一种高含水后期油藏流场分级评价方法与流程
本发明涉及一种高含水后期油藏流场分级评价方法,属于油藏数值模拟应用以及油气田开发流场重构领域,其针对油藏流场重构动态参数进行了定量分级评价,建立了一套基于面通量非主观因素控制的分级评价方法。
背景技术:
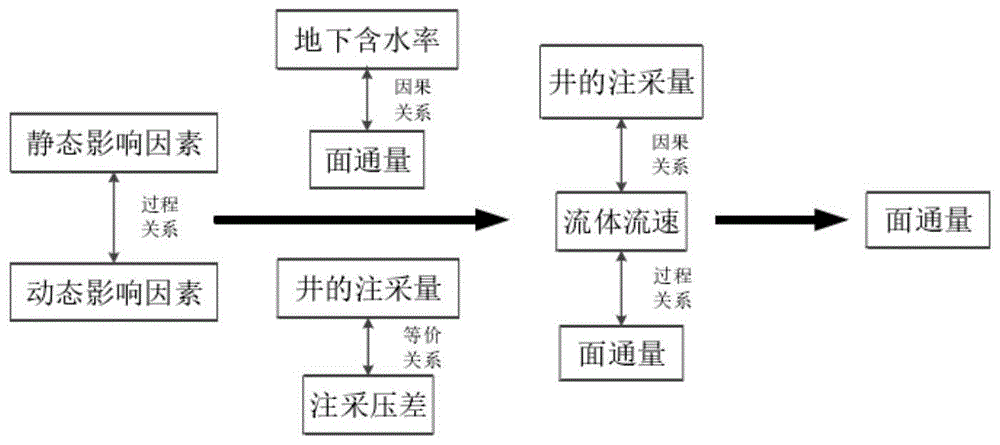
:油藏是流动的矿场,油藏流体的流动可以用流场来表征。流场的表征与评价逐渐成为近年来研究的重点,国外比较缺乏相关内容的研究,国内主要集中在流场表征指标的筛选和评价方法的研究,筛选出的指标对流场演变具有决定性作用,流场表征参数主要有含水饱和度、含水率、冲刷倍数、面通量等多种体系。目前有学者分别对影响油藏流场的静态因素和动态因素进行综合分析,利用逻辑分析法筛选出最终筛选出水通量作为流场评价的唯一指标,但是在表征的过程中指标的分级级别范围人为因素比较大,大部分研究人员都是依据经验和规律人为地制定分级类别数和上下限范围,普遍存在一定的误差,结果具有不确定性。因此,该表征方法无法客观的评价流场,对于高含水后期流场的表征不具有普适性,因而亟需寻找一套非主观因素控制的分级评价方法来系统地表征高含水后期油田流场的体系。技术实现要素:本发明的目的在于避免现有技术中的不足而提供一套描述合理、可靠性强、运用简单的完整的流场分级评价方法。使用面通量作为表征流场的唯一指标,在历史拟合的基础上采用戎下型隶属函数对面通量数据进行归一化处理,将处理结果定义为流场强度,利用模糊c均值聚类分析对流场强度进行分级,建立了完整的流场评价体系。术语解释模糊c均值聚类分析算法fuzzyc-meansalgorithm(fcma)或称(fcm):在众多模糊聚类算法中,模糊c-均值(fcm)算法应用最广泛且较成功,它通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属以达到自动对样本数据进行分类的目的。本发明的技术方案如下:一种高含水后期油藏流场分级评价方法,包括步骤如下:s1、综合分析影响油藏流场的静态因素和动态因素,利用逻辑分析法筛选出合适的流场评价指标,最终确定面通量作为油藏流场评价的唯一指标,如图1;s2、对eclipse导出的面通量场数据进行初步聚类分析,采用模糊c均值聚类(fcm)分析将面通量进行聚类,得到聚类中心和聚类数目,根据聚类数目在0~1范围内给定流场强度定义值;s3、通过分析比较常用的隶属函数(目前,大部分研究人员选择运用隶属函数对场数据进行归一化处理,将数据的变化范围调整到0~1之间),结合特高含水期油藏的特点,可知流场强度的变化规律与戎下型隶属函数的特征最为接近,因此选取戎下型隶属函数对面通量场数据进行归一化处理,根据选取的戎下型隶属函数,利用matlab中curvefitting工具对步骤s2中的聚类点进行拟合,每个聚类点的表达形式为(聚类中心,流场强度定义值),得到隶属函数中未知量的值;s4、对原始每个面通量场数据重新进行数学处理:根据已经确定的戎下型隶属函数,重新对eclipse导出的面通量场数据进行归一化处理,即可得到每个面通量场数据的流场强度;得到的流场强度位于0~1之间,流场中每个网格的强度都不同,没有办法直接比较区域之间的流场强弱,还要进行进一步处理;步骤s4的归一化处理和步骤s3的归一化处理作用和目的有区别,步骤s3是根据确定的分类数目,来确定归一化函数的参数值,步骤s4是根据确定的归一化函数来进行归一化。s5、再次利用模糊c均值聚类分析对数据范围0~1之间的流场强度进行分级;先根据模糊c均值聚类分析聚类出不同分级数下有效性函数的大小,再做出有效性函数和分级数两者之间的关系曲线图,根据有效性函数和分级数两者之间的关系曲线图得到最佳分级数,有效性函数数值最小的分级数为最佳分级数,有效性函数数值越小分类效果越好;然后根据模糊c均值聚类分析,得出每级流场的上限值与下限值;s6、根据s5中计算得到的每级流场的上限值与下限值,利用matlab输出计算后的每级流场的上限值、下限值,将输出的上限值、下限值数据导入油藏数值模拟软件eclipse,得到分级后流场图,达成完整的流场评价体系。在步骤s1中,对于具体的实际区块来说,影响油藏流场强弱的静态因素(孔隙度、渗透率、粘度等)在一定程度上可以预测动态因素的变化,与动态因素之间属于过程关系,所以可不考虑;而动态因素的大小直接影响了流场变化,比较重要的动态因素有含水率、面通量、流体流速和压力梯度等。