一种自动添加校正集样本的方法与流程
本发明涉及石油化工领域的油品性质检测分析方面,基于近红外光谱快速分析技术,建立一种自动添加校正集样本的方法。
背景技术:
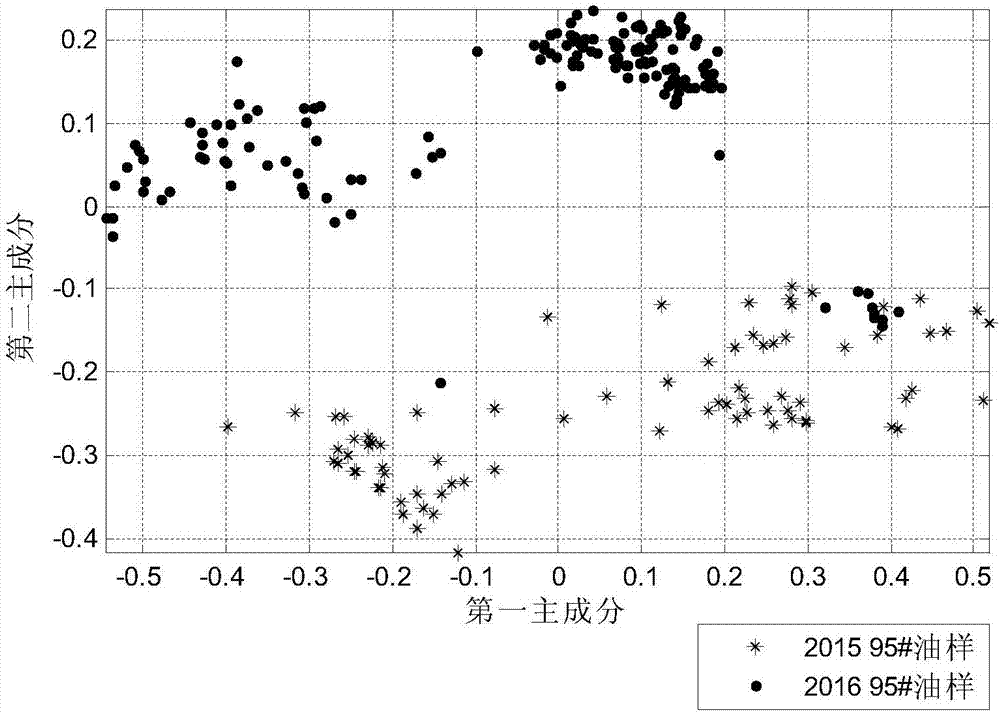
:在油品分析领域,近红外光谱分析技术相比较传统的分析方法具有成熟、快速、无损等优点,因而该技术越来越多应用在油品性质的分析中。利用该技术预测油品的性质,首先要建立与待测样本接近的校正集。在工业生产中,油样往往会随时间变化。例如炼化企业生产的馏分油,在更换原油或改变加工工艺后,油品性质会有不同程度的改变。因此在一段时间后,新样本的分布会偏离原模型校正集样本的分布区域。当待测样本周围分布的校正集样本较少,处于稀疏区时,模型预测效果(特别是采用相似样本建模方法)将变差,预测误差增大,影响生产控制和产品质量。因此需要不断对模型的校正集进行更新,将处于稀疏区中的新油样添加进去,以保证模型的预测精度。目前有企业采用定期人工更新校正集的方法,但这种方法在一次更新较久后的一段时间里,预测精度往往无法保障。自动将稀疏区样本添加进入校正集可有效避免上述问题。技术实现要素:针对上述问题,本发明公开一种自动添加校正集样本的方法,可自动将新样本添加到校正集,以保证模型预测精度,便于生产控制。本发明采用以下技术方案:一种自动添加校正集样本的方法,其特征在于该方法针对炼化企业生产中油样变化的情况,自动将处于校正集稀疏区中的新油样添加进校正集,以保证模型预测精度,本方法具有以下步骤:(1)测定样本的近红外光谱,对新样本和校正集中样本的光谱数据进行常规预处理;(2)对预处理后的光谱数据进行主成分分析,选取主成分分析结果中得分矩阵的前n个列向量,绘制n维主成分分布图;(3)在主成分分布图中以新样本为中心,建立n维的固定框;(4)统计n维框内相似样本数量,与阈值比较,判断样本是否处于密集区,若相似样本数量大于阈值则新样本处于密集区,不添加到校正集,返回步骤(1);否则转步骤(5),考虑加入校正集;(5)判断新样本是否为异常样本,如是异常样本,则不添加到校正集,返回步骤(1),否则转步骤(6);(6)自动将处于稀疏区的样本添加进模型校正集。本方法中,常规预处理包括基线校正和矢量归一化。本方法中n取2或3,在n=2时,选取前两个得分向量绘制二维主成分分布图;当n=3时,选取前三个得分向量绘制三维主成分分布图。当n=3时,三维立体框图的长宽高比为3:2:1。本方法中以新样本在校正集中相似样本数量来判断新样本是否处于稀疏区。在主成分分布图中以新样本为中心,根据贡献率由高到低选择前n个得分向量,建立n维空间上的固定框。统计框内相似样本数量,若大于阈值,则新油样处于密集区,不必添加到校正集;若小于阈值,则新油样处于稀疏区,则自动将处于稀疏区的样本添加进模型校正集。本方法中以杠杆值或马氏距离等标准方法来判断新样本是否属于异常样本。考虑到工业生产中油品性质的变化是渐变的,当某一油品与最近一段时间生产的油品有较大差异,则初步判定该油品为异常样本,先将其放入预备库,继续观察后续邻近时间的油样。若后续连续7天时间内其它油样均与最近一段时间生产的油品都要较大差异,则说明近期油样产生较大变化,将新油样从预备库添加到校正集;否则予以剔除。有益效果:本发明所提供的方法针对油品性质近红外光谱建模中生产变化的情况,自动将处于稀疏区的新样本添加到校正集中,可有效避免建模一段时间后,新样本偏离原校正集样本分布区域的情况。该方法能够随时更新校正集,保证模型预测精度,对于控制生产,确保油品质量具有重要应用价值。附图说明图1是自动添加校正集样本方法的实施流程图图2是实施例中某期间内95#汽油样本数据的主成分分布图图3(a)是实施例中稀疏区样本分布的示例图图3(b)是实施例中密集区样本分布的示例图具体实施过程下面结合附图以及具体的算例,给出详细的计算过程和具体操作流程,以对本发明作进一步说明。