通过设备上的采集进行云卸载位置计算的制作方法
本文中公开的主题总体上涉及用于计算漫游设备的全局位置的方法、系统和程序。
背景技术:
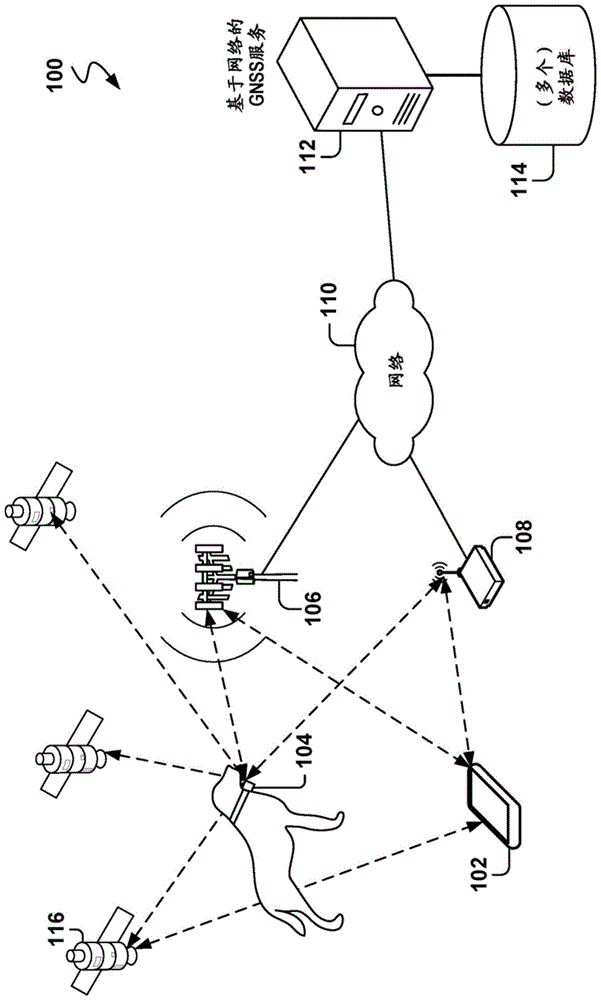
:全球导航卫星系统(gnss)允许设备基于从gnss卫星发送的信号来计算其地理空间位置。gnss的示例包括全球定位系统(gps)、全球导航卫星系统(glonass)和伽利略(galileo)。gnss卫星携带非常稳定的原子钟,并且连续广播其当前时间和位置,该时间和位置可以由具有接收器的基于地面的计算设备利用来计算计算设备的位置。例如,计算设备从多个卫星接收无线电传输,并且使用诸如最小二乘最小化等约束优化技术来计算它们的位置。通常,接收器至少需要4颗可见卫星用于确定其定位。一些定位应用需要跟踪诸如野生动物、汽车或货物等移动对象的位置。但是,连续计算位置可能会耗尽计算设备的电池,并且可能需要使用大量的网络带宽。附图说明附图中的各个附图仅示出了本公开的示例实施例,并且不能被认为是对其范围的限制。图1示出了根据一些示例实施例的用于卸载全球定位计算任务的图。图2示出了根据一些示例实施例的具有用于计算设备的位置的不同任务划分架构的图。图3是根据一些示例实施例的用于云卸载的设备采集全球定位系统(coda-gps)的方法的流程图。图4示出了根据一些示例实施例的在用于计算位置的计算设备的不同组件内的数据流。图5示出了根据一些示例实施例的使用图形处理单元(gpu)以用于使任务并行化的优点。图6是根据一些示例实施例的串行搜索采集的框图。图7是根据一些示例实施例的并行码相位搜索算法的框图。图8示出了根据一些示例实施例的用于执行采集任务的软件架构。图9是根据一些示例实施例的用于通过设备上的采集进行云卸载位置计算的方法的流程图。图10是示出可以在其上实现一个或多个示例实施例的机器的示例的框图。具体实施方式示例方法、系统和计算机程序涉及通过设备上的采集进行云卸载位置计算。示例仅代表可能的变化。除非另有明确说明,否则组件和功能是可选的并且可以组合或细分,并且操作可以按顺序变化或者组合或细分。在以下描述中,出于解释的目的,阐述了很多具体细节以提供对示例实施例的透彻理解。然而,对于本领域技术人员将很清楚的是,可以在没有这些具体细节的情况下实践本主题。利用gnss的设备的位置的计算包括gnss信号的收集、gnss卫星的采集、以及用于基于采集数据来标识定位的计算。诸如云卸载全球定位系统(co-gps)等方法收集原始gnss信号并且将其发送到被称为基于网络的gnss服务的云服务。gnss服务执行采集和定位操作。这种类型的方法与独立gnss接收器相比可以节省大量能耗,因为位置计算过程中的大部分能耗由采集和定位决定。然而,由于大量使用网络带宽和高能耗,co-gps对于很多定位应用而言是成问题的。在一些示例中公开了利用被称为云卸载的设备采集全球定位系统(coda-gps)的新的gnss处理方法的方法、系统、设备和机器可读介质。coda-gps平衡了将计算卸载到云的能效,同时节省了这种卸载带来的传输时间和能耗。使用coda-gps,在被跟踪的设备处进行采集。结果,与co-gps相比,设备侧的工作量增加了。为了维持相同水平的能效,嵌入式通用图形处理单元(gpgpu)(在本文中也简称为gpu)被用于卫星采集。采集所需要的一些操作被并行化,并且然后由gpu执行,gpu非常适合于快速执行并行计算,从而有助于降低能耗。通过批量采集处理可以获取进一步的增强,这节省了与从低功率状态重复唤醒执行采集的硬件处理器和gpu相关的成本。因此,不是实时处理接收的gnss信号,而是批量处理它们。同一批次中的信号采集可以连续执行。实验测试表明,通过执行设备采集,可以显著减少传输到云以用于定位的数据量,而不会损害能效。尽管该方法被称为coda-gps,并且参考gps给出示例实施例,但是受益于本公开的本领域普通技术人员将意识到,该方法将与其他gnss服务一起工作。一个总体方面包括一种方法,该方法包括用于由计算设备的一个或多个处理器收集多个位置的原始全球定位系统(gps)信号的操作。该方法还包括由计算设备将多个位置的原始gps信号存储在存储器中,以及在计算设备处以批处理模式处理原始gps信号以获取用于多个位置的采集数据。该处理还包括:由一个或多个处理器标识用于由图形处理单元(gpu)并行处理的多个任务;由gpu通过将每个任务分配给gpu内的核处理器来并行执行多个任务;以及由一个或多个处理器组合执行多个任务的结果以获取采集数据。该方法还包括由一个或多个处理器将采集数据传输到服务器以用于在服务器处计算多个位置的定位,服务器存储这些定位并且使这些定位可用于定位跟踪应用。一个总体方面包括一种系统,该系统包括:包括指令的存储器、图形处理单元(gpu)和一个或多个计算机处理器。指令在由一个或多个计算机处理器执行时引起一个或多个计算机处理器执行包括以下各项的操作:收集多个位置的原始gps信号;将多个位置的原始gps信号存储在存储器中;以批处理模式处理原始gps信号以获取多个位置的采集数据;标识用于由gpu并行处理的多个任务,gpu通过将每个任务分配给gpu内的核处理器来并行执行多个任务;组合执行多个任务的结果以获取采集数据;以及将采集数据传输到服务器以用于在服务器处计算多个位置的定位,服务器存储这些定位并且使这些定位可用于定位跟踪应用。