一种基于语义感知的Top-k多请求路径规划方法与流程
本发明属于路径导航、规划领域,具体涉及一种基于语义感知的top-k多请求路径规划方法。
背景技术:
近年来,随着无线通信技术、全球定位系统(gps)和智能移动设备的快速发展,大量基于位置的服务(lbs)应运而生。其中,路径规划已经成为热点。迄今为止,在路径规划领域已经进行了大量的研究且取得了相当丰硕的成果。根据目标的不同,路径规划算法可以分为两大类:基于点的路径规划算法和基于活动意图的路径规划算法。
基于点的路径规划。这种方式需要用户对自己的行程具有全面的了解,明确所要到达的地点位置,并且需要用户具有较好的规划能力,明确到达地点的顺序。显然,多数用户无法很好地进行详细的规划。
基于活动意图的路径规划。这种方式对于路径规划的效果较好,但是成本高,而且需要用户明确活动意图的顺序。
这两种算法通过用户请求将poi(pointofinterest)分类,按照用户发出请求的顺序搜索路径,忽略了单个poi能够提供多个服务、满足用户多个请求的实际情况以及用户请求之间存在的实际优先关系。
技术实现要素:
针对现有技术的不足,本发明提供一种基于语义感知的top-k多请求路径规划方法。该方法通过用户活动意向查询能够满足该意向的poi并规划路径,同时考虑到单个poi满足用户多个活动意向的情况。
本发明的技术方案为:一种基于语义感知的top-k多请求路径规划方法,包括:
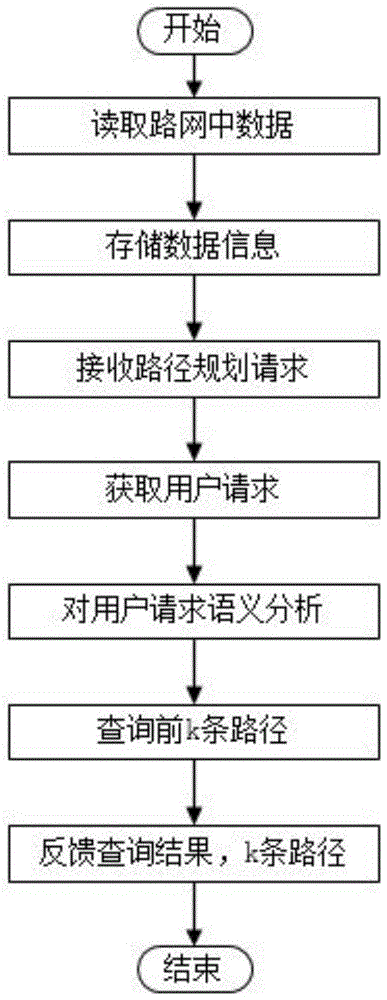
(1)读取路网中poi的地理位置、关键词数据信息,用于路径规划时关键词匹配以及空间距离成本代价的计算;
(2)按定义的数据结构存储从路网中读取到的数据信息,便于路径规划过程中查询关键词对应的poi;
(3)接收路径规划请求;
(4)获取用户输入的多个请求即查询关键词的信息以及当前用户所在的位置信息并存储;
(5)使用lda语义分析算法对用户输入的请求进行语义分析,获取查询关键词与poi关键词之间的语义相似度;得到候选的poi点集合
(6)通过算法搜索从起点出发直到完成用户所有请求的前k条路径,并将形成的路径存入结果集中;
(7)反馈结果集中的路径信息。
上述的路径规划方法,其中,步骤(6)进一步包括:
(a)设置算法中的参数值:(g,s,q,k),其中g代表路网信息,s代表起点,q代表用户请求集合,k代表查询路径数;创建结果集、候选路径集、支配路径集以及被支配路径集;初始化所有参数;
(b)判断路径数是否等于k条,如果是则进入步骤(m),否则进入步骤(c);
(c)从候选路径集合中选择最优的部分路径,即候选路径集中第一条路径;
(d)判断最优的部分路径是否满足用户所有请求,如是进入步骤(e),否则进入步骤(f);
(e)将该路径加入结果集,从被该路径支配的路径中选择最优路径加入候选路径集中,并返回步骤(b),所谓路径支配即给定用户的请求q={q1,…,qj}、第一部分探索的候选路由
其中,qrp(r1)和qrp(r2)分别是两条部分探索路径满足的请求集合,cost(r1)和cost(r2)分别是两条部分探索路径的成本。
(f)判断该路径是否被其他路径支配,如是进入步骤(g),否则进入步骤(j);
(g)将该路径加入支配路径集;
(h)查询当前poi点的第x个最近邻并访问最近邻;
(i)将当前poi点的第x个最近邻加入路径中形成新的路径,并将新的路径加入候选路径集;
(j)将该路径加入被支配路径集中;
(k)判断当前poi点是否为起点s,如是返回步骤(b),否则进入步骤(l);
(l)查询当前点前一个poi点的第x+1个最近邻并访问,形成新的路径加入路径候选集,返回步骤(b);
(m)返回结果。
上述的路径规划方法,其中,所述步骤(h)具体包括以下子步骤:
(h.1)输入当前点即当前路径中最后一个poi点、未完成请求、创建优先队列n存储poi点的近邻、创建集合c存储能够满足优先查询的请求的poi;
(h.2)对未完成请求进行优先级分配,确定优先查询的请求;
(h.3)查询集合c中所有poi,确定所有poi与当前点的距离远近关系,并将poi按照距离由近及远的顺序存入队列n中;
(h.4)根据查询所需的第x个最近邻,输出队列n中第x个元素。
上述的路径规划方法,其中,所述步骤(h.2)具体包括以下子步骤:
(h.2.1)输入未完成的用户请求,判断是否第一次进行优先级分配,如是进入步骤(h.2.2),否则进入步骤(h.2.7);
(h.2.2)遍历所有请求,判断是否与其他请求存在优先级关系,如是进入步骤(h.2.3),否则进入步骤(h.2.4);
(h.2.3)将优先级高请求的优先级定义为1,其他的请求优先级定义为0;
(h.2.4)将请求的优先级定义为1;
(h.2.5)将所有优先级为1的请求加入结果集合;
(h.2.6)将本次结果集保留至第二次优先级分配;
(h.2.7)通过上一次优先级分配产生的结果集和本次未完成的请求进行交集,计算出上一次路径搜索时被满足的请求。
(h.2.8)针对与上一次查询请求存在优先级关系且尚未处理的请求,对它们进行优先级分配;
(h.2.9)将优先级高的请求加入未完成请求集合,并赋值给结果集,本次结果保留至下一次优先级分配;
(h.2.10)反馈结果。
上述的路径规划方法,其中,步骤(h.3)其具体子步骤如下:
(h.3.1)输入优先级分配中反馈的结果集以及能够满足用户请求的poi;
(h.3.2)通过
(h.3.3)通过
(h.3.4)通过ave的值对候选集中poi进行排序。
本发明的有益技术效果为:本发明是一种基于语义感知的top-k多请求路径规划方法,通过对查询关键词的语义分析使查询具有灵活性,同时,通过对用户请求间的优先关系进行分配使路径规划符合实际生活所需。此外,本发明还考虑到poi与提供的服务间的关系,使路径中的poi点尽可能地提供更多的服务,从而减少用户需要访问poi数量,减少时间等成本的损耗。
附图说明
图1为本发明具体实施方式的基于语义感知的top-k多请求路径规划方法的流程图;
图2为本发明具体实施方式的查询前k条路径的流程图;
图3为本发明具体实施方式的查询最近邻的流程图;
图4为本发明具体实施方式的优先级分配的流程图;
图5为本发明具体实施方式的poi距离成本计算的流程图;
图6为本发明具体实施方式的poi网络示例图。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述,以便于本技术领域的技术人员理解本发明。
图1表示出了本发明的基于语义感知的用户多请求top-k路径规划方法的总体流程。请参见图1,下面是对方法中各个步骤的详细描述。
(1)从数据集singapore中读取poi的信息包括空间信息和关键词信息,用于路径规划时关键词匹配以及空间距离成本代价的计算,singapore代表在singapore收集的foursquare签到数据。
(2)按定义的数据结构存储从路网中读取到的数据信息,便于路径规划过程中查询关键词对应的poi,v=(v.λ,v.κ)其中v为poi,v.λ为poi的空间信息,通常为poi的经纬度形式,v.κ为关键字的集合,v.κ={κ1,κ2,...,κj,...,κ|κ|}其中ki为poi的第i个关键字,|p|为poi关键字的总数。
(3)接收路径规划请求。
(4)获取用户输入的多个请求q(q1,q2,...,q|q|)即查询关键词的信息、路径数k以及当前用户所在的位置s的信息并存储。
(5)使用lda语义分析算法对用户输入的请求q(q1,q2,...,q|q|)中的每一个请求qi进行语义分析,获取查询关键词与poi关键词之间的语义相似度sim(k,q),其中k是poi关键词,q是查询关键词;例如,表一中每个元组是一个主题概率分布,分为五个主题。考虑一个想看电影的用户,用户输入一个查询关键词q以及具有关键词“cinema”的当前位置。由公式
