智能导航设备及其路线规划方法、及无人驾驶车辆与流程
本申请涉及导航设备技术领域,具体涉及一种基于多轮语音交互的路线规划方法、一种智能导航设备,以及一种无人驾驶车辆。
背景技术:
全球定位系统(globalpositioningsystem,简称gps)是美国从20世纪70年代开始研制,于1994年全面建成,具有在海、陆、空全方位实时三维导航与定位能力的新一代卫星导航与定位系统。gps系统不仅可用于测量、导航,还可用于测速、测时。通过gps接收到的卫星信号准确定位,可以得知车辆的行驶路线、位置、速度、海拔等信息。
地理信息系统(geographicalinformationsystem,简称gis)从50年代末和60年代初开始出现,是人类在生产实践活动中,为描述和处理相关地理信息而逐渐产生的软件系统。它以计算机为手段,对具有地理特征的空间数据进行处理,以一个空间信息为主线,将其它各种与其有关的空间位置信息结合起来,具有如采集、管理、分析和表达数据等功能。其次,gis处理的数据都和地理信息有着直接或间接的关系。地理信息是有关地理实体的性质、特征、运动状态的表征和一切有用的知识,而地理数据则是各种地理特征和现象间关系的符号化表示。
近年来,gps技术除了应用在传统的车载防盗反劫装置之外,结合gis系统、车载导航仪的应用也日趋广泛。随着汽车工业的发展以及汽车电子市场的逐渐成熟,车载导航产品已初具规模。在欧美及日本,此类车载导航仪使用已比较普遍,目前国内gps汽车导航产品也具有急剧增长的市场趋势。
安卓(android)是基于linux平台的移动终端操作系统,近年来凭借其开源、高效等优势以及厂商的推动,赢得了广大的用户群体。以安卓为操作系统的移动终端本身绝大多数具有高速的运算处理能力以及gps功能,在功能的拓展上有着光明的前途。
同时,语音识别和人机语音交互也在全面发展,现有的各种语音助手类应用(application;以下简称:app),在操作方式上,录音的触发通过按键,录音完毕后,机器播报答案,播报答案时,不能录音。也就是说,现有的语音助手类app只能进行半双工通信,即机器播报时,用户不能说话,用户说话时,机器不能播报。
但是,现有技术中,用户无法利用现有的导航系统直接语音触发并搜寻到目的地,或者手动搜寻的过程中需要用户自己动手去筛选,而且,现有的人机语音交互模式使用起来非常不便,每次一问一答,都需要用户干预,操作繁琐,人机交互方式也很不自然,用户体验度较差。
技术实现要素:
本申请的目的在于,提供一种智能导航设备及其路线规划方法、及无人驾驶车辆,其可以解决上述技术问题,能够方便用户进行语音搜寻到适合用户的路线规划,而且不再需要用户进行手动筛选,同时人机交互过程方便自然,操作简单,较大程度地改善了用户体验。
为解决上述技术问题,本申请提供一种基于多轮语音交互的路线规划方法,所述路线规划方法包括:
在检测到用户表达出行规划意图时,智能导航设备获取用户输入的多轮语音信号;
根据所述多轮语音信号识别所述用户的出行规划;
根据所述出行规划获取与所述出行规划相关的导航记录、历史出行习惯、路线选择偏好、当前路况以及当前时间段限行信息中的至少两个以上综合因素;
根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息。
其中,所述根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息的步骤,具体包括:
对多个所述综合因素进行优先级排序,以给出多个路线建议并提供相应的多条导航信息,其中,所述优先级排序包括按导航记录优先、按历史出行习惯优先、按路线偏好优先、按当前路况优先以及按当前时间段限行信息优先。
其中,所述在检测到用户表达出行规划意图时的步骤,具体包括:
