一种北斗卫星信息传输的压缩实现方法与流程
本发明涉及卫星导航及通信领域,具体涉及一种北斗卫星信息传输的压缩实现方法。
背景技术:
北斗卫星导航系统是我国自主开发的区域卫星导航系统,该系统覆盖我国全境及周边国家,整个系统由天空卫星、地面控制站和用户应用终端三个部分组成。用户应用终端具有定位、导航及短报文数据通信等功能,在定位、导航和通信领域具有广泛的应用。
随着社会和科技的进步与发展,卫星系统已逐步融入社会生活,而北斗系统因其拥有独具的短报文通信功能,不同用户应用终端之间可以通过短报文功能实现信息的交流与沟通,使得短报文通讯的应用在各个领域上得到了极大的推广。除了应用在国防军事、抗震救灾、海洋渔业、森林防火、交通运输等,也广泛应用在户外通信救援、海上船员通信、农业信息交互等领域。在使用的过程中,由于民用的使用受到频度与长度限制,对于用户使用的体验来说受到了很大的限制,往往一条短信的内容长度无法把完整的消息一次传输完毕,而多次传输又要等待频度时间,导致在使用的时候带来很大的不便利。
北斗rd短报文通信是北斗卫星导航系统的一项特色功能,北斗rd通信是北斗卫星导航系统的一种自主研发、与空间位置定位共存的卫星通信功能。北斗rd通信由空间卫星、地面控制总站、地面北斗终端三方共同完成,由地面北斗终端发起,总站控制,空间卫星中转。从空间电文传输的线路上看,现有的北斗rd短报文的通信传输方式均采用开环通信传输的方式,而且北斗的主要任务是定位导航,通信的信道资源就很少,它无法完成实时的话音通信,只能完成数据量较少的短信功能,而对于民用的通讯限制的短报文内容长度,采用混编方式只有78-105个字节,那么一条短报文所发的内容并不多,有时在应用场景下一条短报文往往无法把能表达的文字都写完。
鉴于以上原因,为了满足用户使用的需求,使得卫星信息传输能带来更大的便捷与可用性,现需研究开发一种通信压缩机制,在有限的字节数内继续扩容,进而提高北斗rd通信传输的内容,在推广北斗民用进程方面具有非常重大的实用意义。
目前需要解决北斗短报文传输压缩应用的问题有:
一、普通短报文传输的压缩
卫星短报文字节有限,而对于这种简短的内容用常规的压缩算法反而会越压越大,无法达到压缩的效果,为了满足卫星短报文应用能在民用范围内推广,解决在户外无人区内,只能进行卫星传输信息,并且传输内容少的问题。
二、压缩字典的编制
压缩方式相当于代码加上协议的转换,而这协议就是一个字典,也是压缩方案中最重要的一部分,一个字典的好坏,决定着这个压缩方式的压缩率与处理率,而如何让北斗在有限的字节数里,能套用一个压缩方式达到最优,这就需要对字典进行编排。
三、大数据传输的压缩
在大数据时代,北斗传输也广泛运用在抗震救灾、海洋渔业、森林防火、交通运输、水利电力等领域,但由于频度与内容长度的限制,对于北斗大数据分包传输虽然解决了传输的问题,但传输效率一样会受到限制,如何将大数据进行有效的压缩来减少传输的分帧,从而提高数传效率。
技术实现要素:
为解决现有技术所存在的技术问题,本发明提供一种北斗卫星信息传输的压缩实现方法,通过定制压缩字典对短报文内容进行编码压缩,在有限的字节数内进行扩容,进而提高北斗rd通信的传输速度和增加传输的内容。
本发明采用以下技术方案来实现:本北斗卫星信息传输的压缩实现方法,包括以下步骤:
s1、编制压缩字典,在压缩字典中拟通过北斗卫星传输的内容按序号排列,或通过二进制进行编码;压缩字典包括英文、数字、符号字典和汉字字典;
s2、将拟通过北斗卫星传输的内容提取后进行拆分,然后提取字符进行判断,是否为无效字符,是就重新提取字符,否则判断字符是否为中文,是就查找汉字字典,否就查找英文、数字、符号字典;当为汉字时,开始索引汉字字典,如果没有匹配出对应的汉字词,就输出单个字,如有匹配的汉字词就判断这个词是否为内容里的正则最大化的词,如果否就重新获取字符得到正则最大化的词,如果是就将词语套入词元输出,将所有拟通过北斗卫星传输的内容都分好词后输入最终的分词结果;
