基于多种地震属性评价准则的有利区预测方法与流程
本发明属于地球物理勘探领域和人工智能领域,具体涉及一种基于多种地震属性评价准则的有利区预测方法。
背景技术:
传统有利区预测方法往往采用2-3种常规地震属性,在地质条件复杂的情况下,常规属性相关性差,且不能利用其他未使用地震属性对分类的隐含作用。随着机器学习技术逐渐应用到各个领域,引入机器学习中关于特征选择的相关知识进行关键地震属性的筛选逐渐被重视。但是,进行有利区预测除了要考虑地震属性与类别的相关性大小,同时还要考虑地震属性之间的相关性,单一的特征评价准则往往只能考虑到其中的某一种相关性,存在严重的片面性。
通过引用多种不同类型的特征评价准则,综合考虑地震属性与类别以及地震属性之间的相关性大小,去除不相关及冗余的地震属性,筛选最优地震属性组合,进而结合具有较高分类性能的集成分类器进行有利区预测,得到地震属性与类别标签的映射关系,从而辅助地质勘探人员快速圈定有利区。
技术实现要素:
为了克服单一特征选择方法无法全面评价地震属性重要性的不足,本发明提出了基于多种地震属性评价准则的有利区预测方法,通过综合考虑多种不同类型的特征选择方法,全面评价地震属性的重要性,筛选最优的地震属性组合,实现有利区预测的高效性。
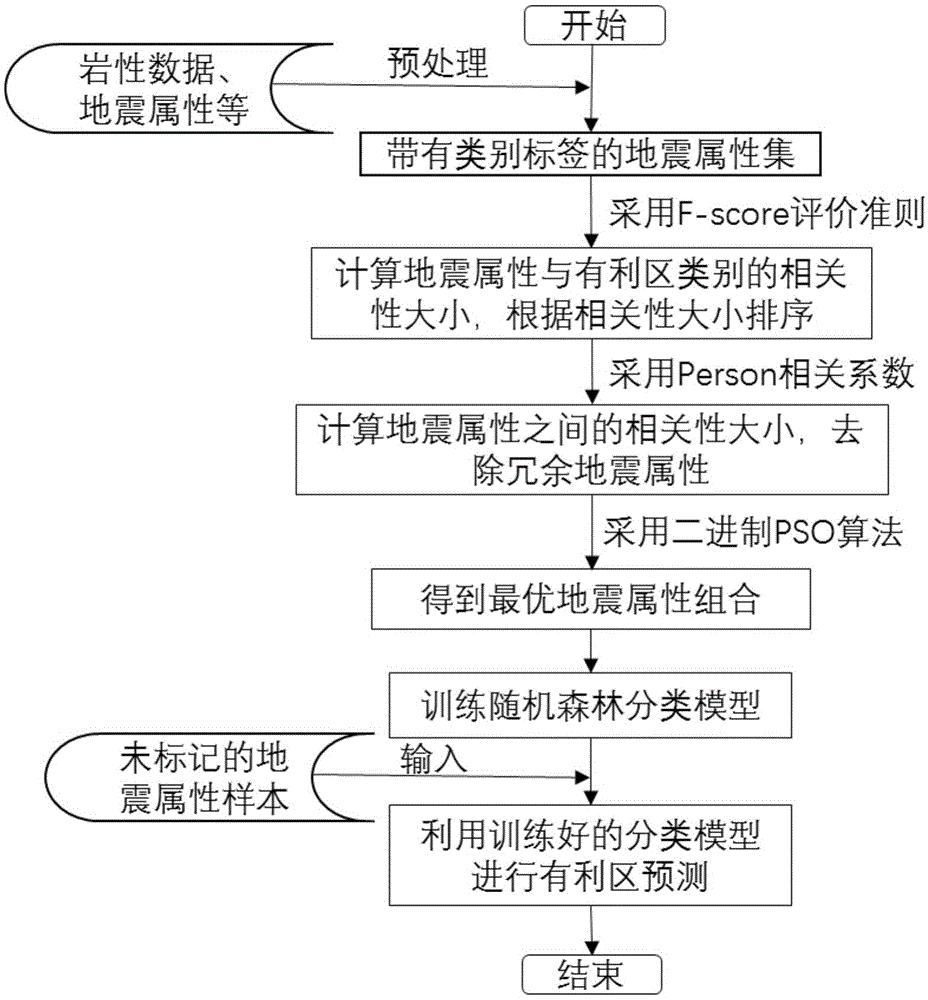
为实现上述目的,本发明技术方案主要包括如下步骤:
a.数据预处理:
从勘探数据库、地震数据体等数据源中提取地震属性以及岩性数据,通过时深转换,匹配地震属性集与有利区类别标签,得到带有类别标签的地震属性集合。将有利区分为有利储层发育区和非有利储层发育区两类,分别标记为1、-1。
b.采用f-score评价准则计算地震属性与有利区类别的相关性大小:
f-score是一种评估地震属性分辨两种不同类别能力的方法,f-score值越大,表明该地震属性与有利区类别的相关性越大,计算所有地震属性的f-score值,根据每个地震属性的f-score值大小排序,f-score值越大,对应的地震属性越靠前。
c.采用person相关系数计算地震属性之间的相关性大小:
person相关系数是衡量地震属性之间相关性大小的一种属性评估方法,通过计算地震属性之间的两两相关性,相关系数越大,表明地震属性之间存在较大的冗余。进一步设定限制阈值,若地震属性i、j之间的相关系数大于阈值,比较地震属性i、j在f-score值中的排序,去除排序靠后的地震属性,从而消除相关性小的冗余属性。
d.采用pso实现最优地震属性组合的筛选:
采用二进制pso算法,每个粒子被编码成长度为地震属性个数的二进制形式,代表地震属性的组合,其中编码1表示保留该地震属性,编码0表示去除该地震属性。在每一次迭代求解的过程中,根据粒子的适应度值更新全局最优位置以及粒子自身经历过的最优位置。
在二进制粒子中,速度的每个分量表示对应的地震属性被保留的概率,因此可以通过sigmoid函数将概率转换为0和1值,从而进入下一步迭代,当达到规定迭代次数时,产生的全局最优解对应的地震属性组合即为最优组合。
e.采用随机森林集成方法实现有利区预测:
(1)从带有类别标签的最优地震属性集合中随机有放回的采样n个样本,重复采样t次,获得t个不同的训练样本集。
(2)选用决策树作为随机森林的单个分类算法,分别在t个训练样本集上训练决策树模型。
(3)将生成的t个决策树组合成随机森林模型,以未知有利区分布区域的地震样本集作为输入,筛选最优地震属性集,将最优地震属性集输入到训练好的随机森林模型进行有利区类别预测。