分析上述动态因素之间的逻辑关系:压力梯度和流体流速之间、面通量和含水率之间均为为定义关系,则可以去除压力梯度、含水率;面通量和流体流速之间属于过程关系,面通量随着时间的导数的反映即为流体流速,所以最终确定面通量为流场表征的唯一指标。优选的,在步骤s3中,戎下型隶属函数表达式为:式中,μx为指标的隶属函数值;x为指标值;a1为指标最小值;a2为指标最大值,a、b为需要求得的未知量。优选的,s4中,根据油藏数值模拟输出各网格的面通量数值,利用戎下型隶属函数进行归一化处理,并将归一化后的面通量定义为流场强度l,见式(2)。其中,m为面通量场数据,m1为面通量场数据最小值,m2为面通量场数据最大值,在戎下型隶属函数中,系数a、b是未知量,目前几乎没有对系数确定的研究,一般是根据相关经验及规律,由实际测得或是理论计算得到的目标变量预测其对应的隶属度分值,接着拟合得出系数a、b的大小。随着油田开发的开展,水驱逐渐冲刷,油藏数值模拟模型中各网格的面通量也随之增大。所以,将归一化处理的对象定为数值模拟结束时间点对应的面通量。优选的,在步骤s5中,先构造有效性函数,vw(vc,uc)定义为紧致性度量和分离性度量的比值,紧致性度量越小,意味着同一类中的数据差异越小,即分散程度越小;分离性度量越大,则意味着不同类之间的数据差异越大,即类间的分离程度越大。因此,vw的最小值对应最佳的模糊c均值聚类划分最佳的最佳聚类数c*。有效性函数如公式(3)所示:式中,vw(vc,uc)为有效性函数,comn(vc,uc)为标准化的紧致性度量,sepn(c,uc)为标准化的分离性度量,vc为相应的聚类中心,uc为模糊划分矩阵,c为聚类数,n为自然数;然后再将步骤s4中得到的流场强度通过模糊c均值聚类分析,得到每级流场的上限值与下限值。进一步优选的,以vw为有效性函数,以模糊c均值聚类为聚类算法,寻求数据集最佳聚类数的具体流程步骤如下:步骤一:对模糊c均值聚类算法和vw有效性函数的参数进行初始化:c=2,m=2,ε=0.00001,其中m和ε为模糊c均值聚类算法中的参数;步骤二:对给定数据集以c为聚类数运行模糊c均值聚类算法,求出相应的聚类中心vc和模糊划分矩阵uc;步骤三:利用步骤二中结果,计算并储存紧致性度量com(vc,uc)和分离性度量sep(c,uc);步骤四:如果c<cmax,令c=c+1,转到步骤二;否则转到步骤五;步骤五:对com(vc,uc)和sep(c,uc)(c=2,3,…,cmax)进行标准化,并根据等式(3)计算出相应的vw(vc,uc);步骤六:找出最小值并记录与之对应的c值,定义该c值为给定数据集的最佳聚类数c*。本发明的有益效果如下:采用面通量作为表征流场的唯一指标,避免了利用多项参数表征流场时易人为主观地分配各参数的权重,具有一定的客观性和准确性;选取戎下型隶属函数对面通量数据进行归一化处理,将处理结果定义为流场强度,克服了线性隶属函数参数变化适用范围小、对数型隶属函数易受极值影响的缺陷;采用模糊c均值聚类分析对流场强度进行分级,克服了人为分级的经验性和主观性,有较强的理论基础。该方法具有一定适用性,可以进行大规模的矿场应用与推广,依据流场的分布与强弱来调整产液结构,进而有效挖潜剩余油。附图说明图1是油藏渗流场量化表征指标筛选流程图;图2是均值聚类示意图;图3是戎下型隶属函数拟合参数;图4是有效性函数随分类数的变化曲线;图5是试验x油田分级前流场平面分布图;其中,nmx3、nmx6-2、ng1-2-1、ng1-4为该油田不同的单砂层的平面分布图;图6是试验x油田分级后流场平面分布图。具体实施方式为了使本领域的技术人员更好的理解本发明的技术方案,下面结合附图和具体实施例对本发明作进一步详细的描述。一种高含水后期油藏流场分级评价方法,包括步骤如下:s1、综合分析影响油藏流场的静态因素和动态因素,利用逻辑分析法筛选出合适的流场评价指标,最终确定面通量作为油藏流场评价的唯一指标,如图1;s2、对eclipse导出的面通量场数据进行初步聚类分析,原始的面通量场数据如图5所示,采用模糊c均值聚类分析将面通量进行聚类,得到聚类中心和聚类数目,如图2,根据聚类数目在0~1范围内给定流场强度定义值;输出试验x油田面通量场数据,然后直接通过模糊c均值聚类分析的相关程序进行初步聚类得到9类。