智能导航设备检测是否有触控输入与出行规划相关的词句,其中,与出行规划相关的词句包括“我想去”、“去某目的地”、“某目的地怎么样”、“某人的家”、“去某酒店吃饭”、“去公司”和“去某景点”。
其中,所述根据所述多轮语音信号识别所述用户的出行规划,具体包括:
接收输入的多轮语音信号;
分帧提取多轮语音信号的语音特征信息,根据语音特征信息和声学模型生成多轮语音信号的识别结果;
根据识别结果和预设静音检测算法初步检测出多轮语音信号的语音端点;
计算多轮语音信号的置信度信息;
解析多轮语音信号的语义信息;
根据置信度信息和语义信息获取多轮语音信号对应的语音解析结果;
根据语音解析结果识别出所述用户的出行规划。
其中,所述根据语音特征信息和声学模型生成多轮语音信号的识别结果,具体包括:
在生成语音特征信息后,采用基于声学模型计算每帧多轮语音信号在每个建模单元上的似然值,通过动态规划算法得到最优状态转移序列及其对应的词序列,并将所得到的最优状态转移序列及其对应的词序列作为识别结果。
其中,所述声学模型为基于神经网络的声学模型,采用所述基于神经网络的声学模型对所述语音特征信息进行识别。
其中,所述计算多轮语音信号的置信度信息的步骤,具体包括:
根据识别结果、多轮语音信号的语音端点和多轮语音信号的信噪比计算多轮语音信号的置信度信息。
其中,所述根据识别结果、多轮语音信号的语音端点和多轮语音信号的信噪比计算多轮语音信号的置信度信息,具体包括:
基于识别结果,计算语音端点之间的每个词的声学后验概率,其中,计算语音端点之间的第k个词的声学后验概率的公式包括:
其中p(x)为多轮语音信号中第k个词的声学后验概率,p(m|x)为第t帧时该词对应建模单元的似然值,
根据语音端点之间的每个词的声学后验概率和信噪比计算每个词对应的置信度信息。
其中,所述根据语音端点之间的每个词的声学后验概率和信噪比计算每个词对应的置信度信息,具体包括:
基于当前词的声学后验概率和信噪比,计算出当前词的置信度cm(x),公式包括:
cm(x)=w*p(x)+(1-w)*snr(x)
其中0≤w≤1,w为权重系数;
计算多轮语音信号对应的置信度的公式包括:
其中,t(x)表示第n个词的持续时间长,cm(x)表示第n个词的置信度;
对每个词对应的置信度进行求和计算,获取得到多轮语音信号的置信度信息。
为解决上述技术问题,本申请还提供一种智能导航设备,所述智能导航设备包括处理器,所述处理器用于执行程序数据,以实现上述的基于多轮语音交互的路线规划方法的步骤。
为解决上述技术问题,本申请还提供一种无人驾驶车辆,设置有处理器,所述处理器执行程序数据时,用于实现上述的基于多轮语音交互的路线规划方法的步骤。
本申请智能导航设备及其路线规划方法、及无人驾驶车辆,在检测到用户表达出行规划意图时,智能导航设备获取用户输入的多轮语音信号,接着根据所述多轮语音信号识别所述用户的出行规划,进而根据所述出行规划获取与所述出行规划相关的导航记录、历史出行习惯、路线选择偏好、当前路况以及当前时间段限行信息中的至少两个以上综合因素,最终能够根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息。通过这种方式,本申请能够方便用户进行语音搜寻到适合用户的路线规划,而且不再需要用户进行手动筛选,同时人机交互过程方便自然,操作简单,较大程度地改善了用户体验。本申请能够实现全语音交互过程,无需用户手动操作。
上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
图1为本申请基于多轮语音交互的路线规划方法的流程示意图。
图2为本申请智能导航设备的模块示意图。
具体实施方式