一个总体方面包括一种包括指令的非暂态机器可读存储介质,这些指令在由机器执行时引起该机器执行包括以下各项的操作:由计算设备的一个或多个处理器收集多个位置的原始全球定位系统(gps)信号;由计算设备将多个位置的原始gps信号存储在存储器中;在计算设备上以批处理模式处理原始gps信号以获取多个位置的采集数据。该处理还包括:由一个或多个处理器标识用于由图形处理单元(gpu)并行处理的多个任务,由gpu通过将每个任务分配给gpu内的核处理器来并行执行多个任务,以及由一个或多个处理器组合执行多个任务的结果以获取采集数据;以及由一个或多个处理器将采集数据传输到服务器以用于在服务器处计算多个位置的定位,服务器存储这些位置并且使这些位置可用于定位跟踪应用。图1示出了根据一些示例实施例的用于卸载全球定位计算任务的图。具有gnss接收器的计算设备(诸如智能电话102、野生生物跟踪器104等)可以在不同时间连接到由蜂窝网络设备(诸如蜂窝基站106、wi-fi路由器108等)提供的无线网络。蜂窝基站106和wi-fi路由器108允许计算设备通过诸如网络110等网络与一个或多个其他计算设备通信。例如,它们可以允许智能电话102或野生生物跟踪器104与基于网络的gnss服务112通信。智能电话102、野生生物跟踪器104和其他设备可以传输从一个或多个卫星116获取的原始gnss信号或部分地处理过的gnss信息(诸如采集数据的输出)以用于处理和存储在数据库114中。在其他示例中,智能电话102和野生生物跟踪器104可以在设备上执行采集和定位两者以产生位置坐标,例如地理位置。地理位置可以在设备上使用,也可以发送到基于网络的gnss服务以用于基于网络定位的应用。gps定位基于具有精确的时间和卫星116的已知位置。gps卫星116携带非常稳定的原子钟并且连续广播其当前时间和位置。天空中有32颗gps卫星(其中一个是冗余的),每颗卫星每天绕地球运转约两个周期。一组地面站监测并且校准卫星参数。这些参数包括年历,年历包含卫星的轨迹的精确值。所有卫星都被时间同步到几微秒内,并且在时钟相关之后,它们的时间戳可以在几纳秒内被同步。具有不太稳定的本地时钟的gps接收器(例如,104)监测多个卫星并且使用约束最小化技术(诸如最小二乘最小化)来计算其位置。由于接收器不知道精确的卫星时间,因此在最小化求解器中通常将时间视为一个变量。通常,至少需要四个可见卫星用于确定定位。gps卫星由32个不同且高度正交的伪随机噪声(prn)序列(称为粗略采集(c/a)码)来区分。当gps接收器首次启动时,接收器会检测可见的卫星。这是通过检测接收信号中对应c/a码的存在来完成的,通常通过将信号与每个已知c/a码模板相关来完成的。由于c/a码被设计为彼此正交,因此可见卫星将在相关结果中显示出尖峰,而不可见卫星将不会导致任何可检测到的尖峰。卫星采集的目的是确定可见gps卫星,并且标识这些卫星的载波频率和编码相位的粗略值。在一些示例实施例中,采集包括:确定哪些卫星对天线可见;确定每个可见卫星的近似多普勒;在c/a码延迟和频率(即,多普勒频移)两者中搜索信号;以及检测信号并且确定其码延迟和载波频率。定位涉及使用来自所采集的一组卫星的gnss信号中的信息来计算位置的操作。这些采集和定位操作是处理器密集型的,因此需要大量能量以执行。对于希望最小化功耗的设备,这可能是成问题的。co-gps有助于减少能耗,但是对于很多定位应用,co-gps可能是成问题的。一个问题是要从计算设备传输到云服务器的数据量过多。对于具有不规则网络连接的计算设备,在发现网络连接时存储并且随后传输的数据量可能非常庞大。例如,co-gps中的一个gps定位确定需要打开gps接收器达10ms。结果,为单个定位确定收集40kb的信号数据(使用16.368mhz采样频率)。如果每分钟进行一次定位采样,则一天中累积到60mb,一周中累积到420mb。这种过多的数据导致传输时间很长和大量能耗。由于在传输之前存储数据需要大量存储器,这也增加了设备成本。作为示例,考虑野生生物跟踪器104,其中野生生物可能长时间不靠近无线网络。当野生生物跟踪器104最终建立与无线网络的连接时,野生生物跟踪器104可能具有吉字节的数据要传输。通常,由于数据传输增加,即使是定期连接到网络的设备(诸如智能电话102或其他物联网(iot)设备)也可能会导致电池使用过多。例如,下面的表1列出了各种无线技术传输60mb的gps信号数据的能耗和所需要的时间。表1上行链路吞吐量所需要的时间能量wi-fi(ieee802.11b)0.94mbps511s204j3g400kbps1200s1398jlte6mbps80s313j图2示出了根据一些示例实施例的具有用于计算设备的位置的不同任务划分架构的图200。图2示出了用于计算位置的三种方式:在设备处计算位置202,通过采集和定位的云卸载(co-gps)在设备处收集信号204,以及通过定位的云卸载(coda-gps)在设备处收集信号和进行采集206。gps信号处理可以大致分为三个步骤:gps信号收集、采集和定位。对于基于设备的gps202,所有位置计算操作都使用设备的计算资源和功能在设备104上执行,并且这些操作包括原始信号收集208、采集210和定位212。对于co-gps204,设备104采集原始gps信号216,并且将原始gps信号传输214到云服务218,原始gps信号在云服务218中用于采集222和定位220。