一种基于深强化学习的航空发动机控制方法、装置与流程
本发明属于航空宇航推进理论与工程中的系统控制与仿真技术领域,具体涉及一种基于深强化学习的航空发动机控制方法、装置。
背景技术:
航空发动机是一个多变量、强非线性、强耦合性、时滞的受控对象。随着发动机升级换代,如何在保证发动机安全稳定运行情况下,设计性能良好的发动机控制器变得越来越困难;而且,对于这样一个复杂多变的控制装置,没有必要的控制是不可能保证其正常工作的;此外,发动机的性能不仅与机械制造技术、材料特性和加工工艺的质量密切相关,而且与控制系统的质量密切相关;同时,发动机控制系统将减轻驾驶员操作的负担。因此,有必要研究如何设计具有高响应速度的航空发动机控制方法。
近年来,基于深度强化学习(deepreinforcementlearning,drl)的控制方法,由于采用无模型、深层学习(deeplearning,dl)等技术,该方法可以随着学习时间的延长,其智能化程度将越来越高,引起了许多研究者的研究兴趣。suigema等人提出了一种基于强化学习(rl)算法的被动动态步行机器人控制器。wang等人采用q学习算法选择双足机器人在不平坦表面上行走的pd控制器参数。ziqiang等人设计的基于bp神经网络的二维双足机器人q学习控制器。mnih等人提出了基于卷积神经网络的深度强化学习方法,并成功地从高维感觉输入中直接学习控制策略。lillicrap等人提出了一个基于确定性策略梯度的无模型算法,该算法可以在连续动作空间上操作。oh等人在minecraft(一个灵活的3d世界)中引入了一组新的rl任务,并使用这些任务系统地比较和对比现有的drl体系结构和基于内存的dll体系结构。上述工作在drl的应用方面取得了很大的控制效果。但目前尚未发现有人对drl在发动机控制中的应用进行研究。
技术实现要素:
本发明所要解决的技术问题在于克服现有技术不足,提供一种基于深强化学习的航空发动机控制方法,采用深度增强学习方法来设计发动机控制器,使得发动机随学习时间增加,其响应速度不断提高,从而提高发动机响应速度。
本发明具体采用以下技术方案解决上述技术问题:
一种基于深强化学习的航空发动机控制方法,首先根据控制指令和反馈参数获得初始的燃油流量,然后根据预设的发动机物理限制对初步的燃油流量进行修正,最后按照修正后的燃油流量向航空发动机输入相应流量的燃油;所述根据控制指令和反馈参数获得初始的燃油流量,具体是通过深度强化学习网络实现,所述深度强化学习网络的动作值函数qj(s,a)如下:
其中s是发动机状态,a是发动机的动作,α是深度强化学习的学习率,r是回报值,γ是回报衰减率,sj是第j时刻发动机状态,st是发动机目标状态;回报值rj的计算公式具体如下:
其中,
优选地,所述深度强化学习网络的输入为当前和过去的燃油流量wfb、过去时刻风扇转子转速nf、压气机转子转速nc、风扇喘振裕度smf、压气机喘振裕度smc以及高压涡轮进口温度t41,所述深度强化学习网络的输出为动作值函数。
根据相同发明构思还可以得到以下技术方案:
一种基于深强化学习的航空发动机控制装置,包括:用于根据控制指令和反馈参数获得初始的燃油流量的控制器,用于根据预设的发动机物理限制对初步的燃油流量进行修正的限制选择单元;用于按照修正后的燃油流量向航空发动机输入相应流量的燃油的执行机构;所述控制器为深度强化学习网络,所述深度强化学习网络的动作值函数qj(s,a)如下:
其中s是发动机状态,a是发动机的动作,α是深度强化学习的学习率,r是回报值,γ是回报衰减率,sj是第j时刻发动机状态,st是发动机目标状态;回报值rj的计算公式具体如下:
其中,
优选地,所述深度强化学习网络的输入为当前和过去的燃油流量wfb、过去时刻风扇转子转速nf、压气机转子转速nc、风扇喘振裕度smf、压气机喘振裕度smc以及高压涡轮进口温度t41,所述深度强化学习网络的输出为动作值函数。
相比现有技术,本发明技术方案具有以下有益效果:
本发明首次将深度强化学习网络应用于航空发动机的直接推力控制,并根据航空发动机的特点设计相应的动作值函数,从而使得发动机随学习时间增加,其响应速度不断提高,从而提高发动机响应速度。
附图说明
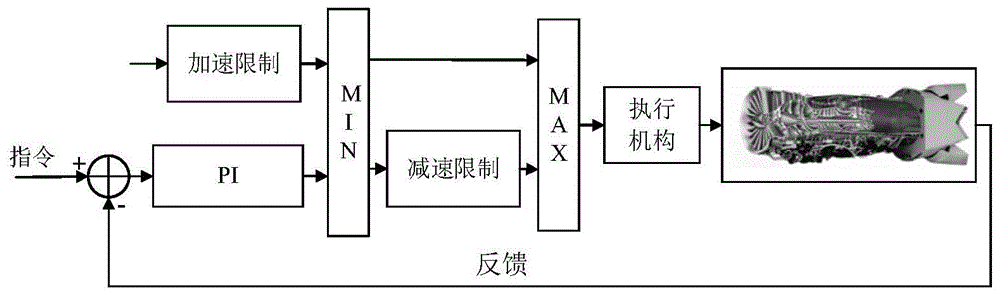
图1为传统航空发动机控制系统的控制结构;
图2为本发明基于drl的航空发动机控制系统结构;
图3为dnn的结构图;
图4为滚动滑动窗口;
图5为反向传播算法原理;
图6为推力响应曲线;
图7为燃油流量变化曲线;
图8为涡轮前温度响应曲线;
图9为风扇转子转速响应曲线;
图10为压气机转子转速响应曲线;
图11为风扇喘振裕度响应曲线;
图12为压气机喘振裕度响应曲线。
具体实施方式
