基于自适应模糊推理的超宽带土壤信号含水量识别方法与流程
一种基于自适应模糊推理的超宽带土壤信号含水量识别方法,用于土壤含水量的测量,属于精细化农业技术应用方向,具体涉及遥感技术、土壤含水量检测技术领域。
背景技术:
在精细化农业中,使用雷达(遥感技术)测量土壤含水量已成为一个研究热点,技术原理为使用雷达探测与收集土壤回波,根据回波特性与土壤性质间的联系反演出土壤含水量。使用雷达(遥感技术)测量土壤含水量的针对农田土壤含水量测量,该技术对土壤和作物的无接触、无破坏,同时该技术操作简单耗时短,可实现对土壤含水量的实时监控。但土壤回波特性与多方面因素有着相互联系,如与土壤性质(土壤盐度、土壤结构、土壤表面粗糙度等),测试环境(温度、湿度、有无植被等),雷达发射波性质(中心频、极化方式、入射角等)相关。考虑多种因素的相互影响,回波特性与土壤含水量之间往往存在强烈的非线性关系,这将使土壤含水量检测产生较大误差。
机载sar雷达测量土壤含水量:使用合成孔径(sar)雷达,测量大范围农田土壤含水量分布。该技术土壤表面粗糙度与植被覆盖等性质十分敏感,仅适合含水量分布粗略检测,且精度较低。
使用地面测量、固定式探地雷达(gpr)对小区域土壤含水量的精确检测。该方法提高了含水量的检测精度,但现有方法使用物理模型反演,该模型无法描绘土壤回波性质与含水量之间强烈的非线性关系,因此在实际测量中依然存在较大误差。
检索到专利号为:201510536304.4的“一种针对超宽带雷达回波的土壤湿度反演方法”和专利号为:2016107440824.1的“一种基于超宽带与非单点模糊逻辑的土壤含水量测量方法”。
专利号为:201510536304.4的公开专利中使用二型模糊逻辑系统预测土壤波形,并提取系统中部分参数进行分类识别。该方法使用的识别算法十分简易,使得最终的识别率不尽理想。同时二型模糊逻辑系统参数繁多,计算成本高。
专利号为:2016107440824.1的公开专利使用非单点一型模糊逻辑系统预测不同土壤含水量,并保留预测结果作为模板用于不同土壤回波的比较识别。该方法使用模糊逻辑系统的预测结果作为模板十分不准确,且在使用模板比较识别土壤回波时,易受到噪声影响。
综上所述,现有技术中的土壤含水量的测量方法不能准确测量土壤回波,从而造成土壤含水量的测量不精确、测量成本高等问题。
技术实现要素:
本发明针对上述不足之处提供了一种基于自适应模糊推理的超宽带土壤信号含水量识别方法,解决现有技术中的土壤含水量的测量方法不能充分利用土壤回波性质,从而造成土壤含水量的测量不精确、测量成本高等问题。
本发明采用的技术方案如下:
一种基于自适应模糊推理的超宽带土壤信号含水量识别方法,其特征在于,如下步骤:
(1)收集土壤的超宽带土壤回波和对应土壤回波的土壤含水量;
(2)对土壤回波进行预处理;
(3)构建自适应模糊推理系统,对预处理后的土壤回波进行特征向量提取;
(4)使用机器学习算法——随机森林算法构建分类器,得到随机森林分类器;
(5)随机森林分类器根据不同土壤含水量对步骤(3)提取的预处理后的土壤回波的特征向量进行分类识别,并输出分类识别结果。
进一步,所述步骤(1)中,使用pulson410超宽带雷达传感器收集土壤回波;使用土壤水分测量仪tdr300记录相应土壤回波的土壤含水量。
进一步,所述步骤(2)的具体步骤如下:
(21)截取收集到的土壤回波中的部分时序序列,截取的部分时序序列未被耦合噪声吞没;
(22)将截取的部分时序序列进行归一化处理,即将截取的部分时序序列的坐标调整至[0,1]间,归一化处理的公式如下:
式中,x(n)代表时序序列中的第n个时序点,xnorm(n)为第n个时序点归一化后的值,xmax与xmin分别为土壤回波中的最大值与最小值,即时序序列中时序点的最大值与最小值;
(23)将归一化处理后的土壤回波复制五次级联在一起,组成一个新的时序序列。
进一步,所述步骤(3)的具体步骤如下:
(31)构建5个阶段的自适应模糊推理系统,其中5个阶段有四个输入,单个输出;具体如下:
(311)阶段1:构建四个输入,每个输入对应两个高斯隶属度函数;高斯隶属度函数的公式如下:
式中,
(312)阶段2:分别从阶段1的四个输入中任选一个高斯隶属度函数,将选出的四个高斯隶属度函数相乘,组成一个规则;规则的组成公式如下:
式中,i表示四个输入中任选一种高斯隶属度函数相乘的组合规则个数中的第几个,ωi表示第i个组合规则。
(313)阶段3:将阶段2中得到的每个ωi进行归一化处理;归一化处理的公式如下:
(314)阶段4:为每个
式中,
(315)阶段5:将16个规则得到的不同ri值进行累加,累加公式如下:
(316)通过步骤(311)-步骤(315)得自适应模糊推理系统的最终表达式,公式如下:
式中,x=(x1,x2,x3,x4),是由自适应模糊推理系统四个输入值组成的输入向量,自适应模糊推理系统由三种参数c,m,σ控制性质;
(32)将步骤(23)得到的新的时序序列不断输入自适应模糊推理系统进行训练,直到输入的新的时序序列能够预测出下一个时序点的值,即训练结束;
(33)提取训练结束后的自适应模糊推理系统的参数c,m,σ组成一个特征向量。
进一步,所述步骤(32)中,将步骤(23)得到的新的时序序列不断输入自适应模糊推理系统进行训练的具体步骤为:
(321)使用最小二乘估计调节训练参数c;具体如下:
(3211)先将ytsk(x)公式转化为如下公式:
式中,j表示第j个线性运算的权向量;
(3212)将所有
y(x)=gt(x)c,
式中,t代表转置;
(3213)使用如下公式对参数c进行训练:
式中,向量ct,gt分别为第t次训练时的c和g(x)的值,c是所有系数
(322)完成最小二乘估计训练后,使用梯度下降法调整自适应模糊推理系统中m,σ的值,调整公式如下:
式中,x(t)表示第t次训练中,输入系统的训练向量,
进一步,所述步骤(4)的具体步骤如下:
(41)选取土壤回波特征向量作为样本,建立样本数据集;
(42)从样本数据集的中抽取样本作为训练子集和测试样本,每个训练子集用于分别训练随机森林的决策树;
(43)从决策树中的特征向量中随机选出多种特征元素构建特征子向量;
(44)在每个决策树中,选择对应的特征子向量中的一个特征元素进行分类,得到分类后的数据子集;
(45)计算数据子集的基尼指数,选择基尼指数最小的分类方法对步骤(44)得到的数据子集进行分类,直到每个数据子集中只有相同的特征元素,即完成决策树的训练;
(46)将步骤(42)中的测试样本对步骤(45)中完成的每个决策树中的特征向量进行分类,得到分类错误次数最少的决策树,即为随机森林分类器。
进一步,所述步骤(45)中,基尼指数的公式如下:
式中,nk表示数据子集属于第k类的样本个数,n为数据子集含有的样本个数,pk和pk′分别表示数据子集中第k类样本与非第k类样本所占比例。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1、本发明中使用自适应模糊推理系统进行特征提取计算成本低,时间消耗少;
2、本发明中使用自适应模糊推理系统进行特征提取,适用随机森林算法对特征进行识别,测量精确,正确测量率可达99.51%。
附图说明
图1为本发明土壤含水量识别的识别框图;
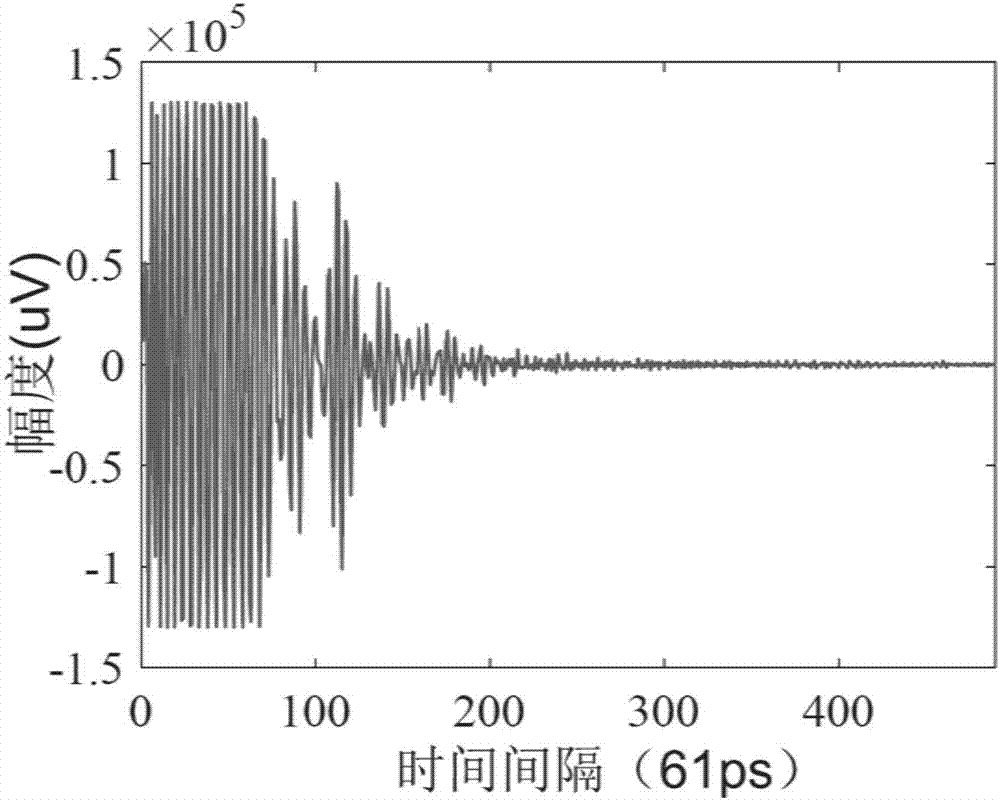
图2为本发明中裸土13.7%体积含水量的土壤回波图;
图3为本发明中自适应模糊推理系统的结构示意图;
图4为本雷达回波输入自适应模糊推理系统的示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
一种基于自适应模糊推理的超宽带土壤信号含水量识别方法,使用pulson410超宽带雷达传感器收集土壤回波,并使用土壤水分测量仪tdr300记录相应回波的土壤含水量。通过简单的预处理,使用自适应模糊系统提取土壤回波特征(即特征向量)。将所有土壤回波特征及其对应的土壤含水量存入数据库。利用数据库中数据对随机森林分类器进行训练,使分类器能够通过特征向量判断不同土壤回波并将其分入对应的土壤含水量类别中。如图1所示。
土壤回波预处理:
如图2所示,采集到的土壤回波是一个时序序列,每两个点间的时间间隔为61ps。由于受到耦合噪声影响,前90个时序点被噪声吞没而无法使用。同时考虑雷达波能土壤渗透的深度有限,最终截取时序序列第91-490个点作为进行利用。
截取的土壤回波(共400点)使用公式如下公式进行归一化处理,归一化处理后将坐标调整至[0,1]间。
式中,x(n)代表时序序列中的第n个时序点,xnorm(n)为第n个时序点归一化后的值,xmax与xmin分别为土壤回波中的最大值与最小值,即时序序列中时序点的最大值与最小值;
将归一化后的土壤回波复制五次级联在一起,组成一个400*5=2000的时序序列。输入自适应模糊推理系统进行特征向量提取。
构建自适应模糊推理系统进行特征向量提取
构建自适应模糊推理系统:
如图3所示,该系统同时存在4个输入,单个输出,系统由5个阶段组成。
构建5个阶段的自适应模糊推理系统,其中5个阶段有四个输入,单个输出;具体如下:
阶段1:构建四个输入,第个输入对应两个高斯隶属度函数;高斯隶属度函数的公式如下:
式中,
阶段2:分别从阶段1的四个输入中任选一个高斯隶属度函数,将选出的四个高斯隶属度函数相乘,组成一个规则;规则的组成公式如下:
式中,i表示四个输入中任选一种高斯隶属度函数相乘的组合规则个数中的第几个,ωi表示第i个组合规则,这种组合方法共可得到16种规则。
阶段3:将阶段2中得到的每个ωi进行归一化处理;归一化处理的公式如下:
阶段4:为每个
式中,
阶段5:将16个规则得到的不同ri值进行累加,累加公式如下:
通过阶段1-阶段5可得自适应模糊推理系统的最终表达式,公式如下:
式中,x=(x1,x2,x3,x4),是由自适应模糊推理系统四个输入值组成的输入向量,自适应模糊推理系统由三种参数c,m,σ控制性质;
利用自适应模糊推理系统进行特征向量提取:
雷达土壤回波的特征向量提取,其原理为使用雷达回波的时序序列不断训练自适应模糊推理系统,当土壤回波的时序序列再次输入自适应模糊推理系统中,该自适应模糊推理系统能够预测出下一个时序点的值,此时认为系统已记录整个雷达回波序列的特性,并提取训练后的系统参数c,m,σ组成一个特征向量。
雷达土壤回波的时序序列输入自适应模糊推理系统方式如图4所示,每次输入系统的训练向量(即特征向量)为(xt,xt+1,xt+2,xt+3)t=1,...,1996,并使用xt+4作为校验值训练自适应模糊推理系统的系统参数。当一个完整的时序序列输入自适应模糊推理系统中(即训练1996次),我们称自适应模糊推理系统完成1组训练,当完成40组训练后,整个训练过程结束,提取训练后自适应模糊推理系统参数,将所有参数拼接一起整合为特征向量,图4中n为输入系统中整个时序序列的长度。
自适应模糊推理系统使用一种复合式的学习方法训练参数。首先使用最小二乘估计(lse)调节c值,然后使用梯度下降法调节系统中m,σ的值。
使用最小二乘估计调节训练参数c;具体如下:
先将ytsk(x)公式转化为如下公式:
式中,j表示第j个线性运算的权向量;
将所有
y(x)=gt(x)c;
使用如下公式对参数c进行训练:
式中,向量ct,gt分别为第t次训练时的c和g(x)的值,c是所有系数
完成最小二乘估计训练后,使用梯度下降法调整自适应模糊推理系统中m,σ的值,调整公式如下:
式中,x(t)表示第t次训练中,输入系统的训练向量,其值为(xt,xt+1,xt+2,xt+3),
训练随机森林分类器
由自适应模糊推理系统提取的土壤回波的特征向量,使用土壤性质(包括湿度)作为标签标记后存入数据库。在训练随机森林分类器时,需使用特征向量进行训练,使用分类标签作校验。
举例说明训练过程:
选择9种不同性质的土壤回波特征向量作为样本,分别为裸土体积含水量13.7%,21.7%,28.3%,29.7%,35.0%,39.0%和沙土土基含水量12.5%,18.8%,23.2%,每种选择600个特征向量,建立一个含有5400个样本的数据集。
从数据集中有放回的随机抽取2000个样本组成训练子集,以有放回抽取训练子集的方法构建1000个训练子集,每个子集分别用于训练随机森林的决策树。同时,将数据集中从未选入训练子集的样本抽取出来作为测试样本进行测试。
从每个决策树中的特征向量中随机选择10种特征元素构建一个特征子向量,该决策树仅使用对应的特征子向量进行分类。
每个决策树中,每次选择特征子向量中的一个特征元素进行分类,使通过该特征元素分类后得到的每个数据子集中,含有的相同土壤含水量标签的样本越多越好(越纯净)。这里使用基尼指数描述分类后的纯度,如下公式:
式中,nk表示数据子集属于第k类的样本个数,n数据子集含有的样本个数吗,pk和pk′分别表示数据子集中第k类样本与非第k类样本所占比例。
计算每种分类的方法后基尼指数的大小,选择基尼指数最小的分类方法分类。利用该方法选择特征向量继续对各个数据子集进行分类,直至每个数据子集中仅含相同土壤含水量标签的样本时停止,完成决策树训练,记录分类流程。
将测试样本带入已训练好的各个决策树中进行分类,计算错误分类次数。从1000个决策树中选择错误分类次数最少的决策树作为最终的随机森林分类器。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!