s3、对拆分好的内容进行压缩字典的索引,编码得到压缩的短报文,通过北斗卫星终端发送出去;
s4、当收到压缩的短报文时,将传输的内容提取出来,先提取前一个字节,判断是否字符表所属的十六进制,如果是就查询字符表,匹配对应十六进制的内容,如果不是字符表的内容,将往后提取多一个字节,组成两个字节后查询压缩字典里的对应内容,将全部字节内容都转换好后输出显示全部。
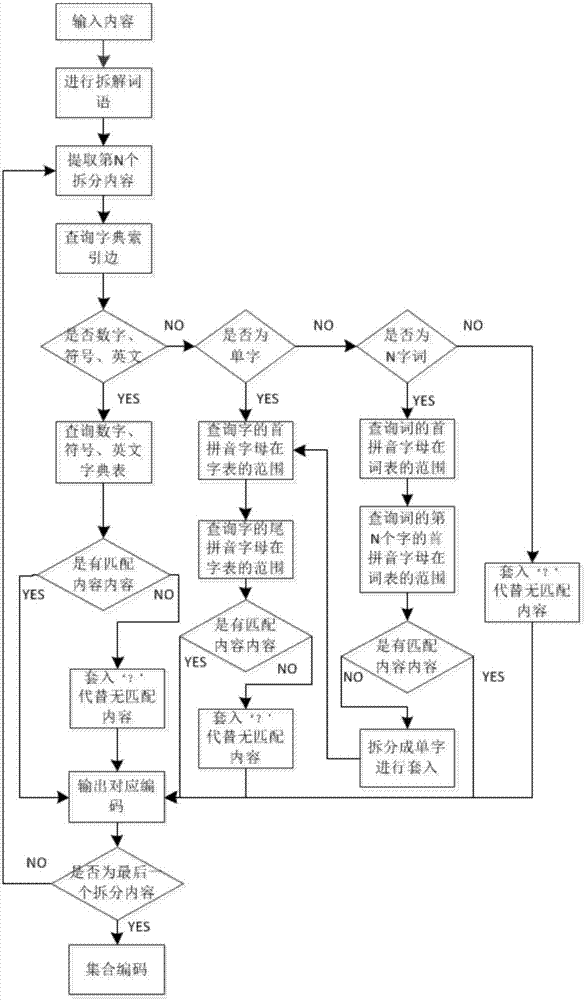
优选地,所述步骤s3对压缩字典索引的过程为:首先判断是否为英文、数字或符号,是就进行英文、数字、符号字典的匹配索引,输出对应的短报文或二进制编码;否则判断是否为单字,若为单字则将单字词的首字母匹配索引表所在的范围,然后将单字词的尾字母匹配索引表所在的范围,在这有效范围内再匹配对应的编码;如果判断为词组,查询词组的第一个拼音字母在索引表的范围和最后一个字所在的拼音词组的范围,然后匹配相应词组的编码;如果英文、数字、符号、单字及词组都无法匹配,采用“?”号代替,并提示更换内容,最后得到的编码集合为压缩的短报文。
优选地,步骤s1所述压缩字典还包括英文词语字典,所述汉字字典包括单字字典和中文词语字典。
优选地,所述步骤s4中,组成两个字节后查询压缩字典里的对应内容过程为:将传输的内容进行分词,然后分好词将提取一个词元,判断词元属于中文还是英文或符号,如果不为中文,判断是否词元大于1,大于1就查找英文词语字典,得到对应的二进制码,然后补上前缀表示为“001”,如果是小于1,就查找英文、数字、符号字典,得到对应的二进制码,然后补上前缀表示为“01”;如果判断为中文,判断是否词元大于1,大于1就查找中文词语字典,得到对应的二进制码,然后补上前缀表示为“1”,如果是小于等于1,就查找单字字典,得到对应的二进制码,然后补上前缀表示为“000”,如果传输的内容在所有压缩字典里都没有匹配,就采用“?”来套入。
优选地,所述压缩字典的字典内容进行结构分类,分为基础字典库、细胞字典库和自定义字典库。
优选地,当拟通过北斗卫星传输的内容是大数据时,先进行压缩,再分包进行传输,当后台接收完全部分包内容后,再进行合并,然后再解压出完整内容。
本发明与现有技术相比,具有如下优点和有益效果:
1、所要传输的内容包含的词组越多,能压缩的字数就越多,在北斗短报文有限的传输字节数里压缩率在0%~50%。
2、对比现有技术,本发明在匹配索引时可以把范围缩小,进行匹配查找时的效率有明显的提高。
3、可以根据用户的需要作为高频字典带入,让用户可以自主选择常用词词典,通过用户的高频词输入习惯来提高压缩率。
4、进行大数据传输的时候,进行压缩后数传,则会减少分包带来的丢包风险率。
5、用协议方式定制指令内容格式,并形成对应的规律,可以进行固定化压缩。
附图说明
图1是本发明对普通短报文传输的压缩分词示意图;
图2是普通报文传输的压缩方法一的压缩流程图;
图3是普通报文传输的压缩方法一的解压流程图;
图4是采用压缩方法一编制短报文方式的示意图;
图5是普通报文传输的压缩方法二的压缩流程图;
图6是普通报文传输的压缩方法二的解压流程图;
图7是本发明一种实施方式的字典编制结构图;
图8是本发明另一种实施方式的字典编制结构图;
图9是自定义字典示意图;
图10是自定义字典里的细胞字典示意图;
图11是自定义字典处理流程图;
图12是大数据传输的压缩和解析流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