co-gps204允许传感设备积极地对其gps接收器执行占空比操作,并且仅记录足够用于后处理的原始gps信号。利用公共可用信息,诸如gps卫星星历和地球海拔数据库,云服务可以从几毫秒的原始数据中得出高质量的gps定位。例如,与独立gps接收器上超过30秒的重信号处理相比,使用被称为cleo的所设计的感测平台,co-gps可以使每个定位标记的能耗降低三个数量级。对于coda-gps206,设备104收集原始gnss信号224并且进行采集226。然后,设备104将诸如时间戳、多普勒和相移信息等采集结果发送228到基于网络的gnss服务230,在基于网络的gnss服务230中执行定位。在gps信号处理的三个步骤中,采集和定位对能耗的影响最大,因此在co-gps中将其卸载到云以实现设备上的能效。co-gps在几毫秒内收集gps基带信号,并且将所有后处理任务卸载到云。过多的数据传输意味着较长的传输时间和大量的能耗,这使co-gps在很多情况下都不适合。示例包括在野生环境中的gps感测应用,诸如野生生物跟踪、资产跟踪和参与式环境感测。在这些应用中,在部署之后不可能或很难访问所跟踪的对象。因此,所收集的数据无法手动提取,而必须通过诸如卫星、3g、lte或wi-fi等无线基础设施上载到服务器。gps采集在计算上是昂贵的。因此,coda-gps的一个目标是提高采集的能效,从而不损害设备侧上的总体能效目标。借助coda-gps,就能效而言,可以利用云卸载策略,而无需支付大量的数据传输成本。coda-gps允许在设备上高效地执行采集,并且仅将定位过程卸载到云。在设备上进行采集至少有两个好处。首先,仅需要将采集结果(其包括每个卫星的仅几个字节来记录码相位和多普勒频移)传输到云。因此,缓解了co-gps中过多数据传输的固有问题。其次,与仅设备的gps202相比,coda-gps206仍然节省了用于解码卫星数据的大部分能量,诸如精确的时间戳和星历。图3是根据一些示例实施例的用于coda-gps的方法的流程图302。尽管顺序地呈现和描述这些流程图中的各种操作,但是本领域普通技术人员将理解,一些或全部操作可以以不同的顺序执行,组合或省略,或者并行执行。在操作302,计算设备接收和收集原始gps信号。由于基带c/a码每毫秒重复一次,因此在理想情况下,1ms的数据足以进行采集。假定基带采样频率为16mhz,则采集所需要的最小数据量为16*1023,即16,368个采样。对于很多gps接收器芯片,每个样本为两位(一位符号和一位大小),因此1ms基带信号的存储要求为4kb。在一种极端情况下,位转换位于1ms信号的中间。由于使用c/a码以50bps来调制数据分组,因此每20ms就有位转换的可能性。由于如果位转换在1ms信号的中间,则对应卫星的采集将失败,因此2ms的基带信号(也称为块)对于卫星采集更为可靠。为了提高定位精度,通常收集多个数据块,例如五个块。因此,在一些示例实施例中,用于单个定位标记的收集数据的大小默认为40kb。采集卫星中的挑战是由卫星的移动以及接收器在地面上的任何移动引起的多普勒频移。例如,一颗上升的gps卫星可以以高达800m/s的速度向接收器移动,从而导致l1*800/c的频移,其等于4.2khz,其中c是光速。对于设置卫星,在相反方向上发生相同大小的频移。为了可靠地计算该频移下的校正量,接收器必须在频移后的500hz范围内生成c/a码。因此,在频率维度上,接收器最多搜索18个窗口。例如,很多gps接收器使用25至40个频率窗口来适应本地接收器的移动并且提供更好的接收器灵敏度。在补偿多普勒频移之后,接收器必须确定码相位延迟。由于接收器可能没有与卫星同步的时钟,并且由于信号传播延迟会受到大气条件的影响,因此接收器必须搜索延迟维度。接收器通常对1023bps的c/a码进行过采样,并且假定接收器以暴力方式对8mhz的基带信号进行采样,接收器将搜索8184个码相位位置以找到最佳相关峰值。因此,采集是一项昂贵的操作,因为它必须为每颗单个卫星搜索多于30个频率窗口乘以8,000加上码相位的可能性。然而,可以通过几种方法来加速采集:连续跟踪、先验辅助和并行搜索。通过连续跟踪,随着卫星和地面上的设备的移动,码相位会随时间变化。在连续操作中,gps接收器使用跟踪模式将先前获取的多普勒频移和编码相位调节为新的多普勒频移和编码相位。这是使用反馈回路的相对便宜的过程。因此,一旦gps接收器产生其第一定位确定,随后的定位估计就变得很快。但是,一旦gps接收器停止跟踪,先前已知的多普勒频移和码相位的效用就会迅速降低。通常,在30秒的非跟踪之后,gps接收器必须重新开始。连续跟踪的一种典型情况是导航。不幸的是,连续跟踪在定位采样间隔通常大于30s的长期跟踪应用中无济于事。加速采集的另一种方式是利用一些先验信息,该方法称为先验辅助。典型示例是辅助gps(a-gps)。当接收器没有卫星及其自身定位的先验知识时,接收器必须搜索整个空间。这是独立gps设备的初始位置确定缓慢和高能耗的主要原因之一。但是,基础设施可以通过多种方式帮助gps接收器更快地启动。具体地,在基于移动台的a-gps(或agps-b)模式下,基础设施提供了最新的星历数据,使得gps接收器不必从卫星信号中解码它们。how的第一成功解码足以提供定位确定。在移动台辅助的a-gps(或agps-a)模式下,基础设施被给与估计的定位,因此其可以为多普勒和码相位搜索提供初始值。这种机制已经广泛应用于智能电话定位。