为更进一步阐述本申请为达成预定申请目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本申请提出的智能导航设备及其基于多轮语音交互的路线规划方法、及无人驾驶车辆的具体实施方式、方法、步骤、结构、特征及其效果,详细说明如下。
有关本申请的前述及其他技术内容、特点及功效,在以下配合参考图式的较佳实施例的详细说明中将可清楚呈现。通过具体实施方式的说明,当可对本申请为达成预定目的所采取的技术手段及功效得以更加深入且具体的了解,然而所附图式仅是提供参考与说明之用,并非用来对本申请加以限制。
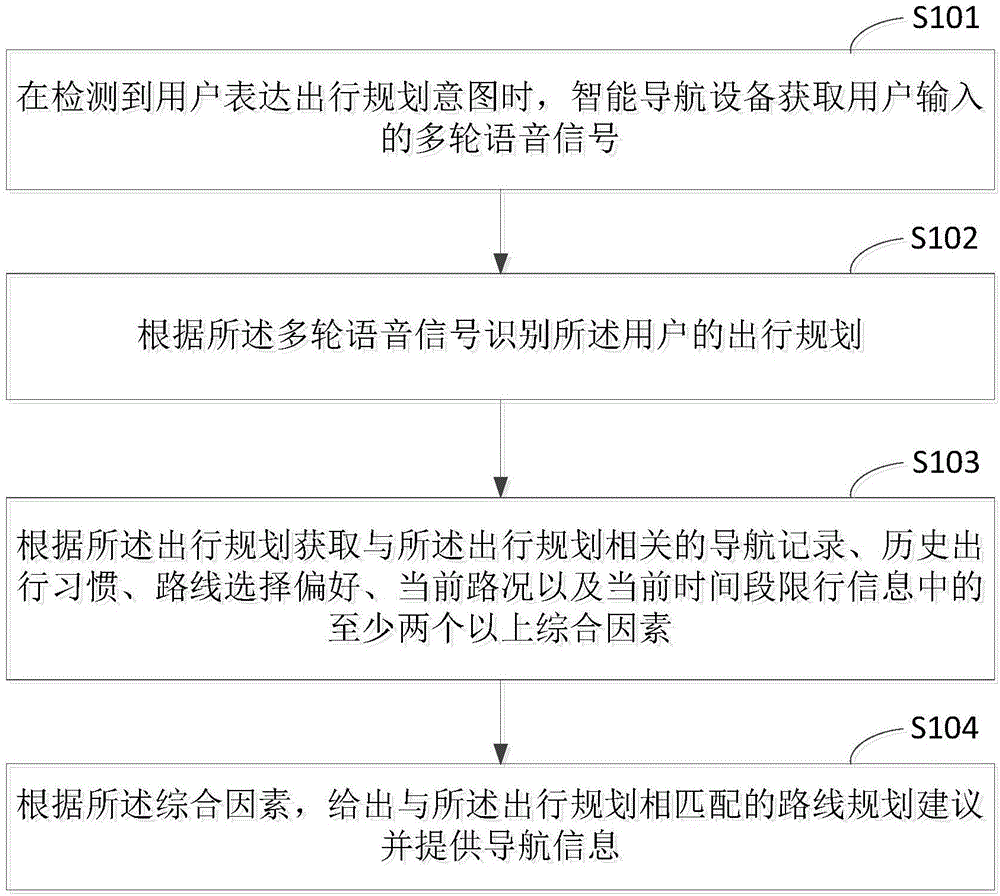
请参阅图1,图1为本申请基于多轮语音交互的路线规划方法的流程示意图,本实施方式所述基于多轮语音交互的路线规划方法包括但不限于如下几个步骤。
步骤s101,在检测到用户表达出行规划意图时,智能导航设备获取用户输入的多轮语音信号。
其中,所述步骤s101在检测到用户表达出行规划意图时的步骤,具体可以包括:智能导航设备检测是否有触控输入与出行规划相关的词句,其中,与出行规划相关的词句包括“我想去”、“去某目的地”、“某目的地怎么样”、“某人的家”、“去某酒店吃饭”、“去公司”和“去某景点”。具体来说,比如,用户用语音说“我想去地王大厦”“我想去一下朋友家”等。
步骤s102,根据所述多轮语音信号识别所述用户的出行规划。
其中,所述步骤s102根据所述多轮语音信号识别所述用户的出行规划,具体可以包括:对所述多轮语音信号进行关键词识别;根据上下文识别结果调整关键词;根据调整后的关键词识别所述用户的出行规划。
需要特别说明的是,所述步骤s102根据所述多轮语音信号识别所述用户的出行规划,具体还可以包括如下过程:
s21,接收输入的多轮语音信号;
s22,分帧提取多轮语音信号的语音特征信息,根据语音特征信息和声学模型生成多轮语音信号的识别结果;
s23,根据识别结果和预设静音检测算法初步检测出多轮语音信号的语音端点;
s24,计算多轮语音信号的置信度信息;
s25,解析多轮语音信号的语义信息;
s26,根据置信度信息和语义信息获取多轮语音信号对应的语音解析结果;
s27,根据语音解析结果识别出所述用户的出行规划。
在本实施方式中,所述s22根据语音特征信息和声学模型生成多轮语音信号的识别结果,具体可以包括:在生成语音特征信息后,采用基于声学模型计算每帧多轮语音信号在每个建模单元上的似然值,通过动态规划算法得到最优状态转移序列及其对应的词序列,并将所得到的最优状态转移序列及其对应的词序列作为识别结果。
值得一提的是,所述声学模型为基于神经网络(dnn,deepneuralnetworks)的声学模型,采用所述基于神经网络的声学模型对所述语音特征信息进行识别。
需要说明的是,所述s24计算多轮语音信号的置信度信息的步骤,具体可以包括:根据识别结果、多轮语音信号的语音端点和多轮语音信号的信噪比计算多轮语音信号的置信度信息。
进一步而言,所述根据识别结果、多轮语音信号的语音端点和多轮语音信号的信噪比计算多轮语音信号的置信度信息,具体可以包括:
基于识别结果,计算语音端点之间的每个词的声学后验概率,其中,计算语音端点之间的第k个词的声学后验概率的公式包括:
其中,p(x)为多轮语音信号中第k个词的声学后验概率,p(m|x)为第t帧时该词对应建模单元的似然值,
根据语音端点之间的每个词的声学后验概率和信噪比计算每个词对应的置信度信息。
在本实施方式中,所述根据语音端点之间的每个词的声学后验概率和信噪比计算每个词对应的置信度信息,具体可以包括:
s31,基于当前词的声学后验概率和信噪比,计算出当前词的置信度cm(x),公式包括:
cm(x)=w*p(x)+(1-w)*snr(x)
其中0≤w≤1,w为权重系数;
