一种基于FOA优化的SOM‑RBF的压力传感器温度补偿方法与流程
本发明涉及压力传感器温度补偿方法,尤其涉及一种基于FOA优化的SOM-RBF的压力传感器温度补偿方法。
背景技术:
压力传感器中,硅压阻式压力传感器使用最为广泛,发展最为成熟。它利用半导体材料的压阻效应来进行压力测量,体积小、灵敏度高。工程应用中由于硅材料和封装介质受温度的影响,导致传感器的实际输出发生漂移,传感器温度补偿问题是提高传感器性能的一个关键环节。压力传感器主要有两种温度补偿方法:硬件补偿和软件补偿。硬件补偿方法存在调试困难、精度低、成本高、通用性差等缺点,不利于工程应用。利用数字信号处理技术的软件补偿能够克服以上缺点。
影响压力传感器温度特性的因素很多,表现为复杂的非线性,传统的线性软件补偿无法满足智能传感器的高精度要求。神经网络具有优秀的非线性系统建模和逼近能力,可实现自适应和自学习,广泛用于非线性系统的回归和拟合、并行处理和优化计算,非常适合应用于解决传感器的温度补偿问题。
BP神经网络可用于传感器温度补偿,利用误差反向传播原理,可达到一定输出精度,但网络相对复杂,随机参数较多。
技术实现要素:
本发明的目的在于克服上述现有技术的缺点和不足,提供一种基于FOA优化的SOM-RBF的压力传感器温度补偿方法。具有较好的补偿精度,一定的鲁棒性和泛化能力。
本发明通过下述技术方案实现:
一种基于FOA优化的SOM-RBF的压力传感器温度补偿方法,包括步骤:
步骤(1):将压力标定实验采集得到的样本数据归一化并随机分为训练数据和测试数据,以训练数据建立基本RBF网络模型,利用迭代误差收敛速度和精度稳定性确定RBF网络隐含层节点数;具体包括:
11)建立RBF网络确定隐含层节点数:
若输入向量Xm=[x1,x2,…,xm]T为m列向量,隐含层具有n个隐含节点,则第i个隐含节点的输出为Φ(||Xm-Xi||),Xi=[xi1,xi2,…,xim]T为基函数的中心;
输出层包含若干线性单元,每个线性单元与所有隐含节点相连,ωij为第i个隐含层到第j个输出层的权值,网络的最终输出是隐含节点输出的线性加权和;
设实际输出为Yk=[yk1,yk2,…,ykm]T,则当训练样本为Xk时,网络的第J个输出神经元的输出为:
基函数选用高斯函数,则:
其中σ为网络扩展值;
随机初始化网络参数,取输出最大相对误差和均方差作为评价标准,并给出目标值;
隐含层节点数从最小值开始向最大值迭代,记录误差变化并根据目标值确定节点数。
步骤(2):利用测试数据和隐含层节点数建立自适应SOM网络得到RBF网络中心值;具体包括:
21)构造SOM网络确定网络中心值:SOM采用拓扑学习,不仅更新获胜神经元的权值,每个神经元拓扑结构内临近的神经元权值也会得到更新,使其不仅可学习输入样本的分布,还能识别输入样本的拓扑结构;
22)SOM网络的训练步骤为:
1)数据处理及参数初始化:选取训练输入数据每个数据为m维向量x=[x1,x2,…,xm],并做归一化处理;随机初始化网络权值ωij,设置最大和最小学习率lrmax和lrmin,设置领域最大值和最小值dmax和dmin;其中i=1,2,…,m为输入向量维数,j=1,2,…,n为RBF隐含层节点个数;
2)构造网络并输入数据:确定网络拓扑结构(邻域范围)并构造SOM网络,将样本数据输入,并计算欧式距离d=||x-ω||,d值最小的神经元即为获胜神经元;
3)更新网络权值:对获胜的神经元拓扑领域内的神经元,采用Kohonen规则进行权值更新:
ω(k+1)=ω(k)+lr(x-ω(k)
4)迭代,更新学习率和拓扑邻域:对网络进行迭代计算,并根据迭代次数更新网络学习率和邻域值:
其中N为最大迭代次数,i为本次迭代次数;
5)判断是否达到最大迭代次数或ω值变化很小,则学习过程结束。
步骤(3):采用FOA对RBF网络扩展参数进行寻优得到完整的优化RBF网络,最后将测试数据输入网络得到补偿输出;具体包括:
31)利用获得的中心值代入RBF网络基函数,将训练数据最终输出的误差最大值作为FOA味道浓度的适应度函数,并进行迭代,获取网络扩展值;
基于果蝇觅食行为的FOA优化算法基本步骤如下:
1)给定群体规模Popsize,最大迭代数maxgen,随机初始化种群位置(X_axia,Y_axia);
2)设定果蝇个体利用嗅觉搜寻食物的随机方向与距离:
Xi=X_axia+RandomValue-x
Yi=Y_axia+RandomValue-y
3)因为食物位置不能确定,利用果蝇个体与原点之间距离的倒数作为味道浓度判定值
4)将味道浓度判定值代入味道浓度判定函数(适应值函数),计算果蝇个体位置的味道;
5)找出该果蝇群体中味道浓度最佳的果蝇,记录并保留最佳味道浓度值BestSmell与其X,Y坐标,这时候果蝇群体利用视觉向该位置飞去;
6)进入迭代寻优,重复执行步骤(2)~(5)并判断最佳味道浓度是否优于前一迭代最佳味道浓度,直至迭代次数达到最大迭代数。
本发明相对于现有技术,具有如下的优点及效果:
本发明以结构简单、实时性好、收敛速度快的RBF神经网络作为基础模型,利用自组织聚类网络,选取RBF网络中心值,克服了以往算法随机选取中心导致网络不稳定和计算量大的问题,提高了模型的泛化能力,然后采用果蝇算法对RBF网络的基函数扩展值进行寻优,避免了传统RBF算法依据经验选取扩展值导致的数据不匹配问题。结合传感器变温实验与提出的温度补偿算法,补偿结果表明模型具有较好的补偿精度,一定的鲁棒性和泛化能力。
附图说明
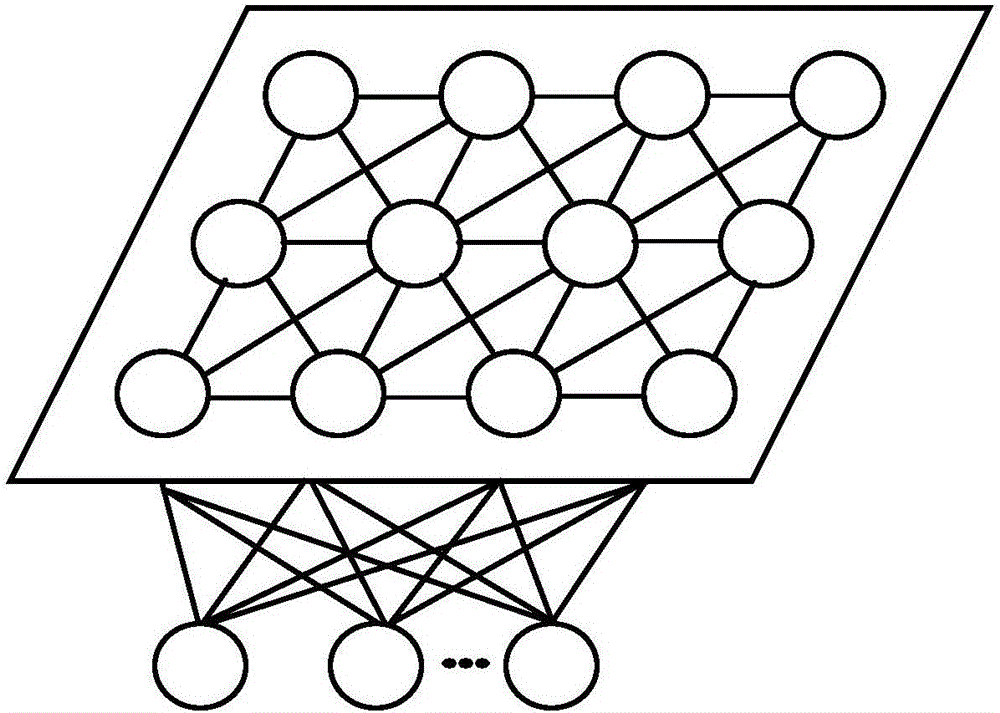
图1是RBF神经网络模型。
图2是自组织映射网络结构。
图3是基于FOA优化SOM-RBF算法流程图。
具体实施方式
下面结合具体实施例对本发明作进一步具体详细描述。
实施例
如图1至3所示。本发明公开了基于FOA优化的SOM-RBF的压力传感器温度补偿方法,可通过如下步骤实现。
(1)建立RBF网络确定隐含层节点数:
RBF网络的结构如附图1所示:
若输入向量Xm=[x1,x2,…,xm]T为m列向量,隐含层具有n个隐含节点,则第i个隐含节点的输出为为基函数的中心。输出层包含若干线性单元,每个线性单元与所有隐含节点相连,ωij为第i个隐含层到第j个输出层的权值,网络的最终输出是隐含节点输出的线性加权和。设实际输出为Yk=[yk1,yk2,…,ykm]T,则当训练样本为Xk时,网络的第J个输出神经元的输出为:
基函数一般选用高斯函数,则:
其中σ为网络扩展值。
随机初始化网络参数,取输出最大相对误差和均方差作为评价标准,并给出目标值。隐含层节点数从最小值开始向最大值迭代,记录误差变化并根据目标值确定节点数。
(2)构造SOM网络确定网络中心值:SOM采用拓扑学习,不仅更新获胜神经元的权值,每个神经元拓扑结构内临近的神经元权值也会得到更新,使其不仅可学习输入样本的分布,还能识别输入样本的拓扑结构,SOM网络模型如附图2所示。
SOM网络的训练步骤为:
1)数据处理及参数初始化:选取训练输入数据每个数据为m维向量x=[x1,x2,…,xm],并做归一化处理;随机初始化网络权值ωij,设置最大和最小学习率lrmax和lrmin,设置领域最大值和最小值dmax和dmin。其中i=1,2,…,m为输入向量维数,j=1,2,…,n为RBF隐含层节点个数。
2)构造网络并输入数据:确定网络拓扑结构(邻域范围)并构造SOM网络,将样本数据输入,并计算欧式距离d=||x-ω||,d值最小的神经元即为获胜神经元。
3)更新网络权值:对获胜的神经元拓扑领域内的神经元,采用Kohonen规则进行权值更新:
ω(k+1)=ω(k)+lr(x-ω(k)
4)迭代,更新学习率和拓扑邻域:对网络进行迭代计算,并根据迭代次数更新网络学习率和邻域值:
其中N为最大迭代次数,i为本次迭代次数。
5)判断是否达到最大迭代次数或ω值变化很小,则学习过程结束。
(3)利用获得的中心值代入RBF网络基函数,将训练数据最终输出的误差最大值作为FOA味道浓度的适应度函数,并进行迭代,获取网络扩展值。
基于果蝇觅食行为的FOA优化算法基本步骤如下:
1)给定群体规模Popsize,最大迭代数maxgen,随机初始化种群位置(X_axia,Y_axia)。
2)设定果蝇个体利用嗅觉搜寻食物的随机方向与距离:
Xi=X_axia+RandomValue-x
Yi=Y_axia+RandomValue-y
3)因为食物位置不能确定,利用果蝇个体与原点之间距离的倒数作为味道浓度判定值
4)将味道浓度判定值代入味道浓度判定函数(适应值函数),计算果蝇个体位置的味道。
5)找出该果蝇群体中味道浓度最佳的果蝇,记录并保留最佳味道浓度值BestSmell与其X,Y坐标,这时候果蝇群体利用视觉向该位置飞去。
6)进入迭代寻优,重复执行步骤2~5并判断最佳味道浓度是否优于前一迭代最佳味道浓度,直至迭代次数达到最大迭代数。
如上所述,便可较好地实现本发明。
本发明的实施方式并不受上述实施例的限制,其他任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!