但是,co-gps和coda-gps的传感器节点均未连接到任何基础设施。即使有coda-gps的基础设施,例如wi-fi,传感器节点也只能机会性地连接到接入点。串行搜索采集是在码分多址系统(cdma)(gps是cdma系统)中常用的一种采集方法。但是,串行搜索是一个按顺序搜索多普勒频率和码相位的所有可能值的费时的过程。如果并行实现搜索过程,则可以显著提高过程的性能。多普勒频率和码相位这两个参数都可以并行化,这表示并行频率空间搜索采集和并行码空间搜索采集。这些并行方法分别在频率空间或码空间中使用傅立叶变换,并且本质上是并行方法。并行码空间搜索的性能优于并行频率空间搜索,因为在码相位维度中搜索步骤的数量明显大于频率维度。下面提供串行搜索和并行码空间搜索采集的更多详细信息,以供参考图6和7进行比较。在操作304,系统检查是否已经达到采集处理条件。例如,自上次采集以来是否已经过去一定量的时间,已经收集了一定量的原始信号数据,存储设备正在接近容量,系统位于用于传输数据的无线网络的范围内,系统的硬件处理器由于与gps处理无关的原因而被唤醒,新的gnss地理位置信号集已经到来等。如果尚未达到采集处理条件,则在操作302处,计算设备可以继续收集原始地理位置信号。如果设备准备执行采集,则该方法进行到操作306。在一些示例实施例中,阈值量的数据被累积,并且当设备具有足够的能量时,gpu被唤醒,gpu处理采集数据以获取码相位和多普勒,并且gpu再次进入睡眠状态。在操作306,处理原始地理位置信号以创建采集数据集。可以对采集数据集加上时间戳,以用于将所获取的卫星和地理位置数据与稍后使用采集数据集计算出的位置相关。在一些示例实施例中,原始地理位置信号由gpu处理,这非常适合gps采集。使用嵌入式gpu,不是像在co-gps中那样对采集算法进行硬编码,而是可以在coda-gps中轻地松插入或拔出不同的采集算法。此外,占空比策略用于gpu辅助设备采集。代替使用coda-gps实时处理gps信号,将数据存储在闪存或其他存储器中,并且然后批量处理数据。这分摊了唤醒gpu并且将gpu设置为采集模式这一相对昂贵的过程。通过批量处理数据,gpu在大多数时间处于睡眠状态,并且仅在需要时且在条件允许时才被激活。在一些示例实施例中,连续执行同一批次中的信号采集。给定从不同定位连续收集的一批基带信号数据,建议的连续处理策略将扫描所有32颗卫星以获取被观测的卫星。然后,基于采集结果,对可见卫星进行预测,并且在下一次采集期间仅扫描预测的卫星。此外,在一些示例实施例中,可见卫星的“位置原理”用于避免在采集期间对所有可能的卫星进行暴力测试。具体地,使用了基于历史采集结果的可见卫星预测算法,从而减少了每次采集的搜索空间。该方法从操作306转到操作308,在操作308,将采集数据排队以供以后处理。在操作310,进行检查以确定采集数据是否准备好传输。例如,条件可以是以下中的任一项:自上次传输以来已经过去一定量的时间,已经收集了一定量的采集数据,存储设备正在接近容量,系统位于用于传输数据的无线网络的范围内,系统的硬件处理器由于与gps处理无关的原因而被唤醒,设备已经收集了足够的能量以进行传输等。如果采集数据准备好传输,则该方法进行到操作312,否则该方法进行到操作300以继续收集原始地理位置信号。在一些实施例中,如果用于存储原始地理位置信号的存储器已满,则可以使该设备进入睡眠状态,并且可以周期性地唤醒该设备以检查该设备是否能够传输。在操作312,计算设备将存储装置中的采集数据集传输到基于网络的gps服务。基于网络的gps服务可以利用每组采集数据以在由对应时间戳指示的时间计算计算设备的位置,并且可以包括采集的每个卫星的码相位和多普勒频移以及时间戳。流程图301指示由基于网络的gnss服务执行的操作,包括用于接收由计算设备发送的采集数据的操作314。在操作316,计算与所接收的采集数据相关联的一个或多个位置,并且在操作318,将计算出的位置存储在数据库中或报告给订阅以接收位置信息的另一设备。coda-gps减少了被传输以用于计算定位所需要的准备量。此外,coda-gps允许通过批量采集操作来优化可用能量的使用。这在诸如动物跟踪等应用中很有用,其中标签包括用于收集能量的太阳能电池板。太阳能电池板在白天或在动物在阳光下时收集能量,但目标在晚上不收集能量。有些动物在夜间可能会移动很多,因此必须考虑可用能量与移动之间的平衡。例如,当没有足够的能量用于传输时,标签仅存储数据,而当有足够的能量用于传输时(例如,第二天在太阳升起之后),则对数据进行处理并且然后进行传输。图4示出了根据一些示例实施例的,在计算设备402的不同组件内的用于计算位置的数据流。由于众所周知,采集是计算密集型的,因此在计算设备402(也称为传感器节点)中利用gpu412。由于其高瞬时功率需求,gpu412通常被认为是高能耗器。然而,本实施例能够同时具有强大的并行化和高能效。众所周知,能耗可以表示为功率乘以时间。减少功率或时间有助于减少能耗。在一些实现中,两个因素都被优化。除了诸如以其他模态感测等专用功能之外,计算设备402还包括gps前端404、数据存储装置424、具有处理器和存储器的cpu410、gpu412以及无线网络接口406(本文中也称为数据传输模块)。当计算设备402需要感测其定位时,gps前端404被打开以记录几毫秒的gps基带信号(本文中也称为原始gps信号),该信号被发送418到存储装置424。