平台进行相应的运动,同时,作业平台将自身的状态信息再次反馈给ddpg网络,从而实现闭环控制。
附图说明
图1为本发明所述的自高空作业平台的结构示意图。
图2为本发明所述的自平衡高空作业平台的爆炸示意图。
图3为本发明所述的减速器的原理图。
图4为本发明所述的自平衡高空作业平台的原理示意图。
图5为本发明所述的ddpg网络的结构示意图。
图6为本发明所述的ddpg网络中的actor网络结构示意图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
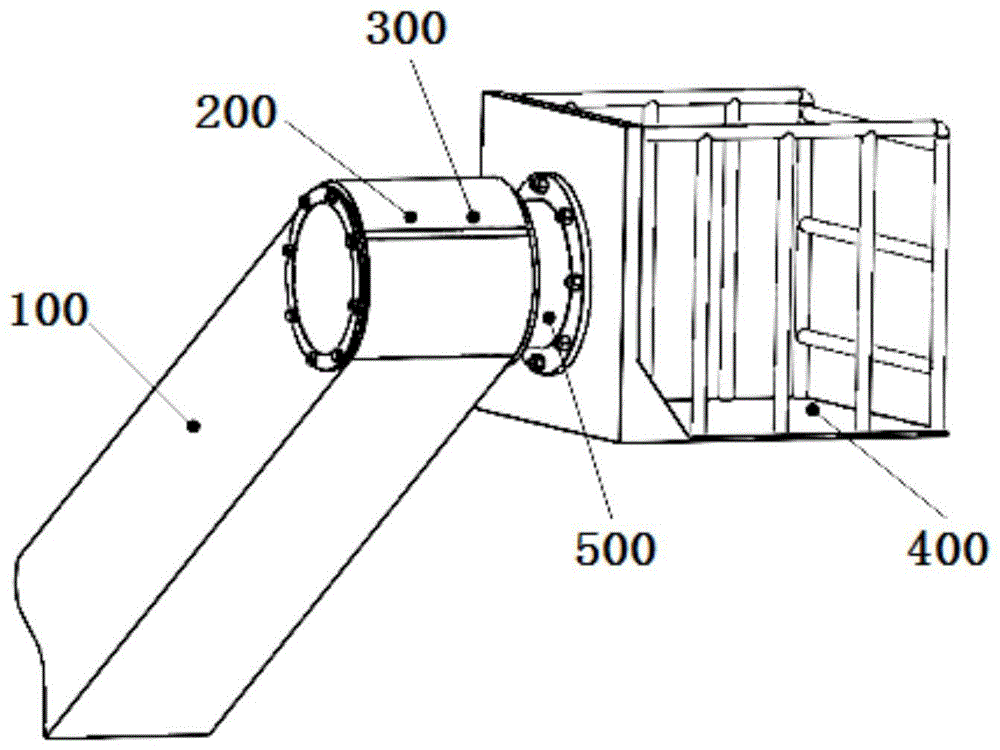
如图1-6所示,本发明提供一种自平衡高空作业台,包括:小臂100、驱动电机200、制动机构300、作业平台400、行星减速机构500、齿圈510、太阳轮520、行星架530、制动盘610、制动器620.
自平衡高空作业台包括驱动部分和平台部分,驱动部分包括:小臂100,内部具有容纳腔,在小臂100的一端,位于小臂的内部,设置有驱动电机,行星减速机构500连接在驱动电机200的输出端,制动机构设置在驱动电机200和行星减速机构500之间。
在本发明中,作为一种优选,驱动电机200为伺服电机。
在本发明中,作为一种优选,行星减速机构为2k-h轮系,减速比能够达到13。
行星减速机构包括:齿圈510、太阳轮520、行星架530,齿圈510固定设置在小臂上,太阳轮520连接驱动电机的输出端,伺服电机将转矩输入到太阳轮520上,行星架与作业平台400固定连接,行星轮固定设置在行星架400上,并与太阳轮520相啮合,行星轮同时与齿圈510的内齿圈内核,将动力由驱动电机传递到作业平台400上。制动机构600包括:制动器610和制动盘620,制动器固定设正在小臂100的内壁上,制动盘620设置在驱动电机200的输出轴上。运算与控制单元与驱动电机200、制动机构300、减速机构500同时电连接,当作业平台400与水平面的夹角以及作业平台400的角加速度超过一定阈值时(具体多少),运算与控制单元对驱动电机200的输出轴进行制动,并同时停止驱动电机200的供电,避免驱动电机200在作业过程张时空而发生危险。
本发明还提供一种自平衡高空作业台的控制方法,通过ddpg网络根据作业平台的位置信息控制驱动电机,使驱动电机带动作业平台进行相应运动,具体包括:
ddpg网络根据作业平台400反馈的平台状态信息给驱动机构发出相应的控制信号,驱动机构对控制信号进行处理后驱动作业平台400进行相应的运动,同时,作业平台将自身的状态信息再次反馈给ddpg网络,从而实现闭环控制。
本发明的实现分为两个阶段,第一阶段:训练ddpg网络。在仿真场景中对自平衡作业平台进行建模,接着在仿真环境中模拟现实工况,对ddpg网络进行训练,并保存训练所得的权重参数。第二阶段:利用训练完成的ddpg网络。将训练好的ddpg网络移植到现实控制器来控制作业平台的姿态,以实现作业平台自平衡的功能。
第一阶段:ddpg网络的训练阶段。该阶段基本原理如下:ddpg网络根据当前传感器所测得的状态决策出当前动作,并执行;接着,环境将给予其一个标量奖励,表明ddpg网络针对当前状态做出的决策的优劣;然后,ddpg网络根据下一采样时刻得到的状态信息,决策出下一时刻的动作。如此循环,ddpg网络通过与环境的交互,产生大量数据,并通过梯度下降方法,从中学习到能最大化奖励的策略,也即最优策略。其中,奖励由奖励函数具体给出,奖励函数由设计人员设计确定,其表达了设计人员想要达到的最终控制目标。
本发明中ddpg网络的状态空间st具有3个状态变量:
其中,θ表征作业平台与水平面归一化的夹角关系,θ∈(-1,1]。当θ=0度时,作业平台呈水平姿态;
本发明中ddpg网络的动作空间at为一维:
at=t;