(6)通过算法搜索从位置s出发直到完成用户所有请求的路径,并将形成的路径存入结果集中,直到结果集中路径数为k,得到前k条最优路径;
(7)反馈搜索结果,即步骤(6)中结果集中的路径信息。
上述步骤中的步骤(6)应用了本发明提出的算法来搜索路径,进一步的细化参见图2,下面是对算法的进一步描述。
(a)设置算法中的参数值:(g,s,q(q1,q2,...,q|q|),k),其中g代表路网信息,s代表起点,q代表用户请求集合,k代表需要查询路径数;创建结果集set、候选路径集r、支配路径集dt以及被支配路径集td;初始化所有参数,将起点s作为部分路径添加进候选路径集r。
(b)判断结果集中路径数是否等于k条,如果是则进入步骤(m),否则进入步骤(c)。
(c)从候选路径集合r中选择最优的部分路径p=(s,v1,...,v|p|),即候选路径集中第一条路径,候选路径集中路径通过依次比较路径实际距离成本与路径完成的请求数量的比值,完成请求数量,路径中poi点数量三个值进行排序,首先按照比值从小到大排序,然后对相同比值的路径,按照完成请求数量从大到小排序,最后对完成请求数量也相同的路径,按照路径中poi数量从小打到排序。通过公式
(d)判断该路径p=(s,v1,...,v|p|)提供的服务
(e)将该路径p加入结果集set,从被该路径支配的路径中选择最优路径加入候选路径集中,并返回步骤(b)。
(f)判断该路径p是否被其他路径支配,如不是进入步骤(g),否则进入步骤(j)。
(g)将该路径p加入支配路径集dt。
(h)查询当前点v|p|的第x个最近邻v|p|+1并访问,查询第x个最近邻的过程中先对请求进行优先级分配,确定优先查询的请求(q2,q3,...,qi),再计算能够满足这些请求的poi与v|p|当前点之间成本,进而求出v|p|+1。
(i)将当前点的最近邻加入路径中形成新的路径p’=(s,v1,...,v|p|,v|p|+1),并将新的路径加入候选路径集。
(j)将该路径p=(s,v1,...,v|p|)加入被支配路径集中。
(k)判断当前点是否起点s,如是返回步骤(b),否则进入步骤(l)。
(l)查询当前点v|p|的前一个poi点即v|p|-1的第x+1个最近邻并访问,此时v|p|是v|p|-1的第x个最近邻,形成新的路径p”=(s,v1,...,v|p|-1,v|p’|)加入路径候选集,返回步骤(b)。
(m)返回结果。
结合图6的示例图。假设给定的查询是(s,<q1,q3,q6,q7,q8>,2)。表二显示了候选路径集合r中的路径的变化。表三显示了每个poi点可以满足的请求。首先,将路径<s>添加到候选路径r中,然后判断结果集set中路径数是否等于k,k=2。此时尚未添加路径进入结果集,所以不满足路径数等于2,从r选择最优部分路径<s>,判断该部分路径是否满足所有请求,不满足则判断是否被其他路径支配,没有被其他路径支配,查询起点s的第一个最近邻v2并访问将此路径加入候选路径集r,之后判断当前点s是不是起点,所以返回步骤(b)即判断结果集中路径数是否等于2,从路径候选集中选择最优路径<s,v2>进行扩展,判断该路径是否满足所有请求,不满足则判断是否被其他路径支配,没有被其他路径支配,查询起点v2的第一个最近邻v3并访问将此路径加入候选路径集r,之后判断当前点v2是不是起点,不是则查询v2前一个poi点的下一个最近邻,即起点s的第二个最近邻,如此类推,直到找到满足k=2为止,输出路径。
上述步骤中,步骤(h)的进一步细化请参见图3。下面结合图3对查询最近邻的过程做进一步的细化。