s32,计算多轮语音信号对应的置信度的公式包括:
其中,t(x)表示第n个词的持续时间长,cm(x)表示第n个词的置信度;
s33,对每个词对应的置信度进行求和计算,获取得到多轮语音信号的置信度信息。
不难理解的是,本申请可以通过置信度信息和语义信息两个维度对多轮语音信号进行判定,可有效地判定多轮语音信号是否被解析正确,提高人机交互时回复语句的准确性,提升用户使用体验。
步骤s103,根据所述出行规划获取与所述出行规划相关的导航记录、历史出行习惯、路线选择偏好、当前路况以及当前时间段限行信息中的至少两个以上综合因素。
步骤s104,根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息。
需要说明的是,所述步骤s104根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息的步骤,具体可以包括:对多个所述综合因素进行优先级排序,以给出多个路线建议并提供相应的多条导航信息,其中,所述优先级排序包括按导航记录优先、按历史出行习惯优先、按路线偏好优先、按当前路况优先以及按当前时间段限行信息优先。
举例而言,当用户语言说“我要去xx”等输入时,导航可以通过多轮语音对话的方式,结合用户的历史出行习惯、路线选择偏好、当前路况,帮助用户选择出当前最快捷舒适的出行路线。其中,多轮语音交互例如“现在高架上面有点堵,要走地面试试吗?”->“美罗大厦附近的停车场已经停满了,要不要停在星游城附近,然后搭个顺风车过去?”等等。
本申请智能导航设备及其路线规划方法、及无人驾驶车辆,在检测到用户表达出行规划意图时,智能导航设备获取用户输入的多轮语音信号,接着根据所述多轮语音信号识别所述用户的出行规划,进而根据所述出行规划获取与所述出行规划相关的导航记录、历史出行习惯、路线选择偏好、当前路况以及当前时间段限行信息中的至少两个以上综合因素,最终能够根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息。通过这种方式,本申请能够方便用户进行语音搜寻到适合用户的路线规划,而且不再需要用户进行手动筛选,同时人机交互过程方便自然,操作简单,较大程度地改善了用户体验。本申请能够实现全语音交互过程,无需用户手动操作。
请接着参阅图2,图2为本申请智能导航设备一实施方式的模块示意图,本申请智能导航设备可以包括处理器21、存储器22和显示器23,其中,所述智能导航设备可以为导航仪、手机、平板电脑、可穿戴设备和车载导航设备等,在此不作限定。
所述处理器21用于执行程序数据,所述存储器22可以用于存储程序数据,所述显示器23可以用于显示用户界面,比如,显示地图、导航、线路以及各种人机界面。
在本实施方式中,所述处理器21用于执行程序数据时,实现的基于多轮语音交互的路线规划方法的步骤包括但不限于如下实施例。
所述处理器21在检测到用户表达出行规划意图时,获取用户输入的多轮语音信号。
其中,所述处理器21在检测到用户表达出行规划意图时的步骤,具体可以包括:所述处理器21检测是否有触控输入与出行规划相关的词句,其中,与出行规划相关的词句包括“我想去”、“去某目的地”、“某目的地怎么样”、“某人的家”、“去某酒店吃饭”、“去公司”和“去某景点”。具体来说,比如,用户用语音说“我饿了”“我想找点好吃的”等。
所述处理器21根据所述多轮语音信号识别所述用户的出行规划。
其中,所述处理器21根据所述多轮语音信号识别所述用户的出行规划,具体可以包括:对所述多轮语音信号进行关键词识别;根据上下文识别结果调整关键词;根据调整后的关键词识别所述用户的出行规划。
需要特别说明的是,所述处理器21根据所述多轮语音信号识别所述用户的出行规划,具体还可以包括如下过程:
s21,接收输入的多轮语音信号;
s22,分帧提取多轮语音信号的语音特征信息,根据语音特征信息和声学模型生成多轮语音信号的识别结果;
s23,根据识别结果和预设静音检测算法初步检测出多轮语音信号的语音端点;
s24,计算多轮语音信号的置信度信息;
s25,解析多轮语音信号的语义信息;
s26,根据置信度信息和语义信息获取多轮语音信号对应的语音解析结果;
s27,根据语音解析结果识别出所述用户的出行规划。
在本实施方式中,所述s22中所述处理器21根据语音特征信息和声学模型生成多轮语音信号的识别结果,具体可以包括:在生成语音特征信息后,采用基于声学模型计算每帧多轮语音信号在每个建模单元上的似然值,通过动态规划算法得到最优状态转移序列及其对应的词序列,并将所得到的最优状态转移序列及其对应的词序列作为识别结果。
值得一提的是,所述声学模型为基于神经网络的声学模型,采用所述基于神经网络的声学模型对所述语音特征信息进行识别。
需要说明的是,所述s24计算多轮语音信号的置信度信息的步骤,具体可以包括:所述处理器21根据识别结果、多轮语音信号的语音端点和多轮语音信号的信噪比计算多轮语音信号的置信度信息。
进一步而言,所述处理器21根据识别结果、多轮语音信号的语音端点和多轮语音信号的信噪比计算多轮语音信号的置信度信息,具体可以包括:
所述处理器21基于识别结果,计算语音端点之间的每个词的声学后验概率,其中,计算语音端点之间的第k个词的声学后验概率的公式包括:
其中,p(x)为多轮语音信号中第k个词的声学后验概率,p(m|x)为第t帧时该词对应建模单元的似然值,
所述处理器21根据语音端点之间的每个词的声学后验概率和信噪比计算每个词对应的置信度信息。
在本实施方式中,所述处理器21根据语音端点之间的每个词的声学后验概率和信噪比计算每个词对应的置信度信息,具体可以包括:
s31,所述处理器21基于当前词的声学后验概率和信噪比,计算出当前词的置信度cm(x),公式包括:
cm(x)=w*p(x)+(1-w)*snr(x)
其中0≤w≤1,w为权重系数;
s32,所述处理器21计算多轮语音信号对应的置信度的公式包括:
其中,t(x)表示第n个词的持续时间长,cm(x)表示第n个词的置信度;
s33,所述处理器21对每个词对应的置信度进行求和计算,获取得到多轮语音信号的置信度信息。
不难理解的是,本申请可以通过置信度信息和语义信息两个维度对多轮语音信号进行判定,可有效地判定多轮语音信号是否被解析正确,提高人机交互时回复语句的准确性,提升用户使用体验。
所述处理器21,根据所述出行规划获取与所述出行规划相关的导航记录、历史出行习惯、路线选择偏好、当前路况以及当前时间段限行信息中的至少两个以上综合因素。
所述处理器21,根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息。
需要说明的是,所述处理器21根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息的步骤,具体可以包括:所述处理器21对多个所述综合因素进行优先级排序,以给出多个路线建议并提供相应的多条导航信息,其中,所述优先级排序包括按导航记录优先、按历史出行习惯优先、按路线偏好优先、按当前路况优先以及按当前时间段限行信息优先。
举例而言,当用户语言说“我要去xx”等输入时,导航可以通过多轮语音对话的方式,结合用户的历史出行习惯、路线选择偏好、当前路况,帮助用户选择出当前最快捷舒适的出行路线,比如,多轮语音交互例如“现在高架上面有点堵,要走地面试试吗?”->“美罗大厦附近的停车场已经停满了,要不要停在星游城附近,然后搭个顺风车过去?”等等。