在一些示例实施例中,需要至少2ms的数据以避免可能的位边界。信号数据被存储以用于进一步处理(例如,卫星采集)。该设备不是实时处理原始gps信号,而是以批处理模式处理相当大的数据(例如,一天或一周内收集的信号数据)。cpu410检索414所存储的原始gps信号,并且与gpu412一起工作以生成采集结果(例如,时间戳、多普勒频移和码相位),该采集结果被存储416在存储装置424中。一旦完成采集,原始信号数据被删除。gpu412被用于处理密集的任务,诸如度量操纵、长快速傅立叶变换(fft)和峰值检测。当捕获到来自接入点的信号时,激活无线网络接口406以将高速缓存的采集结果传送到云,例如co-gpsweb服务408。图5示出了根据一些示例实施例的使用图形处理单元(gpu)412以用于使任务并行化的优点。如上所述,采集的目的是确定可见卫星以及卫星信号的载波频率和码相位的粗略值。由于众所周知,采集是计算密集型的,因此在某些实现中已经利用专用集成电路(asic)来执行采集。常识告诉我们,gpu是低功耗应用的敌人,在大多数情况下都是如此。对gpu的高性能要求已经影响了它们的设计,使其得以优化以实现更高的性能,即使是以较大的功耗为代价。即使在使用低功耗嵌入式gpu时,gpu的瞬时功率也很高。例如,某些gpu在正常使用期间会消耗0.6w至3w之间的功率,而很少使用超过4w的功率。尽管几瓦的功率已经很低,但对于需要极高能效的长期gps传感平台而言,这个功率量仍然是一个挑战。然而,在一些示例实施例中,因为gpu非常适合于数据并行问题并且由于gpu提供的处理速度而抵消了高能耗,所以gpu412被用于采集任务。此外,借助gpu可以实现更高效的采集算法。通常,程序任务502由计算设备执行。一些程序任务504更适合于由cpu410顺序执行,而其他计算密集型任务506则更适合于并行处理。cpu410与gpu412之间的主要区别之一是,cpu410包括几个处理器核,而gpu412可以包括数百个处理器核。另外,cpu410和gpu412可以包括相关的存储器。计算密集型任务506被划分为多个并行任务,这些并行任务被分配给gpu412中的各个核510。在并行计算中,存在两种类型的问题:任务并行问题和数据并行问题。数据并行问题是gpu412的加速处理的理想选择。当所有线程都执行相同指令但对不同数据执行时,gpu架构会更好地工作,因此数据并行问题最适合gpu。例如,矩阵乘法和加法、大离散傅立叶变换以及最大和最小计算就是这类问题。此外,因为gpu比固定电路更灵活,所以gpu比asic电路或fpga更好地完成采集任务。例如,使用gpu,可以权衡信号的采样率:如果存在强信号,则可以对信号进行下采样并且仍然获取良好的结果。为了使gpu可以用于极端能效应用,考虑两个因素:提高gpu的吞吐量和优化gpu的占空比。为了提高采集的吞吐量,实现深度定制的采集算法以充分利用cpu-gpu架构。具体地,通过引入所谓的惰性采集策略(例如,批量执行采集)并且预测潜在的可见卫星,不仅可以优化单个卫星的采集,而且可以减少搜索空间。关于功率,在一些示例实施例中,通过改变cpu和gpu的时钟频率来改变瞬时功率。下面呈现两种定制的采集算法,图6中描述了串行搜索,而图7中描述了并行码相位搜索。图6是根据一些示例实施例的串行搜索采集的框图。串行搜索采集可以用于在诸如gps等码分多址系统(cdma)中进行采集。如图6所示,该算法基于本地生成的prn码序列(由prn码生成器606生成)和本地生成的载波信号(由本地振荡器608生成)的乘积。在一些示例实施例中,prn码生成器606为所有32颗卫星生成prn序列。每个生成的序列具有唯一的码相位,从0到1022个码片(chip)。传入信号602最初与该本地生成的prn序列相乘,然后与prn序列相乘,然后将该信号与本地生成的载波信号和本地生成的载波的90°相移版本相乘,从而分别生成同相信号i和正交信号q。i和q信号在与一个prn码的长度相对应的1ms内积分612,并且最后进行平方运算614并且然后相加以生成输出610。基带信号表示为x[n],并且生成的prn序列表示为prn[n+m],其中n表示第n样本,并且m表示复制的prn码被移相的样本数。本地生成的载波表示为cos[ωn]和sin[ωn],其中ω是弧度频率。相关性r2[m]通过以下离散和来近似:其中l是每个码的样本数。串行搜索被认为是暴力算法,也就是说,测试码相位和多普勒偏移的所有可能组合,并且生成相关性矩阵。设置阈值,并且如果相关性结果中的峰值超过阈值,则采集卫星。如等式1所示,可以通过一系列矩阵运算来执行每个卫星的完全相关。步骤1包括两个运算:其中“.*”是逐元素乘法,carrsin和carrcos是本地生成的载波,prnmat是具有不同码移位的prn码副本的矩阵,l是1ms基带信号的长度。给定多普勒偏移数d,carrsin的尺寸为d×l,carrcos的尺寸为d×l,prnmat的尺寸为l×l。carrsin和carrcos中的每一行对应于特定多普勒偏移的载波。步骤2包括将步骤1的结果乘以prnmat以获取ri和rq,如下:通过将ri和rq的平方与以下等式相结合来计算步骤3:代替移位原始信号,可以循环移位prn码副本,因此可以离线生成具有不同码相位的码副本矩阵。从理论上讲,通过将码副本移位1ms的基带信号就足以实现相关。实际上,为了减轻数据位转换问题,分别对两个1ms的数据执行两个相关。这两个相关结果通过逐元素相加被聚合。