本实施案例在以本发明技术方案为前提下进行实施,但本发明的保护范围不限于下述的实施案例。本案例以95#汽油的终馏点为例,依据汽油的近红外光谱建立预测模型。原模型校正集a由某炼化企业在2014年1月至2016年11月期间生产的296个95#汽油样本组成。向校正集a中添加2016年12月至2017年5月的汽油采样中处于稀疏区的样本,建立新的校正集。选取2016年7月至2017年5月的112个样本进行终馏点预测,说明自动添加校正集样本对预测精度的影响。本案例实施流程如图1所示,具体的实施步骤如下:(1)建立95#汽油校正集扫描95#汽油样本获得近红外光谱数据,截取近红外光谱信息量较大的4000~4800cm-1波数段的吸光度数据,对截取的数据做基线校正和矢量归一化。(2)主成分分析对预处理后的样本光谱数据进行主成分分析,选取分析结果中得分矩阵的前n个列向量,绘制n维主成分分布图。2015至2016年间油样的二维主成分分布如图2所示,2015年全年采样的79个95#油样以“*”表示,2016年全年采样的158个95#油样以“·”表示。图中明显区分出2015年和2016年的油样分布区域,证明工业生产的油样随时间发生较大变化。(3)建立固定框本案例中取n=3。(4)判断新样本是否处于稀疏区建立三维空间上的立体框判断新样本是否处于稀疏区。立体框的长为0.3,宽为0.2,高为0.1,相似样本阈值取为50。对2016年12月至2017年5月采样的61个95#汽油样本进行判断。如果以新样本建立的立体框中相似样本数量少于50,则判定样本处于稀疏区,将该样本放入预备库,继续判断是否为异常样本。为便于观察,以二维分布图示意,如图3(a)所示。如果以新样本建立的立体框中相似样本数量大于50,则判定样本处于密集区,返回步骤(1),继续测量其他样本。如图3(b)所示。对2016年12月至2017年5月采样的61个汽油样本判断结果为,其中有46个样本处于稀疏区,进入预备库。判断是否为异常样本的方法较多,如马氏距离或杠杆值等标准方法。对进入预备库的46个样本判断结果为,其中有2个样本为异常样本,将其余44个样本添加到校正集。(5)比较添加校正集样本前后预测精度的变化校正集a由某炼化企业在2014年1月至2016年11月期间生产的296个95#汽油样本组成。逐步更新校正集a,将2016年12月至2017年5月的汽油采样中处于稀疏区的44个非异常样本自动添加进校正集a,最终形成校正集b。基于校正集a和逐步更新得到的校正集b分别建立模型,对2016年7月至2017年5月的112个样本进行终馏点预测,说明添加校正集样本对样本预测精度的影响。首先获取待测样本和校正集汽油样本的近红外光谱,经过常规预处理后进行主成分分析,寻找相似样本,然后根据相似样本采用偏最小二乘法建立模型,对112个待测样本的性质进行预测,预测结果分别如表1和表2所示。表1原模型预测结果表2新模型预测结果针对汽油终馏点,国家标准规定测量的重复性误差为3℃,再现性误差为5℃。因此将预测结果和化验值的偏差与重复性误差和再现性误差进行比较,以体现模型预测精度。对表1和表2中的数据进行统计,结果如表3所示。表3原模型和新模型比较预测偏差范围原模型数量(占比)新模型数量(占比)[0,3]104(93%)111(99%)(3,5]5(4%)0(0%)[5,+∞]3(3%)1(1%)由表3中数据可知,在添加校正集样本,建立新模型后,112个预测样本中预测偏差低于重复性误差,处于[0,3]范围内的样本数量增加7个,占比提高至99%。同时预测偏差高于再现性误差,处于[5,+∞]范围内的样本数量减少2个,占比降低至1%。样本总体预测偏差降低,预测精度显著提高。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1