本发明采用两种方法改善普通短报文的压缩方式,第一种是一字节代替法,第二种是二进制代替法。
首先我国文字之多是非常惊人的,比较常用的《新华字典》就有10000多个汉字;1990年出版的《辞海》有14872个汉字;1716年编撰的《康熙字典》有47035个汉字;郭沫若生前曾根据日本朋友的估计,我国大约有60000多个汉字;1994年出版的《中华字海》有87019个汉字(其中重复字320个);近来,据日前通过专家鉴定的北京国安资讯设备公司汉字字库,收入有出处的汉字91251个,gbk的汉字国标扩展码,基本上采用了原来gb2312-80所有的汉字及码位,并涵盖了原unicode中所有的汉字20902,总共收录了883个符号,21003个汉字及提供了1894个造字码位。汉语文字存在着很强的结构性,而汉字使用的频率也是非常的不均匀,据国家出版局抽样统计,最常字为2500个,使用频率达97.97%,一级字库常用字3500个,使用频率达99.7%。
方法一(即一字节代替法)的原理,一个字由2个字节组成,转成10进制有65535个,相当于65535个组合,而采用一级字库3500个汉字,等于还有62035个组合可以使用,基于此可以将词语代入这62035个组合里面,那么一个两字节的汉字由4个字节压缩成2个字节,同理一个三字词6个字节、一个四字词8个字节都能用2个字节代替,通常一句话里面都包含多个词组,在编写的语句中,如果里面包含的词组越多,所能压缩的字数就越多,那么在北斗短报文有限的传输字节数里采用此方法的压缩率在0%-50%。
方法二(即二进制代替法)的原理,将内容划分为四个字典,一个是中文词字典,一个是中文单字字典,一个是字符字典(包括英文、数字、符号),一个是英文词组字典。这些词典匹配索引是套入二进制数表示,如图4所示,二进制的首位为“1”的时候,加上后面的15位代表中文词组的内容,15位的二进制组合就有32768个;而首位为“0”的时候,当第二位为“1”时,加上后6位为英文、数字、符号内容,6位单字有63个组合;当第二位为“0”、第三位为“1”,加上13位表示英文词组内容,13位有8192个组合,当第二位、第三位都为“0”时,加上后12位为中文单字的内容,12位就有4096个组合,通过这种方式,就能将中文词、中文单字、英文词进行压缩。
无论采用上述哪种压缩方式对短报文内容进行压缩,均需要编制压缩字典,所编制的字典结构如图7、8所示。所编制字典的字典内容进行结构分类字典库,分为基础字典库、细胞字典库、自定义字典库,用户可以更具自己的输入习惯选择库,从而达到更合适的压缩。首先很多时候,短报文内容里不会只有汉字,而是带有数字、符号、英文,在gbk编码里数字、符号、英文只占用一个字符,如果按照上诉理论去套用表的话,数字、符号、英文就需要采用2个字符,那如果短报文内容里带有较多的数字、符号、英文,就会越压越多,要解决这个问题,就必须要将数字、符号、英文也使用一个字符来表示,那建立一个数字、符号、英文的字典表后,在解析时候就需要解决区分哪些是一个字符的数字、符号、英文,哪些是一个字或者词组;gbk常用的数字、符号、英文有63种,那么可以定义只要开头的是00-3f的,就为数字、符号、英文,数字、符号、英文就采用一个字节,当不为单字符内容的时候就取双字符进行查询对应的汉字表。
图7所示的字典表中,对于短报文中的汉字,由于相应字典中的内容较多,而字典又是自编的,如果按普通做法把汉字在字典里匹配查询出编号,一个字、词查询的速度会慢,而一句话有多个字和词,那一句话下来对字典的查询累计起来就会非常慢,从而影响用户体验感非常差。因此本发明需要对字典索引表进行编排制作,首先单字的时候,就将单字的拼音头和拼音尾作为索引,多次的词组就将第一字的拼音头和最后一个字的拼音尾作为索引,这样在匹配索引的时候就能把范围缩小,而进行匹配时查找效率和处理占用资源都会大大的优化。