根据以下等式,可以在三个步骤1b、2b和3b中加速等式(3)-(5)中的计算:步骤1b(等式(6))是逐元素乘法,步骤2b(等式(7))是矩阵乘法,步骤3b(等式(8))包括平方和求和。因此,串行搜索问题转换成三个子任务,这些子任务是数据并行的,因此可以由gpu并行化和加速。图7是根据一些示例实施例的并行码相位搜索算法的框图。在串行搜索采集中,通过循环移位副本来将接收的数据与副本码相关。这类似于圆形卷积,它是频域中的乘法。因此,等式(1)中的相关运算可以如下转换为圆卷积其中是圆卷积运算,表示离散傅立叶变换(dft),是的逆,而()*表示复共轭计算。传入信号702被混频到基带和同相,并且当通过执行快速傅立叶变换(fft)714计算dft时,正交分量被用作实数和虚数输入。结果乘以在操作710由prn码生成器712通过fft生成的prn码的dft的复共轭708。通过ifft716取逆dft716的幅度来获取圆形卷积。fft算法通常用于实现dft和idft。由于fft的引入消除了对码相位尺寸的搜索,因此该采集方法可以称为并行码相位搜索。在ifft之后,对信号进行平方运算718以生成输出720。用于单个卫星的并行码相位搜索采集的过程可以在五个步骤1c-5c中形式化。步骤1c包括三个运算(等式(10)-(12)),其计算如下:r′=r′i+r′q·j(12)步骤2c为:fft(r’)(13)步骤3c包括如下将步骤2c的结果相乘:步骤4c建立在步骤3c的基础上,如下:步骤5c获取绝对值和平方:r2=|r″|2(16)理论上,认为fft搜索比串行搜索快大约2000倍。与串行搜索采集类似,可以通过将步骤1c-5c的操作划分为五个步骤1d-5d来进一步并行化fft搜索。步骤1d是针对所有多普勒偏移的传入信号与本地生成的载波之间的逐元素乘法。步骤2d和步骤4d是前述的fft和ifft。步骤3d是传入信号与频域中的prn码之间的逐元素乘法。如上所述,gpu可以容易地加速逐元素矩阵运算以及fft和ifft。图8示出了根据一些示例实施例的用于执行采集任务的软件架构。fft在并行码相位搜索采集中的引入消除了对码相位尺寸的搜索,并且可以基于对gps接收器的采样频率不敏感的相关性尖峰来进一步改进。换言之,即使对gps信号进行了下采样,在可见卫星的相关性结果中仍然观察到尖峰。因此,下采样是一种用于设备采集的节能的新方法。在有限的下采样之后,采集仍会捕获可见卫星。但是,提取的多普勒频率和码移位可能不太准确。因此,在特殊情况下(例如,当电池用尽时)将使用下采样。如以上参考图6和7所述,一些操作(604和704)可以离线地预先生成。具体地,在串行搜索采集中预先生成所有32个卫星和所有多普勒偏移的本地载波的循环移位prn码。在并行码相位采集中,频域和本地载波中的prn码也离线生成。如图6所述,串行搜索采集中的第一任务是将传入信号与本地生成的prn码相乘。不是每次执行算法时都生成prn码,而是离线生成所有可能的prn码。称为g1和g2的两个十位线性反馈移位寄存器(lfsr)生成最大长度prn,其长度为210-1,等于1023位。串行搜索采集涉及prn码的所有可能移位版本的乘法。也就是说,除了保存32个可能的prn码之外,还可以保存所有可能的移位版本。在串行搜索采集中,第二步是与本地生成的载波相乘。载波生成器必须生成相位差为90°的两个载波信号,对应于余弦和正弦波。根据所检查的频率区域,载波的频率对应于if±频率阶跃。使用自然指数函数ej2πf生成复数信号。对于并行码相位搜索采集,第一步是将传入信号分别与本地生成的余弦和正弦载波相乘,得到i和q信号分量。在此,prn生成器只为每个采集生成没有码相位的一个码。下一步执行prn码的傅立叶变换,并且将结果进行复共轭。为了获取最大计算效率,所有离线生成的数据都将作为二进制文件直接存储在传感器节点上。在一些示例实施例中,采集算法和惰性采集策略均在cuda框架中实现。gpu基于多线程流式多处理器(sm)。sm以32个并行线程(称为变形体(warp))的组的形式创建、管理、调度和执行线程。每个变形体一次执行一条通用指令。此外,在cuda编程模型中,线程的功能被定义为内核。线程的层次结构由块和立方体表示。为了方便起见,threadidx是3分量向量,因此可以使用一维、二维或三维线程索引来标识线程。这提供了一种自然的方法来跨域(诸如向量、矩阵或字段)中的元素调用计算。在一些示例实施例中,线程的层次结构影响并行化的性能。但是,这里不是这种情况,因为gpu的运行接近其全部容量。因此,所有线程都使用通用的m1024结构。在一些示例实施例中,每个块的1024个线程用于所有逐元素矩阵运算,并且根据所需要的线程的总数分配适当数目的块。图8示出了用于串行搜索采集和并行码相位搜索采集的cuda实现的一些细节。为了在两个矩阵a[d×l](例如,尺寸d×l)和b[d×l]802之间进行逐元素加法,创建了总数为d乘l(d.l)的线程。每个线程处理a[i][j]+b[i][j],并且块数m为d.l/1024。对于两个矩阵a[d×l]和b[d×l]804之间的逐元素乘法,创建了总数为d.l的线程。每个线程处理a[i][j]·b[i][j],并且块数m为d.l/1024。对于矩阵a[d×l]806的逐元素的绝对和平方,创建了总数为d.l的线程。每个线程处理a[i][j]2,块数m为d.l/1024。