本发明的有益效果是:采用f-score计算得到地震属性与类别之间的相关性大小,利用person相关系数计算地震属性之间的相关性,进而去除冗余的地震属性,最后通过pso算法寻找最优的地震属性组合。综合考虑多种属性评价方法,筛选对分类起着关键作用的地震属性组合,从而更加准确地预测有利区。
附图说明
图1是本发明的模型结构图
具体实施方式
下面结合图1对本发明作进一步详细的描述:
a.数据预处理:
从勘探数据库、地震数据体等数据源中提取地震属性以及岩性数据,通过时深转换,匹配地震属性集与有利区类别标签,得到带有类别标签的地震属性集合。将地震属性的个数记为m,有利区分为有利储层发育区和非有利储层发育区两类,分别标记为1、-1。
b.采用f-score评价准则计算地震属性与有利区类别的相关性大小:
f-score是一种评估地震属性分辨两种不同类别能力的方法,f-score值越大,表明该地震属性与有利区类别的相关性越大,第i个地震属性的f-score值定义为:
式中,n+表示样本集中标记为有利储层发育区的样本数量,n-表示标记为非有利储层发育区的样本数量,
根据每个地震属性的f-score值大小排序,f-score值越大,即与类别相关性越大,对应的地震属性越靠前。
c.采用person相关系数计算地震属性之间的相关性大小:
person相关系数是衡量地震属性之间相关性大小的一种属性评估方法,通过计算地震属性之间的两两相关性,相关系数越大,表明地震属性之间存在较大的冗余。person相关系数的计算公式如下:
其中,ri,j表示第i个地震属性与第j个地震属性之间的相关性大小,n表示样本的总数量,xi、xj分别表示第i、j个地震属性向量。
设定限制阈值,若地震属性i、j之间的相关系数大于阈值,比较地震属性i、j在f-score值中的排序,去除排序靠后的地震属性,从而消除相关性小的冗余属性,剩余f个地震属性。
d.采用pso实现最优地震属性组合的筛选:
采用二进制pso算法,每个粒子被编码成长度为地震属性个数f的二进制形式,代表地震属性的组合,其中编码1表示保留该地震属性,编码0表示去除该地震属性。在每一次迭代求解的过程中,根据粒子的适应度值更新全局最优位置以及粒子自身经历过的最优位置,通过以下公式更新速度及当前位置:
d=1,2,…,f
其中,c1、c2为两个正常数,称为加速因子,
在二进制粒子中,速度的每个分量表示对应的地震属性被保留的概率,因此可以通过sigmoid函数将概率转换为0和1值,从而进入下一步迭代,当达到规定迭代次数时,产生的全局最优解对应的地震属性组合即为最优组合。
e.采用随机森林集成方法实现有利区预测:
(1)从带有类别标签的最优地震属性集合中随机有放回的采样n个样本,重复采样t次,获得t个不同的训练样本集。
(2)选用决策树作为随机森林的单个分类算法,分别在t个训练样本集上训练决策树模型。
(3)将生成的t个决策树组合成随机森林模型,以未知有利区分布区域的地震样本集作为输入,筛选最优地震属性集,将最优地震属性集输入到训练好的随机森林模型进行有利区类别预测。
以上所述,仅是本发明的较佳实施例,任何熟悉本专业的技术人员可能利用上述阐述的技术方案加以改型或变更为等同变化的等同实例。凡未脱离本发明技术方案内容,依据发明的技术方案对上述实施例进行的任何简单修改、变更或改型,均属于发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!