图8示意了另一种方式编制的字典表,分开了4个字典,数字、符号、英文字典,单字汉字字典,汉字词组字典,英文词字典。如图9所示,每个字典都将内容和对应的二进制编码进行了录入;录入时,由于采用二进制的方式,前面有0时会缺省,所以为录入内容为中文词语时若不够15位,则在前面补0以补齐至15位,同理录入内容为字符时若不够6位,则在前面补0以补齐至6位,录入内容为英文词语时若不够13位,则在前面补0以补齐至3位,录入内容为中文单字时若不够12位,则在前面补0以补齐至12位。
对于方法一与方法二,会受到压缩组合数量的限制,在压缩体验感中就会降低很多,虽然可以通过增加字典编码的长度来扩充字典容量,但是这样会牺牲压缩率。而随着时代的变迁,新词会越来越多,如何将字典的压缩有效性提高,使得压缩词语更容易出现用户常用的高频词,以突破组合数量的限制,可以通过不断的积累套用更多的字典,这里就采用了一种词典,用户根据自己感性认知的类别作为高频字典带入,让用户可以自主选择常用词词典,通过用户的高频词输入习惯来提高压缩率。
此外,由于大数据需要采用分包、拆包的方式进行传输,而拆分的方式虽然能传输大数据,但是由于频度与内容长度的限制,一条大数据的传输速率一样会非常缓慢,而如果将大数据进行压缩后再传输,这样传输的分包就会减少,而丢包的风险率也会降低。对大数据进行压缩也有两种方案,一是通过通用压缩方式进行压缩,第二种是通过定制压缩字典压缩。第一种通用压缩方式是指采用现有的压缩方式进行压缩,然后通过程序将压缩包转换成卫星传输的十六进制内容,然后再拆包进行传输。第二种压缩方法是通过定制行业规划内容形成字典,由于大数据传输应用都一定会有自己的一套协议方式,既然有协议方式就有固定的指令内容格式,这些格式就会有对应的规律,通过定制化的字典按这些规律进行固定化压缩,那么通过这种定制化的字典就能进行定制压缩。定制化的字典结构与进行短报文传输时所采用的相同,如图7、8所示。
在定制化字典的中文部分,如图10所示,可以将词典做第三部分进行自定义扩充,第一部分为通用常用词,第二部分为细胞常用词,第三部分为自定义词。第一部分整合一些常用的高频词,收集大量的常用词,然后通过统计功能将网上的一些文章聊天等内容进行分词统计,将使用频率高的词提取出来作为基础词库。第二部分归集细胞词库,这些细胞词库可以根据类别的不同划分为多个字典,多个字典就由用户自己选择常用类型的字典,如图9所示,在细胞字典的范围数量内,用户选择自己想要的字典,只要不超出范围,都可以加入到字典里,这样就算范围数量是有限制的,但每个用户都有自己常用的词语输入高频类别,这样就可以有无限的字典,从而达到为用户量身定制更好的字典压缩能力。在第三部分,用户(如救援队等)拥有自己的一些行业或专用词,用户可以自己设定一些词语录入词库中,这样就算没有在录入的字典里,用户也可以根据自己使用的需求,为自身打造一套字典。
自定义词的字典流程如图11所示,后台会根据统计与录入,更新后台常用词字典,然后更新给用户,用户登录后选择字典需要的细胞词和自定义词,组合好自定义字典后同步更新给后台,后台将绑定此用户所使用的字典。当用户输入内容通过字典压缩后,将内容输出给后台;接受到压缩的内容时,调用此用户绑定的字典进行内容的解析,将所解析的内容进行显示与转发。
如图12,对大数据进行压缩与解析,将大数据内容通过压缩得到压缩包,然后转换成十六进制内容,添加压缩方式指令头,再通过拆包分包传输,后台接收到分包后将内容整合,通过识别压缩的方式头,将内容转换回压缩方式的压缩包,通过对应的压缩方式解压,得到完整的内容。