为了在两个矩阵a[d×l]和b[d×l]808之间进行逐元素平方和求和,创建了总数为d.l的线程。每个线程处理a[i][j]2+b[i][j]2,并且块数m为d.l/1024。为了将两个矩阵a[d×l]和b[d×l]810相乘,使用cublas和共享存储器。为了减少对全局存储器的访问次数,线程将矩阵a和b的部分加载到共享存储器中,从而可以更快地访问它们。在一些示例实施例中,整个a和b矩阵被加载到共享存储器中。为了计算fft和ifft812,将批处理模式用于1dfft和ifft,并且在fftw(基于cpu的高效fft库)之后对cufft进行建模。fftw提供了一种称为计划的简单配置机制,该机制针对特定的fft大小和数据类型完全指定了最佳执行计划。这种方法的优势在于,一旦创建了计划,该库就可以存储执行多次计划所需要的任何状态,而无需重新计算配置。在某些情况下,创建计划很慢,可能是因为它是分配存储器和计算先验功能的地方。在一些示例实施例中,所有可能的计划首先被预先创建,并且然后根据需要在之后被重用。图9是根据一些示例实施例的用于利用设备上采集的云卸载位置计算的方法900的流程图。尽管顺序地呈现和描述该流程图中的各种操作,但是本领域普通技术人员将理解,一些或全部操作可以以不同的顺序执行,被组合或省略,或者被并行执行。操作902用于由计算设备的一个或多个处理器收集多个位置的原始gps信号。该方法从操作902进行到操作904,以由计算设备将多个位置的原始gps信号存储在存储器中。该方法从操作904进行到操作906,在操作906,在计算设备处以批处理模式处理原始gps信号以获取多个位置的采集数据。该处理还包括操作908、910和912。在操作908,一个或多个处理器标识用于由图形处理单元(gpu)并行处理的多个任务。在操作910,gpu通过将每个任务分配给gpu内的核处理器来并行执行多个任务。此外,在操作912,一个或多个处理器组合执行多个任务的结果以获取采集数据。该方法从操作912进行到操作914,以由一个或多个处理器将采集数据传输到服务器,以用于在服务器处计算多个位置的定位。服务器存储这些定位,并且使这些定位可用于定位跟踪应用。在一个示例中,方法900还包括:在处理多个任务之前唤醒gpu;以及在获取采集数据之后将gpu置于睡眠状态。在一个示例中,处理原始gps信号包括并行码搜索。在一个示例中,并行码搜索包括:将传入信号混频到基带和同相信号,其中当通过执行快速傅立叶变换(fft)来计算dft以获取第一结果时,将正交分量用作实数和虚数输入;将第一结果与由prn码生成器生成的prn码的dft的复共轭相乘以获取第二结果;对第二结果进行快速傅立叶逆变换以获取第三结果;以及获取第三结果的平方以获取采集数据。在一个示例中,所传输的采集数据包括时间戳、多普勒和相移信息。在一个示例中,原始gps信号包括2ms的gps基带信号。在一个示例中,处理原始gps信号包括串行搜索采集,其中串行搜索采集包括:将传入信号与本地生成的prn序列相乘以获取第一结果,将第一结果与本地生成的载波相乘信号以获取同相信号i,并且将第一结果与本地生成的载波的90°相移版本相乘以生成正交信号q,在1ms内对i和q信号进行积分,并且对积分后的i和q信号求平方以获取采集数据。在一些实验中,结果表明,coda-gps可以显著减少数据传输并且同时享受云卸载的好处,而不会影响能效和定位精度。此外,实验表明,可以将gpu用于低功耗嵌入式应用。图10是示出可以在其上实现一个或多个示例实施例的机器1000的示例的框图。在替代实施例中,机器1000可以作为独立设备操作,或者可以连接(例如,联网)到其他机器。在网络部署中,机器1000可以在服务器客户端网络环境中以服务器机器、客户端机器或两者的能力操作。在一个示例中,机器1000可以在对等(p2p)(或其他分布式)网络环境中充当对等机器。机器1000可以是个人计算机(pc)、平板pc、机顶盒(stb)、膝上型计算机、移动电话、web设备、网络路由器、交换机或网桥、或者能够执行指定该机器要执行的动作的指令(顺序或其他)的任何机器。此外,虽然仅示出了单个机器1000,但是术语“机器”也应当被理解为包括机器的任何集合,这些机器单独地或共同地执行一组(或多组)指令以执行本文中讨论的方法中的任何一个或多个,诸如云计算、软件即服务(saas)或其他计算机集群配置。如本文中描述的示例可以包括逻辑或多个组件或机制,或者可以由其操作。电路系统是在包括硬件的有形实体中实现的电路的集合(例如,简单电路、门、逻辑等)。电路系统成员资格可以随时间推移以及潜在的硬件可变性而变得灵活。电路系统包括可以在操作时单独或组合执行指定操作的成员。在一个示例中,电路系统的硬件可以被不变地设计为执行特定操作(例如,硬连线)。在一个示例中,电路系统的硬件可以包括可变地连接的物理组件(例如,执行单元、晶体管、简单电路等),其包括被物理地修改(例如,磁性地、电气地、通过可变质量的粒子的可移动放置等)以编码特定操作的指令的计算机可读介质。在连接物理组件时,硬件组件的基础电属性会发生变化,例如从绝缘体变为导体,反之亦然。该指令使得嵌入式硬件(例如,执行单元或加载机构)能够通过可变连接用硬件创建电路系统的成员以在操作时执行特定操作部分。因此,当设备正在操作时,计算机可读介质通信地耦合到电路系统的其他组件。在一个示例中,任何物理组件可以在多于一个电路系统的多于一个构件中使用。