本申请智能导航设备及其路线规划方法、及无人驾驶车辆,在检测到用户表达出行规划意图时,智能导航设备获取用户输入的多轮语音信号,接着根据所述多轮语音信号识别所述用户的出行规划,进而根据所述出行规划获取与所述出行规划相关的导航记录、历史出行习惯、路线选择偏好、当前路况以及当前时间段限行信息中的至少两个以上综合因素,最终能够根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息。通过这种方式,本申请能够方便用户进行语音搜寻到适合用户的路线规划,而且不再需要用户进行手动筛选,同时人机交互过程方便自然,操作简单,较大程度地改善了用户体验。本申请能够实现全语音交互过程,无需用户手动操作。
为解决上述技术问题,本申请还提供一种无人驾驶车辆,设置有处理器、存储器和显示屏等,所述处理器执行程序数据时,用于实现上述的基于多轮语音交互的路线规划方法的步骤。其中,其具体实现方式请参阅前面实施例的相关描述,在本技术领域人员容易结合理解的范围内,不作赘述。
本申请的无人驾驶车辆,可以为纯智能全自动无人驾驶的油气车辆、电气车辆,也可以为半自动无人驾驶的油气车辆、电气车辆,其可以设置图2所述的智能导航设备作为辅助操作系统,可以实现全自动语音操作导航。
所述处理器用于执行程序数据,所述存储器可以用于存储程序数据,所述显示器可以为无人驾驶车辆上的显示屏,用于显示用户界面,比如,显示地图、导航、线路以及各种人机界面。
在本实施方式中,所述处理器用于执行程序数据时,实现的基于多轮语音交互的路线规划方法的步骤包括但不限于如下实施例。
所述处理器在检测到用户表达出行规划意图时,获取用户输入的多轮语音信号。
其中,所述处理器在检测到用户表达出行规划意图时的步骤,具体可以包括:所述处理器检测是否有触控输入与出行规划相关的词句,其中,与出行规划相关的词句包括“我想去”、“去某目的地”、“某目的地怎么样”、“某人的家”、“去某酒店吃饭”、“去公司”和“去某景点”。具体来说,比如,用户用语音说“我饿了”“我想找点好吃的”等。
所述处理器根据所述多轮语音信号识别所述用户的出行规划。
其中,所述处理器根据所述多轮语音信号识别所述用户的出行规划,具体可以包括:对所述多轮语音信号进行关键词识别;根据上下文识别结果调整关键词;根据调整后的关键词识别所述用户的出行规划。
需要特别说明的是,所述处理器根据所述多轮语音信号识别所述用户的出行规划,具体还可以包括如下过程:
s21,接收输入的多轮语音信号;
s22,分帧提取多轮语音信号的语音特征信息,根据语音特征信息和声学模型生成多轮语音信号的识别结果;
s23,根据识别结果和预设静音检测算法初步检测出多轮语音信号的语音端点;
s24,计算多轮语音信号的置信度信息;
s25,解析多轮语音信号的语义信息;
s26,根据置信度信息和语义信息获取多轮语音信号对应的语音解析结果;
s27,根据语音解析结果识别出所述用户的出行规划。
在本实施方式中,所述s22中所述处理器根据语音特征信息和声学模型生成多轮语音信号的识别结果,具体可以包括:在生成语音特征信息后,采用基于声学模型计算每帧多轮语音信号在每个建模单元上的似然值,通过动态规划算法得到最优状态转移序列及其对应的词序列,并将所得到的最优状态转移序列及其对应的词序列作为识别结果。
值得一提的是,所述声学模型为基于神经网络的声学模型,采用所述基于神经网络的声学模型对所述语音特征信息进行识别。
需要说明的是,所述s24计算多轮语音信号的置信度信息的步骤,具体可以包括:所述处理器根据识别结果、多轮语音信号的语音端点和多轮语音信号的信噪比计算多轮语音信号的置信度信息。
进一步而言,所述处理器根据识别结果、多轮语音信号的语音端点和多轮语音信号的信噪比计算多轮语音信号的置信度信息,具体可以包括:
所述处理器基于识别结果,计算语音端点之间的每个词的声学后验概率,其中,计算语音端点之间的第k个词的声学后验概率的公式包括:
其中,p(x)为多轮语音信号中第k个词的声学后验概率,p(m|x)为第t帧时该词对应建模单元的似然值,
所述处理器根据语音端点之间的每个词的声学后验概率和信噪比计算每个词对应的置信度信息。
在本实施方式中,所述处理器根据语音端点之间的每个词的声学后验概率和信噪比计算每个词对应的置信度信息,具体可以包括:
s31,所述处理器基于当前词的声学后验概率和信噪比,计算出当前词的置信度cm(x),公式包括:
cm(x)=w*p(x)+(1-w)*snr(x)
其中0≤w≤1,w为权重系数;
s32,所述处理器计算多轮语音信号对应的置信度的公式包括:
其中,t(x)表示第n个词的持续时间长,cm(x)表示第n个词的置信度;
s33,所述处理器对每个词对应的置信度进行求和计算,获取得到多轮语音信号的置信度信息。
不难理解的是,本申请可以通过置信度信息和语义信息两个维度对多轮语音信号进行判定,可有效地判定多轮语音信号是否被解析正确,提高人机交互时回复语句的准确性,提升用户使用体验。
所述处理器,根据所述出行规划获取与所述出行规划相关的导航记录、历史出行习惯、路线选择偏好、当前路况以及当前时间段限行信息中的至少两个以上综合因素。
所述处理器,根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息。
需要说明的是,所述处理器根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息的步骤,具体可以包括:所述处理器对多个所述综合因素进行优先级排序,以给出多个路线建议并提供相应的多条导航信息,其中,所述优先级排序包括按导航记录优先、按历史出行习惯优先、按路线偏好优先、按当前路况优先以及按当前时间段限行信息优先。
举例而言,当用户语言说“我要去xx”等输入时,导航可以通过多轮语音对话的方式,结合用户的历史出行习惯、路线选择偏好、当前路况,帮助用户选择出当前最快捷舒适的出行路线,比如,多轮语音交互例如“现在高架上面有点堵,要走地面试试吗?”->“美罗大厦附近的停车场已经停满了,要不要停在星游城附近,然后搭个顺风车过去?”等等。
本申请无人驾驶车辆,在检测到用户表达出行规划意图时,智能导航设备获取用户输入的多轮语音信号,接着根据所述多轮语音信号识别所述用户的出行规划,进而根据所述出行规划获取与所述出行规划相关的导航记录、历史出行习惯、路线选择偏好、当前路况以及当前时间段限行信息中的至少两个以上综合因素,最终能够根据所述综合因素,给出与所述出行规划相匹配的路线规划建议并提供导航信息。通过这种方式,本申请能够方便用户进行语音搜寻到适合用户的路线规划,而且不再需要用户进行手动筛选,同时人机交互过程方便自然,操作简单,较大程度地改善了用户体验。本申请能够实现全语音交互过程,无需用户手动操作。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于终端类实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上所述,仅是本申请的较佳实施例而已,并非对本申请作任何形式上的限制,虽然本申请已以较佳实施例揭露如上,然而并非用以限定本申请,任何熟悉本专业的技术人员,在不脱离本申请技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本申请技术方案内容,依据本申请的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本申请技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!