图1和图2分别给出了传统航空发动机控制系统和本发明基于drl的航空发动机控制系统的控制结构。如图1、图2所示,它们主要由控制器、加速度限制模块、减速限制模块、最小选择模块和最大选择模块组成。为了使发动机满足风扇和压气机的喘振裕度极限、风扇和压气机的转子转速极限、涡轮进口温度的温度极限和其他物理极限,加速限制模块计算燃油流量,减速限制模块计算燃油流量以避免贫油熄火现象控制器模块计算燃料流以获得期望的推力,最后所得燃油输入最小选择或最大选择模块进行高选或低选,保证发动机在满足各种限制约束的情况下,安全温度运行。传统的发动机控制系统通常采用比例积分(pi)或比例积分微分(pid)作为控制方法。而本发明则采用深度强化学习网络,强化学习将使发动机随着学习时间加长响应速度变得越来越快,为了提高rl的学习能力,采用深度神经网络(dnn)来估计rl的动作值函数。
本发明深度强化学习网络控制器的建立过程具体如下:
步骤1、确定深度神经网络的输入和输出,网络结构,并对深度神经网络进行初始化;
为了保持发动机的动态特性,提高模型的估计精度,输入选择当前和过去的燃油流量wfb、过去时刻风扇转子转速nf、压气机转子转速nc、风扇喘振裕度smf、压气机喘振裕度smc以及高压涡轮进口温度t41,模型输出选动作值函数。dnn的输入和输出是:
由于发动机通常可以简化成具有两个自由度的对象,本发明m1,m2,…,m6都设置为2。
步骤2、根据油门杆指令、发动机输出响应计算得到增强学习的动作值函数;
增强学习是基于无模型的,根据基于q表或dnn选择下一时刻输入,并不需要估计控制对象输入。航空发动机瞬态过程是一个强非线性过程,因此,选择增强学习来更新动作值函数,其中s是发动机状态,a是发动机的动作或控制输入动作值函数更新规则可以被描述为:
其中s是发动机状态,a是发动机的动作(或控制输入),α是深度强化学习的学习率,r是回报值,γ是回报衰减率,sj是第j时刻发动机状态,st是发动机目标状态;
为了使发动机从工作状态快速地响应到另一工作状态,设计回报只rj如下:
其中
步骤3、对神经网络进行训练;
dnn是多输入多输出的非线性映射,可以描述如下:
y=fdnn(x)(4)
其中x是输入向量,y为输出向量。
dnn的结构如图3所示。dnn比传统的神经网络具有更深层的隐含层。dnn隐藏层的增加将提高dnn的拟合能力。dnn的每个隐藏层定义为:
al+1=wlhl+bl(5)
hl+1=σ(al+1)(6)
其中wl是权重矩阵,bl是偏置,σ是激活函数,hl(对于l>0)是第l隐含层l的输出,l=1,2,l,nl,nl是隐含层节点个数。设
传统的在线深层神经网络每次迭代只选取一个数据点计算梯度,具有较好的实时性。然而,只选择一个训练点对噪声敏感,而且不是最好的梯度方向选择。因此,为了提高神经网络的鲁棒性,如图4所示,将在线滑动窗口深度神经网络(onlineslidingwindowdeepneuralnetwork,ol-sw-dnn)应用于控制器设计。在训练数据的每次迭代中,ol-sw-dnn选择长度l的最近点数据。ol-sw-dnn的损耗函数描述为:
在每次迭代计算,w和b更新如下:
其中η是神经网络的学习率。如图5所示,使用反向传播算法来求解网络参数梯度
w,b的梯度更新如下:
其中δl为:
其中l=nnet,nnet-1,l,2,
设
其中nnet为网络层数。
步骤4、计算得到使得动作值函数最大的燃油流量;
在j时刻,以概率ε>0选择随机动作aj,否则选择
步骤5、根据深强化学习、加速、减速算得燃油进行高低选择得到燃油流量,并输入到发动机,得出响应输入,判断发动机是否达到目标值,如果达到则停止,否则返回步骤2。
为验证本发明技术方案的效果,将本发明方法与现有pid方法进行仿真比对。本发明方法与pid的仿真环境都在发动机工作在高度h=0km、马赫数ma=0时的标准大气状态。发动机加速过程是瞬态过程中非线性最强的过程,因此,选择加速过程作为这两种方法的仿真过程。加速起点是油门杆角度pla=20°时发动机的稳定工作状态,加速终点是pla=70°时发动机对应的稳定工作状态。本发明方法和pid的仿真结果如图6~图12所示。图中发动机的参数已经归一化。通过调试,选择了ol-sw-dnn的结构为[13,15,12,10,10,1]。神经网络的学习率α=0.00002。动量因子η=0.6,l=25。
如图6所示,在所提出的方法和pid中,推力增加到设计点的95%的时间分别为3.7秒和5.225秒。结果表明,该方法比pid,加速时间减少了1.525秒。主要原因是drl将从历史中吸取经验,使发动机变得越来越智能化。此外,ols-sw-dnn具有较强的拟合能力,使得所提出的方法具有更强的学习能力。
如图12所示,在发动机的加速过程中,工作点沿喘振极限移动,沿喘振限制线在发动机理论中是最快的路线。如图8~11所示,当在发动机加速过程中应用所提出的方法时,发动机并无超温、超速或发生喘振等现象。结果表明,该控制方法具有较高的控制精度和响应速度。
- 还没有人留言评论。精彩留言会获得点赞!