利用模糊c均值聚类分析得出9个聚类中心,分别为:1.6、240、610、1091、1736、2641、4121、6919、10447,由于流场强度在0~1之间,将各聚类中心的流场强度定义值分别定义为0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9,通常在0~1之间均分,相应的聚类点表示为:(1.6,0.1)、(240,0.2)、(610,0.3)、(1091,0.4)、(1736,0.5)、(2641,0.6)、(4121,0.7)、(6919,0.8)、(10447,0.9)。s3、选取戎下型隶属函数,戎下型隶属函数表达式为:式中,μx为指标的隶属函数值;x为指标值;a1为指标最小值;a2为指标最大值,a、b为需要求得的未知量。运用matlab中curvefitting工具对步骤s2中的(1.6,0.1)、(240,0.2)、(610,0.3)、(1091,0.4)、(1736,0.5)、(2641,0.6)、(4121,0.7)、(6919,0.8)、(10447,0.9)九个聚类点进行函数拟合,得到隶属函数中未知量的值,即得出a=778,b=-0.9044,见图3。s4、根据已经确定的戎下型隶属函数,重新对eclipse导出的面通量场数据进行归一化处理,即可得到每个面通量场数据的流场强度;并将归一化后的面通量定义为流场强度l,见式(2)。其中,m为面通量场数据,m1为面通量场数据最小值,m2为面通量场数据最大值。s5、再次利用模糊c均值聚类分析对数据范围0~1之间的流场强度进行分级;先构造有效性函数,vw(vc,uc)定义为紧致性度量和分离性度量的比值,紧致性度量越小,意味着同一类中的数据差异越小,即分散程度越小;分离性度量越大,则意味着不同类之间的数据差异越大,即类间的分离程度越大。因此,vw的最小值对应最佳的模糊c均值聚类划分最佳的最佳聚类数c*。有效性函数如公式(3)所示:式中,vw(vc,uc)为有效性函数,comn(vc,uc)为标准化的紧致性度量,sepn(c,uc)为标准化的分离性度量,vc为相应的聚类中心,uc为模糊划分矩阵,c为聚类数,n为自然数。以vw为有效性函数,以模糊c均值聚类为聚类算法,寻求数据集最佳聚类数的具体流程步骤如下:步骤一:对模糊c均值聚类算法和vw有效性函数的参数进行初始化:c=2,m=2,ε=0.00001,其中m和ε为模糊c均值聚类算法中的参数;步骤二:对给定数据集以c为聚类数运行模糊c均值聚类算法,求出相应的聚类中心vc和模糊划分矩阵uc;步骤三:利用步骤二中结果,计算并储存紧致性度量com(vc,uc)和分离性度量sep(c,uc);步骤四:如果c<cmax,令c=c+1,转到步骤二;否则转到步骤五;步骤五:对com(vc,uc)和sep(c,uc)(c=2,3,…,cmax)进行标准化,并根据等式(3)计算出相应的vw(vc,uc);步骤六:找出最小值并记录与之对应的c值,定义该c值为给定数据集的最佳聚类数c*。然后再将步骤s4中得到的流场强度通过模糊c均值聚类分析,得到每级流场的上限值与下限值。根据模糊c均值聚类分析聚类出不同分级数下有效性函数的大小,再做出有效性函数和分级数两者之间的关系曲线图,根据有效性函数和分级数两者之间的关系曲线图得到最佳分级数,有效性函数数值最小的分级数为最佳分级数,有效性函数数值越小分类效果越好,见图4。从图4可以看出,当分级数等于4时,有效性函数数值最小,根据有效性函数越小,分类效果越好,因此分级数最佳为4;然后根据模糊c均值聚类分析,得出每级流场的上限值与下限值;分别为0.1411、0.3265、0.5453。即得到如表1所示的流场划分结果。表1试验x油田流场分级标准流场级别x流场强度范围流场性质i≥0.5453强优势流场ii[0.3265,0.5453)优势流场iii[0.1411,0.3265)弱优势流场iv<0.1411非优势流场s6、根据s5中计算得到的每级流场的上限值与下限值,利用matlab将输出的上限值、下限值数据导入油藏数值模拟软件eclipse;利用数值模拟eclipse软件,输出分级后流场图,见图6。图6清楚的表现出油藏的流场强弱关系,为后续的开发提供流场分布依据。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1