一种用于泡沫浮选工况预估的级联特征选择方法
本发明主要涉及泡沫浮选过程自动化感知预测领域、模式识别与特征工程领域,具体涉及一种用于泡沫浮选工况预估的级联特征选择方法。
背景技术:
1、泡沫浮选是一种重要的选矿手段,原理是利用破碎后不同种矿粒在药剂作用下表现出的不同亲水性,将目标矿物从低品位矿物中分离出来并富集。泡沫浮选作为在获取高品位有色金属时应用广泛的方法之一,对我国有色金属的利用率和产量的提高有重大意义。在浮选过程中,存在很多对浮选效果好坏有重要影响的过程变量,如矿浆液位、加药量等,目前主要依靠人工对浮选过程中的泡沫视频进行观察以识别当前工况并据此及时调整操作。然而,人工观察存在着主观性、随机性较强,劳动强度较大的缺陷。因而通过机器视觉提取特征进而判断工况和进行生产指标预测是浮选过程自动化的重要研究方向。目前,泡沫图像特征提取方法繁多,提取出的特征各有不同,特征集往往存在较大的不相关性和冗余性,即某些特征对工况或指标不敏感、表现能力弱和不同特征之间存在较大的信息冗余。这些不相关和冗余的特征不仅为机器学习模型的训练增加了很多不必要的计算代价和时间代价,而且还很有可能使模型过拟合而泛化能力降低。特征选择是应对该问题常用的数据预处理策略,它的思想是从特征集合中选出合适的特征子集,以期在性能不退化的情况下减少模型训练消耗、降低模型复杂度。目前特征选择算法主要分为三类:过滤式(filtermethod)、封装式(wrapper method)和嵌入式(embedded method)。过滤式算法只以预测变量和目标变量为参考,与具体选用的模型无关,结果清晰稳定且速度较快;封装式算法基于模型在不同特征子集上表现好坏来对特征子集做出取舍,而寻找使模型表现最好的特征子集问题可归结为一种优化问题,并存在着遍历复杂度随特征维数呈指数上升的np难现象。
2、名词解释:
3、rbm:restricted boltzmann machine,受限玻尔兹曼机
4、bgsa:binary gravitational search algorithm,二值引力搜索算法
技术实现思路
1、为解决现有技术的不足,本发明采用如下的技术方案:
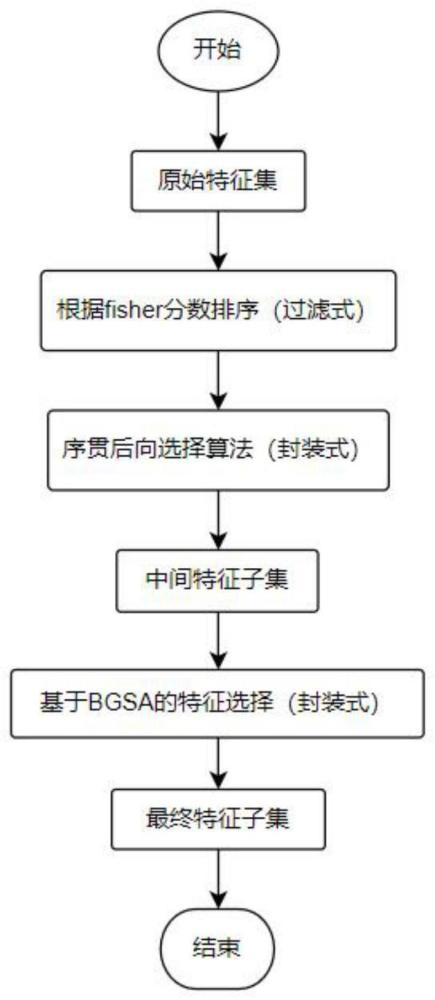
2、一种用于泡沫浮选工况预估的级联特征选择方法,包括如下步骤:
3、步骤一,从浮选现场采集各时刻的预设检测特征的原始数据构成原始数据集并构建机器学习模型;
4、所述预设检测特征包括泡沫图像特征和工况类型特征;原始数据集中将当前时刻的去除尾矿品味数据的原始数据和前两个时刻的原始数据的集合作为一个样本;原始数据集划分为训练集和测试集;
5、步骤二、计算训练集中每个预设检测特征的fisher分数,并按照fisher分数从大到小的顺序对预设检测特征进行排序形成检测特征序列;
6、步骤三、依次删除训练集中检测特征序列中的最后一名预设检测特征对应的数据,直至训练集中仅有一个预设检测特征,每删除一个检测特征序列形成一个训练数据集,训练集也作为一个训练数据集;将所有训练数据集分别输入机器学习模型进行重复训练,统计每次模型训练完成后最终在测试集上的准确率的均值;将平均准确率最高的训练数据集包含的预设检测特征的集合作为中间特征子集;
7、步骤四、采用bgsa优化算法对中间特征子集中的预设检测特征寻优求解,得到预测准确率最高的预设检测特征的集合作为当前历史最优解,非预测准确率最高的预设检测特征的集合为候选解,若某一候选解中含有的预设检测特征种类数少于当前历史最优解的预设检测特征种类,且所述某一候选解的预设准确率与当前历史最优解的差值的绝对值小于预设阈值ε,则将所述某一候选解作为历史最优解,否则将当前历史最优解作为历史最优解;历史最优解中包含的预设检测特征即为选择出的最终的检测特征。