当用户使用字典时,可以先选择好适合自己习性的细胞词,也可以录入自己的常用词。然后用户或设备输入内容,选择压缩方式,压缩方式可以是手动选择,或者通过系统判断最优选择,三种方式中压缩率最高的为最优选择。如果选择的是压缩方法一,如图1,后台将内容进行压缩,首先将内容提取后进行拆分,通过创建一个空词元,然后提取字符进行判断,是否为无效字符,是就重新提取,否则判断字符是否为中文,是就查找汉字匹配字典,否就查找英文匹配字典;当为汉字时,开始索引汉字词字典,如果没有匹配出对应的汉字词,就输出单个字,如有匹配的汉字词就判断这个词是否为内容里的正则最大化的词,如果否就重新获取字符得到正则最大化的词,如果是就将词语套入词元输出,将所有内容都分好词后输入最终的分词结果。
如图2,对拆分好的内容进行压缩字典的索引,首先判断是否为数字、符号、英文,是就进行字符表的匹配索引,输出对应的编码;判断为否时就判断是否为单字,就将单字词的首字母匹配索引表所在的范围,然后将单字词的尾字母匹配索引表所在的范围,在这有效范围内再匹配对应的,有对应的编码则进行匹配输出;如果判断为词组,就通过查询词组的第一个拼音字母在索引表的范围和最后一个字所在的拼音词组的范围,然后匹配相应的词组的编码,如果这些都无法匹配的话,就采用“?”号代替,并提示用户更换内容,最后得到的编码集合就是压缩的内容,可以通过卫星终端发送出去。
当后台收到压缩卫星短报文时,如图3所示,将内容提取出来,先提取前一个字节,判断是否字符表所属的十六进制,如果是就查询字符表,匹配对应十六进制的内容,如果不是字符表的内容,将往后提取多一个字节,组成两个字节然后查询字典表里的对应内容,将全部字节内容都转换好后输出显示全部内容,在转发给用户要发送给的对方。
如果提取的不是字符表的内容,组成两个字节后查询字典前将内容进行分词,然后分好词将提取一个词元,如图5所示,判断词元属于中文还是英文或符号,如果不为中文,判断是否词元大于1,大于1就查找英文词语字典,得到对应的二进制码,然后补上前缀表示为“001”,如果是小于1,就查找英文、数字、符号字典,得到对应的二进制码,然后补上前缀表示为“01”;如果判断为中文,判断是否词元大于1,大于1就查找中文词组字典表,得到对应的二进制码,然后补上前缀表示为“1”,如果是小于等于1,就查找单字字典,得到对应的二进制码,然后补上前缀表示为“000”,如果内容在所有字典里都没有匹配,就采用“?”来套入。
循环处理将所有词元都转换完成后,得到总的二进制字符串,由于最后是以十六进制发送出去,而通过方法二转换出来的内容长度是不固定的,存在最后转出来的十六进制的最后一位不齐的情况,所以要将二进制字符除以8,如果有余数,尾部要补上(8-余数)这么多个0,然后再将这个总的二进制字符串转换成十六进制数,然后打包成卫星短报文发送出去。
当后台收到卫星压缩短报文后,如图6所示,将内容提取出来,然后转换成二进制字符串,通过反推,判断第一位字符是否为“0”,为0就提取前16位,去掉前缀“1”,查询对应的中文词组字典进行索引匹配,输出解析的内容;如果第一位为“0”,判断第二位是否为“0”,如果不是,提取前8位,去掉前缀“01”,查询对应的字符映射表,输出解析的内容;如果第二位不为“0”,则判断第三位是否为“0”,如果不是就提取前16位,去掉前缀“001”,查询对应的英文词组字典映射表,输出解析的内容;如果第三位为“0”,就提取前15位,去掉前缀“000”,查询对应的单字字典映射表,输出解析的内容,通过循环解析,当判断剩余长度无法提取8位,那就将剩余的丢弃,将所有解析的集合在一起,就是所输入的内容。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!