(h.1)输入当前点v、未完成请求q、创建优先队列n存储当前点v的近邻、创建集合c存储能够满足优先查询集合中的请求的所有poi。
(h.2)对未完成请求进行优先级分配,确定优先查询的请求q’(q1,q2,...,q|q’|);
(h.3)查询集合c中所有poi,确定所有poi与当前点的距离远近关系,并将poi按照距离由近及远的顺序存入队列n中;
(h.4)根据查询所需的第x个最近邻,输出队列n中第x个元素,如本次查询当前点的第2个最近邻则只需要输出队列n中的第二个元素,即n[1]。
上述步骤中,步骤(h.2)的进一步细化请参见图4。下面结合图4对优先级分配的过程做进一步的细化。
(h.2.1)输入未完成的用户请求q(q1,q2,...,q|q|),设置优先结果集合set,判断是否第一次进行优先级分配,如是进入步骤(h.2.2),否则进入步骤(h.2.7);
(h.2.2)遍历所有请求q,判断是否与其他请求存在优先级关系,如是进入步骤(h.2.3),否则进入步骤(h.2.4);
(h.2.3)将优先级高请求的优先级定义为1,其他的请求优先级定义为0,如q1和q2之间优先关系且q1比q2优先级高,则q1的优先级设置为1,q2的设置为0;
(h.2.4)将请求的优先级定义为1;
(h.2.5)将所有优先级为1的请求加入结果集合;
(h.2.6)将本次结果集赋值给pre_set,保留至下一次优先级分配;
(h.2.7)通过上一次优先级分配产生的结果集和本次未完成的请求计算出上一次路径搜索时被满足的请求,即通过pre_set与set之间存在的差值得到pre-set中被满足的请求q’;
步骤h.2.6中的下一次仅在第一次分配时存在,指的是保留至第二次分配,第一次分配时运行到步骤h.2.6,下一次代表第二次分配;第二次分配时,通过步骤h.2.1的判断,直接进入步骤h.2.7,此时上一次分配代表第一次分配,且在步骤h.2.9将第二次的结果保留至下一次,即第三次;第三次分配时,上一次代表第二次分配,保留至下一次指第四次如此类推。
(h.2.8)针对与q’存在优先级关系且尚未处理的请求,对它们进行优先级分配;
(h.2.9)将优先级高的请求加入结果集set,将结果集set赋值给pre-set;
(h.2.10)反馈结果集set。
在每次迭代中,该算法对用户请求的优先级进行分类,并首先查询优先级高的请求。该算法为查询关键字分配优先级,并将结果存储在名为pre_set的特定集合中。第一次,我们检查q中的每个关键字,有些关键字之间存在优先级关系。如果其中一个关键字的优先级在这些关键词中最高,我们定义该关键词的优先级为1,否则优先级为0。对于没有优先级关系的关键词,称它们是独立的。这些关键词对其他关键词没有影响,因此我们也定义这些关键词的优先级为1。然后,我们将关键词添加到结果集中,并将结果集分配给pre_set。第一次之后,算法通过完成的服务找到优先级较低的服务,并将该服务存储到结果集中。最后,算法输出结果集。当算法查询最近邻时,通过优先级可以减少候选poi的数量。
上述步骤中,步骤(h.3)的进一步细化请参见图5。下面结合图5对查询第x个最近邻的过
程做进一步的细化。
(h.3.1)输入优先级分配中反馈的结果集以及能够满足用户请求的poi。
(h.3.2)通过
(h.3.3)通过
(h.3.4)通过ave的值对候选集中poi进行排序,方便查询所需的第n个最近邻。
输入优先级分配反馈的结果集以及能够满足用户请求的poi。从vi开始,通过公式对当前点进行扩展,计算两点之间的ave,每个poi点与当前点的平均距离存储在升序排序队列n中;当未完成的服务的数量小于1时,我们直接将当前点与可能的最近邻居之间的实际距离视为ave,并将其存储在队列n中。最后,根据需要输出相应的poi点。
表一
表二
表三
表四
- 还没有人留言评论。精彩留言会获得点赞!