8、进一步的改进,所述泡沫图像特征包括气泡尺寸平均值、气泡尺寸方差、对比度、相关性、能量、均匀性、气泡速度平均值、气泡速度方差、气泡平均爆裂面积和气泡平均爆裂体积方差;所述工况类型特征包括矿石入矿品位特征包括粗选入矿中铅、锌和铁的品位以及粗选尾矿中锌的品位。
9、进一步的改进,所述机器学习模型为选择受限玻尔兹曼机。
10、进一步的改进,所述步骤二中,fisher分数的计算方法如下:
11、s21,设所有样本的第i维预设检测特征的数据集合为ai;将ai按照样本所属的工况类型特征分成4个子集,第j个子集表示为设第j个子集包含的数据量为nj,则第i维预设检测特征的fisher分数fi的计算式为:
12、
13、其中l为工况类型数,表示第j个子集中第i维预设检测特征的第k个数据,表示第i维预设检测特征的数据集合的均值;表示第j个子集中第i维预设检测特征的数据集合的均值。
14、进一步的改进,所述步骤四中,采用bgsa优化算法对中间特征子集中的预设检测特征寻优求解的具体方法如下:
15、s1,将中间特征子集包含的预设检测特征进行任意组合得到所有可能的特征子集组合,分别将各个特征子集组合编码为n维二值向量其中n表示优化前特征集的特征数目即中间特征子集的特征数目;用各维xi的0,1取值表示对应的特征子集是否包含该维预设检测特征,这样n维二值向量的所有形式就与预设检测特征选择的所有可能结果一一对应;
16、s2,以为输入变量,以rbm基于对应特征子集训练后在测试集上准确率的均值为输出变量,将从中间特征子集进一步选择出合适最终特征子集的过程转化为采用bgsa优化算法寻求最优解的过程;bgsa在解决二值问题时,方法如下:设时刻t的质点i在第d维上的速度为则t时刻的跳变概率的计算式为:
17、
18、根据跳变概率,质点各维位置的移动描述为:
19、
20、其中rand是0到1上均匀分布的随机数,代表对x取反;
21、为了更好地收敛,设定速度绝对值的上限vmax,即在bgsa中计算引力时,原来用于表示质点位置间欧式距离的r更变为质点位置间的hanmming距离;
22、s3.设置bgsa的离子数目n,迭代次数iter,精英选取策略中精英数目kbest和万有引力常数g;其中kbest在精英策略中的意义是只有前kbest个最优质点发挥引力作用;
23、
24、
25、其中n表示质点总数,t表示当前时刻,t表示总时长,g(t0)为1;
26、s4历史最优解的更新条件具体表示为:
27、xbest=x,
28、if
29、|fit(xoldbest)-fit(x)|<ε,
30、or
31、fit(x)-fit(xoldbest)>ε
32、其中xbest表示历史最优解,x表示某一候选解,xoldbest表示当前历史最优解,表示向量x各维之和,即向量x中含1的个数,也就是特征子集中特征的维数,ε表示对模型性能指标随机性的考虑和为了追求更小特征子集愿意牺牲性能的最大程度的预设值,当候选解和当前历史最优解的适应度之差在此范围内时,选择更小的特征子集作为历史最优解;fit(x)表示候选解x对应的适应度即候选解x对应的模型准确率均值;当候选解对应的适应度超出当前历史最优解的适应度的值大于ε时,视为候选解对应的模型表现有显著提升,所以将历史最优解更新为候选解。
33、进一步的改进,vmax=6,质点数目n=10,迭代次数iter=50,精英选取策略为精英数目kbest随迭代次数线性衰减至1;万有引力常数g随指数迭代次数线性衰减至0。
34、本发明的优势和有益效果在于:
35、本发明在原始特征数目众多时对于特征选择效果与计算代价之间的关系有一定协调能力,以在有限时间内达到特征选择减少不相关和冗余特征的基本目标,找到能使模型效率和最终表现均有所提升的合适特征子集。
- 还没有人留言评论。精彩留言会获得点赞!