其中,t表示归一化的电机输出力矩,t∈[-1,1]。ddpg网络通过输出期望的电机力矩来间接控制动平台的位置以及角速度。
本发明的奖励函数:
其中,
式中,m0,m1为阈值常数,m0=1,m1=1,reward1为第一奖励分量,reward2为第二奖励分量,done为训练结束标志。reward1与θ和
当done=1,θ=m0、
或当前回合步长超过1000时,本回合训练终止,reward2=-100。
下面介绍ddpg网络的具体结构及其训练过程。
如图5所述,ddpg网络结构,包含一个actor网络、一个actor_target网络、一个critic网络、一个critic_target网络。
actor网络负责给驱动机构发送期望的力矩信号,即at=π(at|st,w)=t,其中,w为actor网络的权重向量。actor网络以当前状态st作为输入,输出为当前状态期望的电机归一化力矩,其同时负责actor网络参数向量w的更新。其原理为:actor网络接收到作业平台4反馈的状态信息
actor_target网络负责根据从经验回放池中采样出的(st,at,st+1,rt+1)元组中的下一状态st+1,选择下一动作at+1,记为π'(at+1|st+1,w'),其网络结构与actor网络一致,网络参数w'定期从actor网络中复制而来。
critic_tartget网络用于计算q'(st+1,at+1,n'),其中,n'为critic_tartget网络的参数值,其网络结构与critic网络一致,参数n'定期从critic网络复制而来。
critic网络用于估计当前状态的价值函数q(st,at,n),其中,n为critic网络的权值,目标q值:
y=rt+1+γq'(st+1,at+1,n');
其中γ=0.99。为了提高网络的学习效率,使学习更加充分,向π(at|st,w)中人为引入噪声n,其可为ornstein-uhlenbec噪声。因此,动作可记为a=π(at|st,w)+n。
为了提高动平台的表现性能,需要对各网络参数进行优化。对于critic网络,其损失函数l(n)定义为:
l(n)=(y-q(st+1,at+1,n))2;
采用梯度下降法来更新n的值,使得q(st+1,at+1,n)的值与目标q值y尽量接近,从而减少critic网络的损失。对于actor网络,损失函数l(w)定义为:
l(w)=-q(st+1,at+1,w);
采用梯度下降法更新权值w,其目标为使当前状态下选择的动作具有最大的价值q。对于actor_tartget以及critic_tartget网络,其网络参数都相应由actor、critic网络复制而来。
训练过程中,每个回合的开始,作业平台与水平面的夹角、角加速度及作业平台的载荷均为-1~1之间的随机值,经过不断地迭代训练,ddpg网络逐渐学习到更优的策略,即能够使得动平台与水平面的夹角最小、角加速度也最小,从而使作业平台能满足实际使用需求。此时,保存ddpg网络的所有权重向量值。
如图6所示,网络输入为
相应地,critic与critic_target网络也含有inputlayer,layer1,layer2,outputlayer。其输入层含有4个神经元,layer1含有64个神经元,layer2含有32个神经元,outputlayer含有1个神经元。
第二阶段,ddpg网络的移植阶段。该阶段将第一阶段训练好的ddpg网络参数移植到现实环境的控制器中来对作业平台进行控制。其原理如下:ddpg网络根据实际环境中传感器测得的当前状态
将归一化的期望电机转矩转换为真实的期望电机转矩,进而利用电机控制器使伺服电机输出相应的转矩,其中,k为转矩转换常数。当作业平台状态改变时,ddpg网络重复上述过程,实现对作业平台姿态的连续调整,使作业平台与水平面的夹角、角加速度不会使人赶到不适。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!