例如,在操作下,执行单元可以在一个时间点在第一电路系统的第一电路中使用,并且可以在不同的时间被第一电路系统中的第二电路或第二电路系统中的第三电路重用。机器(例如,计算机系统)1000可以包括硬件处理器1002(例如,中央处理单元(cpu)、图形处理单元(gpu)、硬件处理器核或其任意组合)、主存储器1004和静态存储器1006,它们中的一些或全部可以经由相互链接(例如,总线)1008彼此通信。机器1000还可以包括显示设备1010、字母数字输入设备1012(例如,键盘)、以及ui导航设备1014(例如,鼠标)。在一个示例中,显示设备1010、输入设备1012和ui导航设备1014可以是触摸屏显示器。机器1000可以另外包括大容量存储设备(例如,驱动单元)1016、信号生成设备1018(例如,扬声器)、网络接口设备1020以及一个或多个传感器1021,诸如gps传感器、罗盘、加速度计或其他传感器。机器1000可以包括输出控制器1028,诸如串行(例如,通用串行总线(usb))、并行或其他有线或无线(例如,红外(ir)、近场通信(nfc)等)连接以通信或控制一个或多个外围设备(例如,打印机、读卡器等)。大容量存储设备1016可以包括机器可读介质1022,在该机器可读介质1022上存储由本文中描述的任何一种或多种技术或功能实现或利用的一组或多组数据结构或指令1024(例如,软件)。在机器1000执行指令1024期间,指令1024还可以全部或至少部分驻留在主存储器1004内,静态存储器1006内或硬件处理器1002内。在一个示例中,硬件处理器1002、主存储器1004、静态存储器1006或大容量存储设备1016的一种或任何组合可以构成机器可读介质。尽管将机器可读介质1022示出为单个介质,但是术语“机器可读介质”可以包括被配置为存储一个或多个指令1024的单个介质或多个介质(例如,集中式或分布式数据库和/或相关联的高速缓存和服务器)。术语“机器可读介质”可以包括能够存储、编码或携带由机器1000执行并且引起机器1000执行本公开的任何一种或多种技术的指令1024或者能够存储、编码或携带由这样的指令1024使用或与之相关联的数据结构的任何介质。非限制性机器可读介质示例可以包括固态存储器以及光学和磁性介质。机器可读介质的具体示例可以包括:非易失性存储器,诸如半导体存储设备(例如,电可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom))和闪存设备;磁盘,诸如内部硬盘和可移除盘;磁光盘;以及cd-rom和dvd-rom盘。指令1024还可以使用多种传输协议(例如,帧中继、因特网协议(ip)、传输控制协议(tcp)、用户数据报协议(udp)、超文本传输协议(http)等)中的任何一种经由网络接口设备1020使用传输介质通过通信网络1026传输或接收。示例通信网络可以包括局域网(lan)、广域网(wan)、分组数据网络(例如,因特网)、移动电话网络(例如,蜂窝网络)、普通老式电话服务(pots)网络、无线数据网络(例如,被称为的电气和电子工程师协会(ieee)1002.11标准系列、被称为的ieee1002.16标准系列)、ieee1002.15.4标准系列、对等(p2p)网络等。在一个示例中,网络接口设备1020可以包括一个或多个物理插孔(例如,以太网、同轴或电话插孔)或一个或多个天线以连接到通信网络1026。在一个示例中,网络接口设备1020可以包括多个天线,以使用单输入多输出(simo)、多输入多输出(mimo)或多输入单输出(miso)技术中的至少一种进行无线通信。术语“传输介质”应当被认为包括能够存储、编码或携带由机器1000执行的指令1024的任何无形介质,并且包括数字或模拟通信信号或用于支持这种软件的通信的其他无形介质。在整个说明书中,多个实例可以实现被描述为单个实例的组件、操作或结构。尽管将一种或多种方法的个体操作示出并且描述为单独的操作,但是可以同时执行一个或多个个体操作,并且不需要按照所示顺序执行操作。在示例配置中呈现为单独的组件的结构和功能可以实现为组合的结构或组件。类似地,呈现为单个组件的结构和功能可以被实现为单独的组件。这些和其他变型、修改、添加和改进落入本文中的主题的范围内。本文中示出的实施例被足够详细地描述,以使得本领域技术人员能够实践所公开的教导。可以使用其他实施例并且从中得出其他实施例,使得可以在不脱离本公开的范围的情况下进行结构和逻辑方面的替换和改变。因此,“具体实施方式”不应当从限制意义上理解,并且各种实施例的范围仅由所附权利要求书以及这些权利要求书所享有的等效物的全部范围来限定。如本文中使用的,术语“或”可以以包括性或排他性的意义来解释。此外,可以为本文中描述为单个实例的资源、操作或结构提供多个实例。另外,各种资源、操作、模块、引擎和数据存储之间的边界在某种程度上是任意的,并且在特定说明性配置的上下文中示出了特定操作。功能的其他分配可以设想并且可以落入本公开的各种实施例的范围内。通常,在示例配置中呈现为单独的资源的结构和功能可以实现为组合的结构或资源。类似地,呈现为单个资源的结构和功能可以实现为单独的资源。这些和其他变型、修改、添加和改进落入如所附权利要求所表示的本公开的实施例的范围内。因此,说明书和附图应当被认为是说明性的而不是限制性的。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1